1. Introduction
The global shift towards mitigating energy imbalances and climate change has accelerated the development of distributed energy systems, with RESs such as wind and solar power replacing traditional fossil fuels [
1]. However, the intermittent nature of RESs presents significant challenges for power systems, affecting both their reliability and economic performance [
2]. As RES penetration increases, so does the uncertainty in power generation, demanding more accurate probabilistic models for operational and planning decisions. These decisions are driven by stochastic optimization frameworks reliant on representative scenario sets to capture RES uncertainties [
3].
Scenario generation replicates the real-world variability of RES outputs through stochastic models that generate synthetic time series data. These models incorporate both historical patterns and future uncertainties. In addition to RES, scenario generation techniques have applications in domains like transportation and smart grid management. Chen et al. [
4] proposed a deep reinforcement learning-based energy management strategy, and Gao et al. [
5] designed a three-stage framework for cophasing power systems with hybrid storage, relying on scenario generation to handle uncertainties and improve scheduling. Existing scenario generation methods are typically parametric [
6], non-parametric, or deep generative models [
7].
Scenario generation based on parametric models assumes that uncertainty in RESs follows a predefined probability distribution, with parameters estimated using historical data [
8]. This two-stage method first defines the uncertainty distribution and then generates scenarios using techniques like Monte Carlo (MC) sampling and Latin hypercube sampling [
9]. Díaz G et al. [
10] developed a wind farm output generation framework using a state-space model, integrating Kalman filtering with a Box–Jenkins model for performance simulation. Zhou R et al. [
11] introduced a probabilistic spatiotemporal method for dynamic optimal power flow analysis, balancing computational complexity and precision with Latin hypercube and copula importance sampling. Guimarães I O et al. [
12] proposed a quasi-sequential MC simulation method for evaluating distributed generation system reliability. While parametric models are efficient, their reliance on artificial distributions can compromise scenario quality, leading to issues such as overfitting, limited generalization, and sensitivity to parameter choices.
Non-parametric methods have gained increasing attention due to their ability to capture the nonlinear and dynamic characteristics of RES generation without relying on fixed distributional assumptions [
13]. These techniques, including moment matching and distance matching, generate scenarios by minimizing discrepancies between generated and target statistical attributes. Li J. et al. [
14] developed a moment-matching method to generate wind power scenarios that reflect its inherent stochasticity, while Li B. et al. [
15] proposed a data clustering approach that improves scenario quality by grouping wind farms based on their correlation structure. Despite these advancements, non-parametric approaches may overlook low-probability, high-impact scenarios, limiting their practical use in complex operational environments. To address these limitations, machine learning techniques have been introduced. Vagropoulos S. I. et al. [
16] applied artificial neural networks to model short-term stochastic scheduling, incorporating cross-variable correlations and scenario reduction techniques. Their method was validated with data from Crete and mainland Greece. Wang H. et al. [
17] used neural networks to model wind power stochastic processes and ramp event probabilities, though their reliance on feature selection limits generalization and reliability.
The rapid development of artificial intelligence has led to significant advancements in deep generative models for scenario generation, including Variational Autoencoders (VAEs) [
18], Normalizing Flows (NFs) [
19], and Generative Adversarial Networks (GANs) [
20]. Li et al. [
21] integrated external meteorological features and internal latent variables into a VAE-GAN framework, employing mutual information maximization to improve controllability and the capability to generate extreme scenarios. However, GAN-based approaches still face notable challenges, including mode collapse, poor temporal consistency, and limited ability to incorporate historical context, making it difficult to model short-term variability and non-stationarity in renewable generation data.
Denoising Diffusion Probabilistic Models (DDPMs) are generative models that add noise to data and reverse the process to recover clean data, making them ideal for modeling both long-term trends and short-term fluctuations in scenario generation. DDPMs offer a mathematically tractable formulation, ensuring stable training, principled uncertainty quantification, and fine-grained control over the sampling process [
22]. Zhao et al. [
23] developed a Conditional Diffusion-based Scenario Generation model to address joint source–load uncertainties in DDPSs. Their model incorporates a Conditional Spatio-Temporal Fusion Module to capture spatio-temporal correlations between multi-energy loads, and a Conditional Scenario Noise Estimation Module to enhance the diversity of generated scenarios. Dong et al. [
24] proposed a Conditional Latent Diffusion Model for short-term wind power scenario generation, decomposing the task into deterministic forecast regression and error scenario generation. Their method uses Numerical Weather Prediction data and an embedding network for efficient forecasting, followed by a denoising network that generates forecast error scenarios, improving accuracy and reducing diffusion complexity [
25,
26]. Despite these advances, many DDPM-based methods use a single-scale diffusion process at all temporal levels [
27], which overlooks the distinct short-term and long-term features of the output, leading to attenuation of short-term fluctuations and distortion of long-term patterns [
28].
Accordingly, this study introduces a novel Multi-resolution Denoising Diffusion Probabilistic Model (MDDPM) for wind–solar power scenario generation. The proposed model incorporates multi-scale time series decomposition, cascaded diffusion modeling, and condition-aware denoising to generate scenarios with physical consistency, statistical controllability, and strong temporal coherence. The core innovations are summarized as follows:
To effectively capture both long-term trends and short-term fluctuations, we employ a multi-scale decomposition strategy within a multi-stage conditional diffusion framework. Initially, low-frequency components are extracted and diffused to establish global structure. High-frequency details are then recursively denoised and integrated into the diffusion process, ensuring accurate cross-scale sequence reconstruction and dynamic adaptability.
To ensure physical realism in generated scenarios, a condition-constrained denoising mechanism is implemented through the incorporation of historical and trend-based priors at each stage. In addition, a forecast-guided fusion strategy is employed to strengthen long-range dependency modeling and improve generalization over extended horizons.
To address the limitations of existing scenario generation methods in capturing both long-term and short-term uncertainties of RESs, we propose a Multi-resolution Denoising Diffusion Probabilistic Model (MDDPM). Our method enhances scenario diversity and realism by integrating historical trends and high-resolution forecast signals through a multi-stage diffusion process. In the remainder of this paper,
Section 2 introduces the MDDPM framework in detail, including the model architecture, conditional inputs, and optimization strategy.
Section 3 describes the experimental design, datasets, and evaluation metrics, followed by a comparative analysis with state-of-the-art baselines. Finally,
Section 4 concludes the paper by highlighting key findings, practical implications, and directions for future research.
2. Multi-Resolution Denoising Diffusion Probabilistic Model
The overall architecture of the proposed multi-resolution conditional diffusion model is illustrated in
Figure 1. The framework consists of three main components: (1) a multi-scale time series decomposition module, which separates the input historical sequence into low-frequency (trend) and high-frequency (fluctuation) components; (2) a cascaded conditional diffusion module, where the generation of low-frequency scenarios is performed first to establish the global structure, followed by the conditional generation of high-frequency components that refine the fine-scale details; (3) a sequence reconstruction mechanism, which integrates all decomposed components into complete future scenarios. This hierarchical design ensures that the model captures both long-term dependencies and short-term variability in renewable energy outputs, enabling physically consistent and statistically diverse scenario generation. This approach enhances the predictability and physical consistency of wind and solar power output data through time-series decomposition, cascaded diffusion modeling, and a conditional denoising mechanism. In this section, we provide a layer-by-layer introduction to the core components of the proposed framework, including the fundamental theory of diffusion models, the Forecast-Guided Fusion strategy, the reverse denoising process, and the model training methodology.
2.1. Denoising Diffusion Probabilistic Models
DDPMs are a class of generative models that learn to transform data distributions into noise and then reverse the process to reconstruct the original distribution. This approach has shown promise in applications such as image generation [
29] and speech synthesis [
30], making it well-suited for modeling the complex and uncertain nature of renewable energy generation over time.
The core principle of DDPMs is based on a Markov chain process, where each step in the diffusion process involves the addition of noise to the data. This noisy version of the data is then iteratively reconstructed to approximate its original state via a reverse process. In the forward process, the model systematically adds Gaussian noise to the original data. This noise is gradually increased step by step, based on a predefined schedule, allowing the model to explore a range of possible variations in the data. In the reverse process, the model iteratively removes this noise, effectively reconstructing a plausible energy output scenario that reflects both the observed data distribution and inherent uncertainties:
In the forward modeling of the diffusion process, the conditional probability distribution
describes how noise is gradually added to the original data at each step, where
is the noise variance at step
k, which lies in the interval
. This process is modeled as a Gaussian distribution:
According to the properties of the Gaussian distribution, the relationship between
and
can be expressed as follows:
Here,
denotes the Gaussian noise sampled at time step
in the diffusion process.
In DDPMs, the reverse diffusion process is defined as a Markov process. Specifically, in the
k-th step of the reverse process,
is obtained by sampling from the following Gaussian distribution:
Here, s is a small offset parameter, and represents the cumulative noise retention ratio for the first k steps. This cosine schedule enables the model to retain more original data in early diffusion stages while gradually increasing noise intensity in later steps.
The objective of the reverse process is to estimate
, which removes noise and recovers the true data. However, since the explicit form of
is unknown and cannot be directly computed using Bayes’ theorem, it is typically inferred from the previous Gaussian conditional distribution
. According to the Markov property of the diffusion process, we have
Here,
denotes the mean predicted by the network, and the loss function
L is defined as
.
Therefore,
can be parameterized as follows:
Here,
and
k serve as the inputs to the prediction model
, while
is the output. Furthermore, the loss function can be reformulated as follows:
In renewable-energy applications such as wind and photovoltaic power generation, our goal is to forecast the next
L time steps of the multivariate energy output
based on the most recent
H historical observations Here,
d denotes the number of output variables (e.g., wind speed, solar irradiance),
H is the length of the historical window, and
L is the prediction horizon. To address this time series forecasting problem, we employ conditional diffusion models as described in prior work.
The initial noise
, where the condition
c is derived from historical data
and used as the network input, i.e.,
, with
representing the conditional network. The denoising process at step
k is expressed as follows:
In the inference process, we begin with an initial noise sequence
, and then iteratively refine it through the reverse steps, gradually generating a sequence of future energy quantities that approximates the desired results. Ultimately, this yields the predicted sequence
.
2.2. Cascaded Conditional Diffusion Module
Inspired by the Cascaded Diffusion Models proposed by Ho et al. [
31], this study applies the concept of cascaded diffusion to the domain of scenario generation. Ho et al. demonstrated that dividing the image generation process into multiple stages with progressively increasing resolutions—each managed by an independent diffusion model—can significantly enhance the quality of high-resolution image synthesis. Building on this idea, we adapt the cascaded generation framework to the context of renewable energy scenario generation and propose a multi-resolution denoising approach for time series data. The core idea is to progressively generate time series trends from coarse to fine resolutions, leveraging seasonal–trend decomposition techniques to effectively capture hierarchical patterns in the data. Specifically, the generation process is divided into multiple stages, with each stage focusing on refining and synthesizing scenario representations at a particular resolution. Each level of generation depends not only on the outputs of the previous stage but also incorporates multi-scale contextual features. This layer-by-layer optimization strategy contributes to the improved fidelity of complex scenario generation and mitigates potential information loss or compression artifacts that may arise in single-stage generation models.
The output data from RESs typically exhibit trend characteristics at multiple temporal scales, such as long-term variations (e.g., interannual and seasonal changes) and short-term fluctuations (e.g., diurnal cycles and transient disturbances). Due to the multi-scale nature of wind and solar power output, conventional single-scale modeling approaches often fail to simultaneously learn both long-term trends and short-term dynamics. As a result, the generated scenarios may lack temporal consistency and struggle to accurately reproduce the dynamic properties of RES outputs. To address this issue, this paper adopts a hierarchical trend extraction mechanism that decomposes the historical time series into multiple resolutions, ensuring that the model can capture the variation patterns of output data across different temporal scales. This enhances both the realism and diversity of the generated scenarios.
To extract trend information across various time scales, a multi-stage smoothing process is employed, which combines mean pooling with padding operations to construct a hierarchical trend structure ranging from fine to coarse granularity. Given a time series segment
, the trend at the finest granularity is first calculated, and then the smoothing kernel size (
) is progressively increased to extract coarser trends. The historical trend is computed as follows:
Here, denotes the kernel size of the smoothing operation, which is progressively increased with s to ensure a smooth transition from fine-grained to coarse-grained trends. During this process, short-term fluctuations are gradually smoothed out, enabling the model to better capture long-term temporal trend changes without being affected by short-term noise. In addition, the padding operation is applied to maintain consistent sequence lengths across different temporal scales, thereby ensuring the stability of the decomposition process.
This hierarchical trend extraction method offers several advantages over traditional time series modeling approaches. First, by generating low-frequency trends before filling in high-frequency details, the model can progressively learn the dynamic evolution patterns of RES output, thereby ensuring temporal consistency in the generated scenarios. Second, traditional single-scale diffusion models struggle to accurately capture local variations in complex time series data, whereas the multi-scale trend decomposition approach adopted in this work enables modeling at multiple temporal scales, significantly improving the model’s ability to fit wind and solar power output data. Furthermore, the high-frequency components of wind and solar outputs are often influenced by stochastic factors such as weather and environmental conditions. Therefore, phase-wise modeling of different scales within the diffusion process enhances the model’s generalization to high-frequency fluctuations, ensuring that the generated scenarios not only capture long-term trends but also accurately reproduce short-term variations.
In each stage
of the MDDPM generation framework, this paper adopts a conditional diffusion model to reconstruct the future trend variable
. This process consists of both a Forecast-Guided Fusion step and a reverse denoising step. During the Forecast-Guided Fusion, Gaussian noise is incrementally added to the input time series data, such that the data distribution gradually approaches a standard normal distribution. The specific formulation is as follows:
where
is noise sampled from a standard normal distribution. In the reverse denoising process, the model begins with random noise and iteratively reconstructs the original data distribution through multiple steps of denoising. Compared with standard diffusion models, the novelty of this approach lies in the introduction of multi-resolution decomposition, allowing the denoising process to progressively recover fine-grained trend features from coarse representations. This significantly enhances the model’s capability to capture both short- and long-term dependencies.
2.3. Multi-Scale Time Series Decomposition Module
The detailed inference steps of the proposed MDDPM are summarized in Algorithm 1. In the MDDPM framework, the denoising process is a critical part of our model, enabling the recovery of trend information across various temporal scales. By progressively refining both long-term trends and short-term fluctuations, the model ensures that generated scenarios maintain consistency with real-world patterns, enhancing their applicability in operational settings like energy dispatch optimization, thereby enhancing the stability and controllability of the model. Specifically, during the
k-th denoising step of the
-th stage, the generation of the sample
is governed by the following probability distribution:
where
includes all parameters of the conditional network and the denoising network, and
denotes the covariance matrix. The mean
is calculated as follows:
where
represents the model’s denoising estimate.
To enhance the stability and controllability of the denoising process, this study introduces a conditional network to guide the generation of the denoising network. The conditional and denoising networks are shown in
Figure 2. Specifically, the inputs to the conditional network include multi-scale historical trend information and condition variables generated by the forecast-guided fusion strategy, allowing the denoising process to effectively leverage available trend information for accurate reconstruction. The conditional network first projects the input time series
into an embedded representation through a projection block:
Subsequently, the embedded trend vector is combined with an extended diffusion step embedding vector
via a convolutional encoder to obtain the denoising representation:
On this basis,
and the condition information
are concatenated along the feature dimension, resulting in a tensor of size
. This tensor is then fed into the decoder, which ultimately outputs the denoising prediction
.
| Algorithm 1 Inference Procedure of the Multi-Resolution Denoising Diffusion Model for Renewable Energy Time Series Generation |
- Require:
Historical power sequence , meteorological condition sequence M, total resolution levels S, number of diffusion steps per level K, diffusion parameters - Ensure:
Generated fine-resolution power sequence - 1:
Multi-Resolution Decomposition: - 2:
for downto 0 do - 3:
- 4:
- 5:
if then - 6:
Construct conditional vector - 7:
else - 8:
Construct conditional vector - 9:
end if - 10:
Initialize - 11:
for do - 12:
if then - 13:
- 14:
else - 15:
- 16:
end if - 17:
Compute timestep embedding - 18:
Obtain network prediction - 19:
Update sample via reverse diffusion: - 20:
- 21:
end for - 22:
- 23:
end for - 24:
return
|
2.4. Forecast-Guided Fusion Strategy
The complete training process for the MDDPM is presented in Algorithm 2. Given an initial data distribution, the Forecast-Guided fusion strategy gradually transforms the data into noise that follows a standard Gaussian distribution. The sampling procedure, also known as the reverse process, learns a Gaussian transformation to generate samples that match the original data distribution. Starting from
sampled from the standard Gaussian, the model progressively reconstructs the data distribution from noise, thereby generating target scenario samples. Therefore,
This study draws inspiration from the sinusoidal positional encoding method employed in Transformers [
32], encoding temporal information using sine and cosine functions at various frequencies. This approach enables the model to learn periodic patterns across different time scales. Specifically, the design of the sinusoidal positional embeddings allows us to encode time at each diffusion step, thereby empowering the model to capture the underlying dynamics of energy generation across multiple temporal resolutions.
In the denoising process, this chapter further introduces a conditional control mechanism to ensure that the model can leverage available historical information for guidance when reconstructing data across multiple temporal scales. Specifically, a positional encoding approach is employed to generate an extended diffusion step embedding vector
during the diffusion phase. This embedding vector is then passed through two fully connected layers with a SiLU activation function for linear transformation:
Here, SiLU is the sigmoid-weighted linear unit, a smooth nonlinear activation function. The embedding vector guides each step of the diffusion process, enabling the model to perform robust reverse denoising operations.
Additionally, this chapter proposes a forecast-guided Fusion Strategy to enhance the model’s ability to capture long-term temporal dependencies. This strategy constructs a new conditional variable by mixing historical trend information
with future target trend
:
where
m is a mixing weight sampled from an analysis distribution, and ⊙ denotes the Hadamard product (element-wise multiplication).
| Algorithm 2 Training Procedure for Multi-Resolution Diffusion Model in Renewable Energy Scenario Generation |
- 1:
repeat - 2:
Sample a pair of sequences from historical wind/solar power data, where is the lookback window and is the future target window. - 3:
Decompose and into multi-resolution trend components: MultiResolutionDecompose, MultiResolutionDecompose. - 4:
for downto 0 do - 5:
Randomly sample a diffusion step . - 6:
Sample Gaussian noise . - 7:
Generate the diffused sample at stage s: - 8:
Obtain the embedding of diffusion step (e.g., by sinusoidal positional encoding and fully connected layers). - 9:
Encode the historical trend: . - 10:
Generate a mixing matrix m (sampled element-wise from ). - 11:
- 12:
if then - 13:
Form the condition: - 14:
else - 15:
Form the condition: - 16:
end if - 17:
Predict the denoised trend: - 18:
- 19:
Update network parameters - 20:
end for - 21:
until convergence or maximum iterations reached
|
2.5. Objective Optimization and Inference Process
The optimization objective is defined as follows:
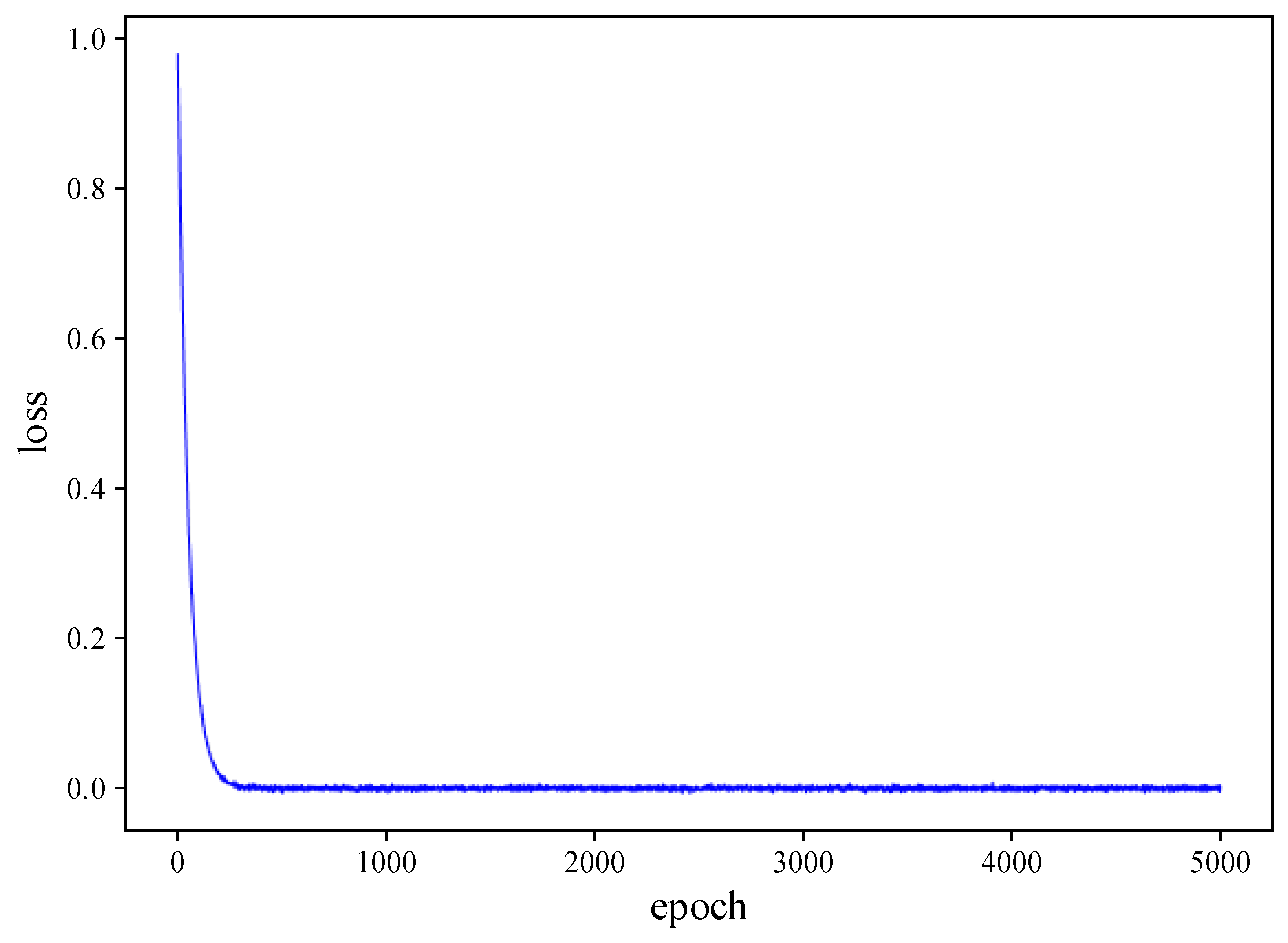
This objective function minimizes the mean squared error between the predicted results and the ground-truth trends, ensuring that the denoising process converges stably and can effectively recover the trend information in the time series.
During inference, the denoising process follows an iterative sampling strategy, starting from standard Gaussian noise
and recursively generating samples as follows:
where
is the standard deviation of the Gaussian noise added at each sampling step. When
,
; otherwise,
.
This autoregressive denoising strategy enables the model to iteratively recover long-term trends in the time series, resulting in wind and solar power scenarios with enhanced physical consistency.
4. Conclusions
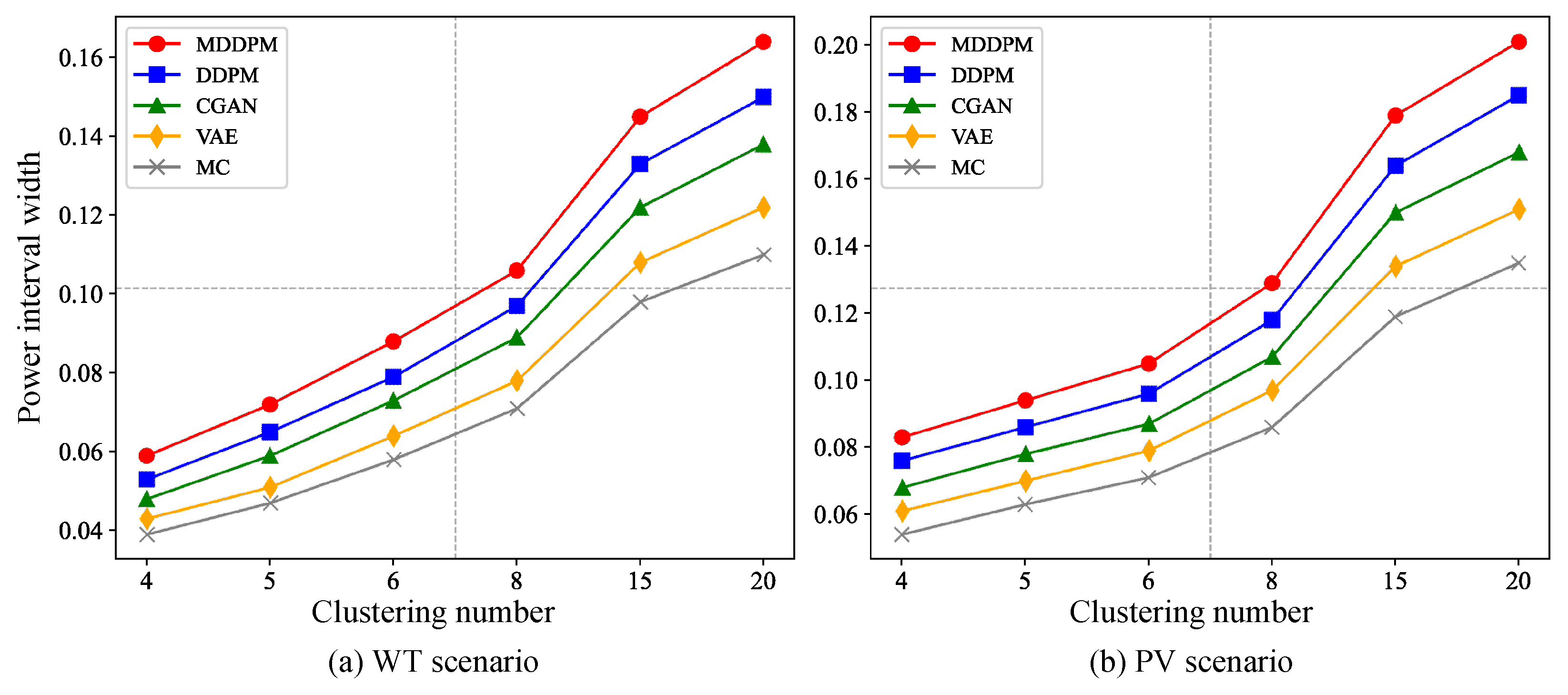
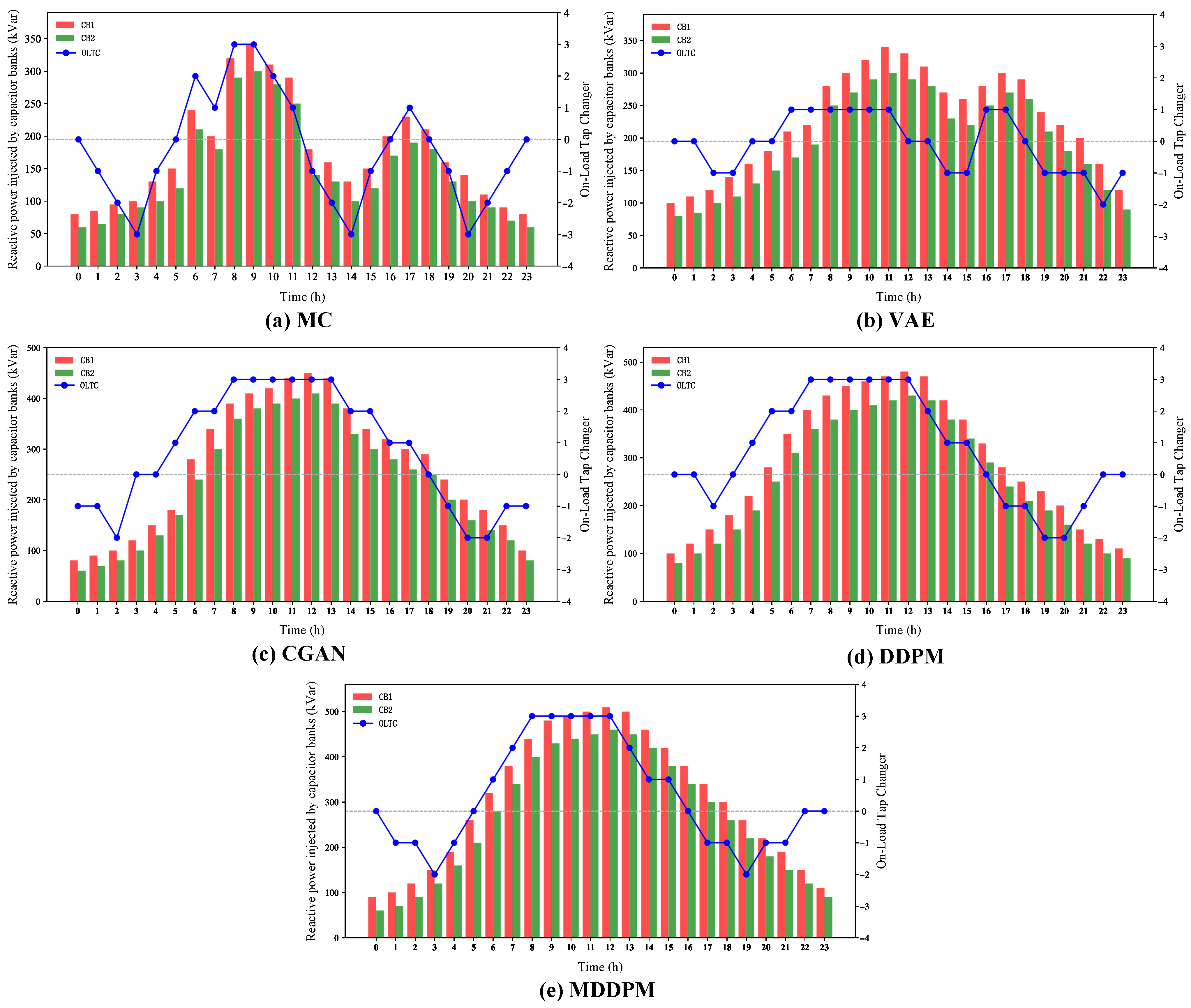
This paper introduces a novel scenario generation framework for wind and photovoltaic power outputs using a Multi-resolution Denoising Diffusion Probabilistic Model (MDDPM). By integrating a multi-scale decomposition strategy and a cascaded conditional denoising diffusion process, this model enhances the accuracy and diversity of generated scenarios, effectively capturing both long-term structural trends (e.g., seasonal variations) and short-term stochastic fluctuations (e.g., daily or weather-related changes). In extensive experiments, the MDDPM outperforms traditional methods, including DDPM, VAE, CGAN, and MC, in terms of scenario accuracy, diversity, and physical consistency.
Despite the promising performance of the proposed MDDPM, there remain areas for future enhancement. The current framework introduces a certain degree of computational overhead due to the multi-resolution structure, which may affect scalability in real-time applications. Additionally, the model’s reliance on historical data quality highlights the importance of robust preprocessing, especially when facing missing or noisy inputs. While our implementation focuses on single-site renewable generation, extending the approach to multi-site or spatially correlated data would further improve its practical applicability. Moreover, balancing accuracy with generalization remains an important consideration to avoid overfitting to historical trends. Incorporating domain-specific physical constraints in future versions could also enhance realism and alignment with real-world operational limits. These aspects represent valuable directions for future work, aiming to further strengthen the model’s flexibility and deployment potential in complex energy systems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}