3.2.1. Data Processing
Based on the above 3D reconstruction, the road surface point cloud plane is not parallel to the axis x and y plane, which affects the subsequent extraction of disease information based on coordinates. Therefore, it is necessary to carry out the coordinate rotation for the reconstructed 3D model. The reconstructed three-dimensional model of the road table contains the disease information of multiple lanes. For each lane, the vehicle load is concentrated on the wheel path. As a result, lateral and longitudinal surface deformations are symmetrically distributed on the lane. To measure rutting and flatness, lane division is necessary.
Before the rotation operation is performed, the plane coordinates of the road surface are determined first. In this study, the plane coordinates of the road surface are iterated by the RANSAC (Random Sample Consensus) algorithm, and then the normal vector of the road surface is determined.
Figure 7 shows the coordinate rotation process.
As a basic road sign, lane lines are often used to define the trajectory of vehicles. In this study, road markings are extracted by intelligent extraction of lane demarcation lines, and then lane division is carried out.
First, the point cloud data of the multi-vehicle road table are loaded into the processing system, which contains the spatial coordinates (X, Y, Z) of each point, as well as color information. According to the color information, set the color threshold and screen out the points close to white, which is the extracted lane line point cloud. The noise removal process based on a statistical filter is carried out to reduce the subsequent fitting error. After the denoised mark line point cloud is obtained, the linear fitting based on the least square method is carried out to determine the mark line linear equation. According to the linear equation obtained, the threshold value is set for the whole road surface point cloud data for segmentation, and the lane point cloud is determined for lane division.
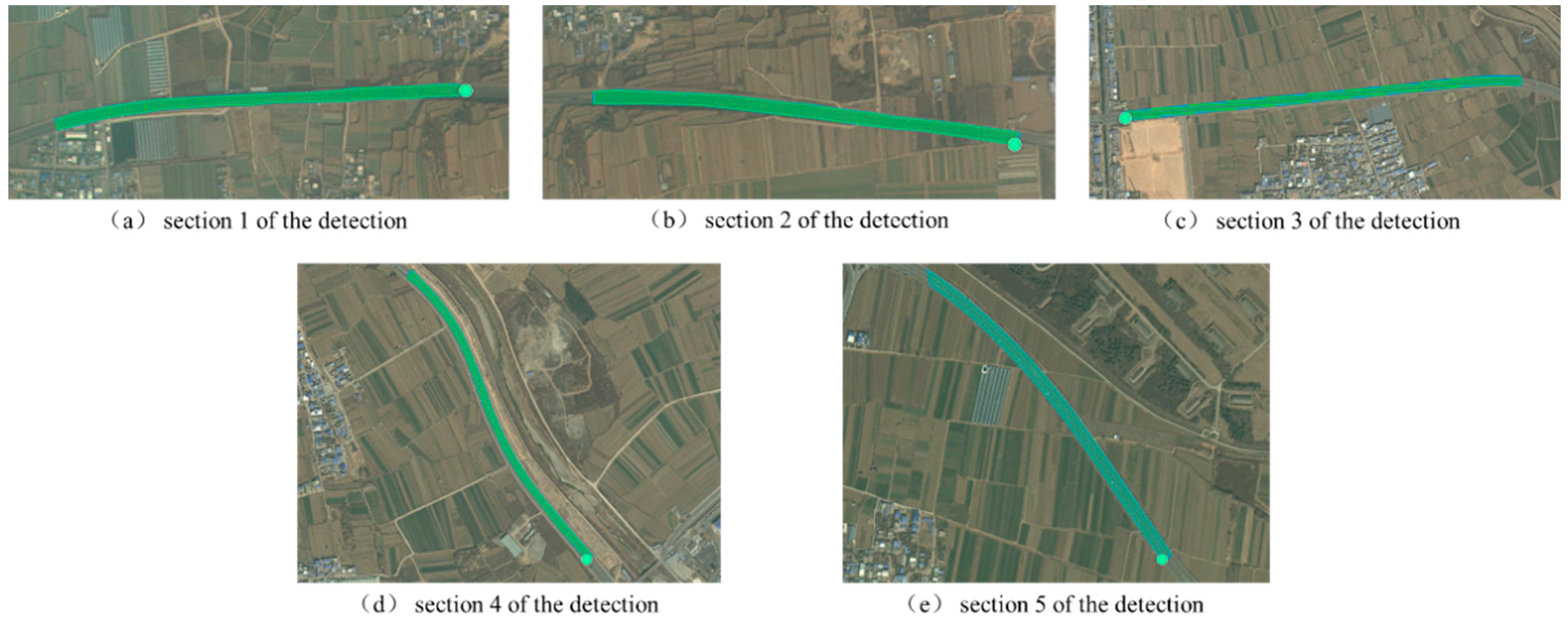
Figure 8 shows the point cloud image after lane segmentation.
3.2.2. Calculation of Road Roughness Based on Vehicle Road Model
Firstly, the lane area is located through lane line segmentation and fitting, and the profile plane extraction line is set according to the curvature of the lane line in the lane according to a certain transverse interval distance. To cover the profile data of the whole lane and the smoothness evaluation, the longitudinal profiles and elevation values of 1/4 and 3/4 transverse positions of each lane were extracted at fixed intervals for a single lane, which was used to calculate the international smoothness values of multiple transverse positions in subsequent models.
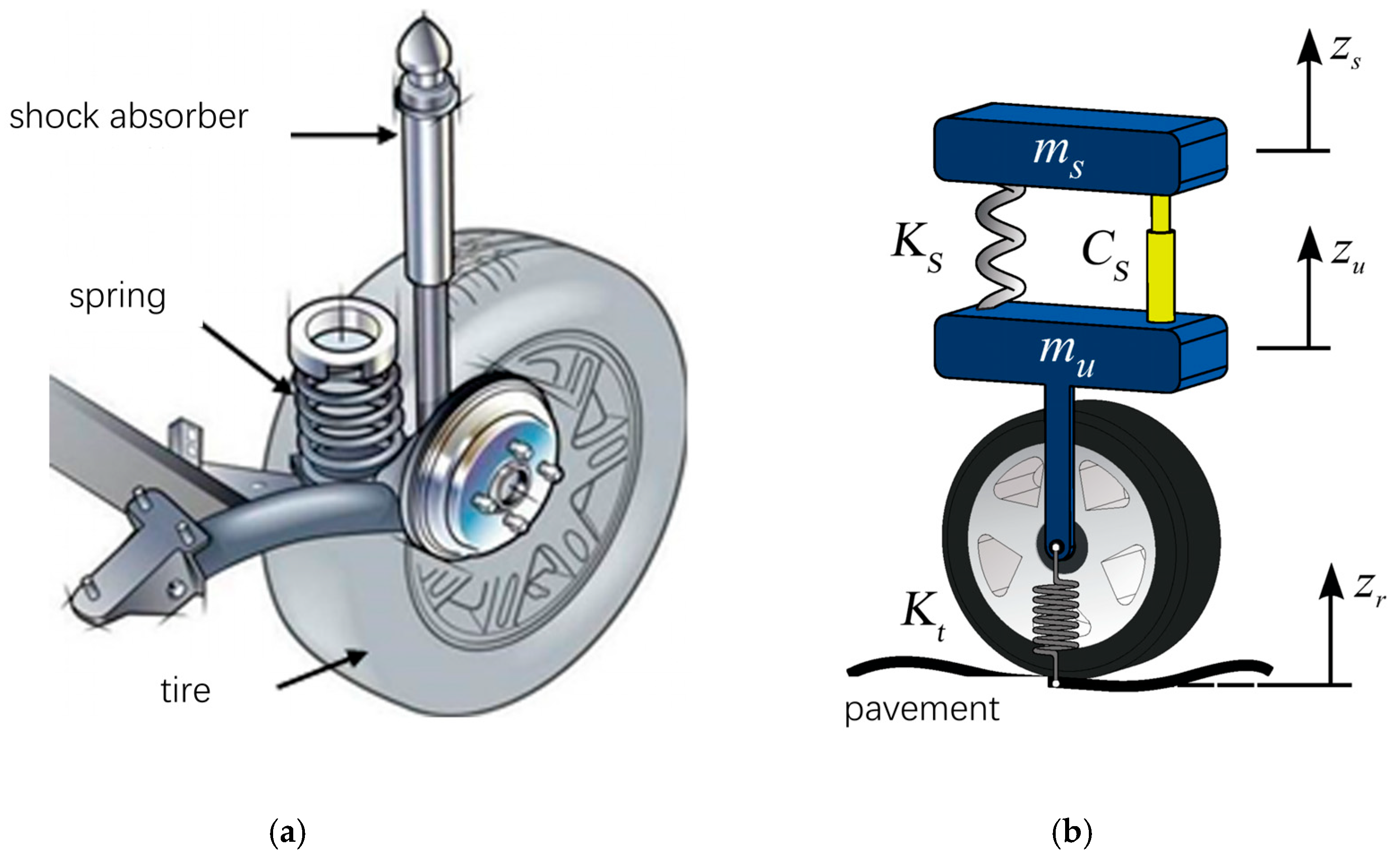
The evaluation index of road roughness is mainly based on the road-suspension response model. The road roughness is characterized by the vertical vibration response generated by the vehicle suspension moving on the road. The vehicle suspension model is the core of flatness evaluation. The degree of freedom of the suspension model can be divided into the two-degrees-of-freedom quarter car model, a four-degrees-of-freedom half-car model, and a seven-degrees-of-freedom whole-vehicle model. Among them, the International Roughness Index (IRI) is the most commonly used pavement roughness evaluation index. This index is a response evaluation index proposed by the World Bank to measure the driving quality of infrastructure in a unified way. Its core is to estimate the dynamic response of vehicle suspension relative to road profile by using a two-degrees-of-freedom quarter car model.
As shown in
Figure 9, the vehicle suspension system includes auxiliary mechanisms such as springs, damping shock absorbers, swing arms, and tires. The mathematical model of a quarter car suspension is composed of a tire, a spring with stiffness
and a shock absorber with damping
, in which the unsprung mass is
and the unsprung mass is
. The system assumes that the tire is always in contact with the road, the tire stiffness is
l, and the vehicle speed is fixed at 80 km/h. According to the one-quarter car model, IRI can be calculated by the following formula:
where
is the length of the road profile;
is the speed of the vehicle;
is the vertical velocity of the sprung mass part;
is the vertical movement distance of the spring-mass part;
is the vertical velocity of the unsprung mass part;
is the vertical movement distance of the unsprung mass part;
is the time differential; and
is the distance differential.
The essence of the IRI calculation formula above is that when the vehicle travels along the road profile curve at a certain speed, the suspension will vibrate up and down under the excitation of the uneven road surface. Therefore, the cumulative motion trajectory of the vehicle suspension relative to the vehicle body is calculated to reflect the road surface flatness. For ease of solution, the formula can be simplified as follows:
where
is the sample number of test points.
According to the above discrete calculation formula, IRI value calculation must obtain the vertical distance difference between each measuring point’s upper and lower parts. In the field physical measurement process, the motion distance of the two parts can be measured by installing sensors on the bottom of the suspension and the body of the test car. In the process of digital simulation, these two parameters need to be solved using the road profile curve and suspension dynamic equation. With the upper part of the suspension spring and the lower part of the spring divided into the center, the following second-order vibration differential equation can be established.
where
is the vertical acceleration of the spring part;
is the vertical acceleration of the unsprung part; and
is the vertical change distance of the pavement profile.
According to the standard suspension parameters of the quarter car, u = m
u/m
s = 0.15, C = C
s/m
s = 6.00 s
−1, K
1 = K
s/m
s = 653 s
−2, K
2 = K
t/m
s = 63.3 s
−2. The above Formulas (10) and (11) can be simplified as follows:
The solution of the above equation depends on calculating
these four state variables,
, which can be converted to the following:
Formula (11) is a non-homogeneous differential equation. According to the initial value of and the gradient of the section curve, at any time can be solved by recursion, and the motion of and at each measuring point can be obtained to calculate IRI.
3.2.3. Pavement Abnormal Deformation Recognition Based on DBSCAN Clustering
In addition to the two common deformation forms of transverse rutting deformation and longitudinal pavement deformation, large-scale abnormal deformation also exists on some pavement, which is mainly caused by factors such as uneven settlement of subgrade, insufficient compaction degree, and shrinkage and expansion of materials. It is difficult to identify large-scale abnormal deformation of pavement because of its random distribution, fuzzy boundary, and complex shape. Limited by the spatial distribution range and complex change characteristics of large-scale abnormal deformation, most current studies reflect the abnormal deformation through the multi-angle one-dimensional cross-section. However, to fully measure the three-dimensional shape of large-scale abnormal deformation, it is necessary to extract the two-dimensional boundary of the disease from the three-dimensional digital elevation map. Therefore, considering the complex form and fuzzy boundary of large-scale abnormal deformation, this paper adopts unsupervised three-dimensional elevation clustering to extract spatial elevation demarcation points and identify abnormal deformation regions.
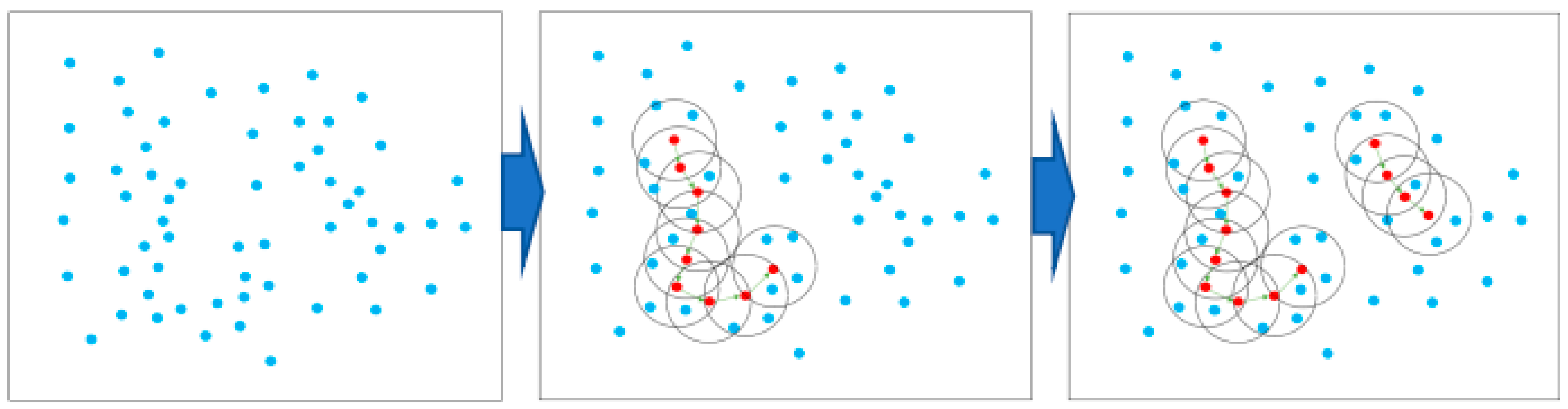
The DBSCAN algorithm identifies clusters by density. Its core principle is to divide data into core points, boundary points, and noise points according to the density of data points. First, the algorithm selects a distance threshold (
) and a minimum number of neighbor points (MinPts) and then starts from any unvisited core point and identifies points in its neighborhood. If the number of points in the neighborhood exceeds MinPts, the points are grouped into the same cluster, and the cluster is recursively expanded until no more points can be added. Finally, the resulting clusters have arbitrary shapes and can effectively identify noisy data. The overall search process is shown in
Figure 10.
The input to the DBSCAN cluster is multidimensional data and is suitable for point cloud data with different densities. Its main goal is to cluster data points based on their density characteristics, which is particularly suitable for discrete, non-spherical spatial distributions. In the clustering process of DBSCAN, you first need to define two important parameters: ε (neighborhood radius) and MinPts (minimum number of points in the neighborhood).
Initial step: In three-dimensional space, each observed data point is first classified according to the given and MinPts conditions. For each point p, calculate the number of points in its neighborhood, defined as follows: , if , then p is labeled as the core point. If p is in the neighborhood of a core point but does not satisfy the core point condition, then p is labeled as a boundary point.
Clustering procedure: Select a core point p from any unvisited point and create a new cluster C. All points in the neighborhood of p and its are added to cluster C. This process can be expressed as follows: . For each newly added point q if q is also the core point, the neighborhood of q is repeatedly checked, and the cluster C is continued to expand. This process continues until no new core can be found.
Clustering complete: At the end of the process, all the core points and the points in their neighborhood form a cluster, and those that are neither core nor boundary points are labeled as noise.
DBSCAN depends on the distance to define a point’s neighborhood. If the horizontal change is obvious but the vertical change is small, the clustering effect of the points is not ideal. In this study, a 3D digital elevation model is used for clustering. Compared with horizontal distribution information, elevation change information is more effective in accurately identifying deformation regions. Therefore, in the process of three-dimensional spatial clustering, weighted factors should be set to scale the data features of different dimensions and strengthen the attention of spatial clustering.
For the original 3D elevation data, the vertical deformation direction data are weighted based on an unchanged horizontal data scale to enhance the difference of this dimension data. Formula (15) is used to solve the weighting factor w of the vertical data so that the variance of the vertical weighted data is not less than that of the horizontal data.
where
are the average values of x axis, y axis, and z axis direction data;
is the total number of sample points of observation data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











