
An Improved Multimodal Framework-Based Fault Classification Method for Distribution Systems Using LSTM Fusion and Cross-Attention

Abstract
1. Introduction
- To tackle the challenges associated with small-scale data, class imbalance, and the risk of mislabeling in fault cause identification, this paper proposes a loss function that merges soft label loss with focal loss.
- Table Transformer and embedding techniques are designed to integrate categorical features, enabling the fusion of discrete information across different dimensions, thereby establishing connections with continuous fault information.
- This paper develops an LSTM-based fusion module to combine continuous information from diverse dimensions, enhancing the model’s capacity to capture dynamic changes in electrical signals.
- A cross-attention module is proposed to integrate both continuous and categorical fault information, improving the model’s diagnostic accuracy by emphasizing critical information from distinct data sources.
2. Methodology
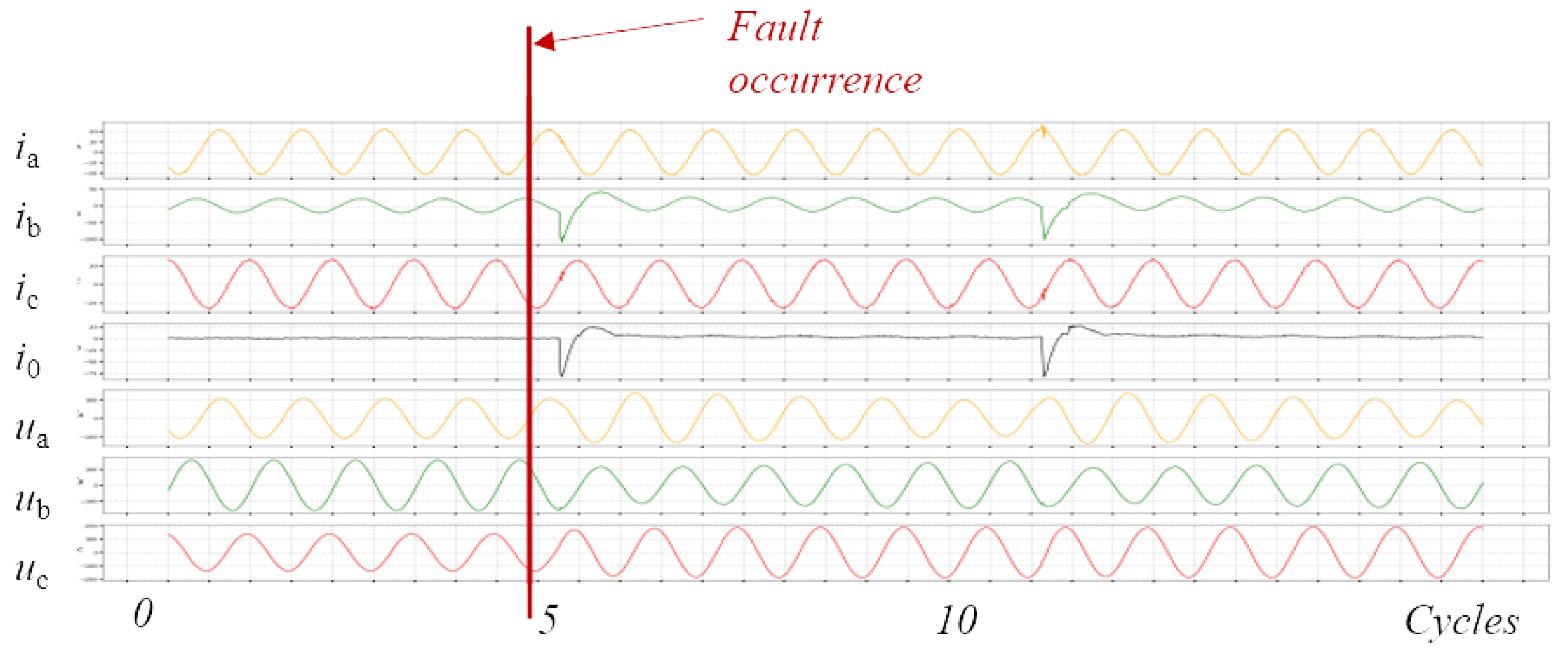
2.1. The Motivation of a Multimodal Data Fusion Model
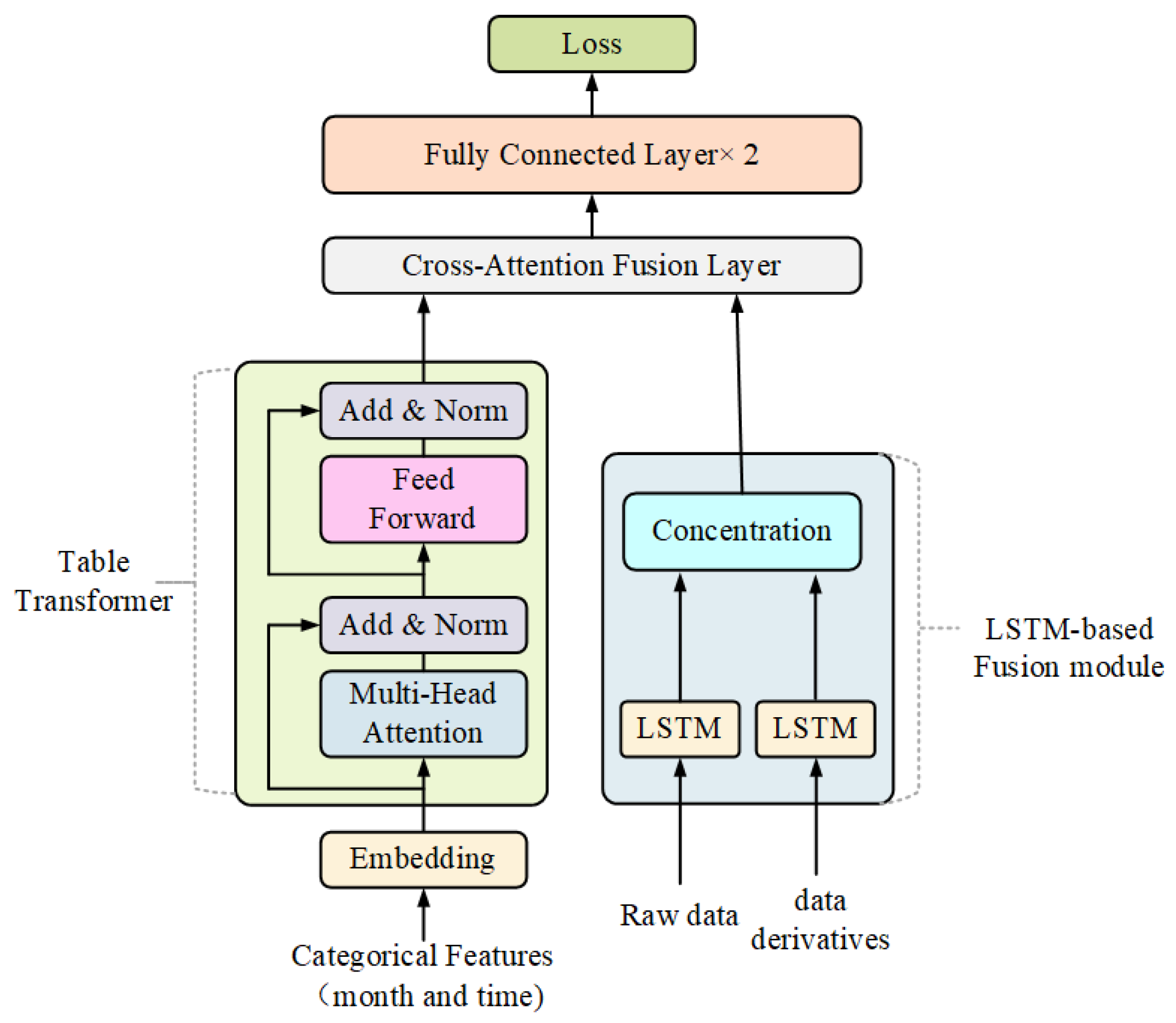
2.2. Proposed Model Structure
2.2.1. Input Layer
2.2.2. Embedding Layer
2.2.3. Table Transformer Module
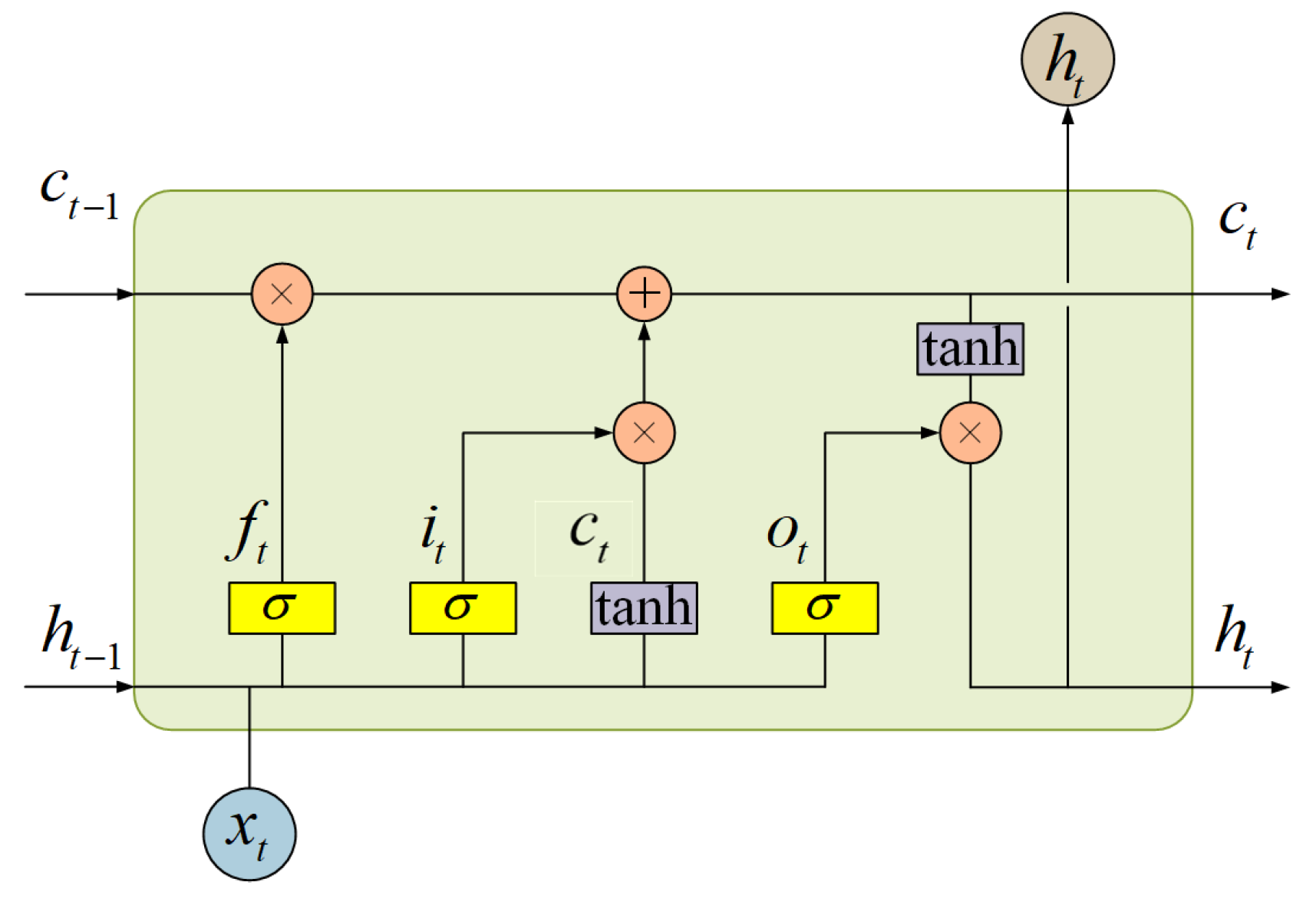
2.2.4. LSTM-Based Multimodal Temporal Data Fusion Module
2.2.5. Cross-Attention Layer for Categorical and Continuous Data Fusion
2.3. Proposed Loss Function
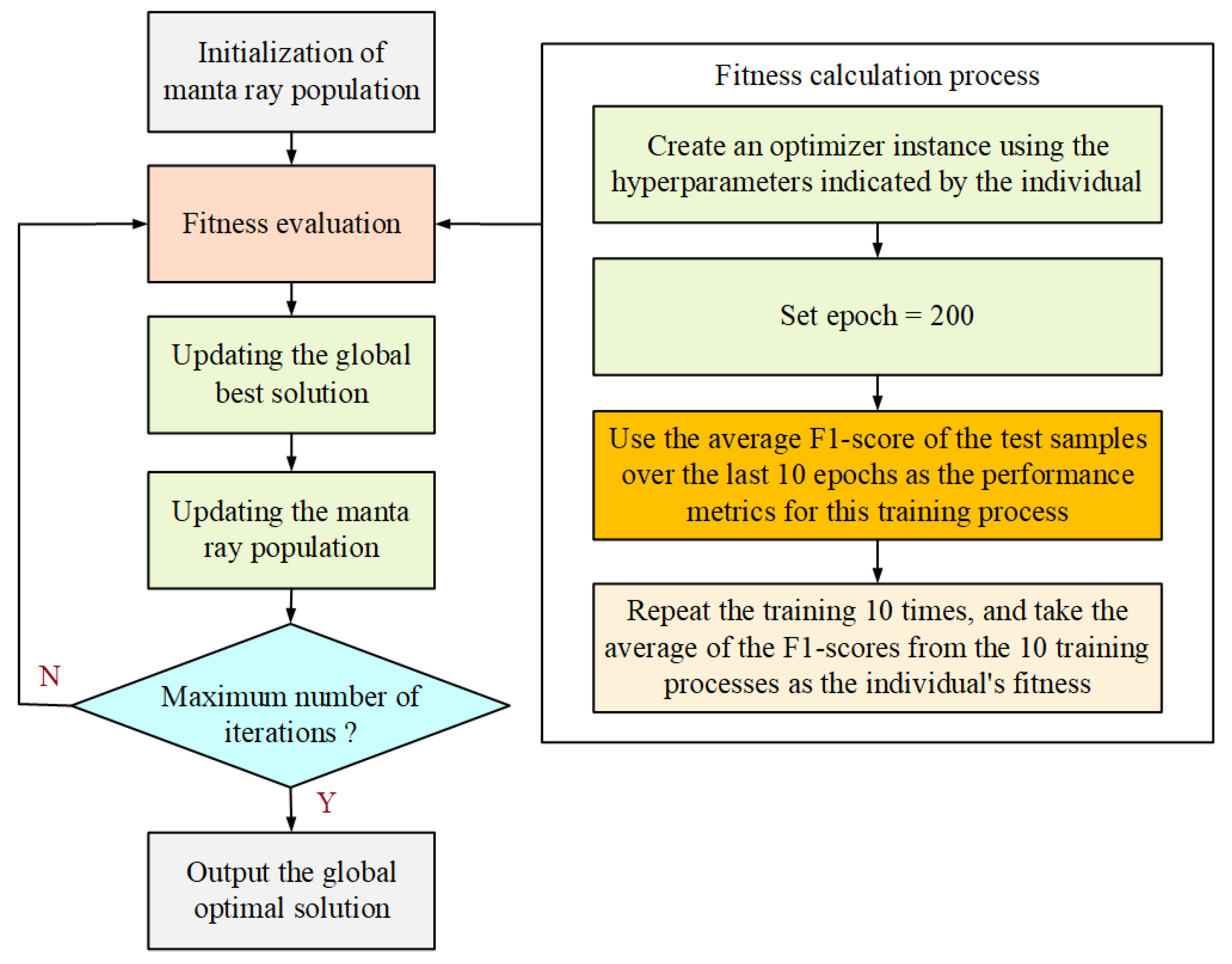
2.4. Hyperparameter Decision Using Manta Ray Foraging Optimization
3. Case Study
3.1. Database Construction
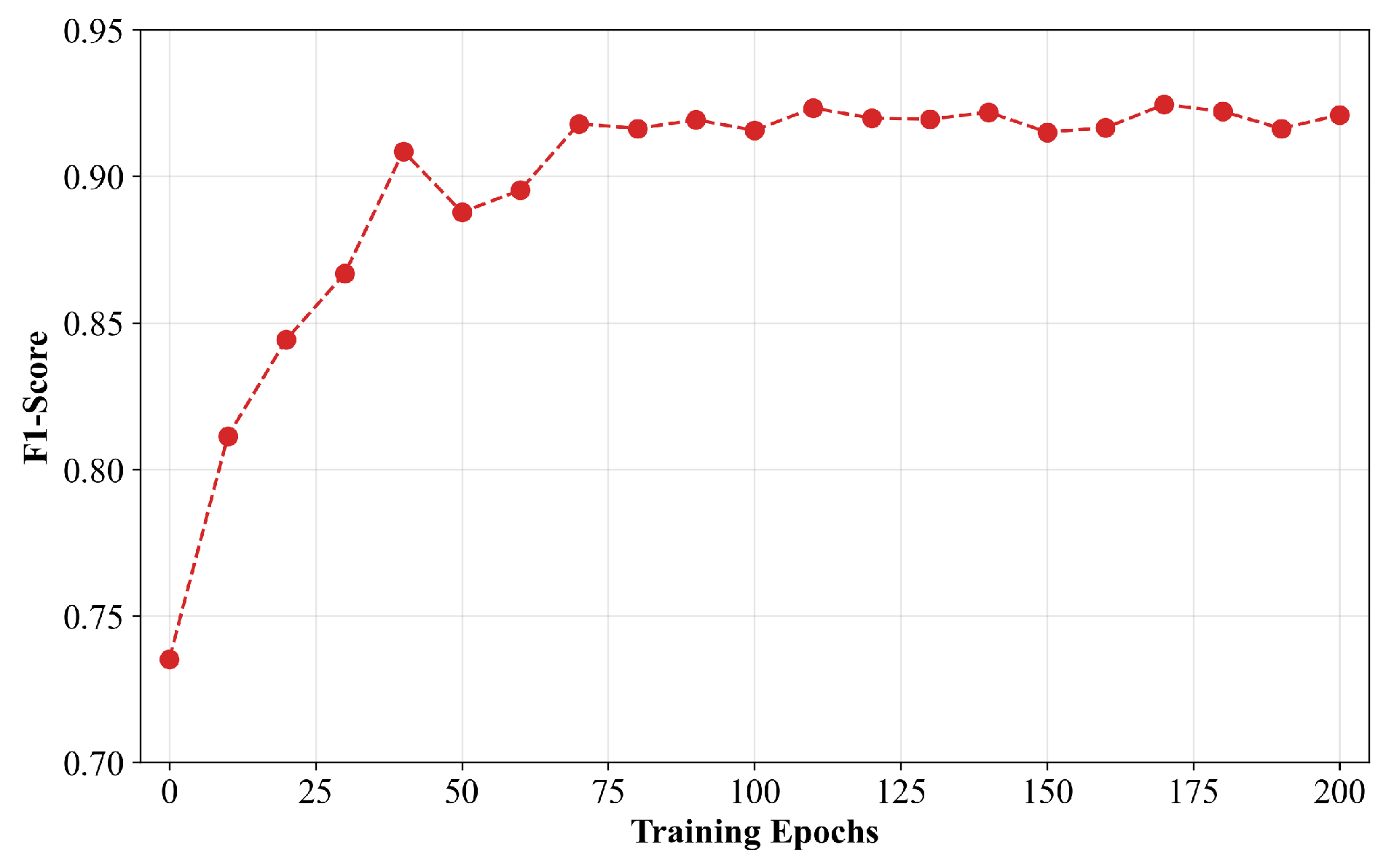
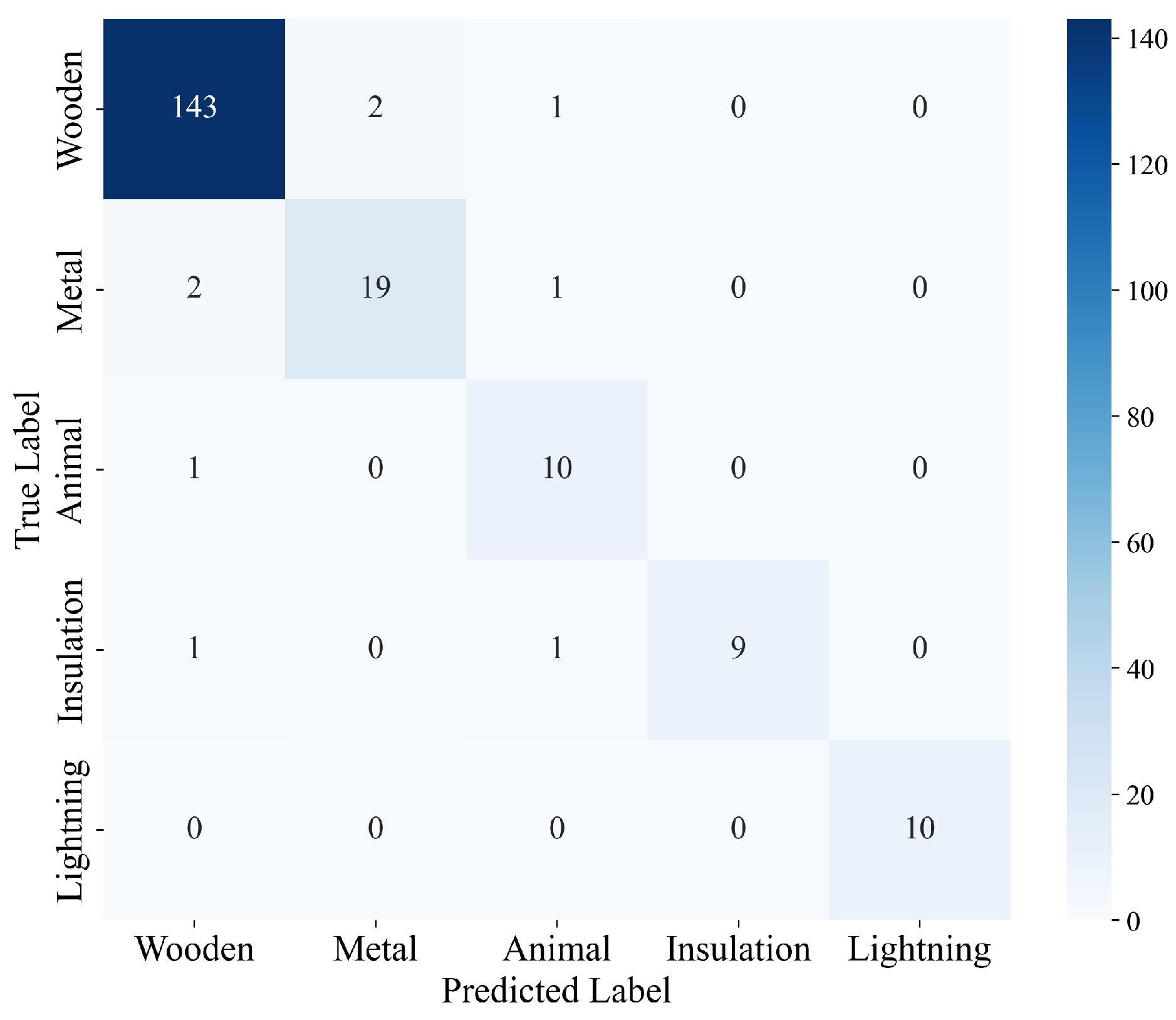
3.2. Evaluation Metrics
3.3. Comparison of Different Feature Map Construction Methods
3.4. Comparison of Different Model Structures
3.5. Comparison of Different Loss Functions
3.6. Comparative Analysis with Existing Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shuvra, M.A.; Rosso, A.D. Root Cause Identification of Power System Faults using Waveform Analytics. In Proceedings of the 2018 Clemson University Power Systems Conference (PSC), Charleston, SC, USA, 4–7 September 2018; pp. 1–8. [Google Scholar]
- Xu, L.; Chow, M.; Timmis, J. Power distribution outage cause identification with imbalanced data using artificial immune recognition system (AIRS) algorithm. IEEE Trans. Power Syst. 2007, 22, 198–204. [Google Scholar] [CrossRef]
- Xu, L.; Chow, M. A classification approach for power distribution systems fault cause identification. IEEE Trans. Power Syst. 2006, 21, 53–60. [Google Scholar] [CrossRef]
- Das, B. Fuzzy logic-based fault-type identification in unbalanced radial power distribution system. IEEE Trans. Power Deliv. 2006, 21, 278–285. [Google Scholar] [CrossRef]
- Silva, K.M.; Souza, B.A.; Brito, N.S.D. Fault detection and classification in transmission lines based on wavelet transform and ANN. IEEE Trans. Power Deliv. 2006, 21, 2058–2063. [Google Scholar] [CrossRef]
- Peng, N.; Ye, K.; Liang, R. Single-phase-to-earth faulty feeder detection in power distribution network based on amplitude ratio of zero-mode transients. IEEE Trans. Power Deliv. 2020, 21, 2058–2063. [Google Scholar] [CrossRef]
- Liu, W.; Hao, D.; Zhang, S.; Zhang, Y. Power System Transient Stability Assessment Based on PSO-DBN. In Proceedings of the 2021 6th International Conference on Power and Renewable Energy (ICPRE), Shanghai, China, 17–20 September 2021; pp. 333–337. [Google Scholar]
- Yang, H.; Meng, C.; Wang, C. Data-Driven Feature Extraction for Analog Circuit Fault Diagnosis Using 1-D Convolutional Neural Network. IEEE Access 2020, 8, 18305–18315. [Google Scholar] [CrossRef]
- Bukhari, S.B.A.; Kim, C.H.; Mehmood, K.K. Convolutional neural network-based intelligent protection strategy for microgrids. IET Gener. Transm. Distrib. 2020, 14, 1177–1185. [Google Scholar] [CrossRef]
- Veerasamy, V.; Wahab, N.I.A.; Othman, M.L.; Padmanaban, S.; Sekar, K.; Ramachandran, R.; Hizam, H.; Vinayagam, A.; Islam, M.Z. LSTM Recurrent Neural Network Classifier for High Impedance Fault Detection in Solar PV Integrated Power System. IEEE Access 2021, 9, 32672–32687. [Google Scholar] [CrossRef]
- Fang, J.; Liu, C.; Zheng, L.; Su, C. A data-driven method for online transient stability monitoring with vision-transformer networks. Int. J. Electr. Power Energy Syst. 2023, 146, 108669. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, D.; Cui, L. CTNet: A data-driven time-frequency technique for wind turbines fault diagnosis under time-varying speeds. ISA Trans. 2024, 154, 335–351. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Cai, W.; Cui, L. Multi-perception graph convolutional tree-embedded network for aero-engine bearing health monitoring with unbalanced data. Reliab. Eng. Syst. Saf. 2025, 257, 110888. [Google Scholar] [CrossRef]
- Li, Y.; Song, X.; Zhao, S.; Gao, F. A line fault cause analysis method for distribution network based on decision-making tree and machine learning. In Proceedings of the Fifth Asia Conference on Power and Electrical Engineering (ACPEE), Chengdu, China, 4–7 June 2020. [Google Scholar]
- Zhao, W.; Zhang, Z.; Wang, L. Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications. Eng. Appl. Artif. Intell. 2020, 87, 103300. [Google Scholar] [CrossRef]
- Smock, B.; Pesala, R.; Abraham, R. PubTables-1M: Towards comprehensive table extraction from unstructured documents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4634–4642. [Google Scholar]
- Cortes, C.; Mohri, M. AUC Optimization vs. Error Rate Minimization. In Advances in Neural Information Processing Systems 16 (NIPS 2003); The MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Müller, R.; Kornblith, S.; Hinton, G.E. When Does Label Smoothing Help? arXiv 2019, arXiv:1906.02629. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. arXiv 2023, arXiv:2304.07288. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Details | Parameters |
|---|---|---|
| Embedding Layer | Time Embedding | Input Dim: 24; Output Dim: 64 |
| Month Embedding | Input Dim: 12; Output Dim: 64 | |
| TabTransformer Module | Self-Attention Layer | Output Dim: 128 |
| Residual Connection | Output Dim: 128 | |
| Feed-Forward Layer | Output Dim: 128 | |
| Residual Connection | Output Dim: 128 | |
| LSTM-Based Fusion | LSTM for E | Output Dim: 128 (Input: ) |
| LSTM for | Output Dim: 128 (Input: ) | |
| Concatenation Layer | Q from LSTM, K/V from TabTransformer | |
| Cross-Attention Fusion | Cross-Attention Layer | Output Dim: 256 |
| Classification Layer | Fully Connected | Output Dim: 32 |
| Fully Connected | Output Dim: 5 (softmax) |
| Month | Daytime (6:00 AM–6:00 PM) | Nighttime (6:00 PM–6:00 AM) |
|---|---|---|
| April–September | 437 | 218 |
| July–December | 180 | 165 |
| Raw Record Data | Electrical Data Derivatives | Month | Time of Day | Accuracy (%) | F1 Score (%) |
|---|---|---|---|---|---|
| √ | 68.52 | 67.21 | |||
| √ | √ | 72.21 | 70.99 | ||
| √ | √ | √ | 86.98 | 85.84 | |
| √ | √ | √ | 88.54 | 87.61 | |
| √ | √ | √ | √ | 92.21 | 91.98 |
| Tab-Transformer | LSTM-Based Fusion | Cross-Attention Fusion | Accuracy (%) | F1 Score (%) |
|---|---|---|---|---|
| √ | √ | 85.21 | 84.99 | |
| √ | √ | 80.29 | 79.87 | |
| √ | √ | 83.85 | 82.22 | |
| √ | √ | √ | 92.21 | 91.98 |
| Configuration | Accuracy (%) | F1 Score (%) |
|---|---|---|
| 2 LSTM Layers | 92.35 | 91.15 |
| TabTransformer (dim = 64) | 90.27 | 88.15 |
| Proposed Method | 92.21 | 91.98 |
| Loss | Accuracy (%) | F1 Score (%) |
|---|---|---|
| The proposed loss | 92.21 | 91.98 |
| 90.02 | 89.87 | |
| 88.93 | 87.75 | |
| 88.98 | 87.05 |
| Method | Accuracy (%) | F1 Score (%) | Test Time (ms) |
|---|---|---|---|
| CNN | 84.77 | 83.70 | 22 |
| LSTM | 81.92 | 80.12 | 28 |
| BiLSTM | 82.98 | 81.70 | 31 |
| GRU | 82.42 | 80.69 | 26 |
| DBN | 76.56 | 74.81 | 28 |
| Proposed | 92.21 | 91.98 | 41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Ma, H.; Gong, C.; Shen, J.; Zhao, Q.; Gu, J.; Guo, Y.; Yang, B. An Improved Multimodal Framework-Based Fault Classification Method for Distribution Systems Using LSTM Fusion and Cross-Attention. Energies 2025, 18, 1442. https://doi.org/10.3390/en18061442
Li Y, Ma H, Gong C, Shen J, Zhao Q, Gu J, Guo Y, Yang B. An Improved Multimodal Framework-Based Fault Classification Method for Distribution Systems Using LSTM Fusion and Cross-Attention. Energies. 2025; 18(6):1442. https://doi.org/10.3390/en18061442
Chicago/Turabian StyleLi, Yifei, Hao Ma, Cheng Gong, Jing Shen, Qiao Zhao, Jun Gu, Yuhang Guo, and Bin Yang. 2025. "An Improved Multimodal Framework-Based Fault Classification Method for Distribution Systems Using LSTM Fusion and Cross-Attention" Energies 18, no. 6: 1442. https://doi.org/10.3390/en18061442
APA StyleLi, Y., Ma, H., Gong, C., Shen, J., Zhao, Q., Gu, J., Guo, Y., & Yang, B. (2025). An Improved Multimodal Framework-Based Fault Classification Method for Distribution Systems Using LSTM Fusion and Cross-Attention. Energies, 18(6), 1442. https://doi.org/10.3390/en18061442