
Exploration of the Ignition Delay Time of RP-3 Fuel Using the Artificial Bee Colony Algorithm in a Machine Learning Framework

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection and Preparation
2.2. BP Neural Network Algorithm
- (1)
- Random sampling of hidden layer neuron counts: For each hidden layer, the number of neurons is randomly sampled from five predefined intervals: [5–15], [15–25], [25–35], [35–45], and [45–55].
- (2)
- Randomized activation function combinations: The candidate activation functions include tansig (hyperbolic tangent), logsig (logarithmic sigmoid), and purelin (linear function). In each training session, activation functions for the hidden and output layers are randomly assigned to allow flexible adjustment of the model’s nonlinear mapping capability. This strategy is particularly effective in multi-hidden-layer architectures, where it alleviates the limitations associated with single activation functions and enhances overall prediction performance.
- (3)
- Random perturbation of weight and bias initialization: Network weights and biases are initialized using different random seeds, and each structure undergoes multiple training runs. A model is considered to have good generalization performance if it achieves a coefficient of determination (R2) greater than 0.95, mean absolute error (MAE) less than 0.1, mean absolute percentage error (MAPE) below 4%, and root mean square error (RMSE) below 0.1. Based on these criteria, models are filtered and the configuration with the best generalization performance—according to R2, MAE, MAPE, and RMSE—is selected as the candidate model.
2.3. Gradient Descent Algorithm
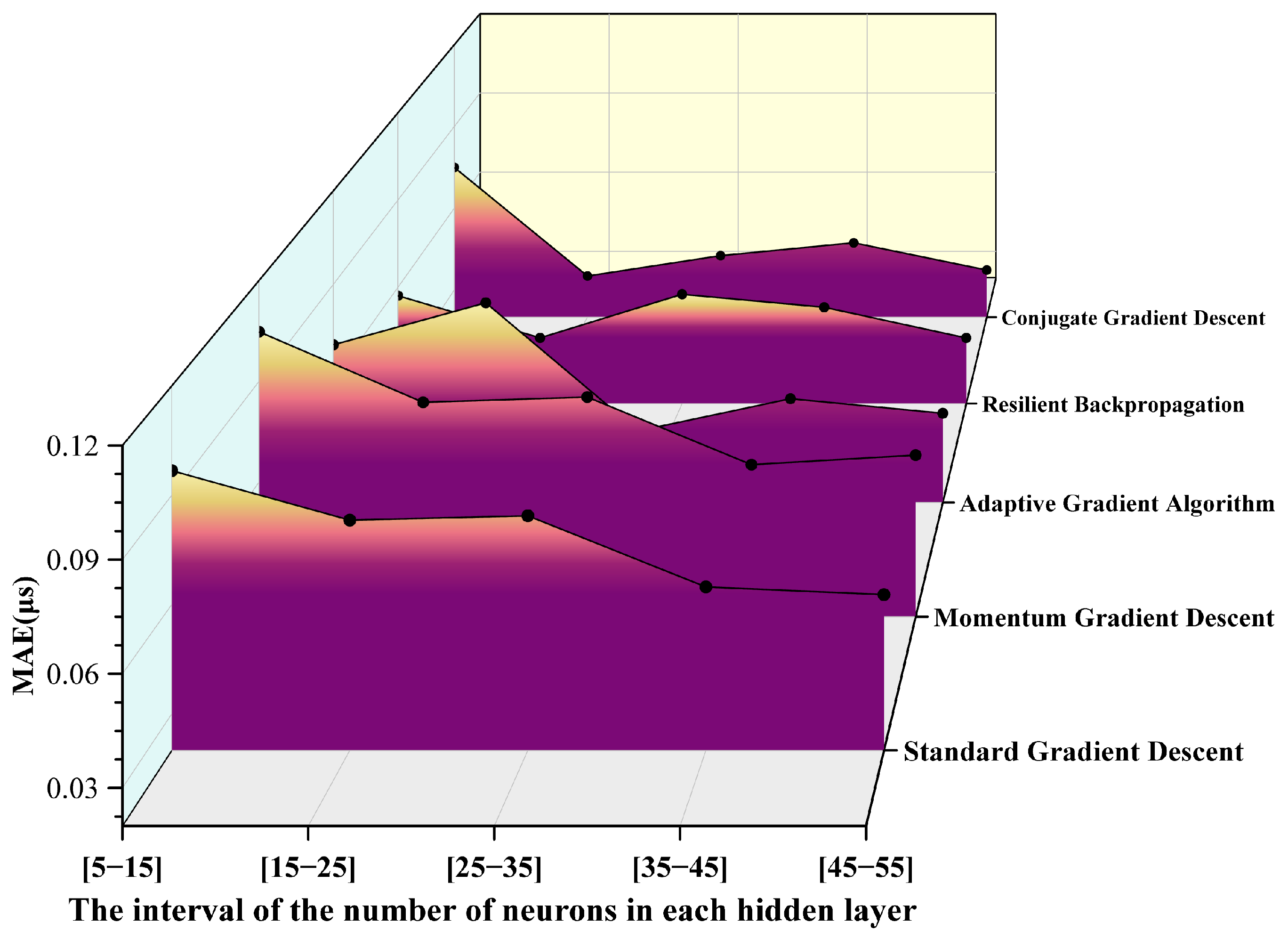
- Standard Gradient Descent (SGD)
- 2.
- Momentum Gradient Descent (MGD)
- 3.
- Adaptive Gradient Algorithm (AGA)
- 4.
- Resilient Backpropagation (RPROP)
- 5.
- Conjugate Gradient Descent (CGD)
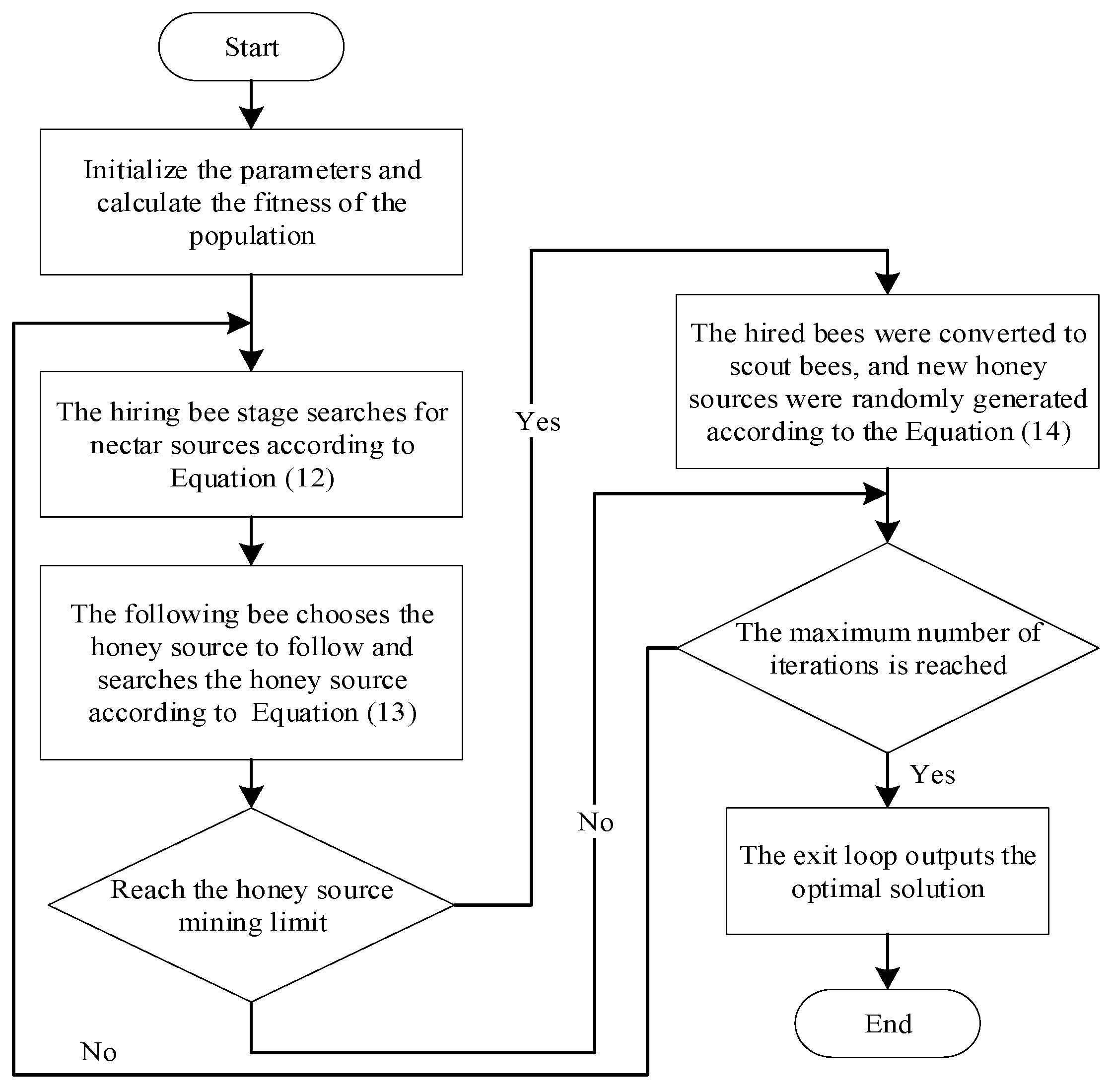
2.4. Artificial Bee Colony Algorithm
2.5. Evaluation of Models
3. Results
3.1. Determination of Hyperparameter Ranges
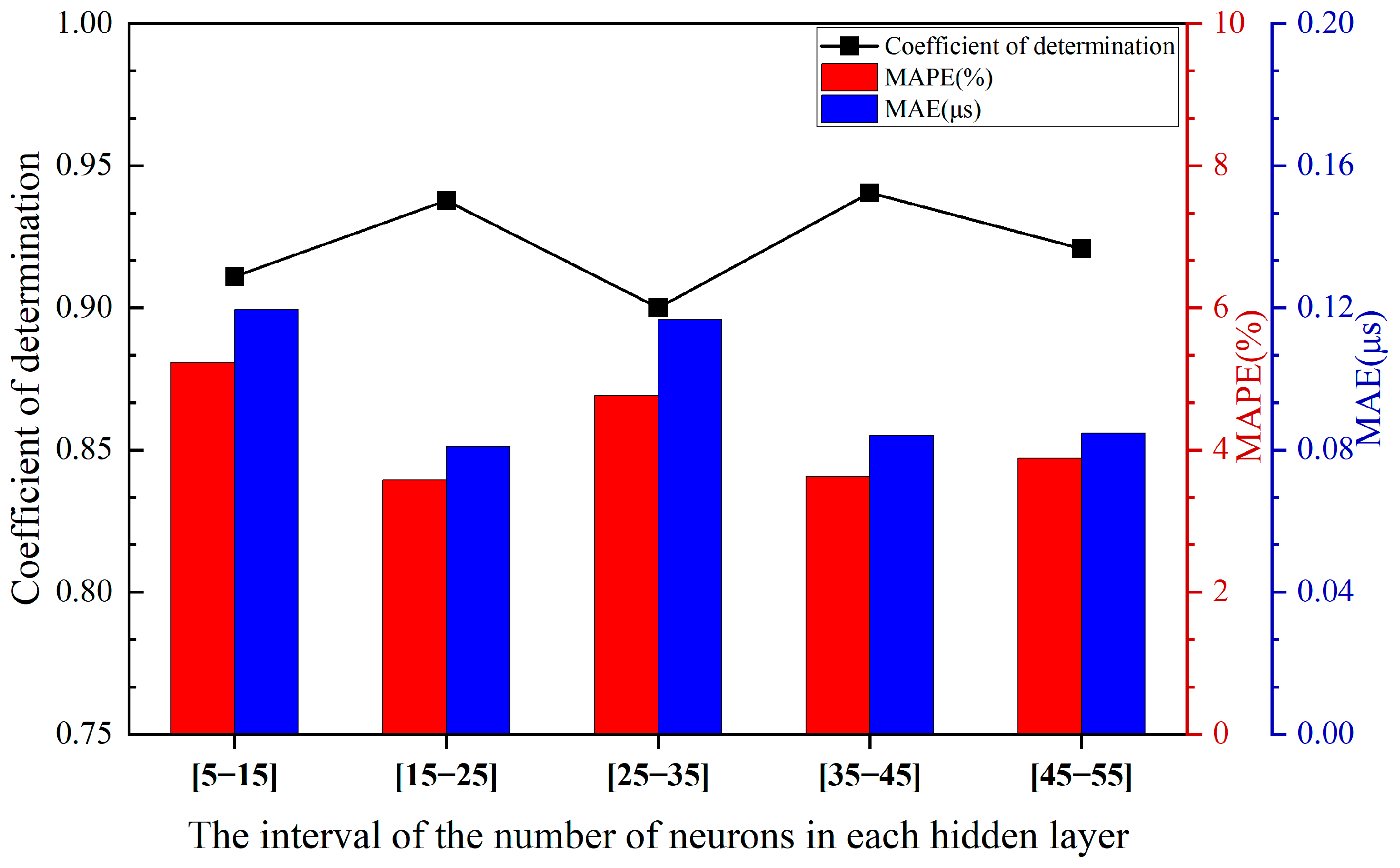
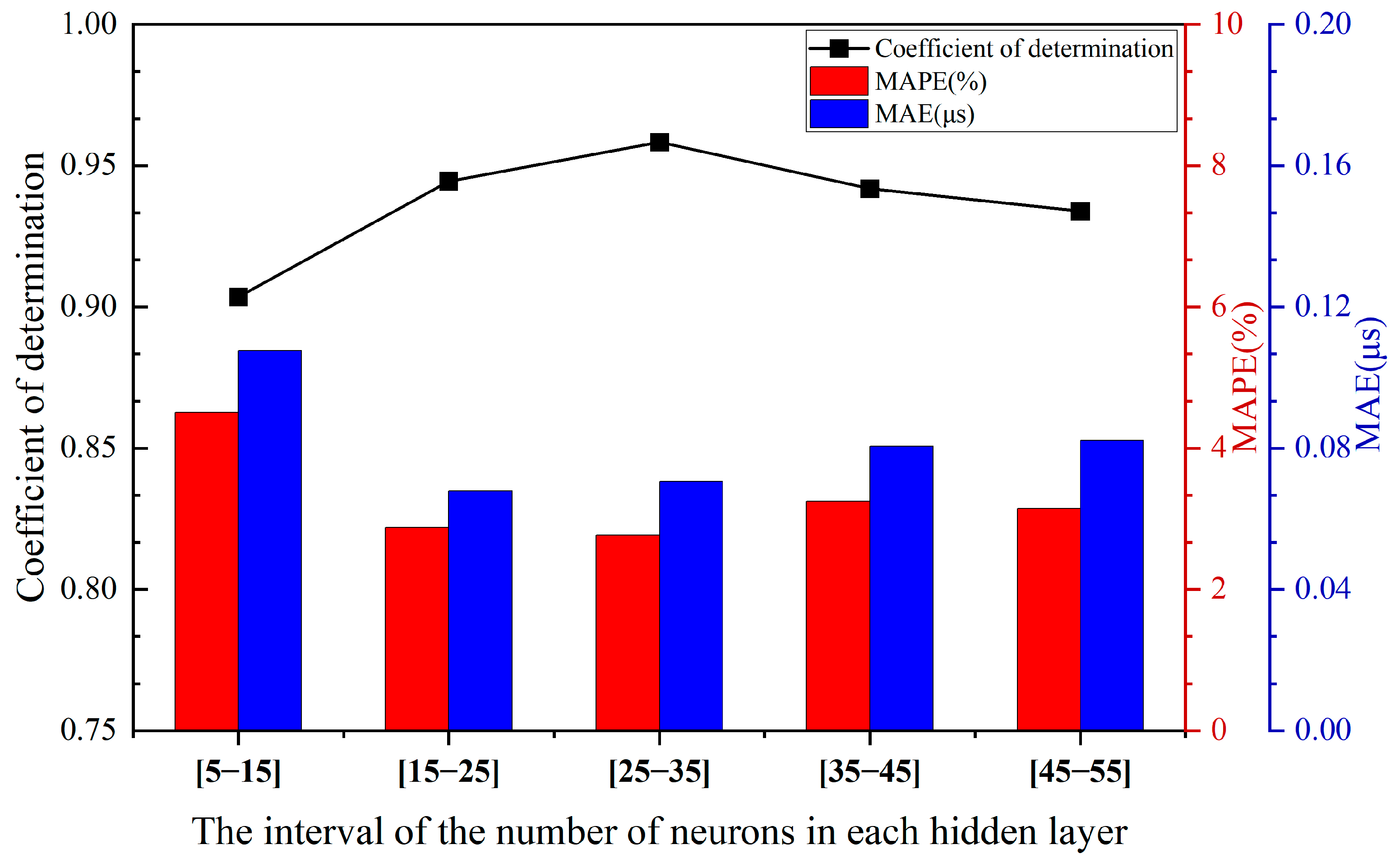
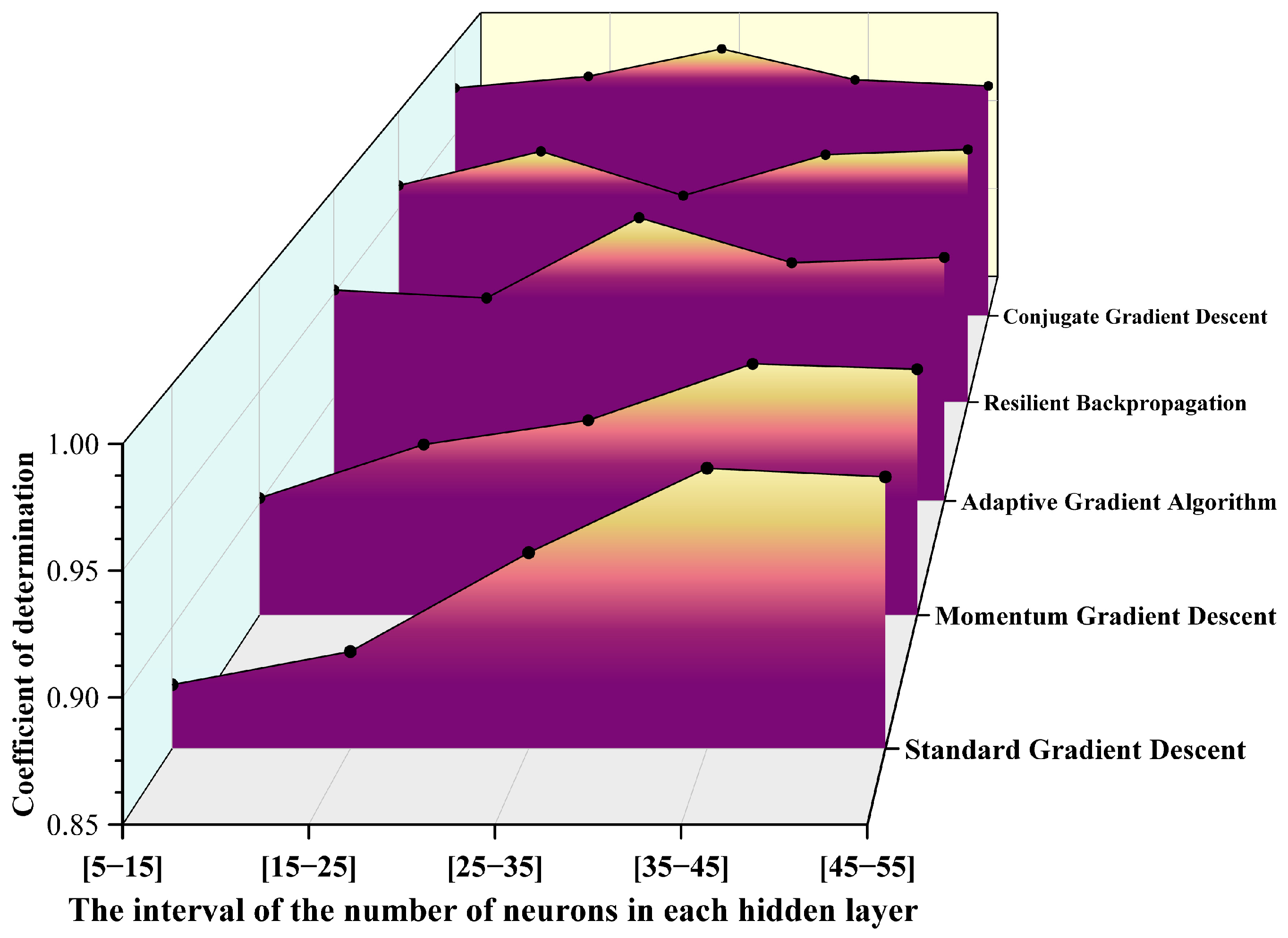
3.1.1. Determination of the Optimal Hidden Layer
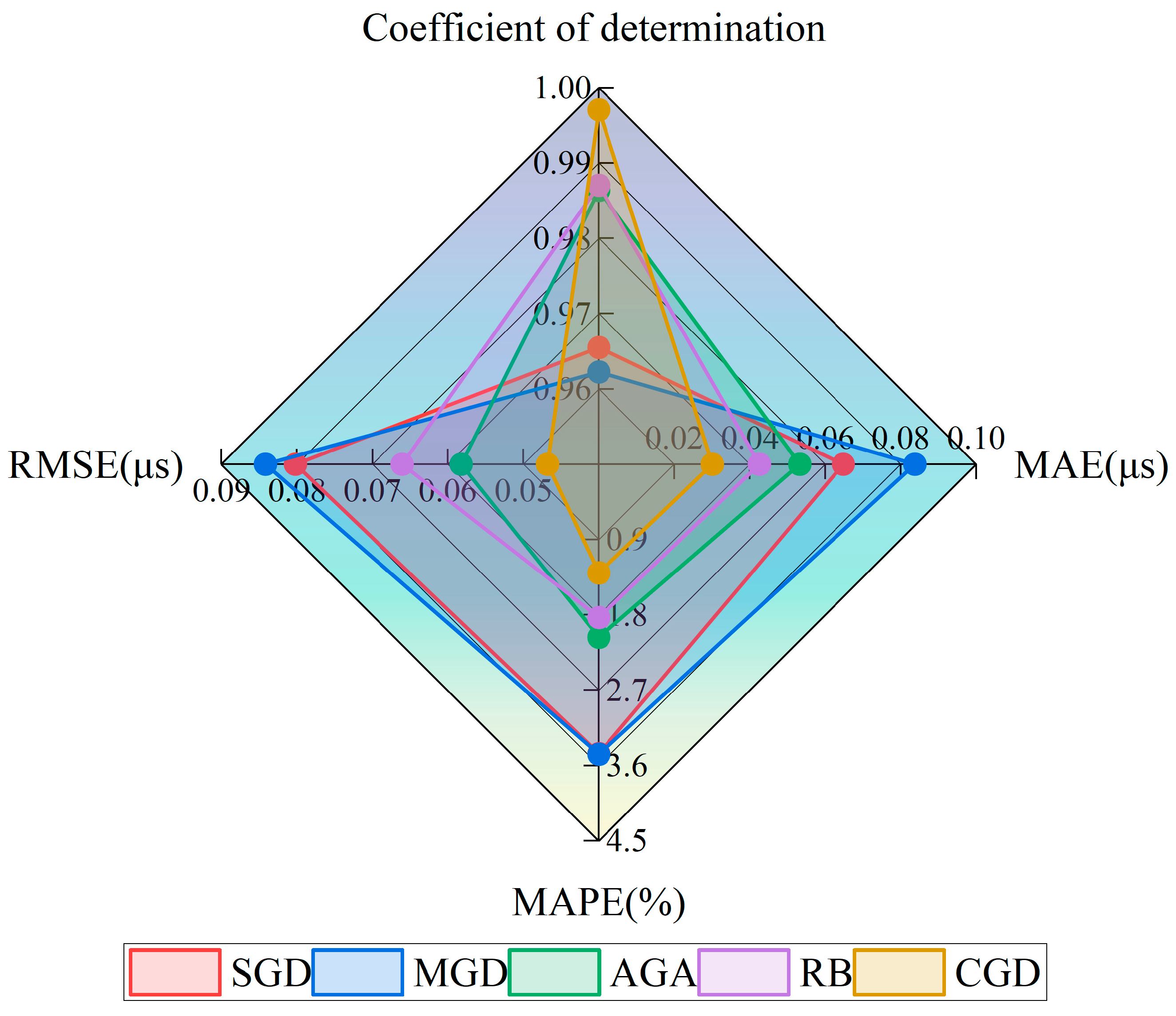
3.1.2. Neural Networks Founded on Diverse Gradient Descent Algorithms
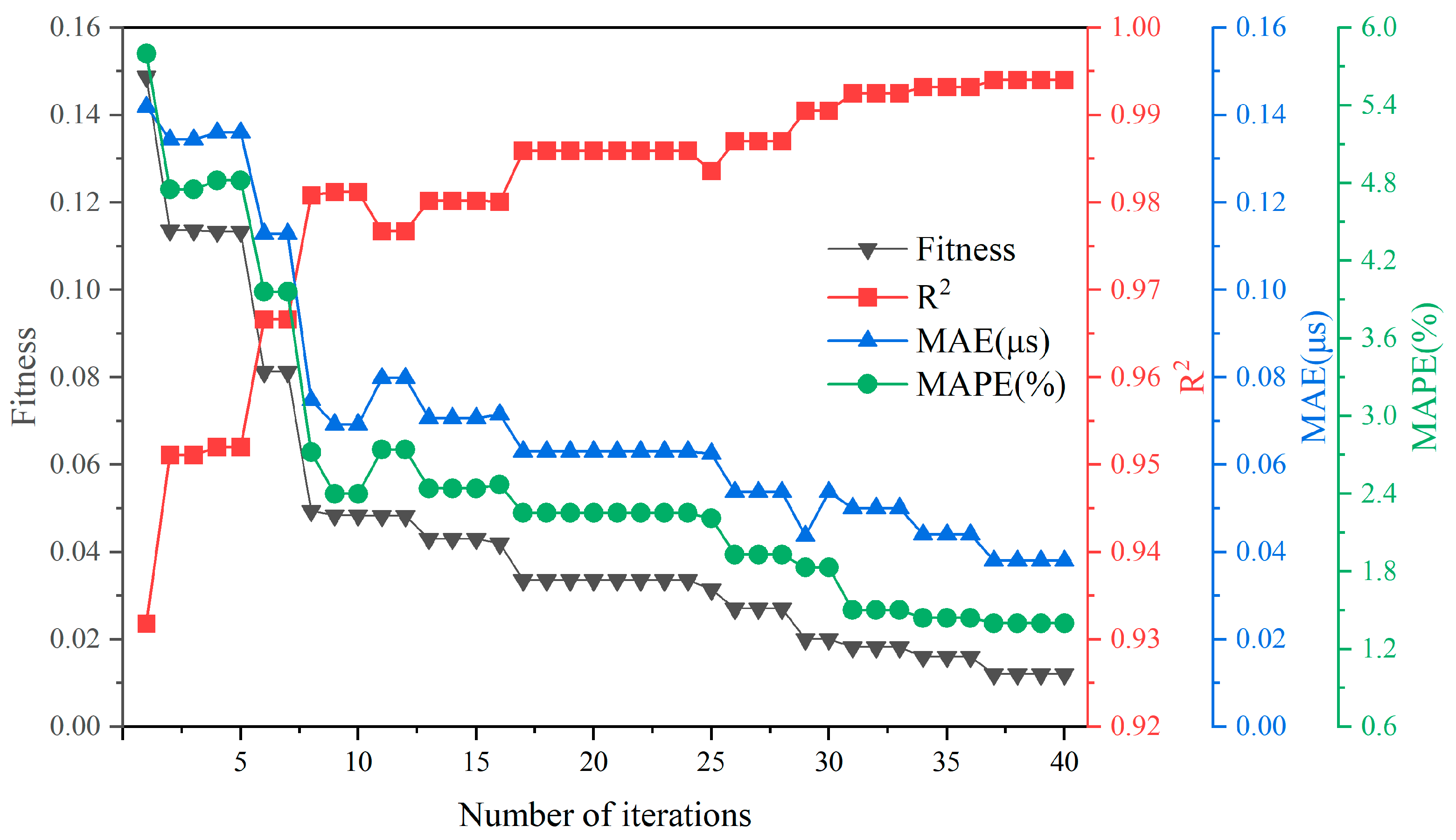
3.2. Optimization Using the Artificial Bee Colony Algorithm
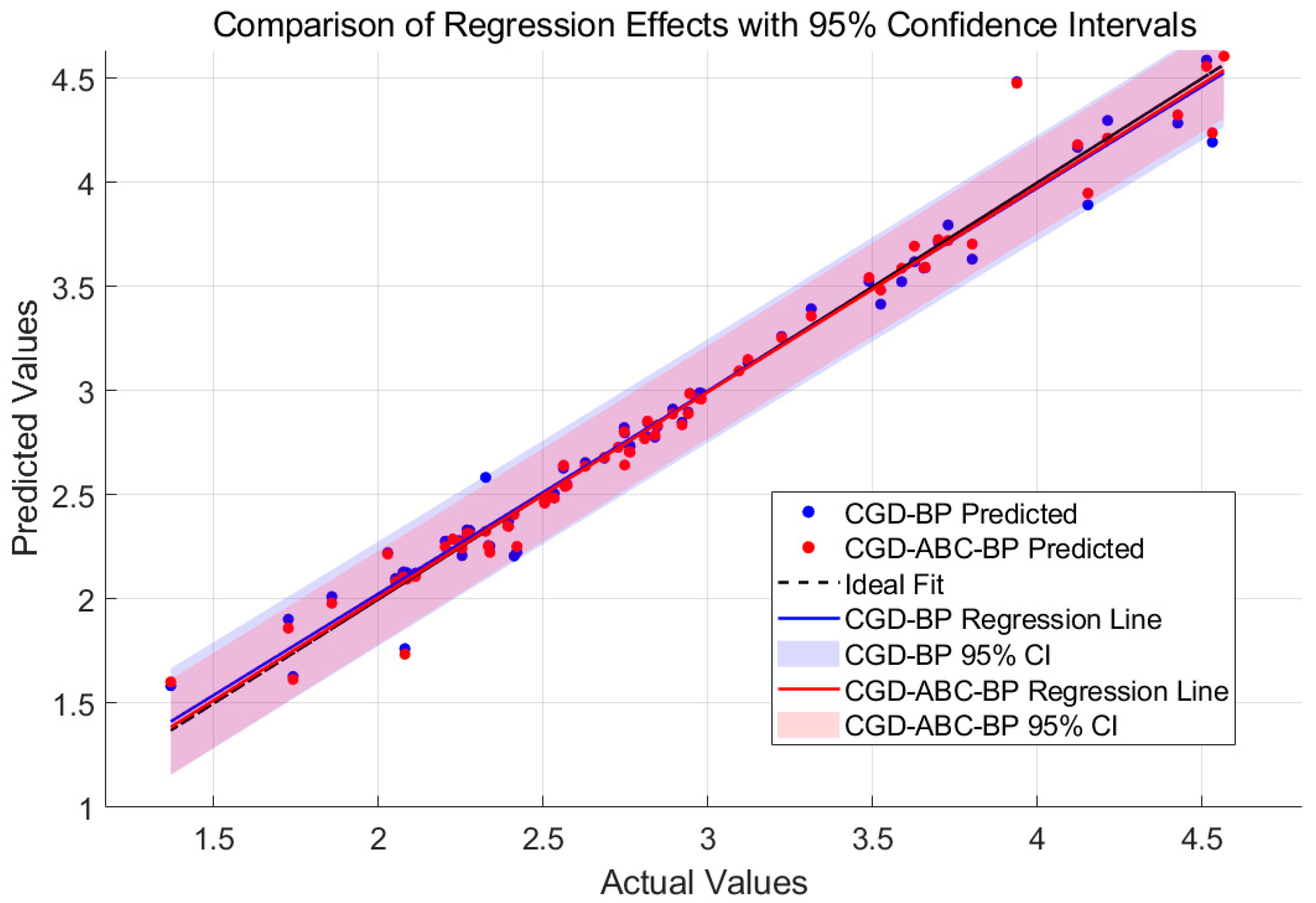
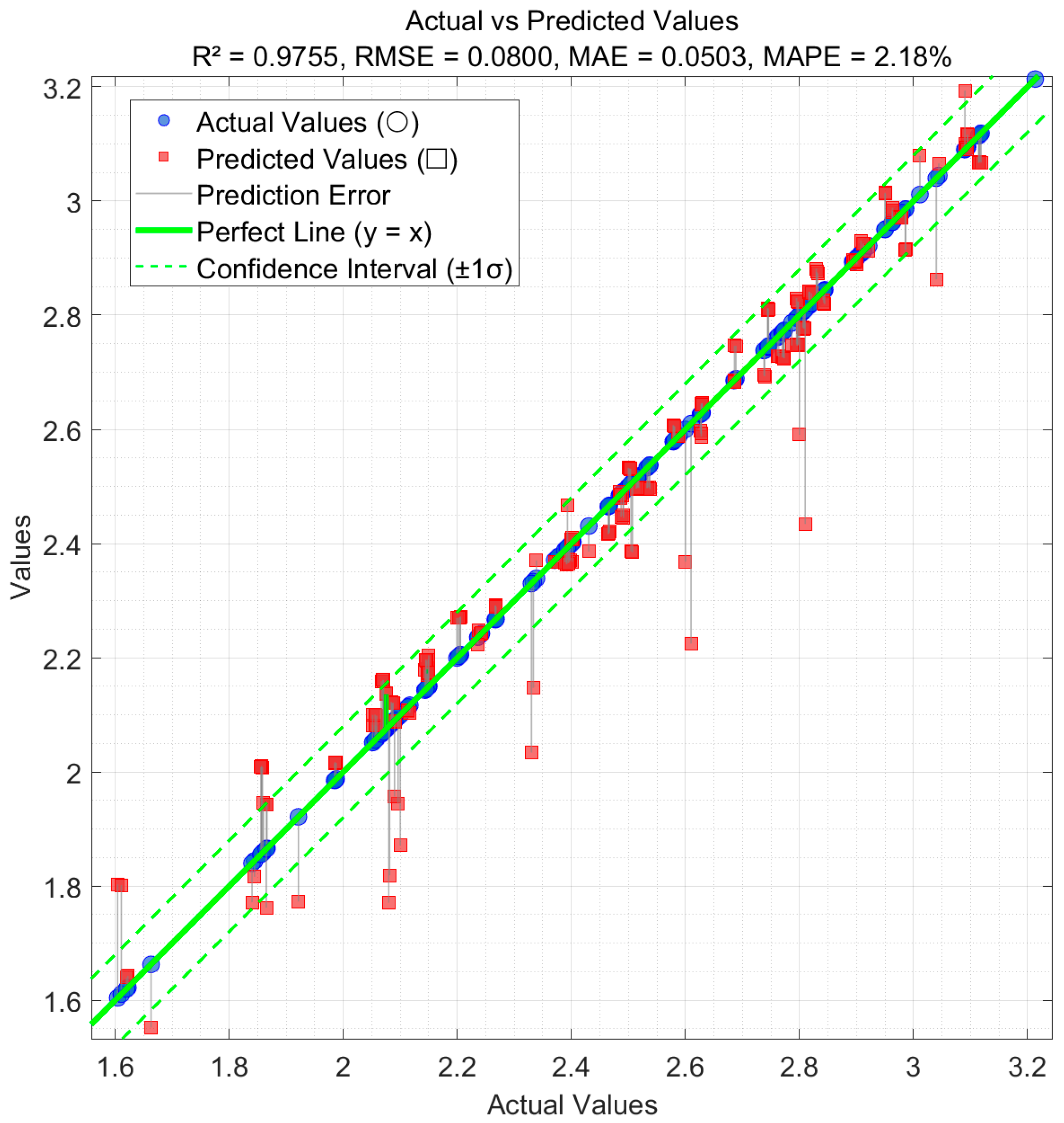
3.3. Evaluation of Model Prediction Effect
3.3.1. The Predictive Performance of the Model
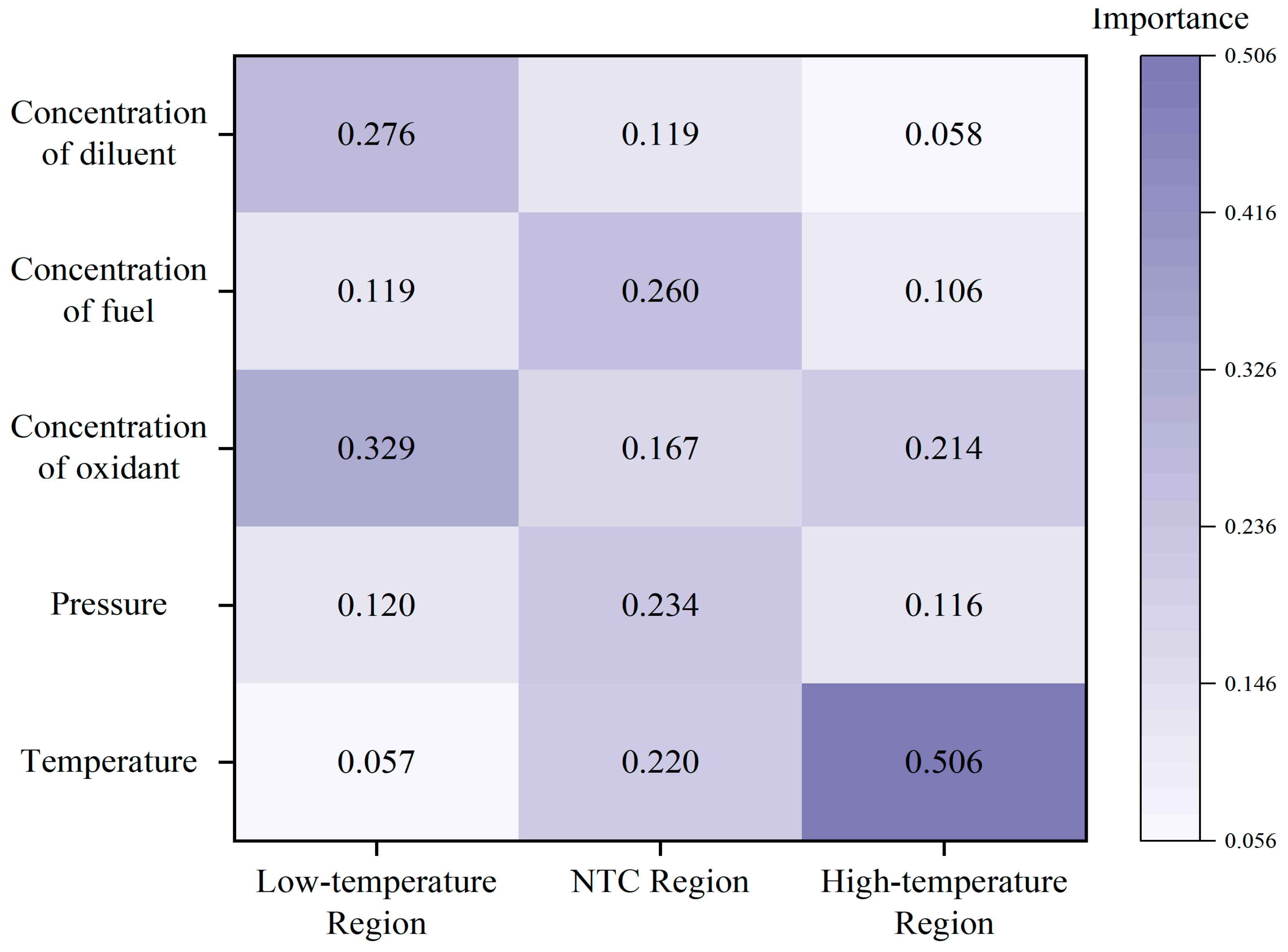
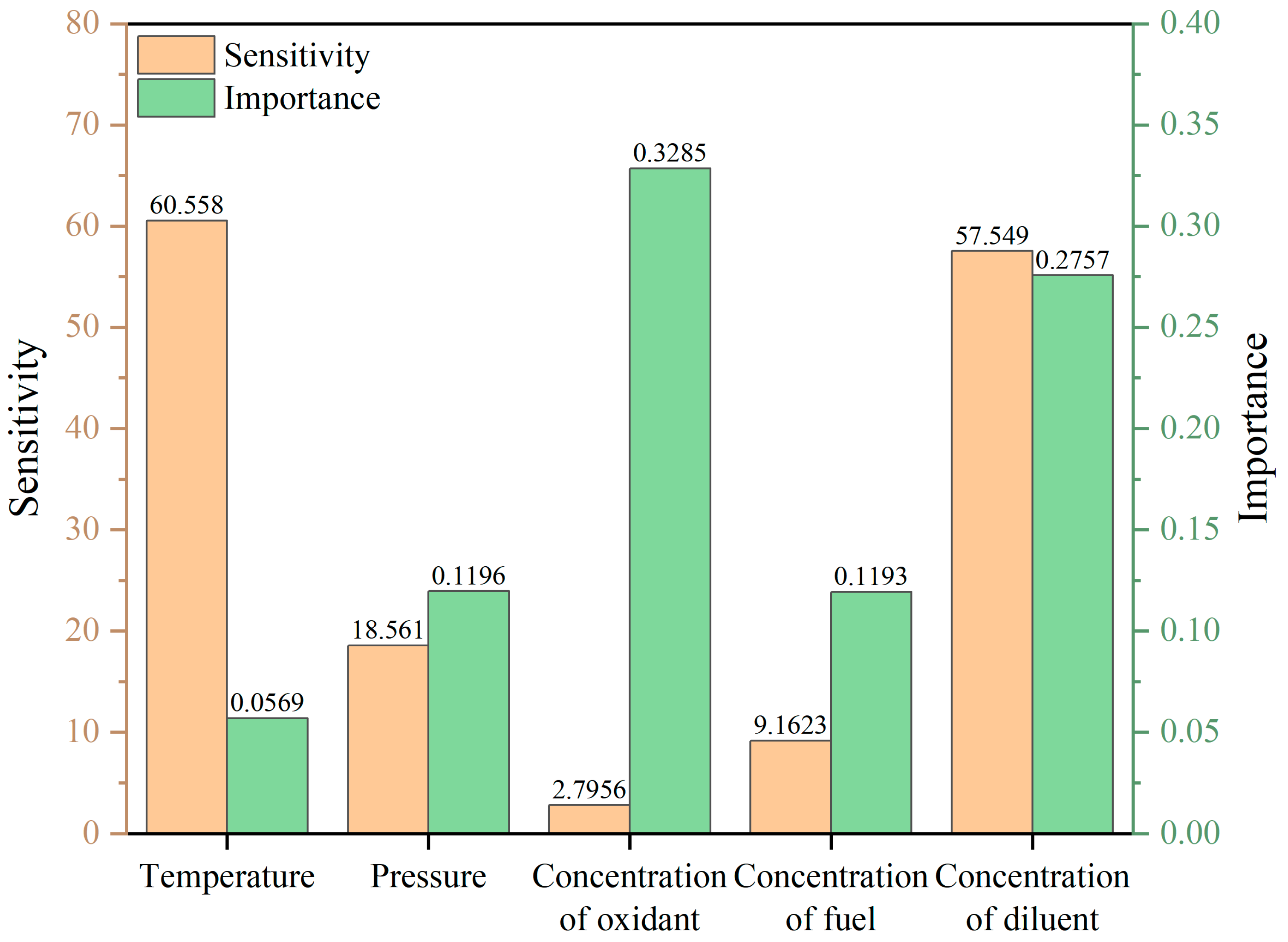
3.3.2. Importance and Sensitivity Analysis
4. Discussion
- Within a five-input, one-output BP neural network framework, a multi-stage optimization model was developed by integrating randomized initialization, conjugate gradient descent (CGD), the artificial bee colony (ABC) algorithm, and L2 regularization. Based on 30 resampling trials, the model achieved average performance metrics of R2 = 0.994 ± 0.001, MAE = 0.04 ± 0.015, MAPE = 1.4 ± 0.05%, and RMSE = 0.07 ± 0.01, demonstrating excellent fitting capability on internal data and structural stability.
- Under various equivalence ratios (φ = 1.0, 1.5, 2.0) and pressure conditions (10–20 bar), the prediction outcomes exhibit high consistency with the experimental results. Notably, in scenarios with moderate equivalence ratios and low-to-medium pressure levels, the predicted points were almost perfectly aligned with the actual measurements. These results highlight the model’s good generalization and robustness in predicting the ignition delay time of RP-3 aviation kerosene. On a completely independent external test set, the model still achieved high accuracy with R2 = 0.9755 and MAPE = 2.18%, further confirming its generalization capability and engineering feasibility. However, its cross-fuel applicability and consistency across different experimental setups require further validation using larger-scale, multi-source datasets.
- In the low-temperature region, the diluent mole fraction exhibited an importance score of 0.2757 and a sensitivity of −57.549, while temperature showed a higher sensitivity (−60.558) but lower importance (0.0569). In the NTC region, temperature had an importance of 0.2195 and a sensitivity of −145.6, while the diluent displayed the highest sensitivity (−140.5). In the high-temperature region, temperature dominated with an importance of 0.5057 and a sensitivity of −201.86. These trends are consistent with well-established combustion kinetic mechanisms, indicating that the model possesses a degree of physical interpretability.
- The current model relies on five macroscopic input features and does not incorporate additional variables. Due to the scarcity of experimental data in extremely fuel-rich (φ > 2.0) and ultra-high-pressure (p > 20 bar) conditions, model extrapolation in these regimes carries a degree of uncertainty. Moreover, the model is specifically trained on RP-3 fuel, and its applicability to alternative fuels or multi-component mixtures remains unverified.
- Future work will focus on integrating the current framework with other machine learning techniques, incorporating input perturbation analysis and explainability tools such as SHAP and LIME, and extending its generalizability through multi-fuel transfer learning strategies.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IDT | Ignition Delay Time |
| BP | Backpropagation |
| R2 | Coefficient of Determination |
| MAPE | Mean Absolute Percentage Error |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| MSE | Mean Squared Error |
| φ | Equivalence Ratios |
| P | Pressure |
| NTC | Negative Temperature Coefficient |
| CVCB | Constant Volume Combustion Bomb |
| RCM | Rapid Compression Machine |
| LIF | Laser-Induced Fluorescence |
| DNN | Deep feedforward Neural Network |
| RF | Random Forest |
| SVM | Support Vector Machine |
| CNNs | Convolutional Neural Networks |
| LSTMs | Long Short-Term Memory Networks |
| SHAP | SHapley Additive exPlanations |
| SGD | Standard Gradient Descent |
| MGD | Momentum Gradient Descent |
| AGA | Adaptive Gradient Algorithm |
| RPROP | Resilient Backpropagation |
| CGD | Conjugate Gradient Descent |
| ABC | Artificial Bee Colony |
| GD | Gradient Descent |
References
- Zeng, W.; Zou, C.; Yan, T.; Lin, Q.; Dai, L.; Liu, J.; Song, Y. High-temperature ignition of ammonia/methyl isopropyl ketone: A shock tube experiment and a kinetic model. Combust. Flame 2025, 276, 114004. [Google Scholar] [CrossRef]
- Dai, L.; Liu, J.; Zou, C.; Lin, Q.; Jiang, T.; Peng, C. Shock tube experiments and numerical study on ignition delay times of ammonia/oxymethylene ether-2 (OME2) mixtures. Combust. Flame 2024, 270, 113783. [Google Scholar] [CrossRef]
- Lin, Q.; Zou, C.; Dai, L. High temperature ignition of ammonia/di-isopropyl ketone: A detailed kinetic model and a shock tube experiment. Combust. Flame 2023, 251, 112692. [Google Scholar] [CrossRef]
- Qu, Y.; Zou, C.; Xia, W.; Lin, Q.; Yang, J.; Lu, L.; Yu, Y. Shock tube experiments and numerical study on ignition delay times of ethane in super lean and ultra-lean combustion. Combust. Flame 2022, 246, 112462. [Google Scholar] [CrossRef]
- Reyes, M.; Tinaut, F.V.; Andrés, C.; Pérez, A. A method to determine ignition delay times for Diesel surrogate fuels from combustion in a constant volume bomb: Inverse Livengood–Wu method. Fuel 2012, 102, 289–298. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Y.; Tang, C.; Huang, Z. Ignition delay times measurement and kinetic modeling studies of 1-heptene, 2-heptene and n-heptane at low to intermediate temperatures by using a rapid compression machine. Combust. Flame 2018, 197, 30–40. [Google Scholar] [CrossRef]
- De Toni, A.R.; Werler, M.; Hartmann, R.M.; Cancino, L.; Schießl, R.; Fikri, M.; Schulz, C.; Oliveira, A.; Oliveira, E.; Rocha, M. Ignition delay times of Jet A-1 fuel: Measurements in a high-pressure shock tube and a rapid compression machine. Proc. Combust. Inst. 2017, 36, 3695–3703. [Google Scholar] [CrossRef]
- Ramalingam, A.; Fenard, Y.; Heufer, A. Ignition delay time and species measurement in a rapid compression machine: A case study on high-pressure oxidation of propane. Combust. Flame 2020, 211, 392–405. [Google Scholar] [CrossRef]
- Mao, Y.; Yu, L.; Wu, Z.; Tao, W.; Wang, S.; Ruan, C.; Zhu, L.; Lu, X. Experimental and kinetic modeling study of ignition characteristics of RP-3 kerosene over low-to-high temperature ranges in a heated rapid compression machine and a heated shock tube. Combust. Flame 2019, 203, 157–169. [Google Scholar] [CrossRef]
- Schulz, C.; Sick, V. Tracer-LIF diagnostics: Quantitative measurement of fuel concentration, temperature and fuel/air ratio in practical combustion systems. Prog. Energy Combust. Sci. 2005, 31, 75–121. [Google Scholar] [CrossRef]
- Shah, Z.A.; Marseglia, G.; De Giorgi, M.G. Predictive models of laminar flame speed in NH3/H2/O3/air mixtures using multi-gene genetic programming under varied fuelling conditions. Fuel 2024, 368, 131652. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, X.; Liu, L. Study on the mechanism of the ignition process of ammonia/hydrogen mixture under high-pressure direct-injection engine conditions. Int. J. Hydrogen Energy 2021, 46, 38871–38886. [Google Scholar] [CrossRef]
- Yamada, S.; Shimokuri, D.; Shy, S.; Yatsufusa, T.; Shinji, Y.; Chen, Y.-R.; Liao, Y.-C.; Endo, T.; Nou, Y.; Saito, F.; et al. Measurements and simulations of ignition delay times and laminar flame speeds of nonane isomers. Combust. Flame 2021, 227, 283–295. [Google Scholar] [CrossRef]
- Mao, G.; Zhao, C.; Yu, H. Optimization of ammonia-dimethyl ether mechanisms for HCCI engines using reduced mechanisms and response surface methodology. Int. J. Hydrogen Energy 2025, 100, 267–283. [Google Scholar] [CrossRef]
- Song, T.; Wang, C.; Wen, M.; Liu, H.; Yao, M. Combustion mechanism study of ammonia/n-dodecane/n-heptane/EHN blended fuel. Appl. Energy Combust. Sci. 2024, 17, 100241. [Google Scholar] [CrossRef]
- Gong, Z.; Feng, L.; Wei, L.; Qu, W.; Li, L. Shock tube and kinetic study on ignition characteristics of lean methane/n-heptane mixtures at low and elevated pressures. Energy 2020, 197, 117242. [Google Scholar] [CrossRef]
- Kelly, M.; Bourque, G.; Hase, M.; Dooley, S. Machine learned compact kinetic model for liquid fuel combustion. Combust. Flame 2025, 272, 113876. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, Y.; Liu, W.; Zhao, C.; Fan, W. Update of the present decomposition mechanisms of ammonia: A combined ReaxFF, DFT and chemkin study. Int. J. Hydrogen Energy 2024, 90, 557–567. [Google Scholar] [CrossRef]
- Gong, Z.; Feng, L.; Li, L.; Qu, W.; Wei, L. Shock tube and kinetic study on ignition characteristics of methane/n-hexadecane mixtures. Energy 2020, 201, 117609. [Google Scholar] [CrossRef]
- Wu, Y.; Li, Y.; Zhang, L. Data-driven modeling of ignition delay time using artificial neural networks. Energy 2020, 193, 116726. [Google Scholar]
- Liu, Y.; Chen, Y. Application of neural network in combustion characteristics prediction of alternative aviation fuels. Fuel 2021, 294, 120576. [Google Scholar]
- Wang, H.; Wang, Z.; Zhang, Y. Prediction of ignition delay times of surrogate jet fuels using machine learning methods. Fuel 2022, 308, 122048. [Google Scholar]
- Zhang, C.; Lin, Y. Ignition delay prediction using deep learning with convolutional neural networks. Combust. Theory Model. 2022, 26, 135–150. [Google Scholar]
- Patel, R.; Saxena, P. Sequence modeling of ignition delay using LSTM networks for real-time combustion diagnostics. Appl. Energy 2023, 345, 121042. [Google Scholar]
- Cui, Y.; Liu, H.; Wang, Q.; Zheng, Z.; Wang, H.; Yue, Z.; Ming, Z.; Wen, M.; Feng, L.; Yao, M. Investigation on the ignition delay prediction model of multi-component surrogates based on back propagation (BP) neural network. Combust. Flame 2022, 237, 111852. [Google Scholar] [CrossRef]
- Ji, W.; Su, X.; Pang, B.; Li, Y.; Ren, Z.; Deng, S. SGD-based optimization in modeling combustion kinetics: Case studies in tuning mechanistic and hybrid kinetic models. Fuel 2022, 324, 124560. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, Y.; Li, S. Improving generalization of neural network-based ignition delay prediction using transfer learning and data augmentation. Combust. Flame 2020, 215, 392–401. [Google Scholar]
- Zhao, Y.; Xu, M. Feature sensitivity and interpretability analysis of neural network predictions in combustion systems. Fuel 2022, 314, 123089. [Google Scholar]
- Chen, B.H.; Liu, J.Z.; Yao, F.; He, Y.; Yang, W.J. Ignition delay characteristics of RP-3 under ultra-low pressure (0.01–0.1 MPa). Combust. Flame 2019, 210, 126–133. [Google Scholar] [CrossRef]
- Liu, J.; Hu, E.; Yin, G.; Huang, Z.; Zeng, W. An experimental and kinetic modeling study on the low-temperature oxidation, ignition delay time, and laminar flame speed of a surrogate fuel for RP-3 kerosene. Combust. Flame 2022, 237, 111821. [Google Scholar] [CrossRef]
- Liu, J.; Hu, E.; Zeng, W.; Zheng, W. A new surrogate fuel for emulating the physical and chemical properties of RP-3 kerosene. Fuel 2020, 259, 116210. [Google Scholar] [CrossRef]
- Yang, Z.Y.; Zeng, P.; Wang, B.Y.; Jia, W.; Xia, Z.-X.; Liang, J.; Wang, Q.-D. Ignition characteristics of an alternative kerosene from direct coal liquefaction and its blends with conventional RP-3 jet fuel. Fuel 2021, 291, 120258. [Google Scholar] [CrossRef]
- Zhang, C.; Li, B.; Rao, F.; Li, P.; Li, X. A shock tube study of the autoignition characteristics of RP-3 jet fuel. Proc. Combust. Inst. 2015, 35, 3151–3158. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Primary Sources | No. of Samples | T/K | Equivalence Ratio (φ) |
|---|---|---|---|---|
| Shock-Tube IDT | Zhang 2015 [33] | 221 | 650-1500 | 1.0, 2.0 |
| Liu 2022 [30], Liu 2020 [31] | 56 | 1000-1700 | 0.5, 1.0, 1.5 | |
| Mao 2019 [9] | 250 | 624-1473 | 0.5, 1.0, 1.5 | |
| Chen 2019 [29] | 37 | 1113-1600 | 0.5, 1.0, 1.5 | |
| Yang 2021 [32] | 29 | 920-1700 | 0.5, 1.0, 2.0 | |
| RCM IDT | Mao 2019 [9] | 107 | 624-1473 | 0.5, 1.0, 1.5 |
| Number | Diluant (%) | Fuel (%) | Oxidizer (%) | P (bar) | 1000/T (K) | Log_Time (μs) | φ |
|---|---|---|---|---|---|---|---|
| 1 | 79 | 0.66 | 20.34 | 20 | 0.88 | 2.25 | 2 |
| 2 | 79 | 0.66 | 20.34 | 20 | 0.92 | 2.46 | 2 |
| 3 | 79 | 0.66 | 20.34 | 20 | 0.93 | 2.50 | 2 |
| 4 | 79 | 0.66 | 20.34 | 20 | 0.93 | 2.48 | 2 |
| 5 | 79 | 0.66 | 20.34 | 20 | 0.94 | 2.54 | 2 |
| 6 | 79 | 0.66 | 20.34 | 20 | 0.96 | 2.63 | 2 |
| 7 | 79 | 0.66 | 20.34 | 20 | 1.02 | 2.92 | 2 |
| 8 | 79 | 0.66 | 20.34 | 20 | 0.88 | 2.26 | 2 |
| … | … | … | … | … | … | … | … |
| 695 | 79 | 2.40 | 18.60 | 0.5 | 0.78 | 2.64 | 0.5 |
| 696 | 79 | 2.40 | 18.60 | 0.5 | 0.81 | 2.71 | 0.5 |
| 697 | 79 | 2.40 | 18.60 | 0.5 | 0.85 | 3.06 | 0.5 |
| 698 | 79 | 2.40 | 18.60 | 0.5 | 0.88 | 3.16 | 0.5 |
| 699 | 79 | 2.40 | 18.60 | 0.5 | 0.90 | 3.22 | 0.5 |
| 700 | 79 | 2.40 | 18.60 | 0.5 | 0.91 | 3.30 | 0.5 |
| Hidden-Layer Structure | Range of the Hidden Layer | R2 | MAPE (%) | MAE (μs) |
|---|---|---|---|---|
| two-hidden-layer structure | [5–15] | 0.91099 | 5.23362 | 0.11951 |
| [15–25] | 0.93781 | 3.57593 | 0.081 | |
| [25–35] | 0.90006 | 4.77065 | 0.1167 | |
| [35–45] | 0.94042 | 3.62867 | 0.08418 | |
| [45–55] | 0.92087 | 3.88182 | 0.08478 | |
| three-hidden-layer structure | [5–15] | 0.90349 | 4.50252 | 0.10757 |
| [15–25] | 0.94449 | 2.87703 | 0.0679 | |
| [25–35] | 0.95831 | 2.77153 | 0.07051 | |
| [35–45] | 0.9418 | 3.24754 | 0.08054 | |
| [45–55] | 0.9339 | 3.14394 | 0.08222 |
| Model Type | R2 | MAE (μs) | MSE (μs2) | MAPE (%) |
|---|---|---|---|---|
| CGD-BP | 0.997 | 0.03 | 0.006 | 1.2 |
| CGD-ABC-BP | 0.994 | 0.04 | 0.007 | 1.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Liu, Z.; Ma, H. Exploration of the Ignition Delay Time of RP-3 Fuel Using the Artificial Bee Colony Algorithm in a Machine Learning Framework. Energies 2025, 18, 3037. https://doi.org/10.3390/en18123037
Liu W, Liu Z, Ma H. Exploration of the Ignition Delay Time of RP-3 Fuel Using the Artificial Bee Colony Algorithm in a Machine Learning Framework. Energies. 2025; 18(12):3037. https://doi.org/10.3390/en18123037
Chicago/Turabian StyleLiu, Wenbo, Zhirui Liu, and Hongan Ma. 2025. "Exploration of the Ignition Delay Time of RP-3 Fuel Using the Artificial Bee Colony Algorithm in a Machine Learning Framework" Energies 18, no. 12: 3037. https://doi.org/10.3390/en18123037
APA StyleLiu, W., Liu, Z., & Ma, H. (2025). Exploration of the Ignition Delay Time of RP-3 Fuel Using the Artificial Bee Colony Algorithm in a Machine Learning Framework. Energies, 18(12), 3037. https://doi.org/10.3390/en18123037