
On the Benefits of Using Metaheuristics in the Hyperparameter Tuning of Deep Learning Models for Energy Load Forecasting

 ,
,  ,
,  ,
,  , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. State of the Art
2.1.1. Overview of Recent Work in Energy Forecasting

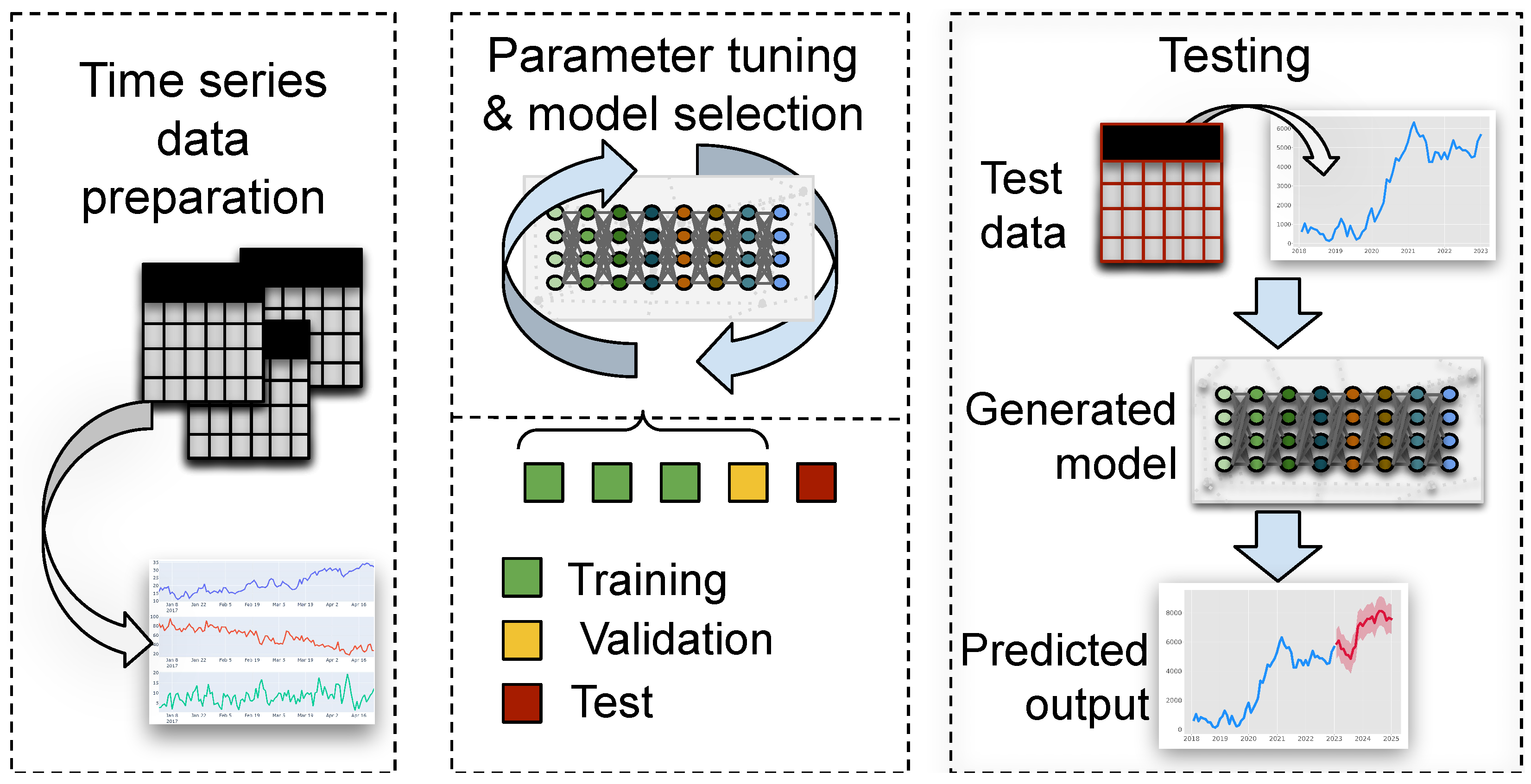{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference, Year | Method | Parameter Tuning | Metrics Used | Time Scale | Dataset |
|---|---|---|---|---|---|
| Aleksei Mashlakov et al. [13], 2021 | DeepAR, DeepTCN, LSTNet and DSANet | Grid and manually | ND, NRMSE | Hourly, from 2012 to 2014 | Electricity consumption, wind and solar power generation, Europe [14] |
| Tae-Young Kim and Sung-Bae Cho [15], 2019 | CNN-LSTM | Manually | MSE, RMSE, MAE, MAPE | 1 min units from December 2006 to November 2010, but used hourly | Individual household power consumption from Sceaux, France [16] |
| Nivethitha Somu et al. [17], 2020 | LSTM | Improved sine cosine optimization algorithm | MSE, RMSE, MAE, MAPE | 30 min interval, from January 2017 to October 2018 | KReSIT academic building energy consumption data |
| Hanjiang Dong et al. [18], 2023 | Transformer Seq2Seq Net, LSTM RNN, GRU RNN | Manually, random search | RMSE, MAE, MAPE | Hourly, from January 2019 to December 2019 | MFRED power consumption records of 390 apartments [19] |
| Dalil Hadjout et al. [20], 2022 | LSTM, GRU, TCN, ensembles | Grid and Manually | MAPE, MAE, RMSE | Monthly, from 2006 to 2019 | Electricity consumption of the economic sector for Algeria |
| Ruixin Lv et al. [21], 2022 | LSTM, GRU, Bi-LSTM, Bi-GRU | Optuna [12] | RMSE, MAE, MAPE, APE | 1 min units from 24 October 2021 to 30 January 2022, used in 15 min intervals | Heating load prediction for a train station building in Tibet |
| Mohamed Aymane Ahajjam et al. [22], 2022 | ResNet, Omni-Scale 1D-CNN, LSTM, InceptionTime | Manually | MAPE, RMSE, CV, FS | 30 min interval, from summer 2020 to late spring 2021 | Electricity consumption of 5 Moroccan households, MORED [23] |
| Ruobin Gao et al. [24], 2022 | edRVFL, LSTM | Bayesian optimization algorithm | RMSE, MASE | 30 min interval, from January, April, July, and October 2020 | Electricity load forecasting from the Australian Energy Market Operator |
| Majed A. Alotaibi [25], 2022 | LSTM | Manually | , MAR | Hourly, 200 randomly chosen readings | Load forecasting modeling power demand in Ontario, Canada |
| Mosbah Aouad [26], 2022 | CNN-Seq2Seq-Att, CNN-Seq2Seq, CNN-LSTM, DNN | Grid search | MSE, RMSE, MAE | 1 min units from 2006 to 2010, used by min, hour, day, week | Individual household power consumption from Sceaux, France [16] |
| Bibi Ibrahim et al. [27], 2022 | Bi-LSTM, GRU | Manually | , MSE, MAPE, MAE | Hourly, from January 2016 to October 2019 | Electricity demand from the National Dispatch Center of Panama |

2.1.2. Electrical Power Load Forecasting Advancements
2.2. Example Dataset
3. Baseline Methods Used within Experiments
3.1. Long Short-Term Memory
3.2. Metaheuristics
3.2.1. Genetic Algorithm
3.2.2. Particle Swarm Optimization
3.2.3. Artificial Bee Colony
3.2.4. Firefly Algorithm
3.2.5. Bat Algorithm
- All units utilize the echolocation to feel the distance, and they can also differentiate betwixt the target prey and surrounding structures.
- Even though the loudness can be varied in numerous ways, it is assumed that it differs, starting with a large (positive) to the minimal value of .
3.2.6. Sine Cosine Algorithm
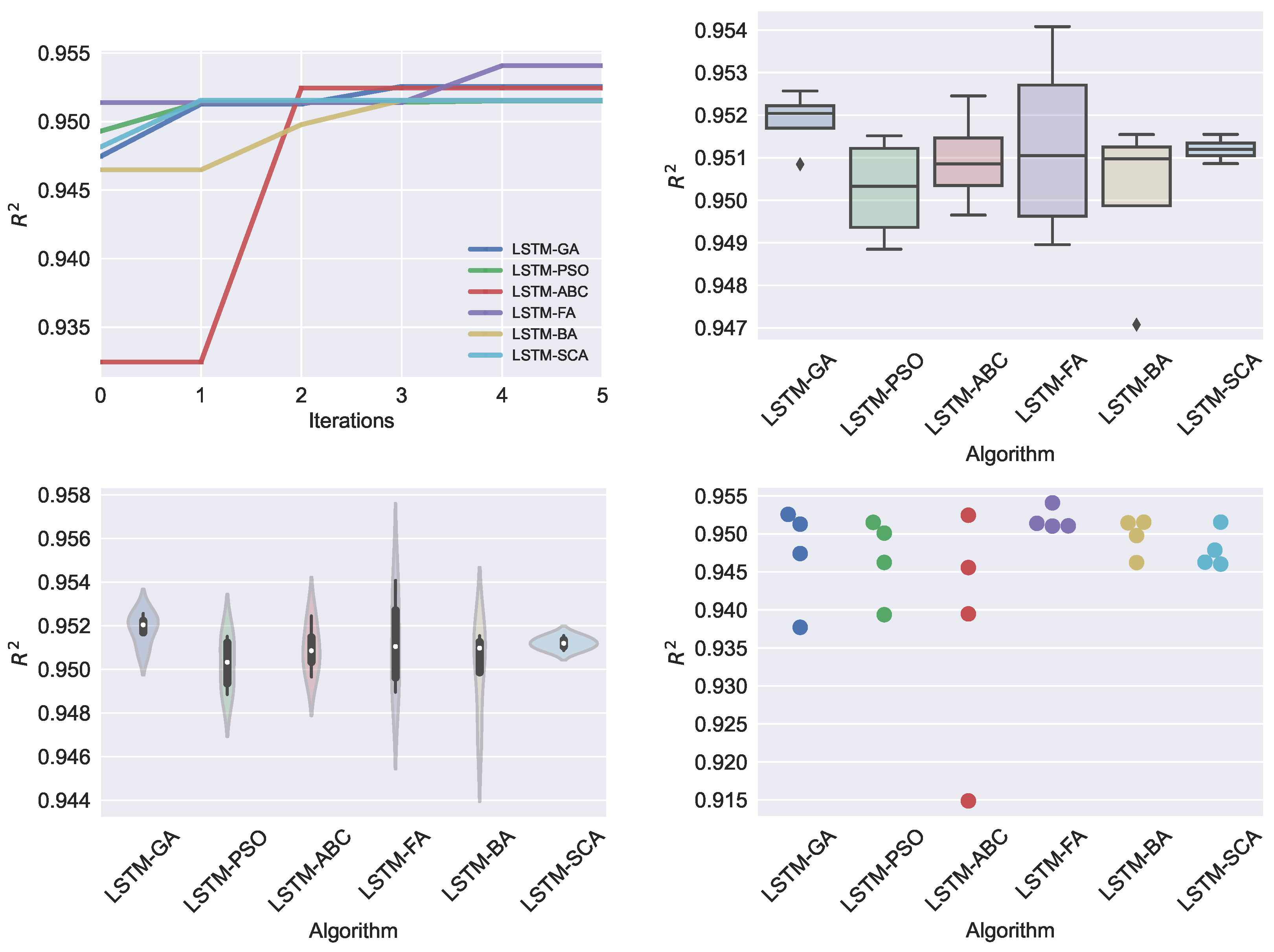
4. Results
- count of neurons ;
- learning rate ;
- training epochs’ count ;
- dropout .
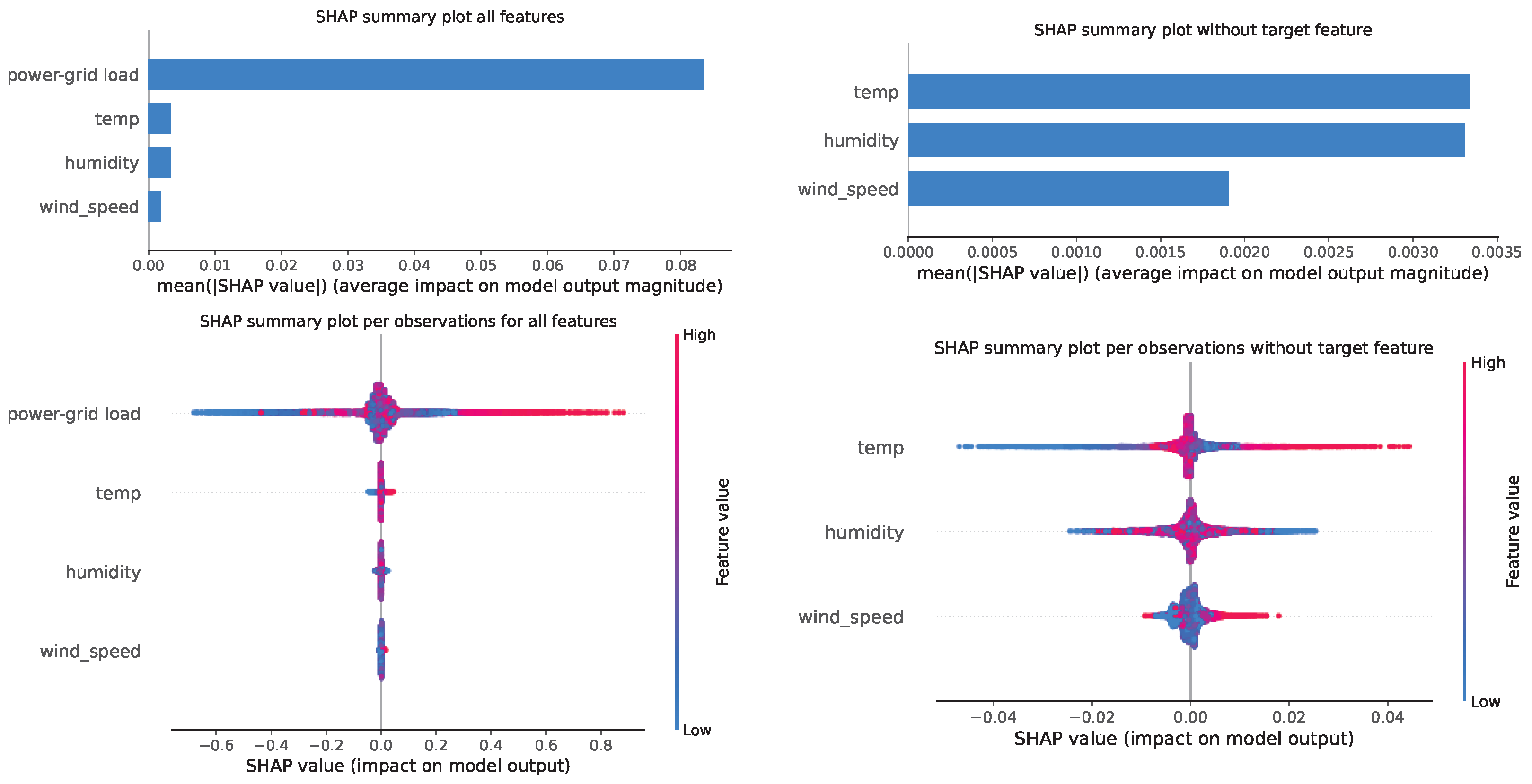
Best Model Interpretation Using Explainable AI
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSTM | Long short-term memory |
| CNN | Convolutional neural network |
| DL | Deep learning |
| ML | Machine learning |
| MSE | Mean squared error |
| RMSE | Root mean squared error |
| MAE | Mean absolute error |
| GA | Genetic algorithm |
| PSO | Particle swarm optimization |
| ABC | Artificial bee colony |
| FA | Firefly algorithm |
| BA | Bat algorithm |
| SCA | Sine cosine algorithm |
References
- World Population to Reach 8 Billion on 15 November 2022. Available online: https://www.un.org/en/desa/world-population-reach-8-billion-15-november-2022 (accessed on 15 November 2022).
- Shah, I.; Iftikhar, H.; Ali, S. Modeling and Forecasting Medium-Term Electricity Consumption Using Component Estimation Technique. Forecasting 2020, 2, 163–179. [Google Scholar] [CrossRef]
- Chinnaraji, R.; Ragupathy, P. Accurate electricity consumption prediction using enhanced long short-term memory. IET Commun. 2022, 16, 830–844. [Google Scholar] [CrossRef]
- Jaaz, Z.A.; Rusli, M.E.; Rahmat, N.A.; Khudhair, I.Y.; Al Barazanchi, I.; Mehdy, H.S. A Review on Energy-Efficient Smart Home Load Forecasting Techniques. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 233–240. [Google Scholar] [CrossRef]
- Reddy, S.; Akashdeep, S.; Harshvardhan, R.; Kamath, S. Stacking Deep learning and Machine learning models for short-term energy consumption forecasting. Adv. Eng. Inform. 2022, 52, 101542. [Google Scholar] [CrossRef]
- Salam, A.; El Hibaoui, A. Energy consumption prediction model with deep inception residual network inspiration and LSTM. Math. Comput. Simul. 2021, 190, 97–109. [Google Scholar] [CrossRef]
- Mahanta Barua, A.; Goswami, P. A Survey on Electric Power Consumption Prediction Techniques. Int. J. Eng. Res. Technol. 2020, 13, 2568. [Google Scholar] [CrossRef]
- Liang, Y.; Niu, D.; Hong, W.C. Short term load forecasting based on feature extraction and improved general regression neural network model. Energy 2019, 166, 653–663. [Google Scholar] [CrossRef]
- Xu, L.; Hou, L.; Zhu, Z.; Li, Y.; Liu, J.; Lei, T.; Wu, X. Mid-term prediction of electrical energy consumption for crude oil pipelines using a hybrid algorithm of support vector machine and genetic algorithm. Energy 2021, 222, 119955. [Google Scholar] [CrossRef]
- Gupta, A.; Chawla, M.; Tiwari, N. Electricity Power Consumption Forecasting Techniques: A Survey; SSRN: Rochester, NY, USA, 2022. [Google Scholar] [CrossRef]
- Torres, J.F.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep learning for time series forecasting: A survey. Big Data 2021, 9, 3–21. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Mashlakov, A.; Kuronen, T.; Lensu, L.; Kaarna, A.; Honkapuro, S. Assessing the performance of deep learning models for multivariate probabilistic energy forecasting. Appl. Energy 2021, 285, 116405. [Google Scholar] [CrossRef]
- Wiese, F.; Schlecht, I.; Bunke, W.D.; Gerbaulet, C.; Hirth, L.; Jahn, M.; Kunz, F.; Lorenz, C.; Mühlenpfordt, J.; Reimann, J.; et al. Open Power System Data—Frictionless data for electricity system modelling. Appl. Energy 2019, 236, 401–409. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Hebrail, G.; Berard, A. Individual Household Electric Power Consumption Data Set; UCI Machine Learning Repository: Irvine, CA, USA, 2012. [Google Scholar]
- Somu, N.; Raman, M.R.G.; Ramamritham, K. A hybrid model for building energy consumption forecasting using long short term memory networks. Appl. Energy 2020, 261, 114131. [Google Scholar] [CrossRef]
- Dong, H.; Zhu, J.; Li, S.; Wu, W.; Zhu, H.; Fan, J. Short-term residential household reactive power forecasting considering active power demand via deep Transformer sequence-to-sequence networks. Appl. Energy 2023, 329, 120281. [Google Scholar] [CrossRef]
- Meinrenken, C.J.; Rauschkolb, N.; Abrol, S.; Chakrabarty, T.; Decalf, V.C.; Hidey, C.; McKeown, K.; Mehmani, A.; Modi, V.; Culligan, P.J. MFRED, 10 s interval real and reactive power for groups of 390 US apartments of varying size and vintage. Sci. Data 2020, 7, 375. [Google Scholar] [CrossRef]
- Hadjout, D.; Torres, J.; Troncoso, A.; Sebaa, A.; Martínez-Álvarez, F. Electricity consumption forecasting based on ensemble deep learning with application to the Algerian market. Energy 2022, 243, 123060. [Google Scholar] [CrossRef]
- Lv, R.; Yuan, Z.; Lei, B.; Zheng, J.; Luo, X. Building thermal load prediction using deep learning method considering time-shifting correlation in feature variables. J. Build. Eng. 2022, 61, 105316. [Google Scholar] [CrossRef]
- Ahajjam, M.A.; Bonilla Licea, D.; Ghogho, M.; Kobbane, A. Experimental investigation of variational mode decomposition and deep learning for short-term multi-horizon residential electric load forecasting. Appl. Energy 2022, 326, 119963. [Google Scholar] [CrossRef]
- Ahajjam, M.A.; Bonilla Licea, D.; Essayeh, C.; Ghogho, M.; Kobbane, A. MORED: A Moroccan Buildings’ Electricity Consumption Dataset. Energies 2020, 13, 6737. [Google Scholar] [CrossRef]
- Gao, R.; Du, L.; Suganthan, P.N.; Zhou, Q.; Yuen, K.F. Random vector functional link neural network based ensemble deep learning for short-term load forecasting. Expert Syst. Appl. 2022, 206, 117784. [Google Scholar] [CrossRef]
- Alotaibi, M.A. Machine Learning Approach for Short-Term Load Forecasting Using Deep Neural Network. Energies 2022, 15, 6261. [Google Scholar] [CrossRef]
- Aouad, M.; Hajj, H.; Shaban, K.; Jabr, R.A.; El-Hajj, W. A CNN-Sequence-to-Sequence network with attention for residential short-term load forecasting. Electr. Power Syst. Res. 2022, 211, 108152. [Google Scholar] [CrossRef]
- Ibrahim, B.; Rabelo, L.; Gutierrez-Franco, E.; Clavijo-Buritica, N. Machine Learning for Short-Term Load Forecasting in Smart Grids. Energies 2022, 15, 8079. [Google Scholar] [CrossRef]
- Saha, B.; Ahmed, K.F.; Saha, S.; Islam, M.T. Short-Term Electrical Load Forecasting via Deep Learning Algorithms to Mitigate the Impact of COVID-19 Pandemic on Power Demand. In Proceedings of the 2021 International Conference on Automation, Control and Mechatronics for Industry 4.0 (ACMI), Rajshahi, Bangladesh, 8–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Ma, G.; Chen, X.; Shen, Q.; Yang, B. Electric load forecasting based on Long-Short-Term-Memory network via simplex optimizer during COVID-19. Energy Rep. 2022, 8, 1–12. [Google Scholar] [CrossRef]
- Tudose, A.M.; Picioroaga, I.I.; Sidea, D.O.; Bulac, C.; Boicea, V.A. Short-Term Load Forecasting Using Convolutional Neural Networks in COVID-19 Context: The Romanian Case Study. Energies 2021, 14, 4046. [Google Scholar] [CrossRef]
- Zhu, J.; Dong, H.; Zheng, W.; Li, S.; Huang, Y.; Xi, L. Review and prospect of data-driven techniques for load forecasting in integrated energy systems. Appl. Energy 2022, 321, 119269. [Google Scholar] [CrossRef]
- Hourly Energy Demand Generation and Weather. Available online: https://www.kaggle.com/datasets/nicholasjhana/energy-consumption-generation-prices-and-weather (accessed on 21 November 2022).
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Stoean, C.; Paja, W.; Stoean, R.; Sandita, A. Deep architectures for long-term stock price prediction with a heuristic-based strategy for trading simulations. PLoS ONE 2019, 14, e0223593. [Google Scholar] [CrossRef]
- Bukhari, A.H.; Raja, M.A.Z.; Sulaiman, M.; Islam, S.; Shoaib, M.; Kumam, P. Fractional neuro-sequential ARFIMA-LSTM for financial market forecasting. IEEE Access 2020, 8, 71326–71338. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Stoean, C.; Stoean, R.; Atencia, M.; Abdar, M.; Velázquez-Pérez, L.; Khosravi, A.; Nahavandi, S.; Acharya, U.R.; Joya, G. Automated Detection of Presymptomatic Conditions in Spinocerebellar Ataxia Type 2 Using Monte Carlo Dropout and Deep Neural Network Techniques with Electrooculogram Signals. Sensors 2020, 20, 3032. [Google Scholar] [CrossRef]
- Stoean, R.; Stoean, C.; Atencia, M.; Rodríguez-Labrada, R.; Joya, G. Ranking Information Extracted from Uncertainty Quantification of the Prediction of a Deep Learning Model on Medical Time Series Data. Mathematics 2020, 8, 1078. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef] [PubMed]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, M.; Bacanin, N.; Venkatachalam, K.; Nayyar, A.; Djordjevic, A.; Strumberger, I.; Al-Turjman, F. COVID-19 cases prediction by using hybrid machine learning and beetle antennae search approach. Sustain. Cities Soc. 2021, 66, 102669. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, M.; Venkatachalam, K.; Bacanin, N.; Djordjevic, A.; Antonijevic, M.; Strumberger, I.; Rashid, T.A. Hybrid Genetic Algorithm and Machine Learning Method for COVID-19 Cases Prediction. In Proceedings of the International Conference on Sustainable Expert Systems: ICSES 2020; Springer Nature: Berlin/Heidelberg, Germany, 2021; Volume 176, p. 169. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M.; Zivkovic, M. Task scheduling in cloud computing environment by grey wolf optimizer. In Proceedings of the 2019 27th Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2019; pp. 1–4. [Google Scholar]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Multi-objective Task Scheduling in Cloud Computing Environment by Hybridized Bat Algorithm. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 21–23 July 2020; pp. 718–725. [Google Scholar]
- Bezdan, T.; Zivkovic, M.; Antonijevic, M.; Zivkovic, T.; Bacanin, N. Enhanced Flower Pollination Algorithm for Task Scheduling in Cloud Computing Environment. In Machine Learning for Predictive Analysis; Springer: Berlin/Heidelberg, Germany, 2020; pp. 163–171. [Google Scholar]
- Zivkovic, M.; Bezdan, T.; Strumberger, I.; Bacanin, N.; Venkatachalam, K. Improved Harris Hawks Optimization Algorithm for Workflow Scheduling Challenge in Cloud–Edge Environment. In Computer Networks, Big Data and IoT; Springer: Berlin/Heidelberg, Germany, 2021; pp. 87–102. [Google Scholar]
- Zivkovic, M.; Bacanin, N.; Tuba, E.; Strumberger, I.; Bezdan, T.; Tuba, M. Wireless Sensor Networks Life Time Optimization Based on the Improved Firefly Algorithm. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1176–1181. [Google Scholar]
- Zivkovic, M.; Bacanin, N.; Zivkovic, T.; Strumberger, I.; Tuba, E.; Tuba, M. Enhanced Grey Wolf Algorithm for Energy Efficient Wireless Sensor Networks. In Proceedings of the 2020 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2020; pp. 87–92. [Google Scholar]
- Bacanin, N.; Tuba, E.; Zivkovic, M.; Strumberger, I.; Tuba, M. Whale Optimization Algorithm with Exploratory Move for Wireless Sensor Networks Localization. In Proceedings of the International Conference on Hybrid Intelligent Systems, Bhopal, India, 10–12 December 2019; pp. 328–338. [Google Scholar]
- Zivkovic, M.; Zivkovic, T.; Venkatachalam, K.; Bacanin, N. Enhanced Dragonfly Algorithm Adapted for Wireless Sensor Network Lifetime Optimization. In Data Intelligence and Cognitive Informatics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 803–817. [Google Scholar]
- Bezdan, T.; Cvetnic, D.; Gajic, L.; Zivkovic, M.; Strumberger, I.; Bacanin, N. Feature Selection by Firefly Algorithm with Improved Initialization Strategy. In Proceedings of the 7th Conference on the Engineering of Computer Based Systems, Novi Sad, Serbia, 26–27 May 2021; pp. 1–8. [Google Scholar]
- Stoean, C. In Search of the Optimal Set of Indicators when Classifying Histopathological Images. In Proceedings of the 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 24–27 September 2016; pp. 449–455. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Zamani, H.; Mirjalili, S. Enhanced whale optimization algorithm for medical feature selection: A COVID-19 case study. Comput. Biol. Med. 2022, 148, 105858. [Google Scholar] [CrossRef] [PubMed]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Glioma Brain Tumor Grade Classification from MRI Using Convolutional Neural Networks Designed by Modified FA. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 21–23 July 2020; pp. 955–963. [Google Scholar]
- Postavaru, S.; Stoean, R.; Stoean, C.; Caparros, G.J. Adaptation of Deep Convolutional Neural Networks for Cancer Grading from Histopathological Images. In Proceedings of the Advances in Computational Intelligence, Cadiz, Spain, 14–16 June 2017; Rojas, I., Joya, G., Catala, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 38–49. [Google Scholar]
- Zivkovic, M.; Bacanin, N.; Antonijevic, M.; Nikolic, B.; Kvascev, G.; Marjanovic, M.; Savanovic, N. Hybrid CNN and XGBoost Model Tuned by Modified Arithmetic Optimization Algorithm for COVID-19 Early Diagnostics from X-ray Images. Electronics 2022, 11, 3798. [Google Scholar] [CrossRef]
- Strumberger, I.; Tuba, E.; Zivkovic, M.; Bacanin, N.; Beko, M.; Tuba, M. Dynamic search tree growth algorithm for global optimization. In Proceedings of the Doctoral Conference on Computing, Electrical and Industrial Systems, Costa de Caparica, Portugal, 8–10 May 2019; pp. 143–153. [Google Scholar]
- Preuss, M.; Stoean, C.; Stoean, R. Niching Foundations: Basin Identification on Fixed-Property Generated Landscapes. In Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, GECCO’11, Dublin, Ireland, 12–16 July 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 837–844. [Google Scholar] [CrossRef]
- Jovanovic, D.; Antonijevic, M.; Stankovic, M.; Zivkovic, M.; Tanaskovic, M.; Bacanin, N. Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection. Mathematics 2022, 10, 2272. [Google Scholar] [CrossRef]
- Petrovic, A.; Bacanin, N.; Zivkovic, M.; Marjanovic, M.; Antonijevic, M.; Strumberger, I. The AdaBoost Approach Tuned by Firefly Metaheuristics for Fraud Detection. In Proceedings of the 2022 IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 17–19 June 2022; pp. 834–839. [Google Scholar]
- Bacanin, N.; Sarac, M.; Budimirovic, N.; Zivkovic, M.; AlZubi, A.A.; Bashir, A.K. Smart wireless health care system using graph LSTM pollution prediction and dragonfly node localization. Sustain. Comput. Inform. Syst. 2022, 35, 100711. [Google Scholar] [CrossRef]
- Bacanin, N.; Zivkovic, M.; Stoean, C.; Antonijevic, M.; Janicijevic, S.; Sarac, M.; Strumberger, I. Application of Natural Language Processing and Machine Learning Boosted with Swarm Intelligence for Spam Email Filtering. Mathematics 2022, 10, 4173. [Google Scholar] [CrossRef]
- Stankovic, M.; Antonijevic, M.; Bacanin, N.; Zivkovic, M.; Tanaskovic, M.; Jovanovic, D. Feature Selection by Hybrid Artificial Bee Colony Algorithm for Intrusion Detection. In Proceedings of the 2022 International Conference on Edge Computing and Applications (ICECAA), Coimbatore, India, 21–23 September 2022; pp. 500–505. [Google Scholar]
- Milosevic, S.; Bezdan, T.; Zivkovic, M.; Bacanin, N.; Strumberger, I.; Tuba, M. Feed-Forward Neural Network Training by Hybrid Bat Algorithm. In Proceedings of the Modelling and Development of Intelligent Systems: 7th International Conference, MDIS 2020, Sibiu, Romania, 22–24 October 2020; Revised Selected Papers 7. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 52–66. [Google Scholar]
- Gajic, L.; Cvetnic, D.; Zivkovic, M.; Bezdan, T.; Bacanin, N.; Milosevic, S. Multi-layer Perceptron Training Using Hybridized Bat Algorithm. In Computational Vision and Bio-Inspired Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 689–705. [Google Scholar]
- Bacanin, N.; Stoean, C.; Zivkovic, M.; Jovanovic, D.; Antonijevic, M.; Mladenovic, D. Multi-Swarm Algorithm for Extreme Learning Machine Optimization. Sensors 2022, 22, 4204. [Google Scholar] [CrossRef]
- Jovanovic, L.; Jovanovic, D.; Bacanin, N.; Jovancai Stakic, A.; Antonijevic, M.; Magd, H.; Thirumalaisamy, R.; Zivkovic, M. Multi-Step Crude Oil Price Prediction Based on LSTM Approach Tuned by Salp Swarm Algorithm with Disputation Operator. Sustainability 2022, 14, 14616. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–55. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Yang, X.S.; Slowik, A. Firefly algorithm. In Swarm Intelligence Algorithms; CRC Press: Boca Raton, FL, USA, 2020; pp. 163–174. [Google Scholar]
- Yang, X.S. A new metaheuristic bat-inspired algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for Solving Optimization Problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]






| Method | Best | Worst | Mean | Median | Std | Var |
|---|---|---|---|---|---|---|
| LSTM-GA | 0.002254 | 0.002336 | 0.002287 | 0.002279 | 3.01 × 10 | 9.05 × 10 |
| LSTM-PSO | 0.002304 | 0.002431 | 0.002364 | 0.002360 | 5.23 × 10 | 2.73 × 10 |
| LSTM-ABC | 0.002259 | 0.002392 | 0.002331 | 0.002335 | 4.82 × 10 | 2.32 × 10 |
| LSTM-FA | 0.002182 | 0.002426 | 0.002315 | 0.002326 | 9.57 × 10 | 9.16 × 10 |
| LSTM-BA | 0.002302 | 0.002515 | 0.002369 | 0.002329 | 8.51 × 10 | 7.24 × 10 |
| LSTM-SCA | 0.002302 | 0.002335 | 0.002319 | 0.002319 | 1.19 × 10 | 1.42 × 10 |
| Method | MAE | MSE | RMSE | |
|---|---|---|---|---|
| LSTM-GA | 0.952567 | 0.036396 | 0.002254 | 0.047475 |
| LSTM-PSO | 0.951516 | 0.036617 | 0.002304 | 0.047998 |
| LSTM-ABC | 0.952452 | 0.036990 | 0.002259 | 0.047533 |
| LSTM-FA | 0.954082 | 0.036149 | 0.002182 | 0.046711 |
| LSTM-BA | 0.951545 | 0.036855 | 0.002302 | 0.047984 |
| LSTM-SCA | 0.951550 | 0.036639 | 0.002302 | 0.047982 |
| Method | MAE | MSE | RMSE | |
|---|---|---|---|---|
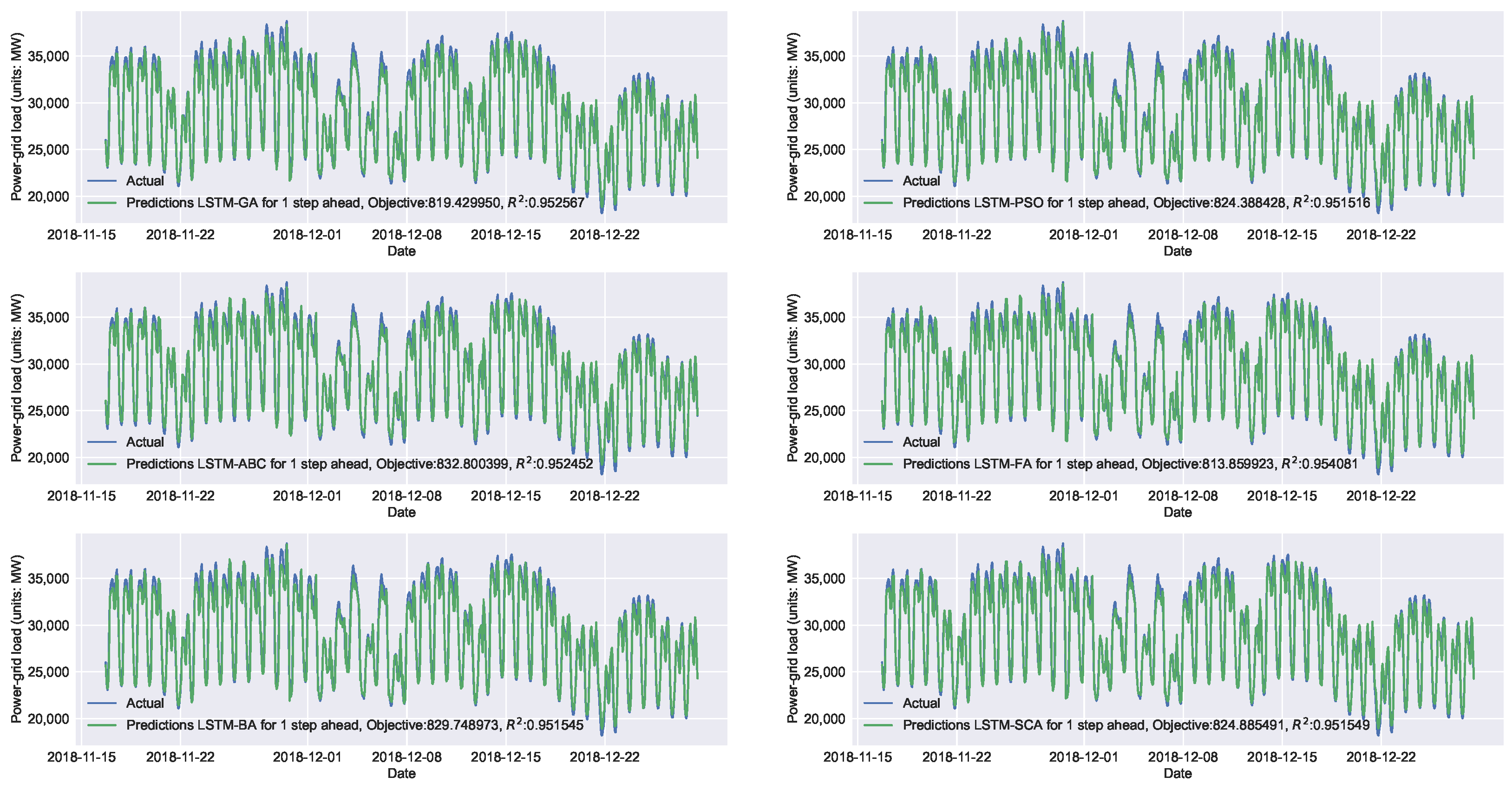
| LSTM-GA | 0.952567 | 819.429950 | 1,142,449.879411 | 1068.854471 |
| LSTM-PSO | 0.951516 | 824.388429 | 1,167,766.517877 | 1080.632462 |
| LSTM-ABC | 0.952452 | 832.800399 | 1,145,217.749855 | 1070.148471 |
| LSTM-FA | 0.954082 | 813.859923 | 1,105,974.502970 | 1051.653224 |
| LSTM-BA | 0.951545 | 829.748974 | 1,167,073.215332 | 1080.311629 |
| LSTM-SCA | 0.951550 | 824.885492 | 1,166,963.126895 | 1080.260675 |
| Method | Neurons | Learning Rate | Epochs | Dropout |
|---|---|---|---|---|
| LSTM-GA | 163.000000 | 0.010000 | 464.000000 | 0.004250 |
| LSTM-PSO | 171.000000 | 0.010000 | 390.000000 | 0.010000 |
| LSTM-ABC | 114.000000 | 0.007583 | 484.000000 | 0.001305 |
| LSTM-FA | 200.000000 | 0.010000 | 496.431039 | 0.002726 |
| LSTM-BA | 100.000000 | 0.010000 | 434.000000 | 0.010000 |
| LSTM-SCA | 151.000000 | 0.004171 | 438.000000 | 0.006704 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bacanin, N.; Stoean, C.; Zivkovic, M.; Rakic, M.; Strulak-Wójcikiewicz, R.; Stoean, R. On the Benefits of Using Metaheuristics in the Hyperparameter Tuning of Deep Learning Models for Energy Load Forecasting. Energies 2023, 16, 1434. https://doi.org/10.3390/en16031434
Bacanin N, Stoean C, Zivkovic M, Rakic M, Strulak-Wójcikiewicz R, Stoean R. On the Benefits of Using Metaheuristics in the Hyperparameter Tuning of Deep Learning Models for Energy Load Forecasting. Energies. 2023; 16(3):1434. https://doi.org/10.3390/en16031434
Chicago/Turabian StyleBacanin, Nebojsa, Catalin Stoean, Miodrag Zivkovic, Miomir Rakic, Roma Strulak-Wójcikiewicz, and Ruxandra Stoean. 2023. "On the Benefits of Using Metaheuristics in the Hyperparameter Tuning of Deep Learning Models for Energy Load Forecasting" Energies 16, no. 3: 1434. https://doi.org/10.3390/en16031434
APA StyleBacanin, N., Stoean, C., Zivkovic, M., Rakic, M., Strulak-Wójcikiewicz, R., & Stoean, R. (2023). On the Benefits of Using Metaheuristics in the Hyperparameter Tuning of Deep Learning Models for Energy Load Forecasting. Energies, 16(3), 1434. https://doi.org/10.3390/en16031434