Research on Quantitative Investment Strategies Based on Deep Learning


Abstract
:1. Introduction
2. Literature Review
3. Models and Quantitative Investment Strategy
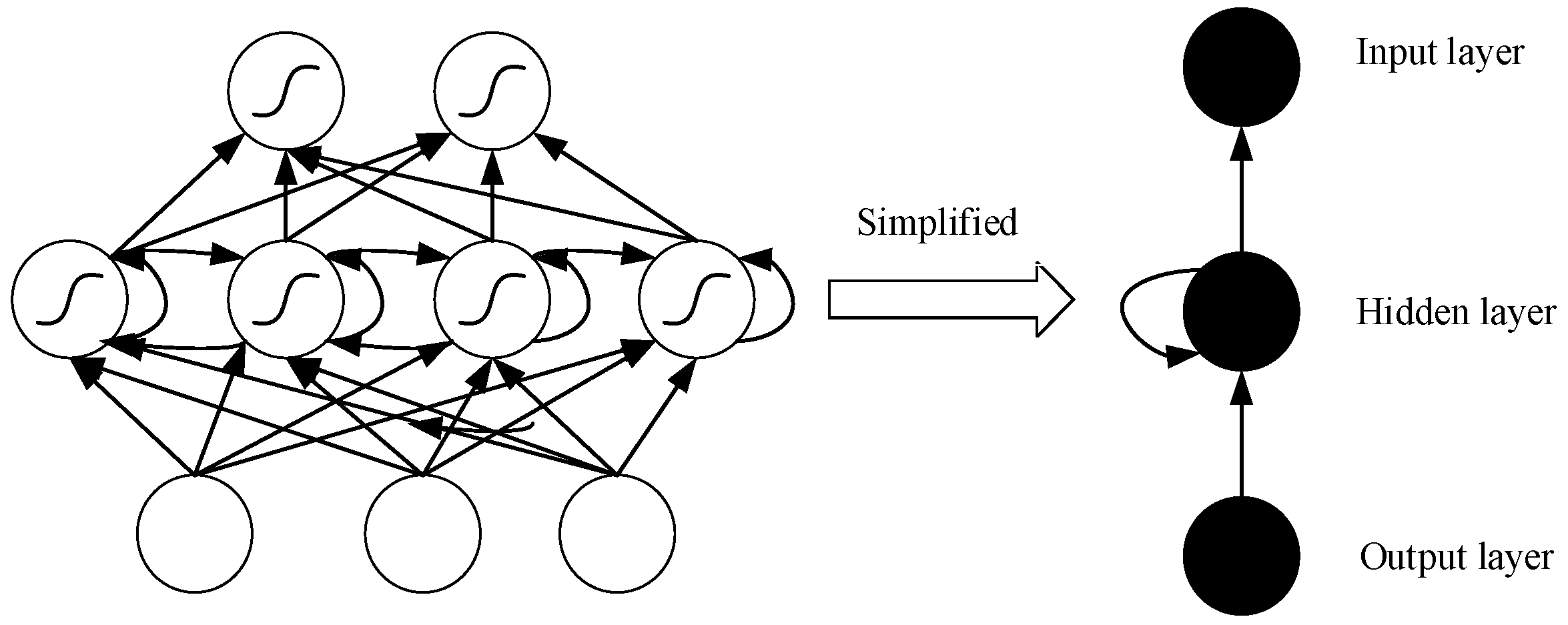
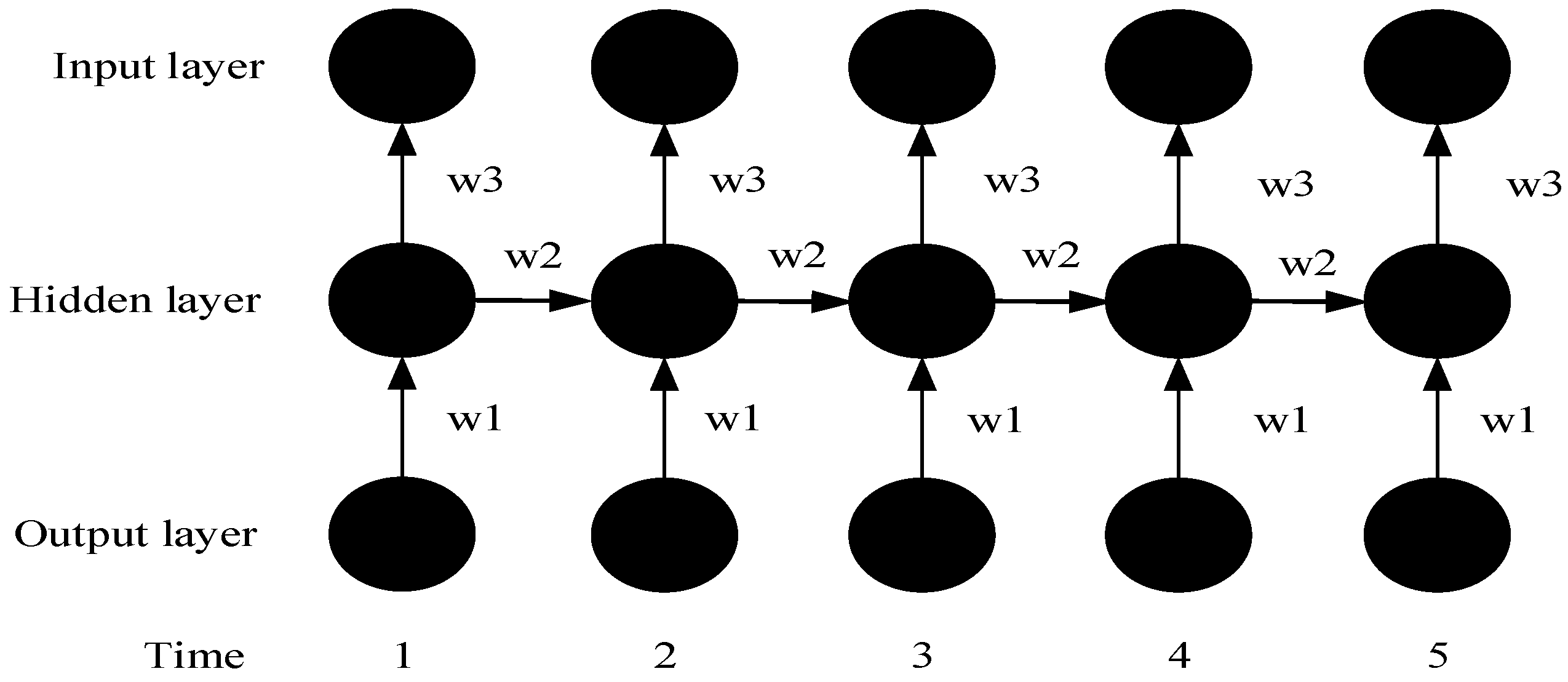
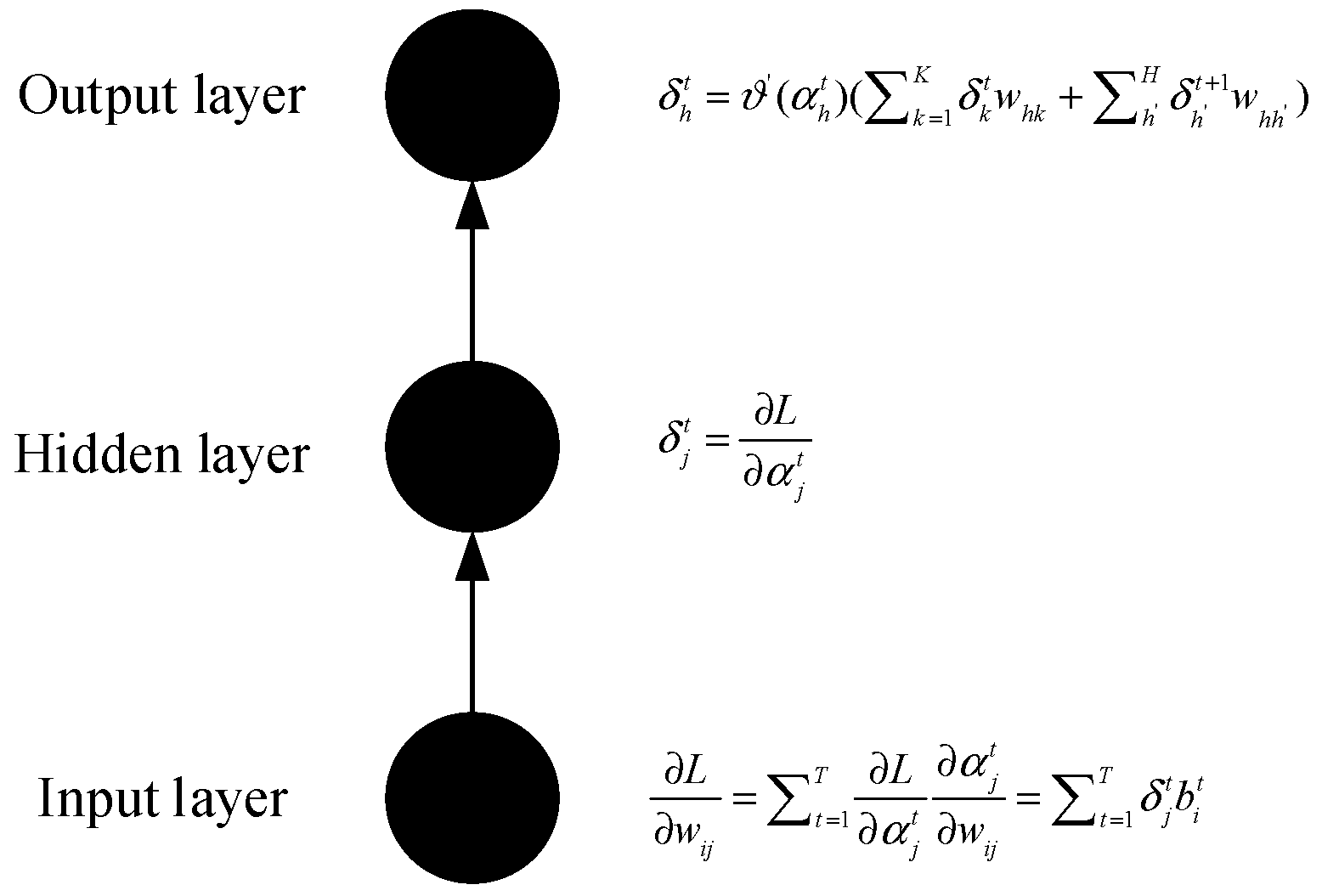
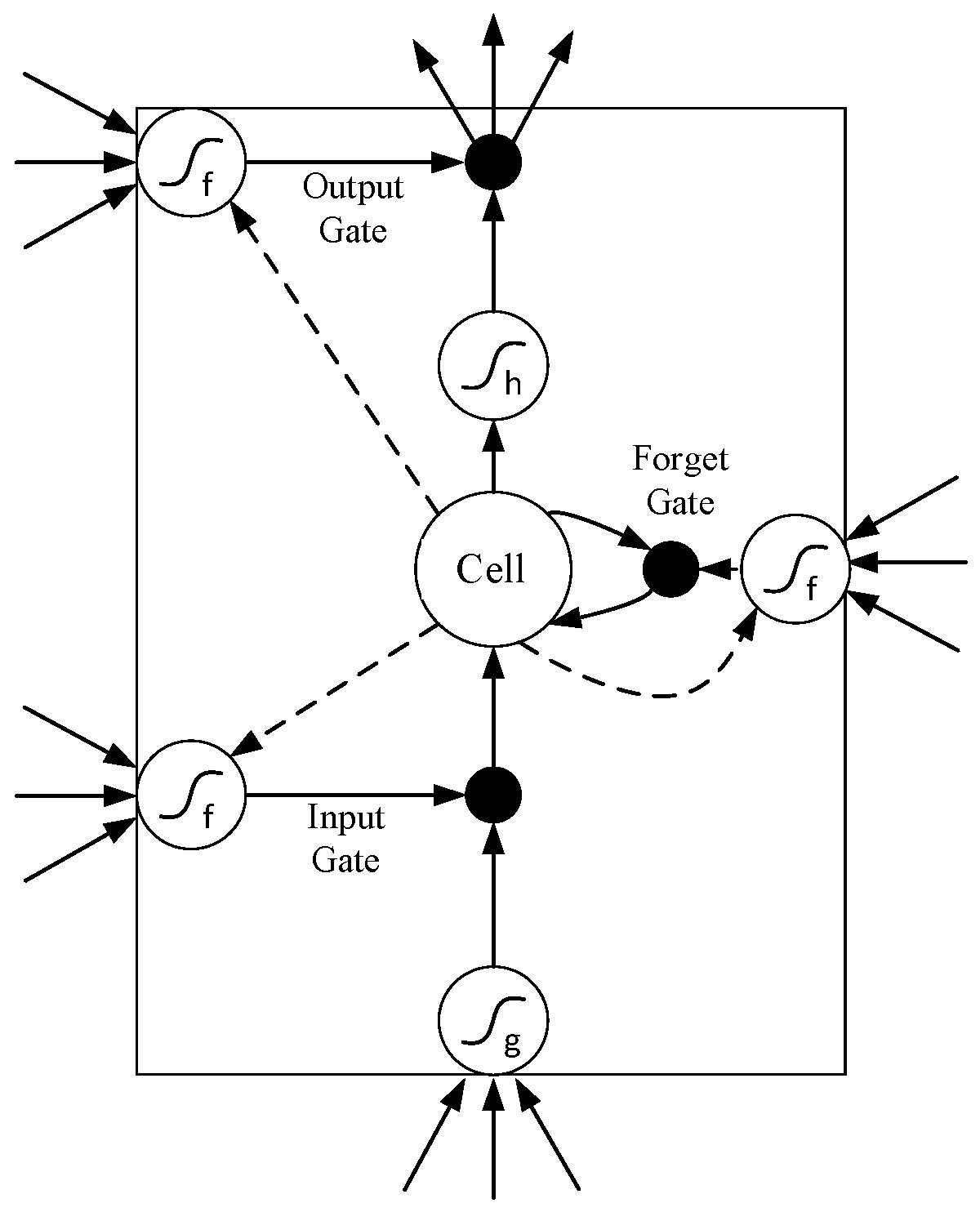
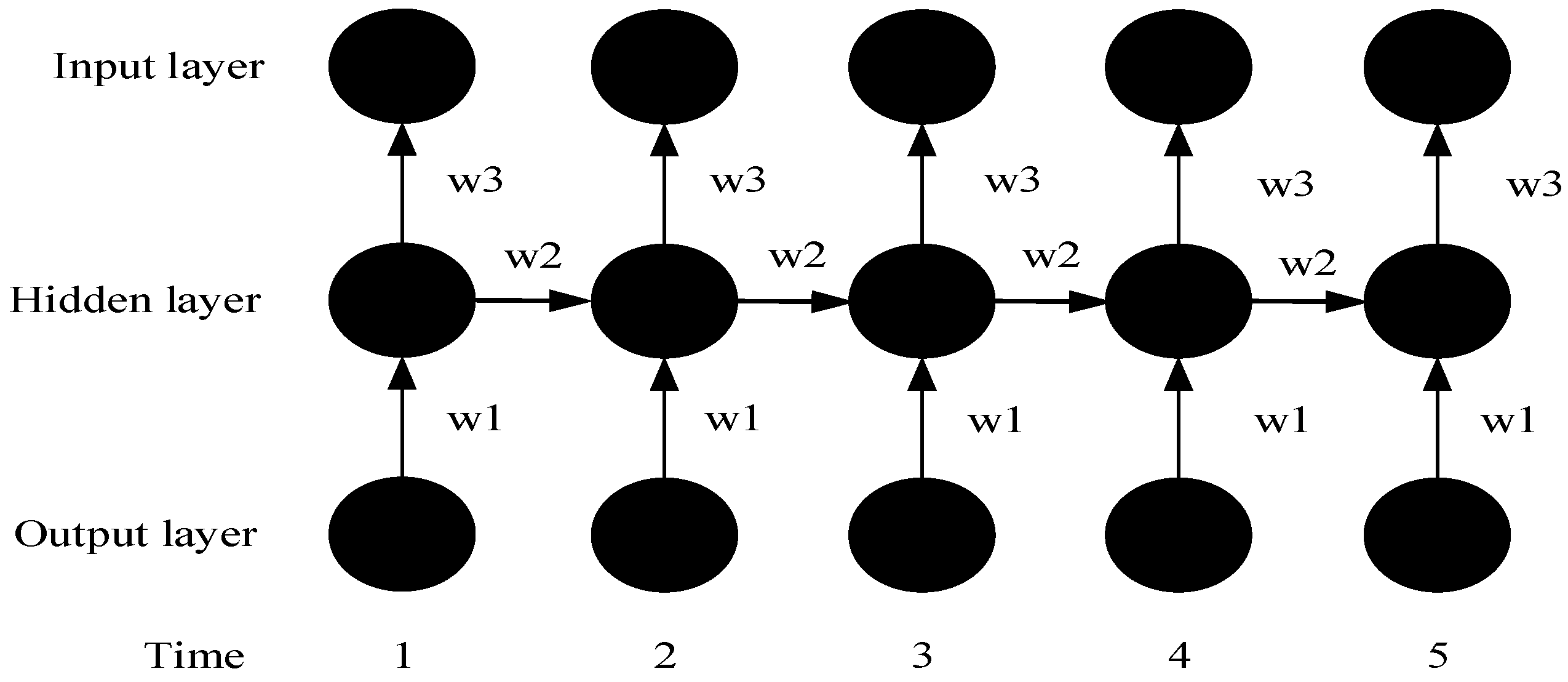
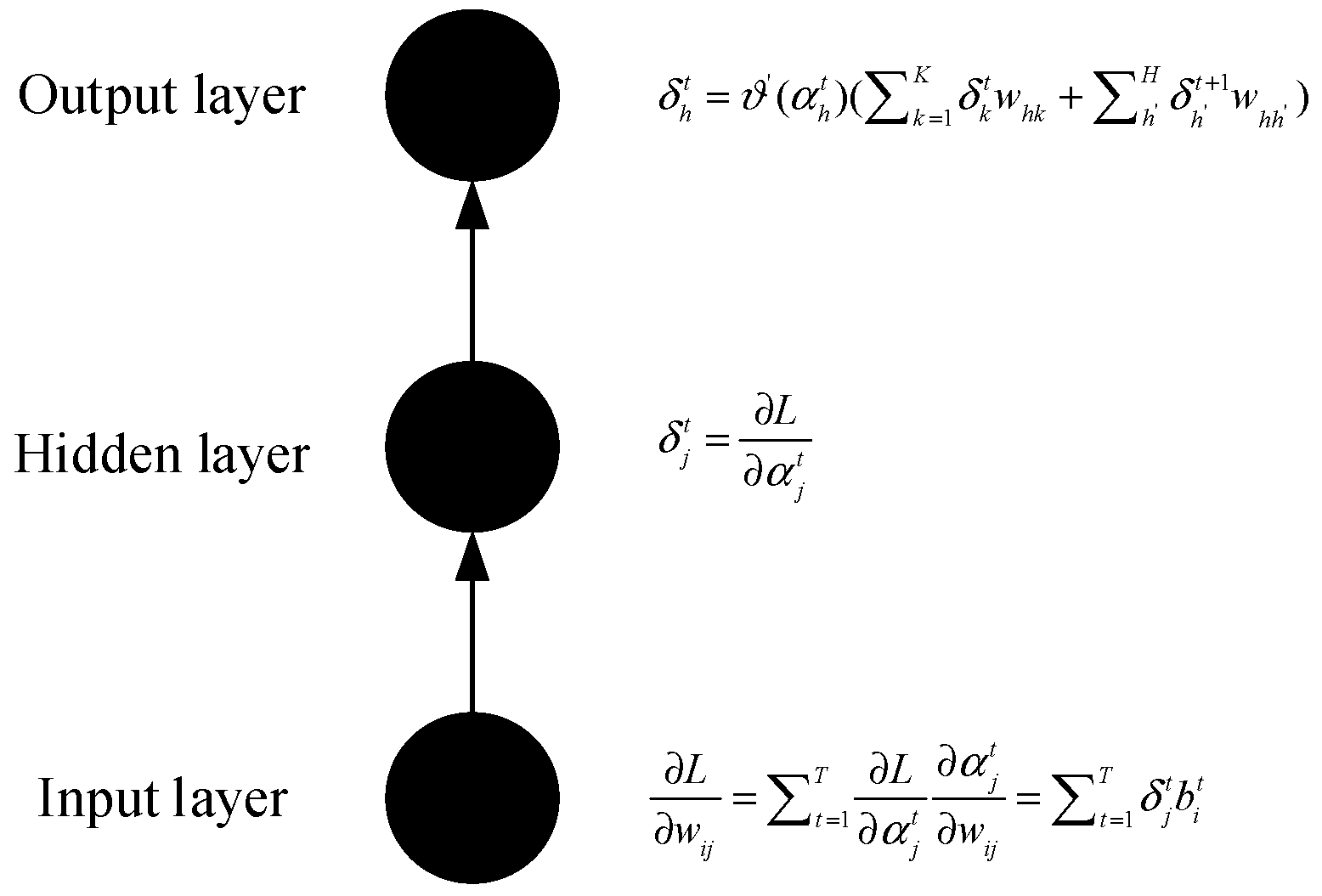
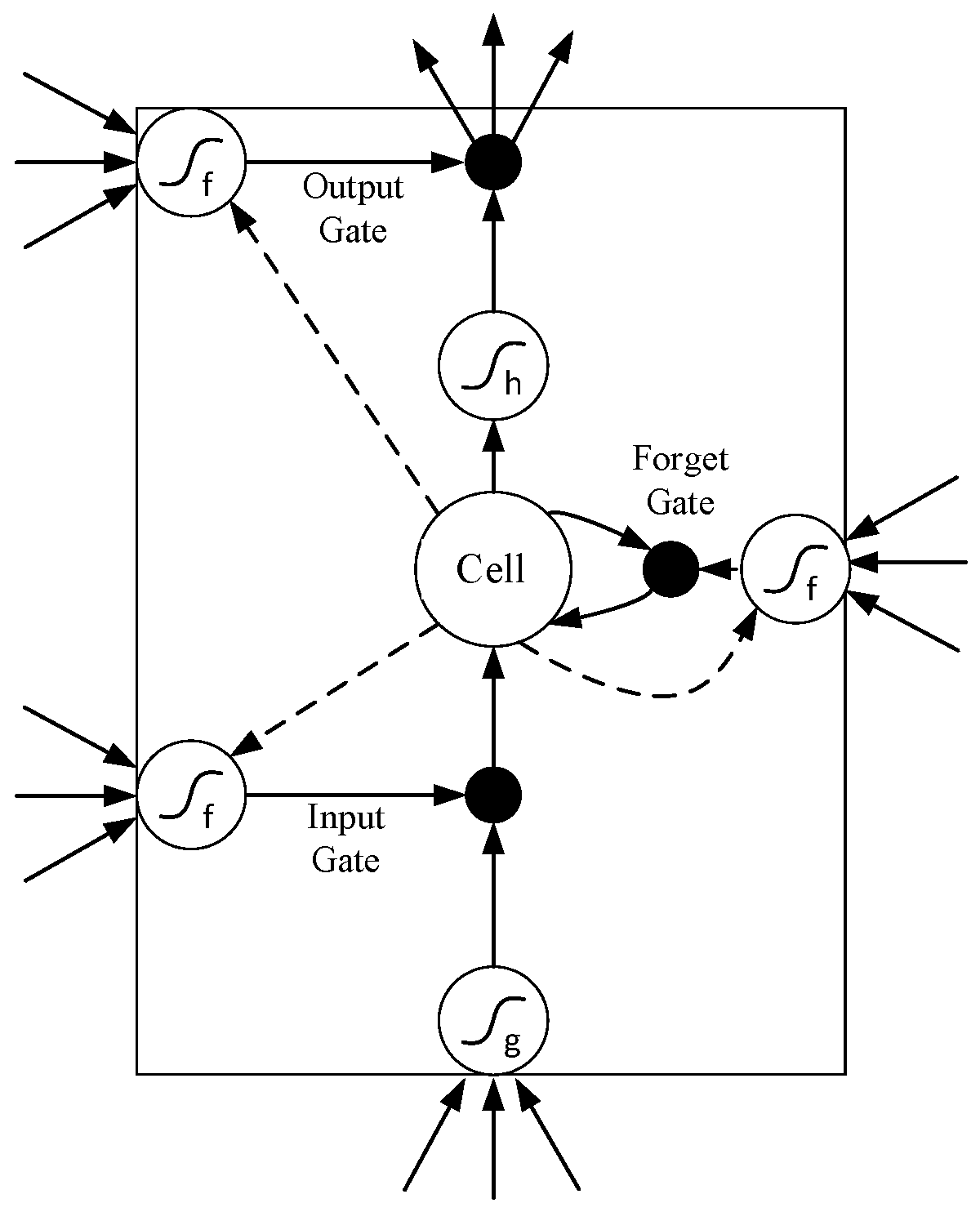
3.1. Long Short-Term Memory (LSTM) Model
3.2. The Support Vector Regression Model
3.3. Quantitative Investment Strategies
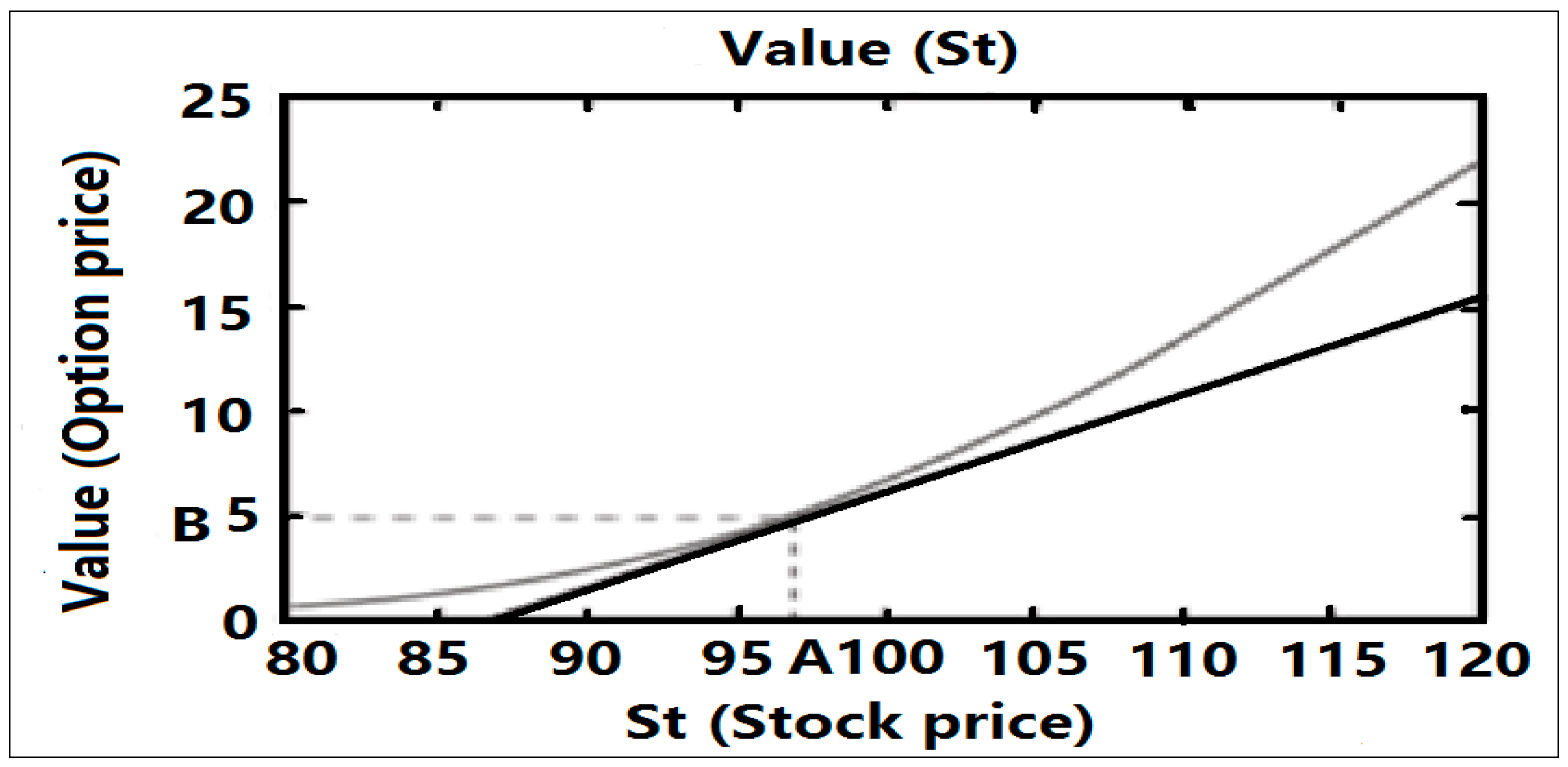
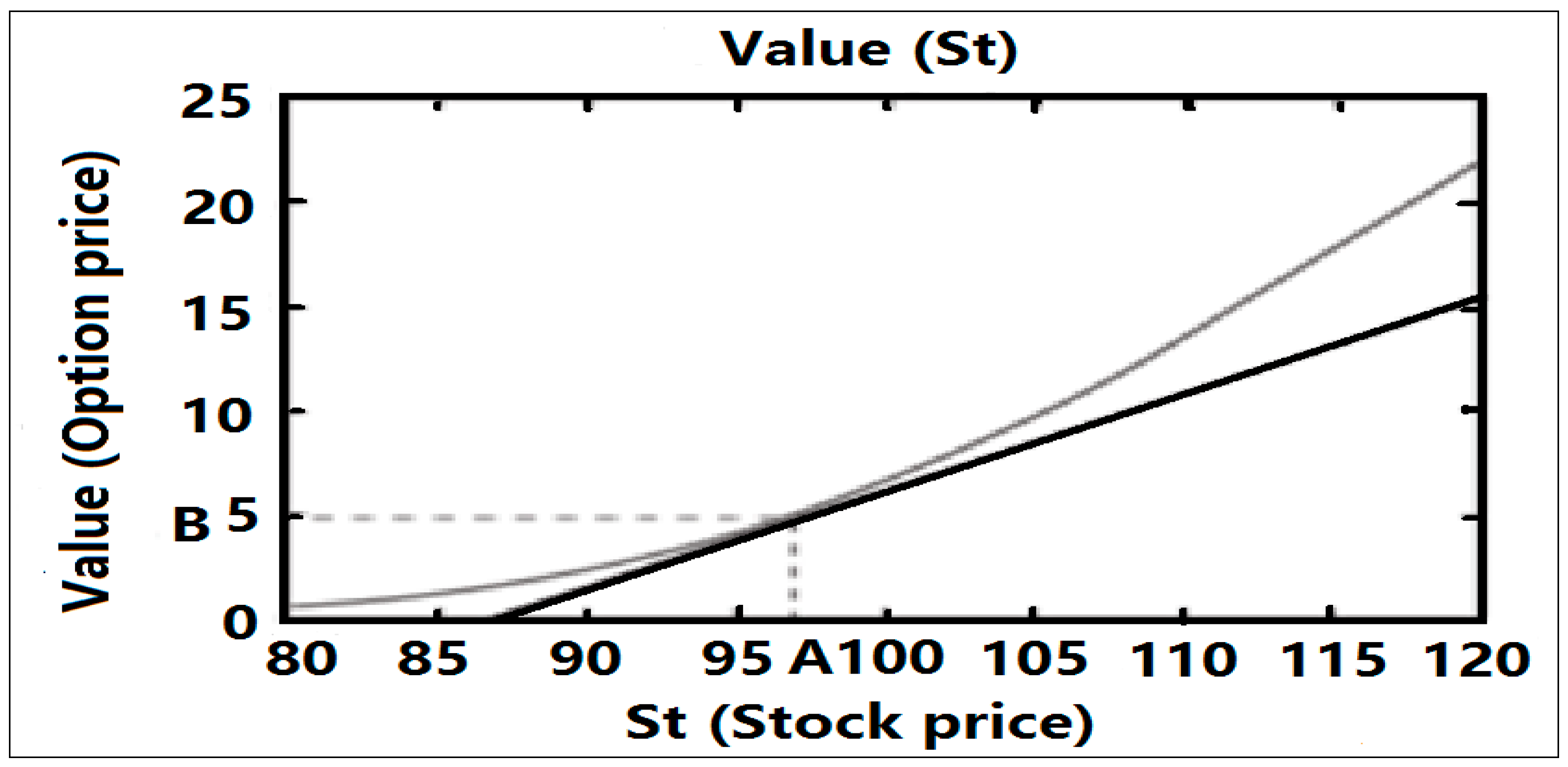
3.3.1. Introduction to the Basics of Options
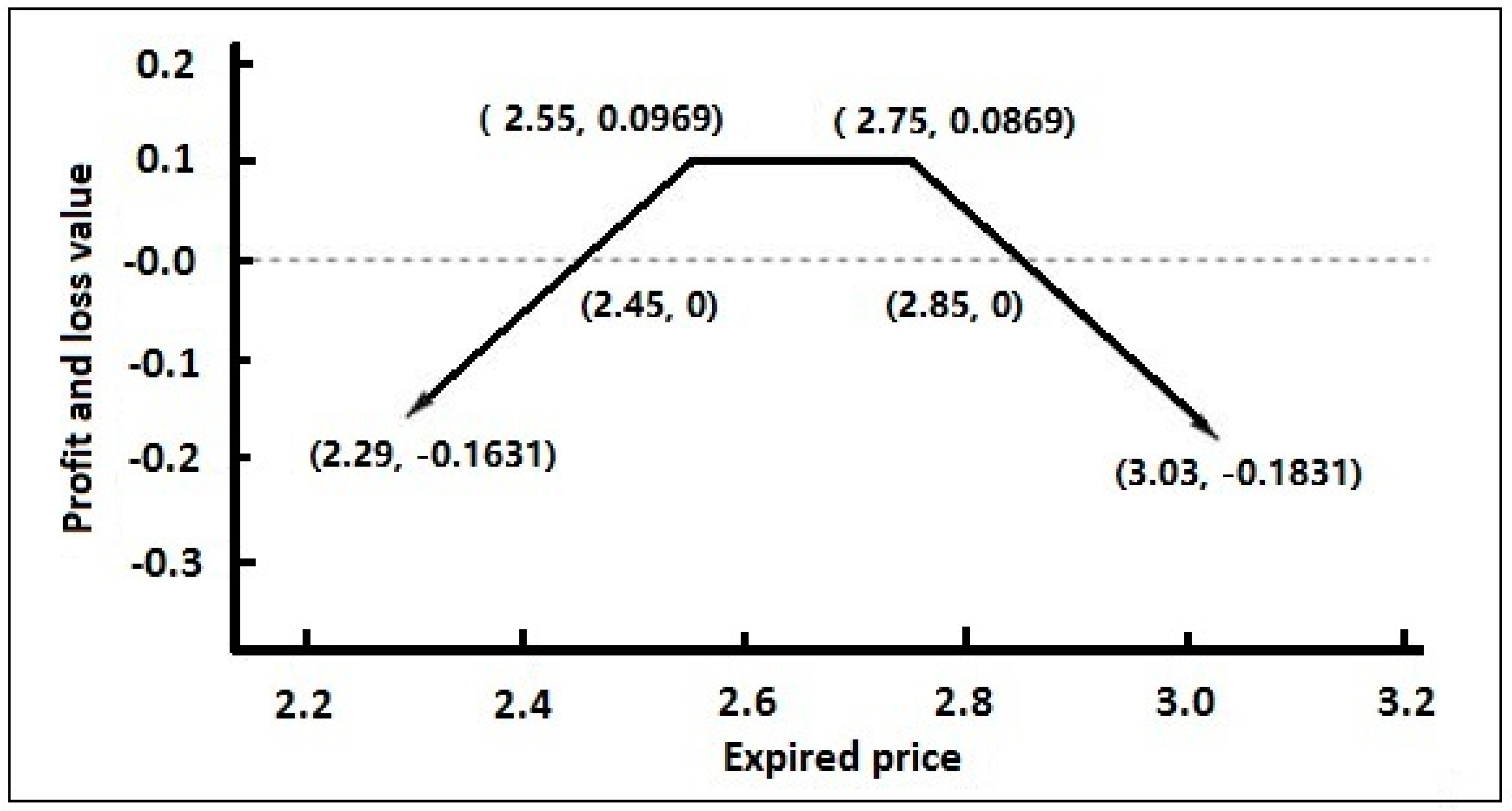
3.3.2. Introduction to Quantitative Investment Strategies
4. Experimental Simulation
4.1. Data Acquisition
4.2. Data Processing
4.2.1. Calculating Historical Volatility
4.2.2. Calculating Implied Volatility
4.2.3. Normalization and Standardization
4.3. Parameters Determination
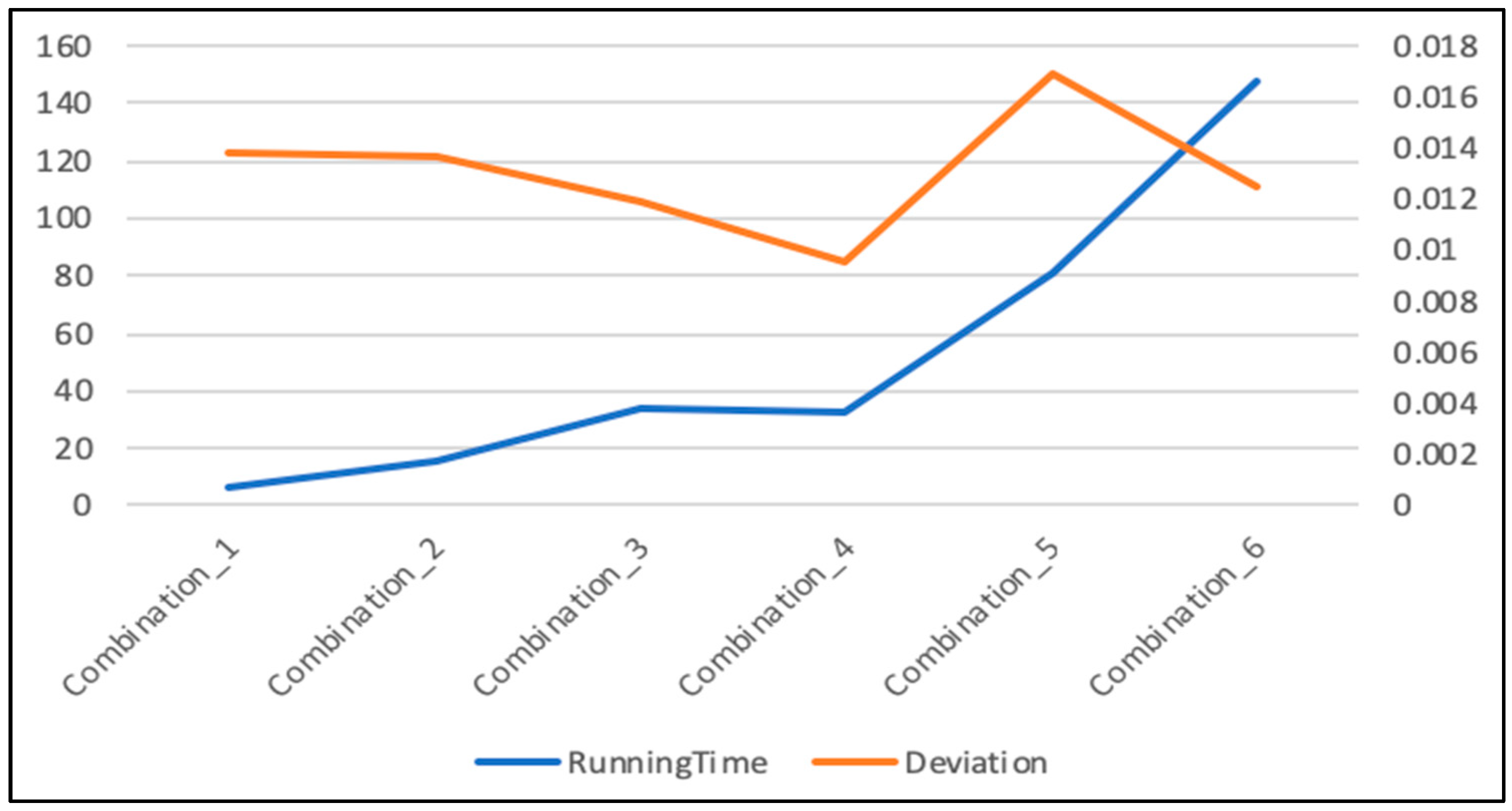
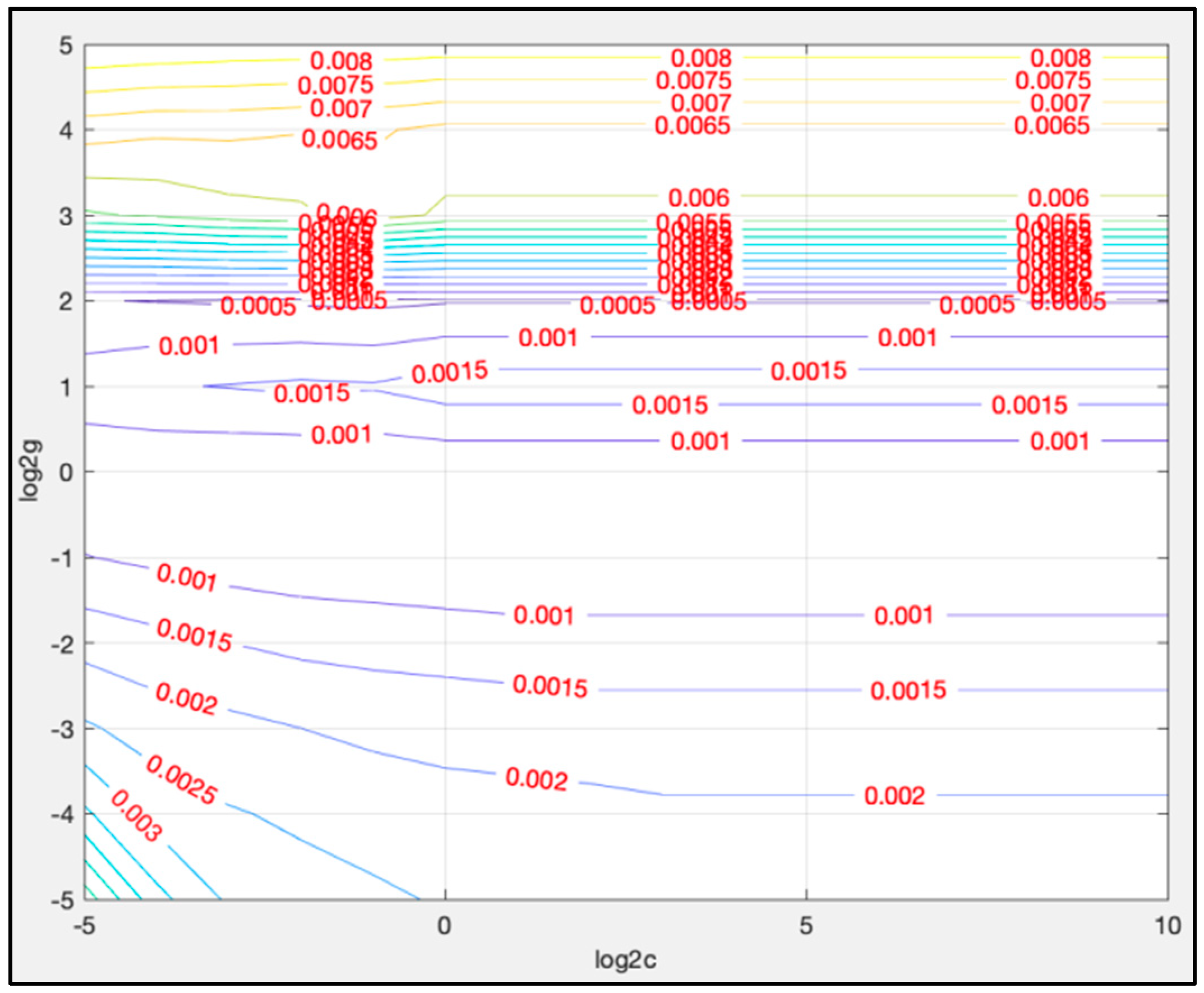
4.3.1. Parameter Determination for LSTM
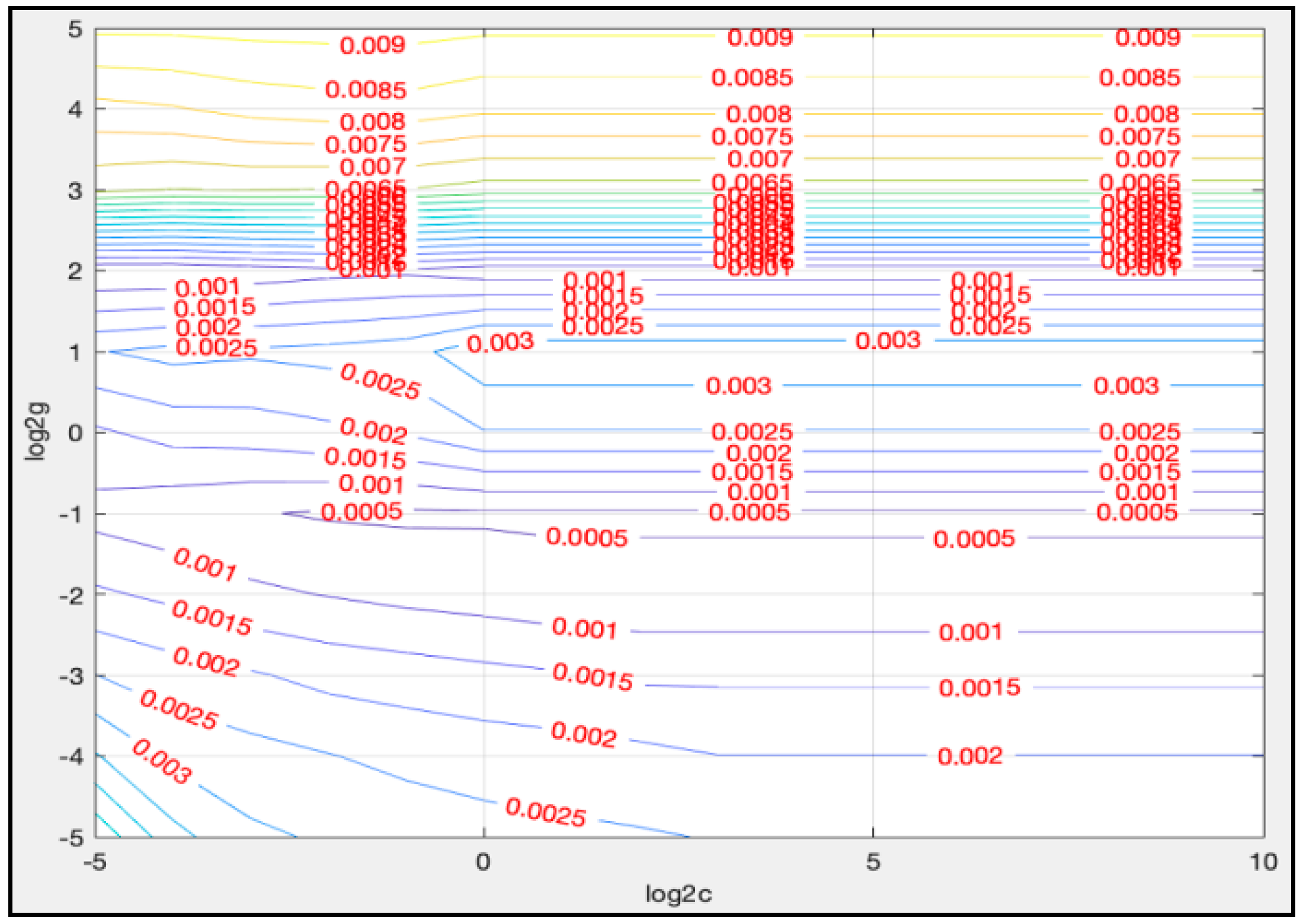
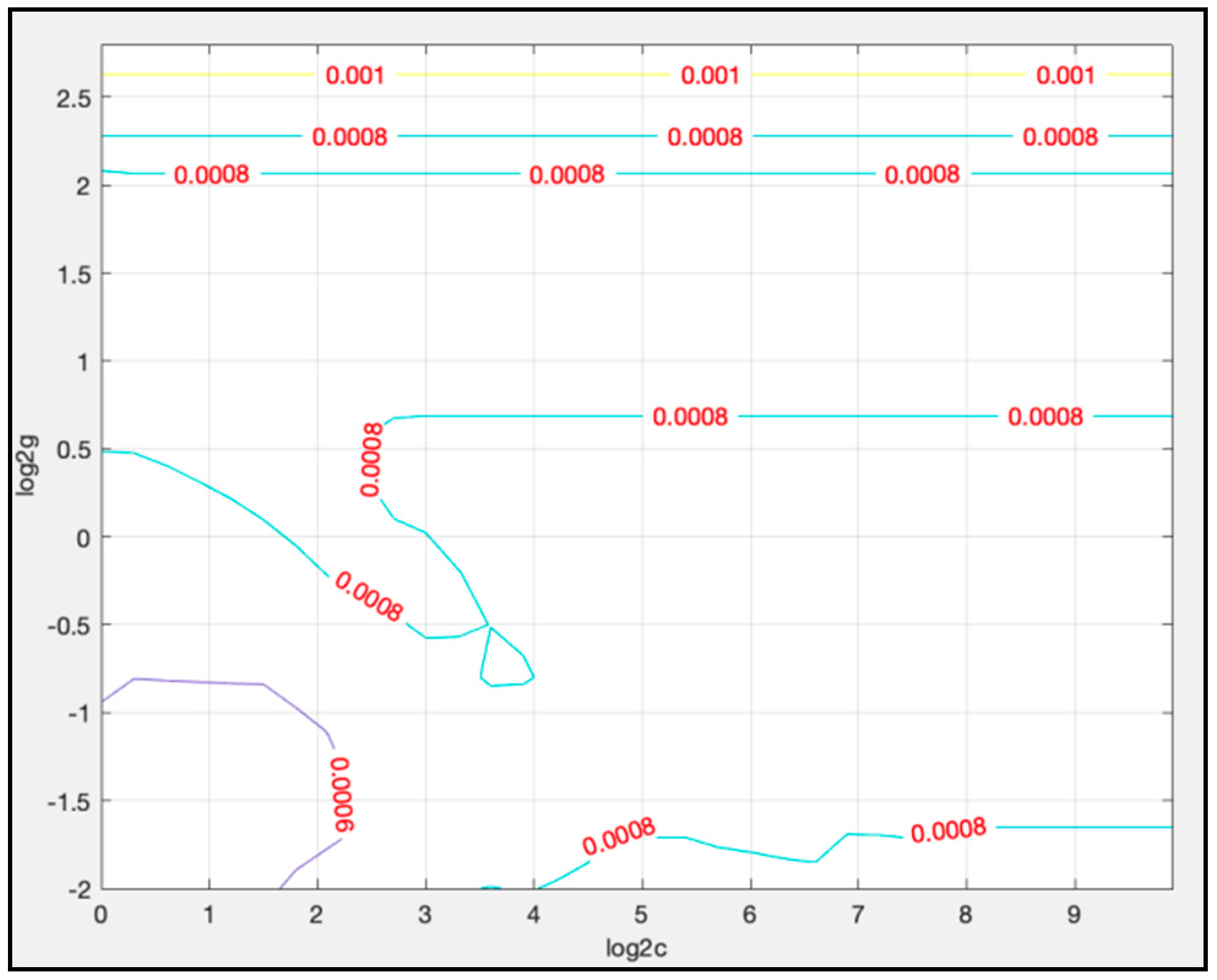
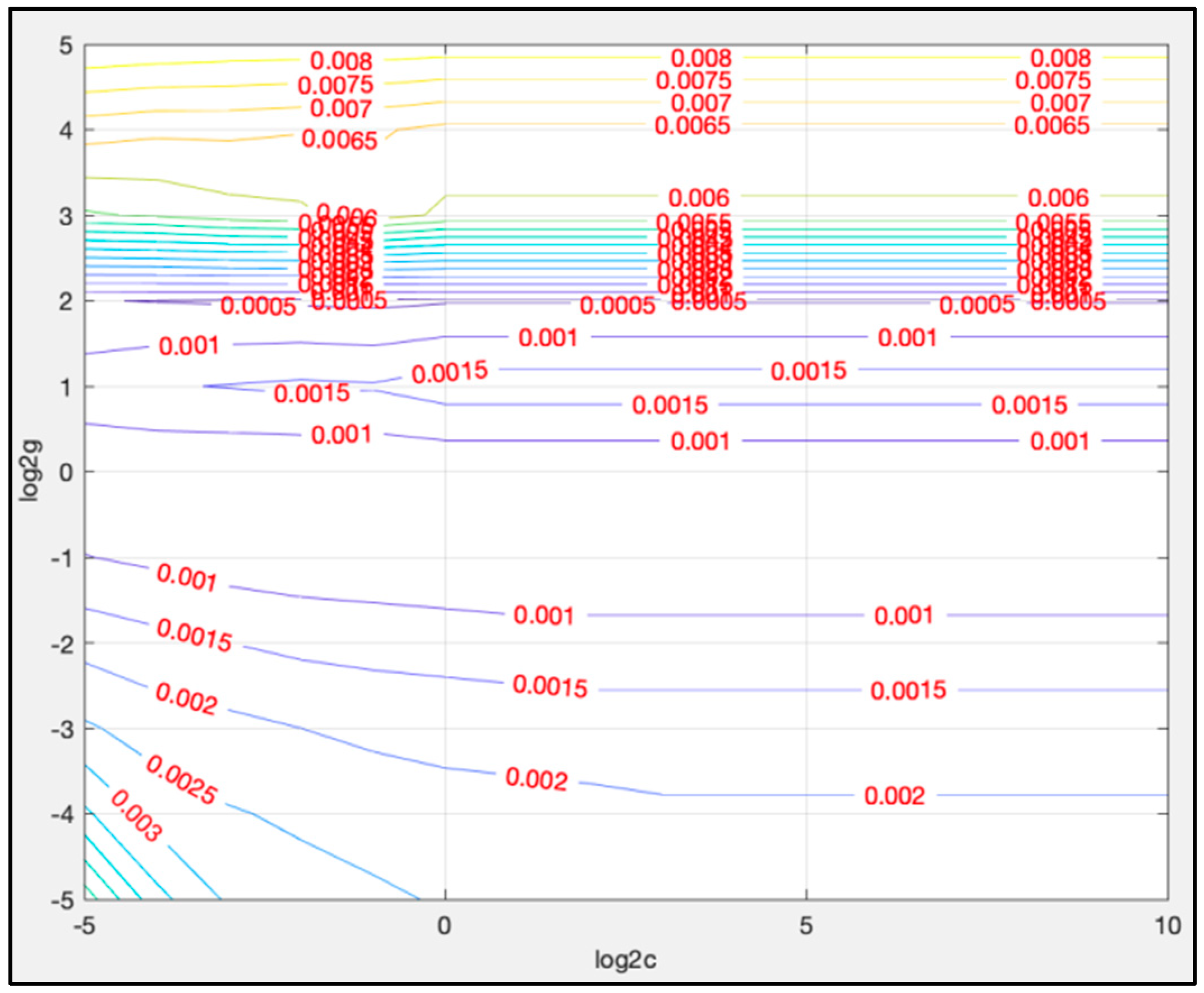
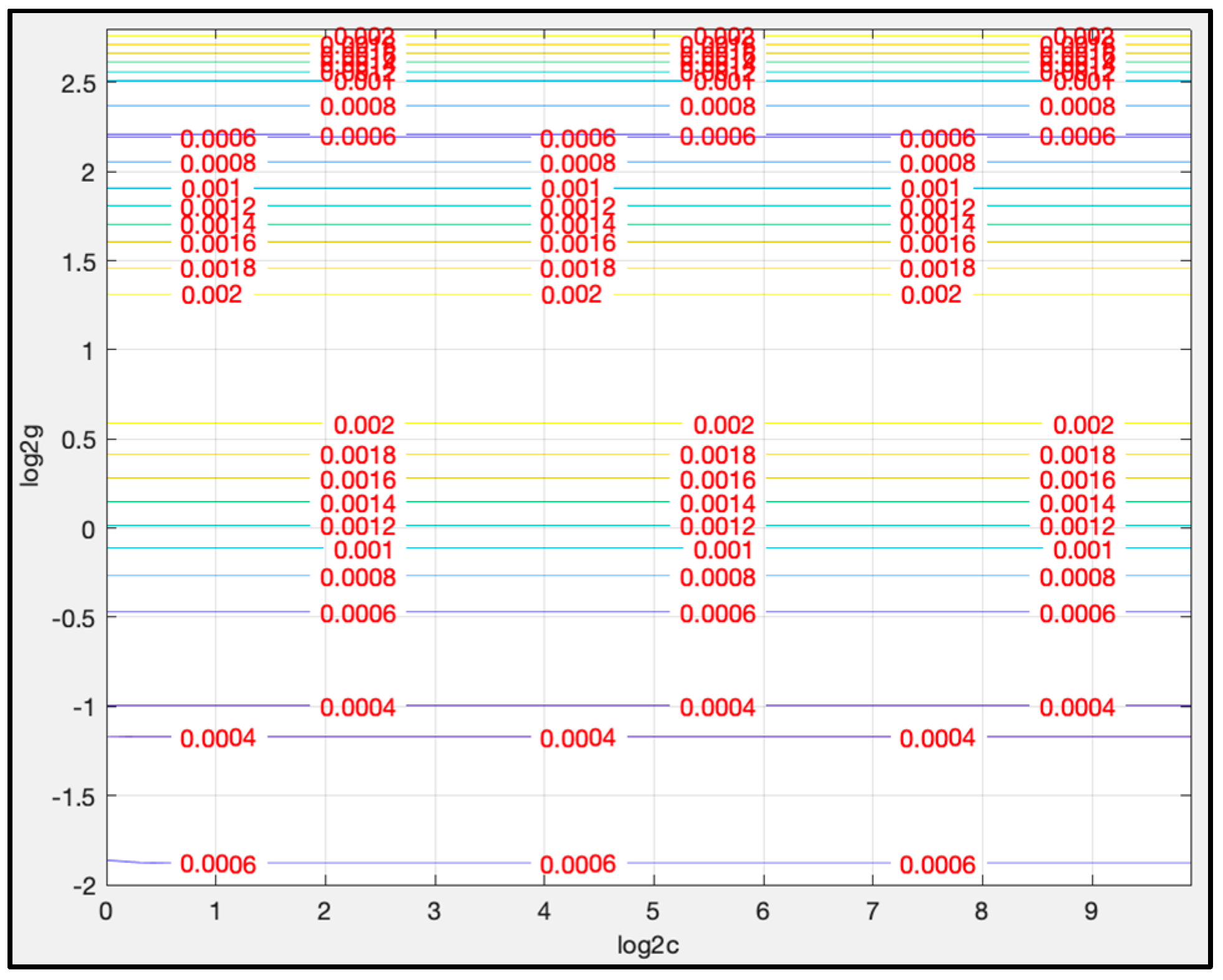
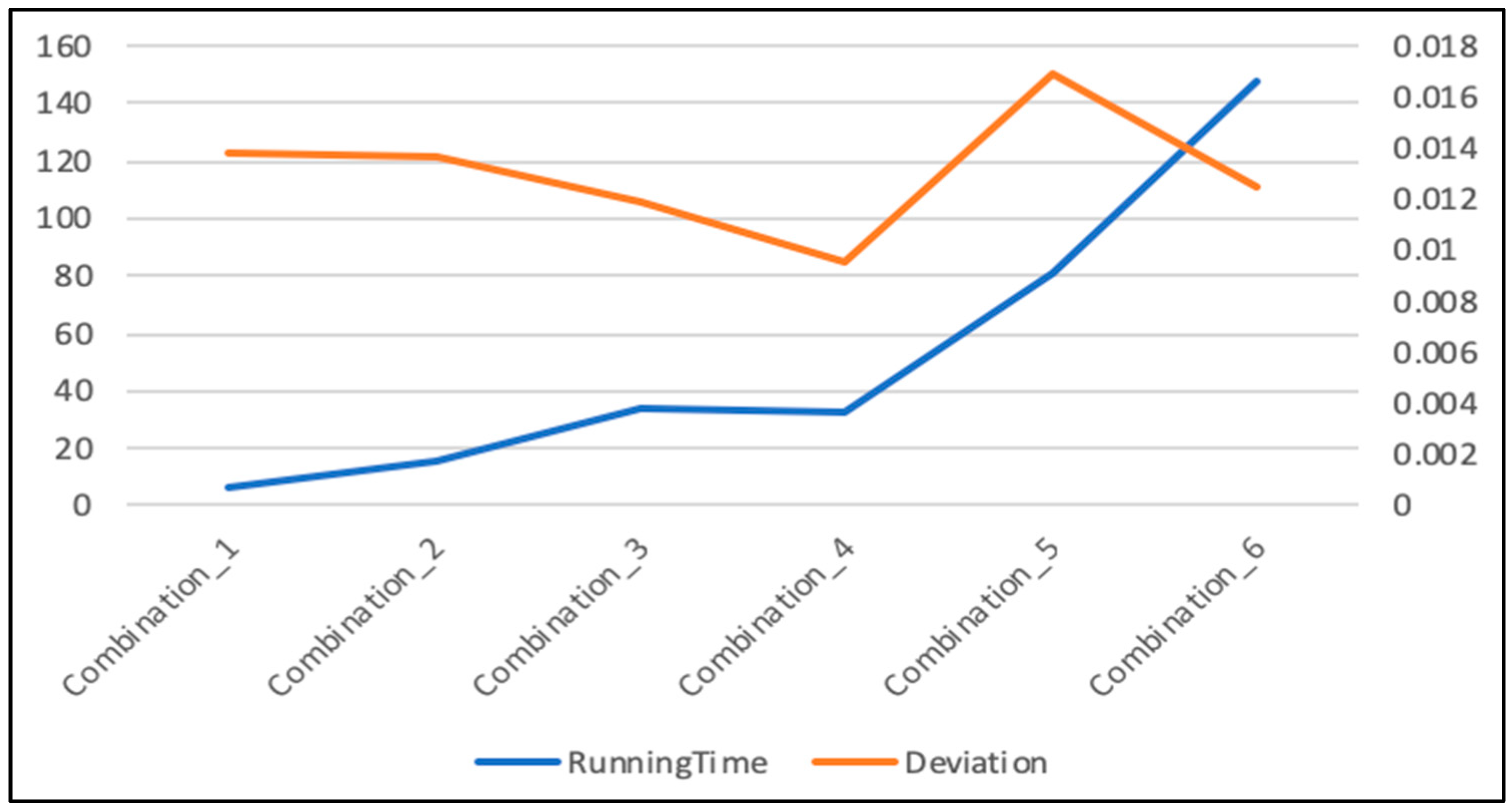
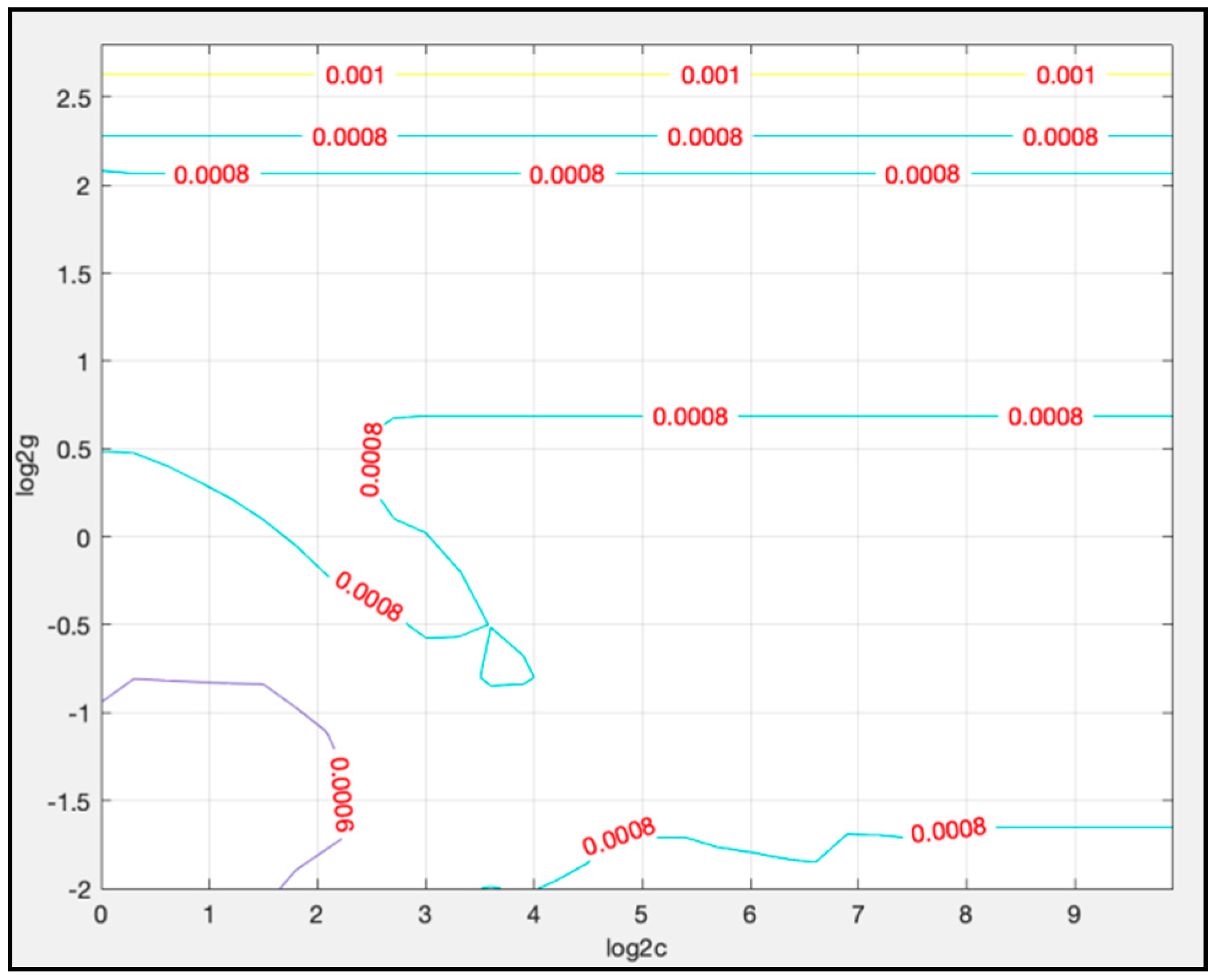
4.3.2. Parameters Determination for LSTM-SVR
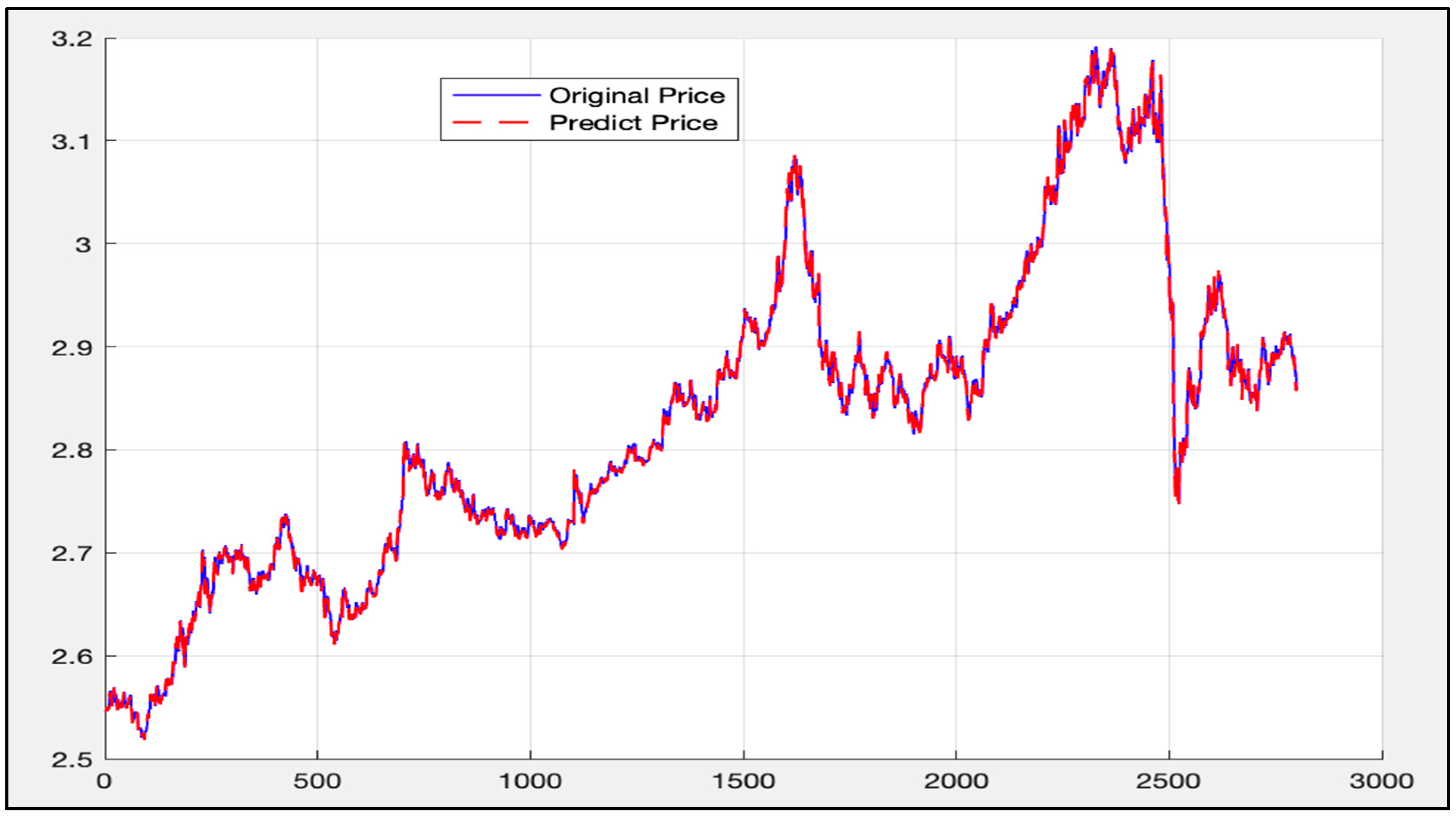
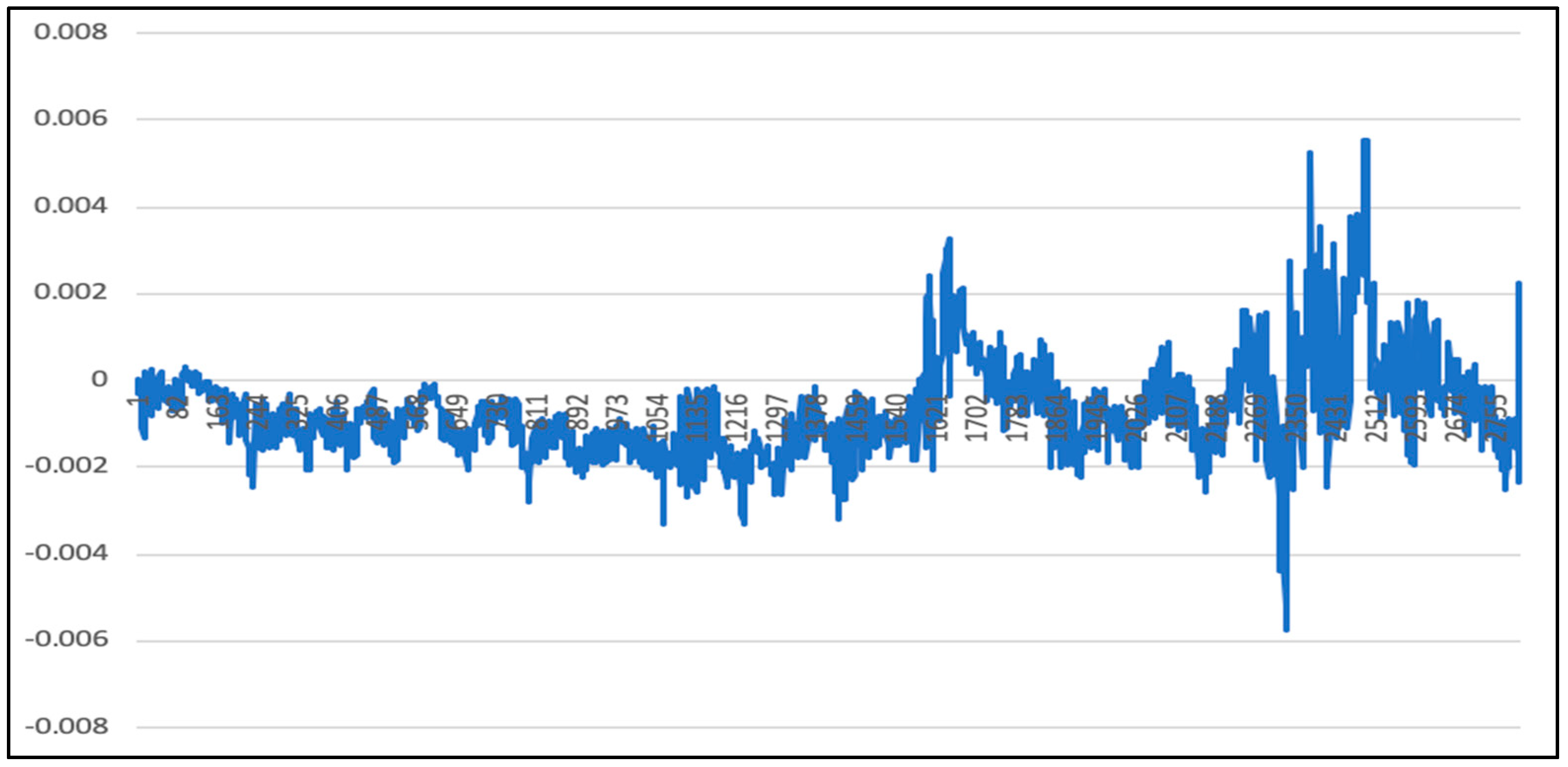
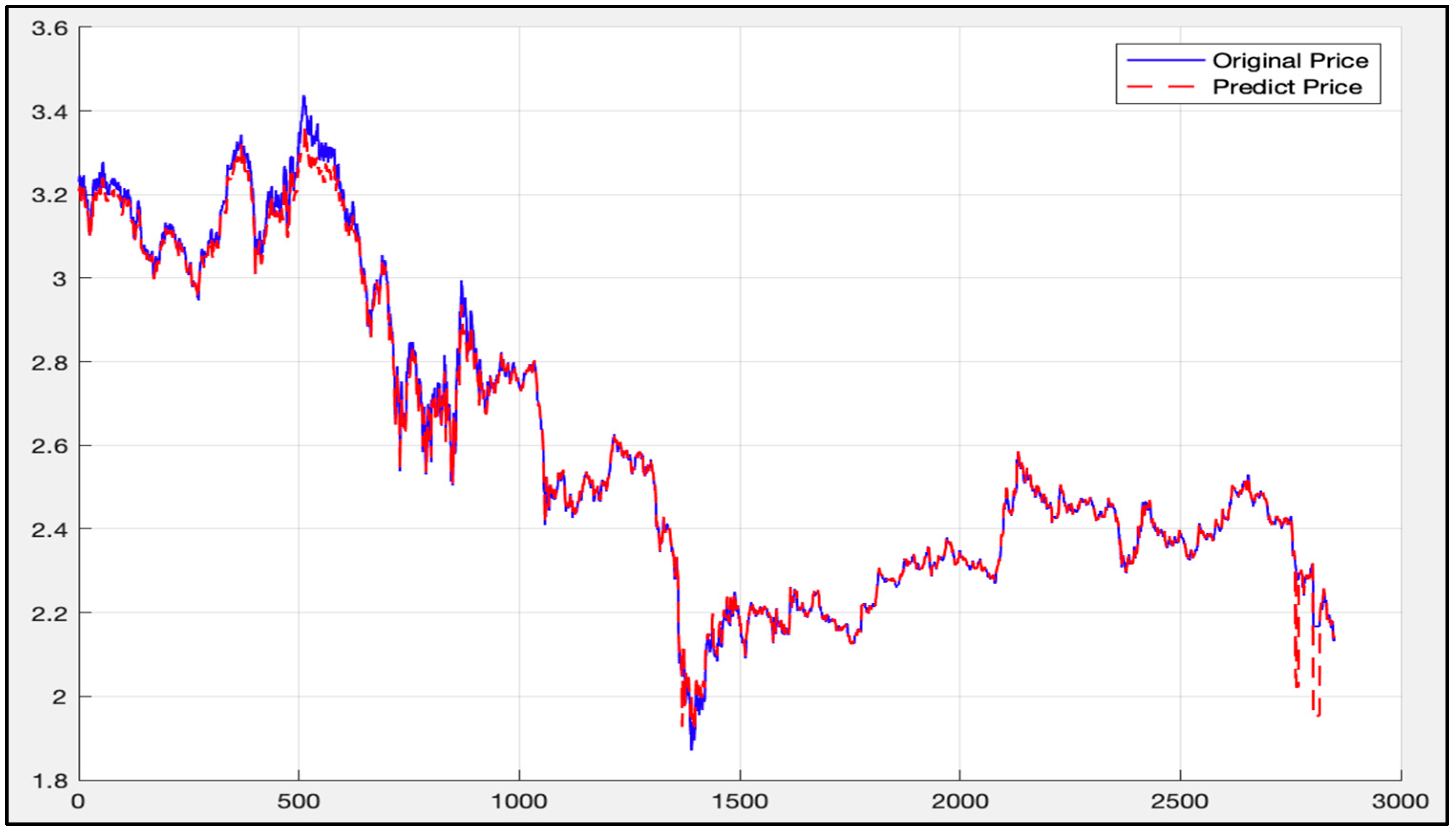
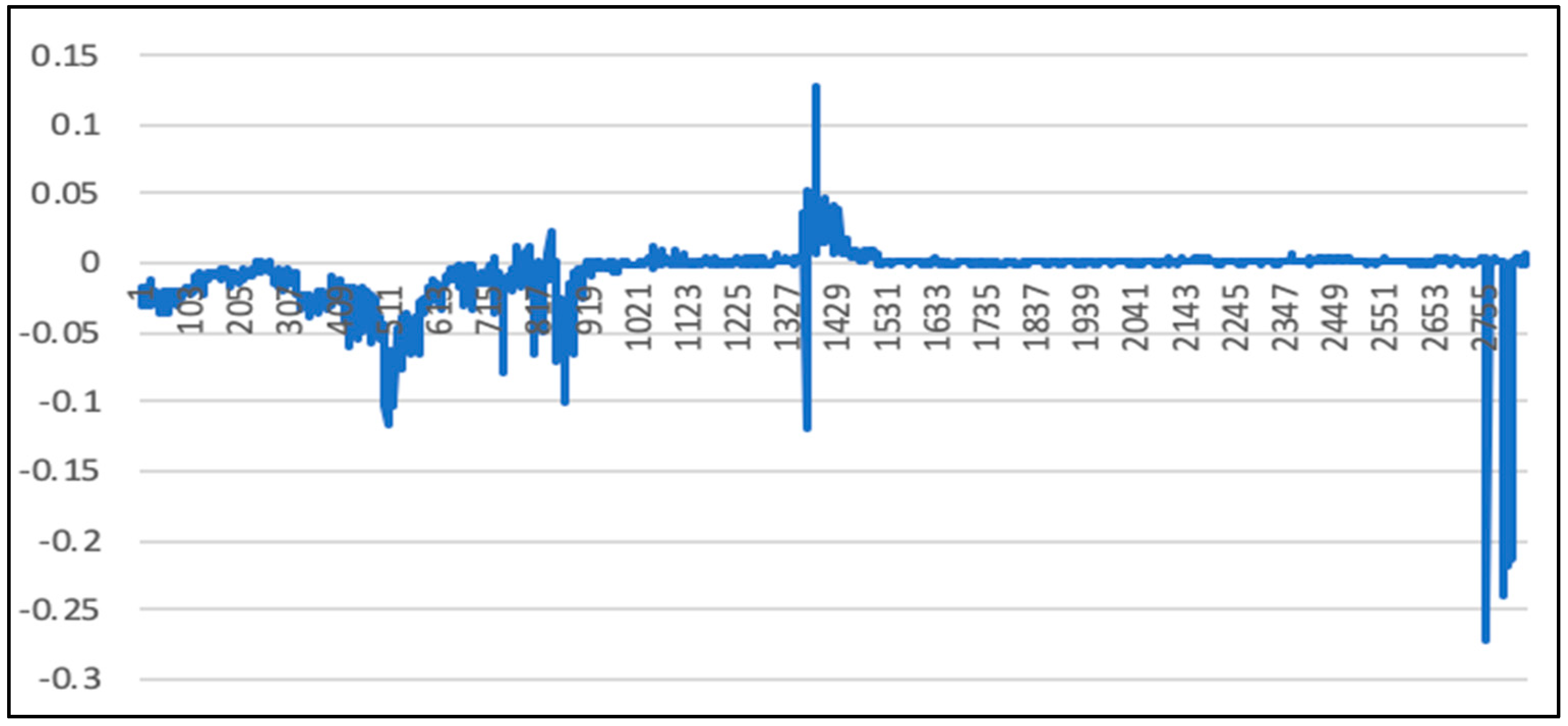
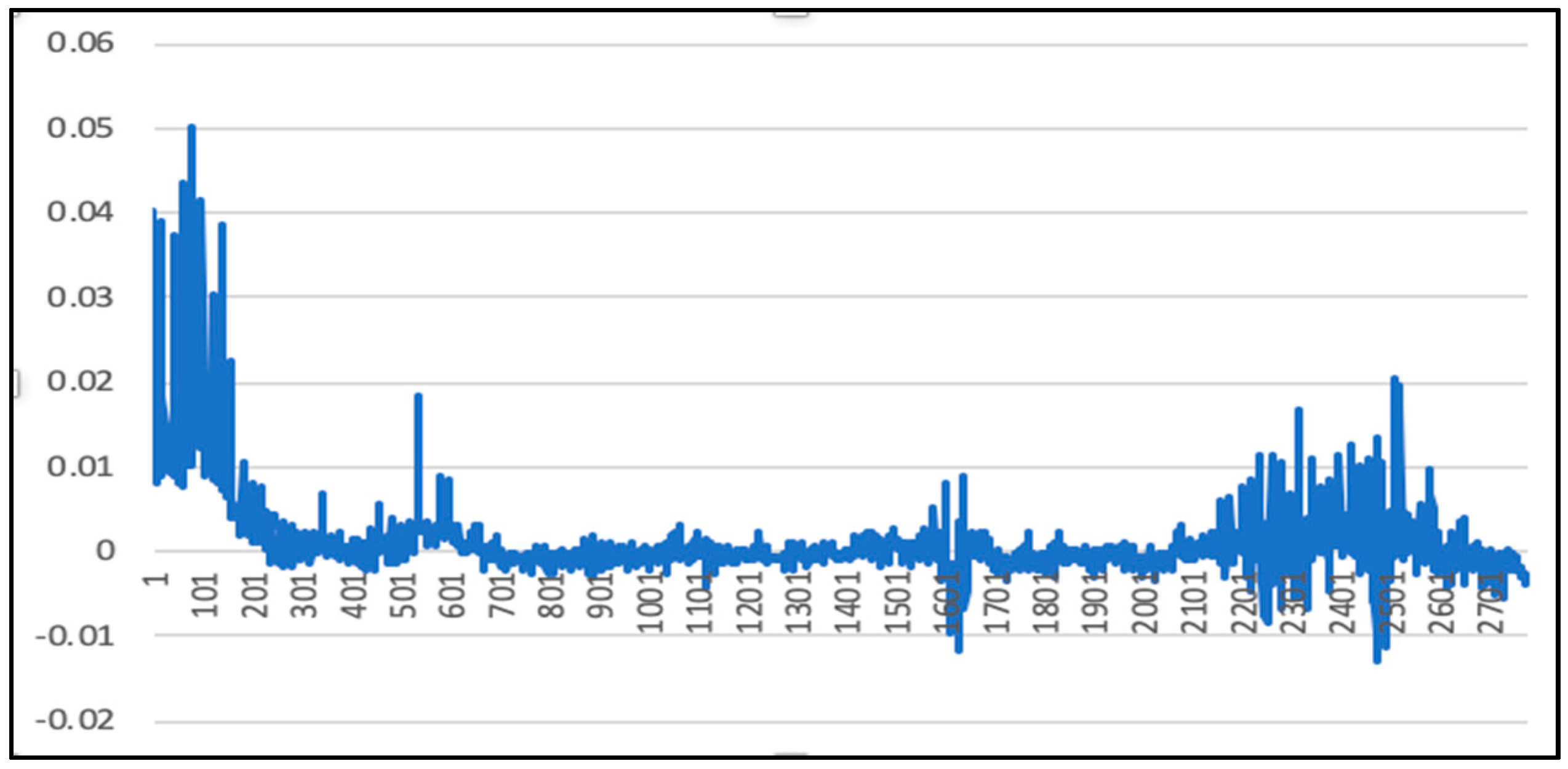
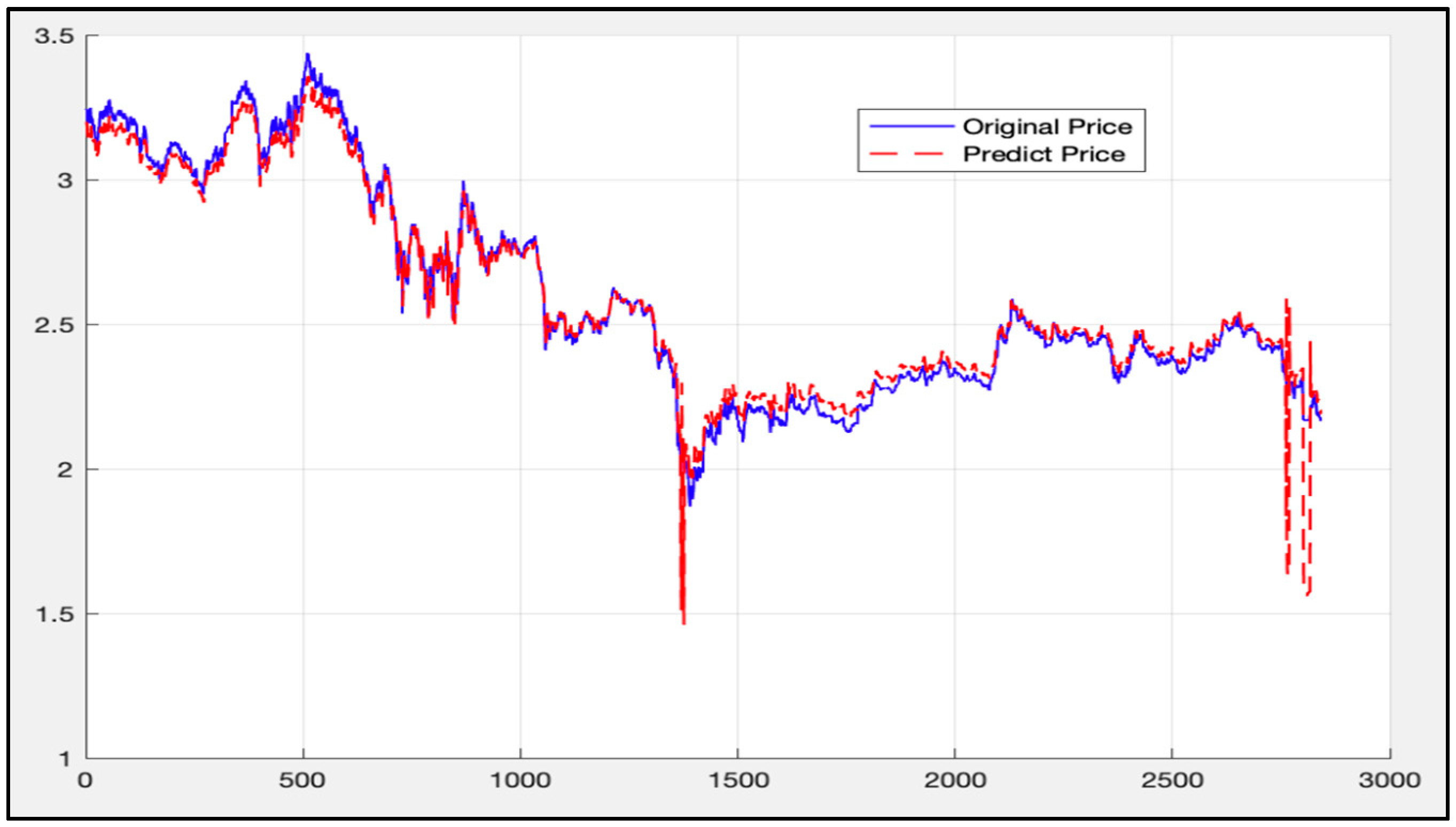
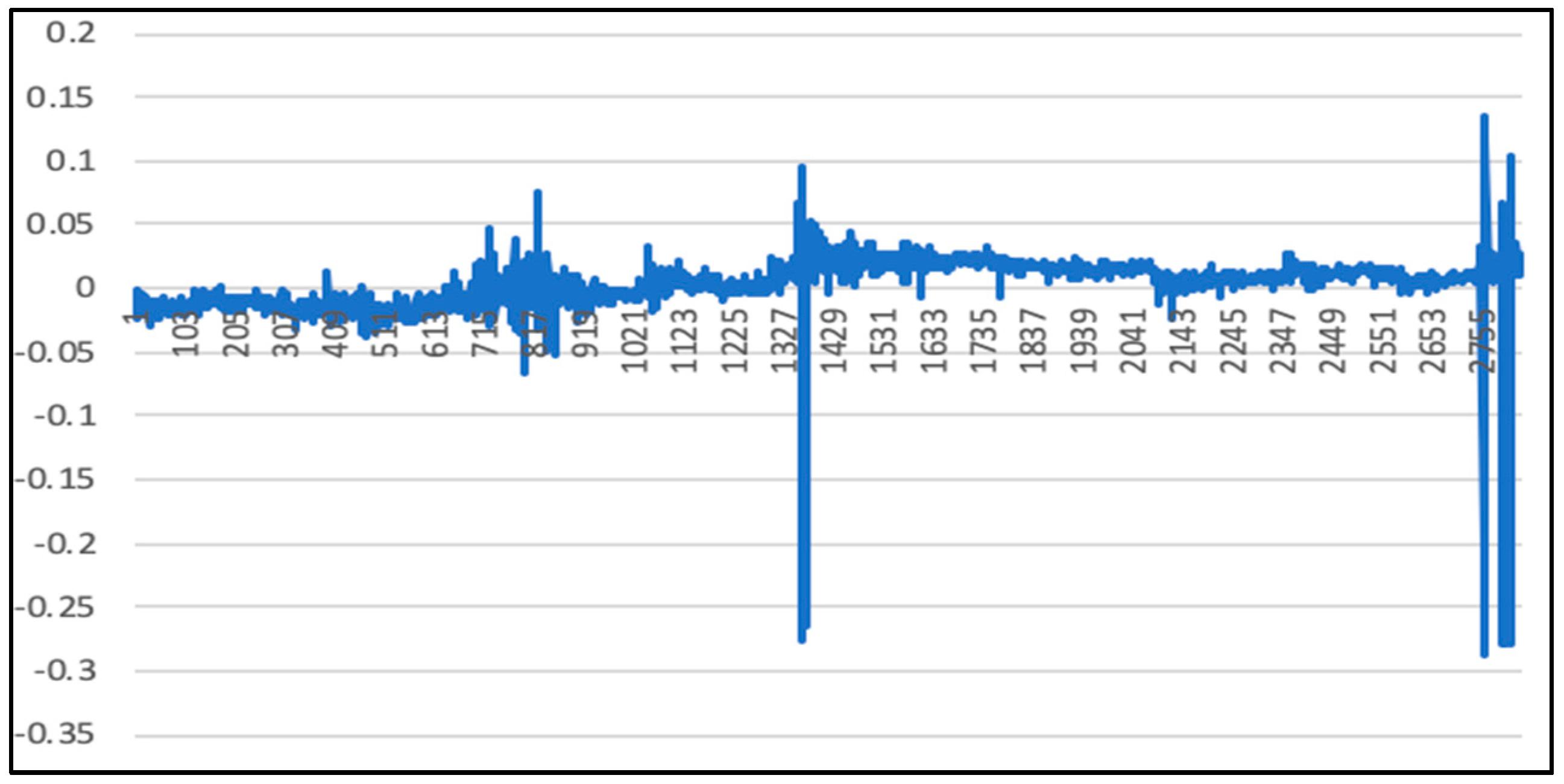
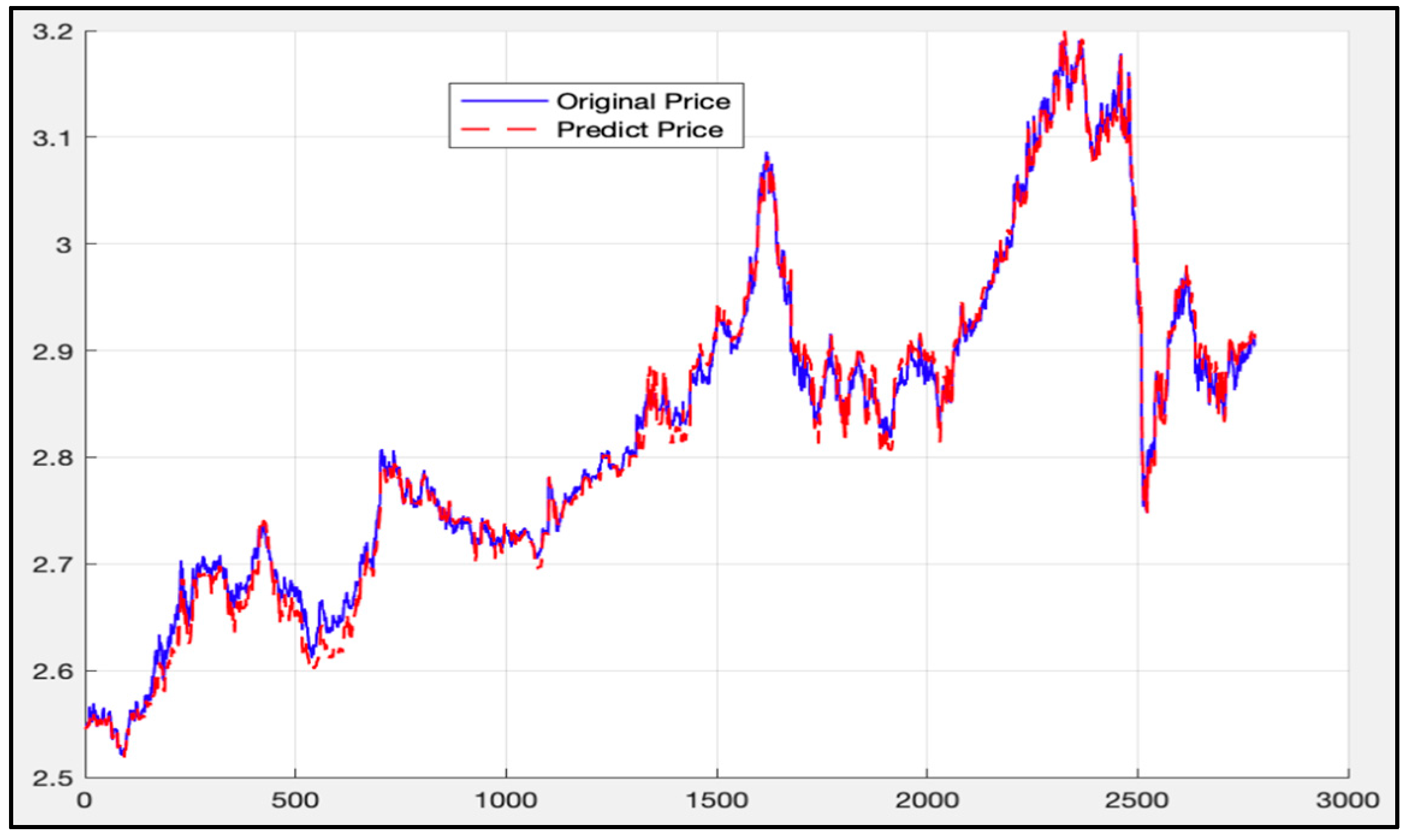
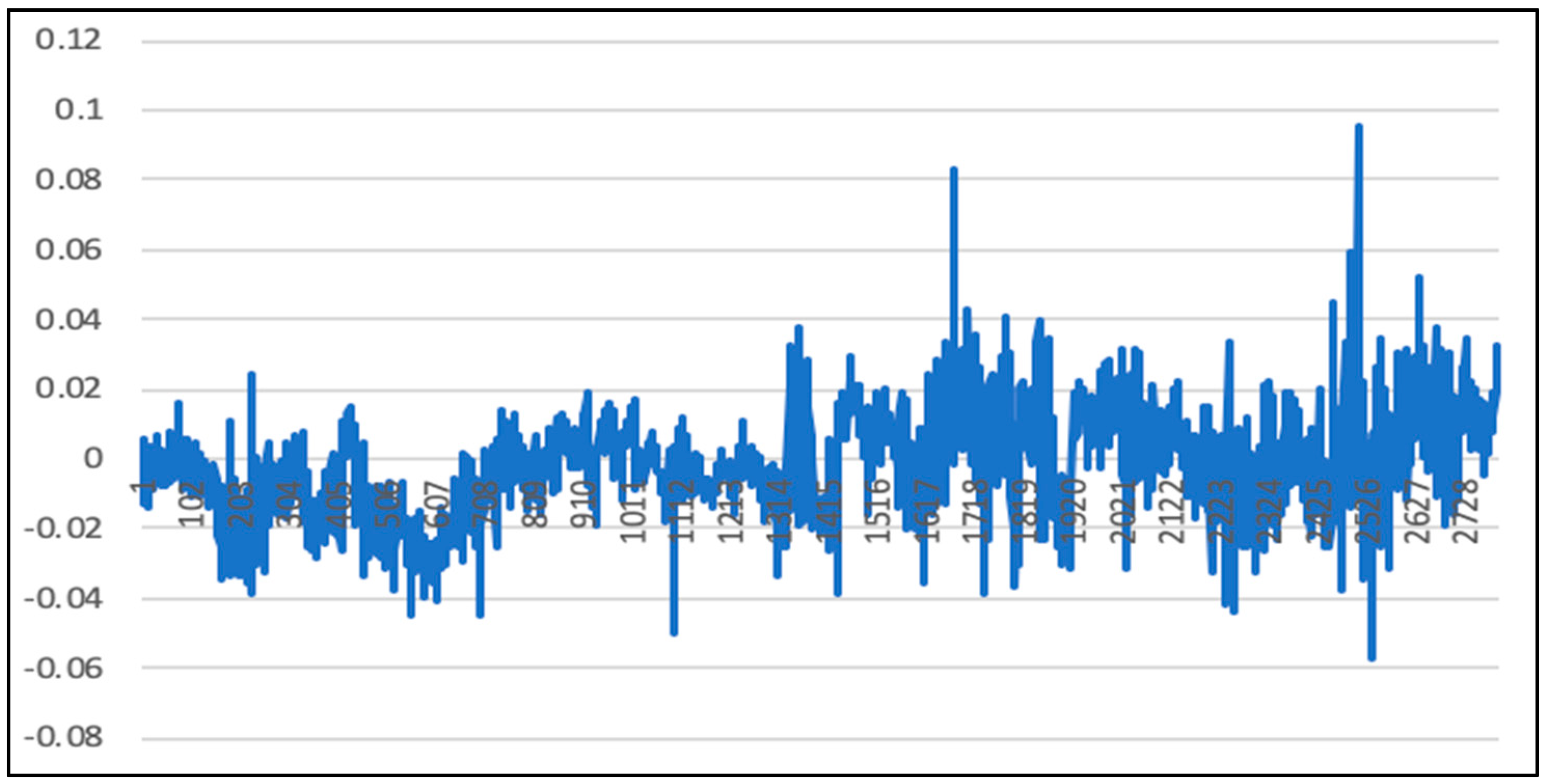
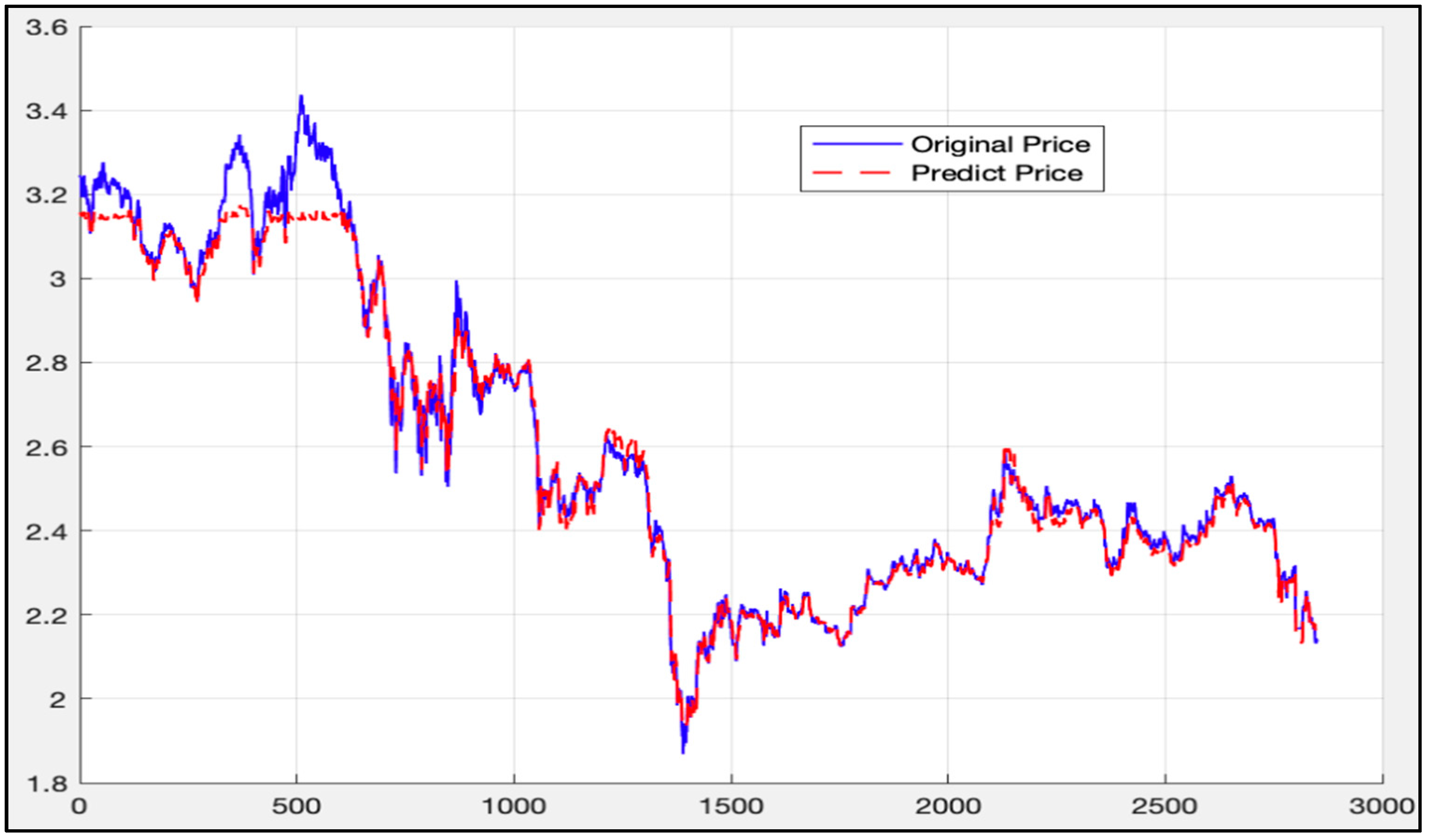
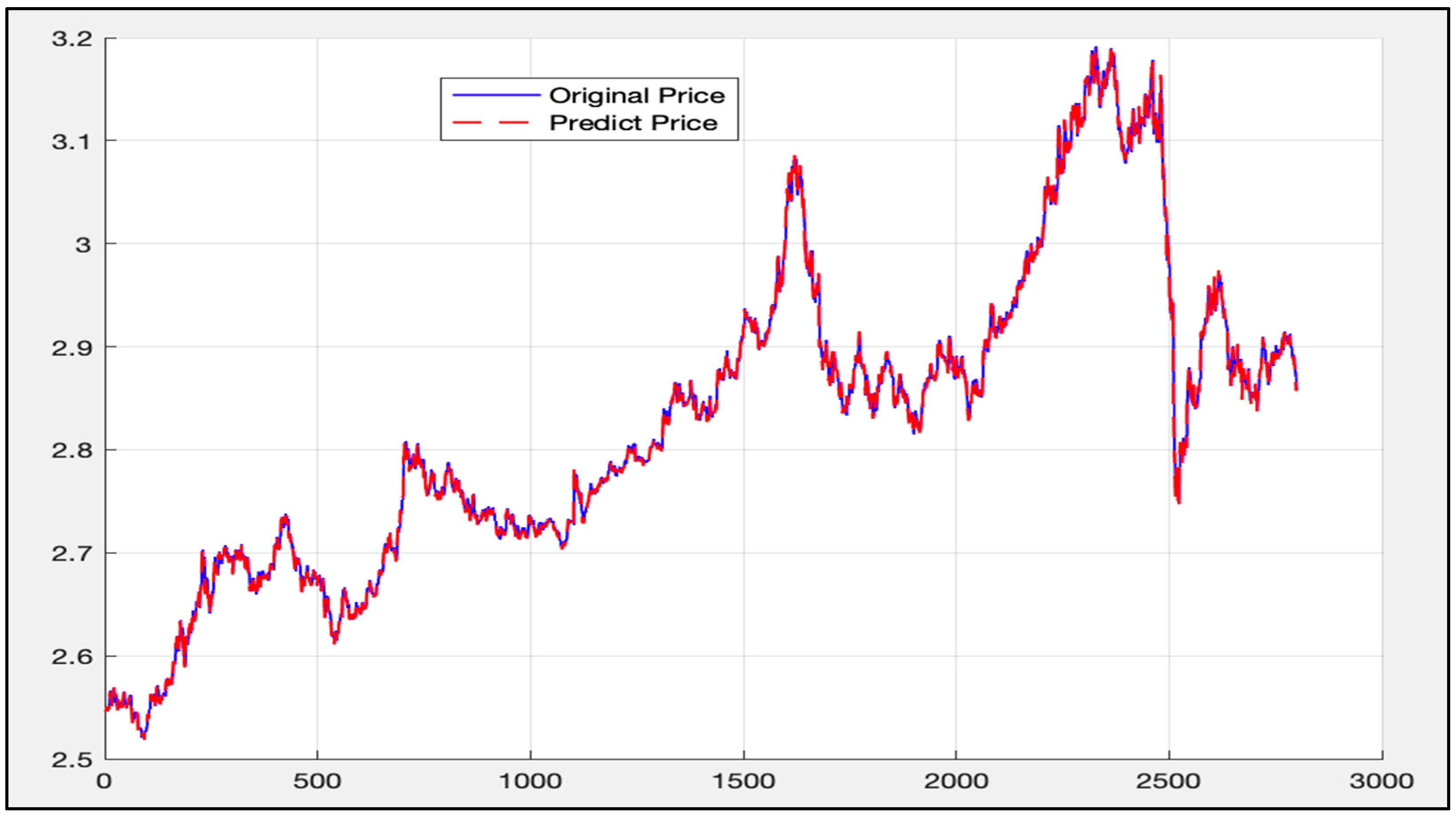
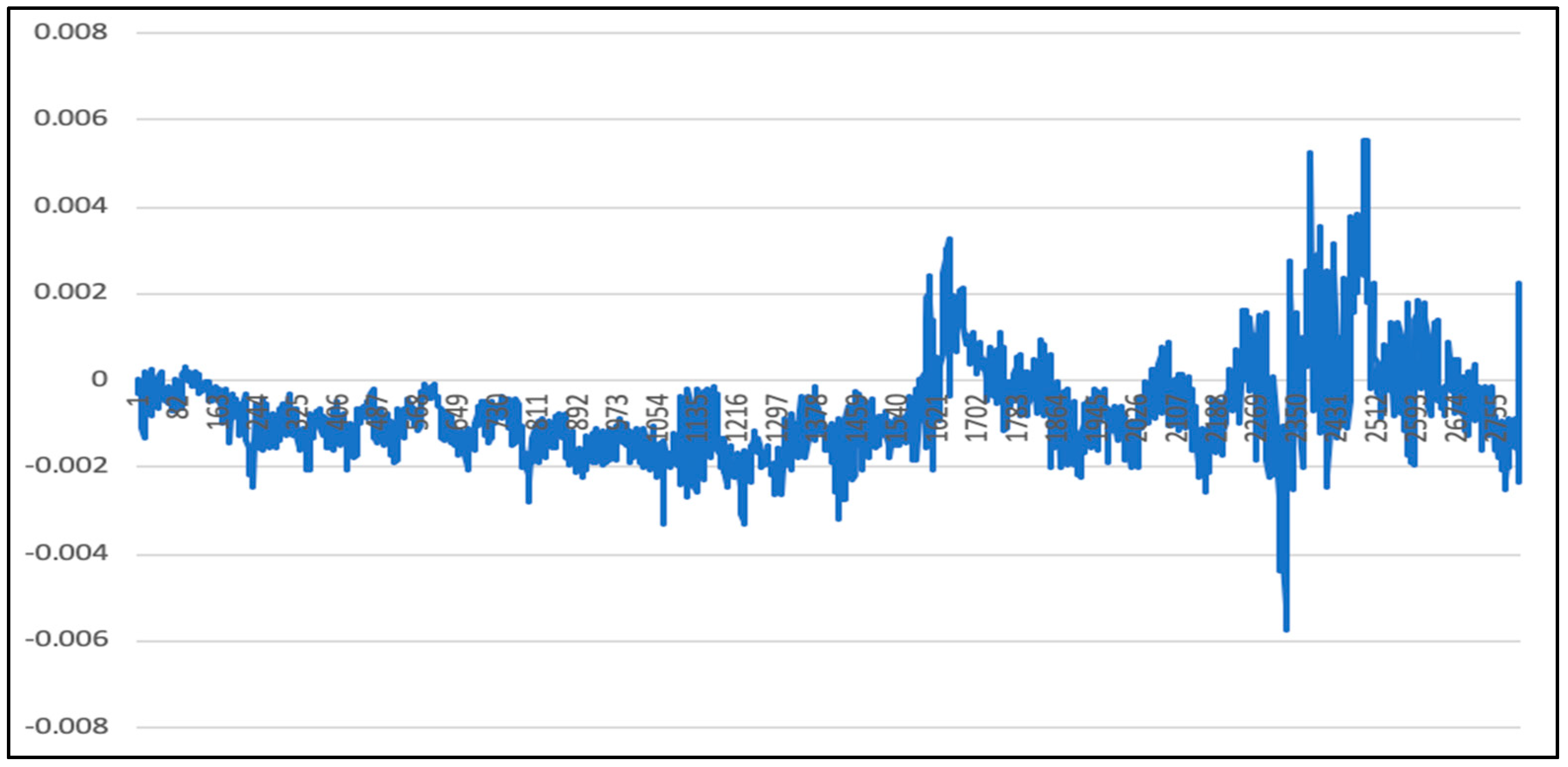
5. Experimental Results and Comparison
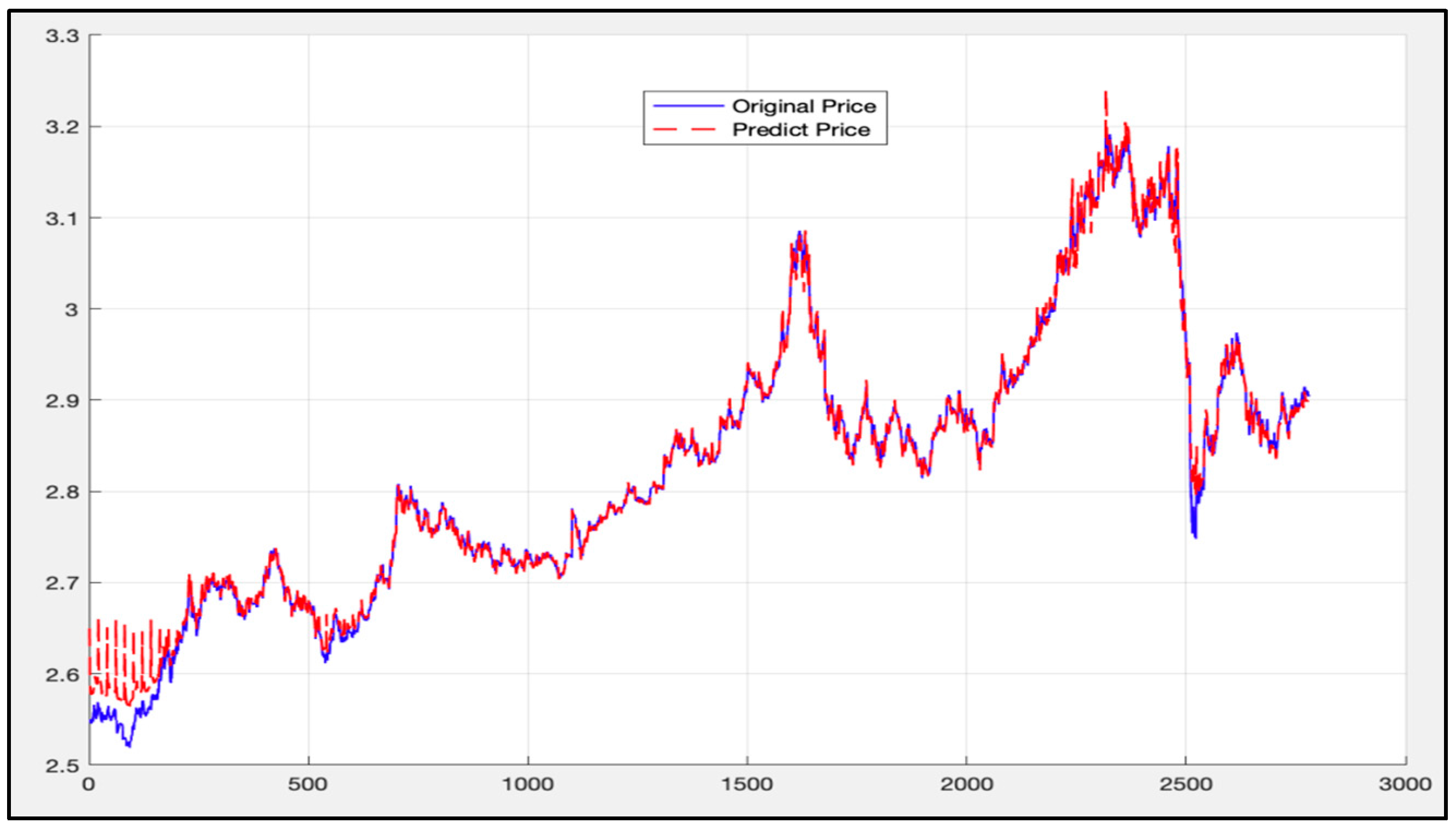
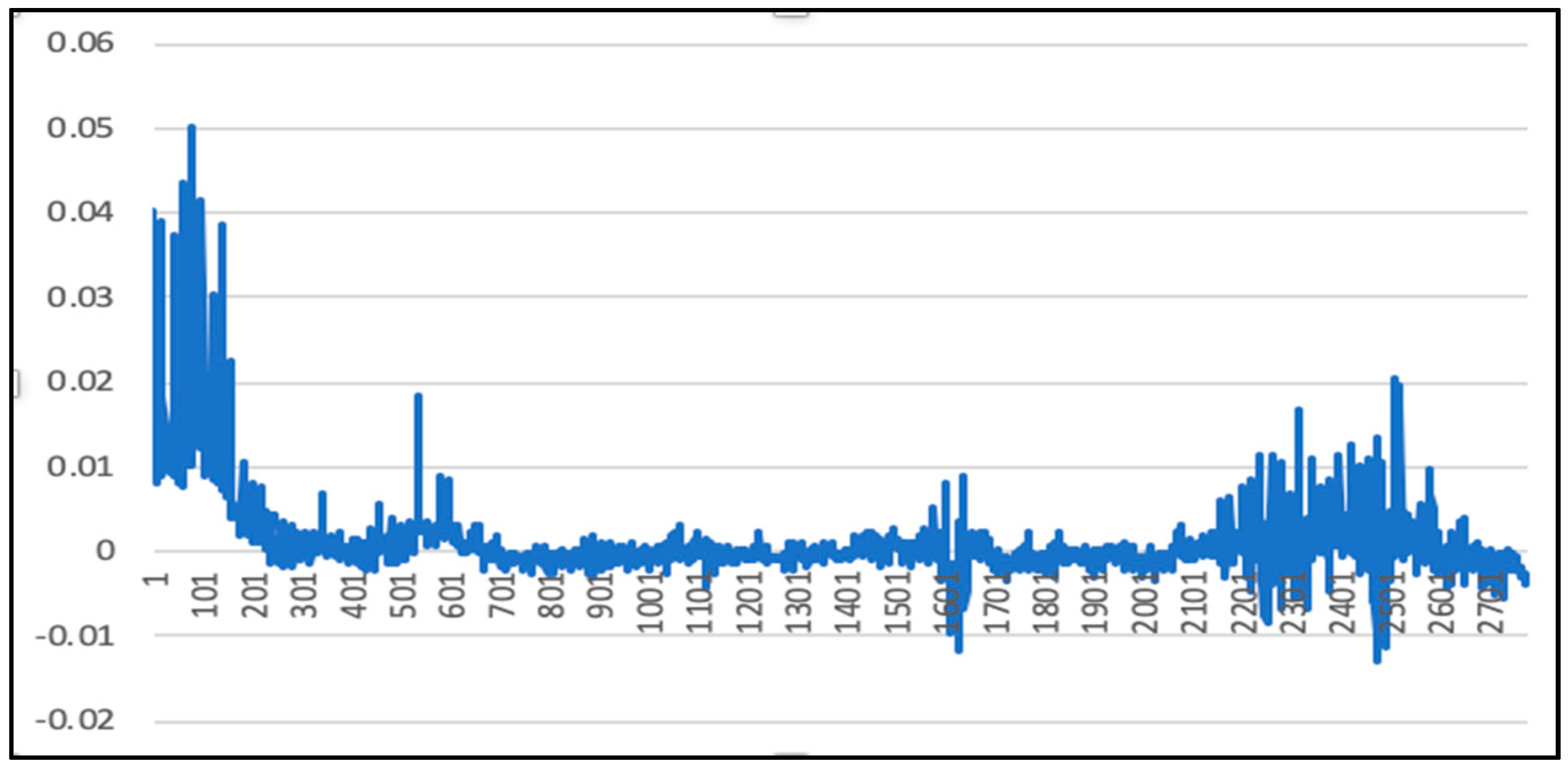
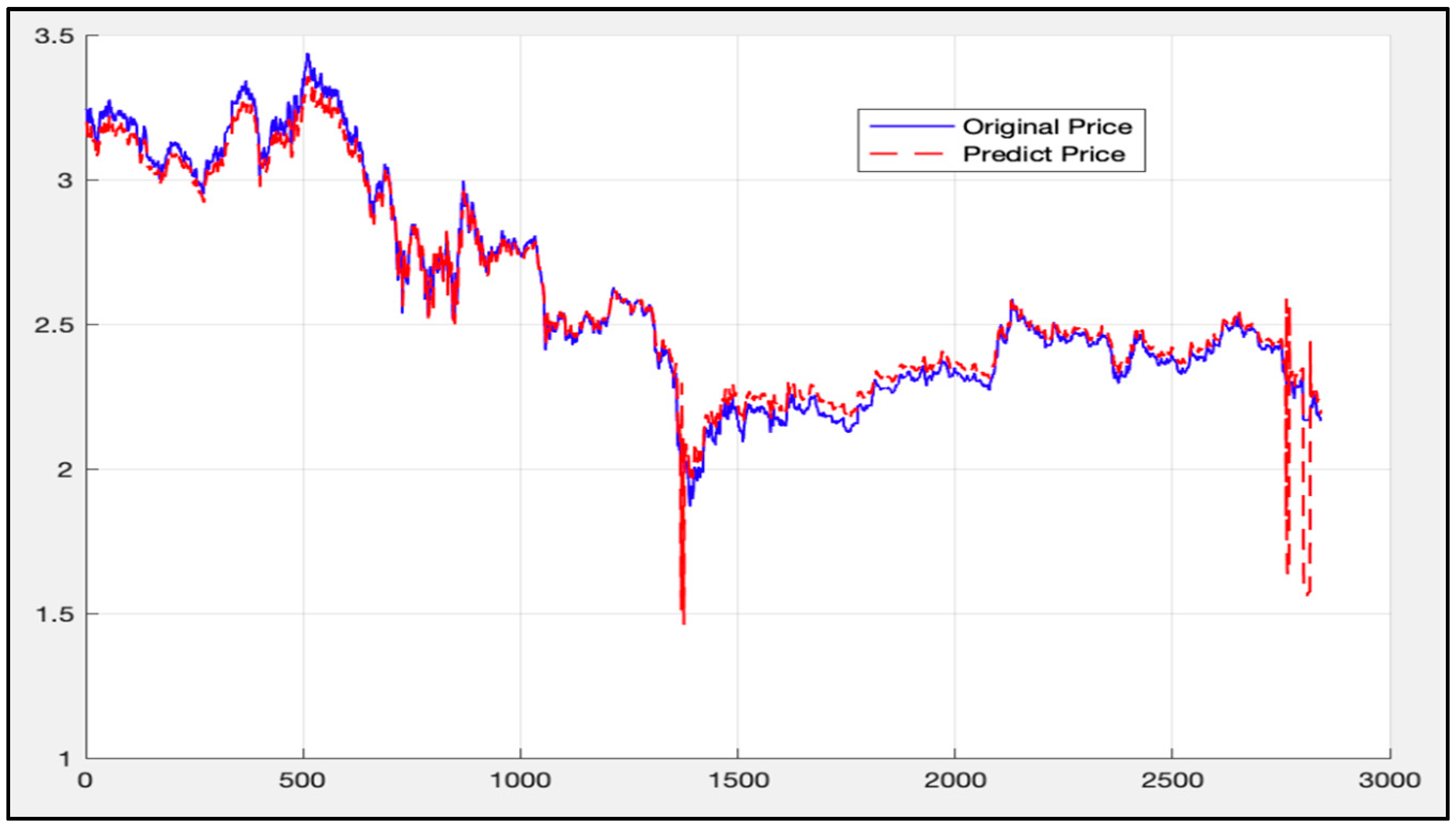
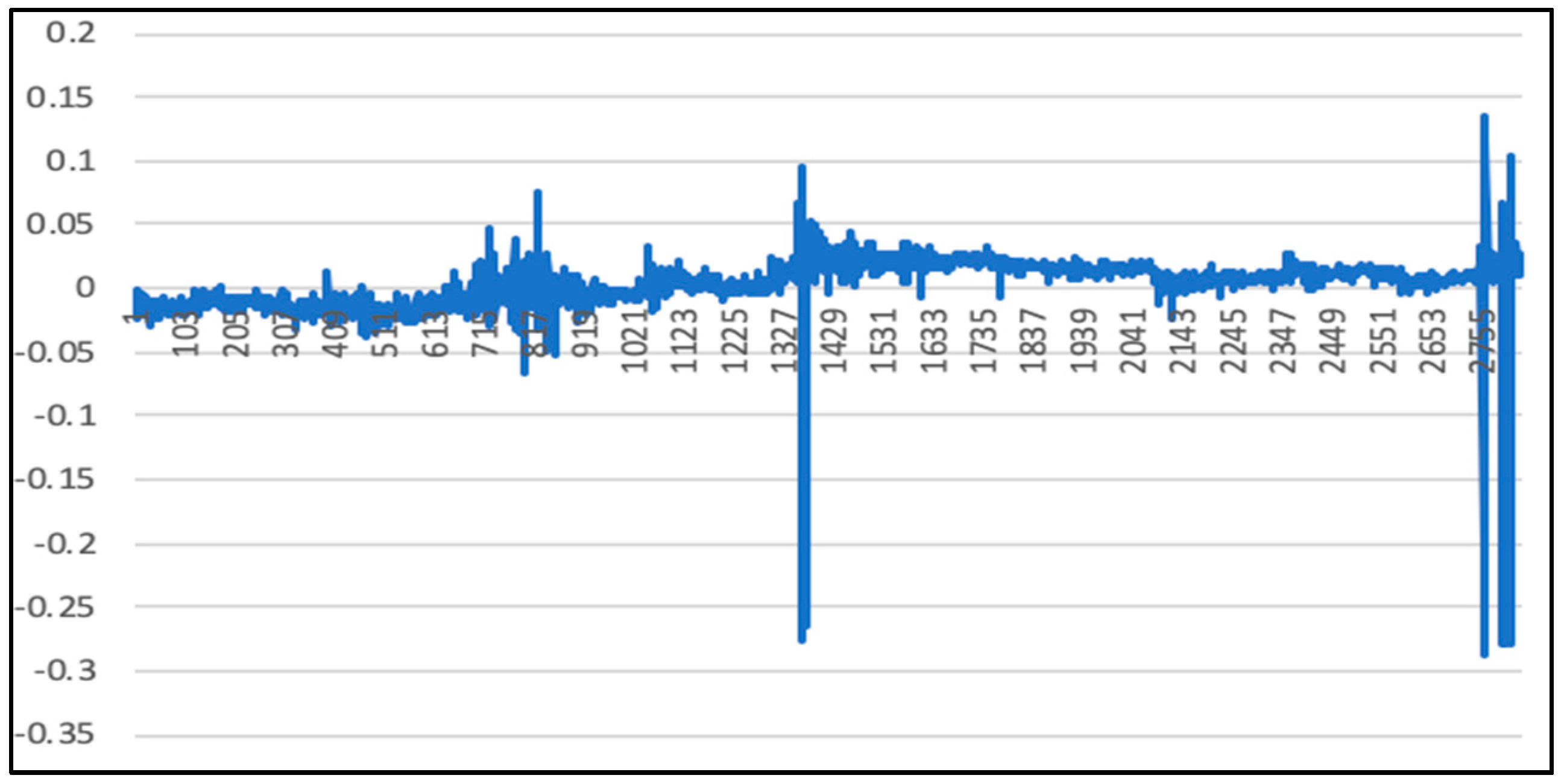
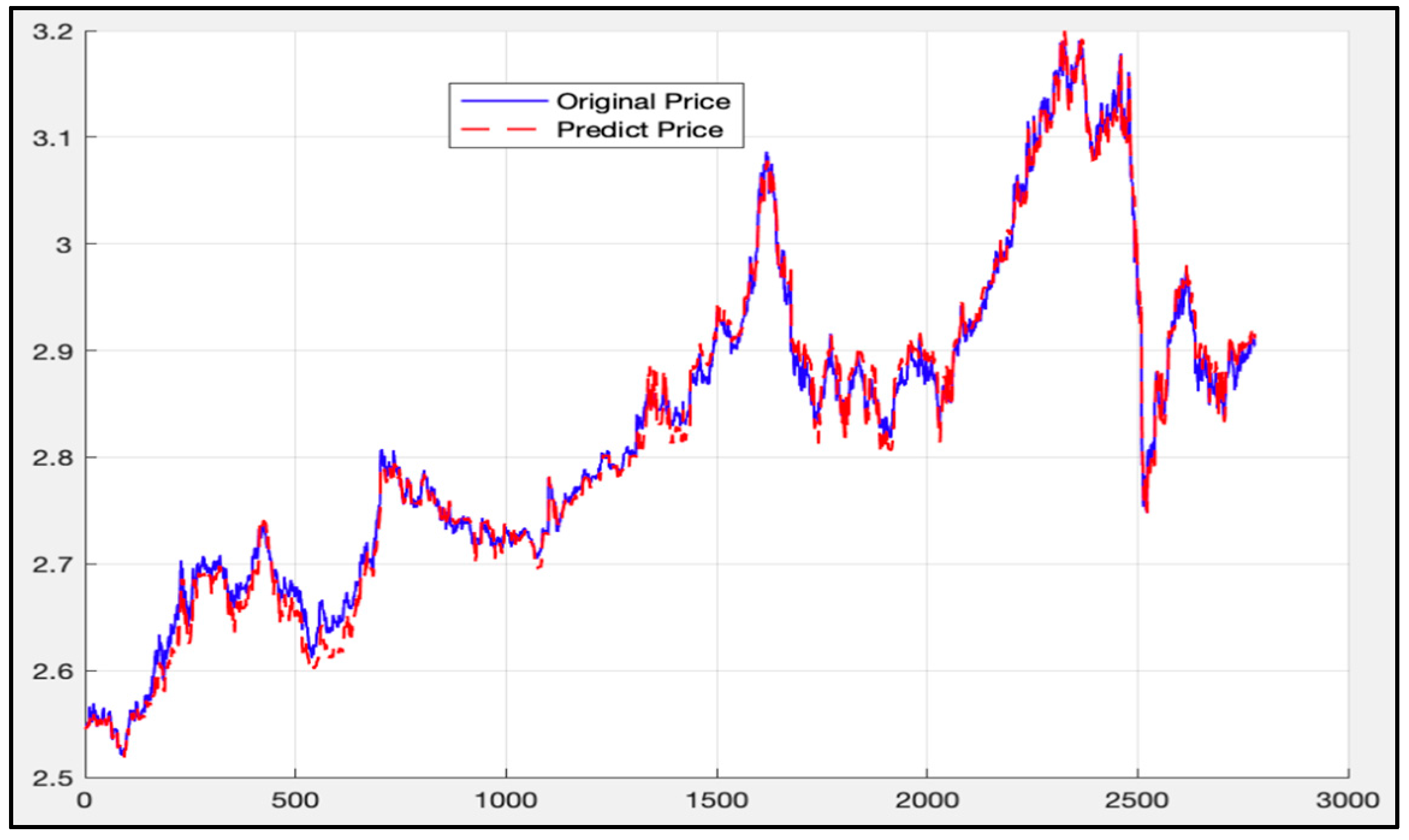
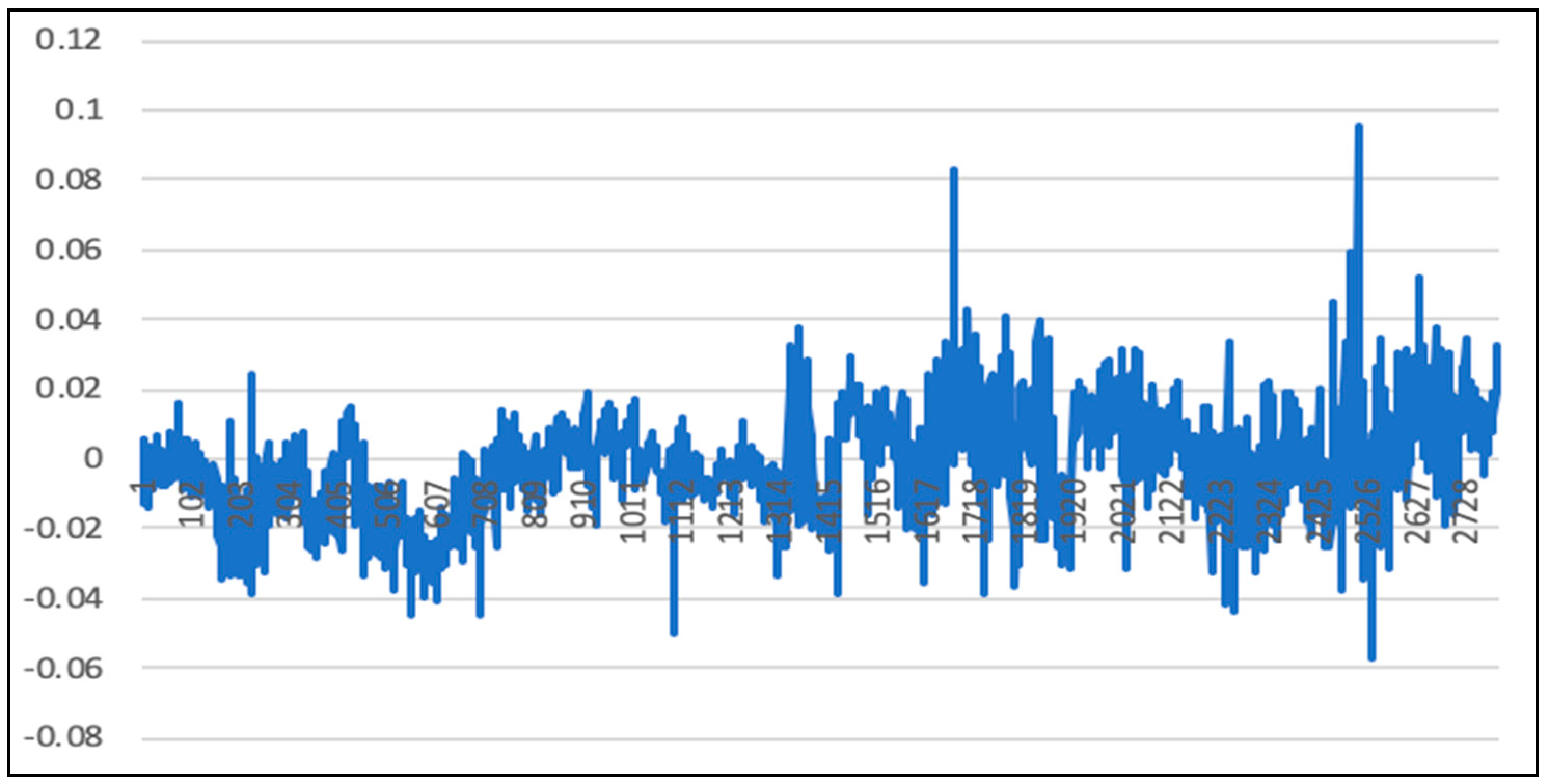
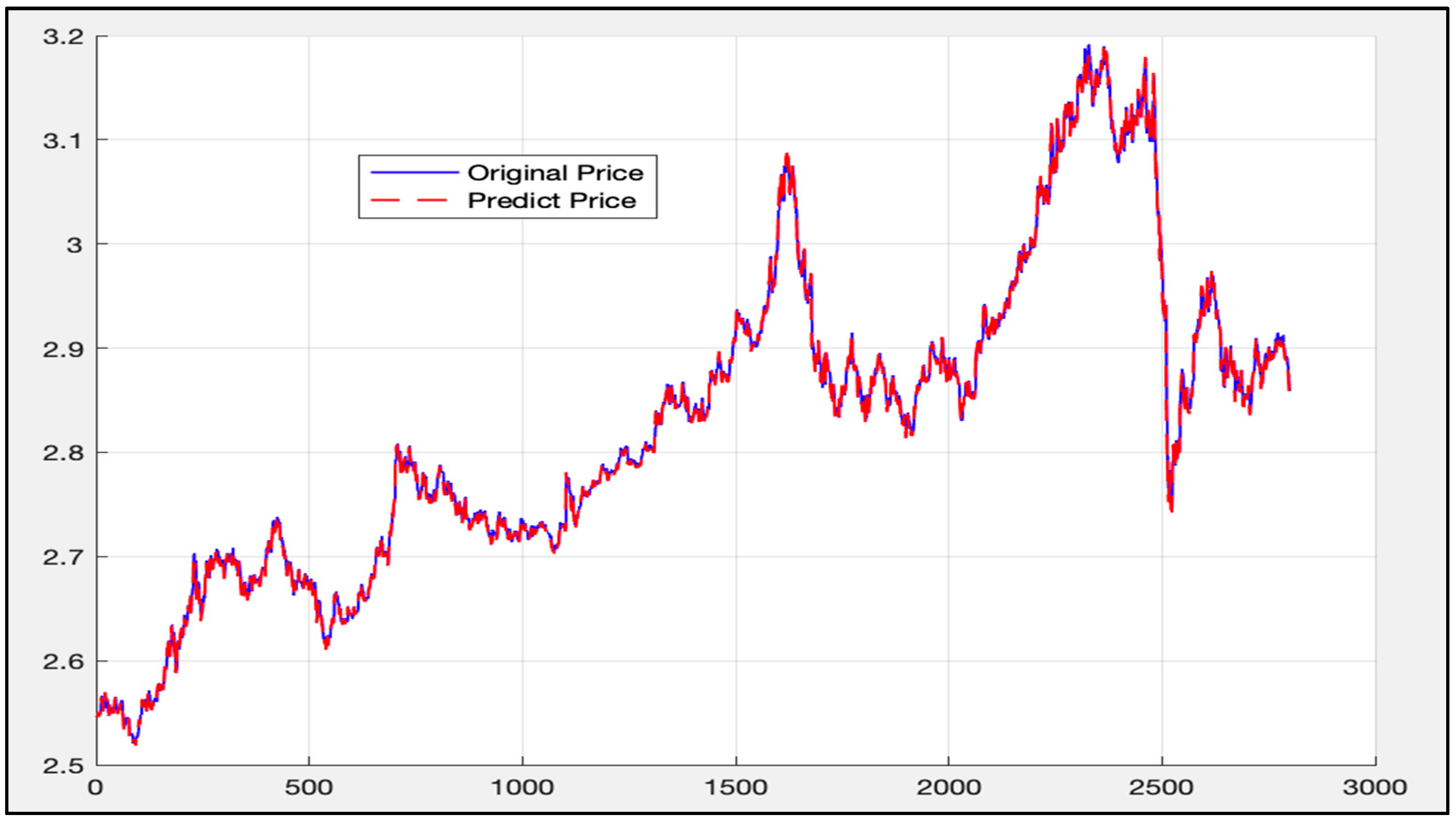
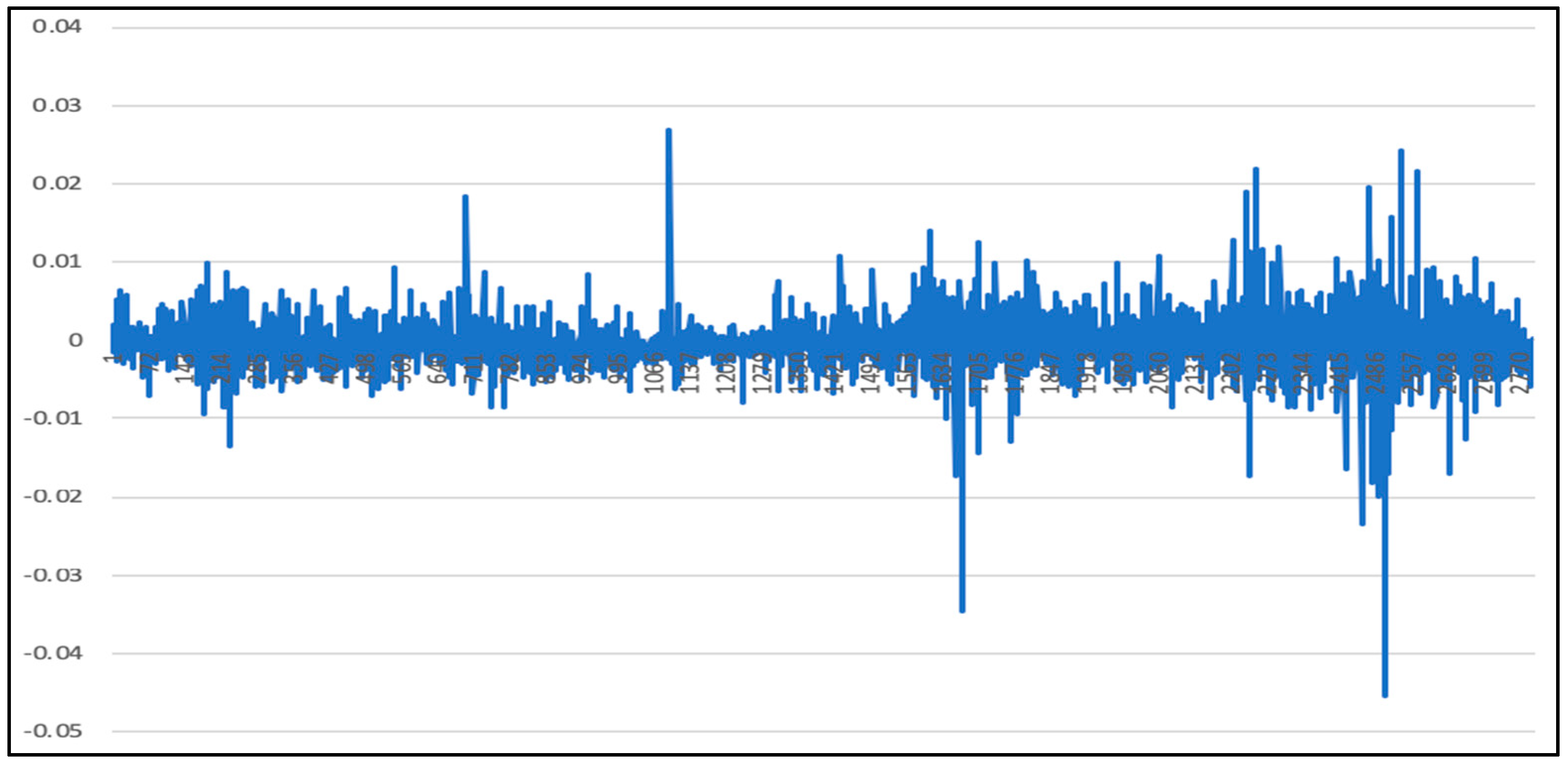
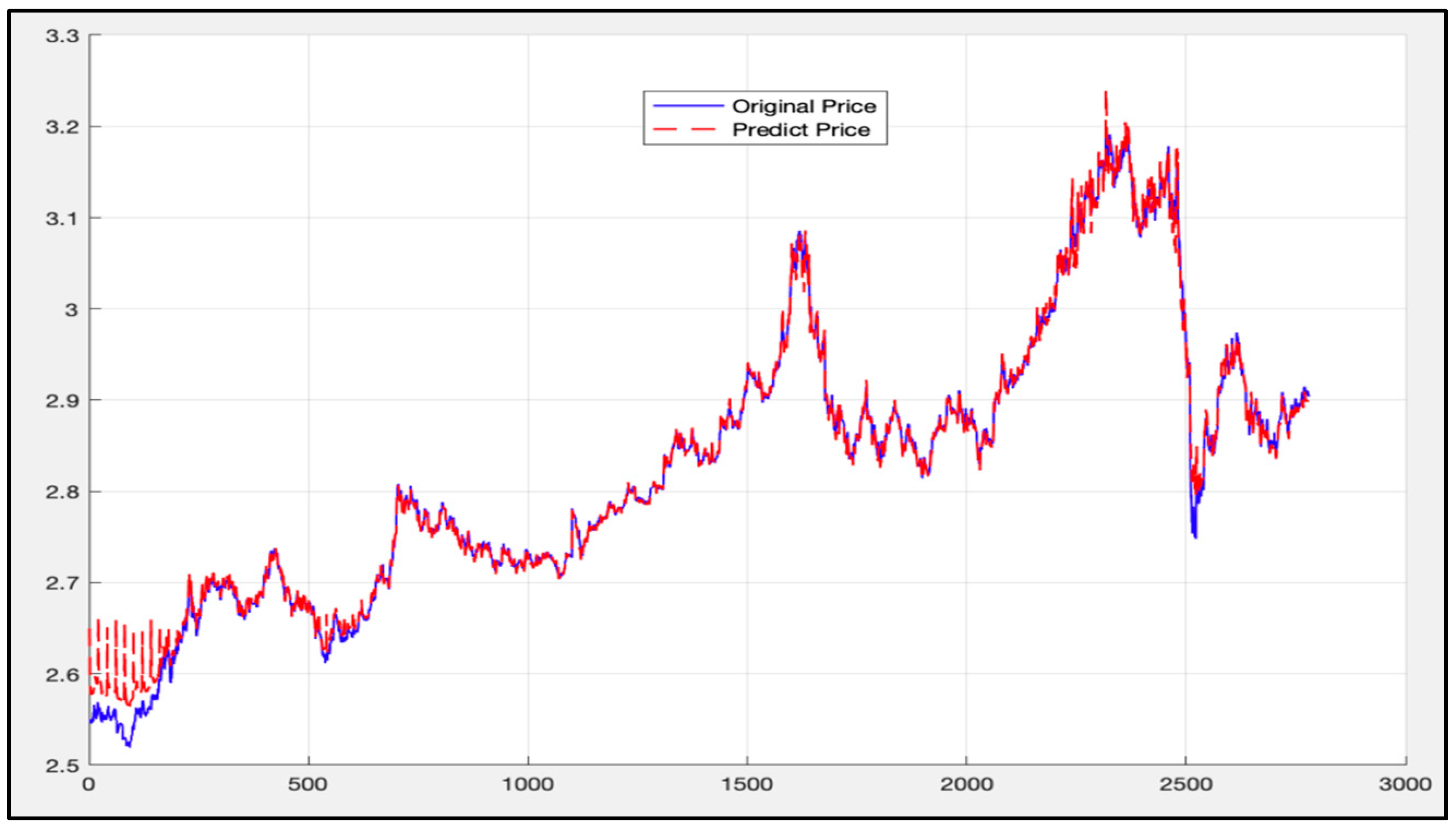
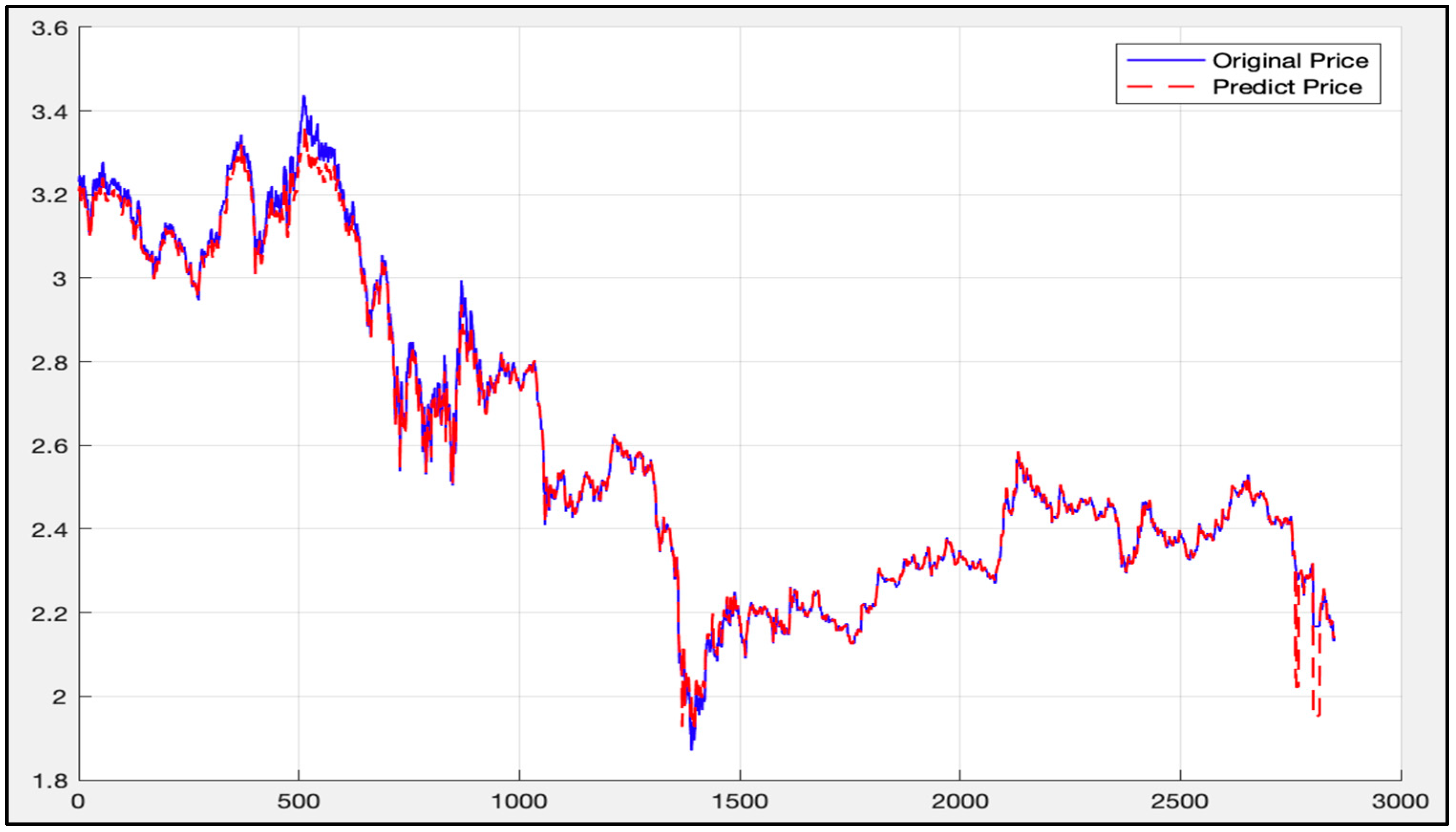
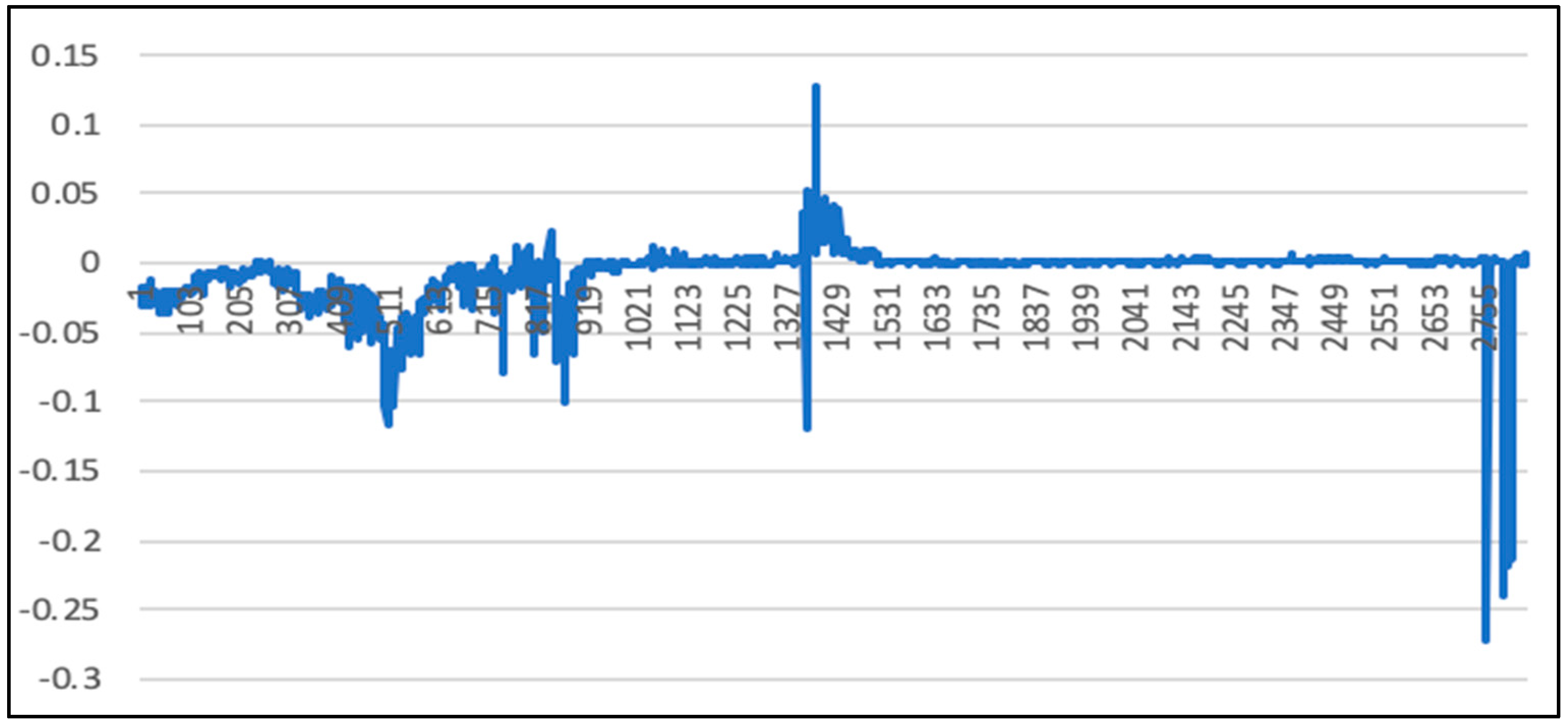
5.1. Analysis of LSTM Model Results
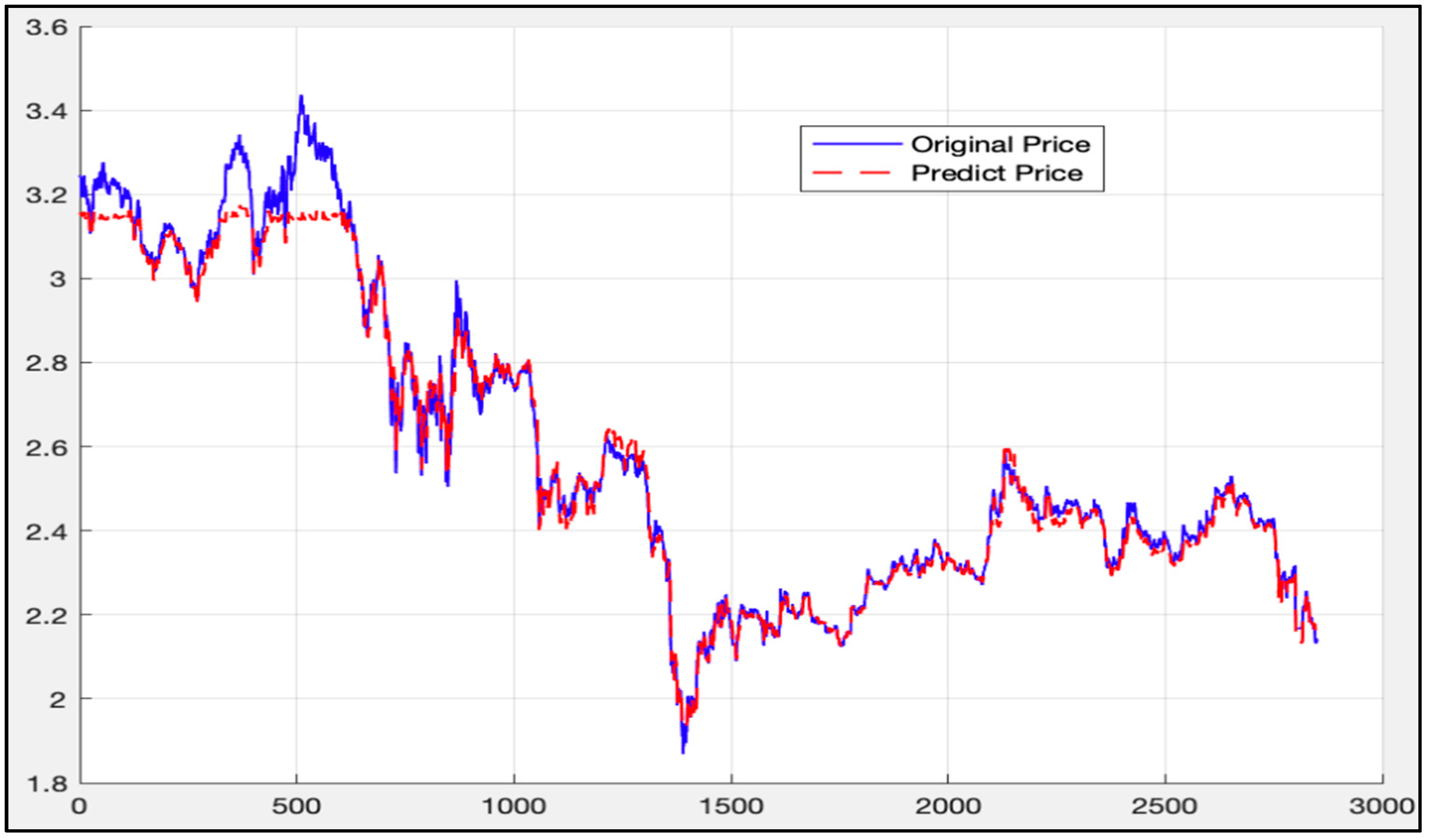
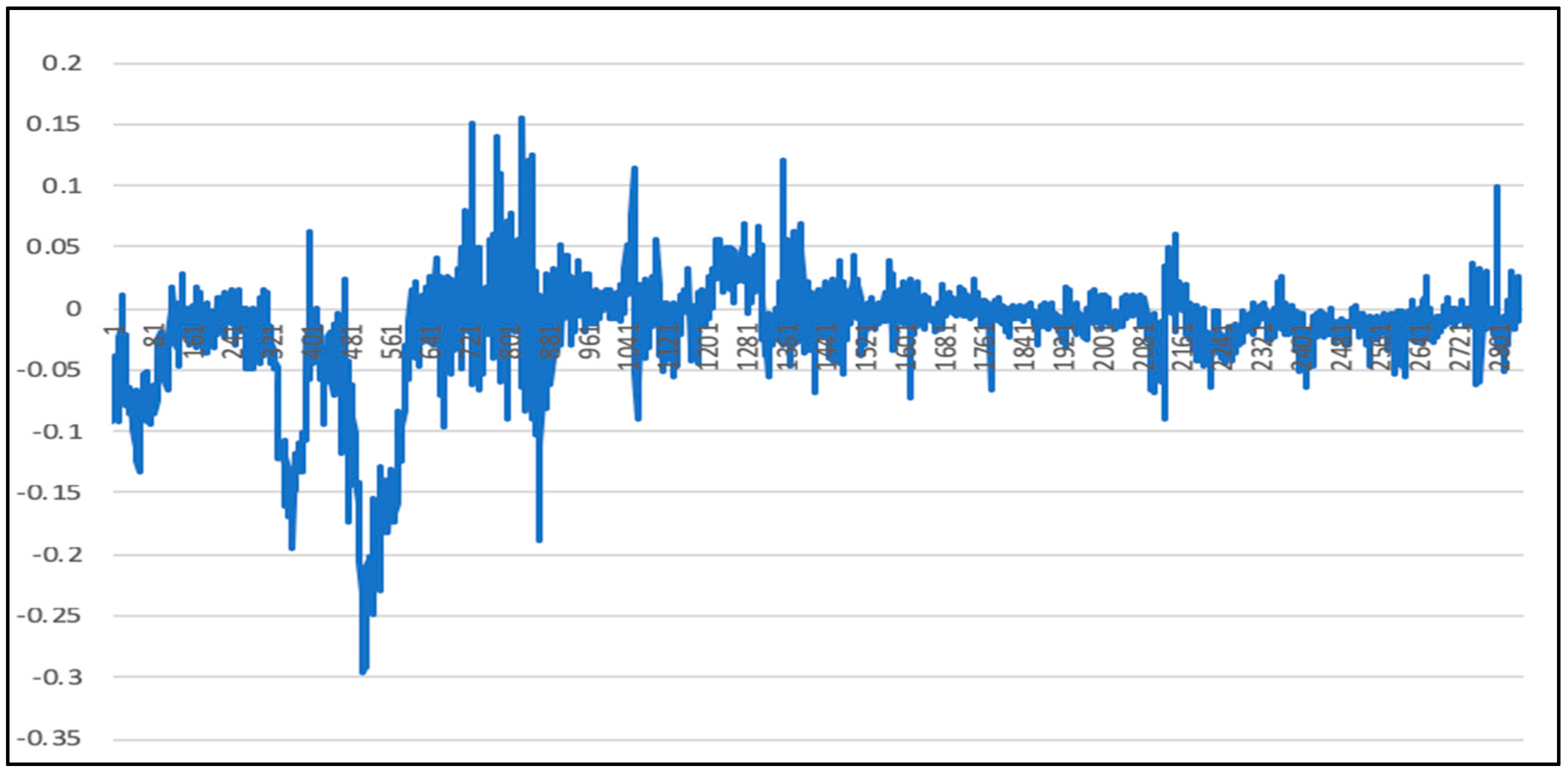
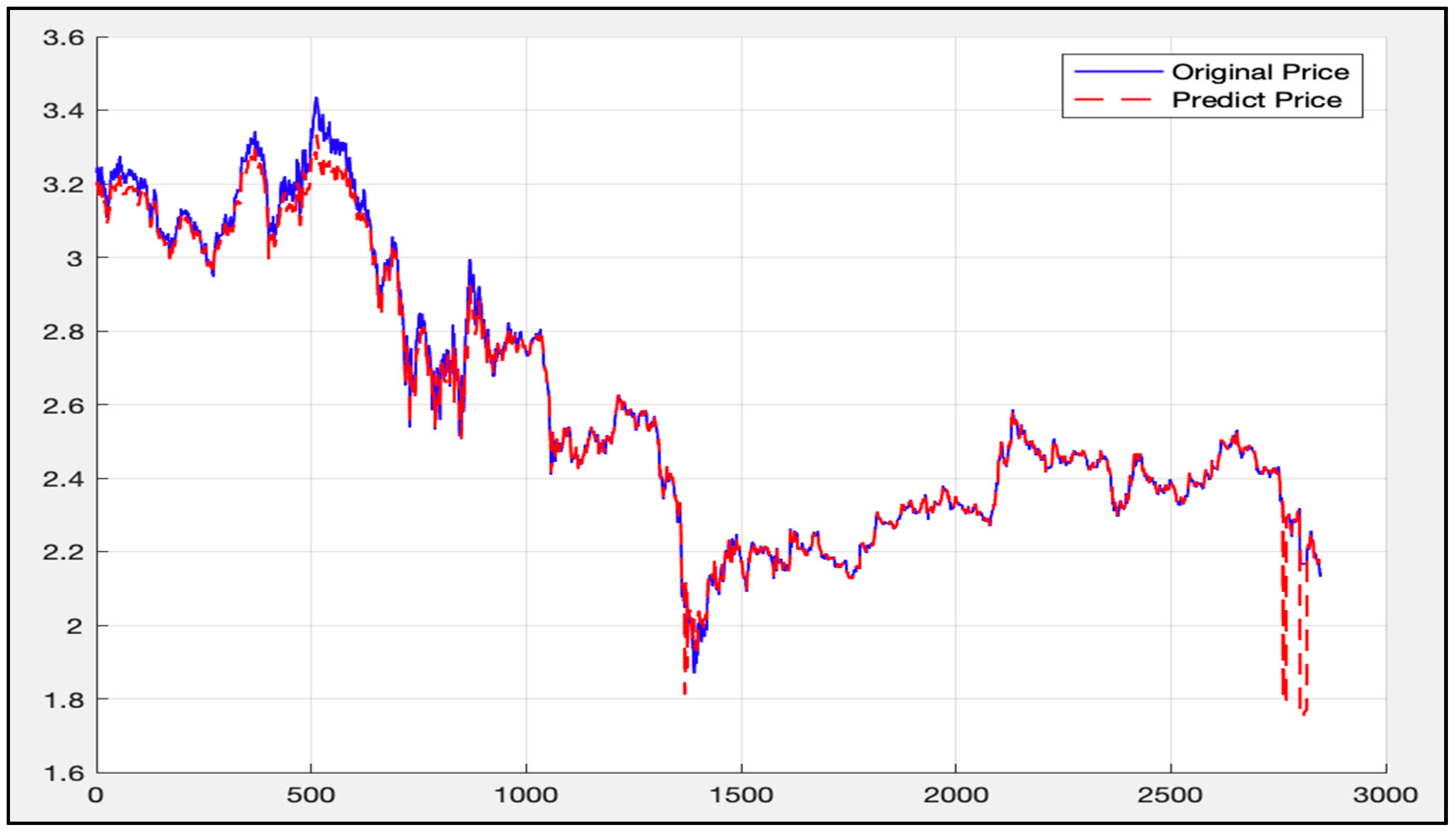
5.2. Randsom Forest Model Results
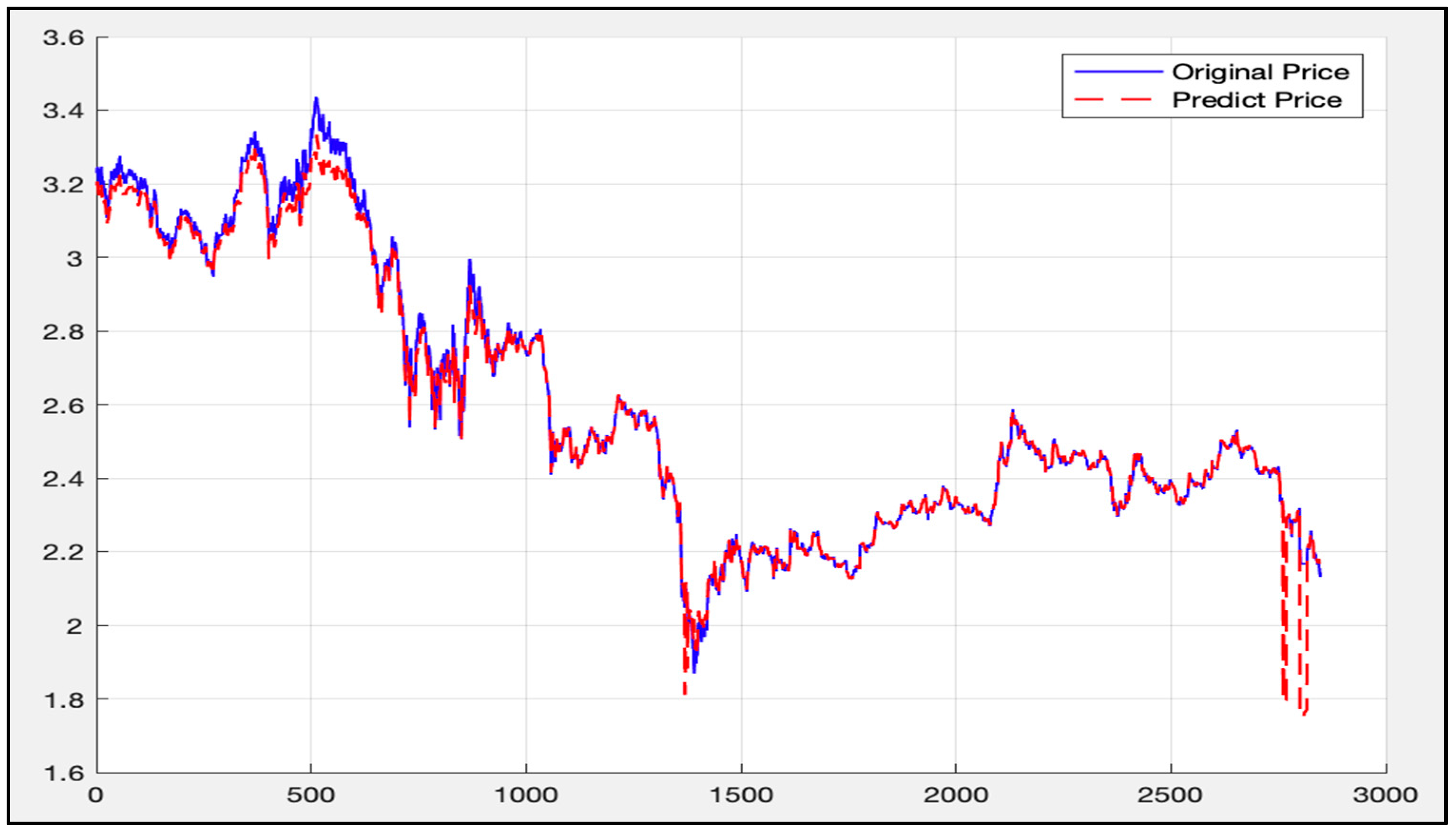
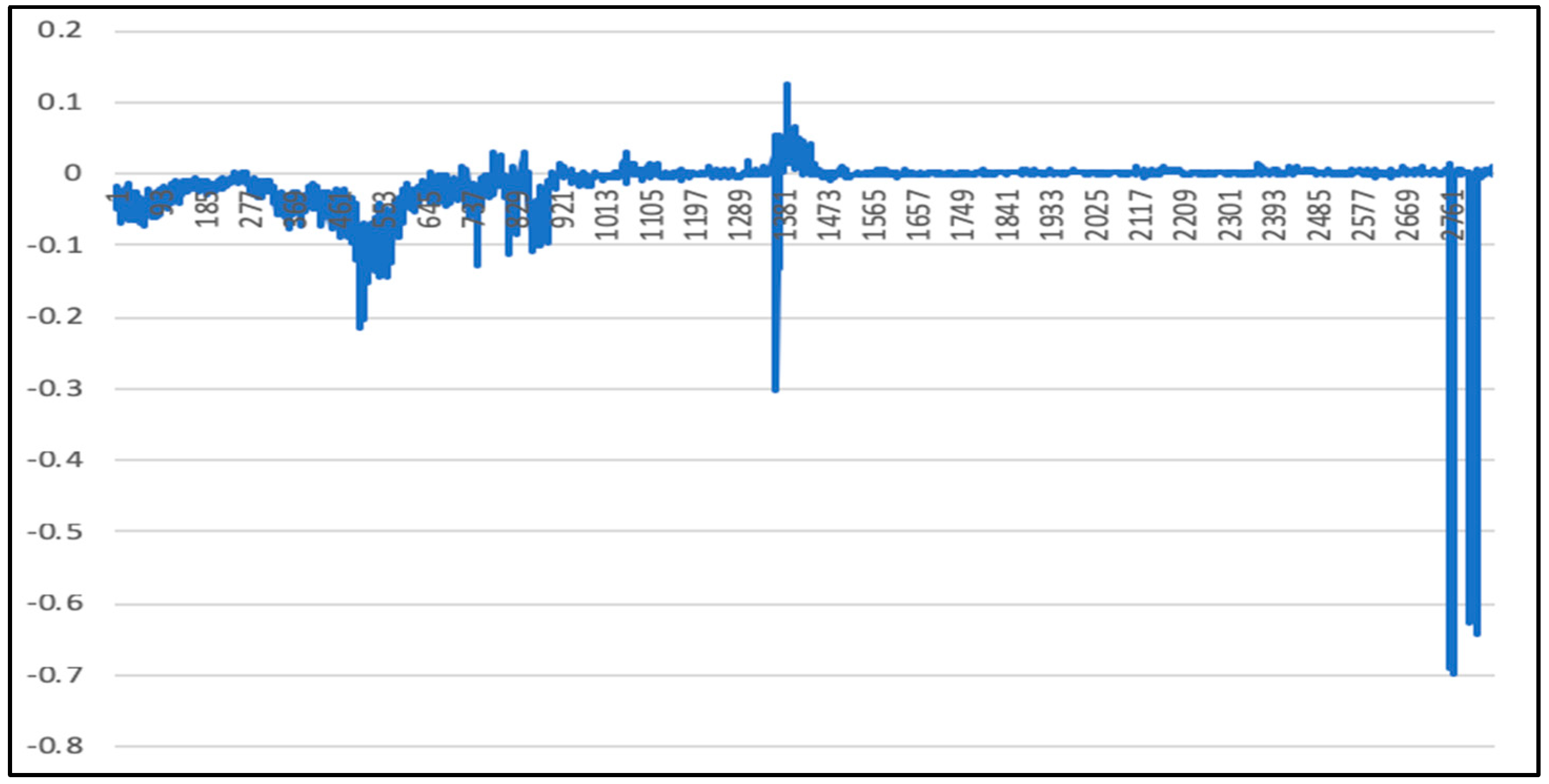
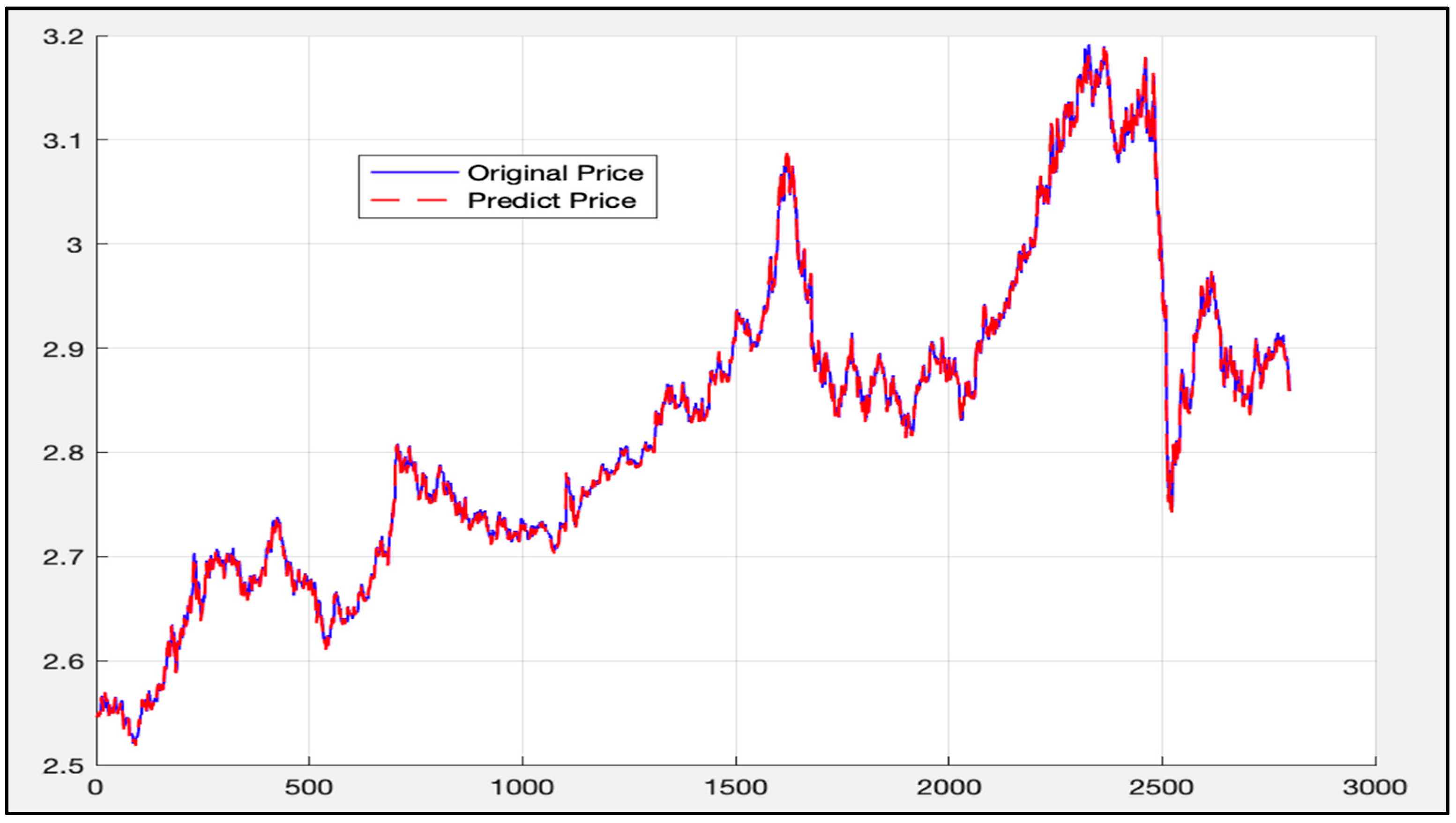
5.3. LSTM-SVR I Model Results
5.4. LSTM-SVR II Model Results
5.5. Comparison of LSTM Model, RF Model, and LSTM-SVR Model Results
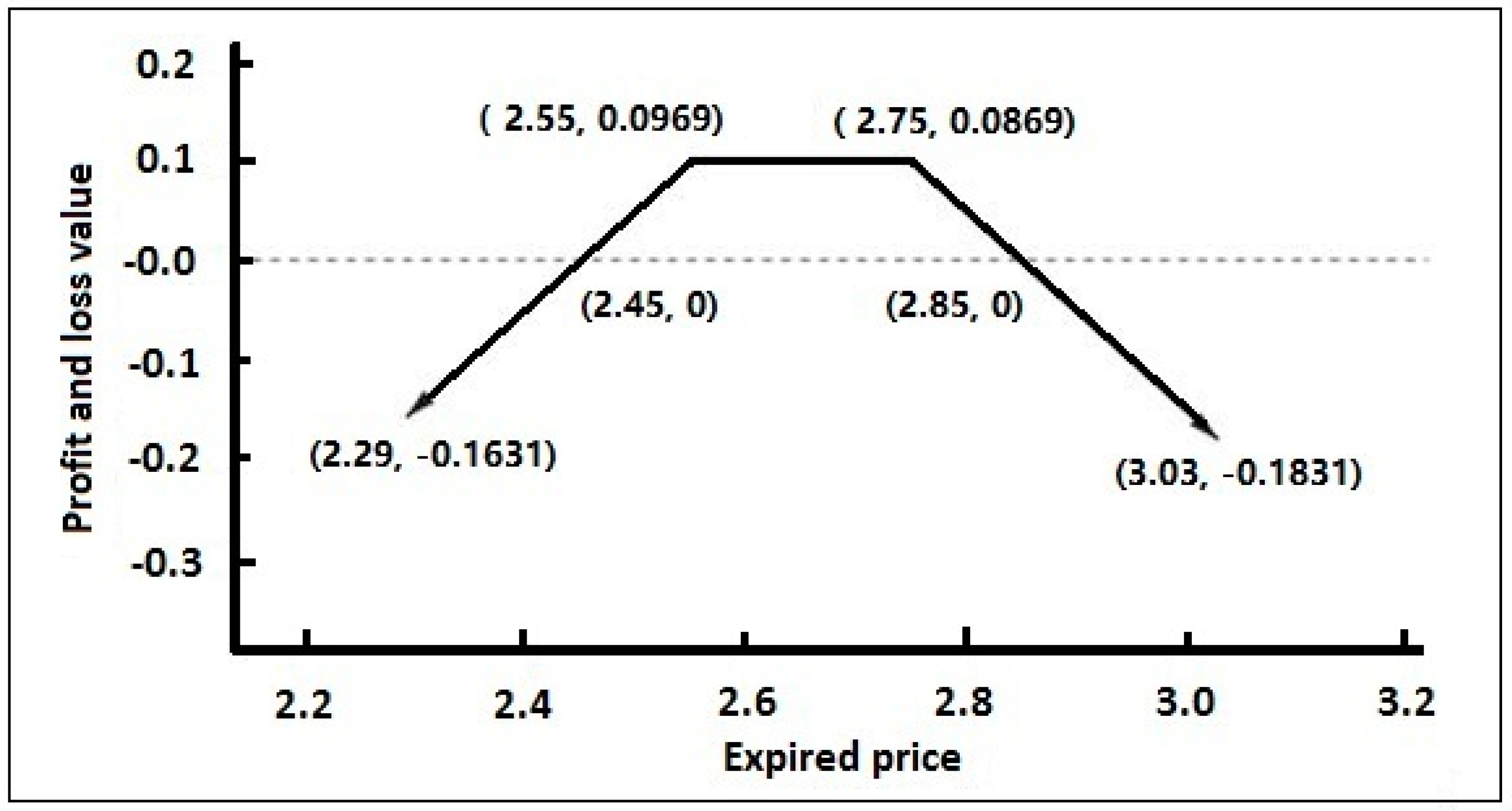
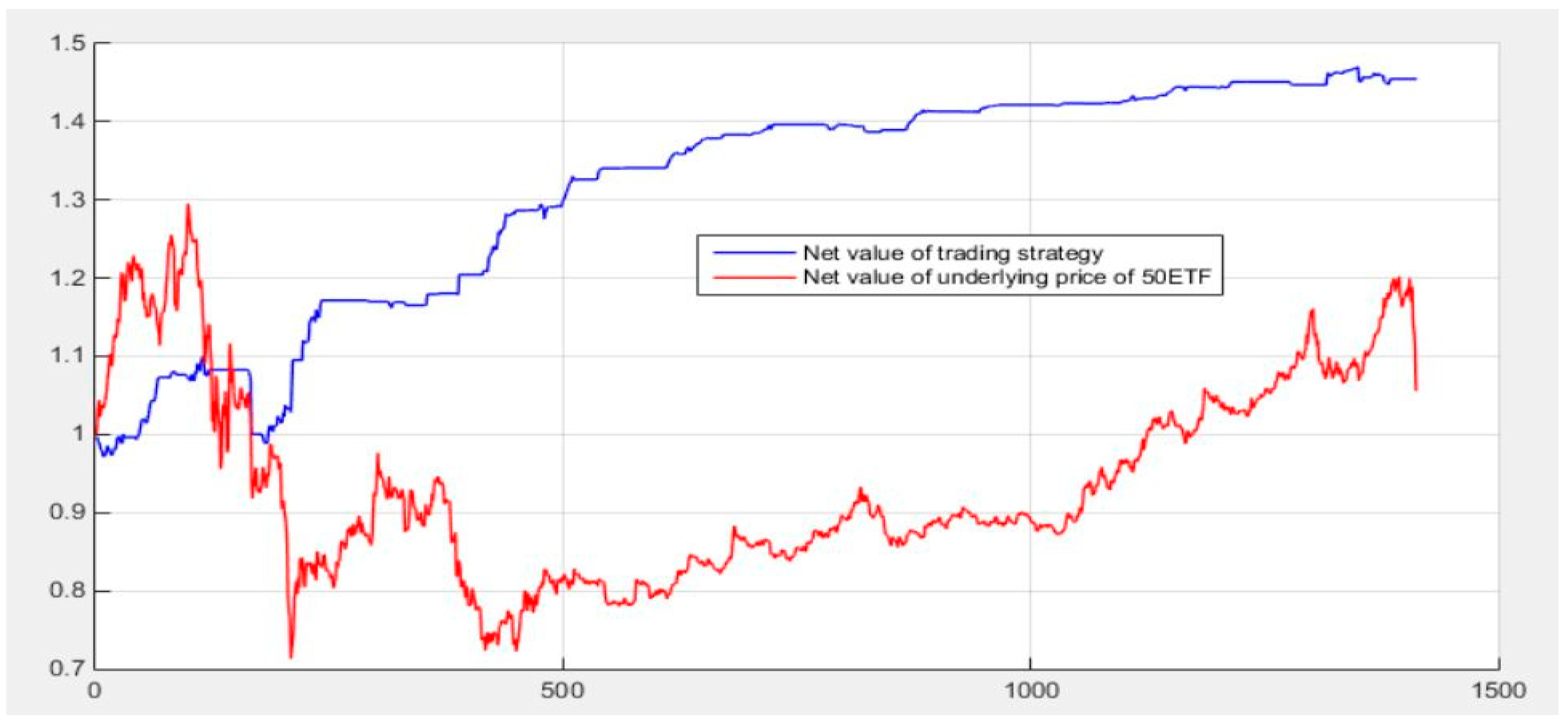
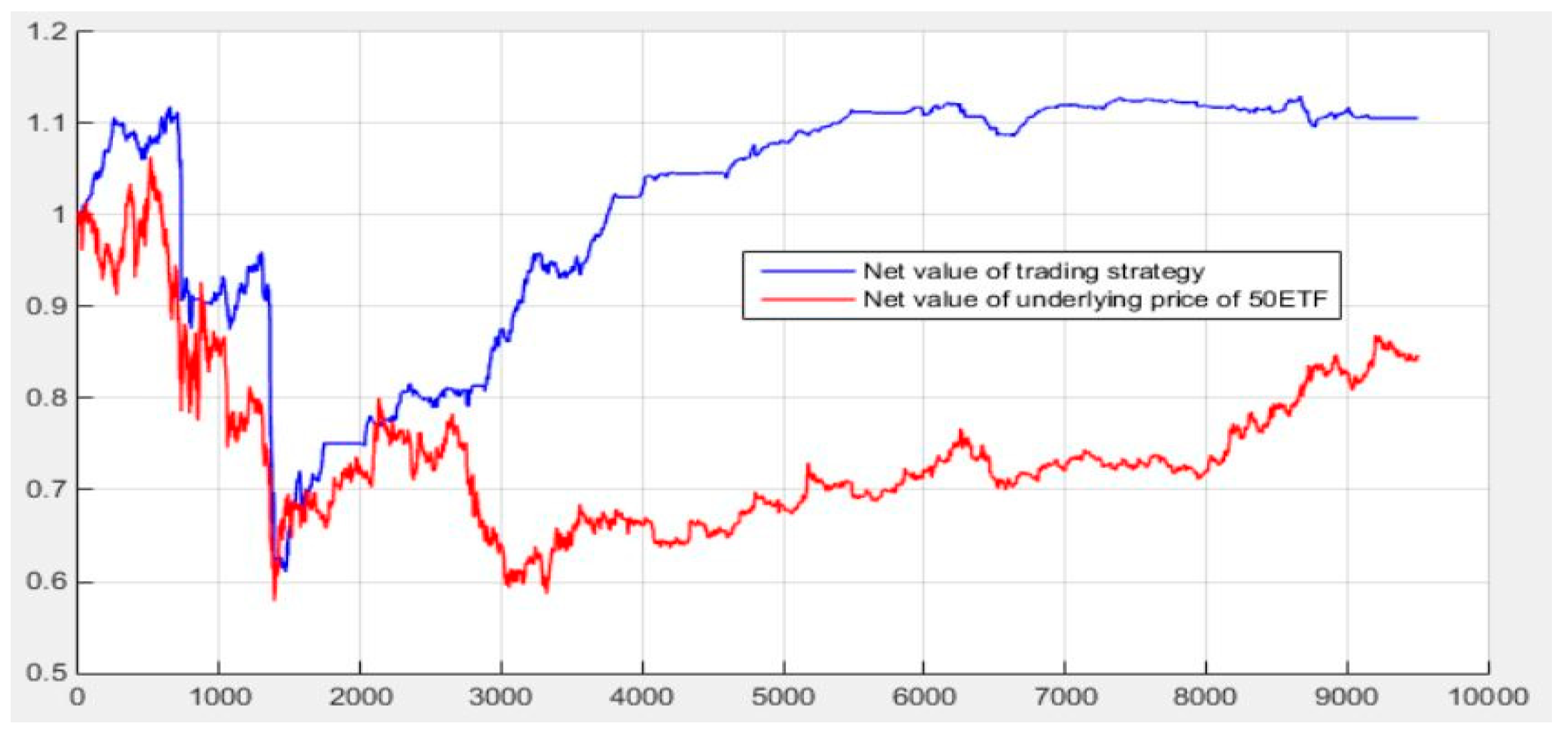
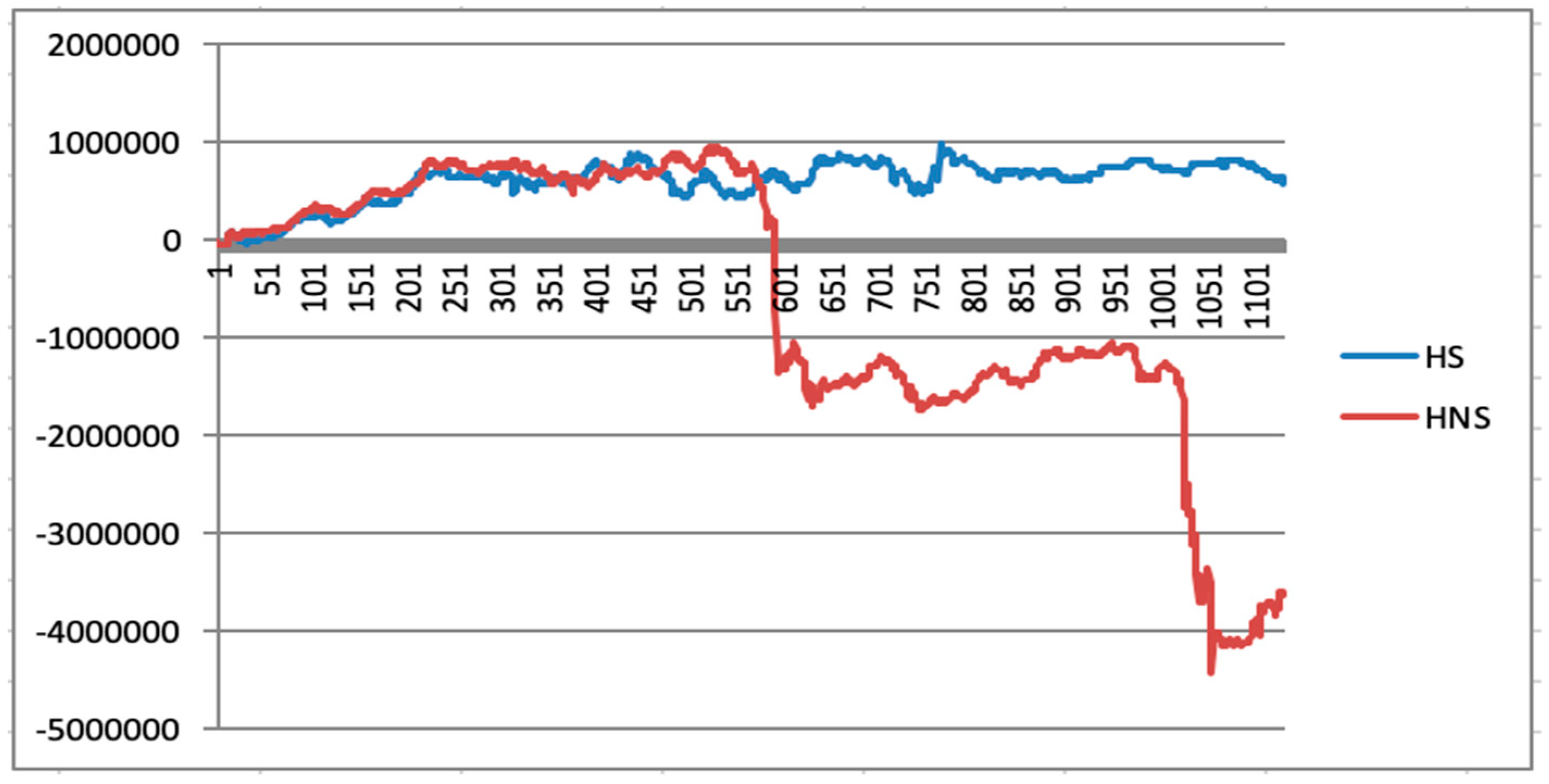
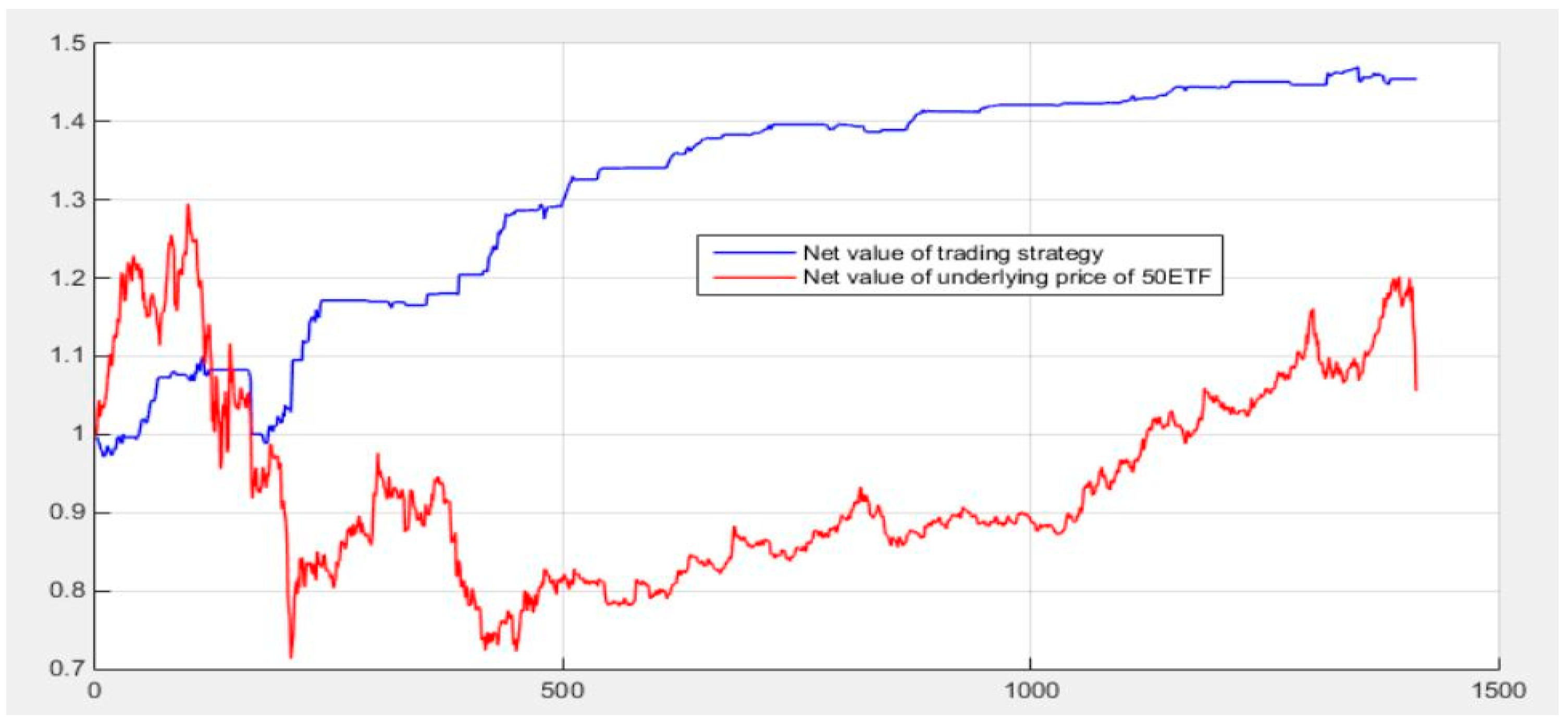
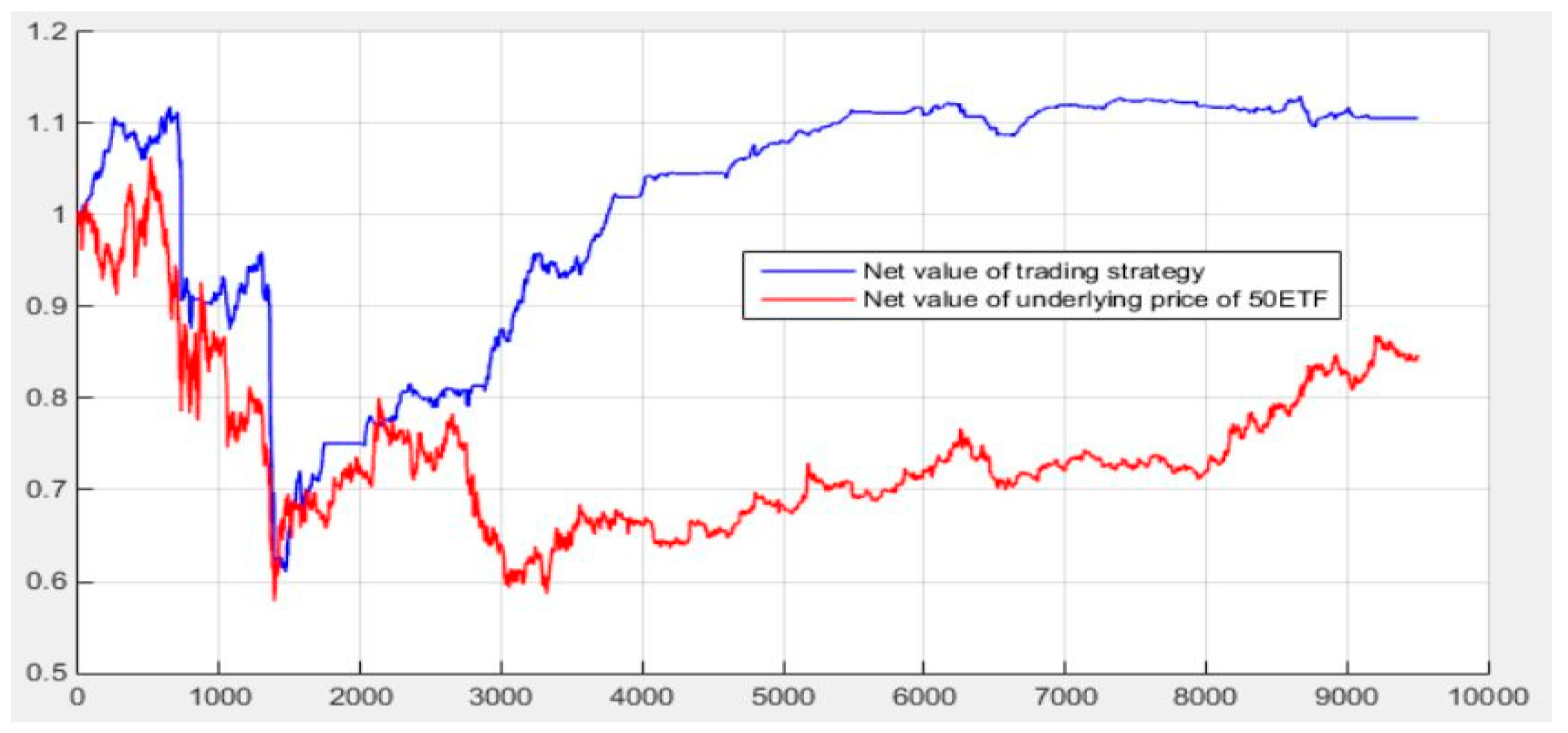
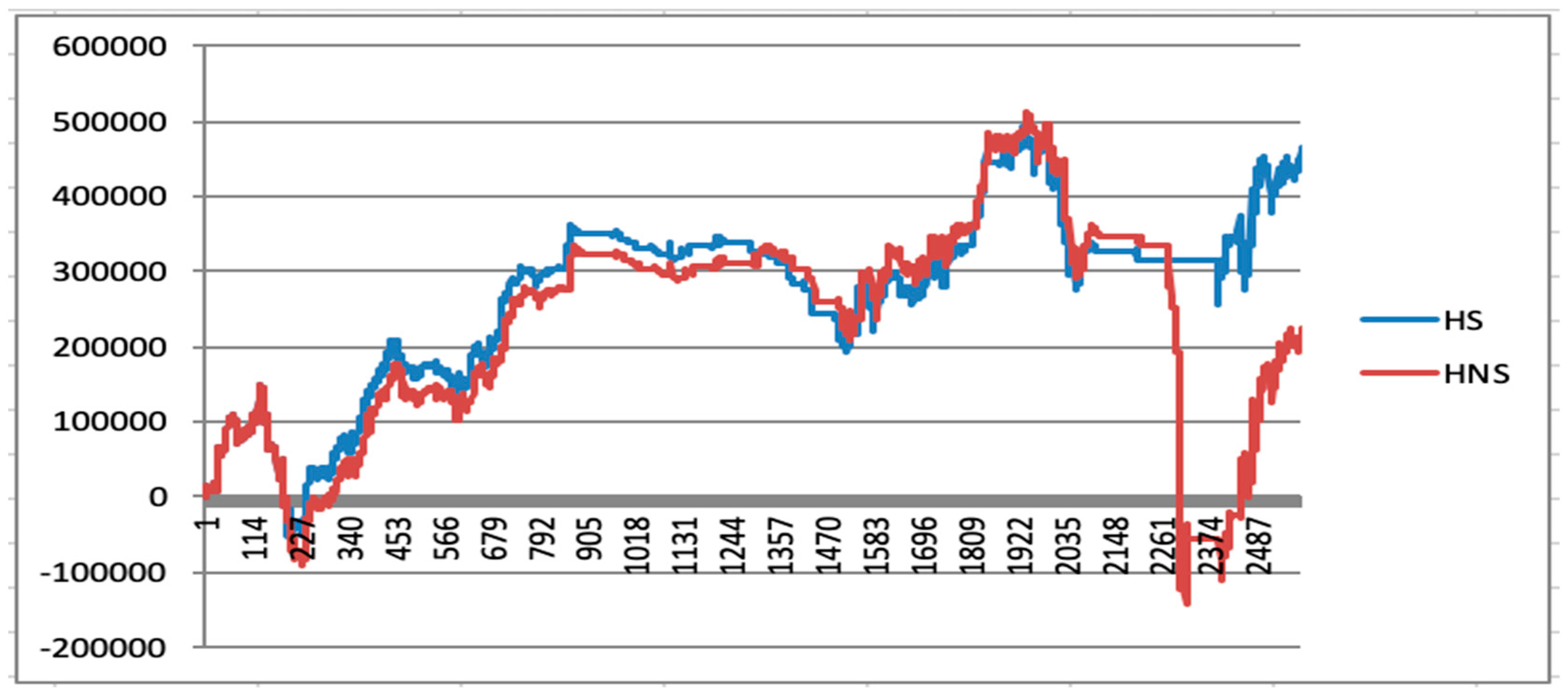
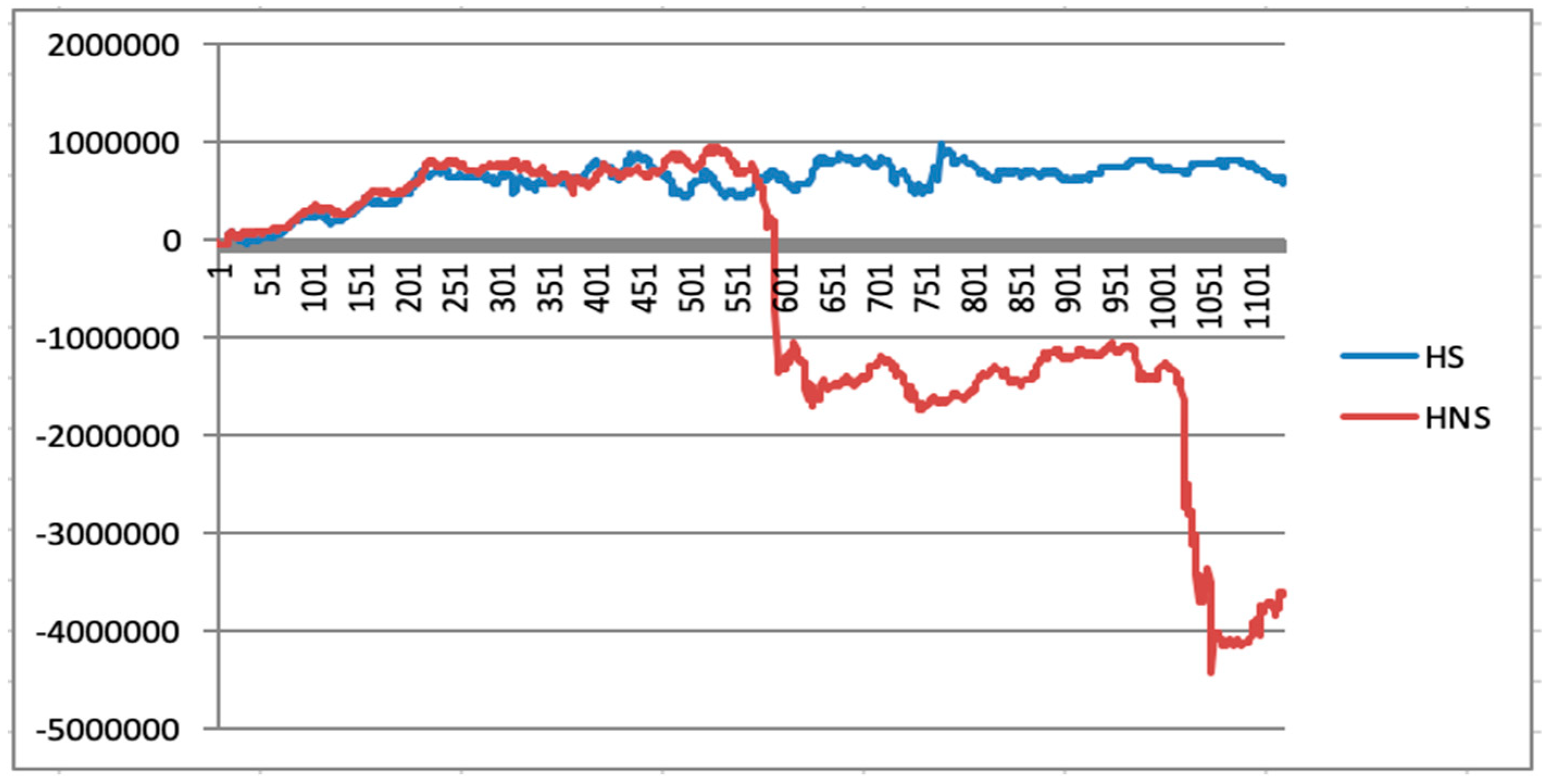
5.6. Initial Quantitative Investment Strategy Results
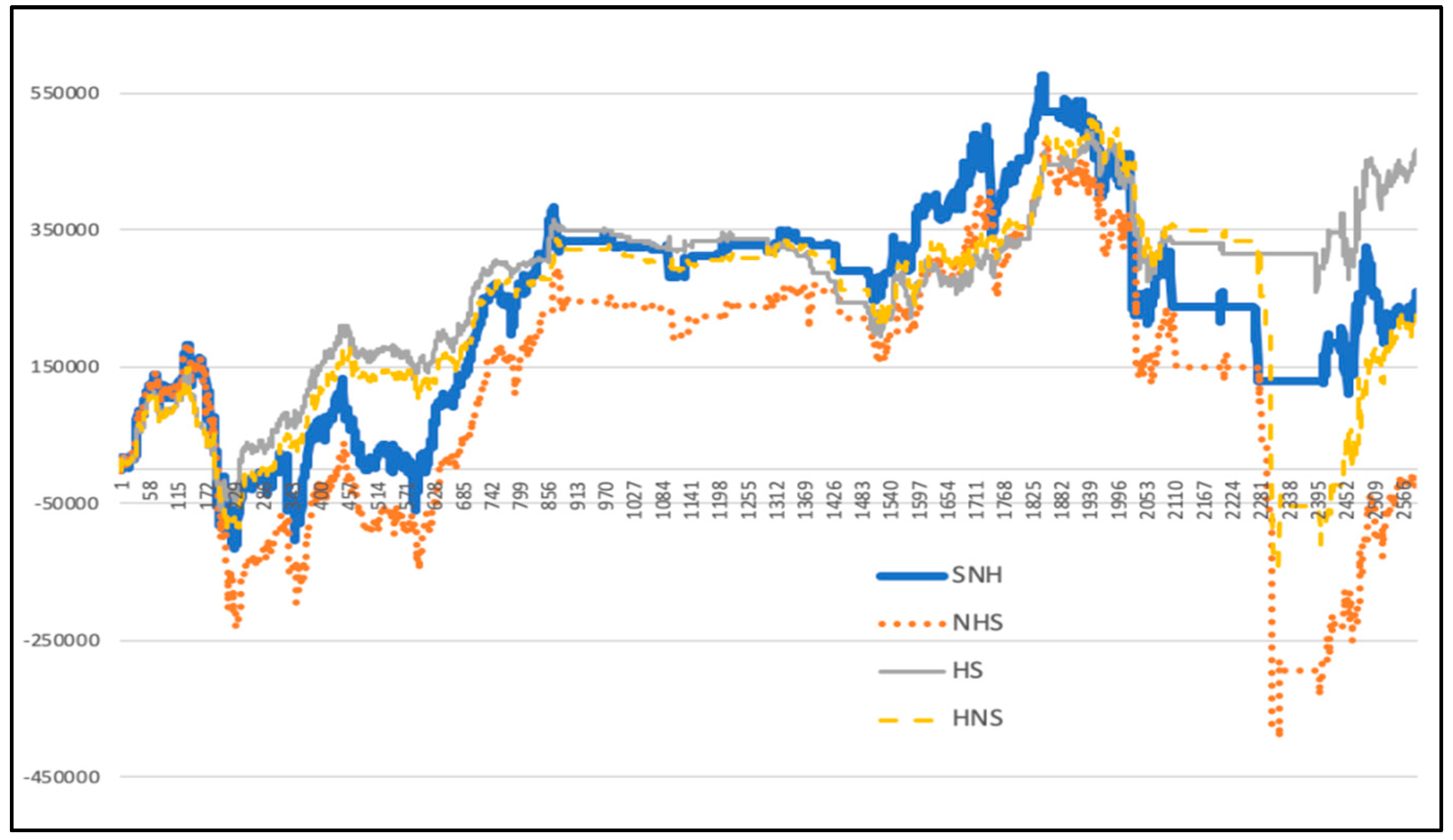
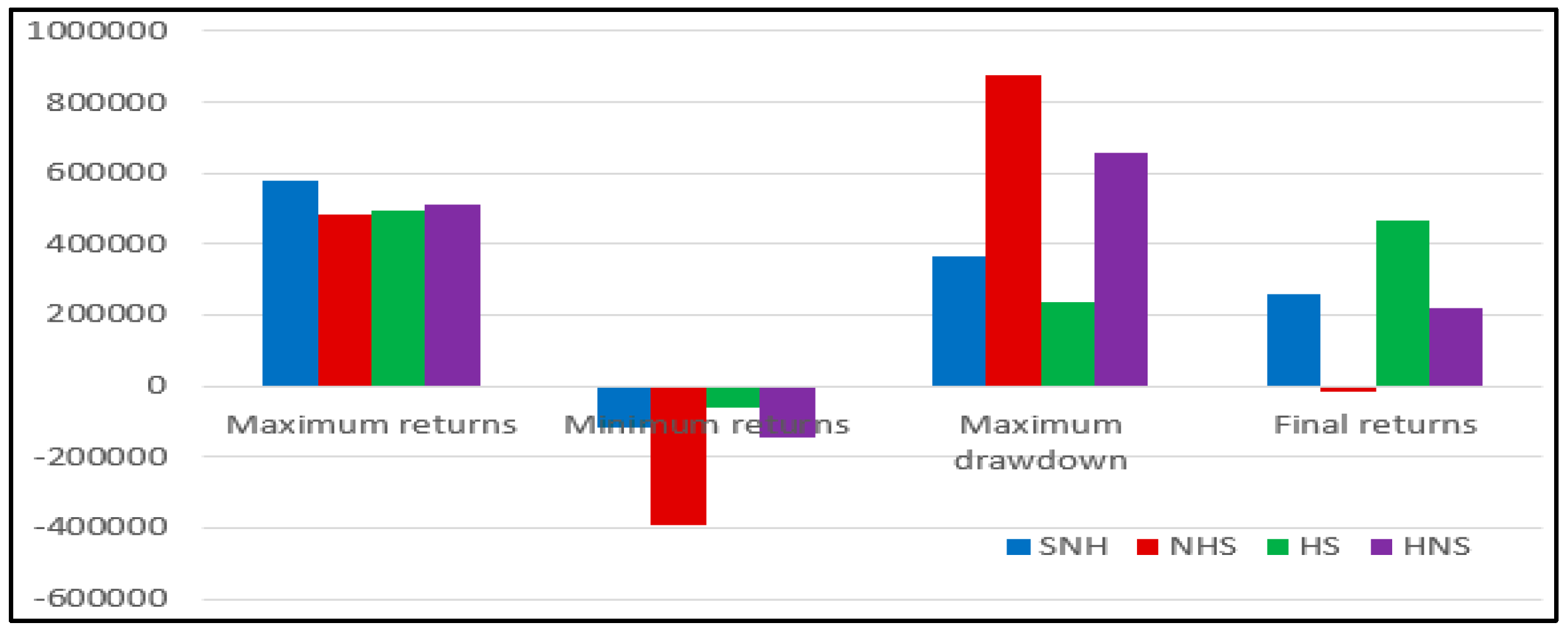
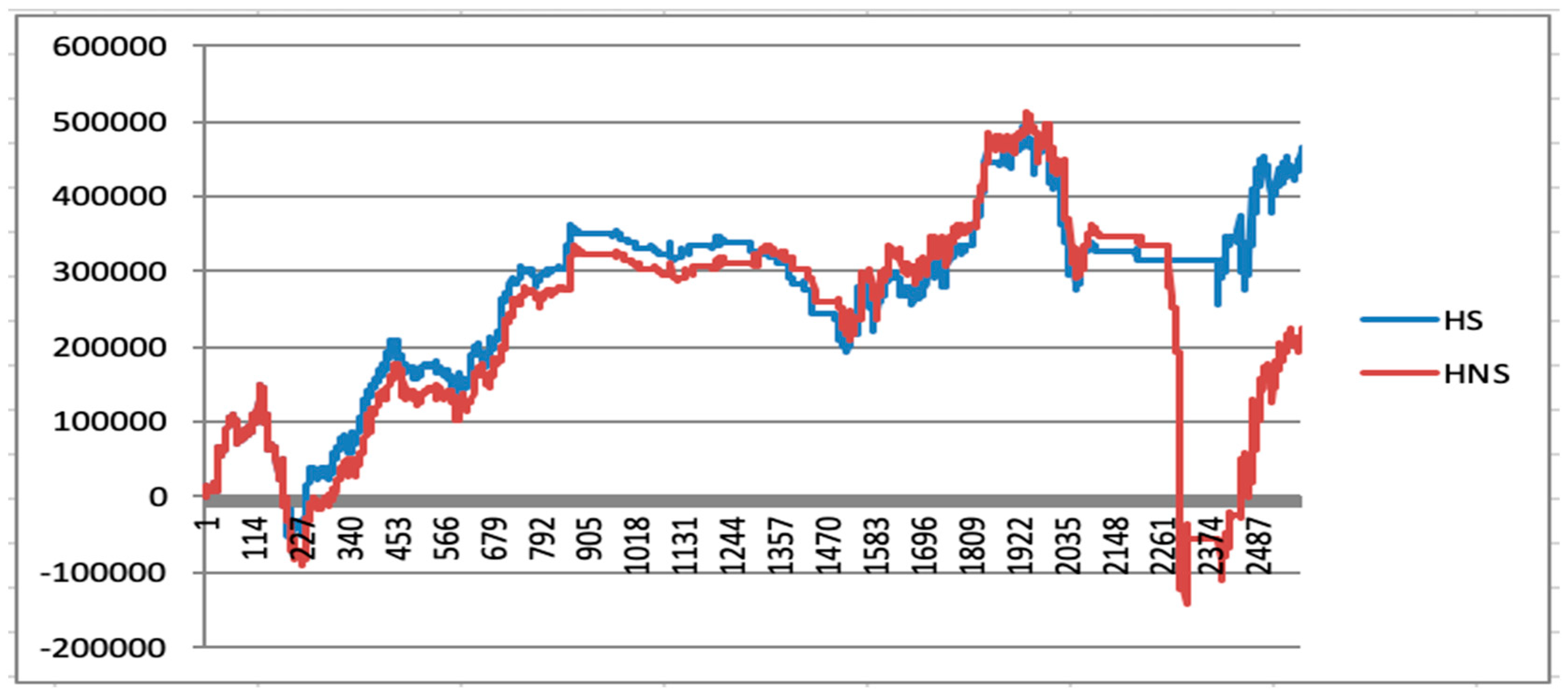
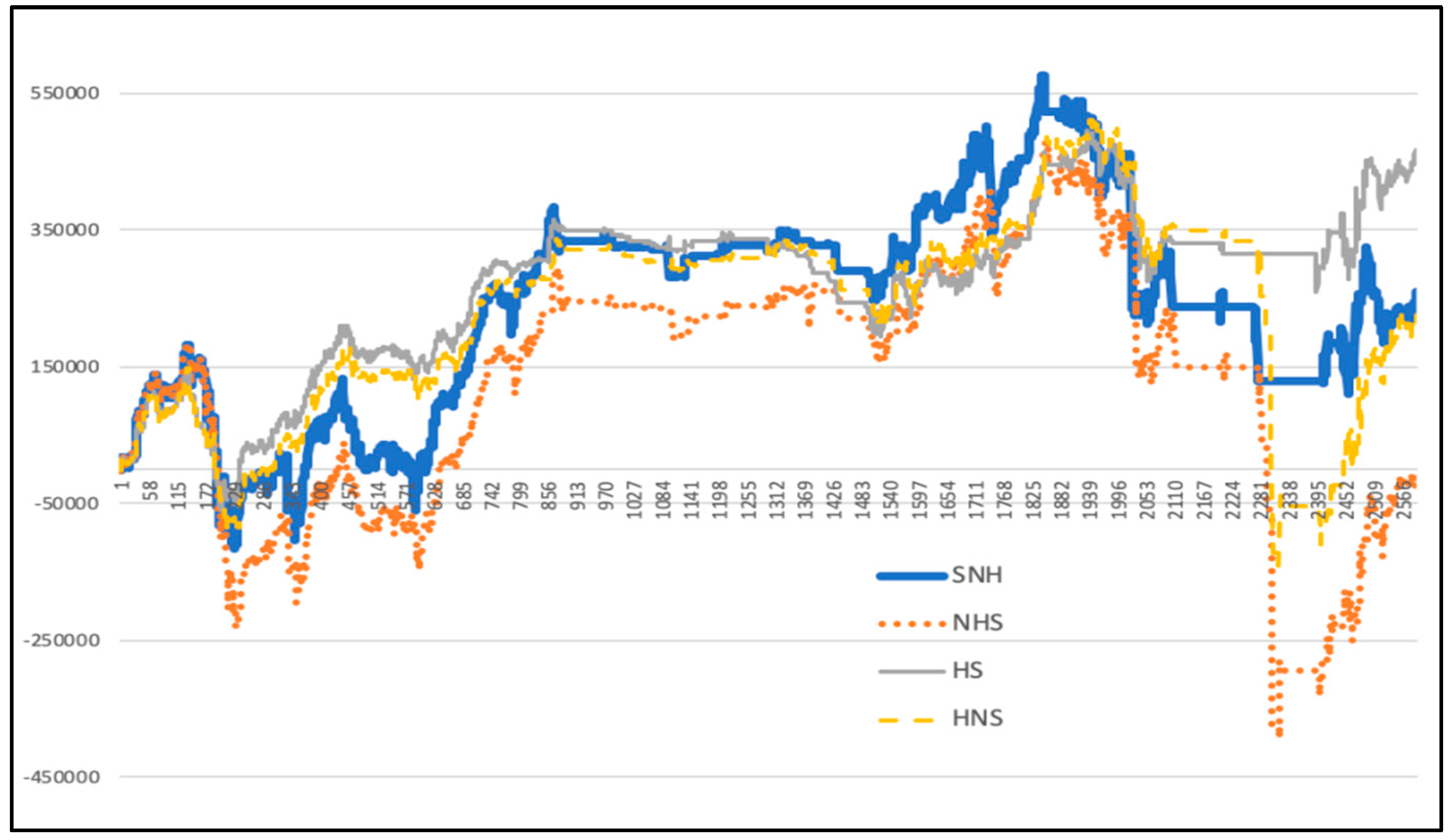
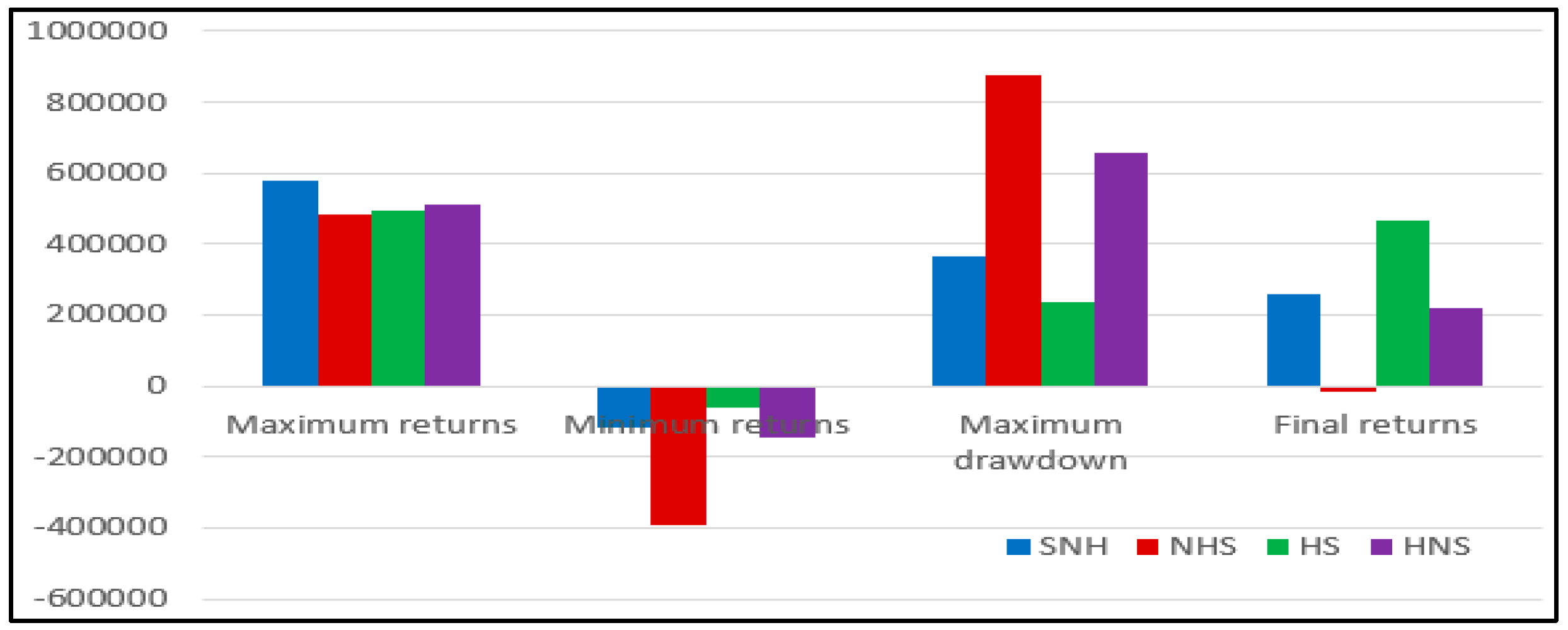
5.7. Quantitative Investment Strategy Results Based on Deep Learning
6. Conclusions and Prospects
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl.-Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Ritika, S.; Shashi, S. Stock prediction using deep learning. Mutimedia Tools and Appl. 2017, 76, 18569–18584. [Google Scholar]
- Masaya, A.; Hideki, N. Deep Learning for Forecasting Stock Returns in the Cross-Section. Stat. Financ. 2018, 3, 1–12. [Google Scholar]
- Kim, K.J. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Heaton, J.B.; Polson, N.G.; Witte, J.H. Deep Learning in Finance. arXiv, 2016; arXiv:1602.06561. [Google Scholar]
- Sun, S.; Wei, Y.; Wang, S. AdaBoost-LSTM Ensemble Learning for Financial Time Series Forecasting. In Proceedings of the International Conference on Computational Science, Wuxi, China, 11–13 June 2018; pp. 590–597. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Temporal Bag-of-Features Learning for Predicting Mid Price Movements Using High Frequency Limit Order Book Data. IEEE Trans. Emerg. Top. Comput. Intell. 2018. [Google Scholar] [CrossRef]
- Chortareas, G.; Jiang, Y.; Nankervis, J.C. Forecasting exchange rate volatility using high-frequency data: Is the euro different? Int. J. Forecast. 2011, 27, 1089–1107. [Google Scholar] [CrossRef]
- Carriero, A.; Kapetanios, G.; Marcellino, M. Forecasting exchange rates with a large Bayesian VAR. Int. J. Forecast. 2009, 25, 400–417. [Google Scholar] [CrossRef]
- Galeshchuk, S. Neural networks performance in exchange rate prediction. Neurocomputing 2016, 172, 446–452. [Google Scholar] [CrossRef]
- Shen, F.; Chao, J.; Zhao, J. Forecasting exchange rate using deep belief networks and conjugate gradient method. Neurocomputing 2015, 167, 243–253. [Google Scholar] [CrossRef]
- Tay, F.E.H.; Cao, L. Modified support vector machines in financial time series forecasting. Neurocomputing 2002, 48, 847–861. [Google Scholar] [CrossRef]
- Sun, J.; Fujita, H.; Chen, P.; Li, H. Dynamic financial distress prediction with concept drift based on time weighting combined with Adaboost support vector machine ensemble. Knowl.-Based Syst. 2017, 120, 4–14. [Google Scholar] [CrossRef]
- Van, G.T.; Suykens, J.K.; Baestaens, D.E.; Lambrehts, A.; Lanckriet, G.; Vandaele, B.; De Moor, B.; Vandealle, J. Financial time series prediction using least squares support vector machines within the evidence framework. IEEE Trans. Neural Netw. 2001, 12, 809–821. [Google Scholar]
- Das, S.P.; Padhy, S. A novel hybrid model using teaching-learning-based optimization and a support vector machine for commodity futures index forecasting. Int. J. Mach. Learn. Cybern. 2018, 9, 97–111. [Google Scholar] [CrossRef]
- Kercheval, A.N.; Zhang, Y. Modelling high-frequency limit order book dynamics with support vector machines. Quant. Financ. 2015, 15, 1315–1329. [Google Scholar] [CrossRef]
- Fan, A.; Palaniswami, M. Stock selection using support vector machines. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July 2001. [Google Scholar]
- Cao, L.J.; Tay, F.H. Support vector machine with adaptive parameters in financial time series forecasting. IEEE Trans. Neural Netw. 2003, 14, 1506–1518. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.W.; Ying, K.C.; Chen, S.C.; Lee, Z.J. Particle swarm optimization for parameter determination and feature selection of support vector machines. Expert Syst. Appl. 2008, 35, 1817–1824. [Google Scholar] [CrossRef]
- Hsu, C.M. A hybrid procedure with feature selection for resolving stock/futures price forecasting problems. Neural Comput. Appl. 2013, 22, 651–671. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, H.; Xiao, J.; Chen, Y. Improving options price forecasts with neural networks and support vector regressions. Neurocomputing 2009, 72, 3055–3065. [Google Scholar] [CrossRef]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M. Using deep learning to detect price change indications in financial markets. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Kai, C.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar]
- Minami, S. Predicting Equity Price with Corporate Action Events Using LSTM-RNN. J. Math. Financ. 2018, 8, 58–63. [Google Scholar] [CrossRef]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Forecasting stock prices from the limit order book using convolutional neural networks. In Proceedings of the 2017 IEEE 19th Conference on Business Informatics (CBI), Thessaloniki, Greece, 24–27 July 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks. Stud. Comput. Intell. 2008, 385, 1–23. [Google Scholar]
- Sun, R.Q. Research on Price Trend Prediction Model of US Stock Index Based on LSTM Neural Network. Master’s Thesis, Capital University of Economics and Business, Beijing, China, 2015. [Google Scholar]
- Guy, C.; Luo, L.; Elizabeth, P.; Juanjuan, F. Predicting Risk for Adverse Health Events Using Random Forest. J. Appl. Stat. 2018, 45, 2279–2294. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector machines. Mach. Learn. 1995, 20, 273–293. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. Neural Inf. Process. Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Hu, J.; Jiang, X.H.; Lu, L.N. A Step-by-step Guide of Options Investment. China Econ. Publ. House 2018, 22, 164–171. [Google Scholar]
- Black, F.; Scholes, M. The Pricing of Options and Corporate Liabilities. J. Polit. Econ. 1973, 81, 637–654. [Google Scholar] [CrossRef]
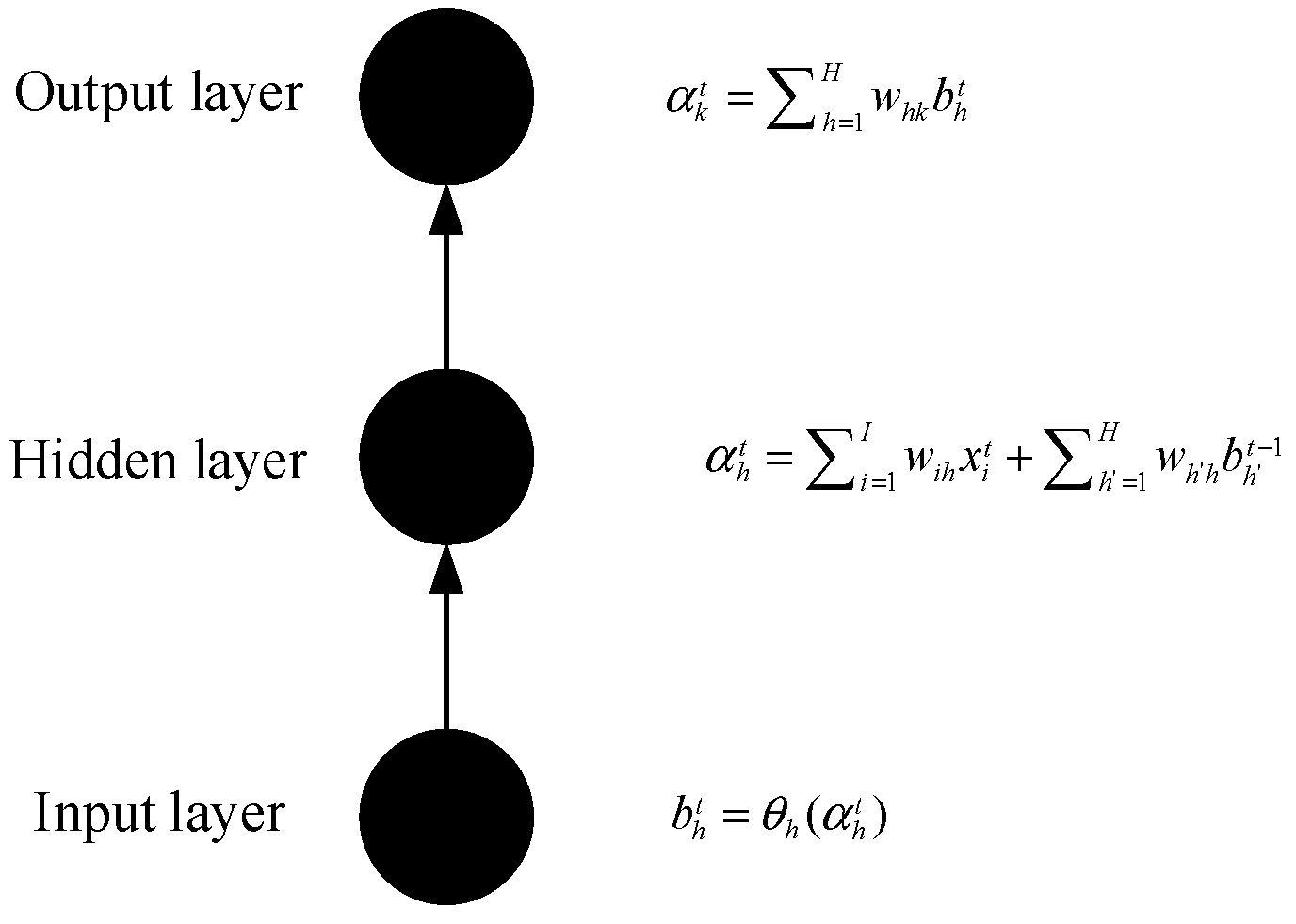

{kind=link}
{kind=link}
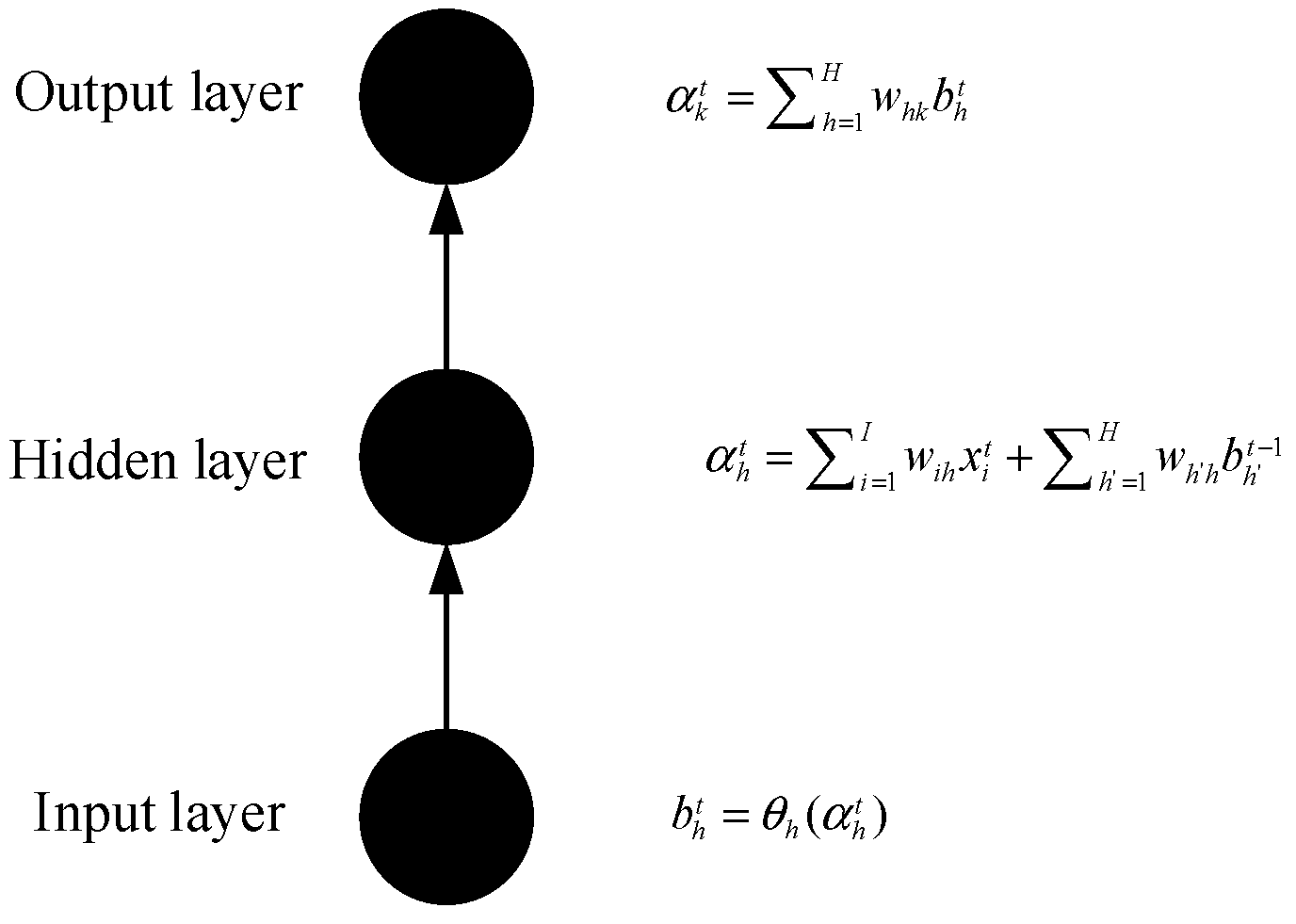{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject Contract Name | Buy or Sell | Quantity | Options Price |
|---|---|---|---|
| 50 ETF buying December 2750 | Sell | 1 | 0.0635 |
| 50 ETF selling December 2550 | Sell | 1 | 0.0334 |
| Hidden Units | Iteration Times | TimeStep | Batch_Size | Runningtime | Deviation |
|---|---|---|---|---|---|
| 20 | 200 | 16 | 80 | 6 min | 0.013833 |
| 20 | 1000 | 16 | 80 | 16 min | 0.013703 |
| 20 | 2000 | 16 | 80 | 34 min | 0.011918 |
| 20 | 2000 | 20 | 60 | 32 min | 0.009551 |
| 60 | 2000 | 16 | 80 | 1 h 21 min | 0.016878 |
| 100 | 2000 | 20 | 60 | 2 h 27 min | 0.012416 |
| Cross-validation mean squared error (MSE) | 0.00117032 |
| Cross-validation squared correlation coefficient | 0.987437 |
| Best cross-validation MSE | 0.000496649 |
| Best c | 1.23114 |
| Best g | 0.378929 |
| Cross-validation mean squared error | 0.00214727 |
| Cross-validation squared correlation coefficient | 0.980383 |
| Best cross-validation MSE | 0.000388862 |
| Best c | 1 |
| Best g | 0.466516 |
| LSTM (Deviation) | RF (Deviation) | |
|---|---|---|
| 20170628 (11:30) –20180314 (10:30) | 0.00232 | 0.00475 |
| 20150414 (10:30) –20160112 (13:45) | 0.00903 | 0.01189 |
| LSTM-SVR I (Deviation, Only Using Output) | LSTM-SVR II (Deviation, Using Hidden State Vector) | |
|---|---|---|
| 20170628(11:30) −20180314(10:30) | 0.00025 | 0.00062 |
| 20150414(10:30) −20160112(13:45) | 0.0023 | 0.00552 |
| SNH | NHS | HS | HNS | |
|---|---|---|---|---|
| Maximum returns | 576,767.6 | 484,294 | 493,478.8 | 511,736.6 |
| Minimum returns | −116,804.2 | −393,156.8 | −61,717.6 | −143,753.8 |
| Maximum drawdown | 362,872.8 | 877,450.8 | 2,352,84.4 | 655,490.4 |
| Final returns | 258,675.6 | −15,720.4 | 464,496 | 219,288. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Chen, J.; Xue, Z. Research on Quantitative Investment Strategies Based on Deep Learning. Algorithms 2019, 12, 35. https://doi.org/10.3390/a12020035
Fang Y, Chen J, Xue Z. Research on Quantitative Investment Strategies Based on Deep Learning. Algorithms. 2019; 12(2):35. https://doi.org/10.3390/a12020035
Chicago/Turabian StyleFang, Yujie, Juan Chen, and Zhengxuan Xue. 2019. "Research on Quantitative Investment Strategies Based on Deep Learning" Algorithms 12, no. 2: 35. https://doi.org/10.3390/a12020035
APA StyleFang, Y., Chen, J., & Xue, Z. (2019). Research on Quantitative Investment Strategies Based on Deep Learning. Algorithms, 12(2), 35. https://doi.org/10.3390/a12020035