

TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity Prediction on Embedded Devices



Abstract
1. Introduction
2. Data Preparation and Model Composition
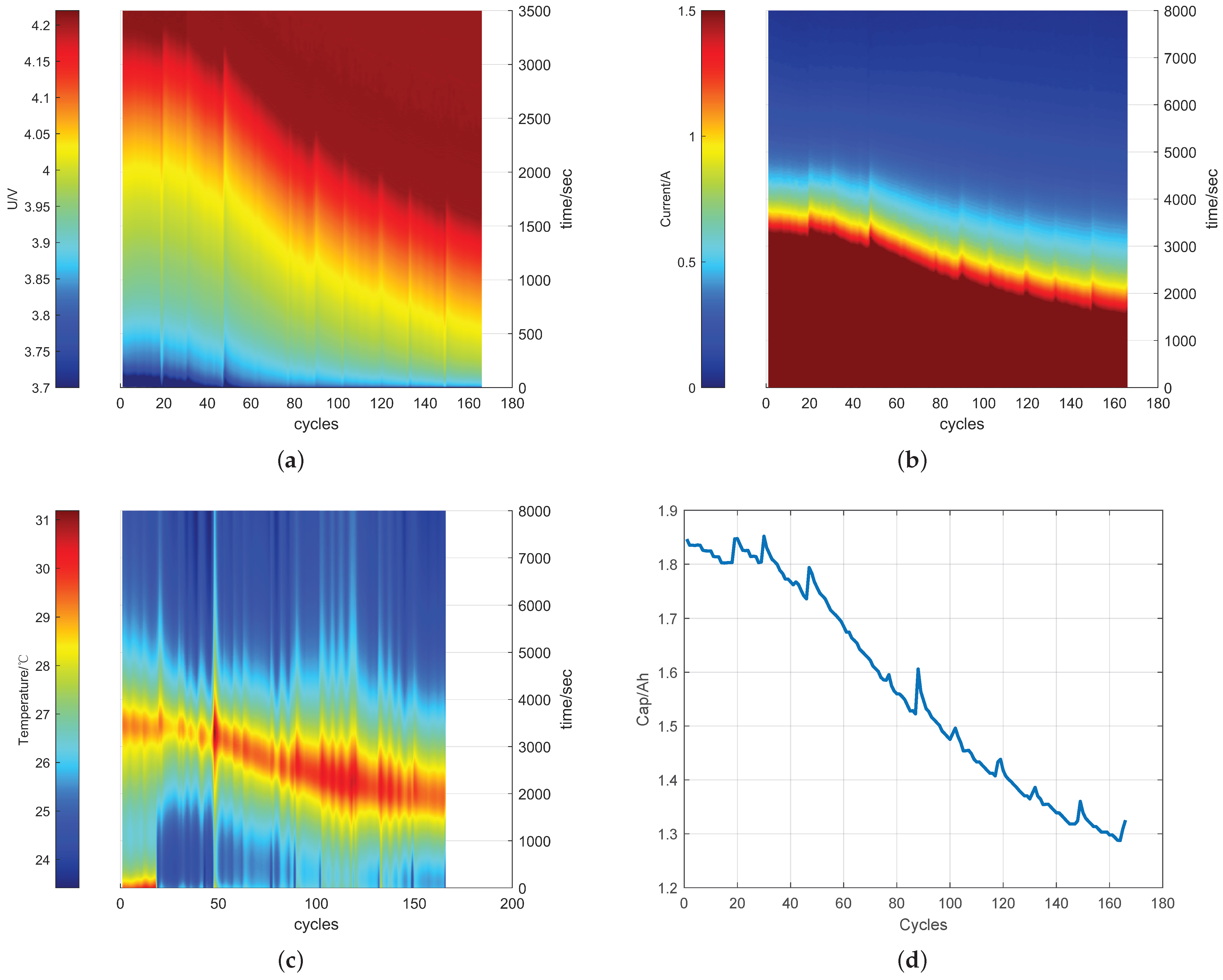
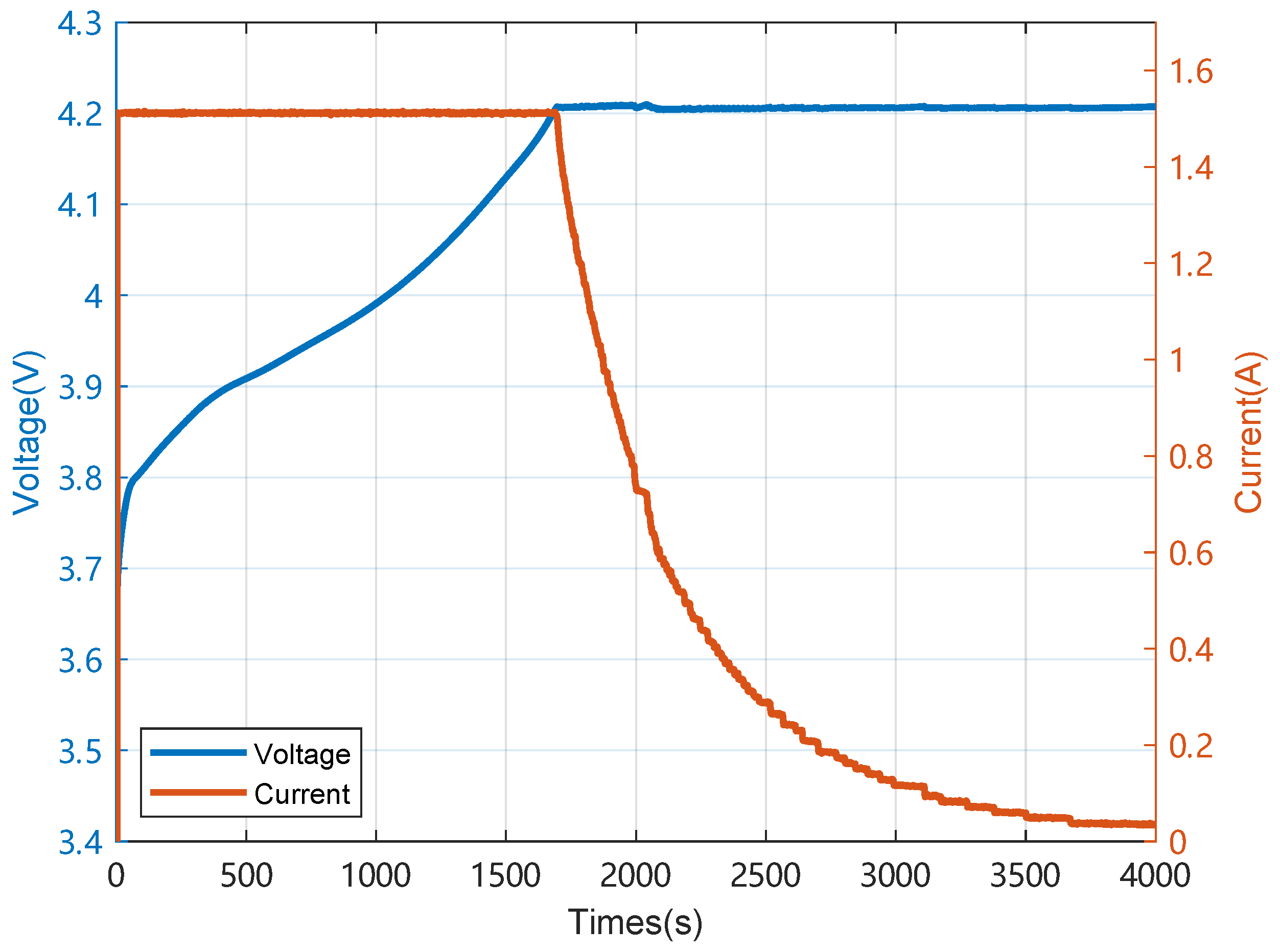
2.1. Data Preparation
2.2. LSTM Network Structure
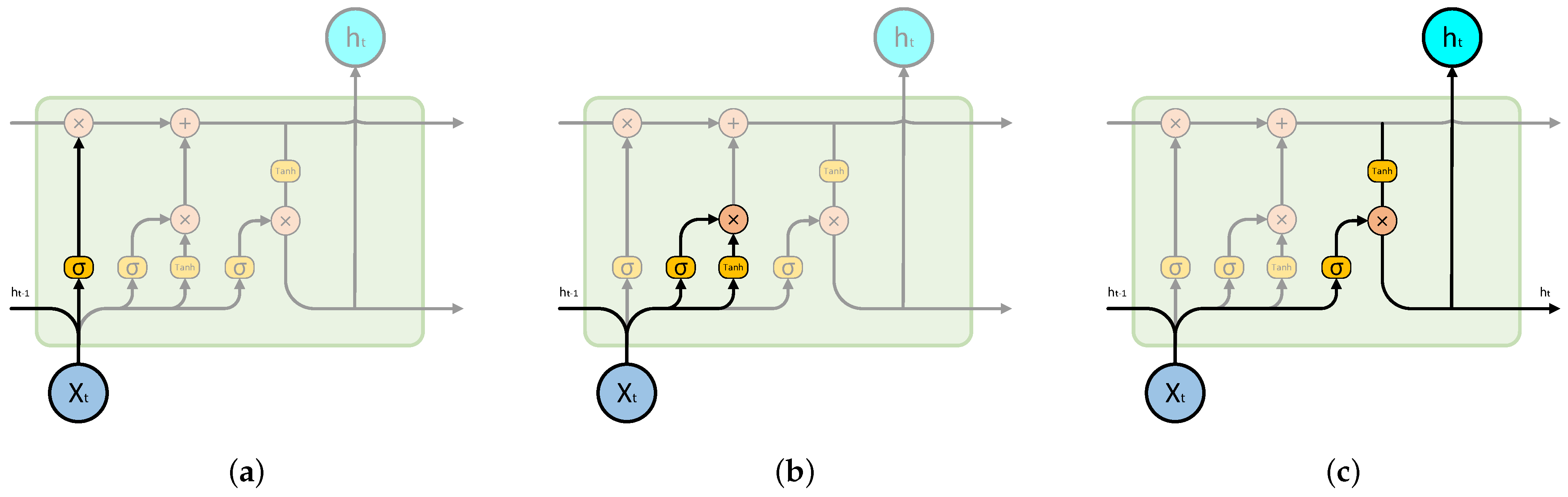
- The structure of the forget gate, shown in Figure 5a, comprises a sigmoid function that takes as input both the output of the previous cell and the input of the present cell. The output value of this sigmoid function falls within the range of for each element in , serving to regulate the extent to which the cell’s previous status is forgotten.
- The structure of the input gate, shown in Figure 5b, interacts with a tanh function to determine which new information should be incorporated. The output of the tanh function results in a new candidate vector. Combining the output of the “forget gate”, which governs the amount of the previous cell that is forgotten, with the output of the input gate, which controls how much new information is incorporated, we obtain an updated status for the memory cell. Consequently, the output of the “forget gate” regulates the degree to which the previous cell is forgotten, and the output of the “input gate” determines how much new information is integrated. Based on these two outputs, the cell status can be updated.
- The structure of the output gate, shown in Figure 5c, is used to filter out the current cell state to a certain extent. First, cell states are activated, and then the output gate generates a value within the range of for each state, controlling the degree to which the cell state is filtered.
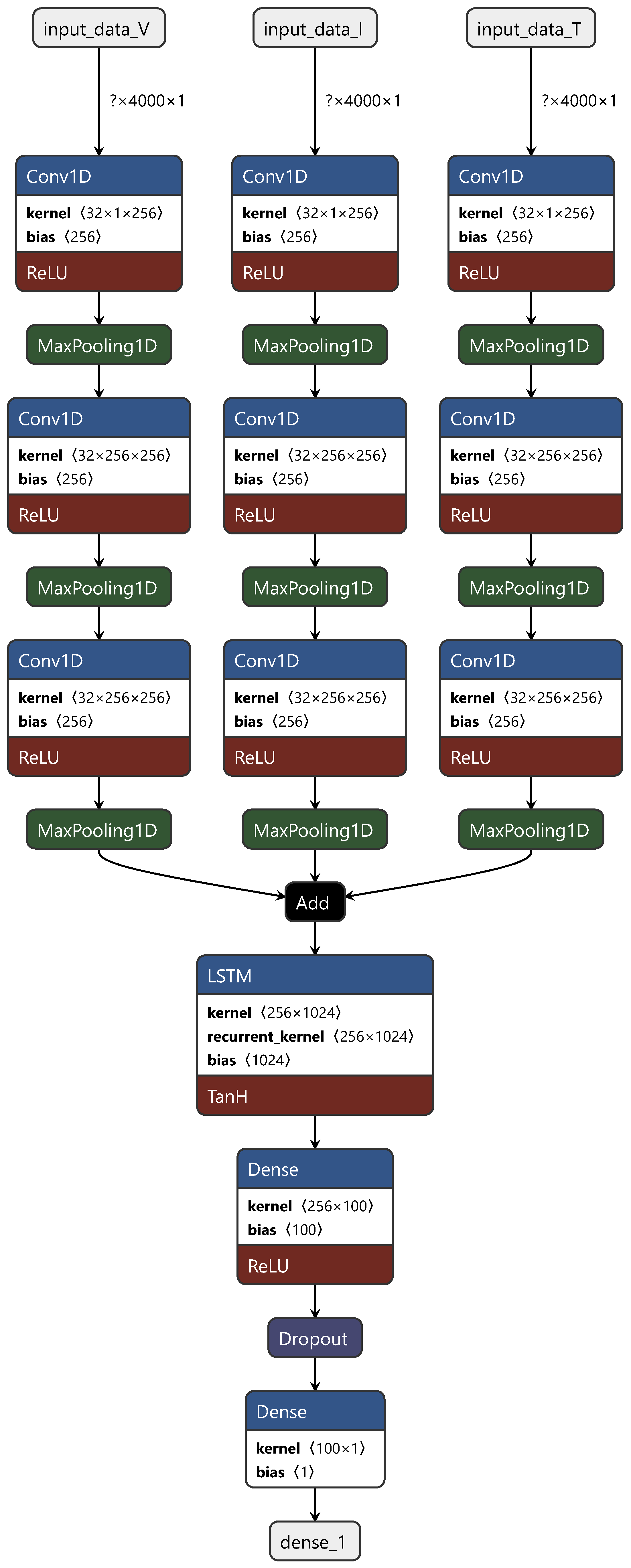
2.3. Model Composition
3. Model Deployment and Optimization
3.1. Hardware Specifications
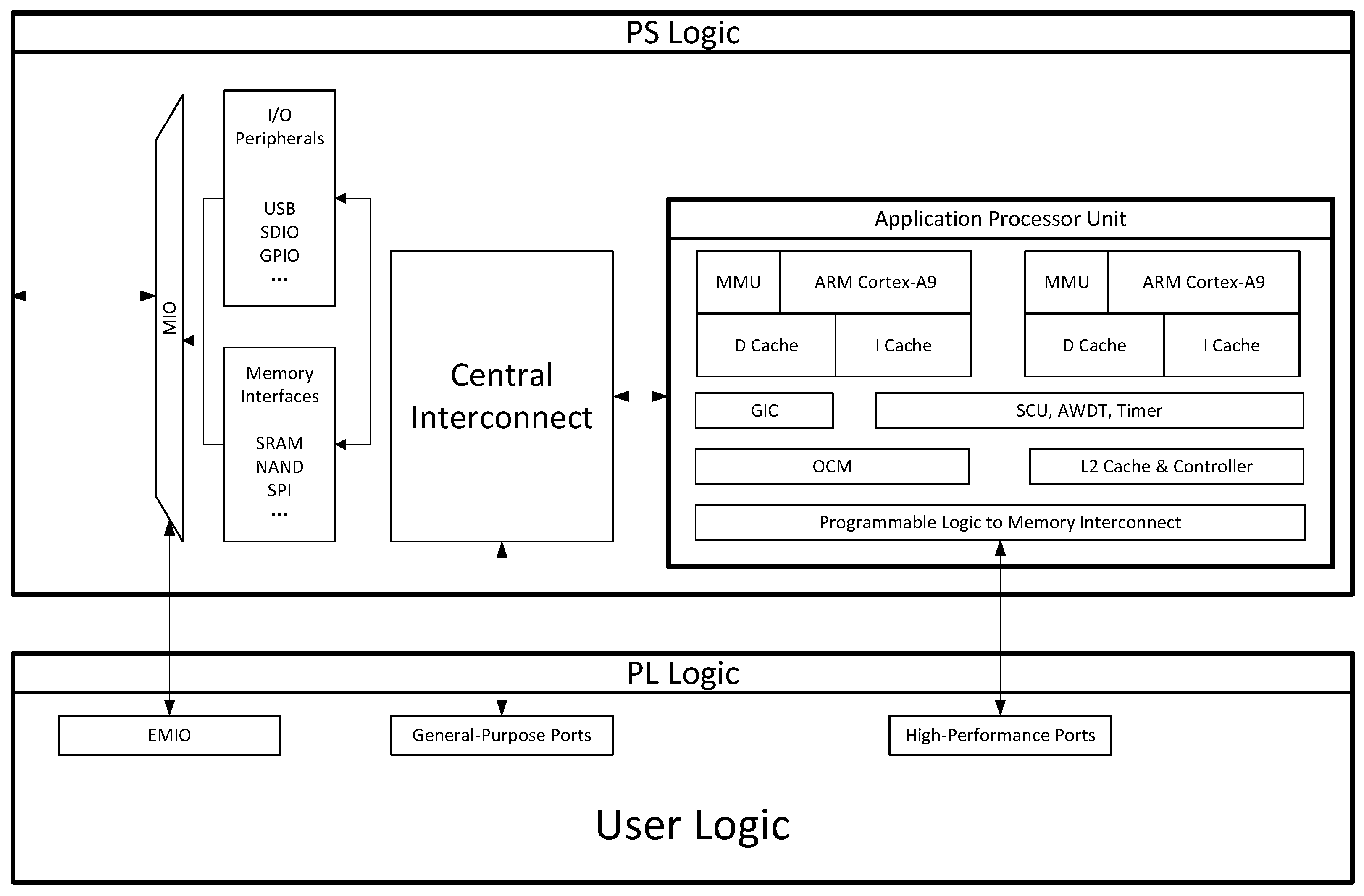
3.2. Model Deployment on FPGA Development Board
3.3. Model Deployment on CPU
3.4. Model Deployment on GPU
3.5. Model Deployment on TensorRT
3.6. Model Optimization with INT8 Quantization
4. Experimental Design and Test Results
4.1. Prediction Deviation Test
4.1.1. Mean Absolute Deviation Metrics
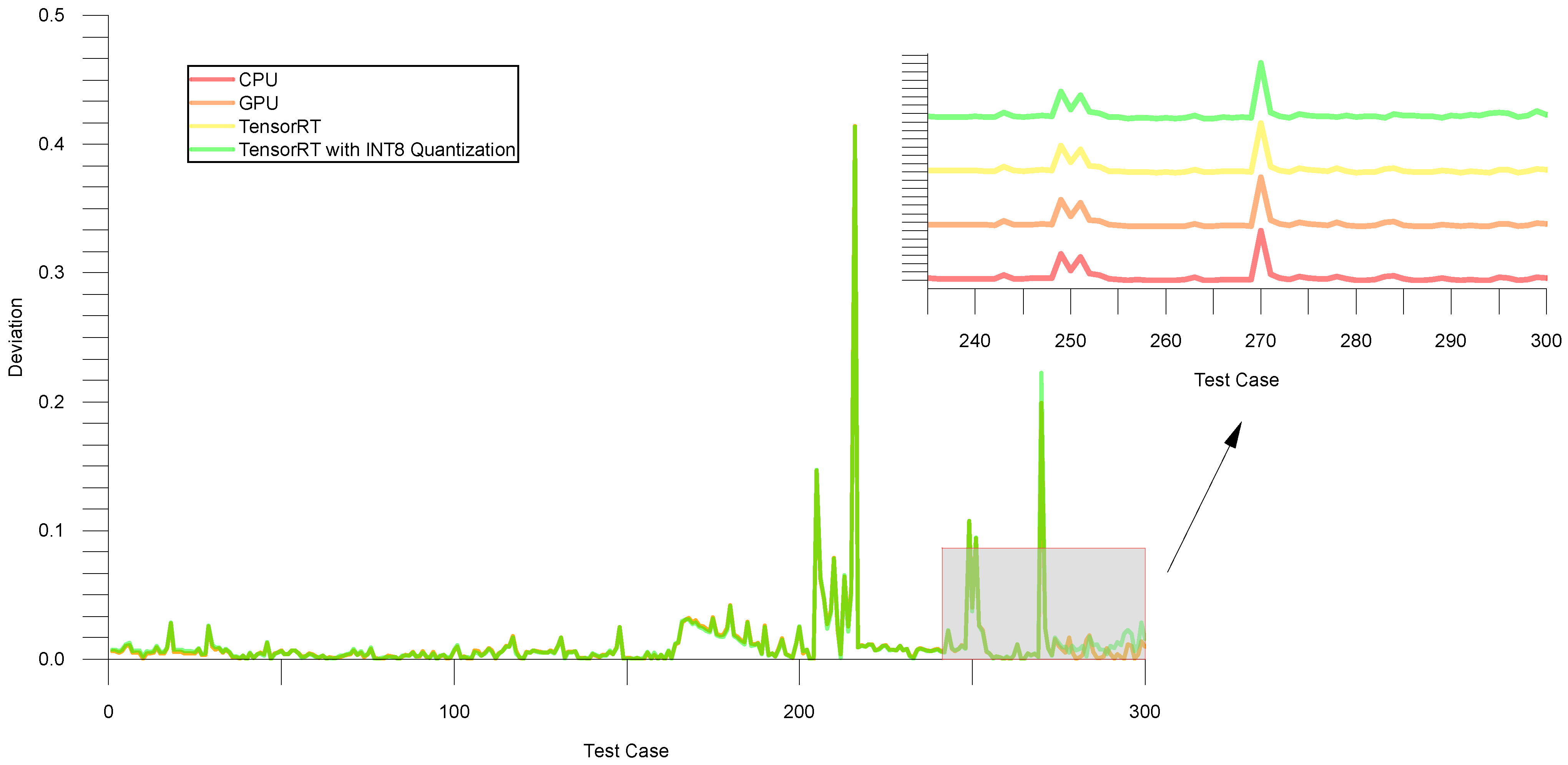
4.1.2. Experiment on Validation Set
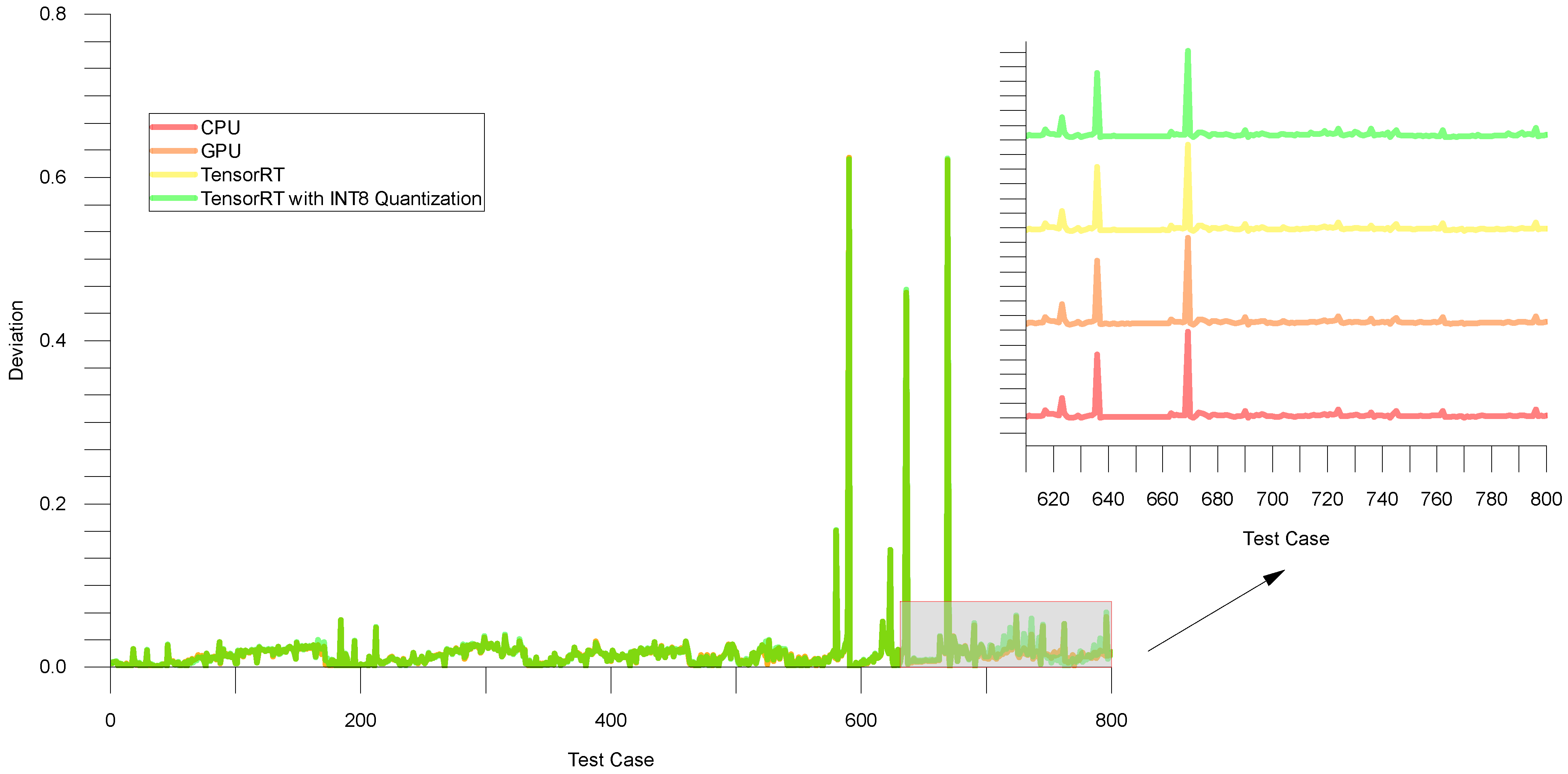
4.1.3. Experiment on Testing Set
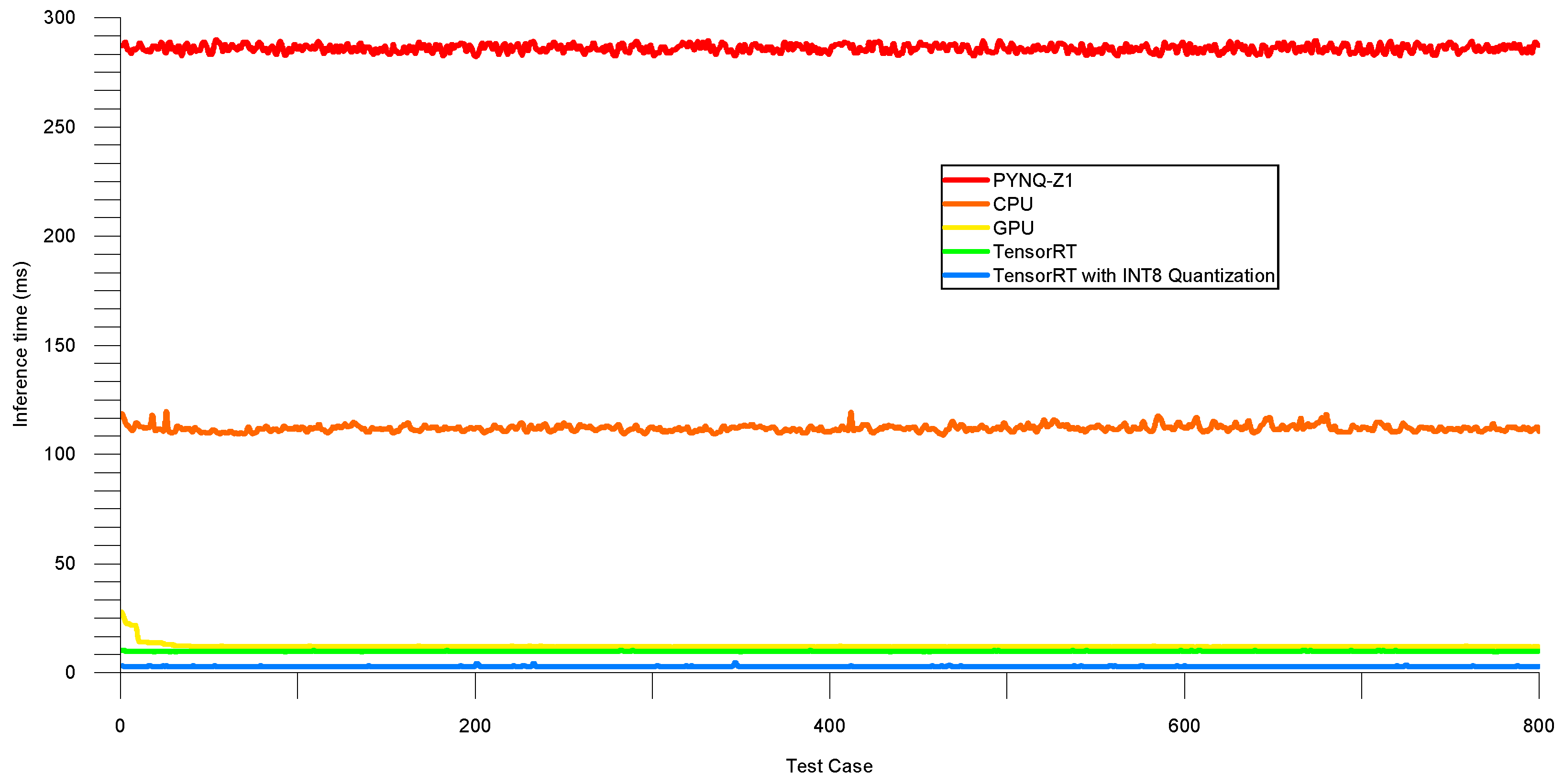
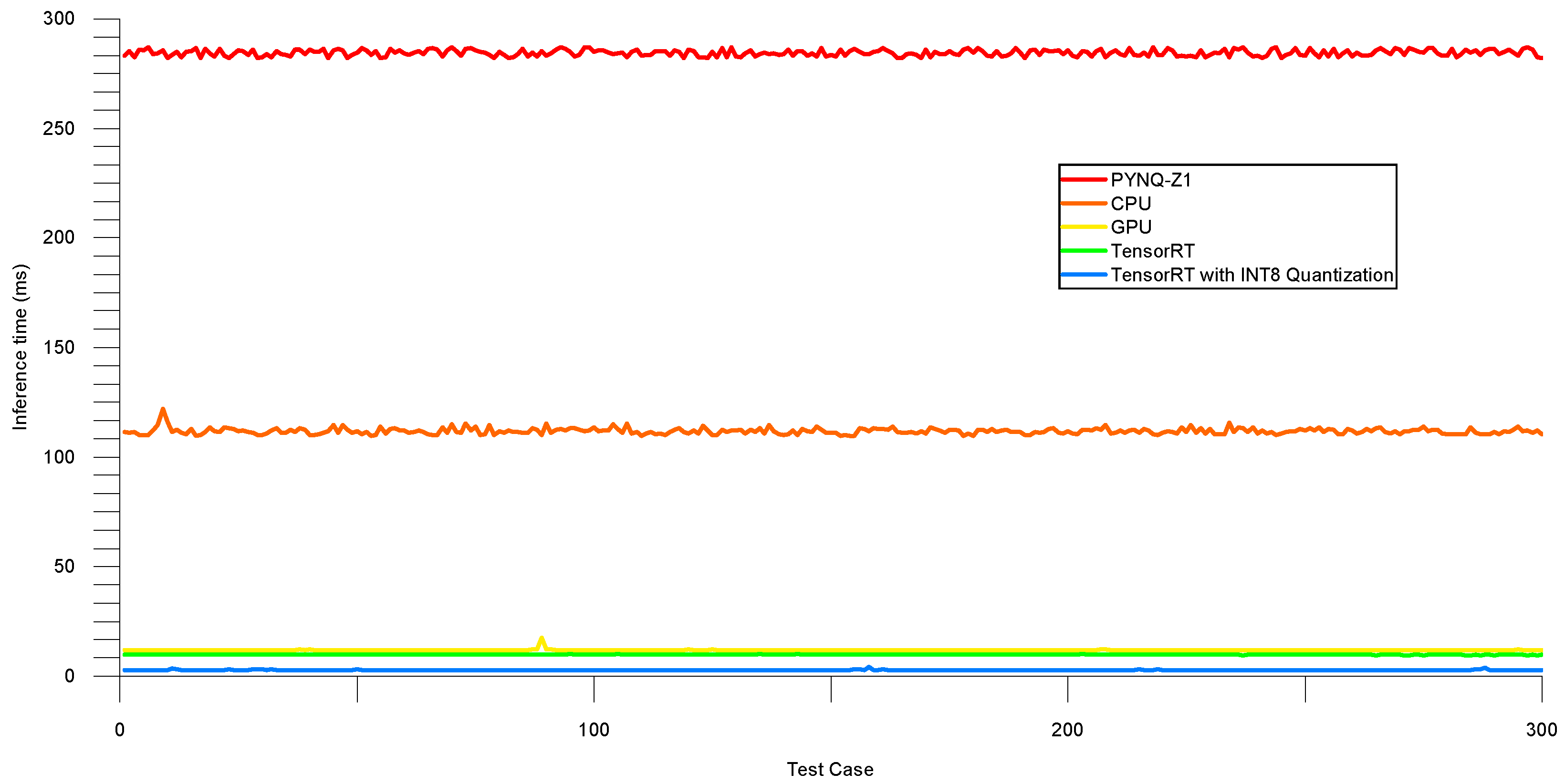
4.2. Inference Latency Test
4.2.1. Experiment on Validation Set
4.2.2. Experiment on Testing Set
5. Future Work and Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manthiram, A. An outlook on lithium ion battery technology. ACS Cent. Sci. 2017, 3, 1063–1069. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, B.; Li, Q.; Cartmell, S.; Ferrara, S.; Deng, Z.D.; Xiao, J. Lithium and lithium ion batteries for applications in microelectronic devices: A review. J. Power Sources 2015, 286, 330–345. [Google Scholar] [CrossRef]
- Masias, A.; Marcicki, J.; Paxton, W.A. Opportunities and challenges of lithium ion batteries in automotive applications. ACS Energy Lett. 2021, 6, 621–630. [Google Scholar] [CrossRef]
- Han, X.; Lu, L.; Zheng, Y.; Feng, X.; Li, Z.; Li, J.; Ouyang, M. A review on the key issues of the lithium ion battery degradation among the whole life cycle. ETransportation 2019, 1, 100005. [Google Scholar] [CrossRef]
- Li, L.L.; Liu, Z.F.; Tseng, M.L.; Chiu, A.S. Enhancing the Lithium-ion battery life predictability using a hybrid method. Appl. Soft Comput. 2019, 74, 110–121. [Google Scholar] [CrossRef]
- Li, Y.; Liu, K.; Foley, A.M.; Zülke, A.; Berecibar, M.; Nanini-Maury, E.; Van Mierlo, J.; Hoster, H.E. Data-driven health estimation and lifetime prediction of lithium-ion batteries: A review. Renew. Sustain. Energy Rev. 2019, 113, 109254. [Google Scholar] [CrossRef]
- Xu, F.; Yang, F.; Fei, Z.; Huang, Z.; Tsui, K.L. Life prediction of lithium-ion batteries based on stacked denoising autoencoders. Reliab. Eng. Syst. Saf. 2021, 208, 107396. [Google Scholar] [CrossRef]
- Li, W.; Sengupta, N.; Dechent, P.; Howey, D.; Annaswamy, A.; Sauer, D.U. Online capacity estimation of lithium-ion batteries with deep long short-term memory networks. J. Power Sources 2020, 482, 228863. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Islam, Z.; Abdel-Aty, M.; Mahmoud, N. Using CNN-LSTM to predict signal phasing and timing aided by High-Resolution detector data. Transp. Res. Part C Emerg. Technol. 2022, 141, 103742. [Google Scholar] [CrossRef]
- Yao, W.; Huang, P.; Jia, Z. Multidimensional LSTM networks to predict wind speed. In Proceedings of the IEEE 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 7493–7497. [Google Scholar]
- Jeong, E.; Kim, J.; Tan, S.; Lee, J.; Ha, S. Deep learning inference parallelization on heterogeneous processors with tensorrt. IEEE Embed. Syst. Lett. 2021, 14, 15–18. [Google Scholar] [CrossRef]
- Saurav, S.; Gidde, P.; Saini, R.; Singh, S. Dual integrated convolutional neural network for real-time facial expression recognition in the wild. Vis. Comput. 2022, 38, 1083–1096. [Google Scholar] [CrossRef]
- Dai, B.; Li, C.; Lin, T.; Wang, Y.; Gong, D.; Ji, X.; Zhu, B. Field robot environment sensing technology based on TensorRT. In Proceedings of the International Conference on Intelligent Robotics and Applications, Yantai, China, 22–25 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 370–377. [Google Scholar]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Park, K.; Choi, Y.; Choi, W.J.; Ryu, H.Y.; Kim, H. LSTM-based battery remaining useful life prediction with multi-channel charging profiles. IEEE Access 2020, 8, 20786–20798. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Liu, Z. A LSTM-RNN method for the lithuim-ion battery remaining useful life prediction. In Proceedings of the IEEE 2017 Prognostics and System Health Management Conference (PHM-Harbin), Yantai, China, 22–25 October 2017; pp. 1–4. [Google Scholar]
- Choi, D.; Lee, D.; Lee, J.; Son, S.; Kim, M.; Jang, J.W. A Study on the Efficiency of Deep Learning on Embedded Boards. J. Converg. Cult. Technol. 2021, 7, 668–673. [Google Scholar]
- Jeong, E.; Kim, J.; Ha, S. TensorRT-Based Framework and Optimization Methodology for Deep Learning Inference on Jetson Boards. ACM Trans. Embed. Comput. Syst. 2022, 21, 1–26. [Google Scholar] [CrossRef]
- Yang, S.; Niu, Z.; Cheng, J.; Feng, S.; Li, P. Face recognition speed optimization method for embedded environment. In Proceedings of the IEEE 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 147–153. [Google Scholar]
- Bachtiar, Y.; Adiono, T. Convolutional neural network and maxpooling architecture on Zynq SoC FPGA. In Proceedings of the IEEE 2019 International Symposium on Electronics and Smart Devices (ISESD), Badung-Bali, Indonesia, 8–9 October 2019; pp. 1–5. [Google Scholar]
- Li, X.; Yin, Z.; Xu, F.; Zhang, F.; Xu, G. Design and implementation of neural network computing framework on Zynq SoC embedded platform. Procedia Comput. Sci. 2021, 183, 512–518. [Google Scholar] [CrossRef]
- Lee, H.S.; Jeon, J.W. Accelerating deep neural networks using FPGAs and ZYNQ. In Proceedings of the 2021 IEEE Region 10 Symposium (TENSYMP), Jeju, Republic of Korea, 23–25 August 2021; pp. 1–4. [Google Scholar]
- Lv, H.; Zhang, S.; Liu, X.; Liu, S.; Liu, Y.; Han, W.; Xu, S. Research on dynamic reconfiguration technology of neural network accelerator based on Zynq. J. Phys. Conf. Ser. IOP Publ. 2020, 1650, 032093. [Google Scholar] [CrossRef]
- Saha, B.; Goebel, K. Battery Data Set, NASA Ames Prognostics Data Repository; NASA Ames Research Center: Moffett Field, CA, USA, 2007. [Google Scholar]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Archit. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Cui, H.; Dahnoun, N. Real-time stereo vision implementation on Nvidia Jetson TX2. In Proceedings of the IEEE 2019 8th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 10–14 June 2019; pp. 1–5. [Google Scholar]
- Jose, E.; Greeshma, M.; Haridas, M.T.; Supriya, M. Face recognition based surveillance system using facenet and mtcnn on jetson tx2. In Proceedings of the IEEE 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 608–613. [Google Scholar]
- Bokovoy, A.; Muravyev, K.; Yakovlev, K. Real-time vision-based depth reconstruction with nvidia jetson. In Proceedings of the IEEE 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–6. [Google Scholar]
- Süzen, A.A.; Duman, B.; Şen, B. Benchmark analysis of jetson tx2, jetson nano and raspberry pi using deep-cnn. In Proceedings of the IEEE 2020 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 26–27 June 2020; pp. 1–5. [Google Scholar]
- Tambara, L.A.; Kastensmidt, F.L.; Medina, N.H.; Added, N.; Aguiar, V.A.; Aguirre, F.; Macchione, E.L.; Silveira, M.A. Heavy ions induced single event upsets testing of the 28 nm Xilinx Zynq-7000 all programmable SoC. In Proceedings of the 2015 IEEE Radiation Effects Data Workshop (REDW), New Orleans, LA, USA, 17–21 July 2015; pp. 1–6. [Google Scholar]
- Sharma, A.; Singh, V.; Rani, A. Implementation of CNN on Zynq based FPGA for real-time object detection. In Proceedings of the IEEE 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–7. [Google Scholar]
- Wang, E.; Davis, J.J.; Cheung, P.Y. A PYNQ-based framework for rapid CNN prototyping. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; p. 223. [Google Scholar]
- Viet Huynh, T. FPGA-based acceleration for convolutional neural networks on PYNQ-Z2. Int. J. Comput. Digit. Syst. 2021, 11, 441–449. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Zou, J.; Zou, Z.; Wang, S. Neural network experiment on PYNQ. In Experience of PYNQ: Tutorials for PYNQ-Z2; Springer: Berlin/Heidelberg, Germany, 2023; pp. 45–79. [Google Scholar]
- Abu, M.A.; Indra, N.H.; Rahman, A.; Sapiee, N.A.; Ahmad, I. A study on Image Classification based on Deep Learning and Tensorflow. Int. J. Eng. Res. Technol. 2019, 12, 563–569. [Google Scholar]
- Kothari, J.D. A case study of image classification based on deep learning using TensorFlow. Int. J. Innov. Res. Comput. Commun. Eng. 2018, 6, 3888–3892. [Google Scholar]
- Escur i Gelabert, J. Exploring Automatic Speech Recognition with TensorFlow. Bachelor’s Thesis, Universitat Politècnica de Catalunya, Barselona, Spain, 2018. [Google Scholar]
- Medvedev, M.; Okuntsev, Y. Using Google tensorFlow machine learning library for speech recognition. J. Phys. Conf. Ser. C IOP Publ. 2019, 1399, 033033. [Google Scholar] [CrossRef]
- Shen, M.; Liang, F.; Gong, R.; Li, Y.; Li, C.; Lin, C.; Yu, F.; Yan, J.; Ouyang, W. Once quantization-aware training: High performance extremely low-bit architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5340–5349. [Google Scholar]
- Mishchenko, Y.; Goren, Y.; Sun, M.; Beauchene, C.; Matsoukas, S.; Rybakov, O.; Vitaladevuni, S.N.P. Low-bit quantization and quantization-aware training for small-footprint keyword spotting. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 706–711. [Google Scholar]
- Park, E.; Yoo, S.; Vajda, P. Value-aware quantization for training and inference of neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 580–595. [Google Scholar]
- Nguyen, H.D.; Alexandridis, A.; Mouchtaris, A. Quantization aware training with absolute-cosine regularization for automatic speech recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 3366–3370. [Google Scholar]
- Nagel, M.; Amjad, R.A.; Van Baalen, M.; Louizos, C.; Blankevoort, T. Up or down? Adaptive rounding for post-training quantization. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 7197–7206. [Google Scholar]
- Fang, J.; Shafiee, A.; Abdel-Aziz, H.; Thorsley, D.; Georgiadis, G.; Hassoun, J.H. Post-training piecewise linear quantization for deep neural networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany; pp. 69–86. [Google Scholar]
- Yuan, Z.; Xue, C.; Chen, Y.; Wu, Q.; Sun, G. PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 191–207. [Google Scholar]
- Liu, X.; Ye, M.; Zhou, D.; Liu, Q. Post-training quantization with multiple points: Mixed precision without mixed precision. In Proceedings of the AAAI Conference on Artificial Intelligence 10, San Jose, CA, USA, 12–16 July 2021; Volume 35, pp. 8697–8705. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Charging | Discharging | Operating Conditions | Dataset | |||||
|---|---|---|---|---|---|---|---|---|---|
| CC a (A) | UV b (V) | CoC c (mA) | CC (A) | CoV d (V) | OT e (°C) | IC f (Ah) | EC g (Ah) | ||
| #5 | 1.5 | 4.2 | 20 | 2 | 2.7 | 24 | 1.86 | 1.32 | Training |
| #6 | 1.5 | 4.2 | 20 | 2 | 2.5 | 24 | 2.04 | 1.18 | |
| #18 | 1.5 | 4.2 | 20 | 2 | 2.5 | 24 | 1.86 | 1.34 | |
| #29 | 1.5 | 4.2 | 20 | 4 | 2 | 43 | 1.84 | 1.61 | |
| #30 | 1.5 | 4.2 | 20 | 4 | 2.2 | 43 | 1.78 | 1.56 | |
| #31 | 1.5 | 4.2 | 20 | 4 | 2.5 | 43 | 1.83 | 1.66 | |
| #39 | 1.5 | 4.2 | 20 | 2 | 2.5 | 24, 44 | 0.47 | 1.31 | |
| #40 | 1.5 | 4.2 | 20 | 4 | 2.7 | 24, 44 | 0.79 | 0.55 | |
| #46 | 1.5 | 4.2 | 20 | 1 | 2.2 | 4 | 1.72 | 1.15 | |
| #47 | 1.5 | 4.2 | 20 | 1 | 2.5 | 4 | 1.67 | 1.15 | |
| #48 | 1.5 | 4.2 | 20 | 1 | 2.7 | 4 | 1.66 | 1.22 | |
| #7 | 1.5 | 4.2 | 20 | 2 | 2.2 | 24 | 1.89 | 1.43 | Validation |
| #32 | 1.5 | 4.2 | 20 | 4 | 2.7 | 43 | 1.89 | 1.63 | |
| #38 | 1.5 | 4.2 | 20 | 1 | 2.2 | 24, 44 | 1.1 | 1.53 | |
| #46 | 1.5 | 4.2 | 20 | 1 | 2.2 | 4 | 1.72 | 1.15 | Testing |
| Type | Specification |
|---|---|
| GPU | 384-core NVIDIA Volta™ |
| CPU | 6-core NVIDIA Carmel ARM® |
| Memory | 8 GB 128-bit LPDDR4x |
| Storage | 64 GB Sandisk microSD card |
| AI Performance | 21 TOPS |
| Type | MAE | MAPE |
|---|---|---|
| PYNQ-Z1 | 0.01624 | 2.77% |
| CPU | 0.01624 | 2.77% |
| GPU | 0.01624 | 2.77% |
| TensorRT | 0.01624 | 2.77% |
| TensorRT with INT8 | 0.01669 | 2.84% |
| Type | MAE | MAPE |
|---|---|---|
| PYNQ-Z1 | 0.01184 | 1.47% |
| CPU | 0.01184 | 1.47% |
| GPU | 0.01184 | 1.47% |
| TensorRT | 0.01184 | 1.47% |
| TensorRT with INT8 | 0.01283 | 1.62% |
| Type | Average (ms) | Median (ms) |
|---|---|---|
| PYNQ-Z1 | 285.943 | 285.956 |
| CPU | 111.975 | 111.754 |
| GPU | 18.835 | 11.869 |
| TensorRT | 9.807 | 9.791 |
| TensorRT with INT8 | 2.897 | 2.874 |
| Type | Average (ms) | Median (ms) |
|---|---|---|
| PYNQ-Z1 | 284.531 | 284.631 |
| CPU | 111.740 | 111.579 |
| GPU | 11.905 | 11.873 |
| TensorRT | 9.772 | 9.754 |
| TensorRT with INT8 | 2.895 | 2.874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, C.; Qian, J.; Gao, M. TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity Prediction on Embedded Devices. Energies 2024, 17, 2797. https://doi.org/10.3390/en17122797
Zhu C, Qian J, Gao M. TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity Prediction on Embedded Devices. Energies. 2024; 17(12):2797. https://doi.org/10.3390/en17122797
Chicago/Turabian StyleZhu, Chunxiang, Jiacheng Qian, and Mingyu Gao. 2024. "TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity Prediction on Embedded Devices" Energies 17, no. 12: 2797. https://doi.org/10.3390/en17122797
APA StyleZhu, C., Qian, J., & Gao, M. (2024). TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity Prediction on Embedded Devices. Energies, 17(12), 2797. https://doi.org/10.3390/en17122797