Generally speaking, there are three kinds of data fusion structure, namely data-level fusion, feature-level fusion and decision-level fusion. Data-level fusion is the lowest layer information, which directly integrates multiple sensor data. A data-level fusion scheme is applied to degradation modeling and prognostic analysis for turbofan engine [
32]. The original measurements are treated by extracting fault feature information, and then the information is integrated called feature-level fusion for fault diagnosis [
33]. A fuzzy-based method in feature-level fusion is presented for gas turbine fault detection and identification [
38]. The intermediate decision of each module combined for final decision in the topmost layer is denoted by decision-level fusion. The Dempster–Shaffer evidence theory (DS) is one of the most common fusion methods since it is simple and easy for implement. The DS has been applied for engine anomaly detection and vibration fault diagnosis [
39]. The WDS in the data hierarchical fusion mechanism and the integration of two different kinds of evidences are discussed for engine gas-path fault diagnosis in this section. The fault mode index by the method-based evidence and fault mode probability by the data-based evidence are combined in the decision layer in the fusion framework.
3.1. Model-Based Fault Diagnosis Using PF-FL Method in Feature Layer
The nonlinear model-based method using PF-FL for engine gas-path fault diagnosis completes by two steps: fault feature parameter estimation and fault identification. The PF algorithm is served as a state estimator to calculate the component performance deviations from their normal values. The deviations of fault feature parameters are then fed to the fuzzy logic system for fault mode recognition. The fault mode index is computed by the PF-FL and used as the model-based evidence.
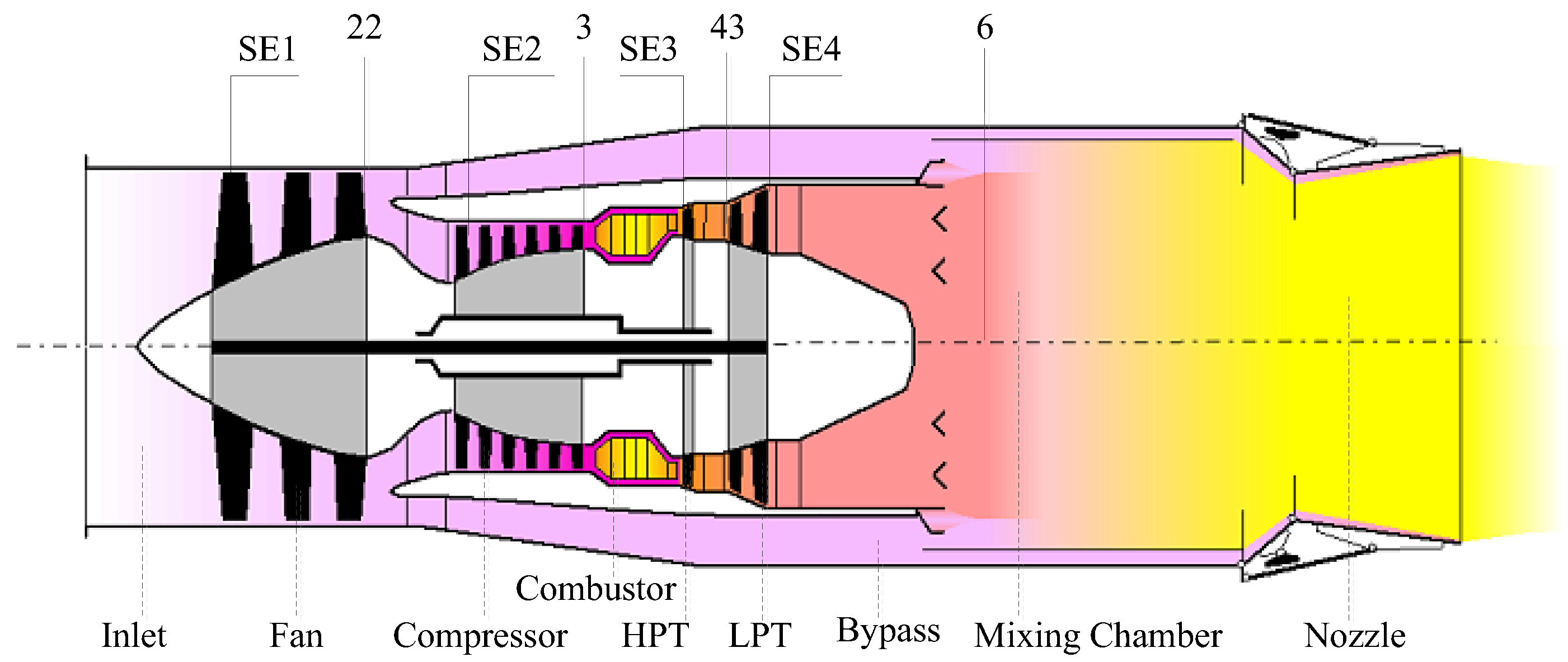
Considering air flow mass, power and momentum conservation laws, a general gas turbine engine simulation is designed [
35]. The characteristic maps of engine rotating components describe aero-thermodynamic relationships of component inputs and outputs in the engine simulation [
36]. The data of engine design operation and component maps are loaded to the general simulation for obtaining a turbofan engine component level model (CLM) [
40]. The nonlinear mathematical model of the engine is given by
where
k is the time index,
y is the 8-element measured output,
x is the 6-element augmented state variable, and
u is the 2-element control input. The noise terms
w and
v represent process uncertainty and measurement uncertainty in the model. Since the PF is based on sequential Monte Carlo sampling theory and aimed to state estimation of nonlinear and non-Gauss system [
41], it is especially suitable to gas turbine engine. Hence, the PF algorithm is employed to the estimation of engine fault feature parameters.
Let
denote the series of the augmented state vector [
NL,
NH,
SE1,
SE2,
SE3,
SE4]
T, and
denote the series of measurement vector [
NL,
NH,
T22,
P22,
T3,
P3,
T43,
T6]
T. Give the probability density function (PDF) of the prior condition is
p(
x0), and the posterior PDF
p(
x0:k|
y1:k) is characterized by a set of weighted random samples
, wherein
N is particle number. The particle set
is related to the weight
, and the PDF at time
k is approximated by
The case for Monte Carlo sampling is to generate particles from the posterior PDF
p(
x0:k|
y1:k), but it is unavailable directly. Then the importance sampling distribution function
q(
x0:k|
y1:k) is expressed before sampling
The
i-th particle weight
can be approximated by
The importance weights is normalized
There is a problem of basic PF algorithm that more particles have negligible weights after several iterations, and it indicates that particle generation degeneracy emerges and a large computational effort for updating particle becomes meaningless [
18]. Then, importance re-sampling is added and each particle is assigned by the weight
whenever the effective particles number
is less than a threshold value
All particles have almost the same significance if
Neff is close to the threshold
Nth. The estimates of fault feature parameters (
SE1,
SE2,
SE3, and
SE4) are obtained by the PF, which are then used for fault location in the feature level. The fault feature estimates by the PF are quantitative representation, and it cannot directly lead to a fault mode decision and utilized for model-based evidence. Fuzzy logic is an approach based on “degrees of truth” rather than the usual “true or false” [
33], and it is applied to recognize engine gas-path fault pattern with continuous fault mode membership. The estimates of fault feature parameter are assigned to fuzzy logic system to acquire the fault mode index that represents performance fault type.
The fuzzy logic rules of fault mode classification give the mapping of fault feature parameters to fault mode index, and are shown in
Table 1. There are four key rotating components (fan, compressor, HPT and LPT), and each component relates to two linguistic variables (Low and High) [
42]. The linguistic variable of engine operating state is Low as fault feature parameter bias less than 1%, and High as it falls into (1%, 5%). The number of fault pattern studied is totally ten, wherein the number of single component failure is four, and double component failure number is six.
As seen in
Table 1, fan fault mode in the fuzzy rule is defined that
SE1 is high, and
SE2,
SE3, and
SE4 are low. The membership function of fuzzy logic is Gauss function. The fuzzy inputs are the estimates of fault feature parameters, and the outputs are fault mode index. Gravity model is used in the defuzzifier process, and the fault mode index is calculated as follows
where
o* is the exact value of fault mode membership,
B( ) is membership function, and
o is one element in the fuzzy set.
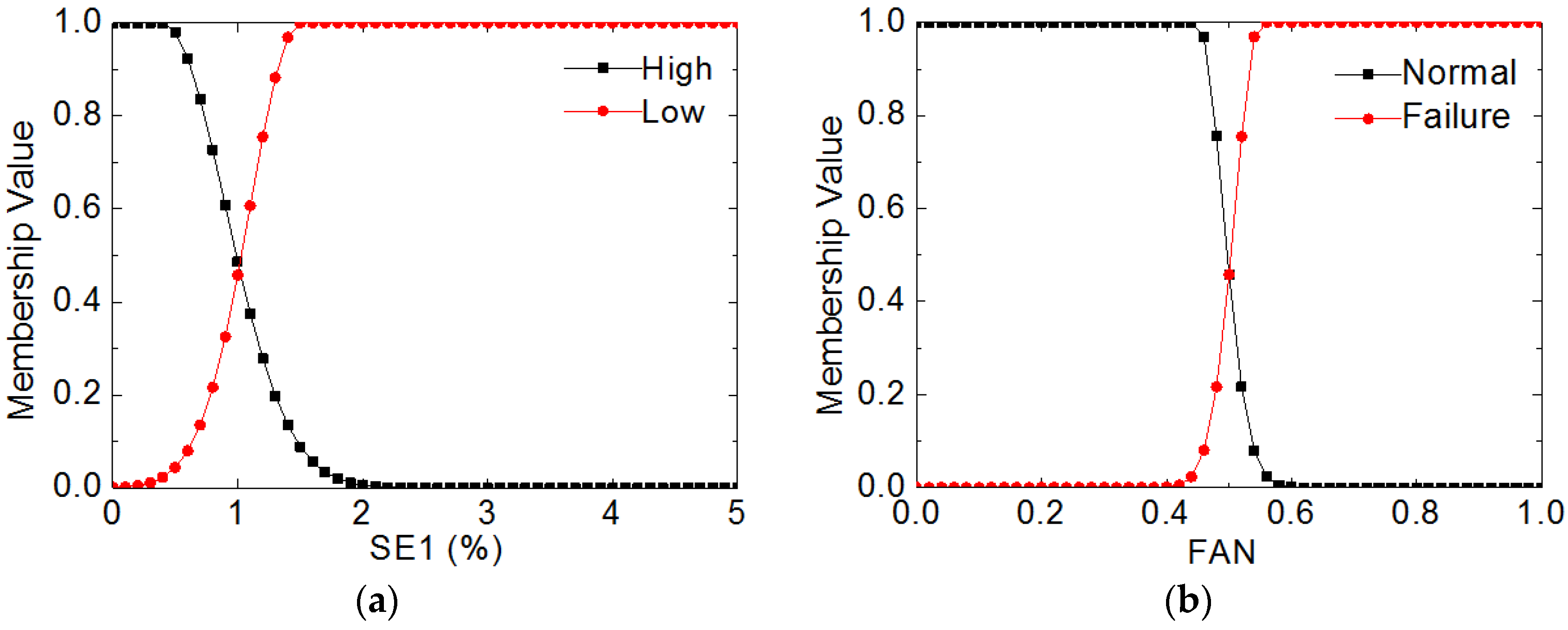
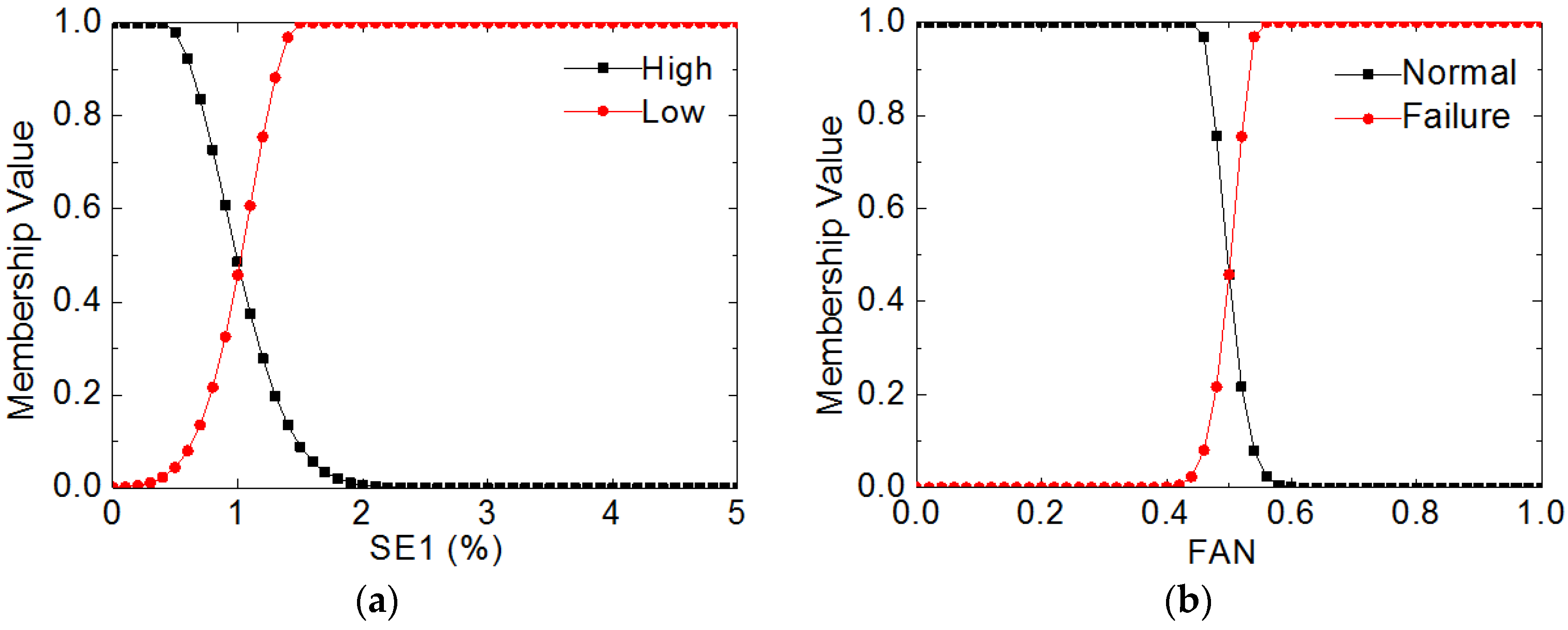
Take fuzzy logic on fan as an example, the membership functions of fault feature parameter
SE1 and Fan fault mode are shown in
Figure 3a,b, respectively. The membership functions for the rest fault feature parameters
SE2,
SE3, and
SE4 and their fault modes are formulated in a similar way.
Engine performance fault classification using fuzzy logic is conducted as follows: the estimates of fault feature parameter are converted to the linguistic variables in the fuzzy subset using the Gauss membership. The linguistic variables corresponding to the outputs are obtained by the fuzzy logic rules. Fuzzy distribution is calculated in the inference machine, and the fault mode index is exactly calculated by defuzzifing. The decision of engine gas-path fault pattern is recognized using fault mode index in the feature layer, and this index is also used as the model-based evidence results for further fault diagnosis in the decision level.
3.2. Data Hierarchical Fusion Diagnosis Using Improved Weighted DS Evidence Theory
The information reasoning and fusion can be done by DS evidence theory, whereas this method might fail in some cases of information incomplete or uncertainty [
43,
44]. In order to improve the confidence of DS evidence theory, the WDS is developed and applied to integrate the model-based evidence E
1 and data-based evidence E
2 to reach a final decision of gas-path fault diagnosis. Let ϴ be an elements set of discernment frame, and it means all performance fault modes, namely, ϴ = {
F1,
F2,
F3,
F4,
F5,
F6,
F7,
F8,
F9,
F10}. The set map
m: 2
ϴ -> [0,1] is a basic probability assignment function (BPAF) in the frame ϴ, and it follows
where the proposition
A,
A1, and
A2 are the subsets of ϴ,
is empty set, and the basic confidence
m(
A) is the confidence level of the proposition
A. When two evidences E
1 and E
2 are concerned in the frame ϴ, their BPAFs are
m1 and
m2, respectively. The propositions
A1 and
A2 are corresponding to the evidences E
1 and E
2, and the propositions A relates to the combination of the former evidences in the frame ϴ. The BPAF of the fusion based on two evidences is expressed as follows
where the parameter
represents the conflicts between two evidences. The inconsistence level of two evidences increases as the larger
K. It has more opportunity to reach a false conclusion once the evidence conflict becomes seriously. The fault feature and fault diagnostic mechanism by the data-based and model-based evidences are different for engine gas-path system, and the WDS fusion method relies on adaptive fused BPAF of two evidences. The confusion matrix in the WDS is used to compute the confidence of each evidence, and the evidence weight in the fused BPAF is tuned to the evidence confidence.
The confusion matrices corresponding to the model-based and data-based evidences are separately expressed
V1 and
V2
where
ni,j is the sample number of the fault mode
i misdiagnosis to fault mode
j, and
ni is the total sample number in fault mode
i. The element
vi,j is the false diagnosis percentage that the fault mode
i is mis-recognized as the mode
j by one evidence. The diagonal elements of the confusion matrix indicate the correct identification rate of every fault mode. In order to increase the effect of evidence that produces less incorrect recognition, the weighted coefficient is introduced
where the coefficient
R(
Fj) depicts the reliability of one evidence for fault diagnostics in the fault mode
j. rank is the descending sort number of basic probability assignment in each fault mode, and smaller series number rank implies larger confidence of the evidence.
k is 2 as the series number rank equals 1, 2 or 3, otherwise
k is 1. The adaptive fused BPAF
m*(
A) is presented as follows
where
Wmi() is the weighted BPAF of the E
i, and
.
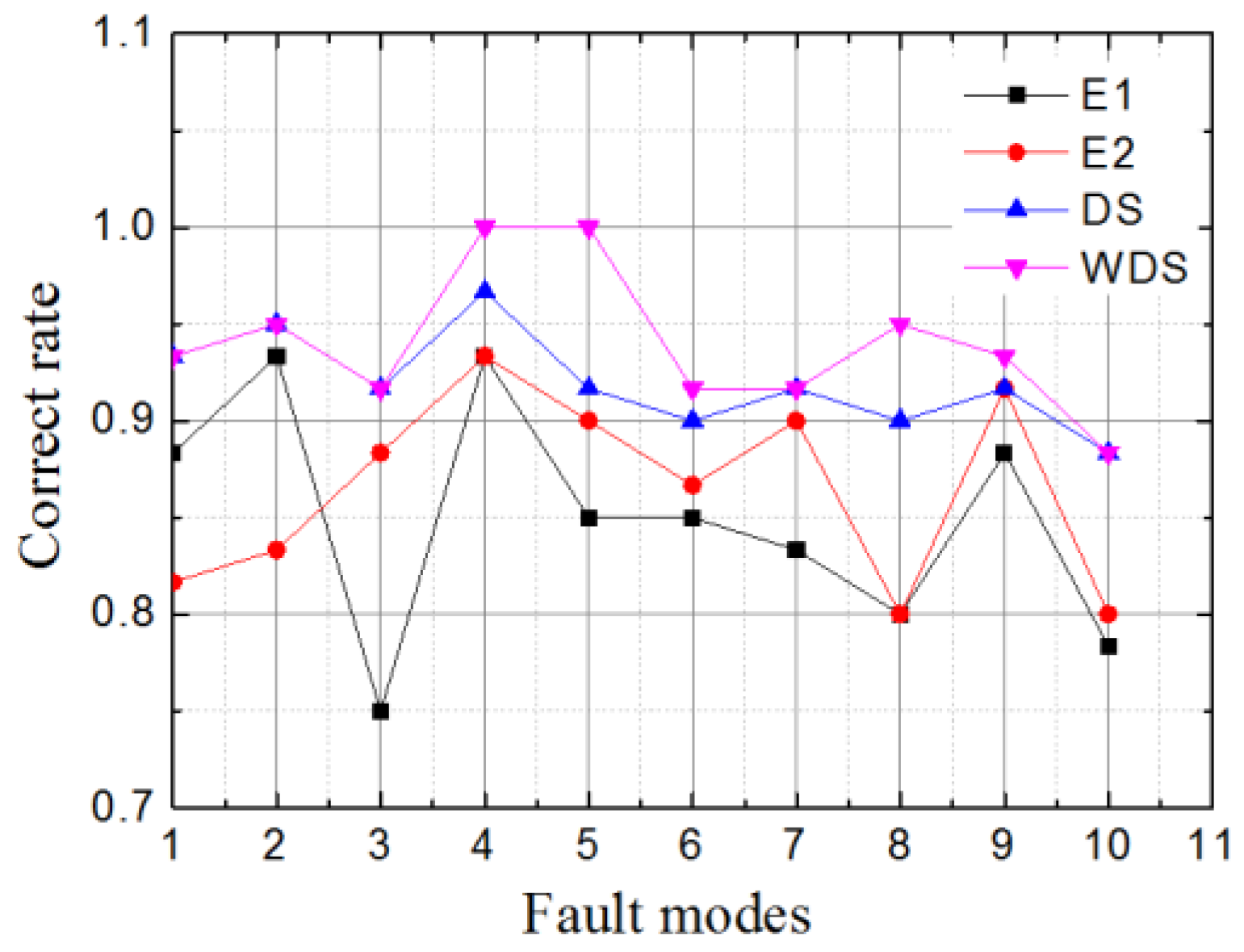
The WDS for fault diagnosis is presented in detail as follows
Step 1: Initiate the confusion matrices V1 and V2, which are calculated from training samples using Equation (25).
Step 2: Load the confusion matrices V1 and V2 to calculate the reliability parameters for two evidences using Equation (26b).
Step 3: Calculate the weighted BPAF of two evidences.
If two evidences E1 and E2 are conflicted
Calculate weighted coefficients for E1 and E2 using Equation (26a)
Calculate the weighted BPAF for E1 and E2 using Equation (27b)
Else
Wm1(A1) = m1(A1) and Wm2(A2) = m1(A2)
Step 4: Combine two evidences to reach adaptive fused BPAF using Equation (27a).
Step 5: Obtain turbofan engine gas-path fault pattern which is corresponded to the largest m*(F).
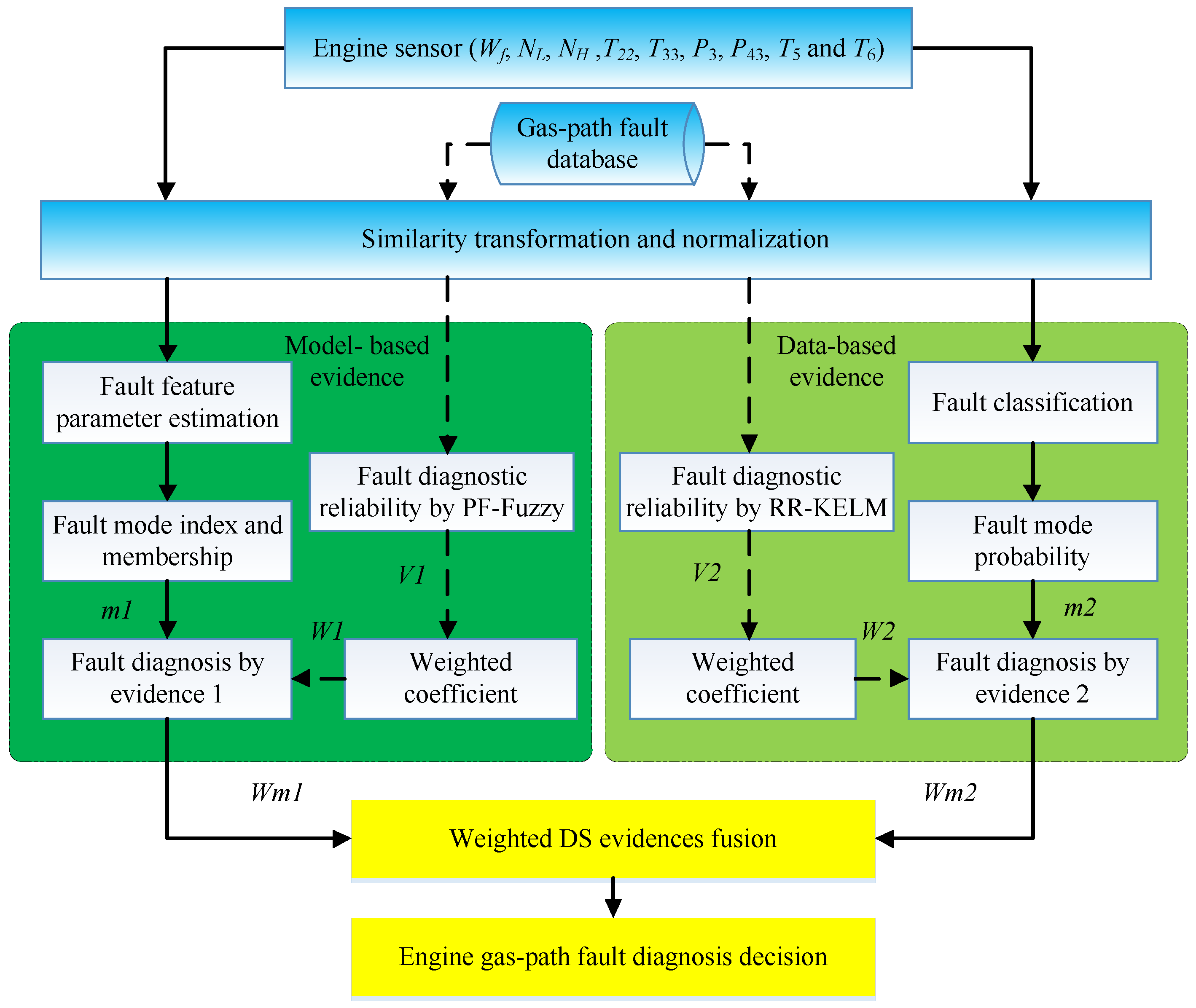
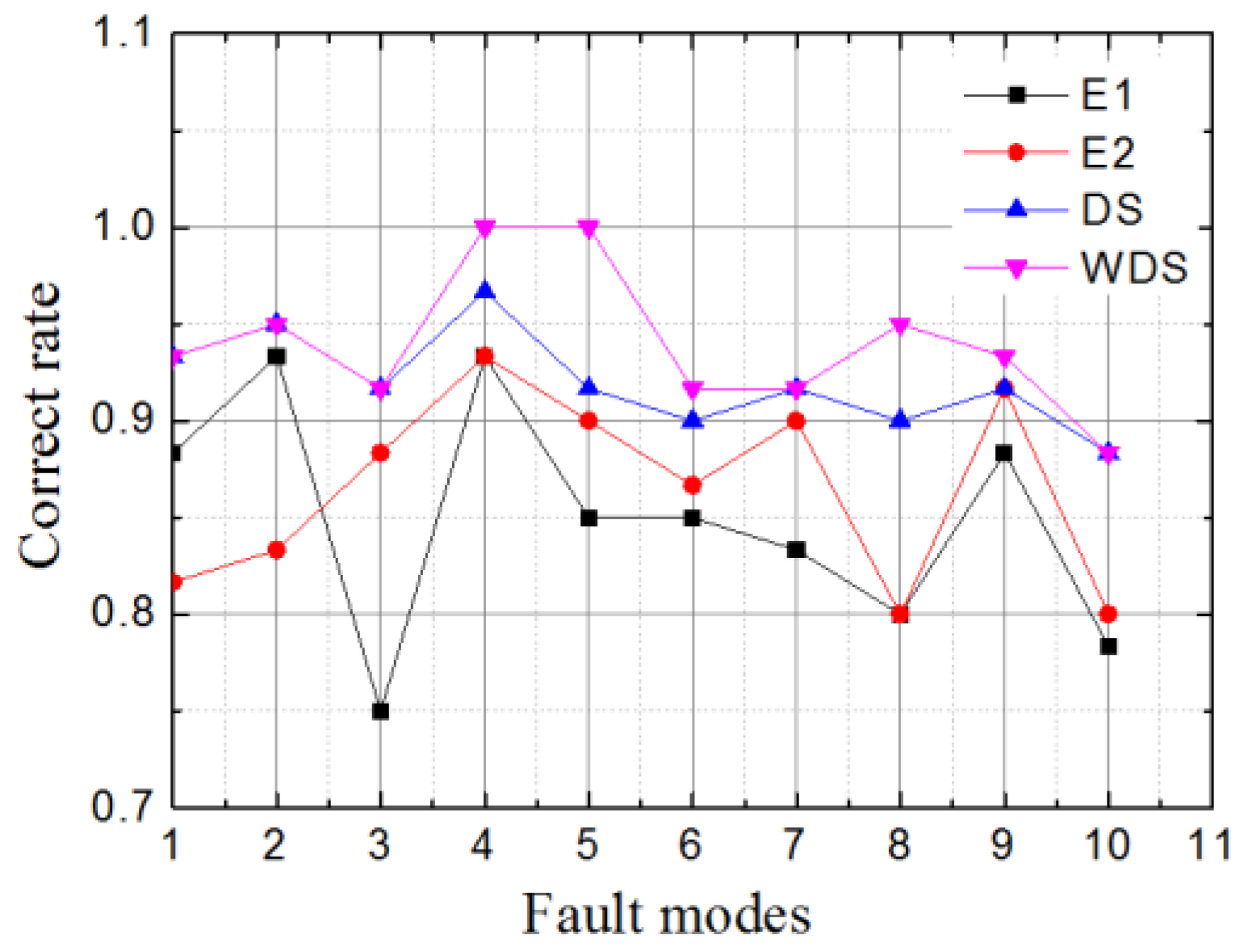
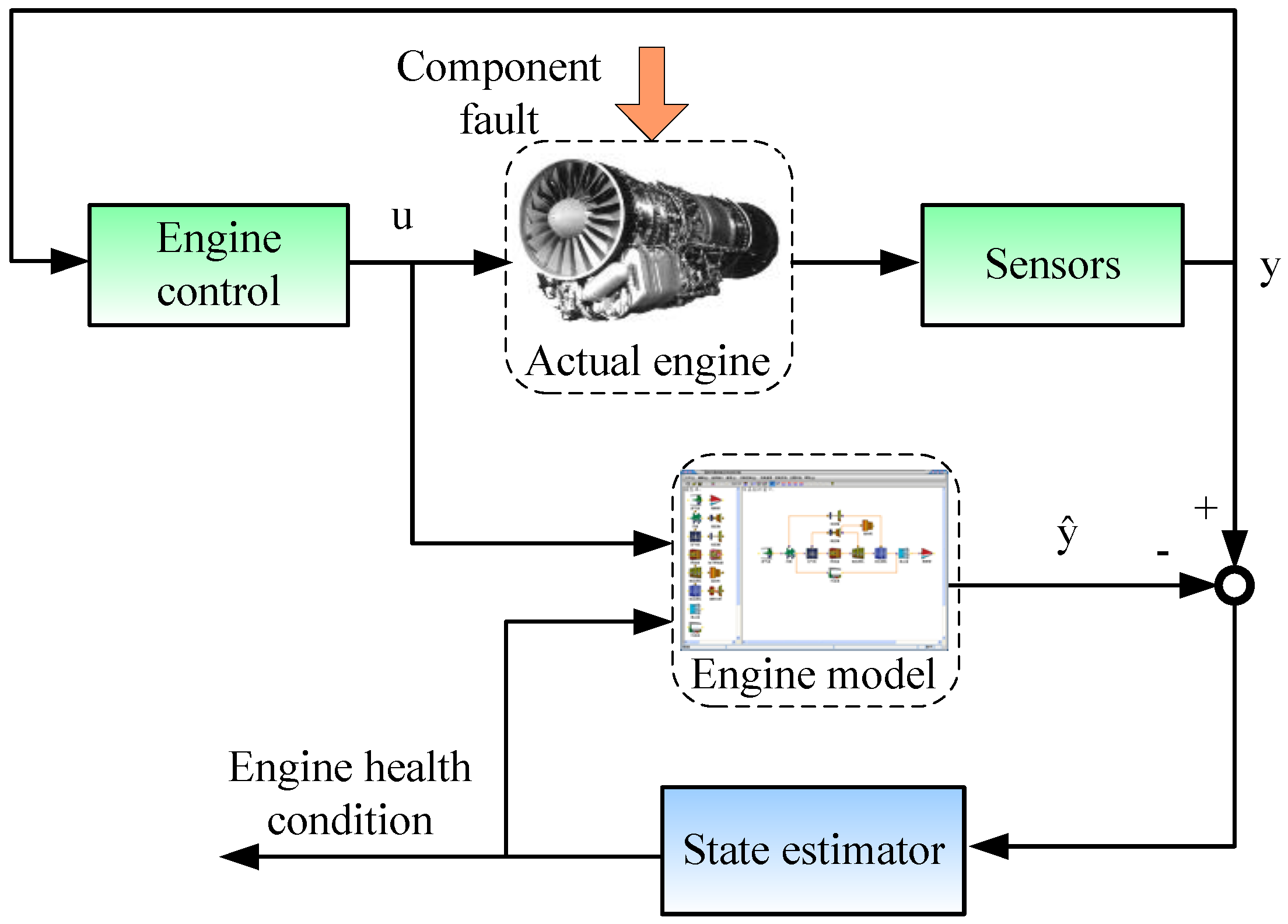
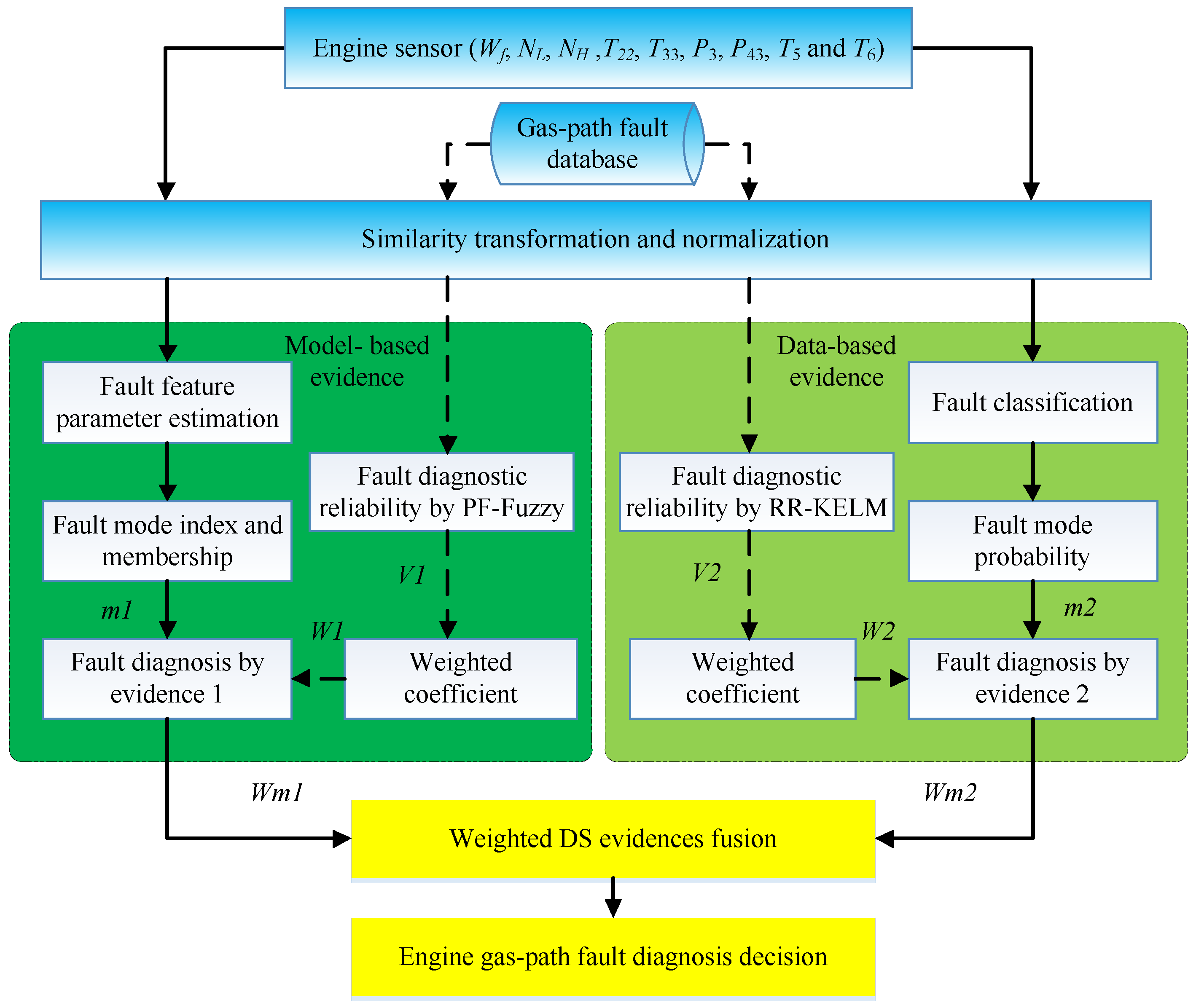
A data hierarchical fusion framework using the WDS is designed to increase the confidence of gas-path fault diagnostics for turbofan engine, and it is shown in
Figure 4. The PF-FL is utilized to reach the model-based evidence for gas-path fault diagnosis, and it runs parallel with the RR-KELM in the hierarchical fusion framework. The sensed data along the engine gas path used for fault diagnosis, like speeds, temperatures, pressures, vary with the power condition and ambient conditions. In order to extend the designed approach to the whole flight envelope and decrease the negative effects of various physical parameters magnitude difference, the aero-thermodynamic parameters are corrected and normalized before the fault diagnosis applications. Details of correction and normalization can be found in Reference [
36].
The engine health parameter deviations are estimated and used as fault feature parameters by fuzzy logic to produce fault mode index. Meanwhile, the RR-KELM is implemented to produce fault mode probability from the engine measurements. The confusion matrices and weighted coefficients are the prior information calculated from engine gas-path fault database. With the help of this prior information, the decisions of evidences about fault mode are obtained using the model-based and data-based methods, and then are combined to reach an engine fault pattern recognition decision by the WDS in the data hierarchical fusion framework.






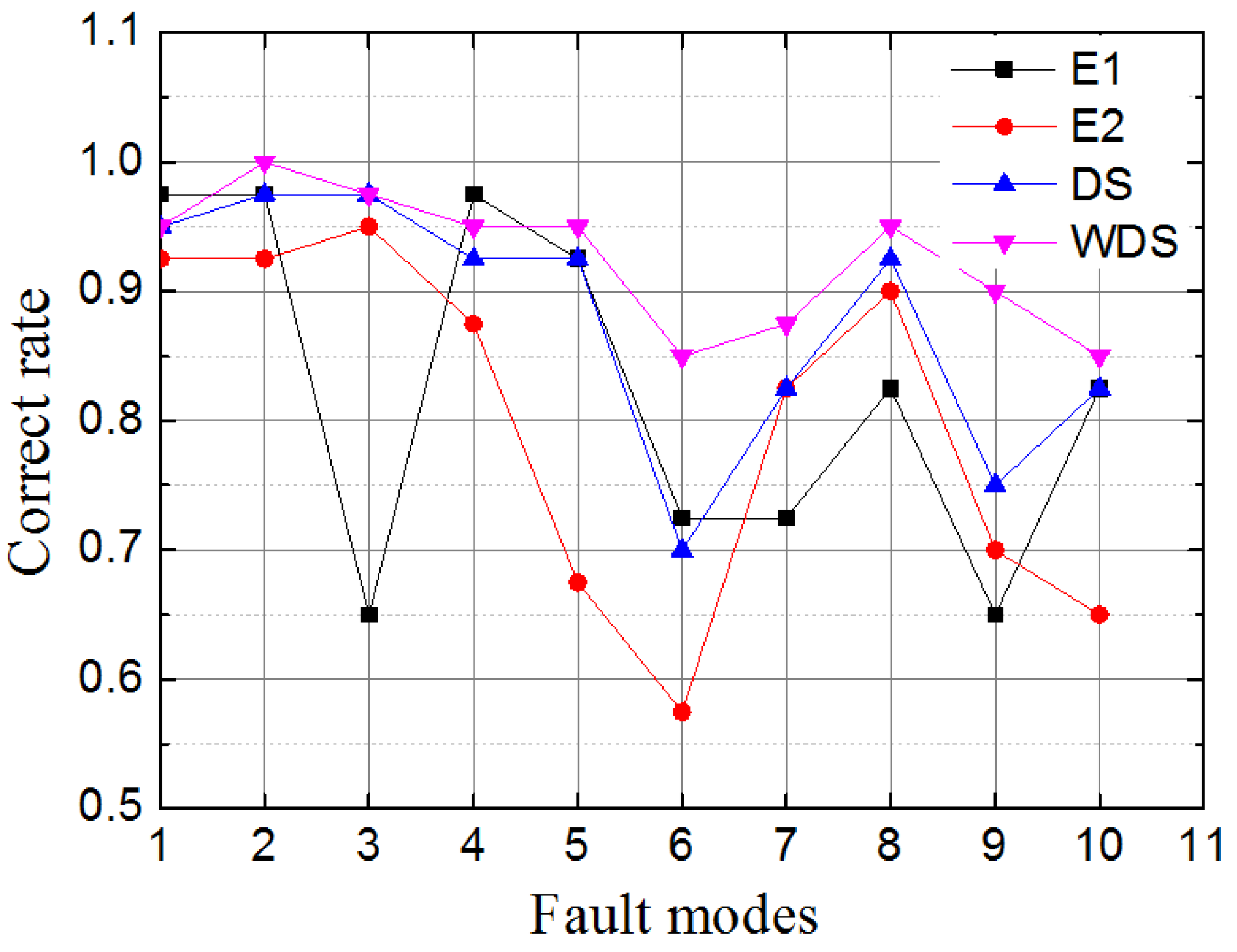
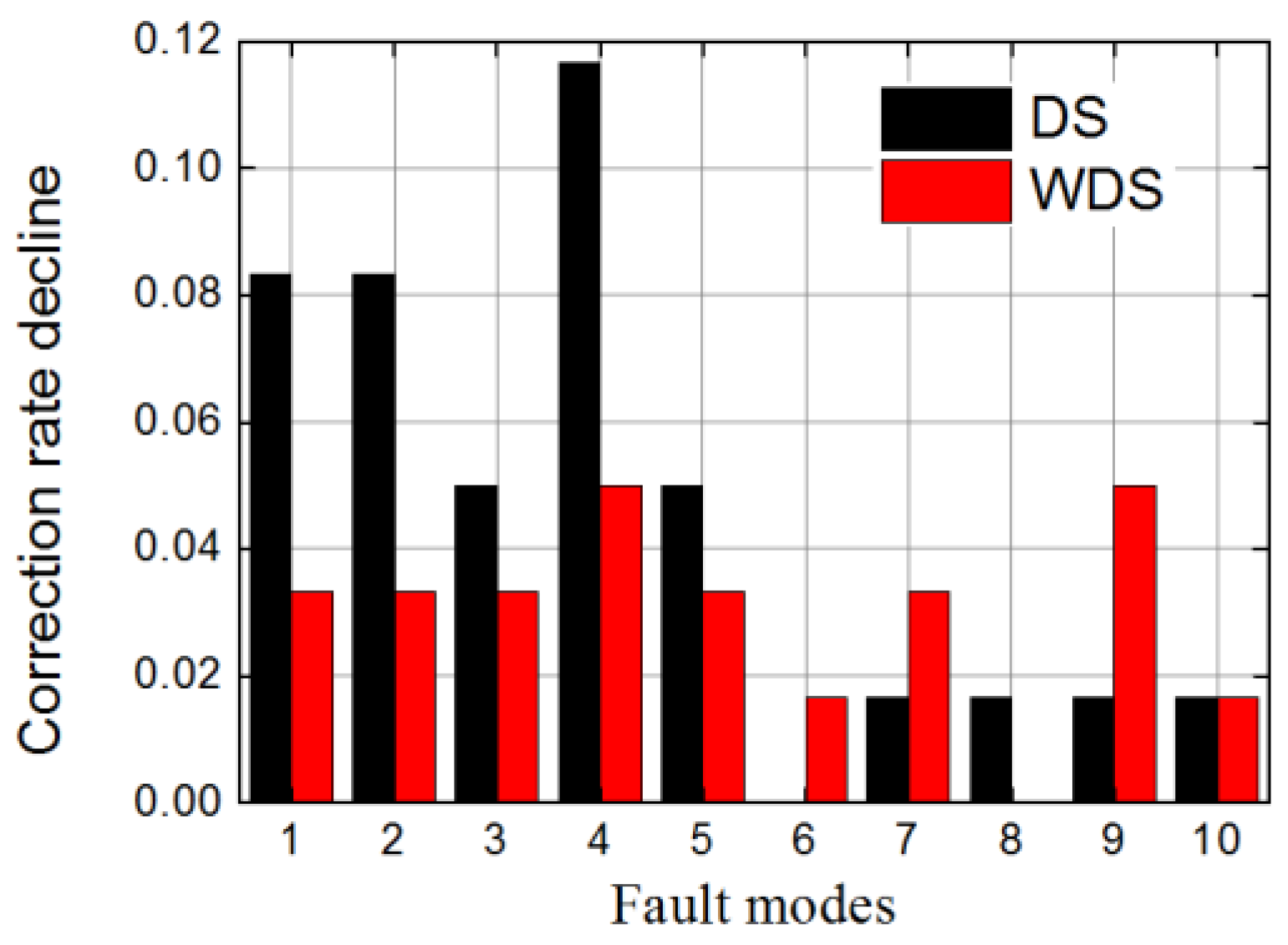

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}