
A Data Protection Method for the Electricity Business Environment Based on Differential Privacy and Federal Incentive Mechanisms



Abstract
1. Introduction
- (1)
- A comprehensive electricity business environment evaluation system has been developed, which considers multiple dimensions, including electricity regulations, public services, and operational efficiency. This system can comprehensively and accurately describe the development level of the electricity business environment to adapt to international trends.
- (2)
- A data protection method for the electricity consumption business environment based on federated learning is proposed. This method, on the basis of traditional federated learning, introduces differential privacy and federated learning incentive mechanisms to solve the data leakage risk of centralized training.
- (3)
- Experimental verification shows that due to the introduction of the incentive mechanism, MAE, MSE, and RMSE have decreased by 10.36%, 19.31%, and 10.84%, respectively, and R2 has increased by 14.05%. Compared with the FNN model and the SVR model, the MLP model reduced MAE by 78.9% and 94.12%, respectively, MSE by 96.86% and 99.27%, respectively, RMSE by 82.15% and 94.31%, respectively, and R2 by 37.95% and 55.62%, respectively.
2. Electricity Business Environment
2.1. Construction of the Electricity Business Environment Evaluation System
2.1.1. Electricity Regulation Quality Indicator
- Collaborative planning and infrastructure development
- Statutory provisions require collaborative planning and infrastructure development with shared excavation permits and one-time digging policies.
- The regulations set time limits for approval/consent by the electricity connection authority.
- 2.
- Regulatory inspection framework for electrical setups
- The law mandates licensed professionals/companies to install and certify internal electrical systems.
- Legal requirements enforce external, independent auditing of on-premise electrical setup work.
- The law mandates licensed professionals/companies to install and certify external electrical systems.
- Statutes mandate third-party examination of outdoor electrical fitting setups.
- 3.
- Ecological sustainability in power supply operations
- The regulations set environmental standards for power generation, including energy efficiency and limits on air pollutants.
- The regulatory framework enforces power generation environmental compliance through penalties and mandatory reporting.
- c.
- The regulatory framework mandates environmental standards for transmission and distribution, including energy efficiency, smart meters, and smart grid development.
- d.
- The regulatory framework establishes pertinent environmental criteria for power delivery and allocation.
2.1.2. Public Service Quality Indicator
- KPI for monitoring service reliability and sustainability
- There are core performance metrics for tracking the dependability of the power supply.
- There are core performance metrics to gauge the environmental viability of power delivery.
- 2.
- Transparency in electricity rate determination and tariff structure
- The regional electricity tariff is publicly available via the utility or regulator’s official online platform.
- Electricity price changes are announced to the public at least one invoicing period prior.
- The methodology for determining users’ final power utility bill is publicly disclosed.
- 3.
- Online power connection request systems
- Businesses can electronically request new commercial power connections.
- Users can track their power connection application progress online.
2.1.3. Electricity Service Operational Efficiency Indicator
- Average customer outage time
- 2.
- Average frequency of customer outages
- 3.
- Electricity Connection Service
2.2. Determination of Indicator Weights
2.2.1. Entropy Weight Method for Calculating Objective Weights
2.2.2. Sequence Relationship Method for Calculating Subjective Weights
2.2.3. Combined Weight Calculation
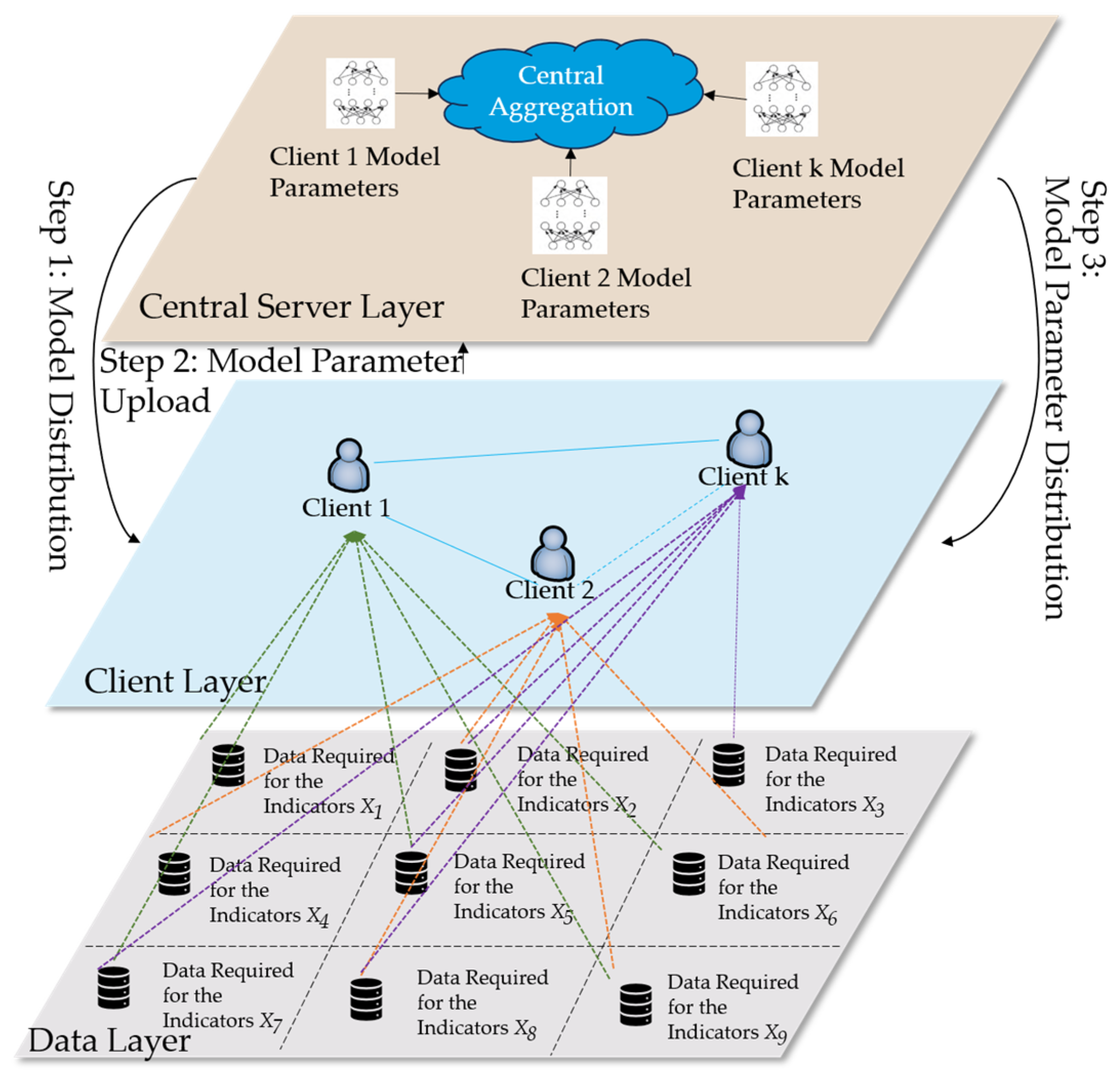
3. Federated Learning
3.1. Horizontal Federated Learning Framework
Multilayer Perceptron Model
3.2. Differential Privacy
3.3. Model Fair Incentive Mechanism
Contribution Measurement Method
3.4. Training Process of the Electricity Business Environment Indicator Model Based on Federated Learning
4. Calculus Analysis
4.1. Data Description
4.2. Data Processing
4.2.1. Handling Data Outliers
4.2.2. Handling Missing Data
4.3. Simulation Results Analysis
4.3.1. Results Analysis
4.3.2. Determination of Indicator Weights
4.3.3. Sensitivity Analysis
4.3.4. Privacy Budget Analysis
4.3.5. Model and Algorithms Comparative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MLP | Multilayer Perceptron Model |
| DP | Differential Privacy |
| FNN | Feed-forward Neural Network |
| SVR | Support Vector Regression |
| MSE | Mean Square Error |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| R2 | Coefficient of Determination |
| PDC | Probability Density Curve |
| Fedavg | Federated Averaging Algorithm |
| Fedprox | Federalized Proximal Algorithm |
| Fednova | Federated Normalized Averaging Algorithm |
| KPI | Key Performance Indicator |
References
- Hu, Z.; Su, R.; Veerasamy, V.; Huang, L.; Ma, R. Resilient frequency regulation for microgrids under phasor measurement unit faults and communication intermittency. IEEE Trans. Ind. Inform. 2024, 21, 1941–1949. [Google Scholar] [CrossRef]
- Li, X.; Hu, C.; Luo, S.; Lu, H.; Piao, Z.; Jing, L. Distributed Hybrid-Triggered Observer-Based Secondary Control of Multi-Bus DC Microgrids Over Directed Networks. IEEE Trans. Circuits Syst. I 2025, 772, 2467–2480. [Google Scholar] [CrossRef]
- World Bank Group. Business Ready Methodology Handbook; World Bank Group: Washington, DC, USA, 2024; pp. 1–147. [Google Scholar]
- Wei, L.; Chen, X.; Yuan, X. Deepening the service connotation to optimize the electricity business environment. China Power Enterp. Manag. 2024, 42, 8–9. [Google Scholar]
- Yang, Z.; Fang, C.; Huang, Y.; Huang, X.; Zhou, Y.; Yao, X.C.; Wu, Y.H. Research on the Construction of the “Supply and Consumption Electricity Community” Based on Optimizing the Electricity Business Environment. Ind. Control Comput. 2021, 34, 124–125. [Google Scholar]
- Yu, L.; Zhou, D.; Wen, H. How Grid Enterprises Can Optimize the Business Environment under the World Bank’s B-READY Framework. China Commer. 2024, 30, 144–145. [Google Scholar]
- Xiao, Y.; Xu, J. Risk Assessment of the Safe Operation of Batteries in Energy Storage Power Stations Based on Combined Weighting and TOPSIS. Energy Storage Sci. Technol. 2022, 11, 2574–2584. [Google Scholar]
- Wang, M.F.; Zheng, J.Y.; Mei, F. Research on the Influencing Factors of Distribution Network Reliability Based on Combined Weighting and Improved Grey Relational Analysis. J. Electr. Eng. 2022, 17, 41–48. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zuo, S.; Xie, Y.; Yao, H.; Ke, Z. TPFL: Privacy-Preserving Personalized Federated Learning Mitigates Model Poisoning Attacks. Inf. Sci. 2025, 702, 121901. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, T.; Ji, J.; Zhang, Y.; Lan, R. Privacy-preserving face attribute classification via differential privacy. Neurocomputing 2025, 626, 129556. [Google Scholar] [CrossRef]
- Zhu, T.; Li, G.; Zhou, W.; Philip, S.Y. Differentially private data publishing and analysis: A survey. IEEE Trans. Knowl. Data Eng. 2017, 29, 1619–1638. [Google Scholar] [CrossRef]
- Jiang, X.; Ji, Z.; Wang, S.; Mohammed, N.; Cheng, S. Differential-private data publishing through component analysis. Trans. Data Priv. 2013, 6, 19. [Google Scholar] [PubMed]
- Yang, J.; Zhou, J. Restore of Mathematical detail: The process of gauss deriving the probability density function of normal distribution. J. Stat. Inf. 2019, 34, 17–21. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data ourselves: Privacy via distributed noise generation. In Location of Advances in Cryptology-EUROCRYPT 2006, Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryp-Tographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Li, H.; Ren, X.; Wang, J.; Ma, J. Continuous location privacy protection mechanism based on differential privacy. J. Commun. 2021, 42, 102–110. [Google Scholar]
- Riedel, P.; Belkilani, K.; Reichert, M.; Heilscher, G.; von Schwerin, R. Enhancing PV feed-in power forecasting through federated learning with differential privacy using LSTM and GRU. Energy AI 2024, 18, 100452. [Google Scholar] [CrossRef]
- Choudhury, O.; Gkoulalas-Divanis, A.; Salonidis, T.; Sylla, I.; Park, Y.; Hsu, G.; Das, A. Differential privacy-enabled federated learning for sensitive health data. arXiv 2019, arXiv:1910.02578. [Google Scholar]
- Wang, Z.; Yu, P.; Zhang, H. Privacy-preserving regulation capacity evaluation for hvac systems in heterogeneous buildings based on federated learning and transfer learning. IEEE Trans. Smart Grid 2022, 14, 3535–3549. [Google Scholar] [CrossRef]
- Wang, G.; Dang, C.X.; Zhou, Z. Measure contribution of participants in federated learning. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Kang, J.W.; Xiong, Z.H.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Primary Indicator | Secondary Indicator |
|---|---|
| Electricity regulation quality indicator | Collaborative planning and infrastructure development |
| Regulatory inspection framework for electrical setups | |
| Ecological sustainability in power supply operations | |
| Public service quality indicator | KPI for monitoring service reliability and sustainability |
| Transparency in electricity rate determination and tariff structure | |
| Online power connection request systems | |
| Electricity service operational efficiency indicator | Average customer outage time |
| Average frequency of customer outages | |
| Electricity connection service |
| Input: Number of communication rounds T, number of clients K and initial model weights . |
| Process: |
| 1: Initialize Global Model Parameters . |
| 2: For t = 1,…, T do |
| 3: For client k = 1,…, K do |
| 4: Receive the model parameter update values after local training from each client, as well as the local training data size for each client. |
| 5: End For |
| 6: Aggregate the model parameter update values uploaded by each participant to obtain : |
| 7: |
| 8: Calculate the contribution of each participant, denoted as Ck, using the contribution measurement method. |
| 9: Based on the contribution, calculate the number of model weight and bias update values allocated to participant k. |
| 10: |
| 11: According to the gradient aggregation distribution method, send the corresponding number of parameter update values , denoted as Mk, to client k. |
| 12: End For |
| End of process. |
| Output: The aggregated model parameter update values and the model parameter update values allocated to each client k. |
| Input: Communication rounds T, the local model parameters from the previous round on client k, the local dataset Dk, and the gradients allocated to each client k. |
| Process: |
| 1: For t = 1,…, T do |
| 2: For each client : |
| 3: Calculate the size of the local dataset required for each client k to compute the electricity business environment indicator. |
| 4: After training on the local dataset, obtain the model parameters for this round and ccalculate the update values for the model parameters as . |
| 5: Add noise to the model parameter update values . |
| 6: Send the local training data size and the model parameter update values to the server. |
| 7: Download the allocated model update values . |
| 8: Combine the update values to obtain the final updated model parameters for this round as . |
| 9: End For |
| 10: End For |
| End of process. |
| Output: The local training data size for client k, the model parameter update values , and the updated model parameters . |
| Month | Final Score | |||
|---|---|---|---|---|
| Average Customer Outage Duration SAIDI | Average Customer Outage Frequency SAIFI | Electricity Connection Service Cost Coefficient F | ||
| 1 | 97.98 | 0.00956 | 0.0064 | 12.79 |
| 2 | 98.69 | 0.00688 | 0.0077 | 11.85 |
| 3 | 98.10 | 0.00656 | 0.0089 | 12.94 |
| 4 | 97.21 | 0.0188 | 0.017 | 12.51 |
| 5 | 95.71 | 0.0305 | 0.037 | 12.91 |
| 6 | 97.24 | 0.0207 | 0.023 | 12.00 |
| 7 | 95.97 | 0.0287 | 0.024 | 13.09 |
| 8 | 94.63 | 0.0388 | 0.046 | 13.37 |
| 9 | 95.13 | 0.0375 | 0.036 | 12.98 |
| 10 | 94.99 | 0.0409 | 0.033 | 12.81 |
| 11 | 95.06 | 0.0399 | 0.055 | 12.18 |
| 12 | 94.02 | 0.0522 | 0.0369 | 12.79 |
| Parameter | Value |
|---|---|
| Number of clients (N) | 2~100 |
| Number of federated training rounds (T) | 50 |
| Learning rate (η) | 0.005 |
| Clipping threshold (C) | 0.8 |
| Constant factor (I) | 0.5 |
| Relaxation factor (δ) | 0.6 |
| Privacy budget (ε) | 8 |
| Indicator Serial Number | Indicator | Subjective Weight | Objective Weight | Combined Weight |
|---|---|---|---|---|
| 1 | Collaborative planning and infrastructure development | 0.0962 | 0.1069 | 0.1021 |
| 2 | Regulatory inspection framework for electrical setups | 0.0836 | 0.0972 | 0.09092 |
| 3 | Ecological sustainability in power supply operations | 0.088 | 0.0884 | 0.08831 |
| 4 | KPI for monitoring service reliability and sustainability | 0.0734 | 0.0803 | 0.07712 |
| 5 | Transparency in electricity rate determination and tariff structure | 0.0863 | 0.0730 | 0.07922 |
| 6 | Online power connection request systems | 0.0822 | 0.0664 | 0.07369 |
| 7 | Average customer outage time | 0.1481 | 0.1797 | 0.1651 |
| 8 | Average frequency of customer outages | 0.1347 | 0.1283 | 0.1303 |
| 9 | Electricity Connection Service | 0.2074 | 0.1797 | 0.1925 |
| Number of Clients | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Add incentive mechanism | MAE | 0.1359 | 0.1297 | 0.1235 | 0.1173 | 0.1112 | 0.1049 | 0.0987 | 0.0924 | 0.0862 | 0.0806 |
| MSE | 0.0351 | 0.0323 | 0.0295 | 0.0267 | 0.0239 | 0.0211 | 0.0183 | 0.0155 | 0.0127 | 0.0107 | |
| RMSE | 0.1875 | 0.1778 | 0.1681 | 0.1583 | 0.1486 | 0.1389 | 0.1291 | 0.1194 | 0.1097 | 0.1009 | |
| R2 | 0.9183 | 0.9241 | 0.9298 | 0.9355 | 0.9413 | 0.947 | 0.9527 | 0.9585 | 0.9642 | 0.9637 | |
| Remove incentive mechanism | MAE | 0.1516 | 0.1449 | 0.1368 | 0.1306 | 0.1247 | 0.117 | 0.11 | 0.1023 | 0.0961 | 0.0901 |
| MSE | 0.0435 | 0.0364 | 0.0303 | 0.0301 | 0.0264 | 0.0235 | 0.0204 | 0.0174 | 0.0141 | 0.0121 | |
| RMSE | 0.2103 | 0.2002 | 0.1894 | 0.1736 | 0.1666 | 0.1536 | 0.1422 | 0.1304 | 0.1223 | 0.1125 | |
| R2 | 0.8052 | 0.8157 | 0.8308 | 0.8352 | 0.8221 | 0.8515 | 0.8434 | 0.8578 | 0.8398 | 0.8467 | |
| Data from multiple provinces were included | MAE | 0.1448 | 0.1366 | 0.1318 | 0.1254 | 0.1177 | 0.1119 | 0.1047 | 0.0973 | 0.0908 | 0.0853 |
| MSE | 0.0373 | 0.034 | 0.0311 | 0.0282 | 0.0255 | 0.0224 | 0.01938 | 0.0165 | 0.0134 | 0.0113 | |
| RMSE | 0.1991 | 0.1896 | 0.1794 | 0.1694 | 0.156 | 0.1477 | 0.1372 | 0.1278 | 0.1163 | 0.1069 | |
| R2 | 0.8618 | 0.8622 | 0.8696 | 0.8778 | 0.8896 | 0.887 | 0.9035 | 0.8986 | 0.9033 | 0.9067 | |
| Evaluation Indicator | MAE | MSE | RMSE | R2 | Computation Time | |
|---|---|---|---|---|---|---|
| Model | MLP | 0.1331 | 0.023 | 0.1522 | 0.9183 | 128.39 |
| FNN | 0.6351 | 0.732 | 0.8525 | 0.6657 | 102.58 | |
| SVR | 2.263 | 3.175 | 2.6733 | 0.5901 | 60.33 | |
| Algorithm | Fedavg | 0.1516 | 0.0351 | 0.1857 | 0.1306 | 128.39 |
| Fedprox | 0.1159 | 0.0284 | 0.1327 | 0.0301 | 174.14 | |
| Fednova | 0.1092 | 0.0264 | 0.1894 | 0.136 | 151.38 | |
| Indicator | t-Statistic | p Value |
|---|---|---|
| MAE | −5.24 | 0.0238 × 10−4 |
| MSE | −6.51 | 0.0195 × 10−5 |
| RMSE | −4.95 | 0.0682 × 10−4 |
| R2 | 2.14 | 0.036 |
| Indicator | t-Statistic | p Value |
|---|---|---|
| MAE | −4.31 | 0.163 × 10−3 |
| MSE | −7.55 | 0.011 × 10−4 |
| RMSE | −5.92 | 0.029 × 10−3 |
| R2 | 3.10 | 0.00297 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Luo, H.; Chen, S.; He, Y. A Data Protection Method for the Electricity Business Environment Based on Differential Privacy and Federal Incentive Mechanisms. Energies 2025, 18, 3403. https://doi.org/10.3390/en18133403
Zhou X, Luo H, Chen S, He Y. A Data Protection Method for the Electricity Business Environment Based on Differential Privacy and Federal Incentive Mechanisms. Energies. 2025; 18(13):3403. https://doi.org/10.3390/en18133403
Chicago/Turabian StyleZhou, Xu, Hongshan Luo, Simin Chen, and Yuling He. 2025. "A Data Protection Method for the Electricity Business Environment Based on Differential Privacy and Federal Incentive Mechanisms" Energies 18, no. 13: 3403. https://doi.org/10.3390/en18133403
APA StyleZhou, X., Luo, H., Chen, S., & He, Y. (2025). A Data Protection Method for the Electricity Business Environment Based on Differential Privacy and Federal Incentive Mechanisms. Energies, 18(13), 3403. https://doi.org/10.3390/en18133403