1. Introduction
The safety of nuclear power plants (NPPs) is increasingly critical due to advances in nuclear technology and equipment complexity. Among the key components, reactor coolant pumps (RCPs) are essential for transferring energy within the coolant system, ensuring stable NPP operation [
1]. However, RCPs usually operate for a long time under extreme conditions (high temperatures and high pressure), making them susceptible to degradation from corrosion and wear [
2]. This vulnerability has led to over 100 documented anomaly-induced shutdowns and maintenance events, imposing significant financial burdens on operators [
3,
4]. RCPs consist of many complex components, the monitored data of which are complex and diverse, posing challenges and becoming an error-prone problem for operators to manually detect anomalous states from a large amount of sensor data through preset thresholds. Consequently, timely and accurate automatic anomaly detection is crucial for enhancing RCP maintenance and operational reliability, mitigating the risk of severe accidents and economic losses.
Current approaches to anomaly detection in nuclear power equipment are categorized into two primary types: supervised and unsupervised algorithms. Supervised algorithms have gained considerable traction and include techniques such as logistic regression [
5], K-Nearest Neighbors (KNNs) [
6], Support Vector Machines (SVM) [
7,
8], Broad Learning Systems (BLSs) [
9], and Artificial Neural Networks (ANNs) [
10,
11,
12]. Within the domain of RCP anomaly detection, supervised techniques have demonstrated significant potential. For instance, Wang et al. [
13] proposed a BLS-based model characterized by a simple network structure and a step-by-step learning approach, which effectively detects coolant leaks with high accuracy. Additionally, convolutional neural networks (CNNs), a type of ANN, are recognized for their ability to automatically identify important patterns within complex data. Yang et al. [
14] transformed fault signals into Symmetrized Dot Pattern (SDP) images, using a depthwise separable CNN to effectively diagnose coolant system faults. Similarly, Zhang et al. [
15] developed a hybrid 1D–2D CNN framework enhanced by Neural Architecture Search, which autonomously optimizes hyperparameters to deliver robust solutions for RCP leak detection and fault diagnosis.
Despite their strengths, supervised methods encounter substantial challenges in anomaly detection of NPP equipment. Due to strict maintenance and inspection measures, the anomalies happen at a far lower frequency than the normal working states in NPPs, and a large number of abnormal samples cannot be provided for supervised methods. In addition, in most cases, NPP accidents are characterized by occasional symptoms, and there are a large number of unlabeled anomalies. It is difficult for supervised methods to identify these unlabeled anomalies. These shortcomings restrict their practical application for RCP monitoring.
In contrast, unsupervised algorithms eliminate the need for labeled data entirely. Classical algorithms such as K-means clustering and Principal Component Analysis (PCA) uncover latent data structures and patterns through distance metrics or linear transformations. However, early unsupervised methods were constrained by their reliance on oversimplified distributional assumptions, exhibiting limited ability in high-dimensional structured datasets. In recent years, unsupervised methods based on neural networks (e.g., Self-Organizing Map (SOM) [
16,
17] and Autoencoder (AE) [
18]) have achieved representation learning of complex features through hierarchical learning and have been widely applied in industrial anomaly detection. For instance, the SOM method, due to its powerful capabilities in local patterns analysis and visualization, has been widely applied in anomaly detection across various industrial fields, including power systems [
19], petroleum [
20], and maritime engineering [
21].
In the field of NPP anomaly detection, specifically in the field of RCP anomaly detection, the current research primarily focuses on critical scenarios like coolant loss. For instance, Cancemi et al. [
22] addressed data scarcity in coolant loss events by training an AE model exclusively on normal operational data and detecting anomalies through reconstruction error thresholds. Similarly, Li et al. [
23] tackled the lack of transient anomaly data by integrating the Variational Autoencoder (VAE) with the Isolation Forest (iForest) algorithm, developing a VAE + iForest model that achieved high-precision detection of RCP anomalies. Furthermore, Sun et al. [
24] proposed a Convolutional Adversarial Autoencoder with Self-Attention (CAAE-SA) to mitigate noise interference in NPP monitoring signals. By employing attention-driven feature weighting, this architecture demonstrated superior performance in diagnosing coolant leakage, oil tank failures, and third-stage shaft seal degradation. Although these deep learning-based methods have achieved remarkable detection accuracy for RCP anomalies, their reliance on deep neural networks introduces new challenges. The black-box nature of deep neural networks makes it difficult to trace the logical relationship between inputs and outputs. This results in opaque decision-making processes and limited interpretability, severely hampering operators’ ability to comprehend anomaly detection criteria and judge decision reliability. It may lead to distrust and misunderstanding of the output results from the anomaly monitoring models by the operators, potentially bringing adverse effects to the safety of NPPs.
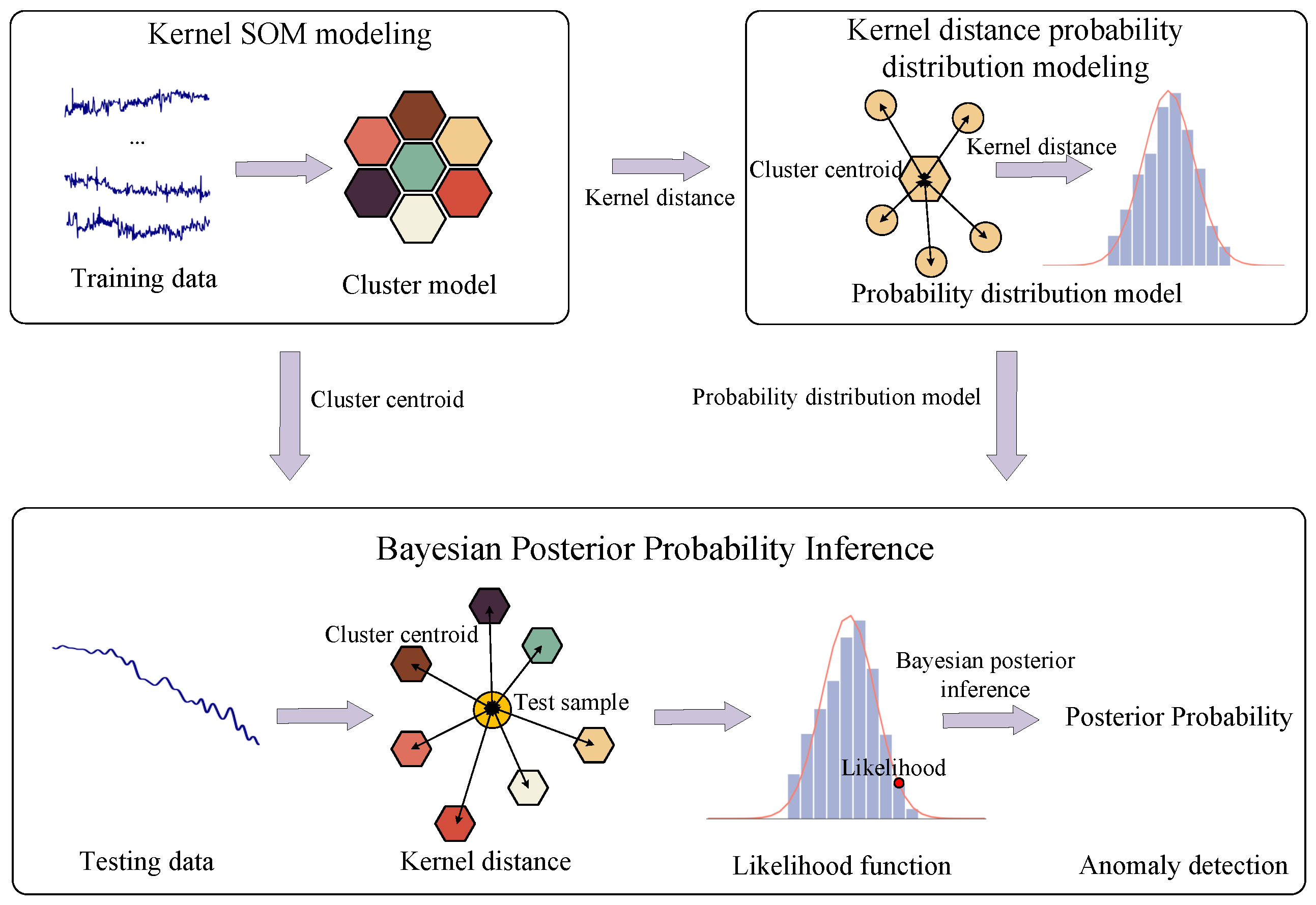
To address these challenges, in this article, we aim to develop an excellent performance and interpretable method for RCP anomaly detection. To this end, this paper designs an unsupervised anomaly detection framework and validates it with real-world monitoring data of an RCP of an NPP. The framework consists of three key components: clustering, distance probabilistic distribution modeling, and Bayesian Posterior Inference. The clustering module is responsible for extracting typical patterns of normal-state data. Distance probability distribution modeling provides prior information on probability distribution for Bayesian Posterior Inference by describing the distribution patterns of data in each cluster from clustering. It acts as a bridge between the clustering module and the Bayesian Posterior Inference module. Finally, sample kernel distances and prior knowledge of distance probability distributions are input into the Bayesian Posterior Inference module to estimate the probability of a sample being normal. In the clustering process, the model needs to thoroughly capture local patterns and features of the normal state to construct a clustering model that effectively represents different subcategories of normal conditions. The Kernel Self-Organizing Map (Kernel SOM) network has a strong ability to extract local patterns and features. Compared to classic SOM, it is more suitable for analyzing nonlinear data. Thus, it is highly suitable for this research. Therefore, the Kernel SOM algorithm has been adopted as the clustering method in this work.
In conclusion, our main contributions are as follows:
A novel anomaly monitoring method for RCPs has been proposed in this paper. To the best of our knowledge, this is the first attempt to analyze the distribution of normal-state data by constructing a probabilistic distribution model and integrating it with posterior inference to construct an anomaly monitoring model for identifying RCP abnormal events.
The method designs a distance probability distribution model that reflects the data distribution. By constructing a distance-based probability distribution model for each clustering cluster, we can directly compare the differences in distance distribution between abnormal and normal data, which helps operators understand the basis for anomaly judgment.
The method designs a traceable anomaly detection framework. By combining the distance distribution model and other prior knowledge with Bayesian Posterior Inference, the proposed method achieves traceability in anomaly detection decisions. This allows operators to trace the detection results and identify the root causes of differences between abnormal and normal states.
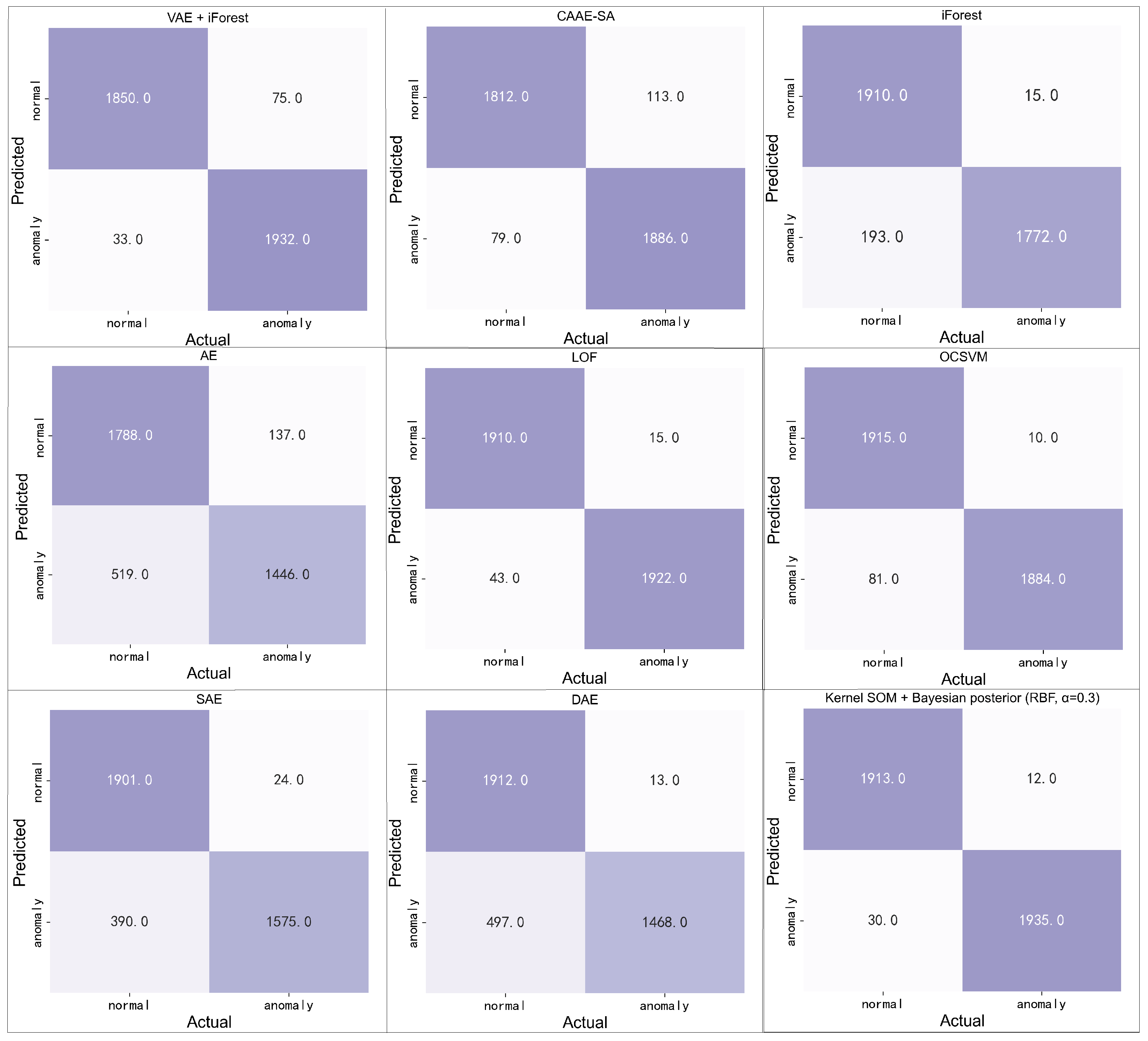
The proposed method was compared with other anomaly detection methods based on monitoring data of RCP anomalies from NPPs. The results demonstrated the superiority of our approach. We believe this generalizable anomaly detection method can be applied to other equipment in NPPs.
The following sections are structured in the following manner:
Section 2 introduces the relevant theories and methods.
Section 3 provides a detailed description of the proposed method.
Section 4 discusses the performance and interpretability of the proposed method.
Section 5 concludes with an overview of the findings and future research directions.
4. Verification and Analysis
In this section, we validate the effectiveness of the proposed method using pressure monitoring data from the mechanical seals of an RCP. By comparing the proposed method with Kernel SOM, we demonstrate the improvement in Kernel SOM performance through probability distribution modeling and posterior inference. The described verification process includes dataset description, feature analysis, modeling, and evaluation. The dataset description elaborates on the sampling process and results of the verification data used. Feature analysis extracted appropriate features based on the differences between the normal and abnormal states of the verification data, which are then fed into the anomaly detection model. Modeling and evaluation completed the selection of hyperparameters during the construction process of the proposed anomaly detection method and verified the effectiveness of the model.
4.1. Evaluation Metrics
To evaluate the performance of the proposed anomaly detection method, the F1-score, a commonly employed metric that balances precision and recall, is used in this paper. Precision represents the proportion of correctly detected anomalies among all detected anomalies. A higher precision indicates fewer false positives. Recall represents the proportion of correctly detected anomalies among all actual anomalies. A higher recall indicates fewer false negatives. The formulas for precision, recall, and F1-score are presented in Equation (
14):
in these formulas, TP (True Positive) represents the number of anomalies correctly detected as anomalies, FP (False Positive) represents the number of normal instances incorrectly detected as anomalies, and FN (False Negative) represents the number of anomalies incorrectly classified as normal.
In addition to these traditional metrics, considering the importance of timely anomaly alarms in NPP equipment monitoring, lag time is introduced as a measure of the timeliness of anomaly detection. This indicator is defined as the difference between the alarm trigger time and the actual occurrence time of the anomaly, providing a measure of the model’s responsiveness.
4.2. Dataset and Preprocessing
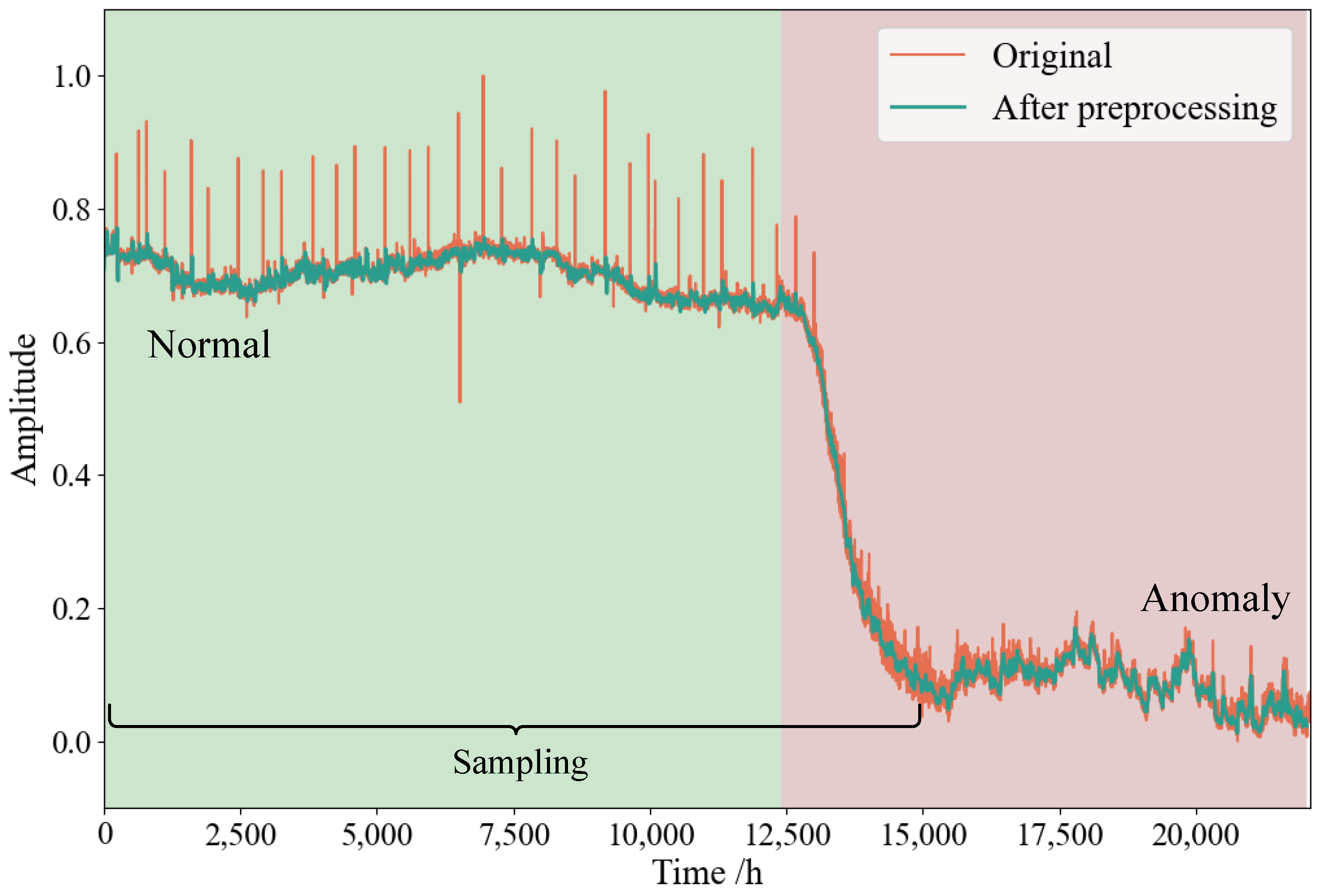
The dataset used in this study consists of pressure monitoring data from the mechanical seal of an RCP of an NPP. The monitoring period spans approximately 22,400 h. As illustrated in
Figure 2, when the monitored pressure deviates from the normal range and exhibits a gradual downward trend, it indicates potential leakage failure in the mechanical seal of the RCP. Based on this observation, we classify the dataset into normal and abnormal states and sample separately for preprocessing. Data preprocessing involved sampling the data with a sliding window method, where the window size is 5 h, and the step size is 1 h. For abnormal data, we specifically selected the falling-edge segments, periods where the pressure begins to decline, to capture the most relevant anomaly data. Finally, as summarized in
Table 1, the normal samples were divided into training and test sets, while all the abnormal samples were used for testing.
4.3. Feature Analysis
When a mechanical seal failure occurs, the monitored pressure values gradually decrease, resulting in deviations from normal operating ranges. This deviation results in distinguishable differences in both time-domain and frequency-domain statistical characteristics between normal and abnormal signals. To characterize these anomalies systematically, we conducted a joint time-frequency analysis of the monitoring signals and extracted the relevant features.
The time-domain features extracted from the pressure signals are summarized in
Table 2. These features capture various aspects of the signal, such as the maximum (Max), minimum (Min), range, mean, slope, root mean square (RMS), skewness, and kurtosis. In addition to time-domain features, frequency-domain features were extracted to capture the signal’s frequency characteristics. The frequency-domain features, including frequency center, root mean square frequency, and variance frequency, are summarized in
Table 3.
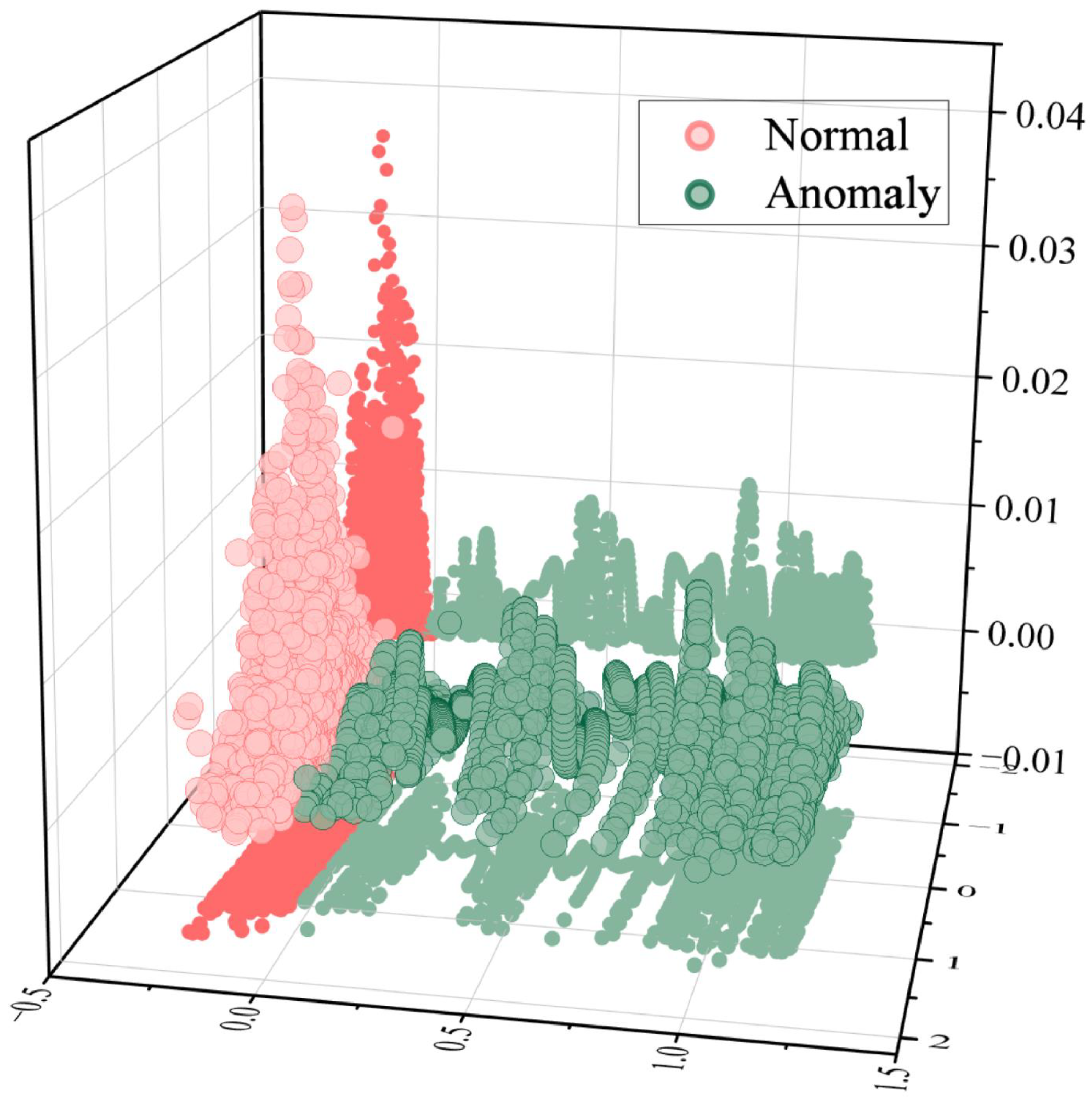
To evaluate the discriminative power of the proposed features across different operational states, the feature distributions under normal and abnormal conditions have been visualized, as illustrated in
Figure 3. It is important to note that, to facilitate visualization, Principal Component Analysis (PCA) was applied to reduce the dimensionality of the extracted features. As illustrated in
Figure 3, normal-state data exhibit a high concentration distribution in the dimensionality-reduced space, reflecting high feature similarity under normal operating conditions. In contrast, abnormal-state data display dispersed distributions with a distinct boundary separating them from normal data. This pronounced divergence confirms that abnormal features significantly differ from normal ones, demonstrating that the proposed features effectively capture discriminative characteristics between operational states.
4.4. Modeling and Evaluation
Given the significant impact of Kernel SOM network size and Kernel function type on model performance, we conducted grid search experiments to explore the performance of the Kernel SOM + Bayesian Posterior Inference model under different network sizes and kernel functions, aiming to find the optimal parameter combination. The grid experiments explore the model performance on the validation set under different hyperparameter combinations by combining kernel functions such as polynomial (Poly), radial basis function (RBF), and exponential with two network sizes of and , respectively. The model performance was evaluated using metrics such as F1-score, and the optimal parameters corresponded to the combination with the best performance indicators.
Furthermore, in the grid experiments, we simultaneously implemented the comparison between the Kernel SOM and Kernel SOM + Bayesian Posterior Inference models to verify the effectiveness of combining Kernel SOM with Bayesian Posterior Inference. The results of the grid experiments are shown in
Table 4.
When analyzing
Table 4, it can be observed that the F1-score values of the Kernel SOM + Bayesian Posterior Inference model are superior to those of the Kernel SOM model under different parameters. This indicates that the comprehensive performance of the Kernel SOM + Bayesian Posterior Inference model is better than that of the Kernel SOM model. In particular, when the network size is
and the kernel function is exponential (
), the F1-score of the Kernel SOM + Bayesian Posterior Inference model is improved by 0.048 compared to the Kernel SOM model, which is a significant improvement in model performance. Those enhancements in performance highlight the effectiveness of probabilistic data distribution modeling and Bayesian Posterior Inference in improving model performance. Additionally, it can be seen that when the network size is
and the kernel function is RBF (
), the F1-score of the Kernel SOM + Bayesian Posterior Inference model reaches the optimal result in the comparison. This indicates that the model performs best under these parameters, which thus act as the optimal parameters. Lastly, the precision and recall values of the Kernel SOM + Bayesian Posterior Inference model under the optimal parameters are 0.9938 and 0.9847, respectively. These values indicate that the model has low false positive and false negative rates and can accurately detect the RCP abnormal state, verifying the effectiveness of the model.
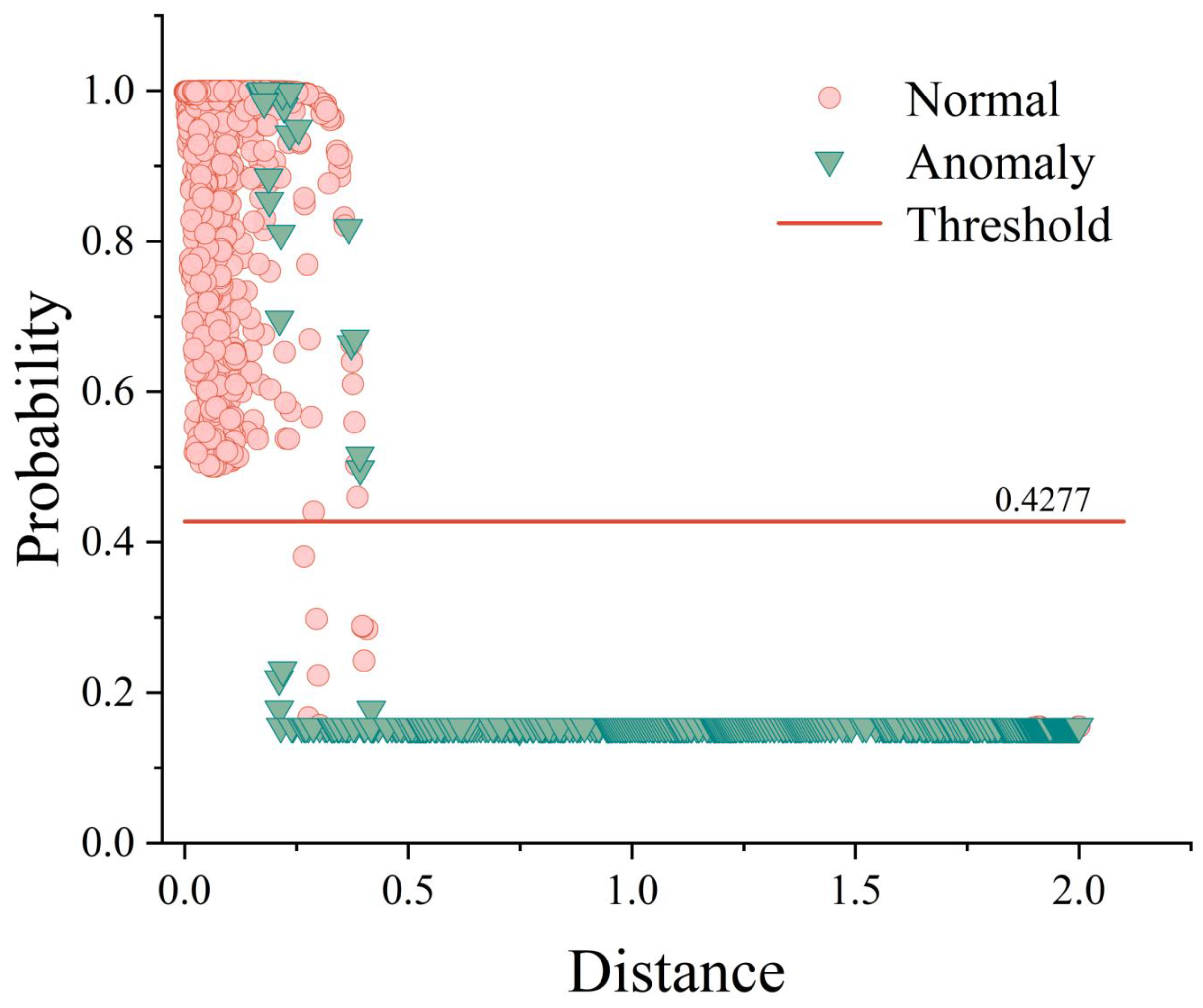
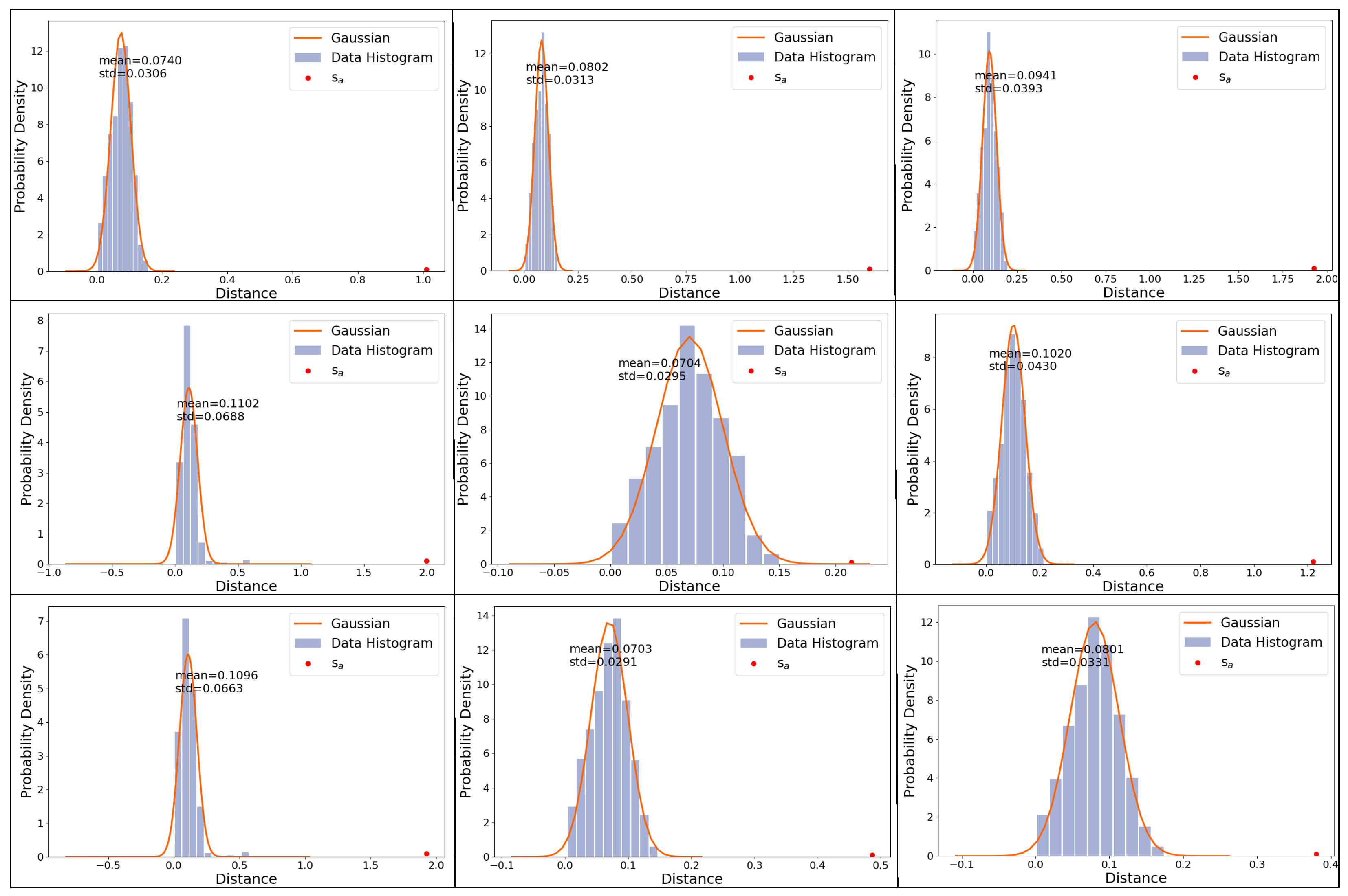
The reason why the performance of the Kernel SOM + Bayesian Posterior Inference model is always better than that of the Kernel SOM model is that the Kernel SOM + Bayesian Posterior Inference model builds a distance distribution probability model reflecting the data of each clustering cluster based on the Kernel SOM. The distance distribution probability model accurately analyzes the data distribution pattern under normal conditions, which creates a clearer boundary between normal and abnormal states. Furthermore, combined with posterior inference, the Kernel SOM + Bayesian Posterior Inference model probabilistically infers the likelihood of data anomalies. Differing from the Kernel SOM that solely relies on distance measurement, this method considers the intrinsic structure and distribution of data. This improves the model’s accuracy in anomaly detection. As shown in
Figure 4, the Kernel SOM + Bayesian Posterior Inference model establishes a clear probabilistic boundary between normal and abnormal samples, effectively achieving the separation and identification of normal and abnormal samples.
6. Conclusions
To address the insufficient interpretability of existing anomaly detection methods for RCP equipment, this study proposes an unsupervised anomaly detection algorithm based on Kernel SOM and Bayesian Posterior Inference. This framework provides an interpretable solution for RCP anomaly identification. The method establishes a precise boundary between normal and abnormal states by constructing a kernel distance probability distribution model for clustering results, providing both a reliable data distribution analysis tool and an interpretable model to enhance anomaly discernibility. Furthermore, by integrating the kernel distance distribution model with Bayesian Posterior Inference, the framework enables probabilistic anomaly assessment and traceable decision-making processes, significantly improving detection performance and interpretability. The verification results demonstrate that the proposed method outperforms other existing advanced and traditional algorithms in detection accuracy. Additionally, the method systematically explains the rationale behind anomaly judgments and identifies critical features influencing detection outcomes, aiding users in pinpointing the root causes of anomalies and distinguishing abnormal from normal patterns.
The proposed method can be applied not only to anomaly detection in RCPs but also to equipment anomaly detection in other engineering fields. Its modules are relatively independent, allowing components such as the clustering module to be adjusted or replaced based on the specific application scenario, which demonstrates its broad potential for use. However, current verification is limited to univariate data due to data acquisition constraints. Future work will extend the method to multivariate data to further enhance anomaly detection rates.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}