
Power Supply Risk Identification Method of Active Distribution Network Based on Transfer Learning and CBAM-CNN

 ,
,
Abstract
1. Introduction
- In order to be able to complete the identification of the faulty line and further identify whether it poses risks such as electrocution of maintenance personnel, we completed the identification of the self-supplied power supply on the faulty line. Compared with the selection of faulty lines only, this method is more comprehensive and helps to reduce the risk of supplying power from the self-provided power supply.
- We propose a combination of CBAM and CNN to achieve active extraction of fault risk features through the CNN and to enhance local feature extraction using the CBAM, so as to achieve high-efficiency feature extraction as well as high-accuracy risk identification.
- We propose a method combining transfer learning and CBAM-CNN, which can maintain a high recognition accuracy despite small samples and solve the problem of low risk recognition accuracy caused by few fault samples in real situations.
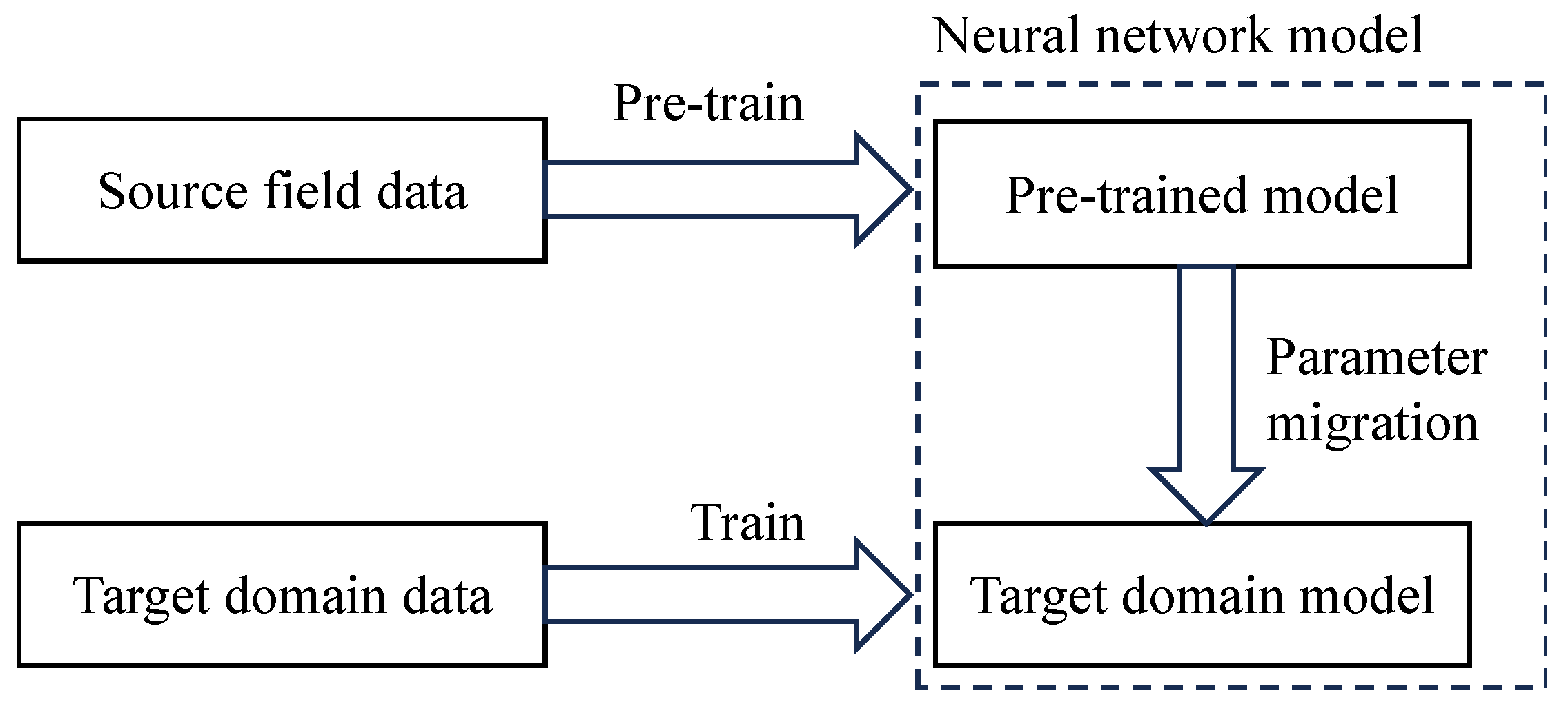
2. Transfer Learning
2.1. Principles of Transfer Learning
2.2. Convolutional Neural Network Pre-Training Process
2.3. CNN Pre-Trained Based on Transfer Learning
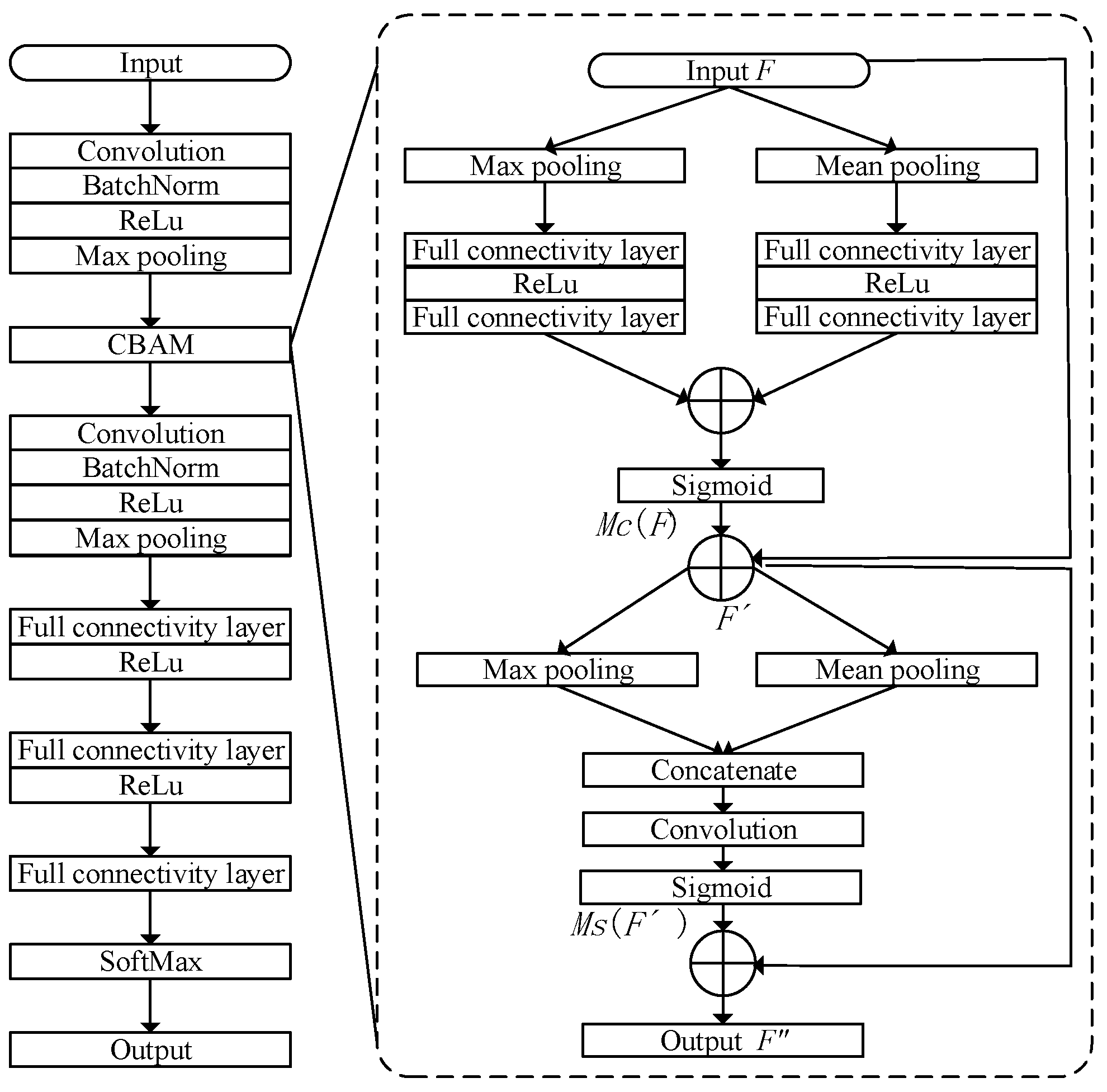
3. Risk Identification Model for Self-Provided Power Supply Integrated with Attention Mechanism
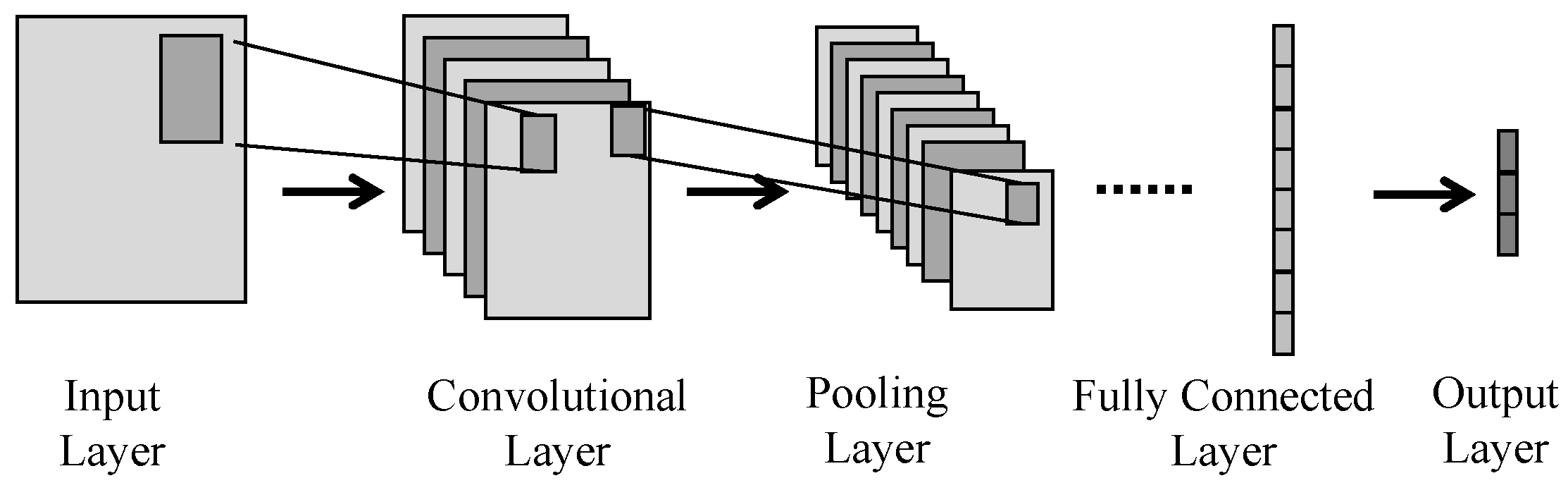
3.1. Convolutional Neural Network
3.1.1. Convolutional Layer
3.1.2. Pooling Layer
3.1.3. Fully Connected Layer
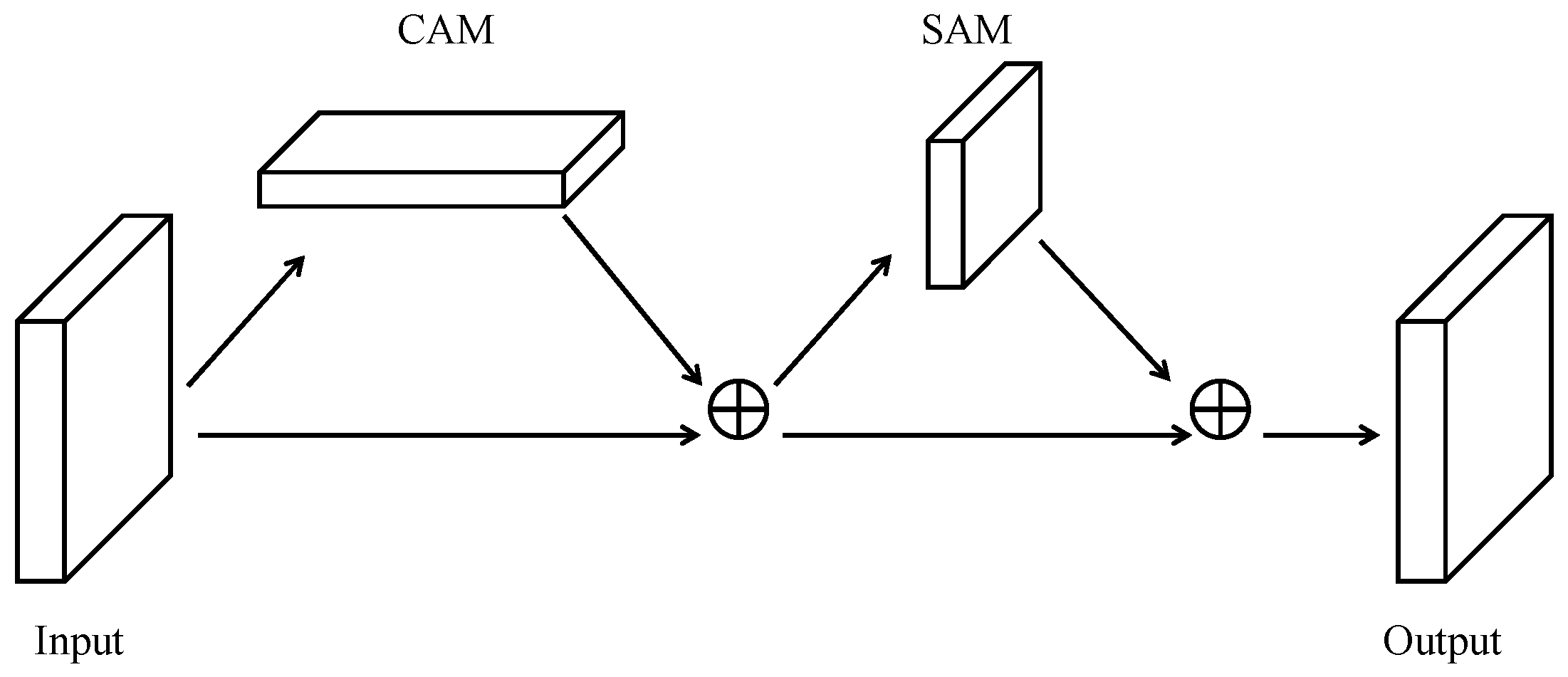
3.2. Convolutional Neural Networks That Fuse Attention Mechanisms
4. Risk Identification of Self-Provided Power Supply in Distribution Network Based on Transfer Learning
5. Simulation Analysis
5.1. Case Design
5.2. Comparative Analysis of Test Results in the Source Domain
5.2.1. Accuracy of Risk Identification of Self-Provided Power Supply
5.2.2. Effectiveness of Noise Immunity
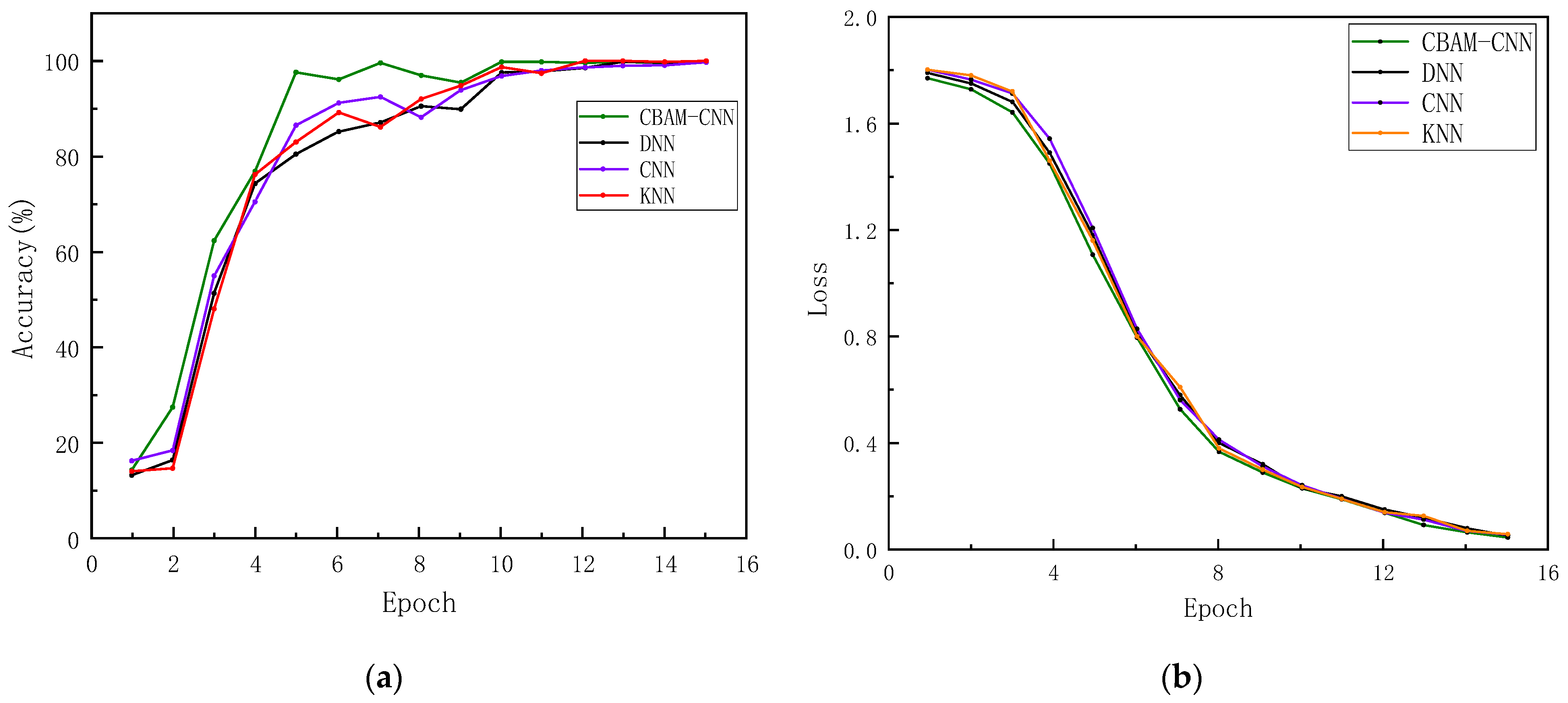
5.2.3. Analysis of the Effectiveness of the Risk Identification Network Model
5.3. Comparative Analysis of Test Results in the Target Domain
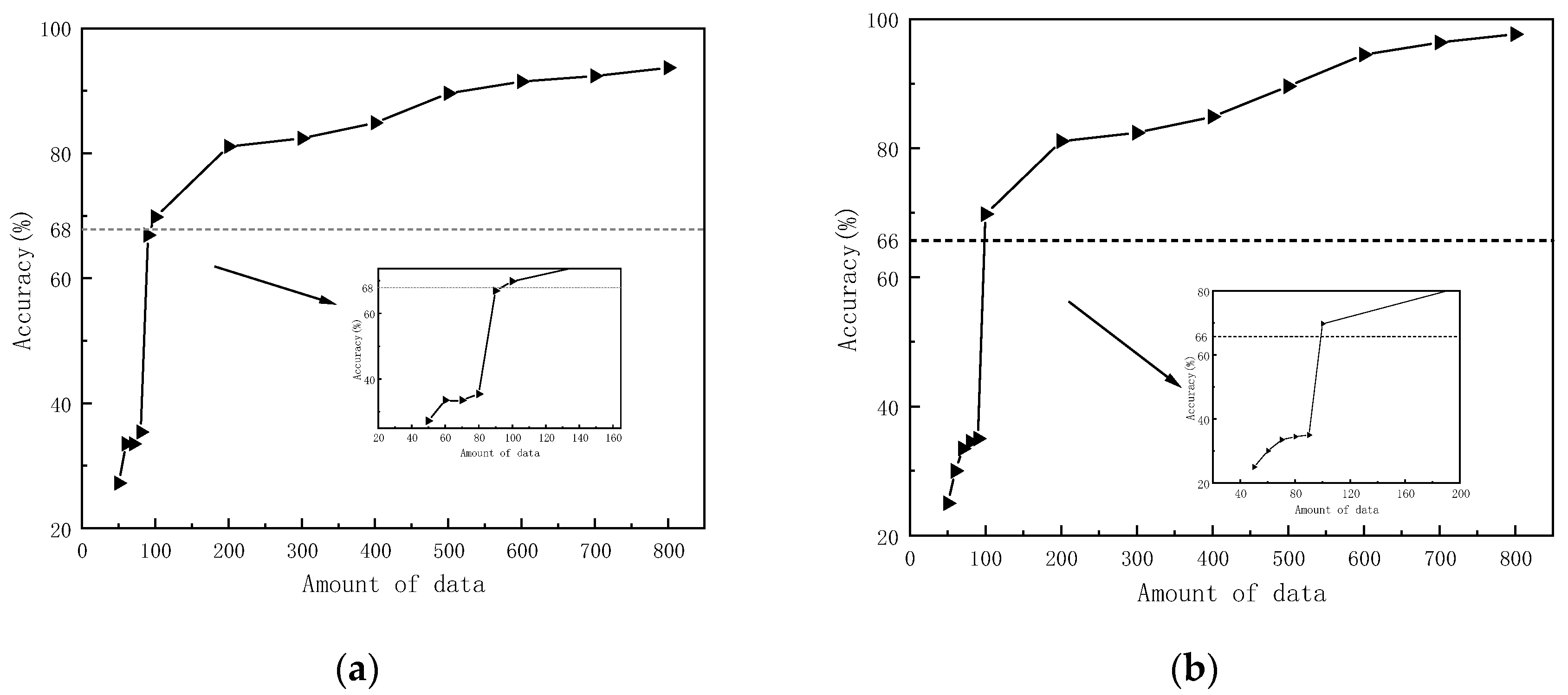
5.3.1. Comparison of the Effect of the Amount of Data in the Target Domain
5.3.2. Comparison of the Results of Different Risk Identification Schemes
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, X.B. Self-contained generator return to send electricity operator electrocution casualties. Rural. Electr. 2017, 25, 35. [Google Scholar]
- Ren, T.G.; Bao, Y.Z. Fault routing of small-current grounded lines in distribution networks based on discrete Fourier transform. Autom. Technol. Appl. 2023, 42, 67–70. [Google Scholar]
- Li, J.L.; Ren, J.Y.; Yuan, H.; Wang, Z.J.; Lei, H.; Zhao, Z.J. Arc-grounding fault routing method for distribution networks based on wavelet analysis. J. Zhengzhou Univ. (Eng. Ed.) 2023, 44, 69–76. [Google Scholar]
- Xie, Q.; Zheng, Q. Single-phase-to-earth Fault Line Selection Method for Medium-voltage Distribution Network Based on Wavelet Packet Analysis. In Proceedings of the 2022 4th International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 9–11 December 2022; pp. 257–261. [Google Scholar]
- Cai, J.; Zhou, B.; Huang, Y.; Zeng, X.J. A new method of fault routing for resonant grounding system based on S-transform time-frequency characteristics. J. Electr. Power Sci. Technol. 2022, 37, 109–116. [Google Scholar]
- Liu, Z.; Gao, H.; Luo, S. A Fault Phase and Line Selection Method of Double Circuit Transmission Line on The Same Tower Based on Transient Component. In Proceedings of the 2019 IEEE 8th International Conference on Advanced Power System Automation and Protection (APAP), Xi’an, China, 21–24 October 2019; pp. 1058–1062. [Google Scholar]
- Ren, H.T.; Zhang, Y. Research on fault line selection of distribution network system based on zero sequence transient current. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 390–394. [Google Scholar]
- Yin, H.W. Power line fault diagnosis technology based on deep transfer learning. Pop. Electr. 2022, 37, 48–50. [Google Scholar]
- Albarakati, A.J.; Azeroual, M.; Boujoudar, Y.; EL Iysaouy, L.; Aljarbouh, A.; Tassaddiq, A.; EL Markhi, H. Multi-Agent-Based Fault Location and Cyber-Attack Detection in Distribution System. Energies 2023, 16, 224. [Google Scholar] [CrossRef]
- Wang, P.; Govindarasu, M. Multi-Agent Based Attack-Resilient System Integrity Protection for Smart Grid. IEEE Trans. Smart Grid 2020, 11, 3447–3456. [Google Scholar] [CrossRef]
- Azeroual, M.; Boujoudar, Y.; Bhagat, K.; El Iysaouy, L.; Aljarbouh, A.; Knyazkov, A.; Markhi, H.E. Fault location and detection techniques in power distribution systems with distributed generation: Kenitra City (Morocco) as a case study. Electr. Power Syst. Res. 2022, 209, 108026. [Google Scholar] [CrossRef]
- Fan, Y.; Ma, Z.; Tang, W.; Liang, J.; Xu, P. Using Crested Porcupine Optimizer Algorithm and CNN-LSTM-Attention Model Combined with Deep Learning Methods to Enhance Short-Term Power Forecasting in PV Generation. Energies 2024, 17, 3435. [Google Scholar] [CrossRef]
- Wang, Z.; Mae, M.; Yamane, T.; Ajisaka, M.; Nakata, T.; Matsuhashi, R. Enhanced Day-Ahead Electricity Price Forecasting Using a Convolutional Neural Network–Long Short-Term Memory Ensemble Learning Approach with Multimodal Data Integration. Energies 2024, 17, 2687. [Google Scholar] [CrossRef]
- Alhanaf, A.S.; Balik, H.H.; Farsadi, M. Intelligent Fault Detection and Classification Schemes for Smart Grids Based on Deep Neural Networks. Energies 2023, 16, 7680. [Google Scholar] [CrossRef]
- Molla, J.P.; Dhabliya, D.; Jondhale, S.R.; Arumugam, S.S.; Rajawat, A.S.; Goyal, S.B.; Raboaca, M.S.; Mihaltan, T.C.; Verma, C.; Suciu, G. Energy Efficient Received Signal Strength-Based Target Localization and Tracking Using Support Vector Regression. Energies 2023, 16, 555. [Google Scholar] [CrossRef]
- Rajawat, A.S.; Goyal, S.B.; Bedi, P.; Constantin, N.B.; Raboaca, M.S.; Verma, C. Cyber-Physical System for Industrial Automation Using Quantum Deep Learning. In Proceedings of the 2022 11th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 16–17 December 2022; pp. 897–903. [Google Scholar]
- Dai, L.; Wang, H. An Improved WOA (Whale Optimization Algorithm)-Based CNN-BIGRU-CBAM Model and Its Application to Short-Term Power Load Forecasting. Energies 2024, 17, 2559. [Google Scholar] [CrossRef]
- Xiao, C. Research on single-phase ground fault routing in distribution network based on KNN algorithm. J. Nanjing Norm. Univ. (Eng. Technol. Ed.) 2020, 20, 27–31. [Google Scholar]
- Hao, S.; Zhang, X.; Ma, R.Z.; Wen, H.; Ma, X.; An, B.Y.; Li, J.H. Fault routing method for small current grounding system based on improved GoogLe Net. Grid Technol. 2022, 46, 361–368. [Google Scholar]
- Zhang, G.D.; Pu, H.T.; Liu, K. Deep learning based fault routing method for small current grounding system. Power Gener. Technol. 2019, 40, 548–554. [Google Scholar]
- Zhang, D.H.; Zhang, X.W.; Sun, H.; He, J.H. Fault diagnosis of AC/DC transmission system based on convolutional neural network. Power Syst. Autom. 2022, 46, 132–145. [Google Scholar]
- Yin, H.R.; Miao, S.H.; Guo, S.Y.; Han, J.; Wang, Z.X. A new method for single-phase ground fault routing in distribution networks based on S-transform correlation and deep learning. Power Autom. Equip. 2021, 41, 88–96. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Huang, Z.P.; Zhang, F.Y.; Zhao, J.M.; Jin, Q. A review of transfer learning issues in emotion recognition. Signal Process. 2023, 39, 588–615. [Google Scholar]
- Zhou, F.Y.; Jin, L.P.; Dong, J. A review of convolutional neural network research. J. Comput. 2017, 40, 1229–1251. [Google Scholar]
- Wang, Y.F. Research on Fault Routing Method Based on Convolutional Neural Network; Zhengzhou University: Zhengzhou, China, 2021. [Google Scholar]
- Xie, L.M.; Huang, C.B. A residual network of water scene recognition based on optimized inception module and convolutional block attention module. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAl), Shanghai, China, 2–4 November 2019. [Google Scholar]
- Sun, Y.F. Research on Adaptive Route Selection Method for Single-Phase Ground Fault in 10 kV Distribution Network; Shenyang Agricultural University: Shenyang, China, 2023. [Google Scholar]
- Wang, Y.Y.; Chen, Q.S.; Zeng, X.J. Faulty Feeder Detection Based on Space Relative Distance for Compensated Distribution Network with IIDG Injections. IEEE Trans. Power Deliv. 2021, 36, 2459–2466. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feeder Types | Phase Sequence | L (mH/km) | r (/km) | C (μF/km) |
|---|---|---|---|---|
| Cable feeder | Positive sequence | 4.6 | 0.135 | 0.0056 |
| Zero sequence | 1.3 | 0.275 | 0.0095 | |
| Overhead feeder | Positive sequence | 0.28 | 0.25 | 0.338 |
| Zero sequence | 1.018 | 2.7 | 0.28 |
| Steps | Fault Automation Simulation Based on Matlab |
|---|---|
| 1 | Modeling of 10 kV distribution network with captive power supply through Matlab/Simulink tool |
| 2 | Parameter setting: divided into two categories with or without self-supplied power, each category has a randomly set fault location, fault phase angle, grounding resistance value |
| 3 | Start the simulation |
| 4 | Stop the simulation after 0.2 s of running |
| 5 | Automatically saves the zero-sequence current simulation data of L lines as a CSV file |
| 6 | Repeat steps 2–5 to generate the required number of samples for each type of fault |
| 7 | Repeat step 6 to obtain N class samples |
| Type | Faulty Lines | The Location of the Fault (%) | Faulty Ground Resistance (Ω) | Fault Initial Phase Angle (°) | Self-Provided Power |
|---|---|---|---|---|---|
| Parameter | L1 L2 L3 L4 | 10 20 30 40 50 60 70 80 90 | 0.01 10 100 500 1000 | 0 30 60 90 | Yes |
| No |
| Fault Parameters | Value | Fault Line Accuracy | Power Supply Identification Accuracy |
|---|---|---|---|
| Fault resistance (Ω) | 1 | 100 | 100 |
| 50 | 100 | 100 | |
| 300 | 100 | 100 | |
| Fault initial phase angle (°) | 20 | 100 | 100 |
| 45 | 100 | 100 | |
| 180 | 100 | 100 | |
| Location of the fault (%) | 25 | 100 | 100 |
| 45 | 100 | 100 | |
| 85 | 100 | 100 |
| Noise Level/dB | Fault Line Accuracy | Power Supply Identification Accuracy | Noise Level/dB | Fault Line Accuracy | Power Supply Identification Accuracy |
|---|---|---|---|---|---|
| 20 | 98.81% | 99.73% | 40 | 98.32% | 99.51% |
| 30 | 99.1% | 99.16% | 50 | 99.71% | 99.65% |
| Noise Level/dB | Fault Line Accuracy | Power Supply Identification Accuracy | Noise Level/dB | Fault Line Accuracy | Power Supply Identification Accuracy |
|---|---|---|---|---|---|
| 60 | 96.51% | 96.24% | 100 | 94.02% | 93.51% |
| 80 | 94.71% | 95.32% | 120 | 91.21% | 91.08% |
| Scheme | Model | Transfer Scheme | Fault Line Accuracy (%) | Power Supply Identification Accuracy (%) | Accuracy of Power Supply Risk Identification (%) |
|---|---|---|---|---|---|
| 1 | CBAM-CNN | Yes | 98.78 | 99.35 | 98.78 |
| No | 69.73 | 66.78 | 66.78 | ||
| 2 | CNN | Yes | 89.02 | 90.02 | 89.02 |
| No | 65.87 | 70.35 | 65.87 | ||
| 3 | KNN | Yes | 85.64 | 82.34 | 82.34 |
| No | 63.41 | 64.87 | 63.41 | ||
| 4 | DNN | Yes | 82.13 | 86.57 | 82.13 |
| No | 61.47 | 63.87 | 61.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Sun, J.; Pan, Y.; Hu, D.; Song, L.; Xu, Z.; Yu, H.; Liu, Y. Power Supply Risk Identification Method of Active Distribution Network Based on Transfer Learning and CBAM-CNN. Energies 2024, 17, 4438. https://doi.org/10.3390/en17174438
Liu H, Sun J, Pan Y, Hu D, Song L, Xu Z, Yu H, Liu Y. Power Supply Risk Identification Method of Active Distribution Network Based on Transfer Learning and CBAM-CNN. Energies. 2024; 17(17):4438. https://doi.org/10.3390/en17174438
Chicago/Turabian StyleLiu, Hengyu, Jiazheng Sun, Yongchao Pan, Dawei Hu, Lei Song, Zishang Xu, Hailong Yu, and Yang Liu. 2024. "Power Supply Risk Identification Method of Active Distribution Network Based on Transfer Learning and CBAM-CNN" Energies 17, no. 17: 4438. https://doi.org/10.3390/en17174438
APA StyleLiu, H., Sun, J., Pan, Y., Hu, D., Song, L., Xu, Z., Yu, H., & Liu, Y. (2024). Power Supply Risk Identification Method of Active Distribution Network Based on Transfer Learning and CBAM-CNN. Energies, 17(17), 4438. https://doi.org/10.3390/en17174438