1. Introduction
The amount of the stored text has been rapidly growing in last two decades together with the Internet boom. Web search engines are nowadays facing the problem how to efficiently index tens of billions web pages and how to handle hundreds of millions of search queries per day [
1]. Apart from the web textual content, there still exist many other systems working with large amounts of text, i.e., systems storing e-mail records, application records, scientific papers, literary works or congressional records. All these systems represent gigabytes of textual information that need to be efficiently stored and repeatedly searched and presented to the user in a very short response time. Compressing became necessary for all these systems. Despite of the technology progress leading to a cheaper and larger data storage, the data compression provides benefits beyond doubt. Appropriate compression algorithms significantly reduce the necessary space and so more data can be cached in a faster memory level closer to processor (L1/L2/L3 cache or RAM). Thus, the compression brings also an improvement in processing speed.
Nowadays, all modern web search engines such as
Google,
Bing and
Yahoo present their results that contain the title, URL of the web page and sometimes link to a cached version of the document. Furthermore, the title is usually accompanied by one or more
snippets that are responsible for giving a short summary of the page to the user. Snippets are short fragments of text extracted from the document content [
1]. They can be static (the few first sentences of the document) or
query-biased [
2], which means that single sentences of the snippet are selectively chosen with regard to the query terms. This situation requires not only fast searching for the query terms but also fast and random decompression of single parts of the stored document.
The inverted index became de-facto standard widely used in web search engines. Its usage is natural since it mimics a standard index used in literature (usually summarizing important terms at the end of a book). The inverted index was natural choice since early beginnings of the Information Retrieval [
3,
4] (for a detailed overview see [
5]). Compressing inverted lists (
IL) is a challenge since the beginning of their usage. It is usually based on integer compressing methods, most typically Golomb code [
6], Elias codes [
7], Rice code [
8] or Variable byte codes [
9,
10]. The positional (word-level) index was explored by Choueka et al. in [
11]. Word positions are very costly to store, however, they are indispensable for
phrase querying,
positional ranking functions or
proximity searching.
Sixteen years ago, a concept of the
compressed self-index first appeared in [
12]. This concept is defined as a compressed index that in addition to search functionality, contains enough information to efficiently reproduce any substring. Thus, the self-index can replace the text itself. The compressed self-index was proposed as a follower of classical string indexes: suffix trees and suffix arrays. However, after a few years of research, self-indexes successfully penetrated into other rather specific disciplines:
biological sequence compression [
13,
14] and
web searching [
15,
16]. Ferragina and Manzini tested the self-index on raw web content [
15] and they reported that self-indexes were still in their infancy and they suffer from their large size. Reported decompression speed was also rather poor, however, using “back of the envelope” calculation (The normalized speed is computed by multiplying the measured decompression speed by a factor
where
P is the average size of a page/file and
B is the size of the block used in compression.) the decompression speed became equal to the block-based compressors. Arroyuelo et al. [
16] compared the
Byte-oriented Huffman Wavelet Tree with the positional inverted index and with the non-positional inverted index together with the compressed text. The self-index stayed behind in query time in comparison to positional inverted index and in index size in comparison to non-positional inverted index. Finally, Fariña et al. presented their word-based self-indexes in [
17]. Their
WCSA and
WSSA indexes work approximately at the same level of efficiency and effectiveness as the compared block addressing positional inverted index in bag-of-words search. However, the presented self-indexes are superior in phrase querying. For a very compact and exhaustive description of the compressed self-indexes, see [
18].
Ferragina and Manzini [
15] report that the compressed positional
ILs are paradoxically larger than the compressed document itself, although they preserve less information than the document. They report a need for better compression of integer sequences. We have chosen a different approach—to amortize the size of the compressed
ILs and to reuse the positional information to store the text itself. Disregarding
stemming,
stopping and
case folding, the positional inverted index represents the same information as the document itself. The only difference is in the structure of the information: (i) for the document, we know a word occurring at some position in the document, we know its neighbours but we do not know its next occurrence until we scan all the following words between the current and the next occurrence of the word; (ii) similarly for the inverted list, we know a word occurring at some position in
IL, we know its previous and its next occurrence, however, it is not known its neighbouring word in the text until we scan possibly all
ILs of the positional inverted index. Considering the second case and the
gap encoding for the
ILs, we have realized that after permeation of single
ILs, we obtain analogous sequence of pointers/integers as in the case of the compressed document using some word-based substitution compression method. The only difference is that pointers do not point to vocabulary entries, however, to a previous occurrence of the same word in the sequence of integers (the pointer is represented by the encoded gap).
Our Positional Inverted Self-Index (
PISI) brings the following contributions. It exploits the extremely high search speed of the traditional positional inverted index [
11]. Searching for a single word, the resulting time depends only on the number of occurrences of the word. The text is composed as a sequence of pointers (pointing to the next occurrence of a given word). The pointers are encoded using the byte coding [
19]. It implies that the search algorithm can easily and fast decompress the pointers and traverse all the occurrences by simple jumping the sequence of the pointers. Furthermore, it applies the idea of self-indexing which means that the indexed text is stored together with the index. Thus, the necessary space is significantly reduced and the achieved compression ratio is lower. All the word forms and the separators are stored in the separated presentation layer proposed in [
17].
PISI provides another appreciable property. It is based on the time-proven concept of the inverted indexing that is well known and widely tested in the field of the Information Retrieval. Furthermore,
PISI can be easily incorporated into some existing document-level search algorithm and shift its search capability to the level of single words and their positions in the document.
3. Positional Inverted Self-Index
We address a scenario that is typical for web search engines or for other
IR systems [
15]. The necessary data structures of the system are distributed among internal RAM memory of many interconnected servers. The used data structures must provide extremely fast search performance across the whole data collection and still allow decompression of individual documents of the collection.
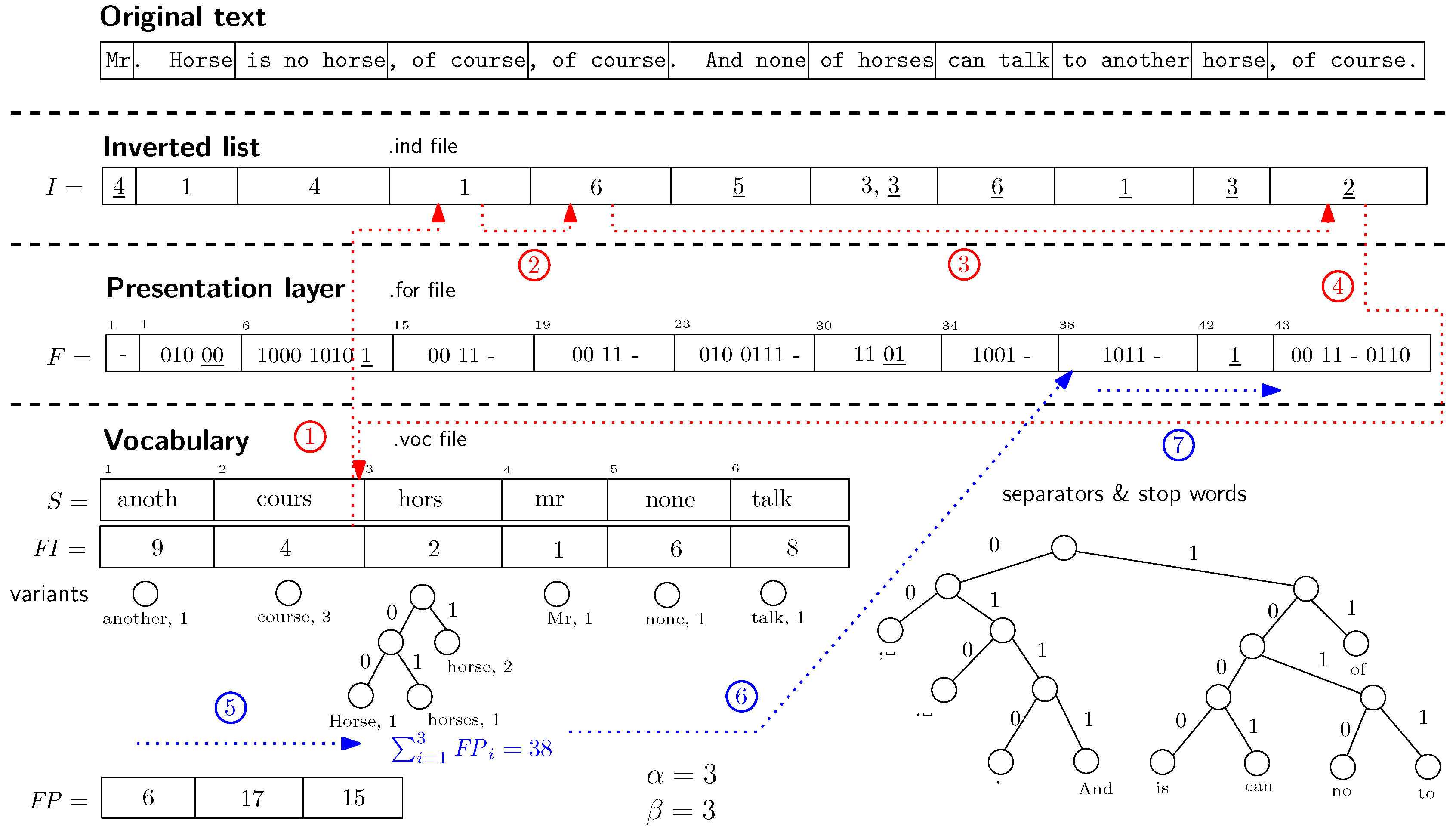
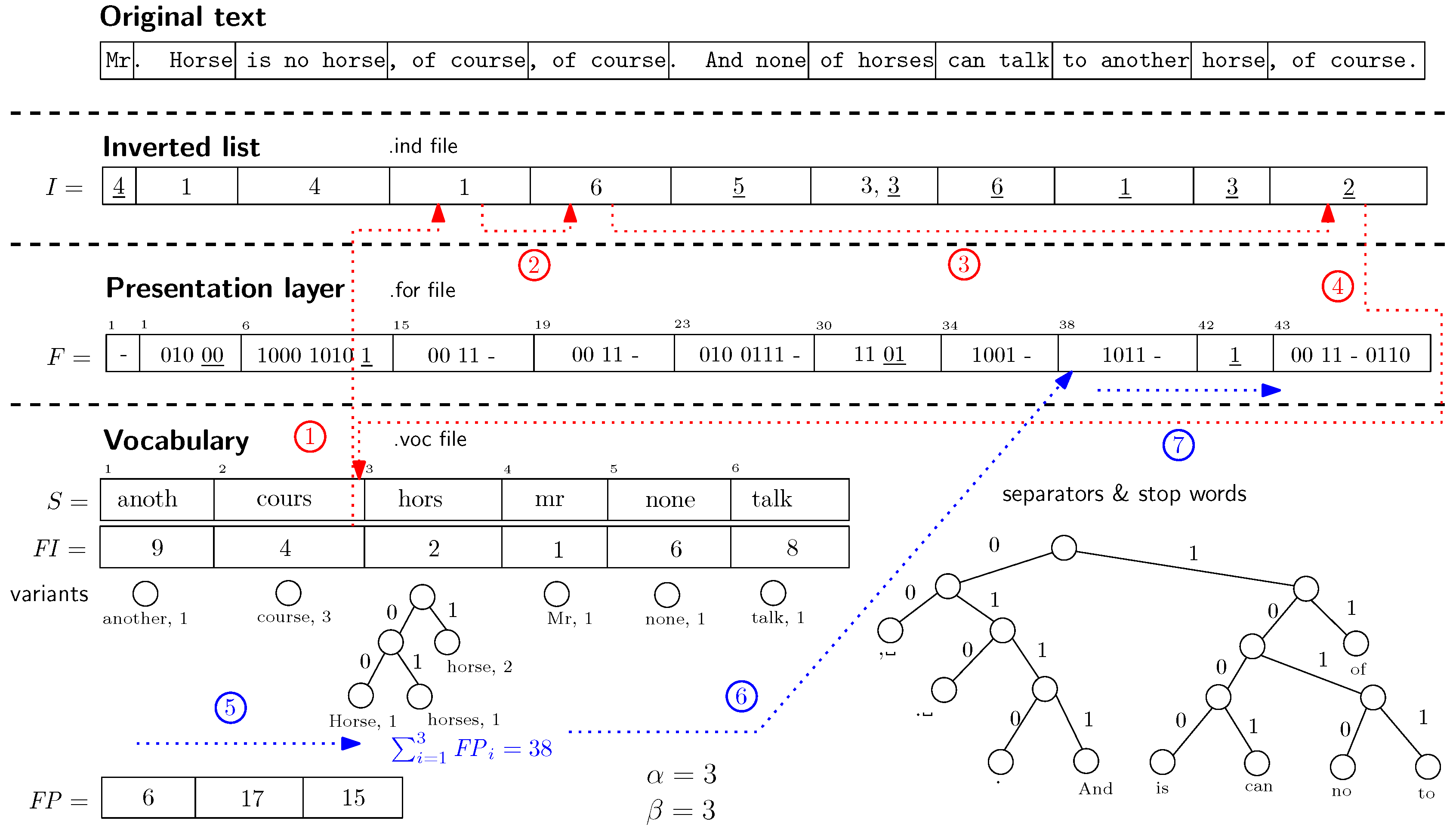
Our proposed data structure
Positional Inverted Self-Index (
PISI) is depicted in
Figure 1. The basic idea behind
PISI is to interleave the inverted lists of single terms. The inverted lists are stored as the offsets between word positions (using gap encoding). Suppose we store the offsets in the form of an arbitrary byte code. Single inverted lists can be transformed into a sequence of pointers where one occurrence points to the next one (using the offset in terms of a vector of all word positions in the processed file). Once the inverted lists are interleaved, we obtain a data structure that provides: (i) a very fast access to the sequences of single terms; (ii) a vector of all terms occurring in the processed file that can replace the file itself; (iii) the notion of a left-hand neighbour and the right-hand neighbour for each of the terms in the processed file.
The interleaved inverted list now represents the vector of term positions where a pointer at every position points to the next occurrence of the same term instead of the term position in the vocabulary. However, during the decompression process it is necessary to determine a certain word in the vector in a reasonable time. PISI inverted list (see array I) is equipped with so-called back pointers that point to the vocabulary position of the term. The period of the back pointers α represents clearly the trade-off between the size of the inverted list and the decompression speed and it means that exactly every α-th occurrence is followed by a back pointer. Finally, the last occurrence of the given term is followed by a back pointer as well.
PISI naturally undergoes all the following procedures during the construction phase. The indexed text is case folded (all letters are reduced to lower case), stopped (so-called stop words are omitted) and stemmed (all words are reduced to their stems using Porter stemming algorithm [
21]).
PISI uses its presentation layer (proposed by Fariña et al. [
17]) to store the information lost during the aforementioned procedures. The presentation layer (see the array
F) contains one (possibly empty) entry for every word of the inverted list. The entry is composed of the Huffman codes of all non-alphanumeric words and all stop words preceding the corresponding word. The entry is terminated by the Huffman code of a variant of the word (the underscored bits in the array
F). The presentation layer needs to be synchronized with the inverted list (array
I).
PISI stores a pointer to the presentation layer for every
β-th word position in the inverted list. The pointers are stored as the offset from the previous pointer in the array
. For
,
PISI stores the pointer for: 3rd, 6th and 9th position in the inverted list. These positions are: 6, 23 and 38. Thus, the stored offsets are: 6, 17 and 15. Furthermore, the vocabulary stores the textual representation of the stems, their word variants and the corresponding Huffman trees used for encoding of these variants. For the stems with just one variant, no Huffman tree needs to be stored and the variant is not encoded in the presentation layer either. The vocabulary also stores the common Huffman tree
that is used to encode the non-alphanumeric words and the stop words. The next component of the vocabulary is the array
storing the first word positions (in the array
I) of the corresponding words in the vocabulary.
Example 1. The dotted lines in Figure 1 describe an example of PISI search procedure. Suppose we search for the term course. First, we apply stemming on the searched term and obtain the stem cours. Next, we look for the stem in the sorted vocabulary. Once the stem is found, the algorithm starts to scan the inverted list at position (see line ①
). The algorithm jumps over the following occurrences (see lines ②
and ③
). Finally, the last occurrence stores a back pointer to the vocabulary (line ④
). The next steps depicted in Figure 1 are described also as procedure getFPointer in Algorithm 1. Suppose we want to decompress the neighbourhood of the last occurrence of the stem cours at position 11 in the inverted list. It is necessary to synchronize the presentation layer with the occurrence in the inverted list. The previous synchronization point is at position . The algorithm sums up the offsets stored in array and it starts at position in presentation layer that corresponds to the 9-th entry (see lines ⑤
and ⑥
). Finally, the algorithm performs decompression of the entries preceding the desired 11-th entry (line ⑦
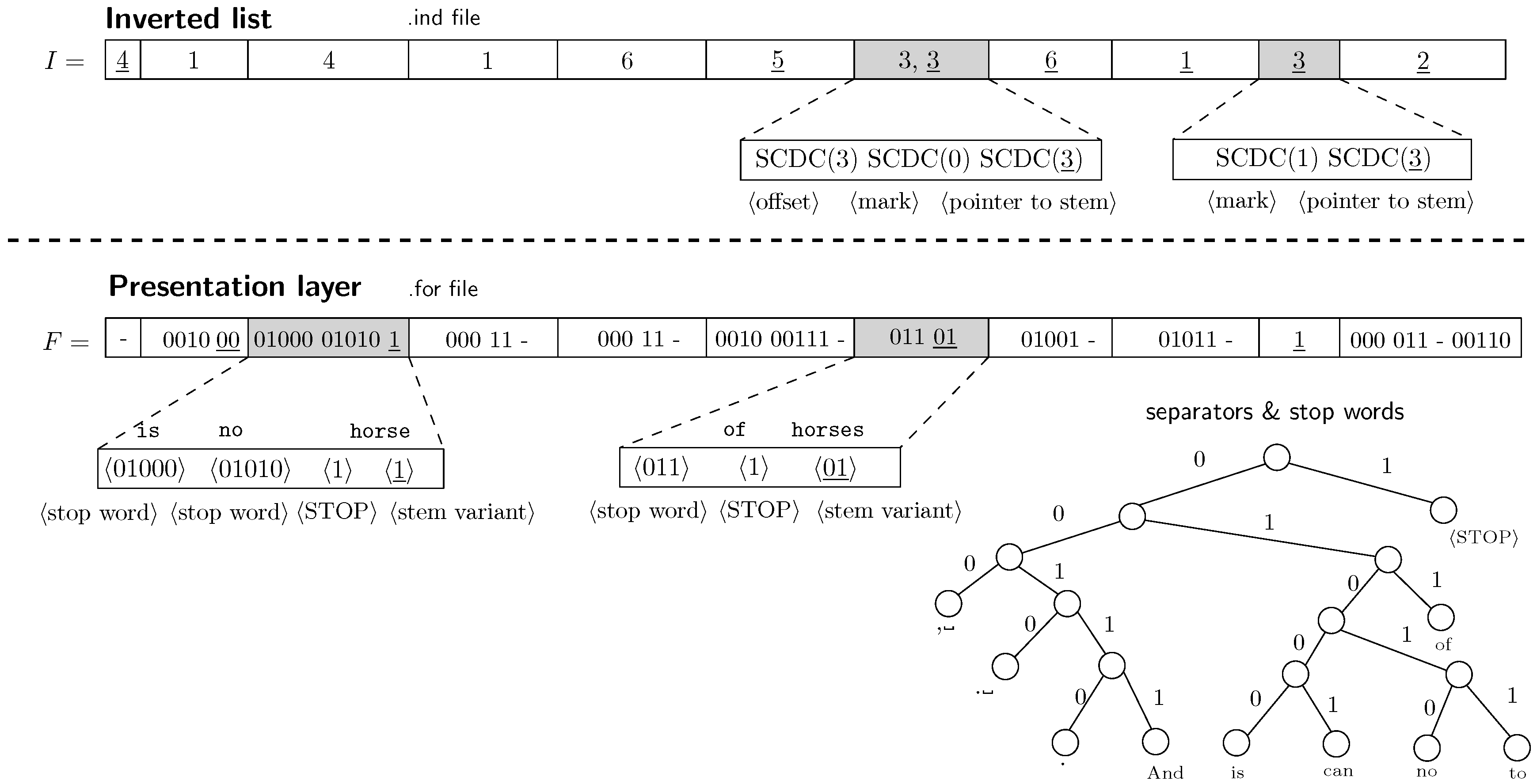
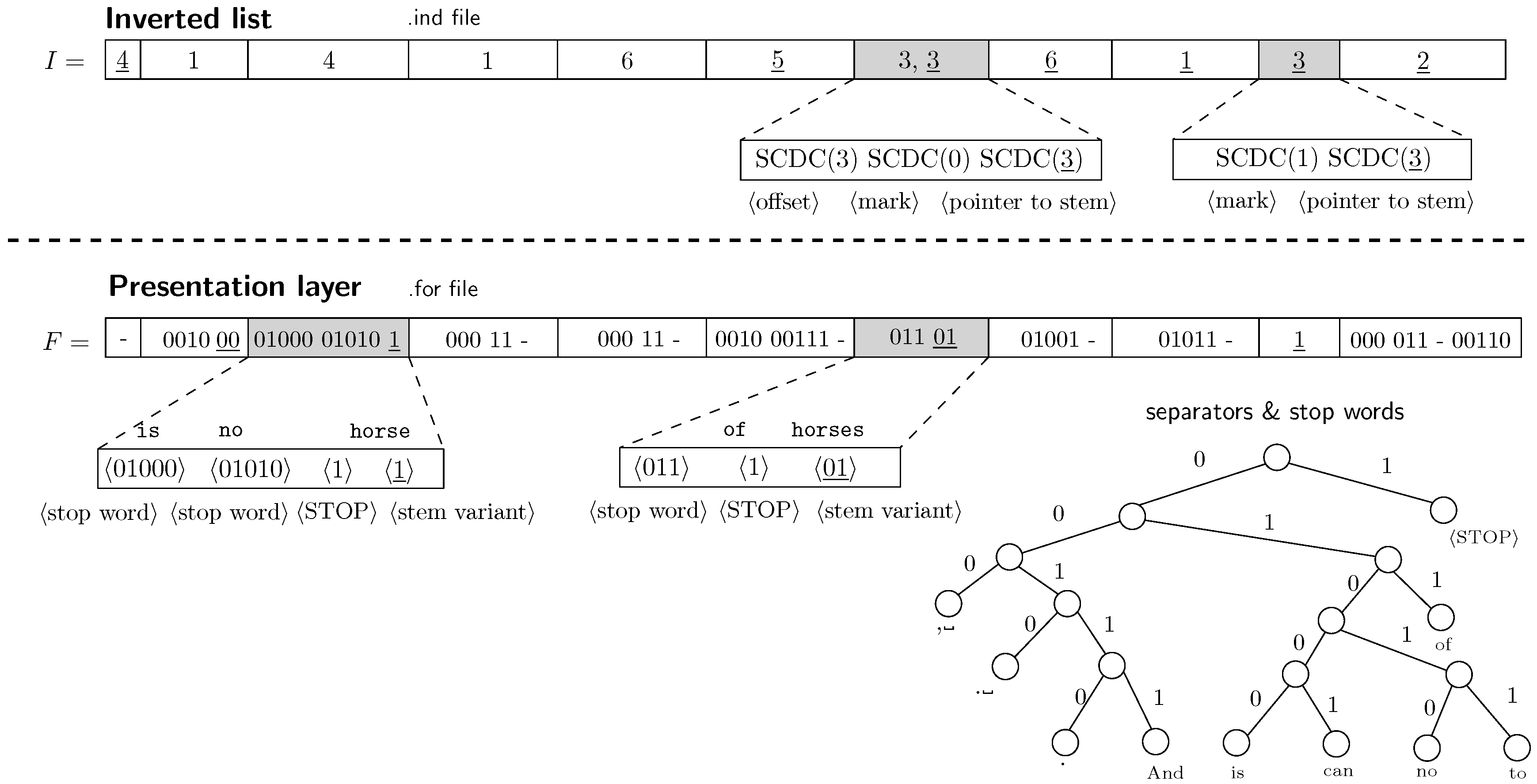
). The entry decompression is basically composed of two steps. First, looking for the stem back pointer. Second, decompression of separators and the stem variant. Figure 2 depicts details of encoding process of the inverted list and the presentation layer. In the inverted list, we need to precede every back pointer by some reserved byte.
PISI uses byte
for every
α-th occurrence that is not the last, and byte
for the last occurrence in the sequence. The byte
is preceded by a pointer to the next occurrence in the inverted list 〈offset〉 and followed by a back pointer to the vocabulary 〈pointer to stem〉. The byte
is followed only by the back pointer. In the presentation layer, it is necessary to mark the end of the sequence of non-alphanumeric words and stop words.
PISI uses a reserved word 〈STOP〉 that obtains the shortest Huffman code in the tree
.
PISI works in so-called
spaceless word model that expects the single space character ␣ as a default separator.
PISI inverted list is encoded using a byte code, particularly
SCDC [
19]. For the sake of efficiency, it is practical to store byte instead of word position offsets in the inverted list. The word position offsets (presented in
Figure 1 and
Figure 2) can be easily transformed into the byte offsets. This small change means only a negligible loss in compression ratio, however, it enables fast traversal of the inverted list of a chosen term without the need of previous preprocessing. This traversal is theoretically (not concerning the memory hierarchy of the computer) of the same speed as in the case of the standard positional inverted index.
Before we give a formal definition of PISI data structure we need to introduce some other concepts. Suppose an input text T composed of single words. T is transformed into using stemming, stopping and case folding. Thus, is a vector of length N composed of single stems extracted from T. The function returns the number of occurrences of the stem s in the vector up to the position i. The function returns the position of the i-th occurrence of the stem s in the vector and it returns 0 if there is no such a occurrence. The function returns the length of the byte code used to encode elements of the vector I up to the position i. Now we can formally define the most important parts of PISI data structure.
Definition 1. The PISI inverted list I is defined as a vector of length N, where N is a number of stems in . The element is composed of the following components encoded using the byte code:mark byte when is the last occurrence of the stem .
mark byte when , where , i.e., is divisible by α and, at the same time, is not the last occurrence of the stem .
representing the pointer (in bytes) to the next occurrence of the stem in terms of the vector I when is not the last occurrence of the stem .
the pointer to the vocabulary representing the stem when , where , or is the last occurrence of the stem .
Definition 2. The PISI presentation layer F is defined as a vector of length N, where N is a number of stems in . The element is composed of the following components encoded using the Huffman code:zero or more Huffman codewords representing the sequence of stop words and separators (except the single space) preceding the stem .
the reserved word 〈STOP〉. This component is required.
the Huffman codeword representing a variant of the stem . This component is included only if the stem has more than one variant.
Algorithm 1 describes the main functions performed by
PISI. The function
getStem returns a stem position in the vocabulary of a word at the position
i. It basically traverses the inverted list using the pointers (see rows 22 and 26). When it reaches the reserved byte
(see line 19) or the reserved byte
(see line 24) it decodes and returns the following pointer to the vocabulary.
| Algorithm 1 PISI Decompression from Byte Position f |
- 1:
function decompress(f, t) - 2:
getFPointer(f); - 3:
while do - 4:
repeat - 5:
Huffman decode at position using ; - 6:
Huffman codeword length; - 7:
output(w); - 8:
until - 9:
getStem(f); - 10:
SCDC codeword length; - 11:
if .size then - 12:
Huffman decode at position using ; - 13:
Huffman codeword length; - 14:
else - 15:
the only word with the stem s; - 16:
output(w); - 17:
function getStem(i) - 18:
while TRUE do - 19:
if then - 20:
; SCDC decode at position i; return s; - 21:
else - 22:
SCDC decode at position i; - 23:
SCDC codeword length; - 24:
if then - 25:
; SCDC decode at position i; return s; - 26:
; - 27:
function getFPointer(i) - 28:
; ; - 29:
; - 30:
while do - 31:
; ; - 32:
; - 33:
while do - 34:
repeat - 35:
Huffman decode at position using ; - 36:
Huffman codeword length; - 37:
until - 38:
getStem(f); SCDC codeword length; - 39:
if .size then - 40:
Huffman decode at position using ; - 41:
Huffman codeword length; - 42:
return ;
|
The function getFPointer is necessary to find a position in the presentation layer F corresponding to the position i in the inverted list I. The algorithm finds the first stored preceding the position i (see line 28). Next, the algorithm sums up offsets stored in (see rows 30–31). In the next while cycle (line 33), the algorithm traverses the inverted list I and correspondingly the presentation layer F. The next repeat-until cycle (see line 34) traverses all the non-alphanumeric words and stop words preceding the word at position f. Next, the algorithm finds a stem s corresponding to the word at position f (see line 38) and decodes the word variant of the stem s (see line 40). Finally, when the actual position f in the inverted list I corresponds to i, the corresponding position in the presentation layer F is stored in .
The function decompress performs the decompression starting at position f and processing next t words. The function exactly mimics the behaviour of getFPointer function (starting from line 33). The only difference is that the function decompress outputs the decoded non-alphanumeric words and stop words of the presentation layer (see line 7) and it outputs the stem variants (see line 16). The condition at line 11 decides, whether the algorithm decodes the stem variant or it outputs the only existing stem variant.
We provide the following theorems defining the space and time complexity of PISI data structure. Theorem 1 defines the upper bound of space needed for PISI inverted list. Theorem 2 defines the upper bound of space needed for PISI presentation layer. Finally, Theorem 3 defines the upper bound of time needed to locate all occurrences of a queried term.
Theorem 1. The upper bound for space of PISI inverted list defined by Definition 1 is where N is a number of stems, n is a number of unique stems, α is a step/period of the back pointers in the inverted list and b is a size of the word of computer memory given in bits.
Proof. Suppose
, which implies that the following space complexities are given in bytes. Consider the
PISI inverted list depicted as
I array in
Figure 1 and
Figure 2. The inverted list
I is composed of
N entries.
of the entries contain the pointers to the next occurrence of the stem of size
. This gives the upper bound of space
.
Suppose where represents the number of occurrences of the stem i. Furthermore, suppose for all , i.e., the number of occurrences of each stem reduced by one is divisible by α. It follows that . Then is clearly divisible by α and this composition of stem occurrences represents the maximum possible number of back pointers for the given parameters N and n.
The sequence of the occurrences of a certain stem is always terminated by the last back pointer for each stem which means another n back pointers. Each back pointer is encoded using bytes and it is marked by a reserved one-byte codeword ( for the last back pointer and otherwise). This gives the space consumed by the back pointers. We conclude the upper bound for space needed for PISI inverted list is . ☐
Theorem 2. The space needed for PISI presentation layer defined by Definition 2 is bounded by with respect to as the probability of a stem variant at position i, as the probability of a separator or a stop word at position j and as the number of separators and stop words.
Proof. The PISI presentation layer is composed of the entries corresponding to the entries of the PISI inverted list. The number of entries is N. Every entry is terminated by a special 〈STOP〉 word followed by encoded stem variant. The presentation layer stores basically text preceding the indexed terms (stems) and the stem variants. Suppose the text surrounding the indexed terms is parsed using the space-less word-based model. Furthermore, suppose an entropy coder working with statistical model composed of these words (separators and stop words) and the special 〈STOP〉 word. The 〈STOP〉 is usually the most frequent word of the model and it is encoded by a constant number of bits (usually one bit). This implies bit needed to encode all the 〈STOP〉 words.
The number of unique stems is n and every stem stores its statistical model of all its variants for . Then represents the probability of the stem variant at position i in terms of the statistical model of stem . Entropy coder encodes this variant using bits, which implies the maximum number of bits necessary to encode all stem variants. It is easy to see that the entropy coder encodes separators using bits where represents a probability of the j-th separator. We conclude that the number of bits needed to encode PISI presentation layer is bounded above by . ☐
Theorem 3. The PISI ensures the operation locate in worst-case time where is the number of occurrences of a queried term, α is the step/period of the back pointers in the inverted list and β is the step/period of the synchronization points synchronizing the inverted list with the presentation layer.
Proof. The simple structure of PISI inverted list ensures that it can be traversed in steps. To determine a position of a term and possibly decompress its neighbourhood it is necessary to synchronize every occurrence with the presentation layer. The synchronization points are stored as the offsets in array and represents a position of the entry corresponding to the stem at position in the inverted list. Suppose the search performed from left to right and the achieved synchronization points are cached during the search. Then the time needed for summation of all necessary synchronization points is bounded by .
One has to decompress β entries from the corresponding synchronization point to achieve a position of the wanted term in the worst case. Decompressing of one entry is composed of two steps. First, to determine the stem. Second, to decompress the separators preceding the stem and decompress the stem variant. Suppose the encoded separators, stem variants and the gaps can be decoded in the constant time. Then the first step can be performed in in the worst case. The second step can be done in time considering standard natural language text with a low constant number of separators between two following stems. Thus, locating one occurrence takes time. We conclude that the time needed to locate all occurrences of one term is bounded above by . ☐
3.1. The Context of PISI Implementation
Suppose an
IR system that uses positional ranking function to score the documents and that extracts snippets for top-scoring documents. According to [
16], the evaluation of a query involves the following steps:
Query Processing Step: Retrieve top- scoring documents according to some standard document ranking function and the given query.
Positional Ranking Step: Rerank the top- documents according to some positional ranking function and the positions of the query terms.
Snippet Generation Step: Generate snippet for top- documents where .
PISI addresses the second and the third step of the aforementioned scenario. In the second step, PISI uses the information about the positions of single words. In the third step, PISI is rewarded for its high decompression speed. For the first step, some traditional (document-level) inverted index must be applied since this step is performed on a very large number of documents.
It implies that, in real implementations, PISI needs to cooperate at least with a standard (document-level) inverted index. The implementation of such a framework is out of the scope of this paper. However, we outline at least the concept of the framework in the following example.
Example 2. Figure 3 depicts an example of the integration of the standard inverted index with PISI.
Both inverted indexes share the vocabulary storing the stems of single words. The vocabulary is alphabetically sorted and except the textual representation of the stem it stores also a pointer to inverted list with documents IDs. Every slot of the inverted list corresponding to a document contains frequency of the given word in the given document , pointer to the first occurrence of the word and the Huffman tree storing concrete variants of the stem. We can observe in Figure 3 that the stem “hors” occurs i.a. in the document . The document contains occurrences of the stem in the tree different variants (see the Huffman tree ). The first occurrence is at the position . The last position of the stem stores a back pointer to the vocabulary entry . The dashed line determines a border between the two components: standard (document-level) inverted index and the word-level inverted index (PISI). 4. Experiments
We designed our experiments with respect to the two main questions we asked. What is the performance of
PISI compared to the word-based self-indexes proposed by Fariña et al. in [
17]? What is the difference in the search speed of
PISI compared to standard positional inverted index?
Thanks to the space limits we focus especially on the first question in this paper. To the second question, we can briefly mention that PISI pays for breaking of locality of the stored inverted lists. Depending on the cache size of the computer, PISI can be up to five times slower in searching than the standard positional inverted index.
We carried out our tests on Intel® CoreTM i7-4702MQ GHz, 8 GB RAM. We used compiler gcc version 4.9.3 with compiler optimization -O3.
All reported times represent measured user time + sys time. All our experiments run entirely in RAM. All the reported experiments were performed on bible.txt file of the Canterbury corpus.
The first experiment provides a space breakdown of
PISI into the single components of the index data structure. Different instances of
PISI are stated in the single columns of
Table 1 according to setting of the parameters
α (the period of the back pointers) and
β (the period of the pointers synchronizing inverted list with the presentation layer). Higher values of both parameters mean better compression ratio but slower decompression. The growing parameter
α reduces the number of the back pointers as well as the reserved bytes. The omitted back pointers cause shorter gaps and thus shorter encoding of the gaps. The parameter
β influences only the array
which stores the pointers to the presentation layer.
Table 1 shows also the space difference between the memory consumption (upper part of the table) and disk storage consumption (lower part of the table). It can be seen that the serialization influences only the vocabulary (
.voc file). In the serialized form, the stem variants are encoded only as the suffix extending the stem and the Huffman trees are encoded as simple bit vectors.
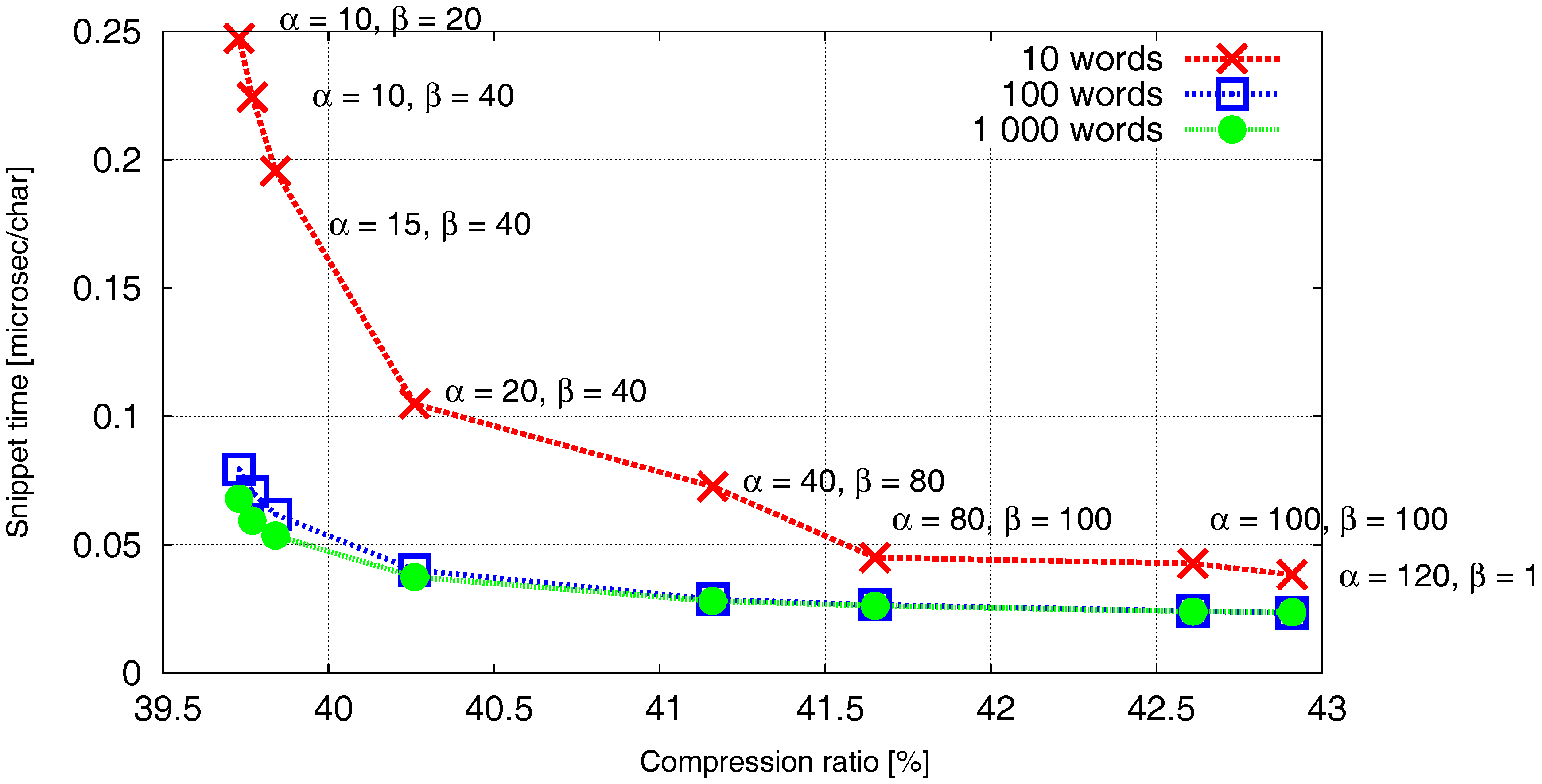
We demonstrate the effect of the parameters
α and
β on the compression ratio and the snippet time in
Figure 4. Generally, we can observe that the parameter
β has lower impact on the compression ratio and the snippet time than the parameter
α. Only the size of
array is influenced by
β and it is not crucial in terms of the total size of
PISI data structure. On the other hand,
β impacts the search and decompression process only at one point when the presentation layer
F has to be synchronized with the inverted list
I. Thus, lower values of
β (i.e., shorter distances between the two following synchronization points) provide only limited gain in terms of the snippet time.
Figure 4 proves that the parameter
α significantly impacts the snippet time at the expense of small increase of the necessary space. This pays approximately up to the value
when
PISI encounters its speed limits. Further increment of
α brings only negligible improvements of the snippet time together with a significant increase of the compression ratio.
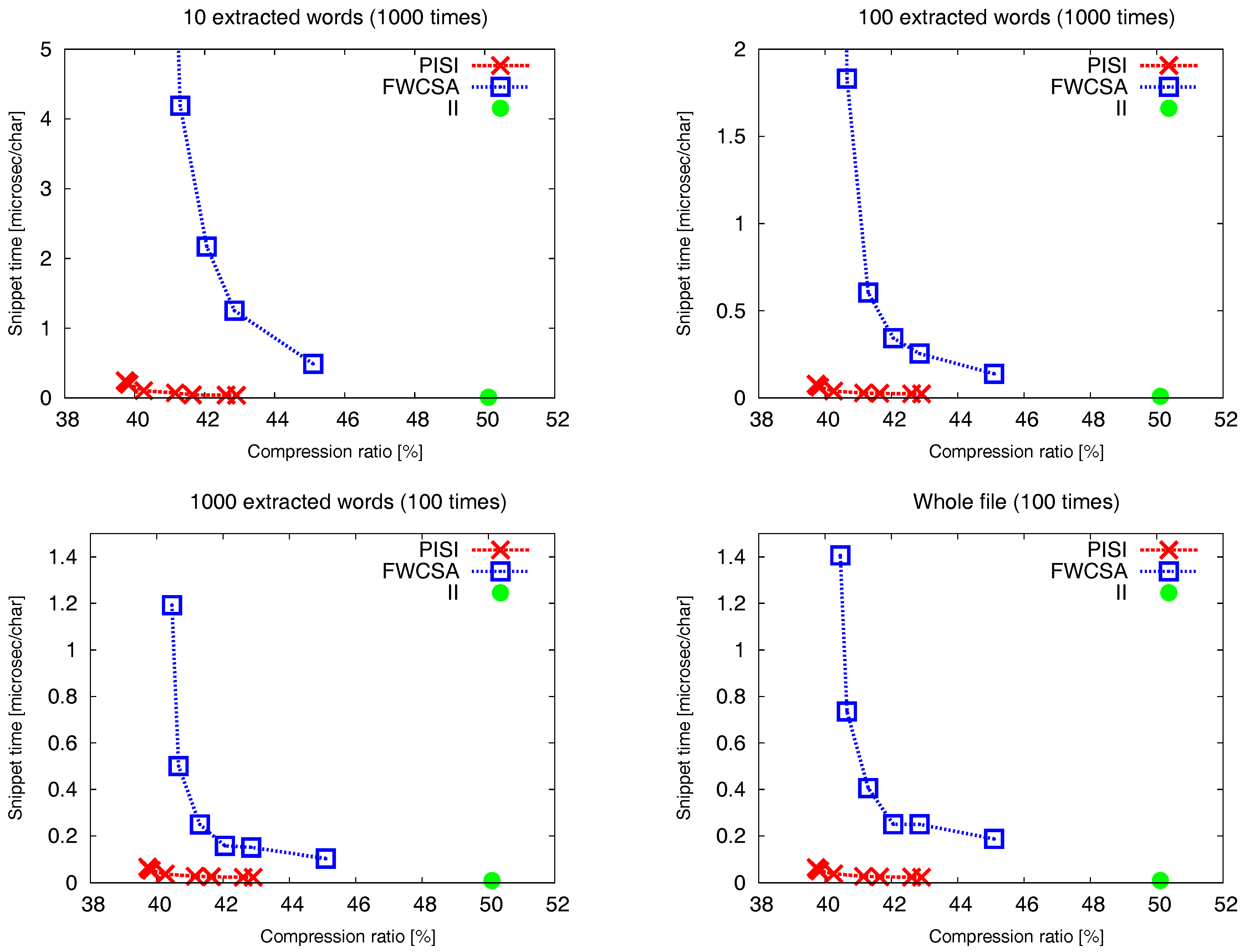
Figure 5 shows a trade-off between the compression ratio and the time needed to extract a snippet. The snippet time includes search time and a time needed to extract a certain number of words (10, 100, 1000 and the whole file). We tested so-called bag-of-words search with four words randomly chosen of the indexed text. We compare three different indexes: our
PISI, word-based self-index
FWCSA proposed by Fariña et al. in [
17] and the standard positional inverted index
II.
II is our implementation and it uses
SCDC encoded inverted lists. The text accompanying the index is
SCDC encoded, as well. All the parameters of
FWCSA were set to power of two ensuring the highest possible speed. Disregarding the number of extracted words, all the presented charts show very similar curves. The standard positional inverted index (
II) provides the best snippet time (
second per extracted character for 1000 extracted words). However, the inverted index together with the compressed file (which cannot be replaced) achieve the worst compression ratio
%. The fastest instance of
PISI with achieved compression ratio
% proved to be 2–3 times slower than
II (with snippet time
s per extracted character for 1000 extracted words). Furthermore,
PISI proved to achieve usually an order of magnitude better snippet time at some level of compression ratio in comparison to
FWCSA, e.g.,
PISI with compression ratio
% achieves snippet time
s per extracted character for 10 extracted words. On the other hand,
FWCSA with compression ratio
% achieves snippet time
s per extracted character for 10 extracted words. Finally,
PISI is able to achieve the best compression ratio among of all tested algorithms, which is
%.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}