1. Introduction
According to the International Energy Agency (IEA) 2023 Electricity Market Report, the global installed capacity of wind power reached 906 GW by the end of 2022, accounting for approximately 8% of the total global energy production. It is expected to exceed 1 TW for the first time this year [
1].
Figure 1 illustrates the forecast by the Global Wind Energy Council (GWEC) for new wind turbine installations from 2022 to 2026, indicating an expected annual compound growth rate of 15%. The IEA aims for renewable energy to contribute 61% of total electricity generation by 2030, and wind power, representing around 20% of renewable energy, has emerged as one of the most effective decarbonization tools for the power system [
2]. However, due to the volatility of wind power generation, integrating a large amount of wind energy into the power grid poses significant challenges to the safety and economic operation of the power system. Therefore, accurate power prediction results serve as the foundation for power system analysis and operational control.
Short-term forecast results can be utilized for decision-making and operational purposes in fields such as computer science and meteorology. These include activities such as formulating power dispatch plans, optimizing generation resource scheduling, responding to emergencies, and conducting market transactions. Stakeholders, such as power market participants, energy traders, and power plant operators, rely on short-term forecast data for their business activities and decision-making processes. The term “recent power forecast” refers to the short-term forecast for the upcoming hours, up to a day. In China, renewable energy plants are required to provide a forecast of their power generation for every 15-min interval for the next 0–24 h to the grid company before 8:00 AM [
3].
Currently, there exist three main categories of wind power prediction methods: physical models, statistical models, and artificial intelligence models [
4]. Physical models often depend on numerical weather prediction (NWP) or time series models. They incorporate various relevant variables to predict wind speeds or wind power [
5]. However, these physical models have limitations in achieving accurate short-term wind power forecasts due to their high computational complexity and slow updates. Traditional statistical models, such as autoregressive moving average (ARMA) models [
6] and autoregressive integrated moving average (ARIMA) models [
7], are commonly used for short-term forecasts within 6 h. These models assist in the control and tracking of wind turbines [
8,
9]. However, most statistical models assume linearity and struggle to handle the irregular and nonlinear characteristics of wind power series.
In recent years, several artificial intelligence models have successfully improved wind power prediction by capturing complex, nonlinear relationships within historical data [
10,
11]. The following deep learning models have been developed and utilized over the past six years: convolutional neural networks (CNN) [
12], recurrent neural networks (RNN), long short-term memory (LSTM) [
13], deep residual networks [
14], stacked autoencoders, deep neural networks (DNN) [
15], gated recurrent networks [
16], and deep hybrid models [
17]. Previous research has demonstrated that deep learning-based models outperform statistical and physical models [
18]. Compared with other renewable energy sources, wind power prediction models based on deep neural networks not only enhance forecast accuracy but also reduce operational costs, thus increasing the competitiveness of wind energy. Recent studies have proposed various approaches to wind power prediction. Some have relied on lagged wind power data or directly correlated variables, such as wind speed and its periodicity, to calculate wind power using specific power curves. For instance, Xu Peihua et al. [
19] introduced the DWT_AE_BiLSTM model based on deep learning for short-term wind power prediction, achieving an accuracy improvement of over 3.4% compared with traditional algorithms. Bangru Xiong et al. [
20] suggested that the AMC-LSTM hybrid model, which integrates multiscale extended features and dynamically allocates weights to physical attribute data using attention mechanisms, effectively addresses the issue of differentiating the importance of input data. Sahra Khazaei et al. [
21] proposed a high-precision hybrid method for short-term wind power prediction utilizing historical wind farm data and numerical weather prediction (NWP) data, where the accuracy of the forecast was significantly impacted by the feature selection method. Ling Huang et al. [
22] presented the BiLSTM-CNN-WGAN-GP model for short-term wind power prediction, which applied a generative adversarial network (WGAN-GP) to extract data distribution characteristics for wind power output and improve prediction accuracy.
Although artificial intelligence models have achieved significant effectiveness in wind power prediction, the characteristics of wind power, such as volatility, periodicity, time-shift, and aggregation [
23], result in varying forecast accuracies for the same model in different seasons. Taking a wind farm in Zaoyang, Hubei Province, China as an example, the forecast accuracy is generally higher in the summer and autumn compared with spring and winter (refer to
Table 1). By analyzing historical data, it can be observed that inaccurate forecasts often occur during weather transitions (sudden weather changes) where the data tends to be underestimated. In China, the east wind prevails in the spring, the southeast wind prevails in the summer, the west wind prevails in autumn, and the northwest wind prevails in the winter. The east and northwest winds exhibit drastic changes and are often accompanied by occurrences of ice cover, whereas the southeast and west winds are relatively calm (refer to
Figure 2). Addressing forecast accuracy during weather transitions could effectively improve overall forecast accuracy for this wind farm.
The authors suggest that the underestimation of forecast data during weather transitions is caused by insufficient samples of weather transition data, resulting in inadequate training of the model. In this study, two volatility indicators, namely mutation rate (MR) and local mutation rate (LMR), are introduced. These indicators, distinct from the volatility characteristic indicators mentioned in [
24], such as amplitude rate (AR), fluctuation rate (FR), and ramp rate (RR), effectively detect weather transition data. Moreover, a data training model similar to TimeGAN [
25] is used to generate weather data samples that exhibit the characteristics of weather transitions. To ensure the usability of the sample data for training, a wind/power function generation algorithm was proposed. The generated training samples, combined with samples generated from historical data, were used to train the wind power prediction model. The results demonstrated a significant improvement in forecast accuracy for the same model, with the most pronounced increase observed during the winter and spring seasons, thus confirming the effectiveness of this model framework.
The remaining sections of this paper are organized as follows:
Section 2 presents the relevant content of the proposed method. In
Section 3, the implementation framework of the method, as well as the extraction of meteorological data during weather transitions and the generation of training samples, are described in detail.
Section 4 provides a detailed analysis of the prediction results of the algorithm for selected stations. Finally,
Section 5 summarizes the algorithm.
3. Day-Ahead Prediction Algorithm Processing Framework
3.1. Introduction of the Framework
To address the demand for day-ahead prediction, we propose an algorithmic processing framework that meets application requirements. The steps are as follows:
- (1)
Construct a training set input X, containing actual wind speed sequences, and a training output Y of an actual power sequence. The training set may also include actual wind direction, numerical forecast data sequences (wind speed and wind direction), as well as time sequences (year, month, day, hour, and minute).
- (2)
Utilize a sigmoid approximation algorithm to eliminate training data that do not adhere to the wind speed–power curve.
- (3)
Calculate the mutation rate for each data group using the mutation rate formula (Equations (7) and (8)). Extract a portion of training data with the highest mutation rates based on the proportion α to form a new training dataset.
- (4)
Employ the newly created training dataset as input to train the data augmentation model.
- (5)
Utilize the trained data augmentation model to generate new training data.
- (6)
Use the sigmoid approximation algorithm to remove generated training data that does not conform to the wind speed–power curve.
- (7)
Merge the newly generated dataset with the originally constructed initial dataset and shuffle the dataset according to specified rules.
- (8)
Train the data using the designed power prediction model.
- (9)
Predict power and perform error analysis on the prediction results.
The algorithm processing framework is depicted in
Figure 10.
3.2. Data-Cleaning Methods
Due to factors such as communication interruptions and equipment malfunctions, certain data points may deviate from the average wind power curve. For instance, there are instances of higher power output at lower wind speeds. This discrepancy may be attributed to faults in the wind speed measurement apparatus. Conversely, during periods of elevated wind speeds, a significant reduction in power output could be indicative of equipment shutdowns.
Consequently, the raw data collected by the system must undergo a specific process of cleaning and interpolation before it can be utilized further. The wind power curve is approximated using the sigmoid function (Equation (10)) for solution. The parameters to be solved are
a and
b, where
a represents the slope and
b represents the center point.
Once the wind power curve function is obtained, it can be processed with specific thresholds for delineation. This process will result in the creation of two enveloping curves centered around the fitted wind power curve. Data beyond the envelope curves will be flagged and subjected to cleaning procedures, whereas data within the envelope boundaries will be retained.
3.3. Data Augmentation Model based on GAN
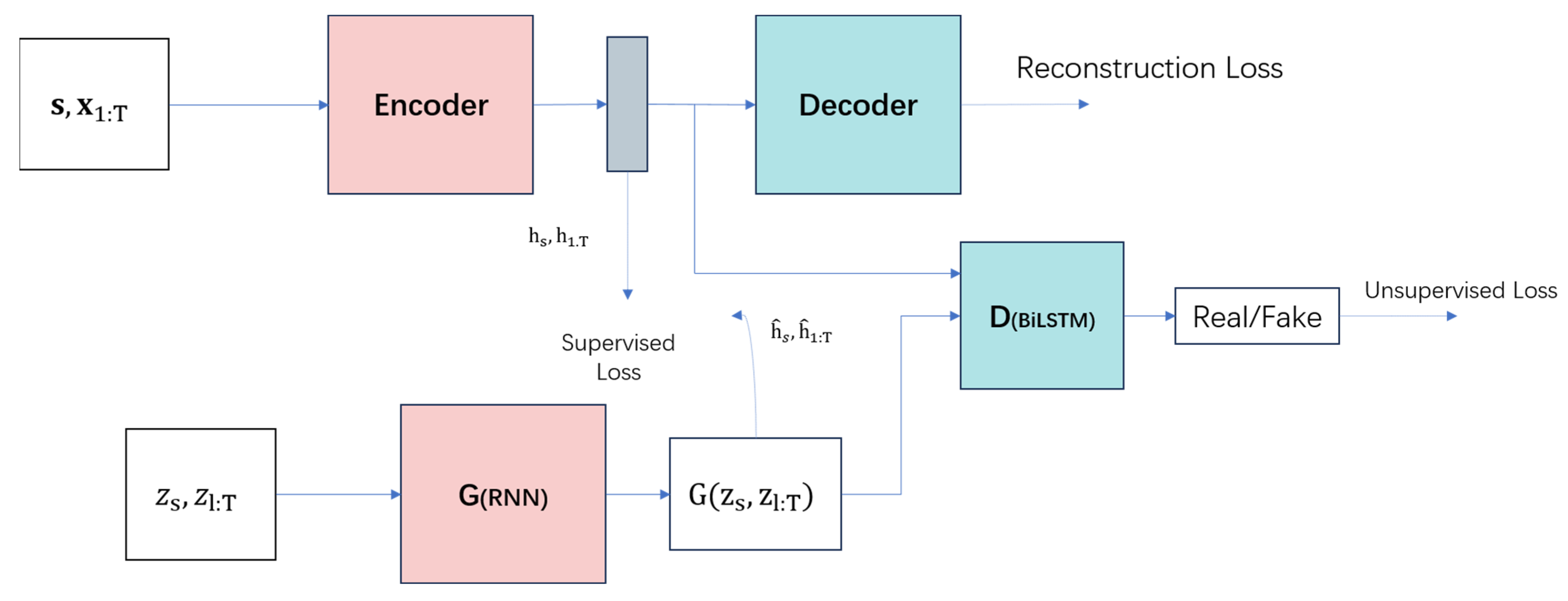
Data augmentation presents a framework (
Figure 11) that leverages both traditional unsupervised GAN training methods and controllable supervised learning techniques. By combining an unsupervised GAN network with a supervised autoregressive model, the network aims to generate a time series with preserved temporal dynamics. The architecture is illustrated in
Figure 11. The framework’s input is perceived to consist of two elements: a static feature and temporal feature. S represents the static feature vector at the encoder input, whereas X represents the temporal feature vector. The generator takes tuples of static and temporal random feature vectors extracted from known distributions. Real and synthetic latent codes
and
are used to compute the network’s supervised loss. The discriminator receives tuples of real and synthetic latent codes, classifying them as real (
) or synthetic (
).
3.3.1. Embedded and Recovery Functions
Within the data augmentation model, an embedding function (Equation (11)) is employed to transform original time series data into a lower-dimensional embedding representation, capturing essential data features. The recovery function (Equation (12)) then transforms the embedding representation back into the original form of time series, preserving the temporal dynamics of the data. In these equations, the tilde (~) operator denotes the representation as real or synthetic. These two components together constitute part of the autoencoder, learning the latent representation of time-series data through an encoding and decoding process, laying the foundation for the generation process. The embedding and recovery functions can be parameterized using any chosen architecture, with the requirement that they are autoregressive and adhere to a causal order (i.e., the output at each step depends only on preceding information).
3.3.2. Generator and Discriminator Functions
In the data augmentation model, the generator (Equation (13)) employs the embedding function and random noise input to produce new synthetic time-series data. Through training, the generator becomes capable of preserving temporal continuity and naturalness. The discriminator function (Equation (14)) assesses the similarity between generated and real sequences, gradually aligning the generated data’s distribution with that of real data through adversarial training mechanisms.
3.3.3. Joint Learning of Encoding, Generation, and Iteration
The data augmentation model employs multiple loss functions for training, including the reconstruction loss of the embedding function (Equation (15)), adversarial losses of the generator and discriminator (Equation (16)), as well as temporal coherence loss (Equation (17)). By optimizing these loss functions, the model can learn the temporal dynamics and features of time-series data. The training process of the model follows an iterative approach, where optimization functions are used to update model parameters in each iteration, minimizing the loss functions. Through multiple iterations, the model progressively enhances the quality and similarity of the generated time series.
The reconstruction loss of the embedding function is utilized to assess the performance of the embedding function. It quantifies the reconstruction error between the output of the embedding function and original time-series data. The objective of this loss function is to ensure that the embedding function is capable of extracting crucial features and temporal dynamics from the original data.
A crucial component supporting the augmentation model is the adversarial loss between the generator and discriminator. The generator’s objective is to produce synthetic time series resembling real data, whereas the discriminator is trained to differentiate between generated and real sequences. The adversarial loss function gauges the adversarial performance between the generator and discriminator by maximizing the generator’s capability to produce authentic samples and minimizing the difference in the discriminator’s accuracy in identifying generated samples.
Relying solely on the binary adversarial feedback from the discriminator may be insufficient to motivate the generator to capture the progressive conditional distribution in the data. To achieve this goal more effectively, additional losses are introduced for further learning. In an alternating, closed-loop fashion, the generator receives the embedded sequence h1:t − 1 of real data (computed by the embedding network) to generate the next latent vector.
The objective of temporal coherence loss is to capture the temporal dynamics of the generated sequence. It measures the coherence between consecutive time steps in the generated time series. The temporal coherence loss encourages the generated sequence to maintain smoothness and continuity over time, capturing the time dependencies present in real data.
In summary, is used to model the dynamic relationships between time steps, with the real latent variables from the embedding network as the target. is used to fit the real distribution through adversarial evaluation.
Through experimentation, this model demonstrates the combination of the versatility of unsupervised GAN methods and the control over conditional temporal dynamics provided by supervised autoregressive models. Leveraging the contributions of supervised learning and jointly trained embedding networks, a GAN-based model achieves consistency with state-of-the-art benchmarks in generating realistic time-series data. resulting in significant improvements.
3.4. Evaluation Criteria for Generated Data from GAN-Based Model
Synthetic data inevitably diverges from the original (actual) data. Given the dataset’s manifold characteristics, visualizing and comprehending them together is an intricate process. To facilitate a more comprehensive comparison and understanding of the interrelationships within datasets, prevalent visualization techniques such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) can be employed. Both techniques leverage dimensionality reduction to visualize datasets with a multitude of dimensions (i.e., features). Though both PCA and t-SNE can achieve this, their primary distinction lies in their goals: PCA strives to retain the global structure of data (by focusing on preserving overall dataset variance), whereas t-SNE aims to preserve local structure (by ensuring proximity of neighboring points in the original data translates to proximity in the reduced space).
In addition to conforming to specific distributions, the generated dataset must also ensure that the actual wind speeds and real power outputs adhere to the corresponding wind speed–power curve. Two approaches can achieve this: (1) Introducing an attention mechanism, which requires modifying the data augmentation model; (2) Directly removing generated data that does not conform to the wind power curve. This framework employs the latter method.
3.5. Day-Ahead Power Forecast Accuracy Calculation Criteria
The day-ahead average power forecast accuracy is determined by calculating the daily root mean square error (
), with the formula for daily
as follows:
where:
: Actual power at time
: Predicted power at time .
: Operating capacity at time .
: Total number of samples.
The accuracy (
) is computed using the formula in Equation (19).
4. Experiments and Results
To verify the effectiveness of the day-ahead predictive algorithm, an experiment was conducted at a wind farm located in Zaoyang City (
Figure 12), Hubei Province. The wind farm comprises up to 16 turbines with a maximum installed capacity of 48 megawatts. The experiment utilized data spanning from 00:00 on 29 June 2021 to 23:45 on 28 February 2023, totaling 58,560 data records with a time interval of 15 min.
4.1. Data Cleansing and Dataset Generation
The number of power generation tasks executed by the wind farm varies each day. Therefore, it is necessary to apply a corrective adjustment to the output power. The formula for this adjustment is as follows:
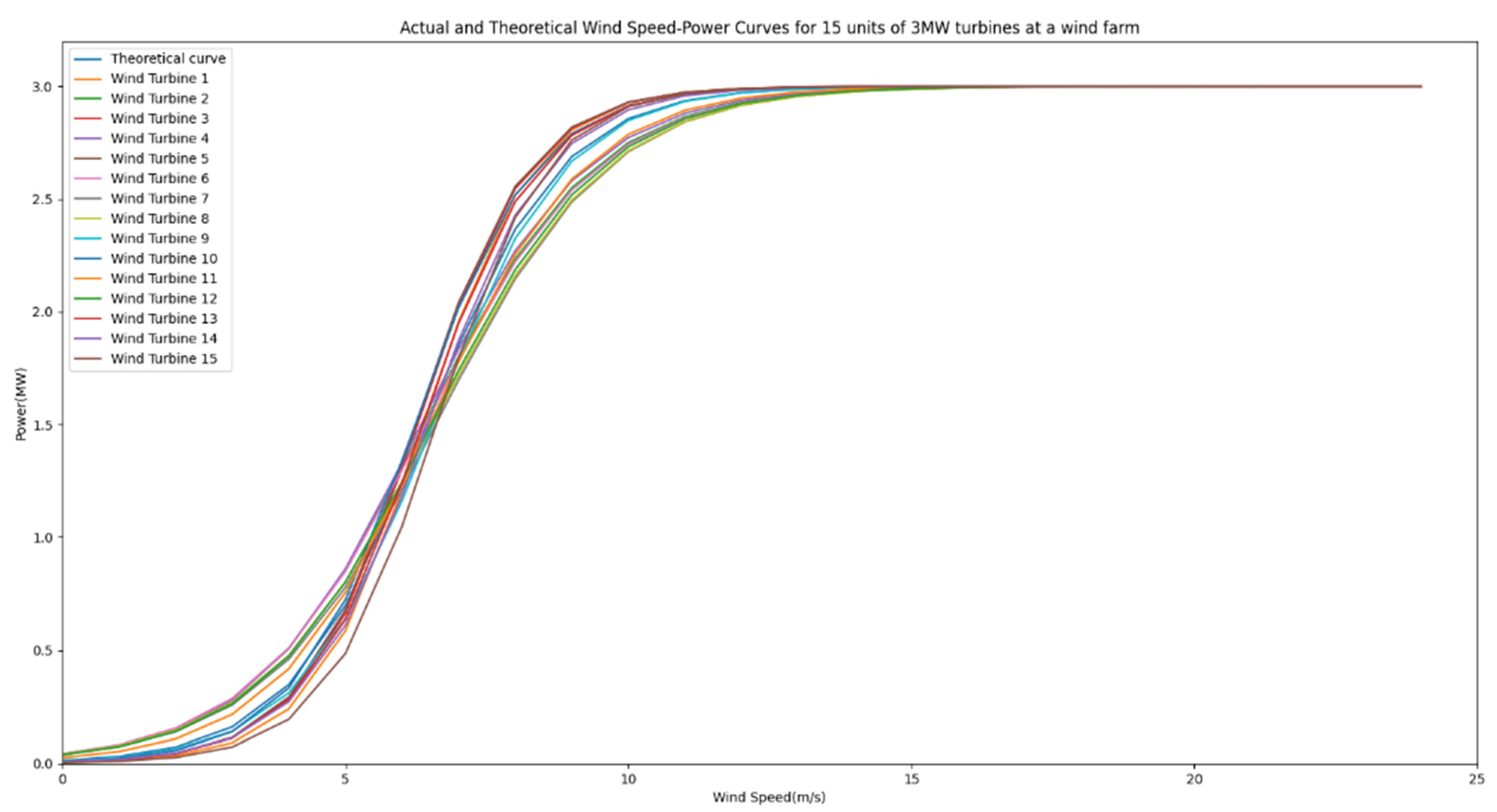
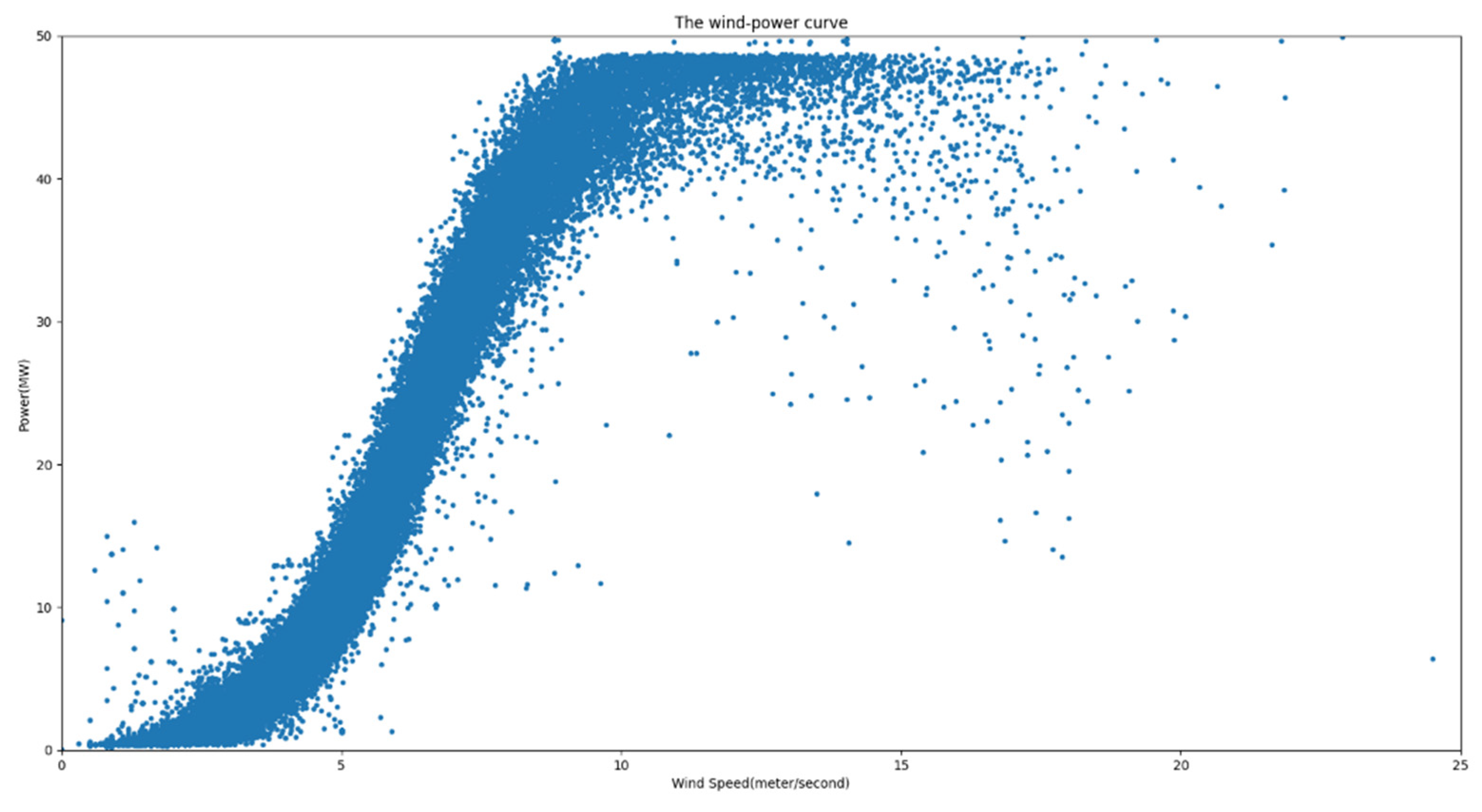
From
Figure 13, it is evident that the majority of the data aligned with the wind power curve distribution. The nominal installed capacity was 48 MW. Utilizing Equation (10), parameter A was computed as 0.83735637, whereas the value of B was determined to be 6.4278509. With the derived wind power curve function, it becomes possible to employ a designated threshold (set at 0.15) for the labeling process. The outcomes of this labeling procedure are illustrated in
Figure 14. The red segment represents the retained valid data, whereas the 468 instances of anomalous data have been marked.
For wind speed data that has undergone the labeling process, subsequent correction using linear interpolation is necessary. According to the linear interpolation formula (Equation (21)), considering a total of
continuous time-series data points denoted as
, …
, …
(where
= 1, 2, …
− 1), Xt + i represents unknown or anomalous values (with a maximum of
− 2 unknown or anomalous values), whereas
and
are known values. Utilizing
and
, interpolation was performed to supplement the data.
where:
is the measured wind speed.
After wind speed correction, the revised power can be computed using Equation (22). From Equation (22), it is evident that
and
represent time-series data. Here,
serves as the reference data with
data points, and
represents the data requiring correction, with n data points. Notably,
<
, and the data needing correction is included within the
time series.
In the formula:
, is the measured power and measured wind speed of the wind farm;
is the Nth time series power value of the data needing correction;
is the Nth time series wind speed value of the reference data;
is the average wind speed of n time series wind speeds of the reference data;
is the average power of n time series powers of the data needing correction;
is the standard deviation of m time series wind speeds of the reference data;
is the standard deviation of m time series wind speeds of the data needing correction; and
is the correlation coefficient between n time series of the reference and corrected power data.
The scatter plot of wind speed–power after correction is illustrated in
Figure 15, with blue dots representing post-correction wind speed and power data. This processed data can subsequently be utilized for dataset generation.
Day-ahead power prediction requires predicting the power values for each 15-min interval of the morning of the upcoming day. This accounts for a total of 96 data points. Consequently, the model’s output is a power sequence with a length of 96. The available training data consists of data from the day before and days prior, encompassing both numerical forecast data and actual collected data. Within this algorithm, data from the last three days, including numerical forecast data and time data for the current day and the day after, are utilized. This results in a training dataset of 39 dimensions, each with a length of 96. To achieve optimal training efficacy, a sliding extraction approach was employed for dataset generation, leading to the creation of 55,392 sets of training data.
4.2. Augmentation and Quality Assessment of High MR Datasets
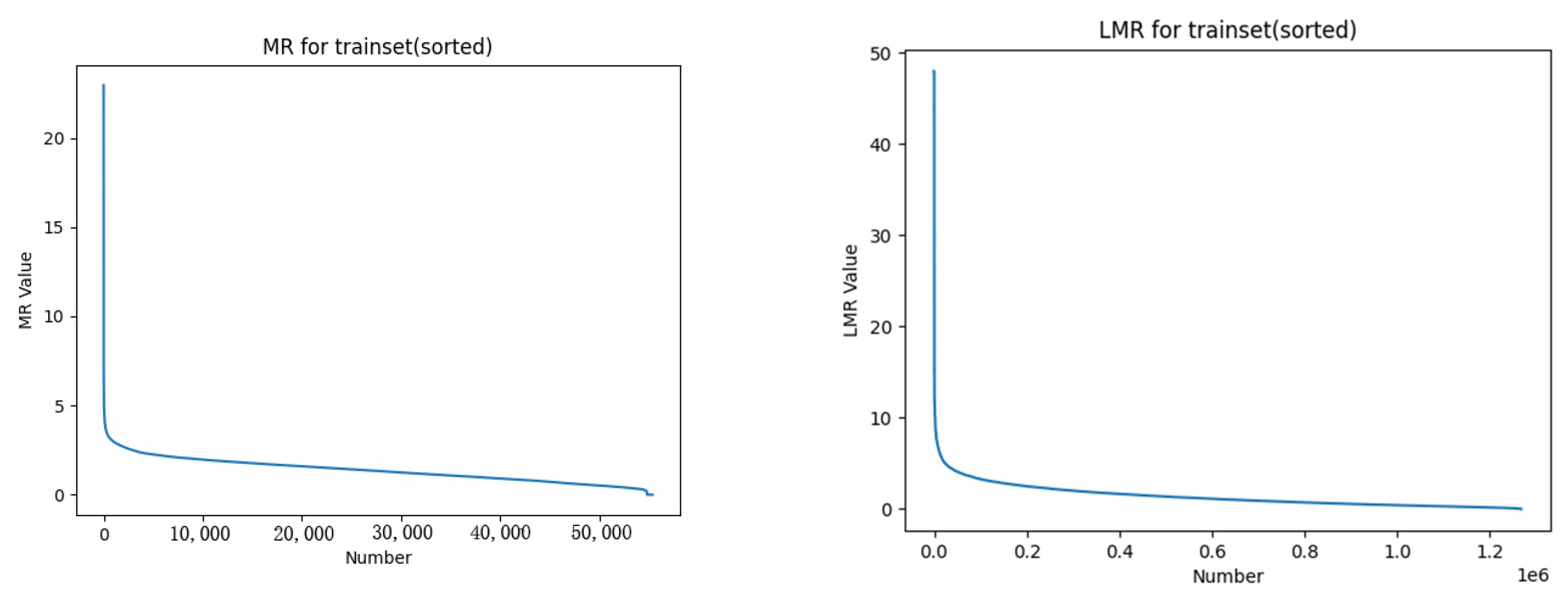
For the generated dataset of over 50,000 sets of training data, mutation rates and average mutation rates were computed according to the respective formulas. The mutation and average mutation rate curves of the training set are illustrated in
Figure 16. From the graph, it is evident that approximately 1% of the data exhibited mutation rates significantly higher than the average mutation rate.
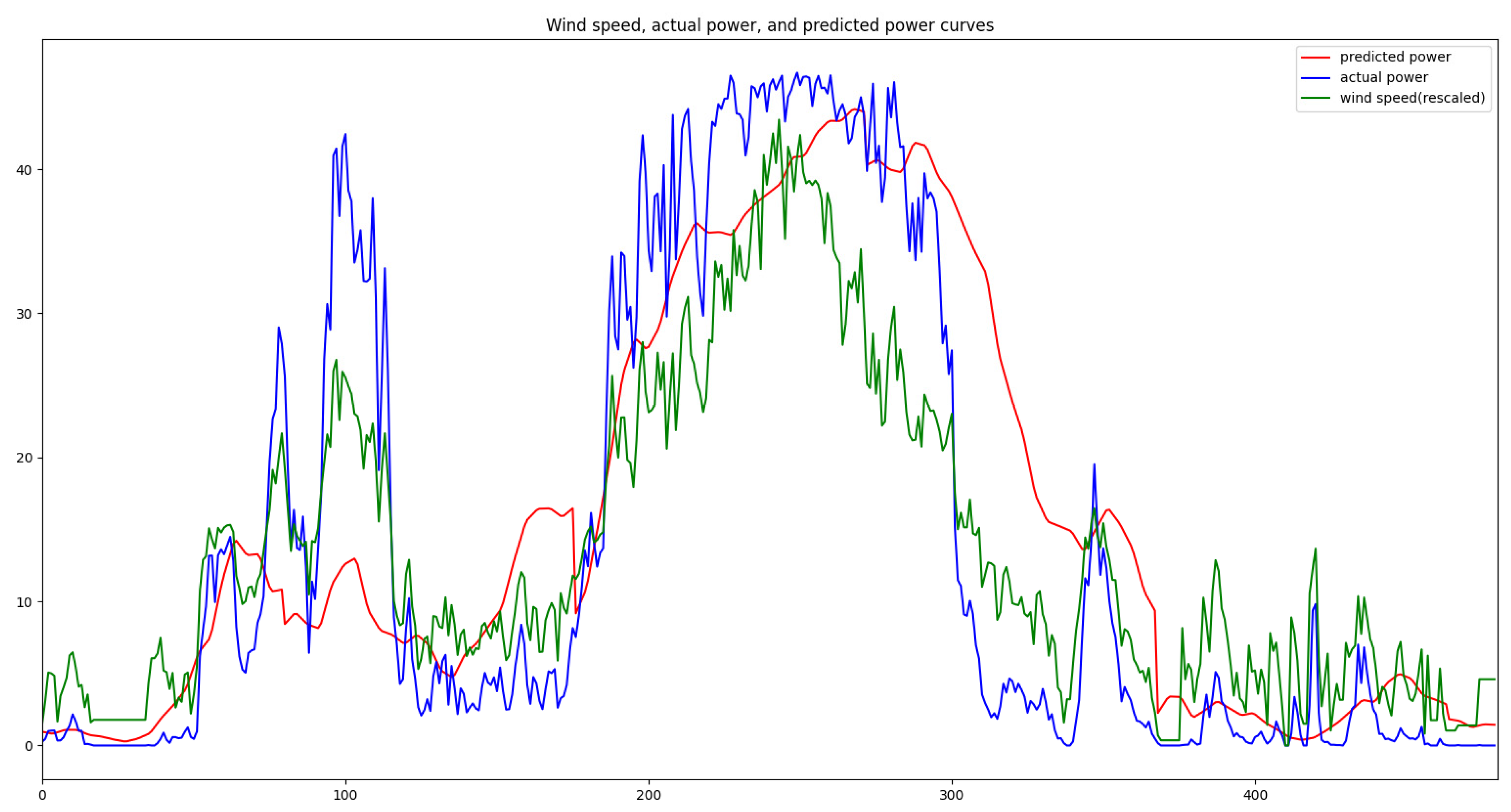
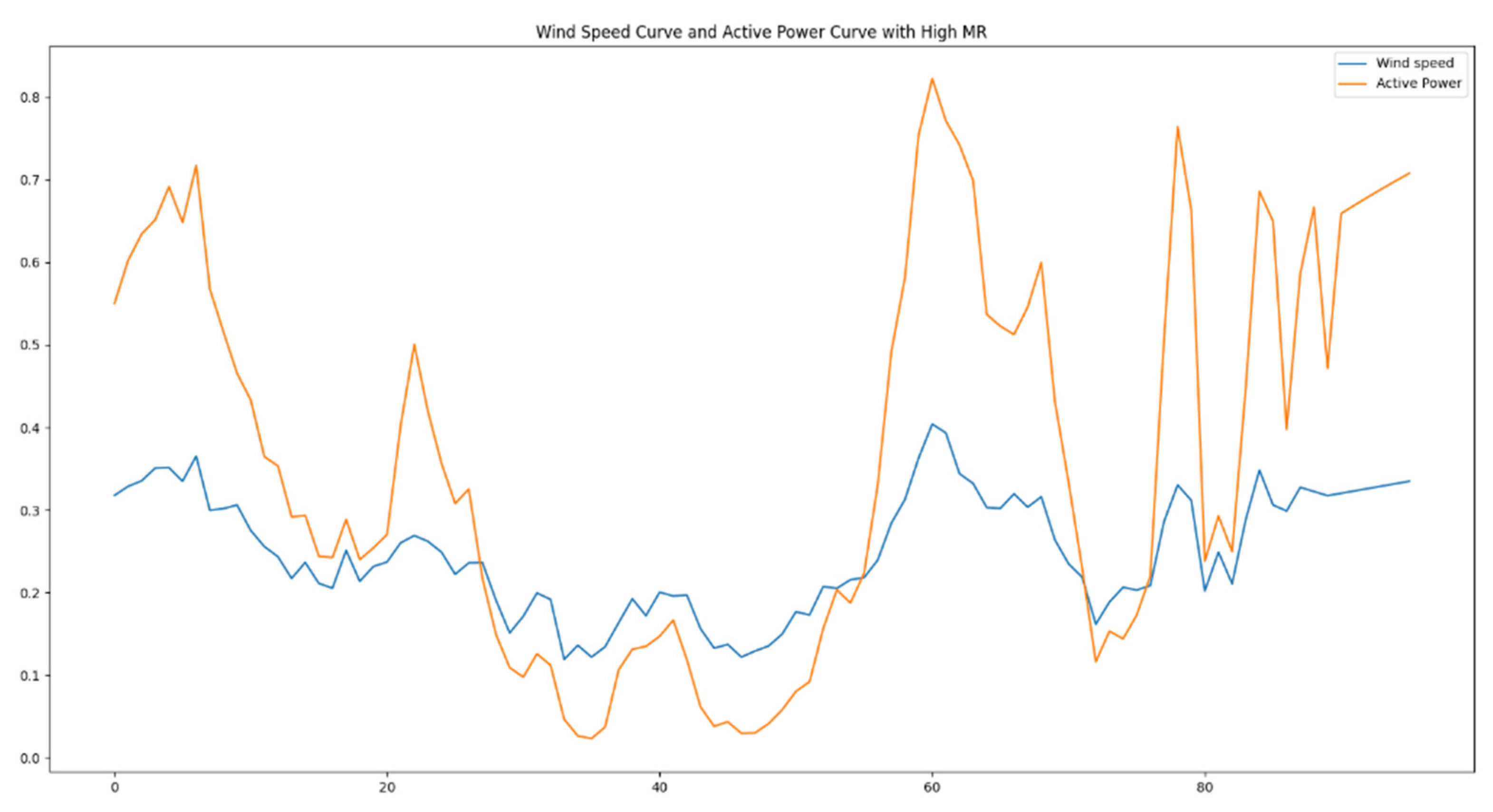
Figure 17 depicts a segment of training data chosen to exhibit the high mutation rates, showcasing the wind speed and power curves. From the graph, it is evident that as wind speed experiences intense fluctuations, there are corresponding substantial fluctuations in the power output. This subset of data within the training set could impact the precision of the model’s predictions. Consequently, data augmentation is necessary for this specific subset of training data.
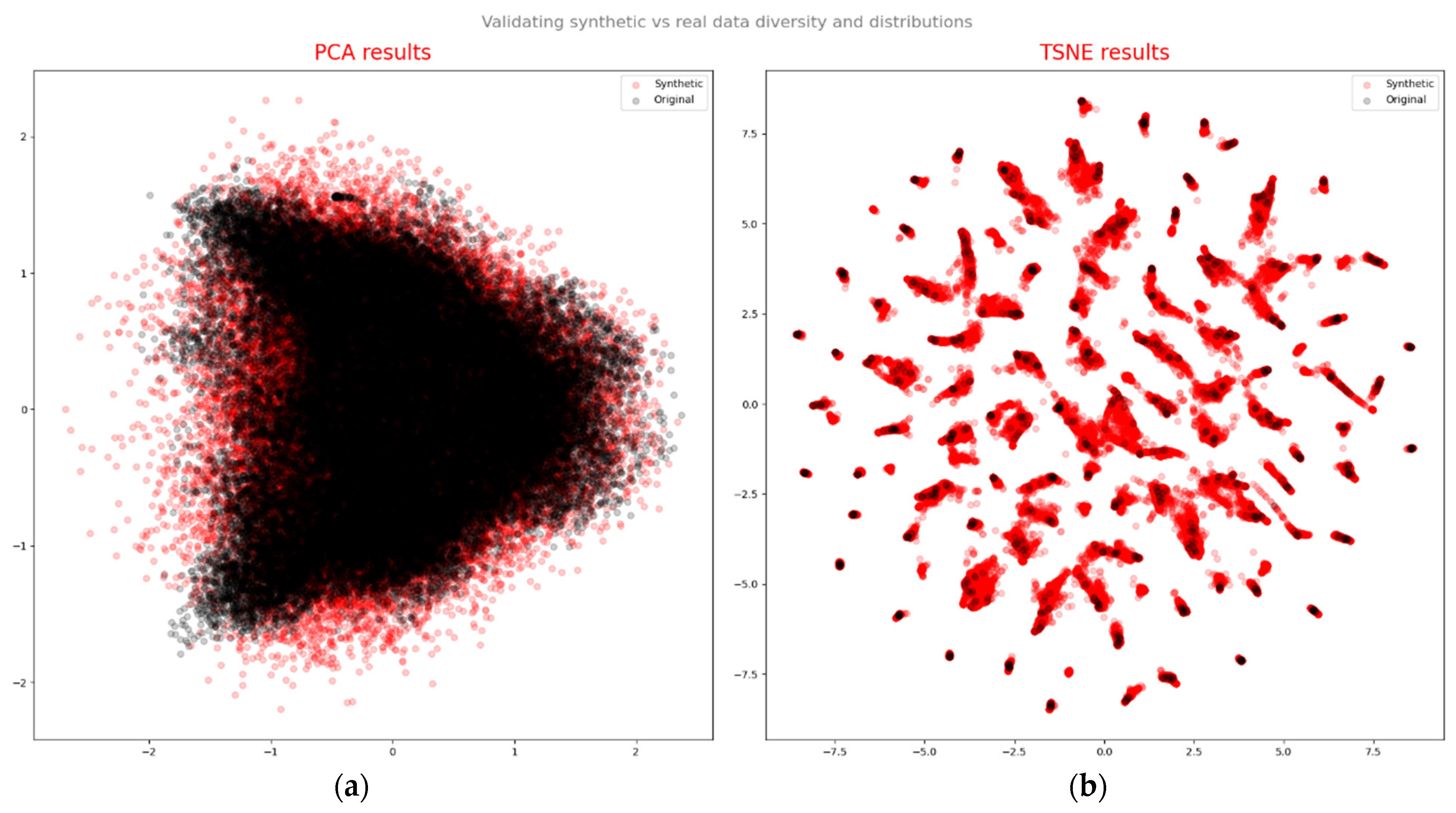
Based on the quality assessment of generated data, an overall evaluation was conducted considering three aspects: diversity, fidelity, and effectiveness of the generated samples. Principal component analysis (PCA), a linear method, identifies a new basis with orthogonal vectors that capture the maximum variance directions in the data. We computed the first two components using real data, then projected both real and synthetic samples onto the new coordinate system (as shown in
Figure 18a). Though PCA plots may not have yielded a definitive conclusion, t-distributed stochastic neighbor embedding (t-SNE) plots revealed a similar distribution pattern between the original (black) and synthetic (red) data (as depicted in
Figure 18b). t-SNE is a non-linear manifold learning technique used for high-dimensional data visualization [
29]. It transforms the similarity between data points into joint probabilities, aiming to minimize the Kullback–Leibler divergence between low-dimensional embedding and high-dimensional data.
Figure 18 presents the outcomes of PCA and t-SNE, qualitatively assessing the similarity of distributions between real and synthetic data. Both methods exhibited strikingly similar patterns and noticeable overlaps, indicating that the synthetic data captured crucial aspects of real-data features.
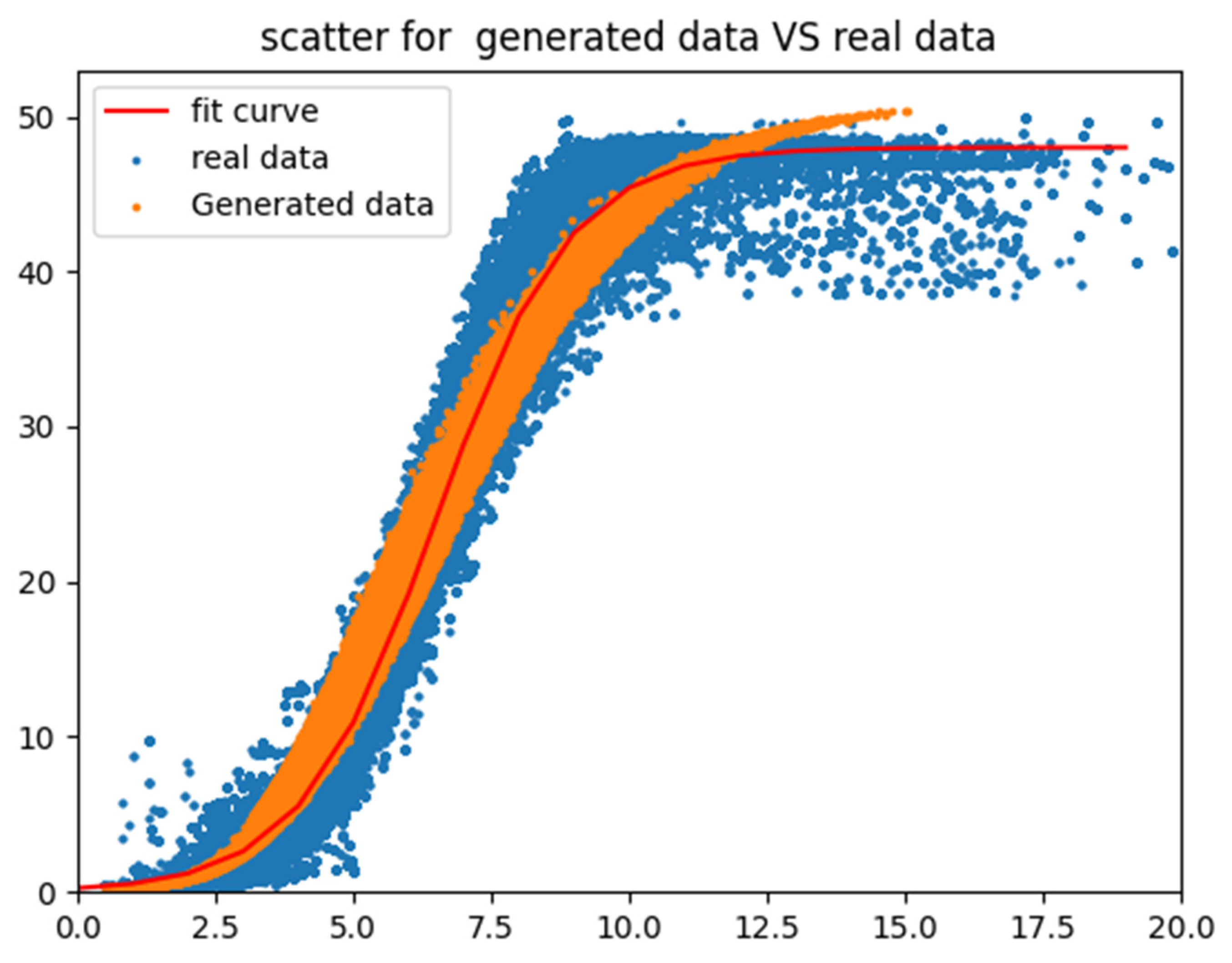
By extracting wind speed and power values from the generated dataset and overlaying them onto a scatter plot based on real data (as shown in
Figure 19), we observed that the generated scatter plot broadly followed the trend of the wind speed–power curve, with the exception of an overestimation in power for wind speeds exceeding 11 m per second.
4.3. Power Prediction Accuracy Comparison
To validate the effectiveness of this framework, we selected several algorithms mentioned in
Table 1, such as LSTM and DWT_AE_BiLSTM, for comparison. The comparison of their performance was conducted based on two dimensions. Firstly, the accuracy of power prediction was evaluated on a monthly basis.
From
Figure 20,
Figure 21,
Figure 22 and
Figure 23, it can be observed that after data augmentation, the LSTM algorithm achieved higher accuracy in power prediction compared with before augmentation, with an average improvement of 3.83%. Specifically, the accuracy improvement exceeded 5.43% in months 3, 4, 6, and 8, and even reached 11.1% in April.
Using the AMC-LSTM algorithm for power prediction in wind farms (
Figure 21 accuracy was improved by 3.02% after extracting mutation data for data augmentation, with a 5.12% improvement in March.
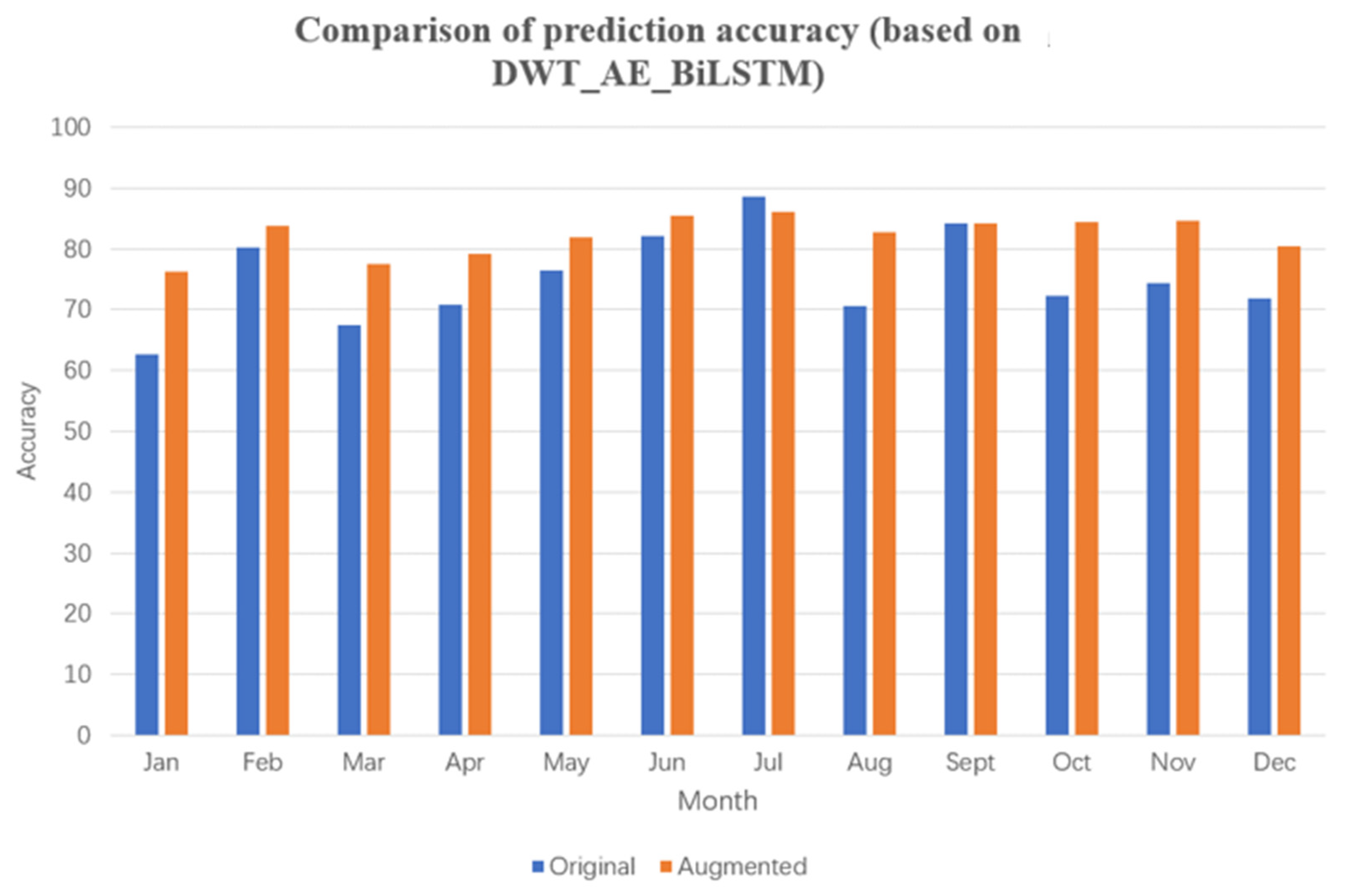
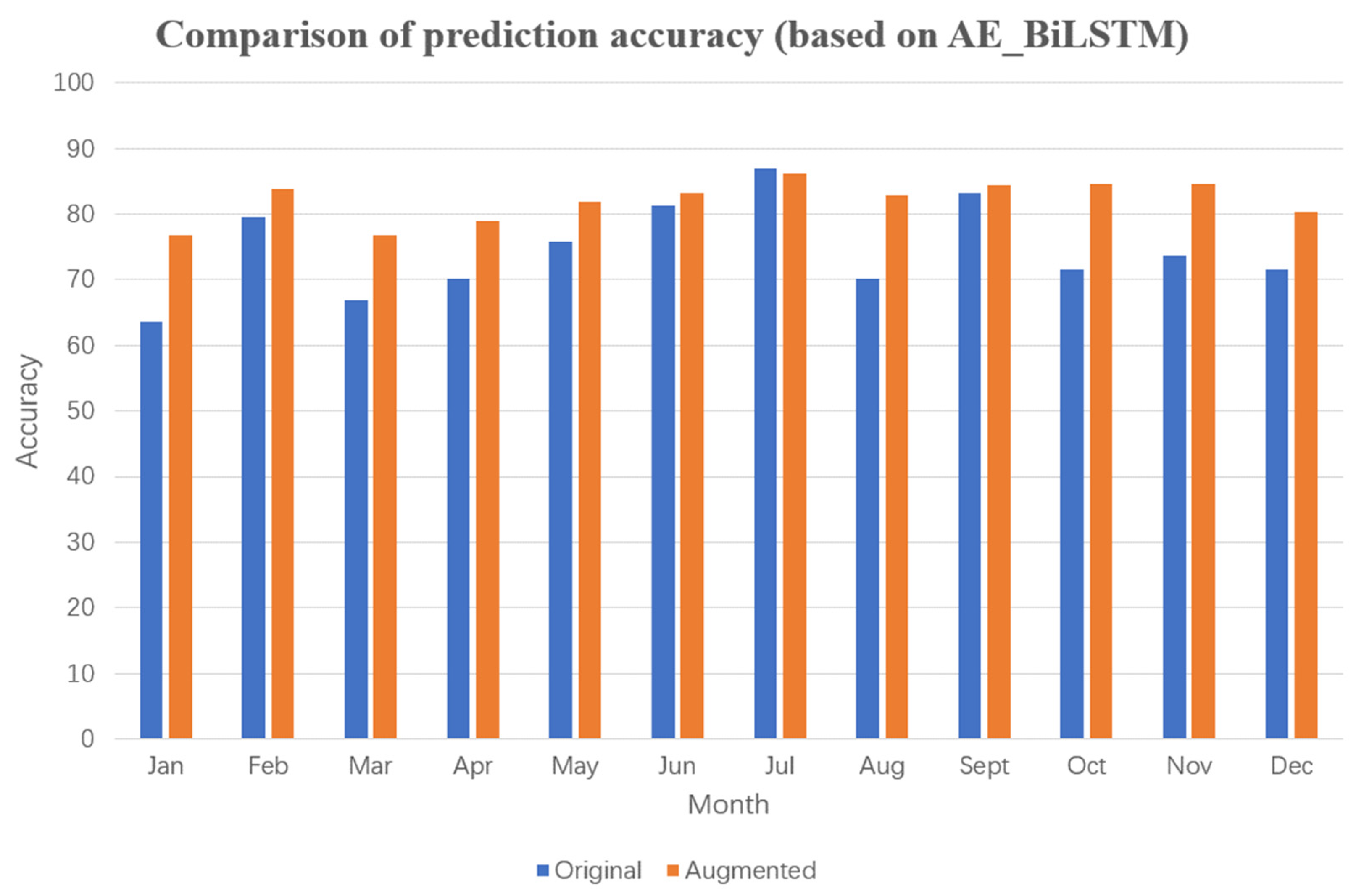
Furthermore, the commonly used DWT_AE_BiLSTM and AE_BiLSTM algorithms were selected for comparative experiments. After data augmentation, the average monthly improvement in prediction accuracy was 7.10 and 7.49%, respectively. These experimental results with four commonly used power prediction algorithms reveal that data augmentation through extraction of mutation data leads to significant improvement in prediction accuracy. In particular, the AE_BiLSTM algorithm, which utilizes data encoding, outperformed the LSTM algorithm in terms of prediction accuracy. However, the DWT_AE_BiLSTM algorithm, which incorporates wavelet processing, underperformed slightly compared with results without wavelet processing, which differs from findings in related literature.
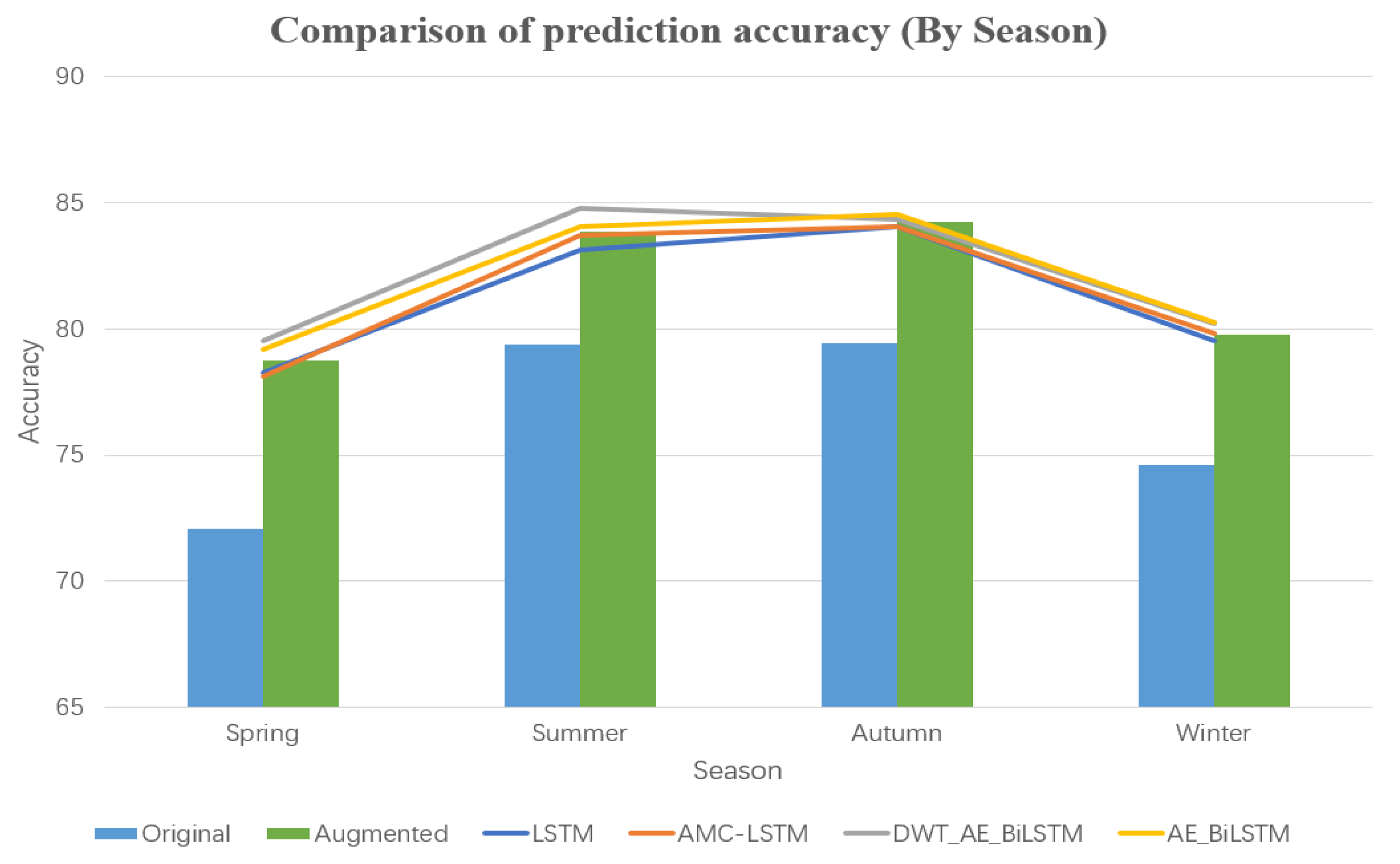
Secondly, we compared the prediction accuracy based on different seasons (
Figure 24). As shown in the figure, accuracy improvement was 6.7, 4.47, 4.82, and 5.36% for spring, summer, autumn, and winter, respectively, with more prominent effects in spring and winter. The DWT_AE_BiLSTM algorithm performed well in the spring and summer seasons, but poorly in autumn and winter. Therefore, in order to achieve better short-term prediction accuracy, it is not advisable to adopt a single prediction model for the entire year. Instead, the prediction model should be selected for each season or even month to month by comparing with prediction performance in previous years.
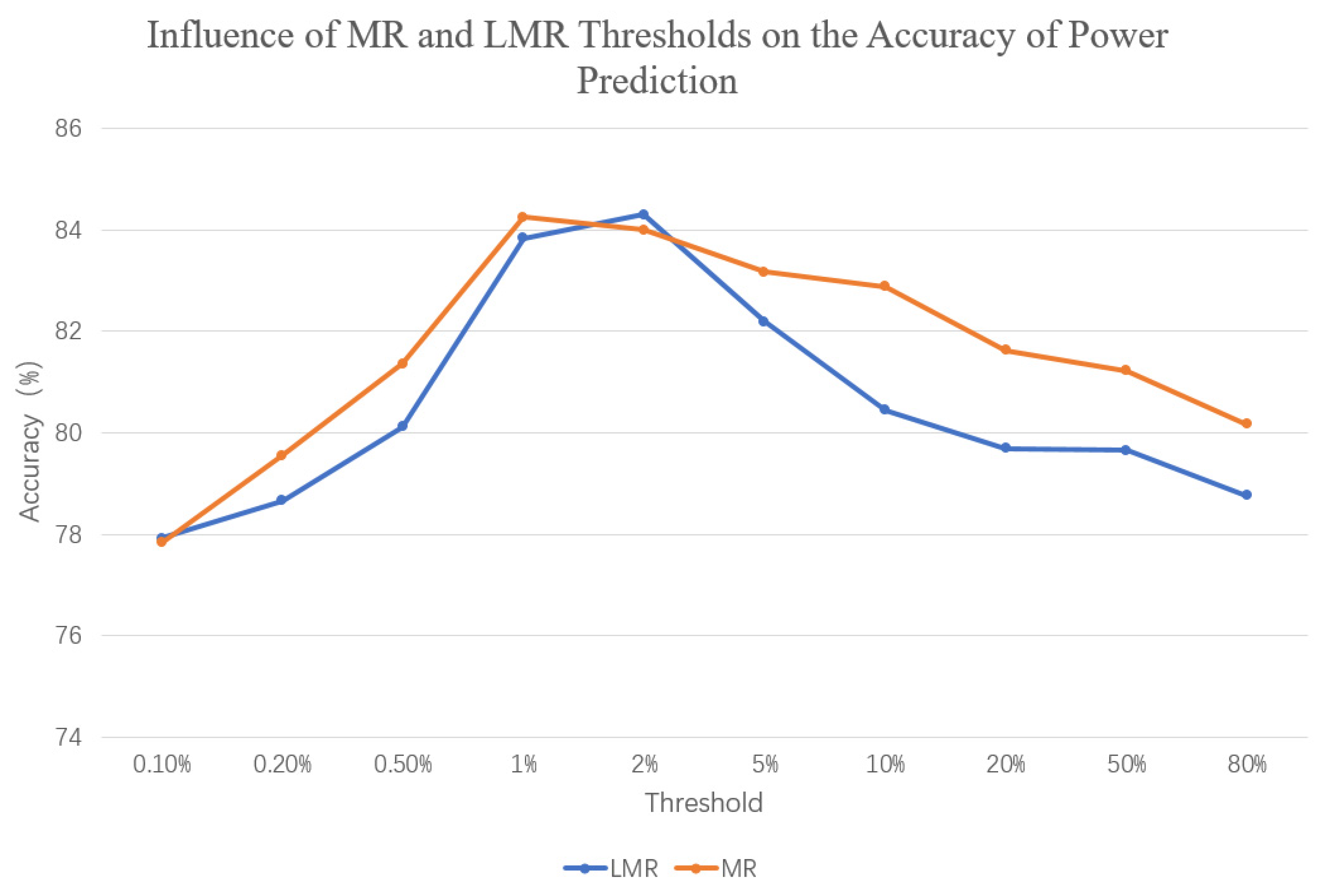
The above experiment used a mutation rate threshold of 1% to obtain the results. In order to further analyze the impact of the selection of local mutation rate (LMR) and mutation rate (MR) on prediction accuracy, the annual prediction accuracy was calculated using several thresholds: 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, and 80% (refer to
Figure 25). From the graph, it can be observed that the selection of mutation directly affected the prediction accuracy. When the values were too small or too large, the results tended to be similar to not performing a dataset expansion. Only by selecting the appropriate threshold could a higher prediction accuracy be obtained. Using the local mutation rate as the threshold for data extraction, the same result was obtained for feedback on prediction accuracy, but the threshold for achieving maximum prediction accuracy was generally larger than the threshold for mutation rate. This is because the mutation rate (MR) averages the entire data segment, resulting in generally smaller values. In order to obtain the appropriate threshold, the following method can be used:
- (1)
Calculate the mutation rate and local mutation rate separately, according to Formulas (7) and (8).
- (2)
Use segmented statistics of the mutation rate or local mutation rate data (e.g., regular processing) to arrange the data in descending order according to the statistical frequency.
- (3)
Calculate the gradient descent maximum mutation rate as the threshold for data extraction, based on the formula:
- (4)
Perform data extraction based on the calculated threshold.
In summary, through the entire experimental process, it was evident that data augmentation through the extraction of mutation data led to a significant improvement in prediction accuracy regardless of the algorithm used for power prediction, with particularly notable improvements in the spring and winter. Months 1, 3, 4, and 8 showed much higher improvements compared with the other months, and these months also experience frequent weather transitions.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}