
Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Method Introduction
2.2. Principle of Texture Feature Extraction
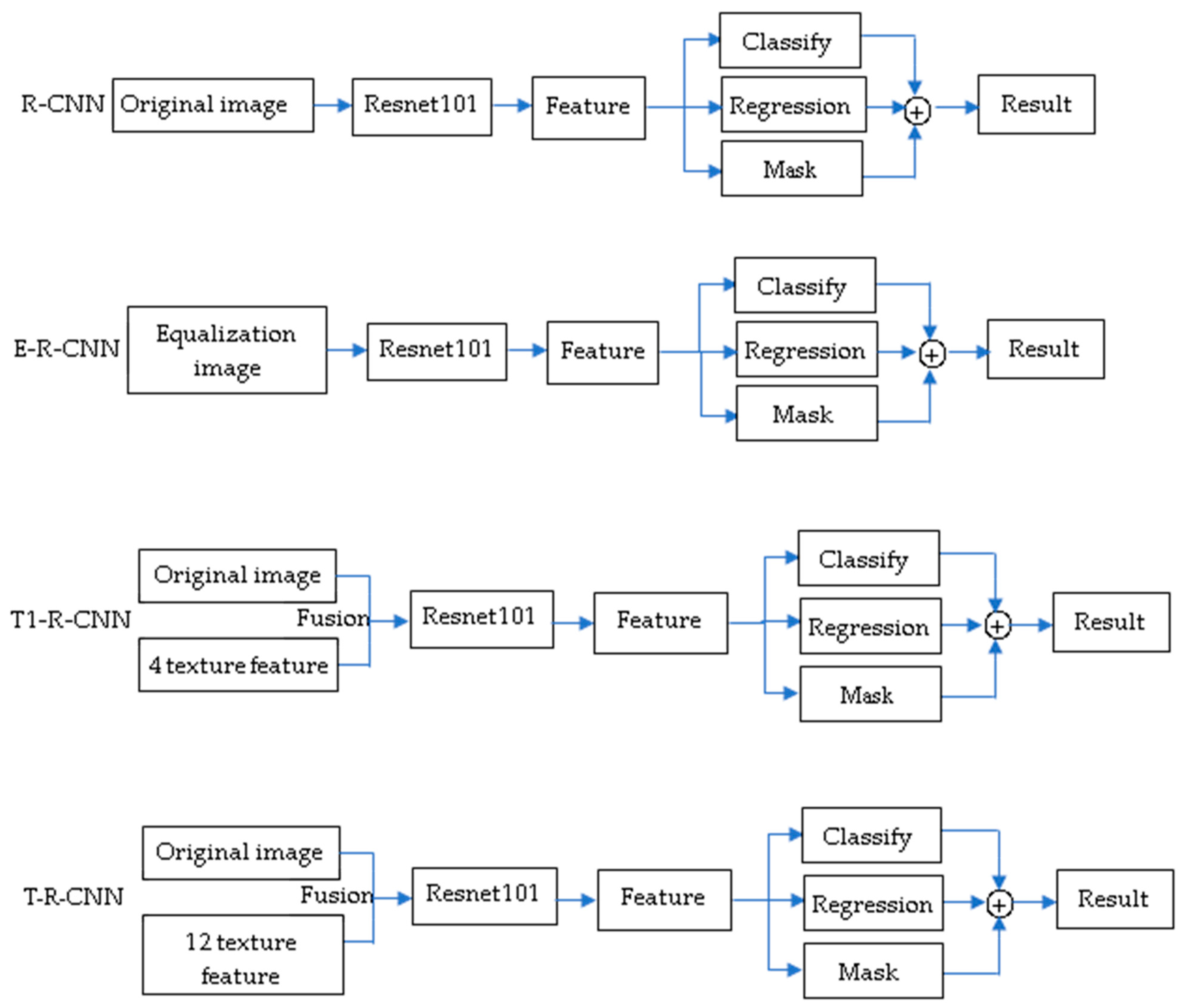
2.3. Construction of Deep Learning Framework Based on Texture Features
2.3.1. Input Layer
2.3.2. Feature Extraction Layer
2.3.3. Full Connection Layer
2.3.4. Loss Function
3. Results
3.1. Sample Preparation
3.1.1. Preparation of Steel Fiber Reinforced Concrete
3.1.2. Concrete Crack Acquisition
3.1.3. Image Clipping
3.2. Image Preprocessing
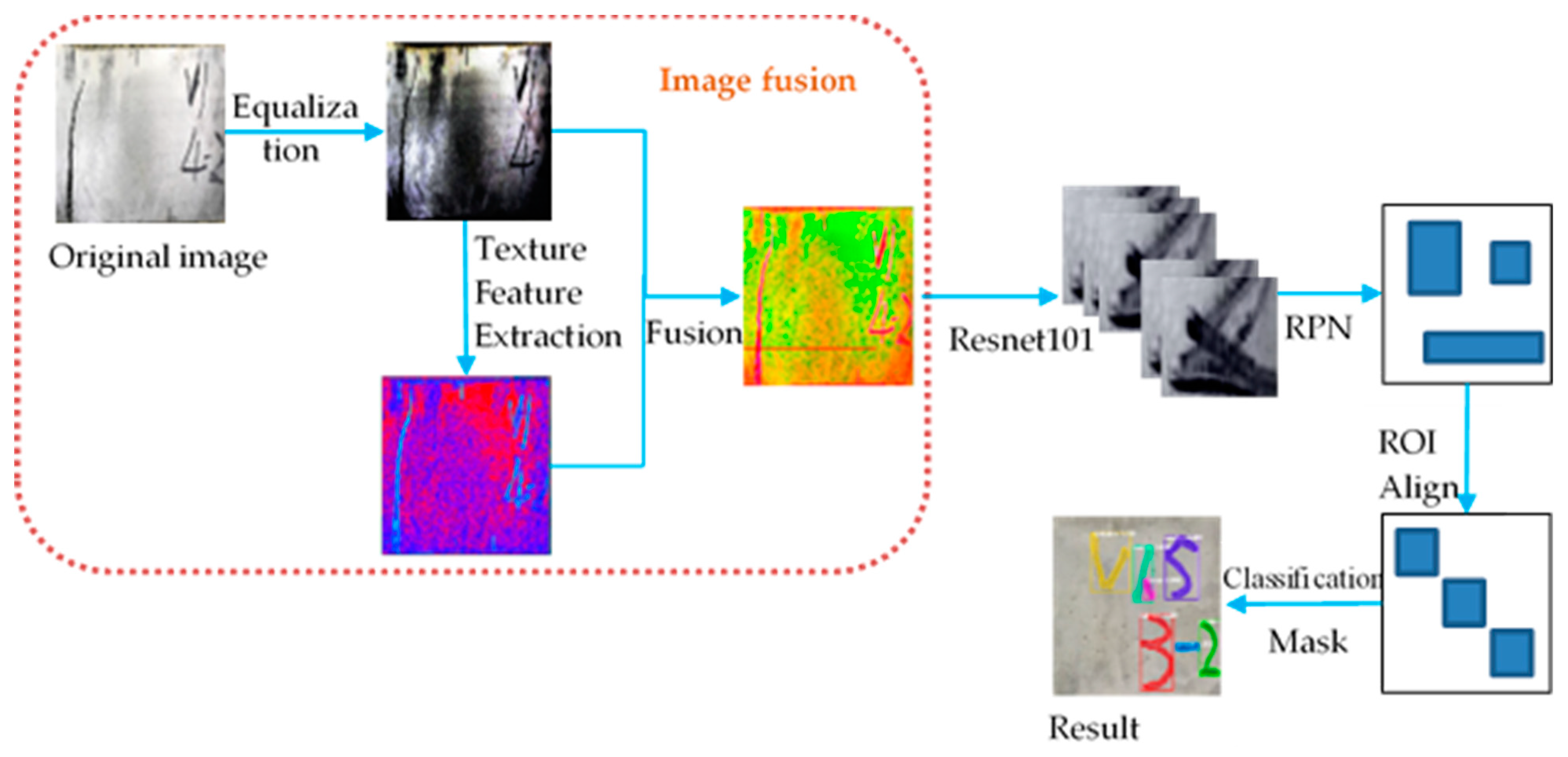
3.3. Texture Feature Extraction and Image Fusion
3.4. Sample Label Making
4. Discussion
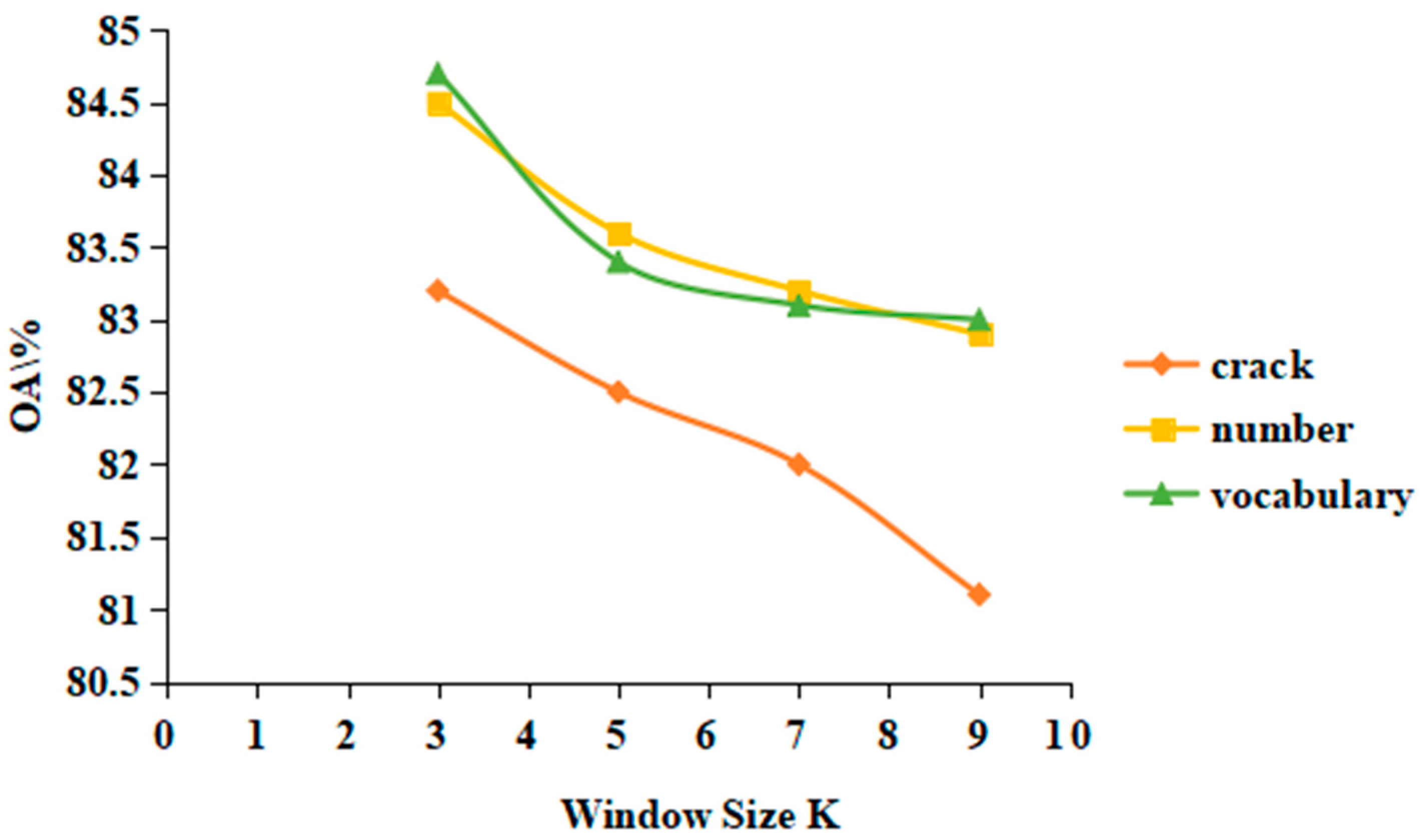
4.1. Parameter Setting
4.2. Analysis of Experimental Results
4.2.1. Target Detection Accuracy Analysis
4.2.2. Comparison of Detection Accuracy and Reliability
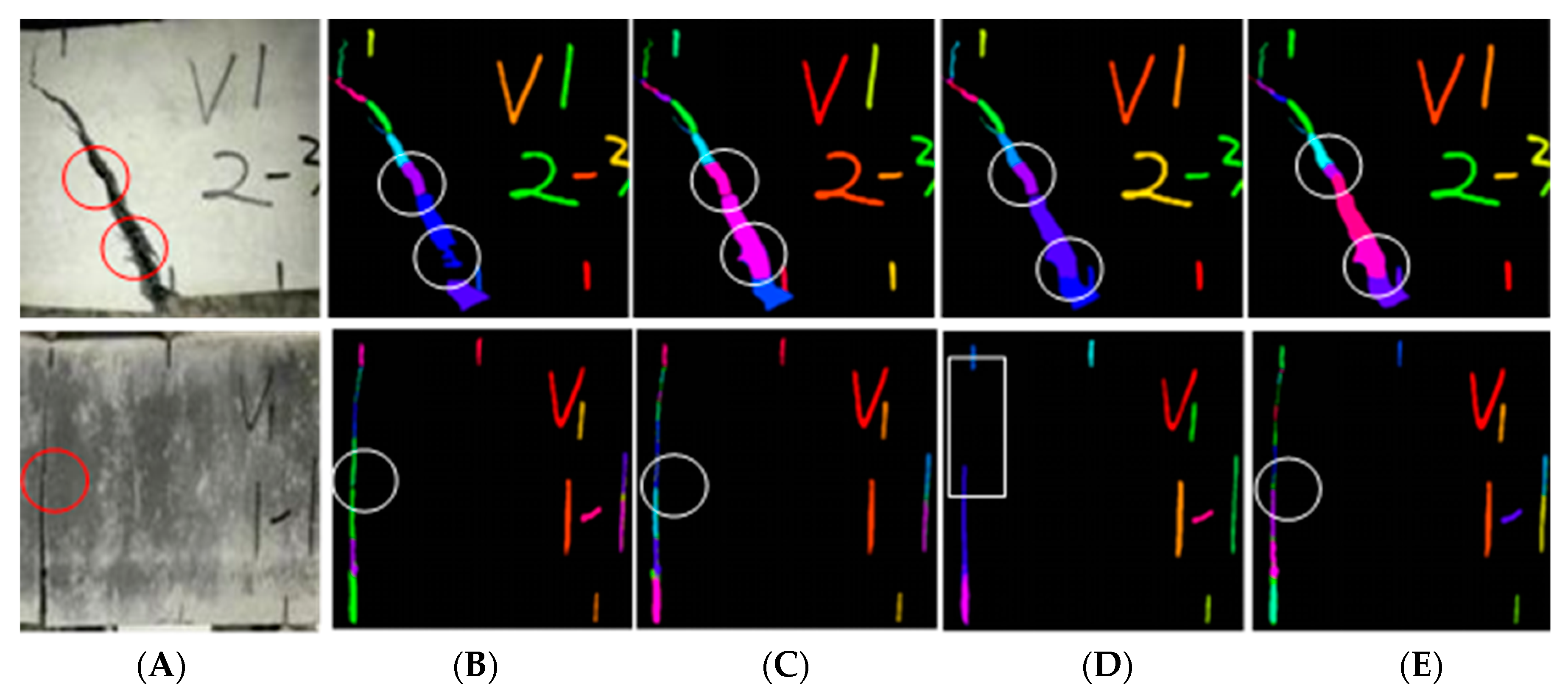
4.2.3. Comparative Analysis of Target Results
4.2.4. Efficiency Evaluation
4.2.5. Error Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, T.; Twumasi, J.O.; Le, V.; Tang, Q.; D’Amico, N. Surface and Subsurface Remote Sensing of Concrete Structures Using Synthetic Aperture Radar Imaging. J. Struct. Eng. 2017, 143, 04017143. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Chang, C.-C.; Xiang, J.; Zhang, C.; Liu, M. An Optical Crack Growth Sensor Using the Digital Sampling Moiré Method. Sensors 2018, 18, 3466. [Google Scholar] [CrossRef] [Green Version]
- Pozzer, S.; Rezazadeh, A.; Dalla, R.F.; Chamberlain, P.Z.M. Semantic Segmentation of Defects in Infrared Thermo-graphic Images of Highly Damaged Concrete Structures. J. Perform. Constr. Facil. 2021, 35, 04020131. [Google Scholar] [CrossRef]
- Jie, X.; Shahzad, A.S.; Xi, C.; Arslan, A.; Furqan, F. Micro-cracking pattern recognition of hybrid CNTs/GNPs cement pastes under three-point bending loading using acoustic emission technique. J. Build. Eng. 2021, 42, 102816. [Google Scholar] [CrossRef]
- Fabio, M.V.; Gustavo, B.; Ana, F.; Micaela, G.C.; Alberto, R.; Ana, J.L. A novel method based on digital holographic interferometry (DHI) to in-situ register the dynamic behavior of concrete 20th century building heritage. In Proceedings of the Optics for Arts, Architecture, and Archaeology VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; p. 117840. [Google Scholar] [CrossRef]
- Aleksandra, K. The Use of the Acoustic Emission Method to Identify Crack Growth in 40CrMo Steel. Materials 2019, 12, 2140. [Google Scholar]
- Gülden, K.U.; Neşe, G. A Study on Multiple Linear Regression Analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef] [Green Version]
- Bahzad, T.J.; Adnan, M.A. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Ninda, A.U.; Warih, M.; Imelda, A. Personality Classification of Facebook Users According to Big Five Personality Using SVM (Support Vector Machine) Method. Procedia Comput. Sci. 2021, 179, 177–184. [Google Scholar]
- Huan, Z.; Liang, X.J.; Liang, J.Y. Attribute and instance weighted naive Bayes. Pattern Recognit. 2021, 111, 107674. [Google Scholar]
- Gang, L.; Qiang, W.L. Automatic crack recognition for concrete bridges using a fully convolutional neural network and naive Bayes data fusion based on a visual detection system. Meas. Sci. Technol. 2019, 31, 075403. [Google Scholar] [CrossRef]
- Sharma, M.; Anotaipaiboon, W.; Chaiyasarn, K. Concrete Crack Detection Using the Integration of Convolutional Neural Network and Support Vector Machine. Sci. Technol. Asia 2018, 23, 19–28. [Google Scholar]
- Prasanna, P.; Dana, K.; Gucunski, N.; Basily, B. Computer-vision based crack detection and analysis. In Proceedings of the SPIE 8345, Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2012, San Diego, CA, USA, 6 April 2012; p. 834542. [Google Scholar] [CrossRef]
- Choudhary, G.K.; Dey, S. Crack detection in concrete surfaces using image processing, fuzzy logic, and neural networks. In Proceedings of the IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 404–411. [Google Scholar]
- Xu, X.; Zhang, X. Crack detection of reinforced concrete bridge using video image. J. Cent. South Univ. 2013, 20, 2605–2613. [Google Scholar] [CrossRef]
- Li, J.; Deng, J.; Xie, W. Damage detection with streamlined structural health monitoring data. Sensors 2015, 15, 8832–8851. [Google Scholar] [CrossRef]
- Adhikari, R.S.; Moselhi, O.; Bagchi, A. Image-based retrieval of concrete crack properties for bridge inspection. Autom. Constr. 2014, 39, 180–194. [Google Scholar] [CrossRef]
- Young, J.C.; Wooram, C.; Oral, B. Deep Learning Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar]
- Spencer, G.; Hung, M.L.; Sul, L. A Genetic Algorithm for Convolutional Network Structure Optimization for Concrete Crack Detection. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; p. 8477790. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Cao, Y.W.; Wang, Y.Z.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Sattar, D.; Robert, J.T.; Marc, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar]
- Zhang, Q.Y.; Barri, K.; Babanajad, S.K.; Alavi, A.H. Real-Time Detection of Cracks on Concrete Bridge Decks Using Deep Learning in the Frequency Domain. Engineering 2020, 7, 1786–1796. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and ComparisonStudy Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef]
- Ding, Y.; Zhou, S.X.; Yuan, H.Q.; Pan, Y.; Dong, J.L.; Wang, Z.P.; Yang, T.Y.; She, A.M. Crack Identification Method of Steel Fiber Reinforced Concrete Based on Deep Learning: A Comparative Study and Shared Crack Database. Adv. Mater. Sci. Eng. 2021, 2021, 9934250. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y.; Huang, W.; Wang, L. Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal Fract. 2022, 6, 95. [Google Scholar] [CrossRef]
- Ruan, Q.Q. Digital Image Processing; Publishing House of Electronics Industry: Beijing, China, 2001. [Google Scholar]
- Mei, A.X.; Peng, W.L.; Qin, Q.M.; Liu, H.P. Introduction to Remote Sensing; Higher Education Press: Beijing, China, 2001. [Google Scholar]
- Faust, O.; Acharya, U.R.; Meiburger, K.M.; Molinari, F.; Koh, J.E.; Yeong, C.H.; Kongmebhol, P.; Ng, K.H. Comparative assessment of texture features for the identification of cancer in ultrasound images: A review. Biocybern. Biomed. 2018, 38, 275–296. [Google Scholar] [CrossRef] [Green Version]
- Midya, A.; Rabidas, R.; Sadhu, A.; Chakraborty, J. Edge weighted local texture features for the categorization of mammographic masses. J. Med. Biol. Eng. 2018, 38, 457–468. [Google Scholar] [CrossRef]
- Latha, M.; Kavitha, G. Segmentation and texture analysis of structural biomarkers using neighborhood-clustering-based level set in MRI of the schizophrenic brain. Magn. Reson. Mater. Phys. Biol. Med. 2018, 31, 483–499. [Google Scholar] [CrossRef]
- Pérez-Barnuevo, L.; Lévesque, S.; Bazin, C. Automated recognition of drill core textures: A geometallurgical tool for mineral processing prediction. Miner. Eng. 2018, 118, 87–96. [Google Scholar] [CrossRef]
- Pham, M.; Lefèvre, S.; Merciol, F. Attribute Profiles on Derived Textural Features for Highly Textured Optical Image Classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1125–1129. [Google Scholar] [CrossRef]
- Lan, Z.; Liu, Y. Study on multi-scale window determination for GLCM texture description in high-resolution remote sensing image geo-analysis supported by GIS and domain knowledge. ISPRS Int. J. Geo Inf. 2018, 7, 175. [Google Scholar] [CrossRef] [Green Version]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [CrossRef] [Green Version]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Vadivel, A.; Sural, S.; Majumdar, A.K. An integrated color and intensity co-occurrence matrix. Pattem Recognit. Lett. 2007, 28, 974–983. [Google Scholar] [CrossRef]
- Baraldi, A.; Parmiggiani, F. An investigation of the textual Characteristics associated with gray level co-occurrence matrix statistical parameters. IEEE Trans. Geosci. Remote Sens. 1995, 33, 293–304. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Average Precision (AP)/% | Mean Average Accuracy (mAP)/% | ||
|---|---|---|---|---|
| Crack | Number | Vocabulary | ||
| M-R-CNN | 86.48 | 87.38 | 88.14 | 87.64 |
| E-M-R-CNN | 90.75 | 87.95 | 90.14 | 89.61 |
| T1-M-T-CNN | 75.76 | 90.29 | 78.45 | 81.50 |
| T-M-R-CNN | 91.06 | 89.33 | 93.54 | 91.31 |
| Number of Training Samples | Iteration Duration/Minute | The Number of Iterations | Total Training Time/Minute |
|---|---|---|---|
| 90 | 19.86 | 200 | 3972 |
| 200 | 44.13 | 200 | 8826 |
| 2000 | 441.33 | 200 | 88,260 |
| 20,000 | 4413.33 | 200 | 882,600 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Pan, Y.; Huang, X.; Yang, D.; Ding, Y.; Duan, R. Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning. Materials 2022, 15, 3940. https://doi.org/10.3390/ma15113940
Zhou S, Pan Y, Huang X, Yang D, Ding Y, Duan R. Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning. Materials. 2022; 15(11):3940. https://doi.org/10.3390/ma15113940
Chicago/Turabian StyleZhou, Shuangxi, Yuan Pan, Xiaosheng Huang, Dan Yang, Yang Ding, and Runtao Duan. 2022. "Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning" Materials 15, no. 11: 3940. https://doi.org/10.3390/ma15113940
APA StyleZhou, S., Pan, Y., Huang, X., Yang, D., Ding, Y., & Duan, R. (2022). Crack Texture Feature Identification of Fiber Reinforced Concrete Based on Deep Learning. Materials, 15(11), 3940. https://doi.org/10.3390/ma15113940