
TCN-GRU Based on Attention Mechanism for Solar Irradiance Prediction

Abstract
1. Introduction
- (1)
- Given the excellent performance of CNN and RNN in the field of prediction, the proposed TGAM model adopted a parallel approach of TCN and GRU for prediction. GRU is suitable for capturing long-term dependencies in sequences; TCN is suitable for capturing localized features and short-term dependencies. The combination of TCN and GRU synthesizes the advantages of each to improve the overall prediction accuracy of the model.
- (2)
- The combination of GRU with the attention mechanism accelerated the capture of the main features, reduced the computational burden and time cost of the neural network, and further improved prediction accuracy
- (3)
- Compared with simply summing the predictions of various algorithms, this study fit the predictions of TCN and GRU through MLP. The MLP can adaptively adjust the coefficients of TCN and GRU, thereby improving overall prediction accuracy.
- (4)
- The GHI is the most important metric for evaluating solar resources. The proposed TGAM took into account the temporal nature of GHI and the map distribution characteristics of monitoring points, accurately predicting GHI and providing a better reference for the selection of photovoltaic power stations.
2. Methodology
2.1. Temporal Convolutional Network
2.1.1. Causal Convolution
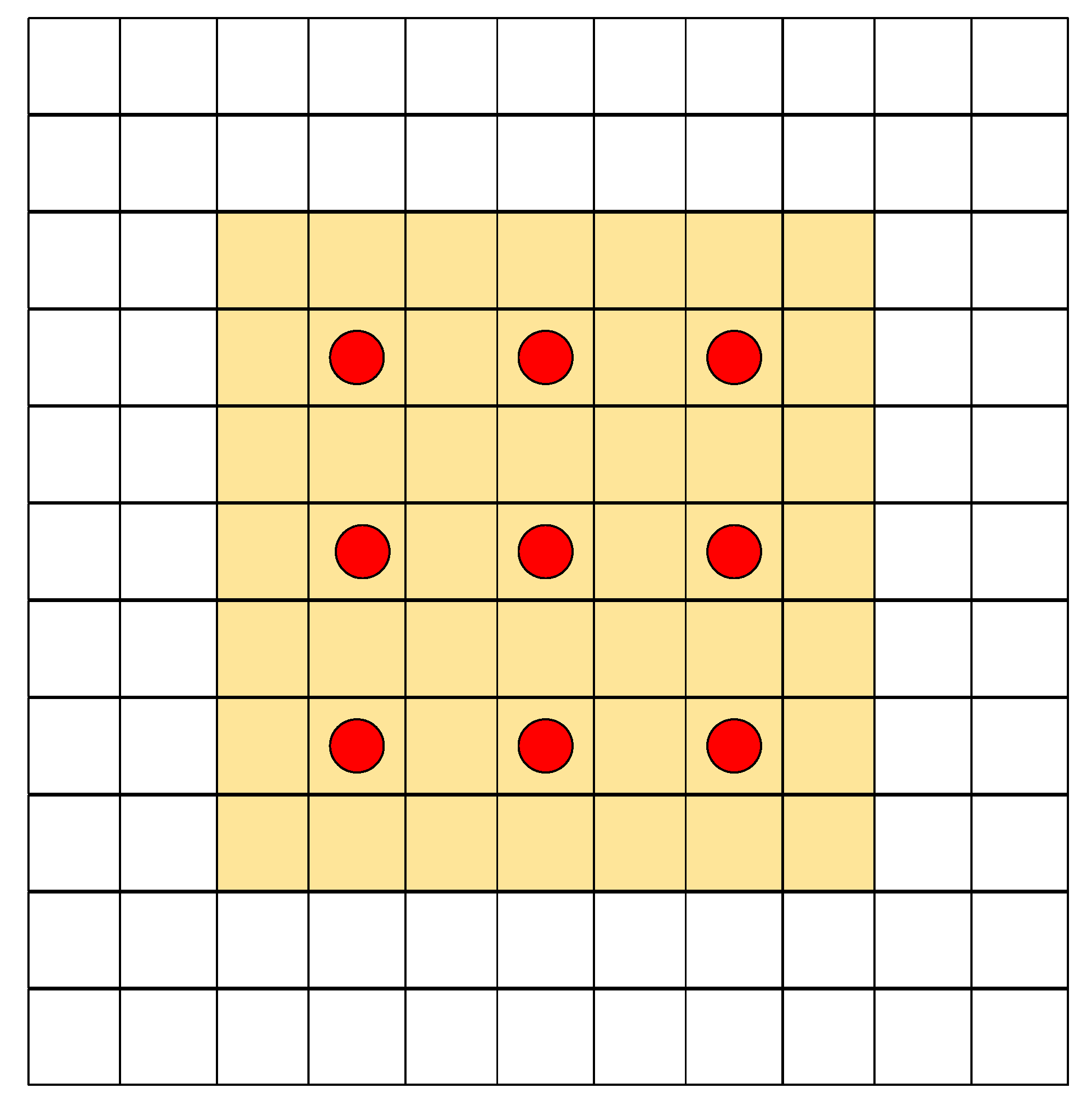
2.1.2. Dilated Convolution
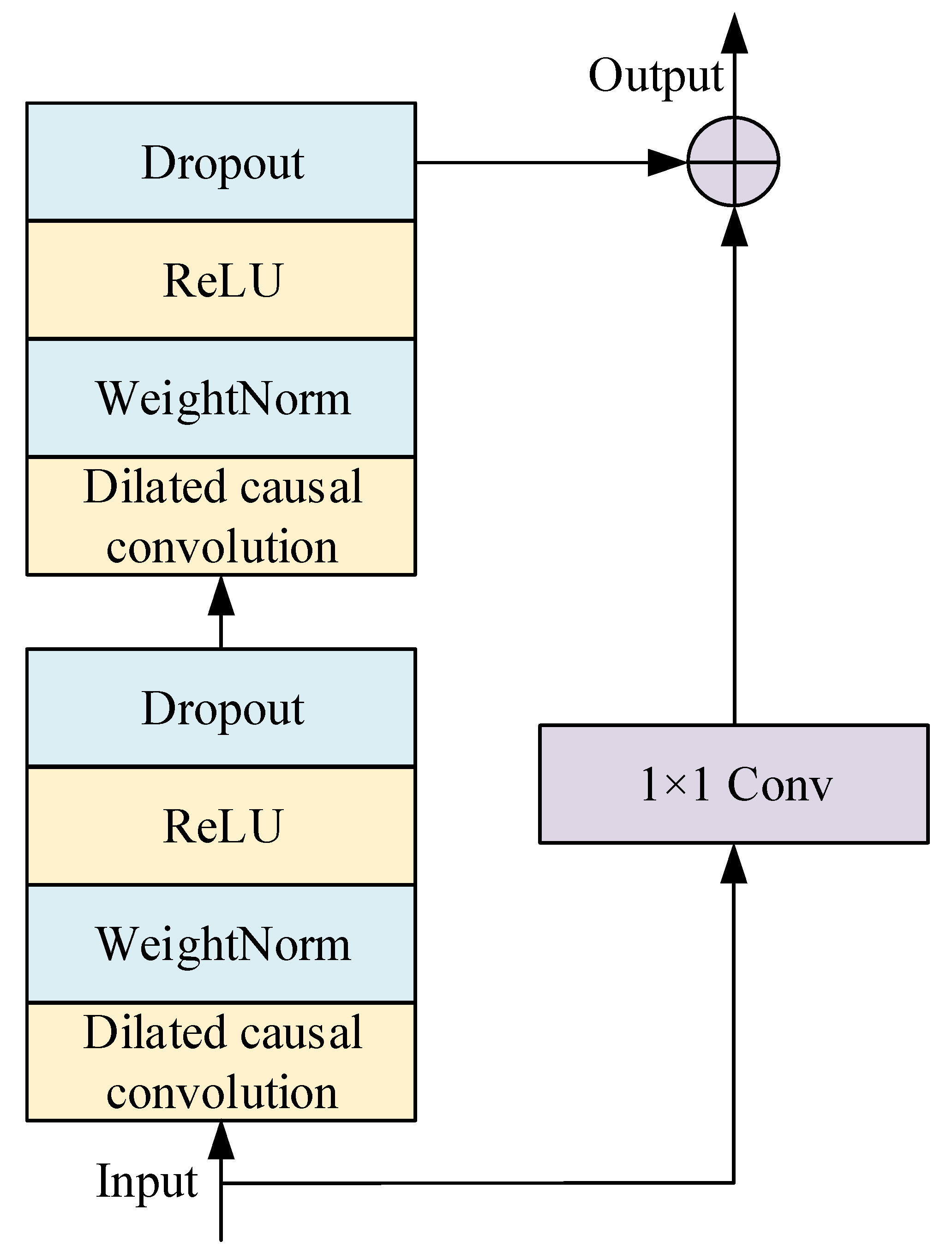
2.1.3. Residual Connection
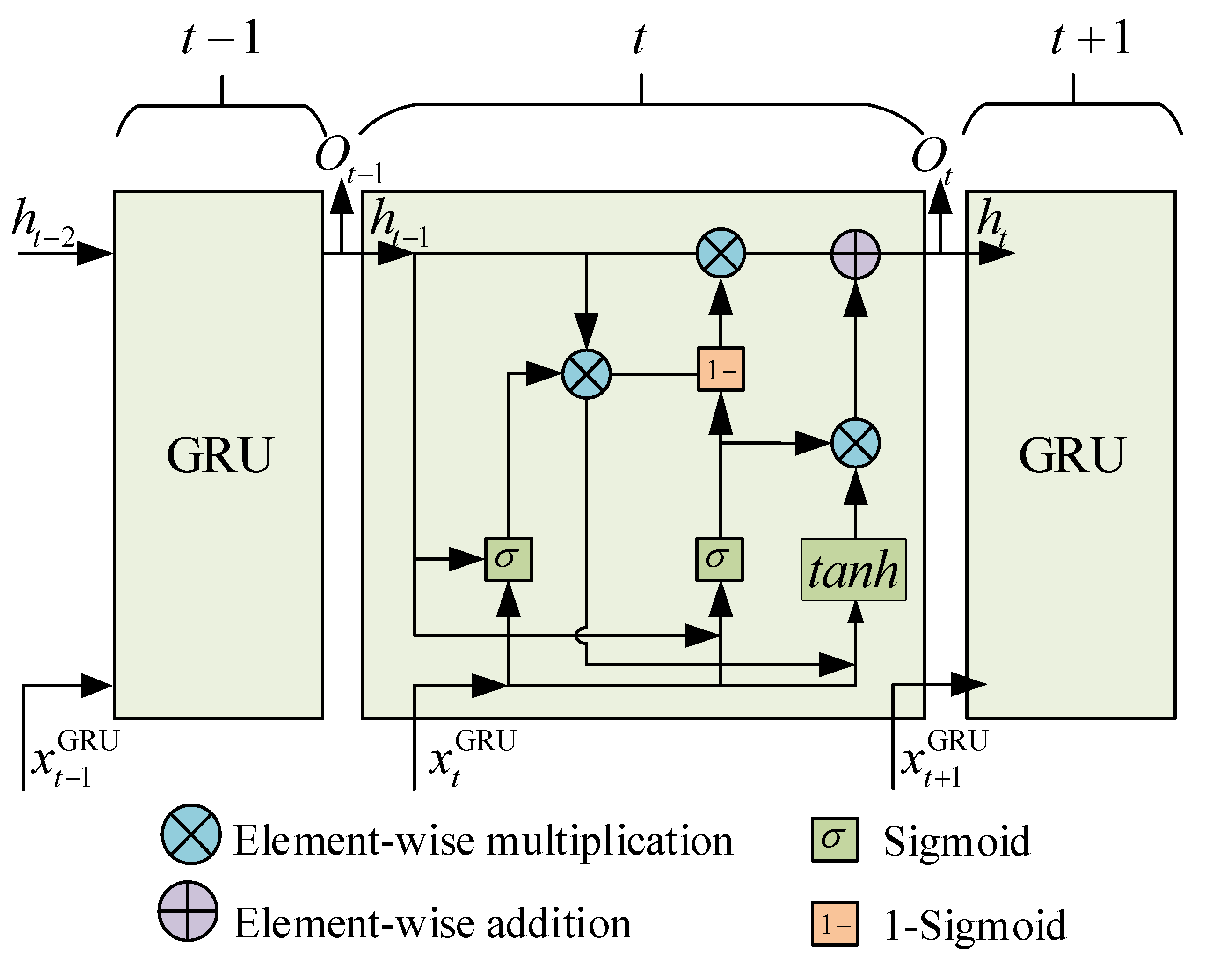
2.2. Gated Recurrent Unit
2.2.1. Update Gate and Reset Gate
2.2.2. Candidate Hidden State and Hidden State
2.3. Attention Mechanism
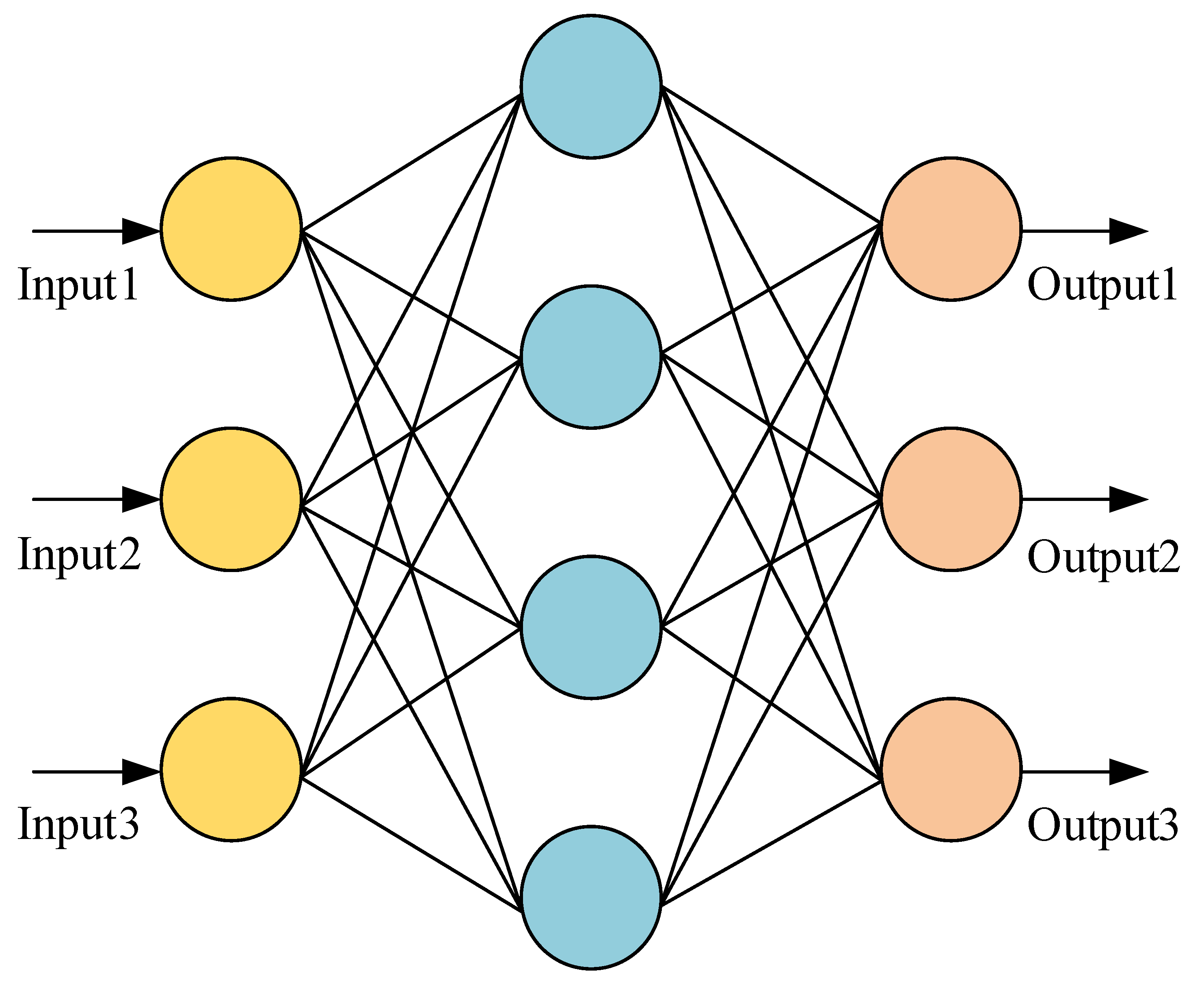
2.4. Multilayer Perceptron
2.5. TCN-GRU-Attention-MLP
3. Case Analysis
3.1. Evaluation Metric
3.2. Parameter Setting
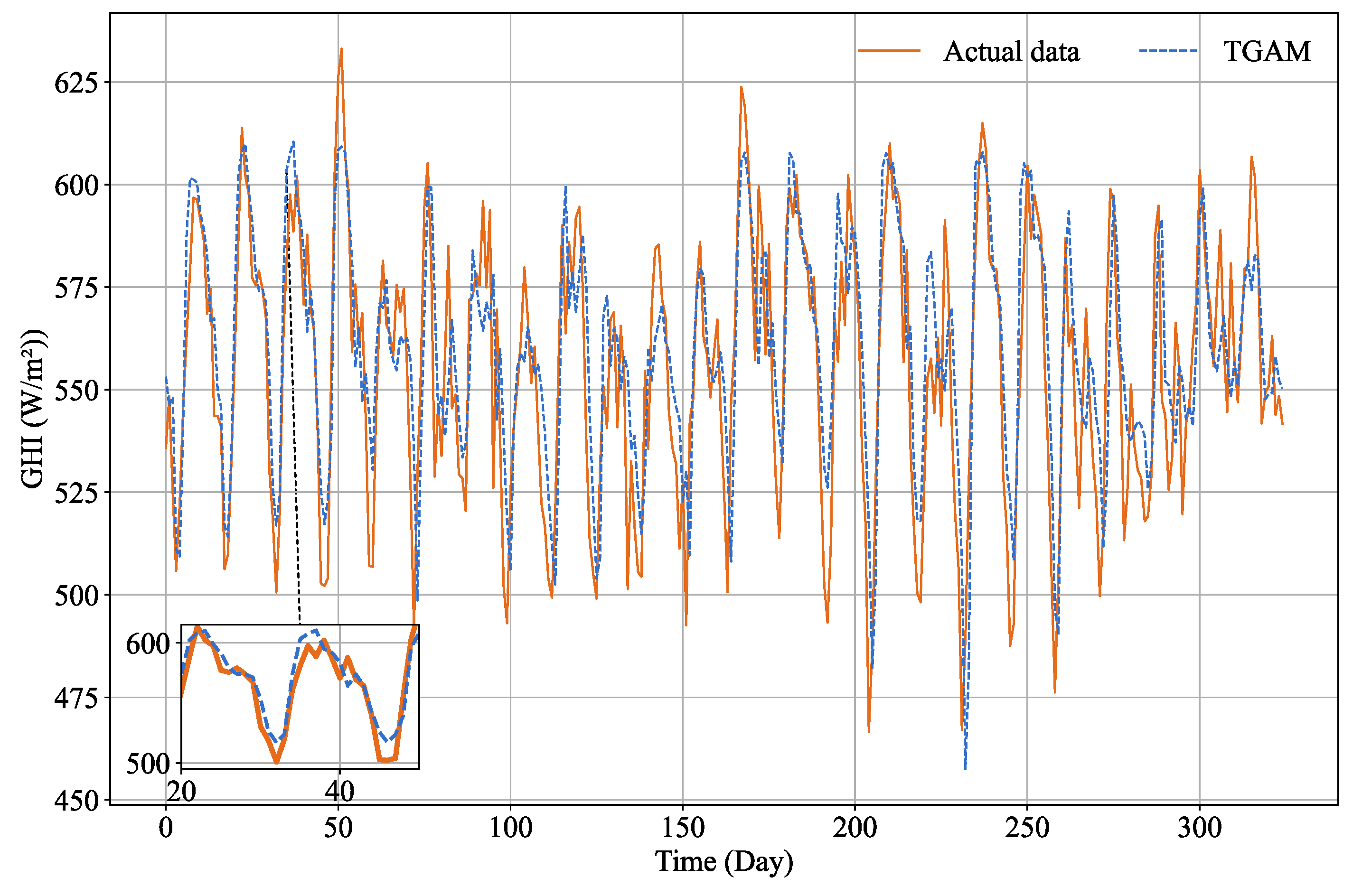
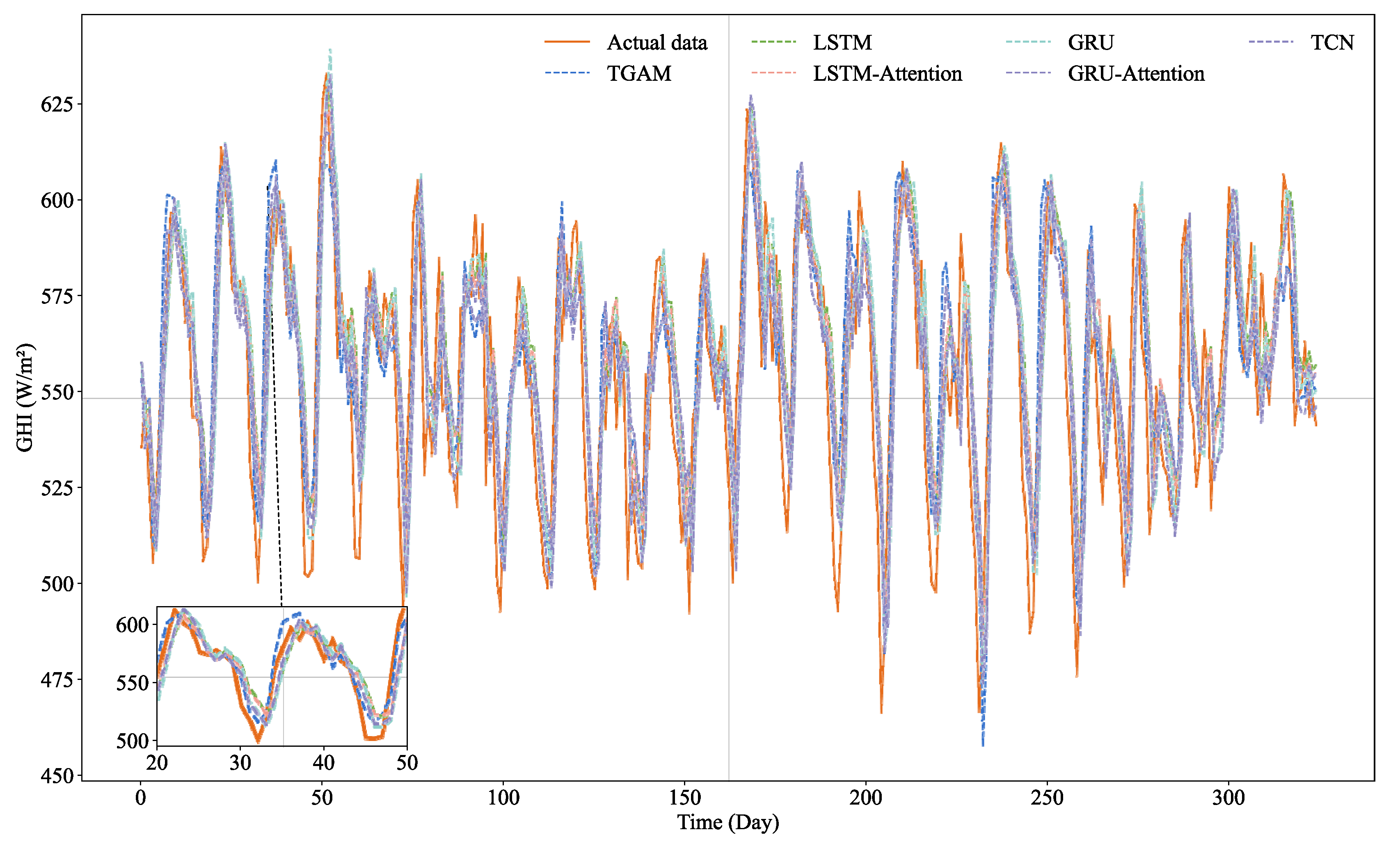
3.3. Result Analysis
4. Discussions
5. Conclusions
- (1)
- The proposed TGAM model integrates TCN and GRU, combining the characteristics of CNN and RNN. TCN extracts deep features of solar radiation, while GRU captures long-term dependencies of solar radiation time series. Two different types of algorithms complement each other to improve the overall prediction accuracy of the model.
- (2)
- The combination of GRU and attention mechanism enables the model to dynamically adjust attention levels based on different parts of the input sequence, improving model performance.
- (3)
- Compared to simply adding up the prediction results of TCN and GRU, this study utilizes MLP to adaptively adjust the weight coefficients of TCN and GRU, thereby avoiding the inclusion of algorithms with poor performance and improving the overall model prediction accuracy.
- (4)
- In addition to considering the relevant characteristics, which affect solar radiation, this study considers the Map distribution features, i.e., latitude, longitude, and altitude, providing a reference basis for the selection of photovoltaic power stations.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, T.; Li, R.; Zhang, H. Induction mechanism and optimization of tradable green certificates and carbon emission trading acting on electricity market in China. Resour. Conserv. Recycl. 2021, 169, 105487. [Google Scholar] [CrossRef]
- National Energy Administration Releases 2022 National Electric Power Industry Statistical Data. Available online: http://www.nea.gov.cn/2023-01/18/c_1310691509.htm (accessed on 30 June 2023).
- Liu, B.; Huo, X. Prediction of Photovoltaic power generation and analyzing of carbon emission reduction capacity in China. Renew. Energy 2024, 222, 119967. [Google Scholar] [CrossRef]
- Lai, C.S.; Zhong, C.; Pan, K. A deep learning based hybrid method for hourly solar radiation forecasting. Expert Syst. Appl. 2021, 177, 114941. [Google Scholar] [CrossRef]
- Jiang, Y.; Long, H.; Zhang, Z. Day-ahead prediction of bihourly solar radiance with a Markov switch approach. IEEE Trans. Sustain. Energy 2017, 8, 1536–1547. [Google Scholar] [CrossRef]
- Sansa, I.; Boussaada, Z.; Bellaaj, N.M. Solar radiation prediction using a novel hybrid model of ARMA and NARX. Energies 2021, 14, 6920. [Google Scholar] [CrossRef]
- García-Cuesta, E.; Aler, R.; Pózo-Vázquez, D. A combination of supervised dimensionality reduction and learning methods to forecast solar radiation. Appl. Intell. 2023, 53, 13053–13066. [Google Scholar] [CrossRef]
- Narvaez, G.; Giraldo, L.F.; Bressan, M. Machine learning for site-adaptation and solar radiation forecasting. Renew. Energy 2021, 167, 333–342. [Google Scholar] [CrossRef]
- Gaviria, J.F.; Narváez, G.; Guillen, C.; Giraldo, L.F.; Bressan, M. Machine learning in photovoltaic systems: A review. Renew. Energy 2022, 196, 298–318. [Google Scholar] [CrossRef]
- Alrashidi, M.; Alrashidi, M.; Rahman, S. Global solar radiation prediction: Application of novel hybrid data-driven model. Appl. Soft Comput. 2021, 112, 107768. [Google Scholar] [CrossRef]
- Villegas-Mier, C.G.; Rodriguez-Resendiz, J.; Álvarez-Alvarado, J.M. Optimized random forest for solar radiation prediction using sunshine hours. Micromachines 2022, 13, 1406. [Google Scholar] [CrossRef]
- Goliatt, L.; Yaseen, Z.M. Development of a hybrid computational intelligent model for daily global solar radiation prediction. Expert Syst. Appl. 2023, 212, 118295. [Google Scholar] [CrossRef]
- Chaibi, M.; Benghoulam, E.M.; Tarik, L.; Berrada, M.; Hmaidi, A.E. An interpretable machine learning model for daily global solar radiation prediction. Energies 2021, 14, 7367. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, Y.; Wang, D.; Liu, X.; Wang, Y. A review on global solar radiation prediction with machine learning models in a comprehensive perspective. Energy Convers. Manag. 2021, 235, 113960. [Google Scholar] [CrossRef]
- Irshad, K.; Islam, N.; Gari, A.A.; Algarni, S.; Algahtani, T.; Imteyaz, B. Arithmetic optimization with hybrid deep learning algorithm based solar radiation prediction model. Sustain. Energy Technol. Assess. 2023, 57, 103165. [Google Scholar] [CrossRef]
- Ehteram, M.; Shabanian, H. Unveiling the SALSTM-M5T model and its python implementation for precise solar radiation prediction. Energy Rep. 2023, 10, 3402–3417. [Google Scholar] [CrossRef]
- Vural, N.M.; Ilhan, F.; Yilmaz, S.F.; Ergüt, S.; Kozat, S.S. Achieving online regression performance of LSTMs with simple RNNs. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7632–7643. [Google Scholar] [CrossRef]
- Zhaowei, Q.; Haitao, L.; Zhihui, L.; Tao, Z. Short-term traffic flow forecasting method with MB-LSTM hybrid network. IEEE Trans. Intell. Transp. Syst. 2020, 23, 225–235. [Google Scholar] [CrossRef]
- Zarzycki, K.; Ławryńczuk, M. Advanced predictive control for GRU and LSTM networks. Inf. Sci. 2022, 616, 229–254. [Google Scholar] [CrossRef]
- Imani, M. Electrical load-temperature CNN for residential load forecasting. Energy 2021, 227, 120480. [Google Scholar] [CrossRef]
- Wang, Z.; Peng, X.; Cao, S.; Zhou, H.; Fan, S.; Li, K.; Huang, W. NOx emission prediction using a lightweight convolutional neural network for cleaner production in a down-fired boiler. J. Clean. Prod. 2023, 389, 136060. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Casillas-Pérez, D.; Salcedo-Sanz, S.; Sharma, E.; Ali, M. Deep learning CNN-LSTM-MLP hybrid fusion model for feature optimizations and daily solar radiation prediction. Measurement 2022, 202, 111759. [Google Scholar] [CrossRef]
- Ghimire, S.; Bhandari, B.; Casillas-Perez, D.; Deo, R.C.; Salcedo-Sanz, S. Hybrid deep CNN-SVR algorithm for solar radiation prediction problems in Queensland, Australia. Eng. Appl. Artif. Intell. 2022, 112, 104860. [Google Scholar] [CrossRef]
- Yang, W.; Xia, K.; Fan, S. Oil logging reservoir recognition based on TCN and SA-BiLSTM deep learning method. Eng. Appl. Artif. Intell. 2023, 121, 105950. [Google Scholar] [CrossRef]
- Zhang, C.; Li, J.; Huang, X.; Zhang, J.; Huang, H. Forecasting stock volatility and value-at-risk based on temporal convolutional networks. Expert Syst. Appl. 2022, 207, 117951. [Google Scholar] [CrossRef]
- Ni, S.; Jia, P.; Xu, Y.; Zeng, L.; Li, X.; Xu, M. Prediction of CO concentration in different conditions based on Gaussian-TCN. Sens. Actuators B Chem. 2023, 376, 133010. [Google Scholar] [CrossRef]
- Tian, C.; Niu, T.; Wei, W. Developing a wind power forecasting system based on deep learning with attention mechanism. Energy 2022, 257, 124750. [Google Scholar] [CrossRef]
- Gao, Y.; Miyata, S.; Akashi, Y. Interpretable deep learning models for hourly solar radiation prediction based on graph neural network and attention. Appl. Energy 2022, 321, 119288. [Google Scholar] [CrossRef]
- Kong, X.; Du, X.; Xue, G.; Xu, Z. Multi-step short-term solar radiation prediction based on empirical mode decomposition and gated recurrent unit optimized via an attention mechanism. Energy 2023, 282, 128825. [Google Scholar] [CrossRef]
- Rajasundrapandiyanleebanon, T.; Kumaresan, K.; Murugan, S.; Subathra, M.S.P.; Sivakumar, M. Solar energy forecasting using machine learning and deep learning techniques. Arch. Comput. Methods Eng. 2023, 30, 3059–3079. [Google Scholar] [CrossRef]
- Lee, J.A.; Dettling, S.M.; Pearson, J.; Brummet, T.; Larson, D.P. NYSolarCast: A solar power forecasting system for New York State. Sol. Energy 2024, 272, 112462. [Google Scholar] [CrossRef]
- Deveci, M.; Pamucar, D.; Oguz, E. Floating photovoltaic site selection using fuzzy rough numbers based LAAW and RAFSI model. Appl. Energy 2022, 324, 119597. [Google Scholar] [CrossRef]
- Elmousaid, R.; Drioui, N.; Elgouri, R.; Agueny, H.; Adnani, Y. Ultra-short-term global horizontal irradiance forecasting based on a novel and hybrid GRU-TCN model. Results Eng. 2024, 23, 102817. [Google Scholar] [CrossRef]
- Yin, L.; Zhou, H. Modal decomposition integrated model for ultra-supercritical coal-fired power plant reheater tube temperature multi-step prediction. Energy 2024, 292, 130521. [Google Scholar] [CrossRef]
- Yin, L.; Xie, J. Multi-feature-scale fusion temporal convolution networks for metal temperature forecasting of ultra-supercritical coal-fired power plant reheater tubes. Energy 2022, 238, 121657. [Google Scholar] [CrossRef]
- Hao, J.; Liu, F.; Zhang, W. Multi-scale RWKV with 2-dimensional temporal convolutional network for short-term photovoltaic power forecasting. Energy 2024, 309, 133068. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; Zhang, S.; Kraus, L.; Adcox, T.; Willardson, R.; Komandur, A.; Komandur, A.; Lu, N. A TCN-based hybrid forecasting framework for hours-ahead utility-scale PV forecasting. IEEE Trans. Smart Grid 2023, 14, 4073–4085. [Google Scholar] [CrossRef]
- Li, Q.; Guan, X.; Liu, J. A CNN-LSTM framework for flight delay prediction. Expert Syst. Appl. 2023, 227, 120287. [Google Scholar] [CrossRef]
- Gupta, U.; Bhattacharjee, V.; Bishnu, P.S. StockNet—GRU based stock index prediction. Expert Syst. Appl. 2022, 207, 117986. [Google Scholar] [CrossRef]
- Xu, Y.; Zheng, S.; Zhu, Q.; Wong, K.C.; Wang, X.; Lin, Q. A complementary fused method using GRU and XGBoost models for long-term solar energy hourly forecasting. Expert Syst. Appl. 2024, 254, 124286. [Google Scholar] [CrossRef]
- Mobarakeh, J.M.; Sayyaadi, H. A novel methodology based on artificial intelligence to achieve the formost Buildings’ heating system. Energy Convers. Manag. 2023, 286, 116958. [Google Scholar] [CrossRef]
- Yin, L.; Wei, X. Integrated adversarial long short-term memory deep networks for reheater tube temperature forecasting of ultra-supercritical turbo-generators. Appl. Soft Comput. 2023, 142, 110347. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Value |
| TCN | Channel | [80,128,176] |
| Kernel size | 3 | |
| Dropout | 0.4 | |
| Dilation size | 2 | |
| GRU | Hidden units | 32 |
| Hidden layers | 5 | |
| MLP | Hidden units | [128,160] |
| Hidden layers | 2 |
| Algorithm | MAE | MAPE | RMSE |
|---|---|---|---|
| LSTM | 18.8 | 0.034 | 23.07 |
| LSTM-Attention | 17.53 | 0.032 | 21.77 |
| GRU | 18.61 | 0.033 | 22.53 |
| GRU-Attention | 16.92 | 0.03 | 20.84 |
| TCN | 16.66 | 0.03 | 20.75 |
| TGAM | 12.6 | 0.02 | 15.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, Z.; Yang, Z.; Yang, X.; Li, J.; Meng, W.; Wei, Z. TCN-GRU Based on Attention Mechanism for Solar Irradiance Prediction. Energies 2024, 17, 5767. https://doi.org/10.3390/en17225767
Rao Z, Yang Z, Yang X, Li J, Meng W, Wei Z. TCN-GRU Based on Attention Mechanism for Solar Irradiance Prediction. Energies. 2024; 17(22):5767. https://doi.org/10.3390/en17225767
Chicago/Turabian StyleRao, Zhi, Zaimin Yang, Xiongping Yang, Jiaming Li, Wenchuan Meng, and Zhichu Wei. 2024. "TCN-GRU Based on Attention Mechanism for Solar Irradiance Prediction" Energies 17, no. 22: 5767. https://doi.org/10.3390/en17225767
APA StyleRao, Z., Yang, Z., Yang, X., Li, J., Meng, W., & Wei, Z. (2024). TCN-GRU Based on Attention Mechanism for Solar Irradiance Prediction. Energies, 17(22), 5767. https://doi.org/10.3390/en17225767