Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient

Abstract
1. Introduction
2. Related Work
3. Methods
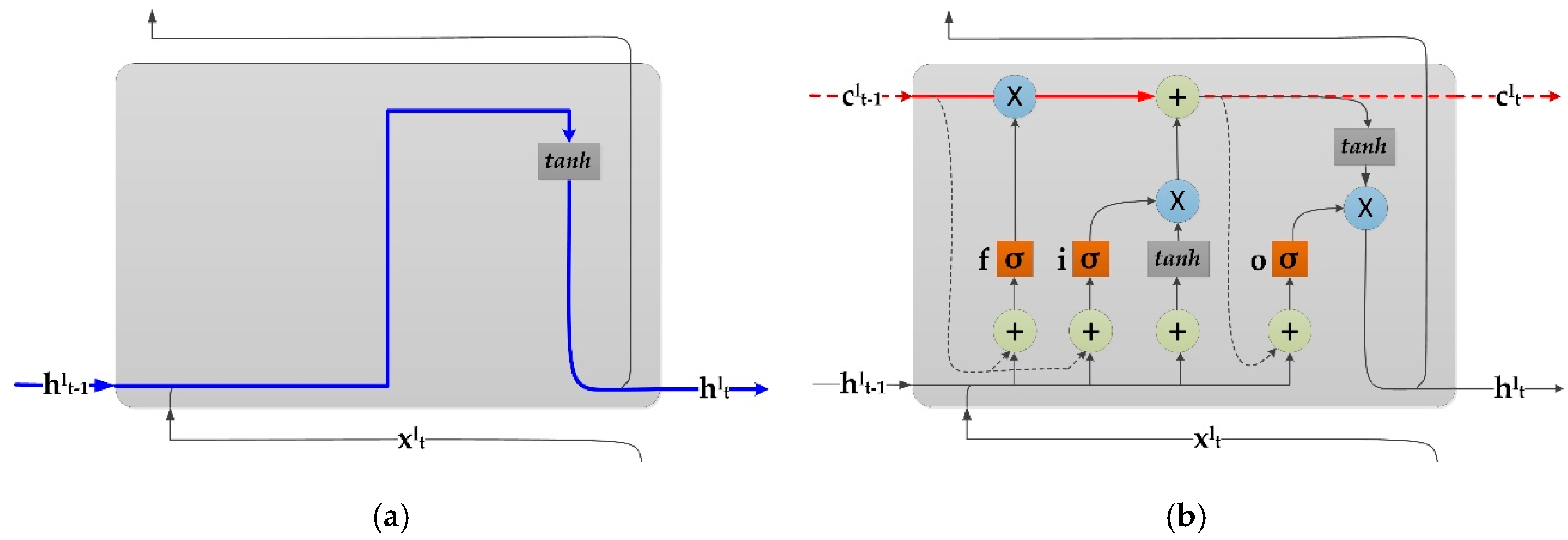
3.1. Long Short-Term Memory RNNs
- Memory unit c: they store the network’s time status;
- Input gates i: they decide whether to pass input information into cell c;
- Output gate o: they decide whether to output the cell information; and,
- Forget gate f: These gates adaptively reset the cell state.
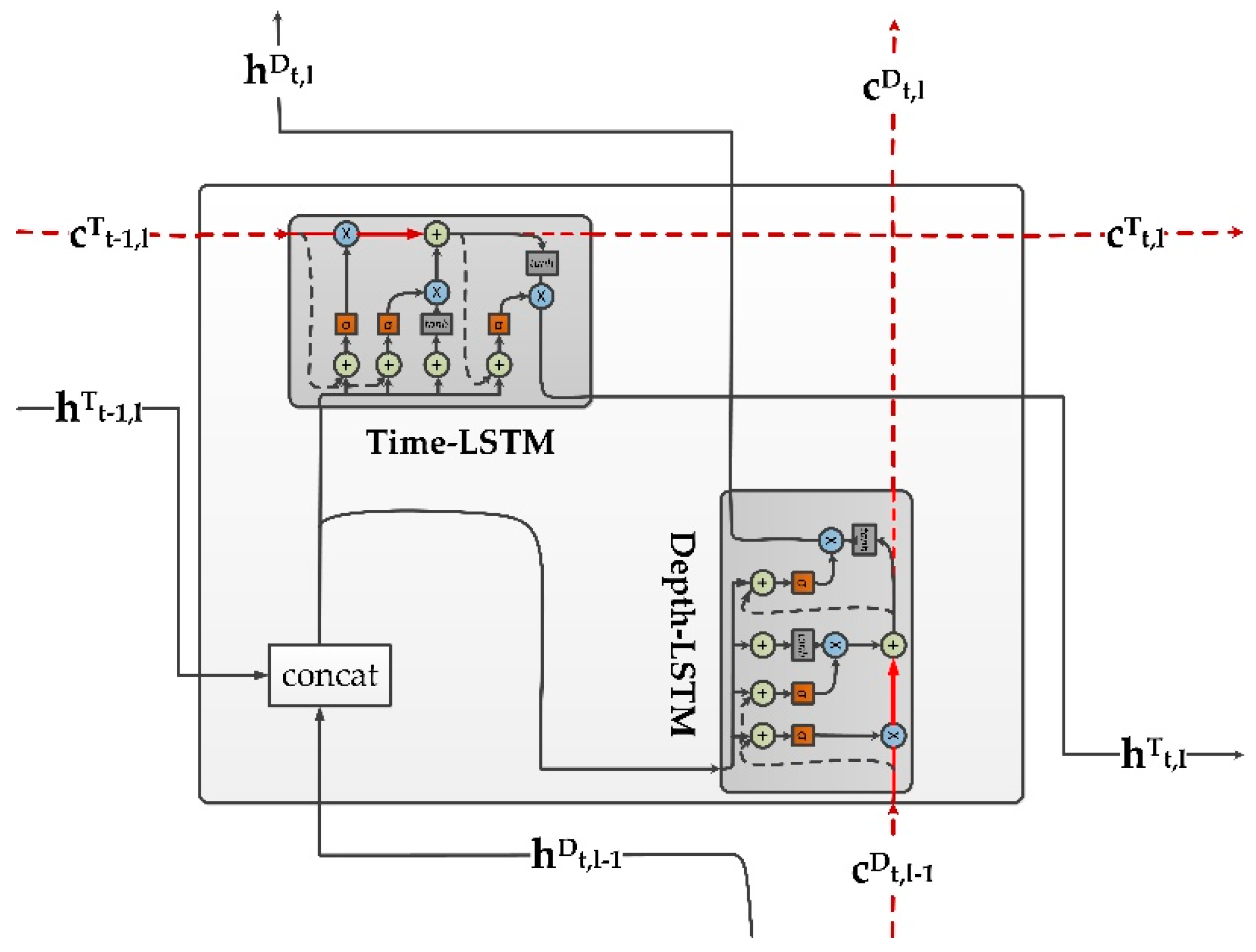
3.2. Grid Long Short-Term Memory RNNs
- The calculation process of Time-LSTM block is as follows:
- The calculation process of Depth-LSTM block is as follows:
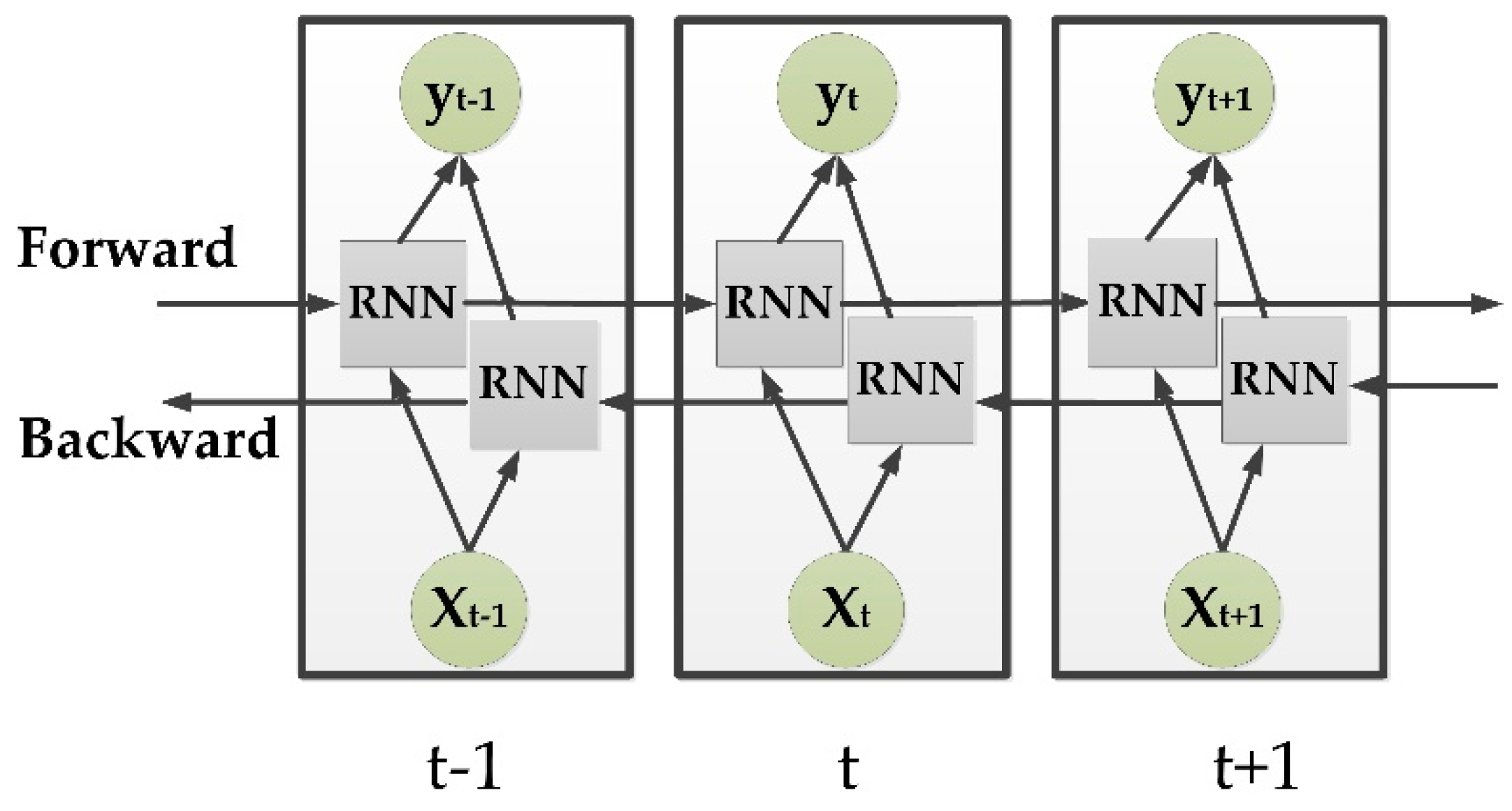
3.3. Bidirectional RNNs
3.4. Vanishing Gradient and Context-Sensitivity
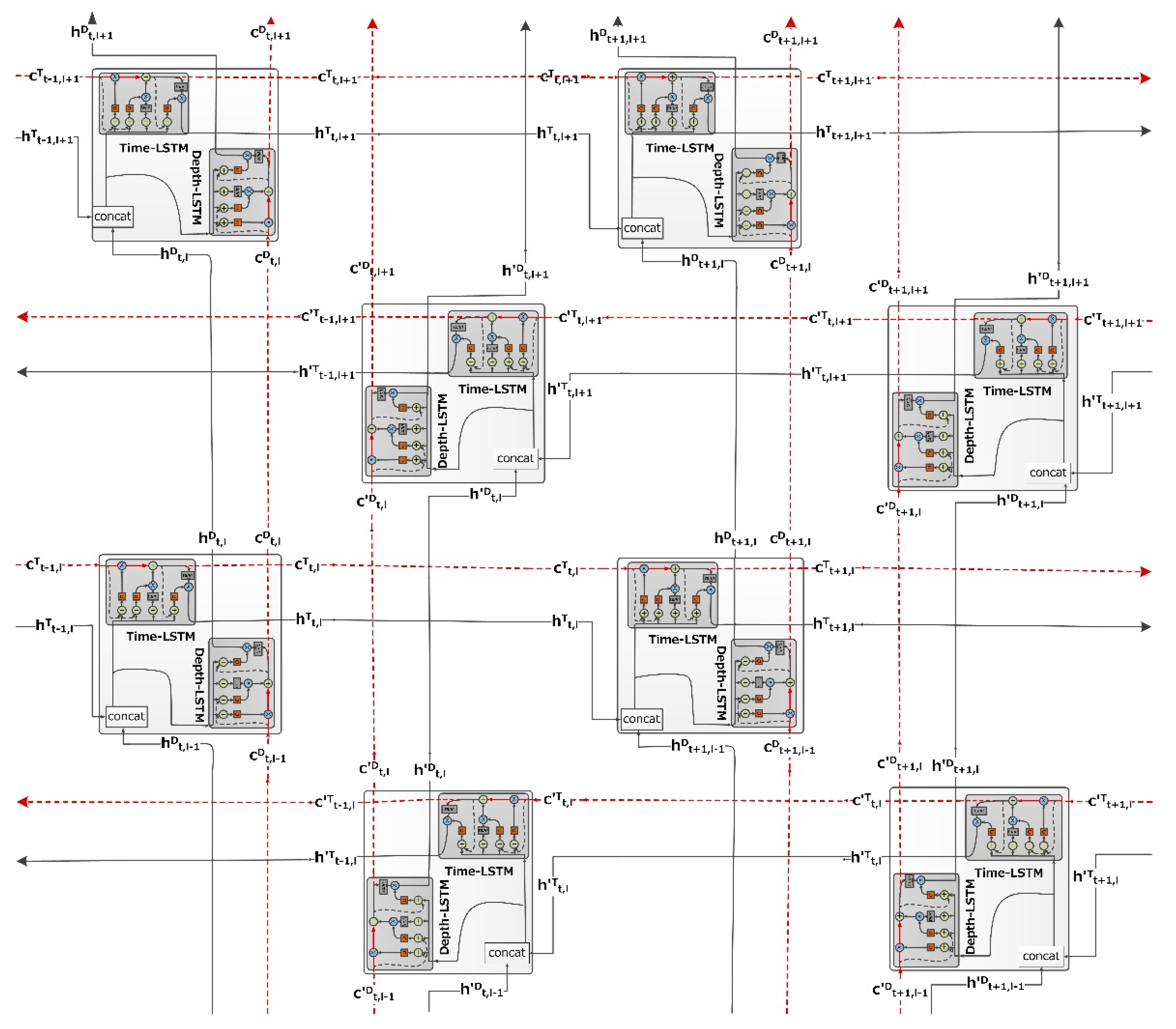
3.5. Bidirectional Grid Long Short-Term Memory RNNs
- The simplified formulas for the Time-LSTM and Depth-LSTM in the forward GridLSTM block are defined, as follows:
- The simplified formulas for the T-LSTM and D-LSTM in the reverse GridLSTM block are defined, as follows:
4. Experiment Setup
4.1. Dataset
4.2. Metrics
4.3. Model Setup
4.4. Preprocessing and Training
5. Results and Discussion
5.1. Grid LSTM Model and Baseline
5.2. Unidirectional/Bidirectional Grid LSTM
5.3. Comparisons with Alternative Deep LSTM
5.4. Deeper Bidirectional Grid LSTM
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Vancouver, BC, Canada, 26–30 May 2013; Volume 38, pp. 6645–6649. [Google Scholar]
- Li, B.; Sim, K.C. Modeling long temporal contexts for robust DNN-based speech recognition. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 7–10 September 2014. [Google Scholar]
- Li, J.; Mohamed, A.; Zweig, G.; Gong, Y. Exploring Multidimensional LSTMs for Large Vocabulary ASR. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing(ICASSP), Shanghai, China, 20–25 March 2016; pp. 4940–4944. [Google Scholar]
- Yu, D.; Li, J. Recent progresses in deep learning based acoustic models. IEEE J. 2017, 4, 396–409. [Google Scholar] [CrossRef]
- Hinton, G.E.; Geoffrey, E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Kang, M.; Tang, B.; Pecht, M. Deep Residual Networks With Dynamically Weighted Wavelet Coefficients for Fault Diagnosis of Planetary Gearboxes. IEEE Trans. Ind. Electron. 2018, 65, 4290–4300. [Google Scholar] [CrossRef]
- Dey, R.; Salemt, F.M. Gate-variants of Gated Recurrent Unit (GRU) neural networks. In Proceedings of the 60th IEEE International Midwest Symposium on Circuits and Systems, Boston, MI, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv, 2014; arXiv:1412.3555. [Google Scholar]
- Kalchbrenner, N.; Danihelka, I.; Graves, A. Grid long short-term memory. arXiv, 2015; arXiv:1507.01526. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the IEEE International Joint Conference on Neural Networks(IJCNN), Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid Speech Recognition with Deep Bidirectional LSTM. In Proceedings of the IEEE Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. arXiv, 2015; arXiv:1511.08308. [Google Scholar]
- Huang, Z.; Xu, W.Y.K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv, 2015; arXiv:1508.01991. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the 15th Annual Conference of the International Speech Communication Association (INTERSPEECH), Singapore, 7–10 September 2014; pp. 338–342. [Google Scholar]
- Zhang, Y.; Chen, G.; Yu, D.; Yaco, K.; Khudanpur, S.; Glass, J. Highway long short-term memory RNNs for distant speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5755–5759. [Google Scholar]
- Kim, J.; Elkhamy, M.; Lee, J. Residual LSTM: Design of a deep recurrent architecture for distant speech recognition. arXiv, 2017; arXiv:1701.03360. [Google Scholar]
- Zhao, Y.; Xu, S.; Xu, B. Multidimensional Residual Learning Based on Recurrent Neural Networks for Acoustic Modeling. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH), San Francisco, CA, USA, 8–12 September 2016; pp. 3419–3423. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hsu, W.N.; Zhang, Y.; Glass, J. A prioritized grid long short-term memory RNN for speech recognition. In Proceedings of the IEEE Workshop on Spoken Language Technology (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 467–473. [Google Scholar]
- Kreyssing, F.; Zhang, C.; Woodland, P. Improved TDNNs using Deep Kernels and Frequency Dependent Grid-RNNs. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1–5. [Google Scholar]
- Hochreiter, S. Untersuchungen zu Dynamischen Neuronalen Netzen. Master’s Thesis, Munich Industrial University, Munich, Germany, 1991. [Google Scholar]
- Graves, A. Long Short-Term Memory; Springer: Berlin, Germany, 2012; pp. 1735–1780. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 22–24 June 2014; pp. 1764–1772. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv, 2013; arXiv:1308.0850. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal. Process. 2002, 45, 2673–2681. [Google Scholar] [CrossRef]
- Wöllmer, M.; Eyben, F.; Graves, A.; Schuller, B.; Rigoll, G. Bidirectional LSTM Networks for Context-Sensitive Keyword Detection in a Cognitive Virtual Agent Framework. Cognit. Comput. 2010, 2, 180–190. [Google Scholar] [CrossRef]
- Williams, R.J.; Peng, J. An Efficient Gradient-Based Algorithm for On-Line Training of Recurrent Network Trajectories. Neural Comput. 1990, 2, 490–501. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Hossan, M.A.; Gregory, M.A. Speaker recognition utilizing distributed DCT-II based mel frequency cepstral coefficients and fuzzy vector quantization. Int. J. Speech Technol. 2013, 16, 103–113. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.R.; Hinton, G. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 256–283. [Google Scholar]
- Variani, E.; Bagby, T.; Mcdermott, E.; Bacchiani, M. End-to-end training of acoustic models for large vocabulary continuous speech recognition with tensorflow. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (INTERSPEECH), Stockholm, Sweden, 20–24 August 2017; pp. 1641–1645. [Google Scholar]
- Seide, F.; Li, G.; Chen, X.; Yu, D. Feature engineering in context-dependent deep neural networks for conversational speech transcription. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Waikoloa, HI, USA, 11–15 December 2011; pp. 24–29. [Google Scholar]
- Graves, A.; Gomez, F. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. Int. Conf. Mach. Learn. 2006, 2006, 369–376. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Layer | Hidden Size | Params | CER (%) | F1 (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|---|---|---|
| LSTM | 2 | 256 | 835,869 | 21.64 | 79.50 | 80.11 | 78.93 |
| GRU | 2 | 256 | 628,765 | 24.62 | 76.68 | 77.38 | 76.12 |
| GridLSTM | 2 | 256 | 2,262,813 | 20.44 | 81.03 | 81.46 | 79.78 |
| Model | Layer | Hidden Size | Params | CER (%) | F1 (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|---|---|---|
| GRU | 2 | 256 | 628,765 | 24.62 | 76.68 | 77.38 | 76.12 |
| BiGRU | 2 | 256 | 1,250,077 | 18.93 | 82.10 | 82.89 | 81.66 |
| LSTM | 2 | 256 | 835,869 | 21.64 | 79.50 | 80.11 | 78.93 |
| BiLSTM | 2 | 256 | 1,664,285 | 16.22 | 83.93 | 84.57 | 83.21 |
| GridLSTM | 2 | 256 | 2,262,813 | 20.44 | 81.03 | 81.46 | 79.78 |
| BiGridLSTM | 2 | 256 | 4,518,173 | 15.06 | 85.77 | 86.30 | 85.38 |
| Model | Layer | Hidden Size | Params | CER (%) | F1 (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|---|---|---|
| LSTM | 2 | 256 | 835,869 | 21.64 | 79.50 | 80.11 | 78.93 |
| LSTM | 5 | 256 | 2,411,805 | 21.85 | 79.37 | 79.80 | 78.42 |
| GridLSTM | 2 | 256 | 2,262,813 | 20.44 | 81.03 | 81.46 | 79.78 |
| GridLSTM | 5 | 256 | 5,812,509 | 17.83 | 83.47 | 83.95 | 82.88 |
| BiGridLSTM | 2 | 256 | 4,518,173 | 15.06 | 85.77 | 86.30 | 85.38 |
| BiGridLSTM | 5 | 128 | 2,925,213 | 13.15 | 88.02 | 88.53 | 87.21 |
| Model | Layer | Hidden Size | Params | CER (%) | F1 (%) | Sensitivity (%) | Specificity (%) |
|---|---|---|---|---|---|---|---|
| BiGridLSTM | 2 | 256 | 4,518,173 | 15.06 | 85.77 | 86.30 | 85.38 |
| BiGridLSTM | 5 | 128 | 2,925,213 | 13.15 | 88.02 | 88.53 | 87.21 |
| BiGridLSTM | 8 | 128 | 4,705,437 | 12.10 | 88.94 | 89.17 | 88.20 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fei, H.; Tan, F. Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient. Algorithms 2018, 11, 172. https://doi.org/10.3390/a11110172
Fei H, Tan F. Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient. Algorithms. 2018; 11(11):172. https://doi.org/10.3390/a11110172
Chicago/Turabian StyleFei, Hongxiao, and Fengyun Tan. 2018. "Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient" Algorithms 11, no. 11: 172. https://doi.org/10.3390/a11110172
APA StyleFei, H., & Tan, F. (2018). Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient. Algorithms, 11(11), 172. https://doi.org/10.3390/a11110172