
Non-Intrusive Load Monitoring Based on Dimensionality Reduction and Adapted Spatial Clustering



Abstract
1. Introduction
- (1)
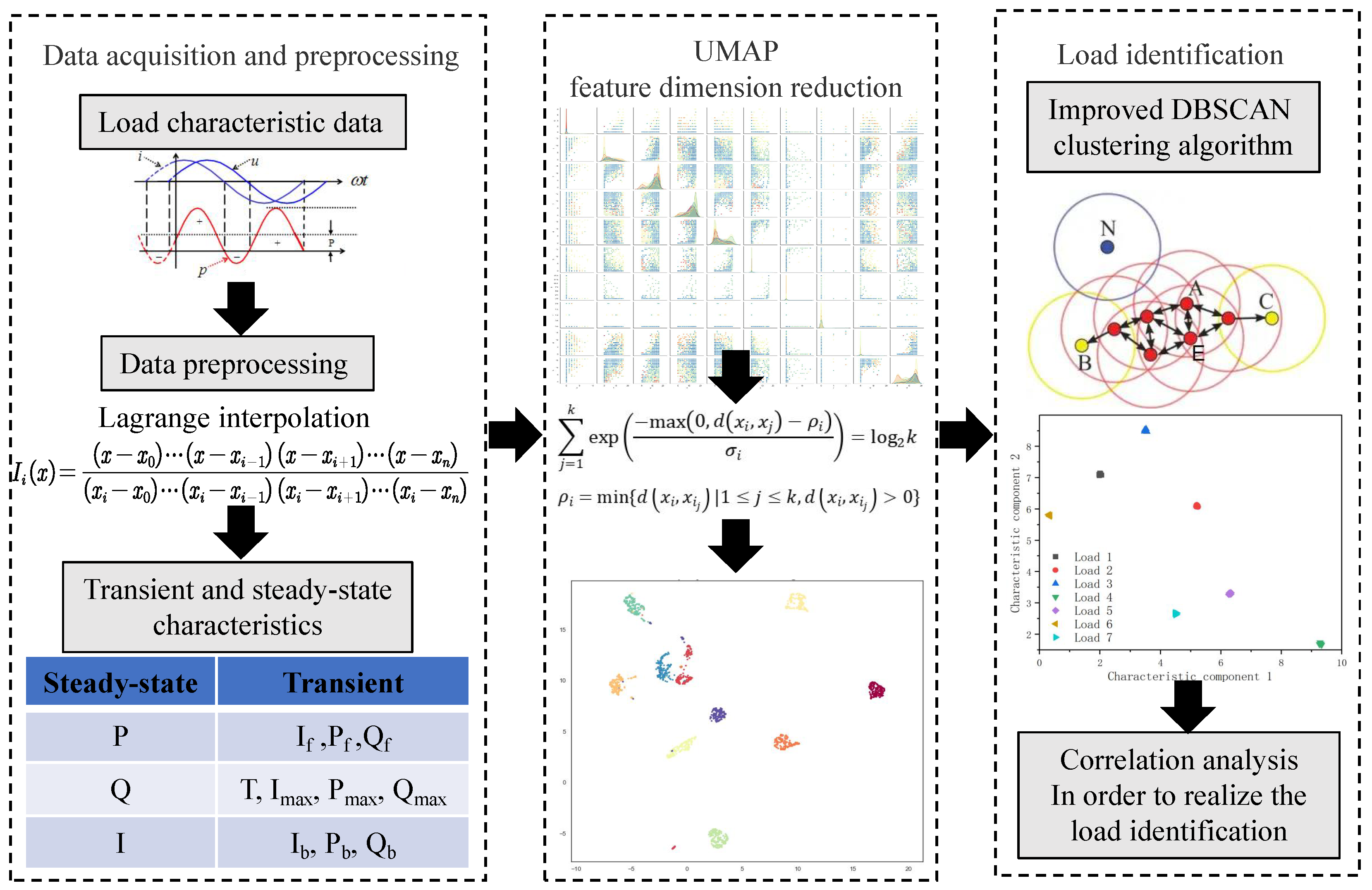
- This paper presents an effective load identification method. By using the UMAP dimensionality reduction algorithm to reduce the selected feature data, the load feature template library is constructed. Then, the improved DBSCAN clustering algorithm is used to realize sample clustering in the template library, and the Euclidean distance between the load to be identified and the cluster center of the template library is calculated to determine the load to be identified.
- (2)
- To overcome the problem of information redundancy caused by excessive load feature dimension, the UMAP algorithm is applied in load feature dimensionality reduction to reduce data correlation and maximize the characterization of payload characteristics.
- (3)
- To improve the accuracy of load identification, we propose an improved DBSCAN clustering method to cluster the feature data in the load feature database and realize load type matching.
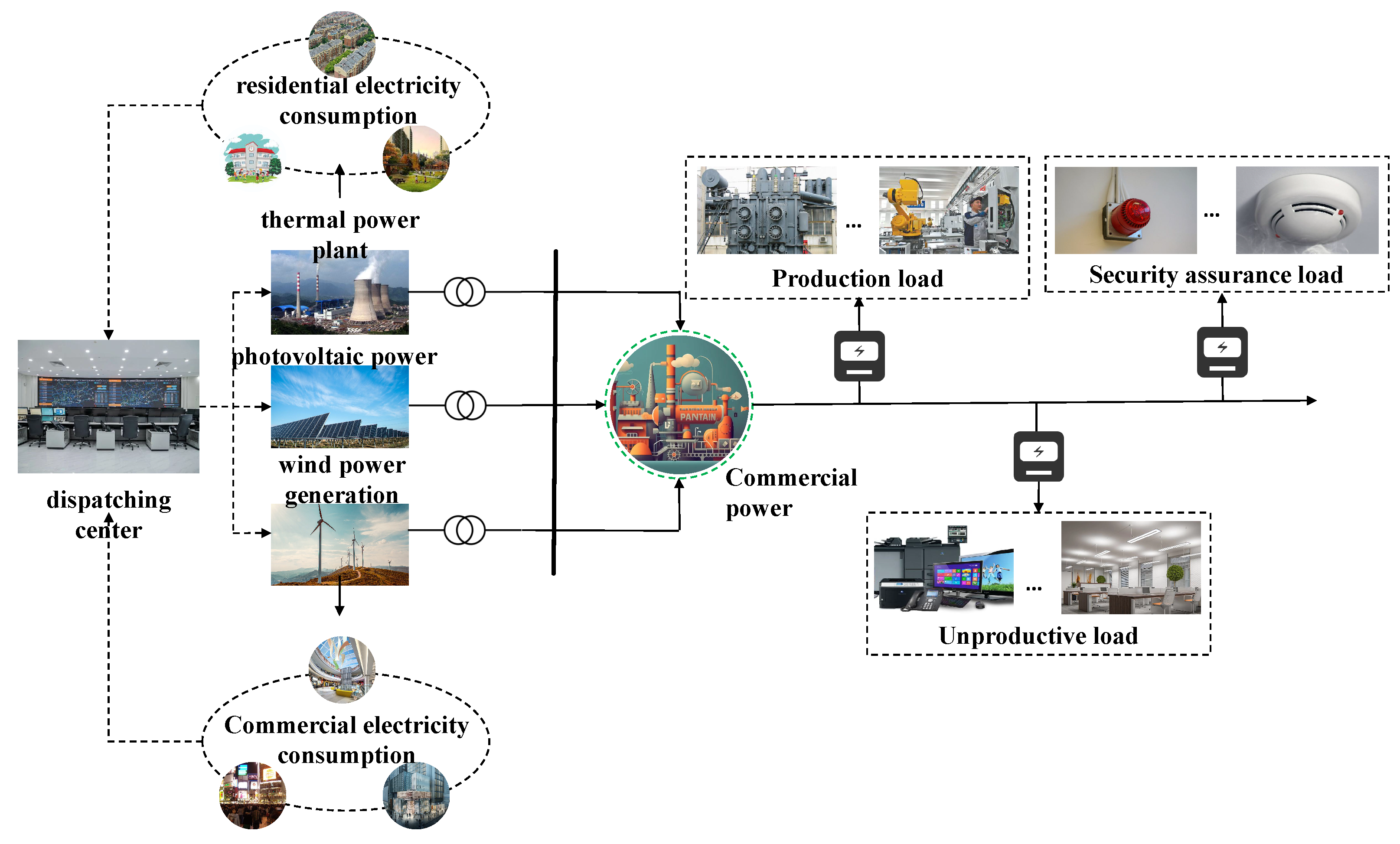
2. Analysis of User Side Load Characteristics
- The load current will show obvious fluctuation characteristics with time;
- When the load is put in and cut out, the instantaneous current will change obviously;
- After the load is switched between working and stopping states, the current waveform on the user side and power line is considered stable.
2.1. Steady-State Feature Extraction of User Load
2.2. User Load Transient Feature Extraction
3. Proposed Load Identification Method
3.1. Dimension Reduction of UMAP Feature Data
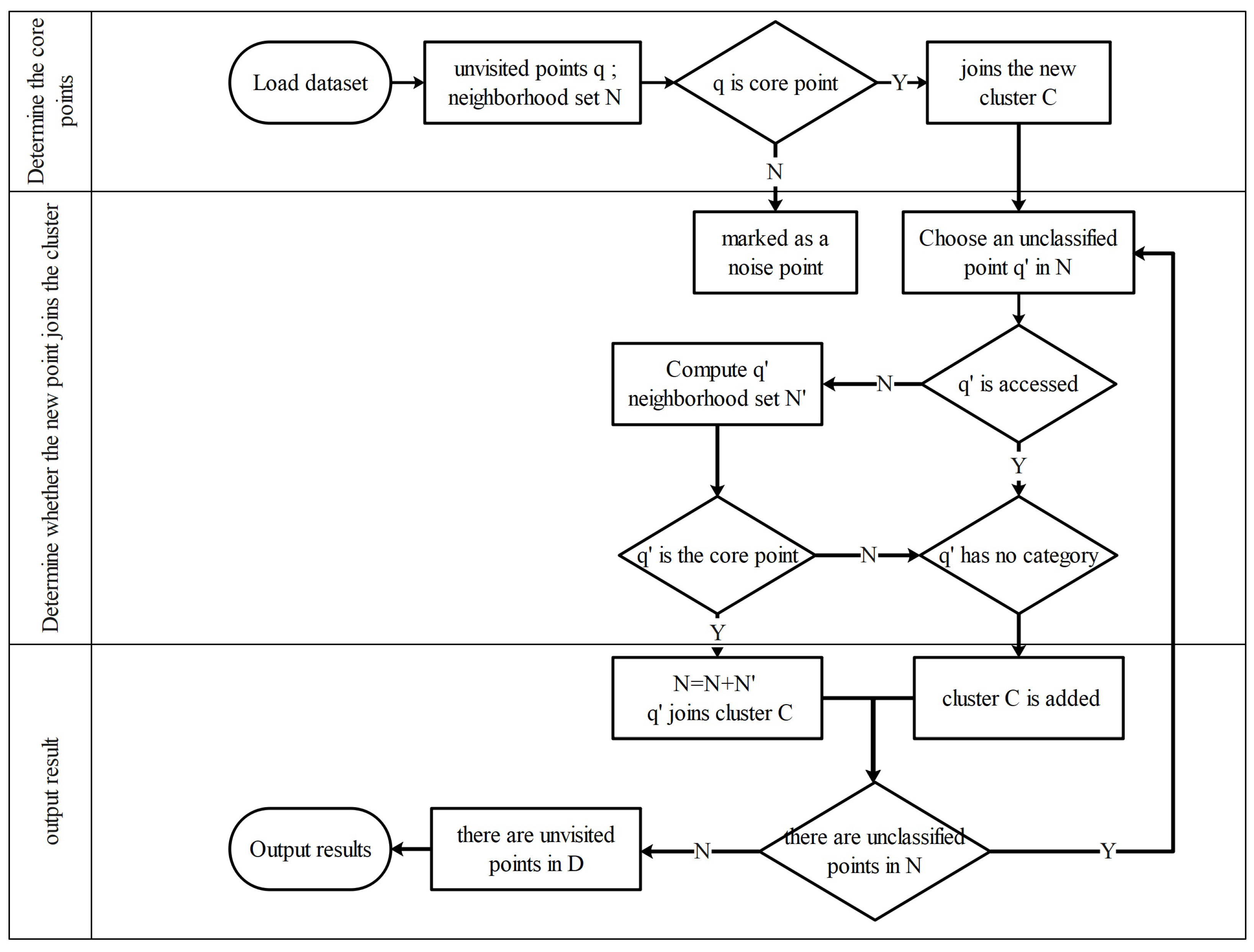
3.2. DBSCAN Feature Clustering Method
- -neighborhood: For , its -neighborhood contains the subsample set in the sample set D whose distance from is not greater than , and the number of this subsample set is denoted as ; that is, .
- Core object: For any sample , is a core object if its -neighborhood corresponding to contains at least samples; that is, .
- Density direct: If point falls within an -radius of point and is recognized as a central element, we consider to be density-reachable from . However, the reverse implication does not hold universally. is density-reachable from , and it does not automatically mean that is density-reachable from . This only becomes true if itself is also identified as a central element.
- Density-reachable: Consider two points and . If a sample sequence is found such that corresponds to , corresponds to , and each is derived directly from its preceding point in density terms, we can say that is density-reachable from [57]. This indicates that density reachability exhibits the property of transitivity. It is important to highlight that all intermediate samples in this sequence must be core objects; this is due to the fact that only core objects have the capability to influence the density of other samples directly. Additionally, it is worth noting that density reachability does not uphold the principle of symmetry, which can be attributed to the inherent asymmetry observed in density direct reachability.
- Density-connected: For sample points and , if there exists a core object sample such that both and can reach density through , then we say that and are density-connected. This density relationship is symmetric.
3.3. UMAP Dimensionality Reduction and Adapted DBSCAN Clustering
4. Example Analysis
4.1. Evaluation Indicators
4.2. Example Analysis
4.2.1. Case I: A Simulation Example
4.2.2. Case II: A Practical Example
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Jiang, Y.; Qiu, C.; Xiong, H.; Bi, M.; Ge, Y.; Li, J.; Cao, Y.; Li, G.; Cui, Z.; et al. Power system real time reliability monitoring and security assessment in short-term and on-line mode. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies-Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 758–763. [Google Scholar]
- Chen, Y.; Lao, K.W.; Qi, D.; Hui, H.; Yang, S.; Yan, Y.; Zheng, Y. Distributed Self-Triggered Control for Frequency Restoration and Active Power Sharing in Islanded Microgrids. IEEE Trans. Ind. Inform. 2023, 19, 10635–10646. [Google Scholar] [CrossRef]
- Chen, Y.; Qi, D.; Hui, H.; Yang, S.; Gu, Y.; Yan, Y.; Zheng, Y.; Zhang, J. Self-triggered coordination of distributed renewable generators for frequency restoration in islanded microgrids: A low communication and computation strategy. Adv. Appl. Energy 2023, 10, 100128. [Google Scholar] [CrossRef]
- Song, D.; Yang, Y.; Zheng, S.; Deng, X.; Yang, J.; Su, M.; Tang, W.; Yang, X.; Huang, L.; Joo, Y.H. New perspectives on maximum wind energy extraction of variable-speed wind turbines using previewed wind speeds. Energy Convers. Manag. 2020, 206, 112496. [Google Scholar] [CrossRef]
- Athanasiadis, C.; Papadopoulos, T.; Kryonidis, G.; Doukas, D. A review of distribution network applications based on smart meter data analytics. Renew. Sustain. Energy Rev. 2024, 191, 114151. [Google Scholar] [CrossRef]
- Zhu, J.; Lu, W. Research on Converged Communication of Power Line and Wireless in Electric Power Communication System. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Xi’an, China, 15–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 5, pp. 627–631. [Google Scholar]
- Schirmer, P.A.; Mporas, I. Non-intrusive load monitoring: A review. IEEE Trans. Smart Grid 2022, 14, 769–784. [Google Scholar] [CrossRef]
- Virtsionis-Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. SAED: Self-attentive energy disaggregation. Mach. Learn. 2021, 112, 4081–4100. [Google Scholar] [CrossRef]
- Hernández, Á.; Nieto, R.; Fuentes, D.; Ureña, J. Design of a SoC architecture for the edge computing of NILM techniques. In Proceedings of the 2020 XXXV Conference on Design of Circuits and Integrated Systems (DCIS), Segovia, Spain, 18–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Hussein, N.M.; Hesham, A.M.; Rashawn, M.A. States and power consumption estimation for NILM. In Proceedings of the 2019 14th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 17–18 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 275–281. [Google Scholar]
- Held, P.; Weißhaar, D.; Mauch, S.; Abdeslam, D.O.; Benyoucef, D. Parameter optimized event detection for NILM using frequency invariant transformation of periodic signals (FIT-PS). In Proceedings of the 2018 IEEE 23rd international conference on emerging technologies and factory automation (ETFA), Torino, Italy, 4–7 September 2018; IEEE: Piscataway, NJ, USA, 2018; Volume 1, pp. 832–837. [Google Scholar]
- Song, D.R.; Li, Q.A.; Cai, Z.; Li, L.; Yang, J.; Su, M.; Joo, Y.H. Model Predictive Control Using Multi-Step Prediction Model for Electrical Yaw System of Horizontal-Axis Wind Turbines. IEEE Trans. Sustain. Energy 2019, 10, 2084–2093. [Google Scholar] [CrossRef]
- Athanasiadis, C.L.; Papadopoulos, T.A.; Doukas, D.I. Real-time non-intrusive load monitoring: A light-weight and scalable approach. Energy Build. 2021, 253, 111523. [Google Scholar] [CrossRef]
- Song, D.; Liu, J.; Yang, J.; Su, M.; Wang, Y.; Yang, X.; Huang, L.; Joo, Y.H. Optimal design of wind turbines on high-altitude sites based on improved Yin-Yang pair optimization. Energy 2020, 193, 116794. [Google Scholar] [CrossRef]
- Virtsionis Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. Variational regression for multi-target energy disaggregation. Sensors 2023, 23, 2051. [Google Scholar] [CrossRef]
- Athanasiadis, C.; Doukas, D.; Papadopoulos, T.; Chrysopoulos, A. A scalable real-time non-intrusive load monitoring system for the estimation of household appliance power consumption. Energies 2021, 14, 767. [Google Scholar] [CrossRef]
- Deng, X.; Zhang, C.; Peng, H.; Bi, G.; Cheng, T.; Zhang, C. Short-Term Load Forecasting for Regional Power Grids Based on Correlation Analysis and Feature Extraction. In Proceedings of the 2022 7th Asia Conference on Power and Electrical Engineering (ACPEE), Hangzhou, China, 15–17 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1081–1085. [Google Scholar]
- Shen, Q.; Ren, L.; Gong, C.; Wang, H. A unified feature parameter extraction strategy based on system identification for the buck converter with linear or nonlinear loads. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 24–27 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 388–393. [Google Scholar]
- Fang, Y.; Liang, X.; Zuo, M.J. Effect of sliding friction on transient characteristics of a gear transmission under random loading. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2551–2555. [Google Scholar]
- Tian, Y.; Wang, H.; Li, A.; Shi, S.; Wu, J. Non-intrusive load monitoring using inception structure deep learning. In Proceedings of the 2020 10th International Conference on Power and Energy Systems (ICPES), Chengdu, China, 25–27 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 151–155. [Google Scholar]
- Feng, T.; Duan, A.; Guo, L.; Gao, H.; Chen, T.; Yu, Y. Deep learning based load and position identification of complex structure. In Proceedings of the 2021 IEEE 16th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 1–4 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1358–1363. [Google Scholar]
- Wei, Y.; Jin, Y.; Ju, P.; Qin, C. Identification Method of the Load Component Proportion based on the Dynamic Response under Large Disturbance. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 824–829. [Google Scholar]
- Song, D.; Fan, X.; Yang, J.; Liu, A.; Chen, S.; Joo, Y.H. Power extraction efficiency optimization of horizontal-axis wind turbines through optimizing control parameters of yaw control systems using an intelligent method. Appl. Energy 2018, 224, 267–279. [Google Scholar] [CrossRef]
- Yang, Z.X.; Yu, G.; Zhao, J.; Wong, P.K.; Wang, X.B. Online Equivalent Degradation Indicator Calculation for Remaining Charging-Discharging Cycle Determination of Lithium-Ion Batteries. IEEE Trans. Veh. Technol. 2021, 70, 6613–6625. [Google Scholar] [CrossRef]
- Wang, X.B.; Luo, L.; Tang, L.; Yang, Z.X. Automatic Representation and Detection of Fault Bearings in In-wheel Motors under Variable Load Conditions. Adv. Eng. Inform. 2021, 49, 101321. [Google Scholar] [CrossRef]
- Chen, H.; Wang, X.-b.; Yang, Z.X. Fast Robust Capsule Network with Dynamic Pruning and Multiscale Mutual Information Maximization for Compound-Fault Diagnosis. IEEE/ASME Trans. Mechatronics 2023, 28, 838–847. [Google Scholar] [CrossRef]
- Chen, S.; Gao, F.; Liu, T. Load identification based on factorial hidden Markov model and online performance analysis. In Proceedings of the 2017 13th IEEE Conference on Automation Science and Engineering (CASE), Xi’an, China, 20–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1249–1253. [Google Scholar]
- Khazeiynasab, S.R.; Zhao, J.; Duan, N. WECC composite load model parameter identification using deep learning approach. In Proceedings of the 2022 IEEE Power & Energy Society General Meeting (PESGM), Denver, CO, USA, 17–21 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Proteasa, V.A.; Ciobanu, R.I.; Dobre, C.; Marin, R.C. Federated Learning for Human Mobility. In Proceedings of the 2023 19th International Conference on Distributed Computing in Smart Systems and the Internet of Things (DCOSS-IoT), Pafos, Cyprus, 19–21 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 780–785. [Google Scholar]
- Wu, Z.; Fu, H. Research on load identification based on load steady and transient signal processing. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Haoguang, L.; Yunhua, Y.; Xuefeng, S. Load parameter identification based on particle swarm optimization and the comparison to ant colony optimization. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 545–550. [Google Scholar]
- Iksan, N.; Udayanti, E.D.; Widodo, D.A. Time-Frequency Analysis (TFA) Method for Load Identification on Non-Intrusive Load Monitoring. In Proceedings of the 2019 4th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 20–21 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 57–60. [Google Scholar]
- Hou, S.; Lu, R.; Yang, C.; Lei, D.; Qin, W. Power system weak bus identification based on voltage distribution characteristic. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Zhi, D.; Shi, J.; Fu, R. Algorithm Implementation of Non-Intrusive Load Monitoring Based on Load Core Feature Identification. In Proceedings of the 2022 5th International Conference on Energy, Electrical and Power Engineering (CEEPE), Chongqing, China, 22–24 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 839–844. [Google Scholar]
- Wang, Z.; Wu, Y.; Zhao, Y.; Wang, J.; Liu, H.; Wang, Y. A Composite-Window-Based Load Event Detection Method in Non-Intrusive Load Monitoring. In Proceedings of the 2023 IEEE 7th Conference on Energy Internet and Energy System Integration (EI2), Hangzhou, China, 15–18 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4911–4916. [Google Scholar]
- Ramaswamy, A.; Bal, A.; Das, A.; Gubbi, J.; Muralidharan, K.; Ramakrishnan, R.K.; Pal, A.; Balamuralidhar, P. Single feature spatio-temporal architecture for EEG Based cognitive load assessment. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Online, 1–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3717–3720. [Google Scholar]
- Kai, D.; Zihang, H.; Shiqi, Y.; Peng, W.; Shuai, W.; Zhengmin, K. A coarse-to-fine strategy based on a supervised learning method for non-intrusive load identification. In Proceedings of the 2023 9th International Conference on Big Data Computing and Communications (BigCom), Qinghai, China, 4–6 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 156–163. [Google Scholar]
- Jawdat, N.; Donnal, J. Unsupervised Identification of Electrical Loads from Aggregate Power Measurements. In Proceedings of the 2022 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Novi Sad, Serbia, 10–12 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Chou, P.A.; Chang, R.I. Unsupervised adaptive non-intrusive load monitoring system. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 3180–3185. [Google Scholar]
- Wang, X.B.; Yang, Z.X.; Yan, X.A. Novel Particle Swarm Optimization-Based Variational Mode Decomposition Method for the Fault Diagnosis of Complex Rotating Machinery. IEEE/ASME Trans. Mechatronics 2018, 23, 68–79. [Google Scholar] [CrossRef]
- Wang, X.B.; Yang, Z.X.; Wong, P.K.; Deng, C. Novel Paralleled Extreme Learning Machine Networks for Fault Diagnosis of Wind Turbine Drivetrain. Memetic Comput. 2019, 11, 127–142. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Yang, Z.; Zhao, Y.; Wang, X. Remaining Useful Life Estimation Combining Two-step Maximal Information Coefficient and Temporal Convolutional Network with Attention Mechanism. IEEE Access 2021, 9, 16323–16336. [Google Scholar] [CrossRef]
- Myasnikov, E. Using UMAP for dimensionality reduction of hyperspectral data. In Proceedings of the 2020 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 6–9 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Tao, T.; Liu, Y.; Qiao, Y.; Gao, L.; Lu, J.; Zhang, C.; Wang, Y. Wind turbine blade icing diagnosis using hybrid features and Stacked-XGBoost algorithm. Renew. Energy 2021, 180, 1004–1013. [Google Scholar] [CrossRef]
- Tao, T.; Yang, Y.; Yang, T.; Liu, S.; Guo, X.; Wang, H.; Liu, Z.; Chen, W.; Liang, C.; Long, K.; et al. Time-domain fatigue damage assessment for wind turbine tower bolts under yaw optimization control at offshore wind farm. Ocean. Eng. 2024, 303, 117706. [Google Scholar] [CrossRef]
- Deng, D. DBSCAN clustering algorithm based on density. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 949–953. [Google Scholar]
- Yu, S.; Song, C.; Gao, P.; Zheng, H. Intelligent electricity consumption forecasting and electricity-theft analysis method based on deep learning. In Proceedings of the 2022 2nd International Conference on Electronic Information Engineering and Computer Technology (EIECT), Yan’an, China, 28–30 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 312–316. [Google Scholar]
- Liang, P.; Wang, W.; Yuan, X.; Liu, S.; Zhang, L.; Cheng, Y. Intelligent fault diagnosis of rolling bearing based on wavelet transform and improved ResNet under noisy labels and environment. Eng. Appl. Artif. Intell. 2022, 115, 105269. [Google Scholar] [CrossRef]
- Liang, P.; Xu, L.; Shuai, H.; Yuan, X.; Wang, B.; Zhang, L. Semisupervised Subdomain Adaptation Graph Convolutional Network for Fault Transfer Diagnosis of Rotating Machinery Under Time-Varying Speeds. IEEE/ASME Trans. Mechatronics 2024, 29, 730–741. [Google Scholar] [CrossRef]
- Lv, G.; Yang, Z.; Jin, Y.; Ding, Y. A novel method of complex PQ disturbances classification without adequate history data. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Wang, W.; Liu, X.; Yan, L.; Yu, H.; Li, R.; Ding, N. The Software Design of Dynamic Loading Identification System of Rock Roadheader. In Proceedings of the 2017 4th International Conference on Information Science and Control Engineering (ICISCE), Changsha, China, 21–23 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 737–740. [Google Scholar]
- He, R.; Hu, B.G.; Zheng, W.S.; Kong, X.W. Robust principal component analysis based on maximum correntropy criterion. IEEE Trans. Image Process. 2011, 20, 1485–1494. [Google Scholar]
- Li, R.; Liu, L. Research on rolling bearing fault diagnosis based on improved local linear embedding algorithm. In Proceedings of the 2022 Global Reliability and Prognostics and Health Management (PHM-Yantai), Yantai, China, 13–16 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–3. [Google Scholar]
- Zhang, Z.; Yu, Y.; Jiang, F.; Cheng, Q.S. Gaussian Process Regression Modeling Based on Landmark Isometric Feature Mapping for Antennas. In Proceedings of the 2021 15th European Conference on Antennas and Propagation (EuCAP), Dusseldorf, Germany, 22–26 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Qiu, M.; Yang, Z.; Nai, W.; Li, D.; Xing, Y.; Li, K. T-distributed stochastic neighbor embedding based on cockroach swarm optimization with student distribution parameters. In Proceedings of the 2021 IEEE 12th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 20–22 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 291–294. [Google Scholar]
- Asanza, V.; Peláez, E.; Loayza, F.; Mesa, I.; Díaz, J.; Valarezo, E. Emg signal processing with clustering algorithms for motor gesture tasks. In Proceedings of the 2018 IEEE Third Ecuador Technical Chapters Meeting (ETCM), Cuenca, Ecuador, 17–19 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Demidov, V.A.; Golosov, S.N.; Boriskin, A.S.; Kazakov, S.A.; Tatsenko, O.M.; Vlasov, Y.V.; Romanov, A.P.; Filippov, A.V.; Bychkova, E.A.; Moiseenko, A.N.; et al. Test of Device Based on Disk Magnetocumulative Generator DMCG480 with Explosive Current Opening Switch. IEEE Trans. Plasma Sci. 2017, 45, 2674–2677. [Google Scholar] [CrossRef]
- Muhammad, A.; Prihatmanto, A.S.; Wijaya, R.; Rosyid, H.A.; Hakim, H.R.; Dana, A.P.; Al Himmah, U.C. Distance measurements method for the demite pronunciation assessment. In Proceedings of the 2018 IEEE 8th International Conference on System Engineering and Technology (ICSET), Bandung, Indonesia, 15–16 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 189–194. [Google Scholar]
- Herrera, R.S.; Salmerón, P.; Litrán, S.P. Distortion sources identification in power systems with capacitor banks. In Proceedings of the 2011 International Conference on Power Engineering, Energy and Electrical Drives, Malaga, Spain, 11–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Arora, S.; Taylor, J.W. Forecasting electricity smart meter data using conditional kernel density estimation. Omega 2016, 59, 47–59. [Google Scholar] [CrossRef]
- Rizzoli, V.; Neri, A.; Masotti, D. Local stability analysis of microwave oscillators based on Nyquist’s theorem. IEEE Microw. Guid. Wave Lett. 1997, 7, 341–343. [Google Scholar] [CrossRef]
- Chang, H.H.; Lian, K.L.; Su, Y.C.; Lee, W.J. Power-spectrum-based wavelet transform for nonintrusive demand monitoring and load identification. IEEE Trans. Ind. Appl. 2013, 50, 2081–2089. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, C.; Zhang, X.; Huang, H.; Su, Y. Decision tree based validation of load model parameters. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literatures | Methods |
|---|---|
| [27] | Hidden Markov model |
| [20,21,28] | Deep learning model |
| [29] | Network for federated learning |
| [30] | Image signal processing method |
| [32] | Time partitioning and V-shaped particle swarm optimization algorithm |
| [33] | Compare each load characteristic data |
| [34,35] | Improved 0–1 multidimensional knapsack algorithm |
| [36] | Event waveform parsing method |
| Sequence Number | Characteristic Index |
|---|---|
| 1 | Active power (P) |
| 2 | Reactive power (Q) |
| 3 | RMS value of current (I) |
| Transient Process | Characteristic Index |
|---|---|
| Before transient | RMS of current |
| Mean active power | |
| Mean reactive power | |
| During transient | Transient duration T |
| Maximum current | |
| Maximum active power | |
| Maximum reactive power | |
| After transient | RMS of current |
| Mean active power | |
| Mean reactive power |
| Load Number | Load Class |
|---|---|
| Load 1 | Lighting |
| Load 2 | Fan |
| Load 3 | Electric control cabinet |
| Load 4 | Motor |
| Load 5 | Air conditioning |
| Load 6 | Compressor |
| Load 7 | Cleaning machine |
| Load Name | Steady-State Feature Cluster Centers | Transient Feature Cluster Centers | ||
|---|---|---|---|---|
| Characteristic Component 1 | Characteristic Component 2 | Characteristic Component 1 | Characteristic Component 2 | |
| Load 1 | 0.082 | 0.054 | 0.083 | 0.032 |
| Load 2 | 0.084 | −0.032 | 0.046 | −0.021 |
| Load 3 | −0.078 | −0.071 | −0.082 | −0.026 |
| Load 4 | 0.083 | 0.049 | 0.068 | −0.054 |
| Load 5 | −0.104 | −0.058 | −0.098 | 0.042 |
| Load 6 | −0.066 | −0.068 | −0.054 | −0.024 |
| Load 7 | 0.075 | −0.027 | 0.063 | −0.035 |
| Loads | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Load 1 | 93.8% | 92.8% | 89.2% | 91% |
| Load 2 | 96.5% | 93.5% | 94.5% | 94% |
| Load 3 | 92.6% | 91.7% | 91.2% | 91.4% |
| Load 4 | 97.4% | 93.4% | 90.4% | 91.9% |
| Load 5 | 96.7% | 94.2% | 93.3% | 93.7% |
| Load 6 | 94.3% | 90.6% | 91.6% | 91.6% |
| Load 7 | 95.8% | 95.2% | 93.8% | 94.5% |
| Total | 95.3% | 93.1% | 92% | 92.5% |
| Loads | Accuracy | Recall | F1-Score |
|---|---|---|---|
| Electric fan | 91% | 97% | 91% |
| Electric hair drier | 92% | 99% | 93% |
| Incandescent light bulb | 95% | 98% | 94% |
| Refrigerator | 95% | 99% | 94% |
| Air conditioner | 97% | 99% | 98% |
| Washing machine | 96% | 97% | 96% |
| computer | 96% | 96% | 96% |
| Total | 94.5% | 97.8% | 94.5% |
| Comparison Method | Accuracy (%) |
|---|---|
| Wavelet transform [62] | 88.5 |
| Decision tree model [63] | 89.6 |
| BP neural network | 90.8 |
| CNNs | 91.6 |
| PCA-DBSCAN | 90.4 |
| t-SNE-DBSCAN | 92.8 |
| UMAP-K-means | 89.5 |
| Ours | 95.3 |
| Load | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Load 1 | 96.3% | 93.9% | 94.2% | 94% |
| Load 2 | 95.5% | 92.6% | 93.1% | 92.8% |
| Load 3 | 96.5% | 93.7% | 93.8% | 93.7% |
| Load 4 | 94.9% | 92.4% | 91.4% | 91.9% |
| Load 5 | 92.4% | 90.3% | 91% | 90.6% |
| Load 6 | 92.7% | 89.8% | 90.6% | 90.2% |
| Load 7 | 95.1% | 92.7% | 91.8% | 92.2% |
| Total | 94.8% | 92.2% | 92.3% | 92.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhou, J.; Lu, C.; Song, L.; Meng, F.; Wang, X. Non-Intrusive Load Monitoring Based on Dimensionality Reduction and Adapted Spatial Clustering. Energies 2024, 17, 4303. https://doi.org/10.3390/en17174303
Zhang X, Zhou J, Lu C, Song L, Meng F, Wang X. Non-Intrusive Load Monitoring Based on Dimensionality Reduction and Adapted Spatial Clustering. Energies. 2024; 17(17):4303. https://doi.org/10.3390/en17174303
Chicago/Turabian StyleZhang, Xu, Jun Zhou, Chunguang Lu, Lei Song, Fanyu Meng, and Xianbo Wang. 2024. "Non-Intrusive Load Monitoring Based on Dimensionality Reduction and Adapted Spatial Clustering" Energies 17, no. 17: 4303. https://doi.org/10.3390/en17174303
APA StyleZhang, X., Zhou, J., Lu, C., Song, L., Meng, F., & Wang, X. (2024). Non-Intrusive Load Monitoring Based on Dimensionality Reduction and Adapted Spatial Clustering. Energies, 17(17), 4303. https://doi.org/10.3390/en17174303