Abstract
OpenMOC-HEX, a neutron transport calculation code with hexagonal modular ray tracing, has the capability of domain decomposition parallelism based on an MPI parallel programming model. In this paper, the optimization of inter-node communication was studied. Starting from the specific geometric arrangement of hexagonal reactors and the communication features of the Method of Characteristics, the computation and communication of all the hexagonal assemblies are mapped to a graph structure. Then, the METIS library is used for graph partitioning to minimize the inter-node communication under the premise of load balance on each node. Numerical results of an example hexagonal core with 1968 energy groups and 1027 assemblies demonstrate that the communication time is reduced by about 90%, and the MPI parallel efficiency is increased from 82.0% to 91.5%.
1. Introduction
The Method of Characteristics (MOC) is a neutron transport method with strong geometric adaptability, high precision, and great parallel potential. It has become the mainstream method for lattice calculation toolkits as well as high-fidelity numerical reactors. There are currently many MOC transport calculation codes for rectangular reactor cores, whereas those for hexagonal reactor cores are less studied.
The hexagonal fuel assembly is widely used in the core design of advanced multi-purpose reactors, such as lead-bismuth fast reactors and sodium-cooled fast reactors in the fourth-generation reactor candidates, because of its compact arrangement, which can increase the coolant flow rate and heat transfer efficiency. Therefore, developing neutron transport solvers capable of hexagonal core simulation and large-scale parallel computing has significant engineering practical importance. At present, some MOC codes are under development to conduct the hexagonal core simulation, such as DeCART [1], SONG [2], NECP-X [3], and ANT-MOC [4].
OpenMOC [5] is an open-source deterministic neutronic code that is developed and maintained by Massachusetts Institute of Technology (MIT) and is used to perform the MOC rectangular reactor cores simulation. OpenMOC-HEX [6] is a neutron transport calculation code developed and maintained by Sun Yat-sen University on the basis of OpenMOC. Leveraging the mature framework, neutron transport solver, and ray tracing module from OpenMOC, OpenMOC-HEX employs a hexagonal modular ray tracing track laydown and realizes domain decomposition parallelism based on the MPI parallel programming model.
Domain decomposition has been widely used in the parallel acceleration of numerical computation [7]. This method can be mapped to a graph partitioning problem, which is an in-depth study in computer science [8] and has been applied to many fields, such as computational fluid dynamics [9] and rectangular reactor [10,11,12] neutronics simulation.
Many studies have explored optimization methods for direct calculation time, focusing on computation time, involving the program’s underlying architecture, mathematical algorithms, calculation, and operation strategies, such as the CMFD acceleration algorithm, GMRES algorithm, etc.
As computing resources become increasingly abundant and the computation process reduces approximation to improve accuracy, parallel scales gradually expand. This introduces new optimization problems, such as load balancing and minimal communication, that were less significant in smaller-scale computing. Research on this new problem, especially the issue of the special hexagonal core geometry, can effectively enhance program performance and efficiency.
In general, the graph partitioning problem is NP-complete, meaning that it is difficult to partition the graph into the best partition. However, there are many well-developed graph partitioning algorithms and libraries, for example, METIS, to be used to minimize MPI communication under the constraint of load balancing [13].
In this paper, the MPI parallel communication of OpenMOC-HEX is optimized. The graph partitioning algorithm is used to reasonably map a good deal of MPI processes onto many multi-core computational nodes to achieve both load balance and communication optimization to improve parallel efficiency.
2. Methodologies
2.1. Hexagonal Lattice Processing
In order to define the hexagonal assembly flexibly and quickly, a hexagonal grid (HexLattice) [6] needs to be established at first, as shown in Figure 1. Then, each grid cell can be filled with different fuel rods. In the MOC solver, obtaining the material parameters of the grid where the segment is located is necessary. Therefore, if the coordinates of any point in the Cartesian coordinate system are given, the number of this grid unit to which the point belongs is required to obtain the material information (fuel rod information) of this grid unit. In the hexagonal grid geometry processing, the method of obtaining the number is shown in Figure 1.
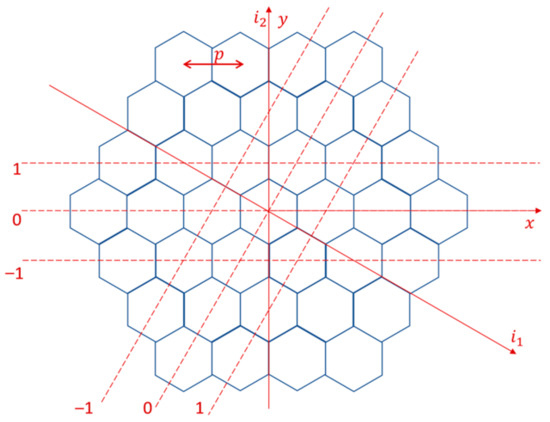
Figure 1.
Hexagonal grid geometry processing.
In Figure 1, the coordinate system is defined, the angle of the coordinate axis is , and the unit length of the coordinate is , where is the center distance of the grating element unit. Calculation of the coordinate from point in the coordinate system is shown in Equation (1).
According to the coordinate , the coordinate points may be located in , , , or . It is necessary to further determine which of the above four grid elements the point is indeed located in. The method is to calculate the distance between the coordinate point and the center point of the four hexagonal grids, and the grid element with the shortest distance is where the coordinate point is located.
2.2. Correspondence Relationship of MPI Communication
The OpenMOC-HEX implements MPI parallelism based on domain decomposition. Each MPI process is responsible for processing a hexagonal assembly, and calculations are coupled by angular flux communication [6] between assemblies for MPI parallelism, as shown in Figure 2.
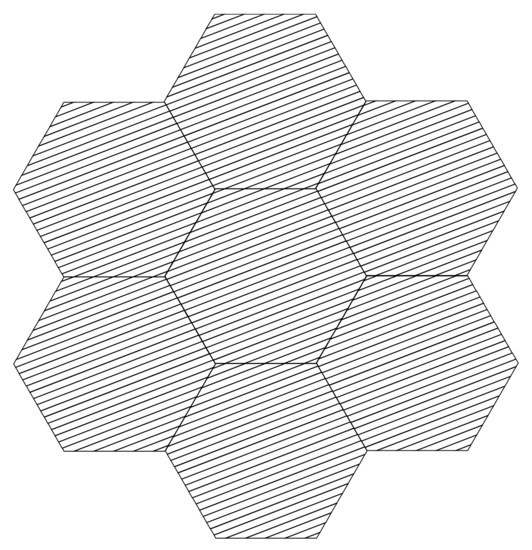
Figure 2.
The track laydown and the central assembly’s six neighboring assemblies.
In order to send angular flux data to the target process accurately, it is necessary to determine the neighboring process number of the hexagonal assembly corresponding to the pre-given assembly and its specific edge. In addition, for the hexagonal assembly of the outermost ring, it is also necessary to determine whether there is a hexagonal assembly on the adjacent edge.
In the OpenMOC-HEX code, the process numbering of the hexagonal assemblies starts from the top hexagonal assembly along a clockwise direction and increases from the outermost ring to the innermost ring. For example, in a three-ring hexagonal core, the MPI process numbering of each assembly is shown in Figure 3.
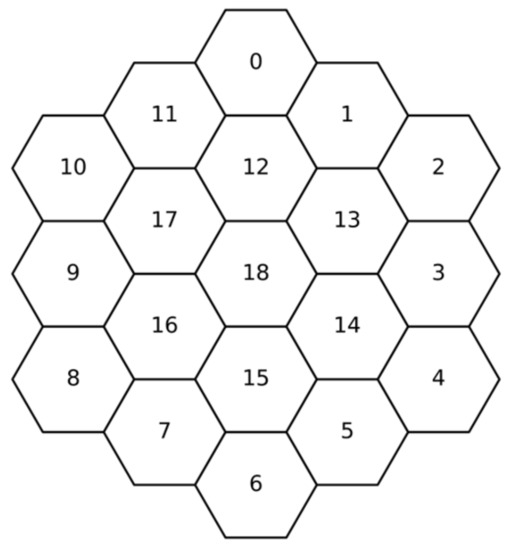
Figure 3.
MPI process numbering of a 3-ring 19-assembly hexagonal core.
It can be seen from Figure 3 that the adjacent edge correspondence of the hexagonal core depends on the number of rings. In order to find out the process number of the hexagonal assembly corresponding to the adjacent side, this study uses the method of transforming the coordinate system and regards the entire core composed of the hexagonal assemblies as a hexagonal grid. Firstly, the coordinates corresponding to the process number mentioned in Section 2.1 is calculated. Secondly, the hexagonal coordinates of the neighbors of the corresponding edges are obtained as shown in Figure 4. Finally, the process numbers of the neighboring assemblies are calculated based on the coordinates of the neighboring assembly.
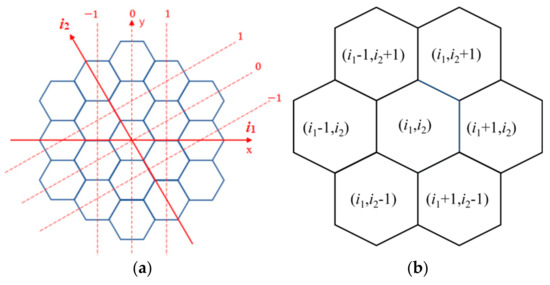
Figure 4.
The coordinate method used to calculate the process number of the neighboring assemblies: (a) coordinates; (b) neighbor coordinates in coordinates
2.3. MPI Communication Analysis of Hexagonal Core
As mentioned in Section 2.2, the communication tasks between different processes of OpenMOC-HEX have strong spatial distribution features, and only adjacent assemblies need to exchange boundary angular flux data. As shown in Figure 5, for the 18th process of the 3-ring 19-assembly core, only processes with the rank of 12, 13, 14, 15, 16, 17 are valid neighbors for communication. Even if the MPI processes have been evenly distributed to each node through the Intel MPI environment variable setting [14], due to the numbering strategy of the hexagonal assembly and the random allocation of MPI processes on the multi-core computational nodes, there will be a large number of unnecessary cross-node communication, resulting in increasing communication time and low parallel efficiency. Therefore, processes must be allocated more appropriately at different nodes, especially for large-scale parallel computations.
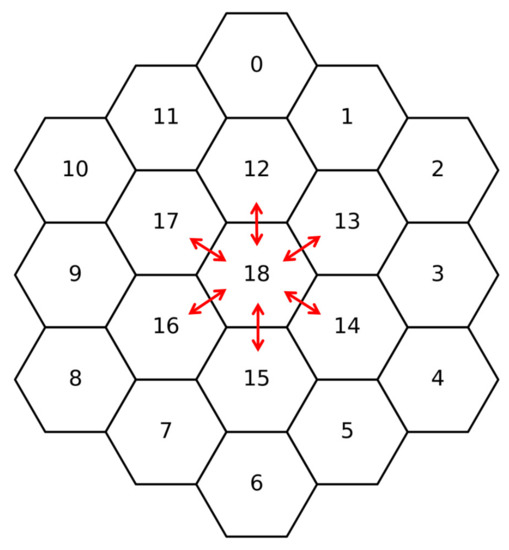
Figure 5.
Communication task diagram of rank18 in a 3-ring 19-assembly core example.
Therefore, considering the usage of graph partitioning and explicit allocation of processes, MPI processes that need to communicate should be arranged in the same computational node as much as possible under the condition of load balance of all nodes. By making a data exchange within nodes rather than across nodes, the communication time of large-scale parallel computing can be reduced by improving data transferring efficiency. Considering the features of the assembly arrangement of hexagonal cores, the number distribution of assemblies is mapped into a topological structure diagram, and the communication optimization is realized by using the existing graph partitioning program METIS5.0 [13].
2.4. Graph Partitioning Program METIS
In order to make full use of the existing high-performance computing resources, the parallel development of many application software pursues the load balance of computing tasks and the minimum communication between different tasks. Such problems can be mapped as highly unstructured graph partitioning problems. Based on this requirement, Karypis Lab developed METIS5.0, a powerful serial graph partitioning software package [13].
The Metis graph partitioning program algorithm is mainly based on multi-level recursive binary segmentation, multi-level kway segmentation, and multi-constraint partitioning mechanisms. It takes the edge-cut minimization as the goal and the load balancing as the constraint condition, and has high-quality partitioning results. It is 10–50% more accurate than spectral clustering and 1–2 orders of magnitude faster than the basic partitioning algorithm. For a graph of millions of vertices, it costs only seconds to cut into 256 classes [15]. Therefore, METIS5.0 meets the needs of OpenMOC-HEX parallel communication optimization.
METIS multi-level partitioning runs as follows: The initial large-scale graph is first coarsened and divided into smaller sub-graphs, then smaller graphs are divided into much smaller graphs, thus transforming the large-scale partitioning problem into a small-scale partitioning problem that can be effectively handled [13]. After the division, METIS will refine the results of the sub-graph division step by step and gradually restore the minor division to the division of the initial graph. At the same time, METIS will continuously optimize and improve the reduction of each layer, and finally obtain high-quality division results [13].
METIS supports the partitioning of multiple graph structures. The basic one is the unweighted graph. The default calculation weight of each vertex and the communication weight with adjacent vertices are remarked as 1. METIS only needs the vertex number and the vertex numbers with which it communicates. On this basis, the computing load weights of different vertices and the communication load weights of different edges can be introduced, and multiple constraints can be added.
Taking the 3-ring 19-assembly core as an example, the unweighted graph format is adopted, assuming the equal computational burden of each process and the equal data exchange amount between adjacent processes. According to the corresponding relationship of the communication area in Section 2.2, the edge data are generated. As shown in Table 1, for the assembly ranked 0, the natural number in [12,−1,11,−1,1,−1] represents the rank of orderly adjacent assembly, and −1 represents the core’s boundary. The edge data are processed using a Python script to generate the graph data required by METIS, as shown in Table 1, the extra first line that represents this graph has 19 vertexes and 42 edges.

Table 1.
The edge file and graph file of the 3-ring 19-assembly example.
3. Results
3.1. Test Environment and the Benchmark
The test uses two supercomputing platforms. Platform 1 is the v6_384 queue of T-Partition of Beijing Super Cloud Computing Center (BSCC), using Intel(R) Xeon(R) Platinum 9242 CPU @ 2.30 GHz CPU (96 cores per node); Center 2 is the t2 queue of T-Partition of BSCC, using Genuine Intel CPU 0000% CPU @ 2.20GHz CPU (48 cores per node). The specific configuration is shown in Table 2.
Table 2.
The specific configuration of the supercomputing platforms.
The test problem is a hexagonal core with a repetitive structure of a small hexagonal assembly. There are two materials in the benchmark, fuel and moderator. The macroscopic section of the material is provided by the RMC program [16]. The core adopts a reflection boundary condition on all boundaries and is repeatedly composed of a single assembly. Taking the 2-ring 7-assembly core as an example, the core structure is shown in Figure 6a, consisting of seven single assemblies with two rings. The structure of a single assembly is shown in Figure 6b, which is composed of a 3-ring 19-grid-element with large and small specifications. The large and small grid elements are shown in Figure 6b.
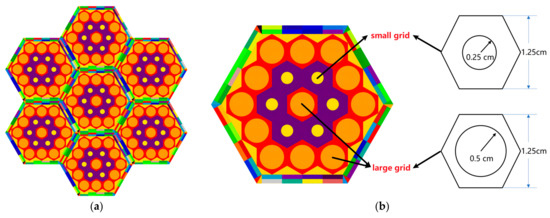
Figure 6.
(a) Core of benchmark; (b) grid elements and assembly.
3.2. Calculation
METIS is used to optimize the distribution of processes on multiple compute nodes based on graph partitioning. Taking the allocation of a 6-ring 91-assembly problem on six nodes as an example, the cross-node allocation of the corresponding assemblies of the process before and after optimization is shown. The different colors of the assemblies in Figure 7 indicate that the processes corresponding to the assemblies are allocated on different nodes. Therefore, the adjacent processes of the same color exchange data within a node, whereas the adjacent processes of different colors exchange data across nodes.
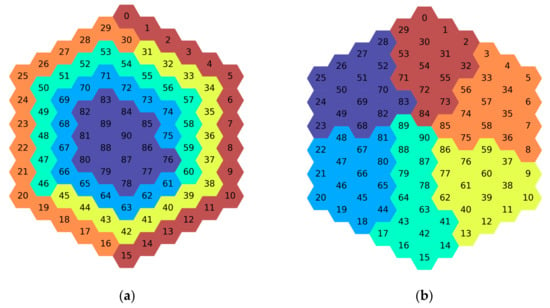
Figure 7.
The cross-node allocation diagram of process and its corresponding assemblies before and after optimization: (a) before optimization; (b) after optimization.
It can be seen that the number of processes requiring a cross-node data exchange after optimization is significantly reduced. Thus, the amount of cross-node data exchange is also reduced.
The monitoring data from the Paramon toolkit, which BSCC uses to monitor the system-level, micro-architecture-level, and function-level performance of the clusters, also support this view. Taking the test problems of the 19-ring 1027-assembly on Platform 1 and 18-ring 919-assembly on Platform 2 as examples, the average communication amount of each node in the InfiniBand network before optimization is 760.37 MB and 1148.14 MB, which is reduced by 88% to 90.58 MB and by 84% to 178.15 MB after optimization, as shown in Table 3 and Table 4.
Table 3.
The Paramon monitoring info of data exchange across nodes of 19-ring on Platform 1.
Table 4.
The Paramon monitoring info of data exchange across nodes of 18-ring on Platform 2.
Using Intel MPI, the binding of processes and computing nodes is implemented on Platform 1 (96 cores per node) and Platform 2 (48 cores per node), respectively [14]. Furthermore, the weak scalability parallel efficiency of OpenMOC-HEX is analyzed. The results are shown in Table 5 and Table 6, and Figure 8 and Figure 9, in which:
Table 5.
Optimization performance on Platform 1 (96 cores per node).
Table 6.
Optimization performance on Platform 2 (48 cores per node).
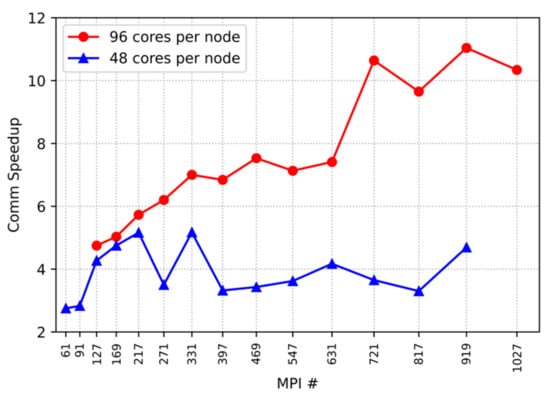
Figure 8.
Speedup of communication time.
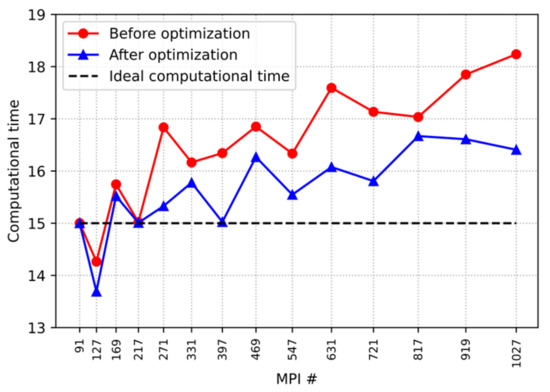
Figure 9.
Computational time before and after optimization on Platform 1 (96 cores per node).
Rings #: number of rings of assemblies constituting the core;
MPI #: the number of MPI processes, equal to the number of hexagonal assemblies;
Nodes #: ceil (MPI processes number/number of cores per node);
Cal time: total time of calculation;
Comm time: angular flux data communication time;
Comm Speedup: the speedup of communication (Communication time before optimization)/(Communication time after optimization);
MPI-UNPIN: the process is not allocated to the specified node before optimization;
MPI-PIN: the process is allocated to the specified node according to the graph partitioning result after optimization.
It can be seen from Figure 8 that in Platform 1 (96 cores per node), the communication acceleration effect of MPI-PIN is positively correlated with the number of processes; in Platform 2 (48 cores per node), the communication acceleration ratio of MPI-PIN is relatively small and does not change significantly with the increase of the number of processes. The reason is preliminarily analyzed. In Platform 2 (48 cores per node), the number of nodes used increases much faster than in Platform 1 as the number of processes increases due to the smaller number of cores of each node. With the rapid growth of inter-node communication, the optimization effect obtained by graph partitioning is limited.
The results of computational time before and after MPI-PIN optimization for the 6 to 19 rings examples measured on supercomputing Platform 1 (96 cores per node) are shown in Figure 9.
This paper mainly discusses MPI communication optimization and it is assumed that there is no communication between nodes when the code runs in a single node. Therefore, the single-node computational time is taken as the ideal computational time. OpenMOC-HEX implements MPI parallelism through domain decomposition, and the number of MPI processes equals the number of hexagonal assemblies. In the ideal case of weak scalability analysis, the computational time should remain unchanged as the number of MPI processes increases.
The test results show that the parallel efficiency after graph partitioning optimization is significantly higher than before. For the 19-ring 1027-assembly example, the parallel efficiency increased from 82.3% to 91.4%. Therefore, it is an effective optimization method for large-scale parallel computing to reduce the cross-node data exchange under the premise of load balancing by optimizing graph partitioning to make the process bound on nodes in a targeted manner.
4. Discussion
In this study, with the help of the graph partitioning algorithm and the METIS library, the optimized allocation of OpenMOC-HEX MPI processes across multi-core nodes is studied to minimize the inter-node communication under the constraint of load balance. As for the benchmark of 19-ring 1027-assembly, the inter-node communication is reduced by 88%, the communication time is reduced by 90%, and the parallel efficiency is increased from 82% to 91.5% after optimization. This demonstrates that the optimizing method proposed in this study is of great importance for improving the efficiency of a high fidelity neutron transport solver.
Combining the additional data exchange information and the communication time acceleration ratio shown in Table 4 and Figure 8, it can be observed that in Platform 2 (48 cores per node), there are significantly more communication data between nodes and a similar reduction in communication volume. However, the communication time acceleration effect is significantly lower than in Platform 1 (96 cores per node). We speculate that this is because the InfiniBand technology used in supercomputers achieves high bandwidth and low latency. Hence, its communication time growth is lower than the growth of data volume, which is beneficial for large-scale computing in computer clusters. The lower communication optimization on Platform 2 is due to its older hardware configuration and higher latency.
In 2D computations, this method has already achieved significant results, and in the future, when implementing computation capabilities for larger parallel scales in 3D hexagonal geometries, the use of graph partitioning algorithms will continue to be explored.
Since OpenMOC-HEX implements assembly-based domain decomposition, equal weights of computation and communication are assumed. The actual purpose of graph partitioning is to achieve load balancing and minimize communication. Its role is not limited to communication optimization. In future studies, the computation and communication weights should be finely tuned considering the actual design of different assemblies.
Furthermore, assembly-based domain decomposition limits the parallel potential of the program. The next step will further optimize the domain decomposition strategy of the program to achieve strong scalability as much as possible. Constrained by the special geometric form of hexagonal geometry, the improvement of the strong scalability of OpenMOC-HEX undoubtedly requires a more in-depth study of graph partitioning methods to complete the optimization of load balancing and minimum communication to maximize the parallel efficiency.
Author Contributions
Conceptualization, J.Z. and W.W.; methodology, J.Z., Z.W. and W.W.; software, J.Z. and W.W.; validation, J.Z., Z.X. and Z.W.; investigation, J.Z., X.P. and W.W.; resources, C.Z. and W.W.; data curation, J.Z. and Z.X.; writing—original draft preparation, J.Z.; writing—review and editing, W.W., Z.W., C.Z., Z.X. and X.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Grants of Nuclear Power Innovation Center, grant number HDLCXZX-2021-HD-030.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors would like to thank BSCC for its technical support in testing and monitoring programs on supercomputing platforms.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cho, J.Y.; Kim, K.S.; Shim, H.J.; Song, J.S.; Lee, C.C.; Joo, H.G. Whole Core Transport Calculation Employing Hexagonal Modular Ray Tracing and CMFD Formulation. J. Nucl. Sci. Technol. 2008, 45, 740–751. [Google Scholar] [CrossRef]
- Chen, Q.; Si, S.; Zhao, J.; Bei, H. SONG-Development of transport modules. Hedongli Gongcheng/Nucl. Power Eng. 2014, 35, 127–130. [Google Scholar]
- Liu, Z.; Chen, J.; Li, S.; Wu, H.; Cao, L. Development and Verification of the Hexagonal Core Simulation Capability of the NECP-X Code. Ann. Nucl. Energy 2022, 179, 109388. [Google Scholar] [CrossRef]
- Yang, W.; Hu, C.; Liu, T.; Wang, A.; Wu, M. Research Progress of China Virtual Reactor (CVR1.0). Yuanzineng Kexue Jishu/At. Energy Sci. Technol. 2019, 53, 1821–1832. [Google Scholar]
- Boyd, W.; Shaner, S.; Li, L.; Forget, B.; Smith, K. The OpenMOC Method of Characteristics Neutral Particle Transport Code. Ann. Nucl. Energy 2014, 68, 43–52. [Google Scholar] [CrossRef]
- Wu, W.; Wang, Z.; Zheng, J.; Xie, Z.; Zhao, C.; Peng, X. Hexagonal Method of Characteristics with area decomposition in parallel. J. Harbin Eng. Univ 2022, 43, 1–5. [Google Scholar]
- Farhat, C. A simple and efficient automatic fem domain decomposer. Comput. Struct. 1988, 28, 579–602. [Google Scholar] [CrossRef]
- Elsner, U. Graph Partitioning—A Survey. Encycl. Parallel Comput. 1999, 97, 27. [Google Scholar] [CrossRef]
- Yao, Y.F.; Richards, B.E. Parallel CFD Computation on Unstructured Grids. In Parallel Computational Fluid Dynamics 1997; Emerson, D.R., Periaux, J., Ecer, A., Satofuka, N., Fox, P., Eds.; North-Holland: Amsterdam, The Netherlands, 1998; pp. 289–296. ISBN 978-0-444-82849-1. [Google Scholar]
- Fitzgerald, A.P. Spatial Decomposition of Structured Grids for Nuclear Reactor Simulations. Ann. Nucl. Energy 2019, 132, 686–701. [Google Scholar] [CrossRef]
- Zhao, C.; Peng, X.; Zhang, H.; Zhao, W.; Li, Q.; Chen, Z. Analysis and Comparison of the 2D/1D and Quasi-3D Methods with the Direct Transport Code SHARK. Nucl. Eng. Technol. 2022, 54, 19–29. [Google Scholar] [CrossRef]
- Zhao, C.; Peng, X.; Zhao, W.; Feng, J.; Zhao, Y.; Zhang, H.; Wang, B.; Chen, Z.; Gong, Z.; Li, Q. Verification of the Direct Transport Code SHARK with the JRR-3M Macro Benchmark. Ann. Nucl. Energy 2022, 177, 109294. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. METIS: A Software Package for Partitioning Unstructured Graphs, Partitioning Meshes, and Computing Fill-Reducing Orderings of Sparse Matrices. Comput. Sci. Eng. 1997. Available online: https://hdl.handle.net/11299/215346 (accessed on 3 February 2023).
- Intel® MPI Library Developer Reference for Linux* OS. 26 August 2022. Available online: https://www.intel.com/content/www/us/en/content-details/740630/intel-mpi-library-developer-reference-for-linux-os.html (accessed on 3 February 2023).
- Karypis, G.; Kumar, V. Multilevelk-Way Partitioning Scheme for Irregular Graphs. J. Parallel Distrib. Comput. 1998, 48, 96–129. [Google Scholar] [CrossRef]
- Kan, W.; Li, Z.; Ding, S.; Liu, Y.; Yu, G. Progress on RMC: A Monte Carlo neutron transport code for reactor analysis. In Proceedings of the International Conference on Mathematics and Computational Methods Applied to Nuclear Science and Engineering, Rio de Janeiro, Brazil, 8–12 May 2011. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).