1. Introduction
Energy management serves as a bridge between demand and supply by entailing the systematic control and optimization of energy resources, encompassing their generation, distribution, and consumption. It provides a balance between sustainable, eco-friendly options and the efficient, responsible utilization of finite resources. This practice has broad applicability across various domains, from industrial operations to individual households. Effective energy management aims to achieve a state of equilibrium, where energy is harnessed efficiently while minimizing adverse environmental impacts. This approach results in reduced greenhouse gas emissions, heightened energy security, and decreased operational costs.
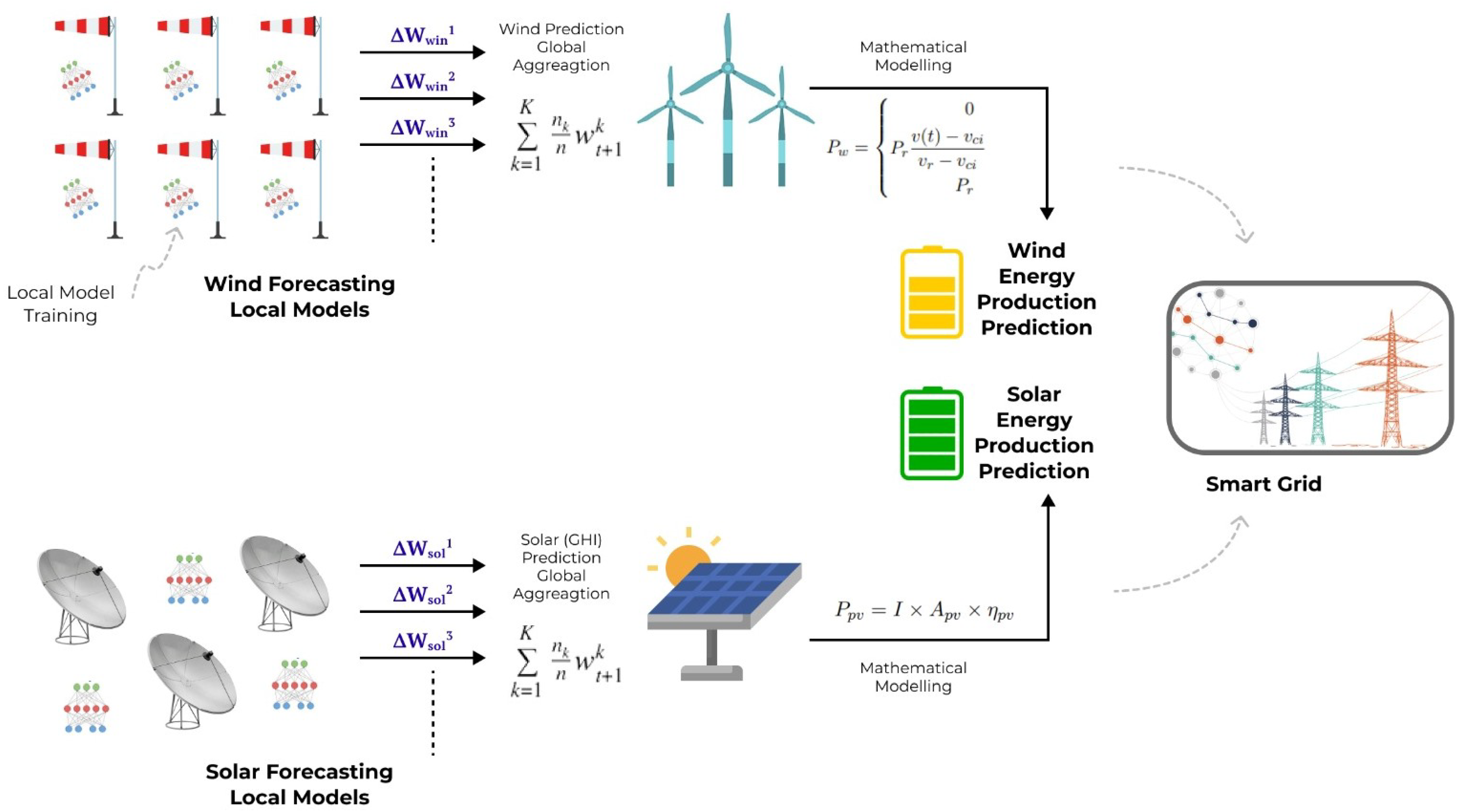
The smart grid is an advanced electrical system [
1] that plays a crucial role in efficient management of energy demand and supply. It leverages digital technology, including smart meters, IoT devices, distributed energy resources, and data analytics. The smart grid facilitates real-time communication and control, integrates renewable sources, optimizes energy usage between renewable and non-renewable resources, and enhances grid reliability, as depicted in
Figure 1.
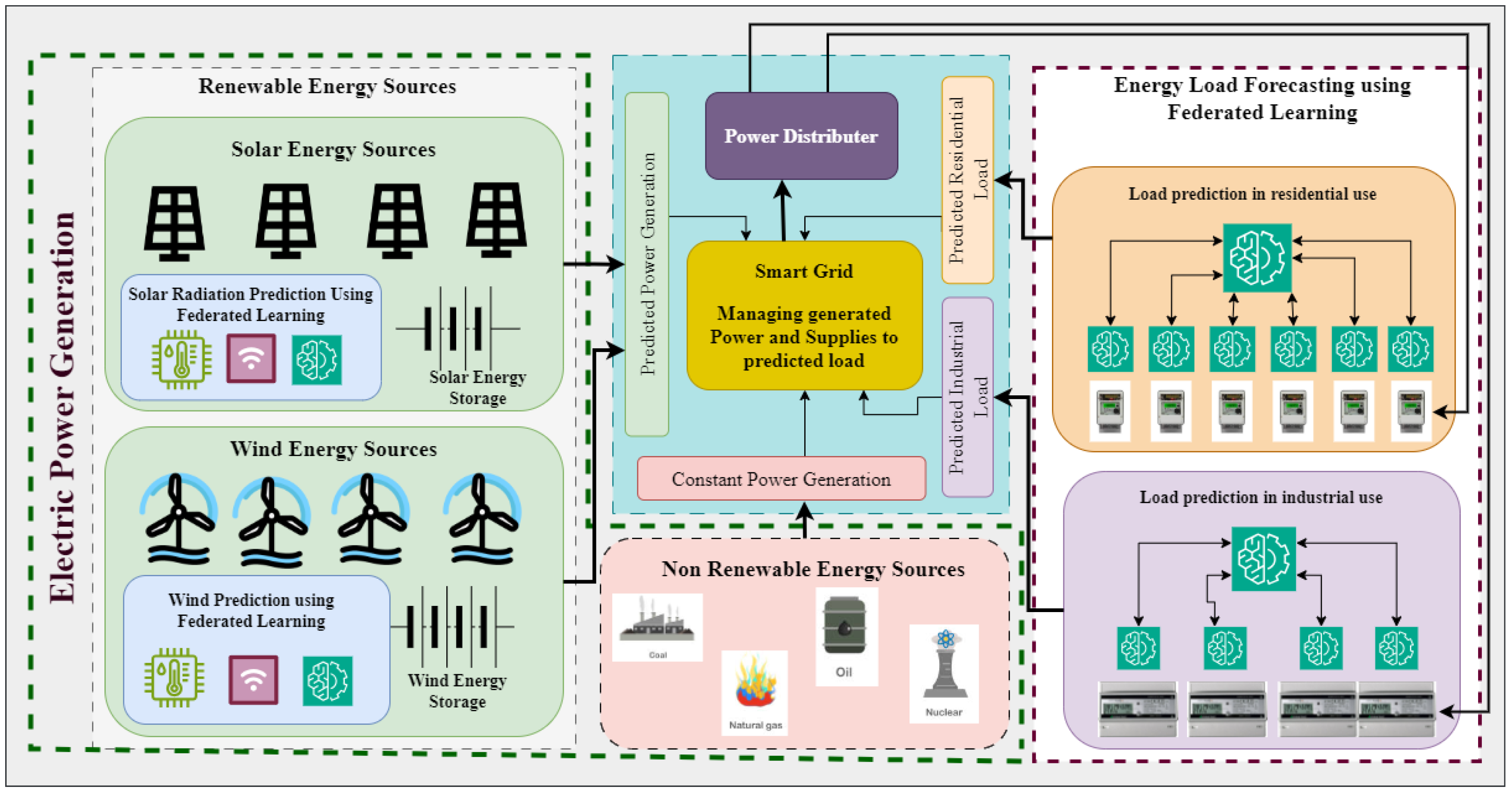
Electrical energy generation employs various energy resources, primarily categorized into renewable energy resources (RER) and non-renewable energy resources (NRERs). Renewable energy resources encompass solar energy (photovoltaic (PV)), wind energy (via windmills), and hydroelectric power. These energy sources harness natural elements such as sunlight, wind, and water bodies to generate electrical energy indefinitely. The exceptional capabilities of renewable resources make them essential for a sustainable and eco-friendly future. The energy generation from RERs is highly variable, and is primarily dependent on weather conditions such as sunlight, rain, clouds, wind speed, temperature, and storms. For instance, energy generated through photovoltaic (PV) panels (solar energy) relies heavily on the amount of solar radiation reaching the panels, with solar radiation playing a pivotal role in their efficiency. Any weather changes, such as cloud cover, can reduce power generation in solar panels. Similarly, power generation from windmills depends on wind energy, with speed and wind direction significantly influencing energy production.
In contrast, non-renewable energy resources include fossil fuels such as coal, oil, and natural gas, which are widely used for electricity generation. The statistics [
3] corresponding to the energy share indicate that non-renewable resources have a significant share in electricity production compared with renewable energy sources. However, NRERs are finite and unsustainable, with detrimental impacts on ecosystems. Power generation from non-renewable sources is constant and can be easily estimated using deterministic approaches.
For the efficient and secure management of electrical energy, the smart grid plays a vital role, where the supply of electricity is carried out based on demands, including commercial and residential needs. However, a key aspect in smart grid electricity management is predicting energy demands or forecasting the load on the smart grid to ensure sufficient supply at specific times. Predictive analysis has now become an essential paradigm in the smart grid. The cutting edge technology of machine learning (ML) has significantly simplified the task associated with load prediction and energy generation by using historical data. Additionally, the prediction of upcoming weather conditions also holds a crucial place in generating electrical energy through RERs. Accurate weather prediction enables the system to efficiently forecast energy generation through RERs.
In traditional ML, predictive analysis for load forecasting is performed by collecting energy consumption data from various smart meters to the central server, which become highly sensitive and critical when shared with other entities, for further processing [
4]. The shared data at the central server are prone to access and being misutilized, as they can be analyzed to obtain sensitive informations. User consumption patterns can provide information about personal habits, behaviors, and even personally identifiable information. For example, discerning a usage pattern in a house may reveal the user’s movements, such as minimal or zero consumption, indicating the absence of residents. Therefore, sharing consumption data for analysis and other predictive tasks raises privacy concerns that can significantly affect the entities associated with the data. Similarly, if a weather station is installed near the power generation setup, sharing IoT collected data for weather prediction can also pose privacy issues, as it may reveal the exact location and information associated with energy generation by the power generation setup. Disclosure of the power setup location and corresponding future energy generation prediction is very detrimental, as attackers may use such information for harmful activities to disturb the smart grid and consequently take down the entire energy system. Thus, it is very necessary to address all of the privacy concerns of data, for which some advanced technology is required.
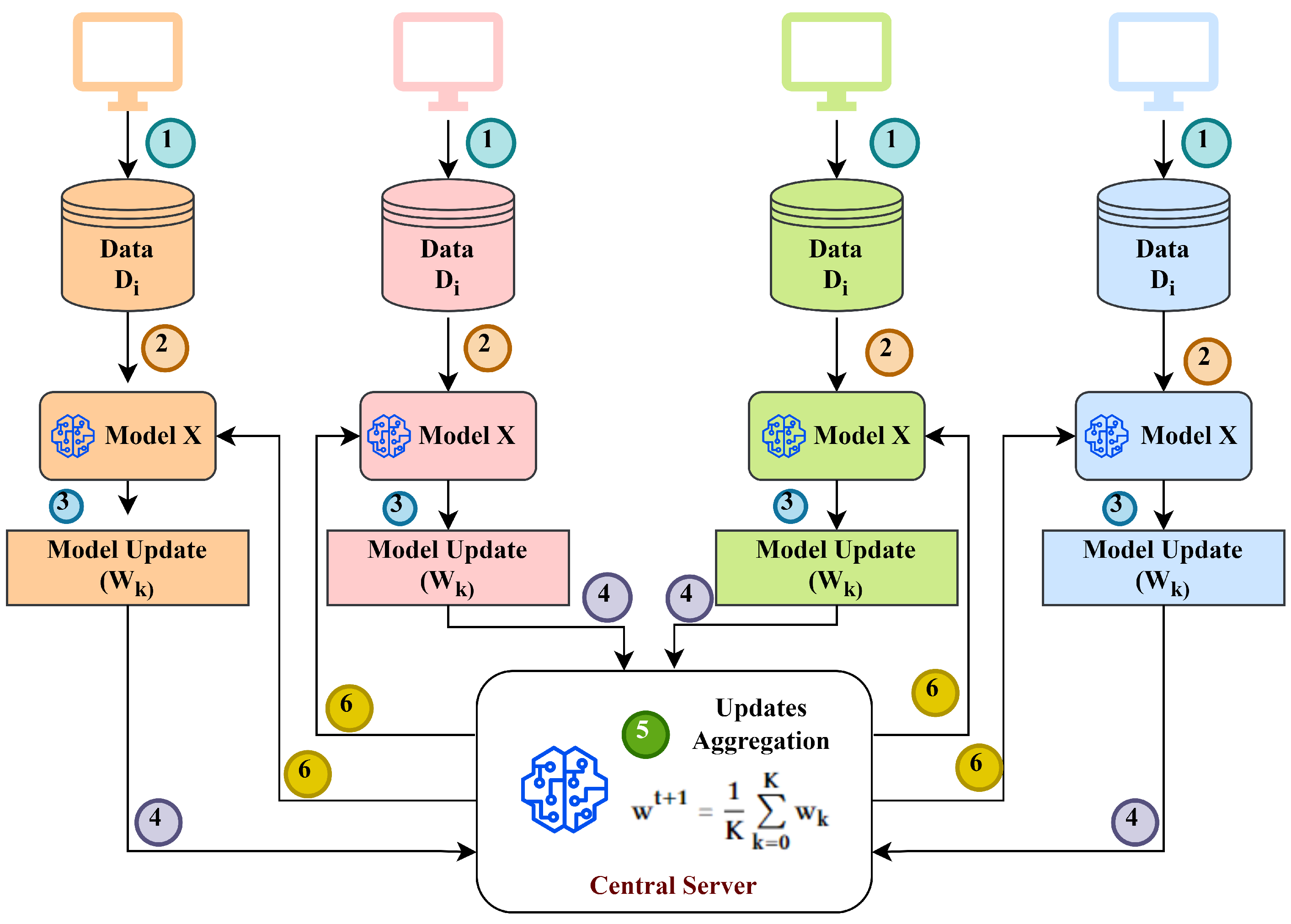
The recent development of machine learning has introduced the concept of federated learning (FL), which performs predictive analysis in a privacy-preserving manner by limiting access to the data of the clients. FL is an innovative ML approach that focuses on data privacy and decentralized model training [
5,
6]. Unlike the centralized ML approach, which compels users or devices to share sensitive data with the central server for model training, FL trains the ML model without sharing user or device data with the central server. It only shares the model updates of the local model with the centrally integrated global model, where the aggregation of all model parameters takes place.
Figure 2 represents the architecture of FL, containing multiple clients, where a local model is installed at every client and is trained with the client’s private data. After local training, the local model updates of all locally trained models are shared with the central server for the aggregation process. After aggregating all of the model updates, it is sent back to all the clients, where clients update their models with the received aggregated model updates. In this way, all the clients are trained with data from every client, without sharing any client data with the central server. This approach ensures that sensitive information remains with the clients, while the model continuously improves with each local update. Predictions related to electric load, weather forecasting, and all other associated predictive tasks can be accomplished through FL without sharing data with any external entity.
In the context of the evolving energy landscape, it is evident that RERs are witnessing substantial development and increasing dependence. However, RERs are inherently contingent upon varying weather conditions, and their ability to generate sufficient power is not consistently reliable. Conversely, a sole reliance on NRERs will inevitably deplete these finite resources over time and its exploitation is not suitable for the environment. Hence, it is essential to ensure fair and-equitable use of resources by considering the dynamic nature of electric load, optimizing the use of resource, fostering eco-friendly orientation, and implementing secure methodologies.
The work proposes a secure federated smart grid (FedGrid) framework that provides an architecture for the smart management of electrical energy in a smart grid by assuring the privacy of the sensitive data used in it. The proposed framework consists of machine-learning models for energy consumption and energy generation prediction, which collectively provides the ability to utilize renewable and non-renewable energy resources efficiently to fulfil residential and industrial energy demands. All such ML models work in a privacy-preserving manner by employing the approach of federated learning, which limits access to consumption and power generation prediction data. The state of the art reveals that none of the work conducted so far has provided a full-fledged framework with comparable capabilities to the proposed FedGrid framework. The ML models in the framework predict the residential and industrial energy consumption, along with solar and wind forecasting individually. The above models in the proposed framework collectively provide the benefit of long and short-term load management, as they inculcate the prior prediction of renewable energy generation and consumption load. Additionally, the energy supply can be optimized for demand in both peak and non-peak hours for both renewable and non-renewable energy sources. By employing these methods, the framework is poised to revolutionize energy management in the smart grid, fostering greater efficiency and sustainability in the face of the ever-evolving energy landscape.
In the remaining sections of the paper,
Section 2 discusses previous research works conducted in the context of energy load forecasting, energy management, renewable energy prediction, and security approaches considered for the smart grid.
Section 3 provides brief overview of the proposed FedGrid framework by discussing its components.
Section 4 presents the methodology and experimental procedures undertaken within the framework, shedding light on the proposed approach.
Section 5 analyzes and discusses the results obtained in the performed experiments. Finally, in
Section 6, we concluded this work by delivering a comprehensive conclusion. Here, we not only summarize our findings, but also delineate various promising avenues for future research in this domain.
2. Literature Review
The proposed work provides a framework for the sustainability of the entire energy infrastructure, comprising important components such as the smart grid for the management of energy demand and supply, energy consumption load forecasting, and the prediction of renewable energy generation. The current phase of framework mainly deals with the predictive models for consumption and energy generation by employing privacy-preserving machine learning for model training, so that the privacy and security of the user data could be maintained. The authors in research work [
7] were the first to initialize federated learning in the load prediction of household consumption using the data of 200 households located in Texas, USA. The data exhibited a heterogeneous nature in consumption patterns, along with a large amount of information. Hence, the work analyzed the effect of data volume and diversity among the participating clients in the training process. The work confirmed the potential of federated learning to address the challenge of privacy and data diversity in the smart-grid domain. Furthermore, authors in [
8] provided a load forecasting model utilizing the long short-term memory (LSTM) network within a federated learning framework. The efficacy of LSTM networks in time-series-based load forecasting is highlighted due to their commendable performance. However, an underlying concern arises during the practical implementation of federated learning, specifically when smart energy meters are employed as clients in the learning process. These meters, despite providing valuable data for model training, may encounter computational limitations while executing complex models like the LSTM network or its alternatives, potentially impeding their effective contribution within federated learning, raising concern regarding the adaptability of the proposed framework in the existing infrastructure setup. On the other hand, the work also considered a dynamic setting, where certain clients joined the federation post-training and utilized the pre-trained model for forecasting. In this way the computationally constrained devices may get some relaxation in the training phase. On the similar path, authors in [
9] utilizes CNN-Attention-LSTM model, leveraging the federated learning methodology with the aim to optimize predictive accuracy within integrated energy systems. Furthermore, authors also implemented various federated learning algorithms, including FedAvg, FedAdagrad, FedYogi, and FedAdam, in their investigation. Their study elucidated the substantial contribution of federated learning in predictive analysis, showcasing the comparative significance of FedAdagrad in load forecasting scenarios.
Federated learning provides privacy during model training in the distributed environment, but it is still being explored for its feasibility and applicability in the existing infrastructure. While traditional machine learning does not require any training-related computation in the client device, in federated learning, the models are trained on the actual client device. As the geographically distributed clients are heterogeneous in nature, this raises the concern of statistical and system heterogeneity. Hence, for the interoperability of the proposed framework within existing systems, it is necessary that clients should use devices with good computational capabilities built in so that the current system can be integrated. Keeping these aspects in consideration, the work [
10] proposes FedForecast framework, which performs federated-learning-based individual load forecasting by ensuring privacy and utilizing edge computing resources. The authors utilized the PecanStreet dataset for training the edge devices while addressing the issue of system heterogeneity.
In spite of preserving the privacy by transferring the model updates instead of data, federated learning is also prone to be attacked and compromised, as attacker might steal the information from the model updates raising the concern of security. In this regard, various strategies have been proposed to secure the model updates while transmission. The author in [
11] proposed FL based short term load forecasting (SLTF) by employing differential privacy and secure aggregation to provide additional security to entire federated learning setup. The authors conducted an analysis of different neural network (NN) architectures and evaluated various scenarios using real-world historical data to assess the performance and privacy implications of FL for STLF. Similarly, authors in [
12] introduced a novel framework to enhance the robustness of federated short-term load forecasting and protect against Byzantine threats. The framework’s core concept involves gradient quantization using the Sign Stochastic Gradient Descent (SignSGD) algorithm. The work provides experimental results, which involve benchmark neural networks and a range of Byzantine attack models. Thus it concludes by highlighting the effectiveness of the proposed approach and demonstrates significant improvements in mitigating Byzantine threats compared to traditional FedSGD models. Furthermore, authors in [
13] developed Differential Privacy-enhanced Federated Learning (DPEFL) for the development of LSTM load forecasting models using data distributed across multiple consumer households. The effectiveness of the DPEFL approach was evaluated through simulations conducted using real-world household data from the Pecan Street dataset, which contains data from households in Texas, USA. The results of these simulations demonstrate that DPEFL is capable of producing high-performance load forecasting models while simultaneously offering various levels of privacy protection.
The proposed framework comprises ML models for renewable energy generation making RER vital for energy generation in smart grid. The generation of energy from these resources are totally dependent on the weather condition. Hence the efficient model to predict the upcoming weather condition is very important. Authors in [
14] proposed a novel federated BayesLSTM-NN forecasting scheme for probabilistic multihorizon solar irradiation forecasting. The method focused on forecasting RERs within the context of integrated electrical grids. Furthermore the authors in [
15] determined an appropriate sizing for a Hybrid Renewable Energy System (HRES) to meet the power demands of a data center. HRES includes wind and solar energy production, along with battery and hydrogen energy storage. It provides a comparative analysis that compares four different forecasting models for solar radiation and wind speed generation putting focusing on SARIMA Model that demonstrates the model effectiveness in solar radiation forecasting over the years, particularly due to its seasonal distribution fit.
4. Methods and Experiment Details
The proposed FedGrid framework manages demand and supply in data driven approach by training ML models for electric load forecasting and prediction of weather for renewable energy generation. The experiment is performed to evalute the performance of these models for their effective contribution in the proposed framework. The experiment was conducted in 02 parts i.e., experiment for load forecasting and experiment for predicting the generation of energy from renewable energy sources. The trained models are evaluated with the performance metric Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE). In the proposed framework it is required that, the models not only showcase strong predictive performance but also address the unique challenges of federated learning in smart grids, ensuring privacy, scalability, adaptability, reliability, and overall positive impacts on energy management and sustainability.
4.1. Electric Load Forecasting
The electric load forecasting is performed for residential load as well as commercial loads using federated learning approach. For the residential load prediction experiment (referred as experiment 1), the dataset was sourced from scientific data 2017 [
17] which was collected from the residential houses of United Kingdom, comprising 8760 h of data from 20 residential buildings at 60-min intervals. After preprocessing the entire dataset, total 19 clients were initially selected for local model training using their private consumption data and data corresponding to 01 residential building is used to test the prediction of the model. The timestampand the energy consumption is taken as parameter for the experiment. At each client, the Long Short Term Memory (LSTM) model was employed, which was trained with the dataset for future predictions. The detailed information about LSTM model is discussed in later
Section 4.1.1. These clients trained their local models with the data and subsequently sent their model updates to the global server for aggregation, where FedAvg algorithm is used to aggregate these model updates. The aggregation of model in FL is very important aspect. The detailed discussion about FedAvg algorithm is provided in later
Section 4.1.2. Similarly, for commercial load forecasting (referred as experiment 2), the dataset was obtained from Mendeley Data [
18] which was collected from the commercial buildings of New Jersey, US, containing 8760 h of data at 60-min intervals. Total 19 clients were chosen for local training and data for 01 client is kept for the testing of the proposed model. The timestamp and the energy consumption is taken as parameter for the experiment. The local models for commercial load forecasting utilized the same LSTM model and followed the FedAvg aggregation algorithm. For the experiment, there exists many possible distribution of data among the participating clients but in this work, we assumed that the distribution of data is independent and identically distributed (IID Data).
Figure 4 represents the architecture of individual model training in FL approach where two different global models are getting trained by obtaining residential client’s local model updates and commercial client’s local model updates.
4.1.1. Long Short Term Memory for Model Training
The above discussed predictive models have used LSTM model [
19] for local training of time series data. The state-of-the-art mention that the LSTM model is widely used and highly accurate for load forecasting in comparison to other existent time series models [
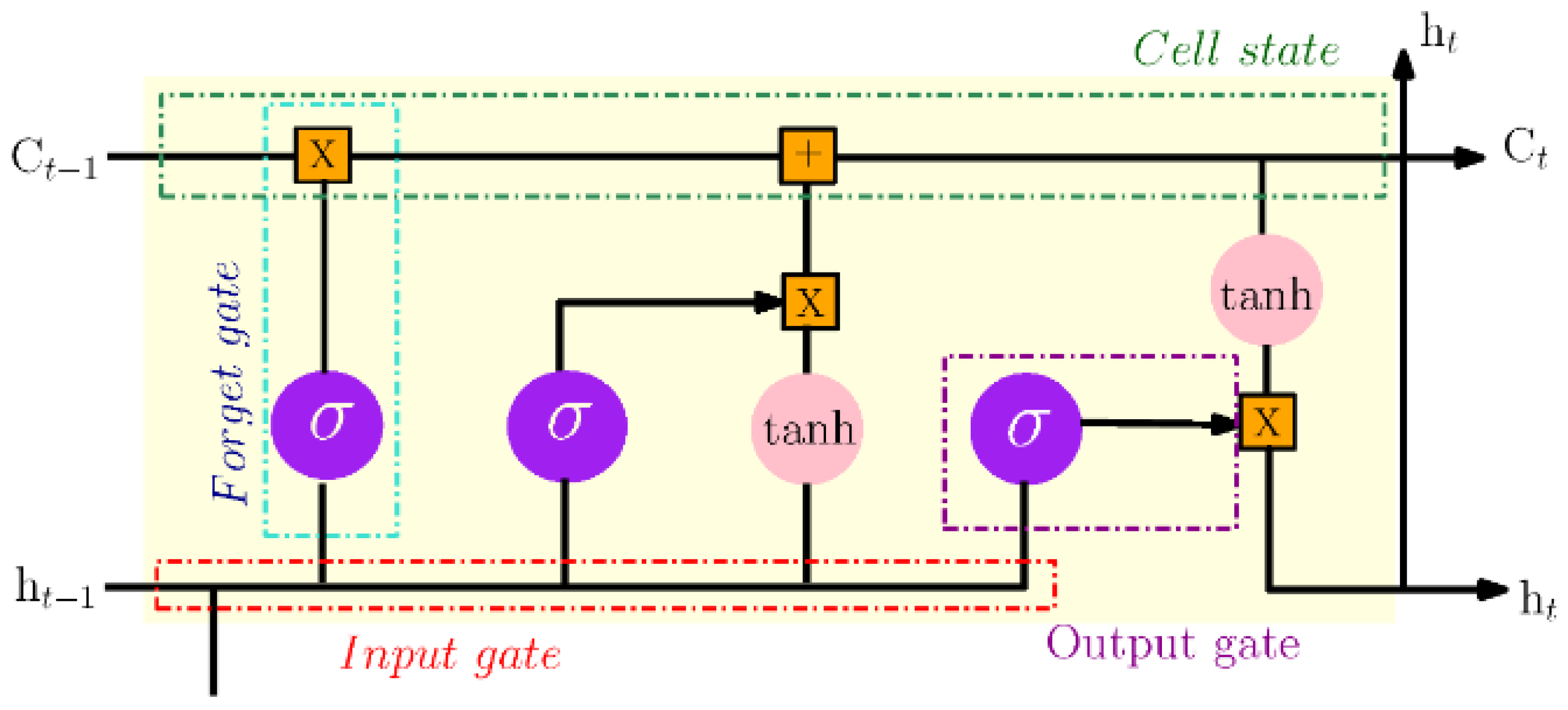
20]. Long short-term memory (LSTM) is a recurrent neural network characterized by a state memory and a multi-layer cell structure. LSTMs are purpose-built for handling sequential data tasks, including time series analysis, image processing, speech recognition, manufacturing, autonomous systems, communication, and energy consumption. It has gained widespread acclaim for their capacity to adeptly capture and represent dependencies in sequential data by incorporating a gating mechanism that leverages information from previous steps to produce output, involving the evaluation of a function that modifies the current LSTM cell state [
20,
21]. The
Figure 5 represents the technical architecture of LSTM which comprises input gate with output as
, output gate with output as
, and forget gate with output as
. The output values for all such gates are computed as follows:
where
is the sigmoid activation function and it can be defined as:
where,
refers to the memory cell
is the update and the activation of the current cell status.
is the input vector
represents the output vector result at time t.
are the weights matrices
the bias vectors.
Figure 5.
The technical architecture the LSTM model [
22].
Figure 5.
The technical architecture the LSTM model [
22].
4.1.2. FedAvg Algorithm: Global Model Aggregation Algorithm
The widely used basic aggregation algorithm for federated learning is FedAvg [
23], which mainly deals with the aggregation of all received model updates from every clients. The FedAvg is the legacy of federated learning as initially the concept of federated learning came with FedAvg. The
Figure 6 depicts the flow of FedAvg algorithm, which can be understood step by step manner as follows:
- i
The server containing global model initializes model weight as and sent to all the clients. At each round, the performance of the global model is evaluated.
- ii
Initially, total clients takes part in the learning process and initializes their local model weight as .
- iii
At initial round, each client starts training their local model from their private dataset and updates the model weight as .
- iv
The model weights of all the clients are then shared with central server, where aggregation of the received models takes place as .
- v
Once aggregation is done, the aggregated weights are return back to the clients, where client updates their model from the received aggregated weights.
- vi
The step iii to v is repeated for round t = 1, 2 … R till the convergence of global model.
In the proposed work the FedAvg aggregation algorithm is used for the model aggregation by assuming the distribution of data among the client is Independent and Identically Distributed (IID). The FedAvg algorithm works well for the IID distributed data but it shows adverse performance when the distribution of data becomes Non-Independent and Identically Distributed (NIID) leading to the issue of statistical heterogeneity [
23]. In FL, the different client with their different model updates are participated. These model updates are obtained from the training of datasets which are different for all the clients. It may be possible that client at different geographical location have different classes in their datasets leading to the NIID distribution when compared with all the participating clients. Hence, consideration of NIID data distribution in the proposed work will also impact the performance of the models. There are different aggregation algorithms like FedProx [
25], which shows better performance as compared to FedAvg in NIID data distribution scenario.
4.2. Energy Generation: Forecasting Energy from Renewable Source
The proposed framework consists of two energy resources i.e., energy from a renewable and energy from a non-renewable resources. This work assumes the generation of energy from non-renewable sources is constant and foreknown. Hence, the work experimented to predict the energy from renewable energy sources because of its high dependency on weather conditions, making varying amount of energy generations. For the experiment, two renewable energy sources i.e., solar energy and wind energy is considered. The following experiment is performed to develop and evaluate two ML models in FL approach to predict the weather parameters for solar and wind energy respectively.
- 1.
Solar Energy Generation Model: Solar energy is generated by photovoltaic plates (PV plate) or solar panels in which large number of solar panels are used for the energy generation. The total generated solar energy can be obtained through the collective calculation of energy generated by individual solar stations. Each solar station comprises of multiple solar panels. The Equation (
8) represents the total solar energy generated by k solar stations for n number of solar panels in each solar stations.
where,
: is the area and
is the efficiency of the
ith solar panel.
The solar panel converts solar radiations into electrical energy and, the amount of energy generated per hour by a PV plate in watt-hours is given by Equation (
9).
where,
: Area (m
2) of the solar panel.
: Global Horizontal Irradiance, which represents the amount of solar radiation received on a horizontal surface (measured in W/m2).
: Efficiency of the solar panel.
In Equation (
9),
and
will be constant for a specific panel, raising the concern to predict varying
i.e., Global Horizontal Irradiance. Hence, the proposed work performed an experiment 3 and developed a ML model using federated learning approach, which would be able to forecast the GHI value. The predicted GHI value would play a crucial role in determining the total energy to be generated by using Equation (
9). In this experiment, each solar energy generation station will comprise a weather station which will work as a client to train a model in FL approach as represented in
Figure 7. The dataset [
26] collected from the solar power plant in island of Santiago, Cape Verde is used for local model training consists of two attributes one is timestamp and another one has GHI values. It is hourly data of a total of 8760 h.
The DSS-LSTM (Dynamic Spatial-Spectral Long Short-Term Memory), which is a stateful LSTM model is employed as local model at each weather station as because it has been proven the best model for the GHI Forecasting [
27]. It is a specialized recurrent neural network tailored for handling spatiotemporal data. It combines spatial and spectral components to capture both spatial and spectral dependencies, making it suitable for tasks such as time series prediction and sequence modeling. The model’s architecture comprises two primary constituents: the spatial component and the spectral component, each playing a pivotal role in comprehensively capturing and analyzing the intricacies within the data.
The spatial component in the DSS-LSTM model aims to capture spatial dependencies within the data. This can be represented using the following Equations (
10)–(
15) in the form of an LSTM (Long Short-Term Memory) cell. An LSTM cell typically includes equations for the input gate (
), forget gate (
), output gate (
), cell state (
), and hidden state (
):
Here, represents the input at time t, denotes the previous hidden state, represents the previous cell state, denotes the sigmoid function, tanh represents the hyperbolic tangent function, ⊙ signifies element-wise multiplication, and W and b are weight matrices and bias vectors, respectively.
The spectral component within the DSS-LSTM model is designed to capture spectral dependencies in the data. This component often involves techniques like Fourier transforms, spectral analysis, or other methods suited to analyze frequency-domain information. The specific equation for the spectral component can vary based on the spectral analysis technique or method employed within the model.
- 2.
Wind Renewable Energy Generation Model: Wind energy, the clean and renewable source of electricity is generated by wind turbines, which gets rotated when the wind blows. More the flow of wind, there will be more energy generation by the turbine. The total wind energy generated by all wind turbines in the wind energy station is calculated by adding the energy generated by each turbine in the station. If there are
n wind turbines and power generated by each wind turbine is
the total power obtained from a wind generating station is given by Equation (
16).
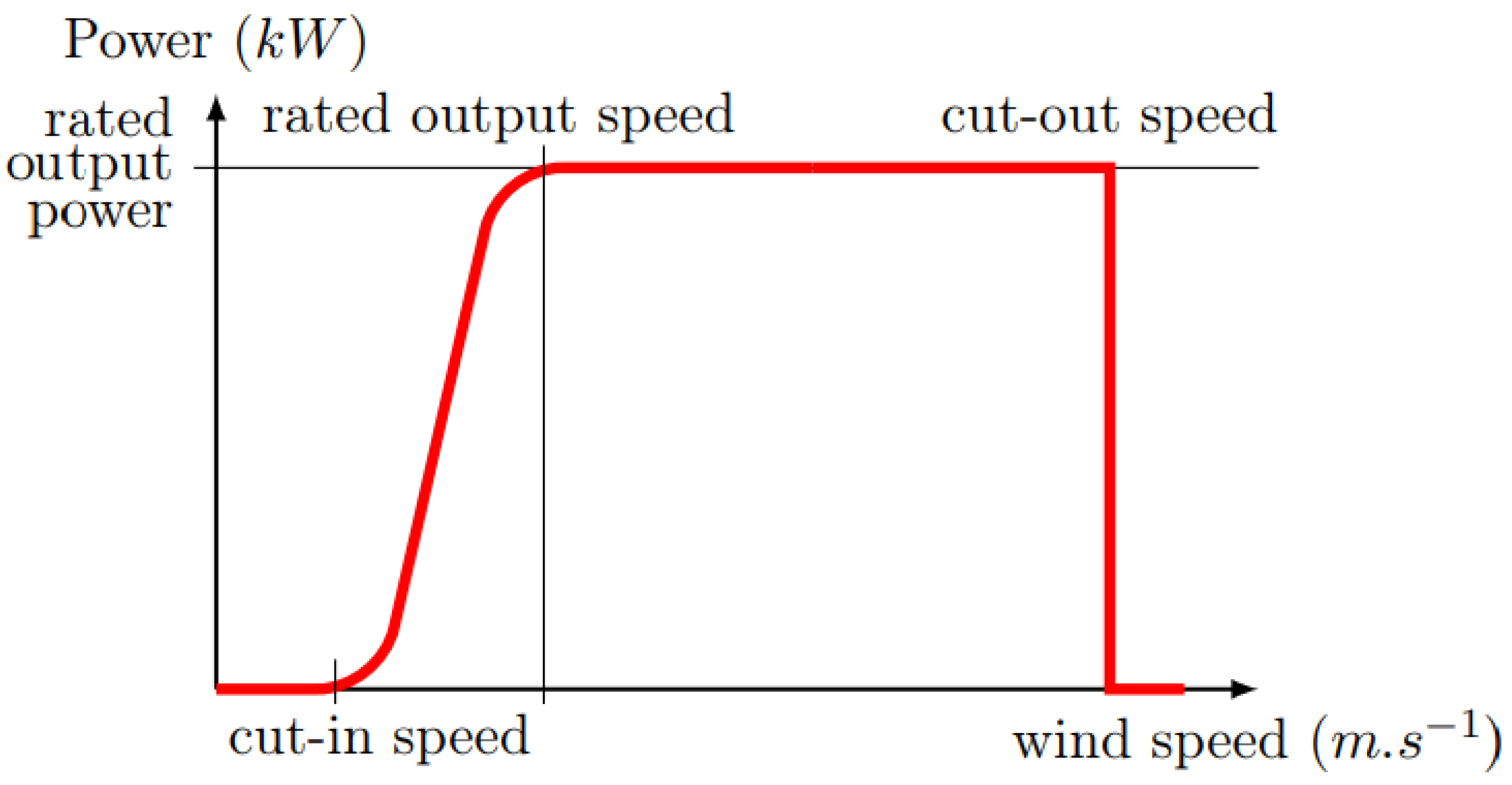
Wind speed, turbine efficiency, location, and maintenance are key factors in wind energy generation. The output power generated by the wind turbine depends on the rotation of wind blade caused by the flow of wind. The power generation
starts when the wind speed reaches to cut-in value
and increases with the increase of wind speed to the rated wind speed
. For the safety reasons and proper function of the wind energy generation system, a cut-out wind speed is set so that when wind speed reaches beyond the “cut-out” speed
, the turbine stops generating energy, as represented in
Figure 8.
The power generation by wind speed can be mathematically represented by Equation (
17) where wind speed in
at any time
t is given as
and nominal power of the wind turbine is given as
.
According to Equation (
17), the electrical energy generated by wind energy system depends mainly on wind speed. If we have exact knowledge of wind speed for a specific time, then the amount of power generation can be determined effectively. Although we should take into account the variability of wind speeds, both short-term (turbulence, gusts) and long-term (seasonal changes, climate patterns), significantly impact the performance of wind turbine power generation estimates. Small variations around optimal wind speeds can cause significant changes in power output. Uncertainties in weather forecasting, spatial variability, and the non-linear nature of turbine power curves contribute to prediction challenges [
28]. The proposed work performed experiment 4 by developing a model that would be able to predict the speed of wind for upcoming time so that the prediction of the amount of electrical energy can be performed. A ML model is trained in FL approach in which each weather station installed near to wind energy generation setup works as a client to train their local model from their collected data as represented in
Figure 7. The dataset [
29] collected from five wind farms near Dallas, New York City, Chicago, Miami, and Los Angeles is used for local model training consists of two attributes one is timestamp and another one has wind speed values. It is hourly data of a total of 8760 h (365 days) containing a timestamp and wind speed that is used for the training by the LSTM model at every client. The experiment was done on a total of 10 local clients which are treated as weather station models for wind speed prediction. The LSTM model has shown its supremacy in forecasting wind speed effectively [
30]. The global aggregation of these locally trained model updates are done by FedAvg algorithm.
5. Results and Analysis
The proposed FedGrid framework provides a privacy preserving methodology for the sustainability of the smart grids, eco-friendly approach and feasible energy pricing policies. It contains several ML models for the prediction of load consumption and energy generation. In this context, experiment 1, 2, 3, and 4 are performed to develop various predictive models under the FedGrid framework, and their evaluation is done. The obtained results along with the key observations are discussed here.
5.1. Residential and Commercial Electric Load Forecasting Model
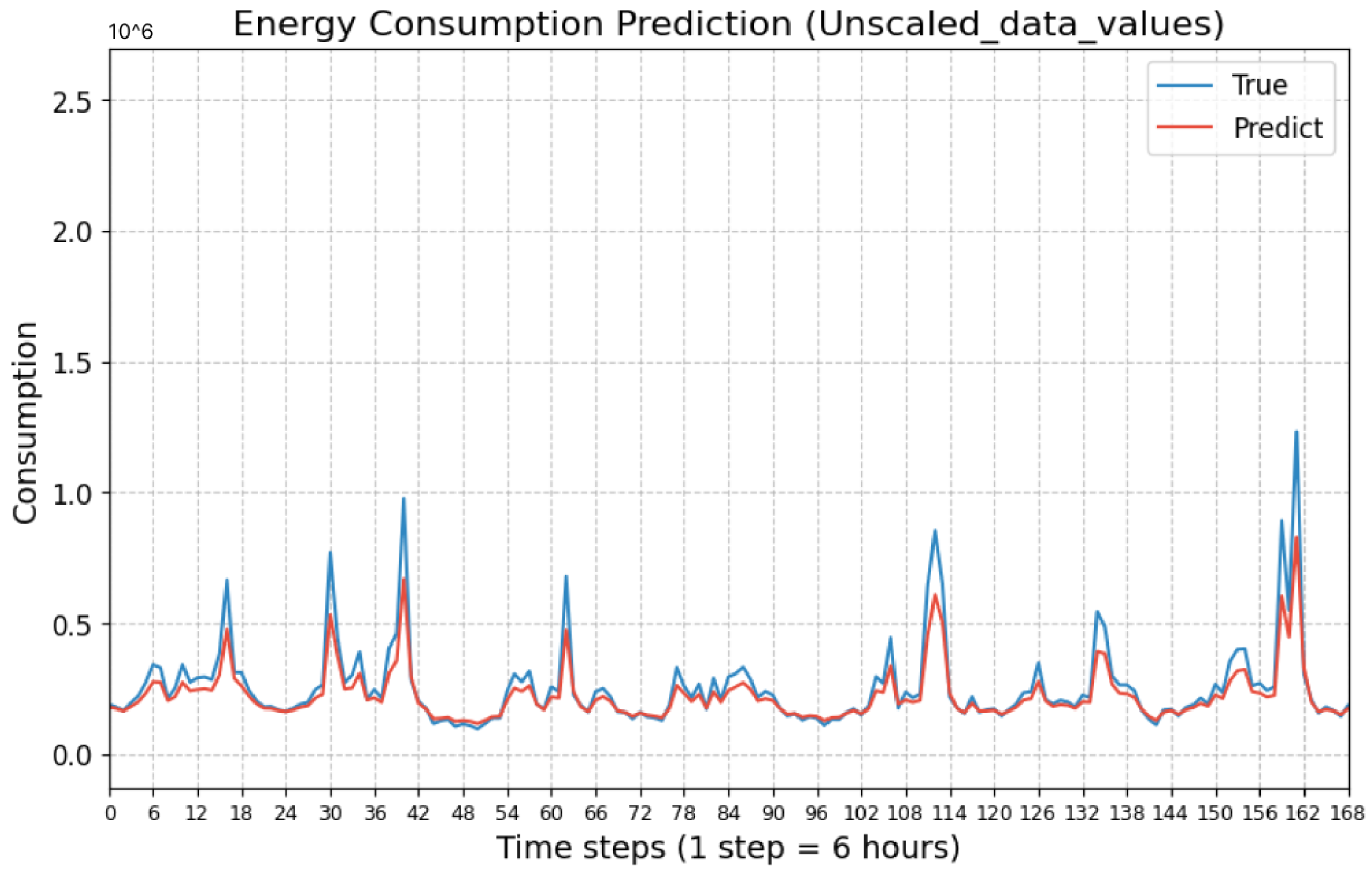
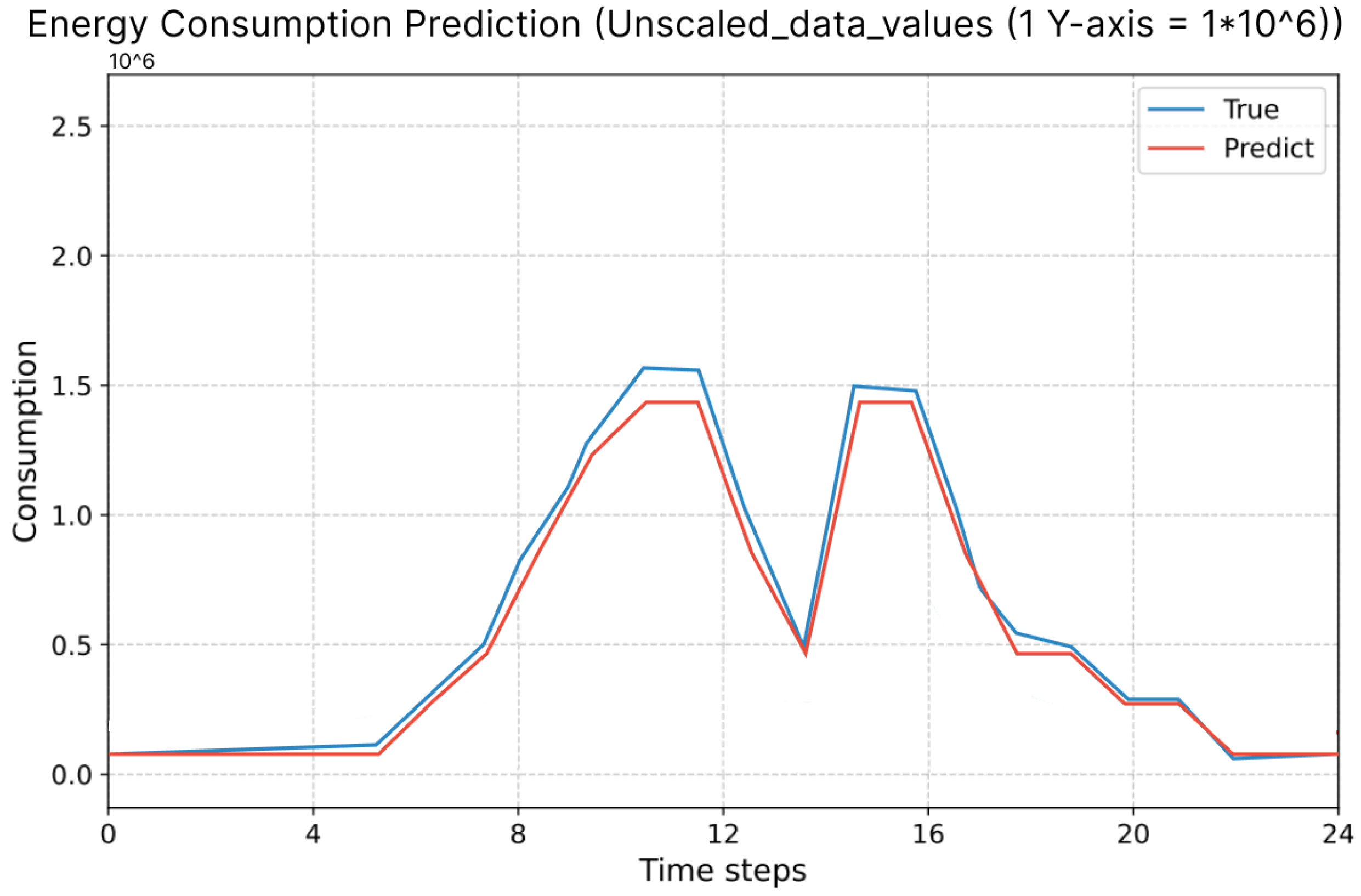
The experiment 1 was performed for residential load forecasting and the corresponding results are represented in the form of
Figure 9 and
Figure 10, which represents the performance of federated global time series model to predict the consumption with the frequency of 1 h and 6 h respectively. Similarly, experiment 2 is performed for commercial load prediction and the corresponding performance of global federated model is represented in
Figure 11. From the analysis of all such graphs representing model performance, it is observed that the model is following the pattern of actual data by showing its significant performance as it could predict high peak time and low peak time of consumption similar to the actual pattern. Hence, the proposed federated model for smart grid systems facilitates the analysis of load demand trends for residential and commercial areas, enabling a data driven approach to efficiently balance the supply and utilization of renewable and non-renewable energy sources for optimized energy management for residential and commercial areas.
5.2. Federated GHI and Wind Speed Prediction Model for Renewable Energy Generation
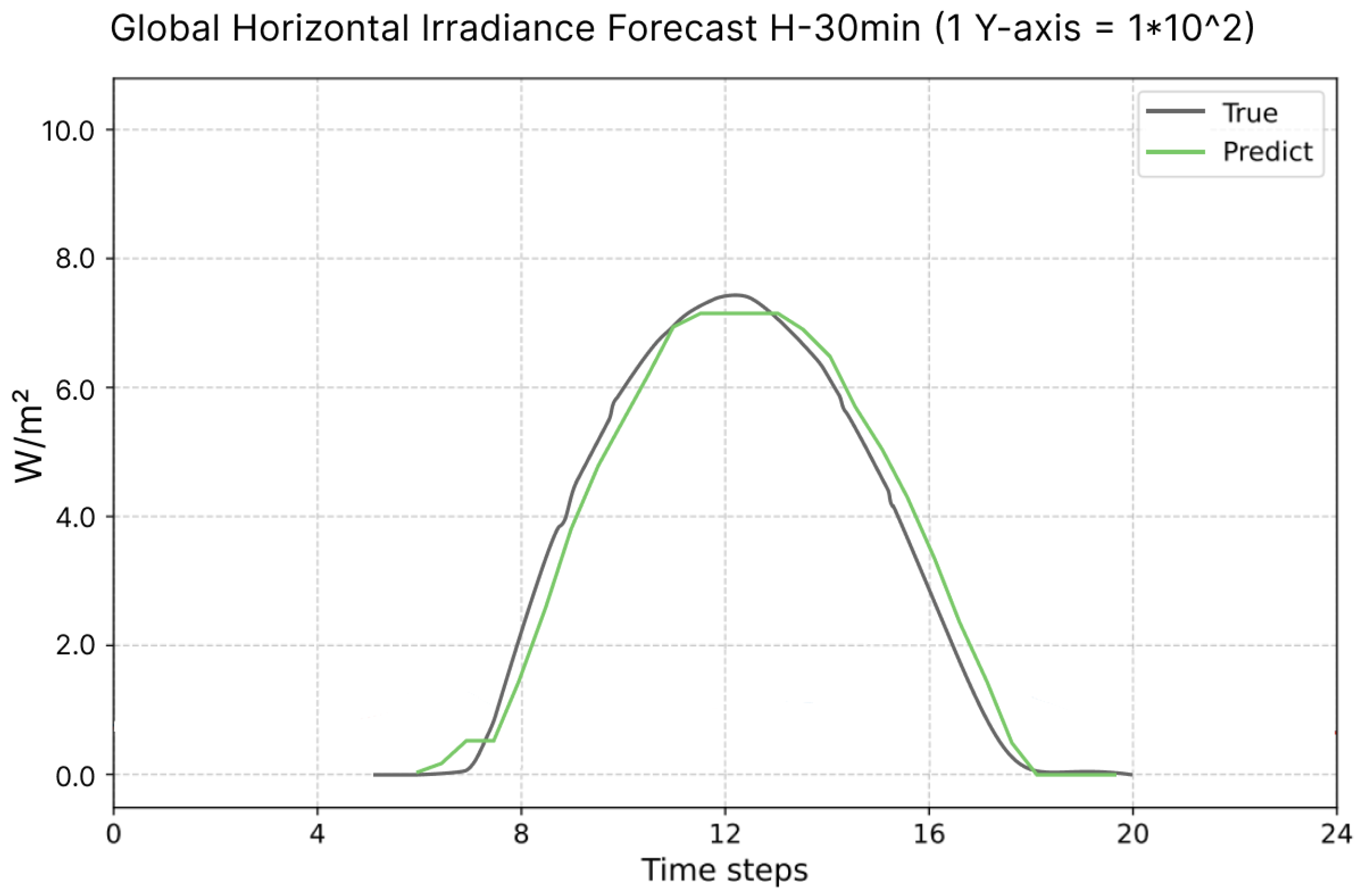
The
experiment 3 is performed for the GHI prediction and the corresponding model performance is represented in
Figure 12. The global model predicted GHI pattern in very similar to the actual GHI pattern for the next 24 h data of GHI testing data. Hence, the calculation of the predicted energy generated by the Solar Energy Generation Station can be done efficiently for future by employing the Equation (
9).
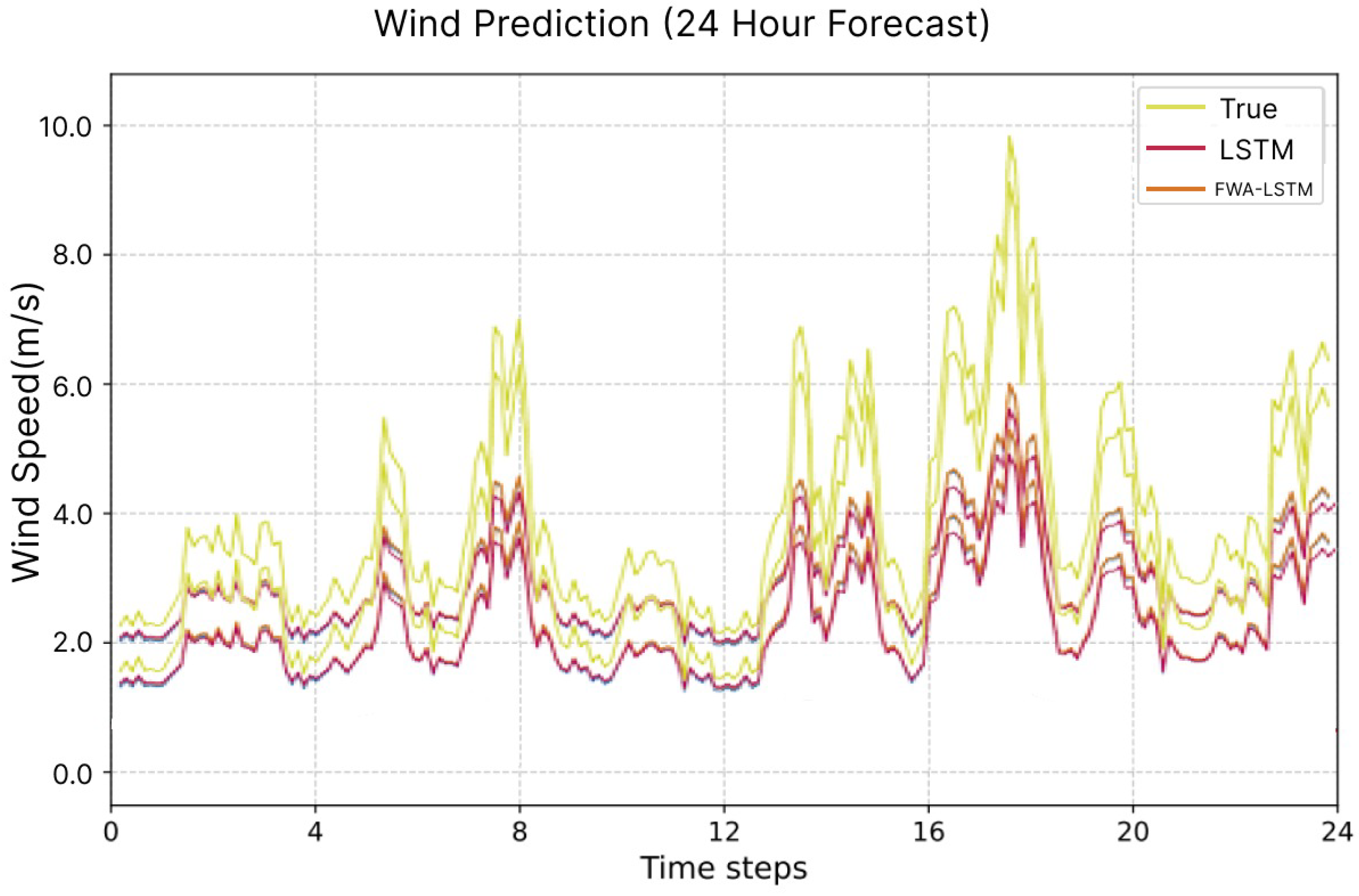
Similarly, the experiment 4 is performed for wind speed prediction and the corresponding model’s performance is represented in
Figure 13. The global model predicted wind speed pattern is kinda similar to the actual wind speed pattern for the next 24 h data but it lags to achieve the exact magnitude of the wind speed. The graph pattern is similar as it can predict when wind speed is high or low but it is unable to get the exact speed values. The accurate prediction of wind energy is not only depends on the wind speed, but it also comprises various other factors which affects the wind turbine propulsion, consequently affecting the energy generation. Wind direction, height from sea level, relative humidity, and pressure are also the important factors affecting the generation of wind energy [
31]. While the the current model only considered the wind speed along with timestamp for wind energy prediction, its enhancement can occur through the training with other parameters for the accurate prediction of wind energy as well as compatibility with the existing energy infrastructures. Yet, for the obtained results, the calculation to predict the energy generated by the wind turbines Energy Generation Station can be done by using Equation (
16) which considers the wind speed as a only factor influencing the wind energy generation.
5.3. Load Consumption VS Anticipated Hourly Energy Production
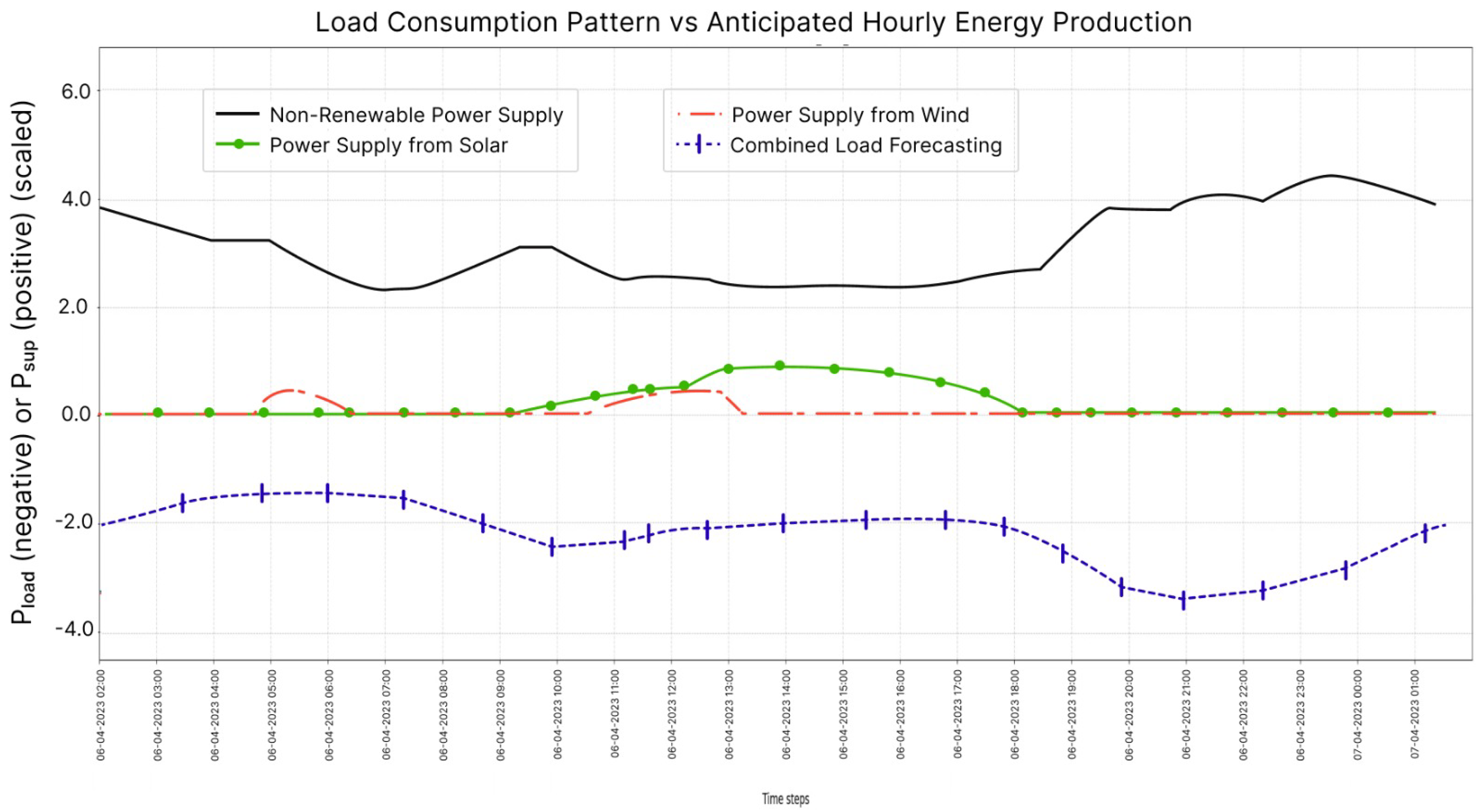
The above experiment 1, 2, 3 and 4 have shown their individual prediction capability in energy consumption and energy generation, as a part of the proposed framework. These models are trained on specific datasets to provide them prediction capability. After training and obtaining the significant performance of these individual models, they are assessed for their applicability and effectiveness in the proposed FedGrid framework. Hence, to analyze the combined effect, benefits and effectiveness of these predictive models in the proposed framework, an experiment was performed with these trained models. The experiment contains the prediction of residential as well as industrial electric load prediction along with the prediction of energy generation from renewable energy resources from the already trained models in experiment 1, 2, 3 & 4. The electricity consumption and energy generation was predicted for next 24 h with the interval of 1 h.
The obtained result for this experiment is shown in the form of graph as
Figure 14. In this line graph, the purple line represents the combined load (residential and industrial load), which is taken as negative value (high negative value refers to more consumption load) and electricity generation through renewable (red and green lines) and non-renewable energy resources (black line) is taken as positive value. It is observed that, the consumption load and power generation varies throughout the day in which, the consumption load ranges −1 to −4, power generation from non-renewable supply varies between +2 to +5 and the power supply from renewable energy resources lies between 0 to +2. The values in the graph represents that, the power supply through NRERs is available all the time throughout the day and contains the ability to fulfill all energy demands. But the renewable source of energy is not available all the time and it cannot fulfill the entire energy demand, as solar energy can’t be generated in the absence of sunlight or GHI and wind energy can’t be generated if (
) ≤ (
) or (
v(
t)) ≥ (
). Hence, there is huge dependability of renewable sources on weather conditions. The predictive models provide that the non-renewable energy source guarantees almost constant power generation throughout the day, while the solar energy production can be estimated to be at higher levels from mid-afternoon till early sunset. Wind energy can often be highly random hence not being a very reliable estimation for energy production. The combined load for households & commercials do seems to have peak values in morning and evening time, while the energy production from solar is maximum in the afternoon.
Although the RERs are not capable of fulfilling the entire energy demands but it can be used in optimizing the use of NRERs resulting in reduced dependency on it. As a point of benefits, the stored renewable energy can be used during peak hours to reduce the energy cost at significant level, during the availability of renewable and non-renewable energy resources, the renewable energy utilization can be prioritize over the non-renewable energy resources and in case of any power interruption with non-renewable energy resources, the renewable energy can overcome it at some extent.
In nutshell, the experiment shows the effectiveness of all the employed models in the proposed framework which creates the sustainable smart grid with data privacy and security. The proposed framework shows its importance in managing the demand and supply along with optimizing the supply through non-renewable energy resources by maintaining the use of renewable energy supply. It shows its benefits in achieving continuous power supply, low energy cost, reduced dependence on non-renewable energy resources and low energy pricing during peak hours (as in many countries the electricity price varies on demand). The framework makes the smart grid flexible so that it can adjust the demand supply program on specific need and rules, which varies throughout the geographical locations across the world.
6. Conclusions and Future Scope
The work proposed a secure framework FedGrid for the effective and privacy preserving oriented supply demand management. The proposed work represents a significant step toward achieving optimal energy resource utilization in a federated smart grid context. The work successfully developed predictive models for residential and commercial energy consumption forecasting along with dedicated models for wind and solar energy generation prediction. The models have been implemented using federated learning to assure the privacy of consumption data being used for the model training. Through a data-driven approach, the work demonstrated the ability to analyze consumption patterns and make informed decisions, i.e., when to switch between renewable and non-renewable energy sources.
This study showcases the potential for data-driven decision-making in smart grid systems, which results in multidimensional benefits in terms of smart grid management, environment friendly methods and socio-feasible policies. The proposed FedGrid framework provides a foundation to efficiently develop demand response program, optimized use of renewable and non-renewable energy resources by switching from one to another and developing the energy policies corresponding to the predictive load and energy generation. In this way, the proposed framework leads to various benefits while promoting the sustainability, which including efficient and cost effective management in smart grid, reduced energy price during normal & during peak load period, assuring the continuous energy supply to other critical infrastructures like transportation, banking, healthcare, telecommunication etc, and reducing the dependency on the non-renewable energy resources by switching to renewable energy sources as per the policy.
The proposed framework presents numerous advantages; however, its implementation in the real world poses several challenges. The predictive components, operating through a federated learning approach in a distributed manner, face hurdles due to heterogeneous client participation, resulting in statistical heterogeneity issues. Additionally, constraints in energy meters accommodating large machine learning models, regulatory and security compliance in smart grid setups, compatibility with existing infrastructures, and ensuring a reliable and resilient federated learning setup are crucial factors that might impede the framework’s real-world implementation, warranting detailed exploration. While showcasing the adaptability of various predictive models within this framework, there remains ample space for expansion, particularly in emphasizing the smart grid’s role beyond power generation and load forecasting. This could involve integrating predictive insights into smart grid operations. Furthermore, extending the framework to encompass Non-IID data distribution, considering diverse renewable energy sources beyond solar and wind, could significantly enrich and enhance the proposed framework’s applicability and effectiveness.
In the current energy system, the smart energy meters with adequate computational resources can be a very useful paradigm for the proposed framework. Keeping the privacy of user data and predicting their upcoming energy utilization may help the grids to modify their policies for the efficient and continuous energy supplies. Additionally, the installed solar energy systems at individual residence or places would also play a crucial role to adapt in the proposed framework.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}