Abstract
Non-uniquely-decodable (non-UD) codes can be defined as the codes that cannot be uniquely decoded without additional disambiguation information. These are mainly the class of non–prefix–free codes, where a code-word can be a prefix of other(s), and thus, the code-word boundary information is essential for correct decoding. Due to their inherent unique decodability problem, such non-UD codes have not received much attention except a few studies, in which using compressed data structures to represent the disambiguation information efficiently had been previously proposed. It had been shown before that the compression ratio can get quite close to Huffman/Arithmetic codes with an additional capability of providing direct access in compressed data, which is a missing feature in the regular Huffman codes. In this study we investigate non-UD codes in another dimension addressing the privacy of the high-entropy data. We particularly focus on such massive volumes, where typical examples are encoded video or similar multimedia files. Representation of such a volume with non–UD coding creates two elements as the disambiguation information and the payload, where decoding the original data from these elements becomes hard when one of them is missing. We make use of this observation for privacy concerns. and study the space consumption as well as the hardness of that decoding. We conclude that non-uniquely-decodable codes can be an alternative to selective encryption schemes that aim to secure only part of the data when data is huge. We provide a freely available software implementation of the proposed scheme as well.
1. Introduction
A coding scheme basically replaces the symbols of an input sequence with their corresponding code-words. Such a scheme can be referred as ambiguous if it is not possible to uniquely decode the code-words back into the original data without using a disambiguation information. In this study, we study non–prefix–free (NPF) codes, where a code-word can be a prefix of other(s), and the ambiguity arises since the code-word boundaries cannot be determined on the code-word stream without explicit knowledge of the individual code-word lengths. Due to the lack of that unique decodability feature, NPF codes has received limited attention [1,2,3,4,5] in the related literature.
The basic approach in dealing with the decodability problem of NPF schemes is to find an efficient way of representing the code-word boundaries. That had been studied in [5] by maintaining an additional compressed bit array supporting rank and select queries [6] to mark the code-word boundaries on the code-word stream. Similar approaches were also independently mentioned in [7,8]. Yet another way is to create a wavelet tree [9] over the code-word lengths, which was studied in [5] as an alternative to maintaining a bit array. Empirical observations in [5] showed that actually NPF codes can provide compression ratios quite close to and sometimes better than the Huffman codes, while providing random access, which is a missing feature in ordinary Huffman codes, in constant or logarithmic time.
Despite efforts to solve unique decodability of ambigious codes, in this study we focus on the privacy and security opportunities provided by the NPF codes. Achieving the security of massive data volumes with less encryption makes sense on platforms where the cost of encryption becomes hefty according to some metrics, e.g., time, memory, energy, or bandwidth. For example, in battery-constrained environments such as mobile devices [10], sensor networks [11], or unmanned aerial vehicles [12], performing less encryption may help to increase the battery life. It had been shown that symmetric security algorithms roughly doubles the energy consumption of normal operation in those environments, and asymmetric security algorithms increase the energy usage per bit in order of magnitudes (around 5 fold) [13]. Previously, selective encryption schemes [14] have been proposed to reduce the encryption load, particularly on transmission of video/image files [15,16,17]. In selective encryption, segments of the data, which are assumed to include important information, e.g., the I-frames in a video stream, are encrypted, while rest of the data is kept plain. We introduce an alternative approach to reduce the amount of encryption required to secure a source data. As opposed to the partial security provided by the selective encryption schemes, we observe that the intrinsic ambiguity of non-prefix-free (NPF) codes gives us an interesting opportunity for the privacy of the whole data.
The main idea of the proposed technique here is to process the n bit long input bit sequence, which is assumed to be independently and identically distributed, in blocks of d bits according to a predetermined d parameter that is typically between 6 and 20. We create non-prefix code-words by using a permutation of the numbers , and then replace every d-bits long symbol in the input with its corresponding NPF code-word of varying bit-length in between 1 to d. We call the resulting bit stream the payload since it includes the actual content of the source. This sequence can not be decoded properly without the code-word boundaries due to the inherent ambiguity of the NPF codes. Therefore, we need to maintain an efficient representation of the code-word boundaries on the payload. We refer to that second bit stream as the disambiguation information throughout the study. In the proposed scheme, the total space consumed by the payload and the disambiguation information introduces an overhead of bits per each original bit, which becomes negligible as d increases, i.e., it is less than 7 bits per a thousand bit when . We prove that the payload occupies , and the disambiguation information takes of the final representation, and the two partitions consume in total almost the same space with the input data.
Following the space consumption analysis, we investigate how much information can be inferred from disambiguation data for the payload and vice versa, which leads us to the conclusion that encrypting one of the partitions and leaving the other one in plain can be considered for the privacy of the data. Since disambiguation information consumes less space, it would be ideal to encrypt it while leaving the payload in plain. However, the other way, encrypting the payload and leaving the the disambiguation information plain can still reduce the to-be-encrypted amount. Yet, nested application of the coding schemes on either partitions can also be considered a good strategy for privacy.
It might have captured the attention of the reader that the analysis assumes the input bit stream is i.i.d., which seems a bit restrictive at a first glance. However, the target data types of the introduced method are mainly the sources that have been previously entropy encoded with some data compression scheme, where each symbol is represented by minimum number of bits close to its entropy according to Shannon’s theorem [18]. Such typical sources are video files in mpeg4 format, sound files in mp3 format, images in JPEG format and similar others. The output of the compression tools squeezing data down to its entropy is actually a quite nice input for our proposal. We support this observation by the experiments performed on various compressed file types on which the results are observed to be very close to the theoretical bounds computed by the uniformly i.i.d. assumption. In that sense, the proposed scheme can also be seen as a method of providing privacy of the compressed data as well.
The outline of the paper is as follows. In Section 2 we introduce the proposed non-UD coding method based on the non–prefix–free codes, and analyze its basic properties mostly focusing on the space consumption of the partitions. We provide verification of the theoretical claims based on uniformly i.i.d. assumption on some files that are already entropy-encoded and investigate the hardness of decoding in absence of the partitions in this section for privacy issues. The implementation of the proposed technique is introduced here and currently available speed is presented as well. Section 3 summarizes the results obtained. We discuss possible practical usage scenarios in Section 4 and then conclude with addressing further research avenues.
2. Materials and Methods
We start with defining the proposed non-UD coding scheme and analyze the space occupied by the disambiguation information, the payload, and the overhead with respect to the original input, which we will assume to be a uniformly and independently distributed bit sequence of length n. We focus next on the complexities of inferring the disambiguation information or the payload in absence of the other.
2.1. Non-Uniquely-Decodable Data Coding
Let denotes an independently and identically distributed bit sequence, and is a predetermined block length. Without loss of generality we assume n is divisible by d. Otherwise, it is padded with random bits. can be represented as , for such that each d–bits long in is from the alphabet . We will first define the minimum binary representation of an integer, and then use this definition to state our encoding scheme.
Definition 1.
The minimum binary representation (MBR) of an integer is its binary representation without the leftmost 1 bit. As an example, by omitting the leftmost set bit in its binary representation as .
Definition 2.
Let be a permutation of the given alphabet , and is a code-word set such that
The representation of the input with the non–prefix–free code-word set W is shown by such that . When a code-word has multiple options, a randomly selected one among the possibilities is used.
The NPF coding of a sample sequence according to the Definitions 1 and 2 with the parameter is shown in Figure 1. The code-words and are sets as their corresponding and values are greater than or equal to . Thus, when or , a randomly selected code-word respectively from sets or , is inserted.

Figure 1.
A simple sketch of the non-prefix-free coding of an input bit sequence , where is the representation of with the block length . is a random permutation of the corresponding alphabet , and W is the non-prefix-free code-word set generated for according to Definition 2. The disambiguation information is computed according to Lemma 2.
Proposition 1.
In a code-word set W that is generated for a block length according to Definition 2, the lengths of the code-words in bits range from 1 to d, where the number of ℓ–bits long code-words for each is , and for there exist 2 sets of code-words each of which includes elements.
Proof.
According to Definition 2, the entities in W are minimum binary representations of numbers . Since the MBR bit-lengths of those numbers range from 1 to d, there are d distinct code-word lengths in W. Each code-word length defines distinct code-words, and thus, total number of code-words defined by all possible values becomes . The remaining 2 code-words out of the items require d–bits long bit sequences. For example, when , the W includes code-words of 1-bit long, code-words of length 2, and code-word sets of length 3-bits as shown in Figure 1. □
Lemma 1.
The non-UD encoding of an i.i.d. bit sequence of length is expected to occupy = bits space.
Proof.
The total bit length of the NPF code-words is simply , where denotes the number of occurrences of the values represented by ℓ–bits long code-words in . Assuming the uniform distribution of , each appears times. The number of distinct values represented by a code-word of length ℓ is for , and two of the values require bit long code-words as stated in Proposition 1. Thus, for , and . The length of the bit-stream can then be computed by
While computing the summation term in Equation (2), we use the formula from basic algebra that , and substitute . □
The NPF coding represents the n bits long input sequence with bits. However, since non-prefix-free codes are not uniquely decodable, cannot be decoded back correctly in absence of the code-word boundaries. Therefore, we need to represent these boundary positions on as well. Lemma 2 states an efficient method to achieve this task.
Lemma 2.
The expected number of bits to specify the code-word boundaries in the is , where .
Proof.
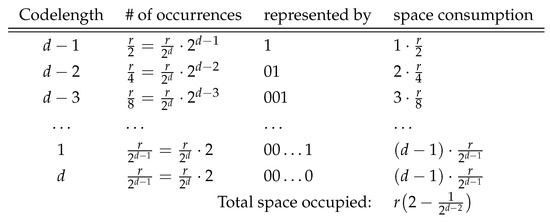
Due to Proposition 1 there are distinct code-words with length ℓ for and 2 code-words (sets) are generated for . Since each d-bits block has equal probability of appearance on , the number of occurrences of code-words having length is . The most frequent code-word length is , which appears at half of the r code-words as . It is followed by the code-word length that is observed times. When we examine the number of code-words with length , we see that this distribution is geometric, as depicted in Figure 2. The optimal prefix-free codes for the code-word lengths are then , which correspond to code-word lengths respectively. Thus, code-word length , which appears times on , can be shown by i bits. We use consecutive zeros to represent the code-word length as the number of occurrences of d–bits long code-words is equal to the number of 1 bit long code-words on . Notice that the representation of the code-word lengths are prefix-free that can be uniquely decoded. Total number of bits required to represent the individual lengths of the code-words can be computed by
□
Figure 2.
The representation of the code-word lengths to specify the code-word boundaries on the NPF stream.
Theorem 1.
The non-UD encoding of n bit long i.i.d. input sequence can be achieved with bits overhead per each original bit.
Proof.
Total overhead can be computed by subtracting the original length n from the sum of the space consumption described in Lemmas 1 and 2. Dividing this value by the n returns the overhead per bit as shown below.
□
Table 1 summarizes the amount of extra bits introduced by the proposed encoding per each original bit in . A large overhead, which seems significant for small d, e.g., , may inhibit the usage of the method. However, thanks to the to the exponentially increasing denominator () in the overhead amount that the extra space consumption quickly becomes very small, and even negligible. For instance, when , the method produces only extra bits per a thousand bit. Similarly, the overhead becomes less than 3 bits per bits, and less than 2 bits per a million bits for the values of and , respectively. Thus, for , an input uniformly i.i.d. bit sequence can be represented with a negligible space overhead by the proposed non-UD encoding scheme.

Table 1.
The payload, disambiguation information, and overhead bits per each original bit introduced by the proposed non-UD coding for some selected d values.
Experimental Verification of the Space Usage Results
During the calculations of the payload and disambiguation information sizes as well as the overhead, the input data has been assumed to be independently and identically distributed. In practice, the input to the proposed method is supposed to be the output of an entropy coder, where the distribution of d–bits long items in such a file may deviate from the perfect assumptions. We would like to evaluate whether such entropy-encoded files still provide enough good uniformity close to the theoretical claims based on uniformly i.i.d. assumption. Therefore, we have conducted experiments on different compressed files to observe how much these theoretical values are caught in practice.
We have selected 16 publicly available files.The first ten files are available from http://corpus.canterbury.ac.nz and http://people.unipmn.it/manzini/lightweight/corpus/. The multimedia files are from https://github.com/johndyer/mediaelement-files, where the first ten are gzip compressed data from different sources and the remaining six are multimedia files of mp3, mp4, jpg, webm, ogv, and flv formats. The first bits of each file is inspected for distinct values of , and the corresponding observed payload and disambiguation information sizes are computed as well as the overhead bits in each case.
Table 2 includes the comparisons of the observed and theoretical values on each analyzed dimension. The payload size, which is the total length of the concatenated NPF code-words, and the disambiguation information size, which is the total length of the prefix–free encoded code-word lengths, are both observed to be compatible with the theoretical claims. This is also reflected on the overhead bits as a consequence. Thus, in terms of space consumption, the experimental results on compressed data support the theoretical findings based on perfect uniformly i.i.d. input data assumption.
Table 2.
Verification of the theoretical claims on selected files for .
2.2. Hardness of Decoding Payload in Absence of Disambiguation Information
The non-UD coding process represents the input data with two elements as the payload and the disambiguation information. We have shown in Lemma 2 that the disambiguation information occupies of the input size. Thus, if one encrypts the disambiguation information and leaves the payload plain, the retrieval of the original sequence will require decoding the payload without the disambiguation information. We provide a combinatorial analysis on the hardness of this decoding below by first proving that disambiguation information of a payload is specific per se, and then use this fact to count the number of possible distinct raw sequences that map to a given payload with the same code-word mapping of .
Lemma 3.
Each distinct disambiguation information on a given NPF stream decodes into distinct input sequence.
Proof.
Let and denote two different disambiguation information, which are actually the code–word length sequences such that , where and are the bit lengths of the ith code–word in the corresponding decoding of the . Since S and are distinct, for some , and are not equal, which causes the corresponding code–words extracted from the NPF code–stream to be of different length. Although there is a chance that different code–words of length d may map onto the same symbol in W according to Definition 2, it is for sure that when the two code–word lengths are different they cannot map onto the same symbol. Thus, it is not possible to find two distinct S and that generate equal sequences. □
Lemma 4.
A payload that is generated for an input n–bits long with the proposed NPF scheme has more than distinct decodings for , where only one of them, which is specified with the disambiguation information, is the original input . When d is chosen to be , different payload generations are possible.
Proof.
We will analyze the input in blocks of d–bits long symbols. Each symbol in a block is mapped to a variable–length non–prefix–free code-word according to the , and when the code–word boundaries are unknown on that code–stream, then many different decoding possibilities appear. We aim to first count how many different decoding would be possible for a block, and then use this information to determine possibilities for the whole code–word stream.
In a block of symbols, the number of ℓ-bits long code–words is for , and 2 for according to Proposition 1. Therefore, the number of possible permutations of those items is more than as shown below.
Let be the number of blocks in an input n–bits long data stream. Since there are more than different decodings per each block, then blocks in total will have more than distinct decoding possibilities. □
Given a payload and the used code–word mapping , the number of distinct original data decodings is shown in Table 3. Notice that only one of them is the correct , and actually generating these possibilities is computationally not feasible. Therefore, decoding the NPF stream without the code–word boundary information is computationally hard for sufficiently large d values, where as a minimum in practice brings a complexity of for possibilities. Thus, encrypting only the code–word boundary information, and transmitting the code–word stream in plain can provide privacy of the whole data in practice. The interesting point here is that the disambiguation information occupies much less space when compared to the total size of the originl data as previously analyzed in Lemma 2, which can provide a significant reduction in the encryption volume required for the data security.
Table 3.
When , the payload size, the disambiguation information size, and the corresponding number of possible decodings are shown. Last column depicts the percentage of the volume to be encrypted to provide privacy with the specified level of ambiguity, i.e., when , encrypting only around 25% of the input volume (2048 bits) introduces an ambiguity of around .
2.3. Hardness of Decoding Disambiguation Information in Absence of Payload
For the users, who would like to keep their data top secret by the standard encryption algorithms, applying the NPF coding scheme can still provide an advantage. In case of such a necessity, the payload is encrypted, and the disambiguation information, which simply specifies the code–word boundaries in the variable–length non–prefix–free code–words stream payload, is kept plain. Now extracting the code-word bits from the payload can be achieved since disambiguation information is plain, however, since the payload bits are encrypted, decoding the original data is not possible.
Considering that larger d values create smaller disambiguation information and increase the payload size, in this case using small d will be preferred with the aim to achieve higher reduction in the to-be-encrypted data volume. On the other side, when d gets smaller, the overhead becomes more significant. For example, when , there appears 10% inflation in the data volume, where both payload and disambiguation information occupy 50% of the inflated data. With that 10 percent inflation it becomes possible to attain 50% decrease in the encryption. Similarly, by choosing , the overhead becomes more acceptable by being around 3 bits per 100 bits, and since the ratio of the payload becomes of the final data, around 33% decrease is achieved in the encryption amount.
We start analyzing how much information is leaked by making the disambiguation information public assuming that the code-word set is also public, and then investigate how much it would help to keep the code-word mapping () secret.
Lemma 5.
The number of distinct payloads that can be generated from a given disambiguation information is by assuming the code-word set W, parameter d, and message length n are known.
Proof.
A code-word of length , which is representing distinct symbols, appears times in the disambiguation information for to and . The d bit long code-words appear times, and represent two distinct symbols. Thus, the total number of distinct sequences that can be generated from a known disambiguation information can be counted by
□
The result of Lemma 5 is consistent with previous Lemma 2 such that the disambiguation information is not squeezing the possible message space by more than its size. In other words, when the codeword set W is known, plain disambiguation information reduces the possible message space to , where .
However, when W is private, and we need to investigate whether that secrecy of W accommodates the leakage due to the plain disambiguation information. Lemma 6 shows that for an attacker using the knowledge revealed by the disambiguation information does not provide an advantage over breaking the encryption on the payload as long as the code-word set W is kept secret.
Lemma 6.
The shrinkage in the possible message space due to public disambiguation information can be accommodated by keeping the code-word set W secret in the non-UD coding of bit long data for .
Proof.
W is a secret permutation of the set containing numbers. Thus, there are distinct possibilities, which defines bits of information. On the other hand, the amount of revealed knowledge about the n bit long input by the disambiguation information is bits. The advantage gained by keeping W secret should accommodate the loss by making disambiguation information public. This simply yields the following equation.
□
Due to Lemma 6, the choice of d creates an upper bound on the size of the input data that will be subject to the proposed non-UD coding scheme. On the other hand, it would be appropriate to select d such that the input size is at least bits to confirm with the computations in the size arguments of the payload and the disambiguation information, which assumed all possible symbols are uniformly i.i.d. on the input. The minimum and maximum block sizes defined by the d parameter are listed in Table 4 considering these facts.
Table 4.
The minimum () and maximum () block sizes that are appropriate according to the proposed non-UD coding scheme for selected d values.
Therefore, given an input bit string , if it is preferred to keep payload secret and disambiguation information plain, achieving the non-UD coding in blocks of the any preferred size in between these values is appropriate in practice. The value of d plays a crucial role both in the security and in the to-be-encrypted data size. It is good to choose large d for better security with less (even negligible when ) overhead. On the other hand, the payload size is inversely proportional with d, and thus, the reduction in the data volume to be encrypted decreases when d increases.
2.4. Implementation of the NPF Encoding
The implementation of the proposed scheme is available at https://github.com/qua11q7/NPFCoding. The Figure 3 presents the speed performance of the implementation on randomly generated files of size 1, 10, 100, and 1000 megabytes respectively. The machine used in the experiments had 16GB memory and Intel i5-6600 CPU with Ubuntu 18.04.2 operating system. For fast processing the implementation follows a similar scheme as in the case of Huffman decoding with lookup tables [19]. Empirical observations showed that this type of look up make sense on small d values, particularly on and . However, on larger d values due to the expansion of the number of tables as well as their sizes the performance is not improved. In the regarding tables, the “NoMap” option means look up tables are not used. We observed that the NPF coding maximizes its speed both in coding and decoding process, when d is chosen to be 8, where around 170 megabyte per second is achieved. The performance does not change much with the file size, and seems totally dependent on the d parameter. The payload and disambiguation sizes and overall percentages are also given and observed to be consistent with the theoretical calculations. The decoding speed is about two times of the encoding speed when d is chosen to be 16 or 20, where it reaches 200 MB per second for on 1GB files. More details about the implementation is available on the mentioned code distribution web site.
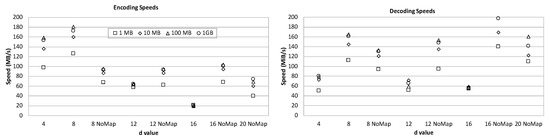
Figure 3.
NPF encoding/decoding speed in megabytes per second on different file sizes with different d values. Note that “NoMap” means no look-up table is used.
3. Results
We have shown that the NPF encoding of an input n–bits long high-entropy data creates a payload of size which requires bits disambiguation information for a chosen d parameter. Larger d, e.g., , values decrease the overhead and total space consumption becomes almost equal with the input.
The hardness of decoding an encoded data without the knowledge of the used code-word set had been addressed as early as in 1979 by Rubin [20], and later by others [21,22]. More recently, non-prefix-free codes have also been mentioned [23] in that sense. We observe that in absence of any of the two partitions in the proposed scheme, decoding the original data is hard, which can help to keep data privacy. We proved that a given payload, which has been generated from an input via a known code-word mapping , has more than possible decodings in absence of the correct disambiguation information, when d is chosen such that . Since a given payload cannot be decoded properly back into the original input without the correct disambiguation information due to this exponential ambiguity, it can be preferred to encrypt only the disambiguation information, and leave the payload plain. In such a case, the amount of to-be-encrypted volume would be of the original data. For instance, this brings a reduction of around when and when . Notice that the ambiguity is computed assuming the mapping is public, where keeping the code–word set secret will introduce additional strength in privacy.
We also analyzed the how much information is released by the disambiguation information regarding the payload. It is proved that when , for , the contraction of the possible message space due to the public disambiguation information can be accommodated by keeping the code-word set secret. Thus, if one encrypts the payload and keeps the code–word mapping secret, an attacker can not gain an advantage by knowing the disambiguation information. Such a scheme can still provide a reduction in encryption cost, which is expected to be much less when compared with the first scenario above. In this case, the d value needs to be small since the ratio of the payload increases with the larger d values. However, since smaller d values generate an overhead, it seems appropriate to use in practice.
4. Discussions
Applying entropy compression before the transmission is a common daily practice. For instance, the mpeg4 encoded video streams, jpg images, or text resources encoded with arithmetic or Huffman schemes are possible data sources fit well to the proposed architecture with their high entropy. It is noteworthy that the security of the high-entropy data has been previously addressed in [24,25,26]. These studies mainly state that although the perfect security of an input data requires a key length equal to its size (one-time pad), the security of high-entropy data can be provided with much shorter key sequences. However, again the data as a whole should be fed into encryption. On the other hand, high entropy data representation with our proposal creates two elements, where encrypting one of them is adequate since decoding the original data from the plain element is hard in absence of the other encrypted element.
A recursive application of the proposed coding can even reduce the to-be-encrypted volume more. For example, after creating the two elements of the non-UD representation, the disambiguation information or the payload can itself be subject to a one more round of NPF coding. We have shown that when , percent is the disambiguation information, and with one more round, the disambiguation information will become less then 7 percent of the final volume, where encrypting only that 7% can be considered for privacy. A similar scenario on the payload can be considered as well.
We assumed that the input to the non-UD encoder is uniformly i.i.d. in ideal case, and empirically verified that the compressed volumes ensures the mentioned results. Actually, applying entropy coding before the encryption is a common daily practice, which makes the proposed method to be directly applicable in such a scenario. The mpeg4 video streams, jpg images, compressed text sequences, or mp3 songs are all typical data sources of high-entropy. Digital delivery of such multi-media content has a significant market share in daily practice [27]. Related previous work [24,25] had stated that although the perfect security of an input data requires a key length equal to its size (one-time pad), high-entropy data can be perfectly secured with much shorter keys. This study addressed another dimension and investigated achieving security of such volumes by encrypting less than their original sizes by using the introduced non-UD coding scheme.
Although we target high-entropy data and analyze space consumption and security features based on the assumption of i.i.d input, it might be also interesting to have a look what would happen if we apply the non-UD coding to normal files with biased distributions. On the corpus we studied, we omitted the compression step on the files that have non-uniform symbol distributions, and applied our proposed coding directly with a randomly selected mapping. The results are given on Table 5, where repeating the same experiment with different assignments reported similar values. The empirical observation on these results show that the disambiguation information is roughly less than one third of the input volume, when the input sequence is not uniformly distributed. Thus, encrypting only the disambiguation information may make sense still on non i.i.d files as well.
Table 5.
The sizes of the payload and disambiguation information when non-UD coding is applied on the files that have non-uniform symbol distribution.
Reducing the amount of data to-be-encrypted can make sense in scenarios where the encryption process defines a bottleneck in terms of some metrics. Non-UD coding becomes particularly efficient on securing large collections over power-limited devices, where the cost of encryption becomes heavy in terms of energy. This reduction also helps to increase the throughput of a security pipeline without a need to expand the relatively expensive security hardware. For instance, let’s assume a case where the data is waiting to be processed by a hardware security unit. When the amount of data exceeds the capacity of this unit, a bottleneck appears, which can be resolved by increasing the number of such security units. However, adding and managing more security units is costly, particularly when the bottleneck is not so frequent, but only appearing at some time. An alternative solution is to use the proposed non-UD coding, where instead of expanding the security units, data can be processed appropriately while waiting in the queue, and the amount to be encrypted can be reduced up to desired level by applying the scheme recursively if needed. Notice that as opposed to previous selective encryption schemes, non-UD coding supports the security of the whole file instead of securing only the selected partitions. Besides massive multimedia files, small public key files around a few kilobytes that are used in asymmetric encryption schemes are also very suitable inputs for the non-UD coding. The exchange of public keys via symmetric ciphers can also benefit from the reduction introduced.
5. Conclusions
We have investigated the non-UD data coding with non-prefix-free codes on high-entropy sources. The proposed scheme represents the input data with two elements as the payload and the disambiguation information, where the later has a smaller footprint depending on the choice of the bit-block length parameter d. Such an encoding can help in privacy protection of the massive volumes with less encryption overhead by keeping one of the partitions secret via encryption, while the other one is kept plain. This encoding model can also help for privacy preserving pattern matching applications without making use of any encryption as well, where an immediate usage can be distributed file storage in cloud environments such that the payload and disambiguation information are stored and maintained by independent vendors, and thus, none can see the data content but still the owner can run efficient search queries. Studying such a scenario for privacy preserving distributed data storage on the cloud can be the next research avenue for non-UD.
6. Patents
Külekci, M.O., Istanbul Teknik Universitesi, 2018. An efficient encryption method to secure data with reduced number of encryption operations. U.S. Patent Application 15/779,853 [28].
Author Contributions
Conceptualization, M.O.K.; methodology, M.O.K. and Y.Ö.; software, Y.Ö.; validation, M.O.K. and Y.Ö.; formal analysis, M.O.K.; investigation, M.O.K. and Y.Ö.; resources, Y.Ö.; data curation, Y.Ö.; writing—original draft preparation, M.O.K.; writing—review and editing, M.O.K. and Y.Ö.; visualization, M.O.K. and Y.Ö.; supervision, M.O.K.; project administration, M.O.K.; funding acquisition, M.O.K.
Funding
This research was funded by TUBITAK, The Scientific and Technical Research Counsel of Turkey, grant number 117E865.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Külekci, M.O. An Ambiguous Coding Scheme for Selective Encryption of High Entropy Volumes. In Proceedings of the 17th International Symposium on Experimental Algorithms (SEA 2018), La’quilla, Italy, 27–29 June 2018; D’Angelo, G., Ed.; Leibniz International Proceedings in Informatics (LIPIcs). Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl, Germany, 2018; Volume 103, pp. 7:1–7:13. [Google Scholar] [CrossRef]
- Dalai, M.; Leonardi, R. Non prefix-free codes for constrained sequences. In Proceedings of the International Symposium on Information Theory (ISIT), Adelaide, Australia, 4–9 September 2005; pp. 1534–1538. [Google Scholar]
- Meiners, C.R.; Liu, A.X.; Torng, E. Bit weaving: A non-prefix approach to compressing packet classifiers in TCAMs. IEEE/ACM Trans. Netw. 2012, 20, 488–500. [Google Scholar] [CrossRef]
- Külekci, M.O. Uniquely decodable and directly accessible non-prefix-free codes via wavelet trees. In Proceedings of the 2013 IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1969–1973. [Google Scholar]
- Adaş, B.; Bayraktar, E.; Külekci, M.O. Huffman Codes versus Augmented Non-Prefix-Free Codes. In Experimental Algorithms; Springer: Berlin, Germany, 2015; pp. 315–326. [Google Scholar]
- Okanohara, D.; Sadakane, K. Practical entropy-compressed rank/select dictionary. In Proceedings of the Meeting on Algorithm Engineering & Expermiments, New Orleans, LA, USA, 6 January 2007; pp. 60–70. [Google Scholar]
- Fredriksson, K.; Nikitin, F. Simple compression code supporting random access and fast string matching. In International Workshop on Experimental and Efficient Algorithms; Springer: Rome, Italy, 2007; pp. 203–216. [Google Scholar]
- Ferragina, P.; Venturini, R. A simple storage scheme for strings achieving entropy bounds. In Proceedings of the Eighteenth annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 690–696. [Google Scholar]
- Navarro, G. Wavelet trees for all. In Annual Symposium on Combinatorial Pattern Matching; Springer: Helsinki, Finland, 2012; pp. 2–26. [Google Scholar]
- Hamad, F.; Smalov, L.; James, A. Energy-aware Security in M-Commerce and the Internet of Things. IETE Tech. Rev. 2009, 26, 357–362. [Google Scholar] [CrossRef]
- Chandramouli, R.; Bapatla, S.; Subbalakshmi, K.P.; Uma, R.N. Battery Power-aware Encryption. ACM Trans. Inf. Syst. Secur. 2006, 9, 162–180. [Google Scholar] [CrossRef]
- Uragun, B. Energy efficiency for unmanned aerial vehicles. In Proceedings of the IEEE 10th International Conference on Machine Learning and Applications and Workshops (ICMLA), Honolulu, HI, USA, 18–21 December 2011; Volume 2, pp. 316–320. [Google Scholar]
- Potlapally, N.R.; Ravi, S.; Raghunathan, A.; Jha, N.K. A study of the energy consumption characteristics of cryptographic algorithms and security protocols. IEEE Trans. Mob. Comput. 2006, 5, 128–143. [Google Scholar] [CrossRef]
- Massoudi, A.; Lefebvre, F.; De Vleeschouwer, C.; Macq, B.; Quisquater, J.J. Overview on selective encryption of image and video: challenges and perspectives. EURASIP J. Inf. Secur. 2008, 2008, 179290. [Google Scholar] [CrossRef]
- Van Droogenbroeck, M.; Benedett, R. Techniques for a selective encryption of uncompressed and compressed images. In Proceedings of Advanced Concepts for Intelligent Vision Systems (ACIVS); University of Liege: Ghent, Belgium, 2002; pp. 90–97. [Google Scholar]
- Lian, S.; Liu, Z.; Ren, Z.; Wang, H. Secure advanced video coding based on selective encryption algorithms. IEEE Trans. Consum. Electron. 2006, 52, 621–629. [Google Scholar] [CrossRef]
- Grangetto, M.; Magli, E.; Olmo, G. Multimedia selective encryption by means of randomized arithmetic coding. IEEE Trans. Multimed. 2006, 8, 905–917. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Mansour, M.F. Efficient Huffman Decoding with Table Lookup. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 2, pp. II–53–II–56. [Google Scholar] [CrossRef]
- Rubin, F. Cryptographic aspects of data compression codes. Cryptologia 1979, 3, 202–205. [Google Scholar] [CrossRef]
- Fraenkel, A.S.; Klein, S.T. Complexity aspects of guessing prefix codes. Algorithmica 1994, 12, 409–419. [Google Scholar] [CrossRef]
- Gillman, D.W.; Mohtashemi, M.; Rivest, R.L. On breaking a Huffman code. IEEE Trans. Inf. Theory 1996, 42, 972–976. [Google Scholar] [CrossRef]
- Muralidhar, R.B. Substitution Cipher with NonPrefix Codes. Master’s Thesis, San Jose State University, San Jose, CA, USA, 2011. [Google Scholar]
- Dodis, Y.; Smith, A. Entropic security and the encryption of high entropy messages. In Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2005; pp. 556–577. [Google Scholar]
- Russell, A.; Wang, H. How to fool an unbounded adversary with a short key. In International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2002; pp. 133–148. [Google Scholar]
- Ryabko, B.Y. A Simply Realizable Ideal Cryptographic System. Probl. Peredachi Inf. 2000, 36, 90–95. [Google Scholar]
- Stergiou, C.; Psannis, K.E. Efficient and secure big data delivery in cloud computing. Multimed. Tools Appl. 2017, 76, 22803–22822. [Google Scholar] [CrossRef]
- Kulekci, M.O. An Efficient Encryption Method to Secure Data with Reduced Number of Encryption Operations. U.S. Patent 15/779,853, 6 December 2018. [Google Scholar]
Sample Availability: The implementation of the proposed non-UD coding is available at https://github.com/qua11q7/NPFCoding. |



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).