
Artificial Intelligence and Machine Learning in Energy Conversion and Management



Abstract
:1. Introduction
- Are AI techniques being applied in energy conversion and management fields? If so, which algorithms and for what tasks (Section 3.1 and Section 3.2)?
- What kind of data and data size are researchers in this field using? Are they relying on simulated data or using real-life data to train and test their AI models? Are papers doing a good job at reporting their data? What tools are they using to conduct these studies? What are the data and algorithms’ memory requirements (Section 3.3, Section 3.4 and Section 3.5)?
- What are the trending AI algorithms? How effective or accurate are they? What are their strengths and limitations (Section 4)?
2. State of the Art
2.1. Bibliographic Study
- Wind Energy: backpropagation neural networks were effective for wind farm operational planning;
- Solar Energy: modeling and controlling photovoltaic systems using backpropagation neural networks;
- Geothermal Energy: artificial neural networks are key tools for geothermal well drilling plans, their control, and optimization;
- Hydroenergy: hydropower plant design and control implement fuzzy, ANN, adaptive neuro-fuzzy inference system (ANFIS), and genetic algorithms for optimization;
- Ocean Energy: ocean engineering and forecasting rely heavily on ANFIS, back propagation neural networks, and autoregressive moving average models;
- Bioenergy: categorization of biodiesel fuel using KNN, SVM, and similar classification algorithms, as well as a hybrid system, combining the elements of a fuzzy logic and ANN, is employed to enhance the heat transfer efficiency and cleaning processes of a biofuel boiler;
- Hybrid Renewable Energy: ANFIS is utilized in hybrid AI techniques to enhance the performance of hybrid photovoltaic–wind–battery systems and ultimately reduce production costs, as well for the modeling of biodiesel systems, solar radiation, and wind power analysis and wavelet decomposition; ANNs and autoregressive methods are used in solar radiation analysis; SVR+ARIMA ( autoregressive integrated moving average) for the tidal ongoing analysis; improved and hybrid ANNs in photovoltaic system load analysis; and data-mining method-based systematic energy control system.
2.2. Document Information Extraction
- Algorithm: the highlighted algorithm used in the publication;
- Energy Topic: the energy conversion domain the publication relates to (i.e., different kinds of renewable energy, nonrenewable energy, energy conversion systems, etc.);
- Energy Task: the specific task highlighted within an energy-related topic (i.e., forecasting, optimization, etc.);
- Energy Domain: the primary energy resource the publication relates to (i.e., wind, solar, natural gas, etc.);
- Data Size: the number of total observations in the dataset used in the publication;
- Data Type: the origin and nature of the data used (i.e., real data (panel data), simulated data (data created through mathematical and computer simulators), time series (data with dates and/or time), images, etc.);
- Performance Measure: the score of accuracy, error, or percentage improvement achieved by the algorithm;
- Performance Measure Type: the name of the performance measure (i.e., root-mean-square error (RMSE), mean squared error (MSE), mean absolute error, R-squared, etc.);
- Comparative Benchmark Performance: the percentage improvement achieved by the highlighted algorithm either over the traditional non-AI method or the next-best AI method;
- Tools Used: the programming language or software applied to achieve the reported results (i.e., MATLAB, Python, etc.);
- Device Memory: the number of GB in the RAM (random-access memory) of the device used to produce numerical data in the publications.
2.3. Overview of ML and AI Algorithms
2.3.1. AI: Beginning, Winter, and Revival
2.3.2. Supervised and Unsupervised Learning Algorithms
- Supervised learning produces a function that maps inputs to estimated outputs by providing the algorithm input–output pairs during training. Supervised learning algorithms are also mainly used for regression problems [36]. These include, but are not limited to, decision trees, random forest, linear and logistic regression, support vector machine, ANN, and other neural network algorithms that use a labeled training set.
- Unsupervised learning algorithms analyze a dataset comprising solely inputs and discern data structures by examining shared characteristics among data points. Unsupervised learning algorithms are commonly used for grouping or clustering data points. Summarizing and explaining data features are other tasks for these algorithms [36], which include, but are not limited to, k-means clustering, principal component analysis, and hierarchical clustering. There also exists semi-unsupervised learning, where only a small part of the training dataset is labeled.
2.3.3. Reinforcement Learning Algorithms
2.3.4. Other Types of Algorithms
3. Machine Learning and Artificial Intelligence in Research on Energy Conversion
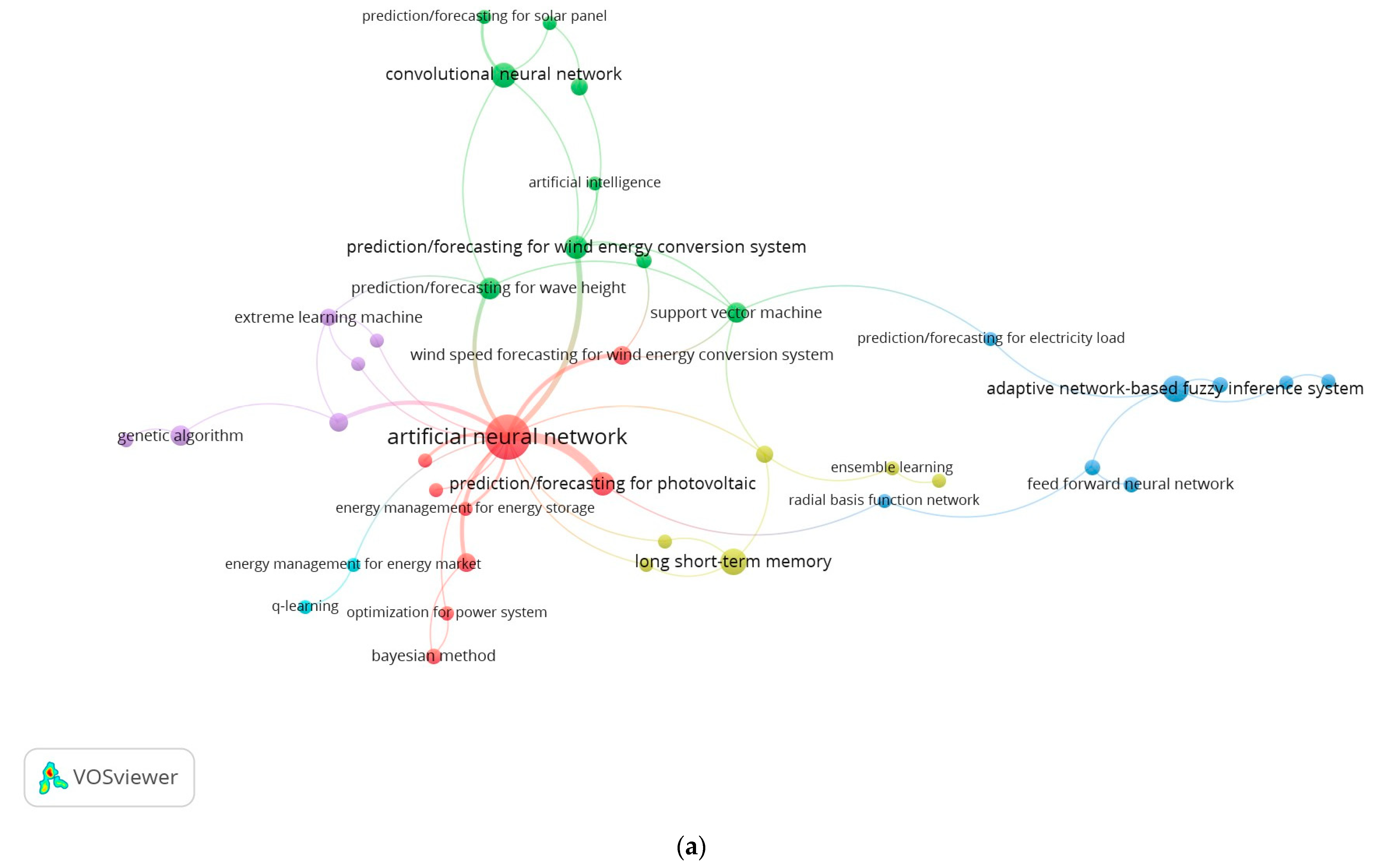
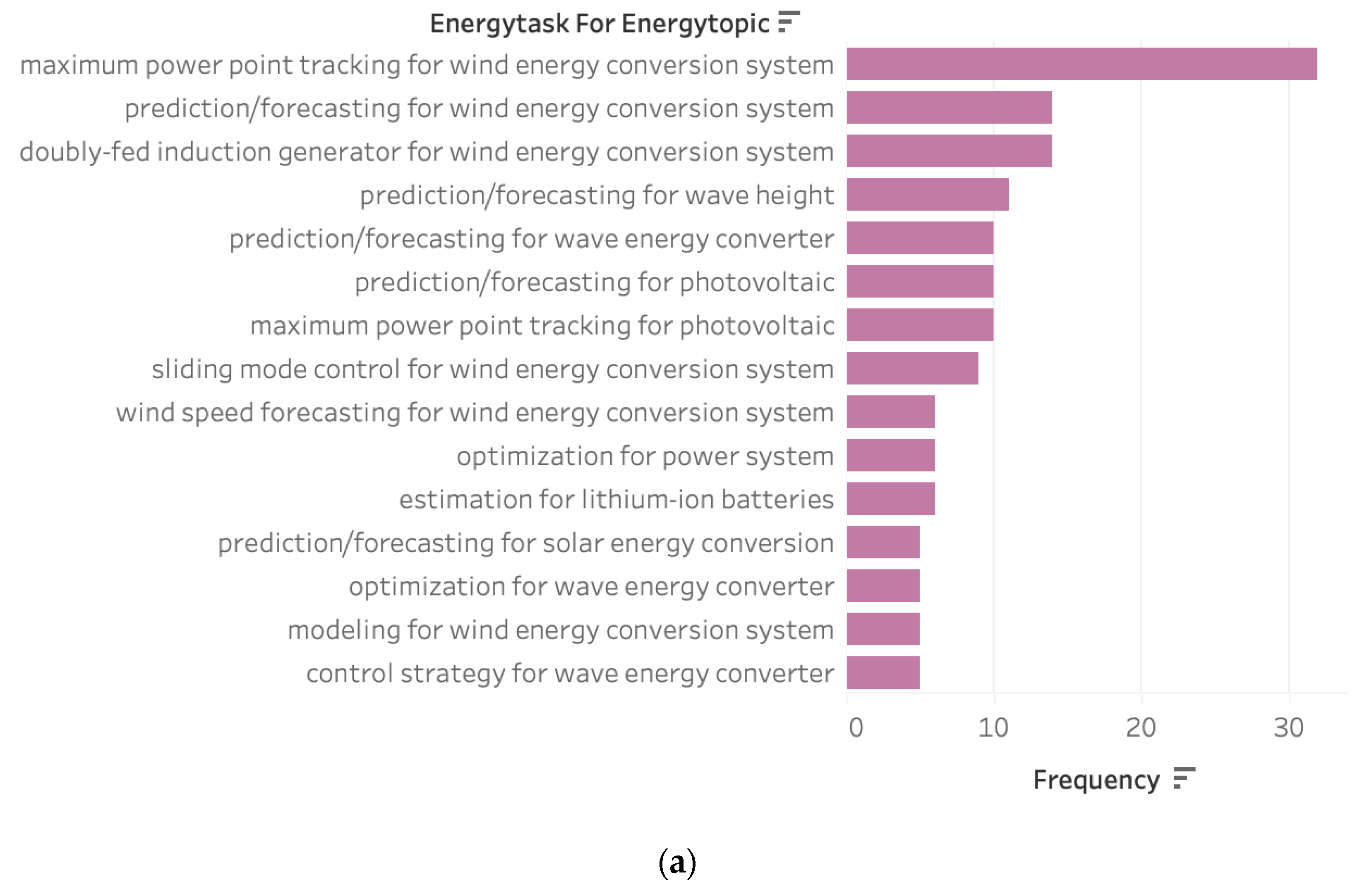
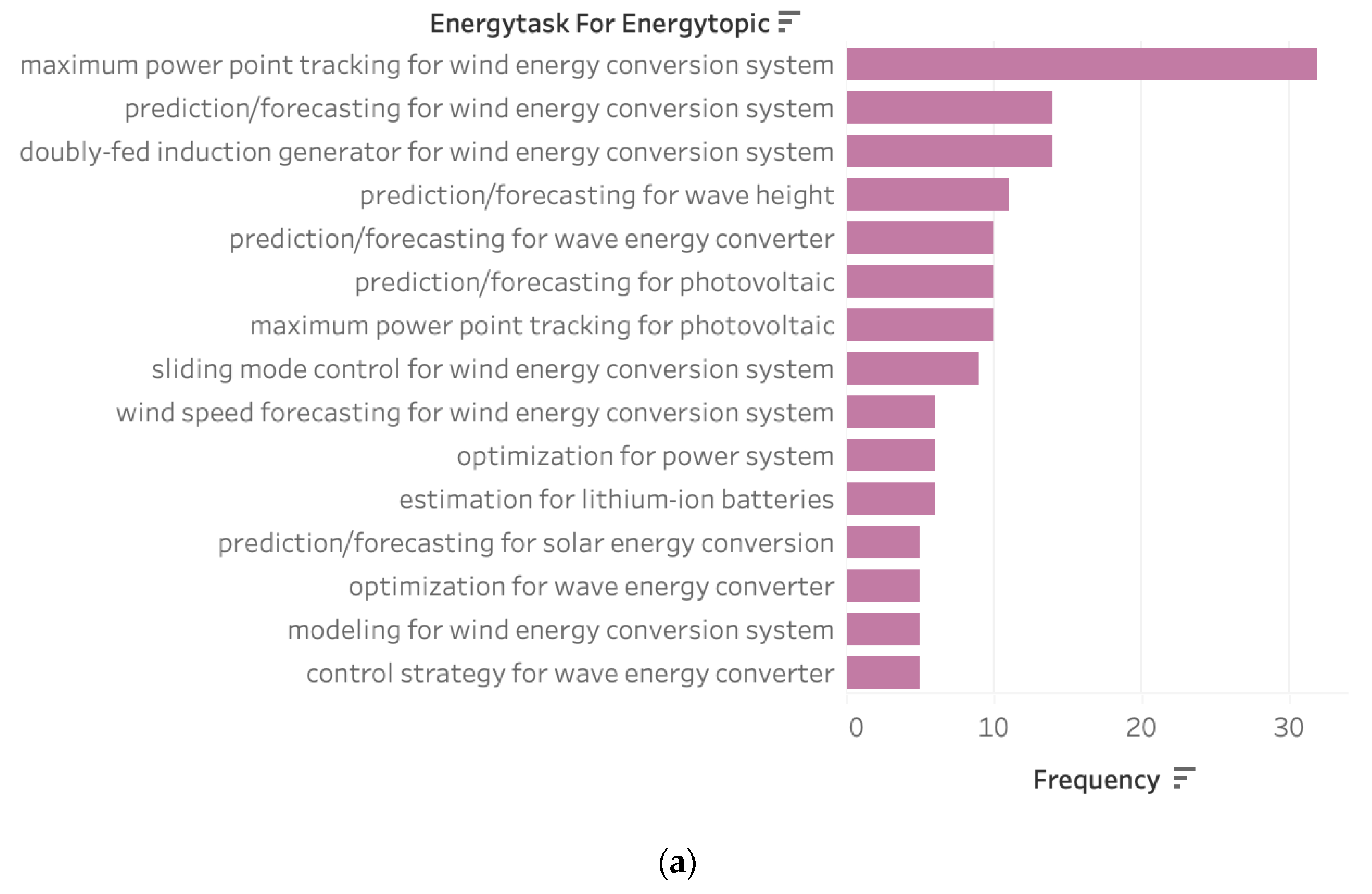
3.1. Most Researched Topics, Tasks, and Domains
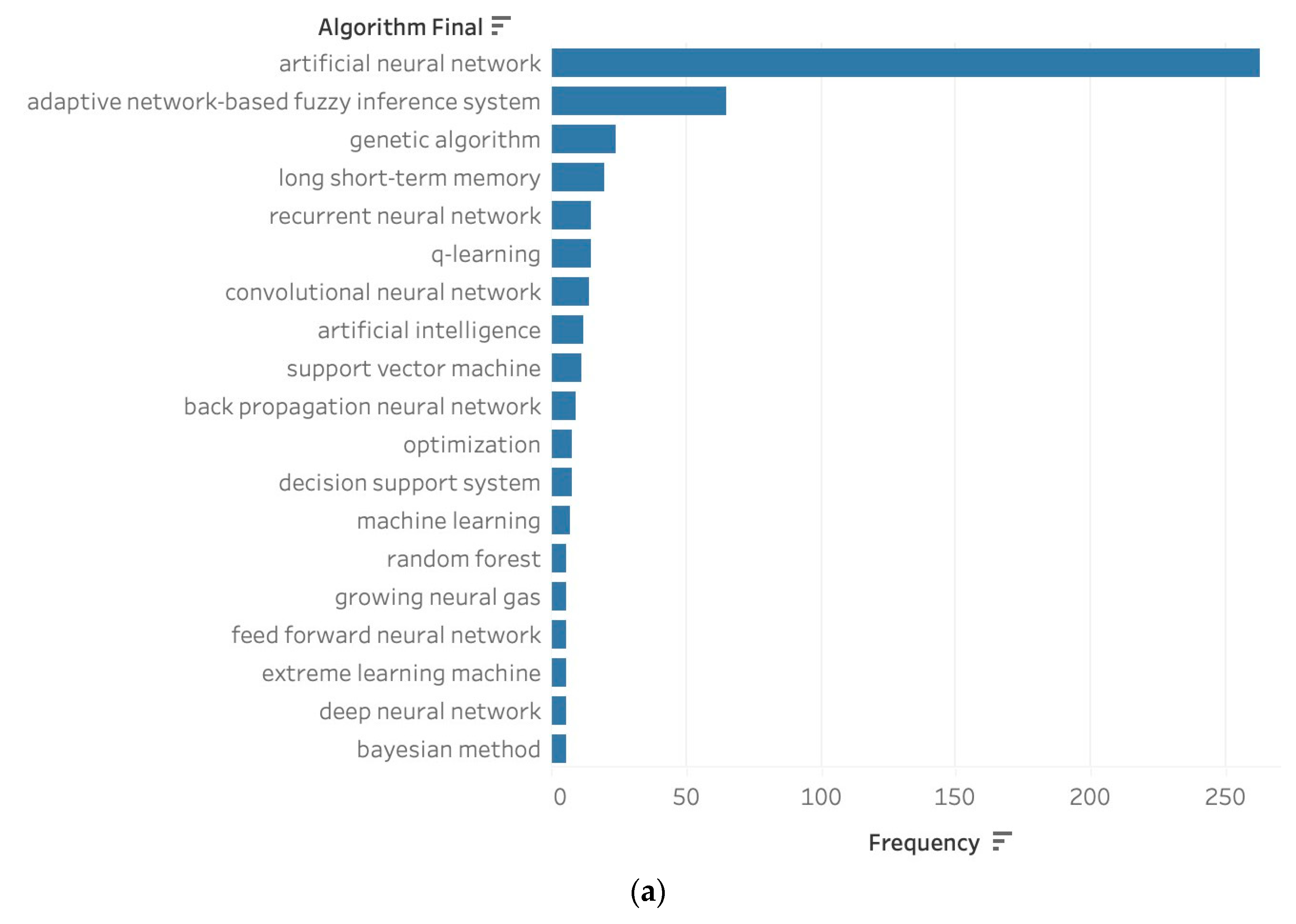
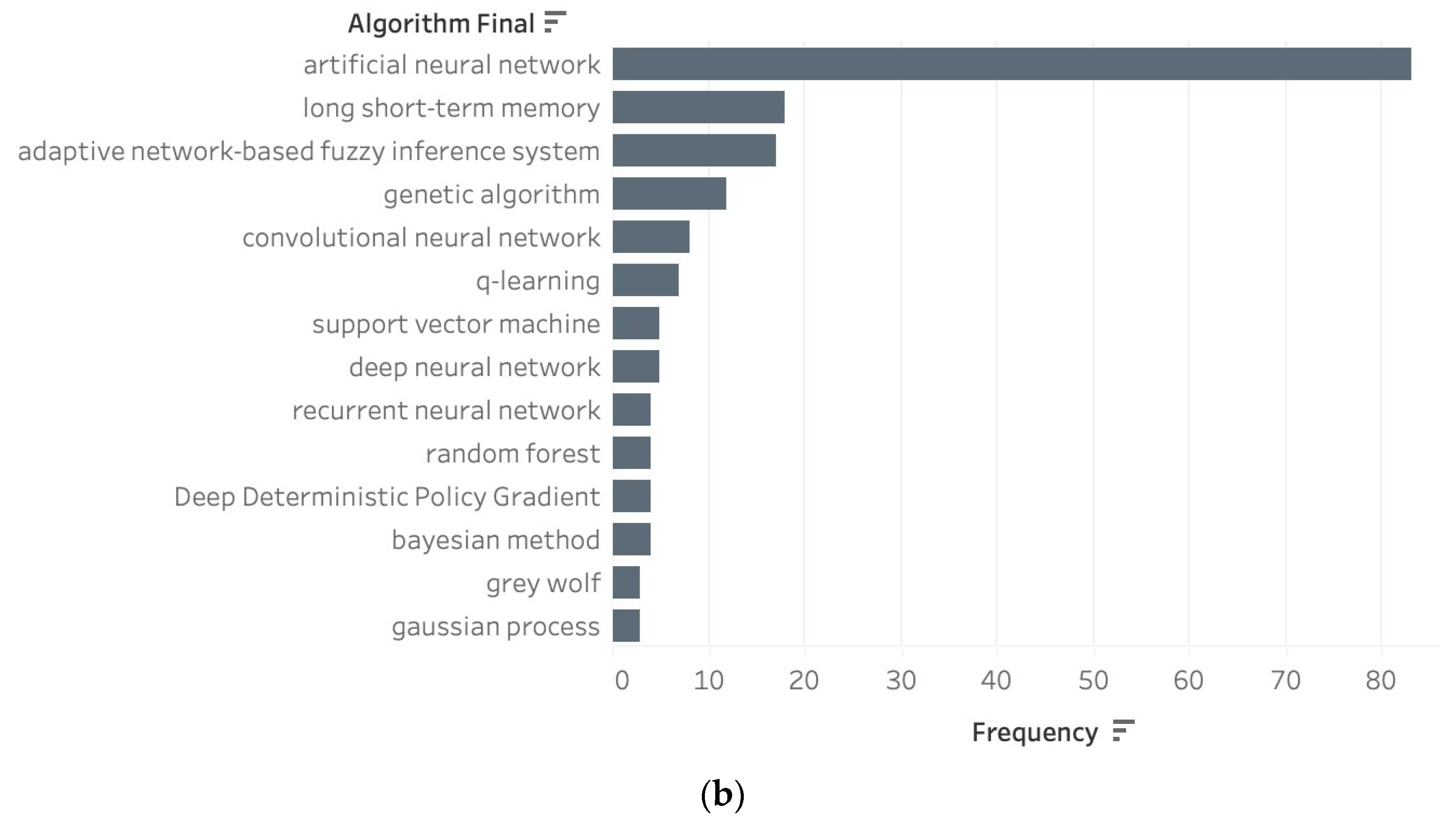
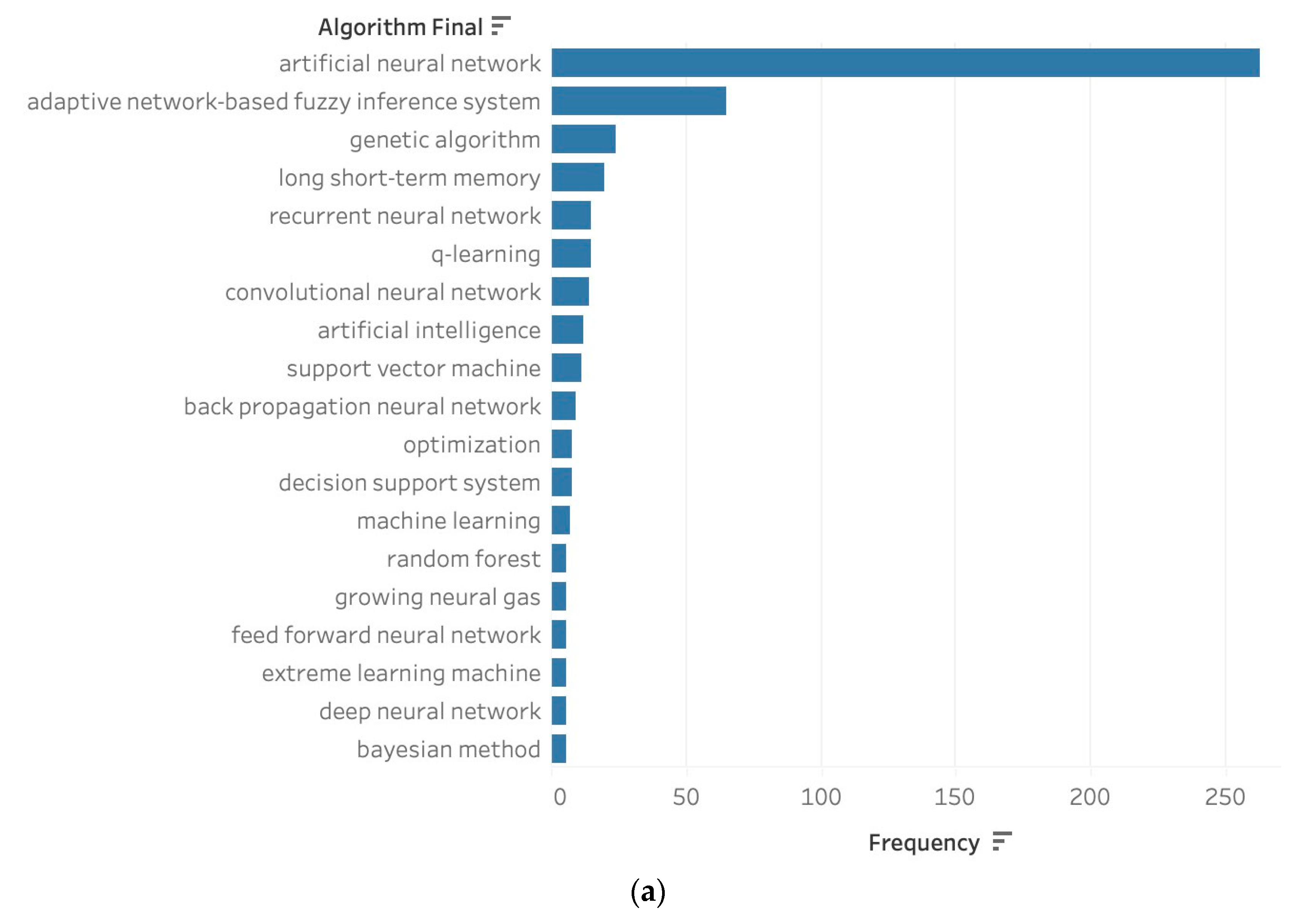
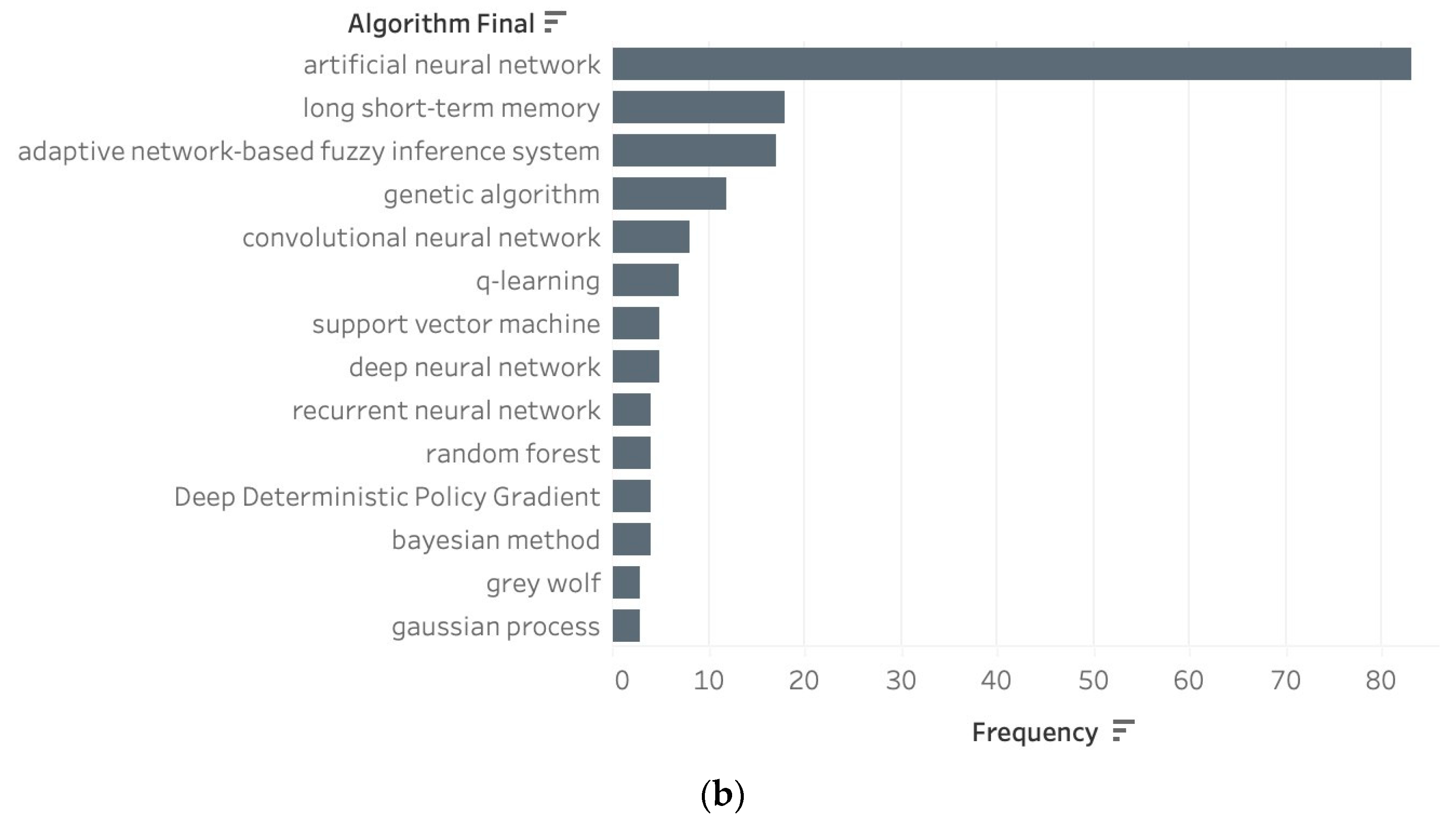
3.2. Most Popular Algorithms
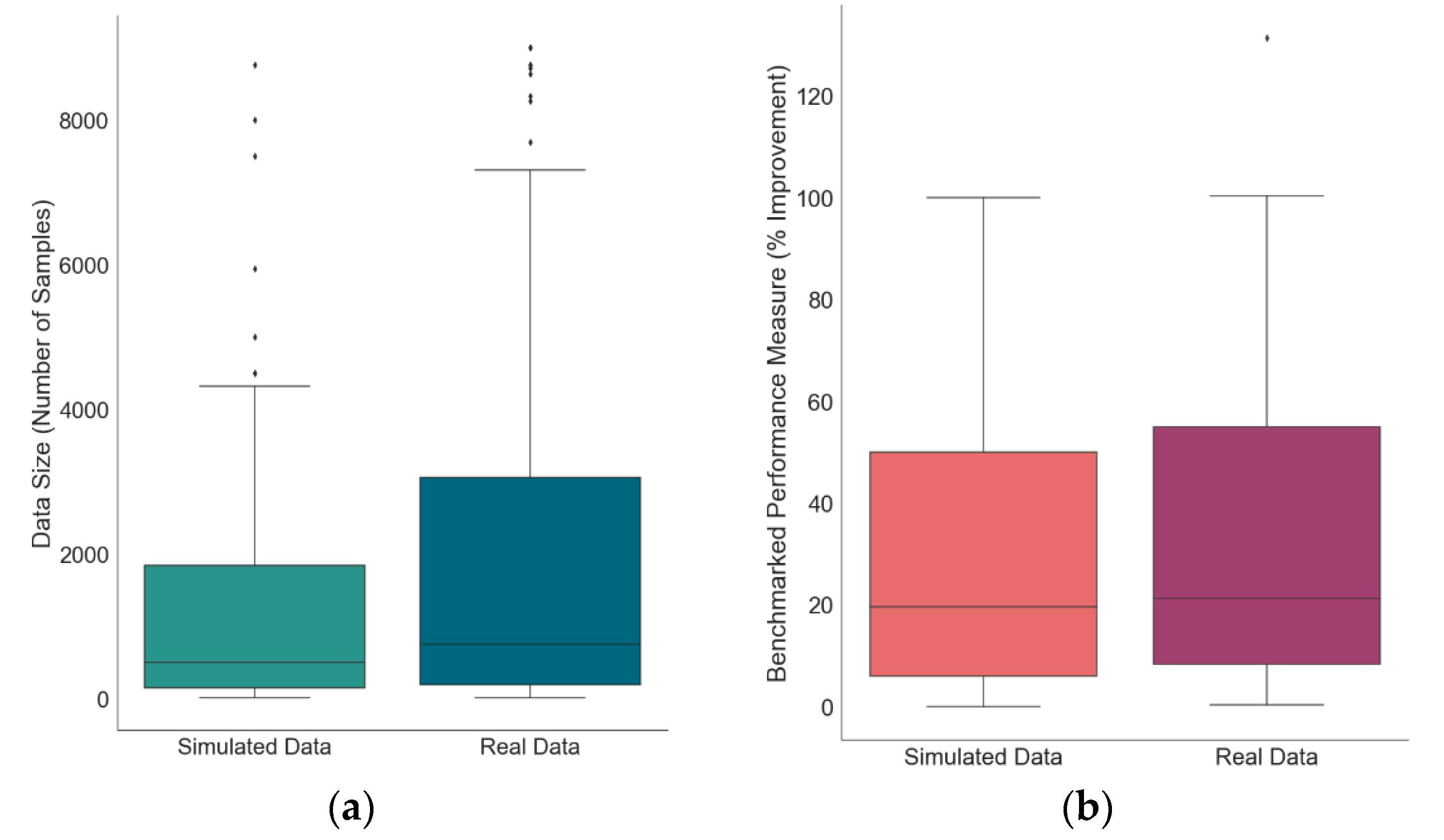
3.3. Simulated Data vs. Real Data
3.4. Tools
3.5. Memory Requirements
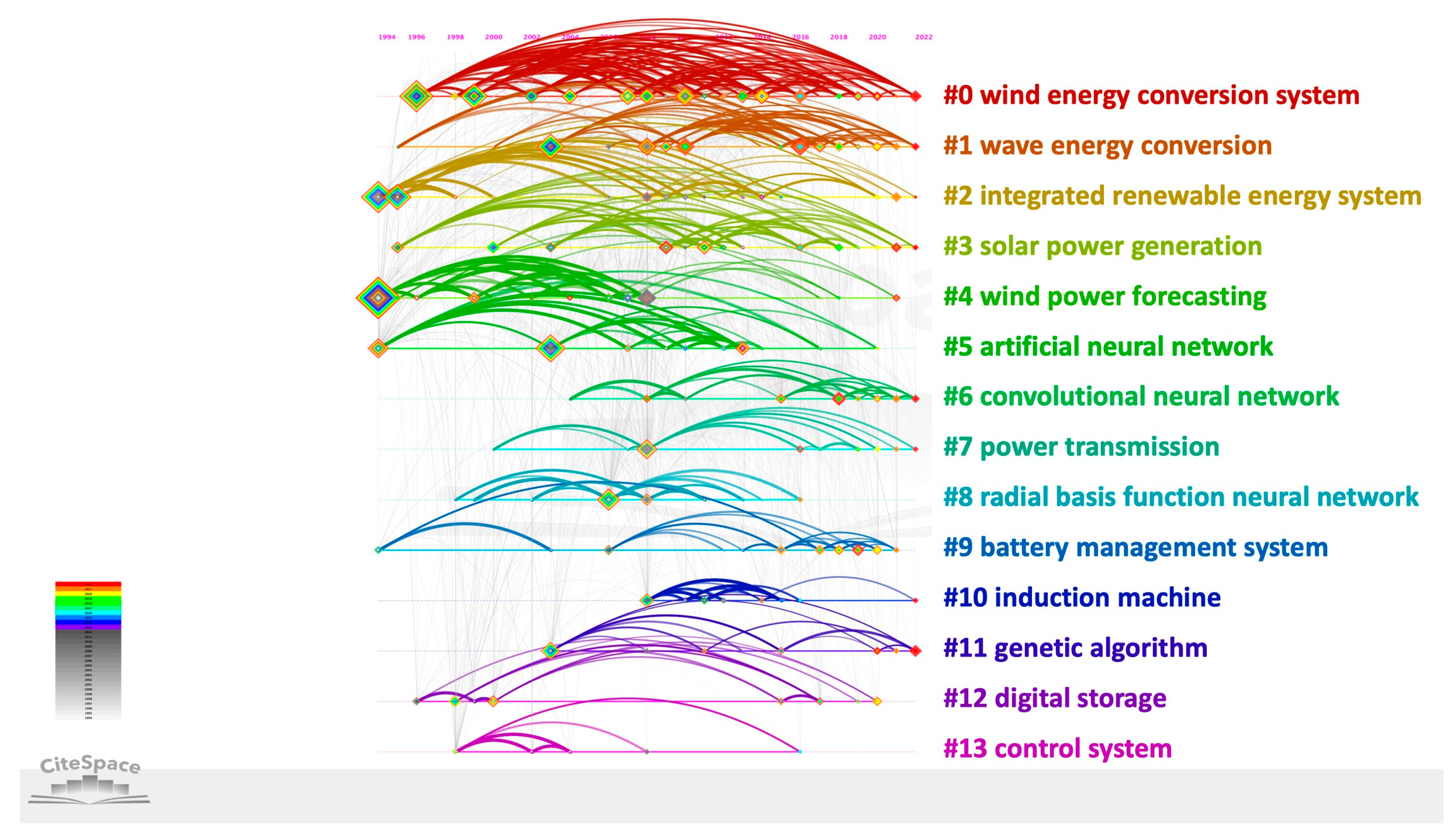
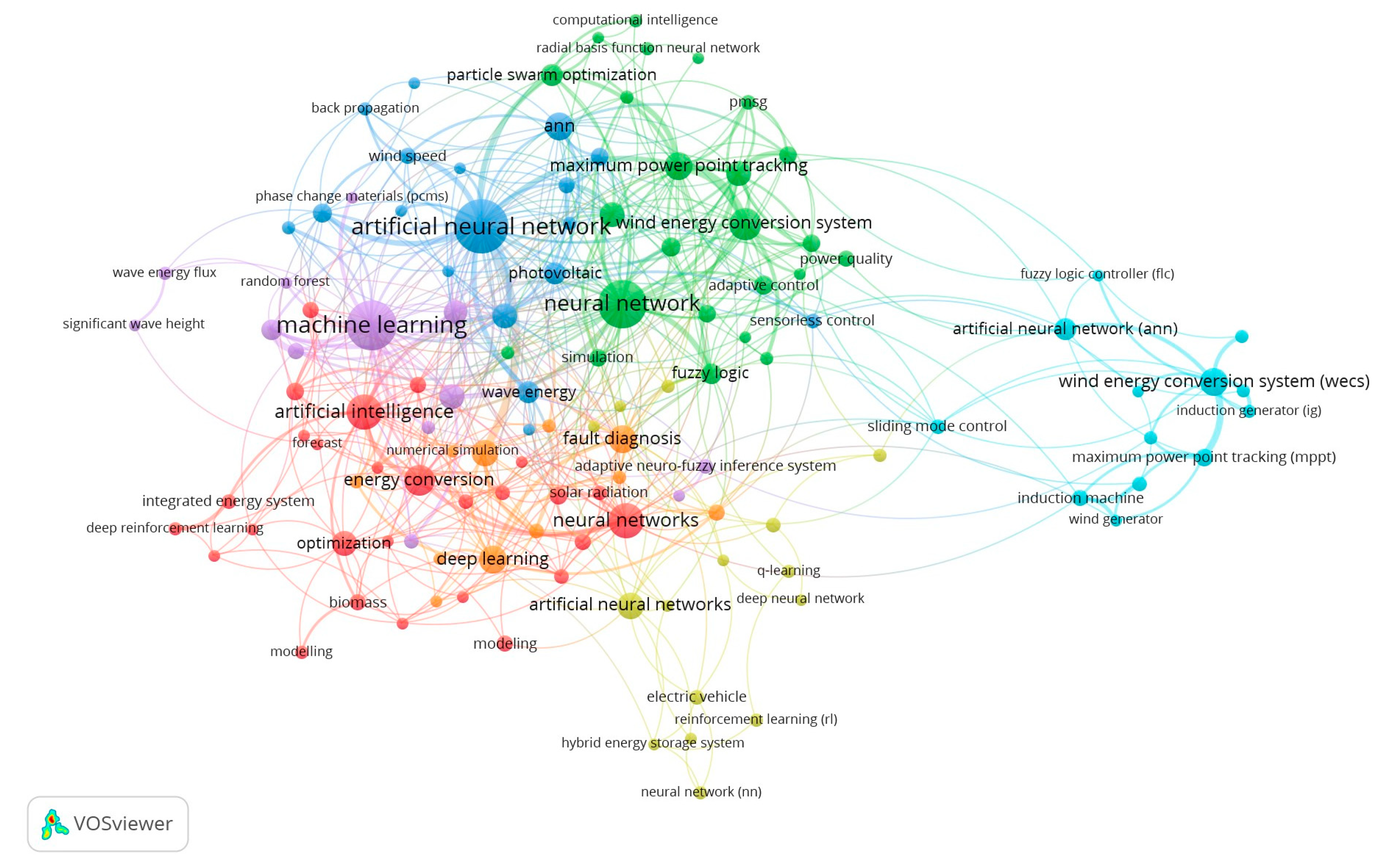
3.6. Research Hotspots and Direction
- Wind Energy Conversion Systems (#0, #4). These two clusters were merged in the analysis as they both describe wind energy conversion. The highest frequency keywords include wind power (141 sources), controller (64 sources), wind turbine (57 sources), maximum power point tracker (41 sources), and neural network (284 sources). In 2016, using MATLAB simulations, a new control technique was introduced using neural networks and fuzzy logic controllers applied to a grid-connected doubly fed induction generator to maximize turbine power output. Based on the simulation findings, the neuron controller significantly reduced the response time while constraining and surpassing peak values compared to the fuzzy logic controller [46]. Moreover, a novel combined maximum power point tracking (MPPT)-pitch angle robust control system of a variable-speed wind turbine using ANNs was reported; the simulations showed a 75% improvement in power generation in comparison to typical controllers [47]. Following this work, others discussed the merge of adaptive neuro-fuzzy controllers and their improved performance on MPPT in WECS [48,49]. Soft computing approaches using optimization were and continue to be explored for MPPT problems. For instance, particle swarm optimization (PSO) tracks the maximum power point without measuring the rotor speed, reducing the controller’s computation needs [50]. As for forecasting, 6400 min of wind measurement arrays were used to achieve a 14% improvement in the accuracy of wind power 12-step ahead forecasting using RNNs [51]. Later, ANNs were used to forecast 120 steps ahead, achieving 27% higher accuracy than the benchmark [52]. Forecasting for WECS and other systems heavily relies on neural networks, as they are robust and accurate. The continuous growth in this field is evident by the consistent links throughout the years of this field. Interest in this cluster continues to grow and be active. However, research on wind power forecasting has become scarce since 2009.
- Wave Energy Conversion Systems (#1). The highest frequency keywords include forecasting (116 sources), wave energy (42 sources) and converters (33 sources), deep neural network (24 sources), and significant wave height (4 sources). Influential data science works in wave energy began catching attention in 2015. Due to the computational complexity associated with analyzing wave energy converter arrays and the escalating computational demands as the number of devices in the system grows, initial significant research efforts focused on finding optimal configurations for these arrays. For instance, a combination of optimization strategies was applied. The suggested methodology involved a statistical emulator to forecast array performance. This was followed by the application of a novel active learning technique that simultaneously explored and concentrated on key areas of interest within the problem space. Finally, a genetic algorithm was employed to determine the optimal configurations for these arrays [53]. These methods were tested on 40 wave energy converters with 800 data points and proved to be extremely fast and easily scalable to arrays of any size [53]. Studies focused on control methods to optimize energy harvesting of a sliding-buoy wave energy converter were reported in [54], using an algorithm based on a learning vector quantitative neural network. Later, the optimization approach became more popular in publications on forecasting for wave energy converters. A multi-input convolutional neural network-based algorithm was applied in [55] to predict power generation using a double-buoy oscillating body device, beating out the conventional supervised artificial network and regression models by a 16% increase in accuracy. It also emphasized the significance of larger datasets, pointing out that increasing the size of the dataset could capture more details from the training images, resulting in improved model-fitting performance [55]. More recent works on forecasting focus on significant wave height prediction using experimental meteorology data and hybrid decomposition and CNNs methods, ultimately achieving 19.0–25.4% higher accuracy [56,57]. Interest in this cluster continues to grow.
- Integrated Renewable Energy System Management (#2). This cluster combines the publications related to the management of integrated renewable energy systems [58], power generation using the organic Rankine cycle [59] and power systems outage outages [60], biomass energy conversion [61,62], and hybrid systems [63] using knowledge-based design tools, mixed-integer linear programming, genetic algorithm, decision support systems, and ANNs. These topics were abundant in the late 1990s and 2005–2015. However, more recent publications on these topics are scarce.
- Solar Power Generation (#3). Containing keywords related to photovoltaics and their systems (29 sources), general solar power (29 sources), and solar–thermal energy conversion (44 sources), this cluster is consistently growing and active. Early works in this cluster focused on power forecasting for photovoltaics since insolation is not constant and meteorological conditions influence output. Ref. [64] reports the choice of the radial basis function neural network (RBFNN) for its structural simplicity and universal approximation property and RNN for it is a good tool for time series data forecasting for 24-hour ahead forecasting with RMSE as low as 0.24. As the solar cells market grew favorably in 2009, publications also explored the feasibility of ANNs for MPPT of crystalline-Si and non-crystalline-Si photovoltaic modules with high accuracy, MSE as low as 0.05 [65,66]. It also explored temperature-based modeling without meteorological sensors using gene expression programming for the first time and other AI models such as ANNs and ANFIS. The ANNs reduced RMSE error by 19.05% compared to the next-best model [67]. Similar studies were conducted using a hybrid ANN with Levenberg–Marquardt algorithm on solar farms with a 99% correlation between predictions and test values [68]. Other than forecasting tasks, publications also range on topics like smart fault-tolerant systems using ANNs for inverters [69] to MPPT of a three-phase grid-connected photovoltaic system using particle swarm optimization-based ANFIS [70]. More recent papers focus on using more attribute-rich data to perform short-term forecasting of solar power generation for a smart energy management system using ANNs [71], gradient boosting machine algorithms [72], and a more complex multi-step CNN stacked LSTM technique [73] with great accuracy. The emergence of complex boosting techniques is interesting because these algorithms tend to learn faster and in a computationally less costly way than NNs but with similar accuracy.
- Deep Learning Algorithms (#5, #6, #8). These clusters were grouped into one because of the popular deep learning algorithms. The artificial neural network (#5) showcases many vertical links; ANNs are popular across almost all energy conversion tasks and domains for their ability to learn and model nonlinear relationships. In [74], ANN algorithms are used to model a diesel engine with waste cooking biodiesel fuel to predict the brake power, torque, specific fuel consumption, and exhaust emissions, ultimately achieving an MSE as low as 0.0004. An application of an ANN with Levenberg–Marquardt learning algorithm technique for predicting hourly wind speed was reported in [75]. ANNs were popular in the early years of adoption until 2015. Recent studies, where ANNs are the highlighted algorithm, tend to be newer areas of exploration in energy conversion and data sciences. For instance, using 36,100 experimental data points of combustion metrics to control combustion physics-derived models, a 2.9% decrease in MAPE was achieved using ANNs. [76]. However, in most recent studies, ANNs are used as the benchmark of comparison for a more complex or efficient method.
- Electric Power Transmission (#7). This cluster contains research related to the stability and management of unified power flow controllers (UPFC), electrical grids, and transmission lines. In 2008, IEEE held a conference titled “Conversion and Delivery of Electrical Energy in the 21st Century”; several noteworthy publications are included in this cluster. A Lyapunov-based adaptive neural network UPFC was applied to improve power system transient stability [87]. Outage possibilities in the electric power distribution utility are modeled using a para-consistent logic and paraconsistent analysis nodes [60]. Linear matrix inequality optimization algorithms were used to design output feedback power system stabilizers, which ultimately improved efficiency by 68%, compared to the standard controller [88]. A first look at the utility of reinforcement learning was explored by applying a Q-learning method-based on-line self-tuning control methodology to solve the automatic generation control under NERC’s new control performance standards, which achieved all proposed constraints and achieved a 6% reduction in error compared to the traditional controller [89]. After a gap of inactivity in this cluster, a resurgence of these topics began in 2020, focusing heavily on reinforcement learning for smart grid control and more thorough agent, environment, and state definition. A Q-learning agent power system stabilizer is designed for a grid-connected doubly fed induction generator-based wind system to optimize control gains online when wind speed varies, amounting to a nine-time more stable controller [90]. The use of an advanced deep reinforcement learning approach is applied to energy scheduling strategy to optimize multiple targets, including minimizing operational costs and ensuring power supply reliability of an integrated power, heat, and natural-gas system consisting of energy coupling units and wind power generation interconnected via a power grid using a robust 60,000 data points and achieving 21.66% efficiency over particle swarm optimization and outperforming a deep Q-learning agent [91]. As energy systems become increasingly integrated with more complex sourcing and distribution, the interest in this field of publications will continue to grow.
- Battery/Charging Management System (#9). This cluster relates to electric vehicle charging, scheduling, and lithium-ion battery management. In dynamic wireless power transfer systems for electric vehicle charging, the degree of LTM significantly affects energy efficiency and transfer capability. An ANN-based algorithm was propositioned to estimate the LTM value; i.e., the controller would have the ability to establish an adjusted reference value for the primary coil current, offsetting the decrease in energy transfer capacity due to LTM, thus leading to a 32% increase in the value of the transferred energy [92]. A neural network energy management controller (NN-EMC) is designed and applied to a hybrid energy storage system using the multi-source inverter (MSI). The primary objective is to manage the distribution of current between a Li-ion battery and an ultracapacitor by actively manipulating the operational modes of the MSI. Moreover, dynamic programming (DP) was used to optimize the solution to limit battery wear and the input source power loss. This DP-NN-EMC solution was evaluated against the battery-only energy storage system and the hybrid energy storage system MSI with 50% discharge duty cycle. Both the battery RMS current and peak battery current have been found to be reduced by 50% using the NN-EMC compared to the battery-only energy storage system for a large city drive cycle [93]. Battery/ultracapacitor hybrid energy storage systems have been widely studied in electric vehicles to achieve a longer battery life. Ref. [94] presents a hierarchical energy management approach that incorporates sequential quadratic programming and neural networks to optimize a semi-active battery/ultracapacitor hybrid energy storage system. The goal is to reduce both battery wear and electricity expenses. An industrial multi-energy scheduling framework is proposed to optimize the usage of renewable energy and reduce energy costs. The proposed method addresses the management of multi-energy flows in industrial integrated energy systems [95]. This field borrows from a diverse set of algorithms.
- Induction Machine, Digital Storage, and Control System (#10, #12, #13). These three clusters have lost momentum and become unexplored in recent years. Regarding the induction machine, a sensorless vector-control strategy for an induction generator operating in a grid-connected variable speed wind energy conversion system was presented using an RNN, offering a 4.5% improvement upon the benchmark [96]. Cluster #12 combines the publications related to the accurate modeling of state-of-charge and battery storage using ANNs and RNNs [97,98,99]. Cluster #13 includes the publications related to maximum point tracking in wind energy conversion systems using neural network controllers [100,101,102] and energy maximization using neural networks, such as learning vector quantitative neural networks, on a sliding-buoy wave energy converter [54].
- Genetic Algorithm (#11). This cluster deals primarily with the application of the genetic algorithm to various energy conversion systems, as well as other optimization techniques. A genetic algorithm solves both constrained and unconstrained optimization problems, similar to how genetics evolve in nature through natural selection and biological evolution. The genetic algorithm revises a population of individual solutions as it explores different solutions. [103]. Evident on the timeline of this cluster is the consistent use of this optimization technique throughout the years; optimization techniques are often part of a typical data science project pipeline, where the data science algorithm transforms inputs into outputs, and the optimization tools can be used to optimize the inputs, outputs, or algorithm itself. Thus, ANNs or other neural networks are often paired up with the genetic algorithm. A review of how the genetic algorithm is often used to optimize the input space of ANN models and investigate the effects of various factors on fermentative hydrogen production was reported in [104]. A multi-objective genetic algorithm was employed to derive a Pareto optimal collection of solutions for geometrical attributes of airfoil sections designed for 10-meter blades of a horizontal axis wind turbine. The process utilized ANN-modelled objective functions and was discussed in [105]. Ref. [106] reported the high performance and durability of a direct internal reforming solid oxide fuel cell by coupling a deep neural network with a multi-objective genetic algorithm, improving the high-power density by 190% while significantly reducing carbon deposition. A similar approach was undertaken to maximize the exergy efficiency and minimize the total cost of a geothermal desalination system [107].
4. Strengths and Weaknesses
4.1. Ranking Publications
4.2. Artificial Neural Networks
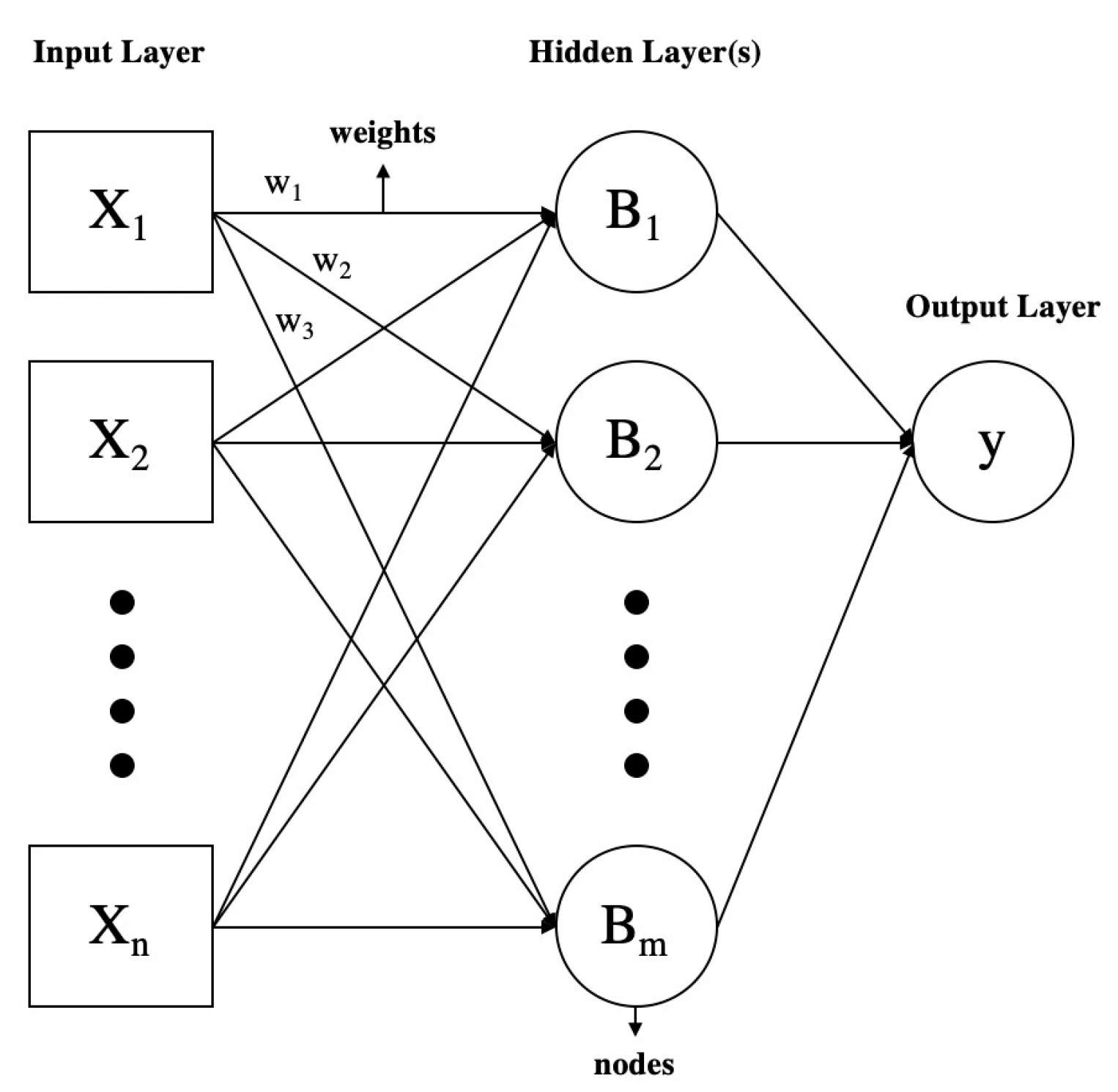
4.2.1. Strengths
- nonlinearity allows for a great fit to almost any dataset,
- noise-insensitivity provides accurate prediction in the presence of slight errors in data, which are common,
- high parallelism allows for fast processing and hardware failure-tolerance,
- the system may modify itself in the face of a changing environment and data by training the neural network once again, and
- its ability to generalize enables the application of the model to unlearned and new data.
4.2.2. Weaknesses
- ANNs’ success depends on both the quality and quantity of the data;
- A lack of decisive rules or guidelines for optimal ANN architecture design;
- A prolonged training time, which could extend from hours to months;
- The inability to comprehensibly explain the process through which the ANN made a given output, often criticized for being black boxes;
- There are parameters that require optimizing, which are at times not intuitively apparent [119].
4.3. Ensemble Learning: XGBoost, Random Forest, Support Vector Machine, Decision Trees
4.3.1. Strengths
4.3.2. Weaknesses
4.4. Long Short-Term Memory
4.4.1. Strengths
4.4.2. Weaknesses
4.5. Convolutional Neural Network
4.5.1. Strengths
4.5.2. Weaknesses
- CNNs’ success also depends on both the quality and quantity of the data;
- A lack of decisive rules or guidelines for optimal CNN architecture design, although different architectures have been studied and show promising results;
- A prolonged training time, which could extend from hours to months;
- The explainability of CNNs outputs is also limited;
- There are parameters and choices in layers that require optimizing, sometimes leading to trial and error until the desired accuracy or error rate is reached.
4.6. Adaptive Network-Based Fuzzy Inference System
4.6.1. Strengths
- Capability to capture the nonlinear structure of a process;
- Strong adaption capability;
- Rapid learning capacity, thanks to its parallel computation capabilities;
- Fewer adjustable parameters than ANNs;
- Universal application.
4.6.2. Weaknesses
4.7. Reinforcement Learning: Q-learning, Deep Deterministic Policy Gradient, Actor Critic
4.7.1. Strengths
4.7.2. Weaknesses
4.8. Other Algorithms Worth Mentioning: Graph Neural Networks and Regression Methods
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| ANN | artificial neural network |
| ANFIS | adaptive neuro-fuzzy inference system |
| ARIMA | autoregressive integrated moving average |
| BPNN | backpropagation neural network |
| CNN | convolutional neural network |
| DDPG | deep deterministic policy gradient |
| GNN | graph neural network |
| LSTM | long short-term memory |
| LTM | lateral misalignment |
| ML | machine learning |
| MPPT | maximum power point tracking |
| MSE | mean squared error |
| NN-EMC | neural network energy management controller |
| RAM | random access memory |
| RBFNN | radial basis function neural network |
| RL | reinforcement learning |
| RMS | root mean square |
| RMSE | root-mean-square error |
| RNN | recurrent neural network |
| SAC | soft actor critic |
| SVM | support vector machine |
| UPFC | unified power flow controller |
| WECS | wind energy conversion systems |
References
- Karsten Würth. What is the Kyoto Protocol? Available online: https://unfccc.int/kyoto_protocol (accessed on 7 November 2022).
- UNFCCC. The Paris Agreement. Available online: https://unfccc.int/process-and-meetings/the-paris-agreement/the-paris-agreement (accessed on 7 November 2022).
- OP26 Outcomes. UN Climate Change Conference UK 2021. 2021. Available online: https://ukcop26.org/the-conference/cop26-outcomes/ (accessed on 7 November 2022).
- IEA. Net Zero Roadmap: A Global Pathway to Keep the 1.5 °C Goal in Reach. 2023. Available online: www.iea.org (accessed on 7 October 2023).
- IEA. Clean Energy Innovation, IEA. 2020. Available online: https://www.iea.org/reports/clean-energy-innovation (accessed on 7 November 2022).
- IEA. Global Hydrogen Review. International Energy Agency, Paris, 2021. Available online: https://www.iea.org/reports/global-hydrogen-review-2021 (accessed on 7 November 2022).
- Incer-Valverde, J.; Patino-Arevalo, L.J.; Tsatsaronis, G.; Morosuk, T. Hydrogen-driven Power-to-X: State of the art and multicriteria evaluation of a study case. Energy Convers. Manag. 2022, 266, 115814. [Google Scholar] [CrossRef]
- IEA. Energy Technology Perspectives 2020. International Energy Agency, Paris. 2020. Available online: https://www.iea.org/reports/energy-technology-perspectives-2020 (accessed on 7 November 2022).
- BloombergNEF. Hydrogen Economy Outlook. Key Messages; Bloomberg Finance L.P: New York, NY, USA, 2020. [Google Scholar]
- IEA. The Future of Hydrogen. International Energy Agency, Paris, 2019. Available online: https://www.iea.org/reports/the-future-of-hydrogen (accessed on 7 November 2022).
- IRENA. The Future of Hydrogen; International Renewable Energy Agency: Abu Dhabi, United Arab Emirates, 2019. [Google Scholar]
- Jacques, B. Notes from the AI Frontier: Modeling the Impact of AI on the World Economy, McKinsey Company. McKinsey Company. 2019. Available online: https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-AI-frontier-modeling-the-impact-of-ai-on-the-world-economy (accessed on 8 November 2022).
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, J.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef] [PubMed]
- EETimes. Digital Data Storage Is Undergoing Mind-Boggling Growth. EETimes. 2016. Available online: https://www.eetimes.com/digital-data-storage-is-undergoing-mind-boggling-growth/ (accessed on 8 November 2022).
- European Commission. Digitalising the Energy System—EU Action Plan; European Commission: Brussels, Belgium, 2022. [Google Scholar]
- Chen, C. A Practical Guide for Mapping Scientific Literature; Nova Science Publishers: Hauppauge, NY, USA, 2016. [Google Scholar]
- Crevier, D. AI: The Tumultuous Search for Artificial Intelligence; BasicBooks: New York, NY, USA, 1993. [Google Scholar]
- Sharma, A.K.; Ghodke, P.K.; Goyal, N.; Nethaji, S.; Chen, W.-H. Machine learning technology in biohydrogen production from agriculture waste: Recent advances and future perspectives. Bioresour. Technol. 2022, 364, 128076. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Du, Y.; Han, S.; Qiu, Q. Global progress in oil and gas well research using bibliometric analysis based on Vosviewer and Citespace. Energies 2022, 15, 5447. [Google Scholar] [CrossRef]
- Chang, C.C.W.; Ding, T.J.; Ping, T.J.; Ariannejad, M.; Chao, K.C.; Samdin, S.B. Fault detection and anti-icing technologies in wind energy conversion systems: A review. Energy Rep. 2022, 8, 28–33. [Google Scholar] [CrossRef]
- Ding, R.; Zhang, S.; Chen, Y.; Rui, Z.; Hua, K.; Wu, Y.; Li, X.; Duan, X.; Wang, X.; Li, J.; et al. Application of machine learning in optimizing proton exchange membrane fuel cells: A review. Energy AI 2022, 9, 100170. [Google Scholar] [CrossRef]
- Alshehri, J.; Alzahrani, A.; Khalid, M. Wind energy conversion systems and artificial neural networks: Role and applications. In Proceedings of the 2019 IEEE Innovative Smart Grid Technologies—Asia (ISGT Asia), Chengdu, China, 21–24 May 2019; pp. 1777–1782. [Google Scholar]
- Ashfaq, A.; Kamran, M.; Rehman, F.; Sarfaraz, N.; Ilyas, H.U.; Riaz, H.H. Role of artificial intelligence in renewable energy and its scope in future. In Proceedings of the 2022 5th International Conference on Energy Conservation and Efficiency (ICECE), Lahore, Pakistan, 16–17 March 2022; pp. 1–6. [Google Scholar]
- van Eck, N.J.; Waltman, L. Software survey: VOSViewer, a computer program for bibliometric mapping. Scientometrics 2009, 84, 523–538. [Google Scholar] [CrossRef]
- Waltman, L.; van Eck, N.J. A smart local moving algorithm for large-scale modularity-based community detection. Eur. Phys. 2013, 86, 471. [Google Scholar] [CrossRef]
- OED Online. Artificial Intelligence; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997. [Google Scholar]
- Sipser, M. Introduction to the Theory of Computation, 3rd ed.; Cengage Learning: Boston, MA, USA, 2013. [Google Scholar]
- McCorduck, P. Machines Who Think, 2nd ed.; A. K. Peters: Natick, MA, USA, 2004. [Google Scholar]
- Lighthill, J. Artificial Intelligence: A Paper Symposium; Science Research Council: London, UK, 1973. [Google Scholar]
- Nilsson, N.J.; Nilsson, N.J. Artificial Intelligence: A New Synthesis; Morgan Kaufmann: San Francisco, CA, USA, 1998. [Google Scholar]
- National Research Council. Funding A Revolution: Government Support for Computing Research; National Academies Press: Washington, DC, USA, 1999. [Google Scholar]
- Ask the AI Experts: What’s Driving Today’s Progress in AI? McKinsey Company. 2018. Available online: https://www.mckinsey.com/capabilities/quantumblack/our-insights/ask-the-ai-experts-whats-driving-todays-progress-in-ai (accessed on 8 November 2022).
- Clark, J. Why 2015 was a breakthrough year in artificial intelligence. Bloom. Technol. 2015, 18. Available online: https://www.pinterest.com/pin/106467978669157536/ (accessed on 8 November 2022).
- Lewis, J.; Schneegans, S.; Straza, T. UNESCO Science Report: The Race Against Time for Smarter Development; UNESCO: Paris, France, 2021; Volume 2021. [Google Scholar]
- Tucker, A.B. Computer Science Handbook; Chapman and Hall/CRC: Newton, MA, USA/Boca Raton, FL, USA, 2004. [Google Scholar]
- van Otterlo, M.; Wiering, M. Reinforcement learning and markov decision processes. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- European Union Agency for Fundamental Rights (FRA). Data Quality and Artificial Intelligence—Mitigating Bias and Error to Protect Fundamental Rights; European Union Agency for Fundamental Rights (FRA): Vienna, Austria, 2019. [Google Scholar]
- Schalkoff, R.J. Artificial Neural Networks; McGraw-Hill Higher Education: New York, NY, USA, 1997. [Google Scholar]
- Hecht-Nielsen, R. Neurocomputing; Addison-Wesley Longman Publishing: Boston, MA, USA, 1989. [Google Scholar]
- Li, F.-F. Large Scale Visual Recognition Challenge 2012 (ILSVRC2012). ImageNet. 2012. Available online: https://www.image-net.org/challenges/LSVRC/2012/results.html/ (accessed on 8 November 2022).
- Seo, D.; Huh, T.; Kim, M.; Hwang, J.; Jung, D. Prediction of air pressure change inside the chamber of an oscillating water column–wave energy converter using machine-learning in big data platform. Energies 2021, 14, 2982. [Google Scholar] [CrossRef]
- MathWorks. MATLAB. Available online: https://www.mathworks.com/products/matlab.html (accessed on 8 November 2022).
- Python Software Foundation. Python. Available online: https://www.python.org/ (accessed on 8 November 2022).
- Medjber, A.; Guessoum, A.; Belmili, H.; Mellit, A. New neural network and fuzzy logic controllers to monitor maximum power for wind energy conversion system. Energy 2016, 106, 137–146. [Google Scholar] [CrossRef]
- Dahbi, A.; Nait-Said, N.; Nait-Said, M.-S. A novel combined mppt-pitch angle control for wide range variable speed wind turbine based on neural network. Int. J. Hydrogen Energy 2016, 41, 9427–9442. [Google Scholar] [CrossRef]
- Moradi, H. Sliding mode type-2 neuro-fuzzy power control of grid-connected DFIG for wind energy conversion system. IET Renew. Power Gener. 2019, 13, 2435. [Google Scholar] [CrossRef]
- Chhipa, A.A.; Kumar, V.; Joshi, R.R.; Chakrabarti, P.; Jasinski, M.; Burgio, A.; Leonowicz, Z.; Jasinska, E.; Soni, R.; Chakrabarti, T. Adaptive neuro-fuzzy inference system-based maximum power tracking controller for variable speed WECS. Energies 2021, 14, 6275. [Google Scholar] [CrossRef]
- Ali Zeddini, M.; Pusca, R.; Sakly, A.; Faouzi Mimouni, M. Pso-based mppt control of wind-driven self-excited induction generator for pumping system. Renew. Energy 2016, 95, 162–177. [Google Scholar] [CrossRef]
- Kariniotakis, G.N.; Stavrakakis, G.S.; Nogaret, E.F. Wind power forecasting using advanced neural networks models. IEEE Trans. Energy Convers. 1996, 11, 762–767. [Google Scholar] [CrossRef]
- Alexiadis, M.C.; Dokopoulos, P.S.; Sahsamanoglou, H.S. Wind speed and power forecasting based on spatial correlation models. IEEE Trans. Energy Convers. 1999, 14, 836–842. [Google Scholar] [CrossRef]
- Sarkar, D.; Contal, E.; Vayatis, N.; Dias, F. Prediction and optimization of wave energy converter arrays using a machine learning approach. Renew. Energy 2016, 97, 504–517. [Google Scholar] [CrossRef]
- Tri, N.M.; Truong, D.Q.; Thinh, D.H.; Binh, P.C.; Dung, D.T.; Lee, S.; Park, H.G.; Ahn, K.K. A novel control method to maximize the energy-harvesting capability of an adjustable slope angle wave energy converter. Renew. Energy 2016, 97, 518–531. [Google Scholar] [CrossRef]
- Ni, C.; Ma, X. Prediction of wave power generation using a convolutional neural network with multiple inputs. Energies 2018, 11, 2097. [Google Scholar] [CrossRef]
- Yang, S.; Deng, Z.; Li, Z.; Zheng, C.; Xi, L.; Zhuang, J.; Zhang, Z.; Zhang, Z. A novel hybrid model based on stl decomposition and one-dimensional convolutional neural networks with positional encoding for significant wave height forecast. Renew. Energy 2021, 173, 531–543. [Google Scholar] [CrossRef]
- Huang, W.; Dong, S. Improved short-term prediction of significant wave height by decomposing deterministic and stochastic components. Renew. Energy 2021, 177, 743–758. [Google Scholar] [CrossRef]
- Ramakumar, R.; Abouzahr, I.; Krishnan, K.; Ashenayi, K. Design scenarios for integrated renewable energy systems. IEEE Trans. Energy Convers. 1995, 10, 736–746. [Google Scholar] [CrossRef]
- Wu, C.; Burke, T.J. Intelligent computer aided optimization on specific power of an otec rankine power plant. Appl. Therm. Eng. 1998, 18, 295–300. [Google Scholar] [CrossRef]
- Da Silva Filho, J.I.; Rocco, A. Power systems outage possibilities analysis by paraconsistent logic. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–6. [Google Scholar]
- Frombo, F.; Minciardi, R.; Robba, M.; Rosso, F.; Sacile, R. Planning woody biomass logistics for energy production: A strategic decision model. Biomass Bioenergy 2009, 33, 372–383. [Google Scholar] [CrossRef]
- Rentizelas, A.A.; Tatsiopoulos, I.P.; Tolis, A. An optimization model for multi-biomass tri-generation energy supply. Biomass Bioenergy 2009, 33, 223–233. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, S.; Zhang, G. Machine learning-based optimal design of a phase change material integrated renewable system with on-site pv, radiative cooling and hybrid ventilations—Study of modelling and application in five climatic regions. Energy 2020, 192, 116608. [Google Scholar] [CrossRef]
- Yona, A.; Senjyu, T.; Saber, Z.Y.; Funabashi, T.; Sekine, H.; Kim, C.-H. Application of neural network to 24-hour-ahead generating power forecasting for pv system. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–6. [Google Scholar]
- Syafaruddin, S.; Hiyama, T.; Karatepe, E. Feasibility of artificial neural network for maximum power point estimation of non crystalline-si photovoltaic modules. In Proceedings of the 2009 15th International Conference on Intelligent System Applications to Power Systems, Curitiba, Brazil, 8–12 November 2009; pp. 1–6. [Google Scholar]
- Celik, A.N. Artificial neural network modelling and experimental verification of the operating current of mono-crystalline photovoltaic modules. Solar Energy 2011, 85, 2507–2517. [Google Scholar] [CrossRef]
- Landeras, G.; López, J.J.; Kisi, O.; Shiri, J. Comparison of gene expression programming with neuro-fuzzy and neural network computing techniques in estimating daily incoming solar radiation in the Basque country (northern Spain). Energy Convers. Manag. 2012, 62, 1–13. [Google Scholar] [CrossRef]
- Çelik, Ö.; Teke, A.; Yıldırım, H.B. The optimized artificial neural network model with Levenberg–Marquardt algorithm for global solar radiation estimation in eastern Mediterranean region of Turkey. J. Clean. Prod. 2016, 116, 1–12. [Google Scholar] [CrossRef]
- Stonier, A.A.; Lehman, B. An intelligent-based fault-tolerant system for solar-fed cascaded multilevel inverters. IEEE Trans. Energy Convers. 2018, 33, 1047–1057. [Google Scholar] [CrossRef]
- Andrew-Cotter, J.; Uddin, M.N.; Amin, I.K. Particle swarm optimization based adaptive neuro-fuzzy inference system for mppt control of a three-phase grid-connected photovoltaic system. In Proceedings of the 2019 IEEE International Electric Machines Drives Conference (IEMDC), San Diego, CA, USA, 12–15 May 2019; pp. 2089–2094. [Google Scholar]
- Rao, C.K.; Sahoo, S.K.; Yanine, F.F. Forecasting electric power generation in a photovoltaic power systems for smart energy management. In Proceedings of the 2022 International Conference on Intelligent Controller and Computing for Smart Power (ICICCSP), Hyderabad, India, 21–23 July 2022; pp. 1–6. [Google Scholar]
- Theocharides, S.; Venizelou, V.; Makrides, G.; Georghiou, G.E. Day-ahead forecasting of solar power output from photovoltaic systems utilising gradient boosting machines. In Proceedings of the 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC) (A Joint Conference of 45th IEEE PVSC, 28th PVSEC 34th EU PVSEC), Waikoloa, HI, USA, 10–15 June 2018; pp. 2371–2375. [Google Scholar]
- Michael, N.E.; Mishra, M.; Hasan, S.; Al-Durra, A. Short-term solar power predicting model based on multistep cnn stacked lstm technique. Energies 2022, 15, 2150. [Google Scholar] [CrossRef]
- Ghobadian, B.; Rahimi, H.; Nikbakht, A.M.; Najafi, G.; Yusaf, T.F. Diesel engine performance and exhaust emission analysis using waste cooking biodiesel fuel with an artificial neural network. Renew. Energy 2009, 34, 976–982. [Google Scholar] [CrossRef]
- Cheggaga, N. New neural networks strategy used to improve wind speed forecasting. Wind. Eng. 2013, 37, 369–379. [Google Scholar] [CrossRef]
- Mishra, C.; Subbarao, P.M.V. Machine Learning Integration With Combustion Physics to Develop a Composite Predictive Model for Reactivity Controlled Compression Ignition Engine. J. Energy Resour. Technol. 2021, 144, 042302. [Google Scholar] [CrossRef]
- Pandarakone, S.E.; Masuko, M.; Mizuno, Y.; Nakamura, H. Deep neural network based bearing fault diagnosis of induction motor using fast Fourier transform analysis. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 3214–3221. [Google Scholar]
- Jeong, H.; Lee, H.; Kim, S.W. Classification and detection of demagnetization and inter-turn short circuit faults in IPMSMs by using convolutional neural networks. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 3249–3254. [Google Scholar]
- Wei, H.; Su, W.; Shi, J. Research on variable speed constant frequency energy generation based on deep learning for disordered ocean current energy. Energy Rep. 2022, 8, 13824–13836. [Google Scholar] [CrossRef]
- Babuška, R. Fuzzy Modeling for Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar]
- Kamalasadan, S. An intelligent coordinated design for excitation and speed control of synchronous generators based on supervisory loops. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–8. [Google Scholar]
- Kamalasadan, S. A new high performance intelligent speed controller for induction motor based on supervisory loops. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–7. [Google Scholar]
- Bonanno, F.; Capizzi, G.; Graditi, G.; Napoli, C.; Tina, G.M. A radial basis function neural network based approach for the electrical characteristics estimation of a photovoltaic module. Appl. Energy 2012, 97, 956–961. [Google Scholar] [CrossRef]
- Huang, H.; Chung, C.-Y. Adaptive neuro-fuzzy controller for static var compensator to damp out wind energy conversion system oscillation. IET Gener. Transm. Distrib. 2013, 7, 200–207. [Google Scholar] [CrossRef]
- Chang, W.-Y. Short-term wind power forecasting using the enhanced particle swarm optimization based hybrid method. Energies 2013, 6, 4879–4896. [Google Scholar] [CrossRef]
- Dastres, H.; Mohammadi, A.; Shamekhi, M. A neural network based adaptive sliding mode controller for pitch angle control of a wind turbine. In Proceedings of the 2020 11th Power Electronics, Drive Systems, and Technologies Conference (PEDSTC), Tehran, Iran, 4–6 February 2020; pp. 1–6. [Google Scholar]
- Chu, C.-C.; Tsai, H.-C. Application of Lyapunov-based adaptive neural network upfc damping controllers for transient stability enhancement. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–6. [Google Scholar]
- Soliman, M.; Emara, H.; Elshafei, A.; Bahgat, A.; Malik, O.P. Robust output feedback power system stabilizer design: An lmi approach. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–8. [Google Scholar]
- Tao, Y.; Bin, Z. A novel self-tuning cps controller based on q-learning method. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–6. [Google Scholar]
- Kosuru, R.; Chen, P.; Liu, S. A reinforcement learning based power system stabilizer for a grid connected wind energy conversion system. In Proceedings of the 2020 IEEE Electric Power and Energy Conference (EPEC), Edmonton, AB, Canada, 9–10 November 2020; pp. 1–5. [Google Scholar]
- Zhang, B.; Hu, W.; Cao, D.; Li, T.; Zhang, Z.; Chen, Z.; Blaabjerg, F. Soft actor–critic-based multi-objective optimized energy conversion and management strategy for integrated energy systems with renewable energy. Energy Convers. Manag. 2021, 243, 114381. [Google Scholar] [CrossRef]
- Tavakoli, R.; Pantic, Z. Ann-based algorithm for estimation and compensation of lateral misalignment in dynamic wireless power transfer systems for ev charging. In Proceedings of the 2017 IEEE Energy Conversion Congress and Exposition (ECCE), Cincinnati, OH, USA, 1–5 October 2017; pp. 2602–2609. [Google Scholar]
- Ramoul, J.; Chemali, E.; Dorn-Gomba, L.; Emadi, A. A neural network energy management controller applied to a hybrid energy storage system using multi-source inverter. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 2741–2747. [Google Scholar]
- Lu, Y.; Liu, W.; Wu, Y.; Huang, J.; Liao, H.; Liu, Y.; Peng, J.; Huang, Z. A hierarchical energy management strategy for battery/ultracapacitor hybrid energy storage systems via supervised learning. In Proceedings of the 2020 IEEE Energy Conversion Congress and Exposition (ECCE), Virtual, 11–15 October 2020; pp. 3698–3703. [Google Scholar]
- Xu, Z.; Han, G.; Liu, L.; Martínez-García, M.; Wang, Z. Multi-energy scheduling of an industrial integrated energy system by reinforcement learning-based differential evolution. IEEE Trans. Green Commun. Netw. 2021, 5, 1077–1090. [Google Scholar] [CrossRef]
- Chen, C.H.; Hong, C.-M.; Cheng, F.-S. Intelligent speed sensorless maximum power point tracking control for wind generation system. Int. J. Electr. Power Energy Syst. 2012, 42, 399–407. [Google Scholar] [CrossRef]
- Soliman, H.; Davari, P.; Wang, H.; Blaabjerg, F. Capacitance estimation algorithm based on dc-link voltage harmonics using artificial neural network in three-phase motor drive systems. In Proceedings of the 2017 IEEE Energy Conversion Congress and Exposition (ECCE), Cincinnati, OH, USA, 1–5 October 2017; pp. 5795–5802. [Google Scholar]
- Giraud, F.; Salameh, Z.M. Neural network modeling of the gust effects on a grid-interactive wind energy conversion system with battery storage. Electr. Power Syst. Res. 1999, 50, 155–161. [Google Scholar] [CrossRef]
- Zhao, R.; Kollmeyer, P.J.; Lorenz, R.D.; Jahns, T.M. A compact unified methodology via a recurrent neural network for accurate modeling of lithium-ion battery voltage and state-of-charge. In Proceedings of the 2017 IEEE Energy Conversion Congress and Exposition (ECCE), Cincinnati, OH, USA, 1–5 October 2017; pp. 5234–5241. [Google Scholar]
- Eskander, M.N. Neural network controller for a permanent magnet generator applied in a wind energy conversion system. Renew. Energy 2002, 26, 463–477. [Google Scholar] [CrossRef]
- Abdesh, M.; Khan, S.K.; Azizur Rahman, M. An adaptive self-tuned wavelet controller for ipm motor drives. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting—Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–4. [Google Scholar]
- Lakshmi, M.J.; Babu, Y.S.K.; Babu, P.M. PMSG based wind energy conversion system for maximum power extraction. In Proceedings of the 2016 Second International Conference on Computational Intelligence Communication Technology (CICT), Ghaziabad, India, 12–13 February 2016; pp. 366–371. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Nath, R.; Das, D. Modeling and optimization of fermentative hydrogen production. Bioresour. Technol. 2011, 102, 8569–8581. [Google Scholar] [CrossRef] [PubMed]
- Mortazavi, S.M.; Soltani, M.R.; Motieyan, H. A pareto optimal multi-objective optimization for a horizontal axis wind turbine blade airfoil sections utilizing exergy analysis and neural networks. J. Wind. Eng. Ind. Aerodyn. 2015, 136, 62–72. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, C.; Zhao, S.; Wang, J.; Zu, B.; Han, M.; Du, Q.; Ni, M.; Jiao, K. Coupling deep learning and multi-objective genetic algorithms to achieve high performance and durability of direct internal reforming solid oxide fuel cell. Appl. Energy 2022, 315, 119046. [Google Scholar] [CrossRef]
- Farsi, A.; Rosen, M.A. Multi-Objective Optimization of a Geothermal Steam Turbine Combined with Reverse Osmosis and Multi-Effect Desalination for Sustainable Freshwater Production. J. Energy Resour. Technol. 2022, 144, 052102. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical Report; California University San Diego La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Dowla, F.U.; Dowla, F.J.; Rogers, L.L.; Rogers, L.L. Solving Problems in Environmental Engineering and Geosciences with Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Swingler, K. Applying Neural Networks: A Practical Guide; Morgan Kaufmann: Burlington, MA, USA, 1996. [Google Scholar]
- Masters, T. Practical Neural Network Recipes in C++; Academic Press Professional: Cambridge, MA, USA, 1993. [Google Scholar]
- Stein, R. Preprocessing data for neural networks. AI Expert 1993, 8, 1–32. [Google Scholar]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Sairamya, N.J.; Susmitha, L.; George, S.T.; Subathra, M.S.P. Hybrid approach for classification of electroencephalographic signals using time–frequency images with wavelets and texture features. In Intelligent Data Analysis for Biomedical Applications; Hemanth, D.J., Gupta, D., Balas, V.E., Eds.; Intelligent Data-Centric Systems; Academic Press: Cambridge, MA, USA, 2019; Chapter 12; pp. 253–273. [Google Scholar]
- Lopez-Guede, J.M.; Ramos-Hernanz, J.A.; Zulueta, E.; Fernadez-Gamiz, U.; Oterino, F. Systematic modeling of photovoltaic modules based on artificial neural networks. Int. J. Hydrogen Energy 2016, 41, 12672–12687. [Google Scholar] [CrossRef]
- Mansoor, M.; Ling, Q.; Zafar, M.H. Short term wind power prediction using feedforward neural network (FNN) trained by a novel sine-cosine fused chimp optimization algorithm (SCHOA). In Proceedings of the 2022 5th International Conference on Energy Conservation and Efficiency (ICECE), Lahore, Pakistan, 16–17 March 2022; pp. 1–6. [Google Scholar]
- Ullah, M.H.; Paul, S.; Park, J.-D. Real-time electricity price forecasting for energy management in grid-tied MTDC microgrids. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23-27 September 2018; pp. 73–80. [Google Scholar]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef] [PubMed]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Breiman, L. Bias, Variance, and Arcing Classifiers; Technical Report, Tech. Rep. 460; Statistics Department, University of California: Berkeley, CA, USA, 1996. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V. Package ‘XGBOOST’. R Version 2019, 90, 1–66. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Shrivastava, P.; Soon, T.K.; Idris, M.Y.B.; Mekhilef, S.; Adnan, S.B.R.S. Lithium-ion battery state of energy estimation using deep neural network and support vector regression. In Proceedings of the 2021 IEEE 12th Energy Conversion Congress & Exposition-Asia (ECCE-Asia), Singapore, 24–27 May 2021; pp. 2175–2180. [Google Scholar]
- Hu, C.; Albertani, R. Wind turbine event detection by support vector machine. Wind Energy 2021, 24, 672–685. [Google Scholar] [CrossRef]
- Ahmed, S.; Khalid, M.; Akram, U. A method for short-term wind speed time series forecasting using support vector machine regression model. In Proceedings of the 2017 6th International Conference on Clean Electrical Power (ICCEP), Santa Margherita Ligure, Italy, 27–29 June 2017; pp. 190–195. [Google Scholar]
- Chen, Z.; Han, F.; Wu, L.; Yu, J.; Cheng, S.; Lin, P.; Chen, H. Random forest based intelligent fault diagnosis for pv arrays using array voltage and string currents. Energy Convers. Manag. 2018, 178, 250–264. [Google Scholar] [CrossRef]
- Kronberg, R.; Lappalainen, H.; Laasonen, K. Hydrogen adsorption on defective nitrogen-doped carbon nanotubes explained via machine learning augmented dft calculations and game-theoretic feature attributions. J. Phys. Chem. C 2021, 125, 15918–15933. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, D.; Yan, J.; Yu, C. Deep learning solution for intra-day solar irradiance fore casting in tropical high variability regions. In Proceedings of the 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC) (A Joint Conference of 45th IEEE PVSC, 28th PVSEC 34th EU PVSEC), Waikoloa, HI, USA, 10–15 June 2018; pp. 2736–2741. [Google Scholar]
- Pani, N.K.K.; Jha, V.A.; Bai, L.; Cheng, L.; Zhao, T. A hybrid machine learning approach to wave energy forecasting. In Proceedings of the 2021 North American Power Symposium (NAPS), College Station, TX, USA, 14–16 November 2021. [Google Scholar]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Future Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Dupond, S. A thorough review on the current advance of neural network structures. Annu. Rev. Control. 2019, 14, 200–230. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Rao, M.; Wang, L.; Chen, C.; Xiong, K.; Li, M.; Chen, Z.; Dong, J.; Xu, J.; Li, X. Data-driven state prediction and analysis of sofc system based on deep learning method. Energies 2022, 15, 3099. [Google Scholar] [CrossRef]
- Ucer, E.; Kisacikoglu, M.; Gurbuz, A.; Rahman, S.; Yuksel, M. A machine learning approach for understanding power distribution system congestion. In Proceedings of the 2020 IEEE Energy Conversion Congress and Exposition (ECCE), Virtual, 11–15 October 2020; pp. 1977–1983. [Google Scholar]
- Soualhi, M.; El Koujok, M.; Nguyen, K.T.P.; Medjaher, K.; Ragab, A.; Ghezzaz, H.; Amazouz, M.; Ouali, M.-S. Adaptive prognostics in a controlled energy conversion process based on long-and short-term predictors. Appl. Energy 2021, 283, 116049. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 8 November 2022).
- Hassoun, M.H. Guide to Convolutional Neural Networks: A Practical Application to Traffic-Sign Detection and Classification; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Ciresan, D.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1237–1242. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Chou, J.-S.; Cheng, T.-C.; Liu, C.-Y.; Guan, C.-Y.; Yu, C.-P. Metaheuristics-optimized deep learning to predict generation of sustainable energy from rooftop plant microbial fuel cells. Int. J. Energy Res. 2022, 46, 21001–21027. [Google Scholar] [CrossRef]
- Bento, P.; Pombo, J.; do Rosario Calado, M.; Mariano, S. Ocean wave power forecasting using convolutional neural networks. IET Renew. Power Gener. 2021, 15, 3341–3353. [Google Scholar] [CrossRef]
- Sun, Y.; Venugopal, V.; Brandt, A.R. Convolutional neural network for short-term solar panel output prediction. In Proceedings of the 2018 IEEE 7th World Conference on Photovoltaic Energy Conversion (WCPEC) (A Joint Conference of 45th IEEE PVSC, 28th PVSEC & 34th EU PVSEC), Waikoloa, HI, USA, 10–15 June 2018; pp. 2357–2361. [Google Scholar]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Močkoř, J. Mathematical Principles of Fuzzy Logic; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Abraham, A. Adaptation of fuzzy inference system using neural learning. In Fuzzy Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2005; pp. 53–83. [Google Scholar]
- Jang, J.-S.R.; Sun, C.-T.; Mizutani, E. Neuro-fuzzy and soft computing—A computational approach to learning and machine intelligence. IEEE Trans. Autom. Control 1997, 42, 1482–1484. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Hezarkhani, A. A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation. Comput. Geosci. 2012, 42, 18–27. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.-S.R. Self-learning fuzzy controllers based on temporal backpropagation. IEEE Trans. Neural Netw. 1992, 3, 714–723. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.; Zhang, H.; Liu, Y.; Han, S.; Li, L. Uncertainty estimation for wind energy conversion by probabilistic wind turbine power curve modelling. Appl. Energy 2019, 239, 1356–1370. [Google Scholar] [CrossRef]
- He, K.; Zhang, C.; He, Q.; Wu, Q.; Jackson, L.; Mao, L. Effectiveness of pemfc historical state and operating mode in pemfc prognosis. Int. J. Hydrogen Energy 2020, 45, 32355–32366. [Google Scholar] [CrossRef]
- Bai, J.; Kadir, D.H.; Fagiry, M.A.; Tlili, I. Numerical analysis and two-phase modeling of water graphene oxide nanofluid flow in the riser condensing tubes of the solar collector heat exchanger. Sustain. Energy Technol. Assess. 2022, 53, 102408. [Google Scholar]
- Melo, F.S. Convergence of Q-Learning: A Simple Proof; Technical Report; Institute of Systems and Robotics: Lisbon, Portugal, 2001; pp. 1–4. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Forestieri, J.N.; Farasat, M. Integrative sizing/real-time energy management of a hybrid supercapacitor/undersea energy storage system for grid integration of wave energy conversion systems. IEEE J. Emerg. Sel. Top. Power Electron. 2019, 8, 3798–3810. [Google Scholar] [CrossRef]
- Zhang, B.; Hu, W.; Li, J.; Cao, D.; Huang, R.; Huang, Q.; Chen, Z.; Blaabjerg, F. Dynamic energy conversion and management strategy for an integrated electricity and natural gas system with renewable energy: Deep reinforcement learning approach. Energy Convers. Manag. 2020, 220, 113063. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Zhu, T.; He, R.; Gong, S.; Xie, T.; Gorai, P.; Nielsch, K.; Grossman, J.C. Charting lattice thermal conductivity for inorganic crystals and discovering rare earth chalcogenides for thermoelectrics. Energy Environ. Sci. 2021, 14, 3559–3566. [Google Scholar] [CrossRef]
- Barker, A.; Murphy, J. Machine learning approach for optimal determination of wave parameter relationships. IET Renew. Power Gener. 2017, 11, 1127–1135. [Google Scholar] [CrossRef]
- Gaafar, E.G.M.; Sidahmed, B.A.M.; Nawari, M.O. The improvement of ldr based solar tracker’s action using machine learning. In Proceedings of the 2019 IEEE Conference on Energy Conversion (CENCON), Yogyakarta, Indonesia, 16-17 October 2019; pp. 230–235. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Programming Languages or Software | Frequency | Years |
|---|---|---|
| MATLAB | 157 | 1999–2022 |
| Python | 35 | 2017–2022 |
| SIMULINK | 20 | 2012–2021 |
| Mathematica | 1 | 2020 |
| Java | 1 | 2020 |
| R | 1 | 2017 |
| C++ | 1 | 2011 |
| Not mentioned | 387 | - |
| Criteria | Weight | Rankine | |||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Data size (number of samples) | 25% | 0–1000 | 1000–9000 | 9000–12,500 | 12,500–16,000 | 16,000–20,000 | +20,000 |
| Data information | 25% | Not mentioned | – | Simulation data | – | – | Real data |
| Performance achieved by an algorithm | 25% | Not mentioned | Objective achieved | 0–10% | 10–30% | 30–100% | +100% |
| Year of publication | 10% | …–1999 | 2000–2010 | 2011–2013 | 2014–2016 | 2017–2019 | 2020–2022 |
| Number of citations (status end 2022) | 10% | 0–5 | 5–10 | 10–15 | 15–50 | 50–100 | +100 |
| Algorithm type | 2.5% | – | Deep learning and graph-based | – | Reinforcement learning | Supervised machine learning and optimization | Supervised machine learning and optimization |
| Memory requirement (GB of RAM) | 2.5% | – | 64, 50, 48, or greater | – | 16 | 8 | 4 or less |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mira, K.; Bugiotti, F.; Morosuk, T. Artificial Intelligence and Machine Learning in Energy Conversion and Management. Energies 2023, 16, 7773. https://doi.org/10.3390/en16237773
Mira K, Bugiotti F, Morosuk T. Artificial Intelligence and Machine Learning in Energy Conversion and Management. Energies. 2023; 16(23):7773. https://doi.org/10.3390/en16237773
Chicago/Turabian StyleMira, Konstantinos, Francesca Bugiotti, and Tatiana Morosuk. 2023. "Artificial Intelligence and Machine Learning in Energy Conversion and Management" Energies 16, no. 23: 7773. https://doi.org/10.3390/en16237773
APA StyleMira, K., Bugiotti, F., & Morosuk, T. (2023). Artificial Intelligence and Machine Learning in Energy Conversion and Management. Energies, 16(23), 7773. https://doi.org/10.3390/en16237773