A Fast Approach to Texture-Less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. The Orientation Compressed Map
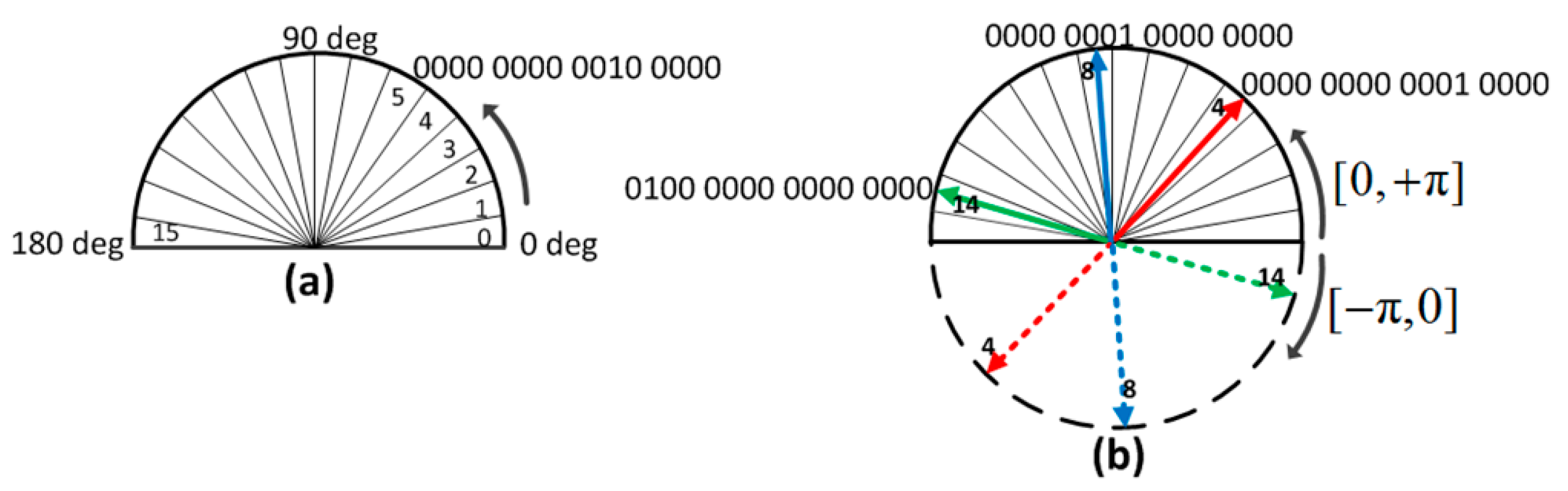
2.1. Quantizing and Encoding the Orientations
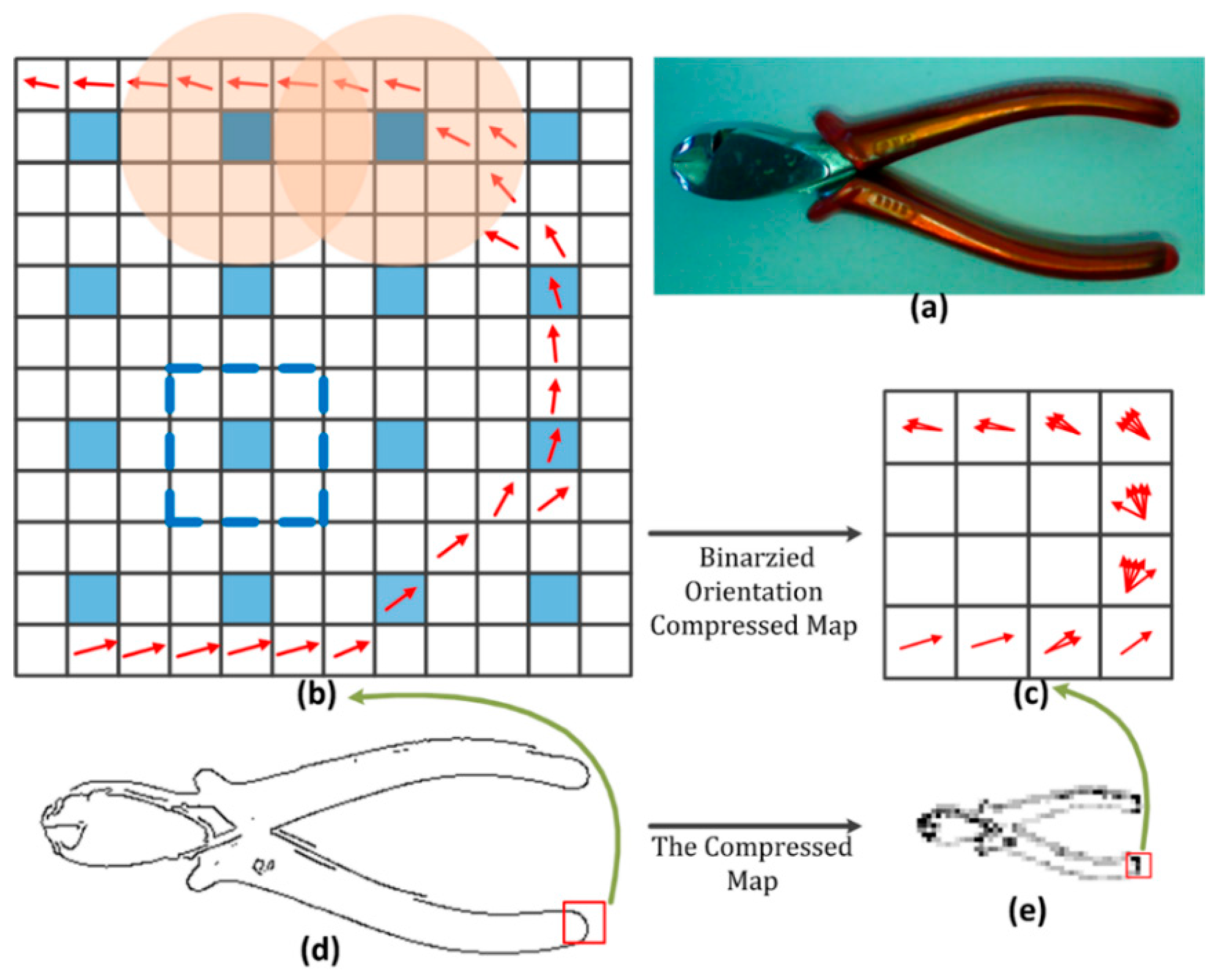
2.2. Orientation Compressing Map
2.3. Similarity Measure and Possible Object Locations
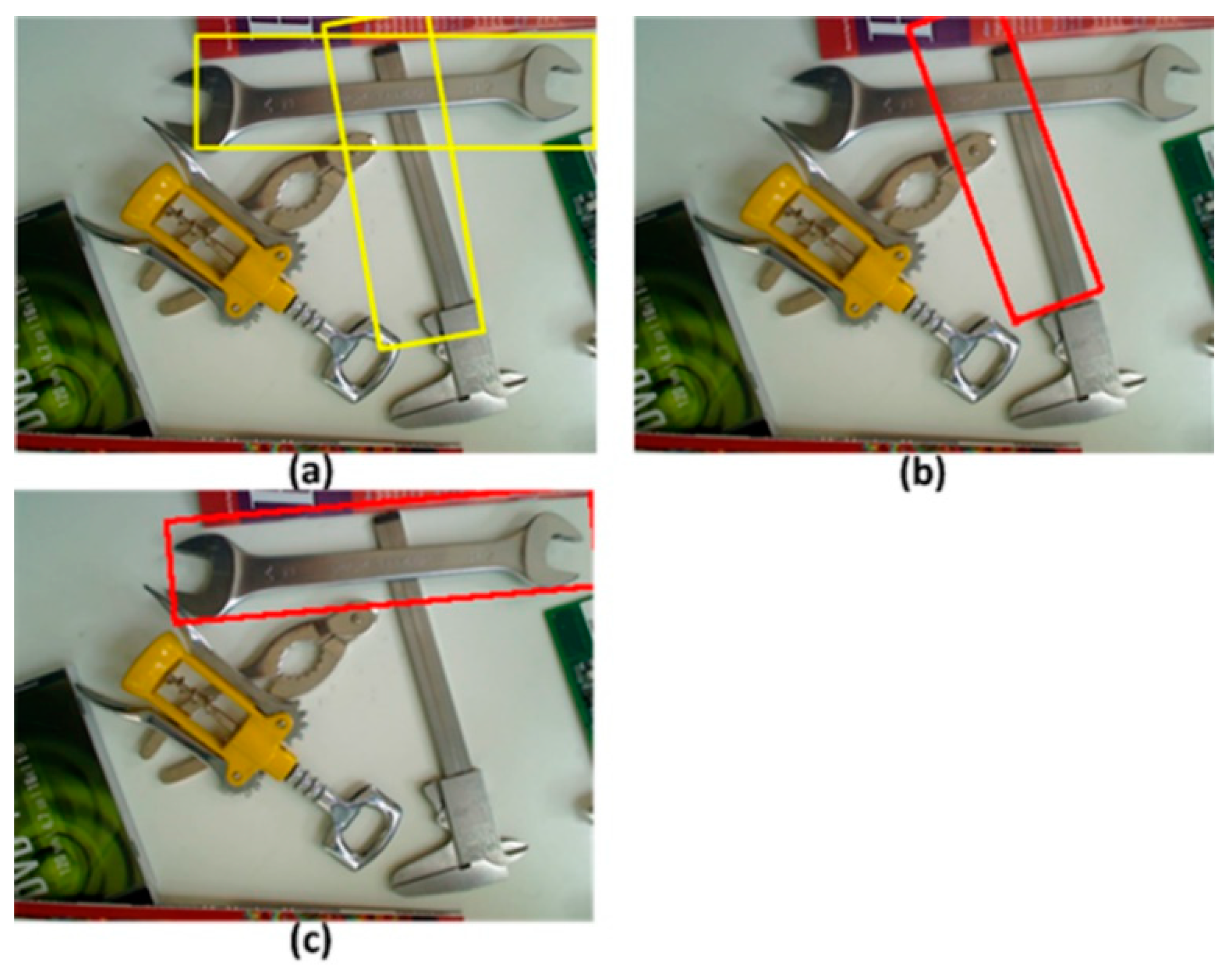
2.4. Extract Possible Object Locations Based on the Orientation Compressing Map
3. Discriminative Regional Weight
3.1. Region Based Weight
3.2. Object Detection
3.3. Object Detection Algorithm
4. Experiment Results
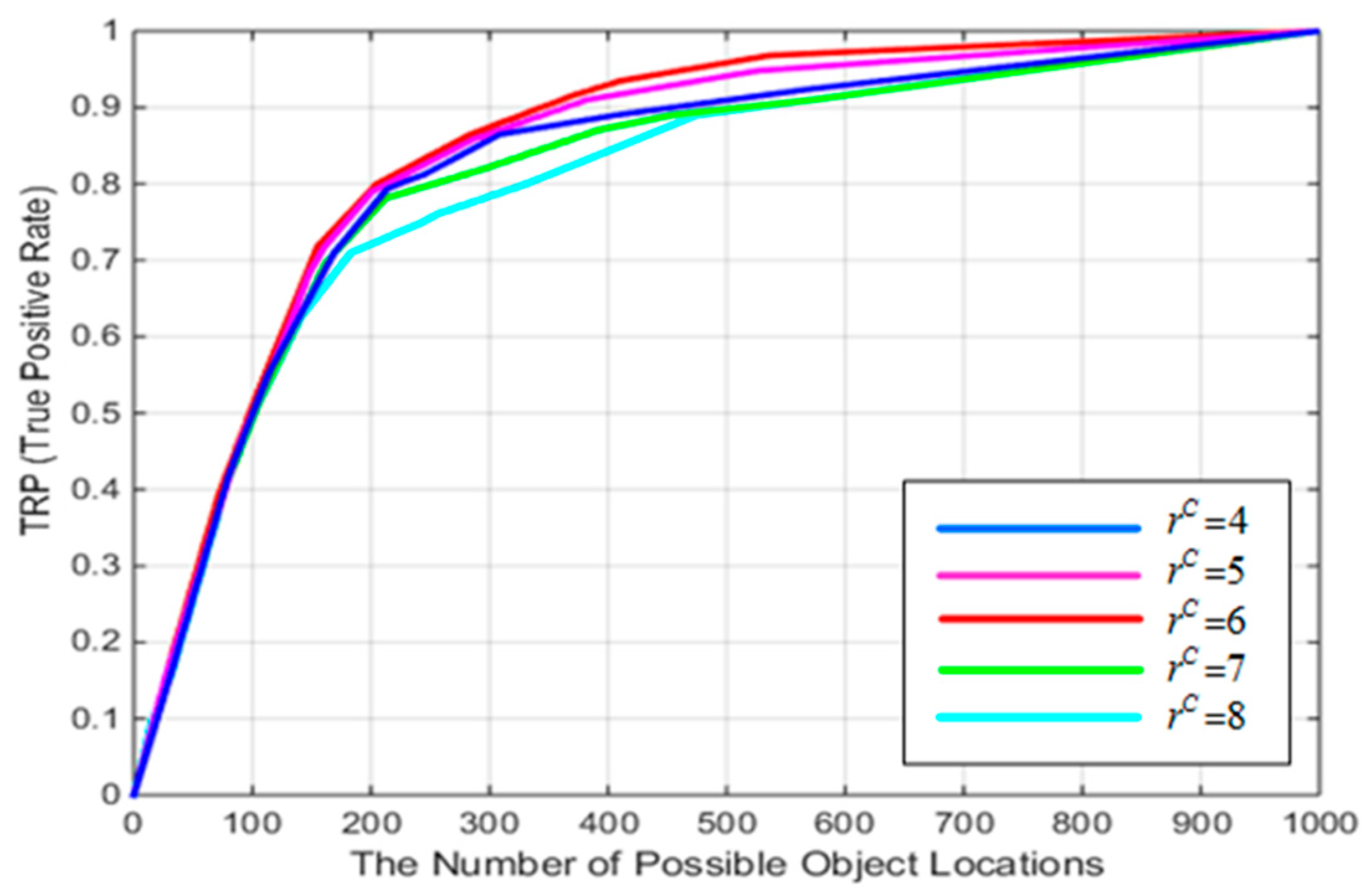
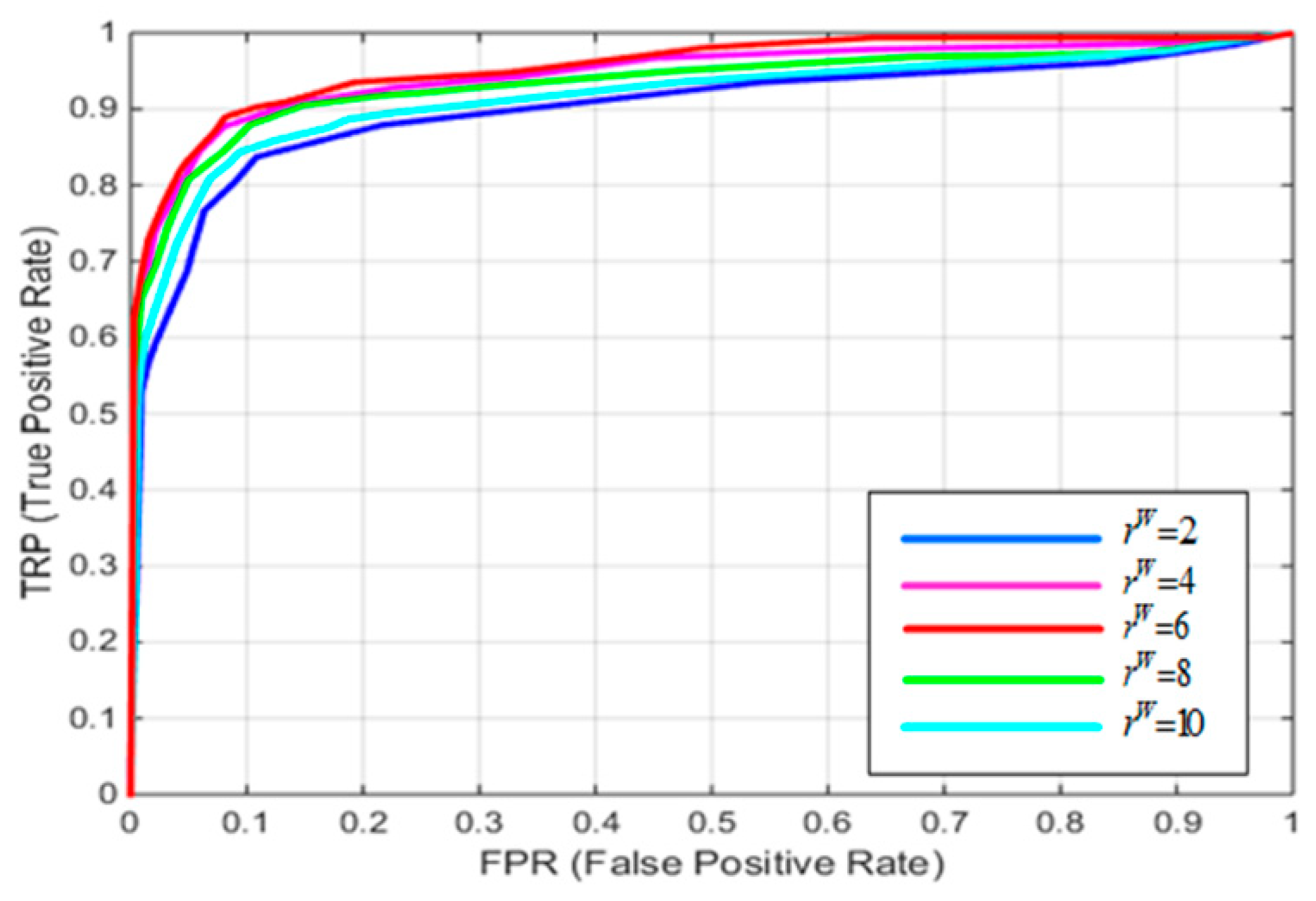
4.1. Parameter Experiment
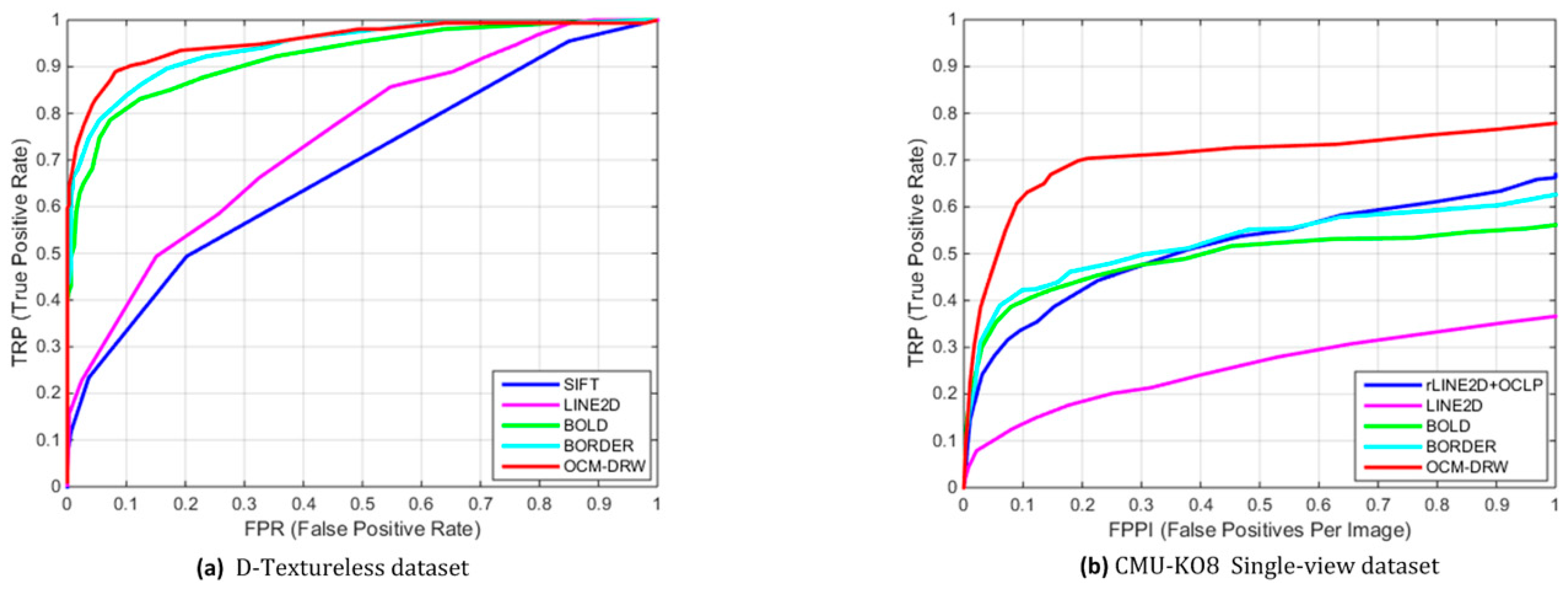
4.2. D-Textureless Dataset Experiment
4.3. CMU-KO8 Dataset Experiment
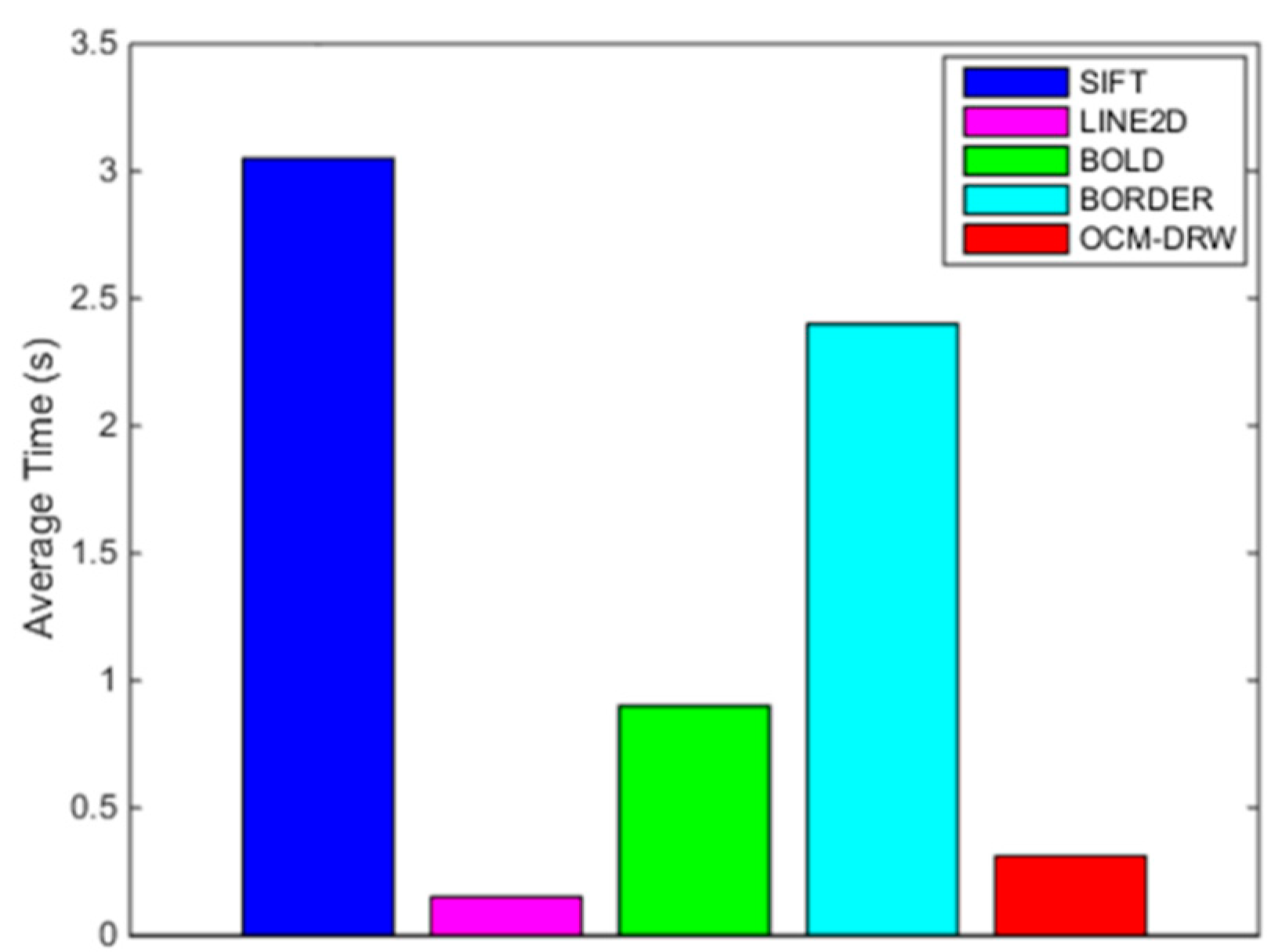
4.4. Timing Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Staffan, E.; Kragic, D.; Jensfelt, P. Object Detection and Mapping for Service Robot Tasks. Robotica 2007, 25, 175–187. [Google Scholar]
- Datta, R.; Joshi, D.; Li, J. Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv. 2008, 40, 5. [Google Scholar] [CrossRef]
- Hodan, T.; Damen, D.; Mayol-Cuevas, W.; Matas, J. Efficient Texture-less Object Detection for Augmented Reality Guidance. In Proceedings of the IEEE International Symposium on Mixed & Augment Reality Workshops, Fukuoka, Japan, 29 September–3 October 2015; pp. 81–86. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D.; Breitkopf, U.; Jung, J. Results of the ISPRS benchmark on urban object detection and 3D building reconstruction. ISPRS J. Photogramm. 2014, 93, 256–271. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, X.; Yang, T.; Li, J. Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network. Electronics 2018, 7, 78. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, W.; Xing, M.; Sun, G. Terahertz Image Detection with the Improved Faster Region-Based Convolutional Neural Network. Sensors 2018, 18, 2327. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Tang, C.; Ling, Y.; Yang, X.; Jin, W.; Zheng, C. Multi-View Object Detection Based on Deep Learning. Appl. Sci. 2018, 8, 1423. [Google Scholar] [CrossRef]
- Ren, M.; Liu, R.; Hong, H.; Ren, J.; Xiao, G. Fast Object Detection in Light Field Imaging by Integrating Deep Learning with Defocusing. Appl. Sci. 2017, 7, 1309. [Google Scholar]
- Li, Y.; Wang, S.; Tian, Q.; Ding, X. Feature representation for statistical-learning-based object detection: A review. Pattern Recogn. 2015, 48, 3542–3559. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded Up Robust Features (SURF). Comput. Vis. Image Underst. 2006, 110, 404–417. [Google Scholar]
- Kim, G.; Hebert, M.; Park, S.K. Preliminary Development of a Line Feature-Based Object Recognition System for Textureless Indoor Objects. In Recent Progress in Robotics: Viable Robotic Service to Human; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 255–268. [Google Scholar]
- David, P.; DeMenthon, D. Object recognition in high clutter images using line features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Beijing, China, 17–20 October 2005; pp. 1581–1588. [Google Scholar]
- Awais, M.; Mikolajczyk, K. Feature pairs connected by lines for object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3093–3096. [Google Scholar]
- Dornaika, F.; Chakik, F. Efficient object detection and tracking in video sequences. J. Opt. Soc. Am. A 2012, 29, 928–935. [Google Scholar] [CrossRef]
- Wang, X.; Shen, S.; Ning, C.; Huang, F.; Gao, H. Multi-class remote sensing object recognition based on discriminative sparse representation. Appl. Opt. 2016, 55, 1381–1394. [Google Scholar] [CrossRef]
- Tombari, F.; Franchi, A.; Di Stefano, L. Bold features to detect texture-less objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1265–1272. [Google Scholar]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A line segment detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of single-phase induction motor based on acoustic signals. Mech. Syst. Signal Process. 2019, 117, 65–80. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Recognition of images of finger skin with application of histogram, image filtration and K-NN classifier. Biocybern. Biomed. Eng. 2016, 36, 95–101. [Google Scholar] [CrossRef]
- Chan, J.; Lee, J.A.; Kemao, Q. BORDER: An Oriented Rectangles Approach to Texture-less Object Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas Valley, NV, USA, 27–30 June 2016; pp. 2855–2863. [Google Scholar]
- Olson, C.F.; Huttenlocher, D.P. Automatic target recognition by matching oriented edge pixels. IEEE Trans. Image Process. 1997, 6, 103–113. [Google Scholar] [CrossRef]
- Gavrila, D.M.; Philomin, V. Real-time object detection for “smart” vehicles. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999; pp. 87–93. [Google Scholar]
- Rucklidge, W.J. Efficiently locating objects using the Hausdorff distance. Int. J. Comput. Vis. 1997, 24, 251–270. [Google Scholar] [CrossRef]
- Hsiao, E.; Hebert, M. Gradient Networks: Explicit Shape Matching Without Extracting Edges. In Proceedings of the Aaai Conference on Aritificial Intelligence, Bellevue, DC, USA, 14–18 July 2013; pp. 417–423. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Fua, P.; Navab, N. Dominant Orientation Templates for Real-time Detection of Texture-less Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 12–20 June 2010; pp. 2257–2264. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed]
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 858–865. [Google Scholar]
- Steger, C. Similarity Measures for Occlusion, Clutter, and Illumination Invariant Object Recognition. In Dagm-symposium Pattern Recognition; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; pp. 148–154. [Google Scholar]
- Hsiao, E.; Hebert, M. Occlusion Reasoning for Object Detection under Arbitrary Viewpoint. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1803–1815. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Qin, H.; Peng, T. A Fast Approach to Texture-less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight. Available online: https://github.com/HanchengYu/OCM-DRW (accessed on 19 January 2018).













© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Qin, H.; Peng, M. A Fast Approach to Texture-Less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight. Algorithms 2018, 11, 201. https://doi.org/10.3390/a11120201
Yu H, Qin H, Peng M. A Fast Approach to Texture-Less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight. Algorithms. 2018; 11(12):201. https://doi.org/10.3390/a11120201
Chicago/Turabian StyleYu, Hancheng, Haibao Qin, and Maoting Peng. 2018. "A Fast Approach to Texture-Less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight" Algorithms 11, no. 12: 201. https://doi.org/10.3390/a11120201
APA StyleYu, H., Qin, H., & Peng, M. (2018). A Fast Approach to Texture-Less Object Detection Based on Orientation Compressing Map and Discriminative Regional Weight. Algorithms, 11(12), 201. https://doi.org/10.3390/a11120201