1. Introduction
The transition to future smart grids marks a fundamental transformation shift in energy management, especially when enhanced by advanced digital technologies, artificial intelligence (AI), and the Internet of Things (IoT) [
1,
2]. These innovations aim to improve efficiency, reliability, and sustainability. Unlike traditional power systems, smart grids feature real-time monitoring, self-healing mechanisms, and decentralized power generation from renewable sources. Most importantly, they enable decentralized forms of control.
Networks designed in this manner facilitate the seamless integration of distributed energy resources (DER) with load flexibility management systems. Achieving this integration relies on the effective use of strategic planning and optimal power flow optimal power flow (OPF) techniques. Strategic planning ensures the successful incorporation of DER, renewable energy sources (RESs), and demand management, while also optimizing grid expansion and infrastructure upgrades. Conversely, OPF techniques identify the most efficient energy distribution strategies by minimizing generation costs and transmission losses while maintaining system stability.
For many years, OPF techniques have been essential tools for the efficient planning and operation of electrical systems [
3,
4]. The goal of this methodology is to determine the most optimal or stable operating point to meet specific cost function objectives while adhering to system constraints. Generally, OPF objectives can be categorized into two types: single-objective minimization and multi-objective minimization [
5,
6,
7].
When discussing traditional methods for solving the optimal power flow (OPF) problem, we can identify two main categories of algorithms: deterministic and stochastic [
8]. The deterministic category encompasses linear and non-linear programming, gradient methods (GM), Newton’s method (NM), and interior point methods (IPM) [
4,
9]. These algorithms rely on specific assumptions regarding the convexity, regularity, continuity, and differentiability of the cost function. Generally, they are quite effective and quick when the cost function is monotonic. However, in modern power networks, cost functions often exhibit quadratic characteristics or non-linearity. This non-linearity affects the input-output behaviors of generating units, resulting in fuel costs that are both non-linear and non-smooth [
10].
To tackle these challenges, several methods have been developed over the years based on metaheuristic techniques [
3,
11,
12]. Among the most well-known of these are the genetic algorithm (GA), particle swarm optimization (PSO), and the artificial bee colony (ABC) algorithm [
9,
13]. Although these methods frequently achieve convergence, they tend to involve a significant computational burden [
14]. In terms of the content of future smart grids, it is necessary to look at new approaches based also on Artificial Intelligence, so other approaches are also becoming popular. In this context, reinforcement learning (RL) has been employed to address various real-world control and decision-making challenges in uncertain scenarios. However, its utilization in power system management has been limited [
15].
For instance, in [
16], an OPF methodology based on Deep Q-Network (DQN) was developed for a network under different loading conditions. In [
17], an RL algorithm was devised to address the AC OPF problem based on proximal policy optimization (PPO). The same authors presented a similar methodology in [
18] applying RL considering several topology changes. The paper uses an offline training method to correctly initialize the parameters of the neural networks (NNs). Although this leads to a considerable improvement in performance, it also introduces an element of great complexity that impacts the reproducibility of the algorithm. For this reason, in this work, an effort has been made to develop a model that does not require pre-training. A common approach, often used due to the scarcity of datasets, is to perturb load values around their nominal value [
17,
19]. However, this method is highly limiting, as it fails to account for extreme load conditions, which at certain hours of the day can drop to zero. In [
20,
21], the authors developed an algorithm based on twin delayed deep deterministic policy gradient (TD3) while considering random load distributions. In this case, the results are presented in an aggregated form, preventing a clear assessment of the RL actual performance. Another approach is the one presented in [
22] where constant loads are used. Finally, in [
8], RL is employed using PPO to solve an OPF to minimize power losses. In [
23], the authors propose a distributed optimal power flow RL-based model which is highly effective when there is a large number of RESs. The main gaps that this article aims to address concern the definition of reward functions that can be of general value for even complex planning scenarios and the possibility of training based on historical data. In this way, the system can create models that can be used to make decisions in real time. The idea is to create a model that learns from real data obtained historically and the network thus driven can be used to react in real time to what happens in the network. Observations are possible because smart grids can measure and exchange information. Starting from these considerations this paper aims to develop a methodology, that learns for the solution of OPF problem and learns how to map the observation on action that can satisfy the cost function. The issue discussed in the paper is that the inclusion of RESs increases the uncertainty in the network, making the optimization problem more challenging and realistic. Unlike traditional methods that primarily focus on quadratic cost functions, this study examines more practical cost formulations that take into account voltage state analysis at various nodes. Additionally, the paper provides comparative assessments with meta-heuristic models, showcasing the effectiveness of the proposed method. A great deal of work has been done on creating the framework, cost functions, and training methodologies, leaving the TD3 algorithm in its classic form to demonstrate the possibilities of standard approaches to solving the problem.
The key contributions of this paper can be summarized as follows:
Formulating the OPF problem as an original Markov decision process (MDP) to be solved using RL.
Using real datasets for training, and validation, incorporating both load and renewable generation data.
Exploring advanced cost functions beyond traditional quadratic formulations, including voltage state analysis at different nodes.
Providing a replicable tool for electrical networks of varying sizes and load characteristics.
Comparing the proposed approach with traditional methods to validate it.
The paper is organized as follows:
Section 2 provides the key principles of RL and describes the utilized algorithm.
Section 3 outlines the formulation of the AC OPF problem.
Section 4 presents the structure of the Data-Driven based AC OPF solver.
Section 5 showcases the results obtained from testing the algorithm on the target network. Finally,
Section 6 contains conclusions and remarks on future work.
3. Problem Formulation
As previously mentioned, the goal of the OPF is to find the optimal generator set-points such that a cost function is minimized while satisfying system and security constraints. The control variables of the AC OPF are the active power generation at the PV buses (slack bus excluded), the voltage magnitude of PV buses, the tap settings of transformers and the eventual shunt VAR compensation. On the other side, the state variables are the active power of the slack bus, the voltage magnitude of PQ buses, the reactive power of all generators and the transmission line loadings. The PQ buses are voltage and reactive power-controlled buses, the PV buses are voltage and active power-controlled buses, and the slack bus is the reference bus that acts as a compensator. In the present paper, both the tap settings and VAR compensation are neglected. Generally, the basic cost function is the total generating fuel cost; each generator has its own cost curve represented by a quadratic function. In this case, given a set of buses
N, a subset of generator buses
G, load demand buses
D and a set of transmission lines
L, the OPF problem can be formulated as [
3]:
where
,
and
are the cost coefficients of the
ith generator. V is the bus voltage.
and
are the net active and reactive power injections at bus
j. The parameters
and
represent the conductance and susceptance between bus
j and
i while
and
are voltage angles at bus
i and
j respectively. Finally,
represents the transmission line load of the
l line [
17]. Regarding the cost function, it is important to emphasize that the network may consider generators operating with different types of fuel. This leads to the function being divided into piecewise continuous quadratic cost functions. Furthermore, to make the function multi-objective, additional terms can be integrated into the quadratic fuel cost function. For instance, to obtain more accurate modelling of the cost function for multi-valve steam turbines, the so-called valve point effect can be considered. When the turbine operates at a valve point, just before the next valve opens, it operates at full efficiency. However, when the turbine operates off a valve point, it works less efficiently due to throttling losses. This effect significantly alters the output of the gas turbine, generating some ripples in the cost function. To account for this effect, a non smooth and non-convex rectified sine function can be added to the quadratic cost function, as detailed in (
16) [
11,
12].
where
and
are two coefficients that take into account the valve point effect.
Additionally, a component accounting for the voltage deviation from the unit at PQ buses can be included, aiming to improve the voltage profile of the entire system [
3] as in (
17).
where
is a scaling factor to balance between the objective function values and to avoid the dominance of one objective over another.
In pursuit of a more comprehensive scenario, (
16) and (
17) can be merged. The function derived in this manner integrates both the valve point effect and voltage fluctuation control and thus all the complexities of the issue at hand
In this research, all four cost functions will be taken into consideration. These will be minimized, considering the operational constraints, through the utilization of an offline-trained DRL agent and subsequently tested in real case scenarios.
4. DRL-Based AC-OPF
To address the AC-OPF problem with RL, it is necessary to model it as an MDP. In other words, starting from a time instant t, the DRL agent must make a decision based on observations of the current state of the environment. This leads to obtaining a reward , which is useful to evaluate the quality of actions, and transition to the state . This section describes the components of the aforementioned MDP: state-action space, reward function, environment, and agent.
4.1. State-Action Space
The states
represent the initial input of the DRL agent. These states encompass the active and reactive power of loads at each bus. These are the observations considered by the agent to perform the actions. The state space can be summarized as in (
19):
where
n is the number of loads in the grid. On the other hand, actions
involve the power output of each generator and its voltage setpoint.
4.2. Reward Function
The cost function assigns a reward every time an action is taken in a state . As previously mentioned, in this paper the intent is to solve the optimal power flow (OPF) problem considering a multi-objective scenario. Initially is set equal to , then , , and finally . In this way, it is possible to observe the changes in the accuracy and performances of the RL algorithm moving from a single to a multi-objective cost function.
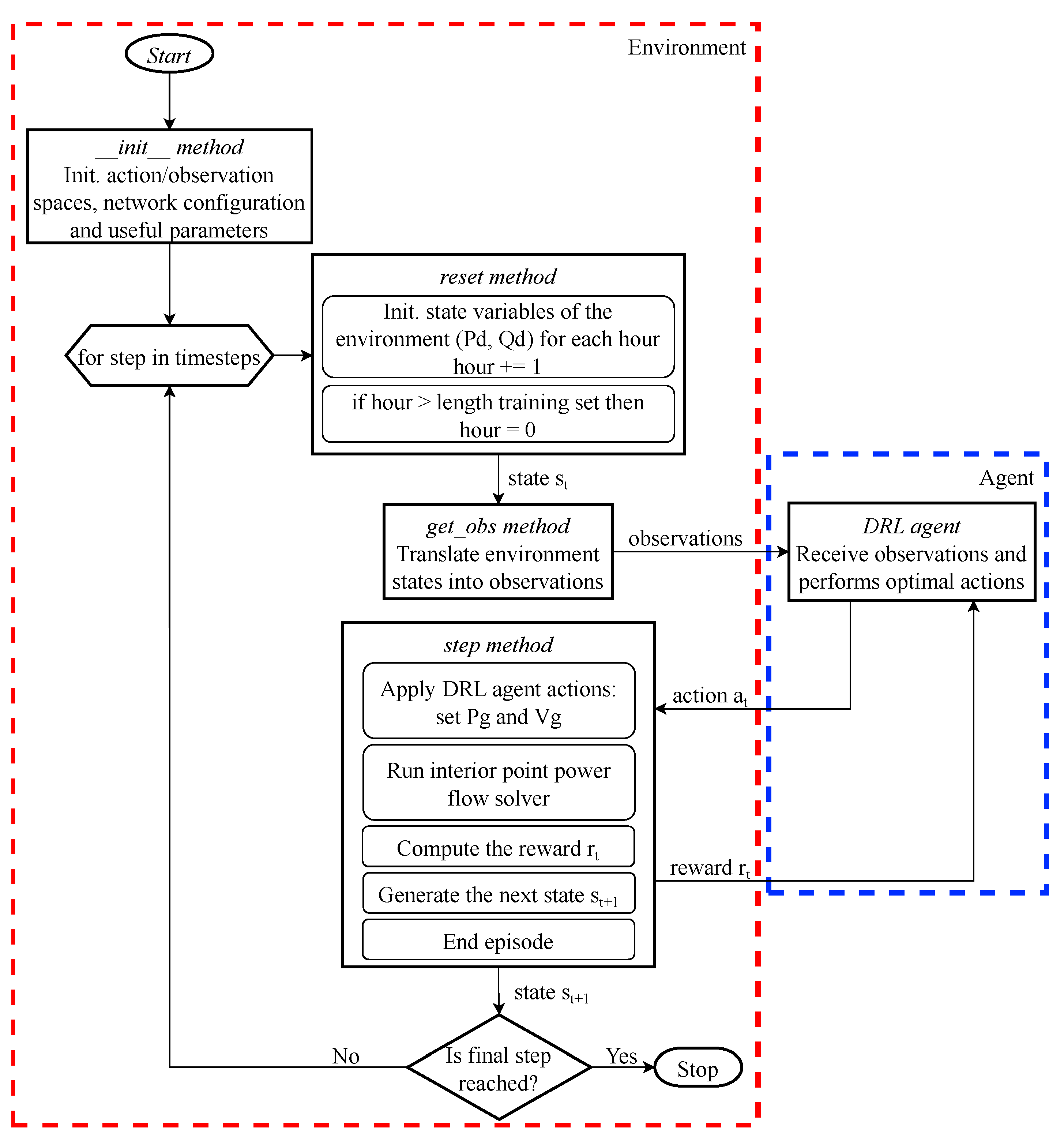
4.3. Environment
The development and structure of the custom environment used to model the MDP problem follows the conventions established by the OpenAI Gym library [
26].
Initialization (init method): It is used to establish the initial state, the action space, the observation space, and other environment-specific properties. It is executed once when the environment is created.
Reset Function (reset method): The reset method is responsible for preparing the environment for a new episode. It returns the initial observation and sets the state to the starting configuration.
Step Function (step method): The core of the custom environment is the step method. This method takes an action as input, updates the environment state, and returns critical information such as the next state, reward, and an indication of whether the episode is complete.
Observation Retrieval (get obs): Involves obtaining observations of the current state after each action, crucial for guiding an agent’s decision-making process.
Additionally, it leverages the Pandapower library for modeling and solving power system-related aspects such as running the PF and building the network. The specific flowchart of the OpenAI Gym-based custom environment and its interaction with the RL agent is summarized in
Figure 2.
4.4. DRL Agent and Training Process
As previously mentioned the algorithm used for training the agent is TD3. Specifically, the agent is trained using real load profiles with episodes of unit length. At the beginning of the episode, the reset method sets the loads values in hour h to the corresponding values of the dataset. Now the index h is used instead of index t for clarity of notation since a timestep corresponds to a specific hour. The agent then generates actions for the environment, leading to power flow (PF) computation, reward calculation, and episode termination. Then, the reset method updates the load values for hour . This sequence continues until the final load values in the training dataset are reached. After this, the hour counter resets, and the training process proceeds until the last step in the training schedule. This approach allows the NN to learn the true dynamics of the system. The model obtained offline can then be used for online network AC OPF, even when dealing with loads significantly different from those used for training.
If the training had been performed with episodes of the same length as the training dataset, the system would not have learned the optimal actions for each hour. Instead, it would have learned to provide actions that, on average, optimize the cumulative reward.
5. Study Cases
The proposed approach for solving the OPF is tested on a modified version of the standard IEEE 118-bus system. Simulations where conducted using Python 3.9. In this regard, both the power grid model and the PF solver have been developed using the Pandapower library [
27]. The TD3 algorithm for RL and its corresponding training process were implemented using the Stable Baselines 3 library [
28]. Specifically, this library enables the training of the agent to understand the network model dynamics and provide power values as output, minimizing the cost function while respecting network constraints. Once the learning process is completed the trained agent is saved and tested on different load profiles to assess the algorithm’s learning correctness. The metaheuristic search algorithm used for testing the performances of the RL model is implemented using the Scikit-opt library.
Overall, five different configurations were tested, evaluating various factors including the presence or absence of renewables, the use of a non-polynomial cost function, and the implementation of direct voltage control (otherwise, the voltage was set at 1 p.u. for all generators). As previously mentioned, a load profile obtained with seed 42 and a generation profile obtained from data collected during 2018 were used for the training. Similarly, a load profile obtained with seed 2 and a generation profile obtained from data collected during 2019 were used for the evaluation. To speed up simulation times, only a subset of data was used for training. In case 1, one hour was selected out of every three from the initial 336 h (thus considering 112 h for each month). This specific number of hours was determined empirically and allows a good balance between the accuracy and speed of simulations. In subsequent scenarios, one hour was chosen for every two hours always considering the first 336 h (thus considering 168 h for each month). For all cases, the training process was conducted over 25,000 episodes. For the evaluation, the entire annual profile was taken into account.
To assess the performance of the model four values were considered: the cost comparison in percentage
, the accuracy ratio
, calculated as in (
21) [
18] and (
22) respectively, the simulation time and generation cost are considered.
With
the cost of the reference,
the total cost obtained using the RL-based controller, and
H the total number of hours considered in the simulation.
An overview of all the scenarios is presented in
Table 1.
All simulations were conducted using an Intel i7-11800H processor running at 2.30 GHz with 32 GB of RAM. Before presenting the results obtained from the simulations, it is essential to describe the data used for agent training and evaluation. This is crucial as it shows the uniqueness of this b10. Indeed, the models obtained from agent training are tested on real profiles and, therefore, have the potential for online use in real network management. Additionally, a subsection of the chapter is devoted to the description of the neural networks used and the hyperparameter tuning process, given their significance in the learning process.
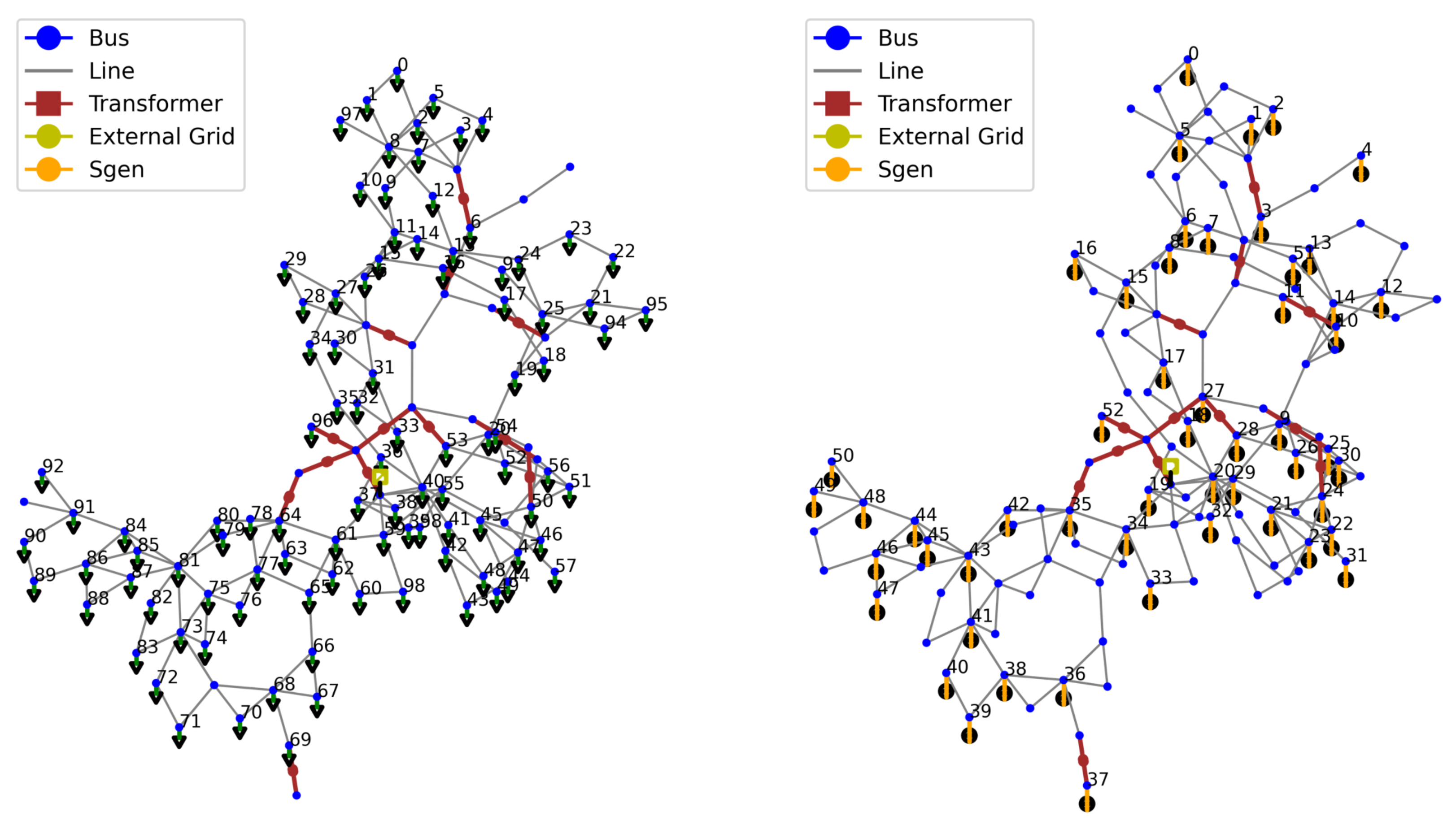
5.1. IEEE 118-Bus System
The IEEE 118-bus test system is a widely used benchmark for power system analysis and research purposes. It represents a simplified model of an actual power system, designed to test and validate various algorithms and methodologies in power system analysis, optimization, and control. The original IEEE 118-bus system contains 19 generators, 35 synchronous condensers, 177 lines, 9 transformers, and 91 loads while the configuration used in this paper is slightly different. It consists of 118 buses, 99 loads, 53 generators, 1 external grid, 173 lines, and 13 transformers operating between voltage levels of 138 - 161 and 345 kV. Overall there are 54 cost functions characterized by the default coefficients. In
Figure 3 all the elements characterizing the network, including their indices are represented. The buses position is set using geographical coordinates so it coincides with the real one.
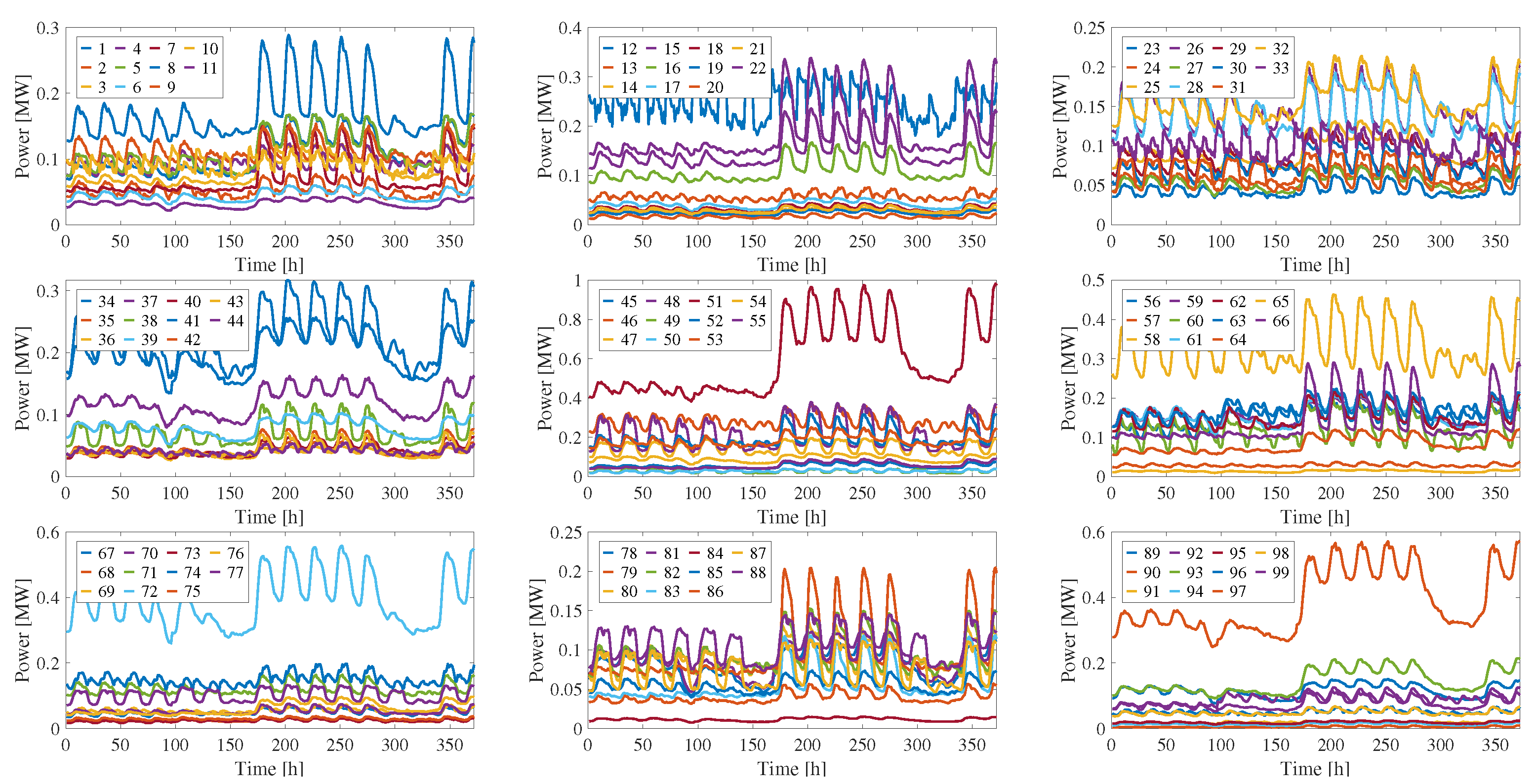
5.2. Loads Profiles
The load profiles used for the training and the evaluation of the agent were extracted from a data collection presented in [
29]. It contains a one-year data repository of hourly electrical load profiles from 424 French industrial and tertiary sectors. The dataset contains 18 electricity load profiles derived from hourly consumption time series collected continuously over one year from a total of 55,730 customers. All data was appropriately scaled to ensure compatibility with the network under analysis. Since the test system includes 99 different loads, a corresponding number of distinct load profiles was required. To address this, 99 new profiles were generated through suitable linear combinations of the original 18, allowing the creation of realistic yet differentiated load behaviors for each network load. This process was repeated twice to obtain two distinct sets of data, one for training and one for evaluation. In
Figure 4, the 99 load profiles used for training (generated using a seed value of 42) are shown. The profiles used for the evaluation were generated similarly using a different seed value of 2. In both cases, the seed was used to generate multiple load profiles from the existing ones. This was necessary due to the limited availability of only 18 real profiles, whose role was limited to serving as building blocks in the generation of the complete set of 99 distinct profiles required for the simulation.
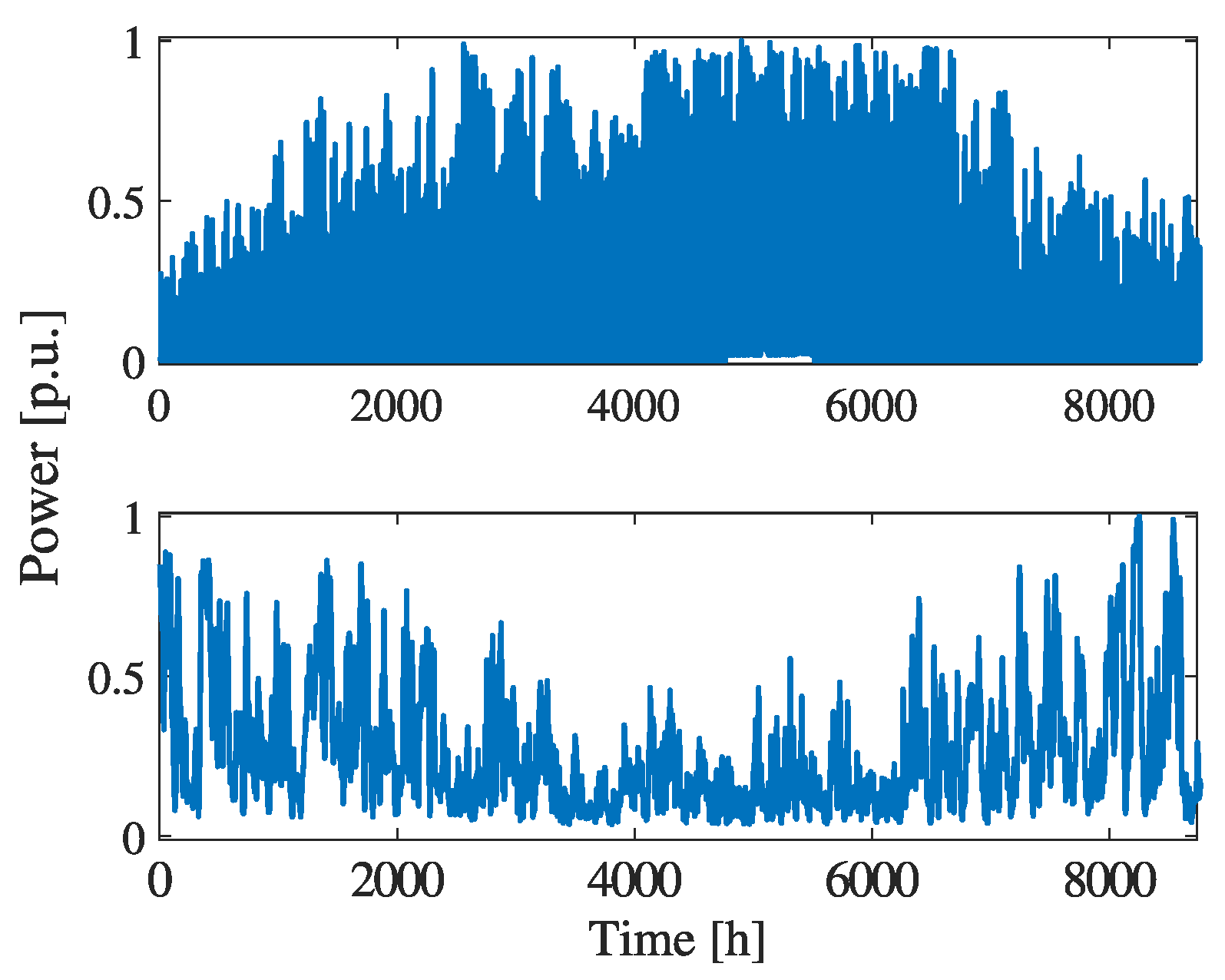
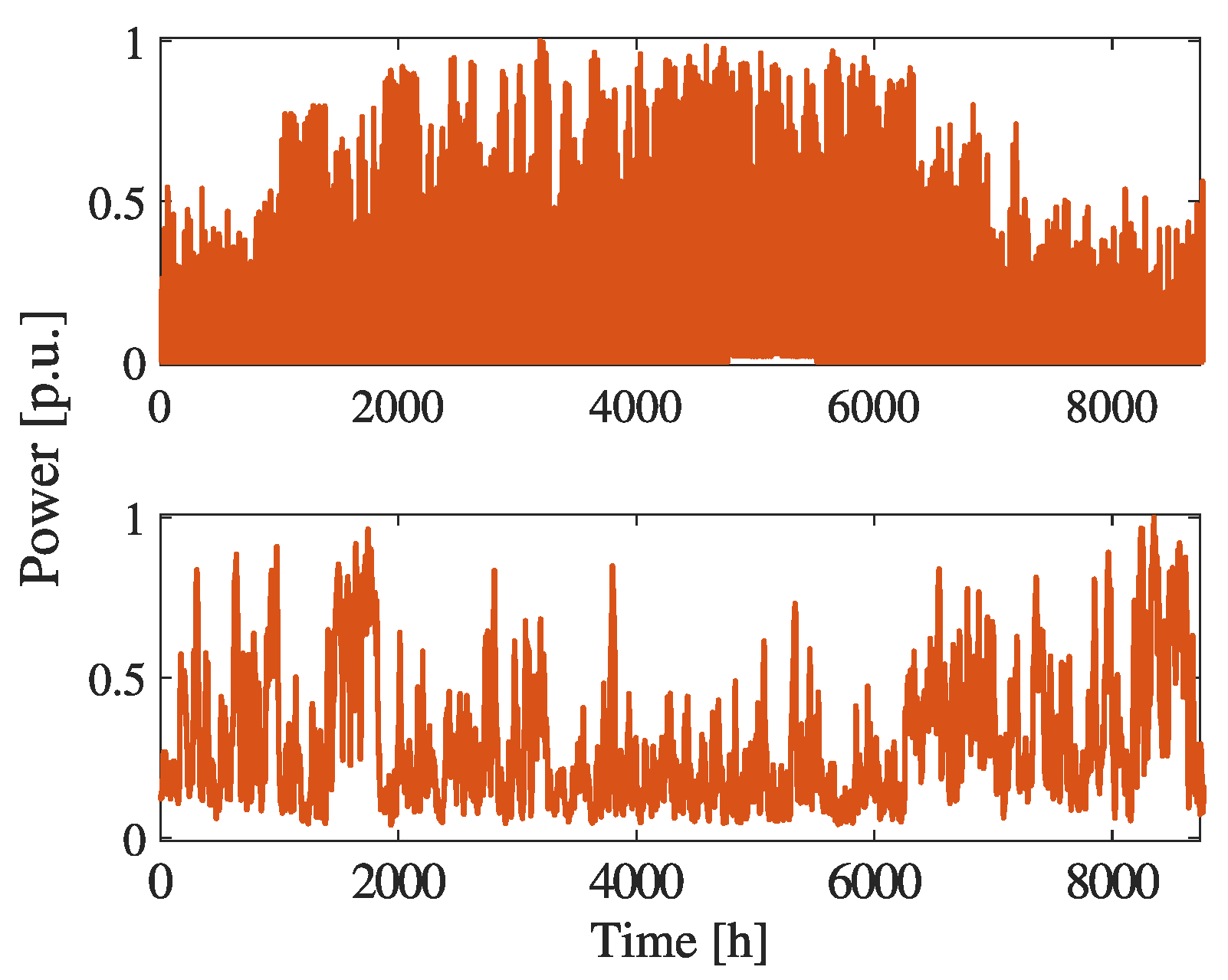
5.3. RES Profiles
To test the algorithm under conditions of uncertainty, renewable energy generators with a peak power of 200
for photovoltaic and a 300
for wind were installed randomly in the network. res generators are modeled as PQ-buses in the PF calculation. The hourly trends of their production profiles were those collected in France during 2018 (for training) and 2019 (for evaluation) and are available on the ENTSO-E website [
30]. The profiles are depicted in
Figure 5 and
Figure 6.
5.4. Neural Network and Hyperparameter Tuning
The TD3 algorithm is characterized by six different neural networks. These have been modeled as simple MLP networks with a number of inputs equal to the number of observations and a number of outputs equal to the number of actions. Case 1 is characterized by 6 hidden layers with (2000, 1000, 1000, 500, 400, 300) neurons. Cases 2 and 3 have 7 hidden layers with (2000, 1000, 1000, 500, 500, 400, 200) since the complexity of the problem has increased. Cases 4 and 5 have 7 hidden layers with (2000, 1000, 1000, 500, 500, 400, 300) due to the higher number of actions to be taken. The number of nodes of the NN, as well as other hyperparameters of the neural network, were obtained using an optimization algorithm based on Optuna [
31]. Practically, various parameter configurations were tested by training the agent with a fixed network configuration. The configuration that yielded the best results in terms of reward was saved and used for all case studies. The parameters are summarized in
Table 2.
All the other hyperparameters are kept at default values.
5.4.1. Case 1
In this initial case, the OPF was executed for the original network without RES. The cost function considered is polynomial, using the default network coefficients , , and for each generator. The Pandapower interior-point method (IPM) solver was employed as a comparative method.
5.4.2. Case 2
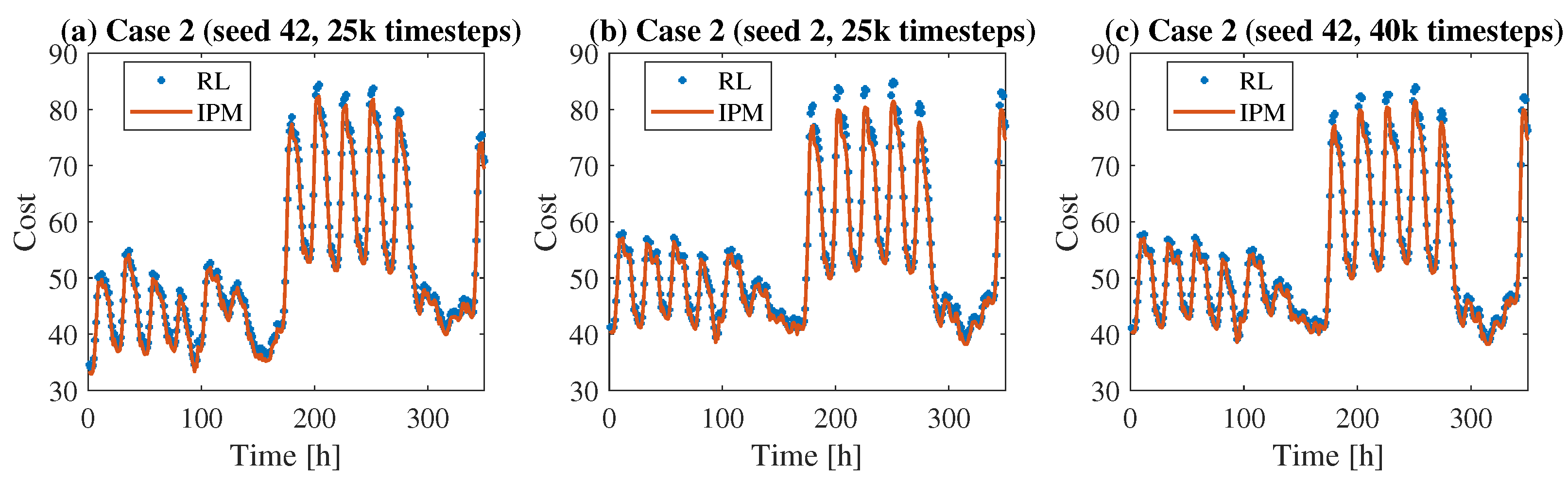
The second case is similar to the previous one, with the addition of some non-dispatchable renewable generators, such as solar and wind. The cost of these generators is set to zero, assuming that the network under investigation prioritizes the dispatch of RESs. Therefore, it is assumed that at each hour, all power generated by non-programmable sources is absorbed by the loads. What can be modified is solely the production profile of the other 53 programmable generators. Since the cost function remains unchanged compared to case 1, the IPM solver is still used as a comparative method. In
Figure 7 the cost values obtained with the algorithms are shown. In
Figure 7c it is evident how the number of timesteps used for the training impacts the accuracy of the RL algorithm.
5.4.3. Case 3
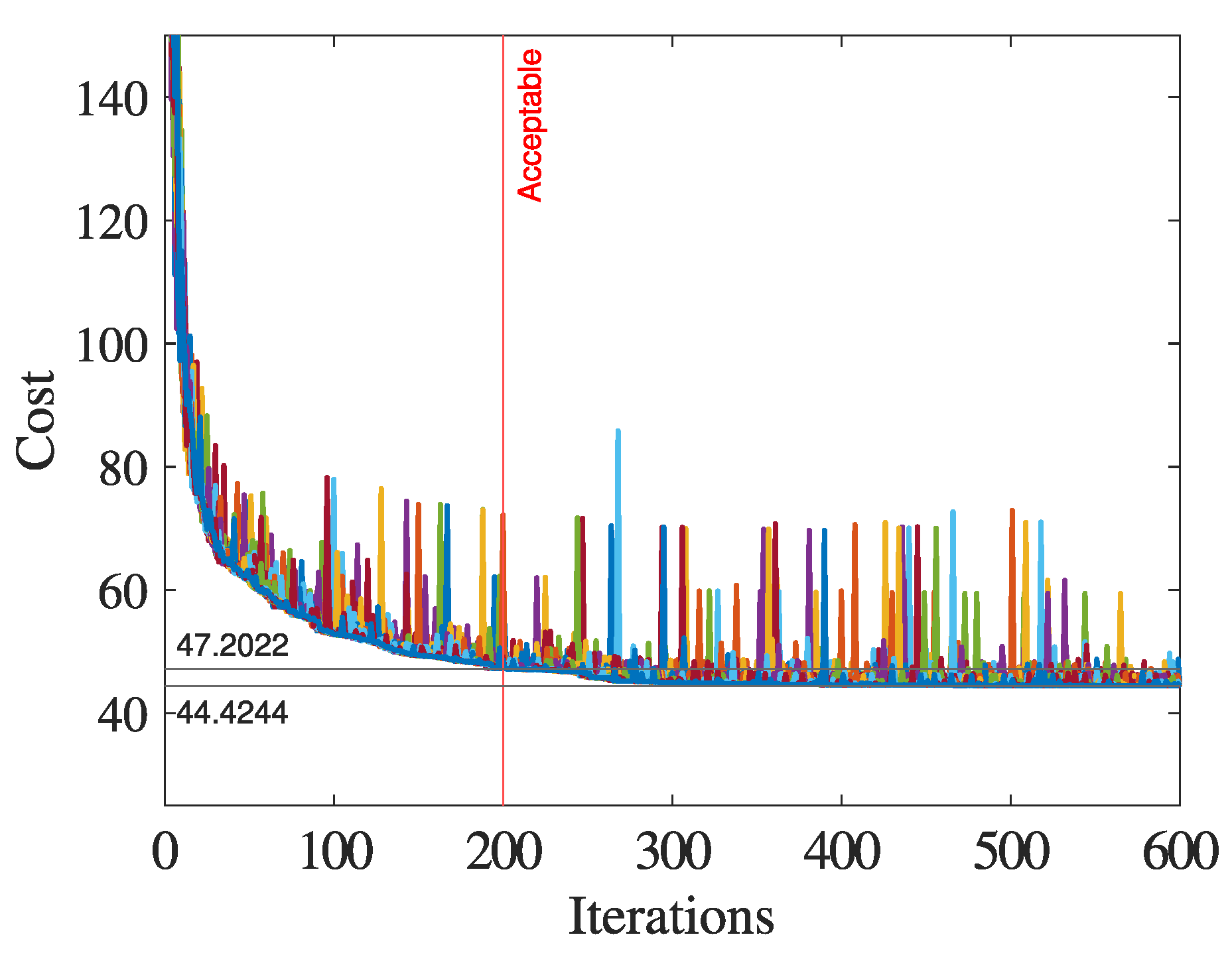
This case takes into account the valve point effect in generators. Therefore, in this scenario, the comparative method used is the genetic algorithm (GA). Initially, particle swarm optimization (PSO) was used as a comparison method. This choice was made because such algorithms typically guarantee convergence for very large action spaces within relatively short time-frames. However, given the size of the network, the PSO in our tests was never able to achieve cost values comparable to those obtained with RL. For this reason, the slower but more robust GA-based method was used. In
Figure 8, it is evident that taking the first set of loads (hour 1) as an example, the algorithm can reach the minimum point in about 600 iterations. The time required for this simulation is approximately 30 min. However, a satisfactory result can be achieved in just 200 iterations, corresponding to about 8 min of simulation. Independently on the number of iterations, the population size was set to 50. Even considering only 200 iterations, the total simulation time exceeds two months. Therefore, we decided to simulate only the first 20 h. This is a time interval sufficient to allow a comparison with the RL. In all simulations where the valve point effect was considered
and
were set to 200 and 0.2 respectively.
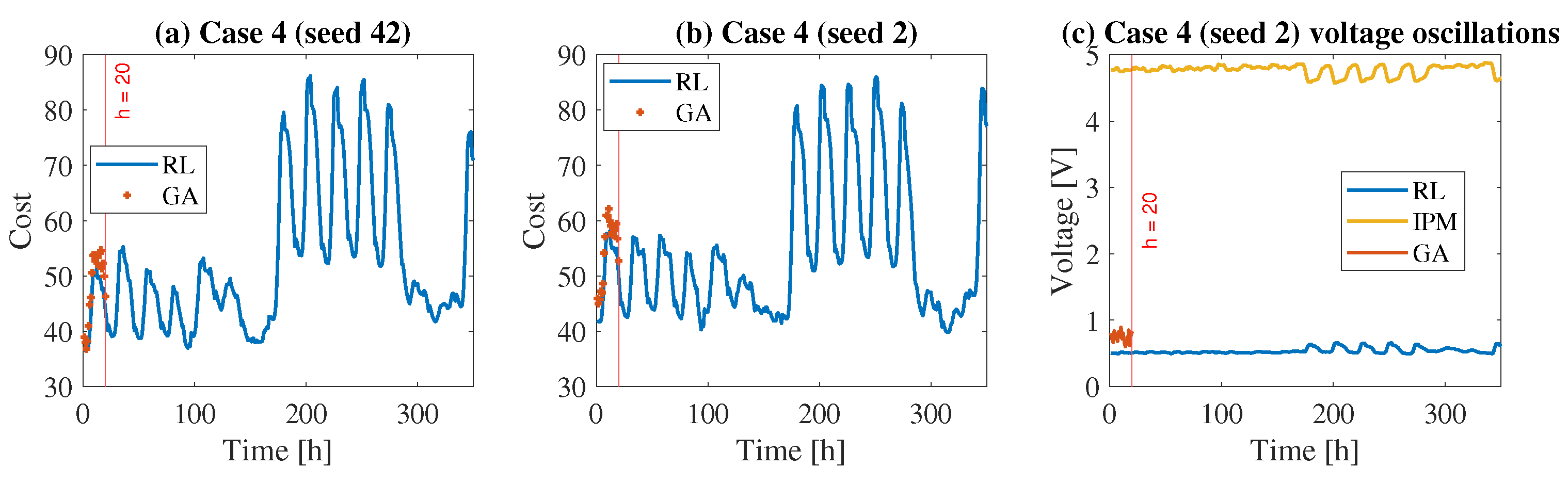
5.4.4. Case 4
This scenario represents the implementation of soft voltage constraints, as described by the cost function
. In this cost function, the primary goal is to minimize voltage fluctuations at each bus, ensuring they stay close to their nominal values (set to 1 p.u.), while also minimizing the overall cost function. The soft constraint introduces a penalty in the cost function to discourage the generation profiles that cause significant voltage deviations from the nominal value (1 p.u.) at the network buses. The GA is used as the method of comparison. The results concerning the first 350 h are summarized in
Figure 9 (GA time refers only to the first 20 h because due the computational time the entire simulation would last more than 2 months). More specifically,
Figure 9c highlights the sum of voltage deviations from the nominal value across all nodes of the network, computed on an hourly basis. This sum represent the portion of the cost function
relate to the soft constraints, and we use it to analyzed the influence of the minimization of this contribution in the three algorithms compared. It is observed that the inclusion of voltage constaints results in a reduction of about 1/5 compared to the case without voltage control(IPM), and nearly a 20% reduction when compared to the results obtained using the ga with voltage control.
5.4.5. Case 5
Here, the cost function is minimized, thereby taking into account all the complexities of the problem. The figure illustrates the annual production profile from programmable sources, considering the valve point effect, voltage control, and the presence of renewable energy sources.
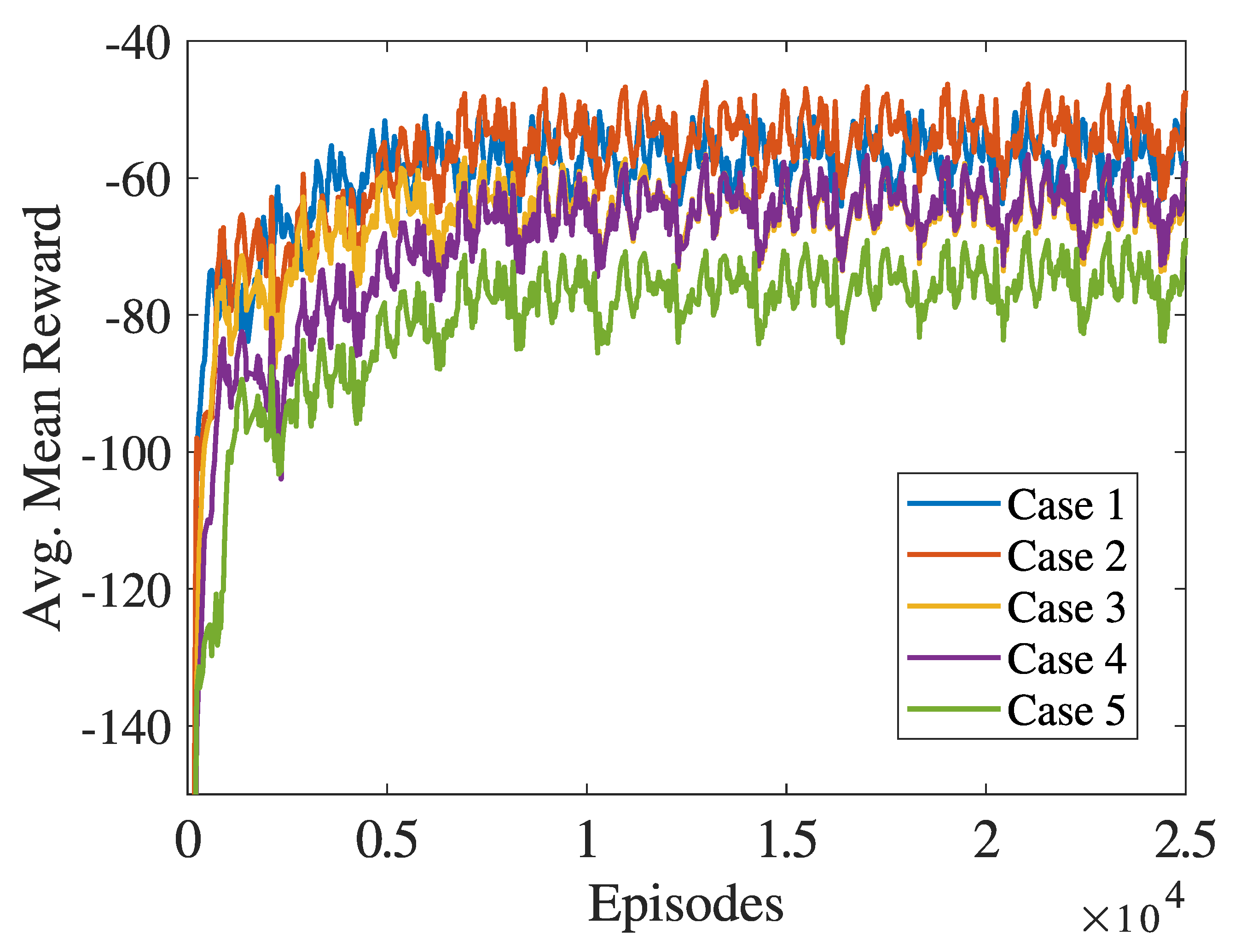
All the numerical results and the training curves are summarized in
Figure 10 and
Table 3. The percentage of times the OPF is solved without violating constraints is
in all cases.
5.5. Practical Applicability to Real-World Power Systems
The presented RL-based OPF framework has promising applicability in real-world power system operations, particularly in contexts requiring fast, adaptive decision-making under uncertainty. A key advantage of the proposed approach is its ability to generalize beyond the specific conditions seen during training. The trained RL agent was evaluated on previously unseen scenarios, featuring different load and generation profiles, including the presence of non-dispatchable RESs, valve-point effects, and voltage regulation objectives. This highlights the method’s robustness and adaptability to dynamic and realistic operating conditions that are often difficult to model explicitly.
Once trained, the policy can be deployed within energy management systems or embedded into distributed controllers to provide near-optimal decisions in real time, avoiding the computational burden of solving OPF from scratch at each step. Moreover, the proposed approach has shown the capability to respect key operational constraints, such as generator limits and voltage deviations, through reward shaping and interaction with the simulated environment. This makes it suitable for deployment in both transmission and distribution networks with high variability and DER integration. The RL-based solution can also be integrated into hierarchical or hybrid control architectures, where its outputs are validated or refined by conventional solvers to ensure operational security and regulatory compliance. The ability to react to novel conditions with fast inference times suggests its suitability for real-time or near-real-time applications, offering a scalable alternative to traditional optimization methods in future power system operation frameworks.
6. Conclusions
This paper proposes a novel methodology based on RL to solve the OPF problem. The approach leverages theTD3 algorithm, enabling the system to reach optimal operating conditions while accounting for complex factors such as the valve-point effect of gas-fired generators, the integration of non-dispatchable RESs, and voltage regulation at the bus level. The method was validated on the IEEE 118-bus system using five distinct case studies. To enhance realism, both the RES generation and load consumption profiles were derived from actual data.
The results demonstrate that the algorithm is both robust and reliable, consistently converging to the optimal solution more quickly than traditional techniques such as the IPM and GA. In the case under study, the RL model achieves a comparable level of accuracy, with only a slight reduction (about 1–2%) compared to ipm, while offering a substantial reduction in computation time of around 30%. Although metaheuristic methods like ga may yield competitive solutions, their computation times become impractically long as network complexity grows, making the RL-based approach a more scalable and efficient alternative. Furthermore, unlike traditional methods, the RL model is inherently suited to handle the uncertainty associated with RESs, whose production is often highly variable and difficult to forecast.
Future research will focus on developing algorithms that initialize the parameters of NN based on historical data, thereby reducing the time required for simulations and increasing the accuracy of the outputs. Additionally, the development of a multi-agent RL model is planned, enabling optimal decentralized management of networks with high RES penetration. In this model, each agent would manage a portion of the electric network and share information with other nodes through a dedicated buffer. This type of logic would allow for managing sudden changes in network topology, for example, due to faults, and planning the provision of ancillary or network support services.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}