Abstract
In recent decades, a variety of organizational sectors have demanded and researched green structural materials. Concrete is the most extensively used manmade material. Given the adverse environmental effect of cement manufacturing, research has focused on minimizing environmental impact and cement-based product costs. Metakaolin (MK) as an additive or partial cement replacement is a key subject of concrete research. Developing predictive machine learning (ML) models is crucial as environmental challenges rise. Since cement-based materials have few ML approaches, it is important to develop strategies to enhance their mechanical properties. This article analyses ML techniques for forecasting MK concrete compressive strength (fc’). Three different individual and ensemble ML predictive models are presented in detail, namely decision tree (DT), multilayer perceptron neural network (MLPNN), and random forest (RF), along with the most effective factors, allowing for efficient investigation and prediction of the fc’ of MK concrete. The authors used a database of MK concrete mechanical features for model generalization, a key aspect of any prediction or simulation effort. The database includes 551 data points with relevant model parameters for computing MK concrete’s fc’. The database contains cement, metakaolin, coarse and fine aggregate, water, silica fume, superplasticizer, and age, which affect concrete’s fc’ but were seldom considered critical input characteristics in the past. Finally, the performance of the models is assessed to pick and deploy the best predicted model for MK concrete mechanical characteristics. K-fold cross validation was employed to avoid overfitting issues of the models. Additionally, ML approaches were utilized to combine SHapley Additive exPlanations (SHAP) data to better understand the MK mix design non-linear behaviour and how each input parameter’s weighting influences the total contribution. Results depict that DT AdaBoost and modified bagging are the best ML algorithms for predicting MK concrete fc’ with R2 = 0.92. Moreover, according to SHAP analysis, age impacts MK concrete fc’ the most, followed by coarse aggregate and superplasticizer. Silica fume affects MK concrete’s fc’ least. ML algorithms estimate MK concrete’s mechanical characteristics to promote sustainability.
1. Introduction
Throughout the previous decades, there has been a strong demand and concern for investigation to develop green structural materials to meet the increasing need from public and private sectors. Concrete continues to be the most widely utilized manmade substance on the planet. Given the considerable environmental impact of cement production, research has concentrated on both reducing the impact on the environment and cost reductions for cement-based products [1,2,3]. The utilization of metakaolin (MK) as an additive or partial substitute for cement is a major area of research in the manufacture of concrete materials.
MK is an alternative to cement that is manufactured by calcining kaolin clays at elevated temperatures ranging from 700 °C to 900 °C. As a cement replacement in concrete structures, MK has been employed as a 10% to 50% replacement, depending on the specific application [4,5,6,7]. It has been shown that MK enhances the mechanical and durability properties when used in place of Portland cement [8,9,10]. The pozzolanic reaction, MK aggregate’s fineness, and the accelerated cement hydration all contribute to an increase in concrete’s compressive strength (fc’) during the early curing phases [11]. Additionally, cement manufacture generates a substantial amount of carbon dioxide (CO2) emissions; this new trend of replacing metakaolin for cement in concrete is part of a comprehensive approach to environmental sustainability. Addition of MK in concrete has various advantages as depicted in Figure 1.
Figure 1.
Advantages of metakaolin in concrete.
The cost, labour, and time consuming complexity of laboratory-based mixture optimisation might be replaced by computational modelling techniques [12]. To determine the optimum concrete mixtures, these approaches generate objective functions from the concrete components and their properties, and then use optimization techniques to determine the best concrete mixtures. Previously, goal functions for linear and nonlinear models were individually created. Due to the very nonlinear connections between concrete qualities and input parameters, the relationships of such models cannot be precisely established. Therefore, researchers are using machine learning (ML) techniques for predicting concrete properties.
Creating a concrete mix with MK in it complicates the determination of the concrete’s fc’ using an analytical formula, as opposed to a standard concrete, which has fewer mix parameters than cement MK specimen. This is mostly because of the enormous number of constituents and the fc’ very nonlinear behaviour in regard to the mix parameters. To this purpose, when basic equations cannot directly connect the input and output values, machine learning (ML) techniques frequently give important alternatives in the context of engineering problem solving [13,14,15,16,17,18,19,20,21,22]. Owing to the intricate nonlinear interactions amongst independent and dependent variables, such techniques can be accomplished with a sufficient level of accuracy if a comprehensive library of sufficient experimental data points is accessible in the area of computational engineering structures and materials. Thus, a wide range of innovative approaches to a wide range of technological problems may be put into practice.
Until now, the literature has primarily focused on the use of ML techniques such as artificial neural network (ANN) in the field of materials science without ensemble learners [23,24,25,26]. These algorithms were utilized to predict the fc’ and elasticity modulus of materials composed of cement [26,27,28,29]. The literature has comprehensive and extensive publications on the use of ANNs in the modelling of concrete materials [30,31,32,33,34,35]. Fuzzy logic algorithms and genetic algorithms approaches have also been utilized in the recent decade in place of ANN models to describe the mechanical properties of cement-based materials [36,37,38,39,40,41].
Since cement-based materials have a limited number of ML methods, it is vital to investigate if other ML techniques may be used to improve their mechanical characteristics. Thus, the present work investigates ML approaches application for predicting the fc’ of MK concrete. Three different individual and ensemble ML predictive models are presented in detail, namely decision tree (DT), multilayer perceptron neural network (MLPNN), and random forest (RF), together with the factors that are most effective, allowing for efficient investigation and prediction of the fc’ of cement-based concrete. The authors employed a comprehensive database of MK concrete mechanical characteristics for model generalisation since it is an essential part of any prediction or simulation work. The reported database contains 551 data points with highly effective input parameters for calculating the fc’ of MK concrete. The database includes a value for cement, metakaolin, coarse and fine aggregate, water, silica fume, superplasticizer, and age, which have a considerable effect on the fc’ of concrete and have rarely been treated as vital input parameters in the past. The trained and created model has produced a holistic map of concrete fc’. Finally, the performance capabilities of the offered models are evaluated in order to select and implement the most predictive model for addressing the mechanical properties of MK concrete.
There has been a surge in increased interest in large-scale production of sustainable, low-priced, and high-performance construction materials that are also robust in adverse ecological circumstances over the previous few decades. One of the world’s most common construction materials—cement-based concrete—required the incorporation of more components and additives than previously used concrete because of environmental concerns. However, the high number of mixture factors and their substantially nonlinear relationship to the mechanical characteristics of concrete, such as the fc’, challenge the analytical methods for numerically estimating the concrete fc’. To this purpose, unconventional methods become a critical instrument for resolving the afore-mentioned complicated optimisation problem. In this perspective, the most widely used ML techniques, such as, DT, MLPNN, and RF, have been suggested for estimating the fc’ of concrete, a critical parameter for the reliable design in structure. Among the proposed ML models, the optimal predictive model has shown to be extremely successful, demonstrating trustworthy projections and, most importantly, showing its highly non-linear mechanical properties.
Additionally, there seems to be a research gap in the study of MK fc’ and its influence on raw materials. It was, thus, necessary to investigate the influence of MK containing concrete’s input parameters/raw components on its anticipated compressive strength using a post hoc model-agnostic approach known as SHapley Additive exPlanations (SHAP) [42,43]. Machine learning (ML) techniques were used to integrate SHAP data in order to get a better understanding of the multifarious non-linear behaviour of the MK design mix for the strength parameter and how each input parameter’s weighting affects the overall contribution. ML approaches may be used to accurately forecast concrete kinds, as previously stated. The experimental setting requires a significant investment in terms of labour, time, and resources to do this. Data modelling and the discovery of interconnected independent components, as well as a rapid reduction in input matrix size are, thus, urgently required. Concrete construction materials may be accurately predicted using machine learning approaches. The use of ML methods may be justified as an alternate strategy to calculating MK fc’ in order to save on both time and money spent on experiments. We used both a stand-alone ML model and an ensemble of ML models in our investigation. Additionally, statistical tests were used to evaluate the models, and their results were compared. Later, a model with precise MK prediction was suggested based on the performance of several statistical factors. In order to get a thorough understanding of mix design in order to achieve MK concrete strength, this research also explained how input factors contributed and how ML models were integrated. Explainable ML techniques and features significance for considerable characteristics of the structure were found to be linked in the study’s overall findings.
2. Data Description
Currently accessible literature has been used to get the data needed to simulate concrete’s fc’ utilising MK [44,45,46,47,48,49,50,51,52,53,54,55]. The predicted output compressive strength data consists of eight input parameters, which include cement, MK, fine and coarse aggregate, water, age of concrete, superplasticizer, and silica fume. Type of cement is not considered as an input parameter, as only one type of cement (Type-I) is utilized for modelling the ML algorithms. Cement and metakaolin are two constituents that are prevalent among those selected for the database. Additionally, attempts were made to choose articles that share common components (admixtures, superplasticizers, etc.). The authors tried to choose publications based on criteria related to materials that are widely used in concrete and make important contributions to concrete’s mechanical characteristics. Further, similar material in varied arrangements is required for modelling ML algorithms. Except for age in days, all characteristics are measured in kilograms/m3. Descriptive statistics are a set of descriptive coefficients that provide a result that may be applied to the whole population or to a sample of the population. In descriptive statistics, measures of central tendency and measures of variability are used (spread). However, variance, standard deviation, maximum and minimum variables, kurtosis, and skewness are all indices of variability. Table 1 and Table 2 and Figure 2 provide the variation in data used to run the models. Various information is reflected in the descriptive analysis’s outcomes, which are derived from the data of all the input variables. Additionally, the table displays the ranges, maximum, and lowest values of each model variable. Nonetheless, the other parameters of the study, such as mean, mode, standard deviation, and the total of all data points for each variable, also reveal the important values. Figure 2 depicts the relative frequency distribution of each parameter utilised in the mixes. A relative frequency distribution illustrates the percentage of total observations that correspond to each value or class of values. It has tight ties to a probability distribution, which is often used in statistics. Figure 2 depicts the link of input parameters by displaying the relative frequency distribution of data items. Each chosen parameter has a significant impact on the concrete’s strength characteristics. In addition, Table 1 displays the lowest and highest variable values including 551 datasets, and Table 2 provides a data analysis check with the variance, range, standard deviation, and mean.

Table 1.
Metakaolin concrete compressive strength model input and output variable ranges.
Table 2.
Statistical description of Metakaolin concrete variables.
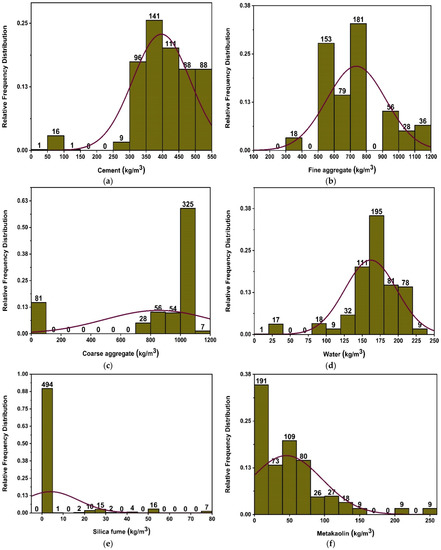
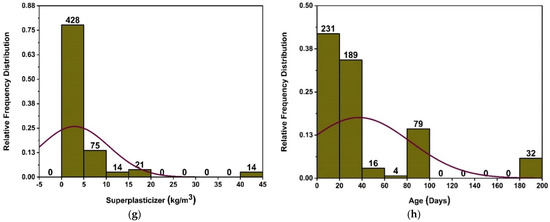
Figure 2.
Compressive strength parameters’ relative frequency distribution; (a) cement, (b) fine aggregate, (c) coarse aggregate, (d) water, (e) silica fume, (f) metakaolin, (g) superplasticizer, and (h) age.
3. Methodology
ML techniques are being used in a variety of fields to anticipate and understand the behaviour of materials. In this work, ML-based techniques comprising of the DT, MLPNN, and RF are employed for forecasting the fc’ of MK concrete. The selection of these methods is based on their prevalence and reliability in the forecast of outcomes in comparable studies, as well as their significance as the top data mining algorithms. In addition, an ensemble algorithm was afterwards employed to simulate the concrete fc’. Figure 3 displays the technique flow chat for ensemble learning.
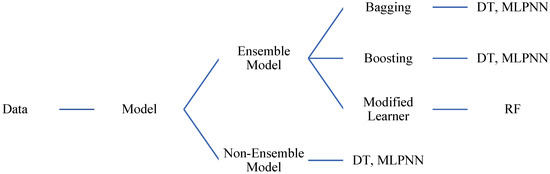
Figure 3.
Flow chart of ML techniques.
3.1. Machine Learning Methods
It has been shown that artificial intelligence (AI) is a more effective modelling methodology than traditional methods. AI has a number of advantages for addressing ambiguous difficulties and is an excellent method for handling such complicated situations. It is possible to identify engineering design parameters using AI-based methods when testing is not possible, resulting in significantly reducing the workload of human testers. In addition, AI could expedite decision making, decrease error, and improve processing efficacy [56]. Recently, a rise of interest in the application of artificial intelligence to all scientific fields has been observed, sparking a range of goals and aspirations. The field of civil engineering has experienced a significant increase for utilizing different AI methods all over its numerous fields. ML, reinforcement learning, and deep learning (DL) are three AI approaches that are proving to be a new category of creative approaches to structural engineering problems. ML is a fast-expanding area of AI that is often used in the construction sector for predicting behaviour of material. One project aims to investigate inclusion of social elements into multi criteria infrastructure assessment strategies, with inclusion of social factors into the assessment of infrastructure’s long-term viability using multi-criteria assessment techniques [57]. In the framework of structural design, exhaustive study on evolutionary computation, an area of artificial intelligence, was conducted [58]. Yin et al. [59] explored AI uses in geotechnical engineering. A study was done to determine the state of high-rise building optimization. [60]. In order to synthesise concepts in the developing field of AI applications in civil engineering, this study was done. This list contains a broad variety of methods: Fuzzy systems (FS), neural networks, expert systems (ES), reasoning, categorization, and learning are only a few examples of evolutionary computing [61].
In spite of the fact that the referenced review papers discussed the use of AI in civil engineering, they mostly concentrated on the usage of old approaches and did not cover latest methods using ensemble techniques. Figure 3 shows an estimation of the fc’ of MK concrete using ML approaches including DT, MLPNN, and RF. These algorithms were selected on the basis of their broad usage in relevant research and their reputation as the finest data prediction algorithms available. In addition, ensemble techniques are employed to predict the concrete modelling strength. In terms of computational speed and processing time, ML models are fairly significant. Compared to conventional models, the rate of error is almost non-existent. A comparison is made among individual and ensemble models in this research. SHAP analysis is performed to find the optimum dosage and contribution of each input parameter towards fc’. Moreover, positive and negative impacts of each input parameter and their effect on other parameters are also studied.
3.1.1. Decision Tree-Based Machine Learning
In DT, any number of nodes can be connected to any number of branches, and each node can have an infinite number of branches. Leaves are the nodes that do not have any outgoing ends, whereas inner nodes are those that do. Using an interior node for a specific event, the case utilized for classification or regression can be partitioned into multiple classes. During the learning process, the input variables play an important role. The algorithm that generates the DT from provided instances serves as the stimulant for the DT. By reducing the fitness function, the implemented algorithm calculates the optimal DT. A regression model is used because there are no classes in the dataset selected for this study, so the independent variables are used instead of the target variable. For each variable, the dataset is broken up into many subsets. The error among the anticipated and the actual values of the pre-specified relation is determined at every split point by the algorithm. The variable having least values of fitness function is selected as the split point after comparing the inaccuracies in the split point across the variable quantity. Repeatedly, this technique is carried out.
In the DT architecture, independent variables are partitioned into homogenous zones by decision rules that recursively split them [62]. DT is primarily concerned with the investigation of a system for making decisions that are suitable for predicting a result given a collection of inputs. DT is referred to as a regression tree or a classification tree, depending on whether the target variables are continuous or discrete [63]. Numerous studies have demonstrated the effectiveness of DT in a variety of real-world situations for the aim of prediction and/or categorization [64].
The primary advantage of DT is its ability to simulate complex interactions between existent variables. Through consideration of how data are distributed, DT models are capable of combining both continuous and categorical variables without making any stringent assumptions [65]. Additionally, developing a DT is straightforward, and the resulting models are easily interpretable. Additionally, when it comes to determining the relative relevance of input characteristics, DT is an excellent choice [66].
DT modelling includes two phases: tree creation and tree pruning [67]. Stage one starts with DT’s root node being identified as the independent variables with the highest performance gain. Following that, according to root values, the training dataset is partitioned into subsets and sub-nodes are created. When the input variables are discrete, a sub-node of the tree is constructed for each conceivable value, whereas in some circumstances, the threshold-finding step results in the generation of two sub-nodes [68]. Following that, each sub-gain node’s share is calculated, and the technique is recurring till all samples in a certain node are classified as belonging to the same class. They are then referred to as “leaf nodes,” and their values are designated as the values of the classes they belong to. A flow chart of DT is shown in Figure 4.
Figure 4.
Flow chart of DT.
3.1.2. Artificial Neural Network-Based Machine Learning
A multilayer perceptron neural network (MLPNN), a network-based DM computing approach, is employed in this research with individual base learner and ensemble base learner methods to model and forecast MK concrete. An ANN program mimics the structure of a biological nervous system’s neurons [69]. Parallel linkages provide the basis of ANNs. In order to transmit the weighted inputs from neurons, these cells use an activation function to transmit the weighted outputs. It is possible to have one or more multi-layers in these activities. Use of the multilayer perceptron network is widespread in brain activity. The perceptual response is created among the number of input parameters and the number of output parameters. There are three types of layers in a network: input, hidden, and output. Between the input and output layers, there is a hidden layer that may have a huge network of hidden layers. The perceptron can handle all of its issues with a single layer, but it is more efficient and helpful to have several hidden layers [70]. Figure 5 depicts a typical neural network design. With the exception of neurons in the input layer, all neurons in a layer perform linear addition and bias computations. Non-linear functions are then calculated in the hidden layers by neutrons A sigmoid function is a word used to describe a non-linear function [71]. This research paper models ANNs using a feed-forward multi-layer perceptron (MLPNN) network. To discover the highest-performing MLPNN, hidden layers and neuron pairs of varied numbers are meticulously selected [72]. In the hidden layer, the link between input and output variables may also be determined using a linear activation function and a nonlinear transit function. In addition, the data extracted from the published literature are separated into training and testing sets. This is conducted to reduce the influence of data overfitting, since overfitting is an intractable issue in machine learning. Randomly, 80 percent of the data is used for training the models and 20 percent for testing the trained models, as recommended by the literature [73].
Figure 5.
Flow chart of MLPNN.
3.2. Bagging and Boosting for Ensemble Approaches
ML classification and prediction accuracy may be improved using ensemble approaches. By combining and accumulating several weaker predictive models, such techniques frequently support decrease training data over-fitting problems (component sub-models). Training data may be manipulated to create various sub-model/classifier components (i.e., 1 to M) that help a learner. Furthermore, the best predictive model may be generated by merging limiting sub-models using averaging combination processes. Bootstrap resampling and benefit collection are two common methods for modelling ensembles that make use of bagging. The first training set substitute’s component replicates the bagging procedure. In product models, specific data samples might appear numerous times, while others do not. An average is computed from the output of each component model. As with the bagging method, this strategy builds a cumulative model that yields several components with more accuracy as compared to the individual model. A weighted average of dependent sub-models is used to set sub-models in the final model, which is referred to as “boosting”. AdaBoost [74] is a rapid ensemble learning algorithm that picks multiple classifier examples repeatedly by distributing weights adaptively across training cases. This approach linearly combines the chosen classifier instances to form an ensemble. Even when a large number of base classifier instances are included in a model, AdaBoost ensembles seldom display an overfitting issue [75]. It is possible to diminish loss function by fitting to a staged additive model. This indicates that a cost function that is not differentiable and is not smoothed has been optimized; it can best be described using an exponential loss function [75]. It is, therefore, possible to employ AdaBoost to tackle a number of classification problems with impressive results. DT, MLPNN, and RF are used in conjunction with ensemble learners to envisage the strength of consistently used concrete in this study.
3.3. Ensemble Learner’s Parameter Tuning
Models of the tuning parameters that are employed in the ensemble methods might consist of (i) factors connected with the optimum model learners’ number and (ii) rate of learning and other attributes that have a significant influence on ensemble algorithms. In this research, twenty sub-models were generated for each ensemble base learner. The component sub-models ranged in size from 10 to 200, and the optimum constructs were selected on the basis of the large values of determination coefficient. Figure 6 illustrates the link between performance of ensemble model and the number of component sub-models. As shown in Figure 6a,b, the assembling model with bagging and boosting yields a significant determination coefficient in the estimation terms. As demonstrated in Figure 6a, the 140th sub-model of DT with bagging as an ensemble of other sub-models provides a stronger relationship than the other sub-models of DT with bagging. Similarly, the 30th sub-model of MLPNN with bagging provides a significant higher correlation coefficient as compared to MLPNN bagging other sub-models. Similarly, as depicted in Figure 6b, the 50th DT AdaBoost and the 180th MLPNN AdaBoost sub-model provide the best results when compared to their other sub-models. Preliminary analysis indicates that the usage of ensemble modelling improves the efficiency of both models.
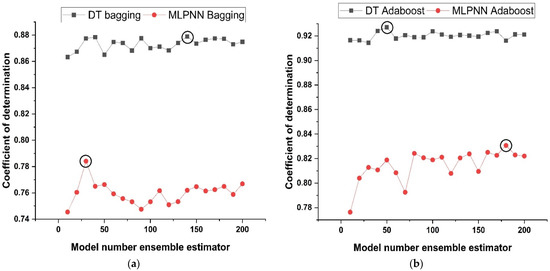
Figure 6.
ML with ensemble sub-models; (a) Bagging; (b) AdaBoost.
3.4. Random Forest Regression Based Machine Learning
The RF model is a regression and classification strategy that has piqued the curiosity of a number of different researchers [76]. The main difference between DT and RF is that one tree is created in DT, but several trees are built in RF, and unlike data are randomly picked and distributed to all the trees in the forest. Each tree’s data are organised into columns and rows, with a variety of column and row sizes to choose from [77]. Each stage of a tree’s development is detailed below:
- The equivalent of two-thirds of the entire dataset is chosen for each tree at random. Bagging is the term used to describe this practise. Predictor variables are picked, and node splitting is done based on the best possible node split on these variables.
- The remaining data are used to estimate the out-of-bag error for each and every tree. To get the most accurate estimation of the out-of-bag error rate, errors from each tree are then added together.
- Every tree in the RF algorithm provides a regression, but the model prioritizes the forest that receives the most votes over all of the individual trees in the forest. The votes might be either zeros or ones. As a prediction probability, the fraction of 1s achieved is provided.
3.5. 10 K Fold Method for Cross Validation
For training and holdout data, the k fold approach for cross validation is often employed to decrease arbitrary sampling prejudice. A stratified 10-fold cross-validation strategy was used in this work to evaluate model performance by dividing the input data into ten distinct subsets. Each of the 10 rounds of model construction and validation uses a different sample of data to test and train the model. As indicated in Figure 7, in order to validate the adequacy of the model, the test subset is utilised. The accuracy of algorithm is calculated as the mean of the 10 models’ accuracy scores after 10 rounds of validation.

Figure 7.
K-fold cross validation method [78].
3.6. Evaluation Criteria for Models
Statistical errors for example root mean squared logarithmic error (RMSLE), square value (R2), mean absolute error root (MAE), and root mean square error (RMSE) are used to assess model performance on a training or testing set. R2 is also called the determination coefficient and is used to evaluate a model’s ability to predict. Concrete’s mechanical characteristics may now be predicted with greater accuracy due to advances in artificial intelligence modelling methods. The models are assessed statistically by calculating error metrics in this research. There are a variety of measures that might help us better understand the model’s inaccuracy. In addition, the model’s performance may be assessed using the variance coefficient and standard deviation. According to the coefficient of determination, the model’s correctness and validity may be confirmed. Models with R2 values ranging from 0.65 to 0.75 indicate promising results, whereas models with R2 values lower than 0.50 reveal disappointing outcomes. Equation (1) can be used to determine R2. The units used in MAE are the same as the ones used in the output. It is possible for a model with a value of MAE that falls within a certain limit to have large errors at some points in time. In order to calculate MAE, Equation (2) is used. RMSE is the under root of the average of squared differences between estimates and measurements. Error squared is calculated by summing the squared errors. This method gives a greater weight to outliers and significant exceptions than other methods, which results in bigger squared differences in certain cases and lower squared differences in others. Using RMSE, the model’s average estimation error given an input can be calculated. Improved models have fewer root mean squared errors of variation. The lower the value of RMSE, the less accurate the model is in predicting the data. Equation (3) is used to determine RMSE. Relative imprecision amongst forecasted and actual values is taken into account by RMSLE. It is the difference between the expected value and the actual value, expressed as a logarithmic scale. RMSLE is calculated using Equation (4).
4. Model Result
4.1. Decision Tree Model Outcomes
As seen in Figure 8, the DT is modelled using various ensemble techniques including bagging and boosting. The actual prediction from individual base learner DT produces a high relationship with predicted values having a R2 = 0.868, as seen in Figure 8a. Figure 8b depicts the error distribution of an individual DT model. Figure 8b indicates that the testing set has an average inaccuracy value of 5.79 MPa. In addition, 82.88 percent of the data exhibit error below 10 MPa, and 11.7% of the data exhibit error between 10–15 MPa. In contrast, each domain of 15–20 MPa, 20–25 MPa, and 35–40 MPa contains 1.8 percent data error, with a maximum and minimum error of 35.3 MPa and 0.085 MPa, respectively, as illustrated in Figure 8b. Individually, DT provide accurate predictions; but, if the DT is an ensemble of several methodologies, it yields a more precise outcome, as seen in Figure 8c–f. Bagging ensemble yields a conclusive and favourable result with R2 = 0.879 and minimal testing data error. The data indicate an inaccuracy of 84.685% below 10 MPa, 9% between 10 and 15 MPa, and 3.6% between 15 and20 MPa. As shown in Figure 8d, only 1.8% of the data fall between 20 and 25 MPa and 0.9% between 30 and 35 MPa, with a maximum and minimum error of about 33.06 MPa 0.029 MPa, respectively. Similar to individual DT and bagging DT algorithms, boosting with AdaBoost produces models with a significant correlation. As seen in Figure 8e–f, this is because of the influence that a strong learner has on the aspect of prediction. A DT AdaBoost ensemble model has a R2 equal to 0.924. The error distribution is minimised by applying AdaBoost with a DT, with an average error of 4.12 MPa, a maximum and minimum error of 34.578 MPa, and 0.065 MPa, respectively. Approximately 92.79%of the data is below 10 MPa, with 6.3% between 10 and 15 MPa and 0.9% between 30 and 35 MPa. Table 3 presents the statistical information pertaining to DT with bagging and boosting ensemble learners.
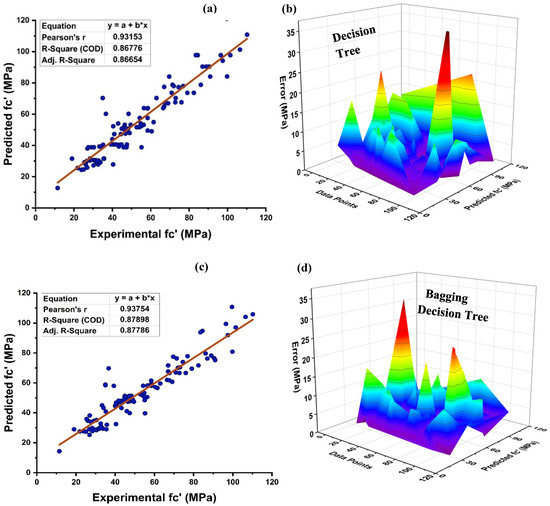
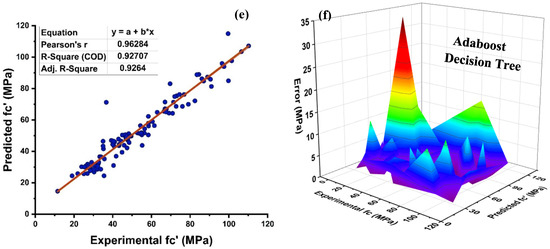
Figure 8.
(a) DT individual base learner regression model; (b) DT individual base learner regression model error distribution; (c) DT-bagging model; (d) DT-bagging model error distribution; (e) DT-AdaBoost regression model; and (f) DT-AdaBoost model error distribution.
Table 3.
DT model statistical evaluation of errors.
4.2. MLPNN Model Outcomes
In the field of ML and AI, neural networks fall under the rubric of supervised learning, and its implementation yields a rigid correlation between prediction and target response. As illustrated in Figure 9, MLPNN is also modelled utilising ensemble learner’s methods, similar to the DT. Figure 9a depicts the actual projection of MK concrete with R2 = 0.724 with its error distribution as seen in Figure 9b. MLPNN error distribution indicates that a test set has an average error of 8.70 MPa, with lowest and highest errors of 0.044 MPa and 35.15 MPa, respectively. However, MLPNN ensemble model reduces the distribution of average error with a rise in the R2 of around 0.767 for bagging and 0.825 for boosting, respectively. The average error for MLPNN-bagging and AdaBoost boosting is 7.29 MPa and 7.05 MPa, respectively, as seen in Figure 9c–f. In addition, a major portion of testing set error is below 10 MPa, with 72.97%, 77.48%, and 74.77% of the data, respectively, for the individual, bagging, and AdaBoost MLPNN models. These ensemble-model outputs also demonstrate a rise in R2 by exhibiting less inaccuracy than the real output. Table 4 illustrates the statistical evaluation of testing data via MLPNN ensemble modelling.
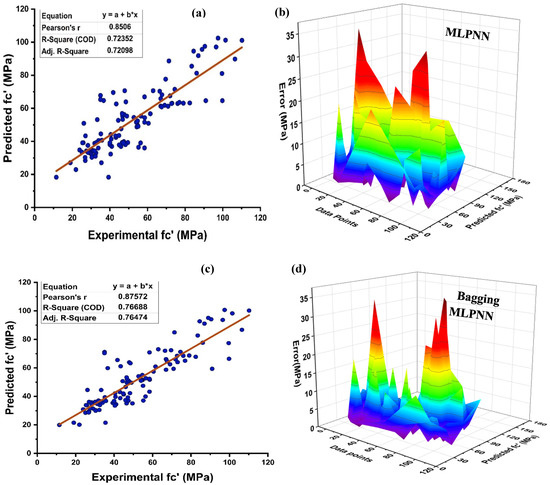
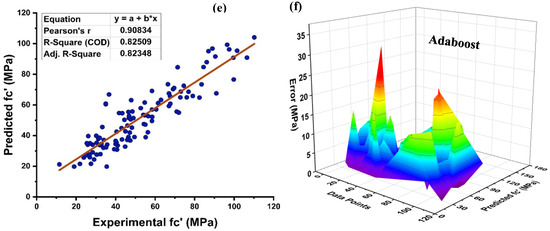
Figure 9.
(a) MLPNN individual base learner regression model; (b) MLPNN individual base learner regression model error distribution; (c) MLPNN-bagging regression; (d) MLPNN-bagging regression model error distribution; (e) MLPNN-AdaBoost regression model; (f) MLPNN-AdaBoost regression model error distribution.
Table 4.
MLPNN model statistical evaluation of errors.
4.3. Random Forest Model Outcomes
Within the framework of the ensemble ML approach, RF represents a hybrid type of bagging and random feature selection, which is a technique for the production of prediction models that is both efficient and easy to use. Figure 10 depicts the prediction accuracy of the RF method for MK concrete. As it is an ensemble model, it exhibits a stubborn R2 = 0.929 correlation with the target values. In addition, the RF model’s prediction may also be tested using an error distribution with an average error of 3.52 MPa. In addition, 90.99 percent of the results indicate that the error falls under 10 MPa, demonstrating the precision of the non-linear estimation of the normal concrete’s strength as shown in Figure 10b.
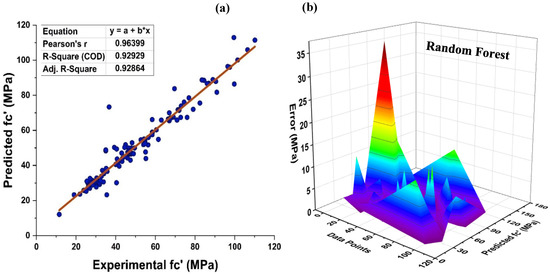
Figure 10.
(a) RF modified learner regression model; (b) RF modified learner regression model error distribution.
4.4. K-Fold Results
The model’s required accuracy is essential to its assessment. To verify the accuracy of prediction models, this validation is necessary. The K fold validation test is employed to validate the correctness of data using data shuffles. Randomly sampling the training data set introduces bias, hence this strategy is used to reduce it. This technique divides the samples evenly into 10 subgroups of the experimental data. One of the 10 subsets is utilised for validation, while the other nine are employed to shape up the strong learner. The procedure is done 10 times and then averaged. In general, it is commonly accepted that the 10-fold cross validation approach accurately reflects the model’s generalisation and dependability [79]. The validation test of all the ensemble models is presented in Figure 11 and Figure 12. All models exhibit a moderate to high correlational link. In addition, the outcomes of cross-validation may be evaluated based on various errors, such as R2, MAE, RMSE, and RMSLE, as shown in Figure 11 for DT and MLPNN and Figure 12 for RF. It displays the validation representation in each 10-fold. Although variations were noticed, it retained a high degree of precision, as seen in Figure 11 and Figure 12. For example, the lowest and highest R2 values for all models are between 0.46 and 0.65 and 0.81 and 0.91, respectively. As demonstrated in Figure 11c–h for DT and MLPNN, MAE, RMSE, and RMSLE are also used to evaluate the accuracy of models with respect to cross-validation. Figure 11c depicts the average MAE value for DT with ensemble bagging and ensemble boosting using 10-fold validation as 11.97 MPa and 9.0 MPa, respectively. Figure 11e reveals that the RMSE offers an average error of about 14.6 MPa and 11.84 MPa for ensemble bagging and ensemble boosting using AdaBoost, respectively. Figure 11g displays RMSLE average errors of 0.106 MPa and 0.07 MPa for DT bagging and boosting, respectively. Figure 11d–f shows that the average MAE, RMSE, and RMSLE for the MLPNN bagging model are 11.06 MPa, 14.92 MPa, and 0.1 MPa, respectively. For the k fold validation of the MLPNN AdaBoost model, values of 12.03 MPa, 15.07 MPa, and 0.08 MPa were found. This demonstrates the precision of models using K-fold cross validation. Figure 12 demonstrates strong association for modified learner model with decreased error for MAE, RMSE, and RMSLE, with average errors of 8.94 MPa, 11.02 MPa, and 0.07 MPa, respectively.
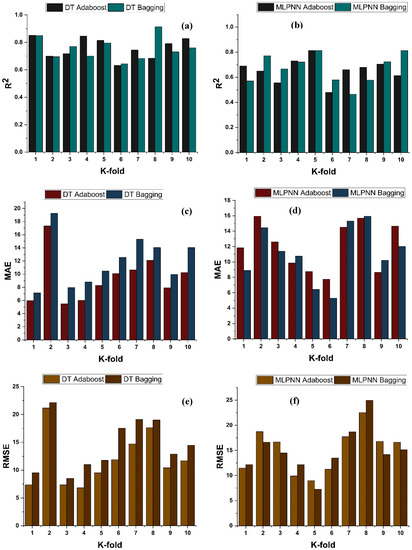
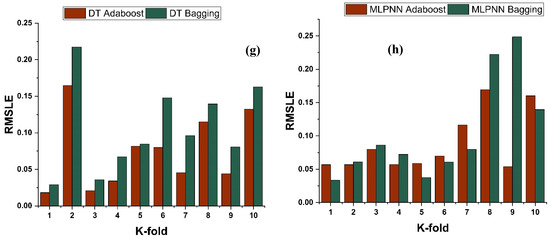
Figure 11.
fc’ models (a,b) indicate R2 models’ result validated with K fold; (c,d) indicate MAE models’ result validated with K fold; (e,f) indicate RMSE models’ result validated with K fold; (g,h) indicate RMSE models’ result validated with K fold.
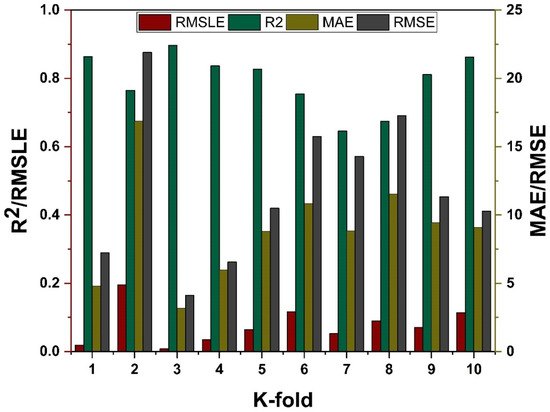
Figure 12.
RF models cross validation with different statistical parameters.
4.5. Model Evaluation and Discussion Based on Statistical Metrics
Comparing the ensemble approaches to the individual ML methods helped show the ensemble algorithm’s potential in comparison to them as depicted in Figure 13. This process is similar to that used for ensemble models, such as starting with a set of values and then using a grid search to find the optimal values. Table 5 shows the target and validated values for each metric. The ensemble ML models outcome have a linear trend, and their projections are more like the ones that were tested, according to this study. Using DT, and MLPNN, is a kind of individual learning, but using ML techniques such as bagging and boosting is a form of ensemble learning. High performance weak learners would gain weight, though weak learners with poor performance will lose weight, since ensemble learning is usually known to include several weak learners produced by individual ML algorithms. Because of this, it is able to provide accurate projections. MAE, RMSE, RMSLE, and R2 are used to evaluate individual and ensemble learners. An ensemble of learners using bagging and boosting has a lower rate of error than an individual learner. A smaller error margin exists between forecasts and outcomes when using ensemble models rather than individual models alone.
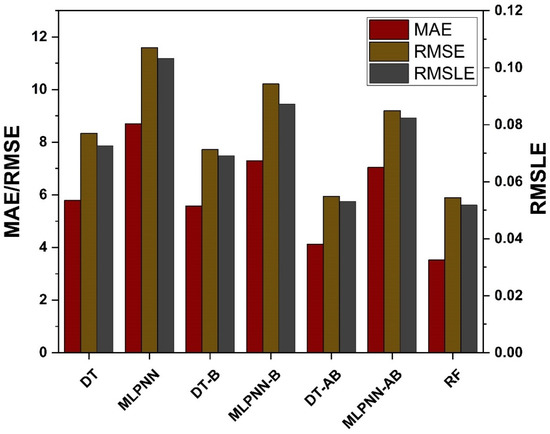
Figure 13.
Statistical analysis of fc’ models.
Table 5.
Model’s statistical errors.
4.6. SHAP Analysis
The values of all of the features that were taken into consideration for the MK concrete fc’ prediction are outlined in the shape of a violin, as illustrated in Figure 14. The Shapley value measures the mean marginal influence that can be attributed to each parameter value over all viable permutations of the parameters. The attributes that have substantial absolute Shapley values are regarded to have a considerable influence. In order to get the global feature effects, the absolute Shapley values for each feature throughout the data were averaged and ranked in decreasing significance as shown in Figure 14. Every single datapoint on the plot indicates a Shapley value for distinct characteristics and occurrences. The location on the x axis and the y axis is defined by the Shapley value and the feature significance, respectively. Elevated places on the y axis represent higher effect of the characteristics on the MK concrete fc’ prediction and the colour scale reflects the feature relevance from low to high. Each dot in Figure 14 signifies an individual point from the dataset. The location of points along the x axis represents the effect of each parameter value on the fc’ prediction. When numerous dots fall in the same location along the x-axis, the dots are stacked to illustrate the density. Age is the most influential parameter followed by coarse aggregate, superplasticizer, water, and other input parameters. Silica fume has the least impact on fc’ prediction of MK concrete as illustrated in Figure 14. Higher SHAP value imply that the model forecasts higher fc’ value, and vice versa. For example, high value of age (red) correlate with increased SHAP value, which suggest high fc’ value. Moreover, each input parameter has positive or negative impact up to a certain limit. In Figure 14, red colour shows high impact (negative or positive) while the blue colour depicts low impact of the input feature on the predicted outcome. SHAP value at the right (greater than 0) on the x-axis shows positive impact of respective input on the fc’. For instance, in the case of input parameters like age and content of coarse aggregate, the positive effect of these factors on MK fc’ can be noted from the right axis of the graph. Coarse aggregate content depicts a constructive impact till optimum content, whereas above this content, the adverse effect is shown on the left side (less than 0) on the x-axis. Super-plasticizer is also key variable for predicting the fc’ of MK concrete. The effect of water on the output fc’ of MK concrete is negative and increasing the water content will reduce the fc’. MK and cement show the same trend. However, SF and fine aggregate tend to have a high positive impact and a low negative impact on the fc’ prediction of MK concrete. SHAP feature dependency graphs were deployed that are coloured by another interacting feature to highlight how the features interact and effect the fc’ of MK concrete. This gives greater information than standard partial dependency charts. The SHAP interaction plot each considered feature is shown in Figure 15. As can be observed from Figure 15a, the dependence and interaction show that high fc’ values for MK concrete can be achieved when for 50 ≤ age ≤ 100 days when CA ≥ 700 kg/m3. Higher fc’ values for age ≤ 50 days can be achieved for 50 ≤ CA ≤ 700 kg/m3. Figure 15b,d,e show that 120–200 kg/m3 of water is required for CA in for different content of CA and FA to achieve higher values of fc’. Moreover, Figure 15f,g illustrate the relation between two important constituents of MK concrete: cement and metakaolin. Higher fc’ for MK concrete can be achieved for MK in the range of 20–100 kg/m3 for concrete having density of 250–450 kg/m3. Additionally, Figure 15h reveals that large quantity of silica fume can be used if early fc’ of MK concrete is desired.
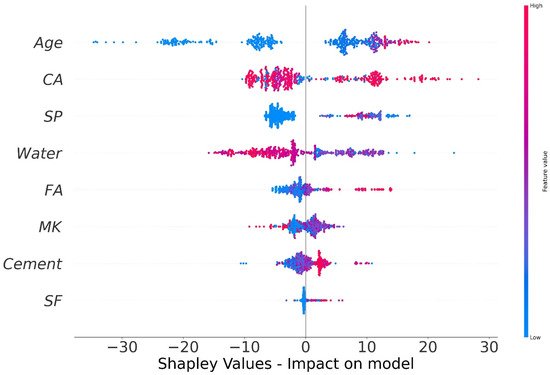
Figure 14.
SHAP plot.
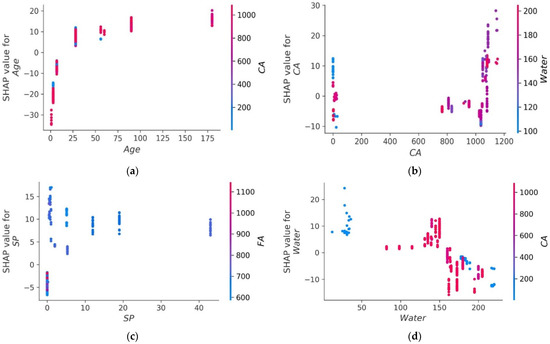
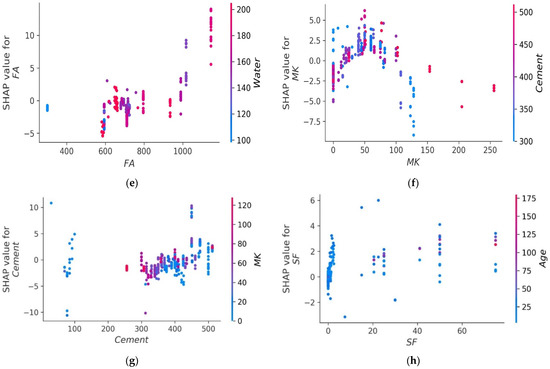
Figure 15.
SHAP interaction plot of parameters: (a) age; (b) coarse aggregate; (c) superplasticizer; (d) water; (e) fine aggregate; (f) metakaolin; (g) cement; (h) silica fume.
5. Conclusions
The primary aim of this study was to assess the accuracy level achieved by various ML approaches to predict MK concrete fc’. Datasets from the literature containing 551 data points were used to train and test the models. The eight most influential constituents of MK concrete including cement, metakaolin, coarse and aggregate, water, silica fume, superplasticizer, and age were considered as input parameters. Individual and ensemble learning models for predicting the fc’ of MK concrete were investigated in this study using DT, MLPNN, and RF. Interaction of input parameters and effect of input parameters of fc’ were studied using SHAP dependency feature graphs. The results of the investigation led the authors to the following conclusions:
- Bagging and AdaBoost models outperform the individual models. As compared to the standalone DT model, the ensemble DT model with boosting and RF demonstrates a 7% improvement. Both techniques have a significant correlation with R2 equal to 0.92. Similarly, an improvement of 14 %, 6%, and 29% was observed in MLPNN AdaBoost, MLPNN bagging, and RF model, respectively, when compared with individual DT model;
- Statistical measures using MAE, RMSE, RMSLE, and R2 were also performed. Ensemble learner DT bagging and boosting depicts a smaller error of about 4%, and 29% for MAE, 8% and 29% for RMSE, 5% and 27% for RMSLE, respectively, when compared to the individual DT model. Similarly, enhancements of 16% and 19% in MAE, 12% and 21% in RMSE, and 16% and 20% in RMSLE were observed for MLPNN bagging and AdaBoost models, respectively, when compared to the individual base learner DT model;
- RF shows improvements of 60%, 49%, and 50% in MAE, RMSE, and RMSLE when compared to the MLPNN individual model. Similarly, improvements of 39%, 29%, and 29% for the RF model, in MAE, RMSE and RMSLE, were observed in comparison to DT individual model;
- The validity of models using R2, MAE, RMSE, and RMSLE were tested using k-fold cross-validation. Fewer inaccuracies with strong correlations were examined;
- The DT AdaBoost model and the modified bagging model are the best techniques for forecasting MK concrete fc’ among all of the ML approaches;
- Age has the greatest impact on calculating MK concrete fc’, followed by coarse aggregate and superplasticizer, according to the SHAP assessment. However, silica fume has the least impact on the fc’ of MK concrete. SHAP dependency feature graphs can illustrate the relationship between input parameters for various ranges;
- Sensitivity analyses depicted that FA contributed moderately to the development of the fc’ models and fsts models. Moreover, cement, SF, CA, and age played vital roles in the development of fc’ models. Tensile strength models showed to be affected least by water and CA;
These ML algorithms can accurately predict the mechanical characteristics of concrete. These models can be utilized to predict the mechanical characteristics of similar databases containing metakaolin with high accuracy. Moreover, SHAP analysis provides an insight to readers regarding the input parameters contribution towards the outcome, and inter-dependency of the input parameters. This will enable the readers to carefully select the input variables for modelling the behaviour of metakaolin concrete. Additionally, ML algorithms employed in this study may provide a sustainable way for the mix design of MK concrete. Traditionally, this process demands lengthy trials in laboratories and a significant number of raw materials in addition to a great deal of manpower.
6. Limitations and Directions for Future Work
Despite the fact that the efforts made in this research has significant limitations, it may still be regarded a data mining-based research. Completeness of dataset is essential for the efficacy of models’ prediction. The range of datasets used for this study was restricted to 551 data points. In addition, the corrosive and flexural concrete behaviour at extreme temperatures was not considered in this work. Indeed, good database management and testing are essential from a technical standpoint. To simulate high-strength concrete, this research included an extensive variety of data with eight variables. Further, it is suggested that a new dataset of concrete at increased temperatures that encompasses numerous environmental factors such as temperature, durability, and corrosion be investigated. Experimental testing data for testing of models are recommended for more accuracy. Given that concrete plays such an important role in the ecosystem, its effects under various situations should be investigated utilising various deep machine learning methods.
Author Contributions
Conceptualization, K.K.; Data curation, A.M.R.B., W.A. and A.M.A.A.; Formal analysis, A.M.R.B., A.N., M.N.A., W.A., M.U. and S.N.; Funding acquisition, K.K.; Investigation, A.N. and M.N.A.; Methodology, A.N., M.N.A. and A.M.A.A.; Project administration, K.K.; Resources, K.K.; Software, W.A.; Supervision, K.K.; Validation, M.U. and S.N.; Visualization, M.U., S.N. and A.M.A.A.; Writing—original draft, A.M.R.B., A.N. and W.A.; Writing—review & editing, K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. 1431], through its KFU Research Summer Initiative.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data is available in the paper.
Acknowledgments
The authors acknowledge the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. 1431], through its KFU Research Summer Initiative.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, T.; Nafees, A.; Khan, S.; Javed, M.F.; Aslam, F.; Alabduljabbar, H.; Xiong, J.-J.; Khan, M.I.; Malik, M. Comparative study of mechanical properties between irradiated and regular plastic waste as a replacement of cement and fine aggregate for manufacturing of green concrete. Ain Shams Eng. J. 2021, 13, 101563. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, A.; Amin, M.N.; Ahmad, W.; Nazar, S.; Abu Arab, A.M. Comparative Study of Experimental and Modeling of Fly Ash-Based Concrete. Materials 2022, 15, 3762. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Alabdullah, A.A.; Abu Arab, A.M. Exploring the Use of Waste Marble Powder in Concrete and Predicting Its Strength with Different Advanced Algorithms. Materials 2022, 15, 4108. [Google Scholar] [CrossRef] [PubMed]
- Vu, D.; Stroeven, P.; Bui, V. Strength and durability aspects of calcined kaolin-blended Portland cement mortar and concrete. Cem. Concr. Compos. 2001, 23, 471–478. [Google Scholar] [CrossRef]
- Batis, G.; Pantazopoulou, P.; Tsivilis, S.; Badogiannis, E. The effect of metakaolin on the corrosion behavior of cement mortars. Cem. Concr. Compos. 2005, 27, 125–130. [Google Scholar] [CrossRef]
- Khatib, J.; Negim, E.; Gjonbalaj, E. High volume metakaolin as cement replacement in mortar. World J. Chem. 2012, 7, 7–10. [Google Scholar]
- Ameri, F.; Shoaei, P.; Zareei, S.A.; Behforouz, B. Geopolymers vs. alkali-activated materials (AAMs): A comparative study on durability, microstructure, and resistance to elevated temperatures of lightweight mortars. Constr. Build. Mater. 2019, 222, 49–63. [Google Scholar] [CrossRef]
- Pavlikova, M.; Brtník, T.; Keppert, M.; Černý, R. Effect of metakaolin as partial Portland-cement replacement on properties of high performance mortars. Cem. Wapno Beton 2009, 3, 115–122. [Google Scholar]
- Kadri, E.-H.; Kenai, S.; Ezziane, K.; Siddique, R.; De Schutter, G. Influence of metakaolin and silica fume on the heat of hydration and compressive strength development of mortar. Appl. Clay Sci. 2011, 53, 704–708. [Google Scholar] [CrossRef]
- Wianglor, K.; Sinthupinyo, S.; Piyaworapaiboon, M.; Chaipanich, A. Effect of alkali-activated metakaolin cement on compressive strength of mortars. Appl. Clay Sci. 2017, 141, 272–279. [Google Scholar] [CrossRef]
- Khatib, J.; Wild, S. Sulphate Resistance of Metakaolin Mortar. Cem. Concr. Res. 1998, 28, 83–92. [Google Scholar] [CrossRef]
- Van Fan, Y.; Chin, H.H.; Klemeš, J.J.; Varbanov, P.S.; Liu, X. Optimisation and process design tools for cleaner production. J. Clean. Prod. 2019, 247, 119181. [Google Scholar] [CrossRef]
- Apostolopoulou, M.; Asteris, P.G.; Armaghani, D.J.; Douvika, M.G.; Lourenço, P.B.; Cavaleri, L.; Bakolas, A.; Moropoulou, A. Mapping and holistic design of natural hydraulic lime mortars. Cem. Concr. Res. 2020, 136, 106167. [Google Scholar] [CrossRef]
- Asteris, P.G.; Douvika, M.G.; Karamani, C.A.; Skentou, A.D.; Chlichlia, K.; Cavaleri, L.; Daras, T.; Armaghani, D.J.; Zaoutis, T.E. A Novel Heuristic Algorithm for the Modeling and Risk Assessment of the COVID-19 Pandemic Phenomenon. Comput. Model. Eng. Sci. 2020, 125, 815–828. [Google Scholar] [CrossRef]
- Banan, A.; Nasiri, A.; Taheri-Garavand, A. Deep learning-based appearance features extraction for automated carp species identification. Aquac. Eng. 2020, 89, 102053. [Google Scholar] [CrossRef]
- Fan, Y.; Xu, K.; Wu, H.; Zheng, Y.; Tao, B. Spatiotemporal Modeling for Nonlinear Distributed Thermal Processes Based on KL Decomposition, MLP and LSTM Network. IEEE Access 2020, 8, 25111–25121. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.-W. ANN-based interval forecasting of streamflow discharges using the LUBE method and MOFIPS. Eng. Appl. Artif. Intell. 2015, 45, 429–440. [Google Scholar] [CrossRef]
- Wu, C.; Chau, K. Prediction of rainfall time series using modular soft computingmethods. Eng. Appl. Artif. Intell. 2013, 26, 997–1007. [Google Scholar] [CrossRef]
- Armaghani, D.; Momeni, E.; Asteris, P. Application of group method of data handling technique in assessing deformation of rock mass. Metaheuristic Comput. Appl. 2020, 1, 1–18. [Google Scholar]
- Nafees, A.; Khan, S.; Javed, M.F.; Alrowais, R.; Mohamed, A.M.; Mohamed, A.; Vatin, N.I. Forecasting the Mechanical Properties of Plastic Concrete Employing Experimental Data Using Machine Learning Algorithms: DT, MLPNN, SVM, and RF. Polymers 2022, 14, 1583. [Google Scholar] [CrossRef]
- Nafees, A.; Javed, M.F.; Khan, S.; Nazir, K.; Farooq, F.; Aslam, F.; Musarat, M.A.; Vatin, N.I. Predictive Modeling of Mechanical Properties of Silica Fume-Based Green Concrete Using Artificial Intelligence Approaches: MLPNN, ANFIS, and GEP. Materials 2021, 14, 7531. [Google Scholar] [CrossRef] [PubMed]
- Nafees, A.; Amin, M.N.; Khan, K.; Nazir, K.; Ali, M.; Javed, M.F.; Aslam, F.; Musarat, M.A.; Vatin, N.I. Modeling of Mechanical Properties of Silica Fume-Based Green Concrete Using Machine Learning Techniques. Polymers 2021, 14, 30. [Google Scholar] [CrossRef] [PubMed]
- Amin, M.N.; Ahmad, W.; Khan, K.; Ahmad, A.; Nazar, S.; Alabdullah, A.A. Use of Artificial Intelligence for Predicting Parameters of Sustainable Concrete and Raw Ingredient Effects and Interactions. Materials 2022, 15, 5207. [Google Scholar] [CrossRef] [PubMed]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A. A Systematic Review of the Research Development on the Application of Machine Learning for Concrete. Materials 2022, 15, 4512. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, W.; Amin, M.N.; Aslam, F.; Ahmad, A.; Al-Faiad, M.A. Comparison of Prediction Models Based on Machine Learning for the Compressive Strength Estimation of Recycled Aggregate Concrete. Materials 2022, 15, 3430. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Al-Faiad, M.A. Assessment of Artificial Intelligence Strategies to Estimate the Strength of Geopolymer Composites and Influence of Input Parameters. Polymers 2022, 14, 2509. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Alabdullah, A.A. Compressive Strength Estimation of Steel-Fiber-Reinforced Concrete and Raw Material Interactions Using Advanced Algorithms. Polymers 2022, 14, 3065. [Google Scholar] [CrossRef]
- Dai, L.; Wu, X.; Zhou, M.; Ahmad, W.; Ali, M.; Sabri, M.M.S.; Salmi, A.; Ewais, D.Y.Z. Using Machine Learning Algorithms to Estimate the Compressive Property of High Strength Fiber Reinforced Concrete. Materials 2022, 15, 4450. [Google Scholar] [CrossRef]
- Amin, M.N.; Ahmad, A.; Khan, K.; Ahmad, W.; Nazar, S.; Faraz, M.I.; Alabdullah, A.A. Split Tensile Strength Prediction of Recycled Aggregate-Based Sustainable Concrete Using Artificial Intelligence Methods. Materials 2022, 15, 4296. [Google Scholar] [CrossRef]
- González-Taboada, I.; González-Fonteboa, B.; Martínez-Abella, F.; Pérez-Ordóñez, J.L. Prediction of the mechanical properties of structural recycled concrete using multivariable regression and genetic programming. Constr. Build. Mater. 2016, 106, 480–499. [Google Scholar] [CrossRef]
- Asteris, P.G.; Moropoulou, A.; Skentou, A.D.; Apostolopoulou, M.; Mohebkhah, A.; Cavaleri, L.; Rodrigues, H.; Varum, H. Stochastic Vulnerability Assessment of Masonry Structures: Concepts, Modeling and Restoration Aspects. Appl. Sci. 2019, 9, 243. [Google Scholar] [CrossRef]
- Asteris, P.G.; Apostolopoulou, M.; Skentou, A.D.; Moropoulou, A. Application of artificial neural networks for the prediction of the compressive strength of cement-based mortars. Comput. Concr. 2019, 24, 329–345. [Google Scholar]
- Ben Chaabene, W.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Alkadhim, H.A.; Amin, M.N.; Ahmad, W.; Khan, K.; Nazar, S.; Faraz, M.I.; Imran, M. Evaluating the Strength and Impact of Raw Ingredients of Cement Mortar Incorporating Waste Glass Powder Using Machine Learning and SHapley Additive ExPlanations (SHAP) Methods. Materials 2022, 15, 7344. [Google Scholar] [CrossRef]
- Ghorbani, B.; Arulrajah, A.; Narsilio, G.; Horpibulsuk, S. Experimental and ANN analysis of temperature effects on the permanent deformation properties of demolition wastes. Transp. Geotech. 2020, 24, 100365. [Google Scholar] [CrossRef]
- Akkurt, S.; Tayfur, G.; Can, S. Fuzzy logic model for the prediction of cement compressive strength. Cem. Concr. Res. 2004, 34, 1429–1433. [Google Scholar] [CrossRef]
- Özcan, F.; Atis, C.; Karahan, O.; Uncuoğlu, E.; Tanyildizi, H. Comparison of artificial neural network and fuzzy logic models for prediction of long-term compressive strength of silica fume concrete. Adv. Eng. Softw. 2009, 40, 856–863. [Google Scholar] [CrossRef]
- Pérez, J.L.; Cladera, A.; Rabuñal, J.R.; Martínez-Abella, F. Optimization of existing equations using a new Genetic Programming algorithm: Application to the shear strength of reinforced concrete beams. Adv. Eng. Softw. 2012, 50, 82–96. [Google Scholar] [CrossRef]
- Mansouri, I.; Kisi, O. Prediction of debonding strength for masonry elements retrofitted with FRP composites using neuro fuzzy and neural network approaches. Compos. Part B Eng. 2015, 70, 247–255. [Google Scholar] [CrossRef]
- Nasrollahzadeh, K.; Nouhi, E. Fuzzy inference system to formulate compressive strength and ultimate strain of square concrete columns wrapped with fiber-reinforced polymer. Neural Comput. Appl. 2016, 30, 69–86. [Google Scholar] [CrossRef]
- Falcone, R.; Lima, C.; Martinelli, E. Soft computing techniques in structural and earthquake engineering: A literature review. Eng. Struct. 2020, 207, 110269. [Google Scholar] [CrossRef]
- Farooqi, M.U.; Ali, M. Effect of pre-treatment and content of wheat straw on energy absorption capability of concrete. Constr. Build. Mater. 2019, 224, 572–583. [Google Scholar] [CrossRef]
- Farooqi, M.U.; Ali, M. Effect of Fibre Content on Compressive Strength of Wheat Straw Reinforced Concrete for Pavement Applications. IOP Conf. Ser. Mater. Sci. Eng. 2018, 422, 012014. [Google Scholar] [CrossRef]
- Younis, K.H.; Amin, A.A.; Ahmed, H.G.; Maruf, S.M. Recycled Aggregate Concrete including Various Contents of Metakaolin: Mechanical Behavior. Adv. Mater. Sci. Eng. 2020, 2020, 8829713. [Google Scholar] [CrossRef]
- Poon, C.; Kou, S.; Lam, L. Compressive strength, chloride diffusivity and pore structure of high performance metakaolin and silica fume concrete. Constr. Build. Mater. 2006, 20, 858–865. [Google Scholar] [CrossRef]
- Qian, X.; Li, Z. The relationships between stress and strain for high-performance concrete with metakaolin. Cem. Concr. Res. 2001, 31, 1607–1611. [Google Scholar] [CrossRef]
- Li, Q.; Geng, H.; Shui, Z.; Huang, Y. Effect of metakaolin addition and seawater mixing on the properties and hydration of concrete. Appl. Clay Sci. 2015, 115, 51–60. [Google Scholar] [CrossRef]
- Ramezanianpour, A.; Jovein, H.B. Influence of metakaolin as supplementary cementing material on strength and durability of concretes. Constr. Build. Mater. 2012, 30, 470–479. [Google Scholar] [CrossRef]
- Shehab El-Din, H.K.; Eisa, A.S.; Abdel Aziz, B.H.; Ibrahim, A. Mechanical performance of high strength concrete made from high volume of Metakaolin and hybrid fibers. Constr. Build. Mater. 2017, 140, 203–209. [Google Scholar] [CrossRef]
- Roy, D.; Arjunan, P.; Silsbee, M. Effect of silica fume, metakaolin, and low-calcium fly ash on chemical resistance of concrete. Cem. Concr. Res. 2001, 31, 1809–1813. [Google Scholar] [CrossRef]
- Poon, C.S.; Shui, Z.; Lam, L. Compressive behavior of fiber reinforced high-performance concrete subjected to elevated temperatures. Cem. Concr. Res. 2004, 34, 2215–2222. [Google Scholar] [CrossRef]
- Sharaky, I.; Ghoneim, S.S.; Aziz, B.H.A.; Emara, M. Experimental and theoretical study on the compressive strength of the high strength concrete incorporating steel fiber and metakaolin. Structures 2021, 31, 57–67. [Google Scholar] [CrossRef]
- Gilan, S.S.; Jovein, H.B.; Ramezanianpour, A.A. Hybrid support vector regression—Particle swarm optimization for prediction of compressive strength and RCPT of concretes containing metakaolin. Constr. Build. Mater. 2012, 34, 321–329. [Google Scholar] [CrossRef]
- Silva, F.A.N.; Delgado, J.M.P.Q.; Cavalcanti, R.S.; Azevedo, A.C.; Guimarães, A.S.; Lima, A.G.B. Use of Nondestructive Testing of Ultrasound and Artificial Neural Networks to Estimate Compressive Strength of Concrete. Buildings 2021, 11, 44. [Google Scholar] [CrossRef]
- Poon, C.S.; Azhar, S.; Anson, M.; Wong, Y.-L. Performance of metakaolin concrete at elevated temperatures. Cem. Concr. Compos. 2003, 25, 83–89. [Google Scholar] [CrossRef]
- Nica, E.; Stehel, V. Internet of things sensing networks, artificial intelligence-based decision-making algorithms, and real-time process monitoring in sustainable industry 4. J. Self-Gov. Manag. Econ. 2021, 9, 35–47. [Google Scholar]
- Sierra, L.A.; Yepes, V.; Pellicer, E. A review of multi-criteria assessment of the social sustainability of infrastructures. J. Clean. Prod. 2018, 187, 496–513. [Google Scholar] [CrossRef]
- Kicinger, R.; Arciszewski, T.; De Jong, K. Evolutionary computation and structural design: A survey of the state-of-the-art. Comput. Struct. 2005, 83, 1943–1978. [Google Scholar] [CrossRef]
- Yin, Z.; Jin, Y.; Liu, Z. Practice of artificial intelligence in geotechnical engineering. J. Zhejiang Univ. A 2020, 21, 407–411. [Google Scholar] [CrossRef]
- Park, H.S.; Lee, E.; Choi, S.W.; Oh, B.K.; Cho, T.; Kim, Y. Genetic-algorithm-based minimum weight design of an outrigger system for high-rise buildings. Eng. Struct. 2016, 117, 496–505. [Google Scholar] [CrossRef]
- Villalobos Arias, L. Evaluating an Automated Procedure of Machine Learning Parameter Tuning for Software Effort Estimation; Universidad de Costa Rica: San Pedro, Costa Rica, 2021. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Debeljak, M.; Džeroski, S. Decision Trees in Ecological Modelling. In Modelling Complex Ecological Dynamics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 197–209. [Google Scholar]
- Murthy, S.K. Automatic Construction of Decision Trees from Data: A Multi-Disciplinary Survey. Data Min. Knowl. Discov. 1998, 2, 345–389. [Google Scholar] [CrossRef]
- Kheir, R.B.; Greve, M.H.; Abdallah, C.; Dalgaard, T. Spatial soil zinc content distribution from terrain parameters: A GIS-based decision-tree model in Lebanon. Environ. Pollut. 2010, 158, 520–528. [Google Scholar] [CrossRef] [PubMed]
- Tso, G.K.F.; Yau, K.W.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Cho, J.H.; Kurup, P.U. Decision tree approach for classification and dimensionality reduction of electronic nose data. Sens. Actuators B Chem. 2011, 160, 542–548. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Abidoye, L.; Mahdi, F.; Idris, M.; Alabi, O.; Wahab, A. ANN-derived equation and ITS application in the prediction of dielectric properties of pure and impure CO2. J. Clean. Prod. 2018, 175, 123–132. [Google Scholar] [CrossRef]
- Ozoegwu, C.G. Artificial neural network forecast of monthly mean daily global solar radiation of selected locations based on time series and month number. J. Clean. Prod. 2019, 216, 1–13. [Google Scholar] [CrossRef]
- Hafeez, A.; Taqvi, S.A.A.; Fazal, T.; Javed, F.; Khan, Z.; Amjad, U.S.; Bokhari, A.; Shehzad, N.; Rashid, N.; Rehman, S.; et al. Optimization on cleaner intensification of ozone production using Artificial Neural Network and Response Surface Methodology: Parametric and comparative study. J. Clean. Prod. 2019, 252, 119833. [Google Scholar] [CrossRef]
- Zhou, G.; Moayedi, H.; Bahiraei, M.; Lyu, Z. Employing artificial bee colony and particle swarm techniques for optimizing a neural network in prediction of heating and cooling loads of residential buildings. J. Clean. Prod. 2020, 254, 120082. [Google Scholar] [CrossRef]
- Shahin, M.A.; Maier, H.R.; Jaksa, M.B. Data Division for Developing Neural Networks Applied to Geotechnical Engineering. J. Comput. Civ. Eng. 2004, 18, 105–114. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the ICML, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Guo, L.; Ge, P.; Zhang, M.-H.; Li, L.-H.; Zhao, Y.-B. Pedestrian detection for intelligent transportation systems combining AdaBoost algorithm and support vector machine. Expert Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Farooq, F.; Ahmed, W.; Akbar, A.; Aslam, F.; Alyousef, R. Predictive modeling for sustainable high-performance concrete from industrial wastes: A comparison and optimization of models using ensemble learners. J. Clean. Prod. 2021, 292, 126032. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the IJCAI, Montreal, QC, Canada, 20–25 August 1995; pp. 113–1145. [Google Scholar]




















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).