
A Comparative Analysis of Machine Learning Algorithms in Energy Poverty Prediction

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
1.1. The Problem of Energy Poverty
1.2. Machine Learning and Energy Poverty
- Modern-day issues often include large amounts of data with multiple features, which are challenging for traditional regression models to handle. ML algorithms though are fundamentally designed to process and analyze large and complex datasets effectively.
- Conventional regression models typically require prior assumptions regarding the correlations between the factors, potentially inserting bias in the analysis or limiting its scope. ML algorithms though learn from real data and identify correlations through the training process, without requiring any prior assumptions.
- ML algorithms are inherently able to address non-linear dependencies, which is a main requirement for studying and analyzing complex phenomena such as energy poverty, whereas traditional regression models are better suited to address linear relationships.
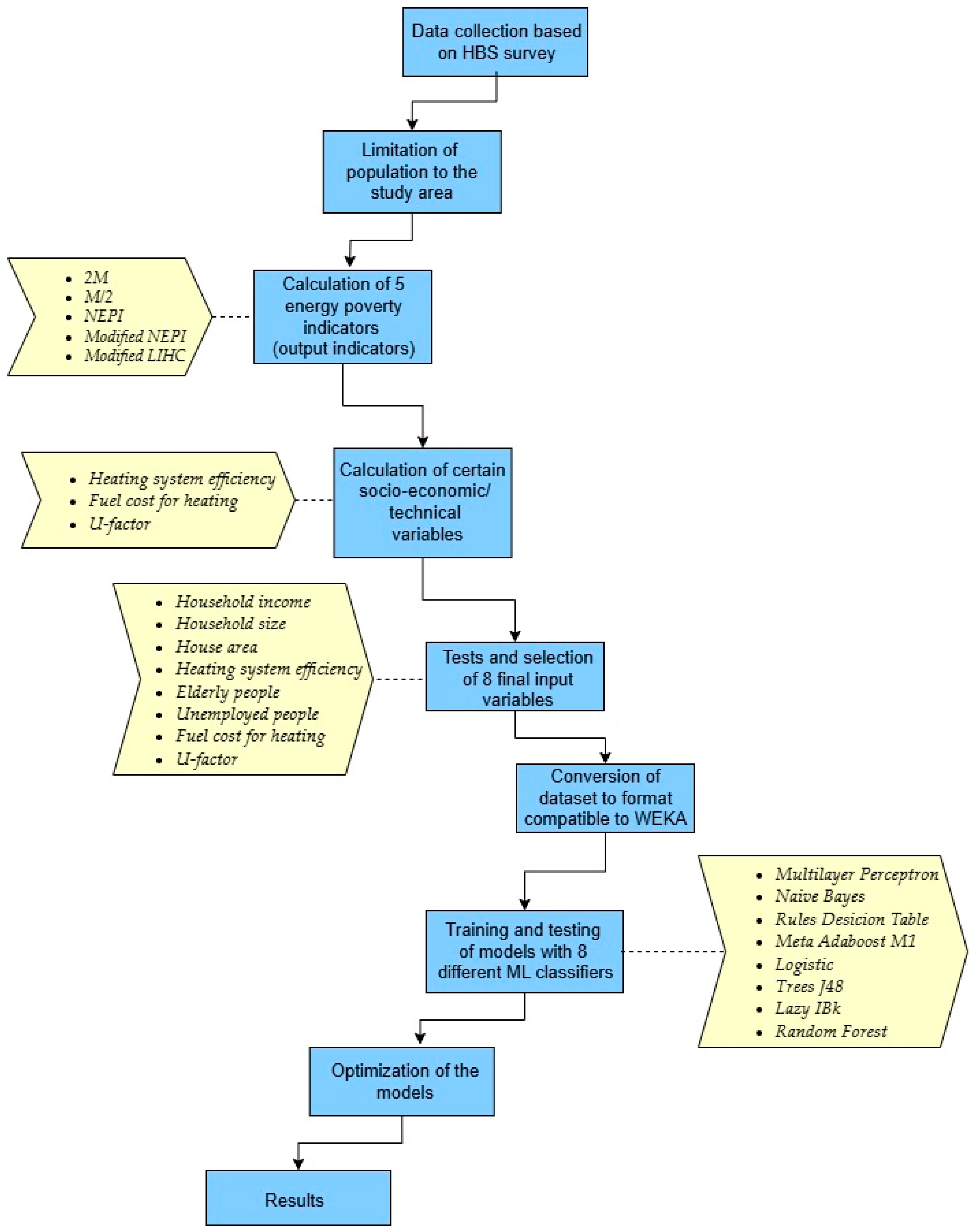
2. Materials and Methods
- The 2M indicator classifies households as energy poor if their ratio of equivalised energy expenses to equivalised disposable income exceeds twice the national median ratio. Both the variables of energy expenses and income were equivalised in order to take into account differences in size and composition of the household, i.e., energy cost was divided by the equivalisation factors and disposable income by the equivalent household size based on the scale of equivalence of the modified OECD, accordingly.
- The M/2 indicator classifies households as energy poor if their absolute equivalised energy expenses are less than half the national median value.
- The official national energy poverty indicator (NEPI) classifies households as energy poor if (i) the annual expenditure on the total final energy consumed in the dwelling is less than 80% of the theoretically required amount of energy and (ii) the equivalised total household income is less than 60% of the median equivalised national income, based on the respective poverty definition in Greece.
- The modified NEPI indicator differs from the NEPI index only in point (i), by setting a different limit for classifying a household as energy poor, i.e., the limit of 60% vs. 80% used in the NEPI indicator [13]. In more detail, the share of 60% of the theoretical energy consumption, needed to guarantee an adequate level of energy services at home, represents the actual energy consumption of Greek households according to Greek circumstances.
- The modified LIHC (low income high cost) classifies households as energy poor if they have an equivalised residual income below 60% of the equivalised median national income. In order to calculate the equivalised residual income, 60% of equivalised required energy costs was deducted from the equivalised total income of the household. Then, this value was compared to 60% of the equivalised median national income, and if it was lower, the household was regarded as energy poor. Energy costs were equivalised according to the equivalisation factors employed in the official LIHC index.
- Household income (HH099): continuous variable in HBS that represents net income, i.e., total income of all sources including non-monetary elements, before income taxes.
- Household size (HB05): integer variable in HBS that represents the number of household members.
- House area (DS017): continuous variable in HBS representing the square meters (m2) of the area of the residence.
- Heating system efficiency: continuous variable expressed in percentage. Estimates were made by the authors based on typical efficiency ratio values of heating systems in buildings.
- Elderly people: binary variable that indicates the presence of elderly people in households (1 if people over 65 years old live in the residence and 0 otherwise).
- Unemployed people: binary variable that indicates the presence of unemployed people in households (1 if unemployed people live in the residence and 0 otherwise).
- U-factor: building continuous technical variable that is expressed in W/m2 K. Estimates were made by the authors based on the proposed coefficients from the “Regulation of Energy Efficiency in Buildings” in Greece [39].
- From the group of functions’ classifiers, multi-layer perceptron (MLP) and logistic regression were selected for the present analysis. More specifically:
- The multilayer perceptron is a kind of artificial neural network, which uses a nonlinear activation function within its hidden layer, providing a nonlinear mapping between the input and the output layer. Its basic structure is divided into three layers, of which one layer defines the input values, another one or more the mathematical function, and, finally, the output layer that captures the final result. A large number of neurons in each layer are linked with weighted connections, in which entire layers of neurons are interlinked through weighted connections with every neuron [41].
- Logistic regression is a type of classification algorithm that is used under supervised learning and determines the likelihood of an event, with a binary output. In contrast with linear regression, which returns a continuous output, logistic regression returns a probability score of the outcome of the binary event. A logistic regression model identifies all the underlying “weights” and “biases” based on the provided dataset during training and understands how to correctly classify the dataset using the dependent categorical variables.
- From the group of decision trees’ classifiers, the J48 classification algorithm and Random Forest were selected for the present analysis. In general, a decision tree builds a tree that utilizes the branching technique to show every possible outcome of a decision. Each internal node in its decision tree representation symbolizes a feature, every branch symbolizes the result of the parent node, and, finally, each leaf symbolizes the class label. In order to classify a case, a top-down “divide and conquer” strategy begins at the root of the tree [42]. More specifically:
- The J48 classification algorithm is based on the C4.5 algorithm, an extension of Ross Quinlan’s ID3, i.e., a statistical decision tree classifier. J48 is extremely useful for examining categorical and continuous data. In WEKA, J48 includes many additional features that can be configured by the user, such as decision tree pruning, missing value estimation, and attribute value range. Pruning, for instance, is the act of selecting the largest tree and removing all the branches below this level. It is an essential process that handles the phenomenon of overfitting [43].
- Random forest classification algorithm is based on forming multiple individual decision trees that are derived from a different sample taken from the dataset. At every tree node, a random subgroup is utilized in order to split the dataset into increasingly uniform subgroups. The subgroup of variables achieving the best performance in terms of data purity is chosen at this tree node. After creating the forest of decision trees, the ultimate outcome of classification is based on voting by every tree. The most votes give the final classification [44].
- From the group of Bayesian classifiers, naïve Bayes was selected for the present analysis. Bayes’ theorem with independent hypotheses among the predictors is the basic concept of the naïve Bayes classifier. The simplest approach to the Bayes network in WEKA is the naïve Bayes, in which all attributes of a dataset, given the target class, are independent of each other. Thus, in naïve Bayes’ network, the class has no “parent”, i.e., it does not receive its properties from another dataset, and each attribute has the class as a unique “parent” [45]. The classification model is created without complex iterative parameter estimation. Due to this feature, Bayesian classifiers are useful even for very large datasets and provide reliable results for complex, real-world problems [41].
- From the group of rules’ classifiers, Decision Table was selected for the present analysis. This algorithm constructs a classifier represented in the form of a decision table and represents a particularly simple classifier regarding its classification methodology. It evaluates subsets of features using a sequential search for the optimal initial choice and is able to use cross-validation for the evaluation procedures. Basically, through the decision table, a comprehensive system is created that includes all possible scenarios of conditions under which classification can be performed, from which the algorithm determines the scenario that presents the highest accuracy and probability of occurrence [46].
- From the group of meta-learning algorithms, AdaBoost.M1 was selected for the present analysis. Meta-learning algorithms transform classification algorithms into more powerful classification tools, significantly improving their learning capabilities. This improvement is achieved by different methods, such as by combining different output data from separate classifiers. WEKA includes numerous meta-learning algorithms, which follow different forms of algorithm improvement. The main ones are boosting, bagging, and randomization, combining classifiers and cost-sensitive learning. From the available improvement algorithms, a boosting-type algorithm was selected. Boosting is a general improvement method that creates a strong classifier from a number of weak classifiers. This is carried out by creating a model from the training data and then creating a second model that tries to correct the errors of the first model. Models are added until the training set is optimally predicted or until a maximum number of models are added. A classic case of a boosting algorithm is AdaBoost.M1 (or AdaBoost). AdaBoost.M1 can be used to boost the performance of any machine learning algorithm, but it works most efficiently on algorithms with low training capacity. Thus, AdaBoost delivers maximum performance when used to boost decision trees [47].
- From the group of lazy classifiers, IBk (instance-based learning with parameter k) was selected for the present analysis. The principle of an IBk algorithm is essentially equivalent to the kNN (k-nearest neighbor) algorithm, using the same distance metric. When classifying with kNN, the value is classified according to the majority presence of its near neighbors. The value is then assumed to belong to the most popular class among its nearest neighbors. A different type of search algorithm can be implemented to enhance the efficiency of nearest neighbor detection. While linear search is the standard approach, alternatives such as ball trees, K-D trees, and so-called “cover trees” are also available. The parameter of this classifier is the distance function. Predictions from multiple neighbors are weighted from the case tested, according to their distance [48].
- Accuracy: It is the main statistical result and the first value taken into account for the evaluation. WEKA presents the number of correct predictions and their percentage over the total predictions made. Τhis percentage is referred to simply as the “Accuracy” of the model. It is defined by the following equation:
- Detailed accuracy by class: The main statistical metrics that represent the accuracy level by class are the following:
- Precision or positive predictive: It refers to the ratio of true positive instances to the total positive (true and false) instances of each class. It is defined by the following equation:Precision = True Positive Instances/(True Positive Instances + False Positive Instances)
- Recall or sensitivity: It refers to the ratio of true positive instances to the sum of true positive and false negative instances of each class. It is defined by the following equation:Recall = True Positive Instances/(True Positive Instances + False Negative Instances)
- F-measure: It expresses the harmonic mean of “Recall” and “Precision” values. It allows a model to be evaluated taking into account symmetrically the above factors in one metric, which is useful when describing the performance of the model. It is defined by the following equation:F–Measure = (2 × Precision × Recall)/(Precision + Recall)
- ROC (receiver operating characteristic) area: It is an accuracy measure, which indicates the ability of the model to accurately predict random data. It aims to be as high as possible for a high-performing model.
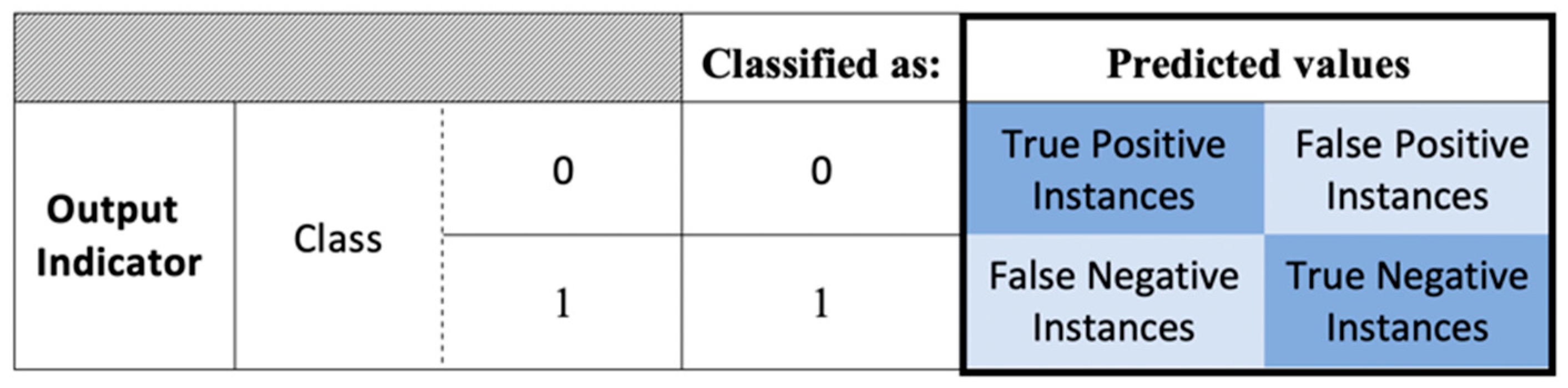
- Confusion matrix: It is a 2 × 2 matrix in which the percentages of true and false instances of each class are presented, with the diagonal elements representing the true instances (true positive and true negative) for each class of the output variable (Figure 1).
3. Results and Discussion
3.1. Prediction of the Indicator “NEPI”

{kind=link}
{kind=link}
{kind=link}
| Prediction of Indicator NEPI–2192 Instances | ||||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Precision | Recall | F-Measure | ROC Area | Class | Accuracy | Confusion Matrix | |
| Multilayer perceptron | 0.959 | 0.960 | 0.959 | 0.973 | Non-energy poor | 93.34% | 96% | 4% |
| 0.820 | 0.816 | 0.818 | 0.973 | Energy poor | 18% | 82% | ||
| 0.933 | 0.933 | 0.933 | 0.973 | (weighted avg) | ||||
| Naïve Bayes | 0.920 | 0.937 | 0.929 | 0.925 | Non-energy poor | 88.23% | 94% | 6% |
| 0.695 | 0.639 | 0.666 | 0.925 | Energy poor | 36% | 64% | ||
| 0.879 | 0.882 | 0.880 | 0.925 | (weighted avg) | ||||
| Rules decision table | 0.937 | 0.969 | 0.953 | 0.968 | Non-energy poor | 92.15% | 97% | 3% |
| 0.838 | 0.709 | 0.768 | 0.968 | Energy poor | 29% | 71% | ||
| 0.919 | 0.922 | 0.919 | 0.968 | (weighted avg) | ||||
| Meta AdaBoost M1 | 0.920 | 0.961 | 0.940 | 0.938 | Non-energy poor | 90.06% | 96% | 4% |
| 0.786 | 0.629 | 0.699 | 0.938 | Energy poor | 37% | 63% | ||
| 0.896 | 0.901 | 0.896 | 0.938 | (weighted avg) | ||||
| Logistic | 0.939 | 0.963 | 0.951 | 0.968 | Non-energy poor | 91.84% | 96% | 4% |
| 0.812 | 0.721 | 0.764 | 0.968 | Energy poor | 28% | 72% | ||
| 0.916 | 0.918 | 0.916 | 0.968 | (weighted avg) | ||||
| Trees J48 | 0.947 | 0.965 | 0.956 | 0.923 | Non-energy poor | 92.79% | 97% | 3% |
| 0.832 | 0.761 | 0.795 | 0.923 | Energy poor | 24% | 76% | ||
| 0.926 | 0.928 | 0.927 | 0.923 | (weighted avg) | ||||
| Lazy IBk | 0.907 | 0.947 | 0.927 | 0.758 | Non-energy poor | 87.77% | 95% | 5% |
| 0.707 | 0.570 | 0.631 | 0.758 | Energy poor | 43% | 57% | ||
| 0.871 | 0.878 | 0.872 | 0.758 | (weighted avg) | ||||
| Random forest | 0.958 | 0.969 | 0.964 | 0.971 | Non-energy poor | 94.02% | 97% | 3% |
| 0.856 | 0.811 | 0.833 | 0.971 | Energy poor | 19% | 81% | ||
| 0.939 | 0.940 | 0.940 | 0.971 | (weighted avg) | ||||
3.2. Prediction of the Indicator “Modified NEPI”
| Prediction of Indicator Modified NEPI–2197 Instances | ||||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Precision | Recall | F-Measure | ROC Area | Class | Accuracy | Confusion Matrix | |
| Multilayer perceptron | 0.947 | 0.962 | 0.954 | 0.972 | Non-energy poor | 92.54% | 96% | 4% |
| 0.826 | 0.771 | 0.798 | 0.972 | Energy poor | 23% | 77% | ||
| 0.924 | 0.925 | 0.924 | 0.972 | (weighted avg) | ||||
| Naïve Bayes | 0.905 | 0.932 | 0.919 | 0.914 | Non-energy poor | 86.62% | 93% | 7% |
| 0.670 | 0.587 | 0.626 | 0.914 | Energy poor | 41% | 59% | ||
| 0.861 | 0.866 | 0.863 | 0.914 | (weighted avg) | ||||
| Rules decision table | 0.931 | 0.967 | 0.949 | 0.952 | Non-energy poor | 91.53% | 97% | 3% |
| 0.832 | 0.697 | 0.758 | 0.952 | Energy poor | 30% | 70% | ||
| 0.912 | 0.915 | 0.912 | 0.952 | (weighted avg) | ||||
| Meta AdaBoost M1 | 0.904 | 0.959 | 0.931 | 0.902 | Non-energy poor | 88.44% | 96% | 4% |
| 0.765 | 0.568 | 0.652 | 0.902 | Energy poor | 43% | 57% | ||
| 0.878 | 0.884 | 0.878 | 0.902 | (weighted avg) | ||||
| Logistic | 0.940 | 0.966 | 0.953 | 0.970 | Non-energy poor | 92.30% | 97% | 3% |
| 0.838 | 0.740 | 0.786 | 0.970 | Energy poor | 26% | 74% | ||
| 0.921 | 0.923 | 0.921 | 0.970 | (weighted avg) | ||||
| Trees J48 | 0.956 | 0.962 | 0.959 | 0.945 | Non-energy poor | 93.36% | 96% | 4% |
| 0.834 | 0.814 | 0.824 | 0.945 | Energy poor | 19% | 81% | ||
| 0.933 | 0.934 | 0.933 | 0.945 | (weighted avg) | ||||
| Lazy IBk | 0.909 | 0.943 | 0.926 | 0.774 | Non-energy poor | 87.80% | 94% | 6% |
| 0.714 | 0.601 | 0.653 | 0.774 | Energy poor | 40% | 60% | ||
| 0.872 | 0.878 | 0.874 | 0.774 | (weighted avg) | ||||
| Random forest | 0.960 | 0.972 | 0.966 | 0.975 | Non-energy poor | 94.45% | 97% | 3% |
| 0.874 | 0.828 | 0.850 | 0.975 | Energy poor | 17% | 83% | ||
| 0.944 | 0.944 | 0.944 | 0.975 | (weighted avg) | ||||
3.3. Prediction of the Indicator “2M”
| Prediction of Indicator 2M–2062 Instances | ||||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Precision | Recall | F-Measure | ROC Area | Class | Accuracy | Confusion Matrix | |
| Multilayer perceptron | 0.968 | 0.986 | 0.977 | 0.934 | Non-energy poor | 93.34% | 99% | 1% |
| 0.772 | 0.587 | 0.667 | 0.934 | Energy poor | 41% | 59% | ||
| 0.954 | 0.957 | 0.955 | 0.934 | (weighted avg) | ||||
| Naïve Bayes | 0.957 | 0.983 | 0.970 | 0.914 | Non-energy poor | 94.33% | 98% | 2% |
| 0.670 | 0.433 | 0.526 | 0.914 | Energy poor | 57% | 43% | ||
| 0.936 | 0.943 | 0.938 | 0.914 | (weighted avg) | ||||
| Rules decision table | 0.973 | 0.997 | 0.985 | 0.965 | Non-energy poor | 97.24% | 100% | 0% |
| 0.951 | 0.653 | 0.775 | 0.965 | Energy poor | 35% | 65% | ||
| 0.972 | 0.972 | 0.970 | 0.965 | (weighted avg) | ||||
| Meta AdaBoost M1 | 0.968 | 0.983 | 0.975 | 0.928 | Non-energy poor | 95.34% | 98% | 2% |
| 0.725 | 0.580 | 0.644 | 0.928 | Energy poor | 42% | 58% | ||
| 0.950 | 0.953 | 0.951 | 0.928 | (weighted avg) | ||||
| Logistic | 0.963 | 0.989 | 0.976 | 0.944 | Non-energy poor | 95.49% | 99% | 1% |
| 0.788 | 0.520 | 0.627 | 0.944 | Energy poor | 48% | 52% | ||
| 0.951 | 0.955 | 0.951 | 0.944 | (weighted avg) | ||||
| Trees J48 | 0.967 | 0.985 | 0.976 | 0.865 | Non-energy poor | 95.54% | 99% | 1% |
| 0.754 | 0.573 | 0.652 | 0.865 | Energy poor | 43% | 57% | ||
| 0.952 | 0.955 | 0.953 | 0.865 | (weighted avg) | ||||
| Lazy IBk | 0.960 | 0.979 | 0.969 | 0.716 | Non-energy poor | 94.23% | 98% | 2% |
| 0.640 | 0.473 | 0.544 | 0.716 | Energy poor | 53% | 47% | ||
| 0.936 | 0.942 | 0.938 | 0.716 | (weighted avg) | ||||
| Random forest | 0.971 | 0.994 | 0.982 | 0.942 | Non-energy poor | 96.70% | 99% | 1% |
| 0.894 | 0.620 | 0.732 | 0.942 | Energy poor | 38% | 62% | ||
| 0.965 | 0.967 | 0.964 | 0.942 | (weighted avg) | ||||
3.4. Prediction of the Indicator “M/2”
| Prediction of Indicator M/2–2274 Instances | ||||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Precision | Recall | F-Measure | ROC Area | Class | Accuracy | Confusion Matrix | |
| Multilayer perceptron | 0.831 | 0.982 | 0.900 | 0.809 | Non-energy poor | 83.47% | 98% | 2% |
| 0.869 | 0.373 | 0.522 | 0.809 | Energy poor | 63% | 37% | ||
| 0.840 | 0.835 | 0.809 | 0.809 | (weighted avg) | ||||
| Naïve Bayes | 0.819 | 0.869 | 0.843 | 0.709 | Non-energy poor | 75.46% | 87% | 13% |
| 0.491 | 0.396 | 0.439 | 0.709 | Energy poor | 60% | 40% | ||
| 0.739 | 0.755 | 0.745 | 0.709 | (weighted avg) | ||||
| Rules decision table | 0.857 | 0.983 | 0.916 | 0.846 | Non-energy poor | 86.28% | 98% | 2% |
| 0.902 | 0.485 | 0.631 | 0.846 | Energy poor | 51% | 49% | ||
| 0.868 | 0.863 | 0.847 | 0.846 | (weighted avg) | ||||
| Meta AdaBoost M1 | 0.814 | 0.966 | 0.884 | 0.818 | Non-energy poor | 80.74% | 97% | 3% |
| 0.746 | 0.309 | 0.437 | 0.818 | Energy poor | 69% | 31% | ||
| 0.798 | 0.807 | 0.776 | 0.818 | (weighted avg) | ||||
| Logistic | 0.790 | 0.950 | 0.862 | 0.725 | Non-energy poor | 77.00% | 95% | 5% |
| 0.567 | 0.207 | 0.304 | 0.725 | Energy poor | 79% | 21% | ||
| 0.736 | 0.770 | 0.727 | 0.725 | (weighted avg) | ||||
| Trees J48 | 0.865 | 0.934 | 0.898 | 0.818 | Non-energy poor | 83.95% | 93% | 7% |
| 0.724 | 0.544 | 0.621 | 0.818 | Energy poor | 46% | 54% | ||
| 0.831 | 0.839 | 0.831 | 0.818 | (weighted avg) | ||||
| Lazy IBk | 0.852 | 0.861 | 0.857 | 0.697 | Non-energy poor | 78.14% | 86% | 14% |
| 0.550 | 0.533 | 0.541 | 0.697 | Energy poor | 47% | 53% | ||
| 0.779 | 0.781 | 0.780 | 0.697 | (weighted avg) | ||||
| Random forest | 0.876 | 0.963 | 0.917 | 0.875 | Non-energy poor | 86.81% | 96% | 4% |
| 0.831 | 0.571 | 0.677 | 0.875 | Energy poor | 43% | 57% | ||
| 0.865 | 0.868 | 0.859 | 0.875 | (weighted avg) | ||||
3.5. Prediction of the Indicator “Modified LIHC”
| Prediction of Indicator Modified LIHC–2427 Instances | ||||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Precision | Recall | F-Measure | ROC Area | Class | Accuracy | Confusion Matrix | |
| Multilayer perceptron | 0.983 | 0.936 | 0.959 | 0.991 | Non-energy poor | 94.69% | 94% | 6% |
| 0.885 | 0.968 | 0.924 | 0.991 | Energy poor | 3% | 97% | ||
| 0.950 | 0.947 | 0.947 | 0.991 | (weighted avg) | ||||
| Naïve Bayes | 0.903 | 0.864 | 0.883 | 0.913 | Non-energy poor | 84.84% | 86% | 14% |
| 0.753 | 0.817 | 0.784 | 0.913 | Energy poor | 18% | 82% | ||
| 0.853 | 0.848 | 0.850 | 0.913 | (weighted avg) | ||||
| Rules decision table | 0.940 | 0.960 | 0.950 | 0.982 | Non-energy poor | 93.33% | 96% | 4% |
| 0.918 | 0.880 | 0.898 | 0.982 | Energy poor | 12% | 88% | ||
| 0.933 | 0.933 | 0.933 | 0.982 | (weighted avg) | ||||
| Meta AdaBoost M1 | 0.962 | 0.876 | 0.917 | 0.973 | Non-energy poor | 89.45% | 88% | 12% |
| 0.791 | 0.931 | 0.856 | 0.973 | Energy poor | 7% | 93% | ||
| 0.905 | 0.895 | 0.896 | 0.973 | (weighted avg) | ||||
| Logistic | 0.959 | 0.961 | 0.960 | 0.987 | Non-energy poor | 94.69% | 96% | 4% |
| 0.922 | 0.919 | 0.921 | 0.987 | Energy poor | 8% | 92% | ||
| 0.947 | 0.947 | 0.947 | 0.987 | (weighted avg) | ||||
| Trees J48 | 0.969 | 0.962 | 0.966 | 0.968 | Non-energy poor | 95.47% | 96% | 4% |
| 0.926 | 0.940 | 0.933 | 0.968 | Energy poor | 6% | 94% | ||
| 0.955 | 0.955 | 0.955 | 0.968 | (weighted avg) | ||||
| Lazy IBk | 0.904 | 0.939 | 0.921 | 0.871 | Non-energy poor | 89.37% | 94% | 6% |
| 0.870 | 0.804 | 0.835 | 0.871 | Energy poor | 20% | 80% | ||
| 0.893 | 0.894 | 0.893 | 0.871 | (weighted avg) | ||||
| Random forest | 0.972 | 0.974 | 0.973 | 0.994 | Non-energy poor | 96.37% | 97% | 3% |
| 0.948 | 0.944 | 0.946 | 0.994 | Energy poor | 6% | 94% | ||
| 0.964 | 0.964 | 0.964 | 0.994 | (weighted avg) | ||||
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IEA. SDG7: Data and Projections. 2023. Available online: https://www.iea.org/reports/sdg7-data-and-projections (accessed on 19 December 2024).
- Samarakoon, S. A justice and wellbeing centered framework for analysing energy poverty in the Global South. Ecol. Econ. 2019, 165, 106385. [Google Scholar] [CrossRef]
- Hesselman, M.; Varo, A.; Guyet, R.; Thomson, H. Energy poverty in the COVID-19 era: Mapping global responses in light of momentum for the right to energy. Energy Res. Soc. Sci. 2021, 81, 102246. [Google Scholar] [CrossRef] [PubMed]
- Carfora, A.; Scandurra, G.; Thomas, A. Forecasting the COVID-19 effects on energy poverty across EU member states. Energy Policy 2022, 161, 112597. [Google Scholar] [CrossRef] [PubMed]
- Baker, S.H.; Carley, S.; Konisky, D.M. Energy insecurity and the urgent need for utility disconnection protections. Energy Policy 2021, 159, 112663. [Google Scholar] [CrossRef]
- Clark, I.; Chun, S.; O’Sullivan, K.; Pierse, N. Energy Poverty among Tertiary Students in Aotearoa New Zealand. Energies 2021, 15, 76. [Google Scholar] [CrossRef]
- Papada, L.; Kaliampakos, D. A Stochastic Model for energy poverty analysis. Energy Policy 2018, 116, 153–164. [Google Scholar] [CrossRef]
- Eurostat. People at Risk of Poverty or Social Exclusion. 2023. Available online: https://ec.europa.eu/eurostat/databrowser/view/sdg_01_10/default/table?lang=en (accessed on 19 December 2024).
- Atsalis, A.; Mirasgedis, S.; Tourkolias, C.; Diakoulaki, D. Fuel poverty in Greece: Quantitative analysis and implications for policy. Energy Build. 2016, 131, 87–98. [Google Scholar] [CrossRef]
- Papada, L.; Kaliampakos, D. Measuring energy poverty in Greece. Energy Policy 2016, 94, 157–165. [Google Scholar] [CrossRef]
- Papada, L.; Kaliampakos, D. Energy poverty in Greek mountainous areas: A comparative study. J. Mt. Sci. 2017, 14, 1229–1240. [Google Scholar] [CrossRef]
- Spiliotis, E.; Arsenopoulos, A.; Kanellou, E.; Psarras, J.; Kontogiorgos, P. A multi-sourced data based framework for assisting utilities identify energy poor households: A case-study in Greece. Energy Sources Part B Econ. Plan. Policy 2020, 15, 49–71. [Google Scholar] [CrossRef]
- Kalfountzou, E.; Tourkolias, C.; Mirasgedis, S.; Damigos, D. Identifying Energy-Poor Households with Publicly Available Information: Promising Practices and Lessons Learned from the Athens Urban Area, Greece. Energies 2024, 17, 919. [Google Scholar] [CrossRef]
- Ntaintasis, E.; Mirasgedis, S.; Tourkolias, C. Comparing different methodological approaches for measuring energy poverty: Evidence from a survey in the region of Attika, Greece. Energy Policy 2019, 125, 160–169. [Google Scholar] [CrossRef]
- Boemi, S.-N.; Avdimiotis, S.; Papadopoulos, A.M. Domestic energy deprivation in Greece: A field study. Energy Build. 2017, 144, 167–174. [Google Scholar] [CrossRef]
- Palmos Analysis. Thessaloniki: 190,000 Households Vulnerable or in a State of Energy Poverty. Available online: https://parallaximag.gr/life/energiaki-ftochia-stopoleodomiko-sigkrotima-thessalonikis (accessed on 20 December 2024).
- Papada, L.; Kaliampakos, D. Being forced to skimp on energy needs: A new look at energy poverty in Greece. Energy Res. Soc. Sci. 2020, 64, 101450. [Google Scholar] [CrossRef]
- Lyra, K.; Mirasgedis, S.; Tourkolias, C. From measuring fuel poverty to identification of fuel poor households: A case study in Greece. Energy Effic. 2022, 15, 6. [Google Scholar] [CrossRef]
- Kalfountzou, E.; Papada, L.; Damigos, D.; Degiannakis, S. Predicting energy poverty in Greece through statistical data analysis. Int. J. Sustain. Energy 2022, 41, 1605–1622. [Google Scholar] [CrossRef]
- Halkos, G.; Kostakis, I. Exploring the persistence and transience of energy poverty: Evidence from a Greek household survey. Energy Effic. 2023, 16, 50. [Google Scholar] [CrossRef]
- Papada, L.; Kaliampakos, D. Artificial Neural Networks as a Tool to Understand Complex Energy Poverty Relationships: The Case of Greece. Energies 2024, 17, 3163. [Google Scholar] [CrossRef]
- Hong, Z.; Park, I.K. Comparative Analysis of Energy Poverty Prediction Models Using Machine Learning Algorithms. J. Korea Plan. Assoc. 2021, 56, 239–255. [Google Scholar] [CrossRef]
- Hassani, H.; Yeganegi, M.R.; Beneki, C.; Unger, S.; Moradghaffari, M. Big Data and Energy Poverty Alleviation. Big Data Cognit. Comput. 2019, 3, 50. [Google Scholar] [CrossRef]
- López-Vargas, A.; Ledezma-Espino, A.; Sanchis-de-Miguel, A. Methods, data sources and applications of the Artificial Intelligence in the Energy Poverty context: A review. Energy Build. 2022, 268, 112233. [Google Scholar] [CrossRef]
- Dalla Longa, F.; Sweerts, B.; Van Der Zwaan, B. Exploring the complex origins of energy poverty in The Netherlands with machine learning. Energy Policy 2021, 156, 112373. [Google Scholar] [CrossRef]
- Al Kez, D.; Foley, A.; Abdul, Z.K.; Del Rio, D.F. Energy poverty prediction in the United Kingdom: A machine learning approach. Energy Policy 2024, 184, 113909. [Google Scholar] [CrossRef]
- Spandagos, C.; Tovar Reaños, M.A.; Lynch, M.Á. Energy poverty prediction and effective targeting for just transitions with machine learning. Energy Econ. 2023, 128, 107131. [Google Scholar] [CrossRef]
- Van Hove, W.; Dalla Longa, F.; Van Der Zwaan, B. Identifying predictors for energy poverty in Europe using machine learning. Energy Build. 2022, 264, 112064. [Google Scholar] [CrossRef]
- Mukelabai, M.D.; Wijayantha, K.G.U.; Blanchard, R.E. Using machine learning to expound energy poverty in the global south: Understanding and predicting access to cooking with clean energy. Energy AI 2023, 14, 100290. [Google Scholar] [CrossRef]
- Pino-Mejías, R.; Pérez-Fargallo, A.; Rubio-Bellido, C.; Pulido-Arcas, J.A. Artificial neural networks and linear regression prediction models for social housing allocation: Fuel Poverty Potential Risk Index. Energy 2018, 164, 627–641. [Google Scholar] [CrossRef]
- Bienvenido-Huertas, D.; Pérez-Fargallo, A.; Alvarado-Amador, R.; Rubio-Bellido, C. Influence of climate on the creation of multilayer perceptrons to analyse the risk of fuel poverty. Energy Build. 2019, 198, 38–60. [Google Scholar] [CrossRef]
- Papada, L.; Kaliampakos, D. Exploring Energy Poverty Indicators Through Artificial Neural Networks. In Artificial Intelligence and Sustainable Computing; Pandit, M., Gaur, M.K., Rana, P.S., Tiwari, A., Eds.; Algorithms for Intelligent Systems; Springer Nature: Singapore, 2022; pp. 231–242. [Google Scholar] [CrossRef]
- Abbas, K.; Butt, K.M.; Xu, D.; Ali, M.; Baz, K.; Kharl, S.H.; Ahmed, M. Measurements and determinants of extreme multidimensional energy poverty using machine learning. Energy 2022, 251, 123977. [Google Scholar] [CrossRef]
- Gawusu, S.; Jamatutu, S.A.; Ahmed, A. Predictive Modeling of Energy Poverty with Machine Learning Ensembles: Strategic Insights from Socioeconomic Determinants for Effective Policy Implementation. Int. J. Energy Res. 2024, 2024, 9411326. [Google Scholar] [CrossRef]
- Balkissoon, S.; Fox, N.; Lupo, A.; Haupt, S.E.; Penny, S.G.; Miller, S.J.; Beetstra, M.; Sykuta, M.; Ohler, A. Forecasting energy poverty using different machine learning techniques for Missouri. Energy 2024, 313, 133904. [Google Scholar] [CrossRef]
- Grzybowska, U.; Wojewódzka-Wiewiórska, A.; Vaznonienė, G.; Dudek, H. Households Vulnerable to Energy Poverty in the Visegrad Group Countries: An Analysis of Socio-Economic Factors Using a Machine Learning Approach. Energies 2024, 17, 6310. [Google Scholar] [CrossRef]
- Ministry of Development. Liquid Fuel Prices Observatory. Available online: http://www.fuelprices.gr/ (accessed on 7 January 2025). (In Greek).
- General Secretariat of Commerce & Consumer Protection. Refinery Prices. Available online: http://oil.gge.gov.gr/ (accessed on 20 December 2024). (In Greek)
- Ministry of the Environment and Energy. Greek Regulation of Energy Efficiency in Buildings-Τ.Ο.Τ.Ε.Ε. KENAK 20701-1/2017’. 2017. Available online: https://www.kenak.gr/files/TOTEE_20701-1_2017.pdf (accessed on 10 January 2025). (In Greek).
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Practical Machine Learning Tools and Techniques. In Data Mining, 4th ed.; Morgan Kaufmann: Waikato, New Zealand, 2016. [Google Scholar]
- Kumar, Y. Analysis of Bayes, Neural Network and Tree Classifier of Classification Technique in Data Mining using WEKA. In Proceedings of the Computer Science & Information Technology (CS & IT); Academy & Industry Research Collaboration Center (AIRCC): Chennai, India, 2012; pp. 359–369. [Google Scholar] [CrossRef]
- Hangloo, S.; Kour, S.; Kumar, S. A Survey on Machine Learning: Concept, Algorithms, and Applications. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. (IJSRCSEIT) 2017, 2, 293–301. [Google Scholar]
- Kaur, G.; Chhabra, A. Improved J48 Classification Algorithm for the Prediction of Diabetes. IJCA 2014, 98, 13–17. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cerquides, J.; de M’antaras, R.L. Maximum a Posteriori Tree Augmented Naive Bayes Classifiers. October 2003. Available online: https://www.iiia.csic.es/~mantaras/ReportIIIA-TR-2003-10.pdf (accessed on 8 January 2025).
- Kalmegh, S.R. Comparative Analysis of the WEKA Classifiers Rules Conjunctiverule & Decisiontable on Indian News Dataset by Using Different Test Mode. Int. J. Eng. Sci. Invent. 2018, 7, 01–09. [Google Scholar]
- Devi, T.; Sundaram, K.M. A comparative analysis of meta and tree classification algorithms using weka. Comput. Sci. 2016, 3, 77–83. [Google Scholar]
- Vijayarani, S.; Muthulakshmi, M. Comparative Analysis of Bayes and Lazy Classification Algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 3118–3124. [Google Scholar]
- Walker, R.; McKenzie, P.; Liddell, C.; Morris, C. Area-based targeting of fuel poverty in Northern Ireland: An evidenced-based approach. Appl. Geogr. 2012, 34, 639–649. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalfountzou, E.; Papada, L.; Tourkolias, C.; Mirasgedis, S.; Kaliampakos, D.; Damigos, D. A Comparative Analysis of Machine Learning Algorithms in Energy Poverty Prediction. Energies 2025, 18, 1133. https://doi.org/10.3390/en18051133
Kalfountzou E, Papada L, Tourkolias C, Mirasgedis S, Kaliampakos D, Damigos D. A Comparative Analysis of Machine Learning Algorithms in Energy Poverty Prediction. Energies. 2025; 18(5):1133. https://doi.org/10.3390/en18051133
Chicago/Turabian StyleKalfountzou, Elpida, Lefkothea Papada, Christos Tourkolias, Sevastianos Mirasgedis, Dimitris Kaliampakos, and Dimitris Damigos. 2025. "A Comparative Analysis of Machine Learning Algorithms in Energy Poverty Prediction" Energies 18, no. 5: 1133. https://doi.org/10.3390/en18051133
APA StyleKalfountzou, E., Papada, L., Tourkolias, C., Mirasgedis, S., Kaliampakos, D., & Damigos, D. (2025). A Comparative Analysis of Machine Learning Algorithms in Energy Poverty Prediction. Energies, 18(5), 1133. https://doi.org/10.3390/en18051133