
Phase Prediction of High-Entropy Alloys by Integrating Criterion and Machine Learning Recommendation Method

 ,
,  ,
, 
Abstract
:
1. Introduction
2. Preliminaries
2.1. Research Background of HEAs
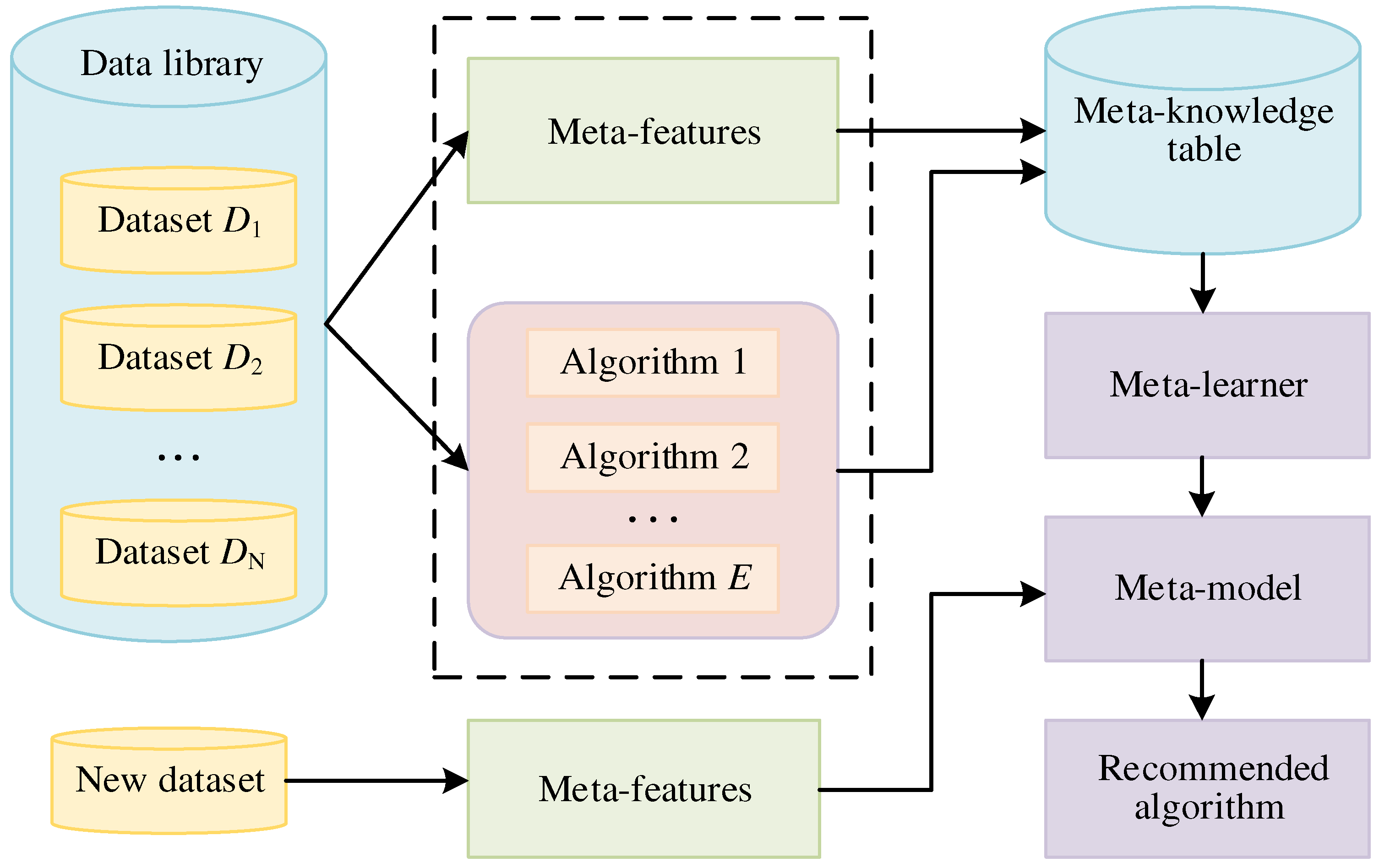
2.2. Meta-Learning
2.3. Shelly Nearest Neighbor
2.4. Decremental Instance Selection for KNN Regression
3. Methodology
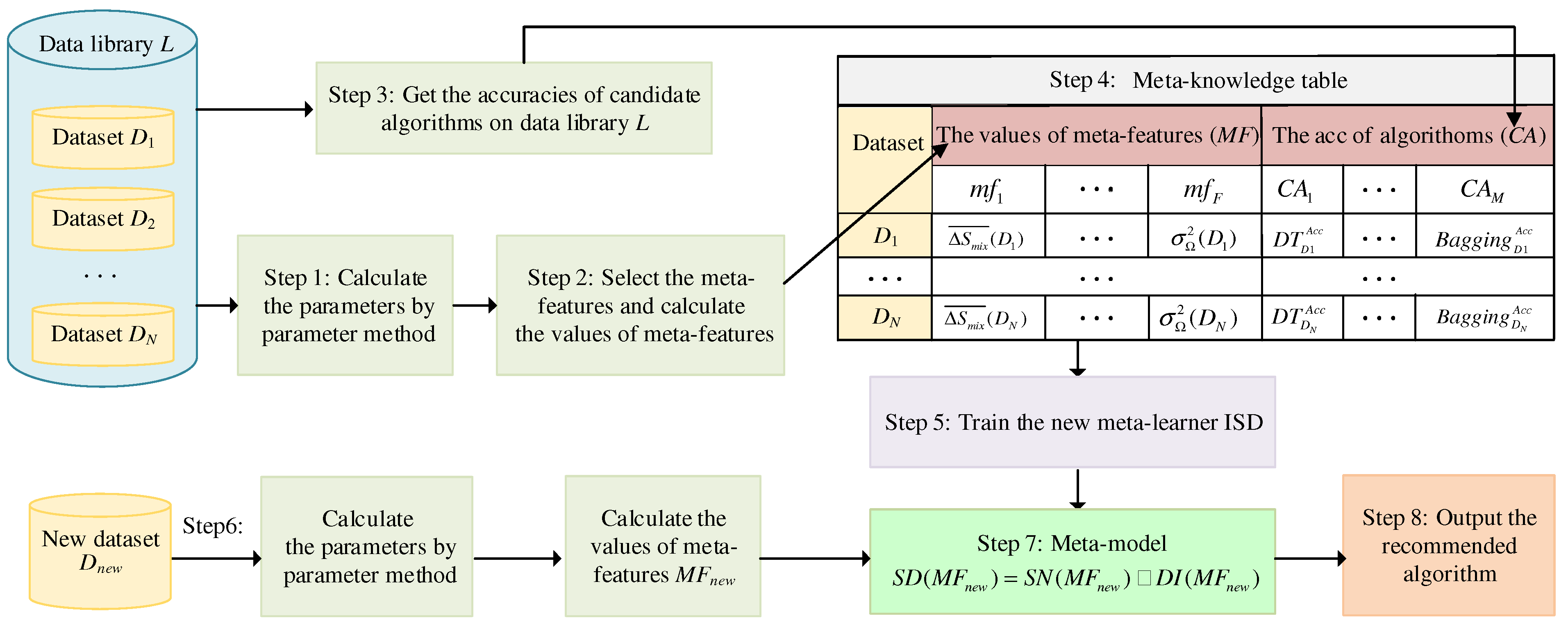
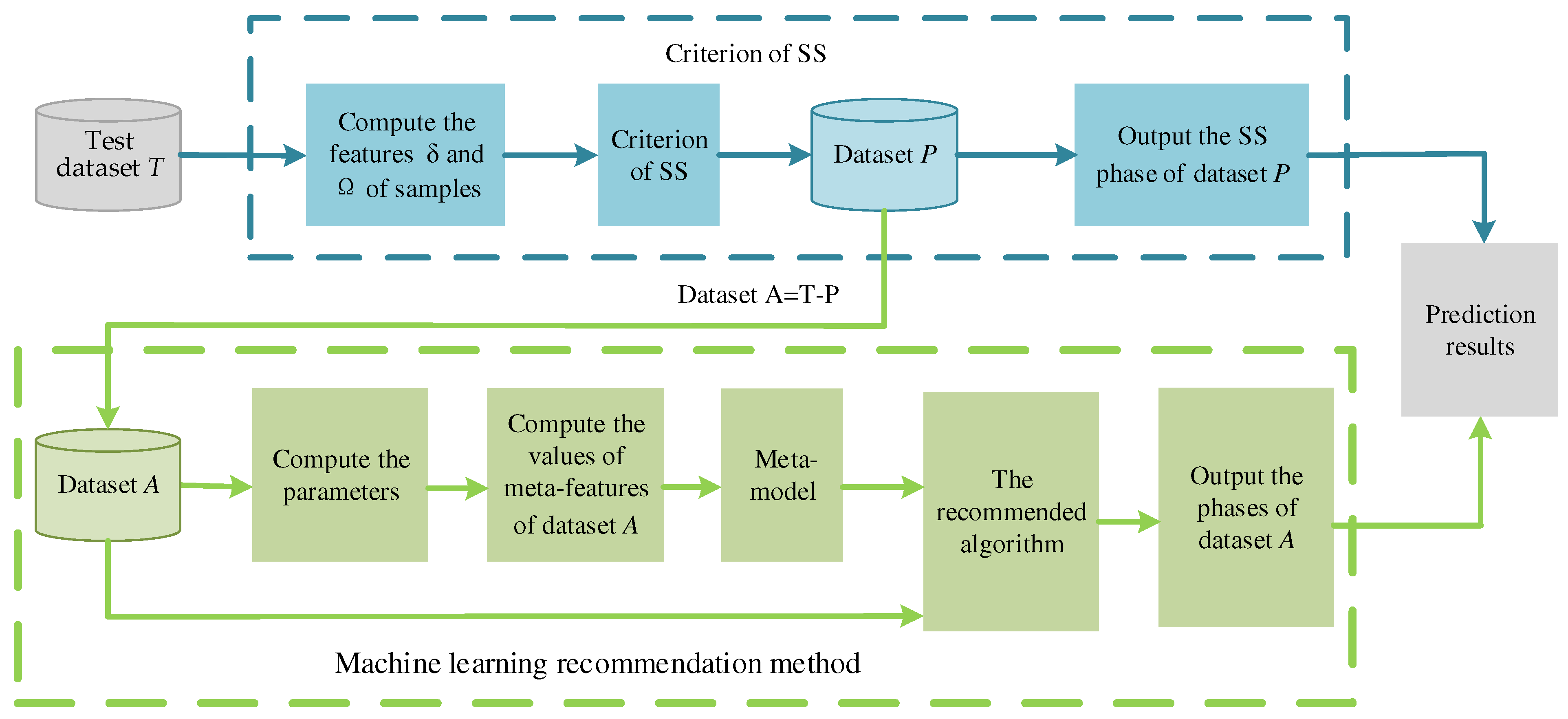
3.1. Machine Learning Recommendation Method
- (1)
- The nearest neighbor set, , for the meta-features, MFnew, of the new dataset, Dnew, is obtained by SNN in Section 2.3 based on the meta-knowledge table.
- (2)
- The subset, S, is obtained by DISKR in Section 2.4, which is the remaining sample on the meta-knowledge table after removing outliers and points that have less effect on KNN. The nearest neighbor set, , for the meta-features, MFnew, is obtained by the first k samples with the smallest distance in DISKR.
- (3)
- Obtain the nearest neighbor set, , for the meta-features, MFnew, of the new dataset, Dnew, by ISD. The nearest neighbor set, , is shown as Equation (15):where the nearest neighbor set, , is obtained by the intersection of and .
3.2. Phase Prediction of HEAs
4. Results and Discussions
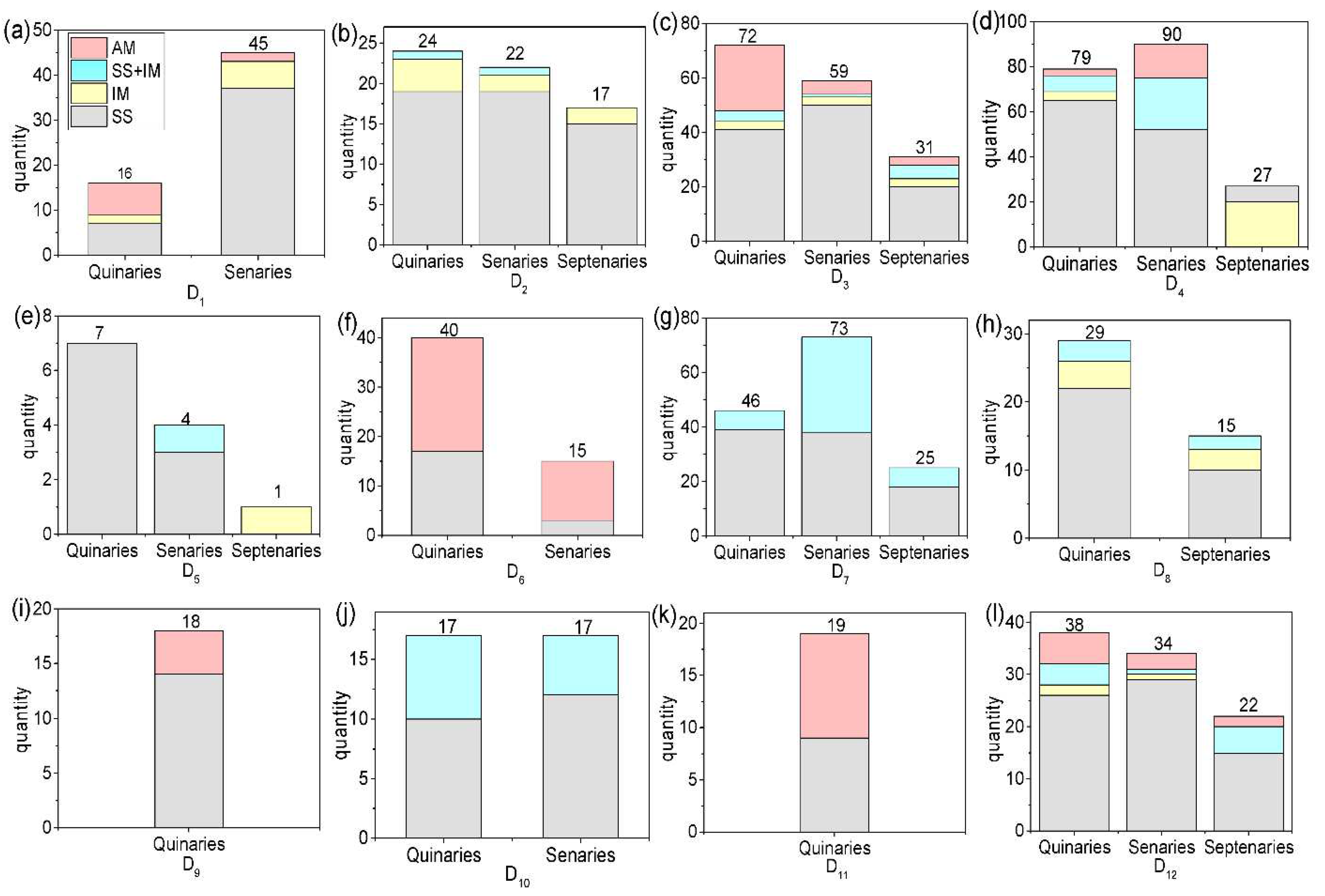
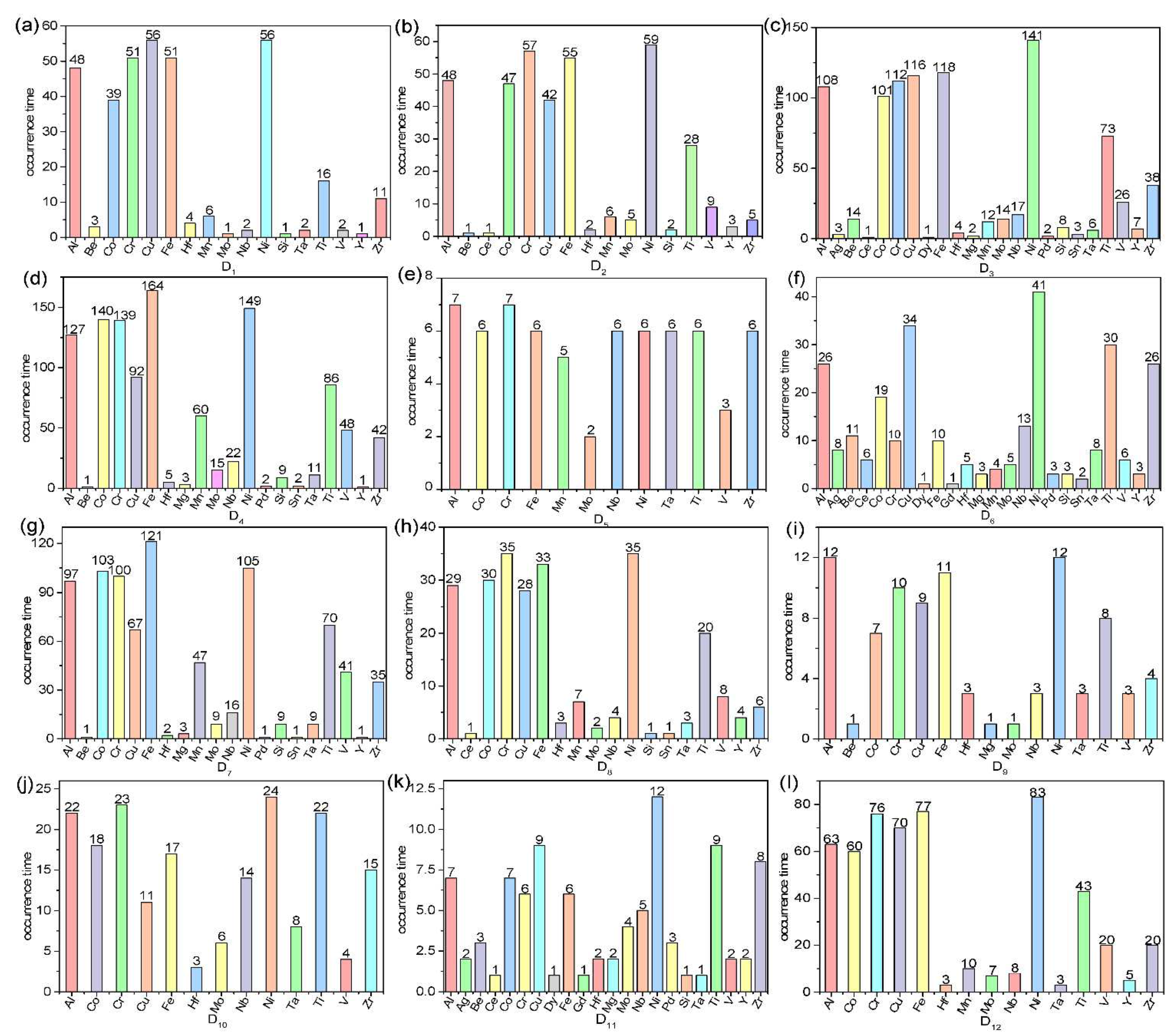
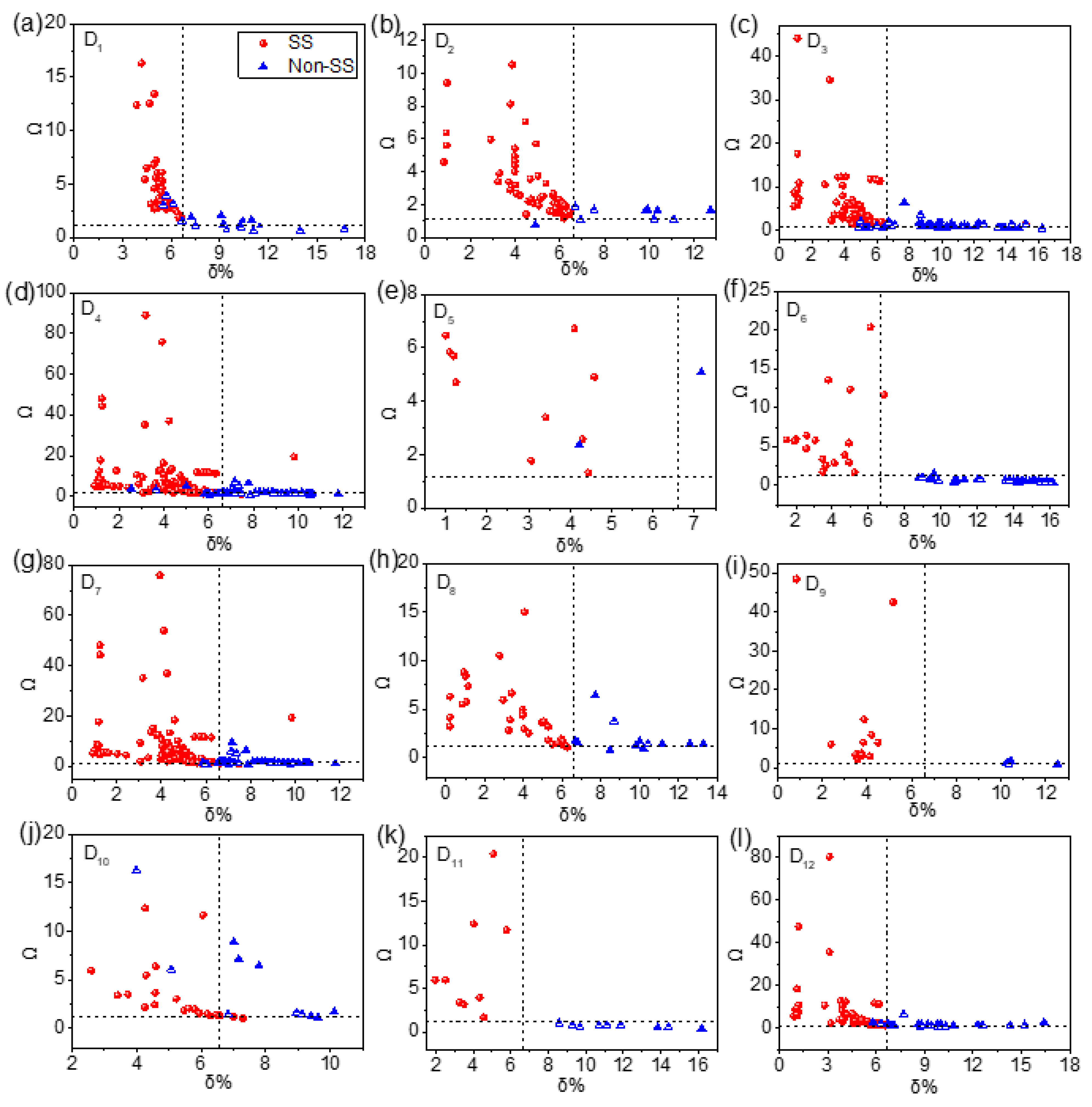
4.1. Overview of Experimental Datasets
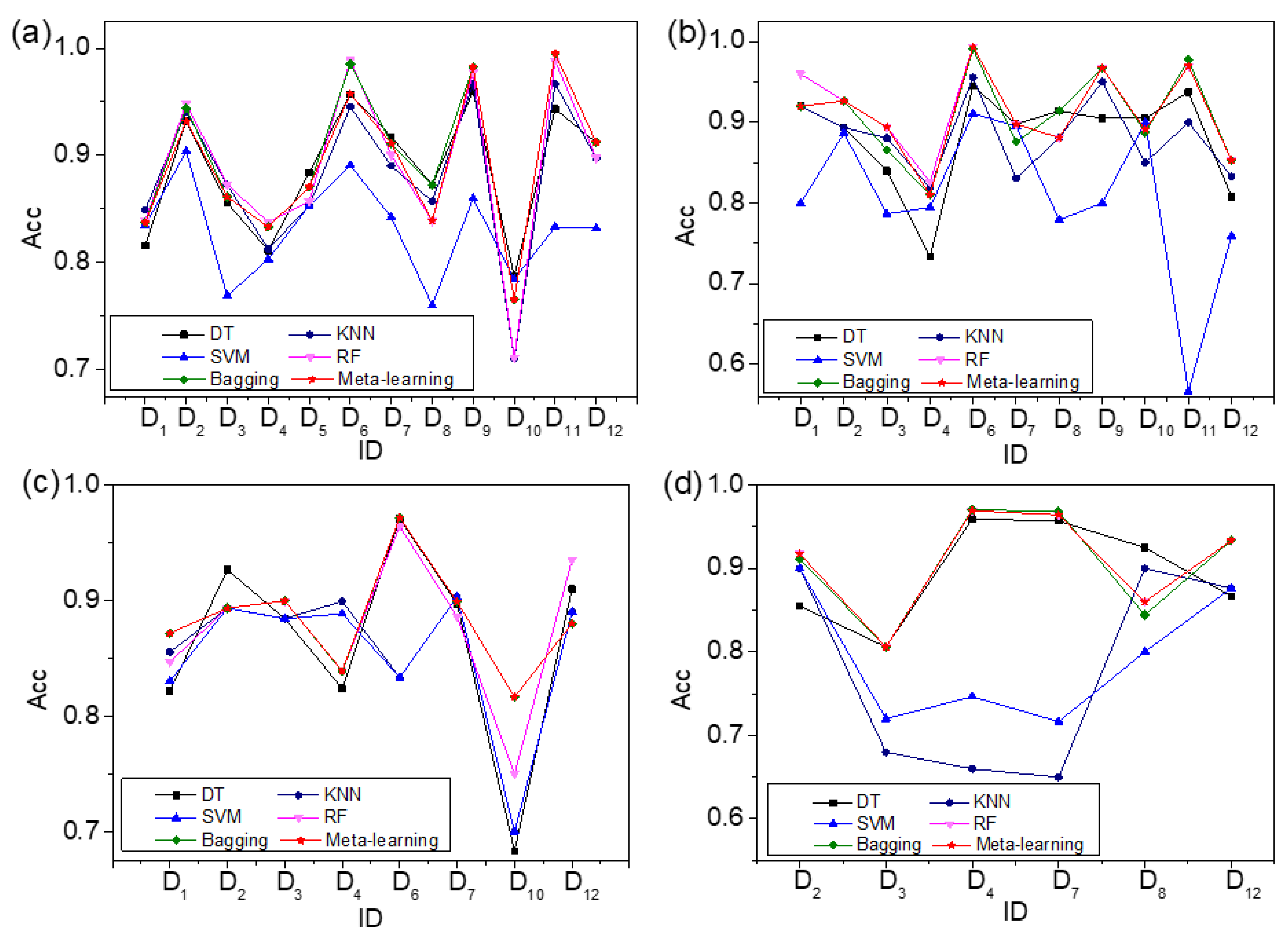
4.2. Comparison between Meta-Learning and Traditional ML Algorithms
4.3. Comparison between MLRM and Meta-Learning
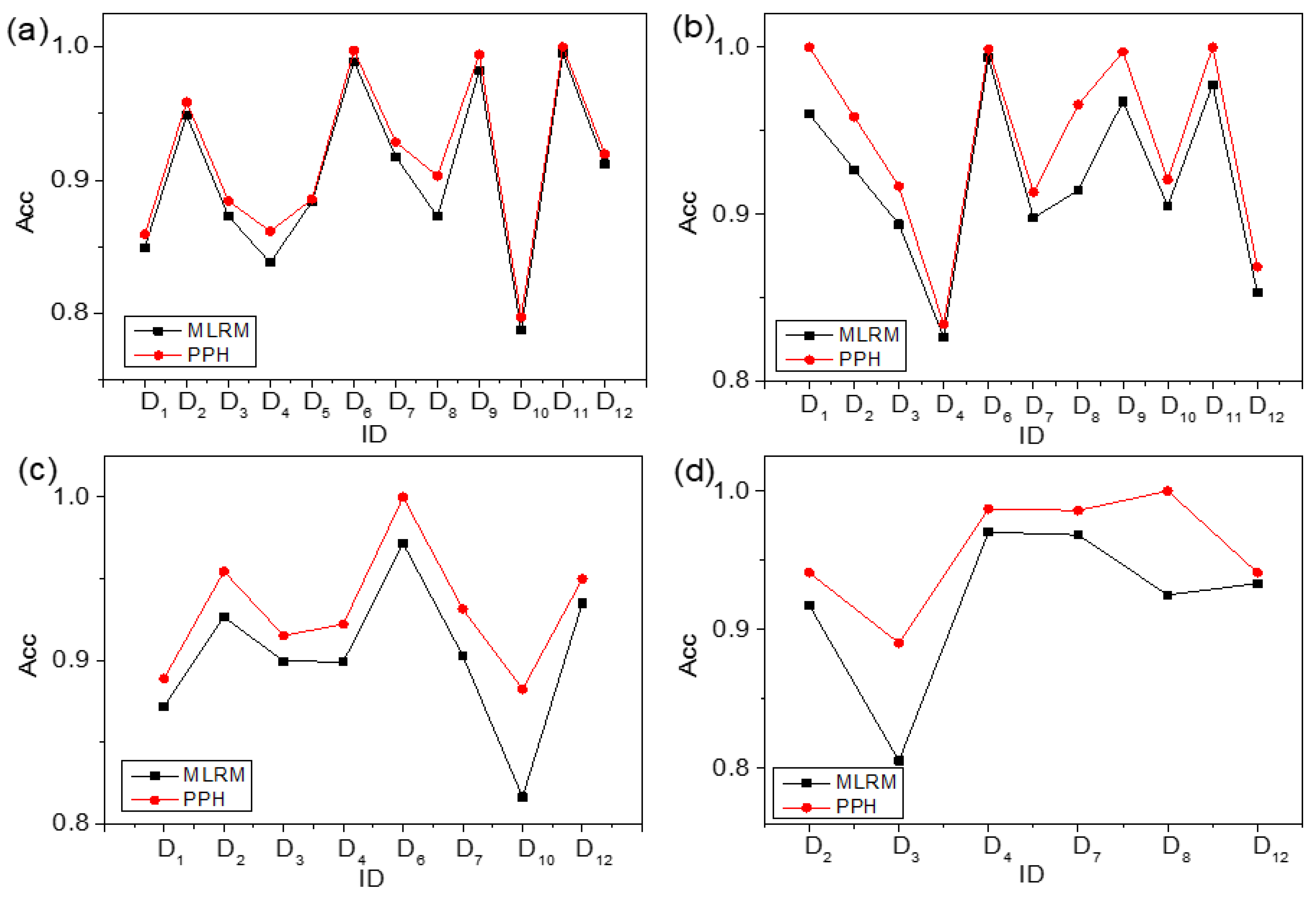
4.4. Comparison between PPH and MLRM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manzoor, A.; Pandey, S.; Chakraborty, D.; Phillpot, S.R.; Aidhy, D.S. Entropy contributions to phase stability in binary random solid solutions. NPJ Comput. Mater. 2018, 4, 1–10. [Google Scholar] [CrossRef]
- Gorniewicz, D.; Przygucki, H.; Kopec, M.; Karczewski, K.; Jozwiak, S. TiCoCrFeMn (BCC + C14) High-Entropy Alloy Multiphase Structure Analysis Based on the Theory of Molecular Orbitals. Materials 2021, 14, 5285. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Paudel, R.; Liu, Y.; Zhao, X.L.; Zhu, J.C. Theoretical and Experimental Studies of the Structural, Phase Stability and Elastic Properties of AlCrTiFeNi Multi-Principle Element Alloy. Materials 2020, 13, 4353. [Google Scholar] [CrossRef] [PubMed]
- Miracle, D.B.; Senkov, O.N. A critical review of high entropy alloys and related concepts. Acta Mater. 2017, 122, 448–511. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhang, Y. Prediction of high-entropy stabilized solid-solution in multi-component alloys. Mater. Chem. Phys. 2012, 132, 233–238. [Google Scholar] [CrossRef]
- Senkov, O.N.; Miracle, D.B. A new thermodynamic parameter to predict formation of solid solution or intermetallic phases in high entropy alloys. J. Alloys Compd. 2016, 658, 603–607. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.C.; Zhang, C.; Gao, P.; Zhang, F.; Ouyang, L.Z.; Widom, M.; Hawk, J.A. Thermodynamics of concentrated solid solution alloys. Curr. Opin. Solid State Mater. Sci. 2017, 21, 238–251. [Google Scholar] [CrossRef]
- Ding, Q.Q.; Zhang, Y.; Chen, X.; Fu, X.Q.; Chen, D.K.; Chen, S.J.; Gu, L.; Wei, F.; Bei, H.B.; Gao, Y.F.; et al. Tuning element distribution, structure and properties by composition in high-entropy alloys. Nature 2019, 574, 223–227. [Google Scholar] [CrossRef]
- Li, Z.M.; Pradeep, K.G.; Deng, Y.; Raabe, D.; Tasan, C.C. Metastable high-entropy dual-phase alloys overcome the strength-ductility trade-off. Nature 2016, 534, 227–230. [Google Scholar] [CrossRef]
- Ye, Y.F.; Wang, Q.; Lu, J.; Liu, C.T.; Yang, Y. High-entropy alloy: Challenges and prospects. Mater. Today 2016, 19, 349–362. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, X.; Liaw, P.K. Alloy Design and Properties Optimization of High-Entropy Alloys. JOM 2012, 64, 830–838. [Google Scholar] [CrossRef]
- Guo, S.; Liu, C.T. Phase stability in high entropy alloys: Formation of solid-solution phase or amorphous phase. Prog. Nat. Sci. Mater. Int. 2011, 21, 433–446. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.M.; Li, J.S.; Tang, Z.W.; Wang, J.; Kou, H.C. Design of high-entropy alloys with a single solid-solution phase: Average properties vs. their variances. J. Alloys Compd. 2018, 742, 430–441. [Google Scholar] [CrossRef]
- Dai, D.B.; Xu, T.; Wei, X.; Ding, G.T.; Xu, Y.; Zhang, J.C.; Zhang, H.R. Using machine learning and feature engineering to characterize limited material datasets of high-entropy alloys. Comput. Mater. Sci. 2020, 175, 1–6. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhou, Y.; He, Q.; Ding, Z.; Li, F.; Yang, Y. Machine learning guided appraisal and exploration of phase design for high entropy alloys. NPJ Comput. Mater. 2019, 5, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Pei, Z.; Yin, J.; Hawk, J.A.; Alman, D.E.; Gao, M.C. Machine-learning informed prediction of high-entropy solid solution formation: Beyond the Hume-Rothery rules. NPJ Comput. Mater. 2020, 6, 1–8. [Google Scholar] [CrossRef]
- Klimenko, D.; Stepanov, N.; Li, J.; Fang, Q.; Zherebtsov, S. Machine Learning-Based Strength Prediction for Refractory High-Entropy Alloys of the Al-Cr-Nb-Ti-V-Zr System. Materials 2021, 14, 7213. [Google Scholar] [CrossRef]
- Dai, W.; Zhang, L.; Fu, J.; Chai, T.; Ma, X. Dual-Rate Adaptive Optimal Tracking Control for Dense Medium Separation Process Using Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4202–4216. [Google Scholar] [CrossRef]
- Islam, N.; Huang, W.J.; Zhuang, H.L.L. Machine learning for phase selection in multi-principal element alloys. Comput. Mater. Sci. 2018, 150, 230–235. [Google Scholar] [CrossRef]
- Huang, W.J.; Martin, P.; Zhuang, H.L.L. Machine-learning phase prediction of high-entropy alloys. Acta Mater. 2019, 169, 225–236. [Google Scholar] [CrossRef]
- Qu, N.; Chen, Y.C.; Lai, Z.H.; Liu, Y.; Zhu, J.C. The phase selection via machine learning in high entropy alloys. Procedia Manuf. 2019, 37, 299–305. [Google Scholar] [CrossRef]
- Liu, H.; Chen, J.; Hissel, D.; Su, H. Remaining useful life estimation for proton exchange membrane fuel cells using a hybrid method. Appl. Energy 2019, 237, 910–919. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Search. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Khan, I.; Zhang, X.C.; Rehman, M.; Ali, R. A Literature Survey and Empirical Study of Meta-Learning for Classifier Selection. IEEE Access 2020, 8, 10262–10281. [Google Scholar] [CrossRef]
- Aguiar, G.J.; Mantovani, R.G.; Mastelini, S.M.; de Carvalho, A.C.P.F.L.; Campos, G.F.C.; Junior, S.B. A meta-learning approach for selecting image segmentation algorithm. Pattern Recognit. Lett. 2019, 128, 480–487. [Google Scholar] [CrossRef]
- Chu, X.H.; Cai, F.L.; Cui, C.; Hu, M.Q.; Li, L.; Qin, Q.D. Adaptive recommendation model using meta-learning for population-based algorithms. Inf. Sci. 2019, 476, 192–210. [Google Scholar] [CrossRef]
- Cui, C.; Hu, M.Q.; Weir, J.D.; Wu, T. A recommendation system for meta-modeling: A meta-learning based approach. Expert Syst. Appl. 2016, 46, 33–44. [Google Scholar] [CrossRef] [Green Version]
- Pimentel, B.A.; de Carvalho, A.C.P.L.F. A new data characterization for selecting clustering algorithms using meta-learning. Inf. Sci. 2019, 477, 203–219. [Google Scholar] [CrossRef]
- Ferrari, D.G.; de Castro, L.N. Clustering algorithm selection by meta-learning systems: A new distance-based problem characterization and ranking combination methods. Inf. Sci. 2015, 301, 181–194. [Google Scholar] [CrossRef]
- Song, Y.S.; Liang, J.Y.; Lu, J.; Zhao, X.W. An efficient instance selection algorithm for k nearest neighbor regression. Neurocomputing 2017, 251, 26–34. [Google Scholar] [CrossRef]
- Zhang, S.C. Shell-neighbor method and its application in missing data imputation. Appl. Intell. 2010, 35, 123–133. [Google Scholar] [CrossRef]
- Lv, W.; Mao, Z.Z.; Yuan, P.; Jia, M.X. Multi-kernel learnt partial linear regularization network and its application to predict the liquid steel temperature in ladle furnace. Knowl. Based Syst. 2012, 36, 280–287. [Google Scholar] [CrossRef]
- Lv, W.; Mao, Z.Z.; Yuan, P.; Jia, M.X. Pruned Bagging Aggregated Hybrid Prediction Models for Forecasting the Steel Temperature in Ladle Furnace. Steel Res. Int. 2014, 85, 405–414. [Google Scholar] [CrossRef]
- Hou, S.; Liu, J.H.; Lv, W. Flotation Height Prediction under Stable and Vibration States in Air Cushion Furnace Based on Hard Division Method. Math. Probl. Eng. 2019, 2019, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Chang, X.J.; Zeng, M.Q.; Liu, K.L.; Fu, L. Phase Engineering of High-Entropy Alloys. Adv. Mater. 2020, 32, 1–22. [Google Scholar] [CrossRef]
- Lemke, C.; Budka, M.; Gabrys, B. Metalearning: A survey of trends and technologies. Artif. Intell. Rev. 2015, 44, 117–130. [Google Scholar] [CrossRef] [Green Version]
- Arjmand, A.; Samizadeh, R.; Dehghani Saryazdi, M. Meta-learning in multivariate load demand forecasting with exogenous meta-features. Energy Effic. 2020, 13, 871–887. [Google Scholar] [CrossRef]
- Smith-Miles, K.A. Cross-disciplinary perspectives on meta-learning for algorithm selection. ACM Comput. Surv. 2009, 41, 1–25. [Google Scholar] [CrossRef]
- Zhang, S.C. Parimputation: From Imputation and Null-Imputation to Partially Imputation. IEEE Intell. Inform. Bull. 2008, 9, 32–38. [Google Scholar]
- Liu, H.W.; Wu, X.D.; Zhang, S.C. Neighbor selection for multilabel classification. Neurocomputing 2016, 182, 187–196. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, C.; Wang, C.X.; Antonov, S.; Xue, D.Z.; Bai, Y.; Su, Y.J. Phase prediction in high entropy alloys with a rational selection of materials descriptors and machine learning models. Acta Mater. 2020, 185, 528–539. [Google Scholar] [CrossRef]
- Tamal, M.; Alshammari, M.; Alabdullah, M.; Hourani, R.; Alola, H.A.; Hegazi, T.M. An integrated framework with machine learning and radiomics for accurate and rapid early diagnosis of COVID-19 from Chest X-ray. Expert Syst. Appl. 2021, 180, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Wani, M.A.; Roy, K.K. Development and validation of consensus machine learning-based models for the prediction of novel small molecules as potential anti-tubercular agents. Mol. Divers. 2021, 1–12. [Google Scholar] [CrossRef]
- Toda-Caraballo, I.; Rivera-Díaz-del-Castillo, P.E.J. A criterion for the formation of high entropy alloys based on lattice distortion. Intermetallics 2016, 71, 76–87. [Google Scholar] [CrossRef]
- Leong, Z.Y.; Huang, Y.H.; Goodall, R.; Todd, I. Electronegativity and enthalpy of mixing biplots for High Entropy Alloy solid solution prediction. Mater. Chem. Phys. 2018, 210, 259–268. [Google Scholar] [CrossRef]
- Poletti, M.G.; Battezzati, L. Electronic and thermodynamic criteria for the occurrence of high entropy alloys in metallic systems. Acta Mater. 2014, 75, 297–306. [Google Scholar] [CrossRef]
- King, D.J.M.; Middleburgh, S.C.; McGregor, A.G.; Cortie, M.B. Predicting the formation and stability of single phase high-entropy alloys. Acta Mater. 2016, 104, 172–179. [Google Scholar] [CrossRef]
- Andreoli, A.F.; Orava, J.; Liaw, P.K.; Weber, H.; de Oliveira, M.F.; Nielsch, K.; Kaban, I. The elastic-strain energy criterion of phase formation for complex concentrated alloys. Materialia 2019, 5, 1–12. [Google Scholar] [CrossRef]
- Peng, Y.T.; Zhou, C.Y.; Lin, P.; Wen, D.Y.; Wang, X.D.; Zhong, X.Z.; Pan, D.H.; Que, Q.; Li, X.; Chen, L.; et al. Preoperative Ultrasound Radiomics Signatures for Noninvasive Evaluation of Biological Characteristics of Intrahepatic Cholangiocarcinoma. Acad. Radiol. 2020, 27, 785–797. [Google Scholar] [CrossRef]
- Jung, Y. Multiple predicting K-fold cross-validation for model selection. J. Nonparametr. Stat. 2017, 30, 197–215. [Google Scholar] [CrossRef]
- Hou, S.; Zhang, X.; Dai, W.; Han, X.; Hua, F. Multi-Model- and Soft-Transition-Based Height Soft Sensor for an Air Cushion Furnace. Sensors 2020, 20, 926. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Parameter | Maximum Value | Minimum Value | Parameter Description |
|---|---|---|---|---|
| 1 | 16.18 | 7.78 | thermodynamic parameter | |
| 2 | 17.12 | −48.64 | chemical parameter | |
| 3 | 35.30 | 0.21 | electronic parameter | |
| 4 | 23.10 | 0.04 | electronic parameter | |
| 5 | 283.50 | 0.37 | chemical thermodynamic parameter |
| Number | HEAs | Phase | |||||
|---|---|---|---|---|---|---|---|
| 0 | AlCr0.5NbTiV | 13.150000 | −15.410000 | 5.230000 | 0.037647 | 1.680000 | SS |
| 1 | Mg65Cu15Ag5Pd5Gd10 | 9.100000 | −13.240000 | 9.360000 | 0.298062 | 0.770000 | AM |
| 2 | AlCoCrFeNiSi0.6 | 14.778118 | −22.755102 | 5.877203 | 0.120010 | 1.090691 | SS+IM |
| 3 | CoFeMnTiVZr0.4 | 14.585020 | −16.049383 | 8.088626 | 0.165697 | 1.692345 | IM |
| 4 | Ti0.2CoCrFeNiCuAl0.5 | 15.445251 | −4.148969 | 0.210000 | 0.118750 | 6.318158 | SS |
| 5 | Al0.5CoCrCuFeNiTi0.8 | 15.995280 | −10.100000 | 5.800000 | 0.137280 | 2.725683 | SS+IM |
| ID | DT | KNN | SVM | RF | Bagging | Meta-Learning |
|---|---|---|---|---|---|---|
| D1 | 0.816 ± 0.012 | 0.849 ± 0.008 | 0.835 ± 0.007 | 0.839 ± 0.010 | 0.837 ± 0.005 | 0.837 ± 0.005 |
| D2 | 0.932 ± 0.003 | 0.941 ± 0.022 | 0.904 ± 0.009 | 0.949 ± 0.013 | 0.944 ± 0.020 | 0.932 ± 0.003 |
| D3 | 0.856 ± 0.008 | 0.873 ± 0.019 | 0.769 ± 0.013 | 0.873 ± 0.003 | 0.861 ± 0.002 | 0.861 ± 0.002 |
| D4 | 0.811 ± 0.005 | 0.813 ± 0.012 | 0.803 ± 0.017 | 0.838 ± 0.009 | 0.833 ± 0.014 | 0.833 ± 0.014 |
| D5 | 0.884 ± 0.030 | 0.853 ± 0.016 | 0.853 ± 0.011 | 0.857 ± 0.012 | 0.871 ± 0.030 | 0.871 ± 0.030 |
| D6 | 0.957 ± 0.009 | 0.945 ± 0.004 | 0.891 ± 0.007 | 0.989 ± 0.007 | 0.985 ± 0.008 | 0.957 ± 0.009 |
| D7 | 0.918 ± 0.010 | 0.890 ± 0.027 | 0.842 ± 0.005 | 0.900 ± 0.008 | 0.911 ± 0.009 | 0.911 ± 0.009 |
| D8 | 0.873 ± 0.025 | 0.857 ± 0.017 | 0.760 ± 0.023 | 0.839 ± 0.011 | 0.872 ± 0.006 | 0.839 ± 0.011 |
| D9 | 0.960 ± 0.003 | 0.967 ± 0.006 | 0.860 ± 0.009 | 0.978 ± 0.010 | 0.983 ± 0.010 | 0.983 ± 0.010 |
| D10 | 0.787 ± 0.009 | 0.711 ± 0.019 | 0.784 ± 0.010 | 0.712 ± 0.012 | 0.766 ± 0.026 | 0.766 ± 0.026 |
| D11 | 0.943 ± 0.006 | 0.967 ± 0.016 | 0.833 ± 0.022 | 0.988 ± 0.002 | 0.995 ± 0.002 | 0.995 ± 0.002 |
| D12 | 0.912 ± 0.004 | 0.898 ± 0.012 | 0.832 ± 0.009 | 0.898 ± 0.015 | 0.912 ± 0.003 | 0.912 ± 0.003 |
| ID | DT | KNN | SVM | RF | Bagging | Meta-Learning |
|---|---|---|---|---|---|---|
| D1 | 0.920 ± 0.005 | 0.920 ± 0.003 | 0.800 ± 0.002 | 0.960 ± 0.027 | 0.920 ± 0.002 | 0.920 ± 0.002 |
| D2 | 0.893 ± 0.015 | 0.893 ± 0.012 | 0.887 ± 0.009 | 0.927 ± 0.005 | 0.927 ± 0.004 | 0.927 ± 0.004 |
| D3 | 0.840 ± 0.005 | 0.881 ± 0.015 | 0.786 ± 0.017 | 0.894 ± 0.010 | 0.866 ± 0.010 | 0.894 ± 0.010 |
| D4 | 0.733 ± 0.034 | 0.819 ± 0.011 | 0.795 ± 0.035 | 0.826 ± 0.034 | 0.810 ± 0.008 | 0.810 ± 0.008 |
| D6 | 0.945 ± 0.025 | 0.956 ± 0.005 | 0.911 ± 0.005 | 0.994 ± 0.002 | 0.991 ± 0.001 | 0.994 ± 0.002 |
| D7 | 0.898 ± 0.007 | 0.831 ± 0.004 | 0.895 ± 0.003 | 0.898 ± 0.005 | 0.876 ± 0.002 | 0.898 ± 0.005 |
| D8 | 0.914 ± 0.004 | 0.881 ± 0.007 | 0.779 ± 0.016 | 0.881 ± 0.003 | 0.914 ± 0.006 | 0.881 ± 0.003 |
| D9 | 0.905 ± 0.027 | 0.950 ± 0.011 | 0.800 ± 0.022 | 0.968 ± 0.006 | 0.968 ± 0.012 | 0.968 ± 0.006 |
| D10 | 0.905 ± 0.004 | 0.850 ± 0.008 | 0.900 ± 0.003 | 0.891 ± 0.027 | 0.888 ± 0.007 | 0.891 ± 0.027 |
| D11 | 0.938 ± 0.006 | 0.900 ± 0.024 | 0.567 ± 0.027 | 0.970 ± 0.009 | 0.978 ± 0.005 | 0.970 ± 0.009 |
| D12 | 0.808 ± 0.025 | 0.833 ± 0.023 | 0.759 ± 0.029 | 0.853 ± 0.022 | 0.853 ± 0.033 | 0.853 ± 0.022 |
| ID | DT | KNN | SVM | RF | Bagging | Meta-Learning |
|---|---|---|---|---|---|---|
| D1 | 0.822 ± 0.015 | 0.855 ± 0.008 | 0.830 ± 0.014 | 0.847 ± 0.007 | 0.872 ± 0.006 | 0.872 ± 0.006 |
| D2 | 0.927 ± 0.009 | 0.893 ± 0.013 | 0.893 ± 0.009 | 0.893 ± 0.020 | 0.893 ± 0.006 | 0.893 ± 0.006 |
| D3 | 0.884 ± 0.008 | 0.884 ± 0.011 | 0.884 ± 0.018 | 0.900 ± 0.014 | 0.900 ± 0.013 | 0.900 ± 0.013 |
| D4 | 0.824 ± 0.012 | 0.899 ± 0.017 | 0.889 ± 0.005 | 0.839 ± 0.010 | 0.838 ± 0.017 | 0.839 ± 0.010 |
| D6 | 0.971 ± 0.010 | 0.833 ± 0.009 | 0.833 ± 0.011 | 0.964 ± 0.017 | 0.972 ± 0.012 | 0.972 ± 0.012 |
| D7 | 0.897 ± 0.007 | 0.903 ± 0.002 | 0.903 ± 0.013 | 0.886 ± 0.008 | 0.899 ± 0.008 | 0.899 ± 0.008 |
| D10 | 0.683 ± 0.023 | 0.700 ± 0.036 | 0.700 ± 0.010 | 0.750 ± 0.032 | 0.817 ± 0.006 | 0.817 ± 0.006 |
| D12 | 0.910 ± 0.020 | 0.890 ± 0.007 | 0.890 ± 0.009 | 0.935 ± 0.005 | 0.880 ± 0.027 | 0.880 ± 0.027 |
| ID | DT | KNN | SVM | RF | Bagging | Meta-Learning |
|---|---|---|---|---|---|---|
| D2 | 0.855 ± 0.031 | 0.900 ± 0.005 | 0.900 ± 0.007 | 0.918 ± 0.022 | 0.911 ± 0.013 | 0.918 ± 0.022 |
| D3 | 0.806 ± 0.016 | 0.680 ± 0.008 | 0.720 ± 0.005 | 0.806 ± 0.007 | 0.806 ± 0.011 | 0.806 ± 0.007 |
| D4 | 0.959 ± 0.009 | 0.660 ± 0.028 | 0.747 ± 0.012 | 0.969 ± 0.013 | 0.970 ± 0.005 | 0.969 ± 0.013 |
| D7 | 0.957 ± 0.015 | 0.650 ± 0.019 | 0.717 ± 0.019 | 0.964 ± 0.009 | 0.968 ± 0.018 | 0.964 ± 0.009 |
| D8 | 0.925 ± 0.033 | 0.900 ± 0.023 | 0.800 ± 0.035 | 0.860 ± 0.018 | 0.844 ± 0.017 | 0.860 ± 0.018 |
| D12 | 0.867 ± 0.027 | 0.876 ± 0.034 | 0.876 ± 0.031 | 0.933 ± 0.022 | 0.933 ± 0.033 | 0.933 ± 0.022 |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | Bagging, KNN | KNN, RF | KNN, RF |
| D2 | DT, Bagging | RF, Bagging | RF, Bagging |
| D3 | Bagging, RF | RF, Bagging | RF, KNN |
| D4 | Bagging, DT | RF, Bagging | RF, Bagging |
| D5 | Bagging, RF | DT, Bagging | DT, Bagging |
| D6 | DT, Bagging | RF, Bagging | RF, Bagging |
| D7 | Bagging, RF | DT, Bagging | DT, Bagging |
| D8 | RF, Bagging | DT, Bagging | DT, Bagging |
| D9 | Bagging, DT | Bagging, RF | Bagging, RF |
| D10 | Bagging, RF | DT, Bagging | DT, SVM |
| D11 | Bagging, RF | Bagging, RF | Bagging, RF |
| D12 | Bagging, RF | Bagging, RF | Bagging, DT |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | Bagging, RF | RF, Bagging | RF, Bagging |
| D2 | Bagging, RF | Bagging, RF | Bagging, RF |
| D3 | RF, Bagging | RF, Bagging | RF, KNN |
| D4 | Bagging, RF | RF, Bagging | RF, KNN |
| D6 | RF, Bagging | RF, Bagging | RF, Bagging |
| D7 | RF, Bagging | RF, Bagging | RF, DT |
| D8 | RF, Bagging | DT, Bagging | DT, Bagging |
| D9 | RF, Bagging | RF, Bagging | RF, Bagging |
| D10 | RF, Bagging | DT, RF | DT, SVM |
| D11 | RF, Bagging | Bagging, RF | Bagging, RF |
| D12 | RF, Bagging | RF, Bagging | RF, Bagging |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | Bagging, RF | Bagging, KNN | Bagging, KNN |
| D2 | Bagging, RF | DT, Bagging | DT, Bagging |
| D3 | Bagging, RF | Bagging, RF | Bagging, RF |
| D4 | RF, Bagging | KNN, SVM | KNN, SVM |
| D6 | Bagging, RF | Bagging, RF | Bagging, DT |
| D7 | Bagging RF | KNN, SVM | KNN, SVM |
| D10 | Bagging, DT | Bagging, RF | Bagging, RF |
| D12 | Bagging RF | RF, DT | RF, DT |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D2 | RF, Bagging | RF, Bagging | RF, Bagging |
| D3 | RF, Bagging | RF, Bagging | RF, Bagging |
| D4 | RF, Bagging | Bagging, RF | Bagging, RF |
| D7 | RF, Bagging | Bagging, RF | Bagging, RF |
| D8 | RF, Bagging | DT, RF | DT, KNN |
| D12 | RF, DT | RF, Bagging | RF, Bagging |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | 0.837 ± 0.005 | 0.849 ± 0.008 | 0.849 ± 0.008 |
| D2 | 0.932 ± 0.003 | 0.949 ± 0.013 | 0.949 ± 0.013 |
| D3 | 0.861 ± 0.002 | 0.873 ± 0.003 | 0.873 ± 0.003 |
| D4 | 0.833 ± 0.014 | 0.838 ± 0.009 | 0.838 ± 0.009 |
| D5 | 0.871 ± 0.030 | 0.884 ± 0.030 | 0.884 ± 0.030 |
| D6 | 0.957 ± 0.009 | 0.989 ± 0.007 | 0.989 ± 0.007 |
| D7 | 0.911 ± 0.009 | 0.918 ± 0.010 | 0.918 ± 0.010 |
| D8 | 0.839 ± 0.011 | 0.873 ± 0.025 | 0.873 ± 0.025 |
| D9 | 0.983 ± 0.010 | 0.983 ± 0.010 | 0.983 ± 0.010 |
| D10 | 0.766 ± 0.026 | 0.787 ± 0.009 | 0.787 ± 0.009 |
| D11 | 0.995 ± 0.002 | 0.995 ± 0.002 | 0.995 ± 0.002 |
| D12 | 0.912 ± 0.003 | 0.912 ± 0.003 | 0.912 ± 0.003 |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | 0.920 ± 0.002 | 0.960 ± 0.027 | 0.960 ± 0.027 |
| D2 | 0.927 ± 0.004 | 0.927 ± 0.004 | 0.927 ± 0.004 |
| D3 | 0.894 ± 0.010 | 0.894 ± 0.010 | 0.894 ± 0.010 |
| D4 | 0.810 ± 0.008 | 0.826 ± 0.034 | 0.826 ± 0.034 |
| D6 | 0.994 ± 0.002 | 0.994 ± 0.002 | 0.994 ± 0.002 |
| D7 | 0.898 ± 0.005 | 0.898 ± 0.005 | 0.898 ± 0.005 |
| D8 | 0.881 ± 0.003 | 0.914 ± 0.004 | 0.914 ± 0.004 |
| D9 | 0.968 ± 0.006 | 0.968 ± 0.006 | 0.968 ± 0.006 |
| D10 | 0.891 ± 0.027 | 0.905 ± 0.004 | 0.905 ± 0.004 |
| D11 | 0.970 ± 0.009 | 0.978 ± 0.005 | 0.978 ± 0.005 |
| D12 | 0.853 ± 0.022 | 0.853 ± 0.022 | 0.853 ± 0.022 |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D1 | 0.872 ± 0.006 | 0.872 ± 0.006 | 0.872 ± 0.006 |
| D2 | 0.893 ± 0.006 | 0.927 ± 0.009 | 0.927 ± 0.009 |
| D3 | 0.900 ± 0.013 | 0.900 ± 0.013 | 0.900 ± 0.013 |
| D4 | 0.839 ± 0.010 | 0.899 ± 0.017 | 0.899 ± 0.017 |
| D6 | 0.972 ± 0.012 | 0.972 ± 0.012 | 0.972 ± 0.012 |
| D7 | 0.899 ± 0.008 | 0.903 ± 0.002 | 0.903 ± 0.002 |
| D10 | 0.817 ± 0.006 | 0.817 ± 0.006 | 0.817 ± 0.006 |
| D12 | 0.880 ± 0.027 | 0.935 ± 0.005 | 0.935 ± 0.005 |
| ID | Meta-Learning | MLRM | TRUE |
|---|---|---|---|
| D2 | 0.918 ± 0.022 | 0.918 ± 0.022 | 0.918 ± 0.022 |
| D3 | 0.806 ± 0.007 | 0.806 ± 0.007 | 0.806 ± 0.007 |
| D4 | 0.969 ± 0.013 | 0.970 ± 0.005 | 0.970 ± 0.005 |
| D7 | 0.964 ± 0.009 | 0.968 ± 0.018 | 0.968 ± 0.018 |
| D8 | 0.860 ± 0.018 | 0.925 ± 0.033 | 0.925 ± 0.033 |
| D12 | 0.933 ± 0.022 | 0.933 ± 0.022 | 0.933 ± 0.022 |
| ID | All | Quinaries | Senaries | Septenaries | ||||
|---|---|---|---|---|---|---|---|---|
| MLRM | PPH | MLRM | PPH | MLRM | PPH | MLRM | PPH | |
| D1 | 0.849 ± 0.008 | 0.859 ± 0.005 | 0.960 ± 0.027 | 1.000 ± 0.000 | 0.872 ± 0.006 | 0.889 ± 0.008 | NULL | NULL |
| D2 | 0.949 ± 0.013 | 0.959 ± 0.007 | 0.927 ± 0.004 | 0.958 ± 0.021 | 0.927 ± 0.009 | 0.955 ± 0.014 | 0.918 ± 0.022 | 0.941 ± 0.009 |
| D3 | 0.873 ± 0.003 | 0.884 ± 0.011 | 0.894 ± 0.010 | 0.917 ± 0.013 | 0.900 ± 0.013 | 0.915 ± 0.009 | 0.806 ± 0.007 | 0.890 ± 0.010 |
| D4 | 0.838 ± 0.009 | 0.862 ± 0.013 | 0.826 ± 0.034 | 0.834 ± 0.016 | 0.899 ± 0.017 | 0.922 ± 0.007 | 0.970 ± 0.005 | 0.987 ± 0.005 |
| D5 | 0.884 ± 0.030 | 0.886 ± 0.009 | NULL | NULL | NULL | NULL | NULL | NULL |
| D6 | 0.989 ± 0.007 | 0.997 ± 0.002 | 0.994 ± 0.002 | 0.999 ± 0.001 | 0.972 ± 0.012 | 1.000 ± 0.000 | NULL | NULL |
| D7 | 0.918 ± 0.010 | 0.929 ± 0.004 | 0.898 ± 0.005 | 0.913 ± 0.005 | 0.903 ± 0.002 | 0.932 ± 0.013 | 0.968 ± 0.018 | 0.986 ± 0.006 |
| D8 | 0.873 ± 0.025 | 0.903 ± 0.020 | 0.914 ± 0.004 | 0.966 ± 0.004 | NULL | NULL | 0.925 ± 0.033 | 1.000 ± 0.000 |
| D9 | 0.983 ± 0.010 | 0.994 ± 0.003 | 0.968 ± 0.006 | 0.997 ± 0.002 | NULL | NULL | NULL | NULL |
| D10 | 0.787 ± 0.009 | 0.797 ± 0.002 | 0.905 ± 0.004 | 0.921 ± 0.012 | 0.817 ± 0.006 | 0.882 ± 0.025 | NULL | NULL |
| D11 | 0.995 ± 0.002 | 1.000 ± 0.000 | 0.978 ± 0.005 | 1.000 ± 0.000 | NULL | NULL | NULL | NULL |
| D12 | 0.912 ± 0.003 | 0.920 ± 0.004 | 0.853 ± 0.022 | 0.868 ± 0.011 | 0.935 ± 0.005 | 0.950 ± 0.019 | 0.933 ± 0.022 | 0.941 ± 0.008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, S.; Li, Y.; Bai, M.; Sun, M.; Liu, W.; Wang, C.; Tetik, H.; Lin, D. Phase Prediction of High-Entropy Alloys by Integrating Criterion and Machine Learning Recommendation Method. Materials 2022, 15, 3321. https://doi.org/10.3390/ma15093321
Hou S, Li Y, Bai M, Sun M, Liu W, Wang C, Tetik H, Lin D. Phase Prediction of High-Entropy Alloys by Integrating Criterion and Machine Learning Recommendation Method. Materials. 2022; 15(9):3321. https://doi.org/10.3390/ma15093321
Chicago/Turabian StyleHou, Shuai, Yujiao Li, Meijuan Bai, Mengyue Sun, Weiwei Liu, Chao Wang, Halil Tetik, and Dong Lin. 2022. "Phase Prediction of High-Entropy Alloys by Integrating Criterion and Machine Learning Recommendation Method" Materials 15, no. 9: 3321. https://doi.org/10.3390/ma15093321
APA StyleHou, S., Li, Y., Bai, M., Sun, M., Liu, W., Wang, C., Tetik, H., & Lin, D. (2022). Phase Prediction of High-Entropy Alloys by Integrating Criterion and Machine Learning Recommendation Method. Materials, 15(9), 3321. https://doi.org/10.3390/ma15093321