Scheduling Non-Preemptible Jobs to Minimize Peak Demand


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- An optimal dynamic programming algorithm for discrete-timescale instances that utilizes branch-and-bound techniques that is fixed-parameter tractable.
- A polynomial-time randomized algorithm based on linear programming that provides an -approximation, where n is the number of jobs, and is the first known approximation for PDM.
- An effective and simple heuristic algorithm that can be used in either an online or offline fashion.
2. Related Work
3. Algorithms
3.1. An Optimal Dynamic Programming Algorithm
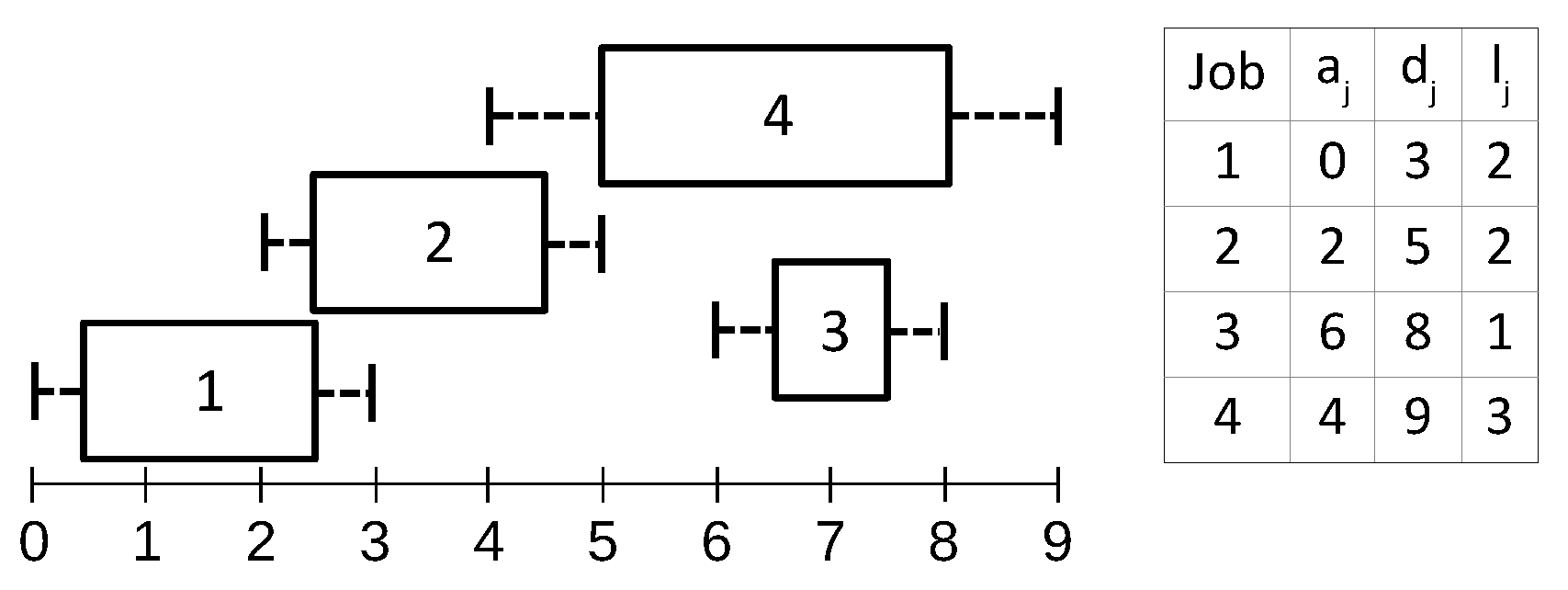
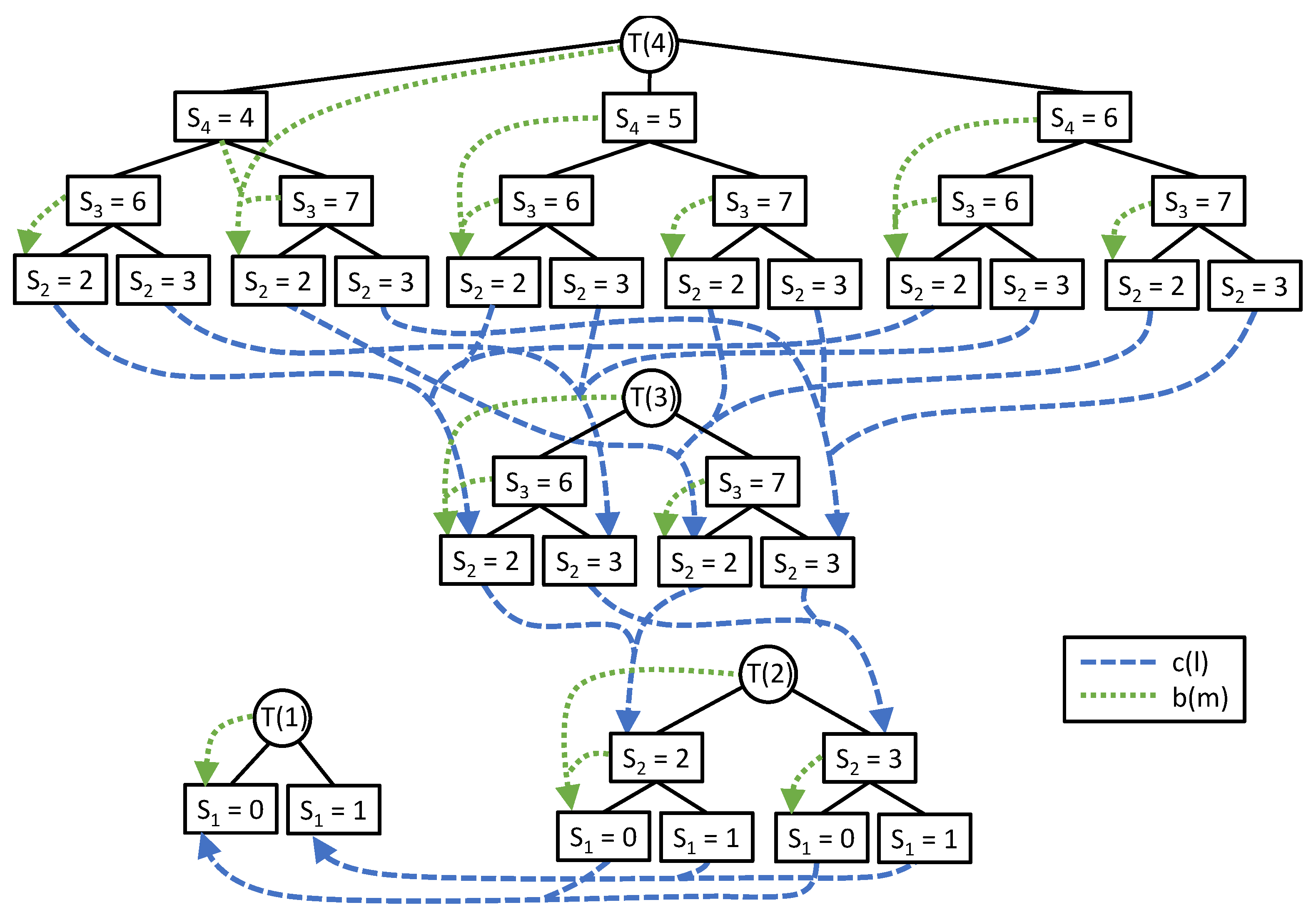
3.1.1. Configuration Lists
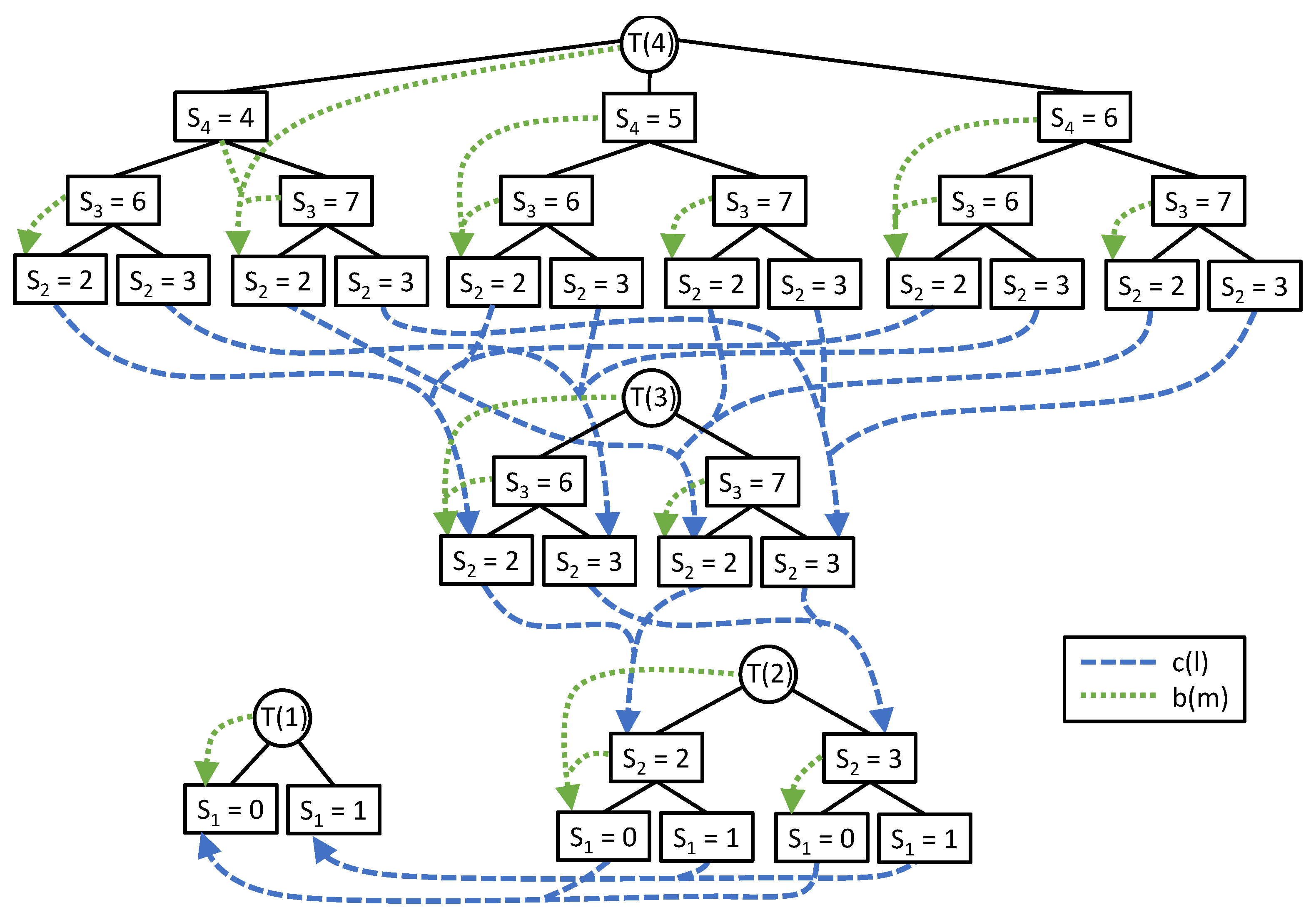
3.1.2. Configuration Trees
3.1.3. Dynamic Programming
3.1.4. Branch-and-Bound Approach
3.1.5. Fixed-Parameter Tractability
3.2. An Approximation Algorithm
3.2.1. Integer Linear Programming Formulation
- J—Set of jobs.
- —A finite set of valid execution intervals for job (an interval is valid for job j if and only if and ).
- —Height of job j.
- L—Set of all left hand time points of intervals in .
- —Peak demand.
- —Indicates if interval is scheduled.
3.2.2. A Randomized Rounding Algorithm
| Algorithm 1 RoundLP |
|
3.2.3. Continuous Timescales
3.3. A Greedy Heuristic
| Algorithm 2 MinFit-Online |
|
| Algorithm 3 MinFit-Offline |
|
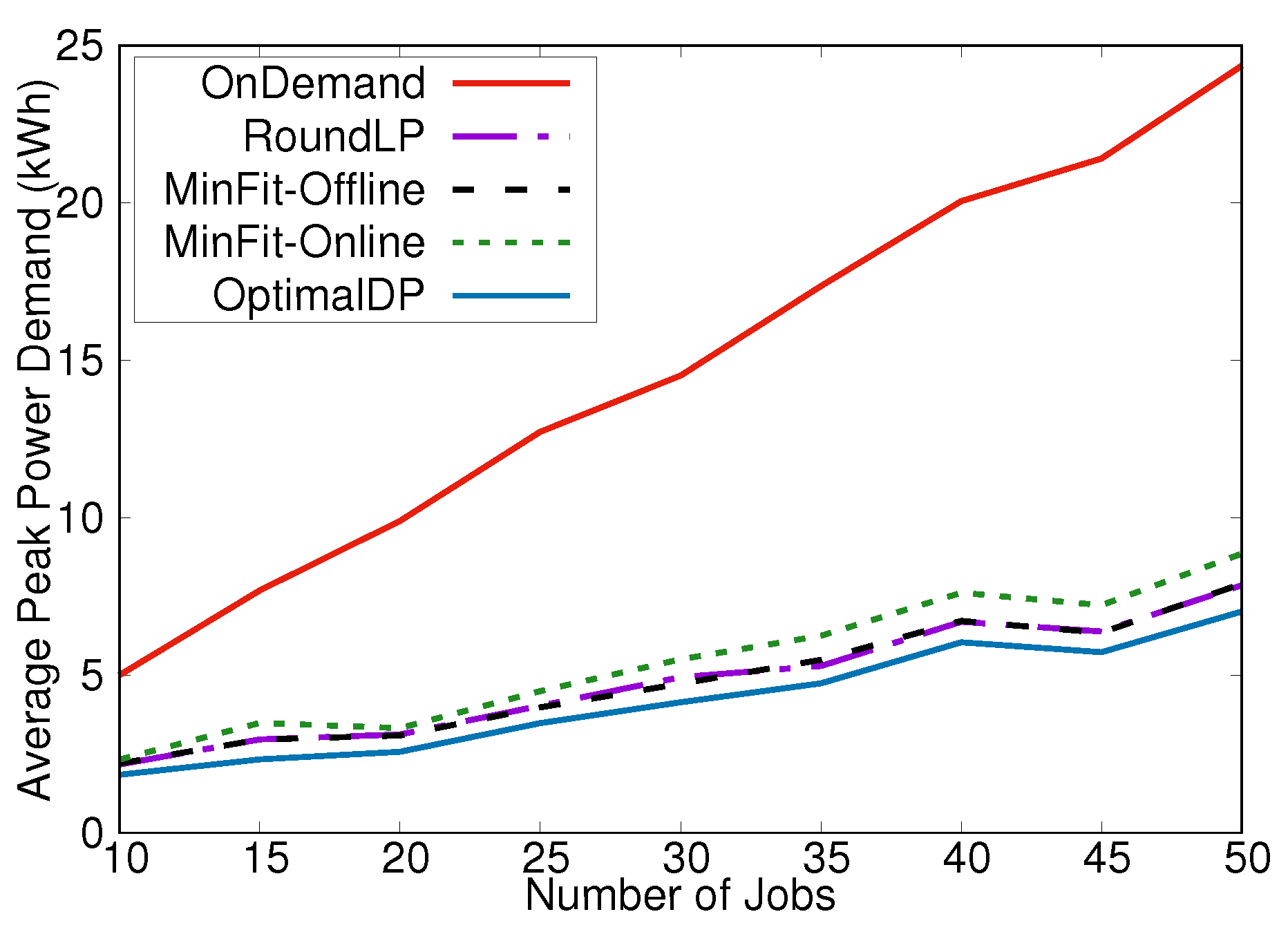
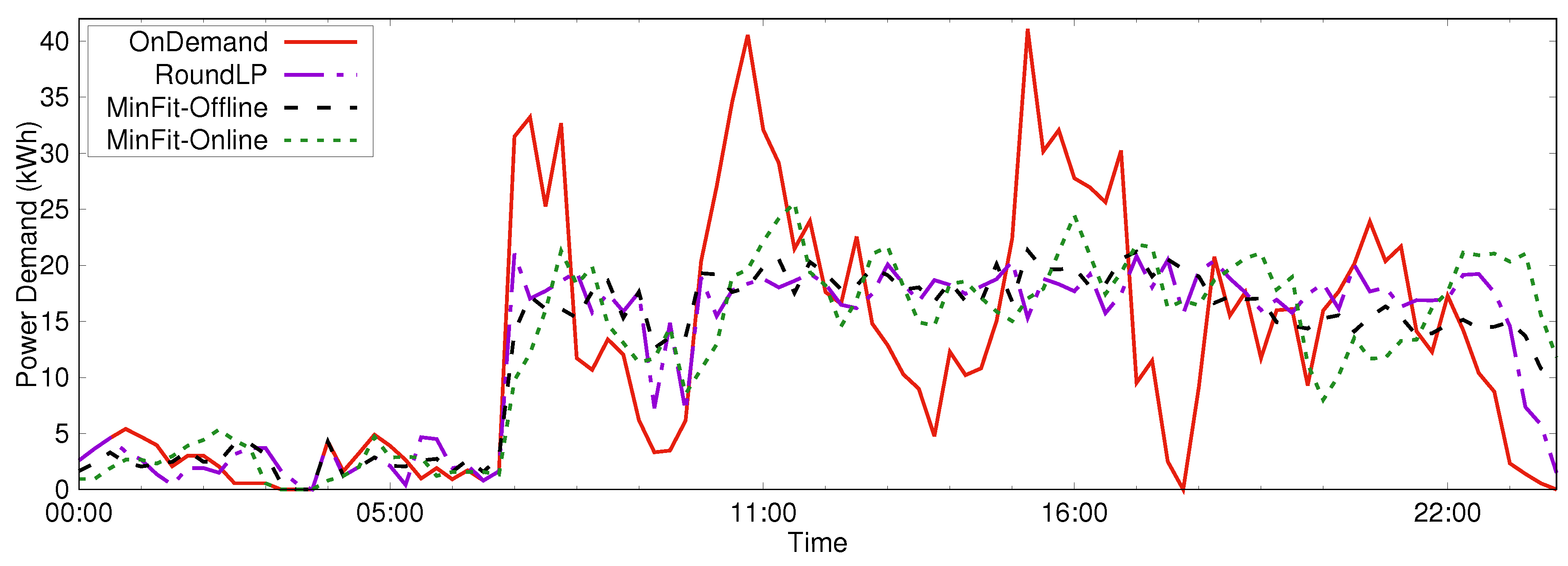
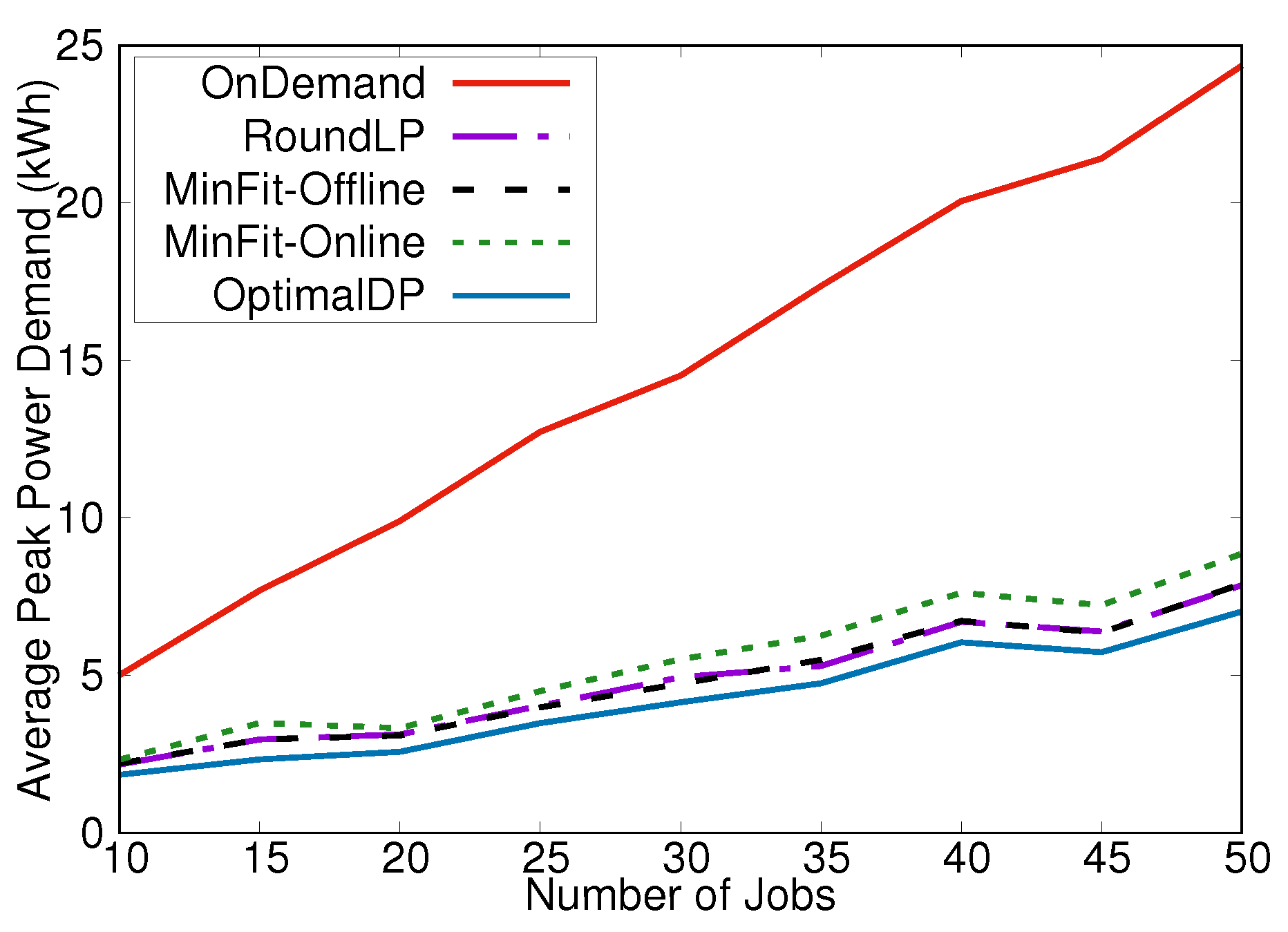
4. Experimental Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Koutsopoulos, I.; Tassiulas, L. Optimal control policies for power demand scheduling in the smart grid. IEEE J. Sel. Areas Commun. 2012, 30, 1049–1060. [Google Scholar] [CrossRef]
- Fathi, M.; Bevrani, H. Adaptive Energy Consumption Scheduling for Connected Microgrids Under Demand Uncertainty. IEEE Trans. Power Deliv. 2013, 28, 1576–1583. [Google Scholar] [CrossRef]
- Yaw, S.; Mumey, B. An Exact Algorithm for Non-preemptive Peak Demand Job Scheduling. In Combinatorial Optimization and Applications; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8881, pp. 3–12. [Google Scholar]
- Logenthiran, T.; Srinivasan, D.; Shun, T.Z. Demand Side Management in Smart Grid Using Heuristic Optimization. IEEE Trans. Smart Grid 2012, 3, 1244–1252. [Google Scholar] [CrossRef]
- Huang, Q.; Li, X.; Zhao, J.; Wu, D.; Li, X.Y. Social Networking Reduces Peak Power Consumption in Smart Grid. IEEE Trans. Smart Grid 2015, 6, 1403–1413. [Google Scholar] [CrossRef]
- Tang, S.; Huang, Q.; Li, X.Y.; Wu, D. Smoothing the energy consumption: Peak demand reduction in smart grid. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 1133–1141. [Google Scholar]
- Yaw, S.; Mumey, B.; Mcdonald, E.; Lemke, J. Peak demand scheduling in the Smart Grid. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 770–775. [Google Scholar]
- Roh, H.T.; Lee, J.W. Residential demand response scheduling with multiclass appliances in the smart grid. IEEE Trans. Smart Grid 2016, 7, 94–104. [Google Scholar] [CrossRef]
- Chuzhoy, J.; Guha, S.; Khanna, S.; Naor, J. Machine minimization for scheduling jobs with interval constraints. In Proceedings of the 45th Annual IEEE Symposium on Foundations of Computer Science, Rome, Italy, 17–19 October 2004; pp. 81–90. [Google Scholar]
- Cieliebak, M.; Erlebach, T.; Hennecke, F.; Weber, B.; Widmayer, P. Scheduling with release times and deadlines on a minimum number of machines. In Exploring New Frontiers of Theoretical Informatics; IFIP International Federation for Information Processing; Levy, J.J., Mayr, E., Mitchell, J., Eds.; Springer: New York, NY, USA, 2004; Volume 155, pp. 209–222. [Google Scholar]
- Ortmann, F.G.; Ntene, N.; van Vuuren, J.H. New and improved level heuristics for the rectangular strip packing and variable-sized bin packing problems. Eur. J. Oper. Res. 2010, 203, 306–315. [Google Scholar] [CrossRef]
- Gu, X.; Chen, G.; Xu, Y. Average-Case Performance Analysis of a 2D Strip Packing Algorithm—NFDH. J. Comb. Optim. 2005, 9, 19–34. [Google Scholar] [CrossRef]
- Baker, B.S.; Schwarz, J.S. Shelf algorithms for two-dimensional packing problems. SIAM J. Comput. 1983, 12, 508–525. [Google Scholar] [CrossRef]
- Raghavan, P.; Tompson, C.D. Randomized Rounding: A Technique for Provably Good Algorithms and Algorithmic Proofs. Combinatorica 1987, 7, 365–374. [Google Scholar] [CrossRef]
- Raghavan, P. Probabilistic construction of deterministic algorithms: Approximating packing integer programs. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science, Toronto, ON, Canada, 27–29 October 1986; pp. 10–18. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. Redd: A public data set for energy disaggregation research. In Proceedings of the SustKDD Workshop on Data Mining Applications in Sustainability, San Diego, CA, USA, 21 August 2011. [Google Scholar]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaw, S.; Mumey, B. Scheduling Non-Preemptible Jobs to Minimize Peak Demand. Algorithms 2017, 10, 122. https://doi.org/10.3390/a10040122
Yaw S, Mumey B. Scheduling Non-Preemptible Jobs to Minimize Peak Demand. Algorithms. 2017; 10(4):122. https://doi.org/10.3390/a10040122
Chicago/Turabian StyleYaw, Sean, and Brendan Mumey. 2017. "Scheduling Non-Preemptible Jobs to Minimize Peak Demand" Algorithms 10, no. 4: 122. https://doi.org/10.3390/a10040122
APA StyleYaw, S., & Mumey, B. (2017). Scheduling Non-Preemptible Jobs to Minimize Peak Demand. Algorithms, 10(4), 122. https://doi.org/10.3390/a10040122