Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks




Abstract
1. Introduction
2. Data Collection
3. Model Development
3.1. Machine Learning Fundamentals
3.1.1. Tabular Generative Adversarial Networks (TGAN)
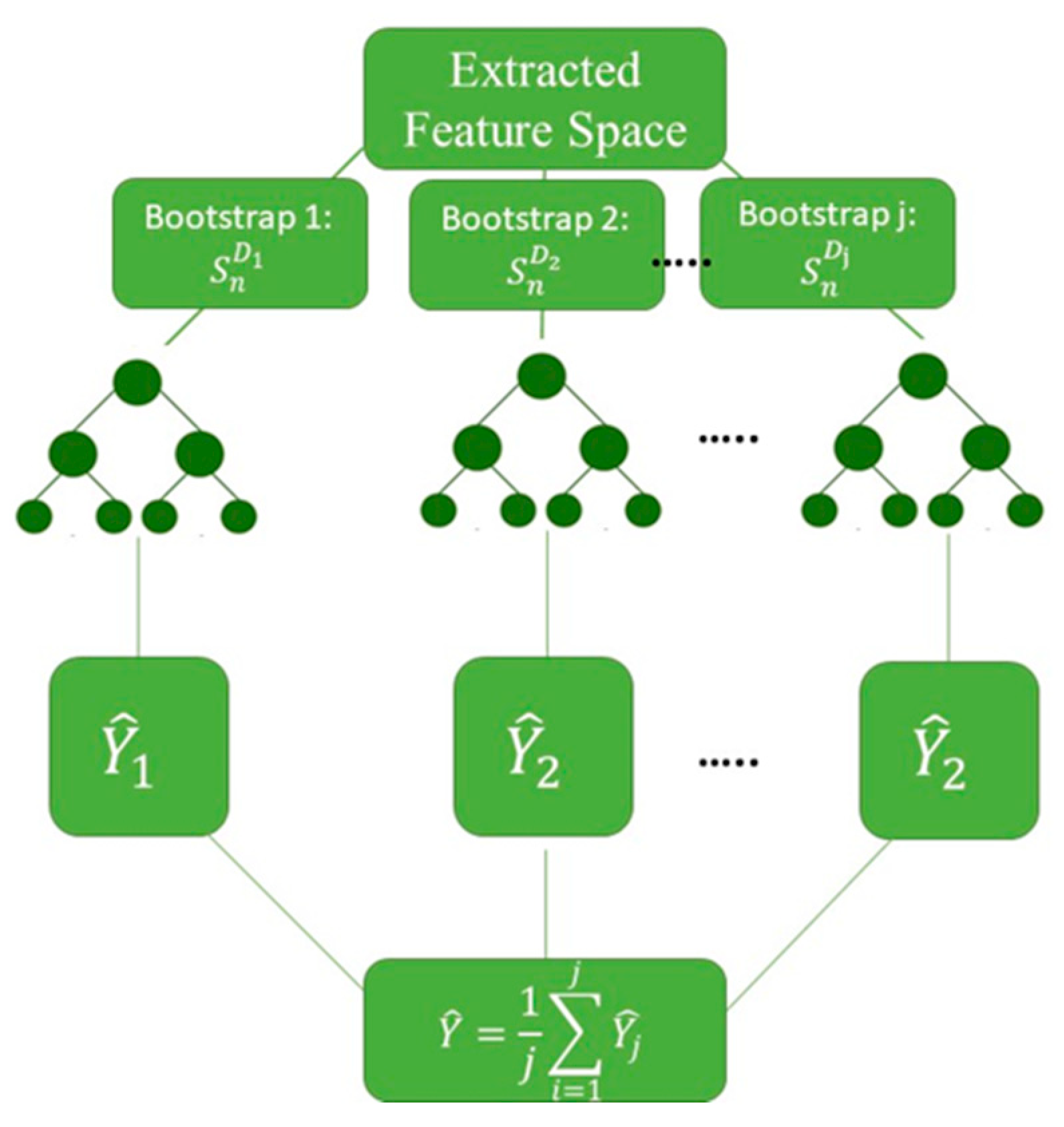
3.1.2. Tree-Based Ensembles
3.2. Performance Evaluation
4. Results and Discussion
4.1. Machine Learning Modeling
4.2. Comparing with Other Studies
5. Parametric Analysis
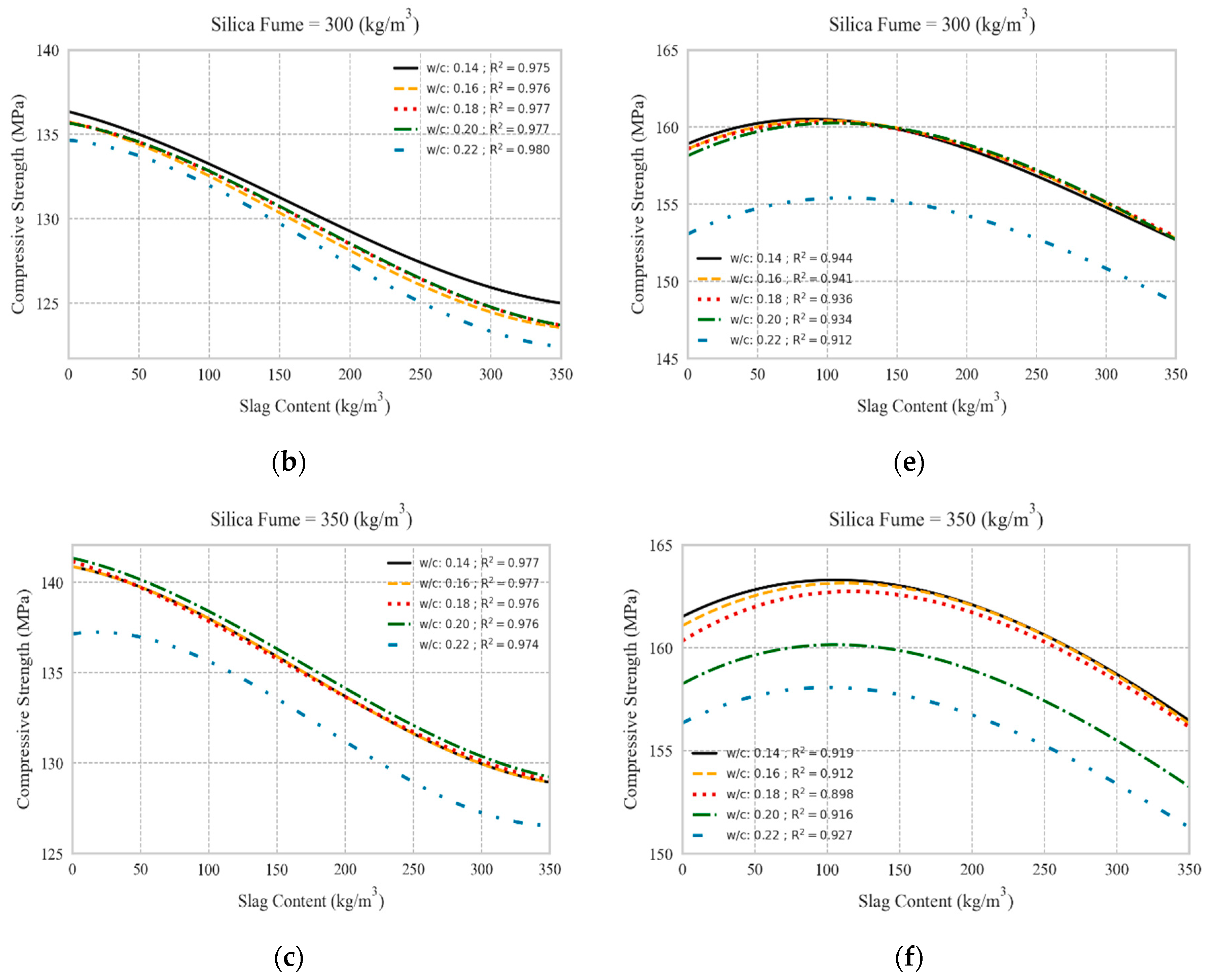
5.1. Replacing Cement with Slag
5.2. Replacing Cement with Fly Ash
6. Limitations of the Model
7. Conclusions and Future Work
- The TGAN can be used to generate plausible synthetic data capable of adequately training powerful and generalized ML models.
- Statistical metrics of R2 of 0.96 and MAE and RMSE values of 6.72 MPa and 7.41 MPa, respectively, were achieved for the testing set when the GBR model was trained with synthetic data and tested on the entire real data.
- Such predictive performance is outstanding when compared to that of existing models in the literature, which achieved significantly lower performance.
- A voting regressor assembled of RFR, ETR, and GBR models was used to perform parametric analysis on UHPC mixture designs. These models captured the behavior of UHPC compressive strength upon variation of the mixture components.
- Therefore, these models can be employed to provide practical insights into the mixture design of UHPC for diverse construction applications, providing enhanced predictive capacity at lower cost and in much shorter time.
- The developed models are data driven based on learning from existing data. Thus, they neither offer an alternative to fracture mechanics approaches, nor would be applicable outside the scope of the data set used in training.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Wang, D.; Shi, C.; Wu, Z.; Xiao, J.; Huang, Z.; Fang, Z. A review on ultra-high-performance concrete: Part II. Hydration, microstructure and properties. Constr. Build. Mater. 2015, 96, 368–377. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Banthia, N. Mechanical properties of ultra-high-performance fiber-reinforced concrete: A review. Cem. Concr. Compos. 2016, 73, 267–280. [Google Scholar] [CrossRef]
- Zhou, M.; Lu, W.; Song, J.; Lee, G.C. Application of ultra-high-performance concrete in bridge engineering. Constr. Build. Mater. 2018, 186, 1256–1267. [Google Scholar] [CrossRef]
- Wang, C.; Yang, C.; Liu, F.; Wan, C.; Pu, X. Preparation of ultra-high-performance concrete with common technology and materials. Cem. Concr. Compos. 2012, 34, 538–544. [Google Scholar] [CrossRef]
- Yu, R.; Spiesz, P.; Brouwers, H. Mix design and properties assessment of ultra-high performance fibre reinforced concrete (UHPFRC). Cem. Concr. Res. 2014, 56, 29–39. [Google Scholar] [CrossRef]
- Yu, R.; Spiesz, P.; Brouwers, H. Effect of nano-silica on the hydration and microstructure development of ultra-high-performance concrete (UHPC) with a low binder amount. Constr. Build. Mater. 2014, 65, 140–150. [Google Scholar] [CrossRef]
- Randl, N.; Steiner, T.; Ofner, S.; Baumgartner, E.; Mészöly, T. Development of UHPC mixtures from an ecological point of view. Constr. Build. Mater. 2014, 67, 373–378. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, S.; Liu, Z.; Wang, F. Utilization of steel slag in ultra-high-performance concrete with enhanced eco-friendliness. Constr. Build. Mater. 2019, 214, 28–36. [Google Scholar] [CrossRef]
- Chen, T.; Gao, X.; Ren, M. Effects of autoclave curing and fly ash on mechanical properties of ultra-high-performance concrete. Constr. Build. Mater. 2018, 158, 864–872. [Google Scholar] [CrossRef]
- Arora, A.; Aguayo, M.; Hansen, H.; Castro, C.; Federspiel, E.; Mobasher, B.; Neithalath, N. Microstructural packing-and rheology-based binder selection and characterization for Ultra-high-Performance Concrete (UHPC). Cem. Concr. Res. 2018, 103, 179–190. [Google Scholar] [CrossRef]
- Alsalman, A.; Dang, C.N.; Hale, W.M. Development of ultra-high-performance concrete with locally available materials. Constr. Build. Mater. 2017, 133, 135–145. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, C.; Khayat, K.H.; Xie, L. Effect of SCM and nanoparticles on static and dynamic mechanical properties of UHPC. Constr. Build. Mater. 2018, 182, 118–125. [Google Scholar] [CrossRef]
- Yang, R.; Yu, R.; Shui, Z.; Gao, X.; Xiao, X.; Zhang, X.; Wang, Y.; He, Y. Low carbon design of an ultra-high-performance concrete (UHPC) incorporating phosphorous slag. J. Clean. Prod. 2019, 240, 118157. [Google Scholar] [CrossRef]
- Hoang, A.L.; Fehling, E. Influence of steel fiber content and aspect ratio on the uniaxial tensile and compressive behavior of ultra-high-performance concrete. Constr. Build. Mater. 2017, 153, 790–806. [Google Scholar] [CrossRef]
- Larsen, I.L.; Thorstensen, R.T. The influence of steel fibres on compressive and tensile strength of ultra-high-performance concrete: A review. Constr. Build. Mater. 2020, 256, 119459. [Google Scholar] [CrossRef]
- Liang, X.; Wu, C.; Su, Y.; Chen, Z.; Li, Z. Development of ultra-high-performance concrete with high fire resistance. Constr. Build. Mater. 2018, 179, 400–412. [Google Scholar] [CrossRef]
- Arora, A.; Yao, Y.; Mobasher, B.; Neithalath, N. Fundamental insights into the compressive and flexural response of binder-and aggregate-optimized ultra-high-performance concrete (UHPC). Cem. Concr. Compos. 2019, 98, 1–13. [Google Scholar] [CrossRef]
- Chaabene, W.B.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Behnood, A.; Golafshani, E.M. Machine learning study of the mechanical properties of concretes containing waste foundry sand. Constr. Build. Mater. 2020, 243, 118152. [Google Scholar] [CrossRef]
- Han, T.; Siddique, A.; Khayat, K.; Huang, J.; Kumar, A. An ensemble machine learning approach for prediction and optimization of modulus of elasticity of recycled aggregate concrete. Constr. Build. Mater. 2020, 244, 118271. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Aslani, F.; Ma, G.; Nener, B. A hybrid intelligent system for designing optimal proportions of recycled aggregate concrete. J. Clean. Prod. 2020, 273, 122922. [Google Scholar] [CrossRef]
- Deng, F.; He, Y.; Zhou, S.; Yu, Y.; Cheng, H.; Wu, X. Compressive strength prediction of recycled concrete based on deep learning. Constr. Build. Mater. 2018, 175, 562–569. [Google Scholar] [CrossRef]
- Castelli, M.; Vanneschi, L.; Silva, S. Prediction of high-performance concrete strength using genetic programming with geometric semantic genetic operators. Expert Syst. Appl. 2013, 40, 6856–6862. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Al-Shamiri, A.K.; Yuan, T.-F. Non-tuned machine learning approach for predicting the compressive strength of high-performance concrete. Materials 2020, 13, 1023. [Google Scholar] [CrossRef] [PubMed]
- Dingqiang, F.; Rui, Y.; Zhonghe, S.; Chunfeng, W.; Jinnan, W.; Qiqi, S. A novel approach for developing a green Ultra-High-Performance Concrete (UHPC) with advanced particles packing meso-structure. Constr. Build. Mater. 2020, 265, 120339. [Google Scholar] [CrossRef]
- Fan, D.; Yu, R.; Shui, Z.; Wu, C.; Song, Q.; Liu, Z.; Sun, Y.; Gao, X.; He, Y. A new design approach of steel fibre reinforced ultra-high-performance concrete composites: Experiments and modeling. Cem. Concr. Compos. 2020, 110, 103597. [Google Scholar] [CrossRef]
- Marani, A.; Nehdi, M.L. Machine learning prediction of compressive strength for phase change materials integrated cementitious composites. Constr. Build. Mater. 2020, 265, 120286. [Google Scholar] [CrossRef]
- Suleiman, A.R.; Nehdi, M.L. Modeling self-healing of concrete using hybrid genetic algorithm–artificial neural network. Materials 2017, 10, 135. [Google Scholar] [CrossRef]
- Abuodeh, O.R.; Abdalla, J.A.; Hawileh, R.A. Assessment of compressive strength of Ultra-high-Performance Concrete using deep machine learning techniques. Appl. Soft Comput. 2020, 95, 106552. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Shin, H.-O.; Yang, J.-M.; Yoon, Y.-S. Material and bond properties of ultra-high-performance fiber reinforced concrete with micro steel fibers. Compos. Part B Eng. 2014, 58, 122–133. [Google Scholar] [CrossRef]
- Yu, R.; Spiesz, P.; Brouwers, H. Development of Ultra-High Performance Fibre Reinforced Concrete (UHPFRC): Towards an efficient utilization of binders and fibres. Constr. Build. Mater. 2015, 79, 273–282. [Google Scholar] [CrossRef]
- Wille, K.; Boisvert-Cotulio, C. Material efficiency in the design of ultra-high-performance concrete. Constr. Build. Mater. 2015, 86, 33–43. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, C.; He, W.; Wang, D. Static and dynamic compressive properties of ultra-high-performance concrete (UHPC) with hybrid steel fiber reinforcements. Cem. Concr. Compos. 2017, 79, 148–157. [Google Scholar] [CrossRef]
- Song, Q.; Yu, R.; Shui, Z.; Wang, X.; Rao, S.; Lin, Z. Optimization of fibre orientation and distribution for a sustainable Ultra-High Performance Fibre Reinforced Concrete (UHPFRC): Experiments and mechanism analysis. Constr. Build. Mater. 2018, 169, 8–19. [Google Scholar] [CrossRef]
- Kang, S.-H.; Jeong, Y.; Tan, K.H.; Moon, J. The use of limestone to replace physical filler of quartz powder in UHPFRC. Cem. Concr. Compos. 2018, 94, 238–247. [Google Scholar] [CrossRef]
- Rajasekar, A.; Arunachalam, K.; Kottaisamy, M. Assessment of strength and durability characteristics of copper slag incorporated ultra-high strength concrete. J. Clean. Prod. 2019, 208, 402–414. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Kim, M.-J. High energy absorbent ultra-high-performance concrete with hybrid steel and polyethylene fibers. Constr. Build. Mater. 2019, 209, 354–363. [Google Scholar] [CrossRef]
- Li, Y.; Tan, K.H.; Yang, E.-H. Synergistic effects of hybrid polypropylene and steel fibers on explosive spalling prevention of ultra-high-performance concrete at elevated temperature. Cem. Concr. Compos. 2019, 96, 174–181. [Google Scholar] [CrossRef]
- Kang, S.-H.; Hong, S.-G.; Moon, J. The use of rice husk ash as reactive filler in ultra-high-performance concrete. Cem. Concr. Res. 2019, 115, 389–400. [Google Scholar] [CrossRef]
- Ghafari, E.; Costa, H.; Júlio, E.; Portugal, A.; Durães, L. The effect of nanosilica addition on flowability, strength and transport properties of ultra-high-performance concrete. Mater. Design 2014, 59, 1–9. [Google Scholar] [CrossRef]
- Gesoglu, M.; Güneyisi, E.; Asaad, D.S.; Muhyaddin, G.F. Properties of low binder ultra-high-performance cementitious composites: Comparison of nanosilica and microsilica. Constr. Build. Mater. 2016, 102, 706–713. [Google Scholar] [CrossRef]
- Khaloo, A.; Mobini, M.H.; Hosseini, P. Influence of different types of nano-SiO2 particles on properties of high-performance concrete. Constr. Build. Mater. 2016, 113, 188–201. [Google Scholar] [CrossRef]
- Janković, K.; Stanković, S.; Bojović, D.; Stojanović, M.; Antić, L. The influence of nano-silica and barite aggregate on properties of ultra-high-performance concrete. Constr. Build. Mater. 2016, 126, 147–156. [Google Scholar] [CrossRef]
- Ahmad, S.; Mohaisen, K.O.; Adekunle, S.K.; Al-Dulaijan, S.U.; Maslehuddin, M. Influence of admixing natural pozzolan as partial replacement of cement and microsilica in UHPC mixtures. Constr. Build. Mater. 2019, 198, 437–444. [Google Scholar] [CrossRef]
- Zhang, H.; Ji, T.; He, B.; He, L. Performance of ultra-high-performance concrete (UHPC) with cement partially replaced by ground granite powder (GGP) under different curing conditions. Constr. Build. Mater. 2019, 213, 469–482. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, C.; Khayat, K.H.; Wan, S. Effects of different nanomaterials on hardening and performance of ultra-high strength concrete (UHSC). Cem. Concr. Compos. 2016, 70, 24–34. [Google Scholar] [CrossRef]
- Gesoglu, M.; Güneyisi, E.; Muhyaddin, G.F.; Asaad, D.S. Strain hardening ultra-high-performance fiber reinforced cementitious composites: Effect of fiber type and concentration. Compos. Part B Eng. 2016, 103, 74–83. [Google Scholar] [CrossRef]
- Sadrmomtazi, A.; Tajasosi, S.; Tahmouresi, B. Effect of materials proportion on rheology and mechanical strength and microstructure of ultra-high-performance concrete (UHPC). Constr. Build. Mater. 2018, 187, 1103–1112. [Google Scholar] [CrossRef]
- Qu, D.; Cai, X.; Chang, W. Evaluating the effects of steel fibers on mechanical properties of ultra-high-performance concrete using artificial neural networks. Appl. Sci. 2018, 8, 1120. [Google Scholar] [CrossRef]
- Abellán-García, J. Four-layer perceptron approach for strength prediction of UHPC. Constr. Build. Mater. 2020, 256, 119465. [Google Scholar] [CrossRef]
- Ziolkowski, P.; Niedostatkiewicz, M. Machine learning techniques in concrete mix design. Materials 2019, 12, 1256. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Zhou, H.; Dong, H. Using deep neural network with small dataset to predict material defects. Mater. Des. 2019, 162, 300–310. [Google Scholar] [CrossRef]
- Butler, K.T.; Davies, D.W.; Cartwright, H.; Isayev, O.; Walsh, A. Machine learning for molecular and materials science. Nature 2018, 559, 547–555. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–11 December 2014; pp. 2672–2680. [Google Scholar]
- Fekri, M.N.; Ghosh, A.M.; Grolinger, K. Generating energy data for machine learning with recurrent generative adversarial networks. Energies 2020, 13, 130. [Google Scholar] [CrossRef]
- Xu, L.; Veeramachaneni, K. Synthesizing tabular data using generative adversarial networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ahmad, M.W.; Reynolds, J.; Rezgui, Y. Predictive modelling for solar thermal energy systems: A comparison of support vector regression, random forest, extra trees and regression trees. J. Clean. Prod. 2018, 203, 810–821. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Persson, C.; Bacher, P.; Shiga, T.; Madsen, H. Multi-site solar power forecasting using gradient boosted regression trees. Sol. Energy 2017, 150, 423–436. [Google Scholar] [CrossRef]
- El Kababji, S.; Srikantha, P. A Data-Driven Approach for Generating Synthetic Load Patterns and Usage Habits. IEEE Trans. Smart Grid 2020. [Google Scholar] [CrossRef]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Browne, M.W. Cross-validation methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef]
- Sih, G.C.; Ditomasso, A. Fracture Mechanics of Concrete: Structural Application and Numerical Calculation: Structural Application and Numerical Calculation; Springer: Dordrecht, The Netherlands, 2012; Volume 4. [Google Scholar]
- Kumar, S.; Barai, S.V. Introduction to Fracture Mechanics of Concrete. In Concrete Fracture Models and Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–8. [Google Scholar]
- Kurumatani, M.; Terada, K.; Kato, J.; Kyoya, T.; Kashiyama, K. An isotropic damage model based on fracture mechanics for concrete. Eng. Fract. Mech. 2016, 155, 49–66. [Google Scholar] [CrossRef]
- Schlangen, E.; Van Mier, J. Simple lattice model for numerical simulation of fracture of concrete materials and structures. Mater. Struct. 1992, 25, 534–542. [Google Scholar] [CrossRef]
- Lilliu, G.; van Mier, J.G. 3D lattice type fracture model for concrete. Eng. Fract. Mech. 2003, 70, 927–941. [Google Scholar] [CrossRef]
- Smith, J.; Cusatis, G.; Pelessone, D.; Landis, E.; O’Daniel, J.; Baylot, J. Discrete modeling of ultra-high-performance concrete with application to projectile penetration. Int. J. Impact Eng. 2014, 65, 13–32. [Google Scholar] [CrossRef]
- Pan, Z.; Ma, R.; Wang, D.; Chen, A. A review of lattice type model in fracture mechanics: Theory, applications, and perspectives. Eng. Fract. Mech. 2018, 190, 382–409. [Google Scholar] [CrossRef]
- Eftekhari, M.; Ardakani, S.H.; Mohammadi, S. An XFEM multiscale approach for fracture analysis of carbon nanotube reinforced concrete. Theor. Appl. Fract. Mech. 2014, 72, 64–75. [Google Scholar] [CrossRef]
- Schlangen, E.; Garboczi, E.J. Fracture simulations of concrete using lattice models: Computational aspects. Eng. Fract. Mech. 1997, 57, 319–332. [Google Scholar] [CrossRef]
- Ngo, T.; Mendis, P.; Krauthammer, T. Behavior of ultrahigh strength prestressed concrete panels subjected to blast loading. J. Struct. Eng. 2007, 133, 1582–1590. [Google Scholar] [CrossRef]
- Hwang, Y.K.; Bolander, J.E.; Lim, Y.M. Evaluation of dynamic tensile strength of concrete using lattice-based simulations of spalling tests. Int. J. Fract. 2020, 221, 191–209. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Designation | Unit | Variable | Designation | Unit |
|---|---|---|---|---|---|
| Cement | C | kg/m3 | Fine aggregate | Sand | kg/m3 |
| Silica fume | SF | kg/m3 | Coarse aggregate | Gravel | kg/m3 |
| Slag | S | kg/m3 | Fiber | Fi | kg/m3 |
| Fly ash | FA | kg/m3 | Superplasticizer | SP | kg/m3 |
| Quartz powder | QP | kg/m3 | Temperature | T | °C |
| Limestone powder | LP | kg/m3 | Relative humidity | RH | % |
| Nano silica | NS | kg/m3 | Age | Age | days |
| Water | W | kg/m3 | Compressive strength | MPa |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| Number of RNN cell’s in generator | 400 | Learning rate | 0.001 |
| Number of fully connected units in generator | 100 | Batch size | 200 |
| Number of layers in discriminator | 2 | Number of train epochs | 20 |
| Number of units per layer in discriminator | 200 | Number of steps in epoch | 6000 |
| - | C (kg/m3) | SL (kg/m3) | SF(kg/m3) | LP (kg/m3) | ||||
| Real | Synthetic | Real | Synthetic | Real | Synthetic | Real | Synthetic | |
| Mean | 737.91 | 751.11 | 25.19 | 21.71 | 136.99 | 148.83 | 41.93 | 39.15 |
| STD | 173.46 | 157.65 | 74.37 | 72.75 | 104.14 | 105.26 | 133.13 | 145.92 |
| Min | 270.00 | 342.37 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 25% | 620.20 | 671.04 | 0.00 | 0.00 | 43.70 | 47.32 | 0.00 | 0.00 |
| 50% | 770.50 | 785.53 | 0.00 | 0.00 | 144.00 | 190.93 | 0.00 | 0.00 |
| 75% | 850.00 | 853.82 | 0.00 | 0.00 | 219.00 | 239.64 | 0.00 | 0.00 |
| Max | 1251.20 | 1266.87 | 375.00 | 378.49 | 433.70 | 433.70 | 1058.20 | 1058.20 |
| - | QP (kg/m3) | (kg/m3) | NS(kg/m3) | W (kg/m3) | ||||
| Real | Synthetic | Real | Synthetic | Real | Synthetic | Real | Synthetic | |
| Mean | 33.27 | 37.45 | 26.26 | 20.29 | 3.64 | 2.76 | 179.89 | 180.75 |
| STD | 79.67 | 82.80 | 67.46 | 60.11 | 7.78 | 6.62 | 25.57 | 23.28 |
| Min | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 90.00 | 102.36 |
| 25% | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 163.00 | 167.11 |
| 50% | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 177.00 | 176.91 |
| 75% | 0.00 | 0.00 | 0.00 | 0.00 | 4.00 | 0.00 | 192.50 | 185.61 |
| Max | 397.00 | 404.49 | 356.00 | 364.81 | 47.50 | 46.20 | 272.60 | 260.98 |
| - | Sand (kg/m3) | Gravel(kg/m3) | SP(kg/m3) | (MPa) | ||||
| Real | Synthetic | Real | Synthetic | Real | Synthetic | Real | Synthetic | |
| Mean | 995.33 | 1019.21 | 154.78 | 81.66 | 30.03 | 31.53 | 123.13 | 120.93 |
| STD | 283.27 | 272.00 | 357.57 | 266.53 | 13.99 | 13.09 | 40.24 | 38.92 |
| Min | 0.00 | 134.88 | 0.00 | 0.00 | 1.10 | 3.38 | 28.51 | 33.64 |
| 25% | 786.40 | 833.32 | 0.00 | 0.00 | 18.00 | 21.16 | 96.00 | 104.69 |
| 50% | 1021.00 | 1050.42 | 0.00 | 0.00 | 30.20 | 32.21 | 122.30 | 111.68 |
| 75% | 1231.00 | 1239.66 | 0.00 | 0.00 | 44.20 | 44.96 | 154.28 | 149.05 |
| Max | 1502.80 | 1488.59 | 1195.00 | 1154.54 | 57.00 | 56.38 | 220.50 | 208.71 |
| - | Tuned Parameters |
|---|---|
| RFR | n_estimators = 90; min_samples_split = 3; max_depth = 22; max_features = 4 |
| ETR | n_estimators = 100; min_samples_split = 3; max_depth = 20; max_features = 10 |
| GBR | n_estimators = 85; learning_rate = 0.9; min_samples_split = 2; min_samples_leaf = 5; max_depth = 16, max_features = 9, subsample = 0.49 |
| Model | TRTR | TSTR | TRTS | TSTS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RFR | ETR | GBR | RFR | ETR | GBR | RFR | ETR | GBR | RFR | ETR | GBR | |
| MAE | 7.24 | 6.03 | 5.46 | 7.98 | 7.63 | 6.72 | 9.83 | 10.10 | 9.11 | 4.85 | 4.57 | 5.34 |
| RMSE | 10.73 | 9.47 | 8.47 | 9.99 | 9.54 | 8.41 | 11.86 | 12.50 | 11.40 | 7.46 | 7.30 | 8.15 |
| 0.92 | 0.94 | 0.95 | 0.93 | 0.94 | 0.95 | 0.90 | 0.90 | 0.90 | 0.96 | 0.96 | 0.96 | |
| Mix Component | Control Mixture 1 | Control Mixture 2 | Case Study 1 | Case Study 2 |
|---|---|---|---|---|
| Cement | 750 | 750 | Replaced by slag | Replaced by fly ash |
| Silica fume | 250 | 250 | Varying: 250, 300, 350 | Varying: 250, 300, 350 |
| Slag | 0 | 0 | Added as replacement of cement | Added as replacement of cement |
| Fly ash | 0 | 0 | - | - |
| Limestone powder | 0 | 0 | - | - |
| Quartz powder | 0 | 0 | - | - |
| Nano silica | 0 | 0 | - | - |
| Water | 105 | 105 | W/C ratio: 0.14, 0.16, 0.18, 0.2, 0.22 | W/C ratio: 0.14, 0.16, 0.18, 0.2, 0.22 |
| Fine aggregate | 1367.39 | 1367.39 | - | - |
| Coarse aggregate | 0 | 0 | - | - |
| Fiber | 0 | 156 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marani, A.; Jamali, A.; Nehdi, M.L. Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks. Materials 2020, 13, 4757. https://doi.org/10.3390/ma13214757
Marani A, Jamali A, Nehdi ML. Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks. Materials. 2020; 13(21):4757. https://doi.org/10.3390/ma13214757
Chicago/Turabian StyleMarani, Afshin, Armin Jamali, and Moncef L. Nehdi. 2020. "Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks" Materials 13, no. 21: 4757. https://doi.org/10.3390/ma13214757
APA StyleMarani, A., Jamali, A., & Nehdi, M. L. (2020). Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks. Materials, 13(21), 4757. https://doi.org/10.3390/ma13214757