1. Introduction
Access control is a fundamental issue of any security system, and it is mainly devoted to checking the truthfulness of users’ claimed identity, in order to both verify personal access rights and support tracing and logging services. Access control implies authorization, and it strongly relies on identity analysis and authentication. Within a company structure, the requirements and rules that preside over the access control may differ with respect to different locations, expected actions, and functions of principals. Moreover, they can vary over time. The main focus of this paper is authentication (i.e., the process of confirming the identity of an entity), and its deployment in a real context within a company security system where it should be responsible for regulating the main access and the transit to the different zones inside the company itself.
Authentication involves the verification of the validity of at least one form of identification (e.g., documents, digital certificate, biometric identifiers, etc.). The most interesting approach for identity assessment falls into the category “checking something that the user is or does” as the factors of authentication, known as inherence factors. Examples of inherence factors are static or dynamic biometric parameters like face, fingerprint, iris, retinal pattern, signature, voice, etc. These biometric identifiers are distinctive and measurable characteristics which can be used to label and describe individuals in an almost unique way [
1]. There are several advantages in using biometrics: they cannot be lost or forgotten, and they require the person under recognition to be present at the check point. Additionally, it is difficult to forge them.
Each biometric has its strengths and weaknesses, and the choice depends on the application. No single biometric is expected to effectively meet the security requirements of all the applications, thus each biometric technique is admissible and there is no “optimal” biometric characteristic [
2]. The match between a specific biometric and an application is determined depending upon the operational mode of the application and the properties of the chosen biometric itself.
Biometrics can be either singularly or simultaneously used for identification. In [
3], a system that couples One-Time-Password technique with face recognition has been proposed. As there is no proof of correlation among the different biometric parameters of an individual, the combination of independent sources of information is very promising for the improvement of the quality of the recognition process. Multi-biometric systems are biometric systems that consolidate multiple sources of biometric evidence; the integration of evidence is known as fusion, and there are various levels of fusion, which can be divided into two broad categories: pre-classification (fusion before matching) and post-classification (fusion after matching) [
4,
5]. Depending on the nature of the sources, multi-biometric systems can also be classified into different categories; multi-sensor systems, multi-algorithm systems, multi-instance systems, multi-sample systems, multi-modal systems, and hybrid systems [
6].
Multi-modal biometric systems are more reliable than uni-modal systems due to the presence of multiple and independent pieces of evidence [
7]. They address the problem of non-universality, since multiple traits ensure sufficient population coverage and provide anti-spoofing measures by making it difficult for an intruder to simultaneously spoof different biometric traits of a legitimate user. A system can operate either in selection or checking mode. The former is an identification process: a person’s traits are acquired to establish the identity of the individual; it is a one-to-many search process in which the biometric characteristics set against all the database entries that represent enrolled users, in order to find those biometric references with a specific degree of similarity. The latter is about verification: a person’s traits are acquired in order to verify the claimed identity (e.g., a user name) of the unknown individual; it is a one-to-one comparison in which the submitted biometric characteristics set against a specified stored biometric reference and returns both the comparison score and the decision.
Both of these operational modes require an enrolment process where a subject presents her/his biometric characteristics to the sensors, in a controlled way, along with the non-biometric information, to form the user template. This subject information could be name, social security number, driver license’s number, etc. Therefore, biometric features from the captured sample and the non-biometric information are stored in the database of the “user templates”. It is clear that determining the “true” identity of an individual is beyond the scope of any biometric technology. Rather, biometric technology can only link a person to a biometric pattern and any identity data (e.g., name) and personal attributes (e.g., age, gender, profession, etc.) that were presented at the time of enrolment in the system [
8].
A challenge–response type of authentication can be strengthened using multi-modal biometric systems, ensuring that “live” users are indeed present at the point of data acquisition, since these systems ask them to present a particular and predefined subset of biometric traits [
9].
The problem of studying the best theoretical method to obtain an effective and efficient system for individuals’ authentication has been widely addressed: there is a huge number of possible solutions, each employing different required credentials, algorithms, and practical deployments [
2,
10]. Nevertheless, the goal of all these systems is to minimize (and possibly set to zero) the number of users who are impostors but manage to be authenticated, or who are enrolled users but are rejected. One of the main difficulties that all these attempts share, is at the level of the decision fusion, which is generally built into the actual code of the decision module. In this work, we aim to make explicit the knowledge and strategies about data fusion in the form of behavior, to be selectively activated according to the actual acquisition status, results, and available biometric traits. As we are considering an indoor application environment where all computing facilities are inside, and where there is quite a small number of enrolled users at a time, we are not concerned with the issues of confidentiality, integrity, and availability that can arise in more general situations [
11]. The setting of the decision thresholds in biometric algorithms usually pursues the balance between the false acceptance rate (FAR) and the false rejection rate (FRR). At the level of the system deployment, the balance between FAR and FRR can differ with respect to the various areas which the access control refers to, and it finally depends on the security requirements (usually stated in the Service Level Agreement at the design level). Hence, the system deployment can benefit from the customization of a kind of general template methodology according to the given security constraints [
12,
13].
2. Materials and Methods
As stated in the previous section, the goal of this project is the design of an adaptive biometric system for indoor access control and presence monitoring. This system should operate within the scope of a medium/large-sized company which needs to keep some areas restricted to particular employees, depending on their roles or responsibilities. Therefore, proper sensors are supposed to be placed at any check point and in every room or structure in which only authorized users are allowed.
The system is intended to handle several different situations:
different types of restricted areas have to be accessed by different types of user, depending on their role;
company employees should be given an easy way to access, since they have to get in and out at least twice a day (they are enrolled in a special database);
partners, suppliers, or auditors, provided with their own company device (thus known by the company) are submitted to an indirect authentication (e.g., having their template stored on their device and sending it to the company for the matching);
since the company is open to the public, clients are supposed to access only the reception area;
some employee is allowed to bring someone else in with them (the system is supposed to know who and where);
the system works autonomously, but proper human intervention is always possible.
The system is intended to operate both in verification and in identification mode. Furthermore, the system is required to guarantee the requirements of the Service Level Agreement (SLA) that affect the expected FAR and FRR values, depending on the different areas or rooms within the company.
In a multi-modal biometric system it is worth coupling non-invasive easy-to-use biometrics at lower accuracy together with more robust but expensive parameters, which can intervene whenever a higher degree of confidence is required. Face and iris recognitions have been chosen for the proposed system.
The face identifier has been chosen because face recognition is a non-intrusive method of authentication and also requires minimum cooperation from the subject. Moreover, face matching is typically fast, even if it may be not very accurate. One popular approach to face recognition is based on the location, dimensions, and proportions of facial attributes such as eyes, eyebrows, nose, lips, and chin and their spatial relationships. The dimensions, proportions, and physical attributes of a person’s face tend to univocally distinguish a single person with good enough confidence. Another approach that is widely used is based on the overall analysis of the face image that represents the face as a weighted combination of a number of canonical faces [
14]. Face recognition involves two major tasks: face location and face recognition. Face location is the determination of the location of the face in the input image. Recognizing the located face means that the face is recognized from a general viewpoint (i.e., from any pose). It is worth mentioning that face recognition can be in a static controlled environment where the used is asked for some degree of cooperation, or in a dynamic uncontrolled environment where the user can be completely unaware of being under analysis [
15]. The visual texture of the iris is formed during fetal development, and stabilizes during the first two years of life. The complex iris texture carries very distinctive information that is useful for personal recognition of high accuracy. Besides, it is extremely difficult to surgically tamper with the texture of the iris and it is rather easy to detect artificial irises (e.g., designer contact lenses) [
5,
16]. Iris recognition is more accurate, but also more invasive because the user has to be very cooperative and the overall acquisition time (pose time plus true acquisition time) can be quite high.
An interesting approach which can be used for face recognition is the Pyramid Match Kernel [
17], whici is based on a fast kernel function which maps unordered feature sets to multi-resolution histograms and computes a weighted histogram intersection in this space. Other methods for implementing face recognition are: the eigenface method using principal component analysis (PCA), which is based on the idea that a high-dimensional dataset is often described by correlated variables and therefore only a few meaningful dimensions account for most of the information; the PCA method finds the directions with the greatest variance in the data, called principal components. The Fisherfaces method uses linear discriminant analysis (LDA), which performs a class-specific dimensionality reduction; in order to find the combination of features that separates best between classes, it maximizes the ratio of between-classes to within-classes scatter [
18]. The chosen methodology is the Local Binary Patterns (LBP). It is based on the extraction of local features from images; the basic idea is to summarize the local structure in an image by comparing each pixel with its neighbourhood. Then, the LBP image is divided into local regions and a histogram is extracted from each one. Finally, the spatially-enhanced feature vector (called Local Binary Patterns Histograms (LBPH) [
18]) is obtained by concatenating all the local histograms. The application of facial recognition is expected to happen in a dynamic but somehow controlled environment in which a person who wants to be authenticated has to walk along a hallway following an ordered queue so that the sensor can easily detect whether a face is present in the acquired image and locate it.
Daughman’s method has been chosen for iris recognition. It consists of several phases: segmentation (i.e., the location of the iris in the eye image), normalization with the Daugman’s Rubber Sheet Model, encoding with the Log-Gabor wavelet and matching using the Hamming Distance [
19].
A previous work involving face and iris for identity verification is described in [
20]. These two biometric traits are combined using two different fusion strategies: the former is based on the computation of either an unweighted or weighted sum and the comparison of the result to a threshold, the latter considers the matching distances of face and iris classifiers as a two-dimensional feature vector and it uses a classifier, such as Fisher’s discriminant analysis and a neural network with radial basis function (RBFNN), to classify the vector as being genuine or an impostor.
A convenient mode in which a multi-modal system can operate is the serial mode: it means that the two biometric characteristics do not have to be acquired simultaneously and that a decision could be arrived at without acquiring all the traits. This last aspect is very important, especially for those applications where there are time constraints, because it leads to a reduction of the overall recognition time.
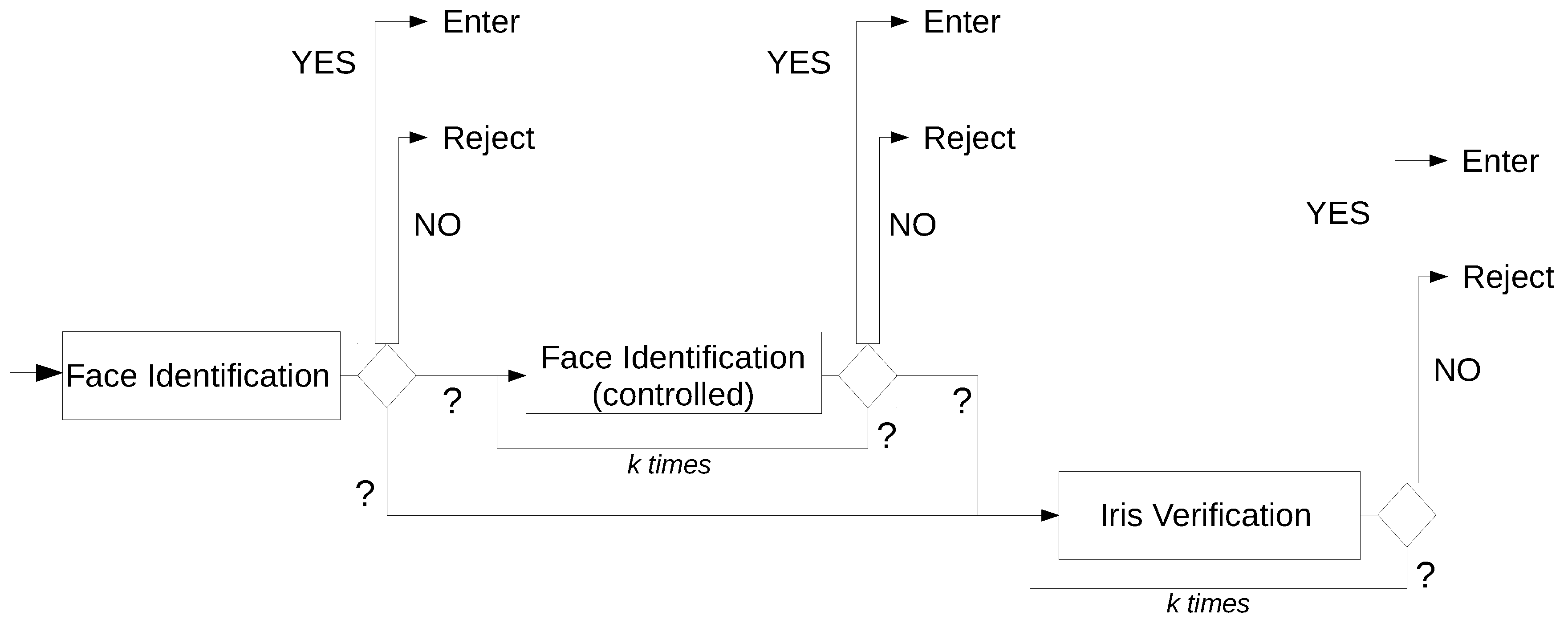
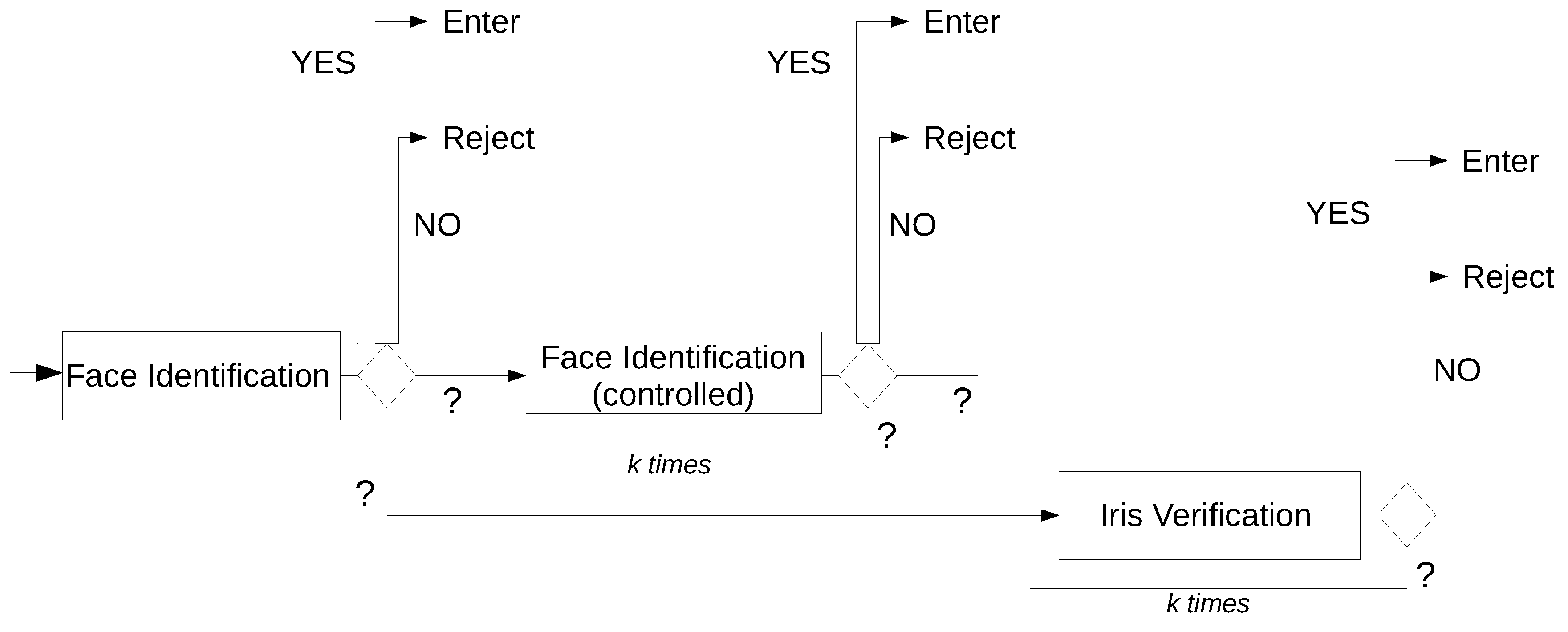
The proposed multi-modal biometric system relies on two different modules: the module for face identification and the module for iris verification. The fusion methodology adopted at the decision level is a post-classification method, and it follows the OR rule; i.e., it is sufficient that only a biometric trait is recognized as genuine to lead to a positive final decision. This serial matching approach gives the possibility of not acquiring all the traits; for example, only face recognition is considered if the information collected at the first module is believed to be enough to determine if a user is genuine or an impostor.
The system consists of several different submodules, each of them providing its own functionality. There are two sensor modules for face and iris acquisition, which capture the raw biometric data. In the feature extraction modules, the acquired data is processed to extract a set of salient and discriminatory features. In the matcher modules, the extracted features are compared against the stored templates, providing a matching score. These last modules encapsulate the decision making modules, which can operate either in verification or identification mode. Moreover, there is the system database module, which stores the biometric templates of the enrolled users.
The system is intended to be adaptive; this means that it does not have a fixed and predefined behaviour, but its working flow depends on the response of the actual recognition process. Such a response depends on the values of evidence from the single decision modules, the number of previous attempts that did not result in a clear decision, and the evaluation of the quality of the acquisition set-up (lighting, focus, occlusions, and so on).
From a numeric value (generally normalized between 0 and 1) that represents the confidence of the matching, each decision module is given three possible different outputs {
YES,
NO,
MAYBE (?)}, depending on the comparison of that value with some predefined thresholds that divide the interval [0,1] in different sub-intervals (see
Figure 1). A decision module outputs the
YES value if the obtained score is within the interval [0,
] and the user is recognized as one of the enrolled users (in identification mode) or their claimed identity has been confirmed (in verification mode). The output value
NO is produced if the obtained score is within the interval [
, 1] and the user is rejected as if they were impostors. The output value
MAYBE (?) results any time the obtained score is within the interval (
,
) and the decision module is not able to make a final decision with a sufficient degree of confidence.
The MAYBE (?) value calls for further processing. From a general point of view, there are two main general choices, which involve either the repetition of the identification with a new acquisition of the same biometric, or passing to the analysis of a different biometric. Within the serial paradigm underlining the proposed system, an unsolvable uncontrolled face identification can reasonably be followed by a controlled face identification any time the degree of uncertainty is not very high. This means that if a user obtains an output score that is similar to a genuine user’s score (but not similar enough), she/he is asked to try the face identification again, augmenting her/his cooperation during data acquisition, because face processing is always faster and less invasive than iris verification. Conversely, if the obtained score is nearer to the NO interval, the user is asked to submit to iris verification in order to keep a high degree of accuracy in the overall recognition performance.
If the unsolvable matching comes from a controlled face identification, it is worth repeating the same process instead of immediately proceeding to iris verification. The number of repetitions can depend on the quality of the resulting matching.
Figure 2 represents the general template of the system flow: the choices are ruled by a special threshold:
, usually set in the middle of the
MAYBE interval, as shown in
Figure 1. Therefore, there are several different ways of working. For example, a user can be immediately identified and authenticated using their face as they approach the entrance; or they can be asked to repeat the face acquisition in a more controlled way; they can be asked to get closer and the authentication mode can be switched to the verification mode using the iris; again, this last phase can be repeated.
Formally, the system works according to some deductive rules which the decision making modules are based on and which represent response behaviors, according to the set-up and status of the acquisition point, the consequent quality of the acquired data, and the actual level of cooperation of the subjects. The effect of those rules strongly depends on the chosen values of the thresholds
,
, and
that must always comply with the constraints shown in
Figure 1.
The following list shows those rules and their effect on the system working flow:
require a controlled face identification if MAYBE is the result of the uncontrolled face identification and the obtained score is in the interval [, ];
require a controlled face identification if MAYBE is the result of the (previous) controlled face identification and the obtained score is in the interval [, ] and the limit of max k repetition has not been reached;
require iris verification if MAYBE is the result of the uncontrolled face identification and the obtained score is in the interval [, ];
require iris verification if MAYBE is the result of the (previous) controlled face identifications and the obtained score is in the interval [, ];
require iris verification if MAYBE is the result of the (previous) iris verifications and the limit of max k repetition has not been reached;
ask for human intervention if NO is the result;
ask for human intervention if the limit of k repetitions has been reached.
The number of repetitions k can be arbitrarily set by the programmer, and human supervision is always permitted.


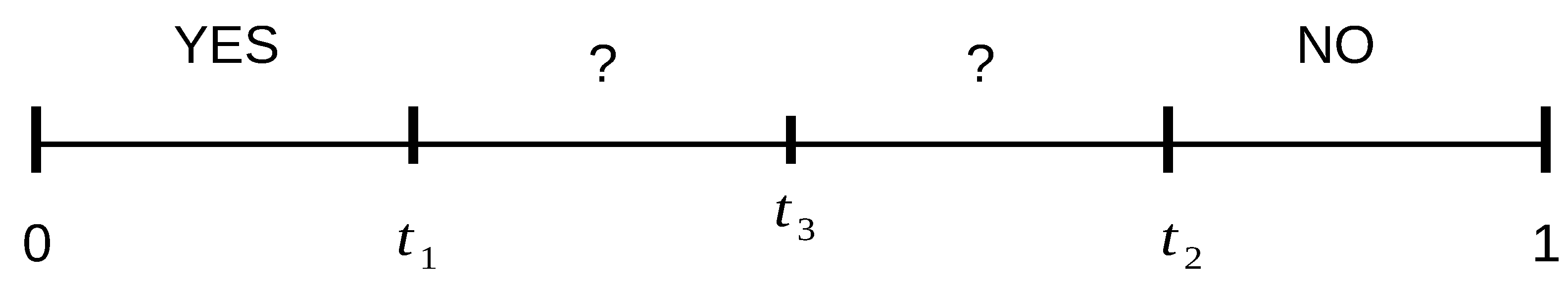
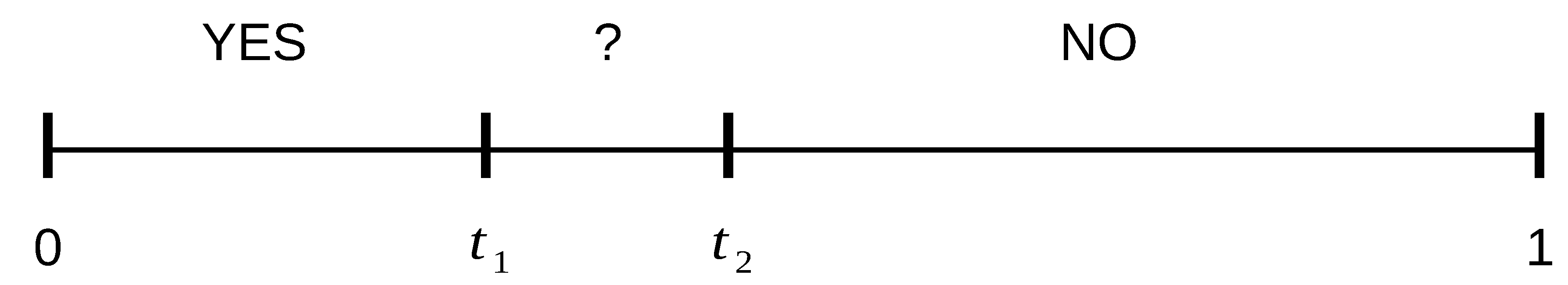

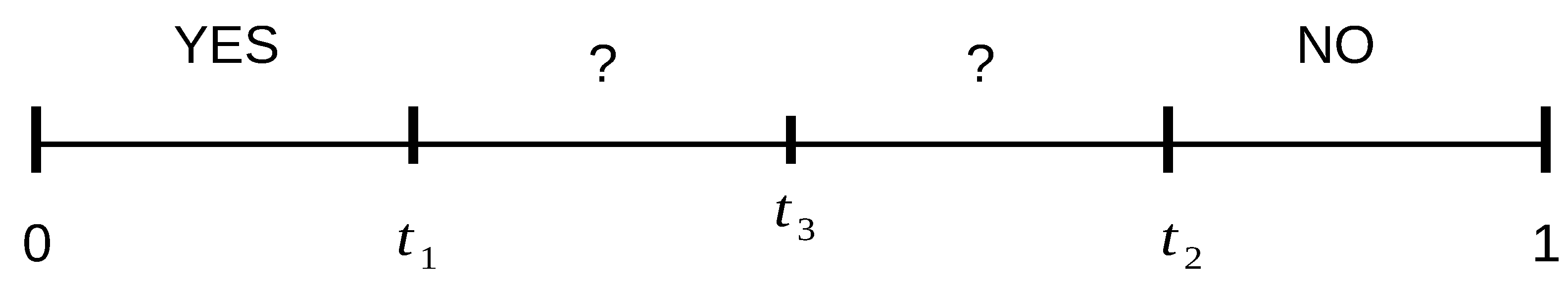{kind=link}
{kind=link}
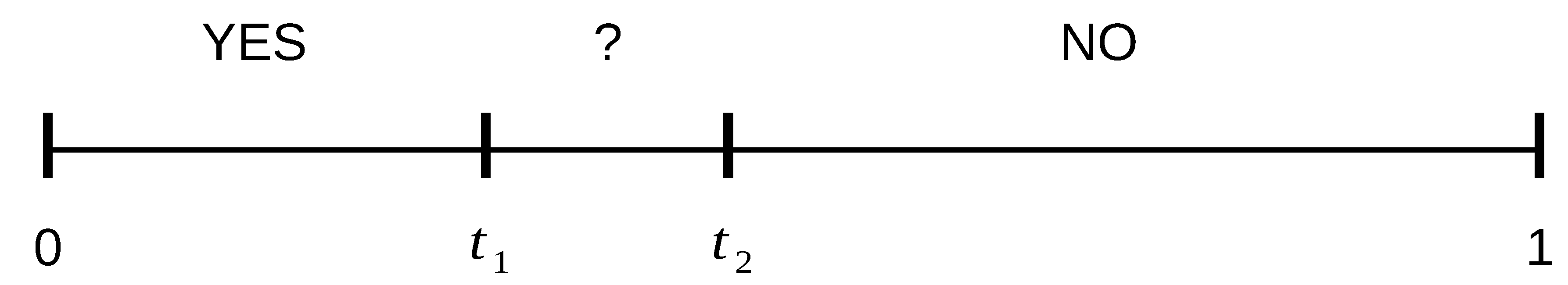{kind=link}