
Feature Engineering for Surrogate Models of Consolidation Degree in Additive Manufacturing


Abstract
1. Introduction
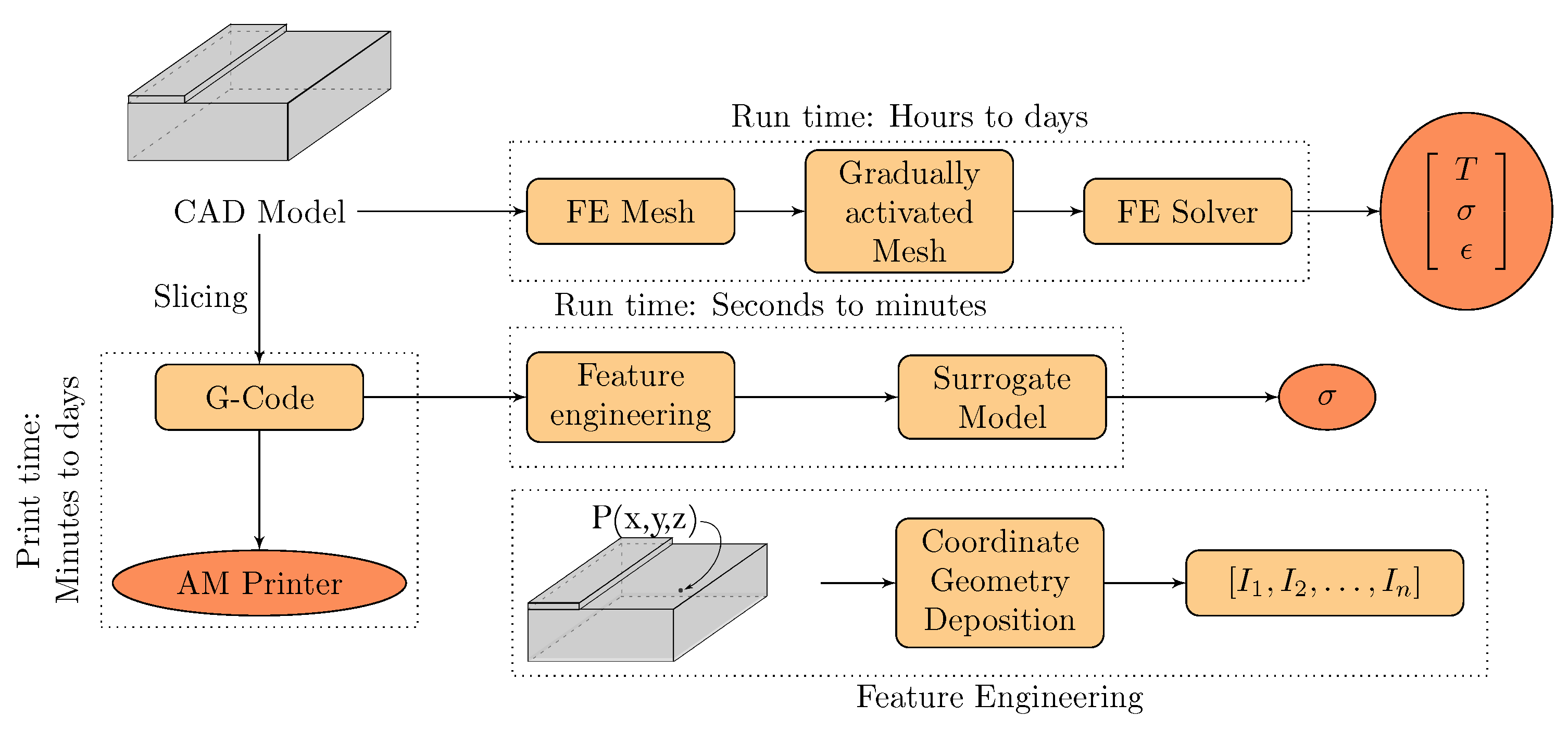
Two Data Regimes and Complexity of the Surrogate Models in AM
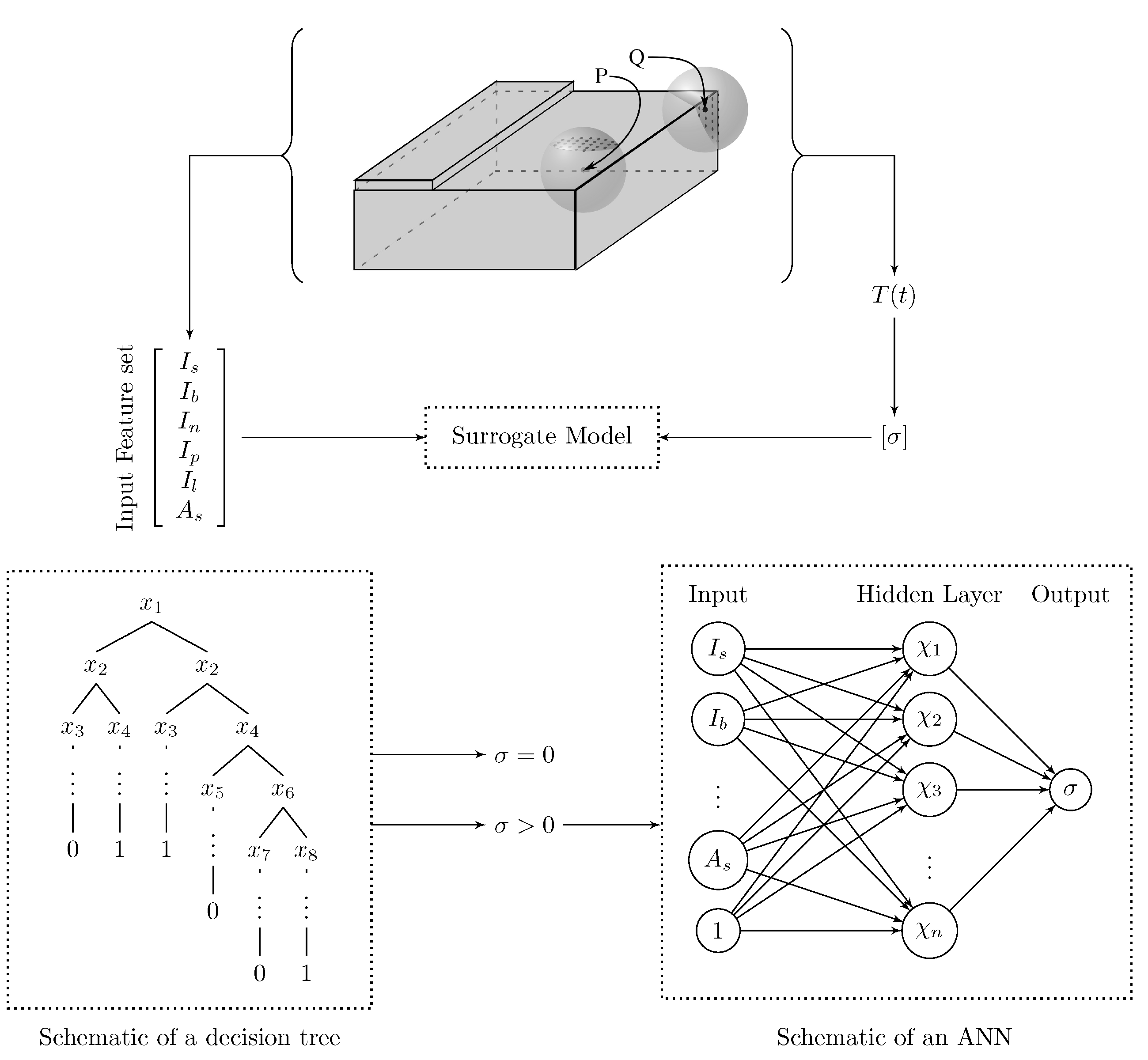
2. Problem Formulation
3. Numerical Model and the Physical Background of the Manufacturing Process
3.1. Heat Transfer Model
3.2. Thermoplastic Consolidation
4. Feature Engineering for the SM of Consolidation Degree
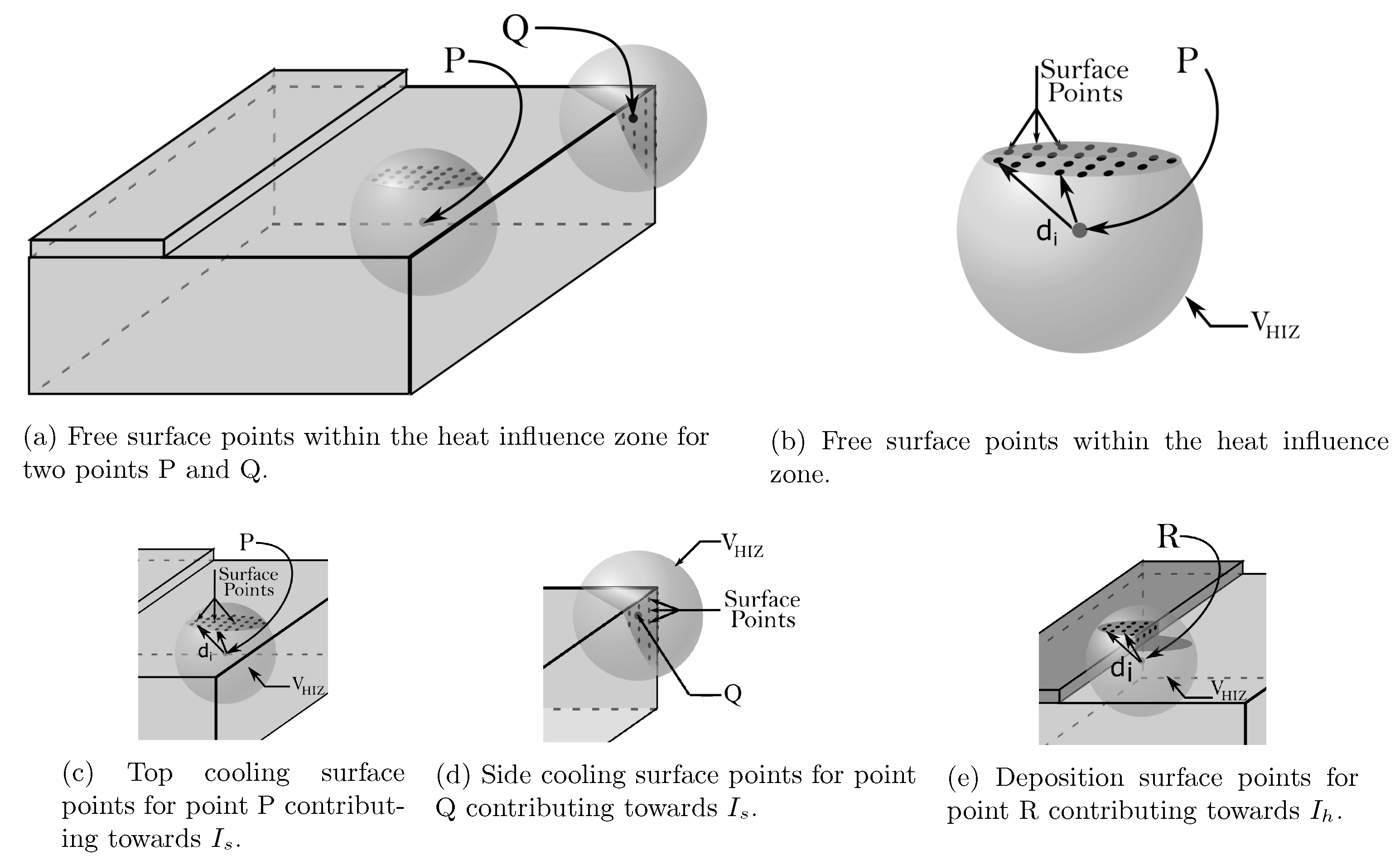
4.1. Limit the Number of Defined Features by Introducing a Heat Influence Zone
4.2. Two Major Pieces of Information: The Distance and the Relative Time
4.3. Designed Features
4.3.1. Geometry-Related Features
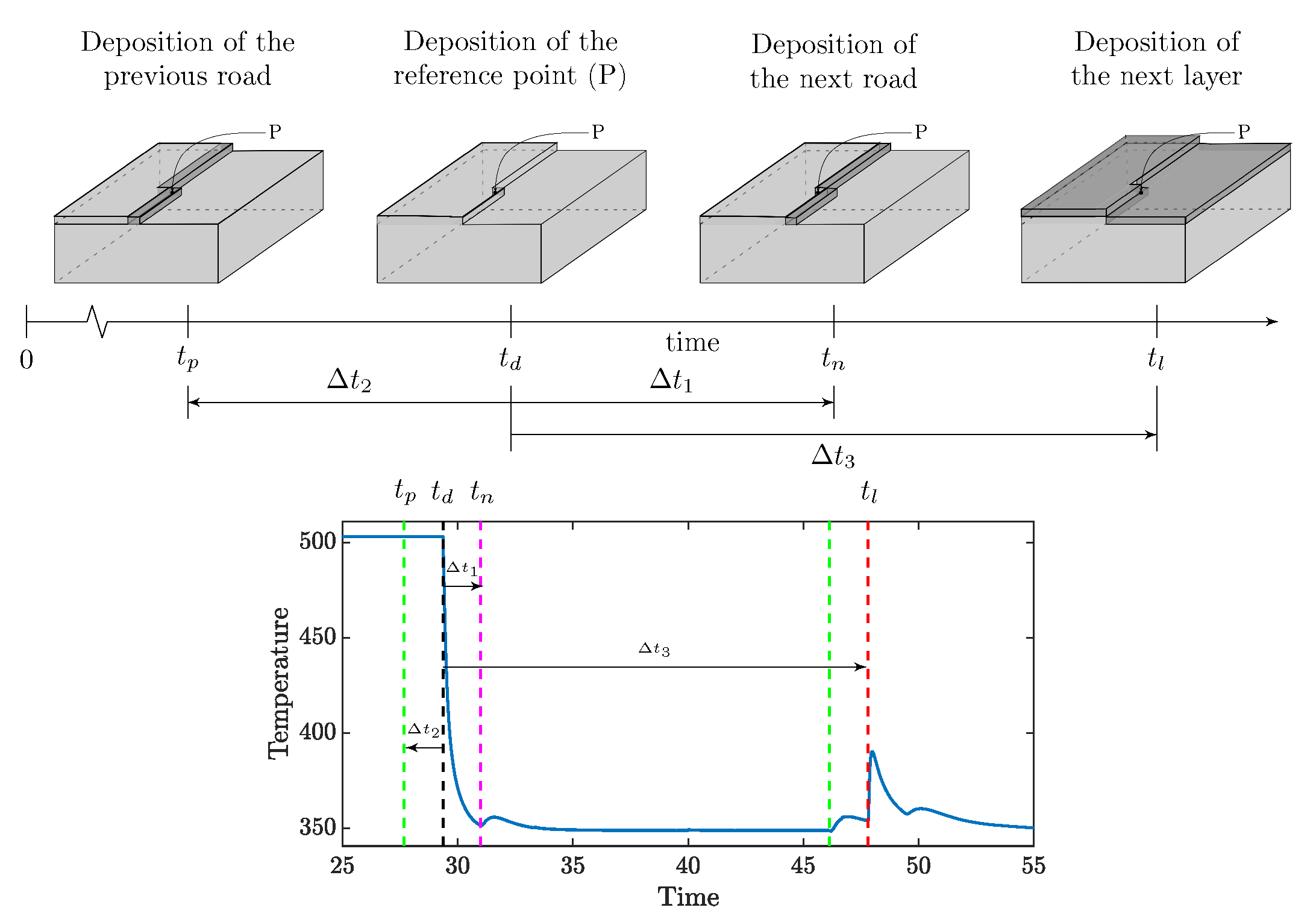
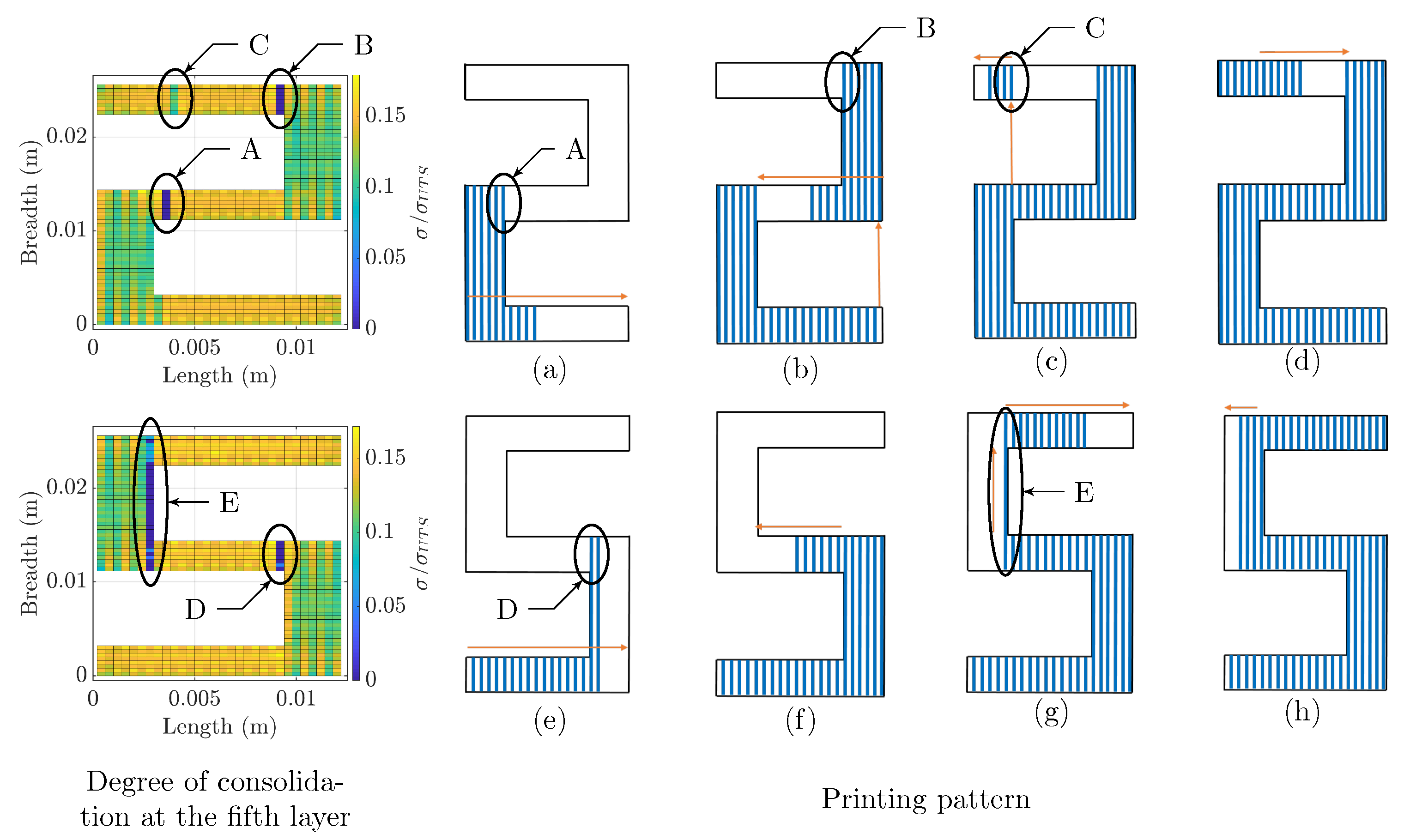
4.3.2. Printing Pattern Related Features
- Next road influence depends on the time at which the adjacent next road is deposited.Consider a point P on a given road, as shown in Figure 3, and its adjacent deposition. The relative time of deposition of the next road affects the heat transfer. Intuitively, if the relative time is long, the point gets sufficient time to cool down, and the heat retention will be lower. Thus, the temperature difference between the next road and P would be higher, and, in terms, heat flow would be higher, which causes high peaks. The effect of the next road can be quantified as:where is the time of deposition of point P and is that of the next road.
- Previous road influence depends on the time at which adjacent previous road was deposited. The previous roads also contribute to heat flow out of P. If the relative time of the previous road deposition is high, it will be at a low temperature, and higher heat will flow from P to the road compared to a more recently deposited one.where is the time of deposition of the neighboring previous deposition.
- Layer influence is the feature capturing the effect of the relative time of deposition of the next layer. This is one of the most influencing parameter as the most significant contributor to reheating is the subsequent layer depositions. The relative time dictates the heat accumulation. Considering the time of deposition of the next layer to be , the influence is given as:
5. Results
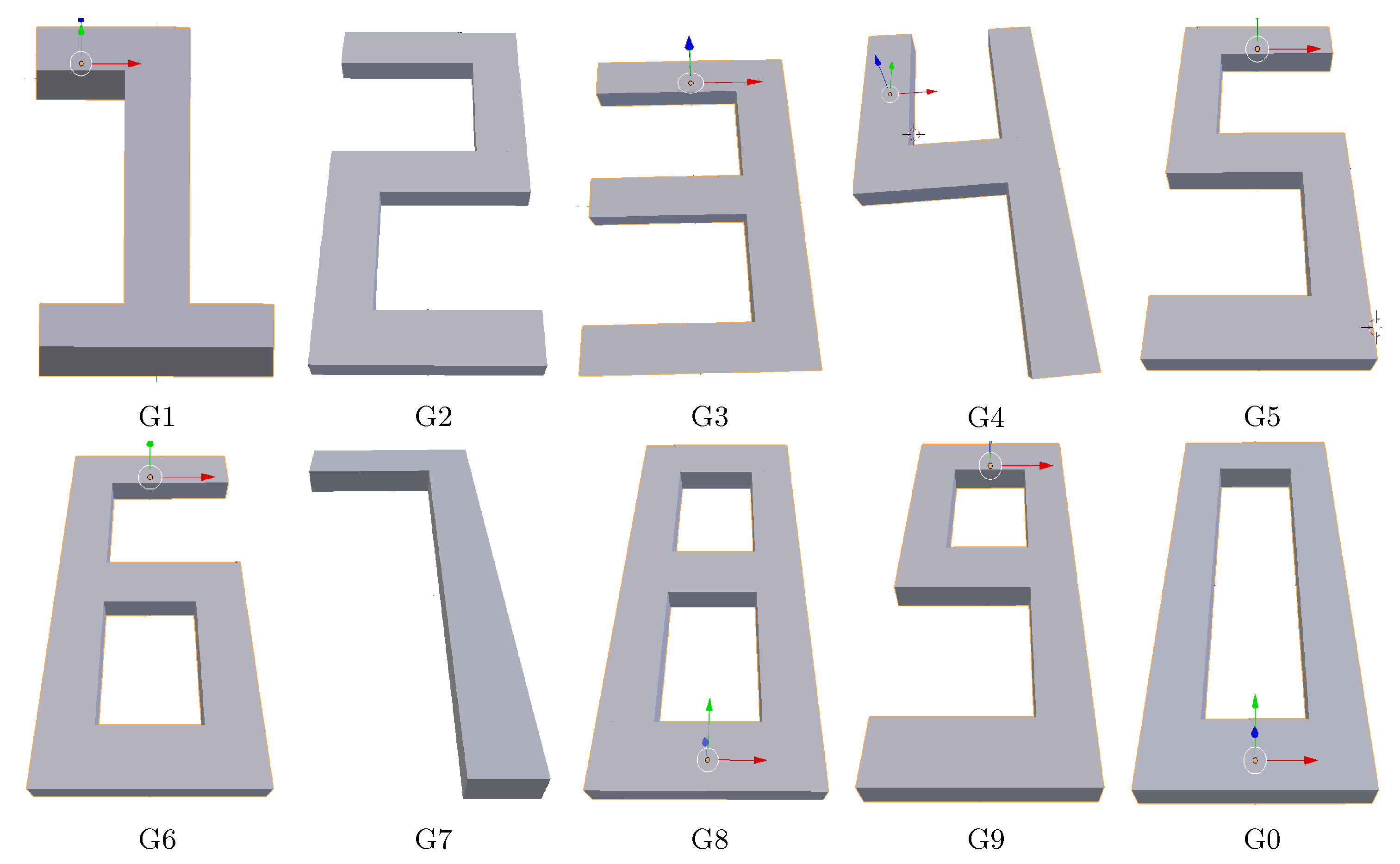
5.1. Data Generation
5.2. Nontrivial Behavior for Relatively Simple Geometries
5.3. Technical Details
5.4. The Architecture of Our Surrogate Model
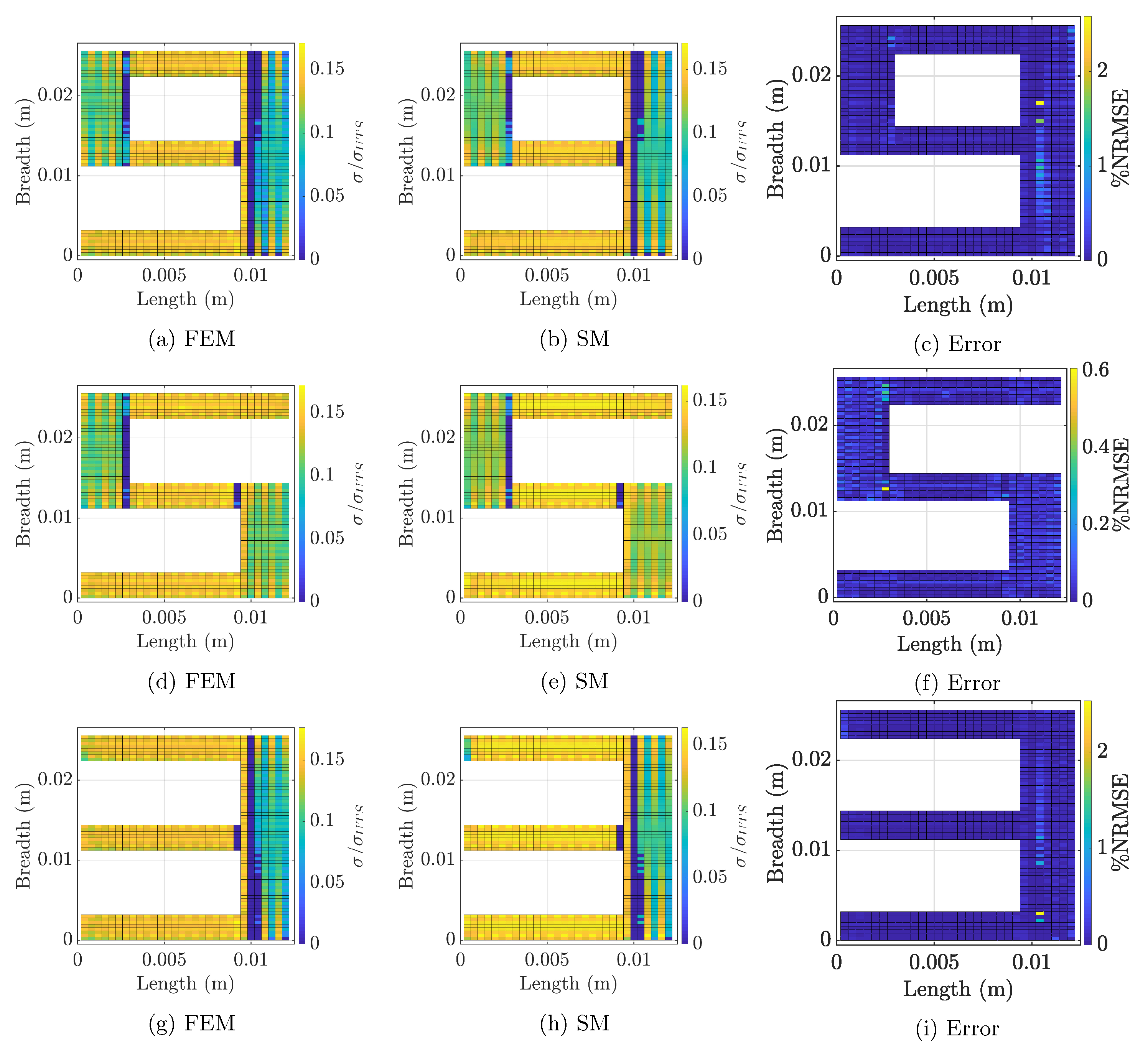
5.5. Testing
5.6. Feature Engineering Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
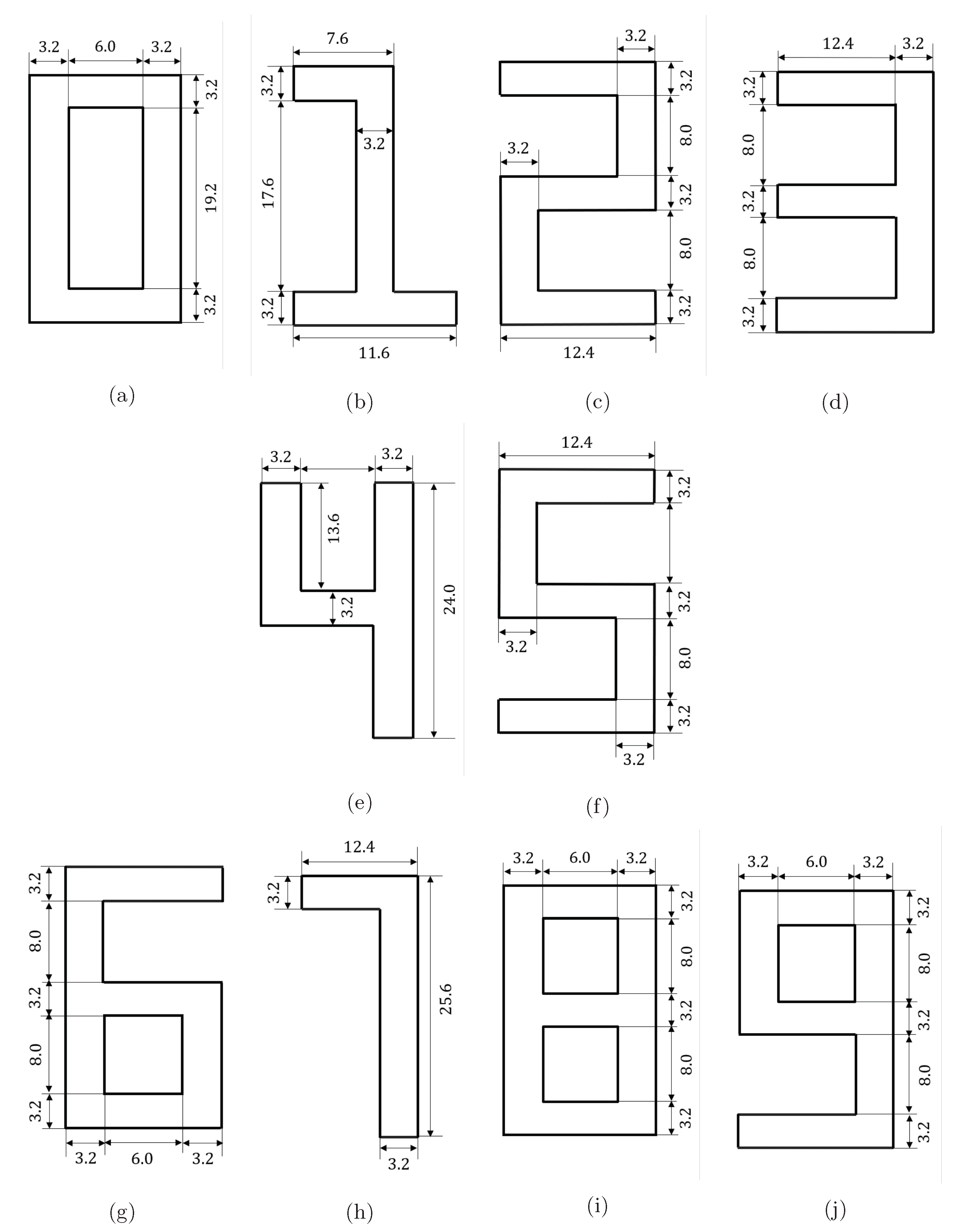
Appendix A. Dimensions of the Digits

References
- Atif Yardimci, M.; Güçeri, S. Conceptual framework for the thermal process modelling of fused deposition. Rapid Prototyp. J. 1996, 2, 26–31. [Google Scholar] [CrossRef]
- Li, L. Analysis and Fabrication of FDM Prototypes with Locally Controlled Properties; University of Calgary: Calgary, AB, Canada, 2002. [Google Scholar]
- Costa, S.; Duarte, F.; Covas, J. Thermal conditions affecting heat transfer in FDM/FFE: A contribution towards the numerical modelling of the process. Virtual Phys. Prototyp. 2015, 10, 35–46. [Google Scholar] [CrossRef]
- Rodríguez, J.F.; Thomas, J.P.; Renaud, J.E. Mechanical behavior of acrylonitrile butadiene styrene (ABS) fused deposition materials. Experimental investigation. Rapid Prototyp. J. 2001, 7, 148–158. [Google Scholar] [CrossRef]
- Zhou, X.; Hsieh, S.J.; Ting, C.C. Modelling and estimation of tensile behaviour of polylactic acid parts manufactured by fused deposition modelling using finite element analysis and knowledge-based library. Virtual Phys. Prototyp. 2018, 13, 177–190. [Google Scholar] [CrossRef]
- Roy, M.; Yavari, R.; Zhou, C.; Wodo, O.; Rao, P. Prediction and Experimental Validation of Part Thermal History in the Fused Filament Fabrication Additive Manufacturing Process. J. Manuf. Sci. Eng. 2019, 141. [Google Scholar] [CrossRef]
- Stockman, T.; Schneider, J.A.; Walker, B.; Carpenter, J.S. A 3D Finite Difference Thermal Model Tailored for Additive Manufacturing. JOM 2019, 71, 1117–1126. [Google Scholar] [CrossRef]
- Neiva, E.; Badia, S.; Martín, A.F.; Chiumenti, M. A scalable parallel finite element framework for growing geometries. application to metal additive manufacturing. arXiv 2018, arXiv:1810.03506. [Google Scholar] [CrossRef]
- Wang, J.; Das, S.; Zhou, C.; Rai, R. Data-Driven Simulation for Fast Prediction of Pull-Up Process in Bottom-Up Stereo-Lithography. In Proceedings of the ASME 2016 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, American Society of Mechanical Engineers, Charlotte, NC, USA, 21–24 August 2016; p. V01AT02A035. [Google Scholar]
- Tapia, G.; Khairallah, S.; Matthews, M.; King, W.E.; Elwany, A. Gaussian process-based surrogate modeling framework for process planning in laser powder-bed fusion additive manufacturing of 316L stainless steel. Int. J. Adv. Manuf. Technol. 2018, 94, 3591–3603. [Google Scholar] [CrossRef]
- Yan, W.; Lin, S.; Kafka, O.L.; Lian, Y.; Yu, C.; Liu, Z.; Yan, J.; Wolff, S.; Wu, H.; Ndip-Agbor, E.; et al. Data-driven multi-scale multi-physics models to derive process–structure–property relationships for additive manufacturing. Comput. Mech. 2018, 61, 521–541. [Google Scholar] [CrossRef]
- Mozaffar, M.; Paul, A.; Al-Bahrani, R.; Wolff, S.; Choudhary, A.; Agrawal, A.; Ehmann, K.; Cao, J. Data-driven prediction of the high-dimensional thermal history in directed energy deposition processes via recurrent neural networks. Manuf. Lett. 2018, 18, 35–39. [Google Scholar] [CrossRef]
- Francis, J.; Bian, L. Deep Learning for Distortion Prediction in Laser-Based Additive Manufacturing using Big Data. Manuf. Lett. 2019, 20, 10–14. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, G.; Li, X.; Xu, X.; Zheng, P.; Stringer, J. Analysis and prediction of printable bridge length in fused deposition modelling based on back propagation neural network. Virtual Phys. Prototyp. 2019, 14, 253–266. [Google Scholar] [CrossRef]
- Viana, F.A.; Gogu, C.; Haftka, R.T. Making the most out of surrogate models: Tricks of the trade. In Proceedings of the ASME 2010 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, American Society of Mechanical Engineers Digital Collection, Montreal, QC, Canada, 15–18 August 2010; pp. 587–598. [Google Scholar]
- Stathatos, E.; Vosniakos, G.C. Real-time simulation for long paths in laser-based additive manufacturing: A machine learning approach. Int. J. Adv. Manuf. Technol. 2019, 104, 1967–1984. [Google Scholar] [CrossRef]
- Roy, M.; Wodo, O. Data-driven modeling of thermal history in additive manufacturing. Addit. Manuf. 2020, 32, 101017. [Google Scholar] [CrossRef]
- Roy, M.; Wodo, O. Quality assurance in additive manufacturing of thermoplastic parts: Predicting consolidation degree based on thermal profile. Int. J. Rapid Manuf. 2019, 8, 285. [Google Scholar] [CrossRef]
- Carslaw, H.S.; Jaeger, J.C. Conduction of Heat in Solids, 2nd ed.; Clarendon Press: Oxford, UK, 1959. [Google Scholar]
- Tsao, C.W.; DeVoe, D.L. Bonding of thermoplastic polymer microfluidics. Microfluid. Nanofluidics 2009, 6, 1–16. [Google Scholar] [CrossRef]
- Khosravani, M.R.; Reinicke, T. Effects of raster layup and printing speed on strength of 3D-printed structural components. Procedia Struct. Integr. 2020, 28, 720–725. [Google Scholar] [CrossRef]
- Nurizada, A.; Kirane, K. Induced anisotropy in the fracturing behavior of 3D printed parts analyzed by the size effect method. Eng. Fract. Mech. 2020, 239, 107304. [Google Scholar] [CrossRef]
- Bastien, L.; Gillespie, J. A non-isothermal healing model for strength and toughness of fusion bonded joints of amorphous thermoplastics. Polym. Eng. Sci. 1991, 31, 1720–1730. [Google Scholar] [CrossRef]
- Williams, M.L.; Landel, R.F.; Ferry, J.D. The temperature dependence of relaxation mechanisms in amorphous polymers and other glass-forming liquids. J. Am. Chem. Soc. 1955, 77, 3701–3707. [Google Scholar] [CrossRef]
- Bartolai, J.; Simpson, T.W.; Xie, R. Predicting strength of additively manufactured thermoplastic polymer parts produced using material extrusion. Rapid Prototyp. J. 2018, 24, 321–332. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H. Computational Methods of Feature Selection; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Koller, D.; Sahami, M. Toward Optimal Feature Selection; Technical report; Stanford InfoLab: Stanford, CA, USA, 1996. [Google Scholar]
- Bahnsen, A.C.; Aouada, D.; Stojanovic, A.; Ottersten, B. Feature engineering strategies for credit card fraud detection. Expert Syst. Appl. 2016, 51, 134–142. [Google Scholar] [CrossRef]
- Seide, F.; Li, G.; Chen, X.; Yu, D. Feature engineering in context-dependent deep neural networks for conversational speech transcription. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, Waikoloa, HI, USA, 11–15 December 2011; pp. 24–29. [Google Scholar]
- Garla, V.N.; Brandt, C. Ontology-guided feature engineering for clinical text classification. J. Biomed. Inform. 2012, 45, 992–998. [Google Scholar] [CrossRef] [PubMed]
- Dan Foresee, F.; Hagan, M.T. Gauss-Newton approximation to Bayesian learning. In Proceedings of the International Conference on Neural Networks (ICNN’97), Houston, TX, USA, 12 June 1997; Volume 3, pp. 1930–1935. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | AM Process | Features (Input of SM) | Output of SM | Reported Data Set | Model |
|---|---|---|---|---|---|
| Mozaffar [12] | DED | Laser power, scan speed, toolpath, geometry | Temperature (time series) | 250,000 | RNN |
| Stathatos [16] | LBAM | Trajectory descriptors | Temperature (time series) | 54,450 | Iterative ANN |
| Francis [13] | LBAM | Thermal images | Distortion field | 21,818 | CNN |
| Our work [17] | FFF | Distance from cooling surfaces | Temperature (time series) | 12,000 | ANN |
| Tapia [10] | L-PBF | Scan speed, laser power, beam size | Melt pool depth (scalar) | 96 | Gaussian process |
| Wang [9] | SLA | Geometry as grid connection | Pull up stress (scalar) | 60 | ANN |
| Category | Associated Characteristic | Engineered Features | Ref. | |
|---|---|---|---|---|
| Geometry | Heat sinks | Weighted effective distance | Figure 2 | |
| Heat source | Weighted effective distance | Figure 2 | ||
| Effective area | Figure 2 | |||
| Base | Weighted effective distance | Figure 2 | ||
| Printing pattern | Next road | Figure 3 | ||
| Previous road | Figure 3 | |||
| Layer | Figure 3 | |||
| Geometry | Time (s) | % Accuracy | |
|---|---|---|---|
| Numerical Model | SM | ||
| One (G1) | 45,780 | 5.9 | 96.4 |
| Two (G2) | 122,210 | 5.8 | 95.5 |
| Three (G3) | 121,494 | 4.3 | 91.4 |
| Four (G4) | 74,701 | 6.0 | 95.0 |
| Five (G5) | 121,029 | 8.1 | 95.2 |
| Six (G6) | 171,000 | 7.3 | 93.6 |
| Seven (G7) | 49,646 | 2.4 | 89.0 |
| Eight (G8) | 239,931 | 4.4 | 93.1 |
| Nine (G9) | 172,732 | 3.9 | 91.9 |
| Zero (G0) | 186,496 | 4.0 | 92.4 |
| Runs | Features | Data Set | ANN Size | Testing Error | |||||
|---|---|---|---|---|---|---|---|---|---|
| Distance Related Features | Size of HIZ (mm) | Extra Feature | Boundary | Unconsolidated Points | G3 | G5 | G9 | ||
| E0 | 0.8 | - | included | included | - | - | - | - | |
| E1 | 0.8 | - | excluded | excluded | 50 | 0.17 | 0.12 | 0.16 | |
| E2 | 0.8 | - | excluded | excluded | 25 | 0.072 | 0.058 | 0.094 | |
| E3 | 0.8 | - | included | excluded | 45 | 0.068 | 0.056 | 0.087 | |
| E4 | 1.6 | - | included | excluded | 40 | 0.056 | 0.045 | 0.073 | |
| E5 | 1.6 | included | excluded | 25 | 0.058 | 0.042 | 0.065 | ||
| E6 | 1.6 | included | classifier | 25 | 0.088 | 0.048 | 0.082 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, M.; Wodo, O. Feature Engineering for Surrogate Models of Consolidation Degree in Additive Manufacturing. Materials 2021, 14, 2239. https://doi.org/10.3390/ma14092239
Roy M, Wodo O. Feature Engineering for Surrogate Models of Consolidation Degree in Additive Manufacturing. Materials. 2021; 14(9):2239. https://doi.org/10.3390/ma14092239
Chicago/Turabian StyleRoy, Mriganka, and Olga Wodo. 2021. "Feature Engineering for Surrogate Models of Consolidation Degree in Additive Manufacturing" Materials 14, no. 9: 2239. https://doi.org/10.3390/ma14092239
APA StyleRoy, M., & Wodo, O. (2021). Feature Engineering for Surrogate Models of Consolidation Degree in Additive Manufacturing. Materials, 14(9), 2239. https://doi.org/10.3390/ma14092239