1. Introduction
Regarding commodity markets, the entirety of last year was unforgettable and catastrophic because, with the most diminution in crude oil and iron ore, the Bloomberg Commodity Index, composed of 22 international commodities’ futures prices, including six agricultural commodities, has dropped over 24 percent compared with 2014, which is the third consecutive annual loss and the largest annual decline since the financial crisis in 2008. Serving as an important composition of international commodity markets, agricultural commodity futures prices have actually begun to show a distinct downward tendency since 2013. Generally speaking, agricultural commodity prices and the relationship between supply and demand mutually affect one another to a large extent. However, over the past few years, although agricultural commodity markets have experienced relatively serious weather disruptions such as El Niño and a potential La Niña, the growth rate of supply of the majority of agricultural commodities, especially food grain, has exceeded the rate of demand, which to some extent makes these prices recover modestly or even keep falling.
Regarded as the three leading world economies, the United States is a large consumer of corn, the European Union is the same for wheat, and China is a large importer of soybean, which means that these agricultural commodities play an important role in these countries’ social economy and daily life. These kinds of food grain market data, including price data, are vital for any future agriculture development project because there is strong mutual influence between price and potential supply and demand, as well as for distribution channels of food grain and the economics of agriculture [
1]. According to the futures price discovery mechanism and the high sensitivity of macroeconomic situations or policies, they can conduct price information to the spot markets in advance. Thus, the price forecasting of these futures prices is expected to not only reduce the uncertainty and control the risk in agricultural commodity markets, but can also be applied to identify and make appropriate and sustainable food grain policies for the government.
A large body of the existing literature, however, has explored the related research of agricultural commodities, such as yield forecasting [
2,
3,
4], price co-movement or volatility [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14], spot price forecasting [
1,
15], market efficiency [
16], and trade policy responses [
17], instead of investigating the predictability of agricultural commodity futures prices [
18,
19,
20,
21]. Fortunately, in past decades, abundant research achievements have been made in forecasting a wide range of time series, some of which can be used for reference to solve the problem of forecasting agricultural commodity futures prices because of the common features of the time series.
Building models to forecast time series is always a complicated, difficult but attractive challenge for scholars, which contributes to the large number of research achievements accumulated. Initially, scholars focus on using single models based on only one linear or nonlinear forecasting method to forecast time series. Some researchers make efforts to apply traditional statistic approaches such as the vector auto-regression (VAR) model, vector error correction models (VECM), autoregressive integrated moving average (ARIMA), and generalized autoregressive conditional heteroskedasticity (GARCH) to discuss price data series. For instance, Mayr and Ulbricht [
22] employ VAR models to forecast GDP based on the log-transforming data from four countries, namely the USA, Japan, Germany and the United Kingdom in a certain period. Kuo [
23] uses data from the Taiwanese market to compare the relative forecasting performance of VECM with the VAR as well as the ordinary least square (OLS) and random walk (RW) applied in past literature. ARIMA is utilized by Sen et al. to forecast the energy consumption and greenhouse gas (GHG) emission of an Indian pig iron manufacturing organization, and two best fitted ARIMA models are determined respectively [
24]. The GARCH model is initially used to forecast the Chicago Board Options Exchange (CBOE) volatility index (VIX) by Liu et al. [
25]. With the fast development of artificial intelligence (AI) techniques, artificial neural network (ANN) and machine learning (ML) are gaining increasing focus on forecasting time series data, aiming to overcome the limitations of traditional statistic methods; for instance, they are unable to easily capture nonlinear patterns. Hsieh et al. [
26] propose the back-propagation neural network (BPNN), integrating with design of experiment (DOE) and the Taguchi method, to further optimize the prediction accuracy. According to Yan and Chowdhury [
27], a multiple support vector machine (SVM) is presented to study the forecasting of the mid-term electricity market clearing price (MCP). In addition, the application of optimization algorithms [
28,
29,
30,
31,
32,
33,
34], such as particle swarm optimization (PSO), artificial bee colony (ABC), fruit fly optimization algorithm (FOA), ant colony optimization (ACO) and differential evolution (DE), has improved the forecasting performance and slowed processing speed of the AI techniques.
However, price time series in the real world rarely appears in a linear or nonlinear pattern solely, but usually covers both patterns, so that hybrid models emerge, combining several single models systematically [
35], which can simultaneously handle linear and nonlinear patterns [
21]. A hybrid methodology that exploits the unique strength of the ARIMA and the SVM is proposed by Pai and Lin [
36] to tackle stock prices forecasting problems, which gains very promising results. Since then, it has not been difficult to find that great research efforts have been made to explore the “linear and nonlinear” modelling framework used in time series prediction. For example, Khashei and Bijari [
37] present a novel hybridization of ANN and ARIMA to forecast three well-known data sets, namely the Wolf’s sunspot data, the Canadian Iynx data and the British pound/US dollar exchange rate. A hybrid model combining VECM and multi-output support vector regression (VECM-MSVR), which is expert in capturing the linear and nonlinear patterns, is devised to make interval forecasting of agricultural commodity futures prices [
21].
Undoubtedly, past literature provides many effective and reasonable models to forecast time series and improve the forecasting performance to some extent. However, these models often cannot thoroughly handle the non-stationarity of random and irregular time series. Thus, based on decomposition techniques such as the wavelet transform (WT) family methods, the empirical mode decomposition (EMD) family approaches, and the variational mode decomposition (VMD) method, a promising concept of “decomposition and ensemble” is developed [
35] to enhance the forecasting ability of the existing models. For example, four real-world time series are predicted through a novel combination of ARIMA and ANN models based on the discrete wavelet transform (DWT) decomposition technique [
38]. Wang et al. [
39] build a novel least square support vector machine (LSSVM) optimized by PSO based on simulated annealing (PSOSA) (abbreviated as PSOSA-LSSVM) to forecast wind speed data preprocessed by the wavelet packet transform (WPT). According to Yu et al. [
40], two kinds of crude oil spot prices, the West Texas Intermediate (WTI) and the Brent, are predicted by the EMD-based neural network. As for intraday stock prices forecasting, Lahmiri [
31] develops a hybrid VMD–PSO–BPNN predictive model that finally shows the superiority over the benchmark model, namely a PSO–BPNN model. Beyond that, many other decomposition-based forecasting models [
41,
42,
43,
44,
45,
46] have been proposed, which greatly enriches the empirical achievement of time series predictive models, on the basis of the “decomposition and ensemble” framework, and further improves time series forecasting performance.
It is evident that the “decomposition and ensemble” modelling framework has been recently well-established to forecast time series in many fields, such as commodity prices, energy demand or consumption, wind speed, etc. Still, however, no research exists on forecasting agricultural commodity futures prices using this kind of promising framework. Thus, in this paper, we aim to put forward four new hybrid models, based on the “decomposition and ensemble” framework, which are utilized to forecast three agricultural commodity futures prices; namely wheat, corn and soybean. Specifically, these four models are based on the PSO–BPNN combined with four different decomposition techniques, namely the WPT, EMD, VMD and intrinsic time-scale decomposition (ITD) [
47], respectively, generating four models, namely the WPT–PSO–BPNN model, the EMD–PSO–BPNN model, the VMD–PSO–BPNN model and the ITD–PSO–BPNN model. Therefore, the data pretreatment effect of different decomposition techniques is horizontally compared. Meanwhile, the decomposition techniques we select include more types, which can contribute to more comprehensive comparison in contrast to Liu et al. [
48].
The reminder of this paper is organized as follows.
Section 2 introduces the methodologies applied in this paper, containing the decomposition methods, the PSO algorithm, the BPNN, and the proposed hybrid models. Research design is concretely described in
Section 3. Then,
Section 4 shows results and analysis of the three study cases. Finally, conclusions of this paper are given in
Section 5.
2. Methodology
This section presents the introduction of the proposed methodology we use to forecast the agricultural commodity futures prices, namely wheat, corn and soybean, which includes decomposition methods, back propagation neural network, particle swarm optimization algorithm, and the proposed hybrid models based on these approaches.
2.1. Decomposition Methods
Recently, signal decomposition techniques have been attracting increasing attention in many research fields, including time series preprocessing. In this part, the four representative decomposition approaches are described as below.
2.1.1. Empirical Mode Decomposition
Serving as an adaptive and highly efficient decomposition approach, the empirical mode decomposition (EMD) is proposed by Huang et al. [
49] to analyze nonlinear and nonstationary time series, which solves the problem that the full description of the frequency content cannot be obtained by single Hilbert transform. Certainly, this decomposition method is based on some assumptions: (1) the original signal at least contains one maximum and one minimum; (2) the characteristic time scale is defined by the time lapse between the extrema; and (3) only when the data totally lack extrema but contain inflection points can it be differentiated once or more times to reveal the extrema. Through the EMD method, the time series data can be converted into a finite and often small number of intrinsic mode functions (IMFs). As for the original data
, the sifting process of EMD is illustrated as follows [
49]:
2.1.2. Wavelet Packet Transform
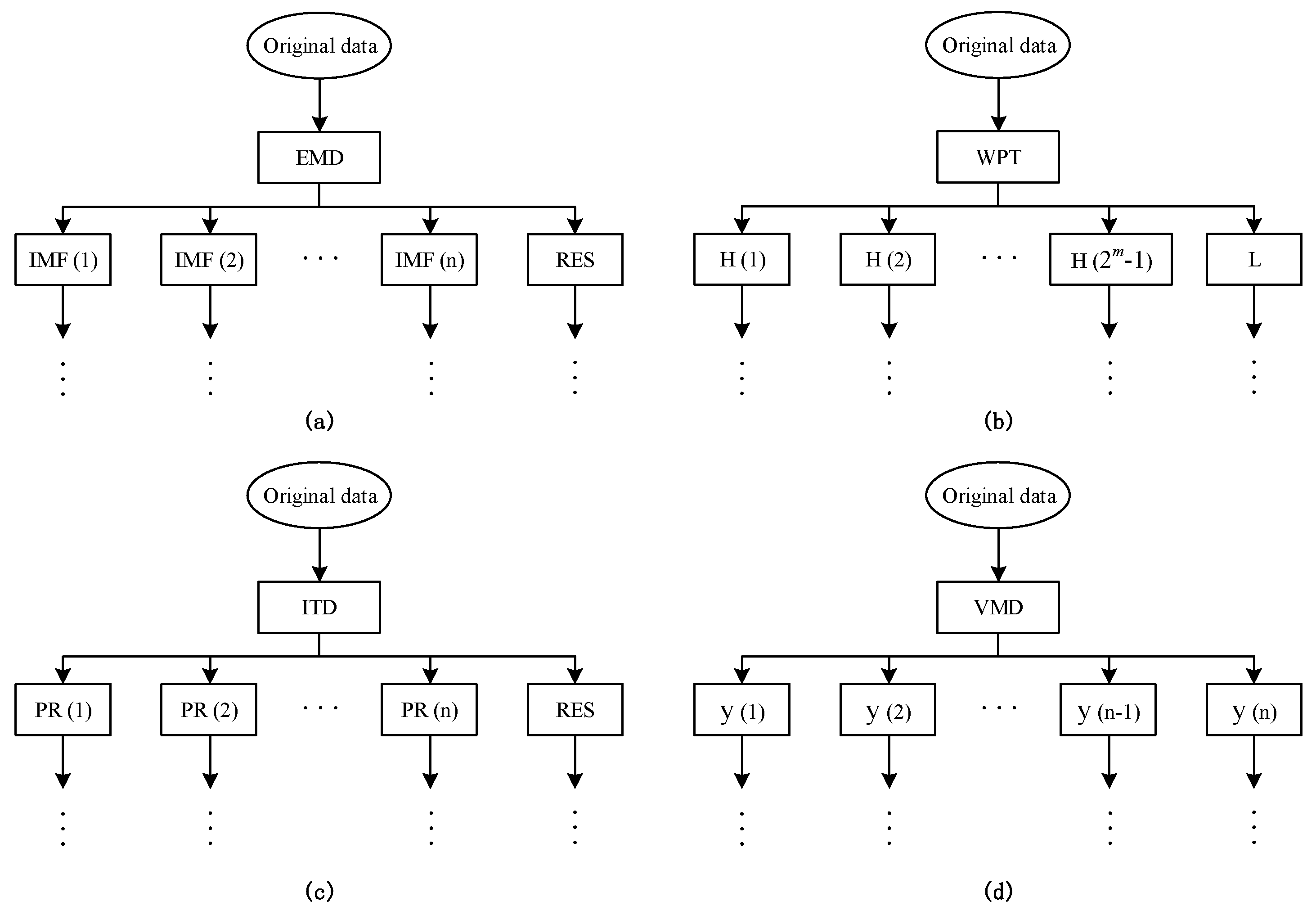
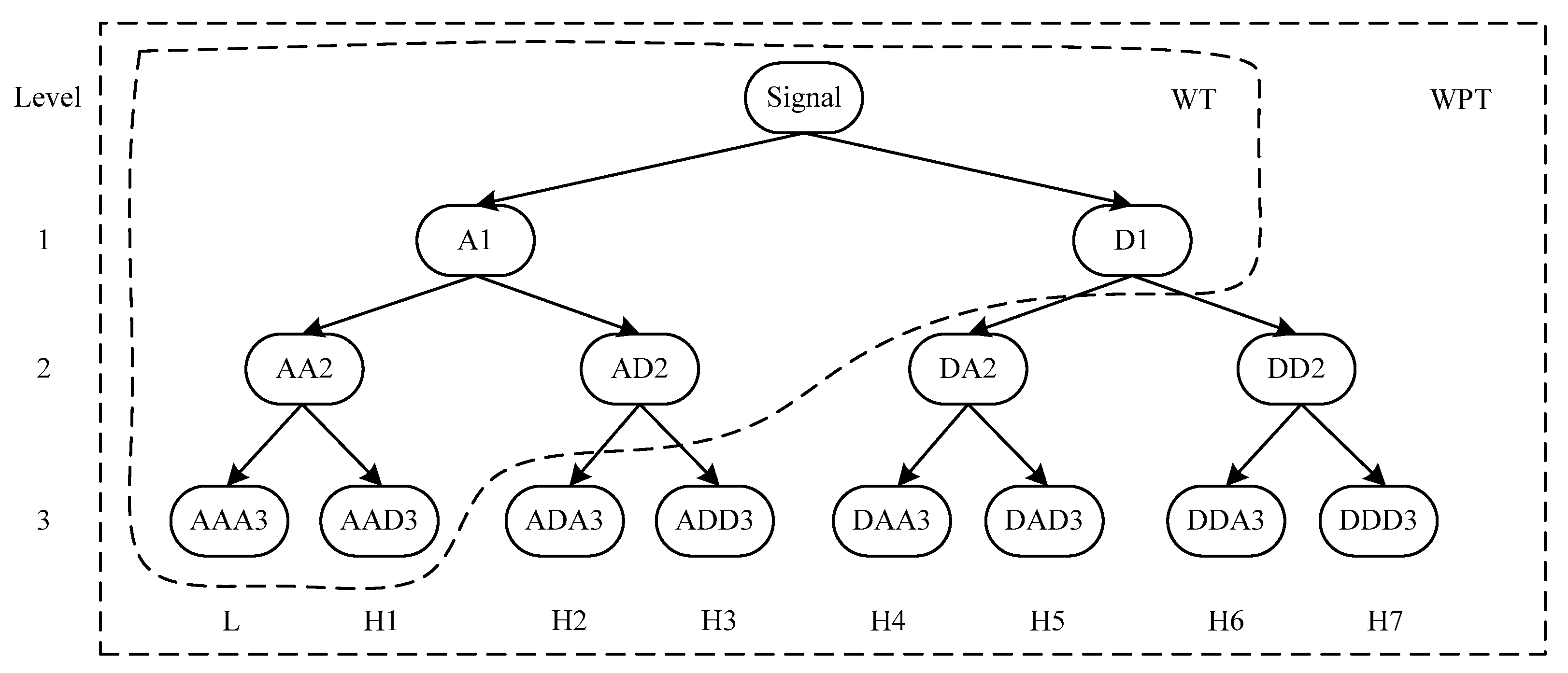
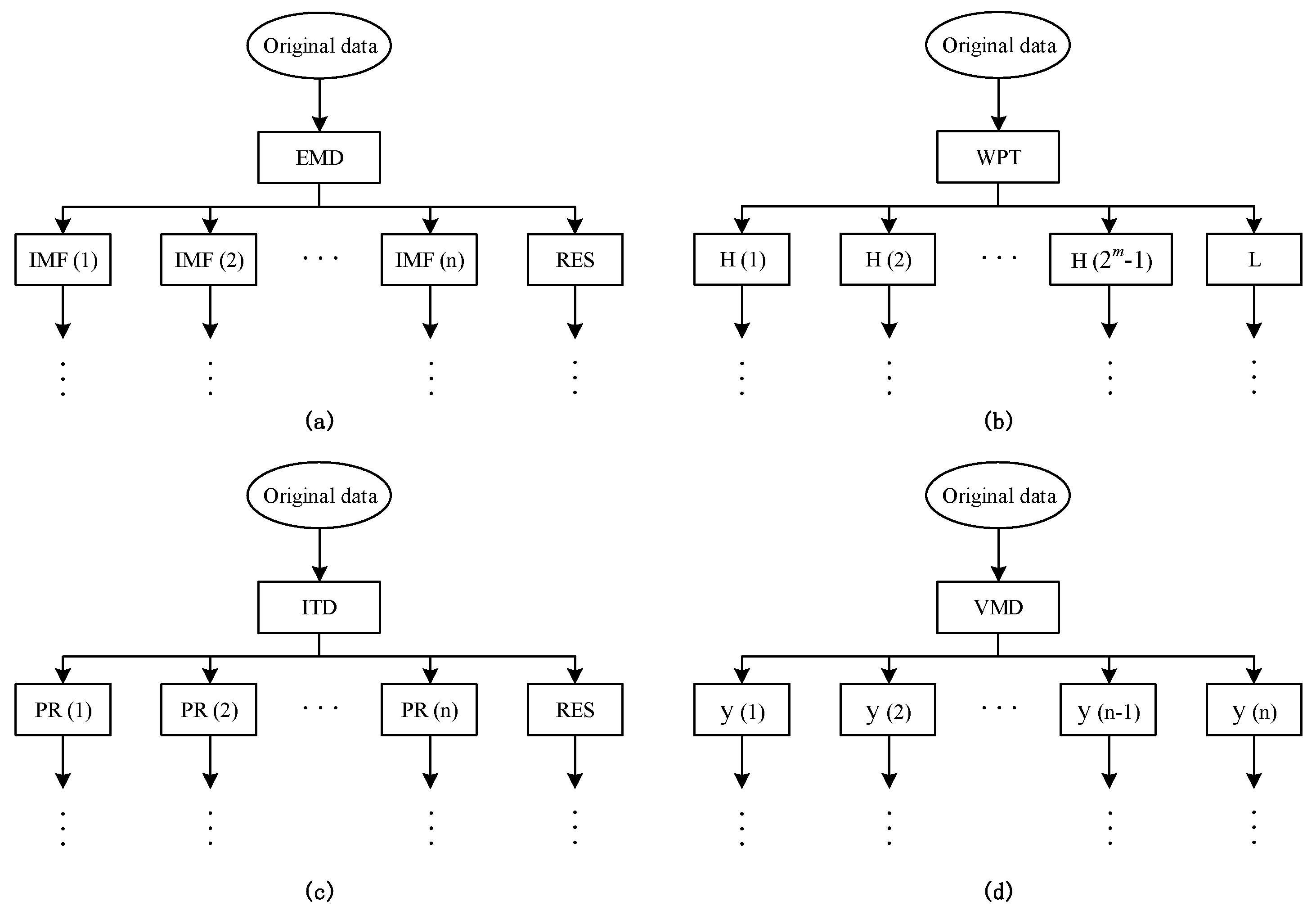
The wavelet transform (WT), first proposed by Mallat [
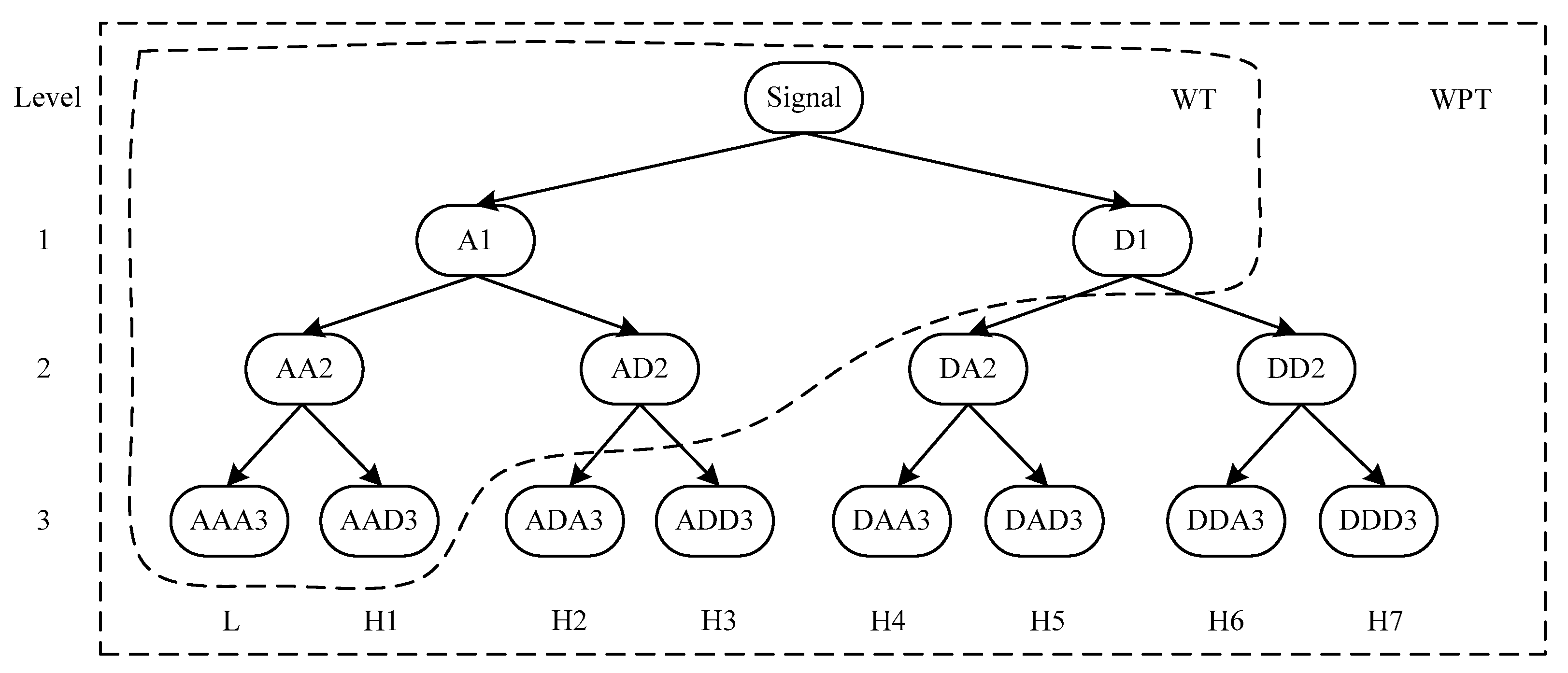
50] to study data compression in image coding, texture discrimination and fractal analysis, is a multi-scale signal processing method with good time-frequency localization features. However, this approach simply decomposes the low frequency sub-series of the original signal and ignores the analysis of the sub-series with high frequencies, which makes it more suitable to process nonstationary and instantaneous signals instead of gradually-changed signals. Thus, the wavelet packet transform (WPT) was developed, based on the WT, to overcome this limitation. Similar to the WT, the WPT decomposes the original signal into a low frequency coefficient (called approximation) and a set of high frequency coefficients (called details). By contrast, the WPT can further convert each detail into another approximation and another detail. Taking three decomposition level as an example, we illustrate the comparison of the decomposition trees of WT and WPT in
Figure 1. As to the WPT, the final decomposition results of three level cover one approximation, L, and seven details, denoted by the H1, H2, …, H7, respectively.
2.1.3. Intrinsic Time-Scale Decomposition
According to Frei and Osorio [
47], the intrinsic time-scale decomposition (ITD) is developed for the efficient and precise time–frequency–energy (TFE) analysis of signals. Based on this approach, a nonlinear or nonstationary signal can be decomposed in to a set of proper rotation (PR) components and a monotonic trend, namely a residual signal. Given a signal
, the decomposition process of ITD algorithm is illustrated as follows:
An operator,
, which extracts a baseline signal from
, is defined. More specifically,
can be decomposed as:
where
and
represent the baseline signal and a proper rotation respectively.
Suppose that
is a real-valued signal, while the local extrema of
is defined as
, and let
be equal to zero. For convenience,
and
are abbreviated as
and
, respectively.
is taken as the right endpoint of the interval, containing extrema due to the neighboring signal fluctuation, where
is constant. Meanwhile, suppose that
and
have been defined on the interval,
, and that
is available for
. Thus, a (piece-wise linear) baseline-extracting operator,
, is defined on the interval
between successive extrema as follows:
where
and the parameter,
, is usually determined as 0.5.
After defining the baseline signal based on Equations (7) and (8), it is possible to define the residual, proper-rotation-extracting operator,
, as:
2.1.4. Variational Mode Decomposition
Variational mode decomposition (VMD) [
51], a newly non-recursive signal processing technique, is utilized to adaptively decompose a real valued signal into a discrete number of band-limited sub-signals, namely the modes
, having specific sparsity properties. Each mode decomposed by the VMD approach can be compressed around a center pulsation
, which is determined along with the decomposition process. To estimate the bandwidth of each mode, the following procedures should be considered: (1) as to each mode
, applying the Hilbert transform to calculate the associated analytic signal so that a unilateral frequency spectrum can be obtained; (2) mixing with an exponential tuned to the respective estimated center frequency in order to shift the mode’s frequency spectrum to baseband; and (3) estimating the bandwidth for each mode
by using the H
1 Gaussian smoothness of the demodulated signal. Thus, the constrained variational problem can be presented as follows:
where
is the original main signal,
is the
kth component of the original signal;
,
and
represent center frequency of
, the Dirac distribution and convolution operator, respectively;
k denotes the number of modes, while
t is time script.
Taking both penalty term and Lagrangian multipliers
into consideration, the above constrained problem can be converted into an unconstrained one that can be addressed more easily, which is shown as follows:
where
represents the balancing parameter of the data fidelity constraint.
The augmented Lagrangian
L is determined in Equation (11) and its saddle point in a sequence of iterative sub-optimizations can be found through using the alternate direction method of multipliers (ADMM). According to this ADMM optimization method, it is assumed that updating
and
in two directions helps to realize the analysis process of the VMD. The complete and detailed procedures of this algorithm are available in [
51]. Consequently, solutions for
and
are described as follows [
51]:
where
,
,
and
denote the Fourier transforms of
,
,
and
respectively, while
n represents the number of iterations.
2.2. Back Propagation Neural Network
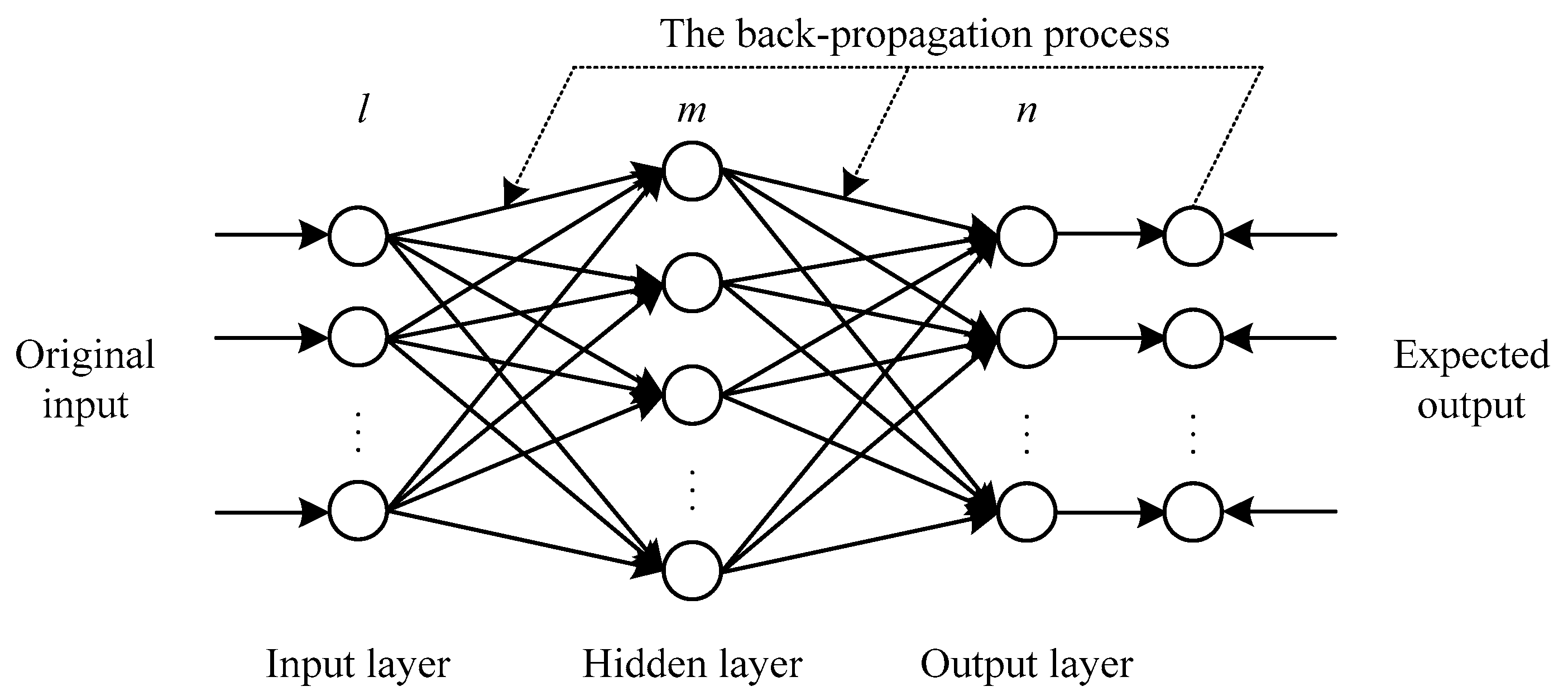
A back propagation neural network (BPNN) is a typical kind of feed-forward artificial neural network based on the back propagation algorithm, which is widely applied in many research areas. Compared with conventional statistic methods, one remarkable advantage of the BPNN is that it can approximate any nonlinear continuous function up to any desired accuracy. Generally speaking, a BPNN consists of one input layer, one or more hidden layer and one output layer. In our study, the number of the hidden layers is determined as one, based on Khandelwal et al. [
38], so that a standard three-layer
BPNN structure is developed, as shown in
Figure 2. More specifically, the mathematical representation of its training process can be described as follows:
The output of the hidden layer nodes,
, can be calculated as:
where
is the connection weight from the
ith input node to
jth hidden node,
means the
ith input data,
represents the bias of
jth hidden neuron, and
denotes the nonlinear transfer function of the hidden layer, which usually is a sigmoid function.
Then, the output of this neural network,
, can be obtained by:
where
represents the weight connecting
jth hidden node to
kth output node,
is the bias of the
kth output neuron, and
means the output layer’s transfer function, which is a linear one by default.
The goal of BPNN is to minimize the error
E, namely the mean square error (MSE) by default, which can be measured by:
where
N is the number of input sample,
denotes the
kth expected output data.
2.3. Particle Swarm Optimization Algorithm
Particle swarm optimization (PSO) is an optimization algorithm based on swarm intelligence put forward by Kennedy and Eberhart in 1995; the basic principle is derived from the artificial life and the predation behavior of groups of birds. In the population, every particle represents a potential solution, and every particle has a fitness degree value, which is determined by the objective function. The movement direction and distance of the particle depend on the speed of the particle, which is adjusted dynamically according to itself and the movement experience of other particles, and the individual obtains optimal solution in the solution space.
In the
d dimension space composed of
n particles, express the speed of particle
i as
, express the position as
,
pbest is the optimal position that particle
i has crossed,
gbest is the optimal position that the population has crossed; in every iteration, particles update their speed and position by individual extremum
pbest and global extremum
gbest, update formulas are shown as follows:
where
is the speed of particle
i in the
kth iteration and
dth dimension;
is inertia weight;
and
are are acceleration factor,
and
are the random numbers ranging from 0 to 1.
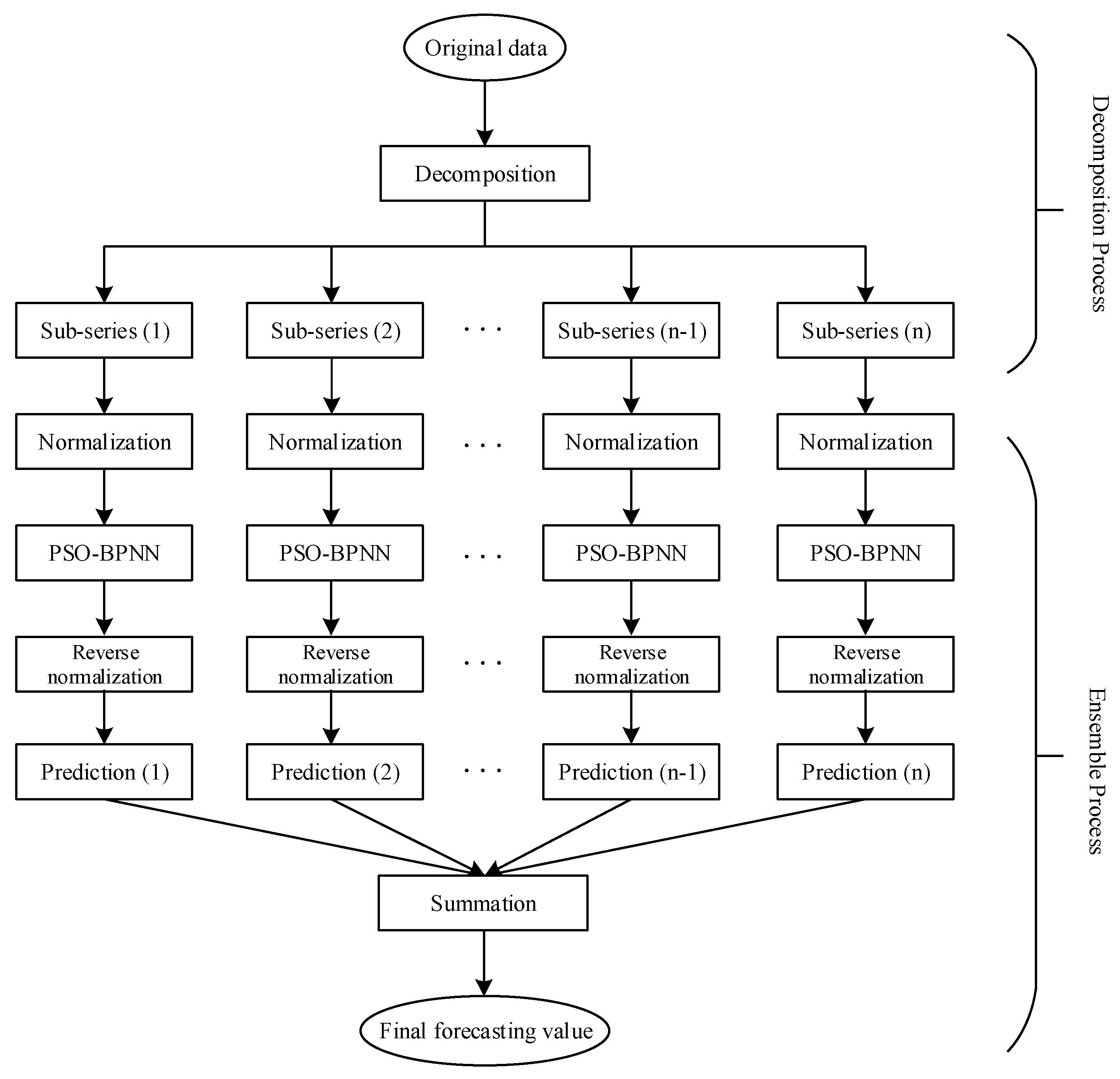
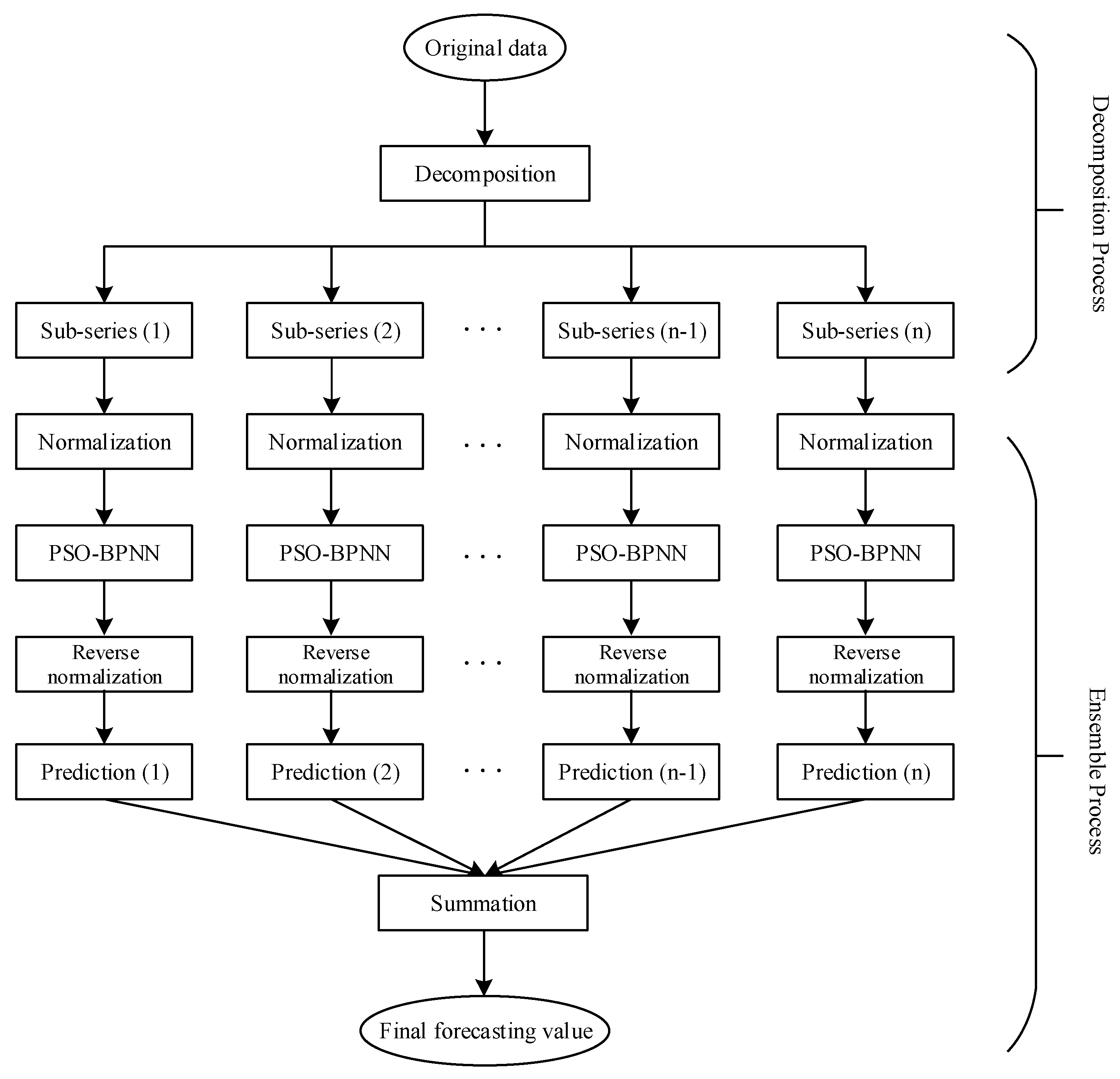
2.4. The Proposed Hybrid Models
In this subsection, the four proposed hybrid models, which contains the WPT–PSO–BPNN model, the EMD–PSO–BPNN model, the ITD–PSO–BPNN model and the VMD–PSO–BPNN model, are developed on the basis of the methodology mentioned above to forecast the day-ahead prices of the wheat, corn and soybean futures which will be described concretely in the next section; the basic structure of these models is given in
Figure 3.
Weight and threshold are two important parameters in the BPNN which would have an influence on the forecasting accuracy. The PSO algorithm, with its advantages of fast rate and high efficiency, is regarded as a widespread optimization tool based on the swarm intelligence. Therefore, we apply this approach in optimizing these two parameters. Furthermore, agricultural commodity futures prices are nonlinear and nonstationary time series data with relatively obvious volatility, which can be handled through the decomposition techniques to some extent. Thus, the hybrid models are established. It is necessary to note that, in our study, all components decomposed are normalized into the range of [0, 1] using linear transference method before entering the next step, for better convergence of the BPNN. Certainly, the output data should be rescaled back by reversing the normalization in order to compute the forecasting accuracy on the basis of the original scale of the data. All calculating and modelling processes involved in this paper are realized in MATLAB R2015b.
4. Results and Analysis
Based on the above detailed description and discussion, this section concentrates on the empirical results and analysis of the forecast day-ahead prices of the wheat, corn, and soybean futures, utilizing four hybrid predictive models, namely the WPT–PSO–BPNN model, the EMD–PSO–BPNN model, the ITD–PSO–BPNN model, and the VMD–PSO–BPNN model, respectively.
4.1. Case of Wheat Futures
In this paper, we focus on one-step-ahead forecasting models so that, with regard to a time series, a certain number of previous data are chosen as the input of the PSO–BPNN model to forecast the latter one, since the length of input may affect models’ forecasting accuracy in some degree. According to comparative analysis of several prediction results with different input length, the optimal length of the PSO–BPNN’s input series turns out to be eight; that is, with regard to a time series
, this study uses
to forecast
; and so on,
can be forecasted by
. Meanwhile, some main parameters of the PSO algorithm and BPNN are set as shown in
Table 2. It should be noted that the parameters listed in
Table 2 are determined through a number of empirical experiments.
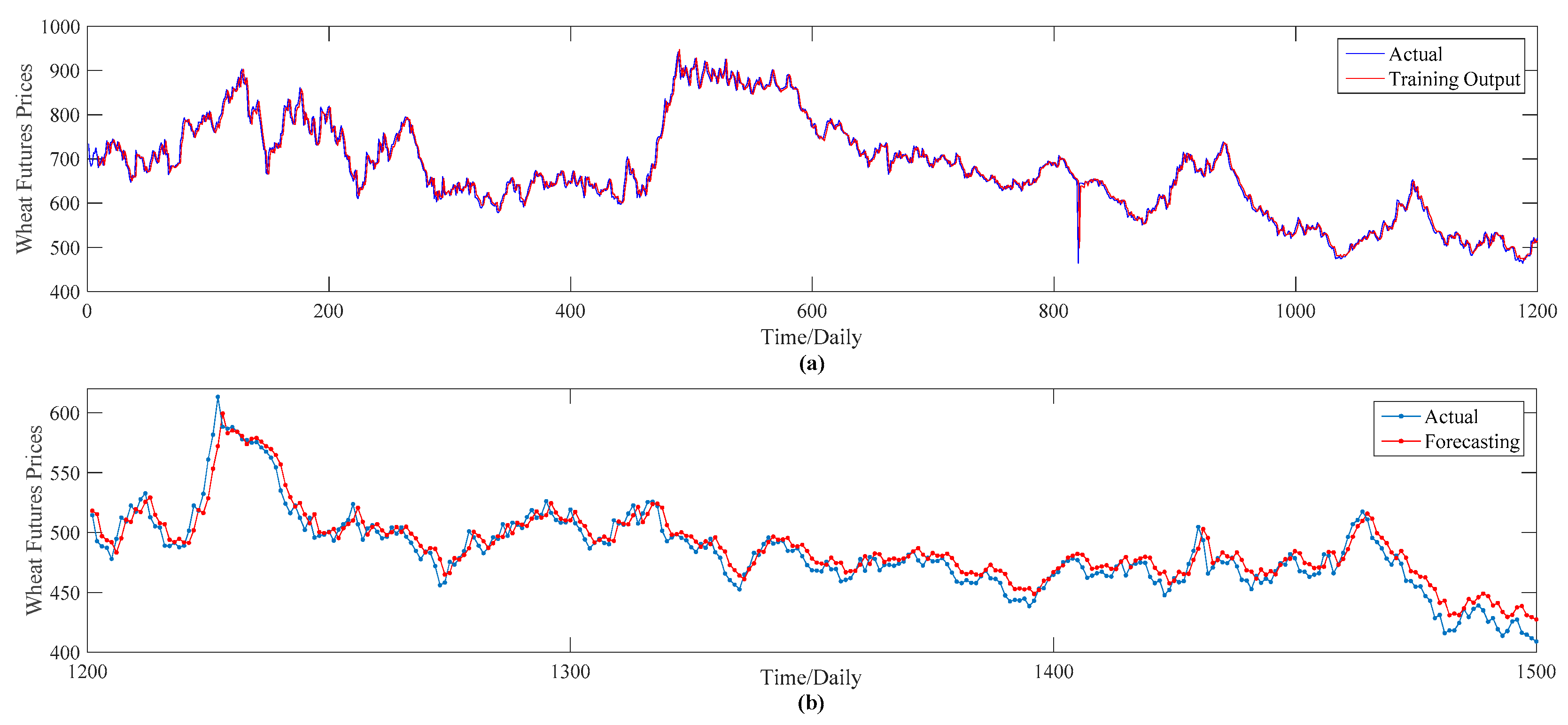
Based on the input length and the main parameter settings of the forecasting model, we use these to conduct our empirical study; this model’s training performance and forecasting performance are shown in
Figure 6a,b, respectively. From this figure, it is obvious that not only the training output values but the predictions are also extremely close to the actual values, meaning that the PSO–BPNN model performs well in forecasting wheat futures prices. In the next discussion of this section, we regard the PSO–BPNN model as the benchmark model to compare its forecasting accuracy with the other four hybrid models proposed in this study. In order to compare the effectiveness of the EMD, WPT, ITD and VMD approaches respectively, we maintain the same parameter settings of this PSO–BPNN model with the four hybrid models throughout the whole paper.
4.1.1. Decomposition Results
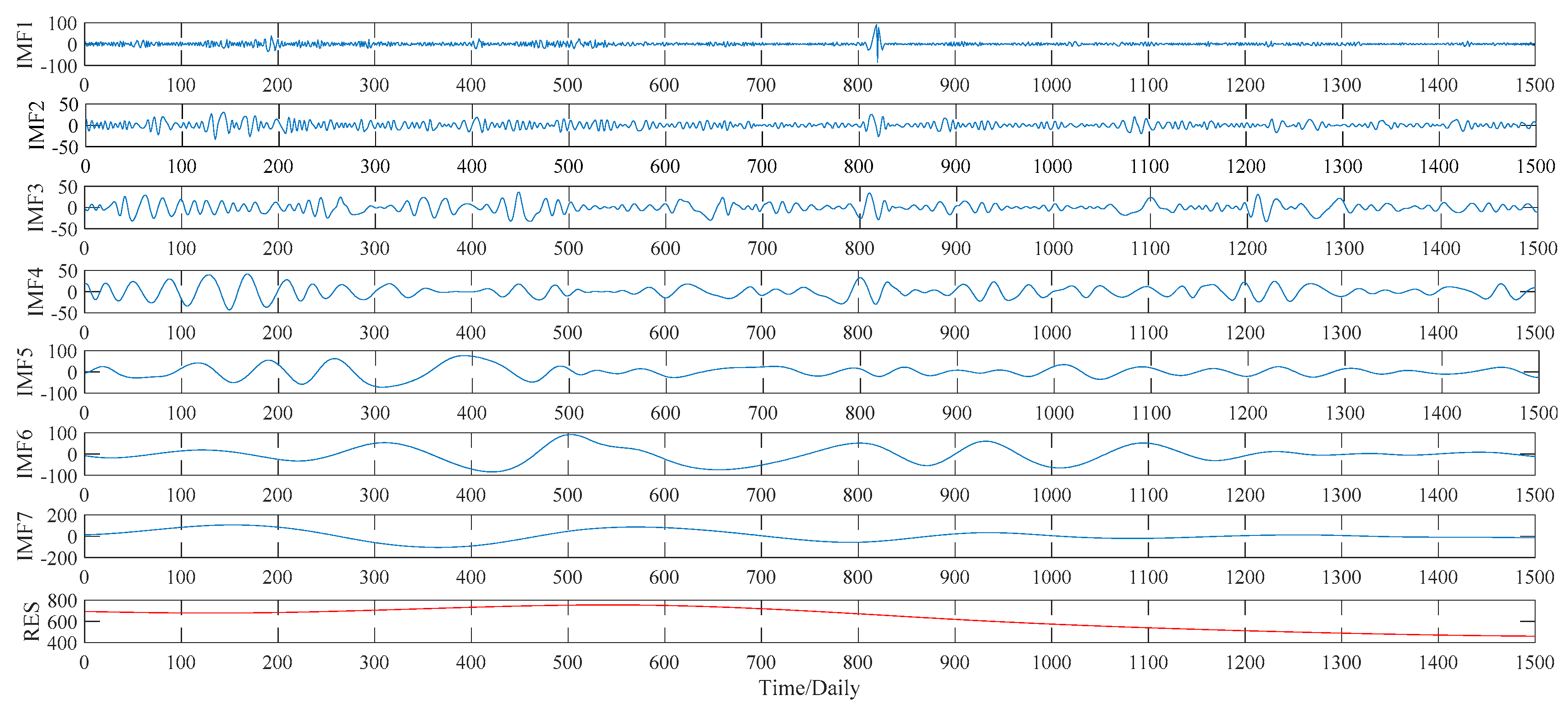
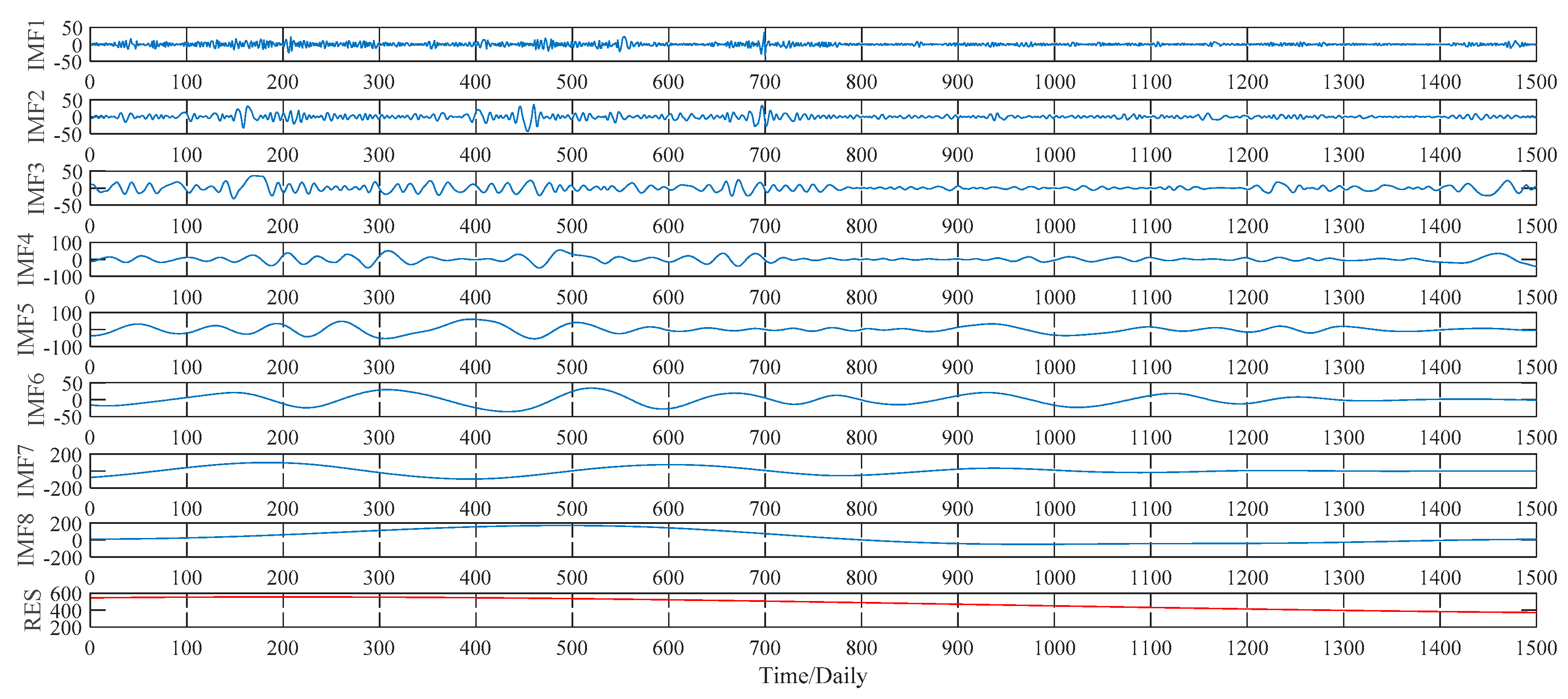
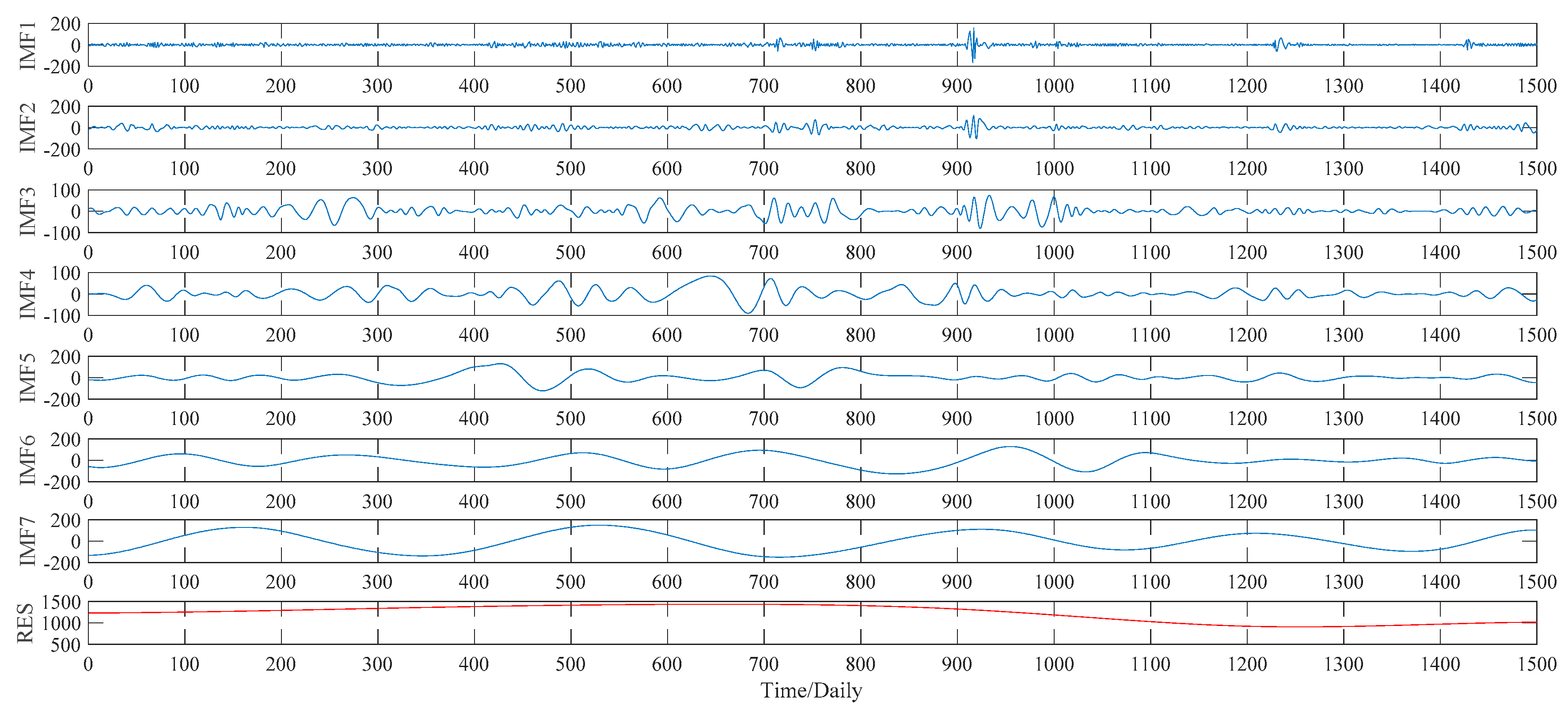
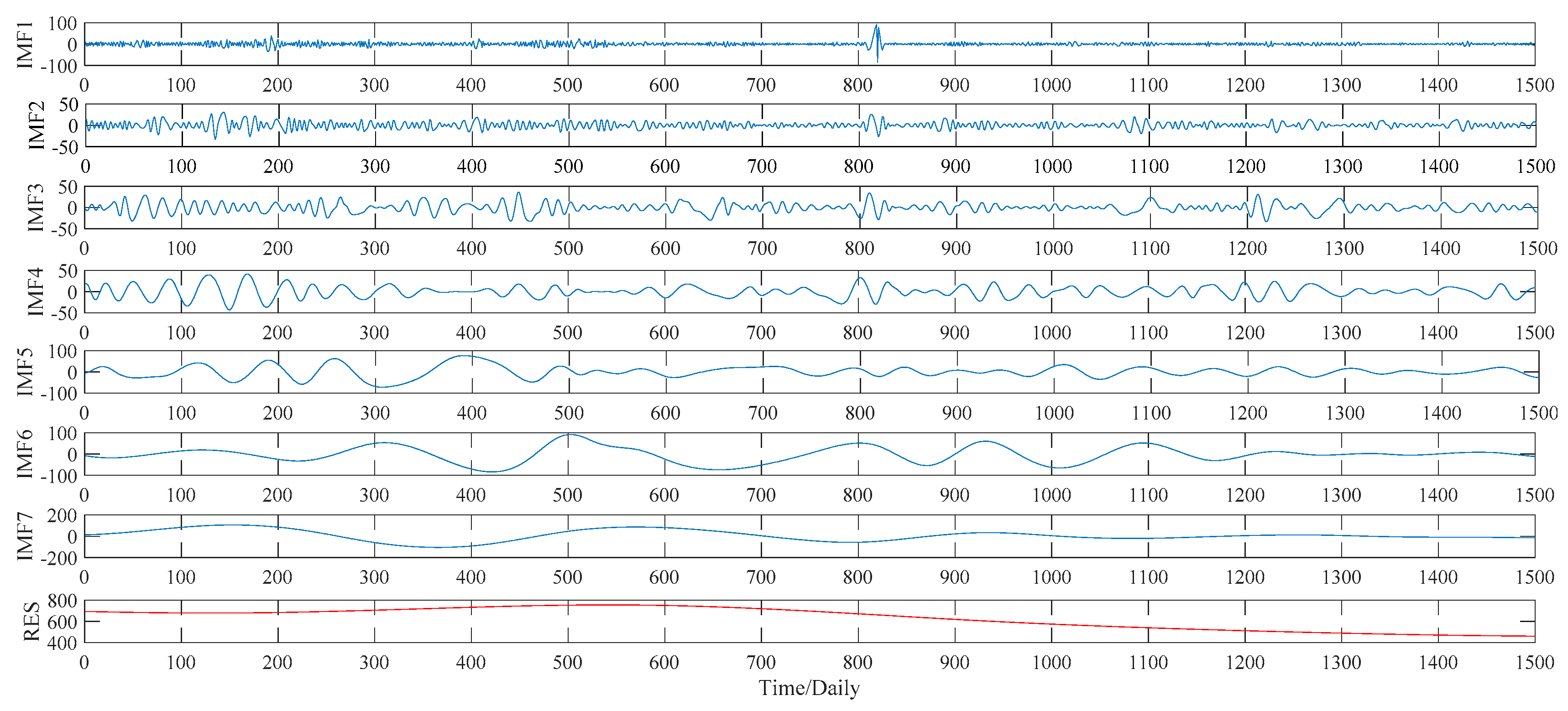
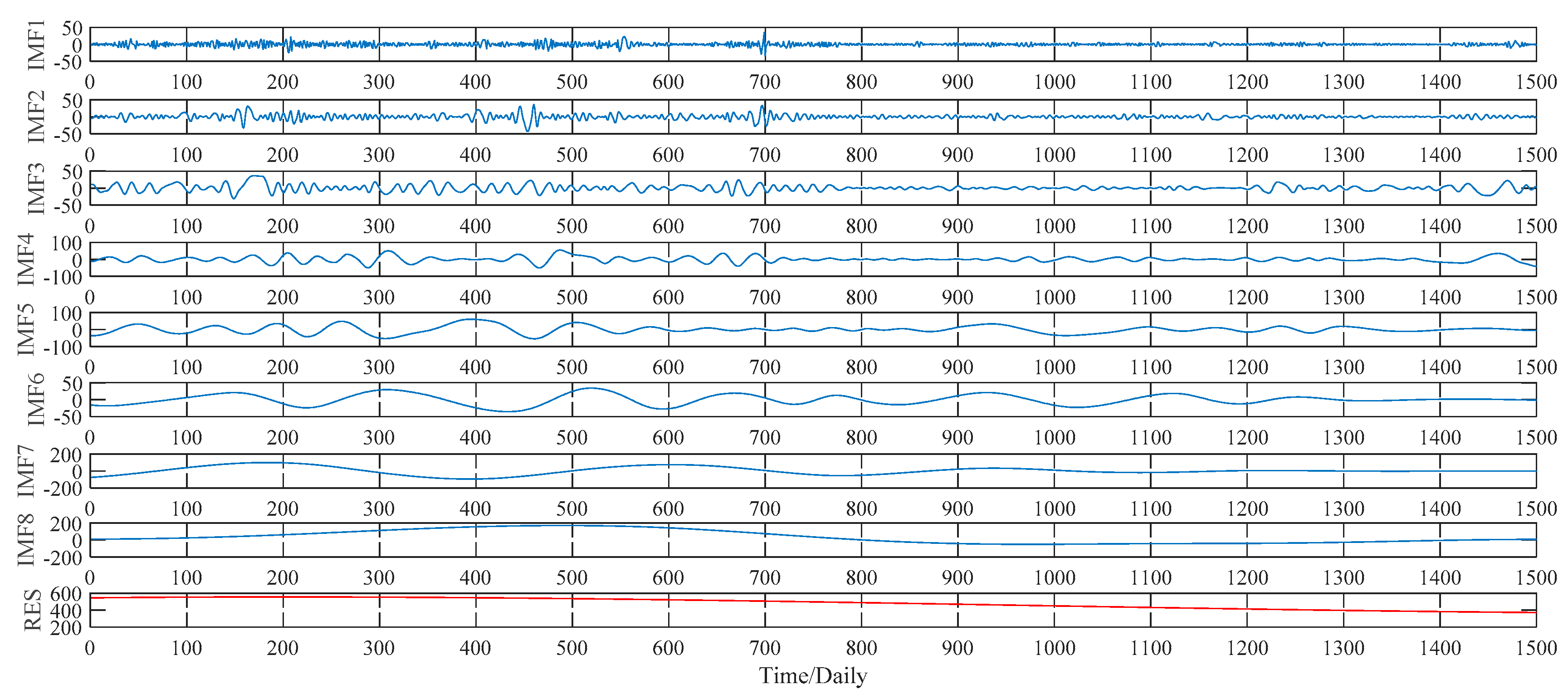
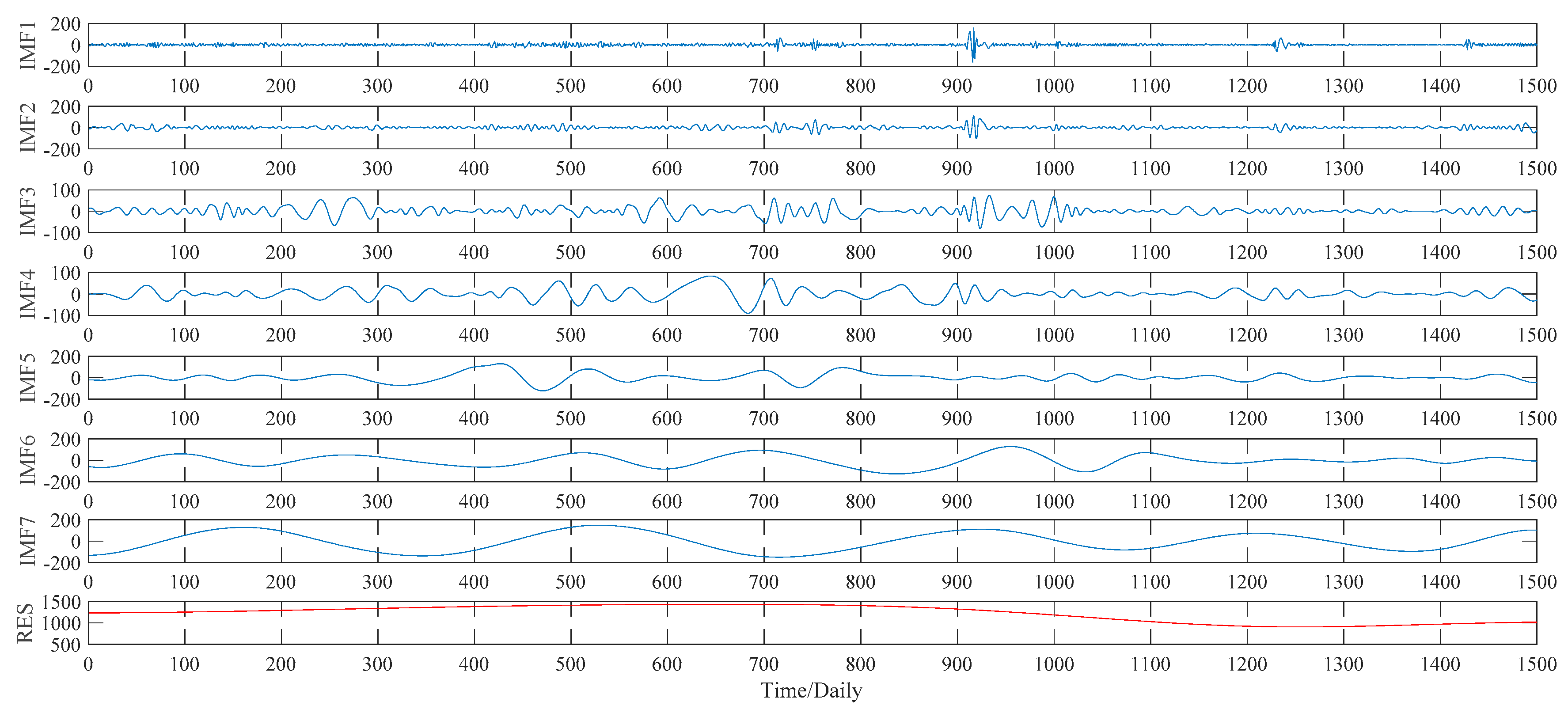
This subsection illustrates the decomposition results of wheat futures prices using EMD, WPT, ITD and VMD approaches, respectively. More specifically, according to the EMD method, the price data series of wheat futures is decomposed into seven IMFs, defined as IMF1, IMF2, …, IMF7, and a residual sub-series, named RES, which are shown in
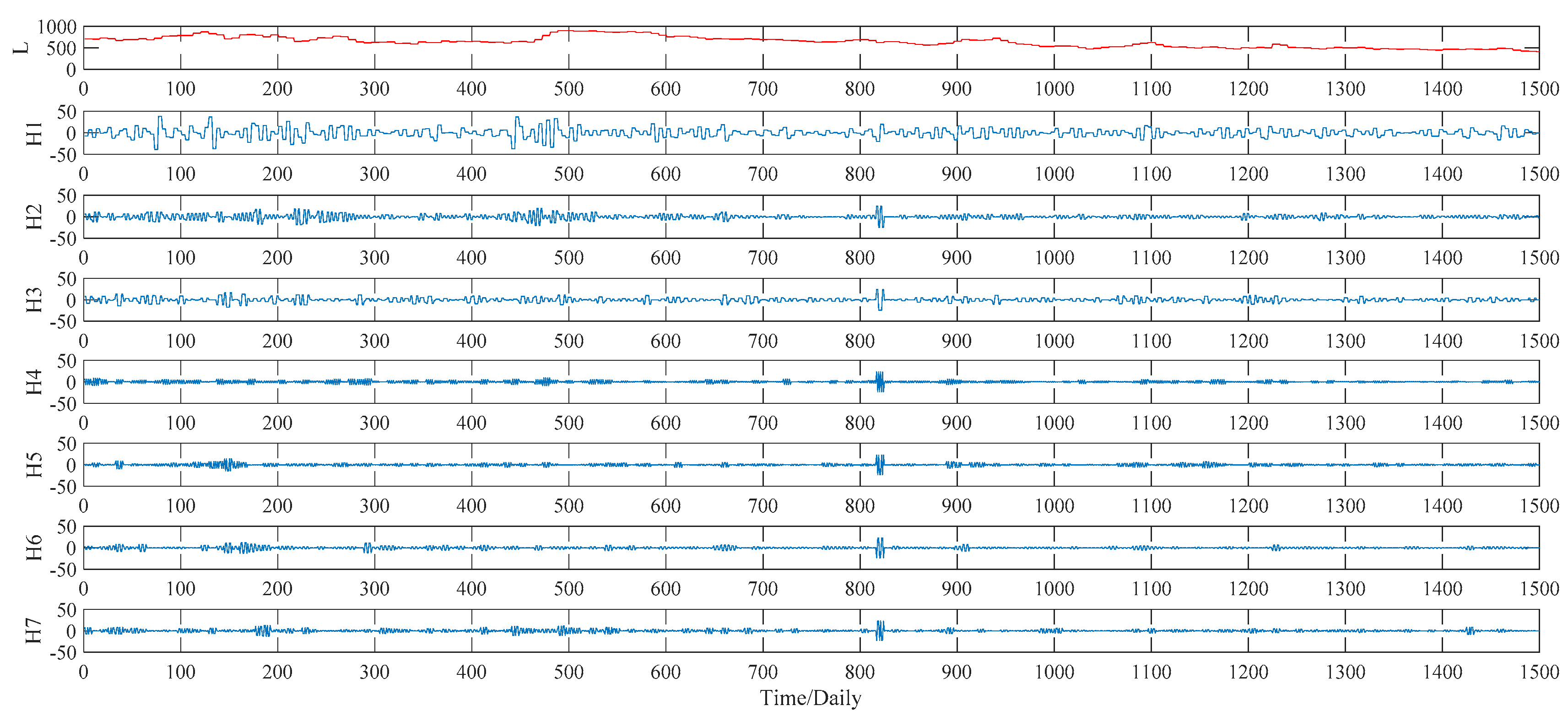
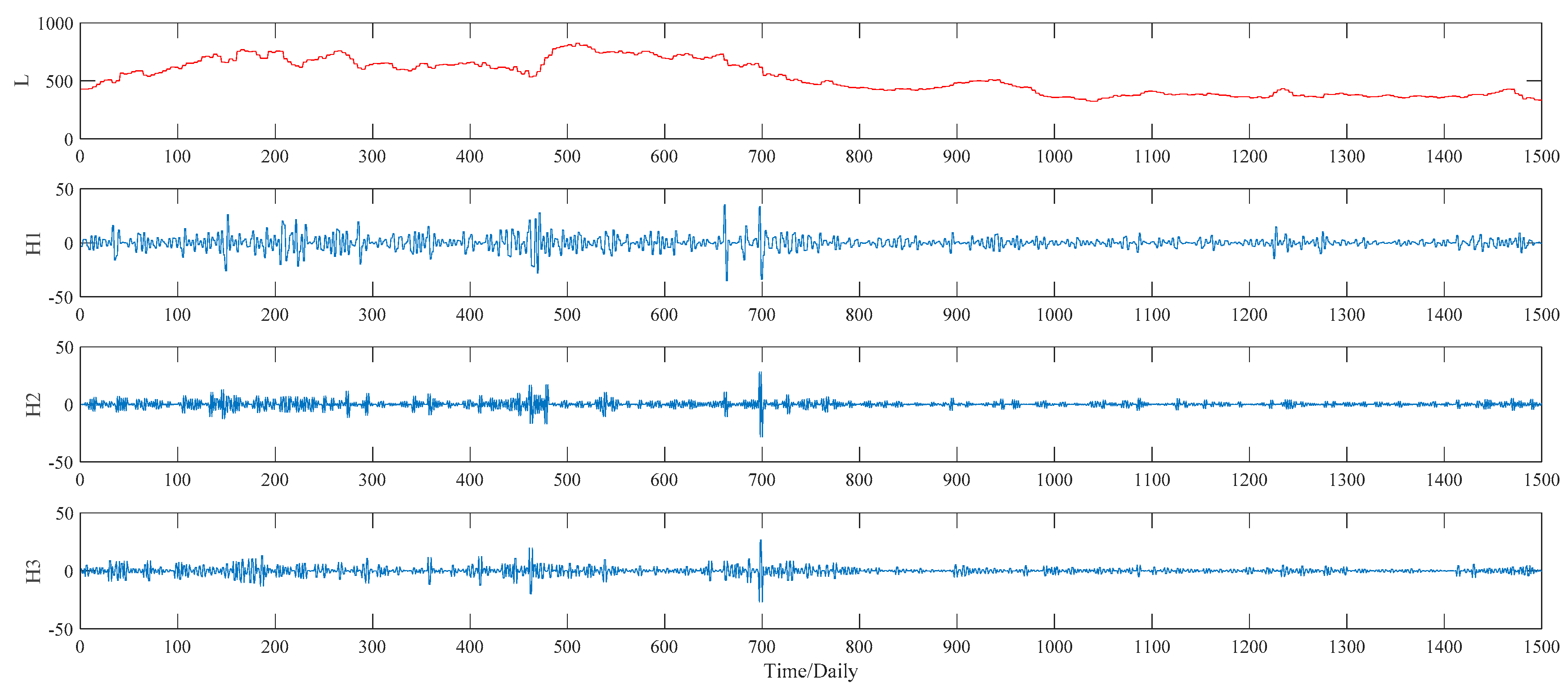
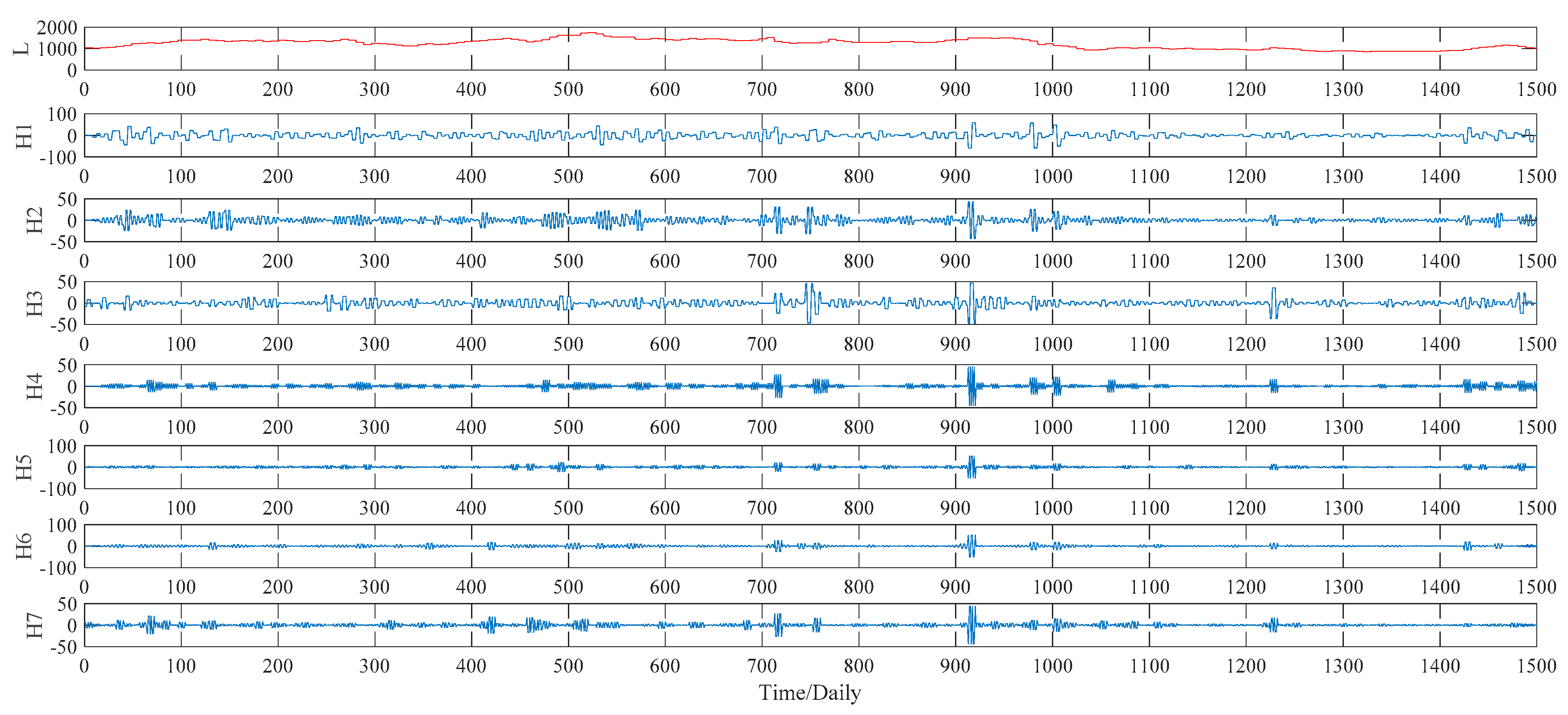
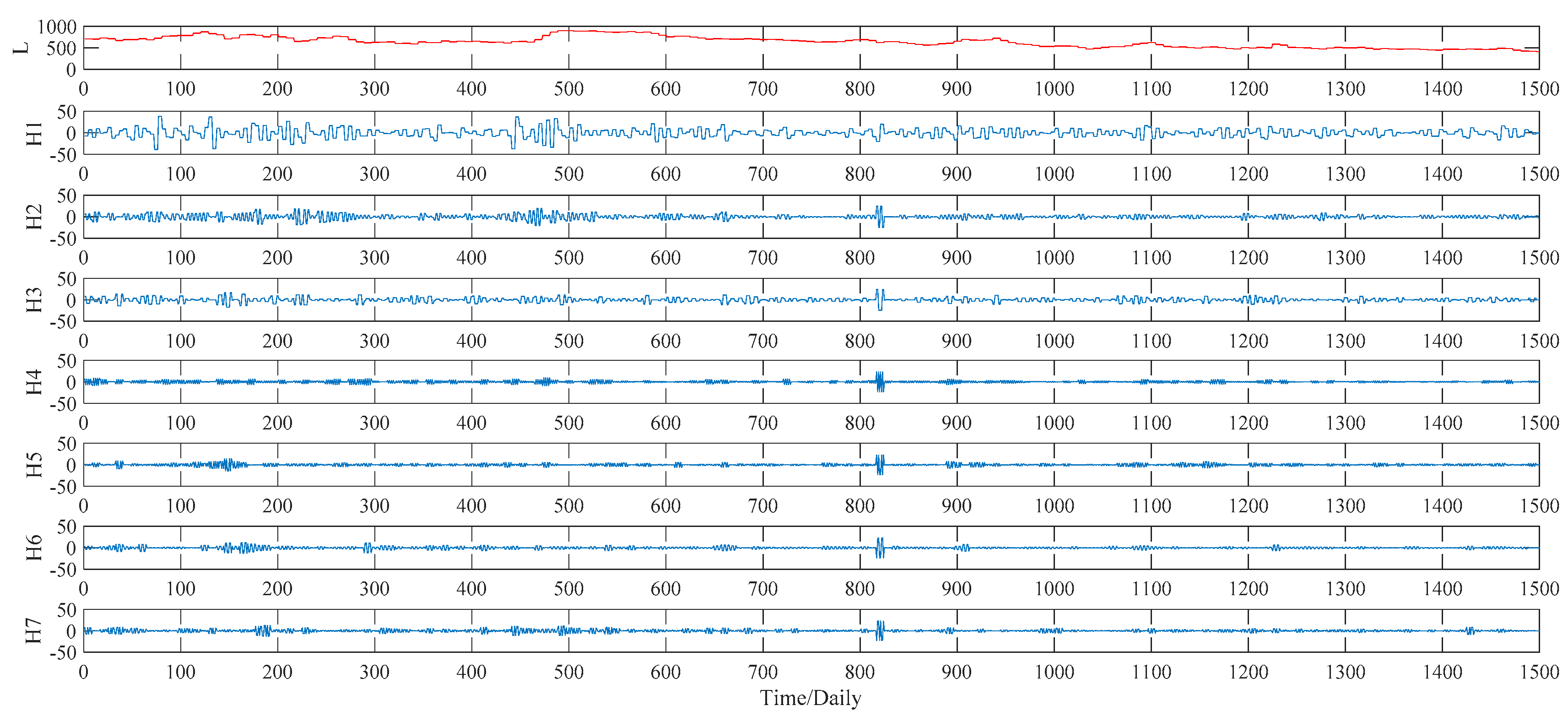
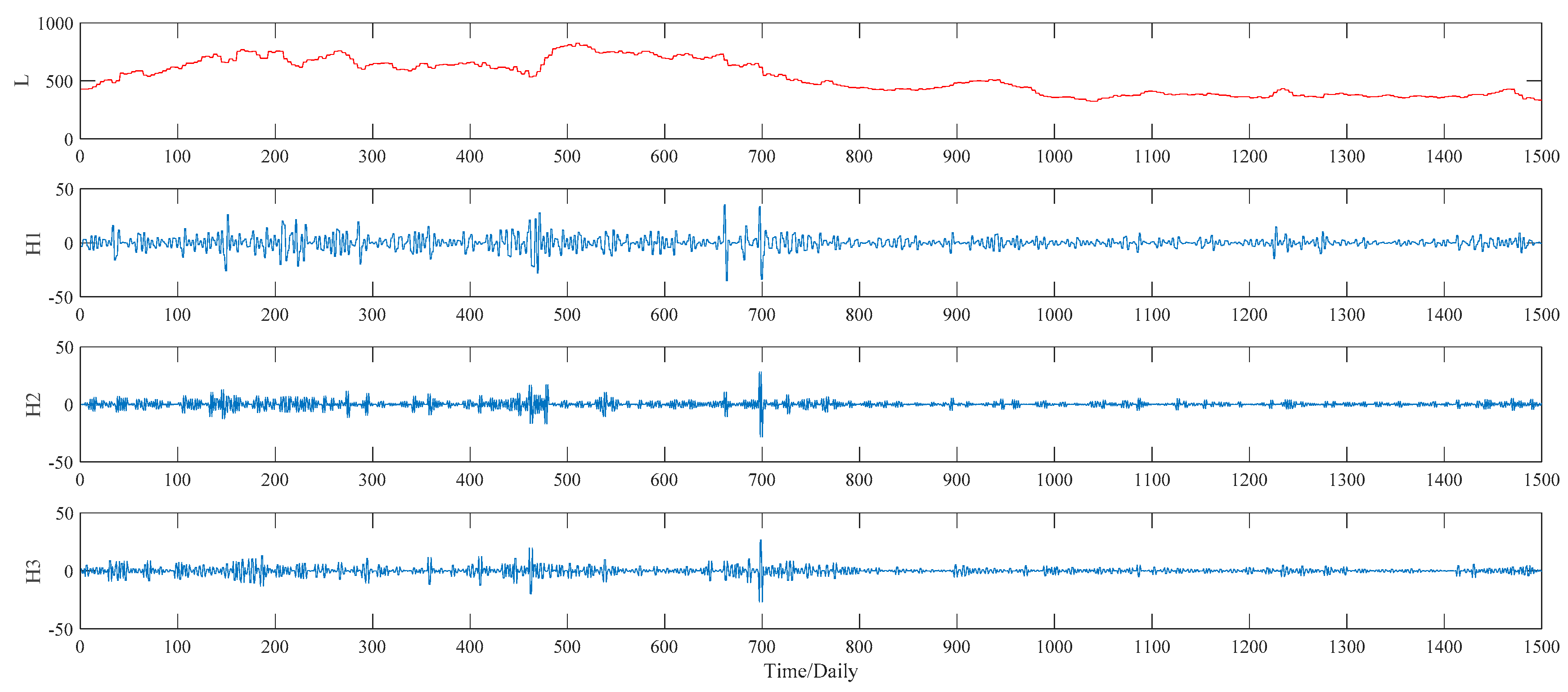
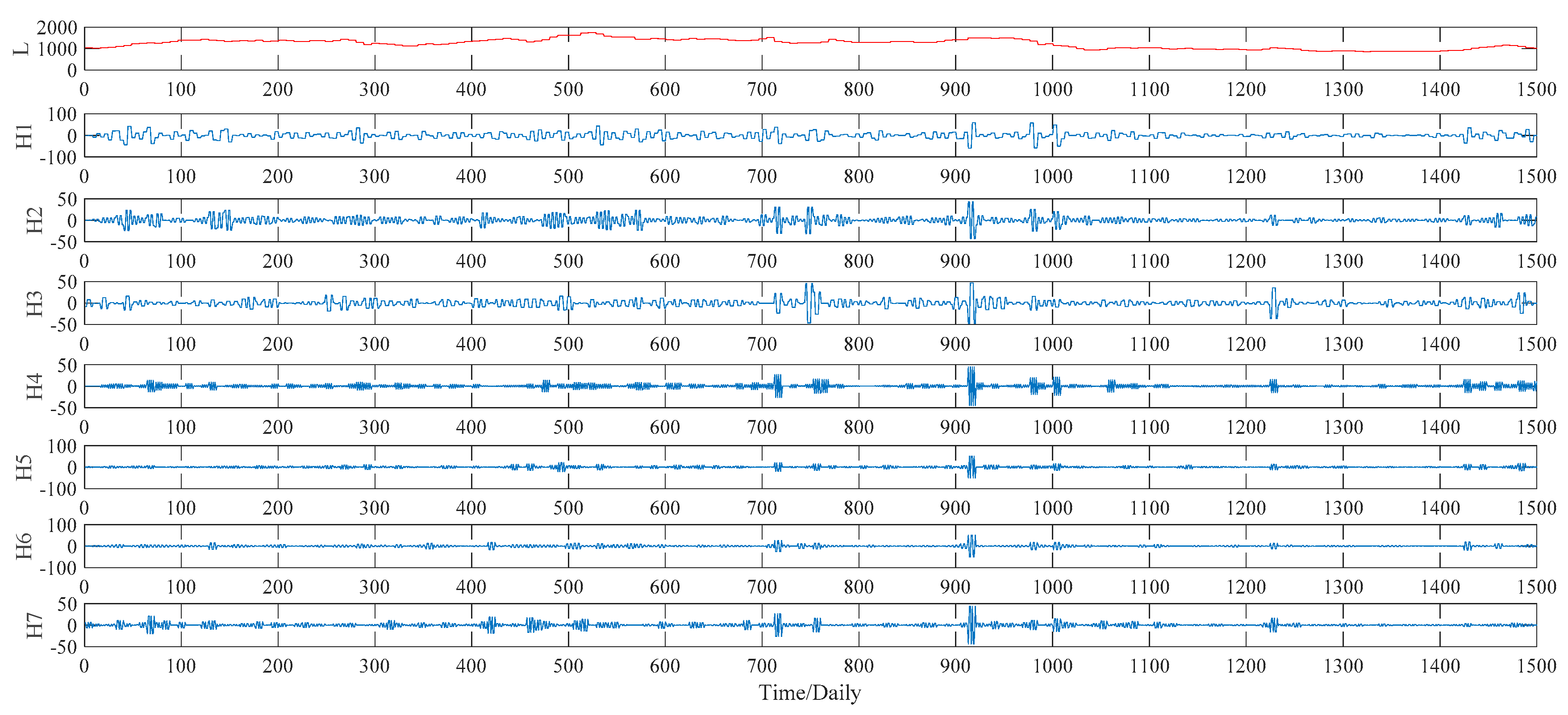
Figure 7. As to the WPT method, two typical decomposition levels, namely two levels and three levels, are taken into consideration in our study, for the sake of finding out the better decomposition level that will improve the PSO–BPNN’s forecasting accuracy more. Finally, the more suitable level turns out to be three, and the three-level decomposition results, including an approximation component L and seven detail components defined as H1, H2, …, H7, of the WPT technique is given in
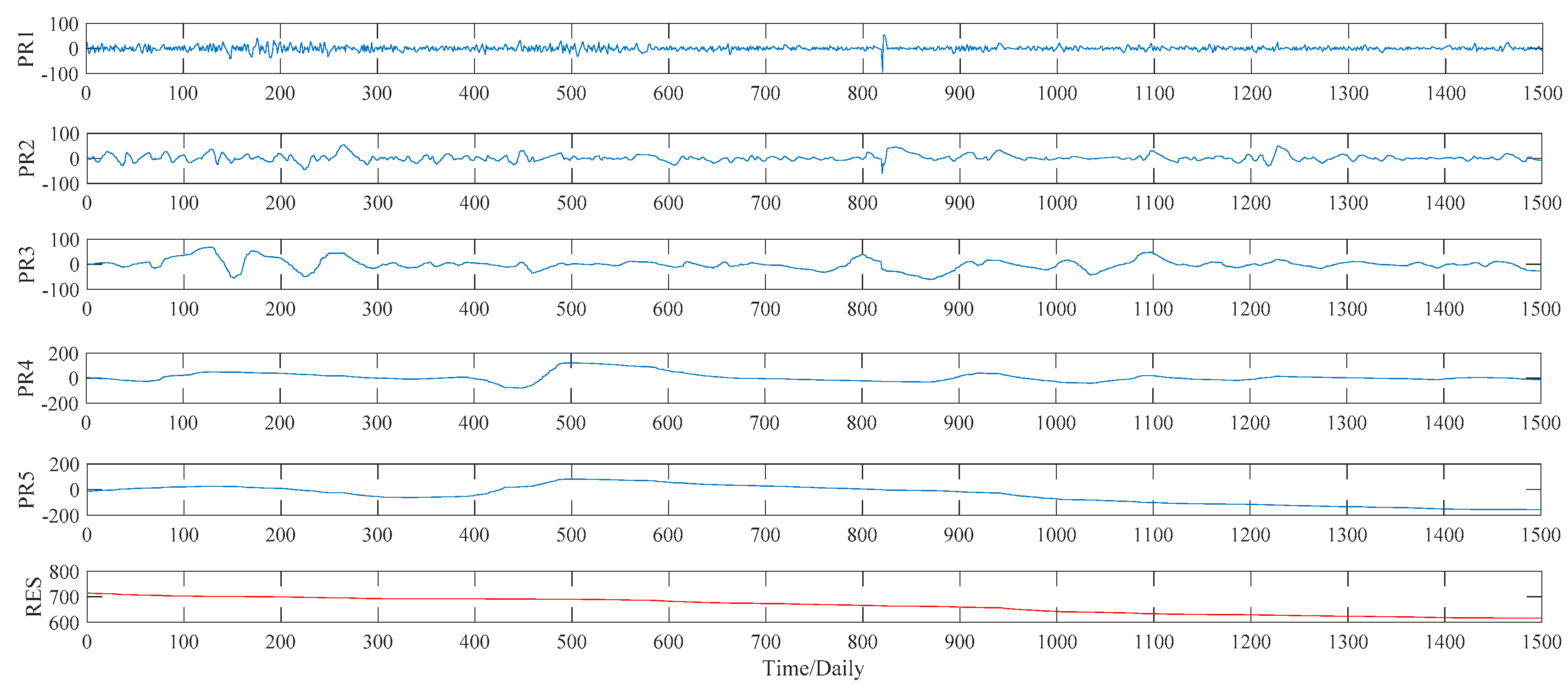
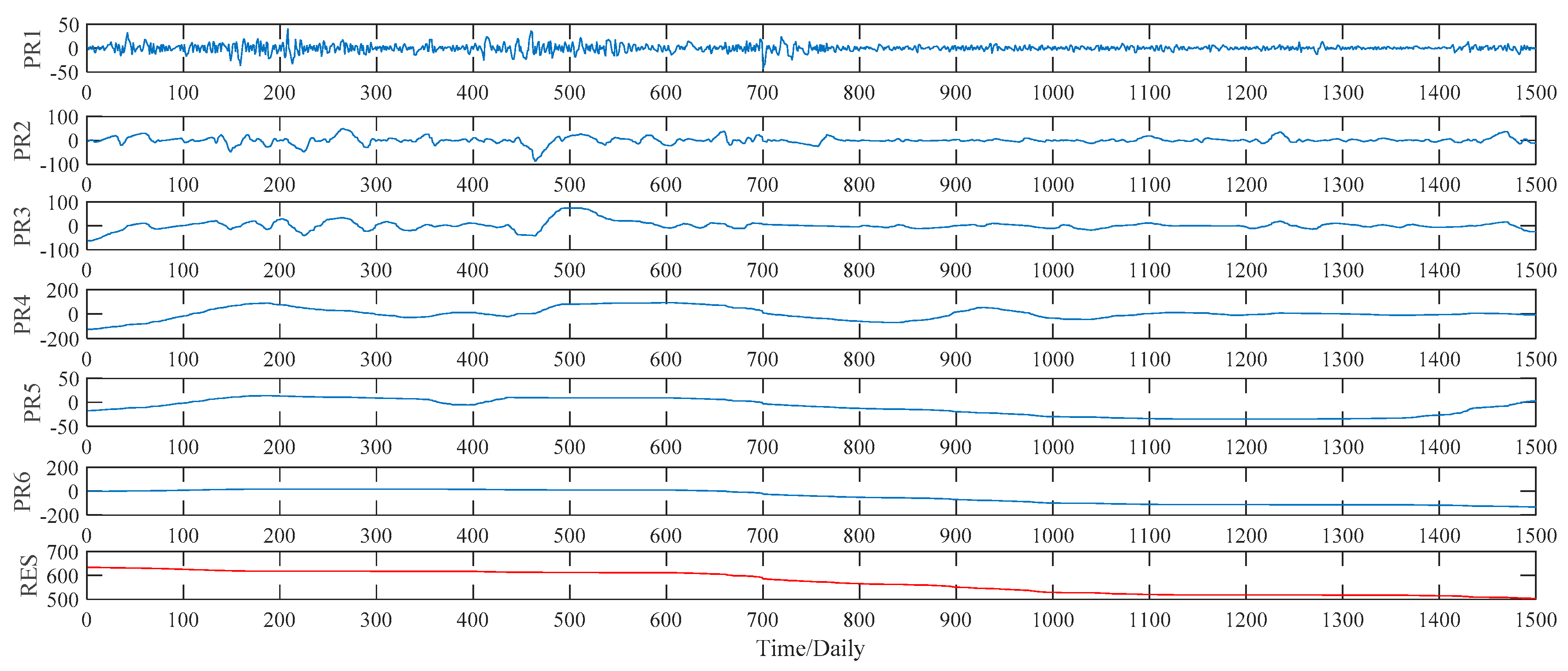
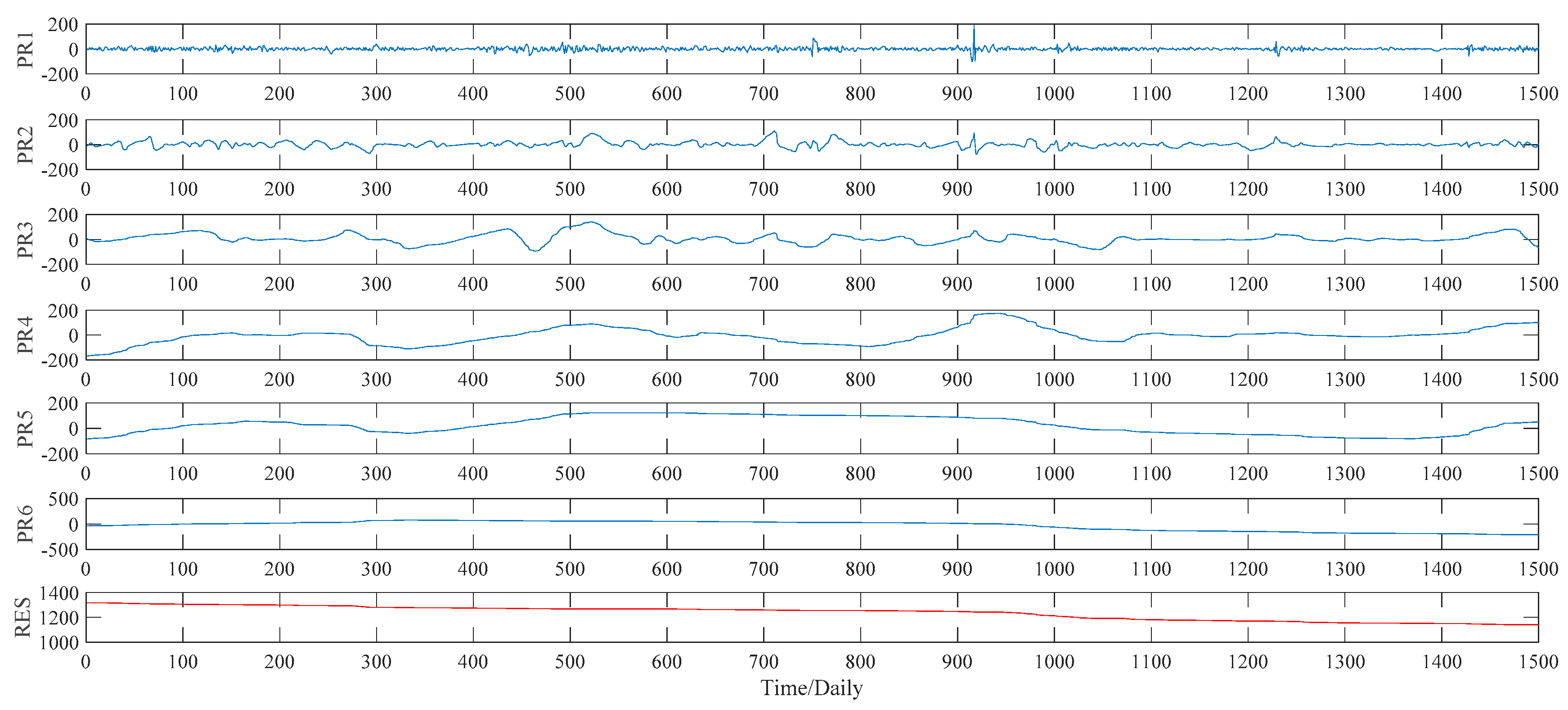
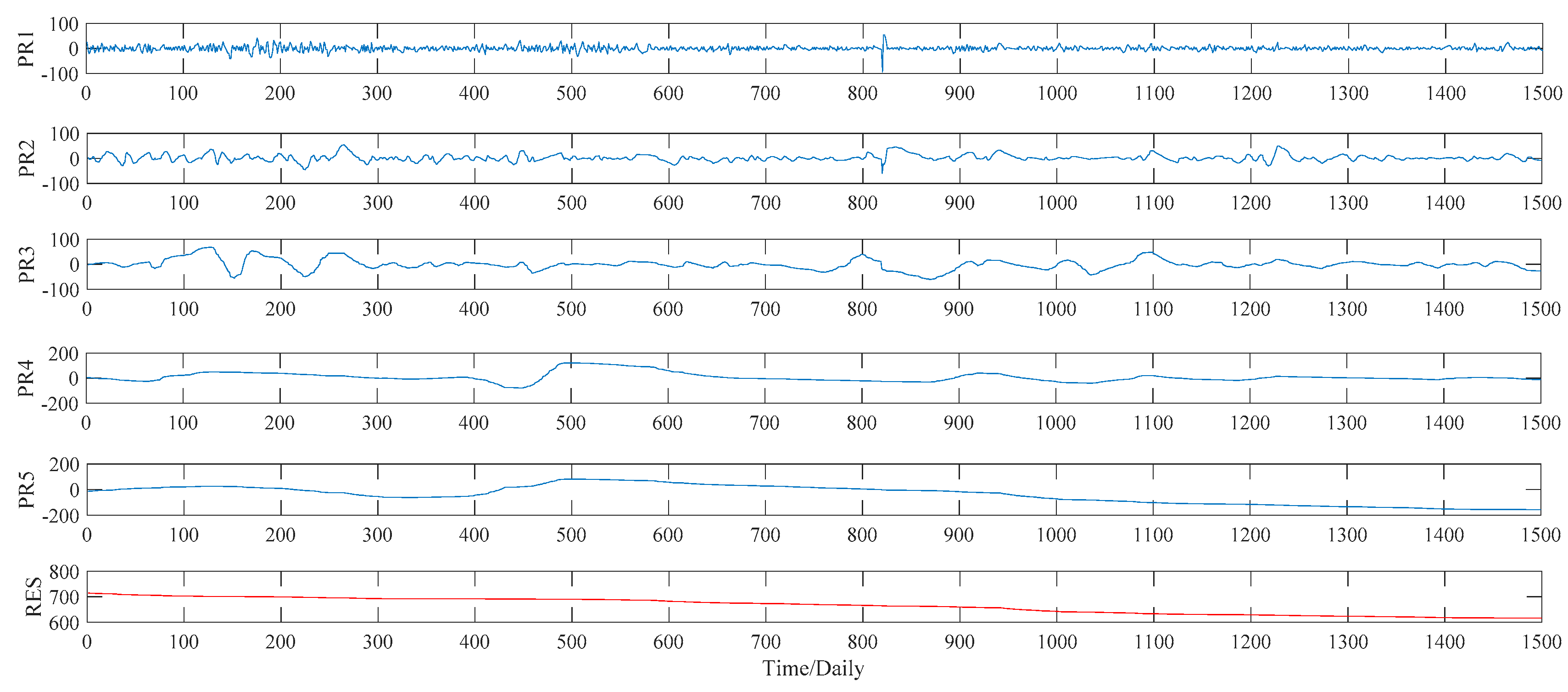
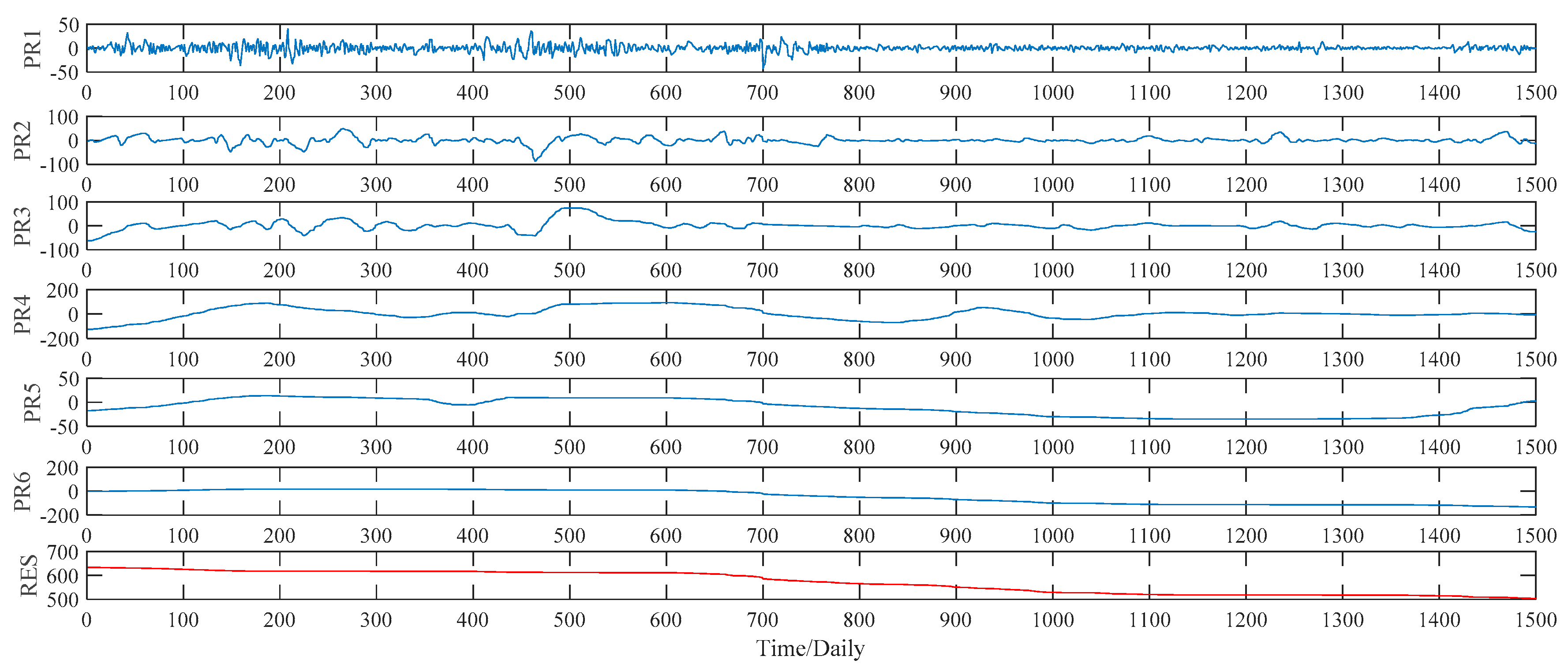
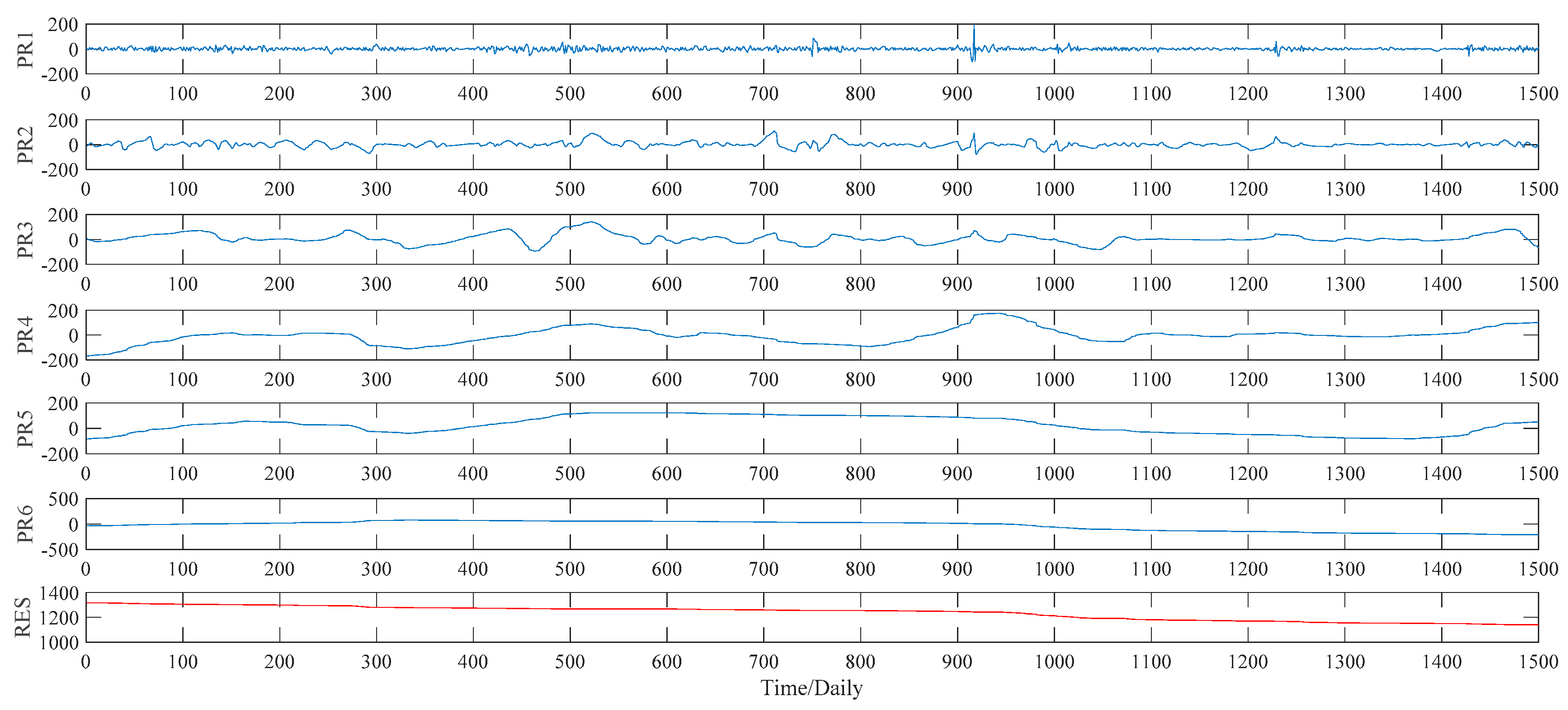
Figure 8. As to the ITD method, the upper limit on the number of decomposition, namely ten, is set manually in our study. Under such a preset, the ITD method automatically divides the sample data into five PRs, and a RES as well. See
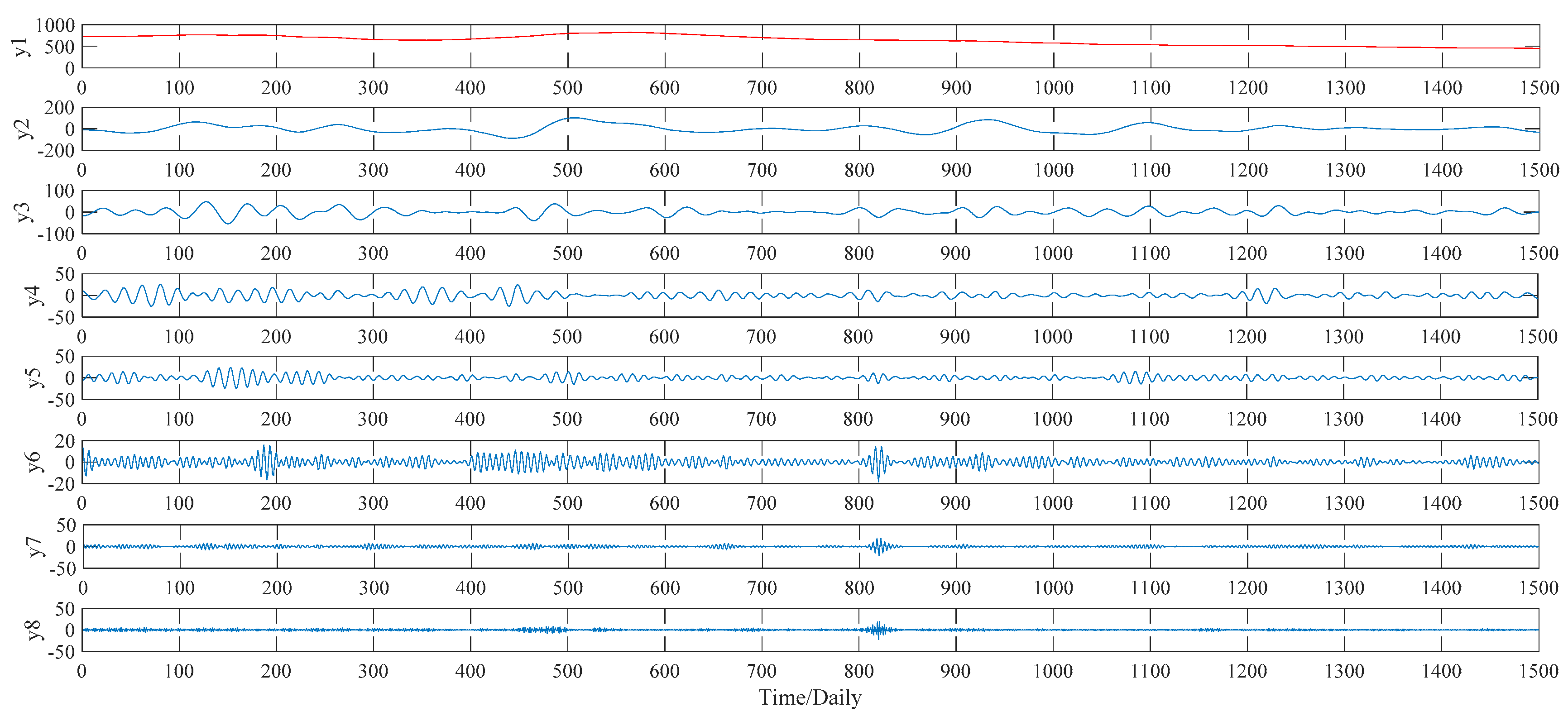
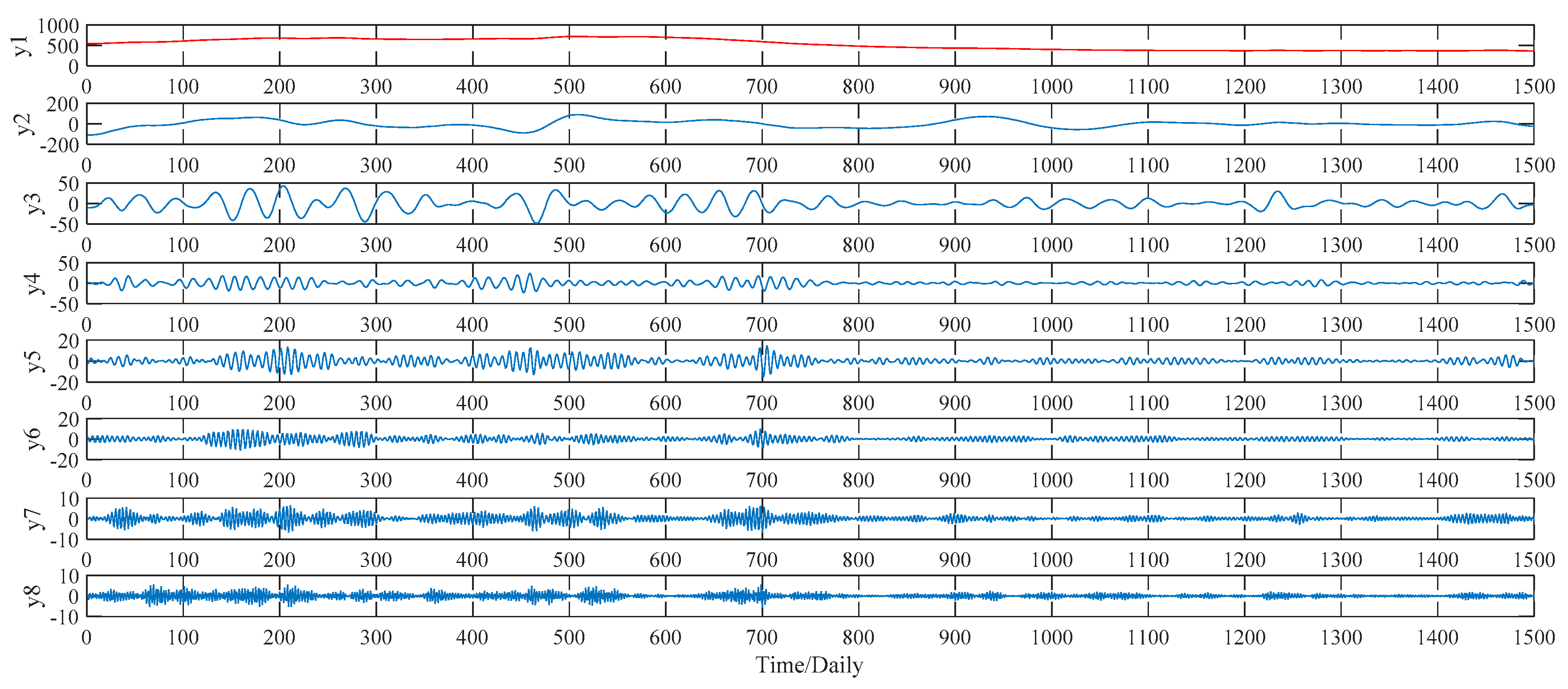
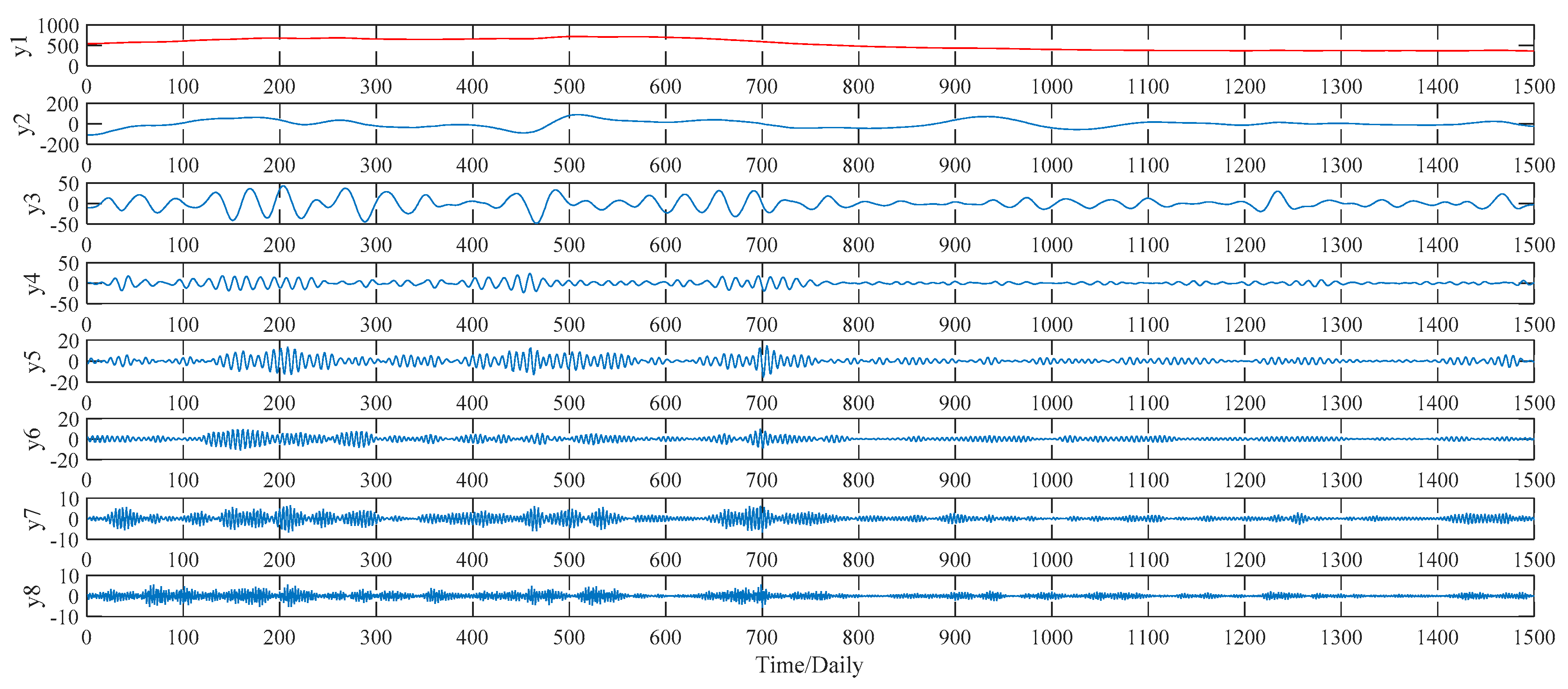
Figure 9 for decomposition results in detail. As to the VMD method, this study compares the decomposition effect of different number of modes, namely from six modes to nine modes. Given the hybrid models’ forecasting accuracy, eight modes, namely y1, y2, …, y8,, are determined eventually, as shown in
Figure 10.
4.1.2. Comparison and Analysis
Based on the decomposition results of these four decomposition methods shown in
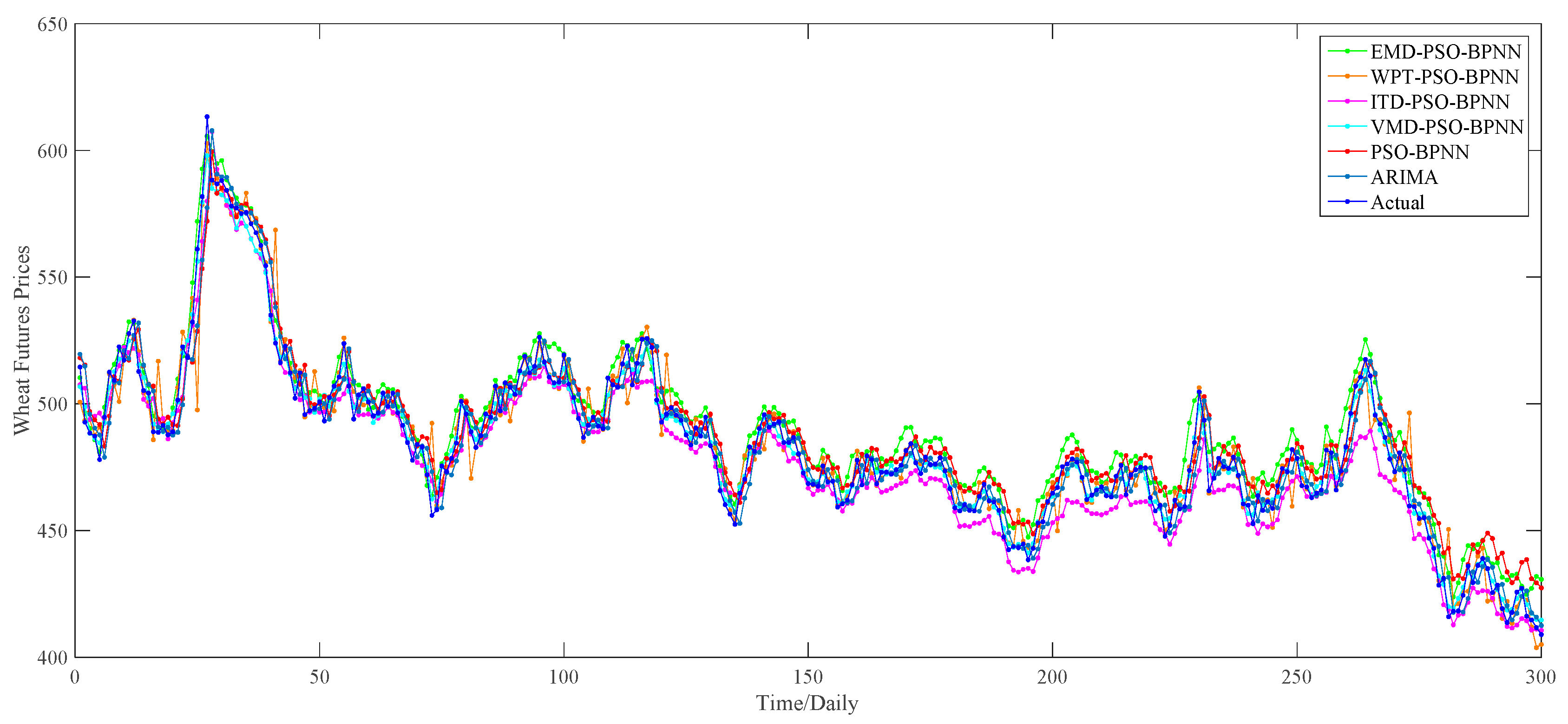
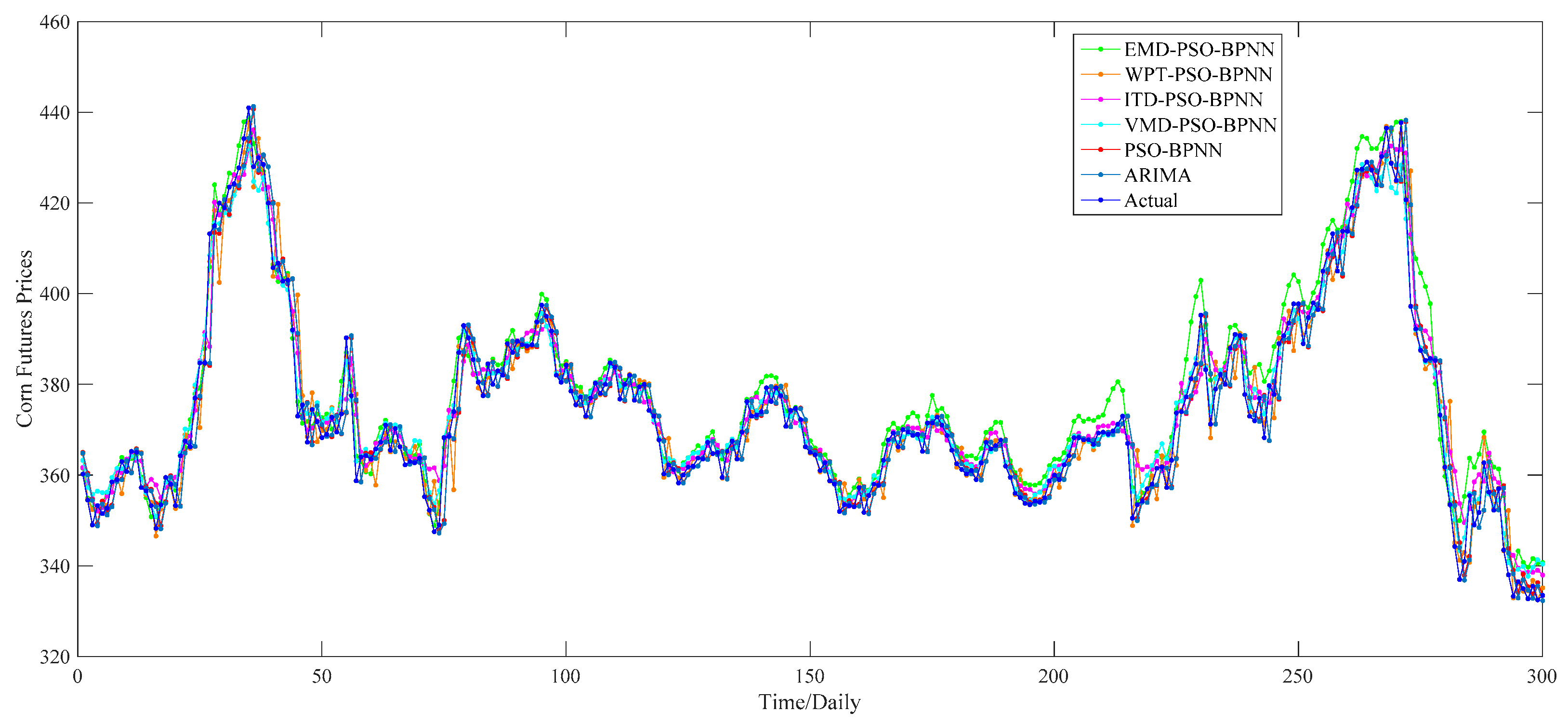
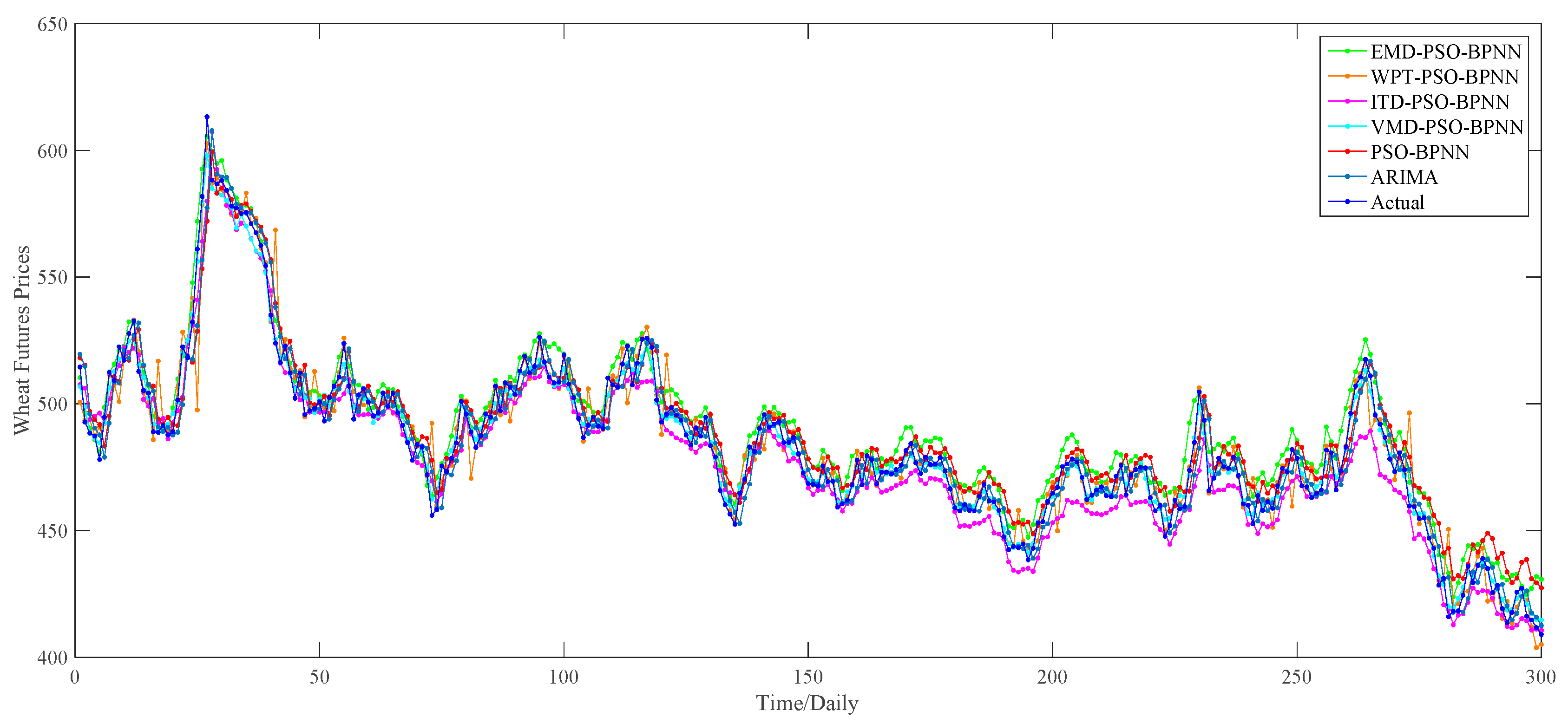
Section 4.1.1, we apply the PSO–BPNN model to implement the forecasting part. As for the decomposition results of each decomposition algorithm, the PSO–BPNN model is utilized to predict the last 20 percent of data, namely 300 forecasting values totally, of each sub-series. Then, 300 predictions of each sub-series are summed up in order to obtain the ultimate 300 forecasting values of the wheat futures prices. For a better comparison of the effectiveness of four hybrid models combined with four different decomposition techniques, we select the PSO–BPNN model without decomposition methods as a benchmark model, aiming to testify the effectiveness of decomposition techniques. Furthermore, the ARIMA model is treated as a comparative model in order to compare the superiority in predictive capability between the ANN-based models and the traditional statistic models. The comparison of one-day-ahead forecasting results among all these models is provided in
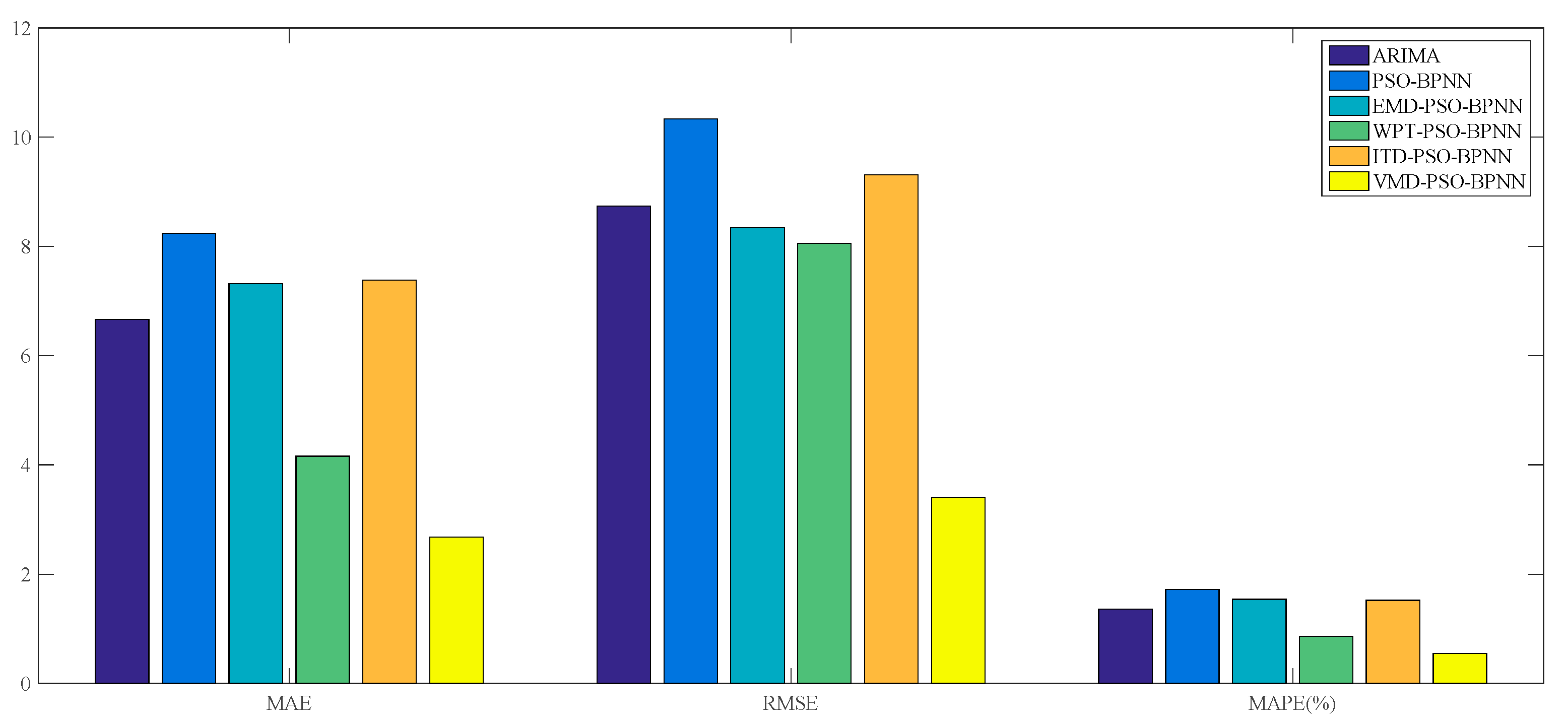
Figure 11. And the forecasting performance is evaluated through three criteria, namely the MAE, RMSE and MAPE, which are given in
Table 3 and
Figure 12.
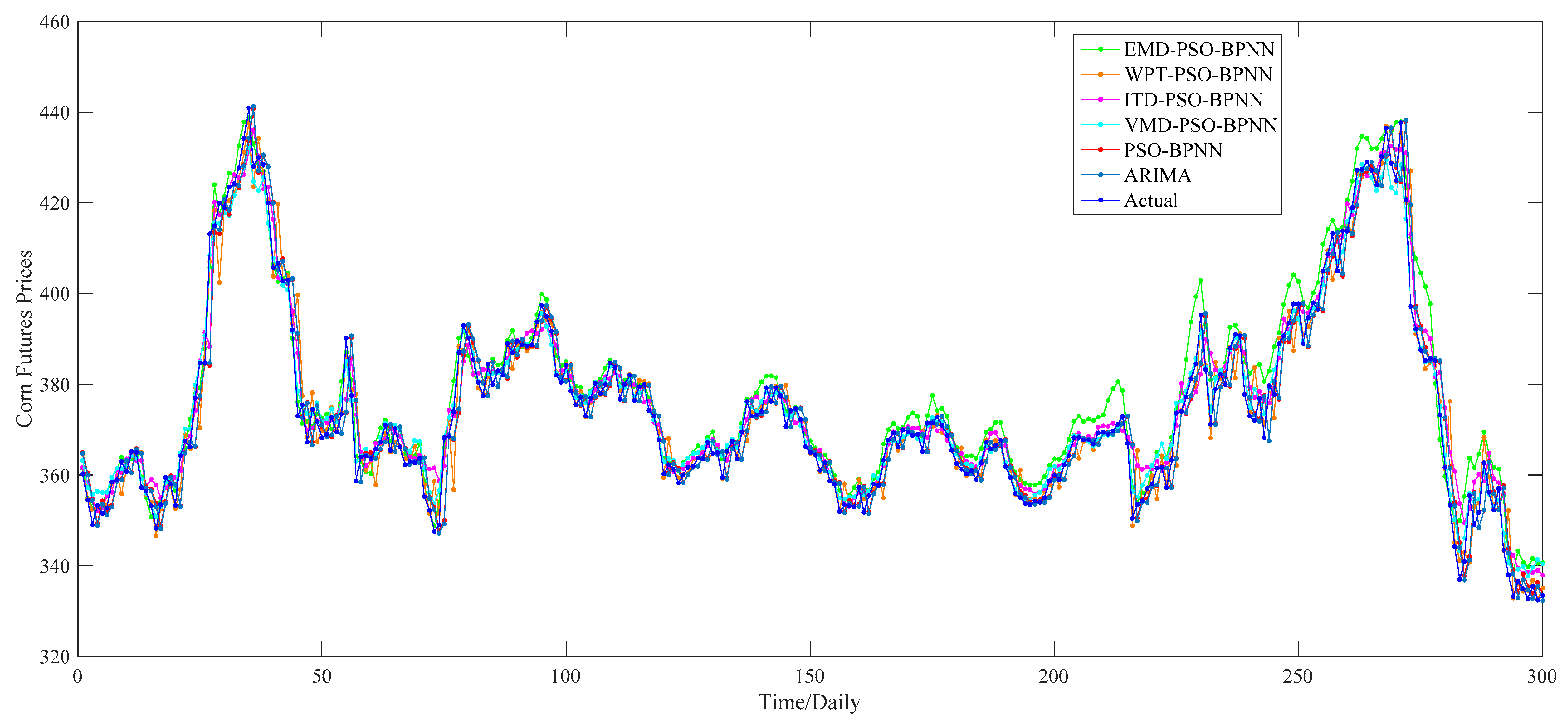
According to the
Figure 11, there exists a preliminary judgment that the forecasting accuracy of the VMD–PSO–BPNN model is higher than any other model proposed in this study, since, during the whole forecasting period, the predictions of this model and actual values always keep a relatively high degree of coincidence compared with others, especially during the second half of the forecasting period.
Furthermore, it can be proved from
Table 3 that, among all these forecasting models mentioned above, the VMD–PSO–BPNN model performs much better than any other model; namely the EMD–PSO–BPNN model, WPT–PSO–BPNN model, ITD–PSO–BPNN model, PSO–BPNN model and ARIMA model, in terms of the values of MAE, RMSE and MAPE, which respectively are 2.68, 3.41 and 0.55% for the VMD–PSO–BPNN model.
For the comparison among ANN-based models, more specifically, on the one hand, the EMD–PSO–BPNN model, WPT–PSO–BPNN model, ITD–PSO–BPNN model and VMD–PSO–BPNN model have a more satisfactory performance than the PSO–BPNN model in terms of these three evaluation criteria, which means that the decomposition methods mentioned in this study can further make the PSO–BPNN model improve its forecasting accuracy of wheat futures; on the other hand, the VMD–PSO–BPNN model shows considerable superiority compared with other hybrid models combined with EMD, WPT and ITD methods respectively, signifying that the VMD method is proven to be more effective to conduct data pretreatment in contrast to the other three decomposition approaches. From a pure data perspective, the values of MAE, RMSE and MAPE of the VMD–PSO–BPNN model have all been reduced by about 68% compared with the PSO–BPNN model and approximately 63% compared with the ITD–PSO–BPNN model, and have decreased by 63.39%, 59.11% and 62.34% respectively compared with the EMD–PSO–BPNN model, and 35.58%, 57.09% and 36.05% respectively compared with the WPT–PSO–BPNN model.
For the comparison between ANN-based models and the ARIMA model, in terms of the MAPE, the value of ARIMA model is a little smaller than the PSO–BPNN model, EMD–PSO–BPNN model and ITD–PSO–BPNN model, while its value is obviously much larger than the WPT–PSO–BPNN model and VMD–PSO–BPNN model.
On the whole, it can be concluded that the WPT–PSO–BPNN model and VMD–PSO–BPNN model, especially the latter one, are more suitable to be used in forecasting the wheat futures prices because they raise the forecasting precision, namely the MAPE, by an order of magnitude, in contrast with the ARIMA model, PSO–BPNN model, EMD–PSO–BPNN model and ITD–PSO–BPNN model. The reasons why the forecasting accuracy of VMD-based hybrid model is superior to other hybrid models lie in the following two causes: (1) the VMD based model searches for a number of modes and their respective center frequencies, such that the band-limited modes reproduce the input signal exactly or in least-squares sense, thus VMD has the ability to separate components of similar frequencies compared with other decomposition methods; (2) VMD is more robust to noisy data such as wind speed, PM
2.5 concentration and agricultural commodity future price. Indeed, since each mode is updated by Wiener filtering in Fourier domain during the optimization process, the updated mode is less affected by noisy disturbances, and therefore the VMD can be more efficiently for capturing signal’s short and long variations than other decomposition methods [
52].
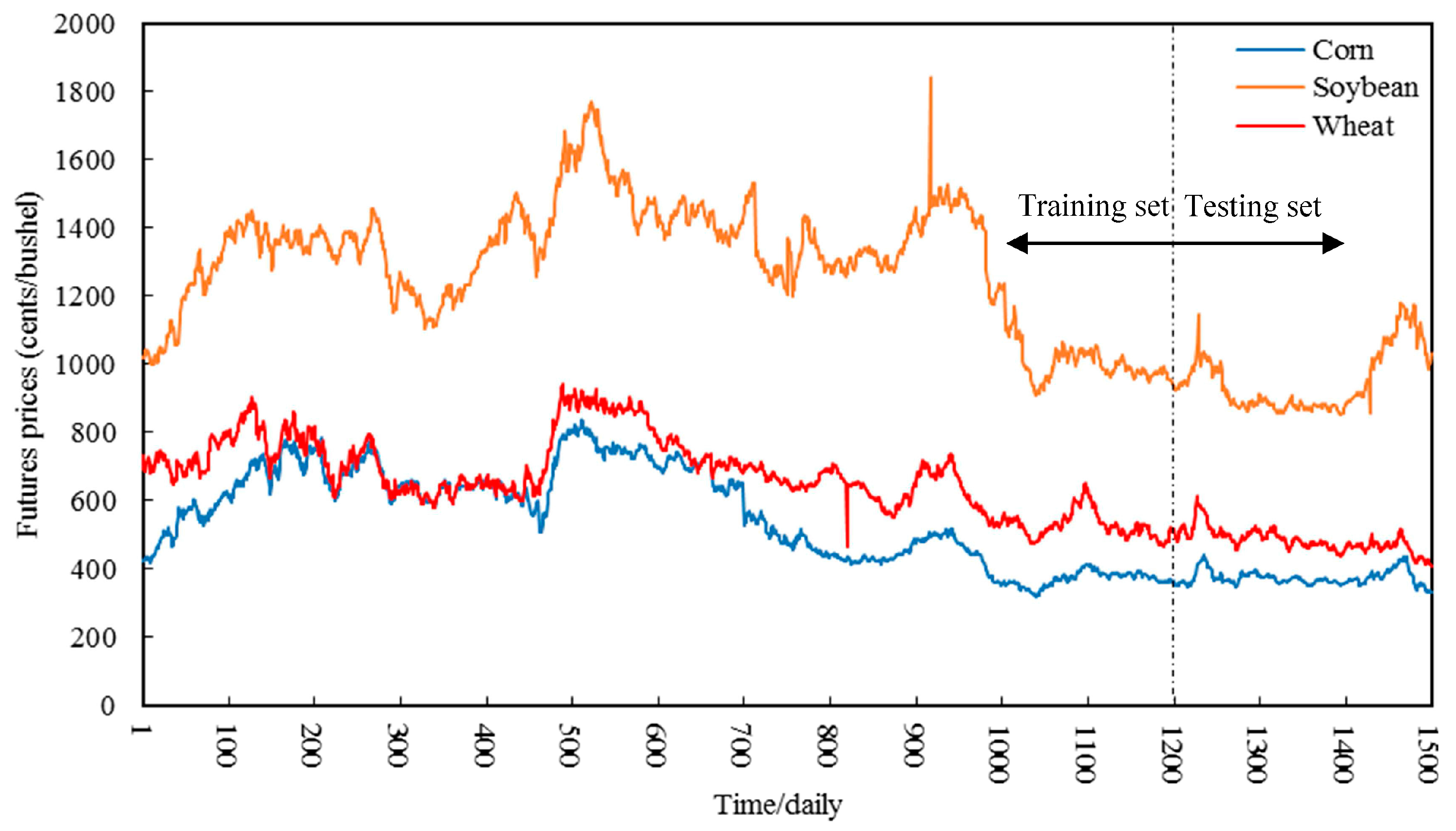
4.2. Case of Corn Futures
Although wheat, corn and soybean prices are strongly correlated [
15], it is still necessary to conduct certain research on different food grain futures in order to verify the applicability and validity of the hybrid models with decomposition methods developed in our study on the aspect of prices forecasting. Thus, this subsection presents the empirical study of forecasting the corn futures prices on the basis of these hybrid models, and the empirical study of soybean futures prices is in the next subsection. Similarly, decomposition results of corn futures prices, based on the EMD, WPT, ITD and VMD techniques respectively, are shown from
Figure 13,
Figure 14,
Figure 15 and
Figure 16, and the comparison between the one-day-ahead predictions and actual values are given in
Figure 17, while the forecasting performance evaluation results are displayed in
Table 4 and
Figure 18, respectively.
Likewise, the empirical results show that the VMD–PSO–BPNN model still outperforms the EMD–PSO–BPNN model, WPT–PSO–BPNN model, ITD–PSO–BPNN model, PSO–BPNN model and ARIMA model, with respect to the forecasting performance evaluation criteria, on the basis of
Table 4 and
Figure 18. But the disparity of forecasting precision between the VMD–PSO–BPNN model and other models is reduced. More specifically, for the comparison among all ANN-based models, similar conclusions with the study case of wheat can be obtained; that is, in respect of the MAE, RMSE and MAPE, the VMD–PSO–BPNN model and WPT–PSO–BPNN model perform much better than the other three models, while the ITD–PSO–BPNN model and EMD–PSO–BPNN model only improve a little compared with the PSO–BPNN model. For the comparison between the ANN-based models and the ARIMA model, all hybrid models with decomposition approaches outperform the ARIMA model, while the PSO-BPNN model (1.14%) almost shares the same forecasting accuracy with the ARIMA model (1.13%) in terms of the evaluation criterion, MAPE.
Moreover, it is worthy of note that there are three hybrid models, combined with the WPT, ITD and VMD respectively, whose forecasting accuracy is improved by one order of magnitude to 0.65%, 0.96% and 0.57%, respectively.
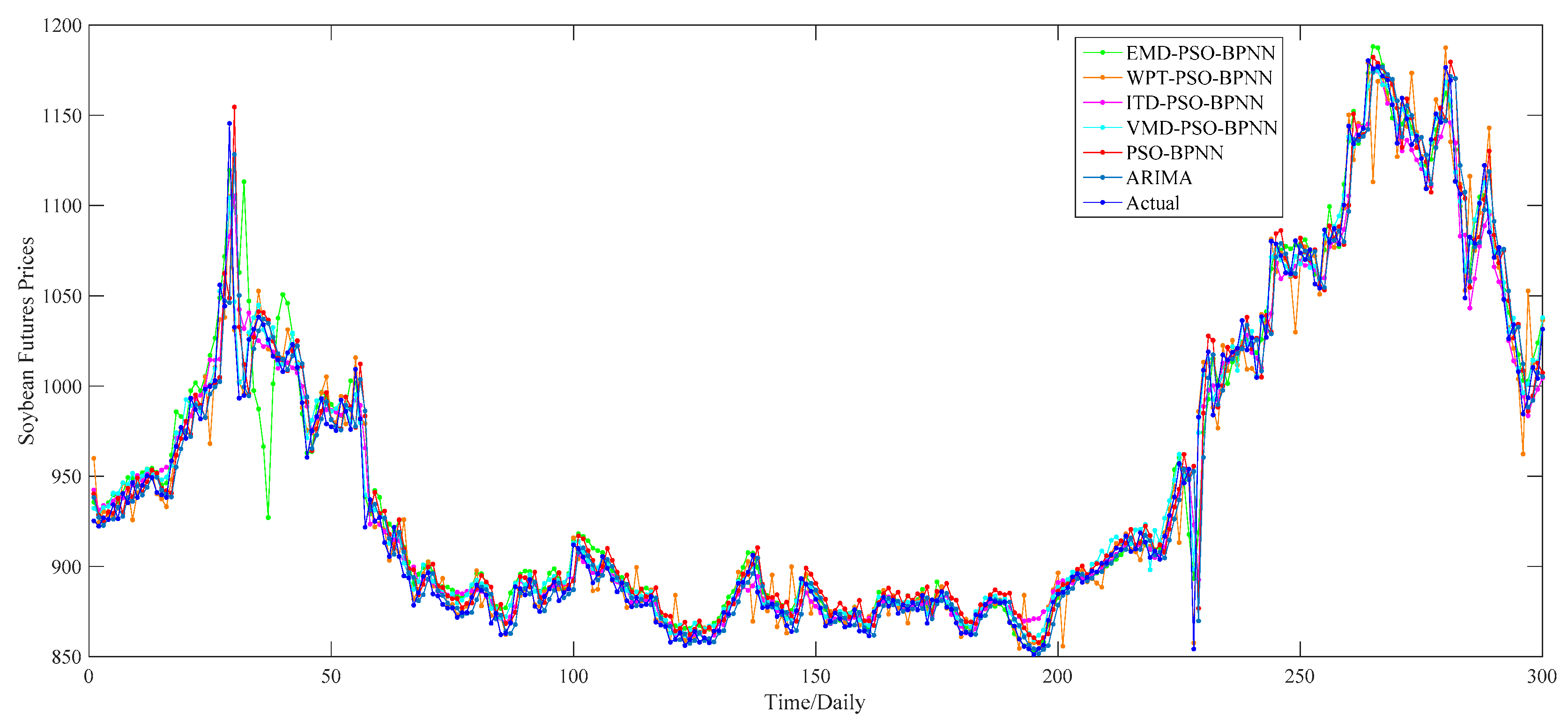
4.3. Case of Soybean Futures
Similarly, the EMD, WPT, ITD and VMD methods are applied to decompose the soybean futures prices in this subsection, whose decomposition results are given from
Figure 19,
Figure 20,
Figure 21 and
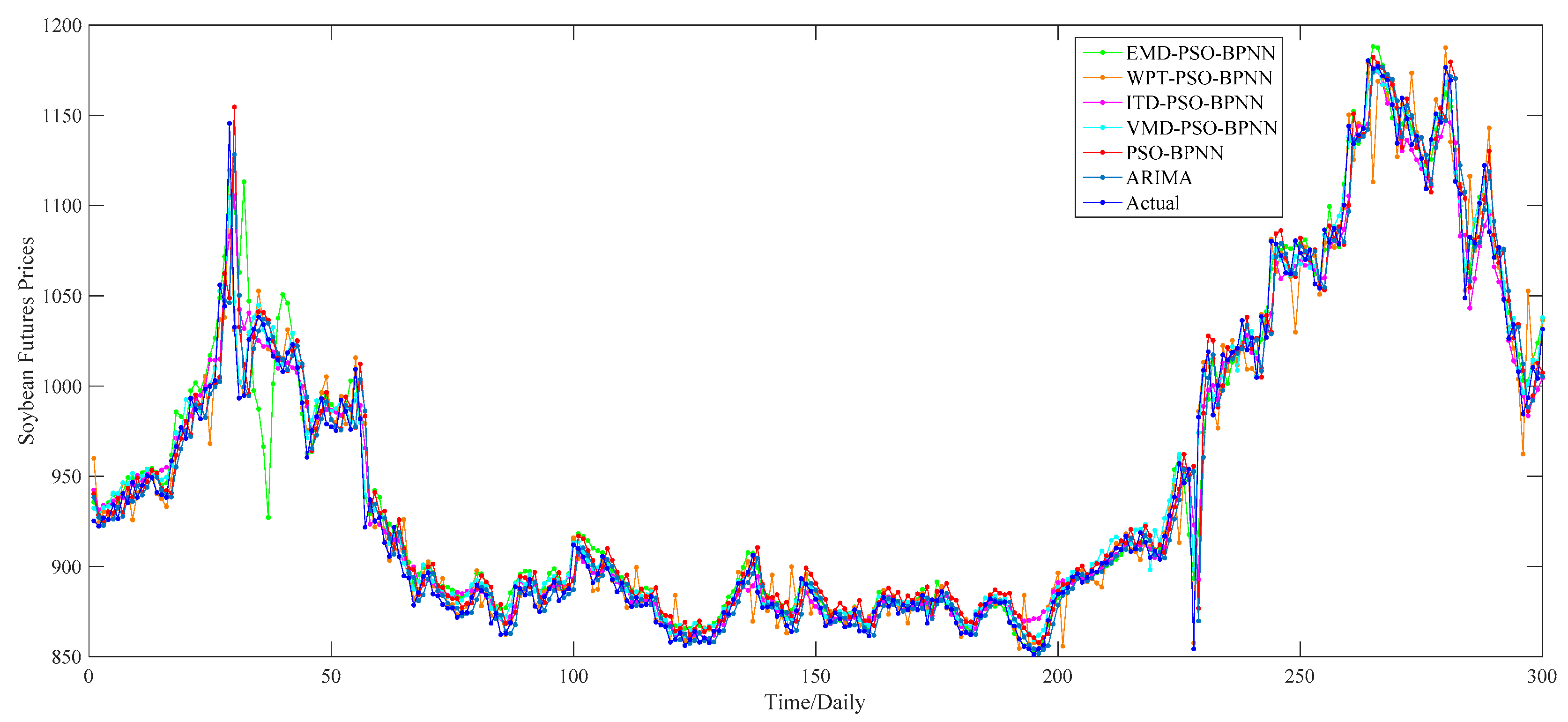
Figure 22, respectively. Based on the decomposition results, we use the four proposed “decomposition and ensemble” hybrid models to forecast the soybean futures prices during the period from 10 August 2010 to 29 July 2016, totally 300 values, regarding the PSO–BPNN model as the benchmark model and ARIMA model as the comparative model. The comparison of the one-day-ahead forecasting results is drawn as shown in
Figure 23 and
Figure 24 and
Table 5, respectively.
According to these figures and table, we can reach conclusions similar to the empirical research on the wheat and corn; i.e., that the VMD–PSO–BPNN model is still the best model to forecast the soybean futures prices among all models proposed in this paper. Based on the value of MAPE, the order of these six models, from big to small, is the PSO–BPNN model (1.20%), ARIMA model (1.11%), EMD–PSO–BPNN model (1.01%), ITD–PSO–BPNN model (0.91%), WPT–PSO–BPNN model (0.70%) and VMD–PSO–BPNN model (0.57%), which shows that hybrid models with decomposition methods, especially the VMD method, have obvious advantages in forecasting the soybean futures prices in contrast with the PSO–BPNN model and ARIMA model.
5. Conclusions
As the world’s leading and most diverse derivatives marketplace, CME Group’s wheat, corn and soybean futures prices are not only important reference prices of agricultural production and processing but also the authority of prices in the international trade of agricultural products, which can reflect the change trend of the corresponding agricultural products’ spot prices in advance to some extent. Thus, forecasting their prices is expected to be an effective method for controlling market risks and making appropriate and sustainable food grain policy for the government. However, current research pays little attention to forecasting food grain futures prices and does not take their nonlinear and nonstationary characteristics into account while making predictions. Based on the above consideration, we propose four hybrid models which combine the PSO–BPNN model with the EMD, WPT, ITD and VMD methods respectively, to forecast wheat, corn and soybean futures prices, which can enrich empirical research on agricultural commodity futures prices forecasting, to some extent.
According to our experimental results, three main conclusions are drawn as follows: (1) it has been proved that the VMD–PSO–BPNN model outperforms the EMD–PSO–BPNN model, WPT–PSO–BPNN model, ITD–PSO–BPNN model, PSO–BPNN model and ARIMA model in all study cases, in terms of three forecasting performance evaluation criteria, namely the MAE, RMSE and MAPE, which suggests that the proposed VMD–PSO–BPNN model has a high common adaptability and serviceability in forecasting the wheat, corn and soybean futures prices; (2) in all study cases, the forecasting performance of all four hybrid models with decomposition methods are superior to the performance of the PSO–BPNN model, which demonstrates that the EMD, WPT, ITD and VMD methods play an extremely significant role in improving the PSO–BPNN model’s forecasting performance of these futures prices; (3) after comparing the results of different “decomposition and ensemble” hybrid models, we find out that the prediction ability of VMD–PSO–BPNN model and WPT–PSO–BPNN model is much better than the ability of EMD–PSO–BPNN model and ITD–PSO–BPNN model, meaning that the VMD and WPT methods, especially the VMD method, are more suitable to be applied to analyzing the prices data of wheat, corn and soybean futures than other two approaches, namely the EMD and ITD.
Conclusively, based on the three evaluation criteria, four “decomposition and ensemble” hybrid models developed in this study perform better than the forecasting model without decomposition techniques, namely the PSO–BPNN model, with respect to the price forecasting of the wheat, corn and soybean futures, which provides a new promising research approach to forecasting prices of agricultural commodity futures.


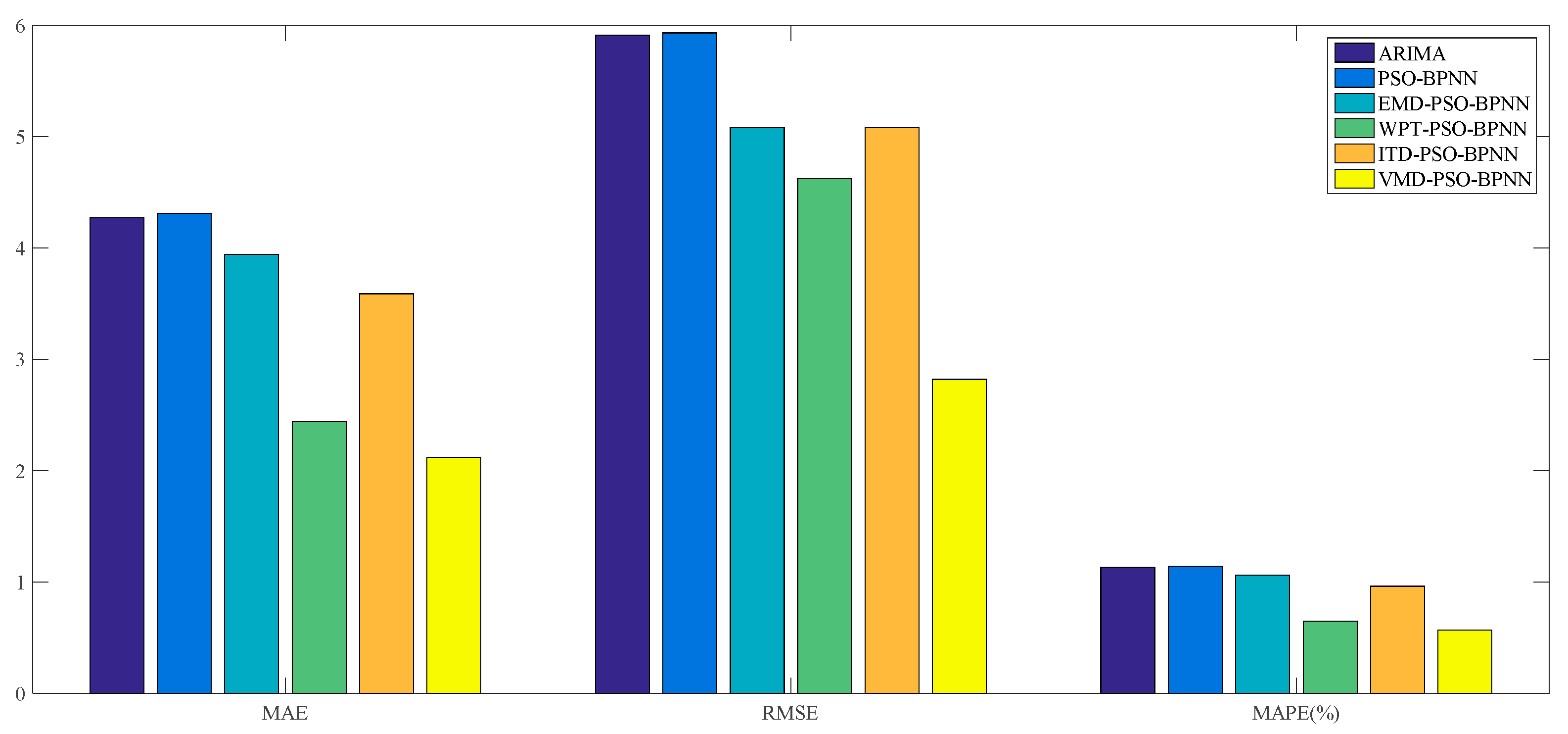



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
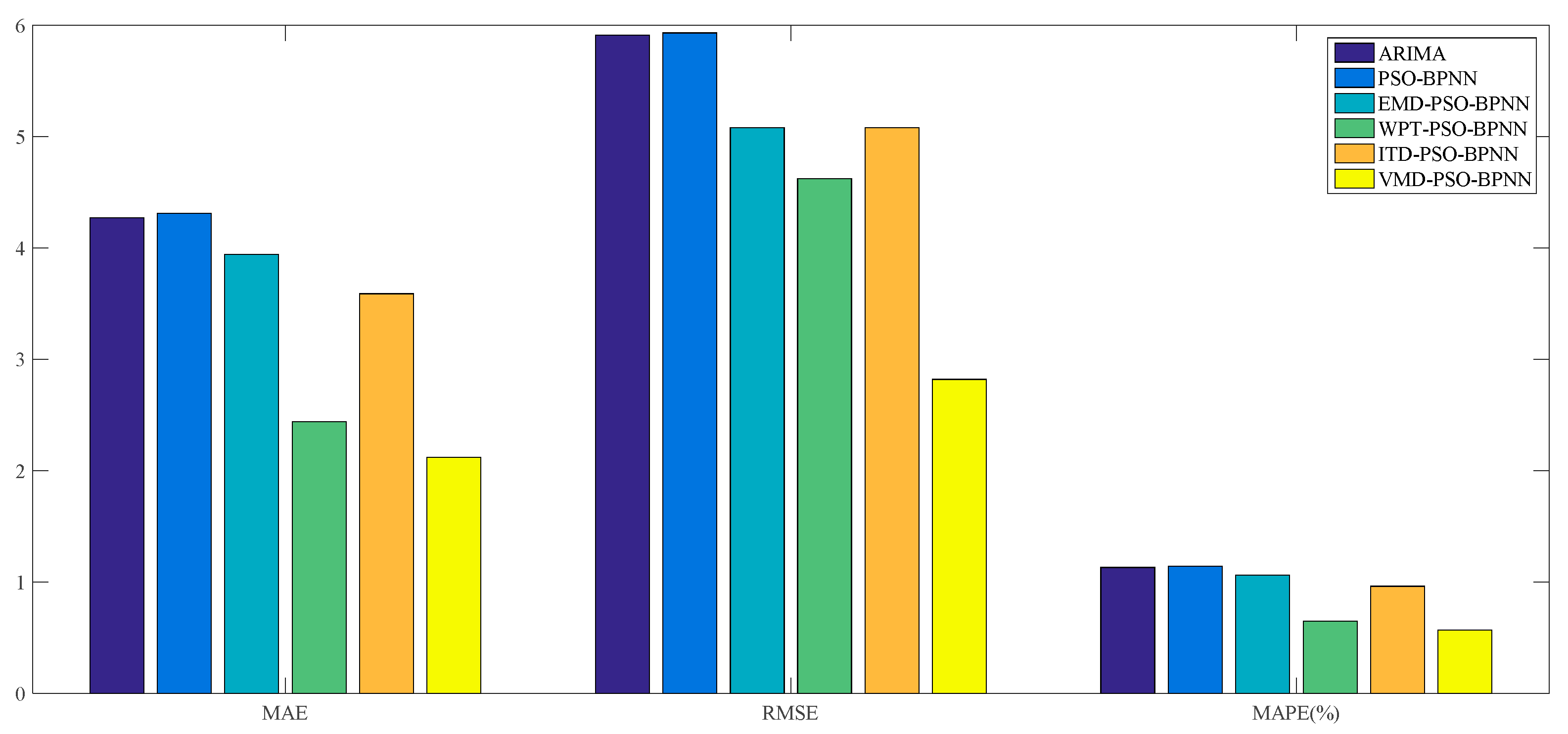{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
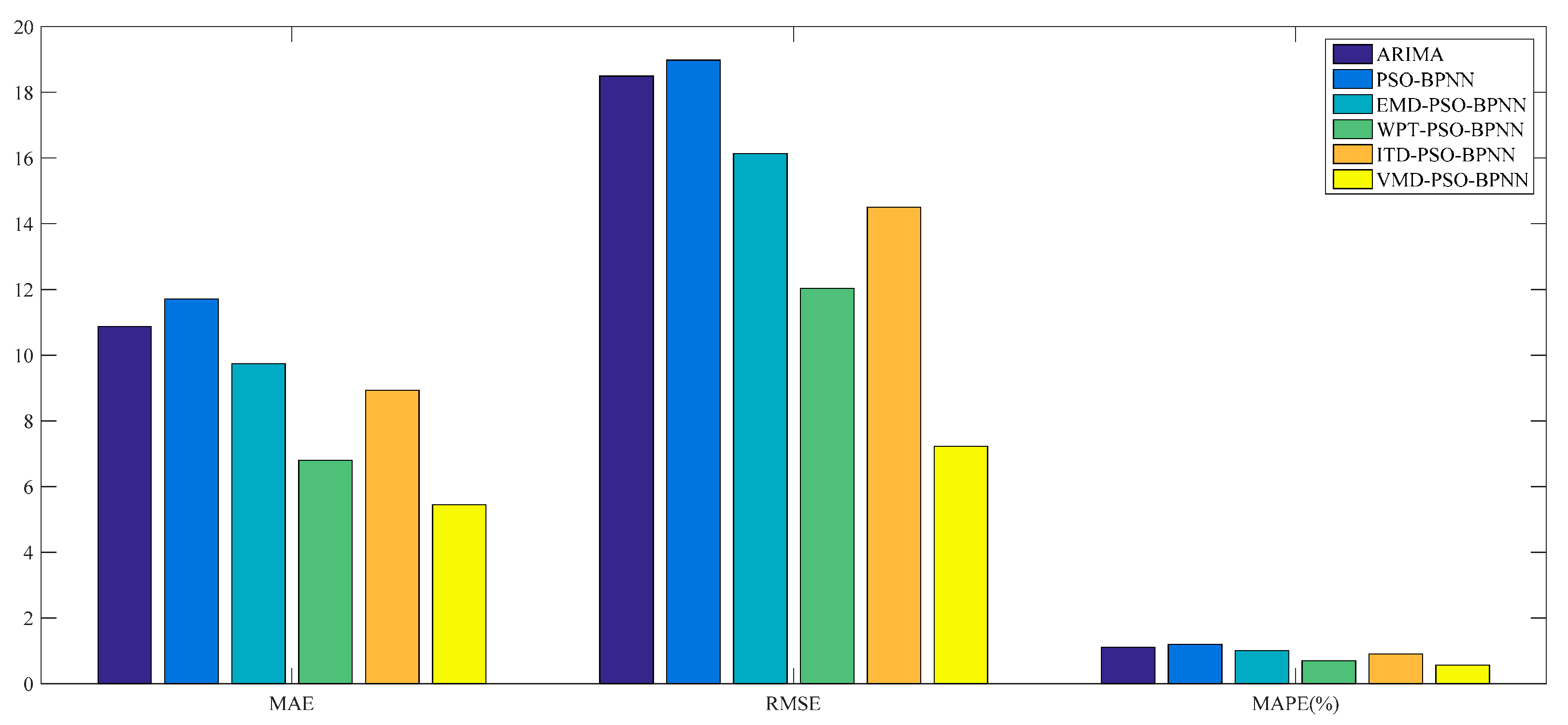{kind=link}