
A Comparative Study of AI-Based International Roughness Index (IRI) Prediction Models for Jointed Plain Concrete Pavement (JPCP)



Abstract
:1. Introduction
2. Methodology
2.1. Data Collection
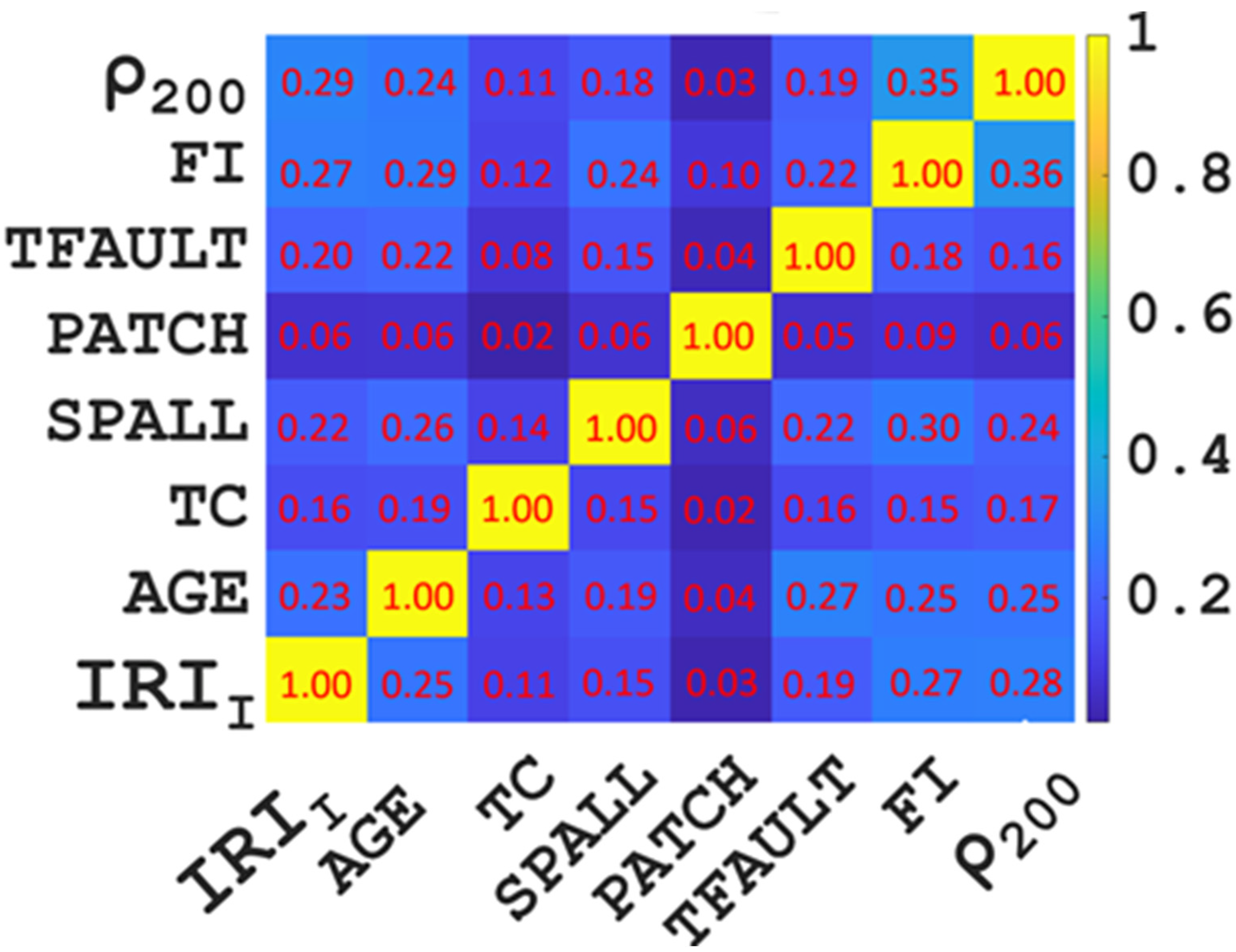
2.2. Correlation Analysis
2.3. Modified Beetle Antennae Search (MBAS)
2.3.1. Beetle Antennae Search (BAS) Algorithm
2.3.2. Support Vector Machine (SVM) Model
2.3.3. Decision Tree (DT) Model
2.3.4. Random Forest (RF) Model
- (1)
- Extraction of the sub-training set. By the Bootstrap method, N samples are randomly extracted from data set D, put back to form K sub-training data sets, and K decision trees are established.
- (2)
- Construction of decision tree. The construction of subclassifies mainly uses a classification regression tree. Firstly, K features are randomly selected from M features at each node of the decision tree as the segmentation feature set of corresponding nodes. The optimal segmentation feature and segmentation node are determined according to relevant criteria. The segmentation node is divided into two nodes, and the corresponding data is also divided into two nodes. The above process is repeated until the stop condition is met.
- (3)
- Construction of random forest. Step (2) is repeated, and stops when K decision trees are generated, and then these are combines into a random forest .
- (4)
- K decision trees in the random forest are used to classify the test data set DT, and K prediction results () are obtained.
- (5)
- The mode in the prediction result of the decision tree is selected as the final prediction result of each sample in the prediction data set.
3. Results and Discussion
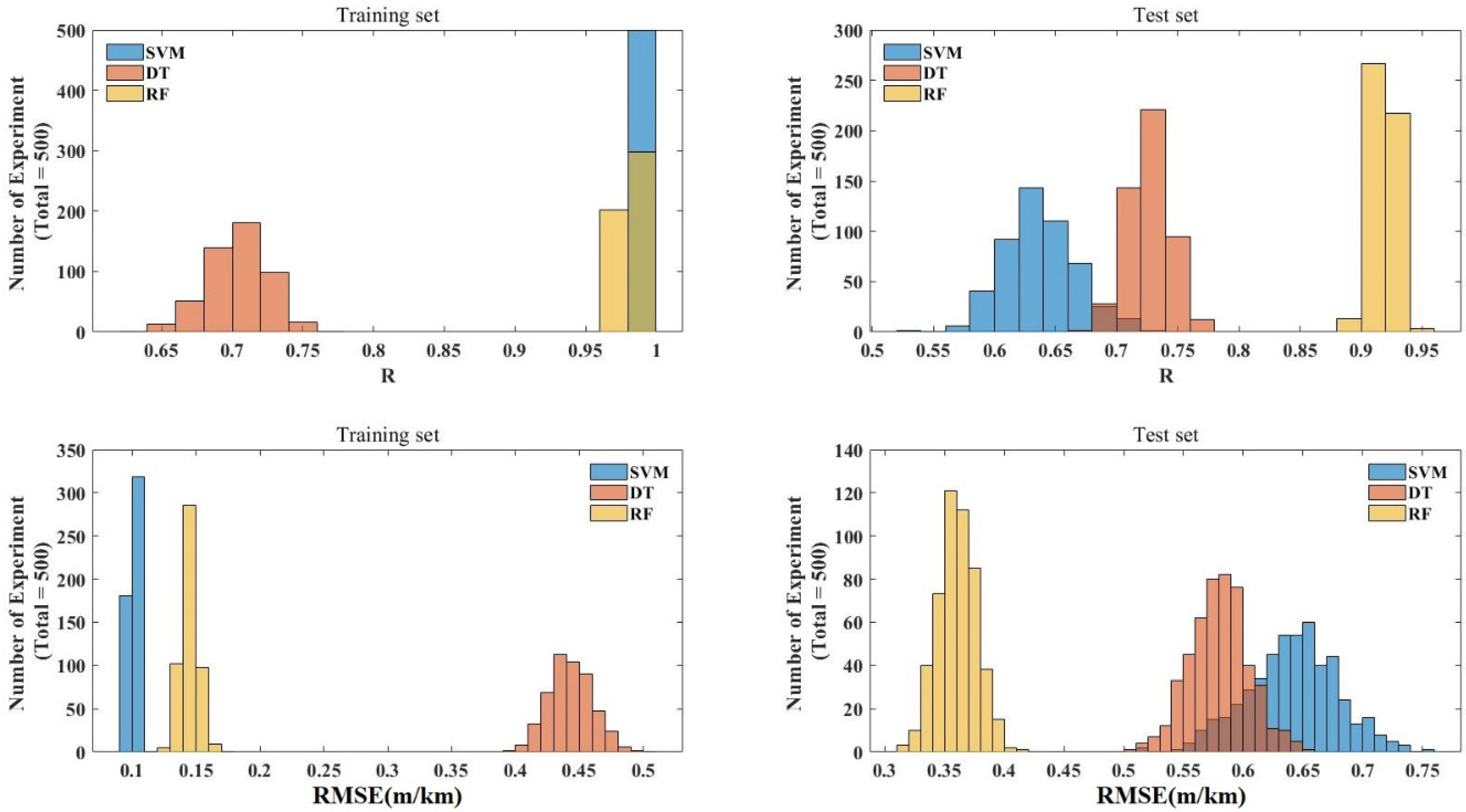
3.1. Results of the Hyperparameter Tuning
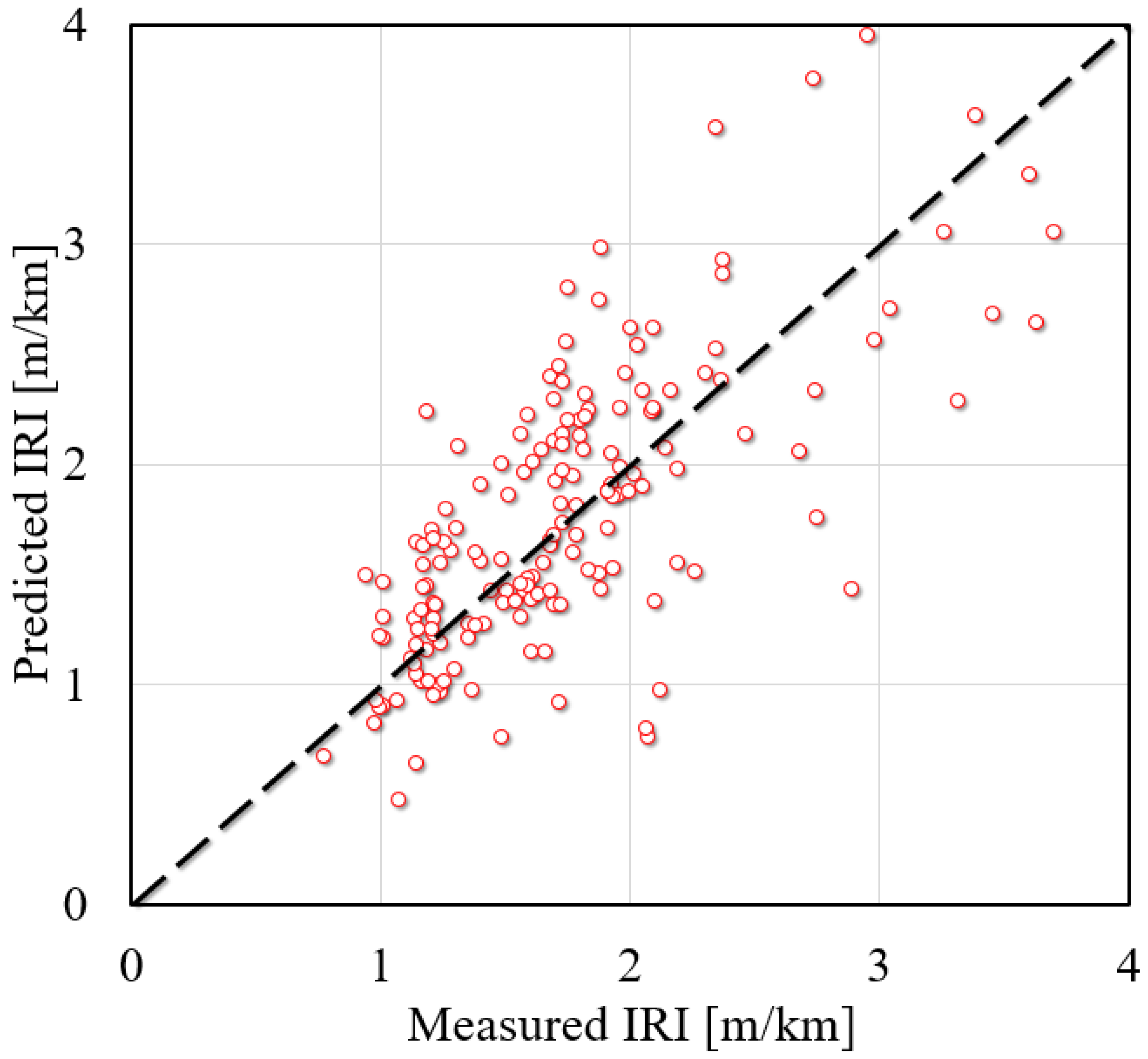
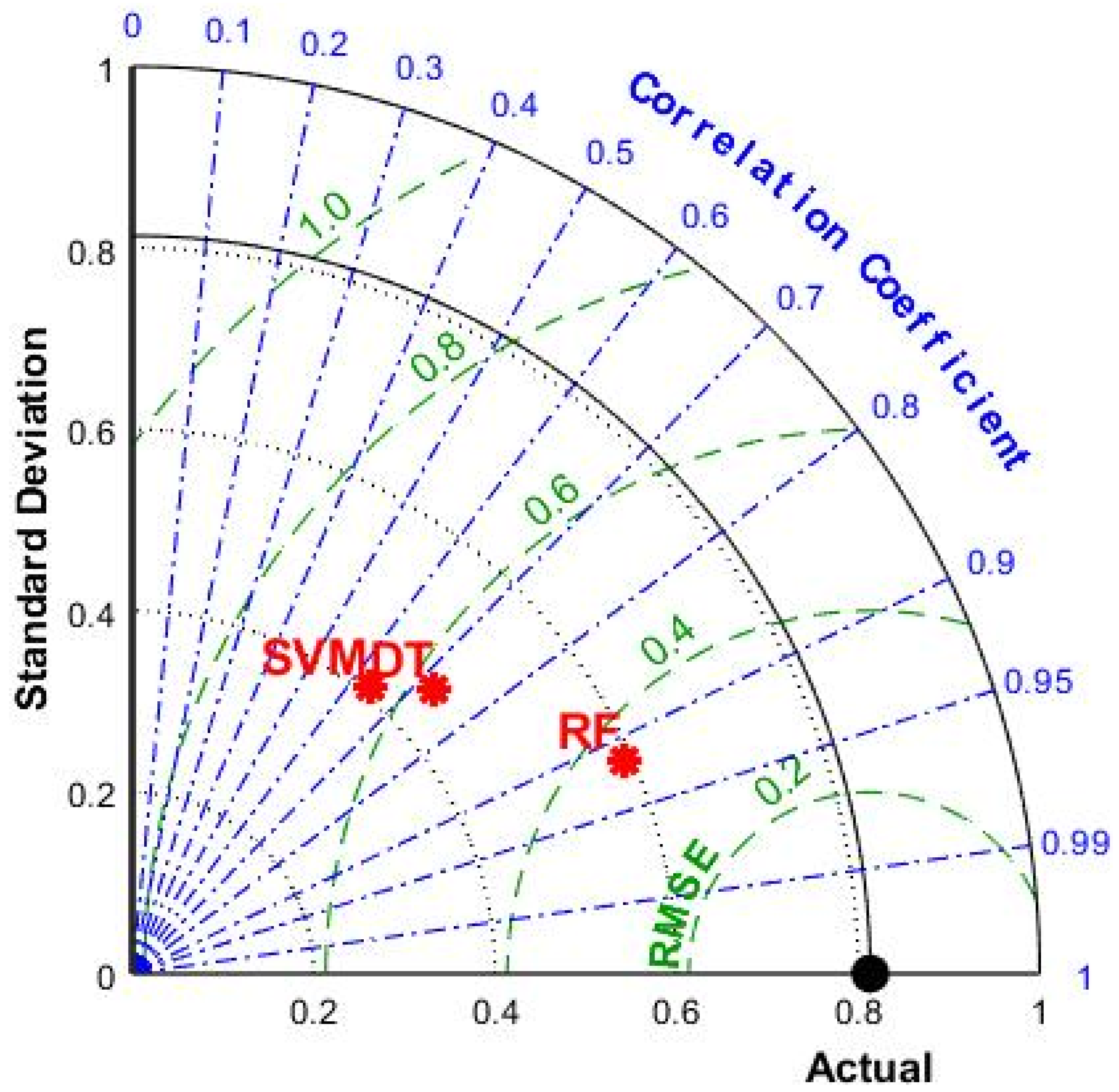
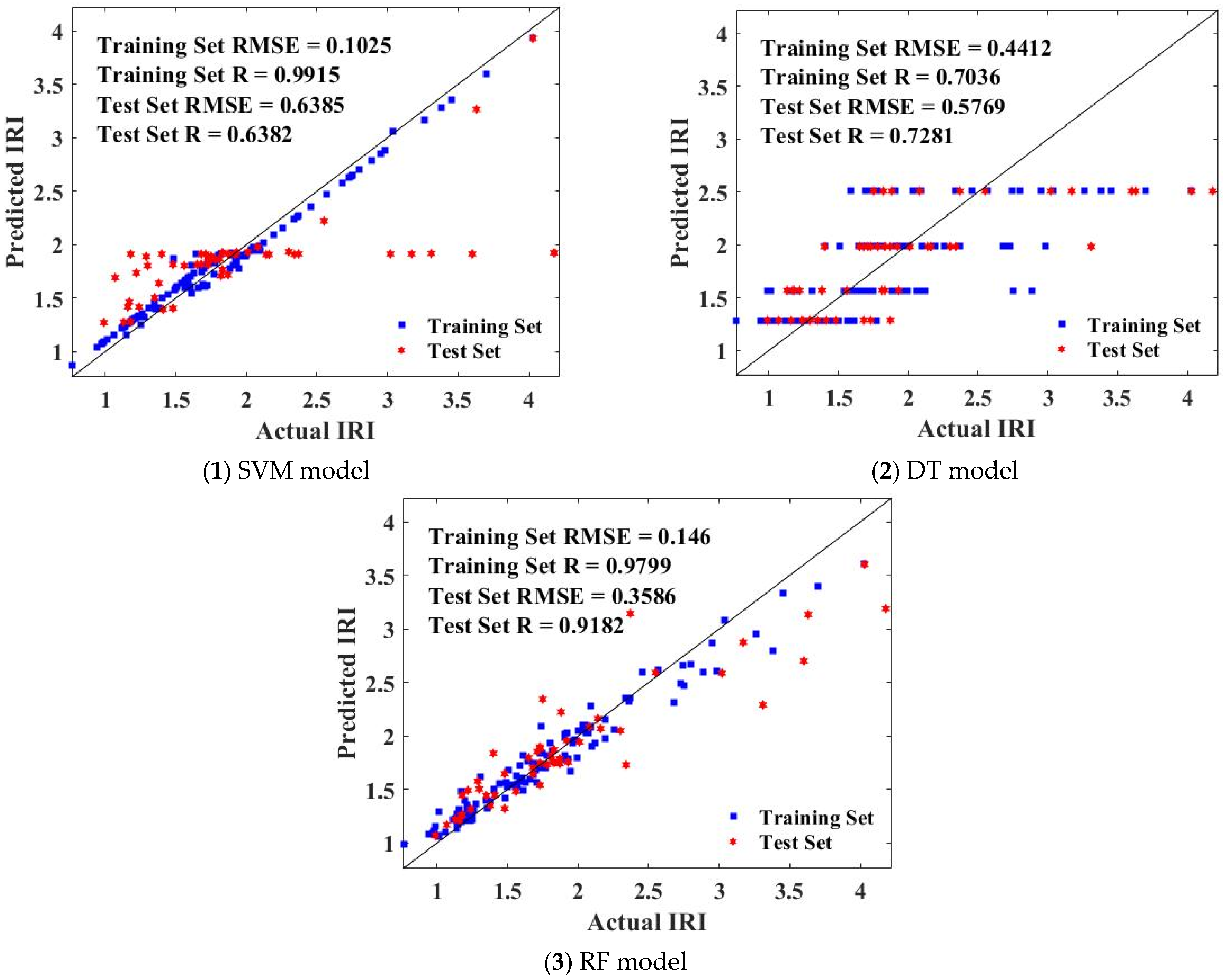
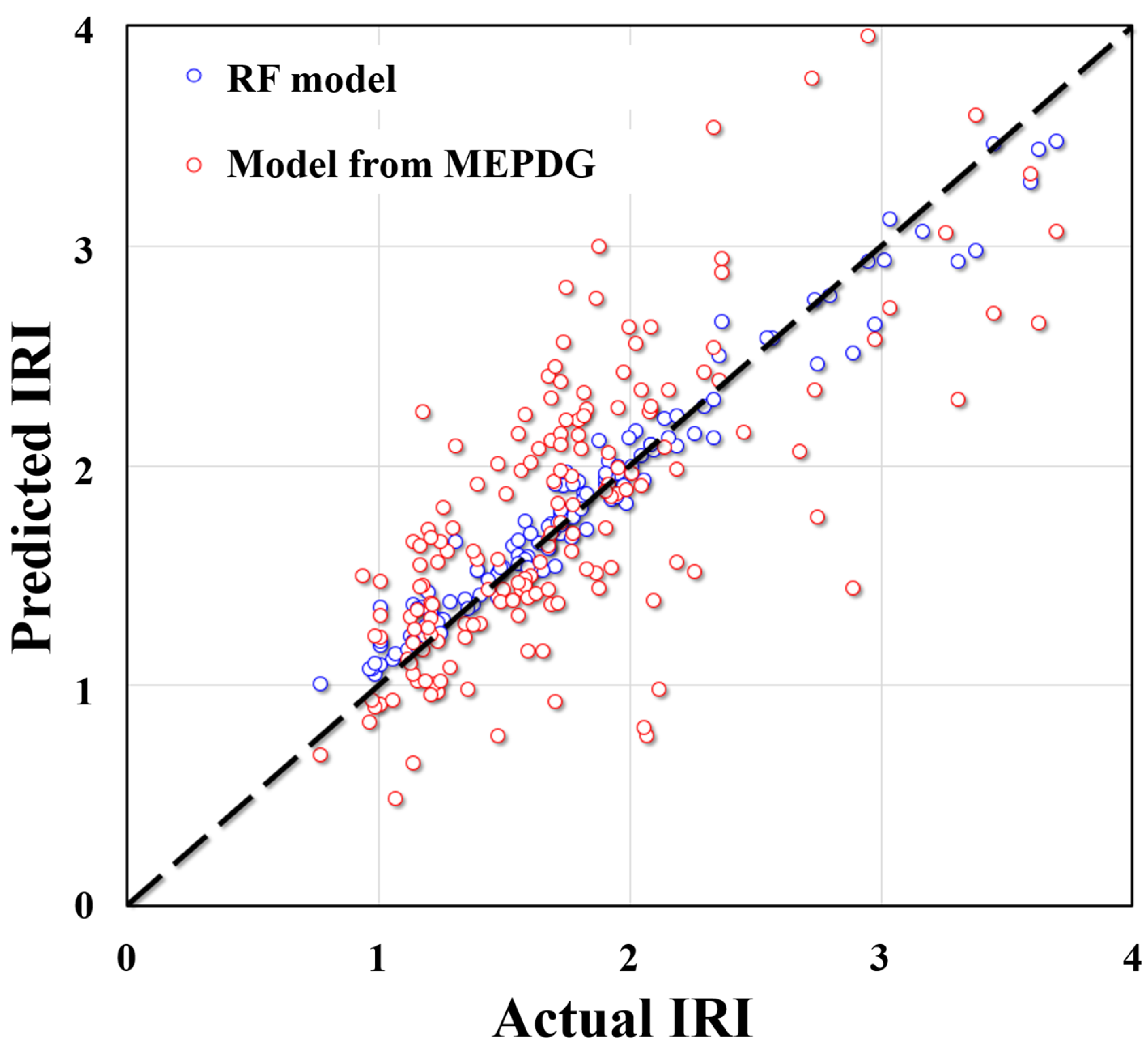
3.2. Comparison of the Predictive Performance
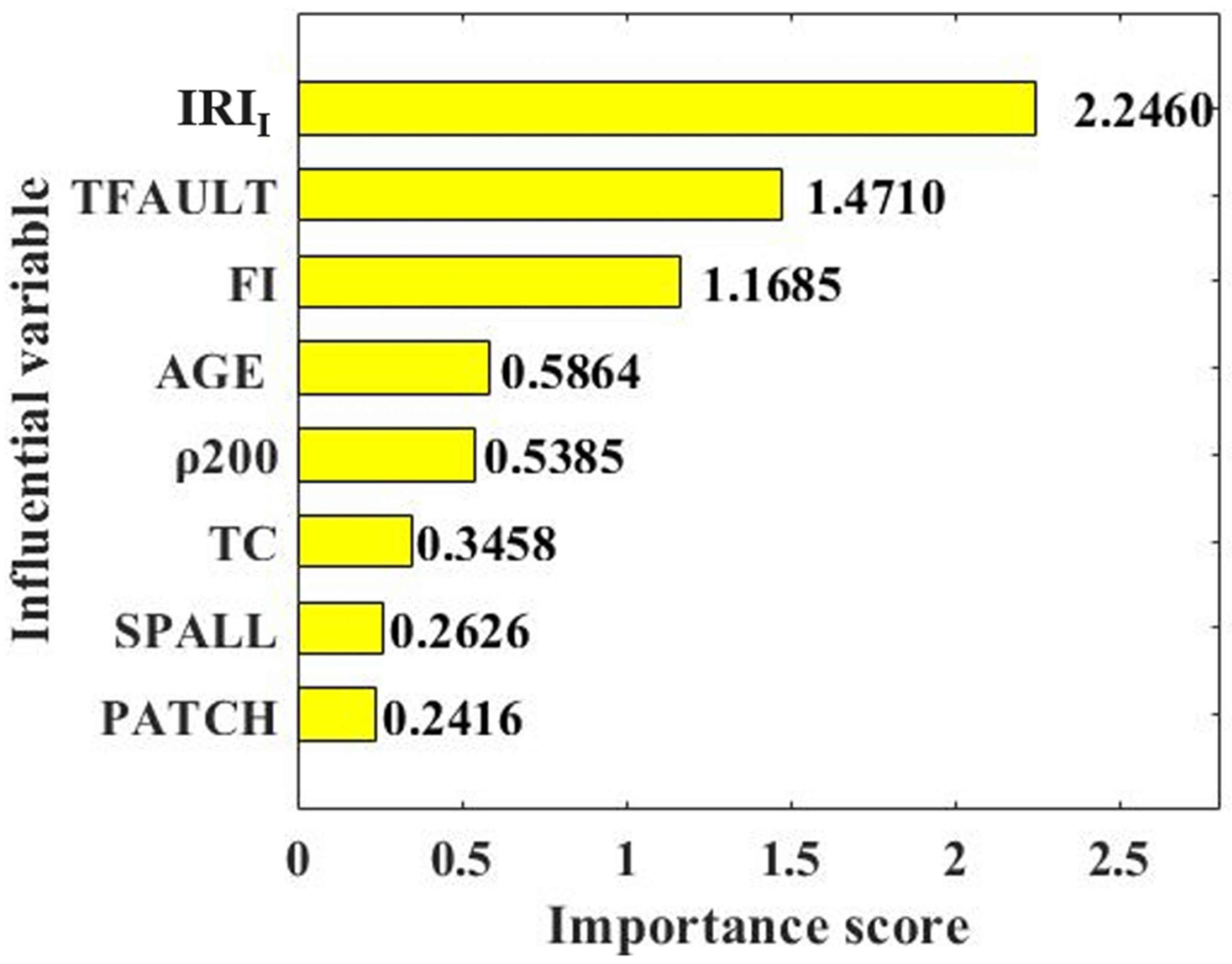
3.3. Variable Importance
4. Conclusions
- (1)
- The data of the input variables (IRII, TFAULT, FI, AGE, ρ200, TC, SPALL, PATCH) in the database had a reasonable distribution, wide coverage, and low correlation. Therefore, using this database to predict the effects of the models, the prediction effect of the IRI of JPCP will not be affected by unreasonable data distribution and a high correlation between variables.
- (2)
- BAS had a good hyperparameter tuning effect on SVM, DT, and RF, indicated by the fact that RMSE values could quickly converge in the process of machine learning. By comparing and analyzing the predicted value and actual value of the IRI of JPCP from the three models in the training set and test set, it was found that RF had the best prediction effect (RMSE value of 0.146 and R value of 0.9799 for the training dataset; RMSE value of 0.3586 and R value of 0.9182 for the training dataset) on the IRI of JPCP in general among the three machine-learning models. In addition, the RF model had no fitting phenomenon due to the introduction of two randomness variables; DT had a poor-fitting effect on the predicted value of the IRI of JPCP.
- (3)
- IRII and TFAULT were the two most important parameters for maintaining the roughness of the road surface. Considering that IRII is an objective parameter of road surface, road engineers should pay more attention to the influence of TFAULT on road surface smoothness in the design process. The effect of SPALL and PATCH on maintaining road surface smoothness was weak, indicated by the low important scores.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hsieh, Y.-A.; Yang, Z.; Tsai, Y.-C.J. Convolutional neural network for automated classification of jointed plain concrete pavement conditions. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 1382–1397. [Google Scholar] [CrossRef]
- Tian, K.; Yang, B.; King, D.; Ceylan, H.; Kim, S. Characterization of curling and warping influence on smoothness of jointed plain concrete pavements. In Proceedings of the International Airfield and Highway Pavements Conference of the Transportation and Development Institute (T and DI) of the American Society of Civil Engineers (ASCE), Chicago, IL, USA, 8–10 June 2021; pp. 110–119. [Google Scholar]
- Zhang, S.; Fan, Y.; Huang, J.; Shah, S.P. Effect of nano-metakaolinite clay on the performance of cement-based materials at early curing age. Constr. Build. Mater. 2021, 291, 123107. [Google Scholar] [CrossRef]
- Xu, W.; Huang, X.; Huang, J.; Yang, Z. Structural Analysis of Backfill Highway Subgrade on the Lower Bearing Capacity Foundation Using the Finite Element Method. Adv. Civ. Eng. 2021, 2021, 1690168. [Google Scholar] [CrossRef]
- Ren, J.; Xu, Y.; Zhao, Z.; Chen, J.; Cheng, Y.; Huang, J.; Yang, C.; Wang, J. Fatigue prediction of semi-flexible composite mixture based on damage evolution. Constr. Build. Mater. 2022, 318, 126004. [Google Scholar] [CrossRef]
- Ren, J.; Xu, Y.; Huang, J.; Wang, Y.; Jia, Z. Gradation optimization and strength mechanism of aggregate structure considering macroscopic and mesoscopic aggregate mechanical behaviour in porous asphalt mixture. Constr. Build. Mater. 2021, 300, 124262. [Google Scholar] [CrossRef]
- Liang, X.; Yu, X.; Chen, C.; Ding, G.; Huang, J. Towards the low-energy usage of high viscosity asphalt in porous asphalt pavements: A case study of warm-mix asphalt additives. Case Stud. Constr. Mater. 2022, 16, e00914. [Google Scholar] [CrossRef]
- Huang, J.; Leandri, P.; Cuciniello, G.; Losa, M. Mix design and laboratory characterisation of rubberised mixture used as damping layer in pavements. Int. J. Pavement Eng. 2021, 23, 2746–2760. [Google Scholar] [CrossRef]
- Grogg, M.; Smith, K.; Williges, C.; Schram, S. Incorporating Pavement Smoothness Benefits to Enhance the Iowa Department of Transportation’s Pavement Type Determination Process. Transp. Res. Rec. 2020, 2674, 563–571. [Google Scholar] [CrossRef]
- Babu, A.; Baumgartner, S.V. Road Surface Roughness Estimation Using Polarimetric SAR Data. In Proceedings of the 21st International Radar Symposium (IRS), Warsaw, Poland, 5–8 October 2020; pp. 281–285. [Google Scholar]
- Putra, T.; Husaini; Machmud, M. Predicting the fatigue life of an automotive coil spring considering road surface roughness. Eng. Fail. Anal. 2020, 116, 104722. [Google Scholar] [CrossRef]
- Wang, L.; Yan, J.; Xie, S.; Wang, C. Testing, Analysis and Comparison for Characteristics of Agricultural Field and Asphalt Road Roughness. INMATEH Agric. Eng. 2020, 62, 147–154. [Google Scholar] [CrossRef]
- Chen, D.; Lv, Z. Artificial intelligence enabled Digital Twins for training autonomous cars. Internet Things Cyber-Phys. Syst. 2022, 2, 31–41. [Google Scholar] [CrossRef]
- Wang, Q.-A.; Zhang, C.; Ma, Z.-G.; Huang, J.; Ni, Y.-Q.; Zhang, C. SHM deformation monitoring for high-speed rail track slabs and Bayesian change point detection for the measurements. Constr. Build. Mater. 2021, 300, 124337. [Google Scholar] [CrossRef]
- Robbins, M.; Tran, N.; Copeland, A. Determining the Age and Smoothness of Asphalt and Concrete Pavements at the Time of First Rehabilitation using Long-Term Pavement Performance Program Data. Transp. Res. Rec. 2018, 2672, 176–185. [Google Scholar] [CrossRef]
- Babu, A.; Baumgartner, S.V.; Krieger, G. Approaches for road surface roughness estimation using airborne polarimetric SAR. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3444–3462. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, H.S.; Lie, S.T.; Yao, Z.; Sheng, Z.H.; Tjhen, L.S. A Simple Approach for Simulating the Road Surface Roughness Involved in Vehicle-Bridge Interaction Systems. Int. J. Struct. Stab. Dyn. 2018, 18, 1871009. [Google Scholar] [CrossRef]
- Huang, J.; Duan, T.; Lei, Y.; Hasanipanah, M. Finite Element Modeling for the Antivibration Pavement Used to Improve the Slope Stability of the Open-Pit Mine. Shock Vib. 2020, 2020, 6650780. [Google Scholar] [CrossRef]
- Loprencipe, G.; Zoccali, P.; Cantisani, G. Effects of Vehicular Speed on the Assessment of Pavement Road Roughness. Appl. Sci. 2019, 9, 1783. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, Q.; Xie, W.; Li, X.; Yin, C. Role of urban surface roughness in road-deposited sediment build-up and wash-off. J. Hydrol. 2018, 560, 75–85. [Google Scholar] [CrossRef]
- Wang, G.; Chen, S.; Xia, M.; Zhong, W.; Han, X.; Luo, B.; Sabri, M.M.S.; Huang, J. Experimental Study on Durability Degradation of Geopolymer-Stabilized Soil under Sulfate Erosion. Materials 2022, 15, 5114. [Google Scholar] [CrossRef]
- Zavagna, P.; Khanal, A.; Souliman, M. LTTP data analysis: Factors affecting pavement roughness for the state of California. J. Mater. Eng. Struct. 2018, 5, 319–332. [Google Scholar]
- Yildirim, Y.; Saygili, G. Pavement smoothness of asphalt concrete overlays. Int. J. Pavement Eng. 2019, 20, 73–78. [Google Scholar] [CrossRef]
- Bhattacharya, B.B.; Darter, M.I. Calibration of Fatigue Cracking and Rutting Prediction Models in Pennsylvania Using Laboratory Test Data for Asphalt Concrete Pavement in AASHTOWare Pavement ME Design. In Proceedings of the International Airfield and Highway Pavements Conference of the Transportation and Development Institute (T and DI) of the American Society of Civil Engineers (ASCE), Chicago, IL, USA, 8–10 June 2021; pp. 37–48. [Google Scholar]
- Zhang, D.-B.; Li, X.; Zhang, Y.; Zhang, H. Prediction Method of Asphalt Pavement Performance and Corrosion Based on Grey System Theory. Int. J. Corros. 2019, 2019, 2534794. [Google Scholar] [CrossRef]
- Al-Qaili, A.H.; Al-Solieman, H. Enhancing MEPDG distress models prediction for Saudi Arabia by local calibration. Road Mater. Pavement Des. 2021, 23, 1681–1693. [Google Scholar] [CrossRef]
- Ishikawa, T.; Lin, T. Applicability of AASHTO MEPDG approach to flexible pavements in cold regions of Japan. In Proceedings of the 16th Pan-American Conference on Soil Mechanics and Geotechnical Engineering (PCSMGE), Cancun, Mexico, 17–20 November 2019; pp. 2931–2933. [Google Scholar]
- Meegoda, J.N.; Gao, S. Roughness Progression Model for Asphalt Pavements Using Long-Term Pavement Performance Data. J. Transp. Eng. 2014, 140, 04014037. [Google Scholar] [CrossRef]
- Jannat, G.E.; Yuan, X.-X.; Shehata, M. Development of regression equations for local calibration of rutting and IRI as predicted by the MEPDG models for flexible pavements using Ontario’s long-term PMS data. Int. J. Pavement Eng. 2016, 17, 166–175. [Google Scholar] [CrossRef]
- Souliman, M.; Mamlouk, M.; El-Basyouny, M.; Zapata, C.E. Calibration of the AASHTO MEPDG for flexible pavement for Arizona conditions. In Proceedings of the Transportation Research Board 89th Annual Meeting, Washington, DC, USA, 10–14 January 2010; pp. 243–286. [Google Scholar]
- Saha, J.; Nassiri, S.; Bayat, A.; Soleymani, H. Evaluation of the effects of Canadian climate conditions on the MEPDG predictions for flexible pavement performance. Int. J. Pavement Eng. 2014, 15, 392–401. [Google Scholar] [CrossRef]
- Ashraf, S. A proactive role of IoT devices in building smart cities. Internet Things Cyber-Phys. Syst. 2021, 1, 8–13. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Nikouei, S.S.; Marto, A.; Fahimifar, A.; Armaghani, D.J.; Mohamad, E.T. Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull. Eng. Geol. Environ. 2019, 78, 3799–3813. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Ghaleini, E.N.; Tootoonchi, H.; Armaghani, D.J.; Haghighi, M.; Hedayat, A. Developing a new intelligent technique to predict overbreak in tunnels using an artificial bee colony-based ANN. Environ. Earth Sci. 2019, 78, 165. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Fahimifar, A.; Ghaleini, E.N.; Momenzadeh, M.; Armaghani, D.J. Development of a new hybrid ANN for solving a geotechnical problem related to tunnel boring machine performance. Eng. Comput. 2020, 36, 345–357. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Monjezi, M.; Shahnazar, A.; Armaghani, D.J.; Farazmand, A. Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 2015, 75, 289–297. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Armaghani, D.J.; Amnieh, H.B.; Majid, M.Z.A.; Tahir, M.M.D. Application of PSO to develop a powerful equation for prediction of flyrock due to blasting. Neural Comput. Appl. 2017, 28, 1043–1050. [Google Scholar] [CrossRef]
- Hajihassani, M.; Armaghani, D.J.; Monjezi, M.; Mohamad, E.T.; Marto, A. Blast-induced air and ground vibration prediction: A particle swarm optimization-based artificial neural network approach. Environ. Earth Sci. 2015, 74, 2799–2817. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Koopialipoor, M.; Marto, A.; Yagiz, S. Application of several optimization techniques for estimating TBM advance rate in granitic rocks. J. Rock Mech. Geotech. Eng. 2019, 11, 779–789. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Koopialipoor, M.; Bahri, M.; Hasanipanah, M.; Tahir, M.M. A SVR-GWO technique to minimize flyrock distance resulting from blasting. Bull. Eng. Geol. Environ. 2020, 79, 4369–4385. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Hatzigeorgiou, G.D.; Karamani, C.; Skentou, A.; Zoumpoulaki, I.; Asteris, P.G. Soft computing-based techniques for concrete beams shear strength. Procedia Struct. Integr. 2019, 17, 924–933. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Hasanipanah, M.; Mohamad, E.T. A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng. Comput. 2016, 32, 155–171. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2021, 33, 4501–4532. [Google Scholar] [CrossRef]
- Xu, W.; Huang, X.; Yang, Z.; Zhou, M.; Huang, J. Developing Hybrid Machine Learning Models to Determine the Dynamic Modulus (E*) of Asphalt Mixtures Using Parameters in Witczak 1-40D Model: A Comparative Study. Materials 2022, 15, 1791. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Zhu, F.; Zhou, M.; Sabri, M.M.S.; Huang, J. Intelligent Design of Construction Materials: A Comparative Study of AI Approaches for Predicting the Strength of Concrete with Blast Furnace Slag. Materials 2022, 15, 4582. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.-A.; Zhang, J.; Huang, J. Simulation of the Compressive Strength of Cemented Tailing Backfill through the Use of Firefly Algorithm and Random Forest Model. Shock Vib. 2021, 2021, 5536998. [Google Scholar] [CrossRef]
- Ma, H.; Liu, J.; Zhang, J.; Huang, J. Estimating the Compressive Strength of Cement-Based Materials with Mining Waste Using Support Vector Machine, Decision Tree, and Random Forest Models. Adv. Civ. Eng. 2021, 2021, 6629466. [Google Scholar] [CrossRef]
- Marcelino, P.; de Lurdes Antunes, M.; Fortunato, E.; Gomes, M.C. Machine learning approach for pavement performance prediction. Int. J. Pavement Eng. 2021, 22, 341–354. [Google Scholar] [CrossRef]
- Yan, K.-Z.; Zhang, Z. Research in Analysis of Asphalt Pavement Performance Evaluation Based on PSO-SVM. In Proceedings of the International Conference on Civil Engineering and Transportation (ICCET 2011), Jinan, China, 14–16 October 2011; pp. 203–207. [Google Scholar]
- Gungor, O.E.; Al-Qadi, I.L. Developing Machine-Learning Models to Predict Airfield Pavement Responses. Transp. Res. Rec. 2018, 2672, 23–34. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, J.; Li, Q.; Fang, N.; Wang, P.; Ding, L.; Li, S. A Hybrid Model for Prediction in Asphalt Pavement Performance Based on Support Vector Machine and Grey Relation Analysis. J. Adv. Transp. 2020, 2020, 7534970. [Google Scholar] [CrossRef]
- Zhu, F.; Wu, X.; Zhou, M.; Sabri, M.M.S.; Huang, J. Intelligent Design of Building Materials: Development of an AI-Based Method for Cement-Slag Concrete Design. Materials 2022, 15, 3833. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Zhou, M.; Zhang, J.; Ren, J.; Vatin, N.I.; Sabri, M.M.S. Development of a New Stacking Model to Evaluate the Strength Parameters of Concrete Samples in Laboratory. Iran. J. Sci. Technol. Trans. Civ. Eng. 2022, 1–16. [Google Scholar] [CrossRef]
- Hall, K.T.; Correa, C.E.; Simpson, A.L. LTPP Data Analysis: Effectiveness of Maintenance and Rehabilitation Options; National Cooperative Highway Research Program: Washington, DC, USA, 2002. [Google Scholar]
- Huang, J.; Duan, T.; Zhang, Y.; Liu, J.; Zhang, J.; Lei, Y. Predicting the Permeability of Pervious Concrete Based on the Beetle Antennae Search Algorithm and Random Forest Model. Adv. Civ. Eng. 2020, 2020, 8863181. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, M.; Yuan, H.; Sabri, M.M.S.; Li, X. Prediction of the Compressive Strength for Cement-Based Materials with Metakaolin Based on the Hybrid Machine Learning Method. Materials 2022, 15, 3500. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Zhou, M.; Yuan, H.; Sabri, M.M.S.; Li, X. Towards Sustainable Construction Materials: A Comparative Study of Prediction Models for Green Concrete with Metakaolin. Buildings 2022, 12, 772. [Google Scholar]
- Huang, J.; Zhou, M.; Sabri, M.M.S.; Yuan, H. A Novel Neural Computing Model Applied to Estimate the Dynamic Modulus (DM) of Asphalt Mixtures by the Improved Beetle Antennae Search. Sustainability 2022, 14, 5938. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Gao, Y. Intelligently Predict the Rock Joint Shear Strength Using the Support Vector Regression and Firefly Algorithm. Lithosphere 2021, 2021, 2467126. [Google Scholar] [CrossRef]
- Huang, J.; Sabri, M.M.S.; Ulrikh, D.V.; Ahmad, M.; Alsaffar, K.A.M. Predicting the Compressive Strength of the Cement-Fly Ash–Slag Ternary Concrete Using the Firefly Algorithm (FA) and Random Forest (RF) Hybrid Machine-Learning Method. Materials 2022, 15, 4193. [Google Scholar] [CrossRef]
- Lv, Z.; Zhang, S.; Xiu, W. Solving the Security Problem of Intelligent Transportation System with Deep Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4281–4290. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Minimum | Maximum | Median | Mean | STD | Variance |
|---|---|---|---|---|---|---|
| IRII | 0.43 | 2.59 | 1.11 | 1.18 | 0.45 | 0.20 |
| AGE | 2.37 | 33.71 | 13.21 | 14.11 | 5.95 | 35.40 |
| TC | 0 | 65.10 | 0 | 5.23 | 11.97 | 143.17 |
| SPALL | 0 | 105.40 | 4.00 | 20.12 | 30.59 | 935.97 |
| PATCH | 0 | 559.20 | 0 | 10.58 | 56.51 | 3193.93 |
| TFAULT | 0 | 1902.30 | 95.00 | 264.83 | 381.11 | 145,246.20 |
| FI | 0 | 186.28 | 54.8 | 303.62 | 441.25 | 194,704.3 |
| 1 | 97.9 | 35.8 | 39.64 | 27.68 | 744.35 | |
| IRI | 0.77 | 4.18 | 1.7 | 1.82 | 0.69 | 0.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Zhou, M.; Sabri, M.M.S.; Huang, J. A Comparative Study of AI-Based International Roughness Index (IRI) Prediction Models for Jointed Plain Concrete Pavement (JPCP). Materials 2022, 15, 5605. https://doi.org/10.3390/ma15165605
Wang Q, Zhou M, Sabri MMS, Huang J. A Comparative Study of AI-Based International Roughness Index (IRI) Prediction Models for Jointed Plain Concrete Pavement (JPCP). Materials. 2022; 15(16):5605. https://doi.org/10.3390/ma15165605
Chicago/Turabian StyleWang, Qiang, Mengmeng Zhou, Mohanad Muayad Sabri Sabri, and Jiandong Huang. 2022. "A Comparative Study of AI-Based International Roughness Index (IRI) Prediction Models for Jointed Plain Concrete Pavement (JPCP)" Materials 15, no. 16: 5605. https://doi.org/10.3390/ma15165605
APA StyleWang, Q., Zhou, M., Sabri, M. M. S., & Huang, J. (2022). A Comparative Study of AI-Based International Roughness Index (IRI) Prediction Models for Jointed Plain Concrete Pavement (JPCP). Materials, 15(16), 5605. https://doi.org/10.3390/ma15165605