


An Improved Short-Term Electricity Load Forecasting Method: The VMD–KPCA–xLSTM–Informer Model


Abstract
1. Introduction
2. Basic Model Principle
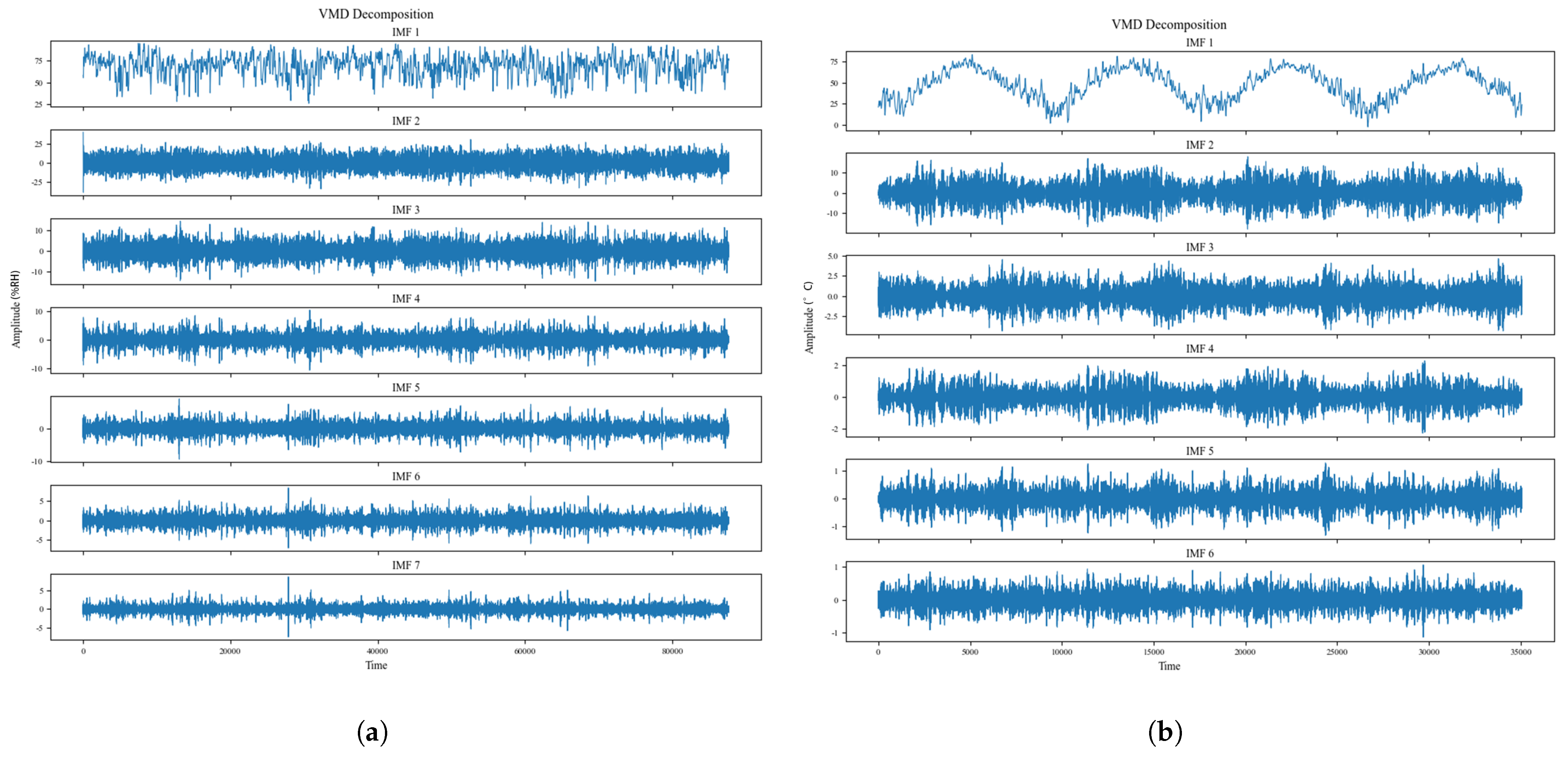
2.1. Variational Mode Decomposition
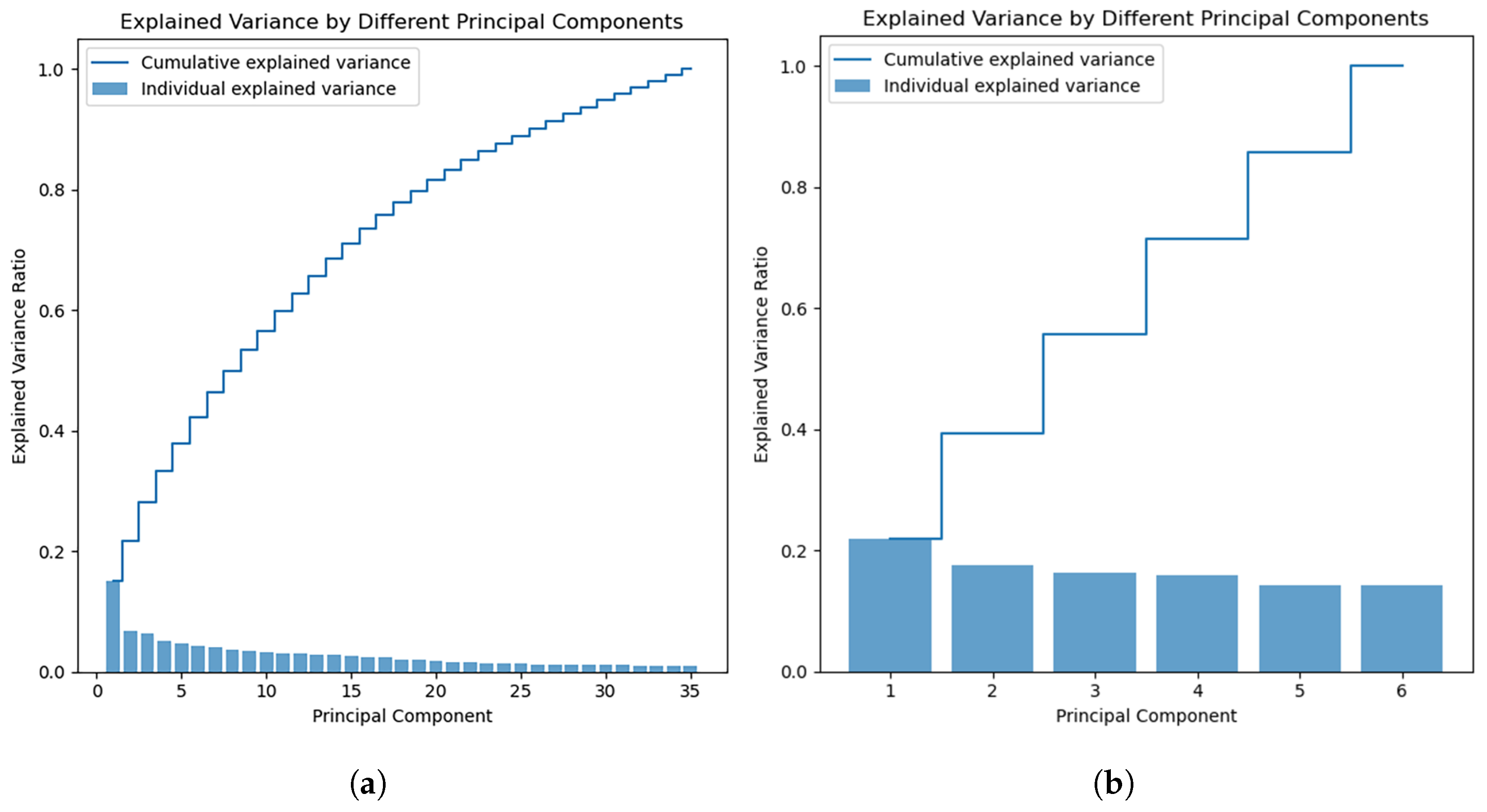
2.2. Kernel Principal Component Analysis
2.3. Extended Long Short-Term Memory Network
- (1)
- Extended Memory UnitOne of the core improvements of xLSTM is the introduction of the Extended Memory Cell, which is updated with the formulawhere is the memory cell state at the current time step, “⊙” denotes that the elements correspond to multiplication, is the forgetting gate, is the input gate, is the candidate memory cell state, is the gating signal of the extended memory cell, and is the extended memory cell. The limited capacity of memory cells in traditional LSTM makes it difficult to effectively capture periodic patterns in power loads spanning weeks or months, and the extended memory cells can significantly improve long-term memory capacity through chunking design;
- (2)
- Multi-Layer Gating MechanismxLSTM introduces a multi-layer gating mechanism that enhances the representation of the model by stacking multiple gating layers. The gating signal of each layer is calculated by the following equation:where l is the number of layers, is the activation function, is the historical information from the previous moment, is the current input, and and are the weights and biases of the lth layer. Electricity load is affected by multiple coupled factors such as temperature, humidity, electricity price, holidays, etc. xLSTM can realize the dynamic selection of input features through the gating mechanism to improve the fitting ability of complex relationships;
- (3)
- Adaptive Time StepxLSTM reduces unnecessary computations by dynamically adjusting the time step through an adaptive mechanism. The formula for the adaptive time step iswhere is the scaling factor of the time step, and and are the weights and biases. Electricity load data contain both high-frequency fluctuations and low-frequency trends, and the adaptive time step allows the model to automatically shorten the step to capture details during critical periods and lengthen the step to reduce computational cost during smooth periods, which improves the forecasting efficiency.
2.4. Informer Network
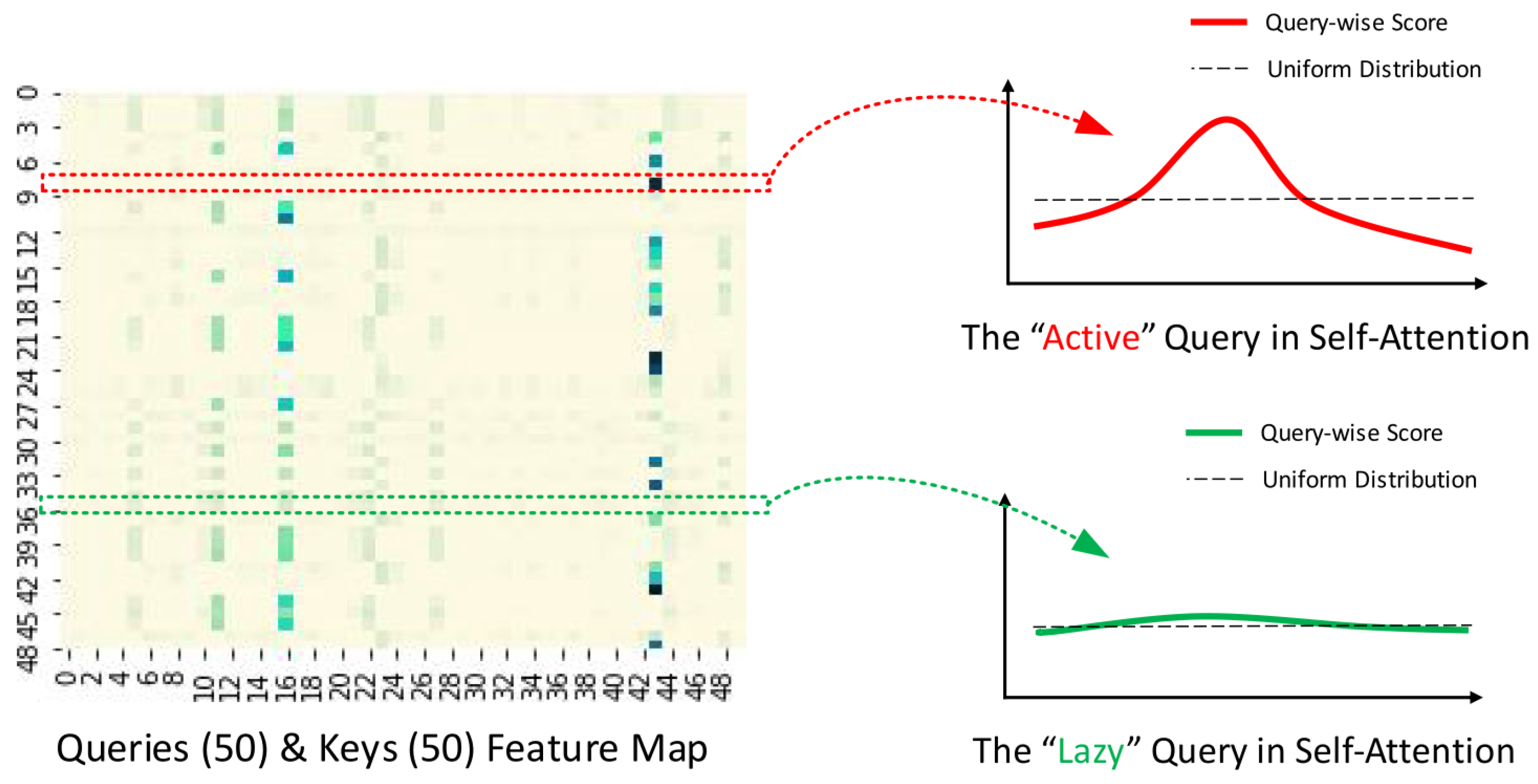
2.4.1. ProbSparse Attention Mechanisms
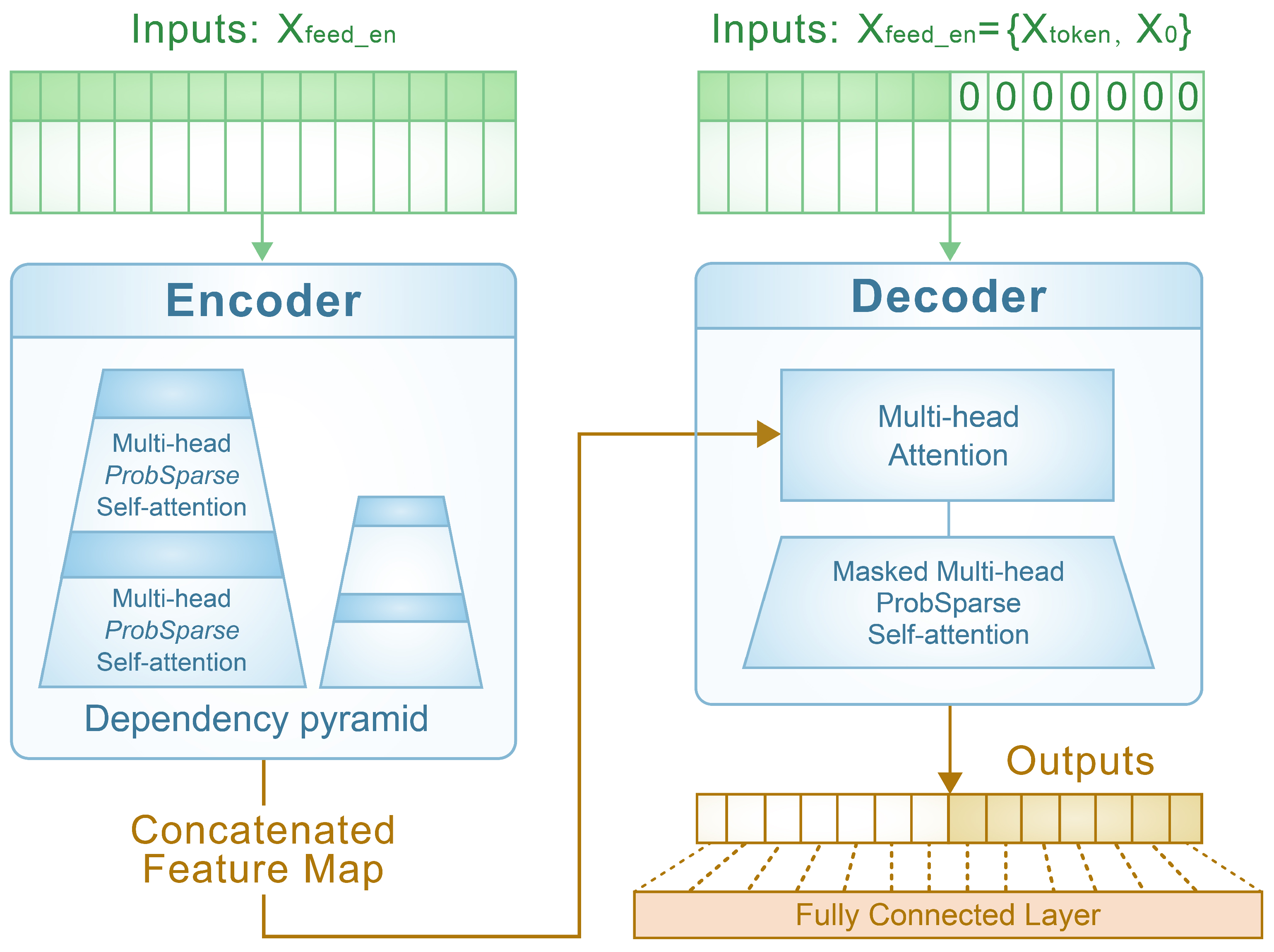
2.4.2. Encoder–Decoder
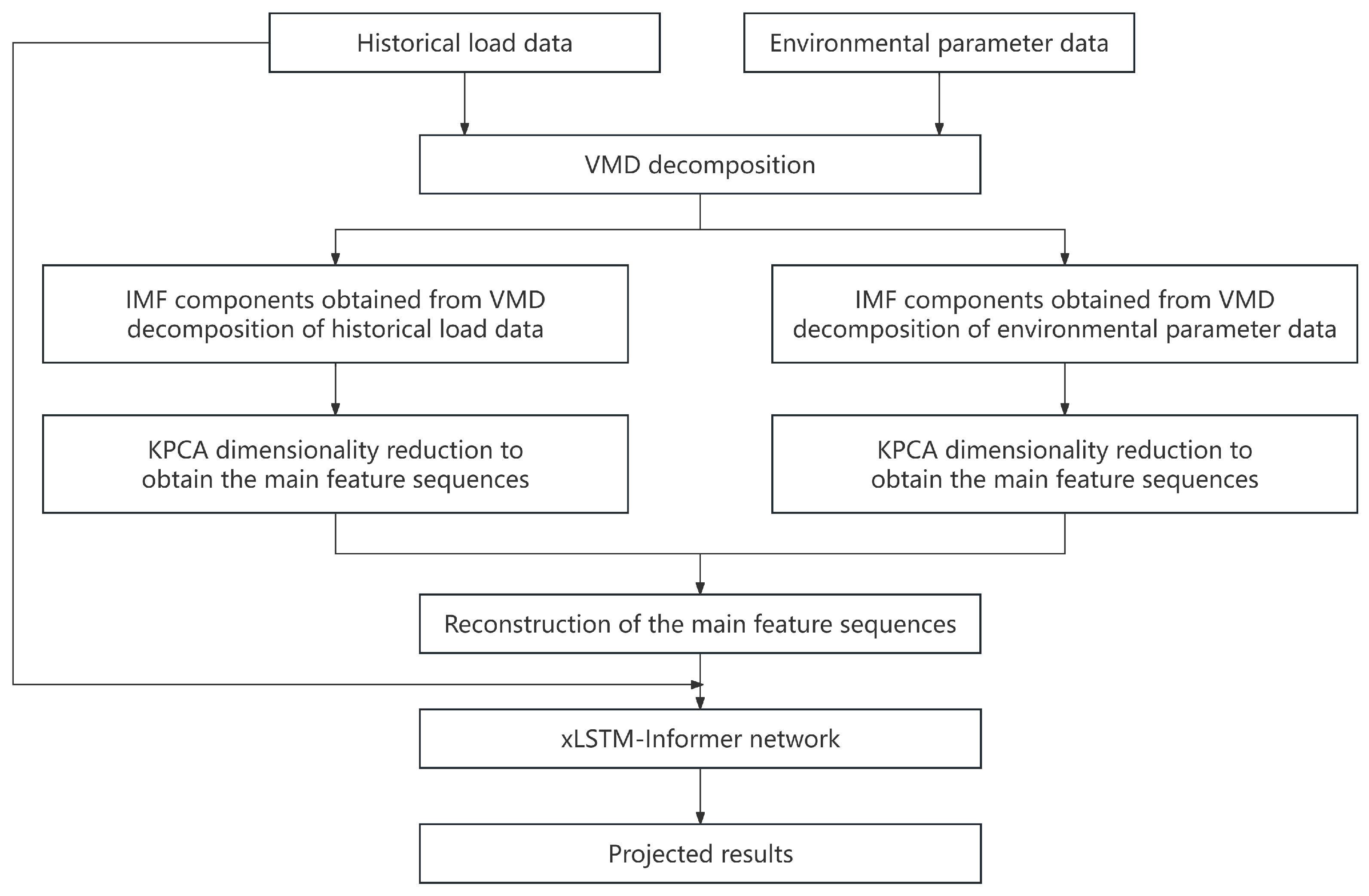
3. VMD–KPCA–xLSTM–Informer Prediction Model
3.1. Construction of the Prediction Model
3.2. Model Evaluation Indicators: MAPE,
4. Experimental Results and Analysis
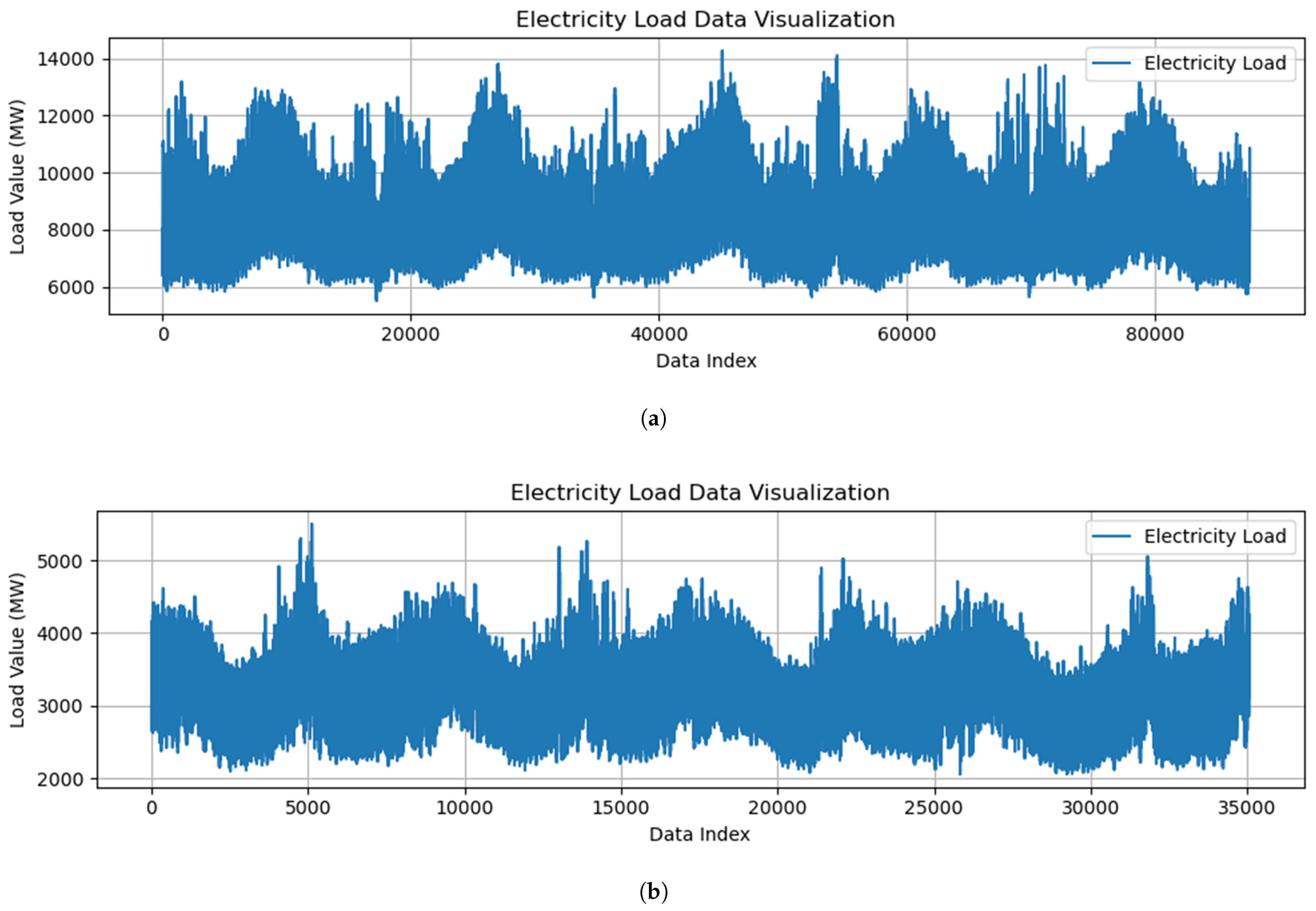
4.1. Datasets and Parameterization
4.2. Variational Mode Decomposition
4.3. Kernel Principal Component Analysis
4.4. Analysis of Experimental Results
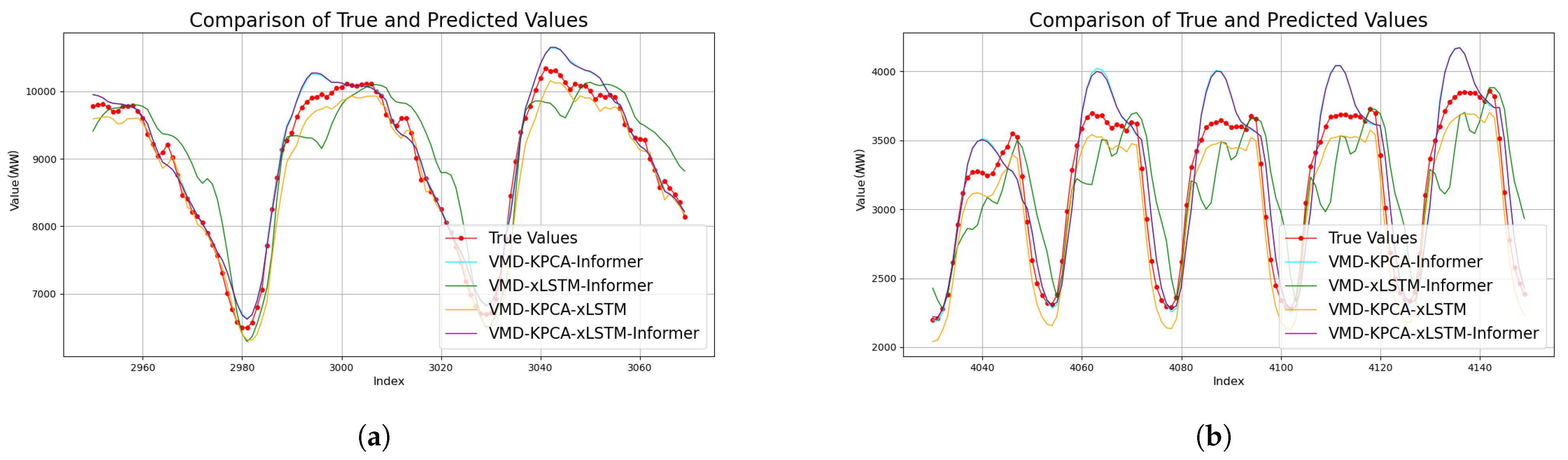
4.4.1. Comparison of Different Inputs
4.4.2. Comparison of Self-Module Prediction Results
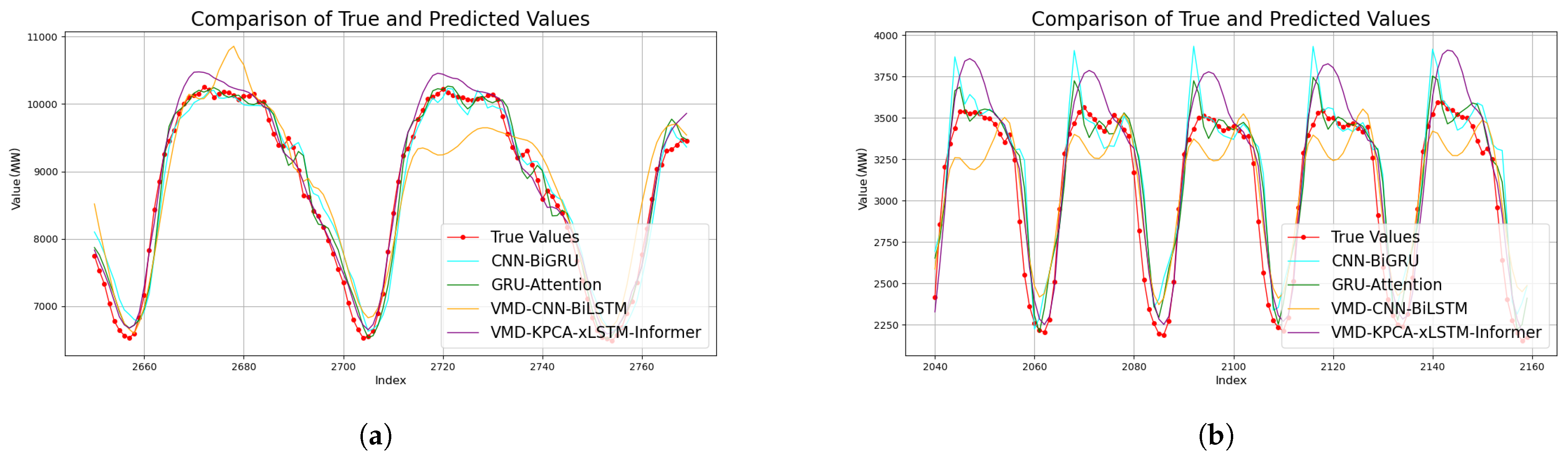
4.4.3. Comparison of Different Model Prediction Results
5. Conclusions
- (1)
- The input data are decomposed using the VMD algorithm. The completeness of decomposition is measured through reconstruction error. This approach reduces data complexity and enhances prediction model performance. In comparisons with publicly available datasets, the proposed method achieves a MAPE reduction of 3.95% on dataset I and 3.18% on dataset II, outperforming the suboptimal GRU–Attention model. Additionally, the metric shows improvements ranging from 0.47% to 13.80%. Notably, the accuracy in capturing sudden load changes is significantly improved. These results demonstrate the effectiveness of VMD decomposition;
- (2)
- The KPCA algorithm filters out components with high contribution as input, effectively reducing computational complexity in model training. Our proposed VMD–KPCA–xLSTM–Informer architecture achieves industry-leading performance on dataset I, with a MAPE of 2.432% and an score of 0.9532. Through KPCA preprocessing, the feature dimension is compressed by over 60%. This dimensionality reduction accelerates algorithm execution while simultaneously improving prediction accuracy;
- (3)
- Comparative experiments conducted with a dual dataset demonstrate significantly better predictive performance when combining historical load data and environmental parameter data, compared to using a single source. On dataset II, the integration reduces the MAPE to 4.940%—a 44.8% improvement over single load input. Simultaneously, the R² increases by 32.4% to 0.8897. These results highlight the model’s enhanced adaptability to complex meteorological factors, confirming that environmental parameters provide critical explanatory power for load fluctuations;
- (4)
- The combined strengths of xLSTM and Informer cascades are effectively leveraged for power load forecasting. These models excel in time-series feature extraction, global dependency modeling, multi-scale adaptation, and robustness, while also enhancing generalization capabilities. On dataset I, the peak load prediction error remains below ±2.5%. This accuracy enables the power grid dispatching system to achieve 72-hour rolling predictions with 95% confidence. Such performance provides reliable technical support for the economic dispatching of the power system.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Cai, H. Short-Term Power Load Forecasting Using a VMD-Crossformer Model. Energies 2024, 17, 2773. [Google Scholar] [CrossRef]
- Wang, C.-C.; Chang, H.-T.; Chien, C.-H. Hybrid LSTM-ARMA Demand-Forecasting Model Based on Error Compensation for Integrated Circuit Tray Manufacturing. Mathematics 2022, 10, 2158. [Google Scholar] [CrossRef]
- Yin, C.; Liu, K.; Zhang, Q.; Hu, K.; Yang, Z.; Yang, L.; Zhao, N. SARIMA-Based Medium- and Long-Term Load Forecasting. Strateg. Plan. Energy Environ. 2023, 42, 283–306. [Google Scholar] [CrossRef]
- Jung, A.-H.; Lee, D.-H.; Kim, J.-Y.; Kim, C.K.; Kim, H.-G.; Lee, Y.-S. Regional Photovoltaic Power Forecasting Using Vector Autoregression Model in South Korea. Energies 2022, 15, 7853. [Google Scholar] [CrossRef]
- Liu, H.; Shi, J. Applying ARMA–GARCH Approaches to Forecasting Short-Term Electricity Prices. Energy Econ. 2013, 37, 152–166. [Google Scholar] [CrossRef]
- Ali, S.; Bogarra, S.; Riaz, M.N.; Phyo, P.P.; Flynn, D.; Taha, A. From time-series to hybrid models: Advancements in short-term load forecasting embracing smart grid paradigm. Appl. Sci. 2024, 14, 4442. [Google Scholar] [CrossRef]
- Chauhan, M.; Gupta, S.; Sandhu, M. Short-Term Electric Load Forecasting Using Support Vector Machines. ECS Trans. 2022, 107, 9731–9737. [Google Scholar] [CrossRef]
- Guo, F.; Li, L.; Wei, C. Short-term load forecasting based on empirical wavelet transform and random forest. Electr. Eng. 2022, 104, 4433–4449. [Google Scholar]
- Yao, X.; Fu, X.; Zong, C. Short-Term Load Forecasting Method Based on Feature Preference Strategy and LightGBM-XGboost. IEEE Access 2022, 10, 75257–75268. [Google Scholar] [CrossRef]
- Lu, S.; Xu, Q.; Jiang, C.; Liu, Y.; Kusiak, A. Probabilistic load forecasting with a non-crossing sparse-group Lasso-quantile regression deep neural network. Energy 2022, 242, 122955. [Google Scholar] [CrossRef]
- Li, K.; Pan, T.; Xu, D. Short-term power load forecasting based on MSCNN-BiGRU-Attention. China Electr. Power 2025, 57, 162–170. [Google Scholar]
- Qian, Y.; Kong, Y.; Huang, C. Review of power load forecasting. Sichuan Electr. Power Technol. 2023, 46, 37–43. [Google Scholar]
- Ibrahim, B.; Rabelo, L.; Gutierrez-Franco, E.; Clavijo-Buritica, N. Machine learning for short-term load forecasting in smart grids. Energies 2022, 15, 8079. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Chen, X.; Shan, O.; Zhang, W. Research on Short Term Power Load Forecasting Based on AHP-K-Means-LSTM Model. Inn. Mong. Electr. Power 2024, 42, 56–63. [Google Scholar]
- Cui, Y.; Zhu, H.; Wang, Y.; Zhang, L.; Li, Y. Short term power load forecasting method based on CNN-SAEDN-Res. Electr. Power Autom. Equip. 2024, 44, 164–170. [Google Scholar]
- Han, J.; Zeng, P. Short-term power load forecasting based on hybrid feature extraction and parallel BiLSTM network. Comput. Electr. Eng. 2024, 119, 109631. [Google Scholar] [CrossRef]
- Beck, M.; Pöppel, K.; Spanring, M.; Auer, A.; Prudnikova, O.; Kopp, M.; Klambauer, G.; Brandstetter, J.; Hochreiter, S. xLSTM: Extended Long Short-Term Memory. arXiv 2024, arXiv:2405.04517. [Google Scholar]
- Haoyi, Z.; Shanghang, Z.; Jieqi, P.; Shuai, Z.; Jianxin, L.; Hui, X.; Wancai, Z. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 2–9 February 2021; pp. 11106–11115. [Google Scholar]
- Zeng, J.; Su, Z.; Xiao, F.; Liu, J.; Sun, X. Short-term electricity load forecasting based on generative adversarial networks and EMD-ISSA-LSTM. Electron. Meas. Technol. 2024, 47, 92–100. [Google Scholar]
- Tang, Y.; Cai, H. Short-term electricity load forecasting based on Pyraformer networks. Eng. J. Wuhan Univ. 2023, 56, 1105–1113. [Google Scholar]
- Yan, Z.; Li, L.; Xu, H.; Zhuang, S.; Zhang, Z.; Rong, Z. Photovoltaic power output prediction based on the white shark algorithm and an improved long short-term memory network. Electr. Gener. Technol. 2025; in press. [Google Scholar]
- Zhong, Y.; Wang, J.; Song, G.; Wu, B.; Wang, T. Ultra-short-term power load prediction under extreme weather based on secondary reconstruction denoising and BiLSTM. Power Syst. Technol. 2024; in press. [Google Scholar]
- Ma, H.; Yuan, A.; Wang, B.; Yang, C.; Dong, X.; Chen, L. Review and prospect of load forecasting based on deep learning. High Volt. Eng. 2025; in press. [Google Scholar]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Tao, P.; Zhao, J.; Liu, X.; Zhang, C.; Zhang, B.; Zhao, S. Grid load forecasting based on hybrid ensemble empirical mode decomposition and CNN–BiLSTM neural network approach. Int. J.-Low-Carbon Technol. 2024, 19, 330–338. [Google Scholar] [CrossRef]
- Zhang, Y.; Ran, Q.; Shi, Z.; Xiong, R. Considering multi-scale inputs and optimizing the short-term load prediction of CNN-BiGRU. Sci. Technol. Eng. 2024, 24, 14679–14689. [Google Scholar]
- Gao, K.; Mou, L. A study of time series forecasting based on quadratic decomposition and GRU-attention. Res. Dev. 2023, 42, 80–87. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Data | Dataset I | Dataset II | ||
|---|---|---|---|---|
| MAPE/% | R2 | MAPE/% | R2 | |
| Environmental parameters data only | 6.562 | 0.7037 | 11.064 | 0.4908 |
| Historical load data only | 4.743 | 0.8553 | 8.944 | 0.6720 |
| Combined historical load data and environmental parameters data | 2.432 | 0.9532 | 4.940 | 0.8897 |
| Predictive Model | I Dataset | II Dataset | ||
|---|---|---|---|---|
| MAPE/% | R2 | MAPE/% | R2 | |
| VMD–xLSTM–Informer | 4.357 | 0.8774 | 9.013 | 0.6719 |
| VMD–KPCA–xLSTM | 2.518 | 0.9519 | 6.173 | 0.8366 |
| VMD–KPCA–Informer | 2.448 | 0.9531 | 5.326 | 0.8657 |
| VMD–KPCA–xLSTM–Informer | 2.432 | 0.9532 | 4.940 | 0.8897 |
| Predictive Model | I Dataset | II Dataset | ||
|---|---|---|---|---|
| MAPE/% | R2 | MAPE/% | R2 | |
| VMD–CNN–BiLSTM | 5.477 | 0.7750 | 5.631 | 0.7882 |
| CNN–BiGRU | 3.195 | 0.9227 | 5.851 | 0.7818 |
| GRU–Attention | 2.532 | 0.9487 | 5.102 | 0.8416 |
| VMD–KPCA–xLSTM–Informer | 2.432 | 0.9532 | 4.940 | 0.8897 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, J.; Cai, H.; Shi, D.; Guo, L. An Improved Short-Term Electricity Load Forecasting Method: The VMD–KPCA–xLSTM–Informer Model. Energies 2025, 18, 2240. https://doi.org/10.3390/en18092240
You J, Cai H, Shi D, Guo L. An Improved Short-Term Electricity Load Forecasting Method: The VMD–KPCA–xLSTM–Informer Model. Energies. 2025; 18(9):2240. https://doi.org/10.3390/en18092240
Chicago/Turabian StyleYou, Jiawen, Huafeng Cai, Dadian Shi, and Liwei Guo. 2025. "An Improved Short-Term Electricity Load Forecasting Method: The VMD–KPCA–xLSTM–Informer Model" Energies 18, no. 9: 2240. https://doi.org/10.3390/en18092240
APA StyleYou, J., Cai, H., Shi, D., & Guo, L. (2025). An Improved Short-Term Electricity Load Forecasting Method: The VMD–KPCA–xLSTM–Informer Model. Energies, 18(9), 2240. https://doi.org/10.3390/en18092240