2.1. Problem Statement and Notation
The problem of downscaling low-resolution data is as follows. Given a low-resolution state
, a target spatial enhancement
for each spatial dimension (
overall), and a target temporal enhancement
, we want to find a function
that will take
, enhance the spatial dimensions by a factor of
and the temporal dimension by a factor of
, and give us a spatiotemporally enhanced high-resolution state
. Under some simplifying assumptions, we can decompose
into separate functions for spatial and temporal enhancement,
. We can further decompose these functions into intermediate enhancement functions if the products of intermediate enhancement factors are equal to
or
. The terms introduced here, along with other frequently used terms, are summarized in
Table 1.
2.2. Data Description
ERA5: We downloaded ERA5 [
49] for 2007–2013 to train the first enhancement step model. ERA5 is an atmospheric reanalysis dataset that is an optimal combination of observations from various measurement sources and the output of a numerical model using a Bayesian estimation process called data assimilation [
50]. ERA5 consists of hourly estimates of several atmospheric variables at a latitude and longitude resolution of 0.25° (~30 km at the equator) from the surface of the earth to roughly 100 km altitude from 1979 to the present day.
As our focus is to generate high-resolution wind resource data, we selected variables from ERA5 close to the surface. We also selected variables that would encourage accuracy during extreme events and over different types of complex terrain. Good model generalization also requires learning the relationships between the low-resolution climate representation and the high-resolution outputs. Prior to training, ERA5 data were regridded to match the 15-times spatially coarsened WTK grid, and ERA5 wind components were bias-corrected to the WTK so that the 2007–2013 monthly means and standard deviations matched those of WTK. This ensured that training was not influenced by bias between low- and high-resolution data, and we applied separate bias correction prior to inference. The ERA5 configuration is summarized in
Table 2. The complete set of training features used is listed in
Table 3.
WTK: WTK is high-resolution (2 km, 5 min) wind data that covers Canada, the United States, and Mexico from 2007 through 2013. We can, in theory, use any ERA-based downscaled data product as high-resolution target data. We selected the National Renewable Energy Laboratory (NREL)’s WTK [
10] because of its extensive use by U.S. stakeholders for wind resource and energy production analysis and because WTK has demonstrated good performance across various performance measures. In particular, WTK shows good agreement with observations for diurnal and seasonal correlation coefficients, mean absolute error (MAE), mean wind speeds, and absolute bias [
51]. The WTK was produced with Weather Research and Forecasting (WRF) version 3.4.1 using ERA-Interim, the predecessor to ERA5, for initialization and boundary conditions. WTK data include wind speed and wind direction at 10, 40, 80, 100, 120, 160, and 200 m above ground level. The wind speed and wind direction data served as the high-resolution targets for our downscaling framework. Coarsened WTK data are also used as the low-resolution data for
and
(ERA5 data are only needed for input to the first enhancement step). The WTK configuration is summarized in
Table 2.
Vortex Wind Data from the International Renewable Energy Agency Global Atlas: We download long-term monthly wind speed means from the International Renewable Energy Agency Global Atlas (data provided by Vortex [
12]) over Ukraine and the contiguous United States (CONUS) to use for bias correction prior to inference. Vortex via the International Renewable Energy Agency Global Atlas provides high-resolution wind speed data globally [
52] and easily downloadable 20-year climatological monthly means. We bias-corrected ERA5 data over Ukraine by matching the corrected ERA5 monthly means over 2000–2020 with the Vortex monthly means. We bias-corrected ERA5 data over CONUS prior to inference used for validation against observational data. Bias correction is described in
Section 2.5.
Meteorological Assimilation Data Ingest System (MADIS): MADIS is a comprehensive collection of meteorological observations covering the entire globe [
53]. It is maintained by the National Oceanic and Atmospheric Administration and is primarily used for weather forecasting, research, and various atmospheric studies. MADIS integrates data from various sources, including federal agencies, research institutions, and commercial entities, ensuring broad coverage and diversity of observations. The dataset undergoes quality control procedures to identify and correct errors, ensuring high-quality data for analysis and modeling purposes.
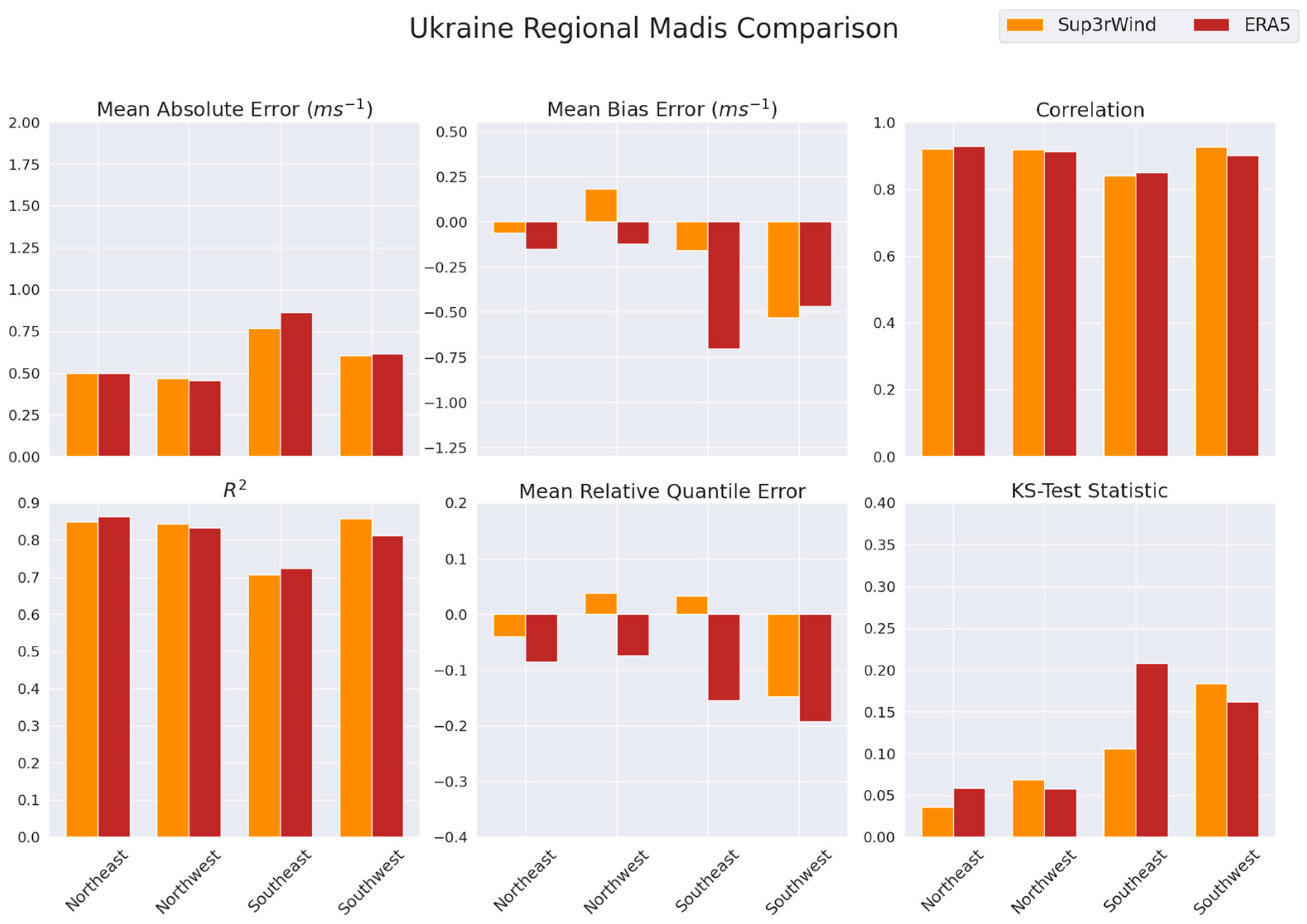
We used the MADIS API to download a full year of surface observations of wind speed and direction for 40 locations within the Ukraine downscaling domain (
Figure 1). The observations for each location were mapped onto an hourly temporal grid using a simple average for time steps containing multiple observations. We removed any locations missing observational data for more than half of the time steps. The resulting validation data consists of 8784 hourly observations of wind speed for 2020 at 10 m height for 37 locations across the modeling domain.
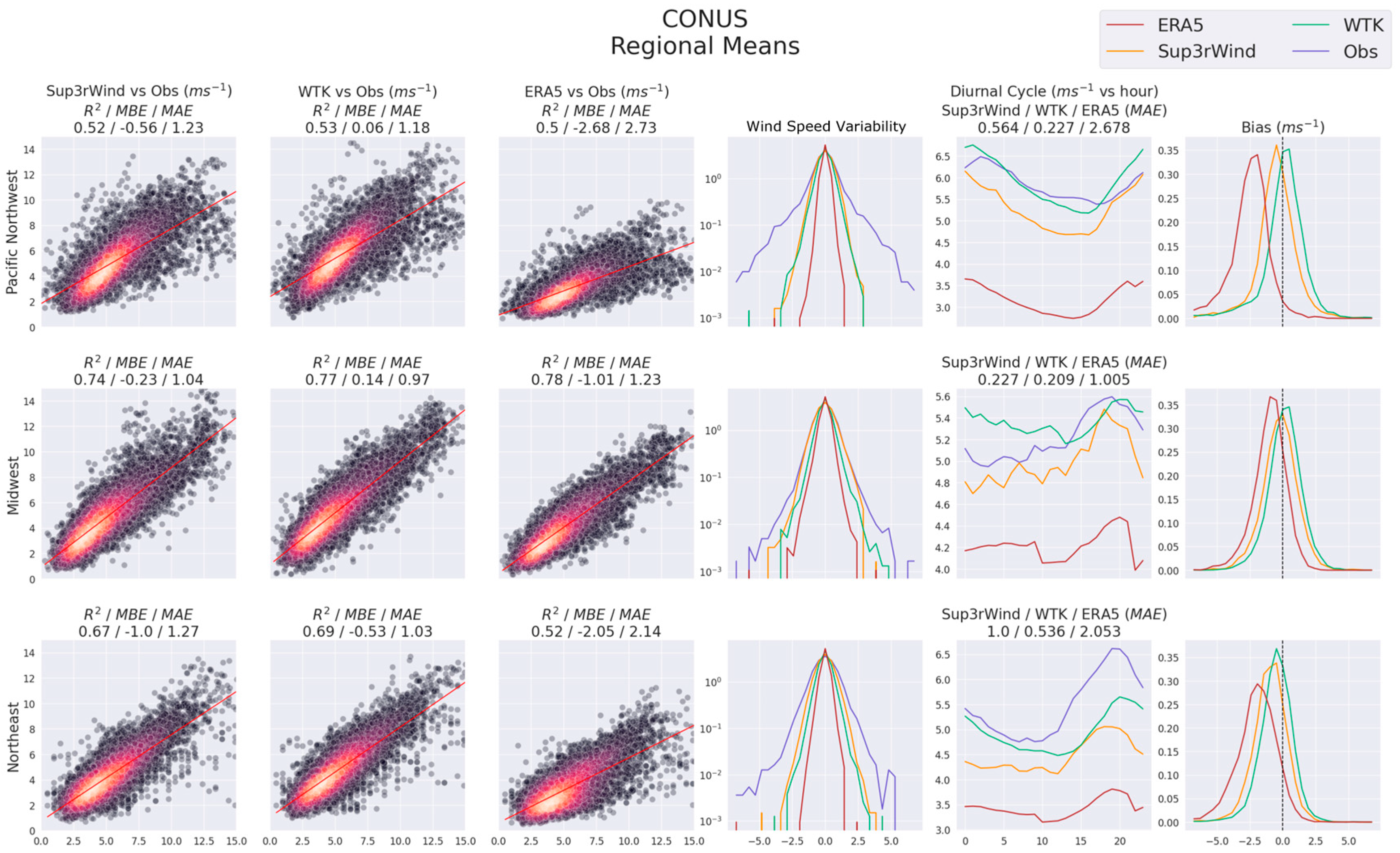
Second Wind Forecast Improvement Project (WFIP2): We used WFIP2 observation data to assess model performance over CONUS. WFIP2 is a U.S. Department of Energy and National Oceanic and Atmospheric Administration-funded effort to improve weather prediction forecast skills for turbine-height winds in regions with complex terrain. A core component of WFIP2 was an 18-month field campaign that took place in the U.S. Pacific Northwest between October 2015 and March 2017 [
54].
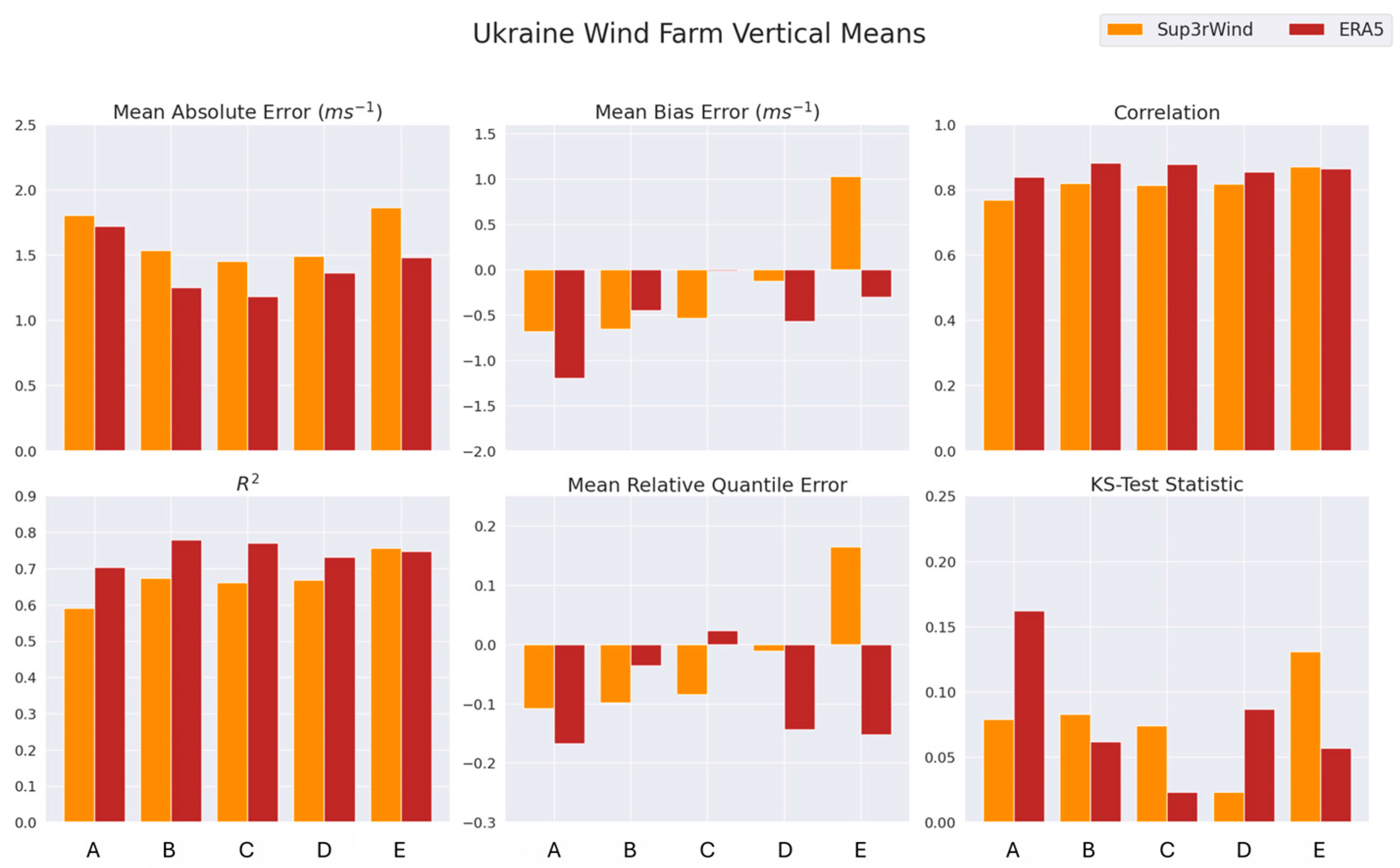
Ukraine Wind Farm Observations: We obtained wind measurement data performed by Deutsche WindGuard Consulting GmbH (Varel, Germany), GEIO-NET Umweltconsulting GmbH (Hannover, Germany), and ENERPARK Inżyniera Wiatrowa Sp. z o. o (Warsaw, Poland) for planned wind farm sites throughout Ukraine. Due to security concerns, we refer to the five wind farm sites as Wind Farm A–E rather than their actual locations. The wind speed measurements for Wind Farm A were conducted using a 100 m high met mast for wind speeds at approximately 100 m and 80 m. Sets of measurements for Wind Farms B and C were performed using a 120 m high met mast, yielding wind speed measurements at approximately 120 m, 100 m, 75 m, and 50 m. The wind speed measurements for Wind Farm D were conducted using a 120 m high met mast for wind speeds at approximately 120 m, 116 m, 100 m, 80 m, and 60 m. Measurements for Wind Farm E were collected using an 82 m high met mast and extrapolated to the turbine hub height of 94 m using wind shear exponents calculated from mast data. This collection of observational wind speeds was used to validate Sup3rWind data across Ukraine (
Section 3.2). The Wind Farm observation heights are listed in
Table 4.
Table 2.
Summary of ERA5 and wind toolkit configurations.
Table 2.
Summary of ERA5 and wind toolkit configurations.
| | ERA5 | Wind Toolkit |
|---|
| Output Variables | Numerous meteorological variables at the surface and 137 pressure levels up to around 80 km. Includes wind speed, wind direction, temperature, pressure, relative humidity, heat fluxes, precipitation, cape, etc. For a complete list, see [55]. | Wind speed, wind direction, air temperature, and pressure at 15 m, 47 m, 80 m, 112 m, 145 m, and 177 m. Interpolated to 10 m, 40 m, 80 m, 100 m, 120 m, 160 m, and 200 m. Surface pressure and relative humidity at 2 m. |
| Resolution | 30 km, hourly. | 2 km, 5 min. |
| Boundary Conditions/Inputs | 4D-Variational Data Assimilation from satellites, surface observations, and other sources. Atmospheric state that best fits model forecast and observations [56]. Assimilation performed with 12 h windows. | 6-hourly scale-selective grid nudging towards ERA-Interim. GTOPO30 terrain data. |
2.3. Model Description
For this work, we trained a total of three super-resolution models, described in
Table 3. The first step,
, performed 3-times spatial enhancement; the second step,
performed 5-times spatial enhancement; and the third step,
performed 12-times temporal enhancement. When these steps were applied successively to a low-resolution state
,
, they performed a total of 15-times spatial enhancement and 12-times temporal enhancement,
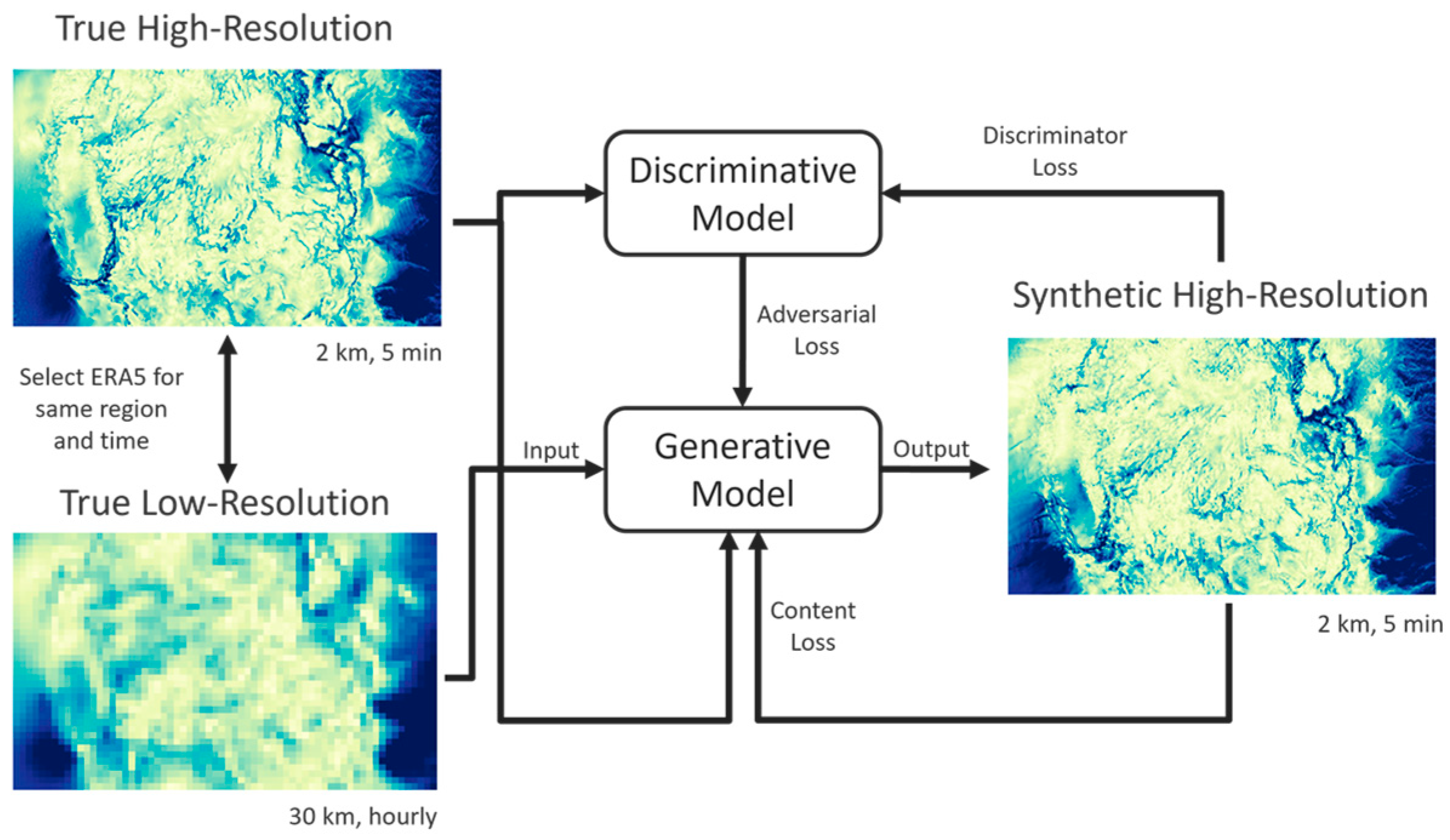
. Training and inference flow are diagrammed in
Figure 2. These models mostly follow the approach in [
40], with a few important distinctions: (1) we used a modified content loss function to encourage model accuracy across extreme values. This loss, shown in Equation (1), includes mean absolute error terms for the minimums and maximums across both space and time; (2) we incorporated mid-network high-resolution topography injection for a more accurate representation of wind flow over fine-scale complex terrain; and (3) we trained on distinct low-resolution and high-resolution datasets, as opposed to using coarsened high-resolution data as the low-resolution GAN input. The topography injection differs from standard model input in that all standard model inputs are low-resolution. As this low-resolution data goes through the model, it is eventually enhanced by up-sampling layers in the middle of the model network. Right after this up-sampling, high-resolution topography data can be combined with the up-sampled data. This high-resolution topography is elevation above sea level data sourced from GTOPO30 [
57].
The loss function used to encourage accuracy across extreme values, , is mean absolute value, is the true high-resolution data, is the high-resolution model output, is the maximum across all time, and is the maximum across all space.
An extensive codebase has been developed to implement easily customizable GAN architectures and handle data extraction, batching, and model training to distribute the forward passes of input data through the GAN across multiple nodes. This codebase is released as the super-resolution for renewable resource data (sup3r) package and is installable through the python package index [
58]. Sup3r version 0.1.2 was used for this work.
Table 3.
30 km, hourly to 2 km, 5 min model steps.
Table 3.
30 km, hourly to 2 km, 5 min model steps.
| Model Step | Enhancement | Training Features | Input Data Source | Output Target Data Source | Training Time |
|---|
| 1.
| Three-times spatial | U/V wind vector components at 10, 100, and 200 m, topography, cape, k index, surface pressure, instantaneous moisture flux, surface temperature, surface latent heat flux, 2 m dewpoint temperature, friction velocity | ERA5 (30 km, hourly) | Coarsened WTK (10 km, hourly) | 240 compute node hours, 2500 epochs |
| 2.
| Five-times spatial | U/V wind vector components at 10, 40, 80, 100, 120, 160, and 200 m + topography | Coarsened WTK (10 km, hourly) | Subsampled WTK (2 km, hourly) | 50 compute node hours, 7000 epochs |
| 3.
| Twelve-times temporal | U/V wind vector components at 10, 40, 80, 100, 120, 160, and 200 m + topography | Subsampled WTK (2 km, hourly) | Original WTK (2 km, 5 min) | 200 compute node hours, 10,000 epochs |
2.4. Model Training
The first step generator,
, was trained with ERA5 data as low-resolution input and WTK coarsened to 10 km hourly as the high-resolution target for 2007–2009 and 2011–2013. We kept 2010 as a holdout year for validation. The WTK data had a nominal resolution of 2 km, 5 min, so high-resolution targets sampled from these data were coarsened five times spatially and subsampled twelve times temporally for the first model step. Both the second- and third-step models were trained on coarsened WTK data, as in [
40]. The input for the second step,
is 10 km, hourly WTK (five times spatially coarsened and twelve times subsampled in time), and the high-resolution target for
was 2 km, hourly WTK (subsampled 12 times temporally). The input for the third step,
is WTK subsampled 12 times temporally, and the high-resolution target is the original WTK. These steps are summarized in
Table 3.
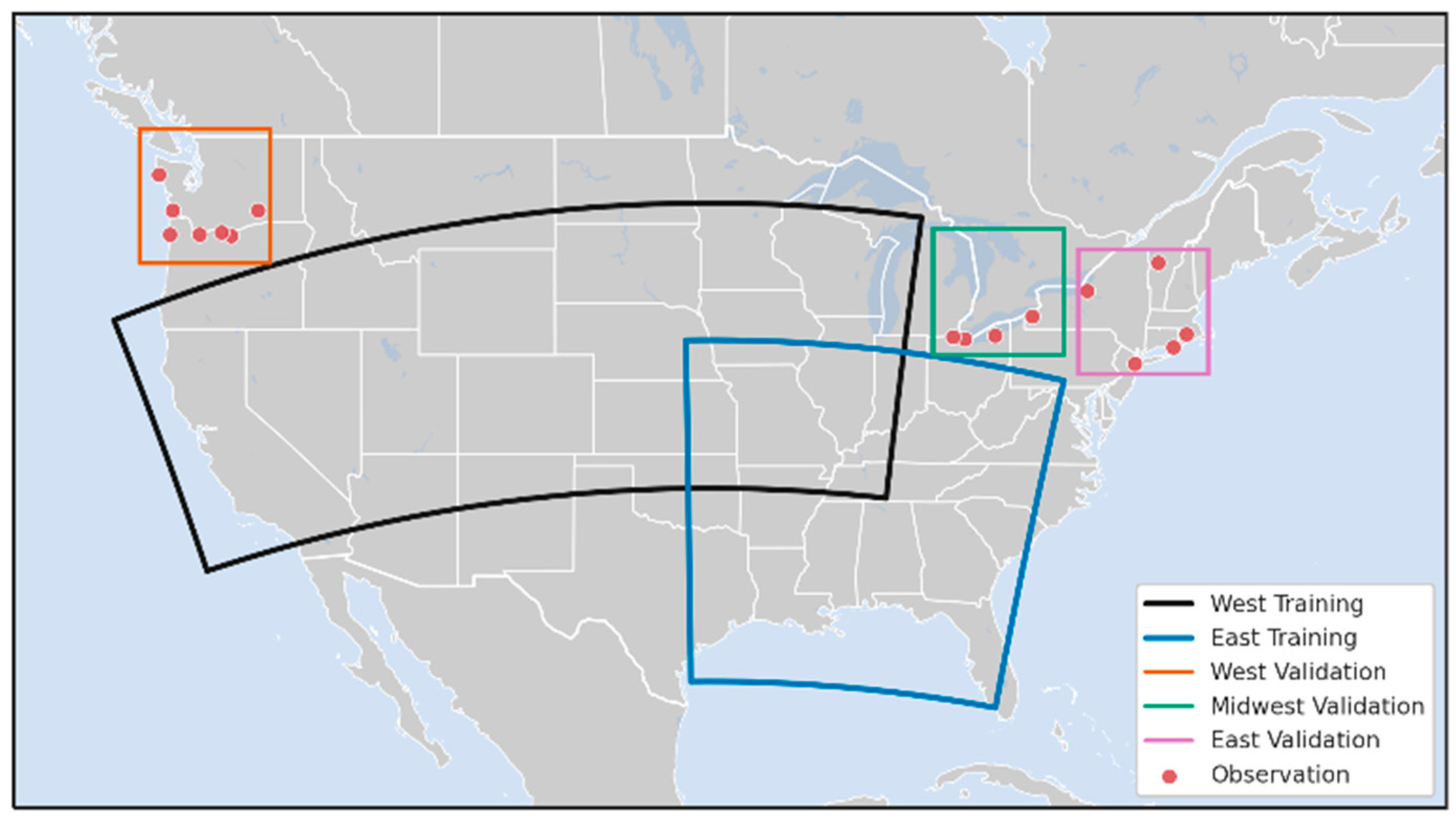
For each model step, training observations were sampled from the domains shown in
Figure 3. Training was performed on the Eagle high-performance computing system at NREL using two NVIDIA V100 GPUs (Taiwan Semiconductor Manufacturing Company, Hsinchu Science Park, Taiwan). Each training epoch consisted of 100 batches, with 64 observations per batch. Batches were built by randomly sampling spatiotemporal chunks from the six training years and two different training domains. Each spatiotemporal chunk was 15 × 15 × 5 low-resolution pixels. For the third step, generator
, random sampling along the time dimension was weighted by the time-specific loss. For instance, if the model was performing worst on summer observations during a given training epoch, more observations were selected from the summer for the next epoch. This data-centric training approach ensures that the model performs well over a wide range of season-specific weather conditions.
2.5. Bias Correction
We performed bias correction on the ERA5 wind speed input data prior to training
and prior to inference. It is well known that ERA5 frequently underestimates wind speeds, especially in complex terrain [
59,
60,
61]. While the GAN models could be trained on biased data to learn bias correction, we were concerned about this not generalizing well to new geographic regions. Thus, we opted for region-specific bias correction on low-resolution input as a preprocessing step. Prior to training, we computed bias correction factors that shifted the 2007–2013 means and standard deviations of the ERA5 to match those of coarsened WTK data. For each ERA5 grid point (
) and wind speed hub height (10 m, 100 m, or 200 m), monthly (
) means (µ) and standard deviations (
σ) were computed for 2007–2013 for both ERA5 and coarsened WTK. ERA5 was then bias-corrected for each grid point, hub height, and month as follows:
where
,
,
, and
are the means and standard deviations for ERA5 and the coarsened WTK, respectively.
To perform bias correction prior to inference, we used monthly mean wind speeds provided by Vortex, described in
Section 2.2. The global availability of the Vortex data allowed us to use it for both CONUS validation and the Ukraine data production. These means were for 2001–2020 and available only as high as 160 m. Standard deviations were not available. We linearly extrapolated to 200 m, then computed multiplicative correction factors using the means:
where
and µ are the 2001–2020 means for Vortex and ERA5, respectively.
2.6. Inference
We downscaled ERA5 over Ukraine, Moldova, and some of Romania (
Figure 1) for 2000–2023, from 30 km hourly to 2 km, 5 min resolution. With models trained only on the CONUS regions shown in
Figure 3, this is a significant geographic generalization. Prior to inference, the ERA5 input data were bias-corrected using long-term monthly means from Vortex, described in
Section 2.2. Inference is a memory-bound process, so we split the input data into chunks and parallelized the forward pass on these chunks independently. The full low-resolution domain was first chunked across the time dimension, and each chunk,
passed through
to perform 15-times spatial enhancement. Chunks were made to overlap in time to enable stitching without seams. Spatially enhanced output was chunked across both space and time, with chunks (
) overlapping across all dimensions and then passed through
to perform the final 12-times temporal enhancement. A year of input for the first two models consisted of 300 chunks. The spatially enhanced input to the final model then consisted of 65,000 spatiotemporal chunks. Forward passes were distributed over 30 compute nodes on the NREL Eagle high-performance computer, and full spatiotemporal enhancement for a year was completed in 40 node hours using 36 CPUs per compute node for inference. This is more than 85 times faster than the dynamical downscaling of ERA5 with WRF to the same 2 km, 5 min resolution based on internal testing with WRF on the same hardware. When using GPUs for inference, the speedup can be as much as 500 times.
Table 4.
Wind farm data details.
Table 4.
Wind farm data details.
| Location | Time Period | Heights |
|---|
| Wind Farm A | January 2012–December 2015 | 100 m, 80 m |
| Wind Farm B | September 2019–September 2020 | 120 m, 100 m, 75 m, 50 m |
| Wind Farm C | November 2020–January 2022 | 120 m, 100 m, 75 m, 50 m |
| Wind Farm D | November 2021–September 2023 | 120 m, 116 m, 100 m, 80 m, 60 m |
| Wind Farm E | January 2022–December 2022 | 94 m |


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}