Since concrete is a composite material, water-cement ratio, aggregate size, maintenance, environmental temperature and humidity, age, concrete construction methods, and other factors will affect its compressive strength, so it is difficult to consider all the factors together. In this paper, the effect of mix on concrete strength is considered, and Dataset 1 is used to test the effectiveness of the ISSA-BPNN-AdaBoost model for concrete compressive strength prediction. Dataset 1 is from the concrete compressive strength dataset of the UCI Machine Learning Library [
33]. Dataset 1 contains 1030 samples of high-strength concrete, each with eight input variables: cement, fly ash, blast furnace slag, high-efficiency water reducer, water, coarse aggregate, fine aggregate, and concrete age. In addition, there is a target output variable, which is the compressive strength of the concrete. The cement used was silicate cement (ASTM Type I). The fly ash was produced by the power plant. Water-quenched blast furnace slag powder was supplied by a local steel plant. The water was ordinary tap water. The chemical admixture was superplasticizer conforming to the ASTM C494 Type G standard. The coarse aggregate was natural gravel with a maximum particle size of 10 mm. The fine aggregate was washed natural river sand with a modulus of fineness of 3.0 [
33].
4.1. Data Analysis and Pre-Processing
The results of the statistical analysis of Dataset 1 are shown in
Table 3, which shows the mean, median, standard deviation, variance, minimum, maximum, and skewness for each variable in the dataset used. In order to reveal the degree of correlation between each type of input variable and the final output variable, nine variables were correlated using the software STATA18 as shown in
Table 4. The magnitude of the coefficients indicates the degree of correlation between two variables, with larger coefficients indicating a stronger correlation and a stronger linear relationship between the two variables. It should be noted that the magnitude of the correlation coefficient, although it can reflect the strength of the linear relationship between the variables, does not indicate causality. Therefore, the significance of the correlation coefficient also needs to be determined by statistical tests to ensure that the observed correlation did not occur by chance.
From
Table 4, it can be seen that the correlation coefficient of cement, fly ash, highly efficient water reducing agent, and concrete age for the compressive strength of concrete is positive, indicating that these variables are positively correlated with the compressive strength of concrete, and with the increase in the amount, the strength of concrete will be increased. The correlation coefficients of blast furnace slag, water, coarse aggregate, and fine aggregate for concrete compressive strength are negative, indicating that these variables are negatively correlated with the concrete compressive strength, and with the increase in the amount, the concrete strength will be reduced. In addition, the effect of cement admixture, highly efficient water reducing agent, water content, and age of concrete on the compressive strength of concrete is significantly greater than the other variables, which proves that these four variables have a greater effect on the compressive strength of concrete. In addition, the correlation coefficients of all variables did not reach more than 0.8, which indicates that there is no covariance problem between the variables, and it is not necessary to delete the variables.
From the dataset, it can be seen that the unit size of each variable is different, which will greatly affect the results of neural network training and prediction, which requires data normalization, so as to improve the convergence speed of the model and to avoid the impact of the differences between the features on the training of the model. In this paper, we use max-min normalization to normalize the data with the following formula:
where
represents the normalization result.
represents the minimum value in the sample.
represents the maximum value in the sample.
is the sample value to be normalized.
4.2. Hyperparameter Setting
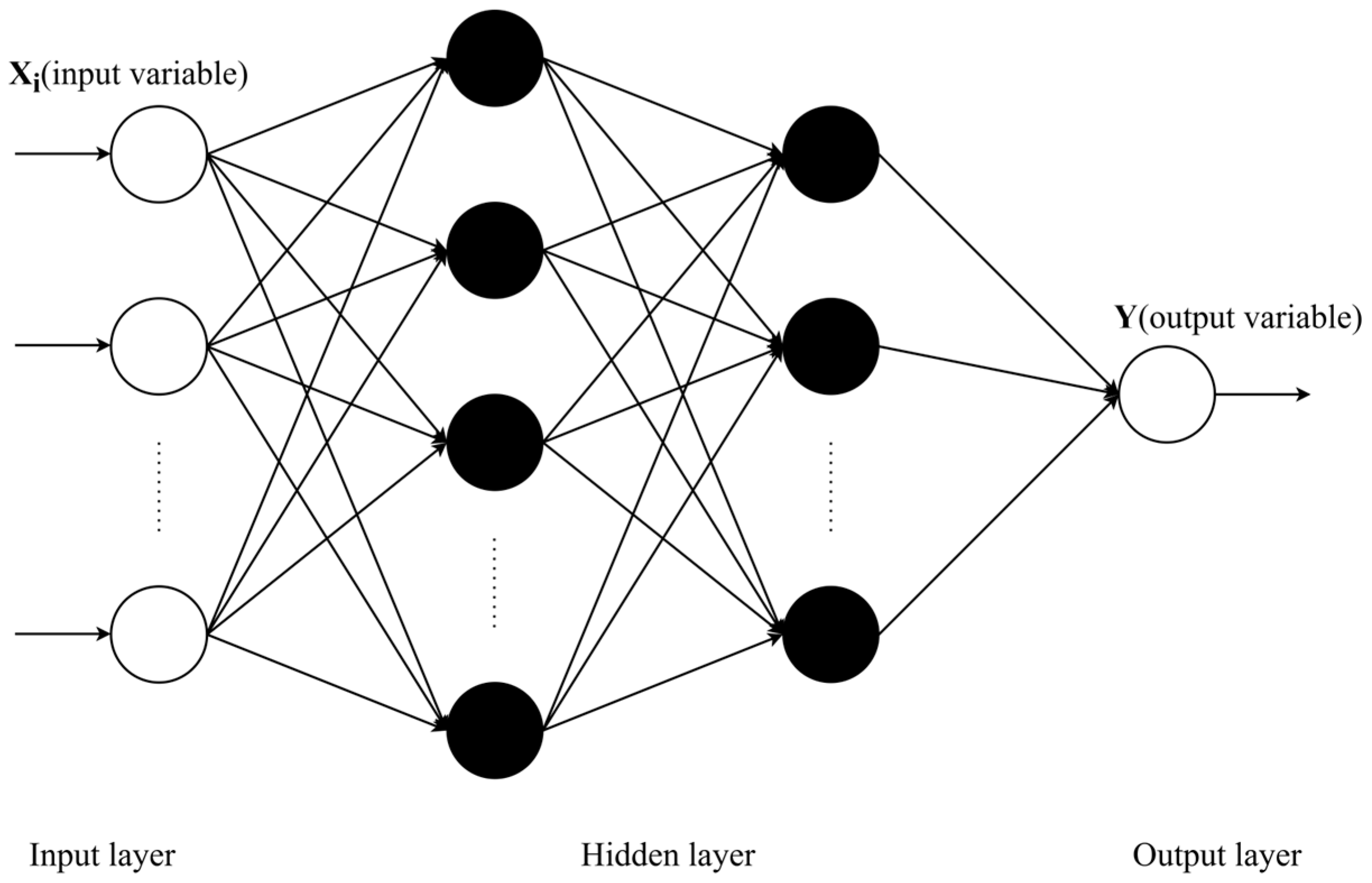
For BPNN, the setting of the hidden layer will directly affect the performance and prediction accuracy of the network. Using too few neurons in the hidden layer will result in underfitting, making the model unable to learn the data features well, thus affecting the prediction ability. On the contrary, using too many neurons will lead to overfitting and make it difficult to achieve the expected results. Therefore, choosing an appropriate number of hidden layer neurons is crucial. Determination of the number of hidden layer units in a BPNN is a complex problem with no fixed answer, so in this paper, we use the trial-and-error method to determine the number of hidden layer neurons in a single weak learner. First, the empirical formula is used to calculate the value range of the hidden layer neurons, then the number of hidden layer neurons is set in this range, and after many training repetitions, the number of hidden layer neurons with the smallest training error of BPNN is chosen. The commonly used empirical formula is as follows:
where
,
, and
represent the number of nodes in the hidden, input, and output layers, respectively.
is a constant in the interval
.
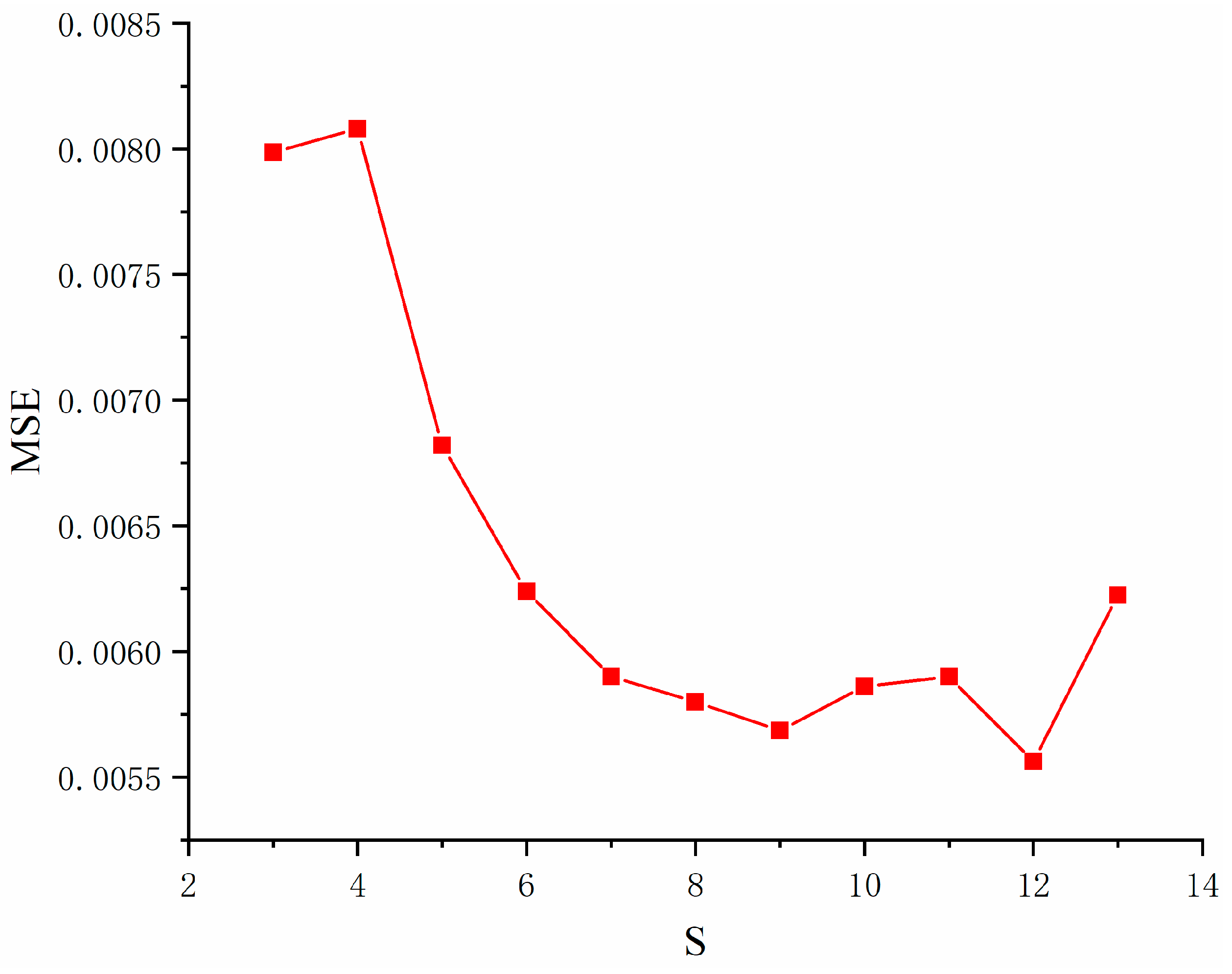
According to the empirical formula, the range of the number of hidden layer neurons is obtained as
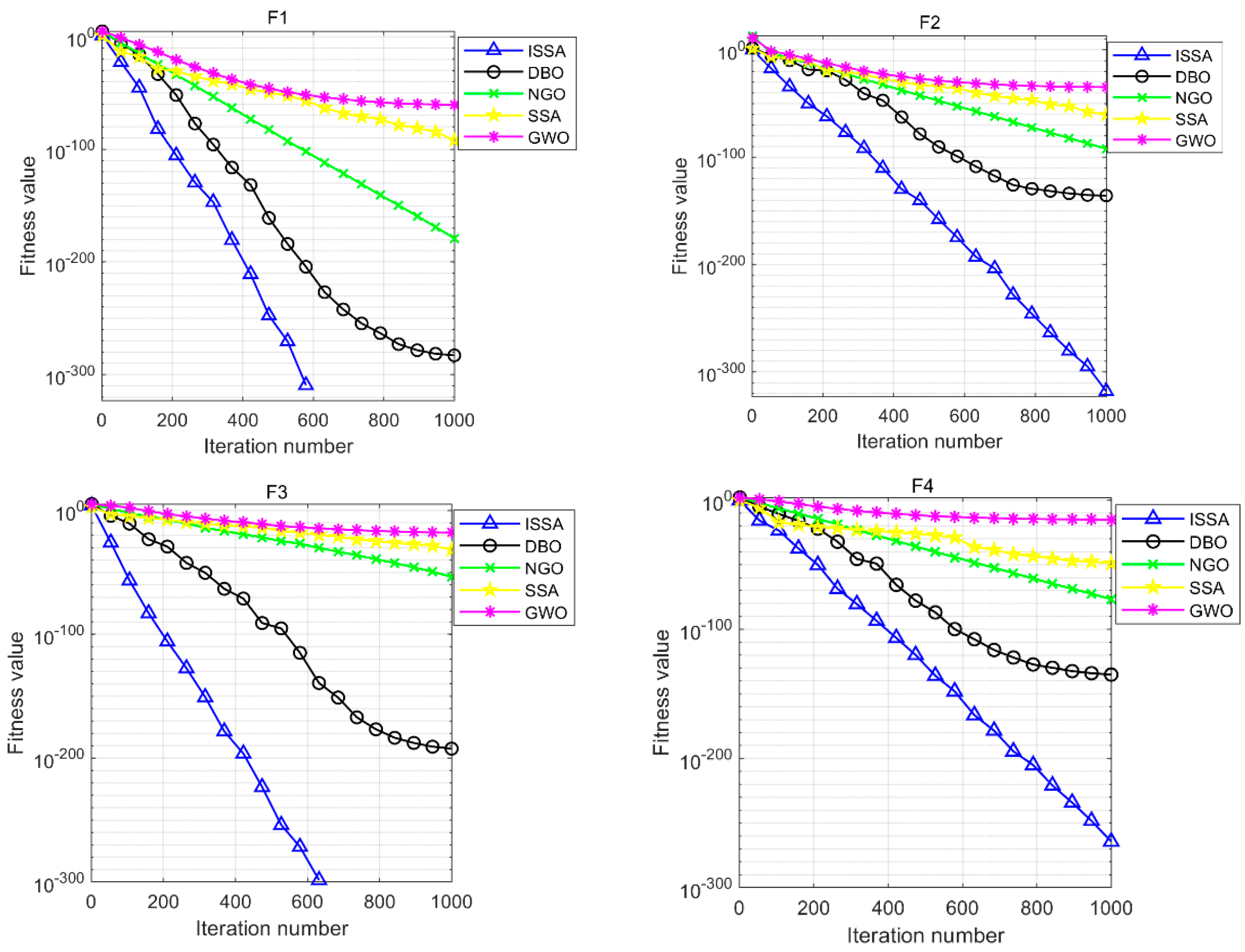
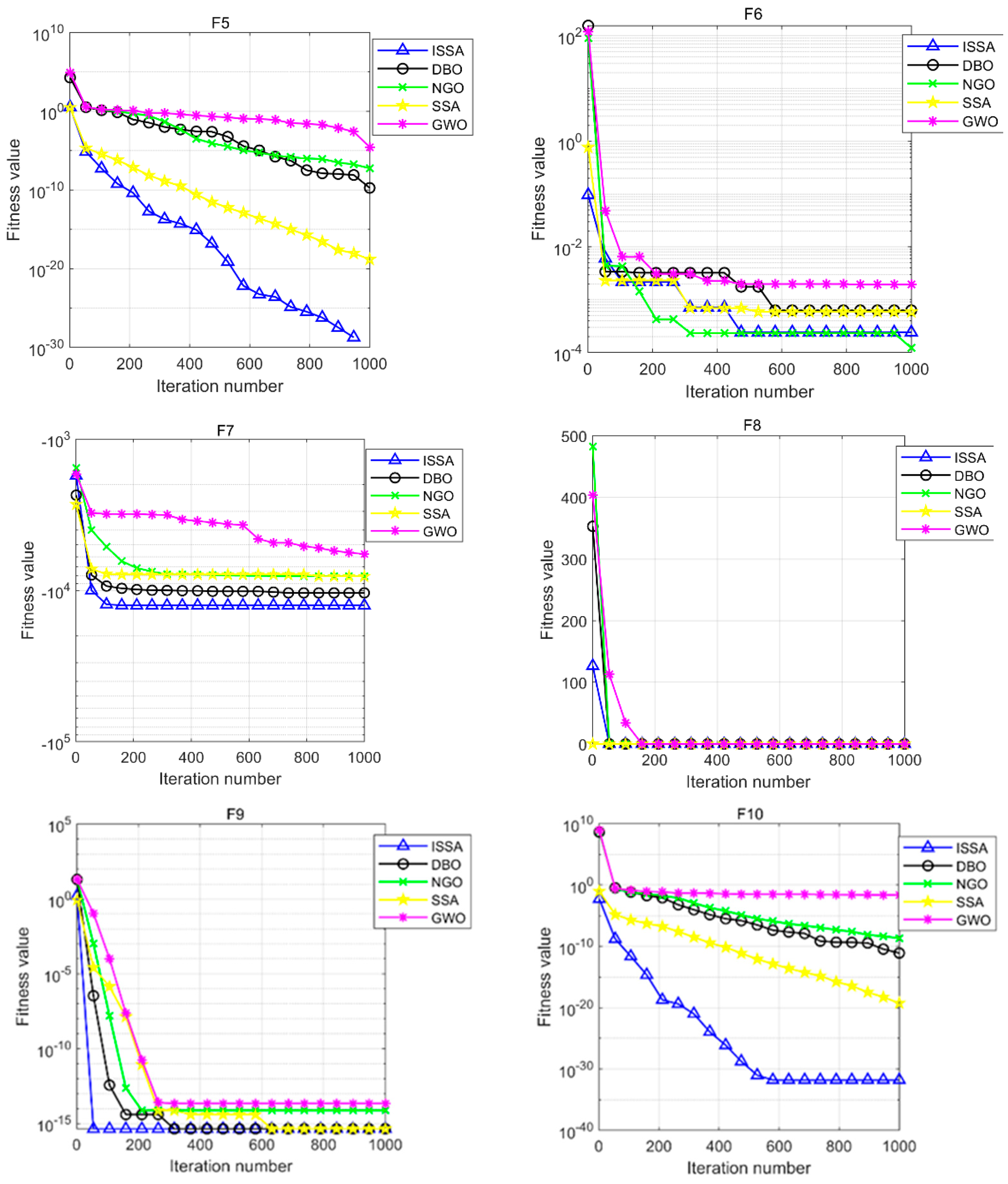
. Different numbers of hidden layer neurons in the interval are substituted into the ISSA-BPNN model for multiple trainings, and the training errors of different hidden layer neurons are obtained as shown in
Figure 7. The results show that the training error of the model is minimized when the number of neurons in the hidden layer in the BPNN is 12. Therefore, in this paper, the number of hidden layer neurons in the neural network of the weak learner is set to 12, and the three-layer structure of the neural network used consists of eight input neurons, 12 hidden layer neurons, and one output layer neuron. For determining the other hyperparameters, 10-fold cross-validation was used. All the training datasets were divided into 10 subsets of the same size, and one of the subsets was used in turn as the validation set for validation, and the remaining portion was used as the training set for training. This was repeated 10 times, and the final performance was taken as the average of the 10 experiments [
34]. By combining this with a grid search, the best hyperparameter pairing can be found. The main hyperparameters are shown in
Table 5.
4.3. Comparison with Ensemble Models
The compressive strength of concrete and the compressive strength prediction results of the ISSA-BPNN-AdaBoost model are compared and analyzed with those of several ensemble learning models, namely RF, AdaBoost, and XGBoost. RF is an ensemble learning method that constructs multiple decision trees and votes or averages their results to obtain a final prediction. XGBoost is an efficient gradient boosting algorithm that improves the performance of the model by incrementally adding prediction trees, where each weak learner is fitted against the residuals of the previous learner to gradually approximate the true value. In addition, it limits the complexity of the model by introducing regularization terms to prevent overfitting.
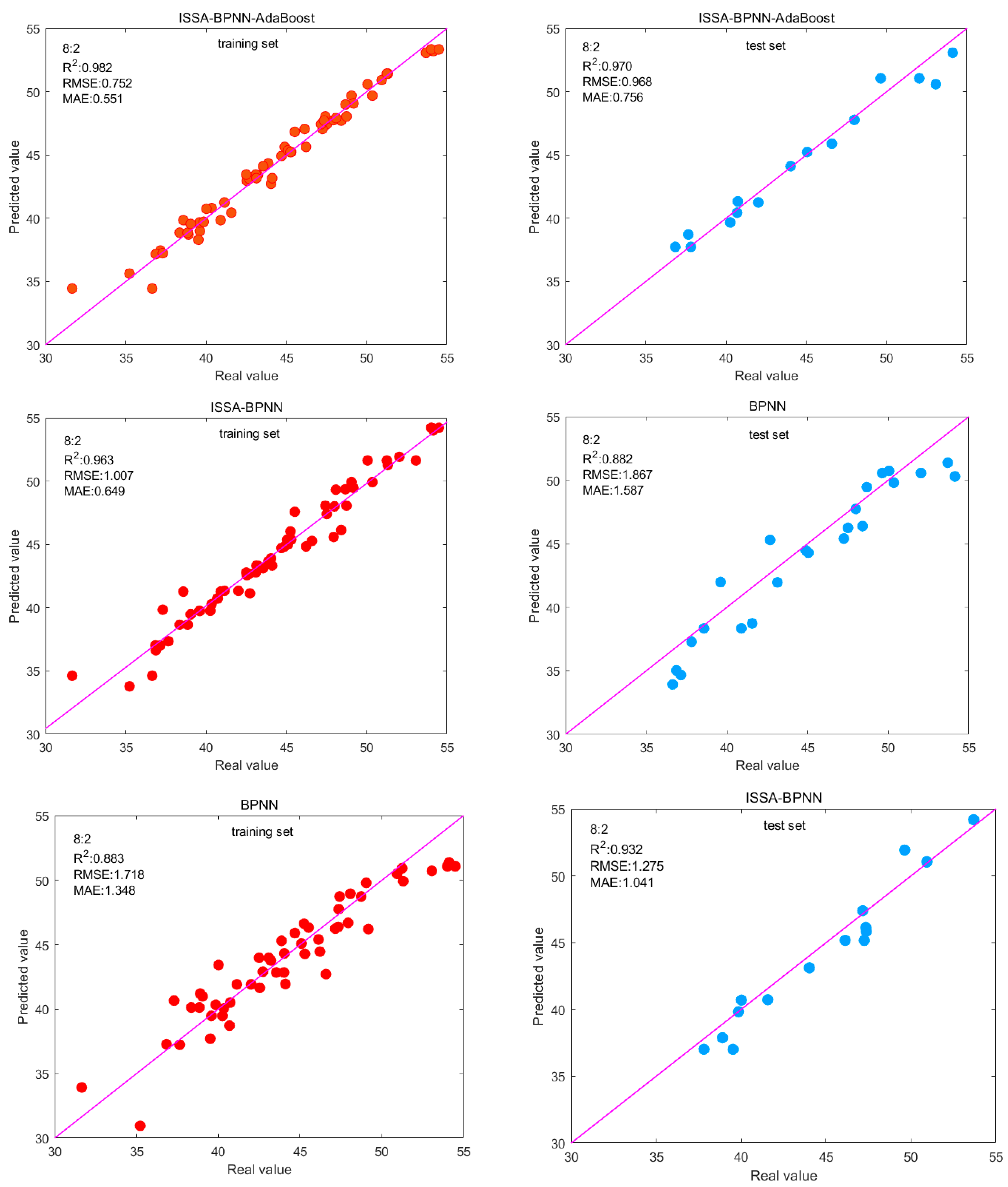
In order to clarify the optimal partition ratio, the dataset was partitioned and tested using three ratios of 7:3, 8:2, and 9:1 for the training set over the test set. In this study, 30 independent calculations were carried out using multiple runs, and the average statistical results are given.
Table 6 gives the specific evaluation metrics of the four machine learning algorithms on the training and test sets. Although sometimes other segmentation ratios work better in the test set, overall, better training and prediction results are obtained using the 8:2 ratio segmentation model.
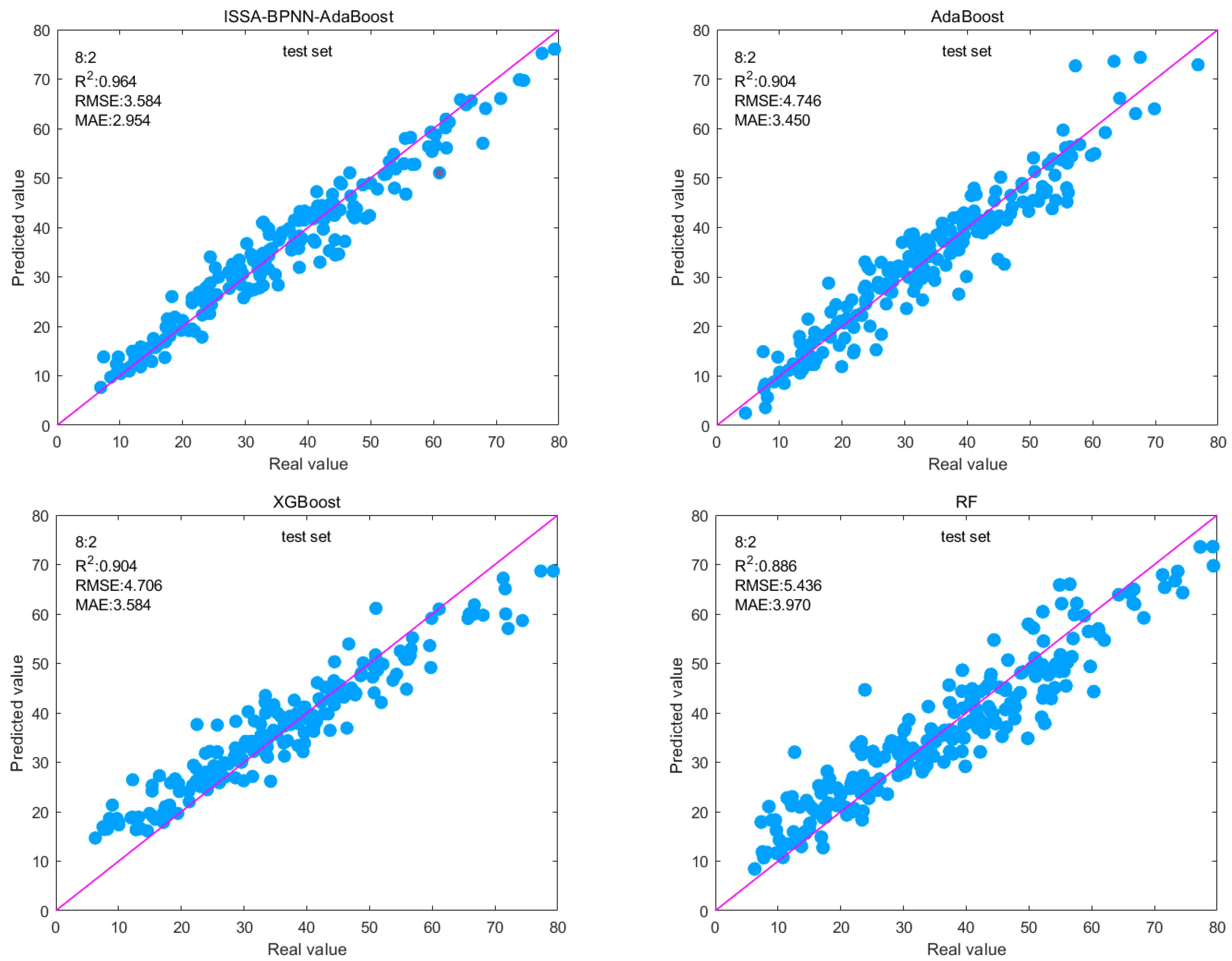
The 8:2 split ratio was analyzed. On the training set, the ISSA-BPNN-AdaBoost model performs the best with RMSE, MAE, and R2 of 3.524, 2.582, and 0.971, respectively, and the difference in the performance of the other ensemble models is not particularly large. The RMSE and MAE of the ISSA-BPNN-AdaBoost model decreased by 11.57% and 12.83%, respectively, compared to the AdaBoost model; 10.54% and 16.87%, respectively, compared to the XGBoost model; and 9.27% and 16.17%, respectively, compared to the RF model. Compared to the AdaBoost model, R2 increased by 2.75%; compared to the XGBoost model, it increased by 3.08%; and compared to the RF model, it increased by 4.75%. This indicates that the ISSA-BPNN-AdaBoost model can fit the training data well and has high prediction accuracy.
On the test set, the ISSA-BPNN AdaBoost model also performed well, with RMSE, MAE, and R2 of 3.548, 2.954, and 0.964, respectively. The RMSE and MAE of the ISSA-BPNN-AdaBoost model decreased by 25.24% and 14.38%, respectively, compared to the AdaBoost model; 30.51% and 23.95%, respectively, compared to the XGBoost model; and 34.73% and 25.59%, respectively, compared to the RF model. Compared to the AdaBoost model, R2 increased by 6.64%; compared to the XGBoost model, it increased by 6.64%; and compared to the RF model, it increased by 8.80%. This means that the ISSA-BPNN-AdaBoost model not only performs well on training data but also maintains good generalization ability on unseen new data, which can be used to predict the strength of concrete. It can be seen that there are conspicuous differences on the test set. Optimizing the base learner enables the ensemble model to achieve better generalization ability, reduces overfitting to the training set, and improves the predictive ability of the model.
The prediction results presented in
Figure 8 can be used as a reference for assessing the predictive ability of the four models. The data points of the prediction results of the four models are scattered around the baseline (y = x). It can be seen that the difference between the predicted and actual values of the ISSA-BPNN-AdaBoost model is small, and the data points are basically arranged around the baseline, which indicates that its prediction results are still more accurate.
4.4. Comparison with Single Model
In order to test the performance of the base learner ISSA-BPNN so as to further evaluate the prediction effect of the ISSA-BPNN-AdaBoost model, five single models, namely, BPNN, SVM, convolutional neural network (CNN), extreme learning machine (ELM), and long short-term memory neural network (LSTM), were also selected to conduct the concrete strength prediction experiments with the ISSA-BPNN in this study. SVM regression, also known as support vector regression (SVR), is based on finding an optimal hyperplane that minimizes the distance between the hyperplane and the sample points. By minimizing this distance, the regression function is obtained to fit the training sample as closely as possible. CNN is a deep learning model that excels in image processing and classification tasks. However, CNN can also be used for regression problems, where convolutional layers are used to extract features from data, pooling layers are used to reduce the size of feature maps, and fully connected layers are used to integrate features and perform regression analysis. ELM is a feed-forward neural network learning algorithm whose core idea is to generate weights and biases layer by layer from the input layer to the hidden layer and then calculate the weights of the output layer directly by least squares or other optimization methods. This reduces the need for iterative computation of the hidden layer weights, thus increasing the training speed. Finally, LSTM is a special type of recurrent neural network that introduces input gates, forget gates, and output gates to control the information flow, thereby solving the problems of gradient vanishing and exploding that may occur in traditional RNNs.
In addition, three different data splitting ratios of 7:3, 8:2, and 9:1 were equally selected for each model. The computational results of each model are shown in
Table 7. It can be seen that in general, the use of the 8:2 ratio segmentation model can get better training and prediction results, while the use of the 9:1 ratio will have a certain overfitting phenomenon, resulting in a decrease in prediction accuracy instead.
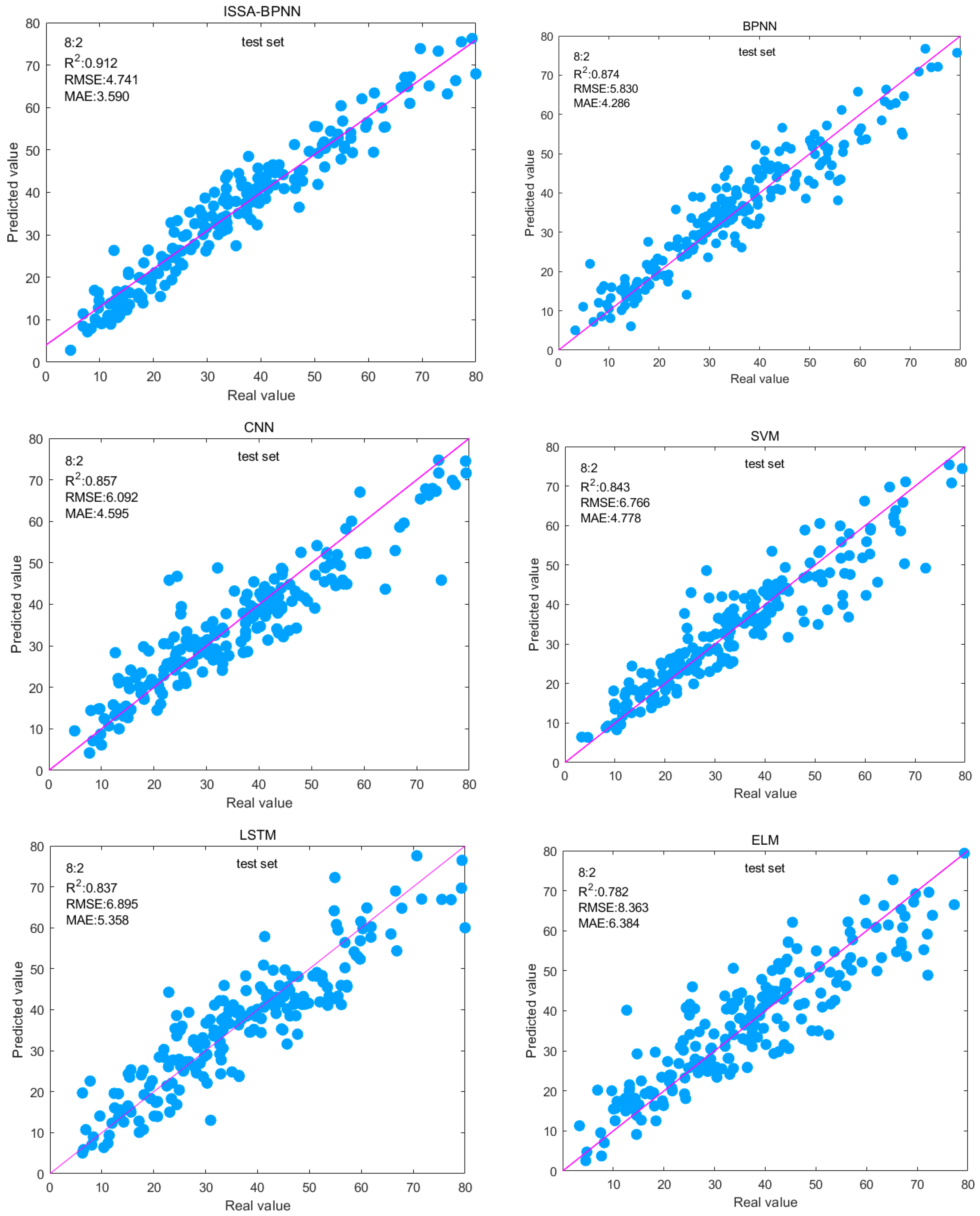
The 8:2 split ratio was analyzed, and the six models’ R
2 values were in descending order of ISSA-BPNN > BPNN > CNN > SVM > LSTM > ELM, and the ISSA-BPNN model obtained the best result. Compared with the base BPNN model, the RMSE and MAE of the test set of the ISSA-BPNN model decreased by 18.68% and 16.24%, respectively, and the R
2 improved by 4.35%. This indicates that ISSA improves the prediction accuracy and stability of the BPNN model by optimizing the initial weights and thresholds of the BPNN.
Figure 9 shows the fitting effect between the predicted and actual values of the test set of each model, from which it can be intuitively seen that the fitting effect of the ISSA-BPNN model is the best among the other models, and the sample points are relatively more concentrated on the base line. The ISSA-BPNN has a fast convergence speed and strong global optimization ability and can accurately predict the concrete compressive strength. Then the ISSA-BPNN-AdaBoost model using it as a base learner will have much better performance. Comparing the evaluation metrics of the ISSA-BPNN-AdaBoost model with the above models, it can be seen that the ensemble learning model outperforms all these single models and the ISSA-BPNN model in predicted effect, and the R
2 is also improved by 5.70% compared to the ISSA-BPNN model.
In summary, whether it is the training set or the test set, among the above machine learning regression algorithms, the three evaluation indexes of the ISSA-BPNN-AdaBoost model are optimal, indicating that the data predicted by the ISSA-BPNN-AdaBoost algorithm model fit well with the real data, and the accuracy and reliability of the prediction results are better than those of other models.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}