4.1. Dataset Description
The two datasets employed in this study originate from residential BESSs located in Europe. Each BESS is composed of six battery sub-modules, and the chemical composition of the corresponding batteries is lithium iron phosphate (LFP). Henceforth, these datasets will be referred to as Dataset 1 and Dataset 2. Both datasets present an initial sampling frequency of 10 min and include monitored variables such as current, voltage, state of charge (SOC), maximum temperature, and minimum temperature. All these variables represent system-level data obtained directly from the BESSs’ monitoring systems. The prediction objectives of this study were the overall maximum and minimum temperatures observed for the entire BESS. These system-level aggregate temperatures are critical for overall thermal management and safety assessment.
To ensure the stability of model training and the reliability of the prediction results, we preprocessed the datasets. Firstly, we conducted a check for missing values within the datasets. For the few missing data points detected, linear interpolation was employed for imputation to maintain the continuity of the time series. Secondly, considering that sensors in practical deployments may produce anomalous readings, we utilized the local outlier factor (LOF) detection algorithm to identify potential outliers in the data [
29]. The LOF algorithm assesses whether a data point is an outlier by calculating the density difference between the point in question and other data points within its neighborhood. Data points identified as outliers by the LOF algorithm were subsequently corrected using linear interpolation in order to mitigate the negative impact of noisy data on model performance.
The raw data spans the period from January 2020 to December 2020. Considering the substantial volume of the original 10 min sampling frequency data and to facilitate efficient model training and evaluation within available computational resources, we downsampled the original 10 min data to 1 h intervals by taking the average. While this approach may smooth out very rapid, sub-hourly thermal transients, the predictive objective of this research was to capture hour-level temperature changes over the upcoming day or multiple days, aiming to provide decision support for BESS thermal management. In this application context, 1 h temporal granularity is more suitable for capturing the dominant daily cycles and key heat accumulation or dissipation trends.
For the subsequent experiments, the data was partitioned such that the first 70% constituted the training set, the following 10% served as the validation set, and the remaining 20% formed the test set. The datasets were standardized; the mean and variance for this standardization were derived from the training set and subsequently applied to the training, validation, and test sets.
4.2. Setup of the Experiments
To evaluate the model’s performance, we adopted three evaluation metrics. In addition to the MSE metric used in the loss function, mean absolute error (MAE) and Root mean square error (RMSE) were also selected. The ways in which they are calculated are presented below:
To validate the effectiveness of the proposed model in regard to BESS temperature prediction, we compared it with the following models: Transformer [
25], Informer [
30], iTransformer [
31], patch time series Transformer (PatchTST) [
23], and time series Transformer with exogenous variables (TimeXer) [
32]. Transformers are classic attention-based models widely applied in various time series forecasting tasks. The Informer model, building upon the Transformer model, introduces improvements to the self-attention mechanism and the encoder–decoder architecture. In contrast, iTransformer, PatchTST, and TimeXer focus their enhancements more on the processing and embedding of time series data.
The aforementioned algorithms were all implemented based on Python 3.9 and PyTorch 2.3.0. They were executed on a computer equipped with a Windows 10 operating system, an Intel
® Core™ i9-10980XE CPU @ 3.00 GHz, and an Nvidia GeForce RTX 3090 GPU. The source code for the comparative models was obtained from the time series library (TSLib) [
24]. The hyperparameters for each model were tuned based on their performance with respect to a dedicated validation set, with the aim of identifying a reasonable and competitive configuration for every model. To ensure the stability and reproducibility of the experimental results and mitigate the impact of randomness, each model in the experimental section was independently run five times with different random seeds. The performance metrics ultimately reported are the means and standard deviations of the results from these five runs.
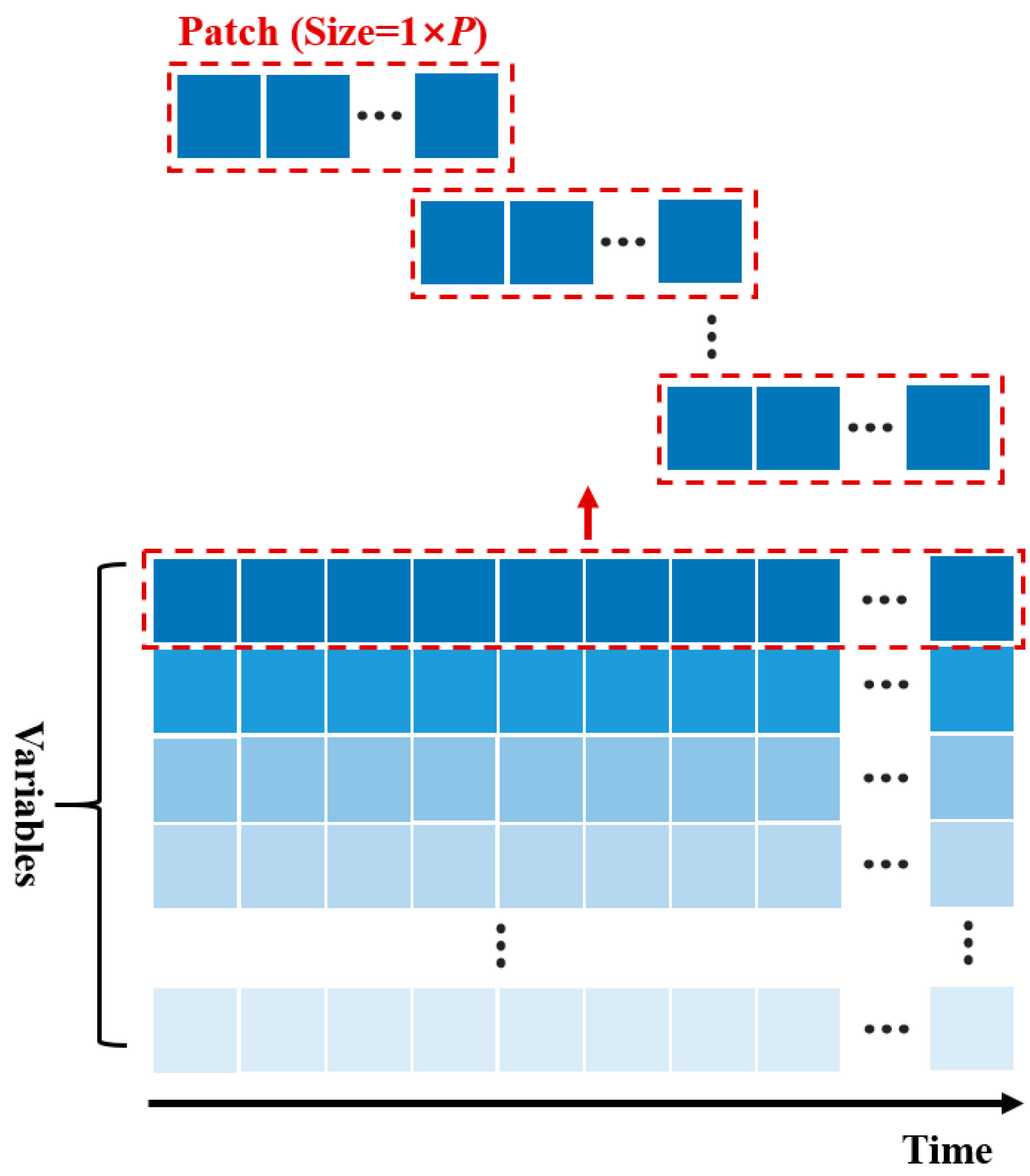
In the experimental setup, the target variables were designated as the maximum and minimum temperatures, while the covariates included current, voltage, and SOC. It should be noted that the method proposed in this paper also treats vectorized timestamps as covariates, whereas other comparative models employ their own respective methods for processing timestamp information. In the experiments, we utilized data from the preceding 7 days to predict data for the subsequent 1, 2, and 3 days; i.e., the look-back window length was 24 × 7 h, and the prediction horizon lengths were 24, 24 × 2, and 24 × 3 h, respectively. All the models adopted an input–output overlapping strategy similar to that pertaining to the Informer [
30], and the normalization method proposed for Non-Stationary Transformers [
33] was also applied to all the models to enhance performance.
To mitigate model overfitting, we adopted an early-stopping strategy during the training process. Specifically, the model’s performance regarding the validation set was continuously monitored. If no improvement in validation performance was observed over five consecutive training epochs, the training process was terminated, and the model parameters that yielded the best performance with respect to the validation set were preserved. This method facilitates halting the training when the model reaches its optimal generalization capability, thus preventing overfitting to the training data.
4.3. Comparative Experiments for Classic 24-Hour Prediction
We initially conducted comparative experiments focusing on the classic 24 h prediction horizon. The CNN block established herein is capable of extracting multi-scale periodic features from long historical look-back windows. However, for some models, such long look-back windows might introduce irrelevant reference information, increasing their processing burden and potentially impacting their accuracy. Considering these factors, for each comparative model, in addition to evaluating performance with the 24 × 7 sampling point look-back window, we also conducted experiments by truncating data from the end of this window to construct new, shorter look-back windows. This approach was employed to ensure that each comparative method could be evaluated with a more appropriate look-back length. The final test results for the two datasets are presented in
Table 2 and
Table 3, respectively, wherein all metrics are reported as the means ± standard deviations over five runs.
Based on the metrics presented in
Table 2, the algorithm proposed in this paper achieved the best test results, and its stability was also extremely high. iTransformer and PatchTST, when using a look-back window truncated to 24 × 5, obtained close tests results, which were second-best overall; the average values of the evaluation metrics for iTransformer were slightly better than those for PatchTST, but the former’s stability was slightly lower. Furthermore, when iTransformer and PatchTST employed a 24 × 7 look-back window, their metrics did not significantly degrade from their respective best performances. This may be attributed to iTransformer’s ability to effectively integrate inter-variable correlations and PatchTST’s proficiency in handling local temporal features.
As for TimeXer, its prediction performance with look-back window lengths of 24 × 5 and 24 × 7 was slightly superior to that with windows of 24 × 1 and 24 × 3; however, overall, the average values of its prediction metrics were poorer. When the look-back window was truncated to 24 × 1, both the Transformer and Informer models achieved their respective best prediction results. When longer look-back windows were employed, the stability of the Transformer and Informer models significantly deteriorated. This suggests that when processing longer look-back windows, their performance might be adversely affected by the introduction of irrelevant reference information.
According to
Table 3, the experiments conducted on Dataset 2 demonstrate that the proposed algorithm again achieved the best test performance. Unlike the experiments conducted on Dataset 1, both the Informer and TimeXer models obtained their respective best average test metrics when the look-back window was truncated to 24 × 1, while the remaining models achieved their respective best average test metrics with a look-back window length of 24 × 7. This result may be attributed to differences between the two datasets. As in the experiments conducted on Dataset 1, iTransformer and PatchTST once again achieved test performances ranking second only to the proposed model, whereas the Transformer and Informer models yielded poorer metrics and exhibited lower stability. This could be attributed to the different perspectives from which each model analyzes the characteristics of time series data.
To provide a more intuitive demonstration of the proposed method’s performance in BESS temperature prediction, we present, using Dataset 1 as an example, plots of the predicted time series curves for each model under the same random seed. For the comparative models, the look-back window lengths that achieved their best average prediction metrics, as reported in
Table 2, were utilized. Due to the large quantity of data,
Figure 4 illustrates only a segment of these data.
As can be seen from
Figure 4, for 1-step-ahead prediction, the proposed method demonstrates excellent tracking between predicted and actual values. During minor data fluctuations, the predicted and actual values align closely, and the method responds quite sensitively to local data variations. However, at higher peak values, the proposed method tends to underestimate these peaks; nevertheless, these errors remain around approximately 2 °C, which is within an acceptable range.
The Transformer model performed poorly in predicting minor fluctuations and was sluggish in responding to minor local changes. It exhibited significant prediction bias around the 0th to 20th sampling points and near the 170th to 220th sampling points. The Informer model also showed notable prediction bias around the 5th to 20th sampling points and near the 170th to 210th sampling points, which may be indicative of the poorer results obtained by the Transformer and Informer models shown in
Table 2. The iTransformer model also exhibited sensitivity to local changes, but it underestimated many minor peaks. PatchTST also demonstrated sensitivity to local data variations, a characteristic closely related to its excellent ability to extract local temporal features. However, its underestimation of some peaks is more pronounced than that of the proposed method. Although TimeXer can capture local data fluctuations reasonably well, its overall estimations of numerical values at each sampling point are generally poor.
To provide a more comprehensive evaluation of each model’s prediction performance for the upcoming 24 h of data, we present, using Dataset 1 as an example, box plots of the prediction errors for each model at every time step within the prediction window. Detailed information is shown in
Figure 5. To ensure the clarity and conciseness of the subplots, outliers are not displayed in the figure.
According to
Figure 5, the median prediction error of the proposed method is close to zero across all time steps, indicating that the model exhibits low systematic bias in temperature prediction. As the prediction horizon increases, the interquartile range (IQR) and the length of the whiskers gradually increase, stabilizing after the fifth time step. The error distribution remains relatively stable and compact. The whisker tips are situated around ±2 °C, which is within an acceptable range.
The median prediction error of the Transformer model is slightly above zero at almost all time steps, indicating a systematic overestimation in its predictions; this overestimation appears more pronounced in the prediction of the maximum temperature. The IQR and whisker length also gradually increase with the prediction step, and the error dispersion for the Transformer model is slightly greater than that for the proposed method. The Informer model’s errors are relatively compact before the sixth prediction step; however, its predictions exhibit systematic overestimation. The median prediction error of the iTransformer model consistently stays near zero, indicating it has minimal systematic prediction bias. However, the compactness of its errors at later time steps is slightly inferior to that of the proposed method. The median prediction error of the PatchTST model is also relatively close to zero, exhibiting low systematic prediction bias, while the compactness of its errors at later time steps is inferior to that of the proposed method. The median prediction error of the TimeXer model remains near zero; however, the dispersion of its errors at earlier time steps is noticeably higher than that of other models. This aligns with the prediction performance depicted in
Figure 4. Overall, the magnitude of its errors is slightly higher than that of the other models.
Furthermore, the optimal results reported for the aforementioned comparative models in the 24-step prediction experiments were achieved after experimenting with various truncated look-back windows. In practical application scenarios where future label data is unavailable, the process of obtaining different results from multiple predictions could inherently introduce interference for decision-makers, making it difficult for them to determine which result is the most reliable. In contrast, the method proposed in this paper only requires accepting the long look-back window directly, and it can automatically extract its multi-scale periodic features and local temporal characteristics, thereby minimizing such interference for decision-makers.
In summary, it can be asserted that the method proposed in this paper not only demonstrates commendable accuracy and prediction stability in the comparative experiments but is also more suitable for providing a reliable basis for decision-making in practical scenarios.
4.4. Comparative Experiments for Other Prediction Horizons
To evaluate the performance of the proposed model under different prediction horizon scenarios, we conducted comparative experiments for 48 h and 72 h predictions. Similar to the classic 24 h prediction, for each comparative model, in addition to evaluating performance using a look-back window of 24 × 7 sampling points, we also conducted experiments by truncating data from the end of this window to construct new, shorter look-back windows. For the 48 h prediction experiments, the final test results for the two datasets are presented in
Table 4 and
Table 5, respectively. Similarly, for the 72 h prediction experiments, the results for the two datasets are shown in
Table 6 and
Table 7, respectively. All metrics in these tables are also reported as the means ± standard deviations over five runs.
According to
Table 4 and
Table 5, the proposed model continued to achieve the best test results, and its stability also remained high. As with the classic 24 h prediction, iTransformer and PatchTST still yielded good test results, and their overall performances were comparable. The stability of the Transformer and Informer models was also relatively poor. TimeXer, on the other hand, yielded moderate performance overall.
In
Table 2,
Table 3,
Table 4 and
Table 5, it can be observed that as the prediction horizon increased, the prediction performance of all the models declined, which aligns with the general pattern in time series forecasting. When the prediction time was extended from 24 h to 48 h, for Dataset 1, the average MSE, MAE, and RMSE values of the proposed model degraded by 14.56%, 8.12%, and 7.03%, respectively. The three average metrics for iTransformer at its best performance degraded by 22.63%, 12.04%, and 10.74%, respectively, and those for PatchTST at its best performance degraded by 20.87%, 12.21%, and 9.94%, respectively. For Dataset 2, the average MSE, MAE, and RMSE values of the proposed model degraded by 28.34%, 15.64%, and 13.29%, respectively. The three average metrics for iTransformer at its best performance degraded by 33.79%, 17.07%, and 15.67%, respectively, while those for PatchTST at its best performance degraded by 33.69%, 18.55%, and 15.62%, respectively.
According to
Table 6 and
Table 7, the proposed model continued to achieve the best average evaluation metrics, and its stability also remained at a high level. After the prediction horizon was extended from 24 h to 72 h, for Dataset 1, the average MSE, MAE, and RMSE values of the proposed model degraded by 25.29%, 14.19%, and 11.93%, respectively. The three average metrics for iTransformer at its best performance degraded by 39.83%, 22.59%, and 18.25%, respectively, while those for PatchTST at its best performance degraded by 33.38%, 18.35%, and 15.49%, respectively. For Dataset 2, the average MSE, MAE, and RMSE values of the proposed model degraded by 43.31%, 23.50%, and 19.71%, respectively. The three average metrics for iTransformer at its best performance degraded by 53.35%, 25.88%, and 23.83%, respectively, while those for PatchTST at its best performance degraded by 50.98%, 26.95%, and 22.88%, respectively.
Based on the metrics, iTransformer and PatchTST were consistently strong competitors with respect to the model proposed in this paper. However, iTransformer primarily focuses on the overall characteristics of the time series and the correlations between monitored variables, whereas PatchTST places greater emphasis on local variations within the time series. The model proposed in this paper can concurrently address inter-variable correlations, the multi-scale periodic characteristics of time series, and local variations within time series. Consequently, the model described herein consistently achieved the best results in terms of evaluation metrics. Furthermore, the aforementioned figures regarding the degree of model degradation also indicate that when the prediction horizon lengthens, the performance decay exhibited by the algorithm proposed in this paper is significantly less than that of iTransformer and PatchTST. This further demonstrates the superiority of the model described in this paper in handling prediction tasks of varying lengths.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}