1. Introduction
The global demand for energy, including oil and natural gas, has increased in recent decades. The world’s energy demand is constantly increasing, and technical development for finding new reservoirs or developing improved oil recovery techniques is always progressing [
1]. Nanoparticles are employed in enhanced oil recovery since 60 to 70% of hydrocarbon in most oil fields is not recovered with primary and secondary recovery schemes [
2]. For example, silica nanoparticles, which are ecologically safe, can improve oil recovery. Nanoparticles have some unique properties due to their tiny size, such as an increased surface area to which other materials can attach, resulting in stronger or lighter materials. However, some nanoparticles can be linked to rocks by surface filtration, straining, and physicochemical filtration, drastically lowering the porosity and permeability of the porous medium [
2,
3]. This is true even though the compact size of nanoparticles favors their transfer in porous media. Therefore, several factors, including nanofluid concentration, injection rate, slug size, and particle size, can affect the transportability of nanoparticles in pore throats. The flow of hydrocarbons in porous media has historically been estimated using numerical models; however, they have become challenging for more sophisticated numerical techniques. Recently, petroleum engineering has become one of the many industries where machine learning is frequently used. In order to create artificial datasets for machine learning algorithms to predict nanoparticle mobility, this study uses mathematical continuum models of nanoparticles in porous media. Artificial neural networks, gradient boosting regression, decision trees, random forests, and RF are the machine learning approaches utilized in the prediction throughout this study.
Nanotechnology provides a novel way to govern petroleum recovery processes. Nanoparticles can alter the fluid’s rheology, improving surfactant solution in EOR processes and lowering the interfacial tension between the aqueous phase and the oil interface [
4,
5]. By altering different rock and fluid characteristics, nanoparticles can improve hydrocarbon recovery. Nanoparticles can convert the rock’s wettability from oil-wet to water-wet [
5]. Other features include conductivity alteration, rock and oil interaction, and wettability modification can also be modified. Moreover, changing the fluid’s viscosity, reducing the interfacial tension, and stabilizing the emulsion leads to an increase in recovery of more than 20% above conventional chemical surfactant-polymer flooding [
6]. As the high temperature inside the reservoir decreases the effectiveness of surfactant and polymer flooding, the nanofluid combination exhibits a stable behavior at higher temperatures [
7]. In oil-wet rocks, oil tends to adhere to the walls of porous media, making the waterflooding process useless since oil droplets cannot easily pass through the matrix’s pores. Recently, it was found that the introduction of nanoparticles can change the wettability of rock to water-wet. Water tends to imbibe to the rock surface in water-wet rock, and as a result of water flooding, oil flows toward the production well, improving oil recovery [
8].
When nanoparticles are injected into the hydrocarbon reservoirs, it is important to understand their transport and properties to identify their mobility. The porous media utilized in laboratory research to study the transport of nanoparticles in porous media are columns filled with sand or glass beads. The retention of nanomaterials in those columns depends on the material size, shape, and surface characteristics. The dispersion of silica nanoparticles in polyacrylamide was discussed by Maghzi et al. [
9]. The experiment examined the rheological characteristics of silica nanoparticles and polyacrylamide. They discovered an improvement in the polymers’ fluid viscosity and pseudoplastic behavior. The spreading behavior of nanofluids combined with surfactants on a solid surface was examined by Wasan and Nikolov [
10]. Ju and Fan [
11] observed the wettability alteration brought on by polysilicon nanoparticles using experimental and computational methods.
Youssif et al. [
12] conducted experiments to investigate the effects of injecting silica nanoparticles with various concentrations and found that when the concentration of nanoparticles increases, the oil recovery factor increases. Khalilinezhad et al. [
13,
14] studied the impact of nanoparticles on the flow behavior of an injected flood in a porous medium using the UTCHEM simulator. They concluded that adding nanoparticles to polymers reduces sandstone retention and adsorption after using a polymer shear thinning model to assess the adsorption of nanoparticles on sandstone surfaces. Copper oxide nanoparticle transport in two-dimensional porous media was investigated by Jeong and Kim [
15]. They looked at how pores gathered copper oxide nanoparticles. They found that nanoparticle flow velocity and surfactant concentration impacted how quickly they accumulated and deposited. Additionally, they discovered that the density affects the flow velocity such that the flow velocity decreases as the number of aggregates increases. Response surface techniques are employed to manage the Walters-B nanofluid stationary point flow brought on by a Riga surface [
16]. Using capillary forces and Brownian diffusion, El-Amin et al. [
17,
18] developed a mathematical model for nanoparticle water suspensions in two-phase flow in porous media. As part of their investigation, they looked at how infused nanoparticles affected the properties of solids and fluids.
Machine Learning is a branch of artificial intelligence concerned with creating and developing algorithms that allow computers to learn behaviors or patterns from empirical data [
19,
20]. Traditionally, mathematical models are utilized to simulate hydrocarbon reservoirs. However, they are complicated and take a long time to compute [
21]. Given the various computer platforms, parallel methods can help tackle such challenges. These issues could be solved using machine learning techniques. To forecast the nanofluid dynamic viscosity over different temperature ranges, Esfe et al. [
22] built an artificial neural network model. A data-driven viscosity prediction model for water-based nanofluids was created by Changdar et al. [
23] utilizing deep learning. Based on well-log data and stochastic gradient boosting regression, Subasi et al. [
24] developed a machine-learning model to predict reservoir permeability. They explored various machine learning techniques, including random forest, artificial neural networks, K-nearest neighbors (KNN), support vector machine (SVM), and stochastic gradient boosting. They found that stochastic gradient boosting outperformed other assessed models in several evaluation metrics tests, including accuracy and root, mean squared error. Nanoparticle transport behavior in porous media was predicted by Zhou et al. [
25] using a data-driven approach to construct the regression and classification models for nanoparticle retention and nanoparticle profiles. They employed one-hot encoding and random forest to fill in all the gaps in their dataset. They performed regression for predicting nanoparticle retention using the CatBoost technique in combination with synthetic minority oversampling. Goldberg et al. in [
26] used the RF regression machine learning model to predict the nanoparticle concentration in a column length and the RF classification model to classify the nanoparticles retention profile shape of nanoparticles transport experiments in a fully saturated column, taking into consideration the physicochemical conditions such as nanoparticle size, coating type, and flow velocity. Irfan and Shafie [
27] developed an ANN model to predict nanoparticle concentration. They built their dataset using the finite difference method simulator.
The current paper is structured as follows:
Section 2 provides the research methodology.
Section 3 presents the results and discussion. Finally, in
Section 4, the conclusion is presented.
3. Results and Discussion
The machine learning codes were written in Python3, implemented in Jupiter Notebook, and executed on a processor of 2.6 GHz Quad-Core Intel Core i7 and memory of 16 GB 2133 MHz LPDDR3. The execution time of DT and RF algorithms was super-fast, around a few seconds. The GBR execution time was 48.7 s. However, the ANN algorithm was more time-consuming, with an execution time of 18 min.
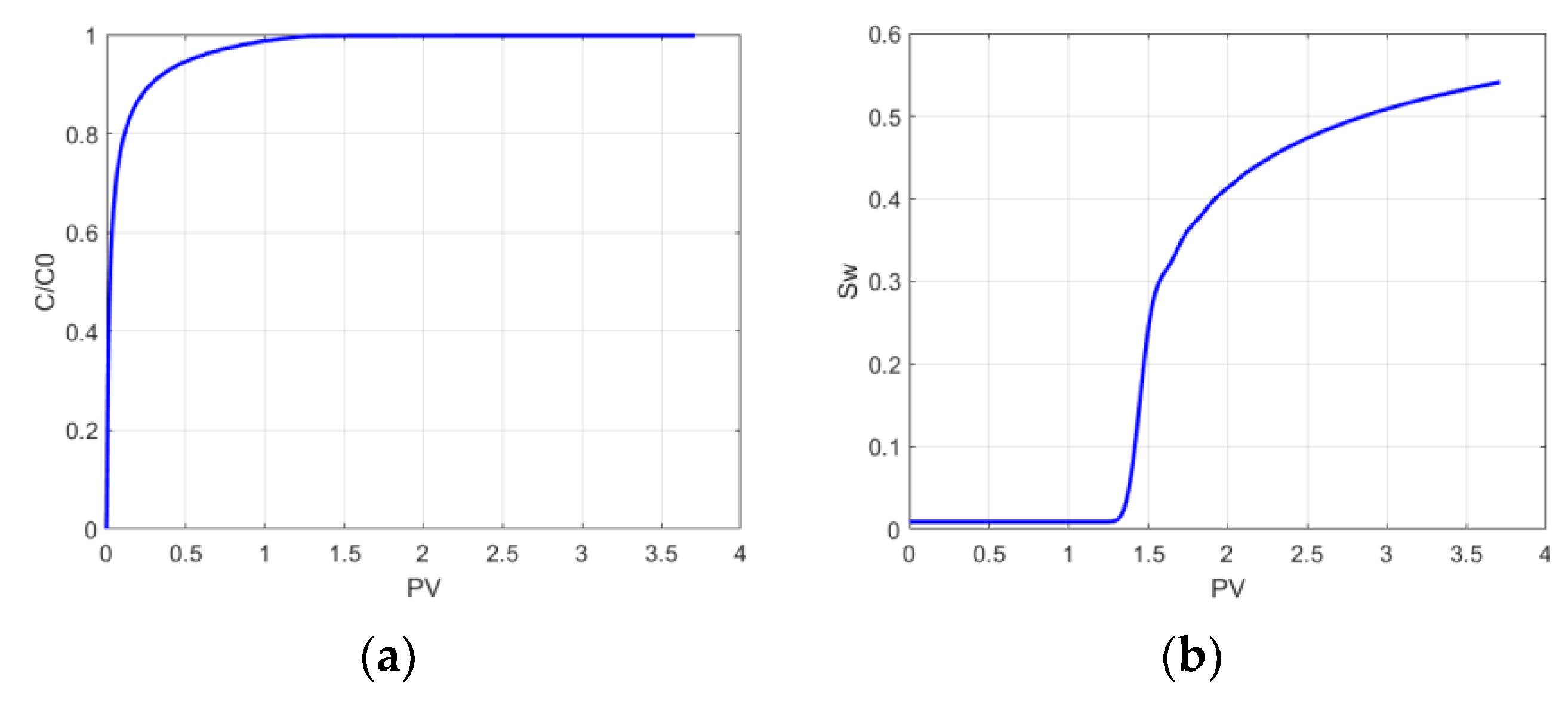
This section discusses the generation of the artificial datasets of the nanoparticle transport model. It covers how the dataset is preprocessed and scaled. It presents the use of features importance to identify the important features. This section also covers the use of different machine learning techniques, different target variables, and the performance evaluations of the models. After selecting the nanoparticles transport model in two-phase flow, the finite difference method is implemented to generate the artificial dataset. The generated dataset contains 288,000 instances for predicting different target variables, including nanoparticle concentration C, water saturation Sw, the relative permeability of oil Krop, and the relative permeability of water Krwp. Accordingly, we used the same datasets four times to predict the four different target variables: C, Sw, Krop, and Krwp. The two phase artificial dataset composed of 38 features or independent variables which are time (t), space (x), (phi0) is the initial porosity, (phi) is the porosity of the medium, (rhoo) is the oil density, (rhow) is the water density, (pc) is the capillary pressure, (k0) is the initial permeability, (K) is the absolute permeability, (kro) is the oil relative permeability, (krw) is the water relative permeability, (kro0) is the initial oil relative permeability, (krw0) is the initial water relative permeability, (krwp) is the relative permeability of water when the surface of porous media is occupied nanoparticles, (krop) is the relative permeability of oil when the surface of the porous media is occupied with nanoparticles, (thetaw) is the ratio of the water relative permeability due to nanoparticles adhering, (thetao) is the ratio of oil relative permeability due to nanoparticle adhering, (g) is the gravitational acceleration, (Sw) is the water saturation, (C) is the nanoparticles concentration in water, (Cs1) is the volume of nanoparticles in water, (Cs2) is the volume of nanoparticles entrapped in pore throats due to plugging, (D) is the diffusion- dispersion tensor, (lamwp) is the mobility ratios of water, (lamop) is the mobility ratio of oil, (lamtp) is the total mobility, (m) is the viscosity, (fo) is the flow fraction of oil, (Sor) is the residual oil saturation, (Siw) is the irreducible water saturation, (a) and (b) are positive constant, (kf) is constant for fluid seepage allowed by the plugged pores, (dnp) is the nanoparticles diameter, (gamaf) is the coefficient of nanoparticles flow efficiency, (aw) and (ao) is surface area in contact with water and oil respectively.
The target (dependent) variables selected for prediction include nanoparticle concentration, water saturation, and relative permeability of oil and water. Some statistical statistics for the dataset variables are shown in
Table 2, including the number of observations, mean, standard deviation, minimum value, quarter, half, and three-quarters values, as well as the highest value for each characteristic. The models are created using four machine learning techniques: decision trees, random forests, gradient boosting regression, and artificial neural networks.
Data preprocessing includes removing empty cells in the dataset and standardizing the values of the dataset. All dataset features are used as input for all used techniques. The values of independent variables are scaled and standardized using the standard scaler function of the scikit-learn library. Moreover, due to this dataset’s large number of features, we selected the most important features for each model to be input parameters to predict the target.
We investigated the correlation of all variables in the dataset with each other to highlight the significant features and to identify features that have an effect on the target variable. It was found that few features in the dataset correlate with each other such that K, krop, phi, t, lamwp, and lamop are highly correlated with each other. On the other hand, C is correlated with Cs1, Cs2, t, lamtp, lamwp, lamop, and Sw.
The generated artificial dataset from the nanoparticle transport model has been used on machine learning algorithms (DT, ANN, GBR, and RF). The dataset has been divided into training and testing sets, 80% for training and 20% for testing the model. The Jupyter Notebook, which is based on the Python programming language, has been used for implementation. The train test split function from the scikit-learn library has been used to split the dataset into training and testing. We generated four subsets: the
x-train and
y-train are used to train the model, while the
x-test is used to evaluate the model. Moreover, the
x-train and the
x-test sets are scaled using the standard scaler function. The algorithm is executed twice, once with scaled data and another run with original unscaled data to check which would give higher performance. Feature importance is a function that gives weights to input features based on their effectiveness at predicting the target variable. It highlights the most important features and helps in reducing the dimensionality of the model and increase its efficiency. The node impurity in scikit-learn is calculated using the Gini feature importance. The reduction in a node’s impurity is weighted by the number of samples reaching that node relative to the overall number of samples (this is called node probability). For example, the equation of a tree with two child nodes is given as:
where
is the node
importance,
is the impurity value of node
,
is the weighted number of samples reaching node
, left
is the child node on the left of node
, and
is the child node on the right of node
. This can be used to determine the feature importance of each decision tree, and for the feature importance, we use the equation:
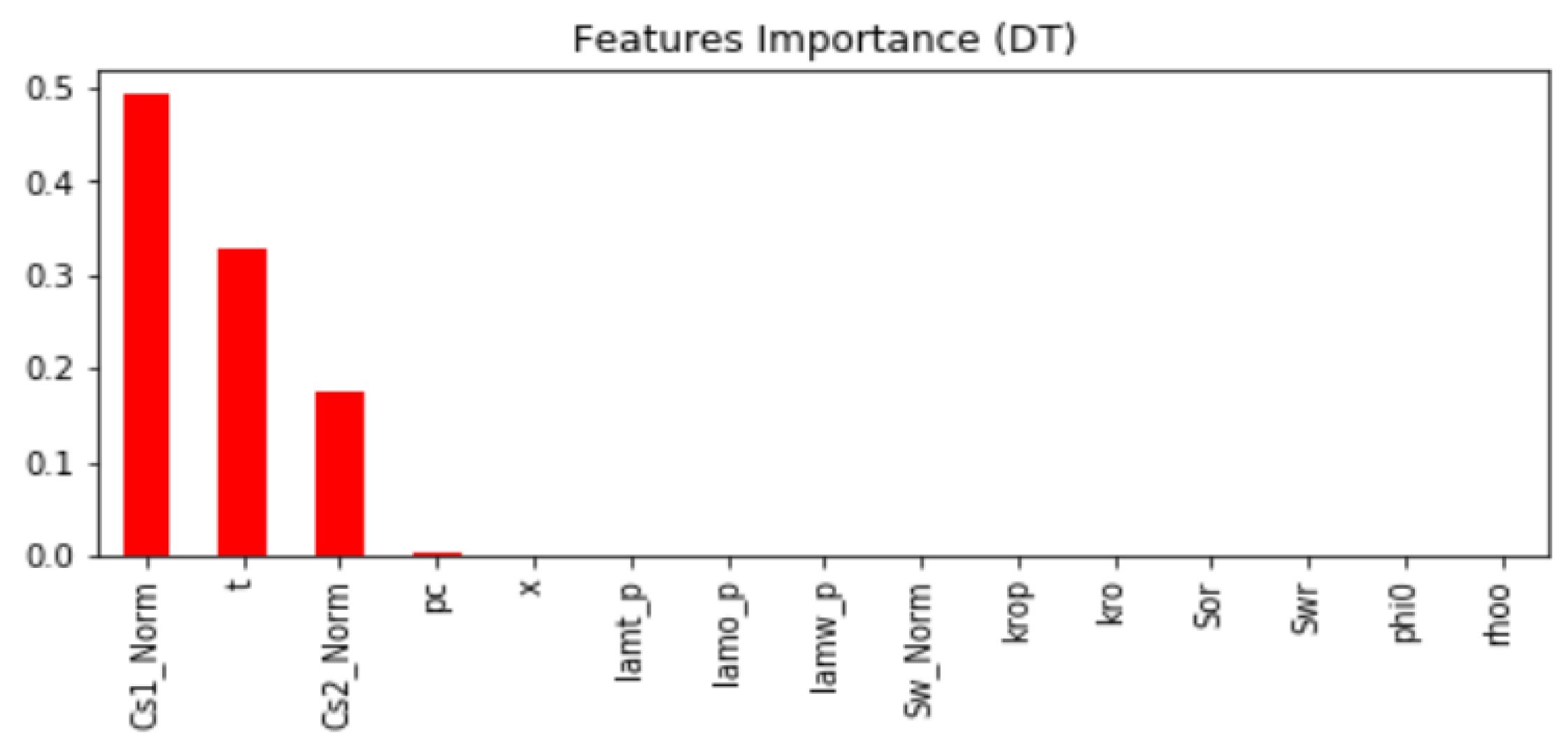
It was found out from most of the models tested that
Cs1,
Cs2, and
t are the most important features that help in predicting the nanoparticles concentration. The score value calculated for each feature is varied from model to model.
Figure 2 presents an example of the feature importance calculated for the DT model.
It can be seen in the feature importance figure that
Cs1,
t, and
Cs2 are the most important features in predicting the nanoparticles concentration
C. A comparative analysis between different machine learning models is provided, and it was found that the ANN model has the lowest root mean square error value of 0.000216 and the highest
value of 0.999999, as shown in
Table 3.
In building the ANN model, we tried different numbers of hidden layers, different numbers of neurons, and different activation functions. We used three hidden layers with six neurons each, a rectifier activation function. Another model was built with three hidden layers of 15 neurons each and a rectifier activation function in the two hidden layers, and a sigmoid activation function in the output layer. We also build a third neural network with three hidden layers with six neurons, each with and rectifier activation function in two hidden layers and the third hidden layer with a tan
h activation function. ReLu activation functions were found to perform better with an RMSE of 0.000216.
Table 4 presents the evaluation of ANN models with different activation functions, and
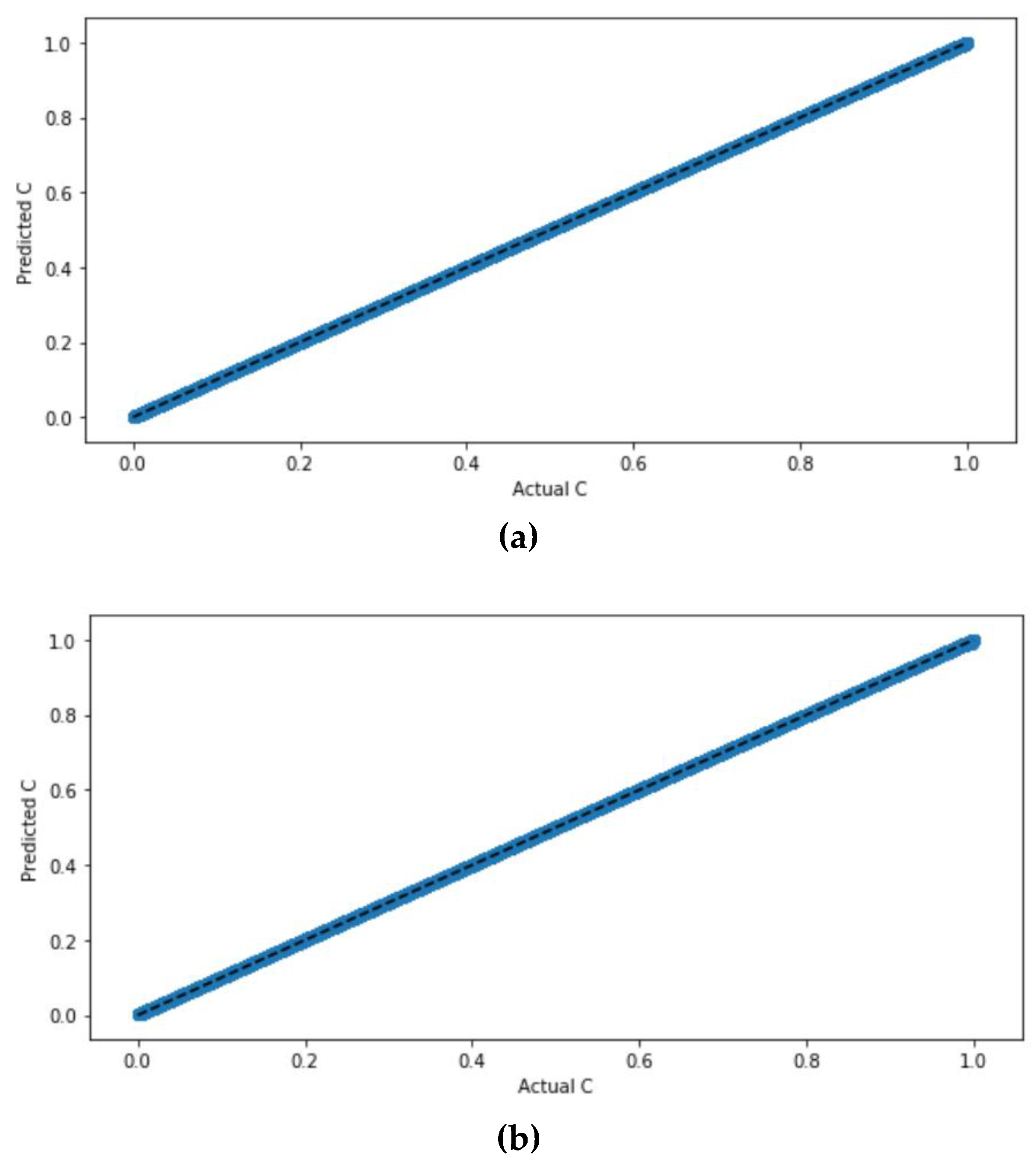
Figure 3 shows their scatter plots.
Figure 3 compares the scatter plots of the ANN model with the scaled dataset with ReLu, sigmoid, and tan
h activation functions. It can be seen from the figure that the scatter plots of the ANN model with all the activation functions are similar with highly correlated values. The precise difference with regard to the accuracy values and error can be determined from the evaluation values listed in
Table 4 that indicate that the ANN model with ReLu, sigmoid, and tan
h activation functions, for the scaled dataset are all accurate with negligible differences.
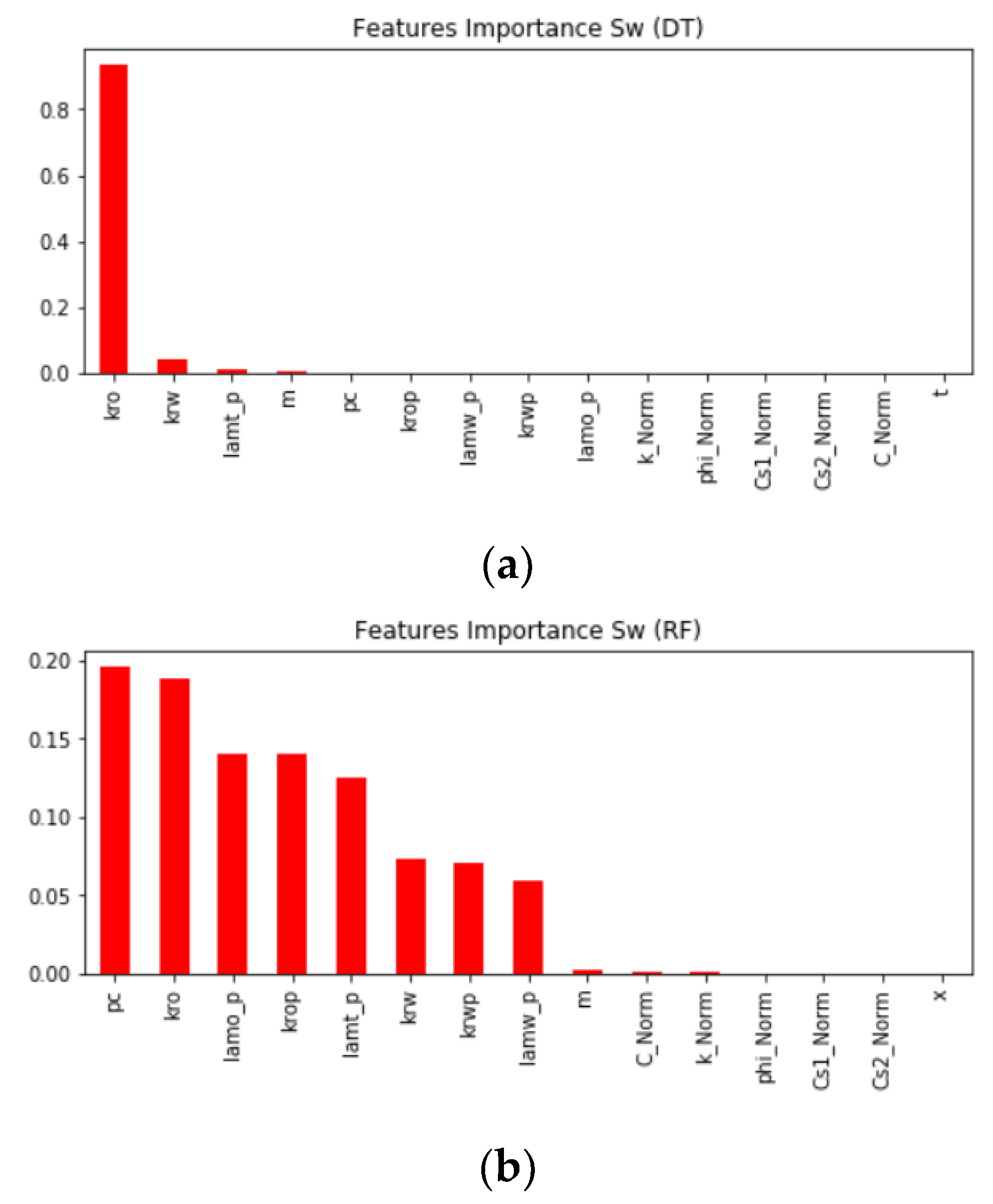
We also checked the features’ importance for each model that predicts the nanoparticle concentrations, and we found out that each model selected different features. The most common features used are
pc,
krw,
kro,
lamop,
lamwp, and
lamtp. The score value calculated for each feature is varied from model to model.
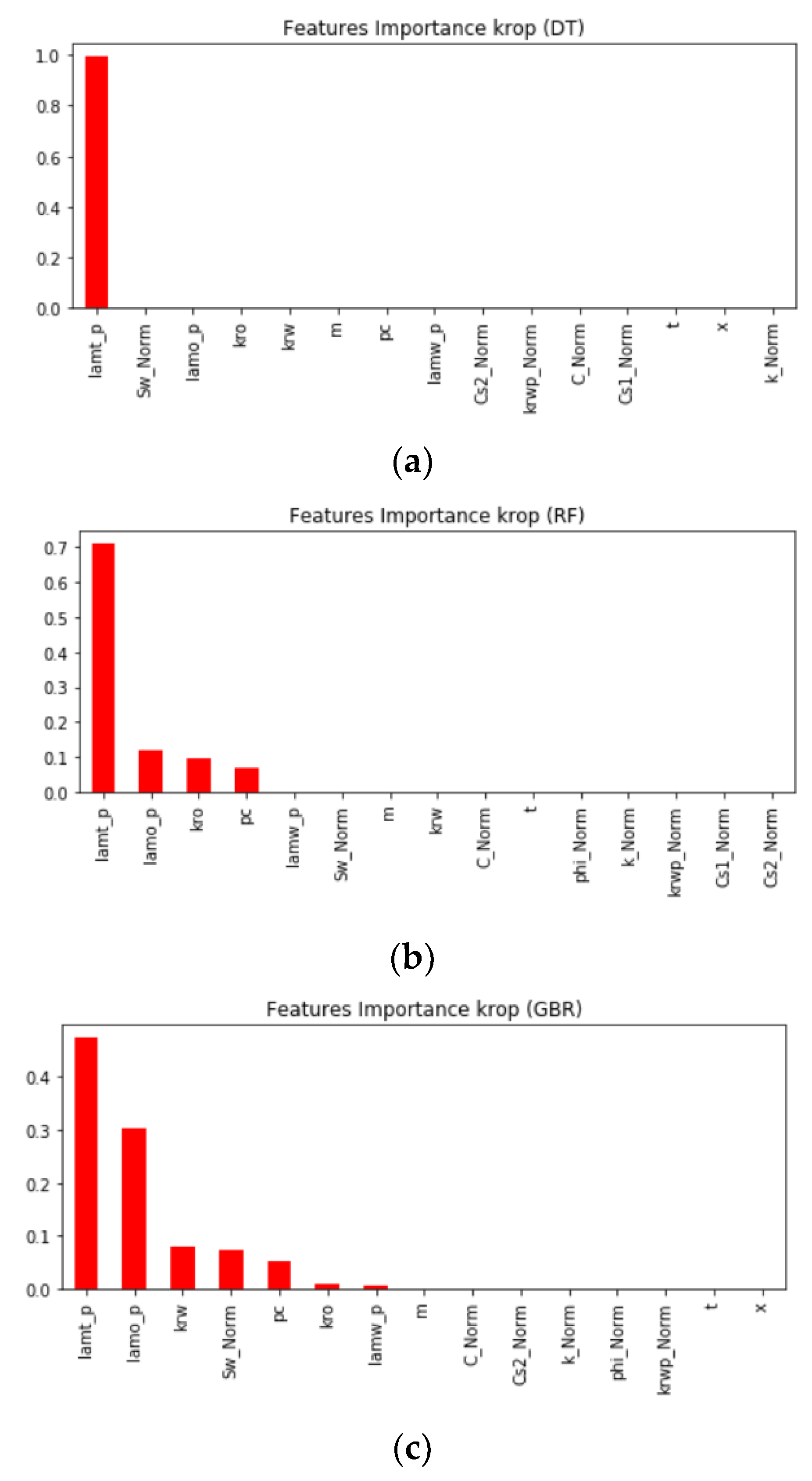
Figure 4 demonstrates the feature importance in predicting
Sw using DT, RF, and GBR models. It is shown from the figure that
pc,
krw,
kro,
krwp,
krop,
lamwp,
lamop,
lamtp, and
m are the most important features in most models.
Evaluating the models using different evaluation metrics, we found out that the ANN model with a standardized dataset and activation function of tan
h performed the best in predicting the nanoparticles concentrations. ANN model had the lowest root mean square error value of 0.000125 and the highest
value of 1.
Table 5 presents the metric evaluation results of all models.
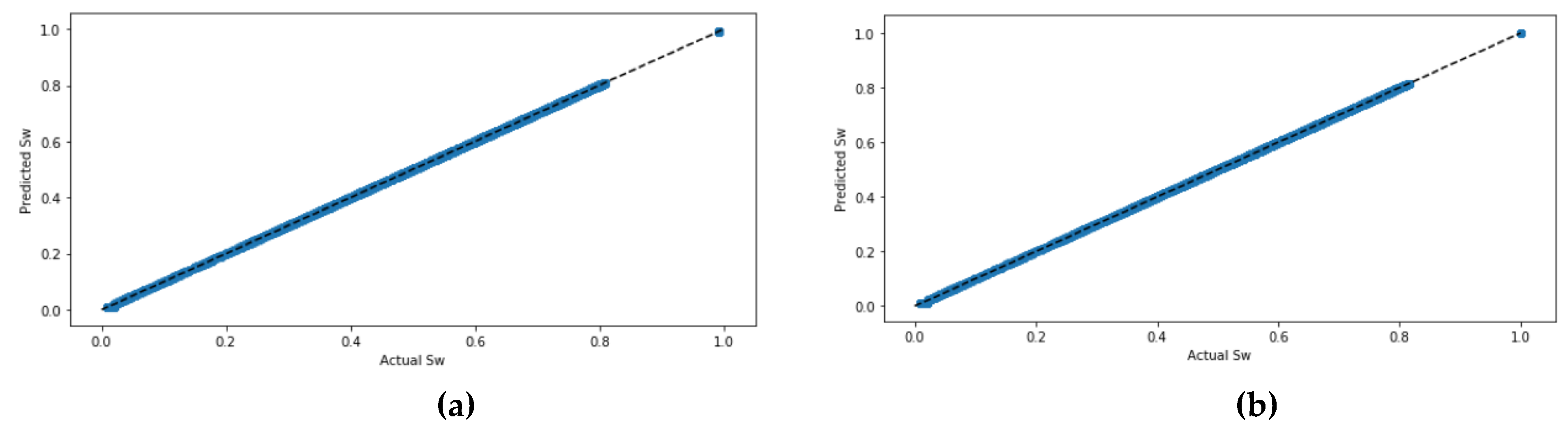
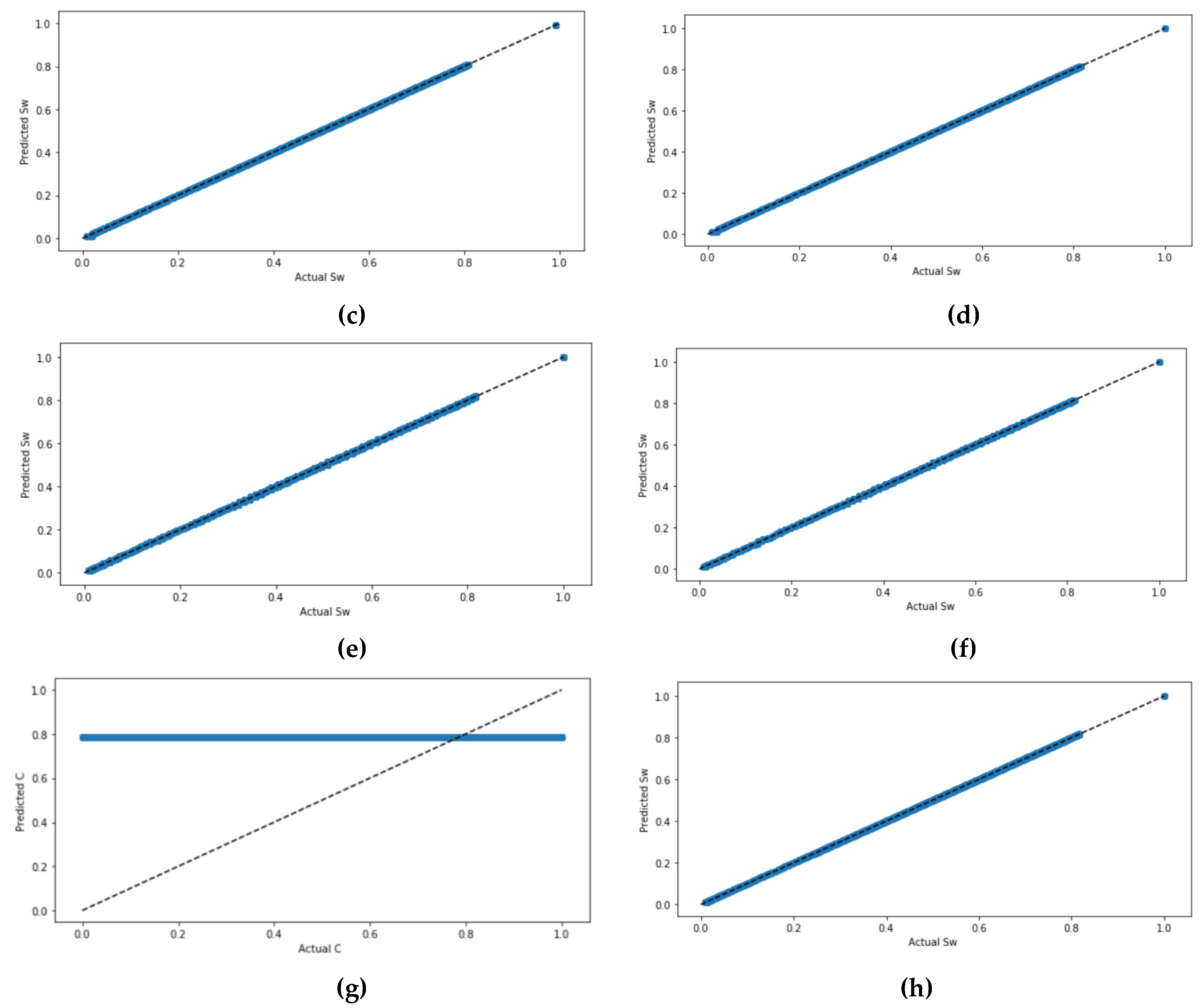
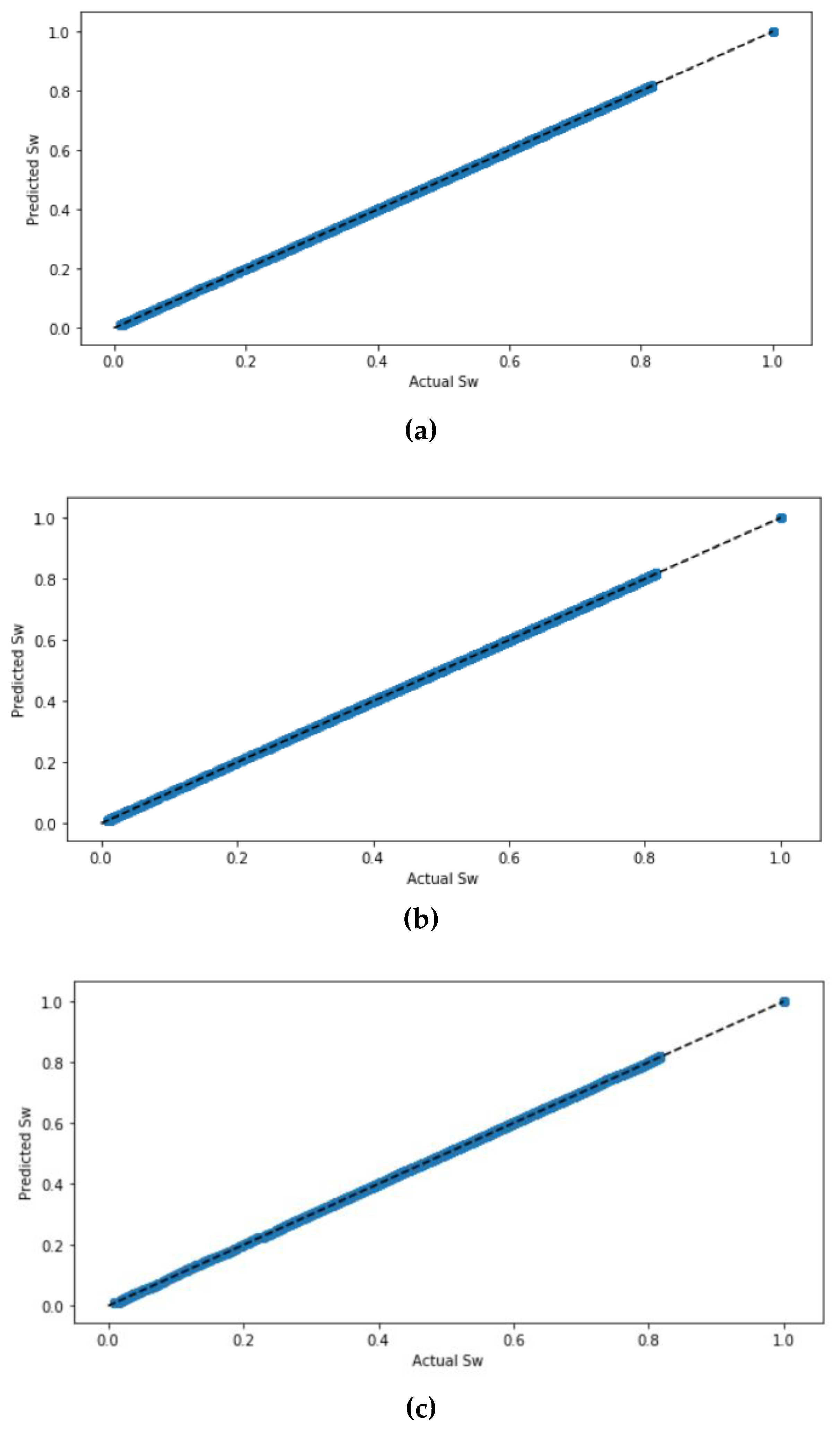
Figure 5 shows the actual values and the predicted values of
Sw for all four ML models. The four models have been graphed twice: one time without scaling the datasets and the other time with scaling the dataset using the StandardScaler. It can be seen that predicting
Sw when the dataset is not standardized had very close results to predicted values when the dataset became standardized, and the values in the figure are correlated. Except in the ANN model, which requires that the dataset standardize prior prediction. The ANN model with the tan
h activation function had the highest correlated values in the scatter plot.
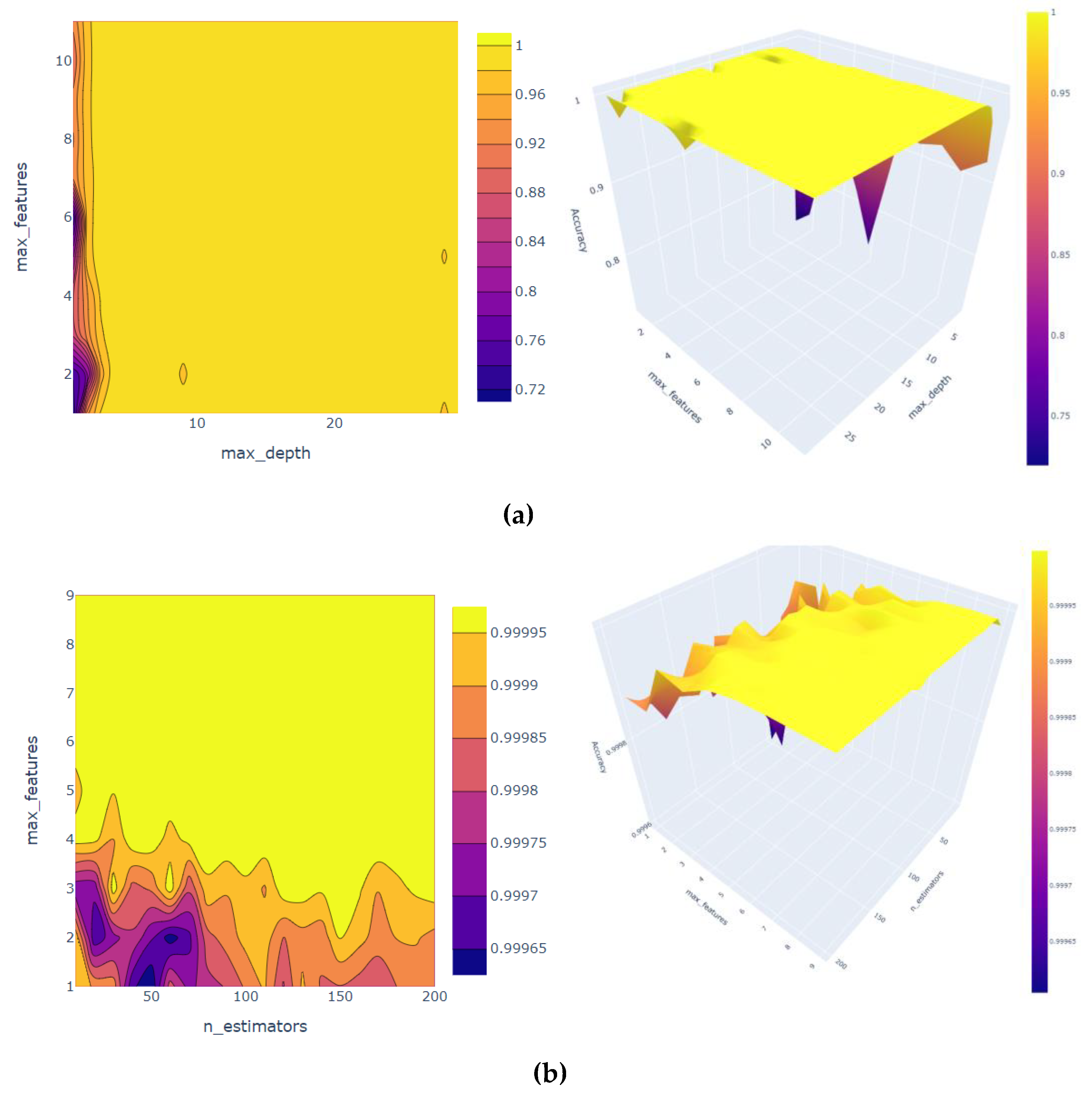
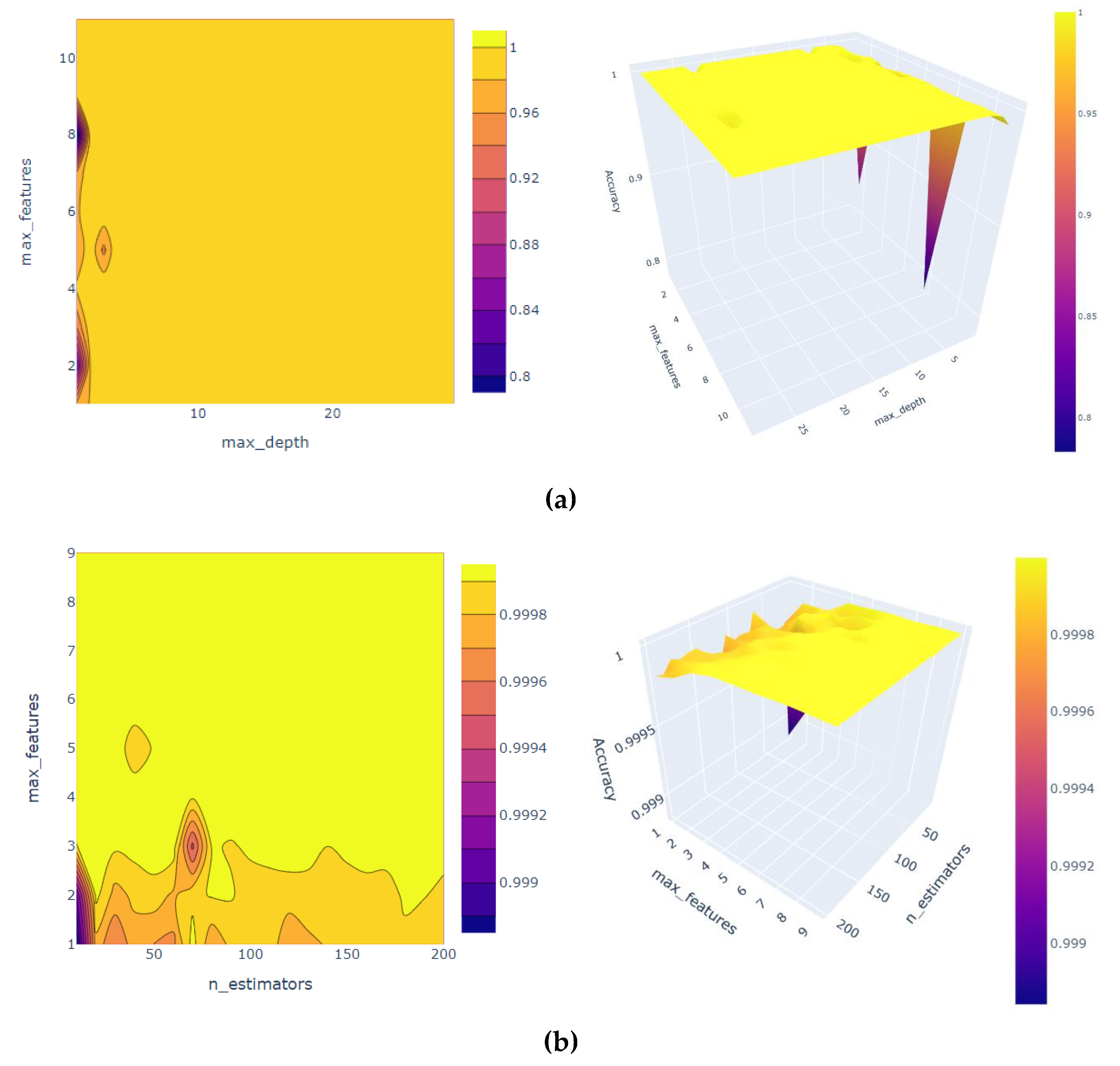
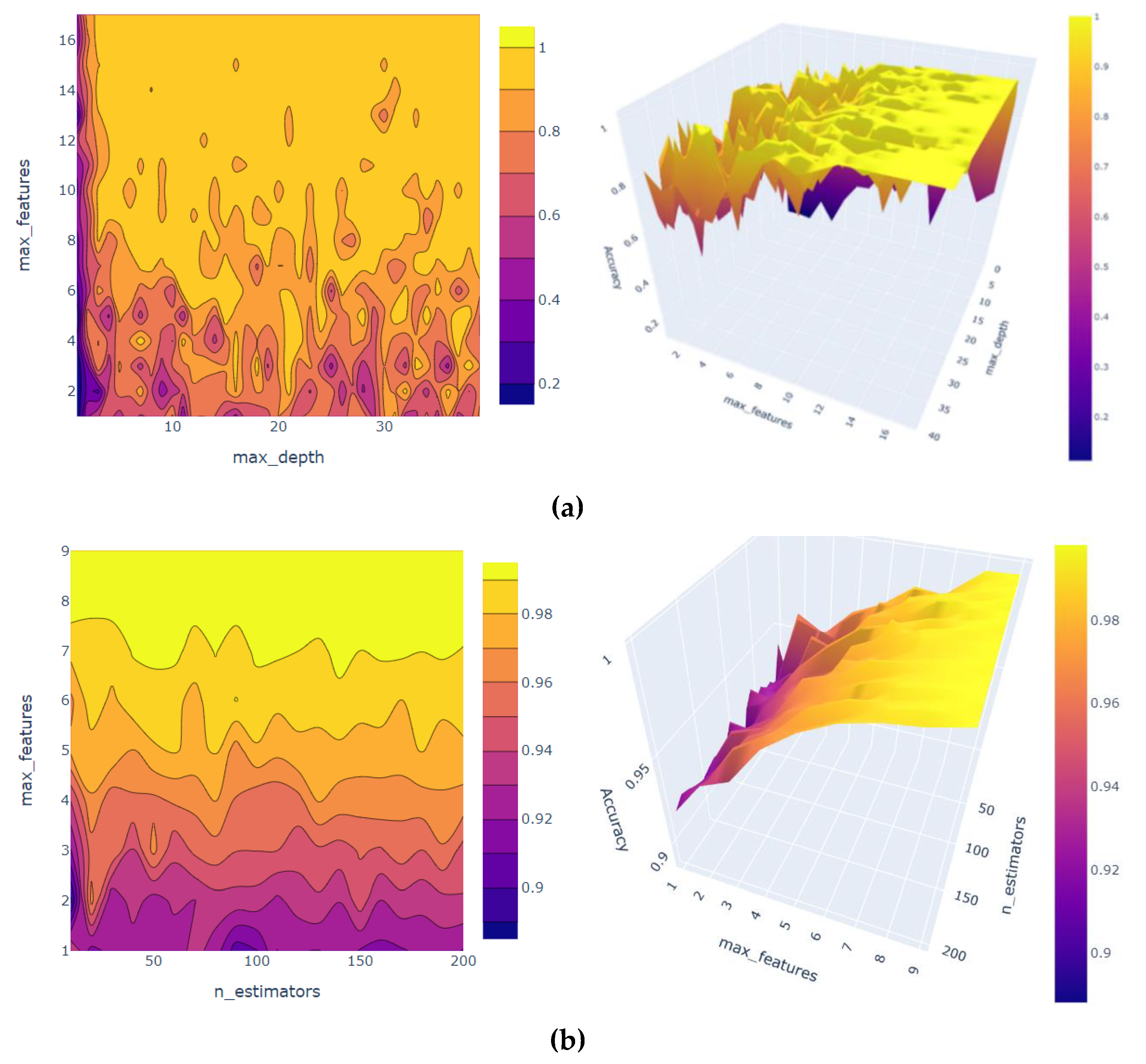
The model parameters are tuned to improve the performance of machine learning models. The hyperparameters, namely, max features and the number of estimators, are used. The 2D contour plot and the 3D surface plot of hyperparameter tuning are presented in
Figure 6. The GridSearchCV was used for RF hyperparameters tuning, and it was found that the best parameters that would give the highest accuracy. For the DT model, the best parameter is a max depth of 19, and max feature of 9 would lead to an accuracy score of 1. When we scaled the data for training the GBR, the RMSE value (0.000605), and when training the model, the RMSE reduced further to reach (0.000292).
Moreover, different activation functions were used in three hidden layers with six neurons each, and we found out that “tan
h” activation functions performed better.
Table 6 presents the evaluation of ANN models with different activation functions, and
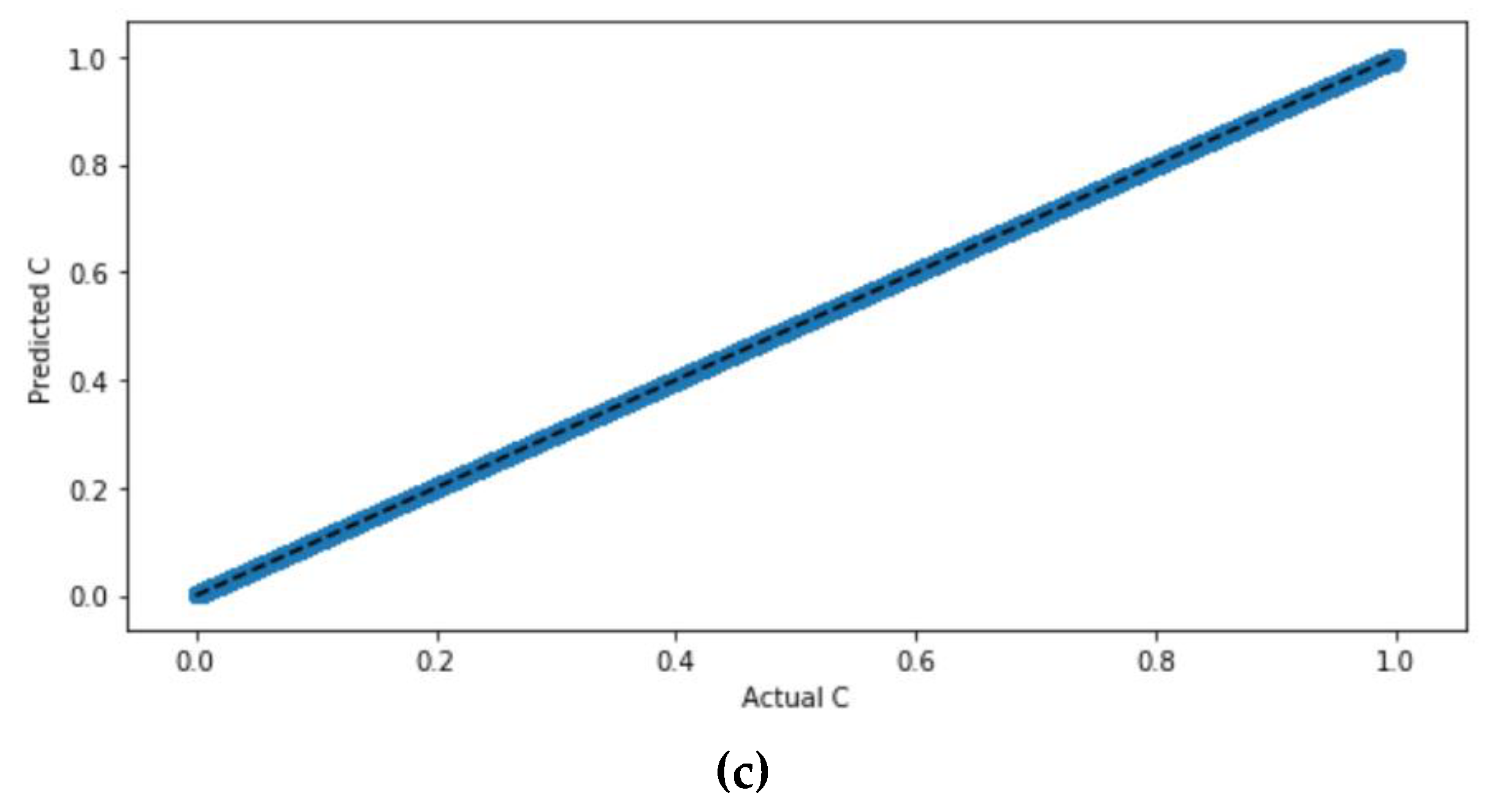
Figure 7 illustrates their scatter plots.
Figure 7 compares the ANN model with the activation functions and shows that they are similar with highly correlated values. The accuracy and error can be determined from
Table 5, which indicates that ANN with the tan
h activation function had the lowest RMSE value and the highest
R2 value.
Now, let us discuss the results of predicting the oil relative permeability
krop. First, we checked the features’ importance for each model when the target variable was
krop, and we found out that each model selected different features. The most important feature found used in all models is
lamtp; other common features used by RF and GBR are
pc,
kro, and
lamop. The score value calculated for each feature is varied from model to model.
Figure 8 presents the feature importance of the DT, RF, and GBR models.
Figure 8 demonstrates the feature importance in predicting
krop using DT, RF, and GBR models. It is shown from the figure that
lamtp,
lamop,
pc,
krw,
kro,
krwp,
krop,
lamwp, and
Sw_Norm are the most important features in most of the models.
Evaluating the models using different evaluation metrics, we found out that most of the models tested have high performance when the target variable is
krop, especially ANN models with standardized dataset and activation function of sigmoid that had RMSE value of 0.000145 and
R2 value of 1.000000.
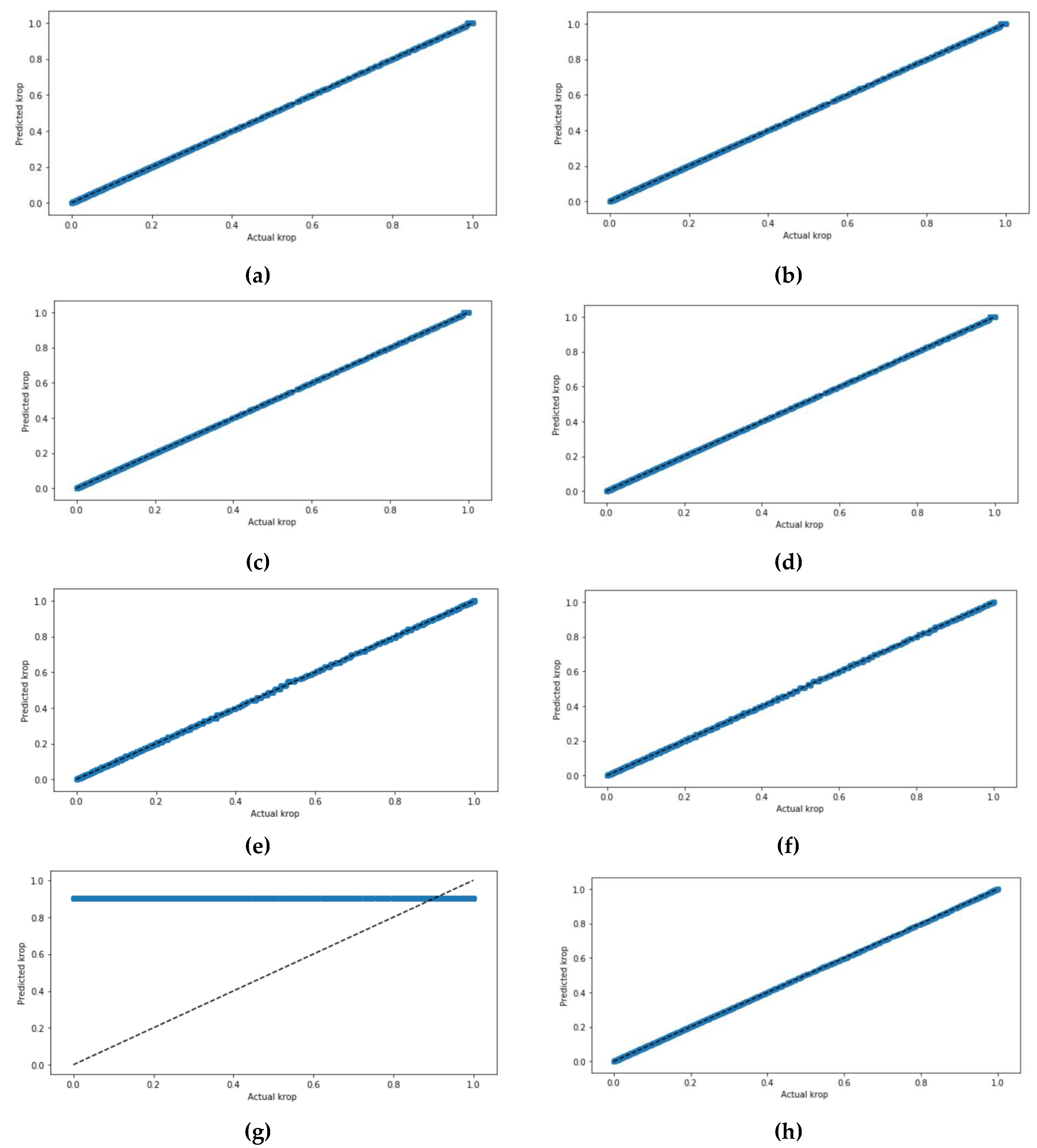
Figure 9 presents the scatterplot between the actual and the predicted
krop.
Table 7 presents the metric evaluation results of all models.
Figure 9 demonstrates the actual values and predicted values of
krop for all four models. It is shown that the scatter plots of all four models have a positive correlation. The scatter plots of each of the four models tested have been graphed twice, one time without scaling the datasets and the other time with scaling the dataset using the StandardScaler. Both scatter plots of each model that predict the
krop had very close results when the dataset was standardized and not standardized in which the values in the figure are highly correlated, except in the ANN model, which requires that the dataset standardize prior prediction. The ANN model with the sigmoid activation function had the highest correlated values in the scatter plot.
Most models when the target variable was
krop had high performance without tuning the hyperparameters. The 2D contour and the 3D surface of the hyperparameter tuning of the RF model are shown in
Figure 10. In the RF technique, the model provided good performance. Moreover, running the GridSearchCV function, we found out the best parameters are max-features of 9, and n-estimators of 40 would give an accuracy score of 1. Moreover, the DT model has a good performance without tuning, and when we run the GridSearchCV function, it provides an accuracy score of 1, a max-depth of 24, and a max-features of 8 would lead to an accuracy score of 1. The GBR model provided good performance in general. Therefore, we did not tune the hyperparameters.
Figure 10 illustrates the 2D contour and the 3D surface of tuning two hyperparameters using GridSearchCV for the relative permeability of oil
krop when the medium surface is occupied with nanoparticles. Each 2D contour plot and 3D surface plot help to visualize the accuracy score of each two combinations of the selected hyperparameters in a color-coded manner. For the DT model, the two selected hyperparameters are max-depth and max-features. The yellow color code in both plots represents the highest accuracy score of 1 for both combinations when the max depth is 24, and the max features are 9. While for the RF model, the two selected hyperparameters are max-features and n-estimators. It is shown that max-features of 9 and n-estimators of 40 had the highest accuracy of a score of 1.
It is noteworthy that the difference between the results of DT and RF can be seen in the 3D surface. It is clear from
Figure 6 and
Figure 10 that the DT model’s accuracy is usually high for all values of the max-features parameter. However, for the RF model, the accuracy was lower with small values of the max-features parameter and increased quickly to reach high accuracy.
The ANN model with different activation functions provided high performance, especially with “tan
h” activation functions (see
Table 8).
Figure 11 compares the ANN prediction for a scaled dataset with ReLu, sigmoid, and tan
h activation functions. It can be seen from the figure that the scatter plots of the ANN model with all the activation functions are similar with highly correlated values. The accuracy and error can be determined from the evaluation values listed in
Table 8, which indicate that ANN with the sigmoid activation function had the lowest RMSE value.
This subsection presents the results of predicting
krwp using DT, GBR, ANN, and RF algorithms. After evaluating all models, we found out that the RF model performed the best compared to other models. We checked the feature’s importance for each model when the target variable was
krwp. The important features in most of the models are
krw,
kro,
K,
t,
Cs1,
Cs2,
Sw, and
pc. The score value calculated for each feature is varied from model to model.
Figure 12 presents the feature importance of the DT, RF, and GBR models.
Figure 12. demonstrates the feature importance in predicting
krwp using DT, RF, and GBR models. It is shown from the figure that
t,
Sw_Norm,
Cs1_Norm,
Cs2_Norm,
pc,
krw, and
kro, are the most important features in most models.
We evaluated the models using different evaluation metrics and found that the RF model performed best when the target variable is
krwp. The lowest RMSE value is 0.000281, and the highest
R2 value is 0.999999.
Table 9 presents the metric evaluation results of all models.
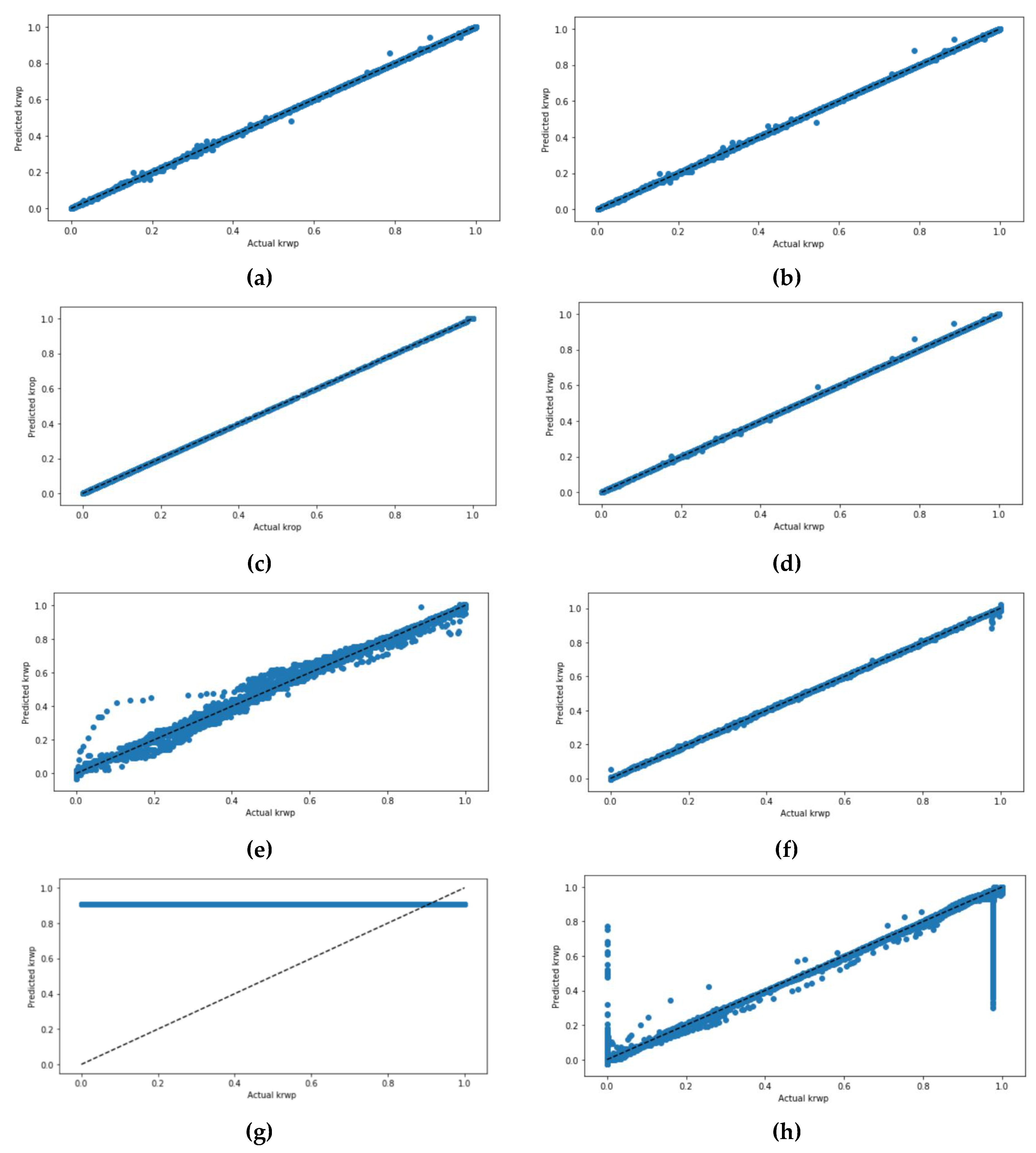
Figure 13 demonstrates the actual values and the predicted values of
krwp for all four models. The scatter plots of all four models have been presented twice; one time without scaling the datasets and the other time with scaling the dataset using the StandardScaler. The DT model shows a minor difference between the scaled dataset and the not scaled dataset. The GBR model, when the dataset was not scaled, had some mispredicted values compared to the scaled dataset. Moreover, the ANN model with a scaled dataset also had some mispredicted values. At the same time, the RF model of the not scaled dataset had the highest correlated values compared to the other models.
The performance of the model can be improved through hyperparameter tuning. In the RF technique, the model provided the highest performance compared to the other model. The 2D contour and the 3D surface of hyperparameter tuning are shown in
Figure 14. The important features are presented in
Figure 9 to train the RF model. Moreover, we ran the GridSerachCV function to check what parameters could give high accuracy. The best parameters of n-estimators of 60 and the max-features of 9 would provide an accuracy score of 1. A max-depth of 39 and max-features of 17 would lead to an accuracy score of 1. Comparing the GBR results with and without scaling, it was found that the scaled dataset would improve the model’s performance.
Three hidden layers have been used with the ANN models with six neurons each. The ReLu activation function has been used in two hidden layers, and the other activation functions have been used in the last hidden layer to monitor the performance of the model. It was found that the ANN model with the tan
h activation function performed better (
Table 10 and
Figure 15).
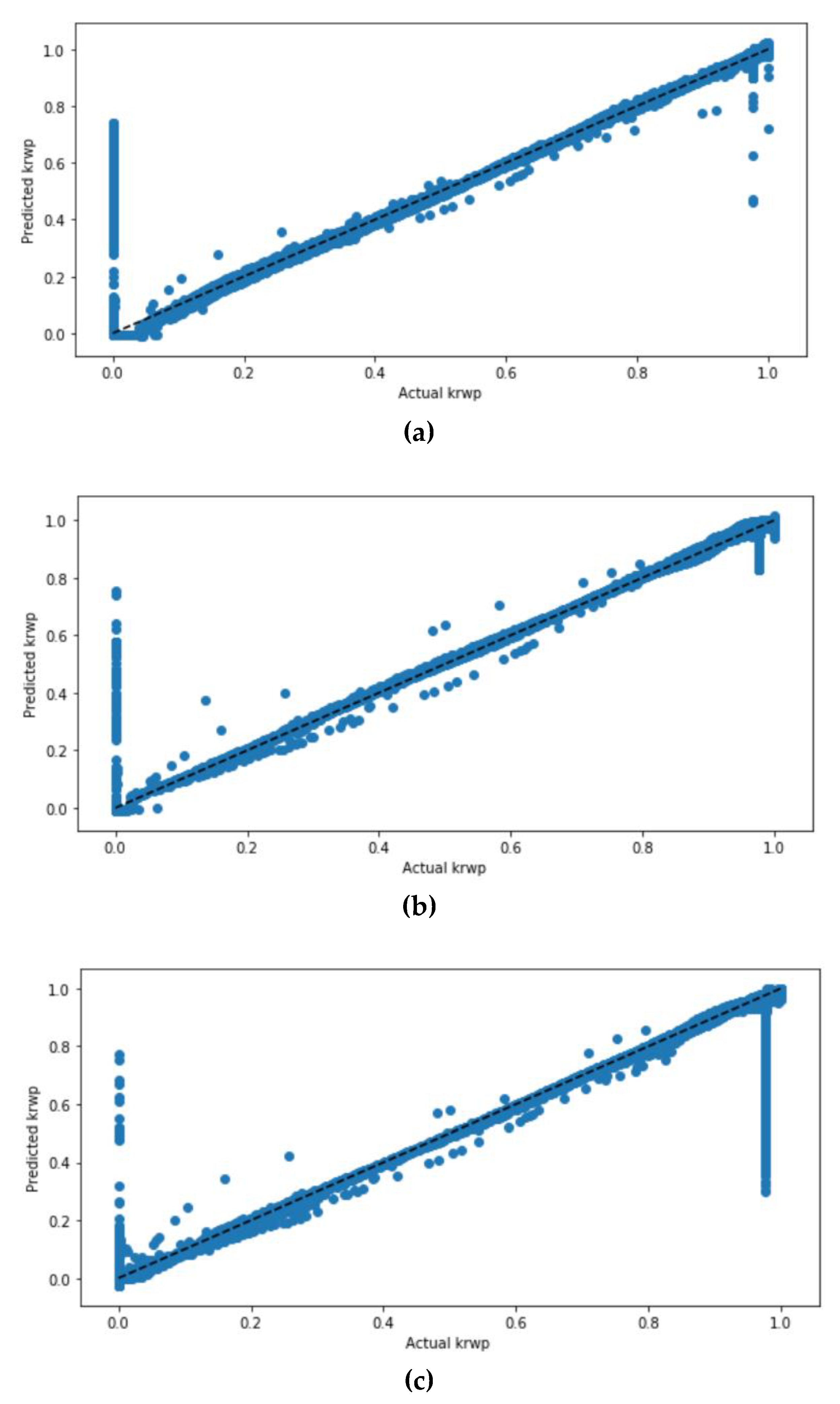
Figure 15 illuminates the 2D contour and the 3D surface of tuning two hyperparameters for the water relative permeability krwp. In the DT model, the two selected hyperparameters were the max-depth and max-features. It can be viewed from the figure that a max-depth of 39 and max-features of 17 had the highest accuracy score of 1. While for the RF model, the two selected hyperparameters are max-features and the number of estimators. It is shown that max-features of 9 and n-estimators of 60 had the highest accuracy of a score of 1.
Figure 15 compares the scatter plots of the ANN model with the scaled dataset with ReLu, sigmoid, and tan
h activation functions. It can be seen from the figure that the scatter plots of the ANN model with the tan
h activation function had the highest correlated values compared to the ANN model that used sigmoid and ReLu activation functions.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}