
Machine Learning and Multilayer Perceptron-Based Customized Predictive Models for Individual Processes in Food Factories



Abstract
1. Introduction
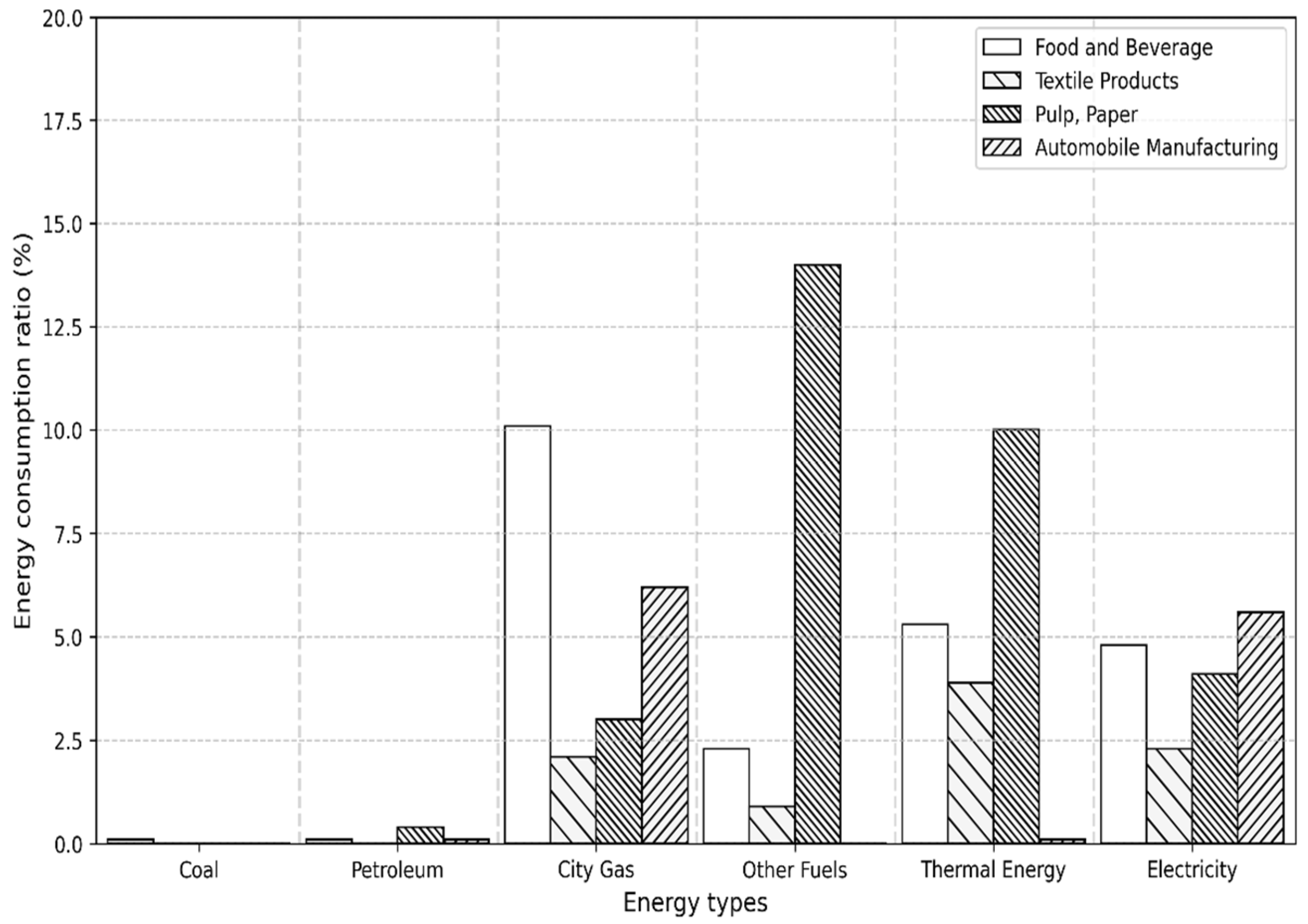
1.1. Current Status and Issues of Energy Consumption in the Industrial Sector
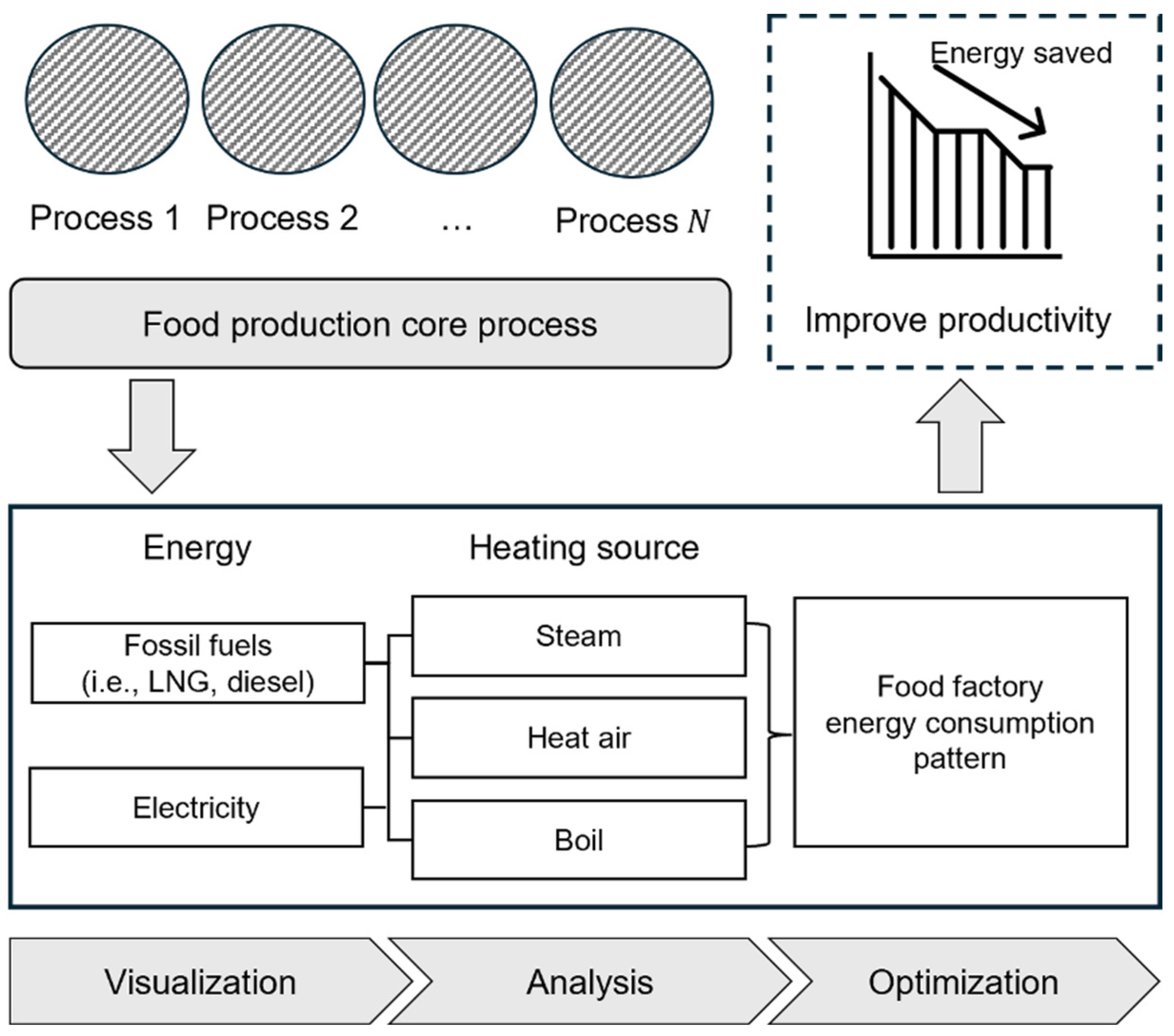
1.2. Role and Importance of FEMS
1.3. Limitations of Existing Studies and the Necessity of This Study
1.4. Background and Motivation
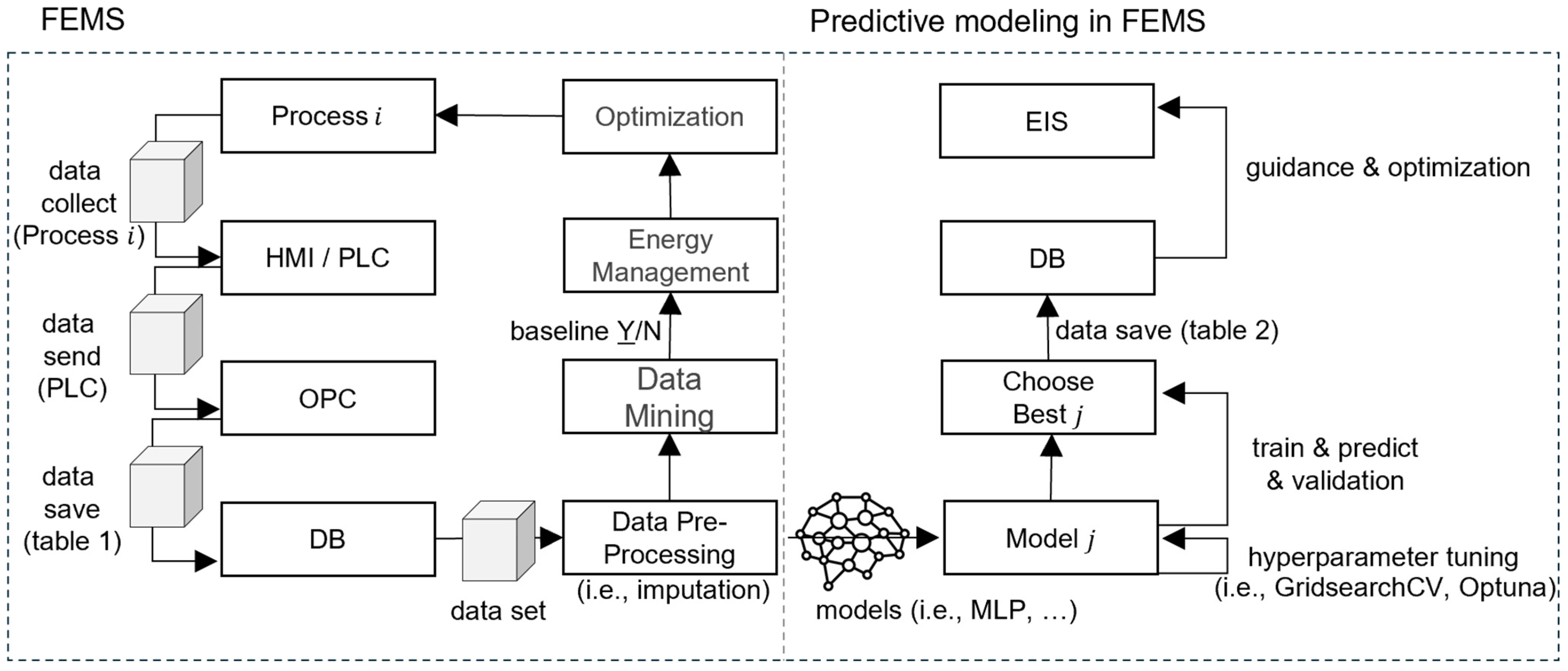
2. Customized Predictive Modeling Approach
2.1. Data Collection and Preprocessing
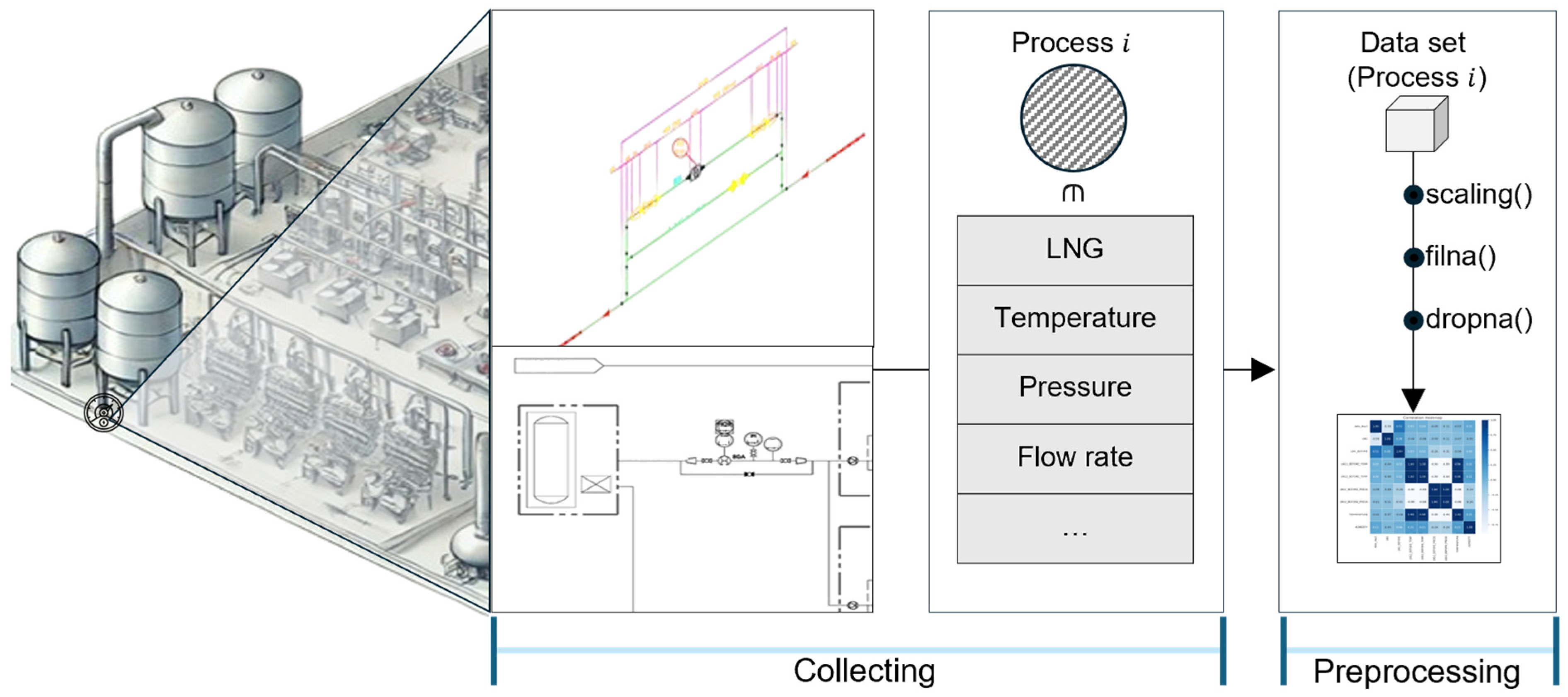
2.1.1. Data Collection
2.1.2. Data Preprocessing
- Data normalization is a crucial step in preprocessing to eliminate bias arising from scale disparities between variables during model training. In this study, min-max scaling was employed to rescale all variable values to a uniform range of 0 to 1. This transformation is achieved using the following equation:
- Min–max scaling facilitates faster convergence in the MLP model and is particularly advantageous when the data do not follow a normal distribution;
- Handling missing values: The dataset consisted of 624 data points, with periods of no measurements—such as factory shutdowns or network failures (e.g., 23 March 2022–4 May 2022; 15 May 2023–2 January 2024; 6 March 2024–30 May 2024)—excluded entirely. Within these 624 data points, approximately 21.5% contained missing values, primarily due to non-operational days such as weekends and holidays. These non-consecutive missing values were addressed through linear interpolation using Pandas’ interpolate and fillna functions to maintain data continuity, which is crucial for time-series energy consumption data. Linear interpolation was chosen for its simplicity and effectiveness, as the missing values on non-operational days reflect predictably low or zero energy use, minimizing any impact on the model’s accuracy. Although energy data can exhibit non-linear patterns, the limited scope of these non-consecutive gaps ensured that linear interpolation did not significantly distort the dataset;
- Handling outliers: Outliers, such as negative values or NaN, arise from abnormal process operations and data entry errors. Statistical methods identified outliers as values exceeding 3σ from the mean for each variable. These outliers were subsequently managed with linear interpolation.
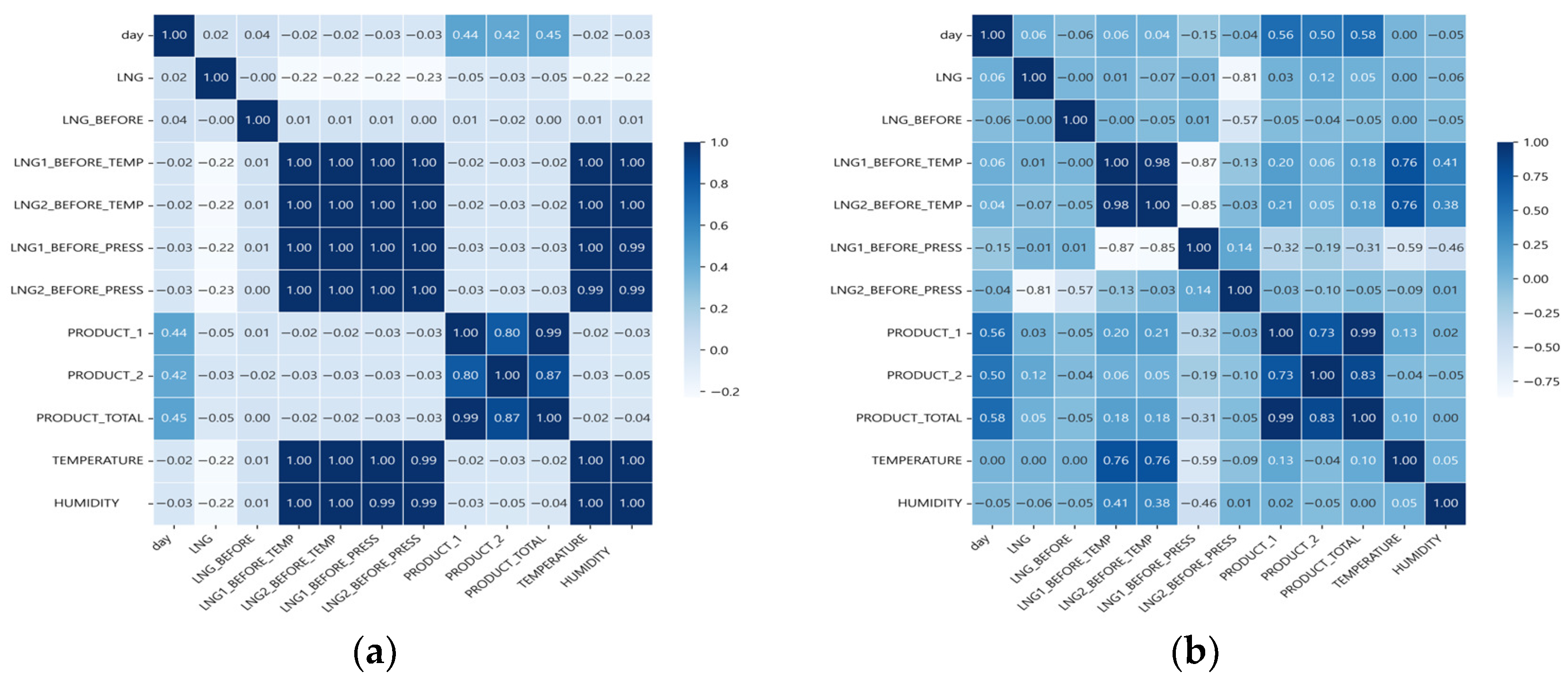
2.1.3. Correlation Analysis
- In Figure 7, LNG exhibits a strong positive correlation with PRODUCT_TOTAL (0.92) and PRODUCT_1 (0.91), suggesting that increased LNG consumption is associated with higher production levels. This strong correlation suggests that production is a key predictor, improving the model’s explanatory;
- Furthermore, LNG1_BEFORE_TEMP and LNG1_BEFORE_PRESS (−0.90), as well as LNG2_BEFORE_TEMP and LNG2_BEFORE_PRESS (−0.89), display strong negative correlations, highlighting the automatic control relationship between temperature and pressure;
- HUMIDITY has a weak correlation with most variables, is unrelated to production and LNG, and displays a weak correlation with day (LNG −0.59, LNG_BEFORE 0.51), indicating a temporal trend. LNG and TEMPERATURE exhibit a strong negative correlation, highlighting the influence of weather on energy input;
- Figure 8a shows correlation coefficients near zero, indicating weak relationships;
- Figure 8b shows that the correlation coefficients among LNG1_BEFORE_TEMP, LNG2_BEFORE_TEMP, TEMPERATURE, and HUMIDITY decreased from 1.00 to between 0.27 and 0.97, demonstrating reduced redundancy. Correlations increased between LNG and PRODUCT_1 (0.03), PRODUCT_2 (0.12), and PRODUCT_TOTAL (0.05). Additionally, the correlation between LNG and day remained stable at a weak positive value of 0.06, despite an apparent intent to suggest a slight increase. This shift likely results from changes in operational patterns due to seasonal variations and the implementation of automatic control.
2.2. Development of LNG Consumption Prediction Models
2.2.1. MLP-Based LNG Consumption Prediction
- Dataset and preprocessing: For the small sample size scenario outlined in Table 2, data were gathered from 2 January 2024 to 14 April 2024 (90 rows) and from 19 August 2024 to 24 November 2024 (91 rows). In the large sample size scenario, data were collected from 7 December 2021 to 1 January 2025 (624 rows, excluding weekends and holidays). Missing values were addressed using linear interpolation and normalized through min–max scaling;
- Hyperparameter optimization: Optimization was executed using Optuna and GridSearchCV. Optimal parameters were identified by varying hidden layer sizes, learning rate, max iter, and solver (Table 3);
- Model training and performance: The MLP model, trained with optimized hyperparameters, was assessed for performance in scenarios involving both small and large sample sizes. When evaluated with a smaller dataset, the model exhibited a satisfactory accuracy and fit, as indicated by the performance metrics. However, with a larger dataset, the model showcased significantly better performance metrics, underscoring its improved accuracy and goodness of fit.
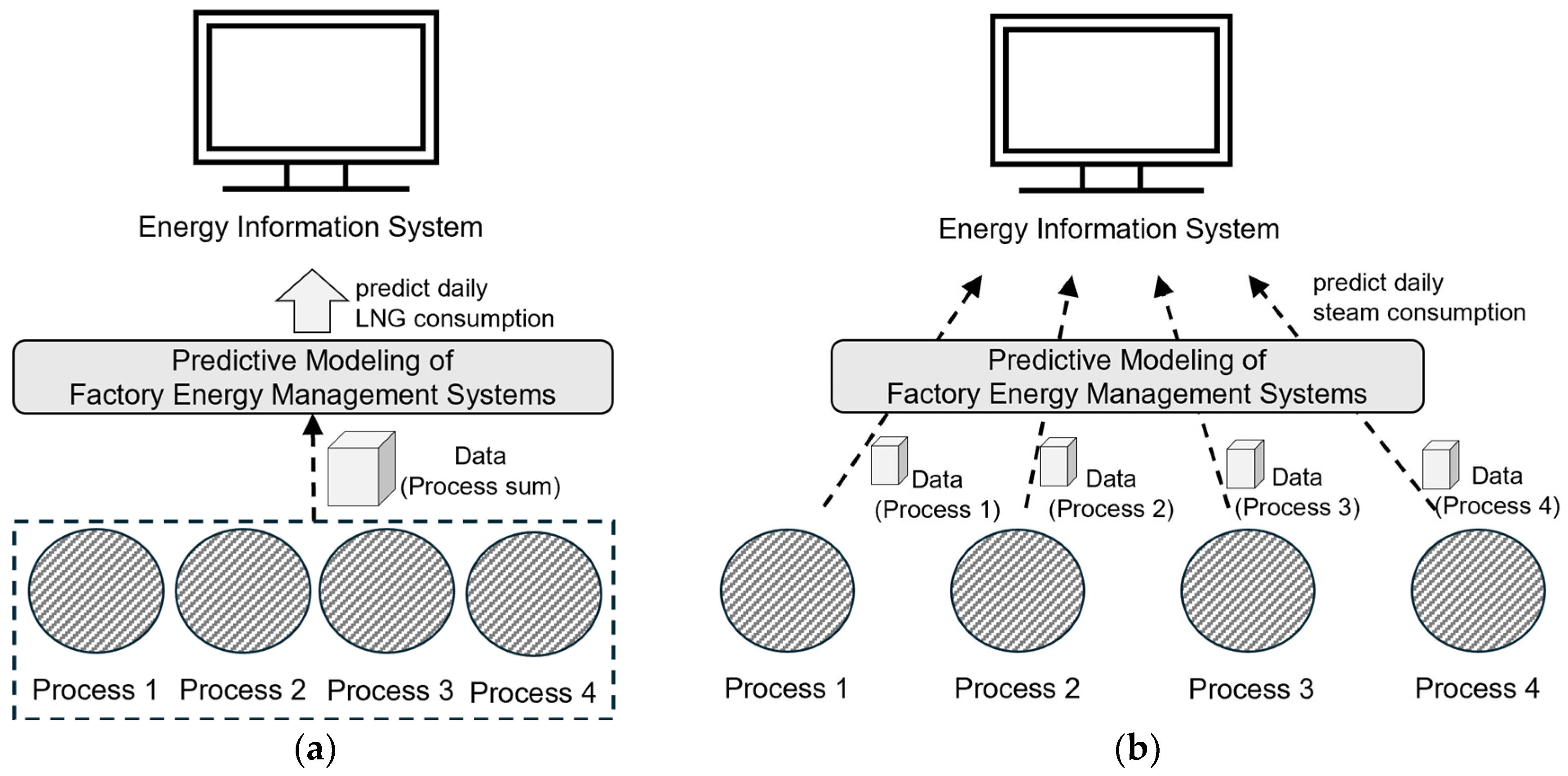
2.2.2. Customized Predictive Models
- Dataset: The dataset for forecasting steam energy consumption across individual processes is detailed in Table 2. These datasets were gathered following the methodology outlined in Section 2.1.1, with data preprocessing steps—such as linear interpolation and min–max scaling for handling missing values—consistently applied to ensure data integrity;
- Model selection and training: For the four food production processes, we utilized linear regression (LR), decision tree (DT), random forest (RF), k-nearest neighbors (KNN), long short-term memory (LSTM), and MLP models. These six models were benchmarked against the baseline persistence model. To guarantee model robustness, k-fold cross-validation was employed during training, as described in Section 2.4.2;
- The performance of each model was evaluated using five metrics: CVRMSE, R2, relative accuracy (100—mean error rate), MAE, and RMSE;
- Best model selection: The best model for each process was ranked using CVRMSE as described in Section 2.4.1.
2.3. Optimization of MLP Prediction Model
Hyperparameter Optimization
- Figure 10a shows the Optuna convergence curve for small-sample data (e.g., LNG consumption prediction), where the MLP reaches an MSE of 0.0302 in 500 trials. Despite the low MSE (red dotted line), the coefficient of variation of the RMSE (CVRMSE = 7.29%) and R2 = 0.96 confirm reliable generalization;
- Figure 10b presents the large-sample scenario: rolling-window validation prevents overfitting, yielding an MSE of 0.0556, CVRMSE = 18.38%, and R2 = 0.87. CUDA-enabled GPU parallelization ensures these 500 trials are completed in just 20–40 min;
- Figure 10c–f validate tuning for individual steam-consumption processes, with MSEs ranging from 0.0343 to 0.0686. Additionally, although a low MSE could suggest overfitting, we concurrently assessed the CVRMSE and R2 to ensure the model’s reliability. Detailed calibrated hyperparameters are provided in Table 4.
2.4. Evaluation Methodology
2.4.1. Performance Metrics
2.4.2. Cross-Validation Strategy
- Data splitting: After sorting the entire dataset chronologically, the initial training set comprises past data, with the subsequent interval used for validation. For example, if the data comprise daily consumption from January to November 2024, the initial training set contains data from January–September, and the October data are used as the validation set;
- Fold progression: The training data-set range is incrementally extended for each fold, while shifting the validation set to subsequent future periods. This methodology generates a total of k folds. In this study, k is set to 5, balancing data size with computational efficiency;
- Model training and evaluation: The model is trained each fold, generating predictions for the corresponding validation set. Performance metrics, including CVRMSE, R2, and MAE, are calculated and recorded for every fold;
- Performance calculation: The metrics from all folds are averaged to assess the generalization performance of the model, which provides a more robust estimate than a single split.
3. Results
3.1. Analysis of LNG Consumption Prediction Results
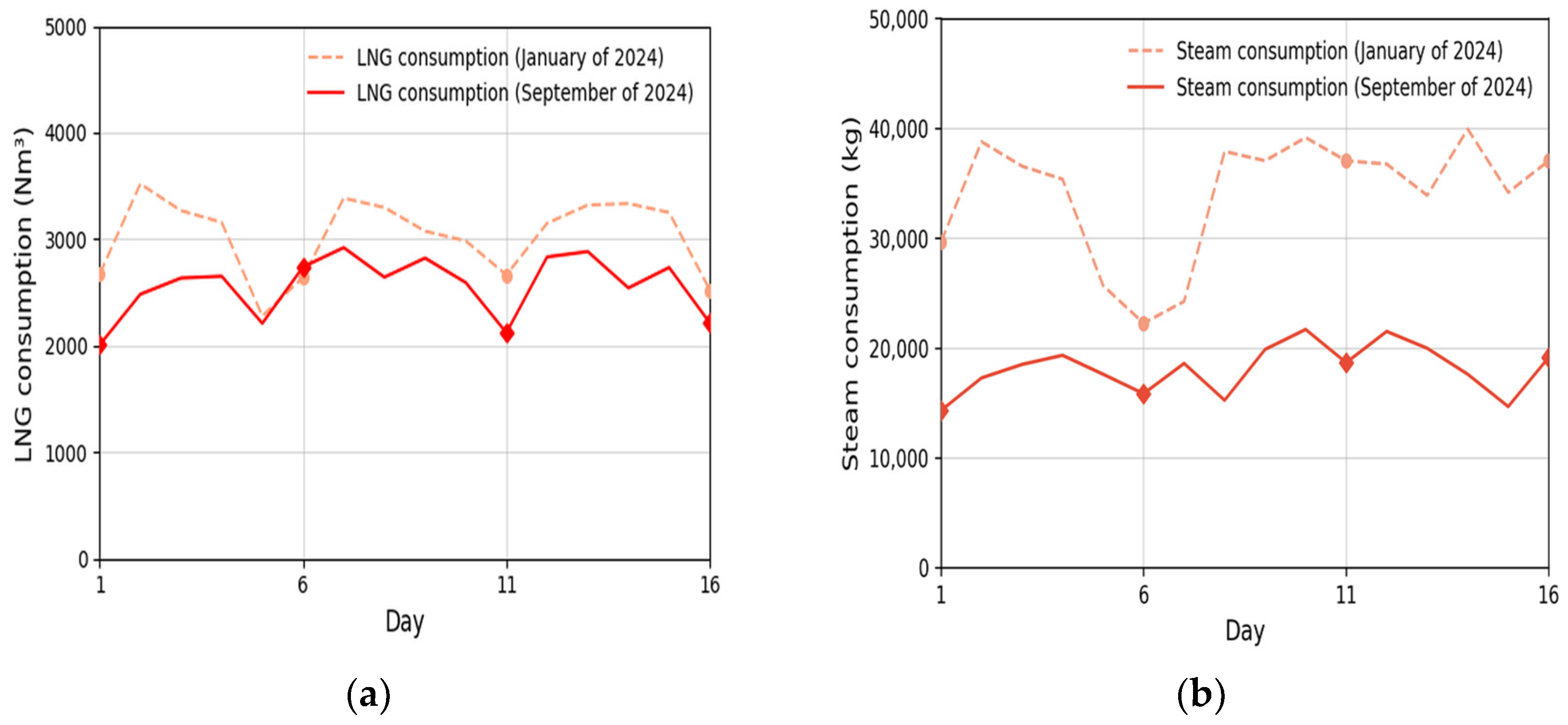
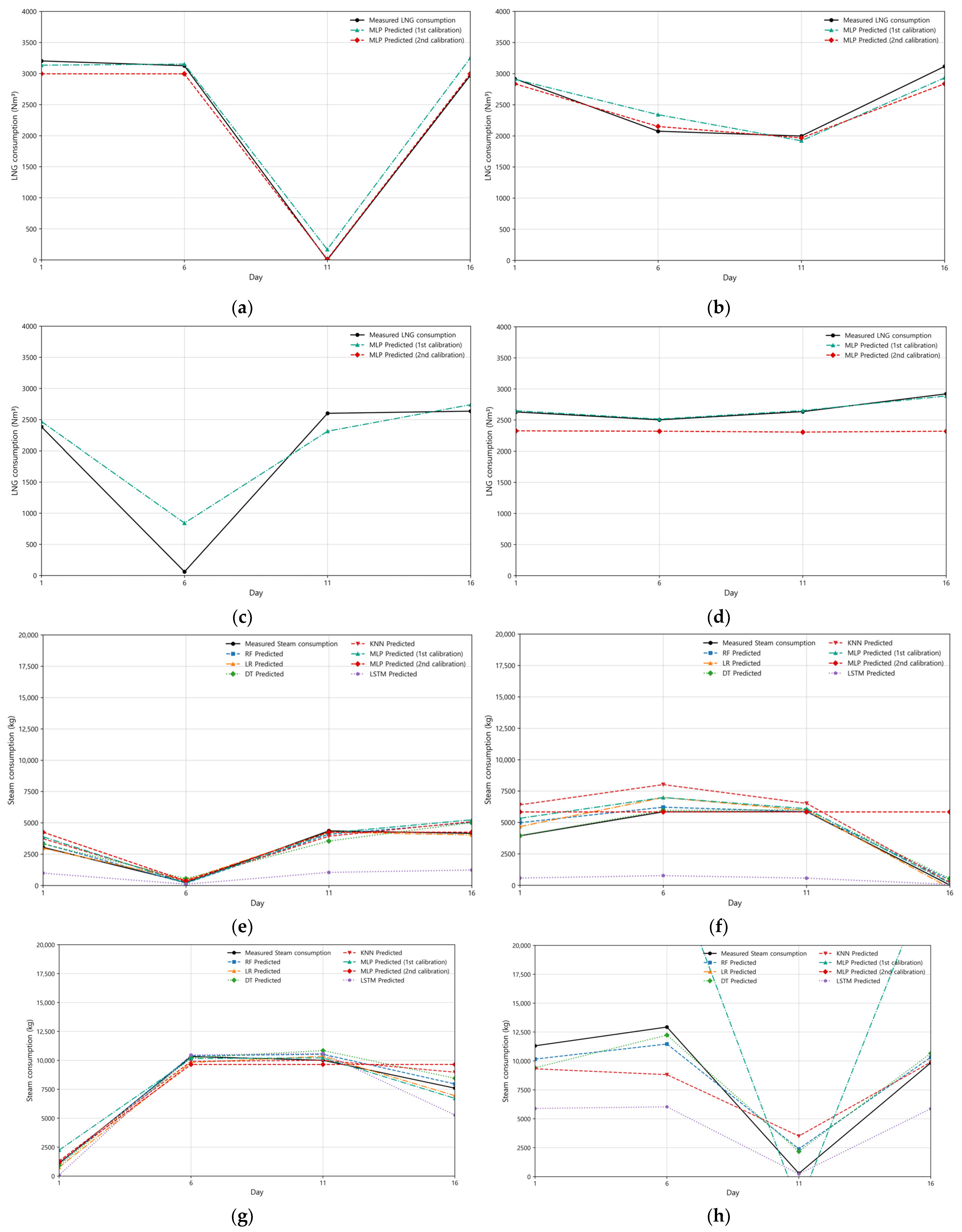
- Figure 11a: Actual LNG consumption (black solid line) starts at approximately 3200 Nm3 on the 1st day, drops to 0 Nm3 on the 11th day due to the weekend, and fluctuates around 3000 Nm3 until the 16th day. After the second calibration, the best possible prediction performance has a CVRMSE of 10.97% and an R2 of 0.9729. Detailed information is provided in Table A1 in Appendix A;
- Figure 11b: During this period, LNG consumption decreases below 3000 Nm3 before rising above 3000 Nm3. The differences are minimal; however, the second calibration results are superior according to the CVRMSE metric. Additional details are available in Table A1 in Appendix A;
- Figure 11c,d: LNG consumption predictions over the entire period highlighted significant variability influenced by operational control methods in the food factory. Initially, the MLP model struggled to capture these patterns using existing features alone. The model’s performance was found to be unsatisfactory based on the evaluation metrics, with a notably low accuracy of −60.2% and a high error rate. To overcome this, we applied k-means clustering with control mode and LNG consumption changes as features, classifying the data into three distinct operational modes, as depicted in Figure 12. The elbow method suggested an optimal (k = 4) based on inertia analysis; however, we selected (k = 3) by prioritizing domain knowledge, reflecting the three primary control methods in the food production process:
- a.
- Cluster 1: High LNG consumption during intensive production phases;
- b.
- Cluster 2: Moderate consumption under standard operating conditions;
- c.
- Cluster 3: Low consumption during reduced production or maintenance periods;
- To predict future energy consumption, we trained the MLP model on the full dataset (624 rows, including weekends) using an iterative learning approach with 30 iterations, as validated in Figure 9. This method progressively improved the model’s performance. Additionally, to evaluate the effect of irregular weekend consumption patterns, we conducted a separate analysis on a subset of 422 rows, excluding weekends. For both scenarios, we employed 5-fold time series cross-validation to ensure robustness and assess generalizability. The cross-validated performance metrics are presented below:
- 1.
- With weekends (624 rows):
- a.
- MLP (1st): R2 = 0.9343, CVRMSE = 18.11%, and relative accuracy = 90.86%;
- b.
- MLP (2nd): R2 = −26.3140, CVRMSE = 369.59%, and relative accuracy = −86.15%;
- 2.
- Excluding weekends (422 rows):
- a.
- MLP (1st): R2 = 0.9855, CVRMSE = 3.99%, and relative accuracy = 98.93%;
- b.
- MLP (2nd): R2 = 0.2261, CVRMSE = 49.34%, and relative accuracy = 68.62%;
- The exceptionally high performance of the initial MLP model in the weekend-excluded scenario (e.g., R2 = 0.9855, accuracy = 98.93%) raised concerns about potential overfitting. However, the use of 5-fold cross-validation confirmed the model’s stability across data splits, mitigating these risks. Excluding weekends reduced noise from irregular operations, contributing to the enhanced metrics in that scenario. In contrast, the full dataset’s broader variability challenged the model, as reflected in the lower performance of the second MLP configuration. These results demonstrate the effectiveness of iterative learning in refining predictions, particularly when operational irregularities are minimized. Future work will focus on extending this approach to minute-by-minute predictions to capture finer energy consumption dynamics across the entire period.
3.2. Analysis of Steam Consumption Prediction Results
3.2.1. Prediction of First Process Steam Consumption
- MLP (first): R2 = 0.8766, CVRMSE = 23.46%, and relative accuracy = 80.97%. Although the CVRMSE exceeded the benchmark value, it reflects the overall trend;
- MLP (second): R2 = 0.7887, CVRMSE = 30.70%, and relative accuracy = 77.72%. After performing hyperparameter tuning, the performance declined, confirming that it failed to adapt to rapid fluctuations;
- LR: R2 = 0.9275, CVRMSE = 17.99%, and relative accuracy = 85.88%, demonstrating the highest performance and fulfilling the ASHRAE;
- LSTM: R2 = −0.5624, CVRMSE = 83.47%, and relative accuracy = 30.68%, which failed to adapt to rapid fluctuations, resulting in the lowest performance;
- RF, DT, KNN: The overall performance metrics are stable; however, they exceed the CVRMSE threshold.
3.2.2. Prediction of Second Process Steam Consumption
- MLP (first): R2 = 0.8991, CVRMSE = 14.24%, and relative accuracy = 87.87%. The performance metrics are lower than RF; however, the fluctuation patterns converged well.
- MLP (second): R2 = −0.2236, CVRMSE = 49.58%, and relative accuracy = 67.90%. It failed to adapt to complex patterns, and its performance significantly deteriorated;
- RF: R2 = 0.9448, CVRMSE = 10.53%, and relative accuracy = 91.27%. It demonstrates the highest performance metrics and fulfills the ASHRAE;
- LSTM: R2 = −2.7628, CVRMSE = 86.94%, and relative accuracy = 20.88%. It displays a large error due to the failure to capture sudden fluctuations;
- LR, DT, KNN: The overall performance metrics are stable, but KNN exceeded the CVRMSE threshold.
3.2.3. Prediction of Third Process Steam Consumption
- MLP (first): R2 = 0.8944, CVRMSE = 11.29%, and relative accuracy = 90.66%. Although these values are lower than RF, some of the altered patterns have been reflected;
- MLP (second): R2 = 0.8898, CVRMSE = 11.53%, and relative accuracy = 90.13%. Its performance declined because of overestimation due to sudden fluctuations;
- RF: R2 = 0.9494, CVRMSE = 7.81%, and relative accuracy = 93.93%. It demonstrated the highest performance metrics and fulfilled the ASHRAE;
- LSTM: R2 = 0.5615, CVRMSE = 23.00%, and relative accuracy = 81.30%. Failure to capture pattern fluctuations and low performance metrics;
- LR, DT, KNN: The overall performance metrics are stable, however, KNN exceeded the CVRMSE standard.
3.2.4. Prediction of Fourth Process Steam Consumption
- RF: R2 = 0.8981, CVRMSE = 14.10%, and relative accuracy = 90.13%. It demonstrates the highest performance metrics and satisfies the ASHRAE;
- Remaining models: Data learning failure and large errors.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Figure | Model | CVRMSE (%) | R2 | MAE | RMSE | Accuracy (%) |
|---|---|---|---|---|---|---|
| Figure 11a | MLP 1st calibration | 19.96 | 0.9102 | 237.0984 | 387.7772 | 87.79 |
| MLP 2nd calibration | 10.97 | 0.9729 | 159.0842 | 213.0216 | 91.81 | |
| Figure 11b | MLP 1st calibration | 9.48 | 0.9420 | 168.5217 | 218.9589 | 92.70 |
| MLP 2nd calibration | 9.49 | 0.9418 | 155.2266 | 219.2299 | 93.28 | |
| Figure 11c | MLP 1st calibration | 18.11 | 0.9393 | 406.4781 | 2202.3578 | 90.86 |
| MLP 2nd calibration | 369.59 | −26.3140 | 9968.3642 | 67,530.7877 | −86.15 | |
| Figure 11d | MLP 1st calibration | 3.99 | 0.9855 | 21.5512 | 57.5394 | 98.93 |
| MLP 2nd calibration | 49.34 | 0.2261 | 730.0746 | 1001.9369 | 64.49 | |
| Figure 11e | RF | 21.38 | 0.8975 | 426.2081 | 551.5178 | 83.48 |
| LR | 17.99 | 0.9275 | 364.2008 | 463.9081 | 85.88 | |
| DT | 22.59 | 0.8856 | 464.8917 | 582.5901 | 81.98 | |
| KNN | 23.80 | 0.8730 | 483.9433 | 613.8071 | 81.24 | |
| MLP 1st calibration | 23.46 | 0.8766 | 490.9475 | 605.0911 | 80.97 | |
| MLP 2nd calibration | 30.70 | 0.7887 | 574.6001 | 791.7610 | 77.72 | |
| LSTM | 83.47 | −0.5624 | 1787.8485 | 2152.9816 | 30.68 | |
| Figure 11f | RF | 10.53 | 0.9448 | 420.2974 | 507.0947 | 91.27 |
| LR | 13.38 | 0.9109 | 505.7798 | 644.4721 | 89.50 | |
| DT | 15.07 | 0.8869 | 563.1399 | 725.8443 | 88.31 | |
| KNN | 32.70 | 0.4675 | 1257.5071 | 1575.1337 | 73.89 | |
| MLP 1st calibration | 14.24 | 0.8991 | 583.9819 | 685.7077 | 87.87 | |
| MLP 2nd calibration | 49.58 | −0.2236 | 1545.8112 | 2387.7591 | 67.90 | |
| LSTM | 86.94 | −2.7628 | 3810.3715 | 4187.1636 | 20.88 | |
| Figure 11g | RF | 7.81 | 0.9494 | 533.4156 | 686.8483 | 93.93 |
| LR | 11.56 | 0.8891 | 858.7890 | 1016.8857 | 90.24 | |
| DT | 9.02 | 0.9325 | 622.5294 | 793.1962 | 92.92 | |
| KNN | 11.15 | 0.8970 | 776.3059 | 980.2767 | 91.17 | |
| MLP 1st calibration | 11.29 | 0.8944 | 821.4078 | 992.6260 | 90.66 | |
| MLP 2nd calibration | 11.53 | 0.8898 | 868.2246 | 1013.9786 | 90.66 | |
| LSTM | 23.00 | 0.5615 | 1644.4155 | 2022.4278 | 81.30 | |
| Figure 11h | RF | 14.10 | 0.8981 | 904.7940 | 1292.8765 | 90.13 |
| LR | 255.68 | −32.5291 | 20,520.2984 | 23,449.7457 | −123.74 | |
| DT | 19.83 | 0.7983 | 1271.5333 | 1818.8817 | 86.14 | |
| KNN | 23.33 | 0.7208 | 1612.7525 | 2139.9555 | 82.42 | |
| MLP 1st calibration | 177.86 | −15.2253 | 13,347.1730 | 16,312.6076 | −45.53 | |
| MLP 2nd calibration | 172.49 | −14.2608 | 15,293.2360 | 15,820.3497 | −66.75 | |
| LSTM | 90.27 | −3.1794 | 7559.7347 | 8279.0734 | 17.57 |
References
- Korea Energy Agency. 2022 Industry Sector Energy and GHG Emission Statistics; Korea Energy Agency: Ulsan, Republic of Korea, 2023; Available online: https://www.energy.or.kr/front/board/View9.do?boardMngNo=9&boardNo=24155 (accessed on 21 April 2025).
- Ministry of Trade, Industry and Energy. 3rd National Energy Basic Plan; Ministry of Trade, Industry and Energy: Sejong, Republic of Korea, 2019; Available online: https://netzero.gm.go.kr/download/%EC%A0%9C3%EC%B0%A8%20%EC%97%90%EB%84%88%EC%A7%80%EA%B8%B0%EB%B3%B8%EA%B3%84%ED%9A%8D_%EC%82%B0%EC%97%85%ED%86%B5%EC%83%81%EC%9E%90%EC%9B%90.pdf (accessed on 21 April 2025).
- Mariano-Hernández, D.; Hernández-Callejo, L.; Zorita-Lamadrid, A.; Duque-Pérez, O.; García, F.S. A review of strategies for building energy management system: Model predictive control, demand side management, optimization, and fault detect & diagnosis. J. Build. Eng. 2021, 33, 101692. [Google Scholar] [CrossRef]
- Lee, D.; Cheng, C.C. Energy savings by energy management systems: A review. Renew. Sustain. Energy Rev. 2016, 56, 760–777. [Google Scholar] [CrossRef]
- Popov, D.; Akterian, S.; Fikiin, K.; Stankov, B. Multipurpose system for cryogenic energy storage and tri-generation in a food factory: A case study of producing frozen french fries. Appl. Sci. 2021, 11, 7882. [Google Scholar] [CrossRef]
- Li, X.; Gao, J.; You, S.; Zheng, Y.; Zhang, Y.; Du, Q.; Xie, M.; Qin, Y. Optimal design and techno-economic analysis of renewable-based multi-carrier energy systems for industries: A case study of a food factory in China. Energy 2022, 244, 123174. [Google Scholar] [CrossRef]
- Hu, G.; You, F. AI-enabled cyber-physical-biological systems for smart energy management and sustainable food production in a plant factory. Appl. Energy 2024, 356, 122334. [Google Scholar] [CrossRef]
- Jagtap, S.; Rahimifard, S.; Duong, L.N. Real-time data collection to improve energy efficiency: A case study of food manufacturer. J. Food Process Preserv. 2022, 46, e14338. [Google Scholar] [CrossRef]
- Al Momani, D.; Al Turk, Y.; Abuashour, M.I.; Khalid, H.M.; Muyeen, S.; Sweidan, T.O.; Said, Z.; Hasanuzzaman, M. Energy saving potential analysis applying factory scale energy audit—A case study of food production. Heliyon 2023, 9, e14216. [Google Scholar] [CrossRef]
- Geng, D.; Evans, S.; Kishita, Y. The identification and classification of energy waste for efficient energy supervision in manufacturing factories. Renew. Sustain. Energy Rev. 2023, 182, 113409. [Google Scholar] [CrossRef]
- Munguia, N.; Velazquez, L.; Bustamante, T.P.; Perez, R.; Winter, J.; Will, M.; Delakowitz, B. Energy audit in the meat processing industry—A case study in Hermosillo, Sonora Mexico. J. Environ. Prot. 2016, 7, 14–22. [Google Scholar] [CrossRef]
- Tanaka, K.; Managi, S. Industrial agglomeration effect for energy efficiency in Japanese production plants. Energy Policy 2021, 156, 112442. [Google Scholar] [CrossRef]
- Kluczek, A.; Olszewski, P. Energy audits in industrial processes. J. Clean. Prod. 2017, 142, 3437–3453. [Google Scholar] [CrossRef]
- Walther, J.; Weigold, M. A systematic review on predicting and forecasting the electrical energy consumption in the manufacturing industry. Energies 2021, 14, 968. [Google Scholar] [CrossRef]
- Bermeo-Ayerbe, M.A.; Ocampo-Martinez, C.; Diaz-Rozo, J. Data-driven energy prediction modeling for both energy efficiency and maintenance in smart manufacturing systems. Energy 2022, 238, 121691. [Google Scholar] [CrossRef]
- Kapp, S.; Choi, J.K.; Hong, T. Predicting industrial building energy consumption with statistical and machine-learning models informed by physical system parameters. Renew. Sustain. Energy Rev. 2023, 172, 113045. [Google Scholar] [CrossRef]
- Corigliano, O.; Aligieri, A. A comprehensive investigation on energy consumptions, impacts, and challenges of the food industry. Energy Convers. Manage. X 2024, 23, 100661. [Google Scholar] [CrossRef]
- Ladha-Sabur, A.; Bakalis, S.; Fryer, P.J.; Lopez-Quiroga, E. Mapping energy consumption in food manufacturing. Trends Food Sci. Technol. 2019, 86, 270–280. [Google Scholar] [CrossRef]
- Lee, H.; Kim, D.; Gu, J.H. Prediction of food factory energy consumption using MLP and SVR algorithms. Energies 2023, 16, 1550. [Google Scholar] [CrossRef]
- ASHRAE. ASHRAE Guideline 14-2014: Measurement of Energy Demand and Savings; American Society of Heating, Refrigerating and Air-Conditioning Engineers: Atlanta, GA, USA, 2014; Available online: https://scholar.google.com/scholar_lookup?title=Measurement%20of%20Energy%20and%20Demand%20Savings&author=ASHRAE%2C%20ASHRAE%20Guideline%2014-2014&publication_year=2014 (accessed on 21 April 2025).
- Webster, L.J.; Bradford, J. M&V Guidelines: Measurement and Verification for Federal Energy Projects, Version 5.0. Technical Report; U.S. Department of Energy Federal Energy Management Program: Washington, DC, USA, 2015. Available online: https://www.energy.gov/sites/prod/files/2016/01/f28/mv_guide_4_0.pdf (accessed on 21 April 2025).
- Schreiber, J.; Sick, B. Model selection, adaptation, and combination for transfer learning in wind and photovoltaic power forecasts. Energy AI 2023, 14, 100249. [Google Scholar] [CrossRef]
- Berrisch, J.; Narajewski, M.; Ziel, F. High-resolution peak demand estimation using generalized additive models and deep neural networks. Energy AI 2023, 13, 100236. [Google Scholar] [CrossRef]
- Ansar, T.; Ashraf, W.M. Comparison of Kolmogorov–Arnold Networks and Multi-Layer Perceptron for modelling and optimisation analysis of energy systems. Energy AI 2025, 20, 100473. [Google Scholar] [CrossRef]
- Radaideh, M.I.; Rigopoulos, S.; Goussis, D.A. Characteristic time scale as optimal input in Machine Learning algorithms: Homogeneous autoignition. Energy AI 2023, 14, 100273. [Google Scholar] [CrossRef]
- Piantadosi, G.; Dutto, S.; Galli, A.; De Vito, S.; Sansone, C.; Di Francia, G. Photovoltaic power forecasting: A Transformer based framework. Energy AI 2024, 18, 100444. [Google Scholar] [CrossRef]




| Feature | Unit | Description |
|---|---|---|
| day | 1~7 | Day of the week (i.e., Monday: 1~Sunday: 7) |
| LNG | Nm3 | LNG consumption of the day |
| LNG_BEFORE | Nm3 | Previous day’s LNG consumption |
| LNG1_BEFORE_TEMP | °C | Previous day’s LNG temperature at food factory 1 |
| LNG2_BEFORE_TEMP | °C | Previous day’s LNG temperature at food factory 2 |
| LNG1_BEFORE_PRESS | kPa | Previous day’s LNG pressure at food factory 1 |
| LNG2_BEFORE_PRESS | kPa | Previous day’s LNG pressure at food factory 1 |
| PRODUCT_1 | kg | Production volume of food factory 1 |
| PRODUCT_2 | kg | Production volume of food factory 2 |
| PRODUCT_TOTAL | kg | Production volume of food factories 1 and 2 |
| TEMPERATURE | °C | Average outdoor temperature of the previous day |
| HUMIDITY | % | Average outdoor humidity of the previous day |
| LNG consumption prediction dataset range | Small sample size case | January 2 to April 14 of 2024 (90 rows calibration dataset) |
| August 19 to November 24 of 2024 (91 rows calibration dataset) | ||
| Large sample size case | December 7 of 2021 to January 1 of 2025 (624 rows calibration dataset, 422 rows excluding weekends dataset) | |
| Individual processes prediction dataset | Small sample size case | August 17 to November 29 of 2024 (105 rows 1st process calibration dataset) |
| August 18 to November 29 of 2024 (69 rows 2nd process calibration dataset) | ||
| June 3 to November 29 of 2024 (166 rows 3rd process calibration dataset) | ||
| June 3 to November 29 of 2024 (167 rows 4th process calibration dataset) |
| Hyperparameter | Hyperparameter Calibration (Small Sample Size) | Hyperparameter Calibration (Large Sample Size) |
|---|---|---|
| Activation | ReLU | ReLU |
| Alpha | 1.0721 | 0.0004 |
| Batch size | Auto | auto |
| Hidden layer size | 112 | 57 |
| Learning rate | adaptive | adaptive |
| Max iteration | 482 | 421 |
| Solver | LBFGS | LBFGS |
| Tol | 0.0001 | 0.0073 |
| Hyperparameter | 2nd Calibration (Small Sample Size) | 2nd Calibration (Large Sample Size) | 1st~4th Individual Processes |
|---|---|---|---|
| Activation | tanh | ReLU | tanh |
| Alpha | 0.000001 | 0.02306047461918005 | 0.000001 |
| Batch size | auto | auto | auto |
| Hidden layer size | (150, 150, 150) | (50, 50, 50) | (150, 150, 150) |
| Learning rate | adaptive | adaptive | Adaptive |
| Solver | LBFGS | Adam | LBFGS |
| Tol | 1.95 × 10−4 | 1.72 × 10−5 | 1.95 × 10−4 |
| Epochs | 482 | 259 | 482 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, B.; Kim, D.; Cho, W.; Gu, J.-H. Machine Learning and Multilayer Perceptron-Based Customized Predictive Models for Individual Processes in Food Factories. Energies 2025, 18, 2964. https://doi.org/10.3390/en18112964
Lim B, Kim D, Cho W, Gu J-H. Machine Learning and Multilayer Perceptron-Based Customized Predictive Models for Individual Processes in Food Factories. Energies. 2025; 18(11):2964. https://doi.org/10.3390/en18112964
Chicago/Turabian StyleLim, Byunghyun, Dongju Kim, Woojin Cho, and Jae-Hoi Gu. 2025. "Machine Learning and Multilayer Perceptron-Based Customized Predictive Models for Individual Processes in Food Factories" Energies 18, no. 11: 2964. https://doi.org/10.3390/en18112964
APA StyleLim, B., Kim, D., Cho, W., & Gu, J.-H. (2025). Machine Learning and Multilayer Perceptron-Based Customized Predictive Models for Individual Processes in Food Factories. Energies, 18(11), 2964. https://doi.org/10.3390/en18112964