Historically, the concept of “sensitivity analysis” arose from the need to predict and quantify the changes induced in the model’s responses by changes in the model parameters and to rank the importance of the model’s parameters in affecting the model’s responses. Initially, such predictions were performed by simply recomputing the result of interest using the variations of interest in the model parameters. Evidently, the results provided by such re-computations are specific to the respective parameter variation. Furthermore, such re-computations become unfeasible for large-scale models with many parameters. Nevertheless, such re-computations had become the basis for computing approximately, using finite differences, various partial derivatives of the response with respect to model parameters, which played the role of “sensitivities of responses with respect to parameters”. Subsequently, statisticians introduced various quantities (e.g., “measures of sensitivities” and/or “sensitivity indicators”) to play the role of “sensitivities” by using statistical quantities related to the variance of the response that might be induced by the variances assumed to be known, of the model parameters. These statistical measures and methodologies to compute them will also be mentioned briefly in this Section.
Mathematically, the only unambiguous concept for defining the “sensitivity of a function to its underlying parameters” is in terms of the partial derivatives of the respective function with respect to its underlying parameters. Thus, the “first-order sensitivities” of a model response are the first-order partial functional derivatives of the response with respect to the parameters; the “second-order sensitivities” are the second-order partial functional derivatives of the response with respect to the parameters; and so on; the “nth-order sensitivities” are the nth-order partial functional derivatives of the model response with respect to the model parameters.
There are three major areas of scientific activities that are built on the availability of response sensitivities to model parameters as follows: (i) sensitivity analysis; (ii) uncertainty quantification; and (iii) predictive modeling, which combines measured and computational information to obtain best-estimate predictions of model responses and parameters, with reduced predicted uncertainties. The current state-of-the-art in these three areas of scientific activities will be reviewed briefly in this Section.
3.1. High-Order Sensitivity Analysis
The scope of “sensitivity analysis” is to predict and quantify the changes induced in the model’s response by changes in the model parameters and to rank the importance of the model’s parameters in affecting the model’s response. Mathematically, the soundest concept for predicting unambiguously the changes induced in a function of parameters stemming from changes in the respective parameters is provided by the multivariate Taylor series of the function with respect to its component parameters. Hence, the concept of “sensitivity of a function to its underlying parameters” is based on the role of the partial derivatives of the respective function with respect to its underlying parameters. Specifically, the “first-order sensitivities” of a model response are the first-order partial functional derivatives of the response with respect to the parameters; the “second-order sensitivities” are the second-order partial functional derivatives of the response with respect to the parameters; and so on; the “nth-order sensitivities” are the nth-order partial functional derivatives of the model response with respect to the model parameters. Since the expected (or nominal) parameter values,
, are known, the formal expression of the multivariate Taylor series expansion of a model response, denoted as
, as a function of the model parameters
around
has the following well-known formal expression:
where
. Since the explicit expression of
as a function of the model parameters
is not available, the explicit expressions of the sensitivities of
are not available for numerical evaluation. It is evident from Equation (4) that, for a model comprising a total number of
-parameters, for each model response, there are
first-order sensitivities,
distinct second-order sensitivities,
distinct third-order sensitivities, and so on. The number of sensitivities increases exponentially with the order of the respective sensitivities; hence, their computation by conventional methods (e.g., finite difference schemes, statistical assessments), which require re-computations using the original model (with suitably altered parameter values) is hampered by the curse of dimensionality [
5] while providing approximate (often inaccurate), rather than exact, values for the sensitivities. The only extant method that overcomes, to the largest possible extent, the curse of dimensionality while providing exact expressions for computing efficiently sensitivities of all orders is the “
nth-Order
Comprehensive
Adjoint
Sensitivity
Analysis
Methodology (nth-CASAM)” developed by Cacuci [
21,
23] by extending the original adjoint sensitivity analysis methodology conceived by Cacuci [
1,
2]. The nth-CASAM requires computations in
linearly increasing higher-dimensional Hilbert spaces, as opposed to exponentially increasing parameter-dimensional spaces. In particular, for a scalar-valued response associated with a model comprising
model parameters, the nth-CASAM requires one adjoint computation for computing exactly all of the first-order response sensitivities, as opposed to at least
forward computations, as required by other methods to obtain approximate values for these sensitivities. All of the (mixed) second-order sensitivities are computed exactly by the nth-CASAM in most
computations, as opposed to needing at least
computations, as required by all other methods, and so on. For every lower-order sensitivity of interest, the nth-CASAM computes the “
next-higher-order” sensitivities in
one adjoint computation performed in a linearly increasing higher-dimensional Hilbert space. The nth-CASAM applies to any model (deterministic, statistical, etc.) and is also applicable to the computation of sensitivities of
operator-valued responses, which cannot be obtained by statistical methods when the underlying problem comprises many parameters. The larger the number of model parameters, the more efficient the nth-CASAM becomes for computing arbitrarily high-order response sensitivities.
The practitioners of statistical methods cavalierly downplay the importance of the Taylor series by labeling it as being “local” (as opposed to “global”—as they usually characterize the statistical methods). In reality, the range of validity of the Taylor series is provided by its radius of convergence. The accuracy—as opposed to the “validity”—of the Taylor series in predicting the value of the response at an arbitrary point in the phase space of model parameters depends on the order of sensitivities retained in the Taylor expansion: the higher the respective order, the more accurate the respective response value predicted by the Taylor series. In the particular cases when the response happens to be a polynomial function of the model parameters, the Taylor series is actually exact (not only “non-local”). In contradistinction, no statistical method is ever “exact.
The need for the computation of higher-order sensitivities has been amply illustrated by Cacuci and Fang [
22], using as a paradigm model the
poly
ethylene-
reflected
plutonium (acronym “PERP”) reactor physics benchmark [
15], which is included in the Nuclear Energy Agency (NEA) International Criticality Safety Benchmark Evaluation Project (ICSBEP). The composition and dimensions of this benchmark are summarized in
Appendix A. The distribution of neutrons within the benchmark is modeled by the linear time-independent inhomogeneous neutron transport (Boltzmann) equation (see
Appendix A), which is solved numerically (after discretization in the energy, spatial, and angular independent variables) using the software package PARTISN [
25] and SOURCES4C [
26]. The numerical model of the PERP benchmark includes 21,976 parameters, of which the following 7477 parameters have non-zero (but imprecisely known) nominal values: 180 group-averaged total microscopic cross-sections; 120 fission process parameters; 60 fission spectrum parameters; 10 parameters describing the experiment’s nuclear sources; 6 isotopic number densities; and 7101 non-zero group-averaged scattering microscopic cross-sections (the remaining scattering cross-sections, out of a total of 21,600, have zero nominal values). Solving the Boltzmann equation with these many parameters is representative of a “large-scale computation”.
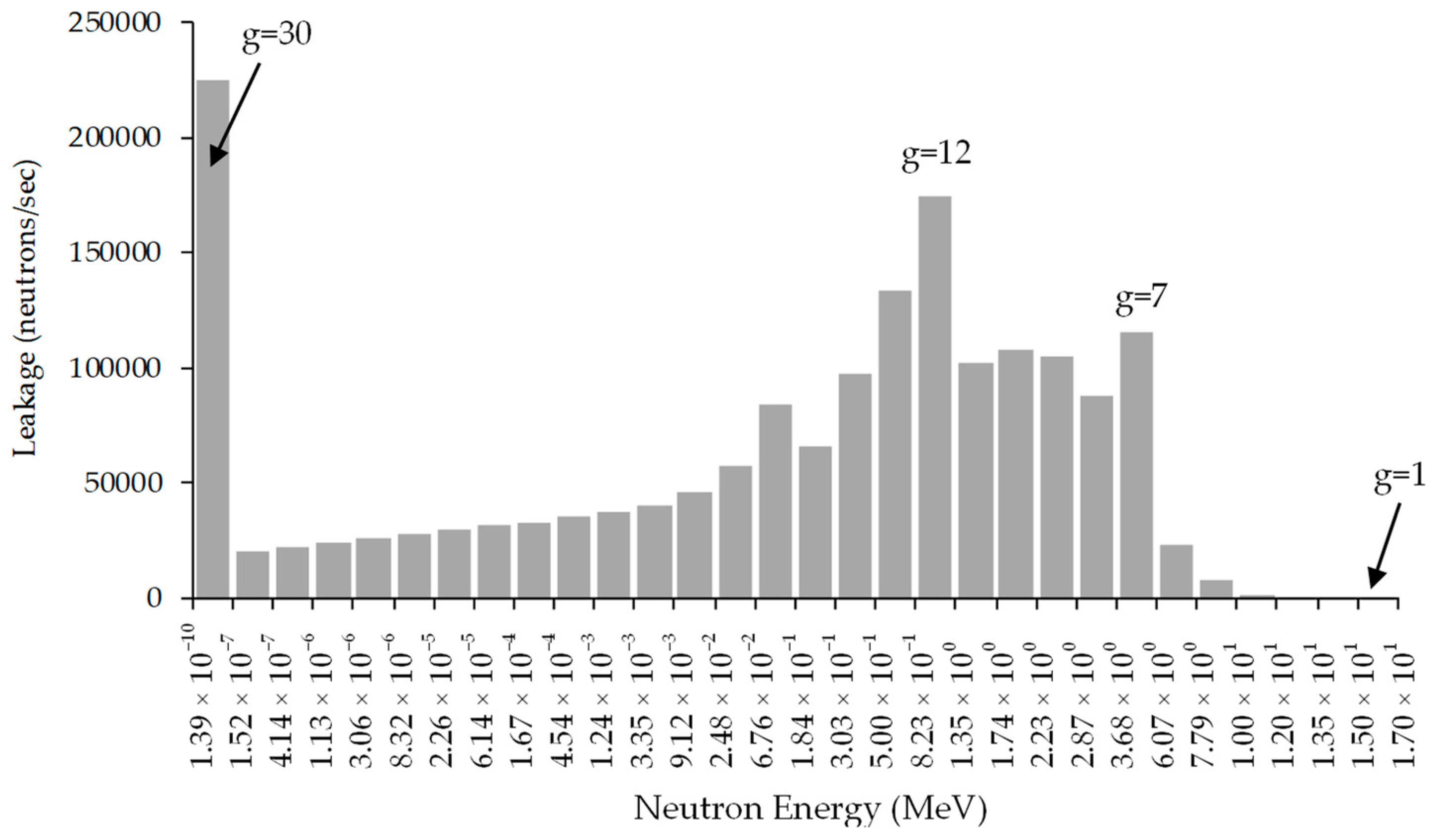
The response of interest for the PERP benchmark is the total neutron leakage from the PERP sphere (numerical value:
neutrons/s), which is plotted in histogram form as a function of energy in
Figure 1 [
22].
All of the first-order sensitivities of the leakage response with respect to the 7477 non-zero parameters were computed [
22] using the First-Order Comprehensive Sensitivity Analysis Methodology (first-CASAM). The vast majority of these sensitivities had relative values below 10%, but 16 of them exceeded unity in absolute value; the largest of all of the first-order relative sensitivities was the sensitivity of the leakage response with respect to the total group cross-section, denoted as
, of Hydrogen (labeled isotope #6) in group 30, which had the relative value
. Among the benchmark’s parameters, the total microscopic cross-sections had the largest impact on the leakage response; the following sensitivities of this response with respect to the microscopic total cross-sections of hydrogen also had large values for energy groups 17–20 [
;
;
;
;
). Also included in the top 16 were the (relative) sensitivities of the leakage response with respect to the total microscopic cross-sections of
239Pu (labeled isotope #1) in energy groups 12 and 13, which had the values
and
, respectively.
The second-order sensitivities also must be computed in order to compare them with the values of the largest first-order sensitivities and consequently decide which, if any, of the second-order sensitivities must be retained for subsequent uses (e.g., for uncertainty quantification and/or data assimilation and predictive modeling). Therefore, all of the distinct (7477 × 7478/2) second-order sensitivities of the PERP benchmark’s leakage response with respect to the benchmark’s parameters were computed [
9,
10,
11,
12,
13,
14,
22] by applying the Second-Order Comprehensive Sensitivity Analysis Methodology (second-CASAM). It was thus established that ca. 1000 relative second-order sensitivities had absolute values larger than unity, with over 50 of them having absolute values between 10.0 and 100.0. The overall largest second-order relative sensitivity was the unmixed second-order sensitivity of the leakage response with respect to the total microscopic cross-section of hydrogen in energy group 30, which had the value
.
These findings have motivated the computation [
16,
17,
22] of the third-order sensitivities of the leakage response with respect to the benchmark’s total cross-sections. It was found there that 45,970 of such third-order sensitivities had absolute values between 1.0 and 10.0; 11,861 of such third-order sensitivities had absolute values between 10.0 and 100.0, and 1199 of such third-order sensitivities had absolute values larger than 100.0. All of the largest first-, second-, and third-order sensitivities involved the microscopic total cross-section for the lowest (30th) energy group of isotope
1H (i.e.,
). The largest overall third-order sensitivity is the mixed third-order sensitivity
, which also involves the microscopic total cross-section for the 30th energy group of isotope
239Pu (i.e.,
). The total microscopic cross-section of isotopes
1H and
239Pu are the two most important parameters affecting the PERP benchmark’s leakage response since they are involved in all of the large second- and third-order sensitivities.
These results subsequently motivated the computation [
18,
19,
22] of the fourth-order sensitivities of the leakage response with respect to the total microscopic cross-section of hydrogen. Depending on the specific energy group, the values of the fourth-order relative sensitivity were found to be ca. 2 to 7 times larger than the corresponding third-order ones, ca. 5 to 52 times larger than the values of the corresponding second-order sensitivities, and ca. 8 to 220 times larger than the values of the corresponding first-order sensitivities. For illustrative purposes, the energy-dependence of the first- through fourth-order sensitivities of the leakage response with respect to the total microscopic cross-sections of hydrogen are depicted in
Figure 2 [
22], which underscores the overwhelming importance of the second- and higher-order sensitivities.
3.2. High-Order Uncertainty Quantification
In practice, the model parameters are not known exactly, even though they are not bona fide random quantities. For practical purposes, however, these model parameters are considered to be variates that obey a multivariate probability distribution function, denoted as
. Although this distribution is seldom known, the various moments of
can be defined in a standard manner by using the following notation for the “expected (or mean) value” of a function,
, of the parameters, which is defined over the domain of definition of
:
In particular, the vector of expected values,
, of the model parameters
, is defined as follows:
In practice, the expected values—which are taken as the nominal values for carrying out the computation of responses using the mathematical/numerical model—are known (or assumed to be known). In order to perform “uncertainty quantification/analysis” of the uncertainties induced in the responses by uncertainties in the parameters, it is necessary to also know the covariances,
, between two parameters,
and
, which are defined as follows:
In Equation (7), the quantities
and
denote the standard deviations of
and
, respectively, while
denotes the correlation between the respective parameters. Occasionally, the higher-order correlations between parameters can also be obtained. Formally, the third-order correlation,
, among three parameters is defined as follows:
The fourth-order correlation
among four parameters is defined as follows:
The Taylor series shown in Equation (4) can be used in conjunction with the definitions provided in Equations (5)–(9), as was first performed by Tukey [
27], to obtain the expressions for the moments of the response distribution. Using the Taylor series shown in Equation (4), Cacuci [
21] has presented expressions for the first six moments of the joint distribution of responses and parameters, including the sixth-order in standard deviations.
The effects of high-order sensitivities on the moments (i.e., mean, variance, skewness) of the response distribution will be illustrated in this Section by considering the leakage response of the PERP reactor physics benchmark discussed in
Section 3.1 above in the phase space of total microscopic cross-sections since the largest sensitivities of the leakage response are with respect to these parameters. A complete uncertainty analysis of the PERP leakage response can be found in the book by Cacuci and Fang [
22].
The microscopic cross-sections will be considered to be uncorrelated and normally distributed in order to simplify the algebraic complexities. Under these conditions, the first three moments of the distribution of the leakage response are provided by the following expressions [
22]:
- (i)
The expected value of the leakage response has the following particular expression:
where the superscript “U,N” indicates contributions from
uncorrelated and
normally distributed parameters; the subscript
t indicates group-averaged microscopic “total” cross-section, and the letter “
L” denotes “leakage response”. In Equation (10), the contributions from the third-order (and all odd-order) sensitivities vanish because the parameters are uncorrelated. Furthermore, the quantity
represents the leakage response computed using the nominal cross-section values, and the quantities
and
denote the contributions from the second-order and fourth-order response sensitivities, respectively, which are provided by the following expressions:
In Equations (11) and (12), the quantity represents the “j1-th microscopic total cross-section” while the quantity denotes the total number of microscopic total cross-sections for groups and isotopes contained in the PERP benchmark. The traditional notation “” for “microscopic cross-sections” is not used in the formulas to be presented in this section since this notation will be used to denote “standard deviation”.
- (ii)
The variance of the leakage response for the PERP benchmark takes on the following particular form:
where
,
,
and
denote the contributions of the terms involving the first-order through the fourth-order sensitivities, respectively, to the variance
and are defined by the following expressions:
- (iii)
The third-order moment of the leakage response for the PERP benchmark takes on the following particular form:
where
,
,
, and
denote the contributions to
of the terms involving the first-order through the fourth-order sensitivities, respectively; these quantities have the following expressions:
The skewness, denoted as
, of the response
indicates the degree of the distribution’s asymmetry with respect to its mean and is defined as follows:
Using Equations (10)–(22), the effects of the sensitivities of various orders on the leakage response’s expectation, variance, and skewness have been quantified by considering uniform standard deviations of 1% (small) and 5% (moderate), respectively, for the microscopic total cross-sections. These results are presented in
Table 1 and
Table 2, respectively.
The results presented in
Table 1 were obtained by considering a small relative standard deviation of 1% for each of the uncorrelated microscopic total cross-sections of the isotopes included in the PERP benchmark. The effects of the second-order and fourth-order sensitivities on the expected response value
are both negligibly small since
and
. The results presented in the second column in
Table 1 imply that
,
, and
, indicating that the contributions stemming from the first-order sensitivities to the response variance are significantly larger (ca. 70%) than those stemming from higher-order sensitivities. By comparison, the second-order sensitivities contribute about 6% to the response variance; the third-order sensitivities contribute about 20% to the response variance, while the fourth-order ones only contribute about 4% to the response variance. The results presented in
Table 1 also indicate that
,
and
; thus, the contributions to the third-order response moment
stemming from the second-order sensitivities are the largest (e.g., around 53% in this case), followed by the contributions stemming from the third-order sensitivities, while the contributions stemming from the fourth-order sensitivities are the smallest. The response skewness,
, is positive, causing the leakage response distribution to be skewed toward the positive direction from its expected value.
Table 2 presents results obtained by considering a moderate relative standard deviation of 5% for each of the uncorrelated microscopic total cross-sections. These results show that
, thereby indicating that the contributions from the second-order sensitivities to the expected response are around 65% of the computed leakage value
, and contribute around 17% to the expected value
of the leakage response. Furthermore, the results presented in
Table 2 also imply that
, indicating that the contributions from the fourth-order sensitivities to the expected response are about 2.1 times larger than the computed leakage value
, and contribute around 56% to the expected value
. Therefore, if the computed value,
, is considered to be the actual expected value of the leakage response, neglecting that the fourth-order sensitivities would produce an error of ca. 210%.
For a typical relative standard deviation of 5% for the uncorrelated microscopic total cross-sections, the results presented in
Table 2 indicate that
,
, and
, which means that the contributions from the third- and fourth-order sensitivities to the response variance are remarkably larger than those from the first- and second-order ones. The results in
Table 2 also show that
,
, and
; thus, the contributions from the third-order sensitivities are the largest (e.g., around 60%), followed by the contributions from the fourth-order sensitivities, which contribute about 30%; the smallest contributions stem from the second-order sensitivities.
The results shown in
Table 1 and
Table 2 highlight the fact that the successively higher-order terms become increasingly less important for small (1%) parameter uncertainties but become increasingly more important for larger (e.g., 5%) parameter uncertainties. Applying the ratio test for convergence of infinite series to the third- and fourth-order sensitivities indicates that a uniform relative parameter variation of ca. 5% (which would correspond to a 5% uniform relative standard deviation for the model parameters) would yield a ratio of about unity, which is near the boundary of the domain of convergence of the Taylor series expansion shown in Equation (4). Consequently, if relative standard deviations of parameters that have large sensitivities (e.g., Hydrogen
1H and/or Plutonium
239Pu, in the case of the PERP benchmark) were larger than 5% for certain model parameters, then the respective standard deviations would need to be reduced by re-calibrating the respective parameters. Such a re-calibration could be performed by using measurements of parameters and/or responses in conjunction with the high-order predictive modeling methodology developed by Cacuci [
28,
29], which will be briefly reviewed in the next subsection.
3.3. High-Order Predictive Modeling
Consider that the total number of computed responses and, correspondingly, the total number of experimentally measured responses is
. The information usually available regarding the distribution of such measured responses comprises the first-order moments (mean values), which will be denoted as
,
, and the second-order moments (variances/covariances), which will be denoted as
,
, for the measured responses. The letter “e” will be used either as a superscript or a superscript to indicate
experimentally measured quantities. The expected values of the experimentally measured responses will be considered to constitute the components of a vector denoted as
. The covariances of the measured responses are considered to be components of the
-dimensional covariance matrix of measured responses, which will be denoted as
. In principle, it is also possible to obtain correlations between some measured responses and some model parameters. When such correlations between measured responses and measured model parameters are available, they will be denoted as
,
, and they can formally be considered the elements of a rectangular correlation matrix, which will be denoted as
. As discussed in
Section 3, cf. Equations (6) and (7), the model parameters are characterized by the vector of mean values
and the covariance matrix
.
Cacuci [
28,
29] has applied the MaxEnt principle [
30] to construct the least informative (and hence, most conservative) distribution that includes all of the available computational and experimental information up to fourth-order sensitivities, thus obtaining the following expressions for the “best-estimate” (indicated by the superscript “
be”) predicted responses and calibrated model parameters:
- (i)
Optimally predicted “best-estimate” values for the predicted model responses :
The vector
in Equation (23) has components
, each of which denotes the expected value of a generic computed response
and is obtained from Equation (4) in the following form, up to and including fourth-order standard deviations of parameters:
The covariance matrix
of the computed responses in Equation (23) comprises as elements the covariances,
, of two responses,
and
, respectively. Using Equations (4) and (24), one obtains the following expression:
- (ii)
Optimally predicted “best-estimate” values for the responses and calibrated parameters:
where the components of the covariance matrix
of computed responses and parameters have the following expressions up to and including fourth-order standard deviations of parameters, obtained by using Equations (4) and (24):
Since the components of the vector , and the components of the matrices and can contain arbitrarily high-order response sensitivities to model parameters, the expressions presented in Equations (23) and (26) generalize the previous formulas of this type found in data adjustment/assimilation procedures published to date (which contain at most second-order sensitivities). The best-estimate parameter values are the “calibrated model parameters”, which can be used for subsequent computations with the “calibrated model”;
- (iii)
Optimally predicted “best-estimate” values for covariance matrix, , for the best-estimate responses :
As indicated in Equation (28), the initial covariance matrix for the experimentally measured responses is multiplied by the matrix , which means that the variances contained on the diagonal of the best-estimate matrix will be smaller than the experimentally measured variances contained in . Hence, the incorporation of experimental information reduces the predicted best-estimate response variances in by comparison to the measured variances contained a priori in . Since the components of the matrix contain high-order sensitivities, the formula presented in Equation (28) generalizes the previous formulas of this type found in data adjustment/assimilation procedures published to date;
- (iv)
Optimally predicted “best-estimate” values for the posterior parameter covariance matrix for the best-estimate parameters :
The matrices and are symmetric and positively definite. Therefore, the subtraction indicated in Equation (29) implies that the components of the main diagonal of must have smaller values than the corresponding elements of the main diagonal of . In this sense, the combination of computational and experimental information has reduced the best-estimate parameter variances on the diagonal of . Since the components of the matrices , , and contain high-order response sensitivities, the formula presented in Equation (29) generalizes the previous formulas of this type found in data adjustment/assimilation procedures published to date;
- (v)
Optimally predicted “best-estimate” values for the posterior parameter correlation matrix and/or its transpose , for the best-estimate parameters and best-estimate responses:
Since the components of the matrices and contain high-order sensitivities, the formulas presented in Equations (30) and (31) generalize the previous formulas of this type found in data adjustment/assimilation procedures published to date.
It is important to note from the results shown in Equations (23)–(31) that the computation of the best estimate parameter and response values, together with their corresponding best-estimate covariance matrices, only involves a single matrix inversion, for computing
, which entails the inversion of a matrix of size
. This is computationally very advantageous since
, i.e., the number of responses is much lower than the number of model parameters in the overwhelming majority of practical situations. The
unmatched guaranteed reduction in predicted uncertainties in the predicted responses (and model parameters)
and the essential impact of higher-order sensitivities has been recently illustrated by Fang and Cacuci [
31] by applying the second-BERRU-PM methodology [
28,
29] to the
poly
ethylene-
reflected
plutonium OECD/NEA reactor physics benchmark, which was already described briefly in
Section 3.1. The results predicted by using Equations (23) and (28) in conjunction with typical measurement uncertainties (relative standard deviation of 10%) and typical uncertainties (relative standard deviation of 5%) for the total cross-sections (which are the model parameters considered in this illustrative example) are presented in
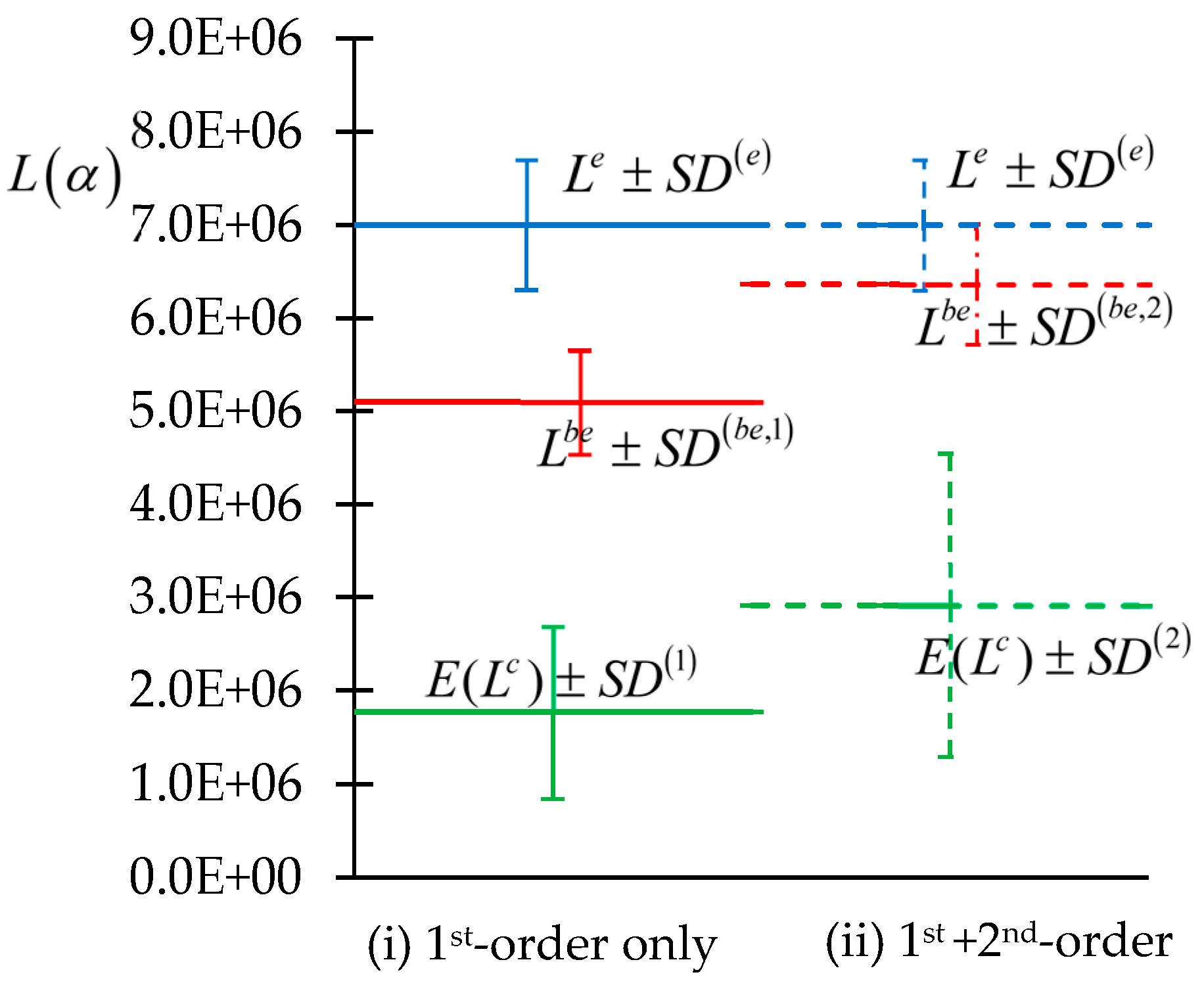
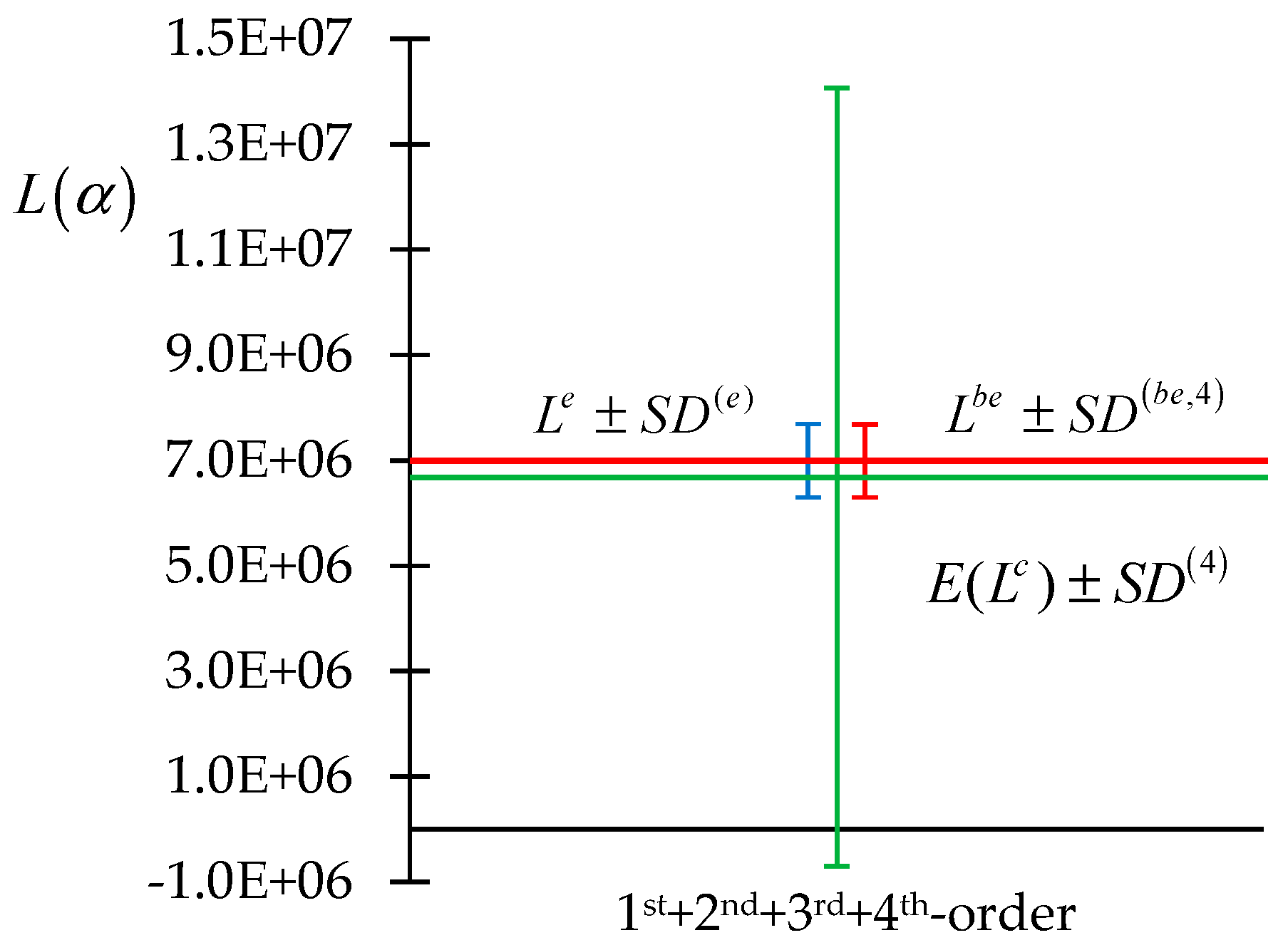
Figure 3 and
Figure 4, below. The leakage of neutrons through the outer sphere of the plutonium benchmark is denoted by the letter “L” in
Figure 3 and
Figure 4. In
Figure 3 and
Figure 4, the superscript “e” denotes “experimentally measured quantities”, while the superscript “be” denotes “best-estimate optimally predicted quantities”. The standard deviation of the experimentally measured response is denoted as
; the standard deviation of the computed response is denoted as
, and the “best-estimate” standard deviation of the best-estimate response is denoted as
. The values 1, 2, and 4, taken on by the index “
i” in the superscripts of these standard deviations, correspond, respectively, to the inclusion of only the first-order sensitivities, the inclusion of the first- and the second-order sensitivities, and the inclusion of the first + second + third + fourth-order sensitivities. The parameters (microscopic group-averaged total cross-sections) considered for obtaining the results depicted in
Figure 3 and
Figure 4 were considered to be uncorrelated and normally distributed, having uniform relative standard deviations of 5%.
The numerical results [in units of
] that correspond to the graphs in
Figure 3 and
Figure 4 are as follows:
;
;
;
;
;
;
.
These results depicted in
Figure 3 and
Figure 4 imply the following conclusions:
(i) The nominal (value of the) computed response, , coincides with the expected value of the computed response, , only if all sensitivities higher than first-order are ignored. Otherwise, the effects of the second- and higher-order sensitivities cause the expected value of the computed response, , to be increasingly larger than the nominal computed value , i.e., ;
(ii) As indicated in
Figure 3, the inclusion of only the first- and second-order sensitivities
appears to indicate that the “computations are inconsistent with the computations” since, in these cases, the standard deviation of the measured response does not overlap with the standard deviation of the computed response. However, this indication is proven to be
false by the result depicted in
Figure 4, which shows that the inclusion of the third- and fourth-order sensitivities renders the computation to be “consistent” with the measurement. This situation underscores the
importance of including not only the second-order but also the higher (third- and fourth) order sensitivities;
(iii) As predicted by the second-BERRU-PM methodology, the best-estimate response value, , always falls in between the “expected value of the computed response”, , and the experimentally measured value , i.e., . As higher-order sensitivities are included, the predicted response value, , approaches the experimentally measured value, . Remarkably, all three of these quantities become clustered together, with , when all sensitivities, from first to fourth order, are included;
(iv) It is also apparent that the predicted standard deviation of the predicted response is smaller than either the originally computed response standard deviation or the measured response standard deviation, i.e., and . This reduction in the magnitude of the predicted response standard deviation is guaranteed by the application of the second-BERRU-PM methodology; this reduction is even more accentuated when the higher (second-, third-, fourth-) order sensitivities are also included;
(v) The results depicted in
Figure 3 and
Figure 4 also indicate that the second-order response sensitivities must always be included, even if only to quantify the need for including (or not) the third- and/or fourth-order sensitivities;
(vi) As indicated in
Figure 3 and
Figure 4, the standard deviation of the computed response increases as sensitivities of increasingly higher order are incorporated, as would logically be expected. However, this fact has no negative consequences after the second-BERRU-PM methodology is applied to combine the computational results with the experimental results since, as shown in
Figure 3 and
Figure 4, the second-BERRU-PM methodology reduces the predicted best-estimate standard deviations to values that are smaller than both the computed and the experimentally measured values of the initial standard deviations. The results obtained confirm the fact that
the second-
BERRU-PM methodology predicts best-estimate results that fall in between the corresponding computed and measured values while reducing the predicted standard deviations of the predicted results to values smaller than either the experimentally measured or the computed values of the respective standard deviations.
The second-BERRU-PM methodology also yields best-estimate optimal values for the (posterior) calibrated parameters, as indicated in Equation (26), along with reduced predicted uncertainties (standard deviations) for the predicted parameters, as shown in Equation (29). The best-estimate calibrated parameters thus obtained are subsequently used in the respective calibrated computational models to compute best-estimate responses, which will have smaller uncertainties since the calibrated parameters have smaller uncertainties than the original uncalibrated parameters. Such subsequent computations yield results practically equivalent to the predicted response value and the predicted best-estimate reduced standard deviation ; because of the page limitation, however, these results cannot be reproduced here.
Fundamental Advantages of the Second-BERRU-PM Methodology over the Second-Order Data Assimilation
This section will describe the decisive advantages of the second-BERRU-PM methodology over the Second-Order Data Assimilation methodology. The Second-Order Data Assimilation methodology relies on using the second-order procedure to minimize a user-defined functional, which is meant to represent, in a chosen norm (usually the energy norm), the discrepancies between computed and experimental results (“responses”). The “Second-Order Data Assimilation” [
32,
33] considers that the vector of measured responses (“observations”), denoted by the vector
, is a known function of the vector of state-variables
and the vector of errors
, having the expression:
, where
denotes the vector of dependent variables, and
is a known vector-function of
. The error term,
, is considered here to include “representative errors” stemming from sampling and grid interpolation; the mean value of
corresponds to
, and the covariance matrix of
corresponds to
. As described in [
32,
33],
is often considered to have the characteristics of “white noise”, in which case,
is a normal distribution with mean
and covariance
. In addition, it is assumed that the prior “background” information is also known, being represented by a multivariate normal distribution with a known mean, denoted as
, and a known covariance matrix denoted as
, i.e.,
. The posterior distribution,
, is obtained by applying Bayes’ Theorem to the above information, which yields the result
, where
. The maximum posterior estimate is obtained by determining the minimum of the functional
, which occurs at the root(s) of the following equation:
where
denotes the Jacobian matrix of
with respect to the components of
.
The “first-order data assimilation” procedure solves Equation (32) by using a “partial quadratic approximation” to
, while the “second-order data assimilation” procedure solves Equation (32) by using a “full quadratic approximation” to
, as detailed in [
32,
33], to obtain the “optimal data assimilation solution”, which is here denoted as
, as the solution of Equation (32).
The following fundamental differences become apparent by comparing the “Data Assimilation” result represented by Equation (32) and the Hi-BERRU-PM results.1. Data assimilation (DA) is formulated conceptually [
32,
33] either only in the phase space of measured responses (“observation space formulation”) or only in the phase space of the model’s dependent variables (“state space formulation”). Hence, DA can calibrate initial conditions as “direct results” but cannot directly calibrate any other model parameters. In contradistinction, the second-BERRU-PM methodology is formulated conceptually in the most inclusive “joint phase space of parameters, computed and measured responses”. Consequently, the second-BERRU-PM methodology simultaneously calibrates responses and parameters, thus simultaneously providing results for forward and inverse problems;
2. If the experiments are perfectly well known, i.e., if , Equation (32) indicates that the DA methodology fails fundamentally. In contradistinction, Equations (23)–(31) indicate that the second-BERRU-PM methodology does not fail when because, in any situation, ;
3. The DA methodology also fails fundamentally when the response measurements happen to coincide with the computed value of the response, i.e., when is at some point in the state space. In such a case, the DA’s Equation (32) yields the trivial result . In contradistinction, the Hi-BERRU-PM methodology does not yield such a trivial result when the response measurements happen to coincide with the computed value of the response, i.e., when , because the difference , which appears on the right sides of Equations (23), (26) and (28)–(31), remains non-zero due to the contributions of the second- and higher-order sensitivities of the responses with respect to the model parameters, since for . This situation clearly underscores the need for computing and retaining (at least) the second-order response sensitivities to the model parameters. Although a situation when is not expected to occur frequently in practice, there are no negative consequences (should such a situation occur) if the second-BERRU-PM methodology is used, in contradistinction to using the DA methodology;
4. The second-BERRU-PM methodology only requires the inversion of the matrix
of size
. In contradistinction, the solution of the “first-order DA” requires the inversion of the Jacobian
of
, while the solution of the “second-order DA” also requires the inversion of a matrix-vector product involving the Hessian matrix of
; these matrices are significantly larger [
32,
33] than the matrix
. Hence, the second-BERRU-PM methodology is significantly more efficient computationally than DA;
5. The DA methodology [
32,
33] is practically non-extendable beyond “second-order”. A “third-order DA” would be computationally impractical because of the massive sizes of the matrices that would need to be inverted. In contradistinction, the second-BERRU-PM methodology presented herein already comprises the fourth-order sensitivities of responses to parameters and can be readily extended/generalized to include even higher-order sensitivities and parameter correlations.
All of the above
advantages of the second-
BERRU-PM methodology over the DA methodology stem from the fact that the second-
BERRU-PM methodology is fundamentally anchored in physics-based principles (thermodynamics and information theory) formulated in the most inclusive possible phase space (namely, the combined phase space of computed and measured parameters and responses), whereas the DA methodology [
32,
33] is fundamentally based on the minimization of a subjective user-chosen functional.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}