Entropy-Based Bagging for Fault Prediction of Transformers Using Oil-Dissolved Gas Data

Abstract
:1. Introduction
2. Algorithm of Entropy-Based Bagging
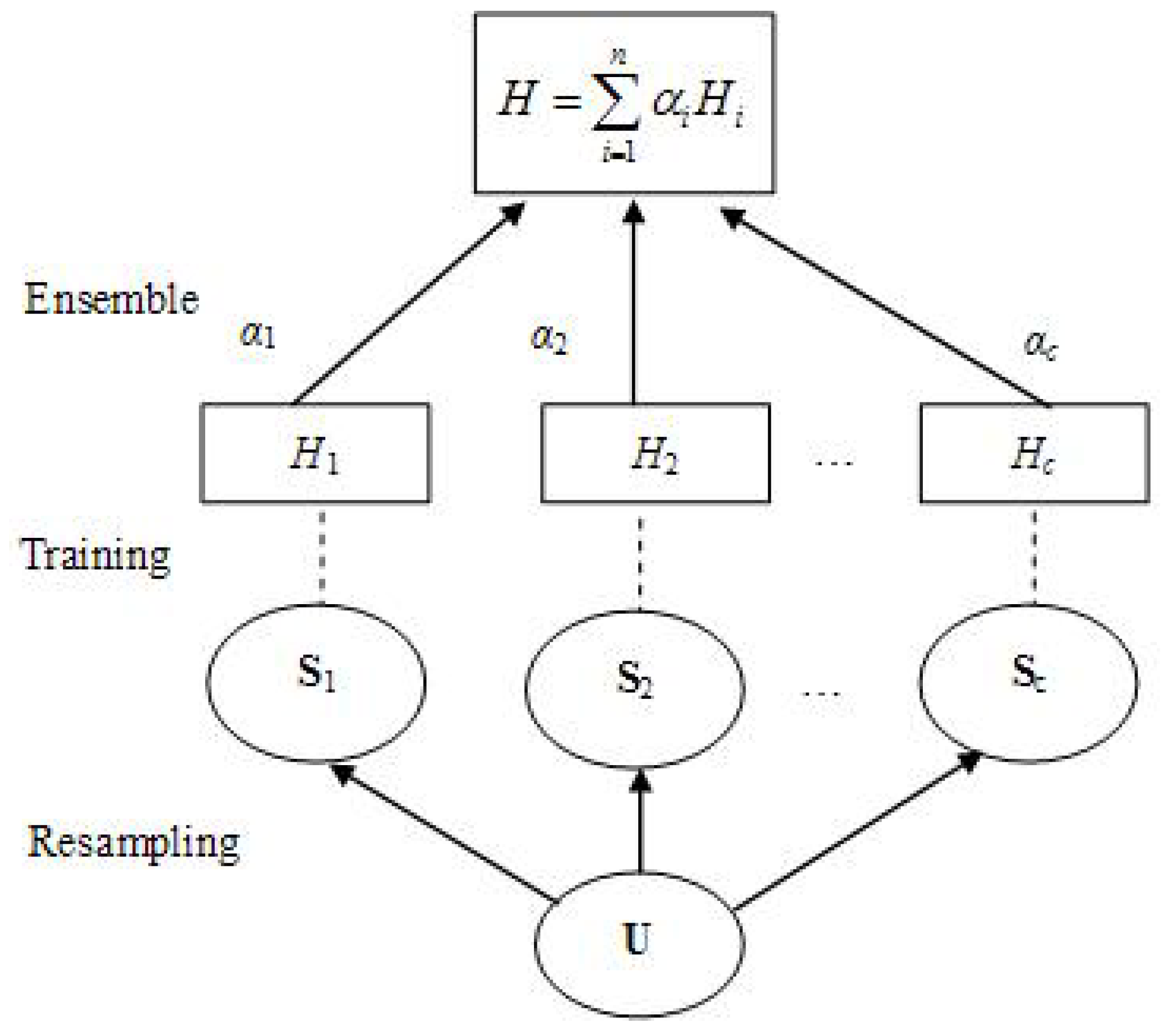
2.1. Basic Process of Bagging
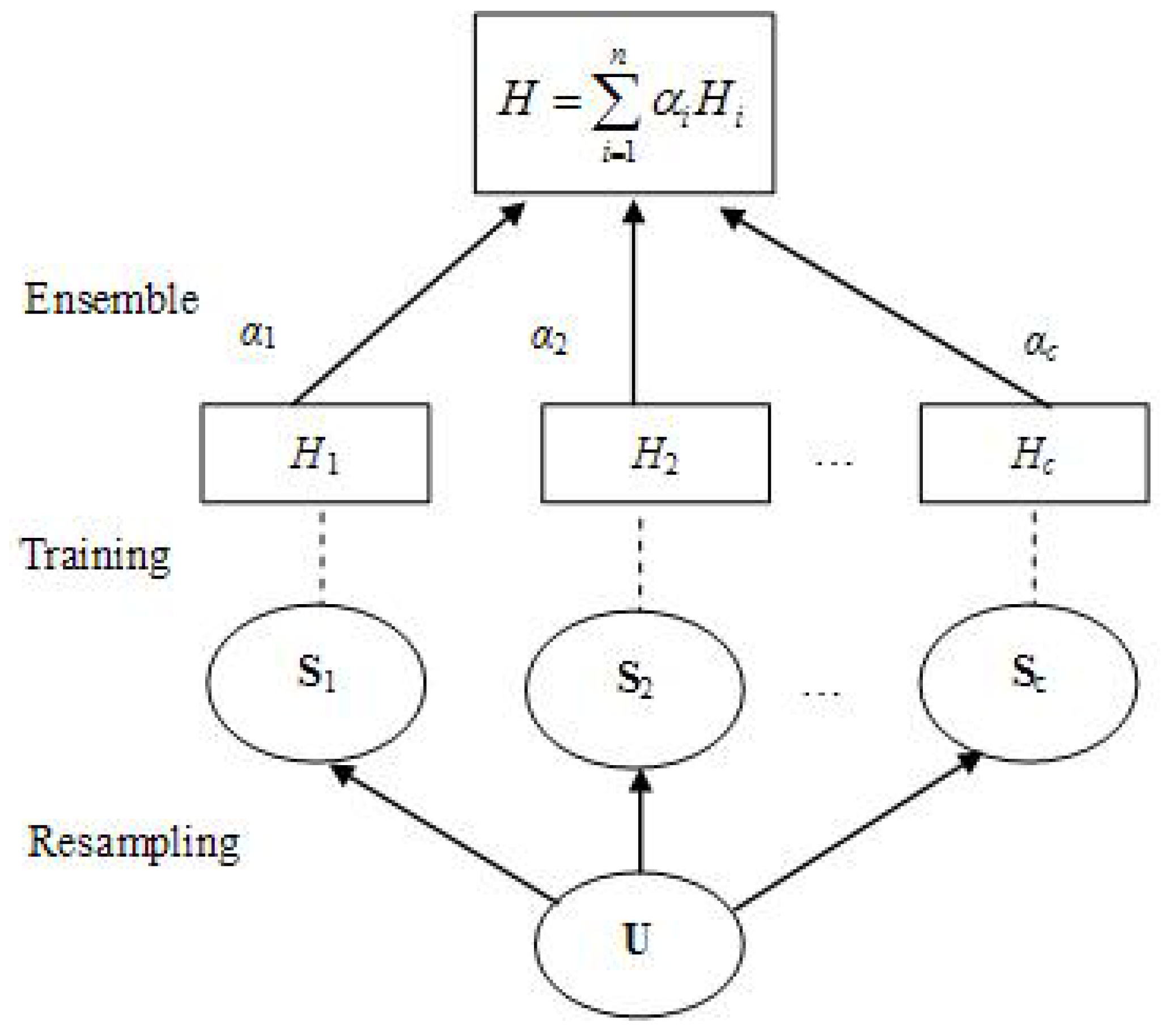
2.2. Data Resampling Based on Comprehensive Information Entropy
2.2.1. Computation of Sample Entropy
- (1)
- Form a set of m sample data segment defined as:
- (2)
- Calculate d[X(i), X(j)], the distance between X(i) and X(j), defined as the maximum absolute difference between any two vectors of the two sample data segments:If ui is a q-dimensional vector, the value of is calculated as below:
- (3)
- Given a tolerance parameter r, calculate the number whereby is smaller than r. is a measure to describe the similarity degree between the sample data segment X(i) and the sample data sequence U. is defined as:where the function count(·) is to calculate the number that is smaller than r.
- (4)
- For i∈[1, N − m + 1], calculate the average of as below:
- (5)
- Form a new set of m+1 sample data sequence as below:For i∈[1, N − m + 1], calculate and as follows:
- (6)
- Calculate the sample entropy E of the sample data sequence as:When N is a finite number, the sample entropy of the sample data sequence can be estimated as:
2.2.2. Comprehensive Information Entropy
2.2.3. Procedures of Data Resampling
- (1)
- Generate randomly a vector R = [r1,r2, ⋯ ,rn], where ri is a random number between 0 and 1;
- (2)
- Let k = 0 and form a vector T = [r1p(u1),r1p(u2), ⋯ ,rnp(un)];
- (3)
- Find the index corresponding to the maximum element of T;
- (4)
- Let k = k + 1, T(k) = 0, and give the index to I1(k);
- (5)
- Let S1(k) = U[I1(k)];
- (6)
- Repeat steps from (3) to (5) until k = m.
2.2.4. E-Bagging Procedures
- (1)
- Calculate the comprehensive information entropy of sample data by using (12) to obtain Si, where I = 1, 2, ⋯, c;
- (2)
- Use Si to train the member prediction function Hi;
- (3)
- Repeat steps (1) and (2) until the completion of training of the member prediction function Hc;
- (4)
- Combine the member prediction functions H1, H2, ⋯, Hc to obtain the ensemble prediction function H by using (1).
3. Examples of Transformer Fault Prediction
3.1. Processing of Sample Data

{kind=link}
{kind=link}
| Additional Information | Types | Mapping Values |
|---|---|---|
| Voltage levels (kV) | 35 | 1 |
| 110 | 2 | |
| 220 | 3 | |
| Running time (Year) | [0, 5) | 1 |
| (5, 10] | 2 | |
| (10, 15] | 3 | |
| (15, 20] | 4 | |
| (20, ∞) | 5 |
3.2. Results and Analysis
3.2.1. Prediction Accuracy
| Model | E-Bagging | Bagging | Individual |
|---|---|---|---|
| CF | 3.01% | 3.48% | 4.80% |
| SVM | 6.03% | 6.53% | 7.41% |
| BPNN | 6.12% | 6.44% | 7.53% |
| GM | 6.94% | 7.01% | 7.91% |
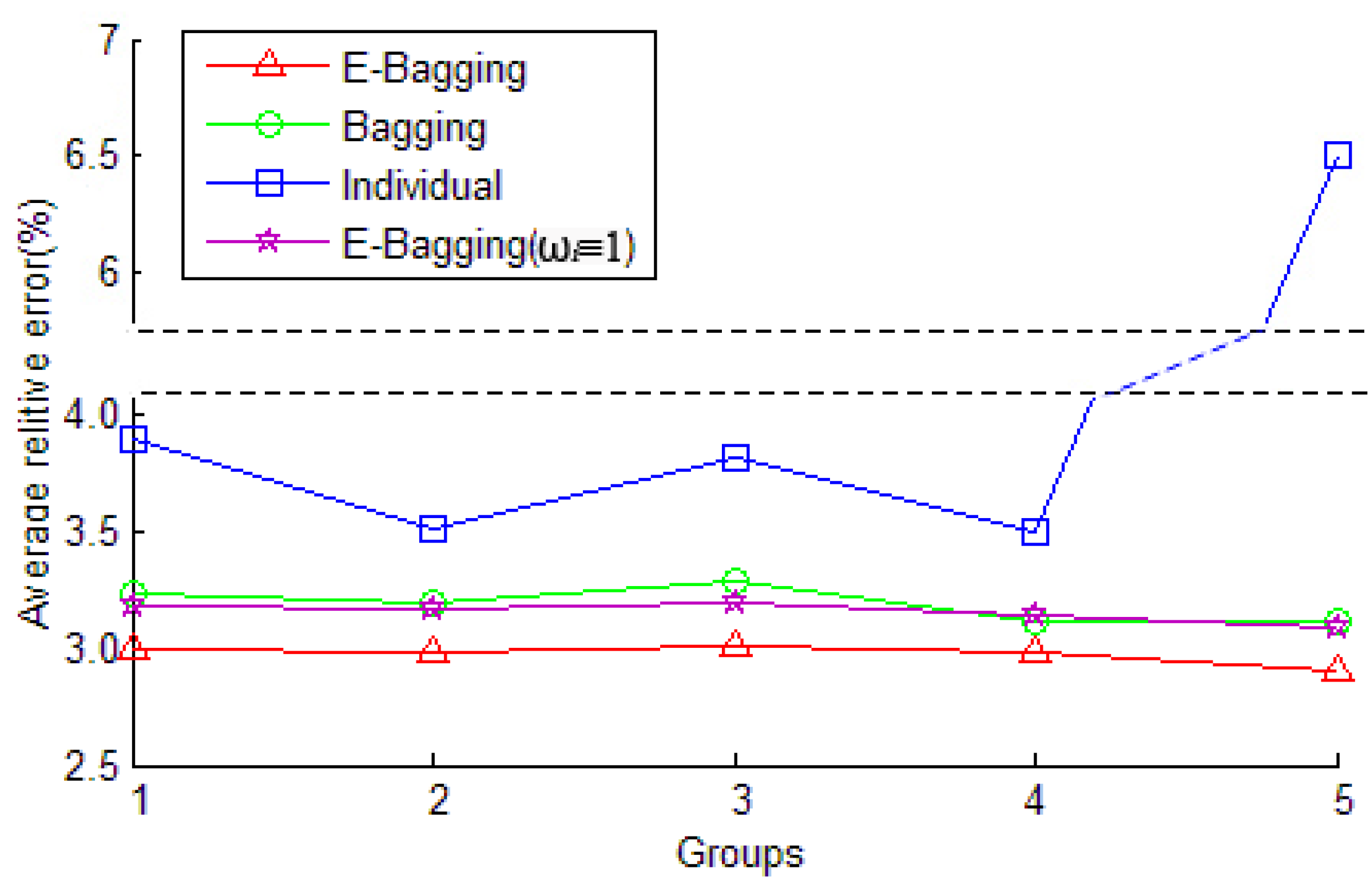
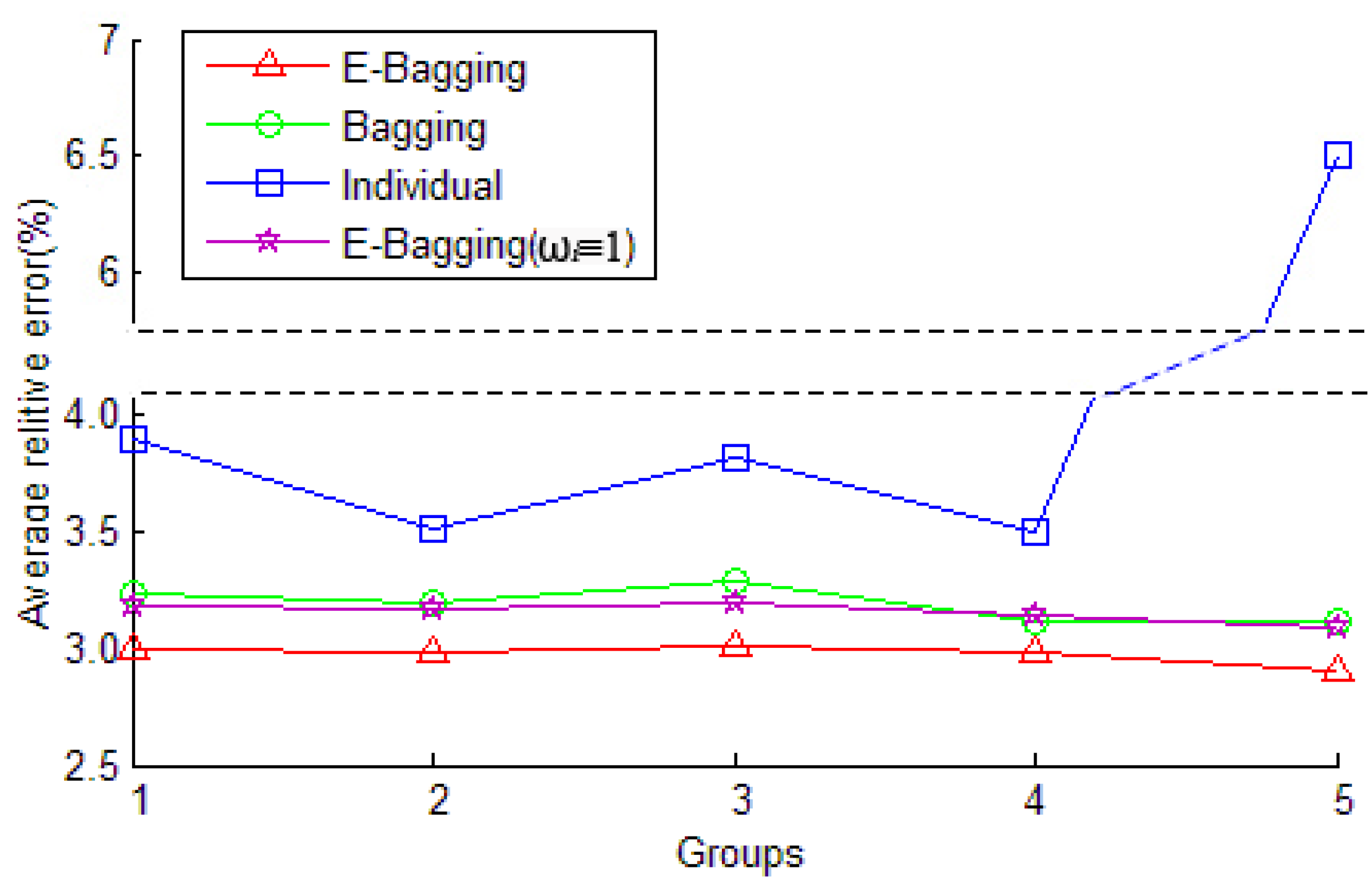
3.2.2. Prediction Stability
| Group No. | Individual Model | E-Bagging | E-Bagging (ωi≡ 1) | Bagging | Individual |
|---|---|---|---|---|---|
| Group 1 | CF | 2.99% | 3.18% | 3.23% | 3.90% |
| SVM | 6.23% | 6.59% | 6.69% | 7.81% | |
| BPNN | 6.28% | 6.43% | 6.68% | 7.83% | |
| GM | 6.94% | 7.01% | 7.21% | 8.01% | |
| Group 2 | CF | 2.98% | 3.17% | 3.20% | 3.51% |
| SVM | 6.21% | 6.41% | 6.61% | 7.21% | |
| BPNN | 6.29% | 6.50% | 6.72% | 8.43% | |
| GM | 6.92% | 7.07% | 7.29% | 8.69% | |
| Group 3 | CF | 3.01% | 3.20% | 3.29% | 3.82% |
| SVM | 6.20% | 6.45% | 6.56% | 7.95% | |
| BPNN | 6.29% | 6.46% | 6.71% | 7.01% | |
| GM | 6.97% | 6.95% | 7.33% | 8.92% | |
| Group 4 | CF | 2.98% | 3.14% | 3.11% | 3.50% |
| SVM | 6.22% | 6.39% | 6.53% | 7.21% | |
| BPNN | 6.24% | 6.29% | 6.43% | 8.83% | |
| GM | 7.02% | 6.94% | 7.10% | 8.57% | |
| Group 5 | CF | 2.91% | 3.09% | 3.12% | 6.51% |
| SVM | 6.01% | 6.49% | 6.51% | 9.51% | |
| BPNN | 6.12% | 6.35% | 6.42% | 8.99% | |
| GM | 6.88% | 6.96% | 8.16% | 10.28% |
| E-Bagging | E-Bagging (ωi ≡ 1) | Bagging | Individual | |
|---|---|---|---|---|
| CF | 0.000338 | 0.000383 | 0.000678 | 0.011424 |
| SVM | 0.000826 | 0.000709 | 0.000645 | 0.008423 |
| BPNN | 0.000647 | 0.000761 | 0.001370 | 0.007246 |
| GM | 0.000472 | 0.000484 | 0.003792 | 0.007550 |
4. Conclusions
- (1)
- The resampling is an important process of Bagging. The comprehensive information entropy of sample data is helpful to select representative sample data for training during the resampling process and to improve the generalization ability of Bagging.
- (2)
- The E-Bagging method improves the prediction accuracy of transformer faults. E-Bagging generates significantly smaller average relative transformer fault prediction errors, based on 1200 sample data of oil-dissolved gas, than the traditional Bagging and individual prediction algorithms.
- (3)
- E-Bagging shows a good generalization ability of prediction of transformer faults. The stability of the E-Bagging was shown to be greater than the traditional Bagging and individual prediction algorithms through examples of training with various sample data.
Acknowledgements
References
- Wu, C.J.; Hu, C.H.; Yen, S.S.; Yin, C.C.; Chiu, C.C.; Lee, Y.M. Application of regression models to predict harmonic voltage and current growth trend from measurement data at secondary substations. IEEE Trans. Power Deliv. 1998, 13, 793–799. [Google Scholar]
- Zhou, L.J.; Wu, G.N.; Zhang, X.H.; Zhu, K. prediction of power transformer faults based on time series of weighted fuzzy degree analysis. Autom. Electr. Power Syst. 2005, 29, 53–55. [Google Scholar] [CrossRef]
- Wahab, M.A.A.; Hamada, M.M.; Mohamed, A. Artificial neural network and non-linear models for prediction of transformer oil residual operating time. Electr. Power Syst. Res. 2011, 1, 219–227. [Google Scholar] [CrossRef]
- Shaban, K.; El-Hag, A.; Matveev, A. A cascade of artificial neural networks to predict transformers oil parameters. IEEE Trans. Dielectr. Electr. Insul. 2009, 16, 516–523. [Google Scholar] [CrossRef]
- Sencan, A.; Kizilkan, O.; Bezir, N.C.; Kalogirou, S.A. Different methods for modeling absorption heat transformer powered by solar pond. Energy Convers. Manag. 2007, 3, 724–735. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Liao, R.J.; Sun, C.X.; Du, L.; Hu, J.L. A GA-based Grey Prediction Model for Predicting the Gas-in-oil Concentrations in Oil-filled Transformer. In Proceedings of the Conference Record of the 2004 IEEE International Symposium on Electrical Insulation, Indianapolis, IN, USA, September 2004; pp. 74–77.
- Song, B.; Peng, Z.H. Short-term forecast of the gas dissolved in power transformer using the hybrid grey model. Kybernetes 2009, 38, 489–496. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, B.D.; Yuan, Y.C.; Pei, Z.C. Transformer Fault Prediction Based on Support Vector Machine. In Proceedings of the 2nd International Conference on Computer Engineering and Technology, Chengdu, China, April 2010; pp. 513–516.
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 8, 123–140. [Google Scholar]
- Ratsch, G.; Onoda, T.; Muller, K.R. Soft margins for adaboost. Mach. Learn. 2001, 3, 287–320. [Google Scholar] [CrossRef]
- Galvao, R.K.H.; Araujo, M.C.U.; Martins, M.D.; Jose, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. An application of subagging for the improvement of prediction accuracy of multivariate calibration models. Chemom. Intell. Lab. Syst. 2006, 3, 60–67. [Google Scholar] [CrossRef]
- Borra, S.; di Ciaccio, A. Improving nonparametric regression methods by bagging and boosting. Comput. Stat. Data Anal. 2002, 38, 407–420. [Google Scholar] [CrossRef]
- Oliveira, A.L.I.; Braga, P.L.; Lima, R.M.F.; Cornelio, M.L. GA-based method for feature selection and parameters optimization for machine learning regression applied to software effort estimation. Inf. Softw. Technol. 2010, 52, 1155–1166. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [PubMed]
- Yang, T.F.; Liu, P.; Li, Z.; Zeng, X.J. A new combination forecasting model for concentration prediction of dissolved gases in transformer oil. Proc. CSEE 2008, 28, 108–113. [Google Scholar]
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Zheng, Y.; Sun, C.; Li, J.; Yang, Q.; Chen, W. Entropy-Based Bagging for Fault Prediction of Transformers Using Oil-Dissolved Gas Data. Energies 2011, 4, 1138-1147. https://doi.org/10.3390/en4081138
Zheng Y, Sun C, Li J, Yang Q, Chen W. Entropy-Based Bagging for Fault Prediction of Transformers Using Oil-Dissolved Gas Data. Energies. 2011; 4(8):1138-1147. https://doi.org/10.3390/en4081138
Chicago/Turabian StyleZheng, Yuanbing, Caixin Sun, Jian Li, Qing Yang, and Weigen Chen. 2011. "Entropy-Based Bagging for Fault Prediction of Transformers Using Oil-Dissolved Gas Data" Energies 4, no. 8: 1138-1147. https://doi.org/10.3390/en4081138
APA StyleZheng, Y., Sun, C., Li, J., Yang, Q., & Chen, W. (2011). Entropy-Based Bagging for Fault Prediction of Transformers Using Oil-Dissolved Gas Data. Energies, 4(8), 1138-1147. https://doi.org/10.3390/en4081138