Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis †

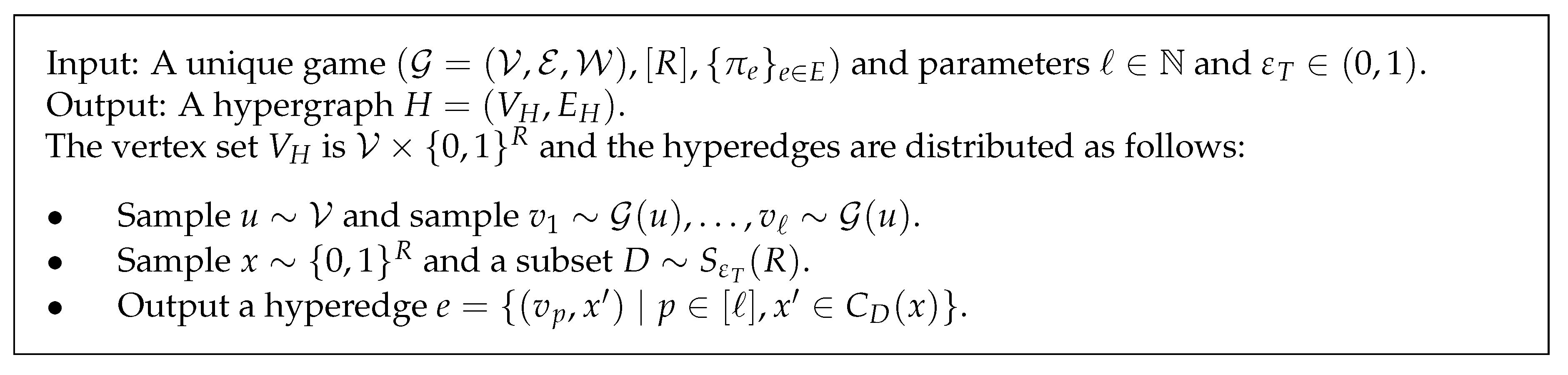{kind=link}
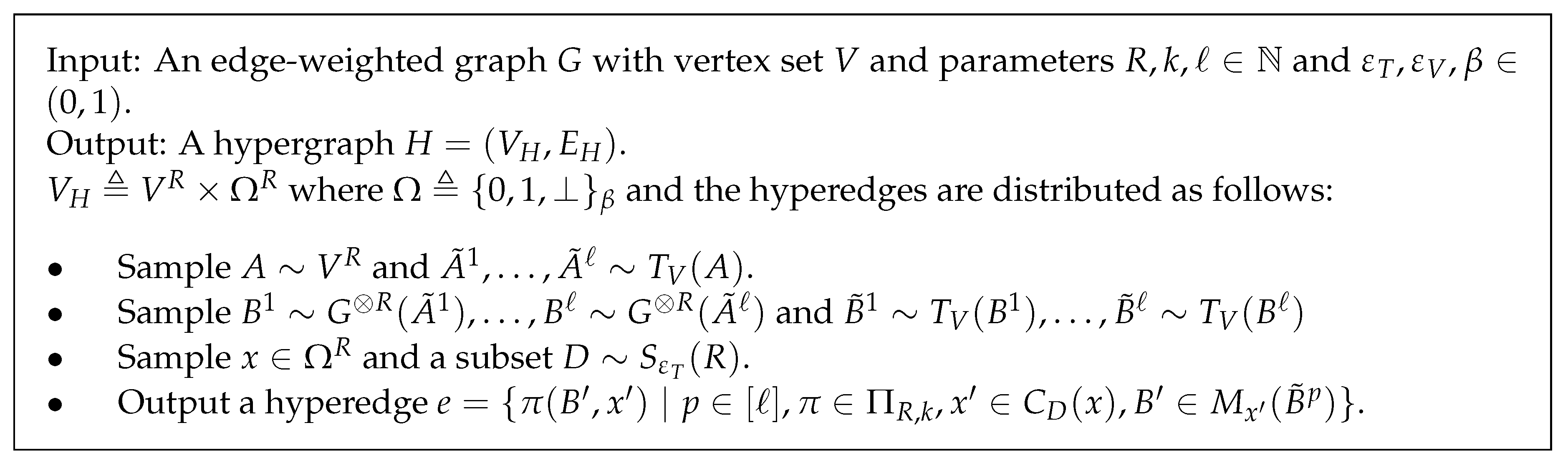{kind=link}
Abstract
:1. Introduction
- (Completeness) There exists of size such that .
- (Soundness) For every of size , .
1.1. Maximum Edge Biclique and Maximum Balanced Biclique
- (Completeness) There is a bisection of s.t. .
- (Soundness) For every set of size at most , .
1.2. Minimum k-Cut
1.3. Densest At-Least-k-Subgraph
2. Inapproximability of Minimum k-Cut
3. Inapproximability of Densest At-Least-k-Subgraph
- (Completeness) There exists of size such that .
- (Soundness) For every with , .
- . In this case, and we have
- . In this case, we have
4. Inapproximability of MEB and MBB
- (Completeness) G contains as a subgraph.
- (Soundness) G does not contain as a subgraph.
4.1. Preliminaries
4.2. Bansal-Khot Long Code Test and A Candidate Reduction
- (Completeness) If is a long code, the test accepts with large probability. (A long code is simply j-junta (i.e. a function that depends only on the ) for some .)
- (Soundness) If are balanced (i.e. ) and are “far from being a long code”, then the test accepts with low probability.A widely-used notion of “far from being a long code”, and one we will use here, is that the functions do not share a coordinate with large low degree influences, i.e., for every and every , at least one of and is small.
4.3. RST Technique and The Reduction from SSE to MUCHB
- Let denote the R-tensor graph of ; the vertex set of is and, for every , the edge weight between is the product of in G for all .
- For each , denote the distribution on where the i-th coordinate is set to with probability and is uniformly randomly sampled from V otherwise.
- Let denote the set of all permutations ’s of such that, for each , .
- Let denote the probability space such that the probability for are both and the probability for ⊥ is .
- Sample and .
- Sample and .
- Sample two random .
- Output an edge with .
4.4. Completeness
- For , let denote the set of all coordinates i in j-th block such that and , i.e., .
- Let denote the first block j with , i.e., . Note that if such block does not exist, we set .
- Let be the only element in . If , let .
- . Observe that, if occurs, then there exist and such that , and or . For brevity, below we denote the conditional event by E. By union bound, our observation gives the following bound.We can now bound the first term byConsider the other term in Equation (5). We can rearrange it as follows.
- . Let and be two different (arbitrary) elements of . Again, for convenient, we use E to denote the conditional event . Now, let us first split as follows.Observe that, when , for every . Hence, for to occur, there must be such that at least one of is not in S. In other words,Combining this with Equation (8), we have .
4.5. Soundness
4.5.1. Decoding an Unique Games Assignment
4.5.2. Decoding a Small Non-Expanding Set
4.6. Putting Things Together
- Let , and so that the term in Lemma 3 is .
- Let so that the error term in Lemma 3 is at most .
- Let and be as in Theorem 4.
- Let be as in Lemma 8 and let .
- Let where so that the error term in Lemma 3 is at most .
- Let so that the error term in Lemma 3 is at most .
- Let .
- Finally, let where is the parameter from the SSEH (Conjecture 2).
5. Conclusions
Acknowledgments
Conflicts of Interest
Appendix A. Reduction from MUCHB to Biclique Problems
Appendix B. Gap Amplification via Randomized Graph Product
- (Completeness) contains as a subgraph.
- (Soundness) does not contain as a subgraph.
Appendix C. Comparison Between SSEH and Strong UGC
- (Completeness) There exists an assignment such that .
- (Soundness) For every assignment , .
- (Completeness) There exists an assignment such that .
- (Soundness) For every assignment , . Moreover, satisfies for every of size .
- There is not only an assignment that satisfies almost all constraints, but also a partial assignment to almost the whole graph such that every constraint between two assigned vertices is satisfied.
- The graph in the soundness case has to satisfy the following vertex expansion property: for every not too small subset of , its neighborhood spans almost the whole graph.
- (Completeness) There exists a subset of size at least and a partial assignment such that every edge inside S is satisfied.
- (Soundness) For every assignment , . Moreover, satisfies for every of size where denote the set of all neighbors of S.
References
- Arora, S.; Lund, C.; Motwani, R.; Sudan, M.; Szegedy, M. Proof Verification and the Hardness of Approximation Problems. J. ACM 1998, 45, 501–555. [Google Scholar] [CrossRef]
- Arora, S.; Safra, S. Probabilistic Checking of Proofs: A New Characterization of NP. J. ACM 1998, 45, 70–122. [Google Scholar] [CrossRef]
- Håstad, J. Some Optimal Inapproximability Results. J. ACM 2001, 48, 798–859. [Google Scholar] [CrossRef]
- Håstad, J. Clique is Hard to Approximate within n1−ε; Springer: Berlin/Heidelberg, Gemany, 1996; pp. 627–636. [Google Scholar]
- Moshkovitz, D. The Projection Games Conjecture and the NP-Hardness of ln n-Approximating Set-Cover. Theory Comput. 2015, 11, 221–235. [Google Scholar] [CrossRef]
- Dinur, I.; Steurer, D. Analytical approach to parallel repetition. In Proceedings of the STOC ’14, Forty-Sixth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 31 May–3 June 2014; pp. 624–633. [Google Scholar]
- Khot, S. On the Power of Unique 2-prover 1-round Games. In Proceedings of the STOC ’02, Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 767–775. [Google Scholar]
- Khot, S.; Regev, O. Vertex cover might be hard to approximate to within 2 − ε. J. Comput. Syst. Sci. 2008, 74, 335–349. [Google Scholar] [CrossRef]
- Khot, S.; Kindler, G.; Mossel, E.; O’Donnell, R. Optimal Inapproximability Results for MAX-CUT and Other 2-Variable CSPs? SIAM J. Comput. 2007, 37, 319–357. [Google Scholar] [CrossRef]
- Raghavendra, P.; Steurer, D. Graph Expansion and the Unique Games Conjecture. In Proceedings of the STOC ’10, Forty-Second ACM Symposium on Theory of Computing, Cambridge, MA, USA, 5–8 June 2010; pp. 755–764. [Google Scholar]
- Raghavendra, P.; Steurer, D.; Tulsiani, M. Reductions Between Expansion Problems. In Proceedings of the CCC ’12, 27th Conference on Computational Complexity, Porto, Portugal, 26–29 June 2012; pp. 64–73. [Google Scholar]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman & Co.: New York, NY, USA, 1979. [Google Scholar]
- Johnson, D.S. The NP-completeness Column: An Ongoing Guide. J. Algorithms 1987, 8, 438–448. [Google Scholar] [CrossRef]
- Peeters, R. The Maximum Edge Biclique Problem is NP-complete. Discrete Appl. Math. 2003, 131, 651–654. [Google Scholar] [CrossRef]
- Khot, S. Improved Inaproximability Results for MaxClique, Chromatic Number and Approximate Graph Coloring. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Las Vegas, NV, USA, 14–17 October 2001; pp. 600–609. [Google Scholar]
- Khot, S.; Ponnuswami, A.K. Better Inapproximability Results for MaxClique, Chromatic Number and Min-3Lin-Deletion. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Venice, Italy, 10–14 July 2006; pp. 226–237. [Google Scholar]
- Zuckerman, D. Linear Degree Extractors and the Inapproximability of Max Clique and Chromatic Number. Theory Comput. 2007, 3, 103–128. [Google Scholar] [CrossRef]
- Feige, U. Relations Between Average Case Complexity and Approximation Complexity. In Proceedings of the STOC ’02, Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 534–543. [Google Scholar]
- Feige, U.; Kogan, S. Hardness of Approximation of the Balanced Complete Bipartite Subgraph Problem; Technical Report; Weizmann Institute of Science: Rehovot, Israel, 2004. [Google Scholar]
- Khot, S. Ruling Out PTAS for Graph Min-Bisection, Dense k-Subgraph, and Bipartite Clique. SIAM J. Comput. 2006, 36, 1025–1071. [Google Scholar] [CrossRef]
- Ambühl, C.; Mastrolilli, M.; Svensson, O. Inapproximability Results for Maximum Edge Biclique, Minimum Linear Arrangement, and Sparsest Cut. SIAM J. Comput. 2011, 40, 567–596. [Google Scholar] [CrossRef]
- Bhangale, A.; Gandhi, R.; Hajiaghayi, M.T.; Khandekar, R.; Kortsarz, G. Bicovering: Covering Edges With Two Small Subsets of Vertices. SIAM J. Discrete Math. 2016, 31, 2626–2646. [Google Scholar] [CrossRef]
- Manurangsi, P. Almost-Polynomial Ratio ETH-Hardness of Approximating Densest k-Subgraph. In Proceedings of the STOC ’17, 49th Annual ACM SIGACT Symposium on Theory of Computing, Montreal, QC, Canada, 19–23 June 2017; pp. 954–961. [Google Scholar]
- Impagliazzo, R.; Paturi, R.; Zane, F. Which Problems Have Strongly Exponential Complexity? J. Comput. Syst. Sci. 2001, 63, 512–530. [Google Scholar] [CrossRef]
- Dinur, I. Mildly exponential reduction from gap 3SAT to polynomial-gap label-cover. ECCC Electron. Colloq. Comput. Complex. 2016, 23, 128. [Google Scholar]
- Manurangsi, P.; Raghavendra, P. A Birthday Repetition Theorem and Complexity of Approximating Dense CSPs. In Proceedings of the ICALP ’17, 44th International Colloquium on Automata, Languages, and Programming, Warsaw, Poland, 10–14 July 2017; pp. 78:1–78:15. [Google Scholar]
- Jerrum, M. Large Cliques Elude the Metropolis Process. Random Struct. Algorithms 1992, 3, 347–359. [Google Scholar] [CrossRef]
- Kučera, L. Expected Complexity of Graph Partitioning Problems. Discrete Appl. Math. 1995, 57, 193–212. [Google Scholar] [CrossRef]
- Berman, P.; Schnitger, G. On the Complexity of Approximating the Independent Set Problem. Inf. Comput. 1992, 96, 77–94. [Google Scholar] [CrossRef]
- Blum, A. Algorithms for Approximate Graph Coloring. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1991. [Google Scholar]
- Goldschmidt, O.; Hochbaum, D.S. A polynomial algorithm for the k-cut problem for fixed k. Math. Oper. Res. 1994, 19, 24–37. [Google Scholar] [CrossRef]
- Saran, H.; Vazirani, V.V. Finding k Cuts Within Twice the Optimal. SIAM J. Comput. 1995, 24, 101–108. [Google Scholar] [CrossRef]
- Naor, J.S.; Rabani, Y. Tree Packing and Approximating k-cuts. In Proceedings of the SODA ’01, Twelfth Annual ACM-SIAM Symposium on Discrete Algorithms, Washington, DC, USA, 7–9 January 2001; pp. 26–27. [Google Scholar]
- Zhao, L.; Nagamochi, H.; Ibaraki, T. Approximating the minimum k-way cut in a graph via minimum 3-way cuts. J. Comb. Optim. 2001, 5, 397–410. [Google Scholar] [CrossRef]
- Ravi, R.; Sinha, A. Approximating k-cuts via Network Strength. In Proceedings of the SODA ’02, Thirteenth Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 6–8 January 2002; pp. 621–622. [Google Scholar]
- Xiao, M.; Cai, L.; Yao, A.C.C. Tight approximation ratio of a general greedy splitting algorithm for the minimum k-way cut problem. Algorithmica 2011, 59, 510–520. [Google Scholar] [CrossRef]
- Gupta, A.; Lee, E.; Li, J. An FPT Algorithm Beating 2-Approximation for k-Cut. arXiv, 2018; arXiv:1710.08488. [Google Scholar]
- Andersen, R.; Chellapilla, K. Finding Dense Subgraphs with Size Bounds. In Proceedings of the International Workshop on Algorithms and Models for the Web-Graph 2009, Barcelona, Spain, 12–13 February 2009; pp. 25–37. [Google Scholar]
- Andersen, R. Finding large and small dense subgraphs. arXiv, 2007; arXiv:cs/0702032. [Google Scholar]
- Khuller, S.; Saha, B. On Finding Dense Subgraphs. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Rhodes, Greece, 5–12 July 2009; pp. 597–608. [Google Scholar]
- Bergner, L. Small Set Expansion. Master’s Thesis, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 2013. [Google Scholar]
- Kortsarz, G.; Peleg, D. On Choosing a Dense Subgraph (Extended Abstract). In Proceedings of the 34th Annual Symposium on Foundations of Computer Science, Palo Alto, CA, USA, 3–5 November 1993; pp. 692–701. [Google Scholar]
- Feige, U.; Seltser, M. On the Densest k-Subgraph Problem; Technical Report; Weizmann Institute of Science: Rehovot, Israel, 1997. [Google Scholar]
- Srivastav, A.; Wolf, K. Finding Dense Subgraphs with Semidefinite Programming. In Proceedings of the International Workshop on Approximation Algorithms for Combinatorial Optimization, Aalborg, Denmark, 18–19 July 1998; pp. 181–191. [Google Scholar]
- Feige, U.; Langberg, M. Approximation Algorithms for Maximization Problems Arising in Graph Partitioning. J. Algorithms 2001, 41, 174–211. [Google Scholar] [CrossRef]
- Feige, U.; Kortsarz, G.; Peleg, D. The Dense k-Subgraph Problem. Algorithmica 2001, 29, 410–421. [Google Scholar] [CrossRef]
- Asahiro, Y.; Hassin, R.; Iwama, K. Complexity of finding dense subgraphs. Discrete Appl. Math. 2002, 121, 15–26. [Google Scholar] [CrossRef]
- Goldstein, D.; Langberg, M. The Dense k Subgraph problem. arXiv, 2009; arXiv:0912.5327. [Google Scholar]
- Bhaskara, A.; Charikar, M.; Chlamtac, E.; Feige, U.; Vijayaraghavan, A. Detecting high log-densities: An O(n1/4) approximation for densest k-subgraph. In Proceedings of the STOC ’10, 42nd ACM Symposium on Theory of Computing, Cambridge, MA, USA, 5–8 June 2010; pp. 201–210. [Google Scholar]
- Alon, N.; Arora, S.; Manokaran, R.; Moshkovitz, D.; Weinstein, O. Inapproximabilty of Densest k-Subgraph from Average Case Hardness. Unpublished Manuscript. 2018. [Google Scholar]
- Bhaskara, A.; Charikar, M.; Vijayaraghavan, A.; Guruswami, V.; Zhou, Y. Polynomial Integrality Gaps for Strong SDP Relaxations of Densest k-subgraph. In Proceedings of the SODA ’12, Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms, Kyoto, Japan, 17–19 January 2012; pp. 388–405. [Google Scholar]
- Braverman, M.; Ko, Y.K.; Rubinstein, A.; Weinstein, O. ETH Hardness for Densest-k-Subgraph with Perfect Completeness. In Proceedings of the SODA ’17, Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Barcelona, Spain, 16–19 January 2017; pp. 1326–1341. [Google Scholar]
- Manurangsi, P. On Approximating Projection Games. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2015. [Google Scholar]
- Chlamtác, E.; Manurangsi, P.; Moshkovitz, D.; Vijayaraghavan, A. Approximation Algorithms for Label Cover and The Log-Density Threshold. In Proceedings of the SODA ’17, Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Barcelona, Spain, 16–19 January 2017; pp. 900–919. [Google Scholar]
- O’Donnell, R. Analysis of Boolean Functions; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Mossel, E.; O’Donnell, R.; Oleszkiewicz, K. Noise stability of functions with low influences: Invariance and optimality. Ann. Math. 2010, 171, 295–341. [Google Scholar] [CrossRef]
- Svensson, O. Hardness of Vertex Deletion and Project Scheduling. Theory Comput. 2013, 9, 759–781. [Google Scholar] [CrossRef]
- Bansal, N.; Khot, S. Optimal Long Code Test with One Free Bit. In Proceedings of the FOCS ’09, 50th Annual IEEE Symposium on Foundations of Computer Science, Atlanta, GA, USA, 5–27 October 2009; pp. 453–462. [Google Scholar]
- Louis, A.; Raghavendra, P.; Vempala, S. The Complexity of Approximating Vertex Expansion. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science (FOCS), Berkeley, CA, USA, 26–29 October 2013; pp. 360–369. [Google Scholar]
- Kleinberg, J.; Papadimitriou, C.; Raghavan, P. Segmentation Problems. J. ACM 2004, 51, 263–280. [Google Scholar] [CrossRef]
- Alon, N.; Feige, U.; Wigderson, A.; Zuckerman, D. Derandomized Graph Products. Comput. Complex. 1995, 5, 60–75. [Google Scholar] [CrossRef]

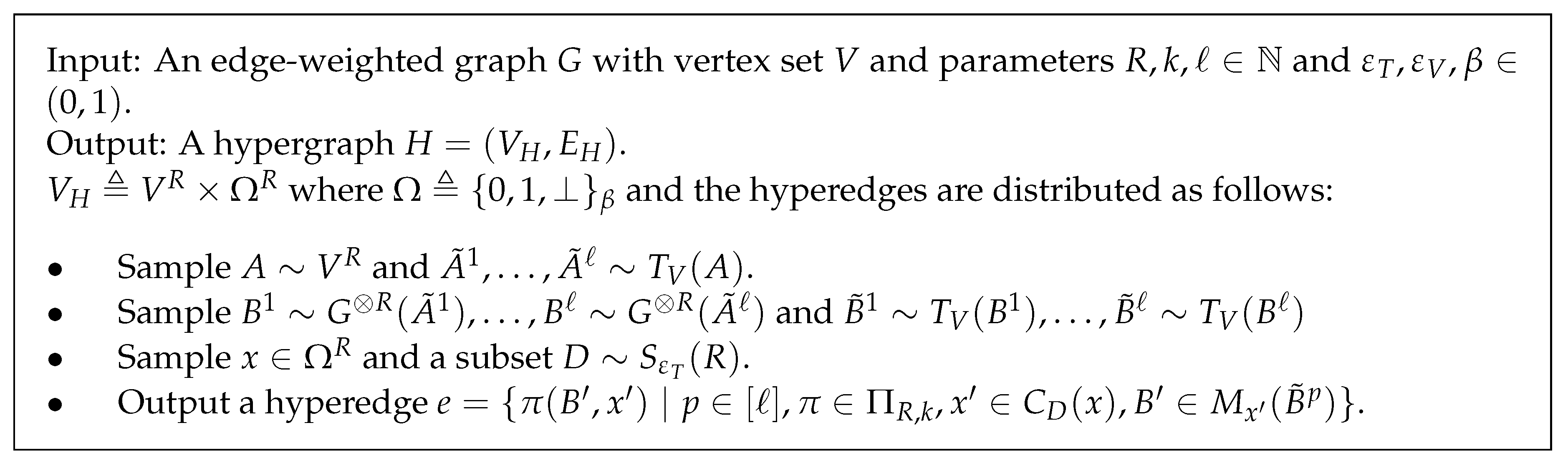
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manurangsi, P. Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis. Algorithms 2018, 11, 10. https://doi.org/10.3390/a11010010
Manurangsi P. Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis. Algorithms. 2018; 11(1):10. https://doi.org/10.3390/a11010010
Chicago/Turabian StyleManurangsi, Pasin. 2018. "Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis" Algorithms 11, no. 1: 10. https://doi.org/10.3390/a11010010
APA StyleManurangsi, P. (2018). Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis. Algorithms, 11(1), 10. https://doi.org/10.3390/a11010010