3.1. Selection of Clustering Algorithms and Characterization of Load Curves
For the characterization of distribution transformer load curves, we applied clustering algorithms such as K-shape, DBSCAN, and DTW with K-means to evaluate their ability to efficiently group time series. The selection of the optimal algorithm was based on several internal validation metrics, allowing us to quantify the cohesion and separation of the generated clusters and obtain the validation of an expert in electricity consumption in the study area.
The results of the metric evaluations are presented in
Table 7. The results indicate that the DTW algorithm with K-means offers the best overall performance, standing out in terms of centroid representation error (0.6177). This suggests that its centroids are the most representative of the curves within each cluster. In addition, it obtains the highest values in Cross-Correlation Similarity (0.9552) and Temporal Consistency (0.9642), showing that the loading patterns within each cluster are homogeneous and stable over time. Likewise, the Silhouette Index (0.355) and the Calinski–Harabasz Index (179.4344) confirm that the segmentation generated is compact and well differentiated. In contrast, DBSCAN, although it achieves a lower Davies–Bouldin index (1.0736) and the highest Temporal Consistency (0.9759), presents a negative Silhouette Index (−0.2297), which indicates that the clusters are not well separated and that there is an overlap between them, which could make the interpretation of the results difficult.
Although K-shape presents intermediate values in most metrics, its Davies–Bouldin index (1.9458) is the highest, indicating a smaller separation between clusters and a less defined group structure. In addition, its lower Cross-Correlation Similarity (0.8074) suggests that the time series clustered in this model presents a lower degree of cohesion compared to DTW with K-means.
It is important to note that, although some metrics, such as centroid representation error, Silhouette Index, and Davies–Bouldin values, do not present optimal values in all cases, previous studies suggest that internal metrics alone are not sufficient to validate a clustering model. According to Ref. [
28], we require an expert in electrical aspects, who, based on their knowledge of the behavior of electricity consumption in the study area, can interpret the results and validate the quality of the clustering. Under this premise, based on the analysis of the load curves obtained with the different algorithms, it is concluded that the results obtained with DTW with K-means are acceptable for the segmentation of distribution transformer load curves. A detailed explanation of these results, including the centroids of the obtained clusters, is provided further down in the document.
From the analysis performed, it is concluded that the most suitable algorithm for the characterization of distribution transformer load curves is DTW with K-means.
Figure 4a presents the results of the elbow method, used to determine the optimal number of clusters. This method measures distortion, defined as the sum of the distances between the curves and their centroids, showing that as the number of clusters increases, the inertia decreases due to the higher specificity in the segmentation. It is observed that using between 4 and 6 clusters could allow us to adequately segment the load curves; however, to validate this choice, the silhouette index is analyzed in
Figure 4b, where it is identified that the best performance is obtained with 2 or 3 clusters. Since the objective of the study is to characterize the load curves with more homogeneous groups, it is chosen to use 2 clusters as the best configuration. However, if there were more transformer load records, new clusters could be created to represent the electrical behavior based on the different types of clients connected to the transformers.
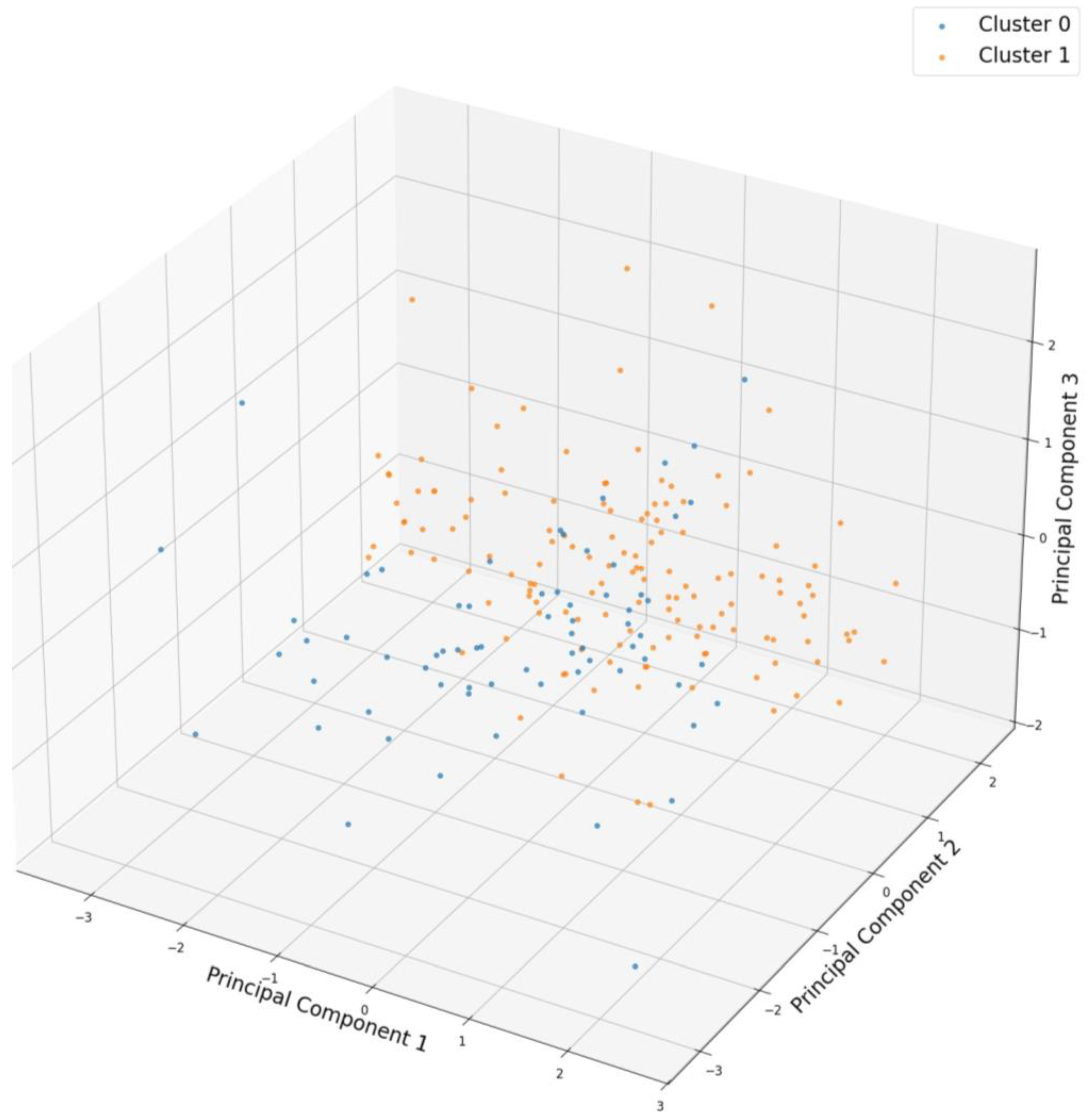
To visualize the distribution of the curves in a lower-dimensional space, Principal Component Analysis (PCA) was applied, the results of which are presented in
Figure 5. In this three-dimensional representation, the blue points correspond to the series grouped in cluster 0, while the orange points represent the series in cluster 1. Partial overlap is observed between the load curves because both clusters share similar load patterns, meaning that the series within each cluster follow a common trend but are not identical. Additionally, the more dispersed points indicate greater variability within each group, reflecting small differences in the behaviors of the series and highlighting the internal diversity of each cluster. This behavior reinforces the choice of two clusters as the most appropriate and representative means of segmenting the data, ruling out the need for more clusters.
Figure 6a shows a boxplot of cross-correlation similarities, where an average close to 95% is observed, confirming the high cohesion of the curves within each cluster. On the other hand,
Figure 6b presents the results of the temporal consistency index, with values above 90% seen in both clusters, validating the stability of the loading patterns over time. These indicators support the choice of the model and demonstrate that the segmentation achieved effectively captures the structure of the distribution transformer load curves.
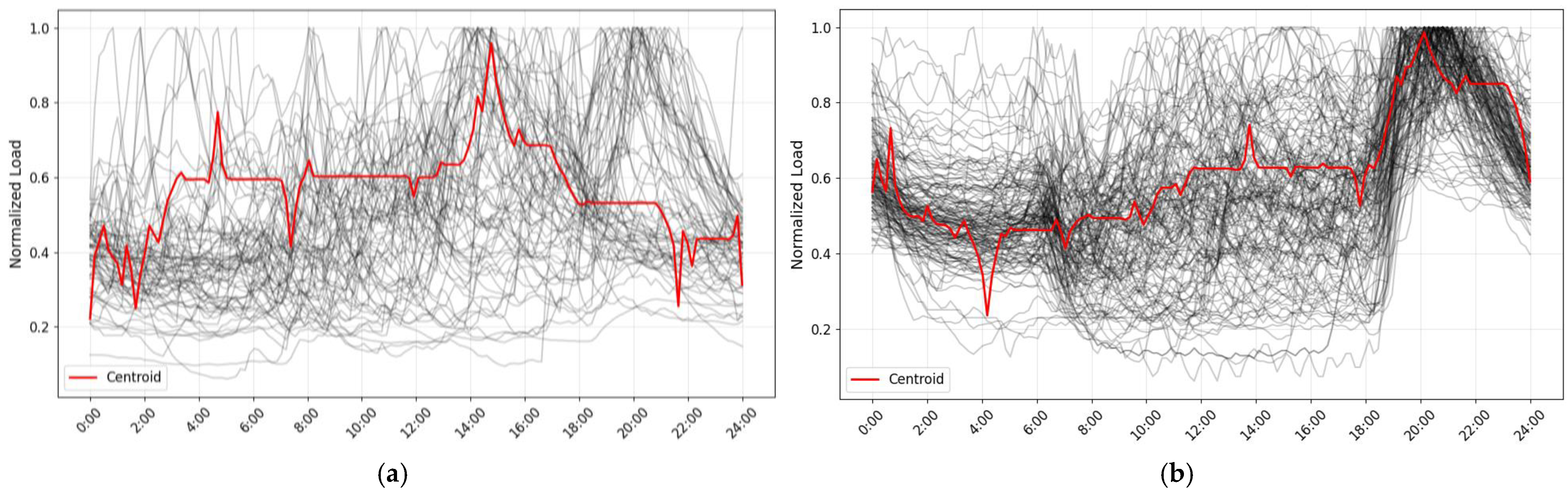
The DTW with a K-means algorithm allowed us to classify the load curves of the distribution transformers for the day of maximum demand, identifying two main types of behavior, as shown in
Figure 7. In this visualization, the centroids and curves associated with each cluster are presented. However, there are peaks at the red centroids that do not allow for the adequate characterization of the load curves. To attenuate these peaks and achieve a more representative characterization of consumption patterns, the median was calculated at each point in the time series. The result of this transformation is observed in
Figure 8, where median-based centroids provide a more robust view of overall load trends.
The first group of curves, shown in
Figure 8a, corresponds to transformers with a higher proportion of commercial and industrial customers. These curves show an increase in load from 08:00 to 18:00, reflecting the operating hours of these types of users. Subsequently, demand decreases progressively in the evening hours. On the other hand, the second group of curves, shown in
Figure 8b, characterizes predominantly residential transformers, whose consumption peaks occur after 18:00, coinciding with the switching on of public lighting and the increase in residential demand. This behavior is also evident in the reduction in consumption after 06:00, when public lighting is turned off, thus consolidating the relationship between residential consumption patterns and nighttime electricity demand.
Figure 9 shows the curves determined by DBSCAN, the gray lines are the data from the transformers and the red line is the centroid of each cluster. This algorithm does not require prior knowledge of the number of clusters; on the contrary, the algorithm automatically detects clusters thanks to its ability to identify groups of densely connected points in a dataset, which allows it to identify those curves that do not belong to any clusters as atypical or unique. As such, it is not ideal for curve characterization, which is the objective of this study. The unique curves shown in
Figure 9 can be attributed to the limited number of transformer samples. If we measured a greater number of transformers with similar connected loads, it would be possible to reduce unique curves and form new groups that reflect the curves based on the different types and quantities of connected customers. This would allow for more accurate representation of electrical behavior at a global level.
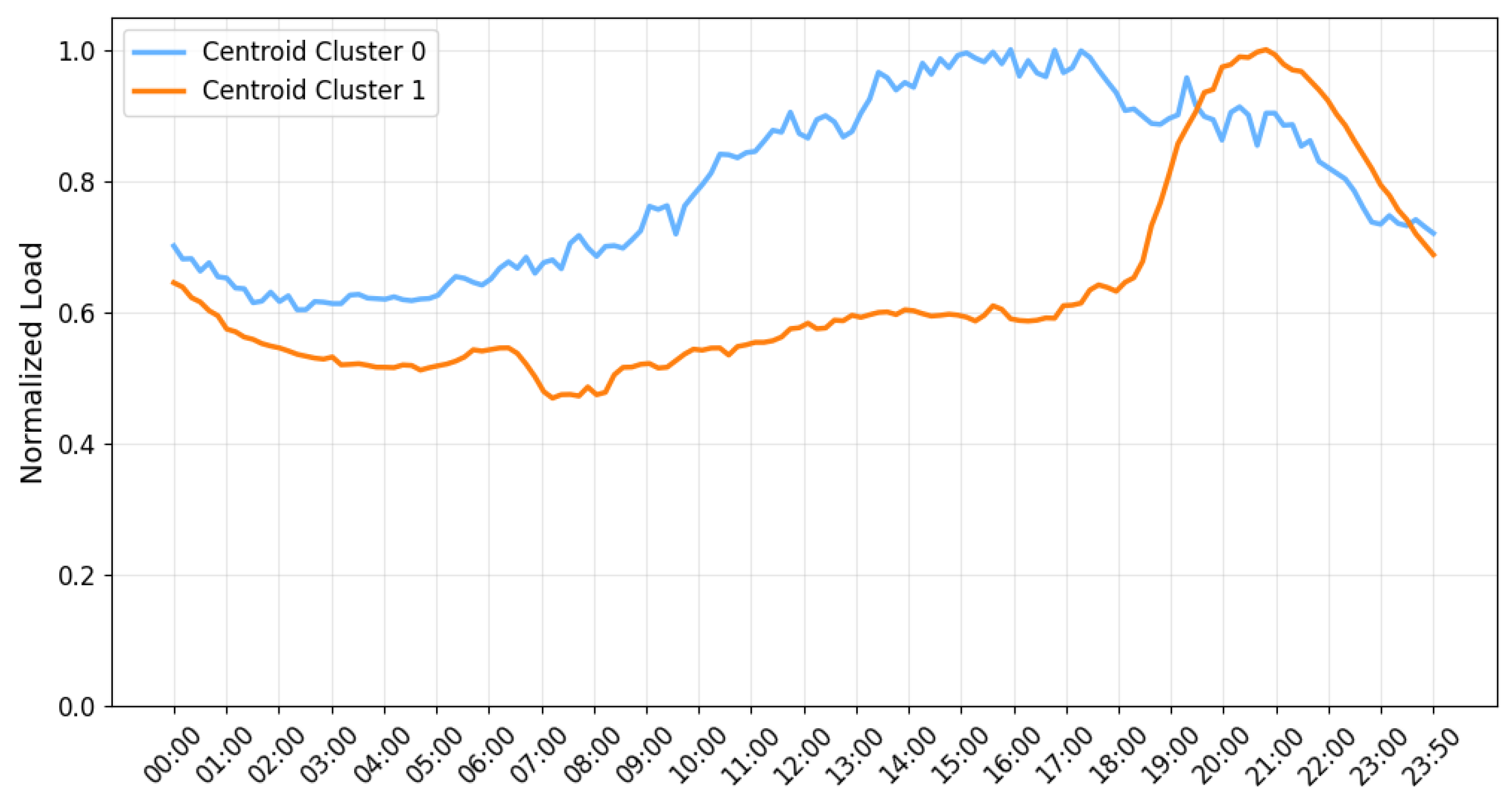
Based on the results obtained from the centroids with DTW and K-means, the curves were normalized to generate a per-unit curve, shown in
Figure 10, allowing the characterization of the load curves of distribution transformers by multiplying the maximum load by each point of the characterized curve. It is important to note that the obtained load signal patterns not only facilitate the characterization of the load behavior of distribution transformers but also serve as a key tool for the management and planning of the distribution system’s operation.
The analysis of these load curves can be used to identify potential overloads or imminent failures in the equipment, facilitating the analysis of their technical condition. By integrating these load patterns into the operational planning of the distribution system, the maximum power demands in different areas can be anticipated more accurately, allowing for the more efficient adjustment of the electrical infrastructure to meet these needs.
Additionally, these patterns can contribute to dynamic load management, enabling analysis with load profiles in electrical networks to more effectively assess energy losses or the integration of distributed generation sources. These sources, which exhibit variable behavior over time, have a dynamic impact on distribution networks, with effects that are not static but rather vary depending on the different times of the day.
3.2. Transformer Curve Type Prediction Algorithm Selectrion
With the types of curves labeled on the distribution transformers using the clustering methodology, the dataset was divided, using 80% for training and 20% for testing. The objective was to develop a prediction model capable of estimating the transformer load curve as a function of the independent variables established in
Table 2.
To select the most suitable algorithm, the Random Forest, Support Vector Machine (SVM), neural network, and LightGBM (Light Gradient Boosting Machine) models were evaluated. The key metrics used for the comparison are presented in
Table 8. The results show that Random Forest achieved the best overall performance, standing out with an accuracy of 0.78. It also demonstrated a consistent performance across the metrics for both Cluster 0 and Cluster 1. In particular, the precision (0.67/0.83) and recall (0.60/0.86) are fairly balanced between the two clusters and show superior to the results of the other algorithms, suggesting that the model is not only capable of performing accurate classification but also maintains a good level of generalization. This means it can identify patterns and make accurate predictions about new samples not seen during training. The F1-score of 0.63/0.84 demonstrates a good balance between precision and recall, indicating that the model is able to correctly identify both common and less frequent cases, such as those in Cluster 0, without losing performance in either category. These results highlight that Random Forest has excellent generalization capabilities, adapting well to different types of data and avoiding overfitting, which is crucial for effectively predicting transformer load curves in various scenarios.
Due to its superior performance, Random Forest was selected and adjusted with the optimal parameters in
Table 9 for the prediction of distribution transformer load curves. In
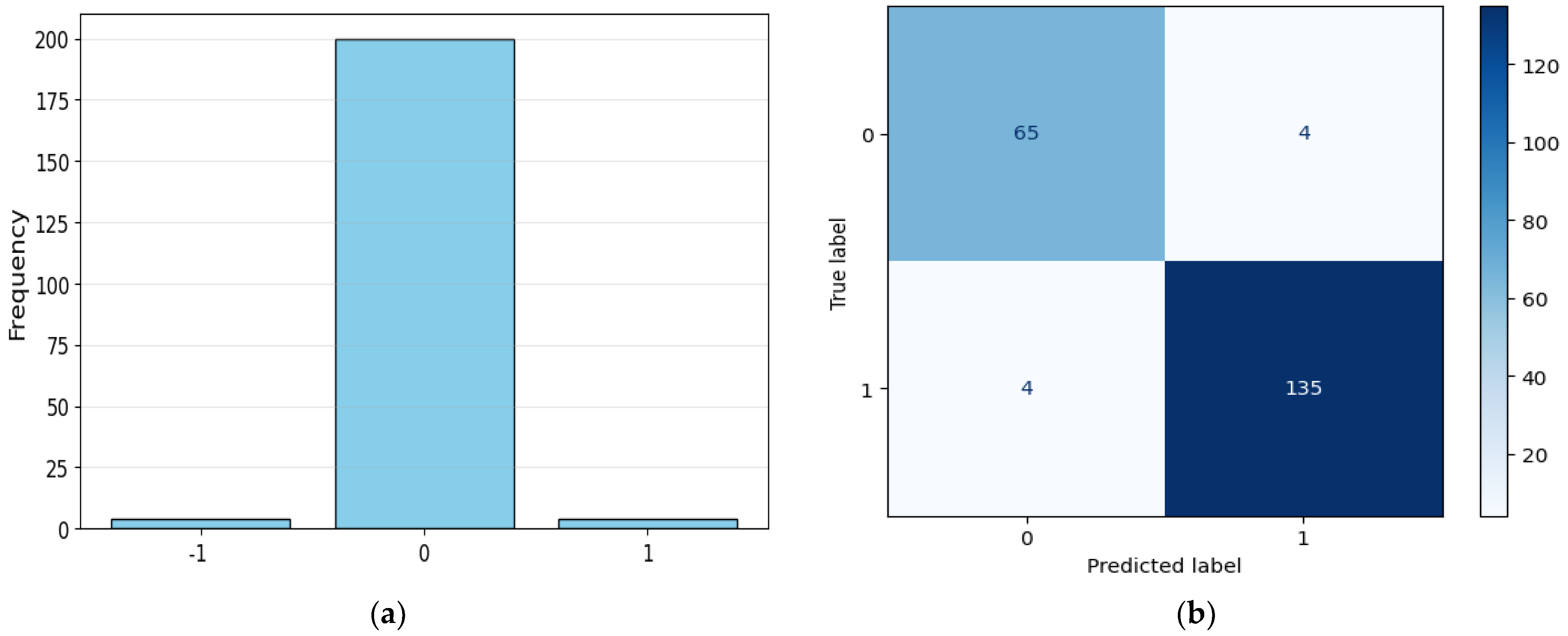
Figure 11a, the difference between the actual values and the model predictions is shown, evidencing high accuracy in most cases. Additionally,
Figure 11b presents the confusion matrix, where it is observed that, out of a total of 208 transformers, the model correctly predicts 200, while 8 are misclassified, yielding an accuracy of 96%.
3.3. Transformer Load Prediction Algorithm Selectrion
To determine the best algorithm for distribution transformer loadability prediction, the dataset was divided into 80% training and 20% test groups to train a distribution transformer load curve prediction model as a function of the independent variables set out in
Table 3.
For the prediction of transformer loadability, four machine learning algorithms were evaluated: Random Forest, XGBoost, neural networks, and Support Vector Machine (SVR).
Table 10 presents the results obtained using the different evaluation metrics, where it is evident that the SVR model obtained the best performance, reaching an R
2 of 0.90, which indicates that it is capable of explaining 90% of the variability in the data. In addition, it registered the lowest Mean Absolute Error (MAE) at 2.28, the lowest Mean Squared Error (MSE) at 11.20, and an RMSE of 3.35, demonstrating greater accuracy and stability in its predictions compared to the other models. On the other hand, the neural networks algorithm shows the lowest performance with an R
2 of 0.77, which can be attributed to the limited amount of training data available. Although neural networks are robust models for learning complex patterns, they require large volumes of data to avoid overfitting. Without enough data, the model may lose its ability to generalize, as evidenced by the high MAPE of 185.28%.
In order to assess the impact of hyperparameters on the model results, the parameters of the models with the best scores, specifically XGBOOST and SVR, were adjusted.
Table 11 presents the modified hyperparameters, while
Table 12 shows the results obtained when predicting the load of the transformers. The results indicate a decrease in model accuracy, although SVR remains the most accurate algorithm for load prediction.
The Support Vector Machine (SVR) algorithm was selected for its superior performance in the evaluation metrics, showing better prediction capability compared to the other models tested. To optimize its performance, the parameters detailed in
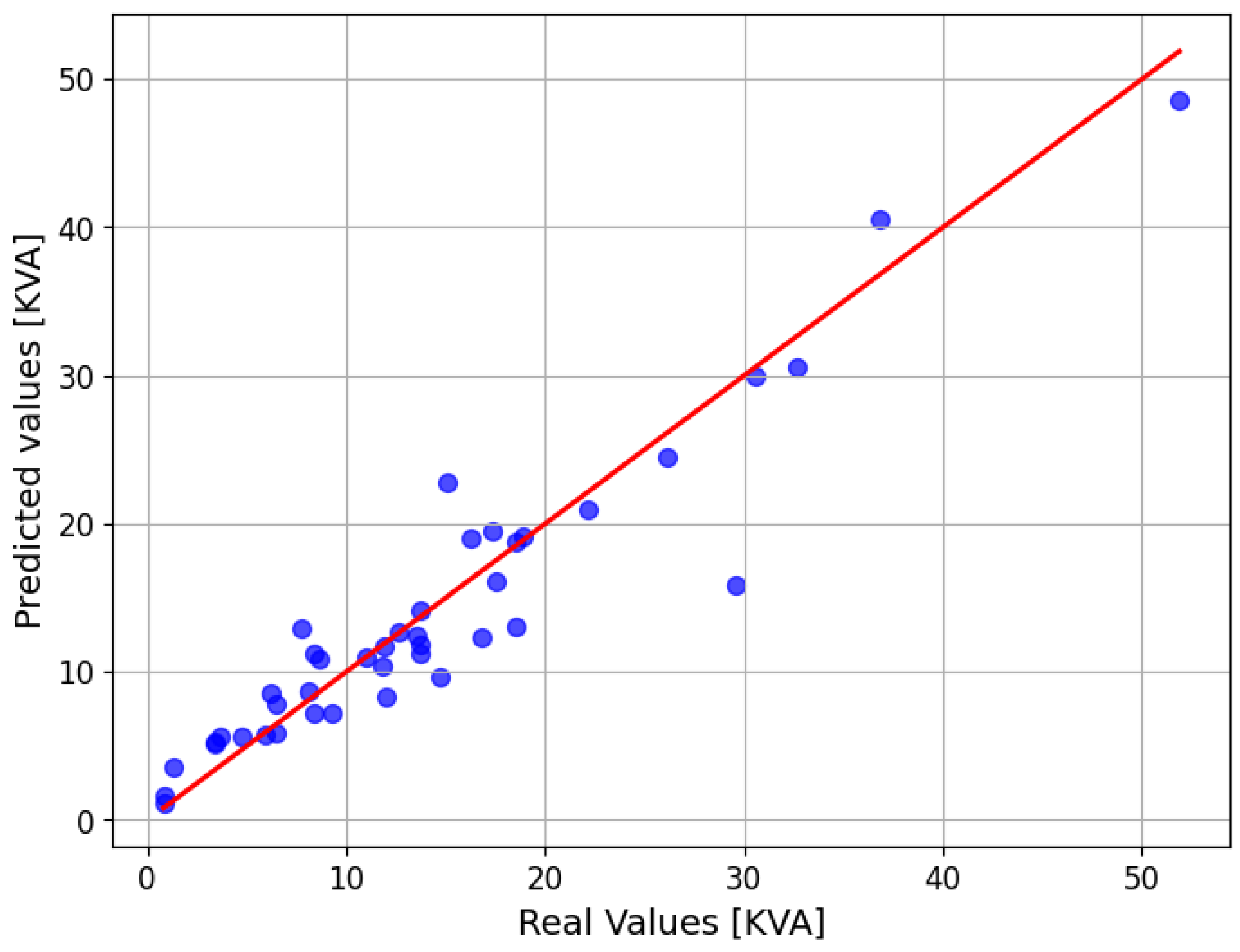
Table 13 were configured, adjusting the hyperparameter C to control the error penalty and epsilon to define the prediction tolerance. These adjustments allowed us to improve the accuracy of the estimations, ensuring a balance between bias and variance in the prediction of distribution transformer loads. In
Figure 12, the graphical comparison between the real values and the power values predicted by the SVR model is presented, while
Figure 13 illustrates the projection of real versus predicted loads as a function of their associated customers.
To validate model training to predict the transformer load,
Figure 14a presents a residual plot where the blue points do not show any evident pattern around the red horizontal line, indicating that the model is capturing the relationships between variables correctly without systematic errors. This random behavior of the residuals suggests the good performance of the selected algorithm. On the other hand,
Figure 14b shows a comparison between the distribution of real and predicted values, and a high similarity between both curves can be observed. This reinforces the validity of the model and demonstrates that the predictions made by the algorithm are consistent with the observed data, supporting its effectiveness in predicting transformer loads.
3.4. Model Evaluation
The load prediction model developed was applied to the 16,696 transformers of EEASA in operation during the year 2024. Their actual coincident power at 19:20 was 127,428.21 kVA. It is important to note that this demand only corresponds to transformers with customers metered at low voltages, and excludes those associated with private customers metered at medium voltages. This segmentation was performed with the purpose of evaluating the accuracy of the model, which predicts transformer loads based on customers, who are classified by tariff type (residential, commercial, industrial, and other) and public lighting power using data obtained from the GIS database.
The model estimated the maximum load power of each transformer and, by applying the normalized load curves found in this study, calculated the total power coincident at 19:20, obtaining a value of 129,275.67 kVA. When comparing this result with the demand registered in 2024 (127,428.21 kVA), the model was validated with an accuracy of 98.55%, which shows its high adjustment capacity and reliability in the representation of the real behavior of the demand in the distribution network.
In terms of installed capacity, the total power in transformers with customers in EEASA’s GIS database in the year 2024 amounted to 400,831 kVA, which represents an average loadability of these transformers of 31.79% (127,428.21/400,831). Applying the model to guarantee the correct distribution of infrastructure with the growth of future demand, a load increase of 40% was considered in addition to the demand projected by the model, allowing the transformers to be sized efficiently. Through this adjustment, the closest commercially available power for each transformer was determined, resulting in a 39.27% reduction in installed power, from 400,831 kVA to 243,437.50 kVA, with a new average loadability of 52.35%.
In
Figure 15, the power distribution of real transformers (blue) compared to the suggested transformers (orange) is shown. A significant increase is observed in transformers of 5 kVA and 15 kVA, which indicates a reduction in the installation of equipment of 10, 25, and 37.5 kVA, as well as equipment with higher capacities. This resizing allows for greater efficiency in the use of the electrical infrastructure, optimizing the operation without compromising the reliability of the system.
3.5. Analysis and Discussions
This study highlights how the use of advanced data science and machine learning techniques can significantly improve the characterization and prediction of distribution transformer load curves. In the initial phase of the analysis, the segmentation of time series using clustering algorithms allowed the identification of distinct patterns of power consumption. The comparison of internal validation metrics shows that the DTW method with K-means offers a superior clustering structure, standing out for its low centroid representation error (0.6177) and high Temporal Consistency (0.9642), which reflects adequate coherence in the temporal behavior of the data. In contrast, although DBSCAN showed good performance in detecting single curves, its low compactness and high Davies–Bouldin index (1.0736) indicate that it is not the most suitable method for the generalized segmentation of load curves. Furthermore, the analysis of other metrics, such as the Silhouette Index (0.355) and the Calinski–Harabasz Index (179.4344), for DTW with K-means reinforces the ability of this approach to generate more compact and well-defined groupings. These results underscore the importance of complementing quantitative metrics with the expert validation of the electrical domain, which allows for the accurate interpretation of the relevance of each clustering in electrical infrastructure planning.
From the point of view of predictive modeling, the results highlight that algorithm selection depends on the nature of the problem. In the classification of load curves, Random Forest showed the best performance, reaching an accuracy of 78%, and maintained a good balance between recall and accuracy, making it a suitable choice for this task. Regarding the prediction of the power demanded by the transformers, Support Vector Machine (SVR) proved to be superior, with an R
2 of 0.90, the lowest MAE (2.28), and the lowest RMSE (3.35). These results are consistent with previous studies, such as that of Ref. [
22], which used SVR to predict the energy consumption of electric boilers with an R
2 of 0.84. In contrast, other approaches, such as Multilayer Perceptron (MLP) artificial neural networks (ANNs), did not perform well, suggesting that these techniques have limitations in this context. In research such as Ref. [
12], overfitting problems were found in LSTM models, which reinforces the advantage of simpler and more efficient models such as SVR. In turn, the transformer model, although promising, showed considerable variability in its performance depending on the specific transformer, indicating that this type of model may require a more adaptive approach in dynamic scenarios. Compared to the hybrid approach proposed in Ref. [
17], which combined GRUs and TCNs, the SVR algorithm used in this study achieved comparable results, but with a more simplified model.
On the other hand, the neural networks applied in this study did not perform well, especially in terms of MAPE (185.28%) and R2 (0.77), suggesting that this model does not adequately fit the data in this task. In summary, SVR stands out as the most robust model; these findings reinforce the idea that, in regression problems applied to electrical infrastructure, models based on convex optimization techniques, such as SVR, can be more effective than deep learning approaches, which often require finer hyperparameter tuning to achieve stability.
Finally, the application of the prediction model to EEASA’s 16,696 transformers allowed us to estimate a projected coincident power of 129,275.67 kVA, validating the model with an accuracy of 98.55%. This suggests that the model has high reliability and can be used with confidence for decision making. In addition, the optimization in transformer allocation resulted in a 39.27% reduction in installed power, from 400,831 kVA to 243,437.50 kVA, with an improvement in average loadability, which increased from 31.79% to 52.35%. These results underscore the positive impact of machine learning on energy management, allowing for the more efficient sizing of electrical infrastructure and more sustainable planning. However, although the results of the study are favorable, it is recommended to include a larger number of transformer samples to further improve the training of the model and cover all possible combinations of consumers connected to this equipment.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}