
Adaptive Clustering Long Short-Term Memory Network for Short-Term Power Load Forecasting


Abstract
:1. Introduction
- (1)
- To enhance the accuracy of short-term load forecasting (STLF), we utilize a bee-foraging learning particle swarm optimization (BFLPSO) algorithm [27] to adaptively optimize the parameters of MDSC, thereby improving clustering performance.
- (2)
- We employ a 9-dimensional load feature vector as SVM classification features to determine the similar cluster for the prediction day. Subsequently, LSTM is utilized to generate the power load curve for the predicted day.
- (3)
- Experiments are conducted using one year of historical load data from a substation in Foshan City, Guangdong Province, China. The experimental results validate the effectiveness of our proposed algorithm.
2. Clustering Process
2.1. MDSC Clustering Algorithm
2.2. Optimizing the Parameters of MDSC with BFLPSO
2.3. The Steps of the Clustering Process
3. Prediction Process
3.1. Load Characteristic Vector
3.2. Similar Cluster Selection Based on SVM
3.3. LSTM Training
3.4. The Steps of Prediction Algorithm
4. Experiment and Analysis
4.1. Experimental Environment
4.2. Experimental Data
4.3. Analysis of Experimental Results
4.3.1. Experiment 1: Clustering Experiment
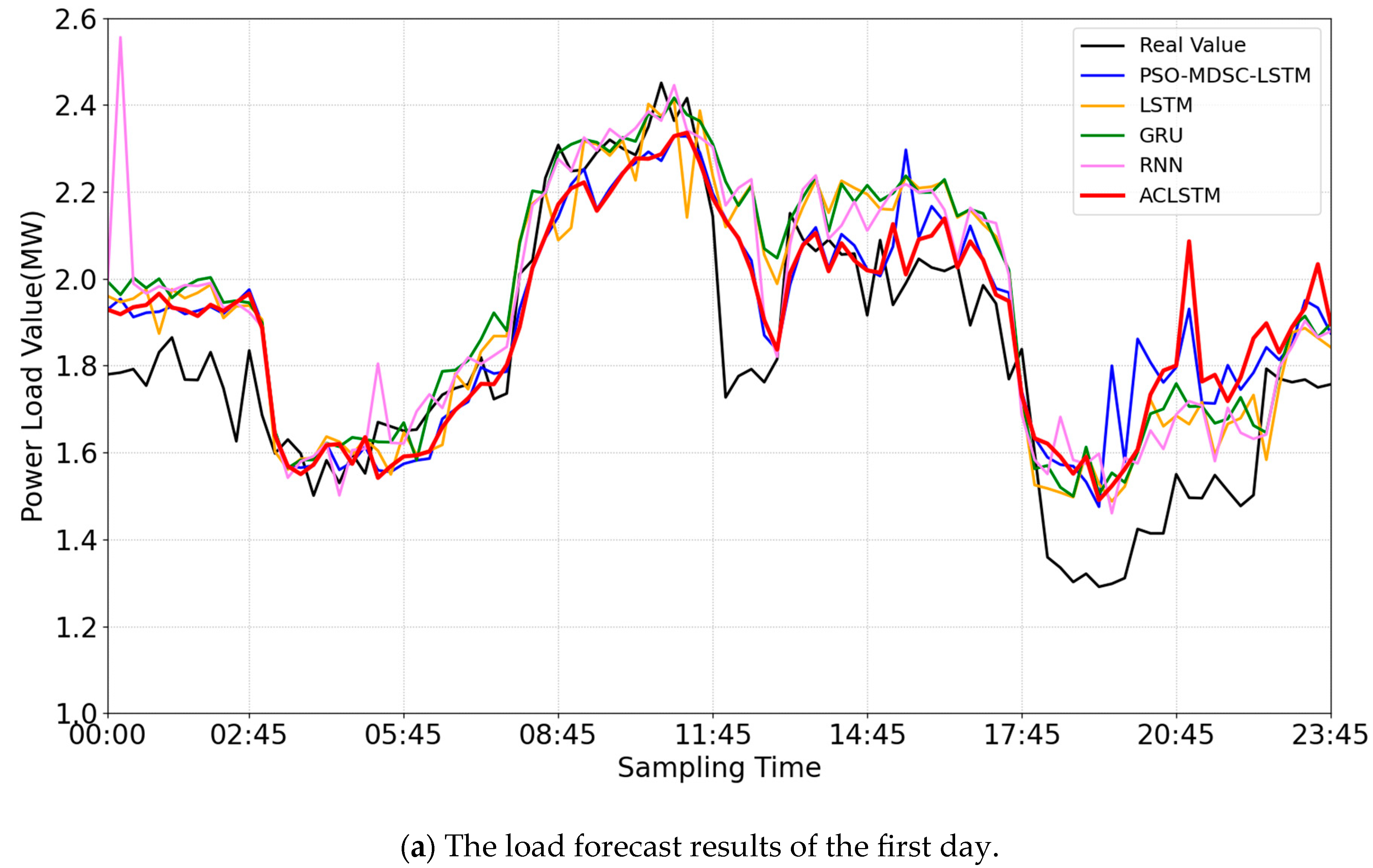
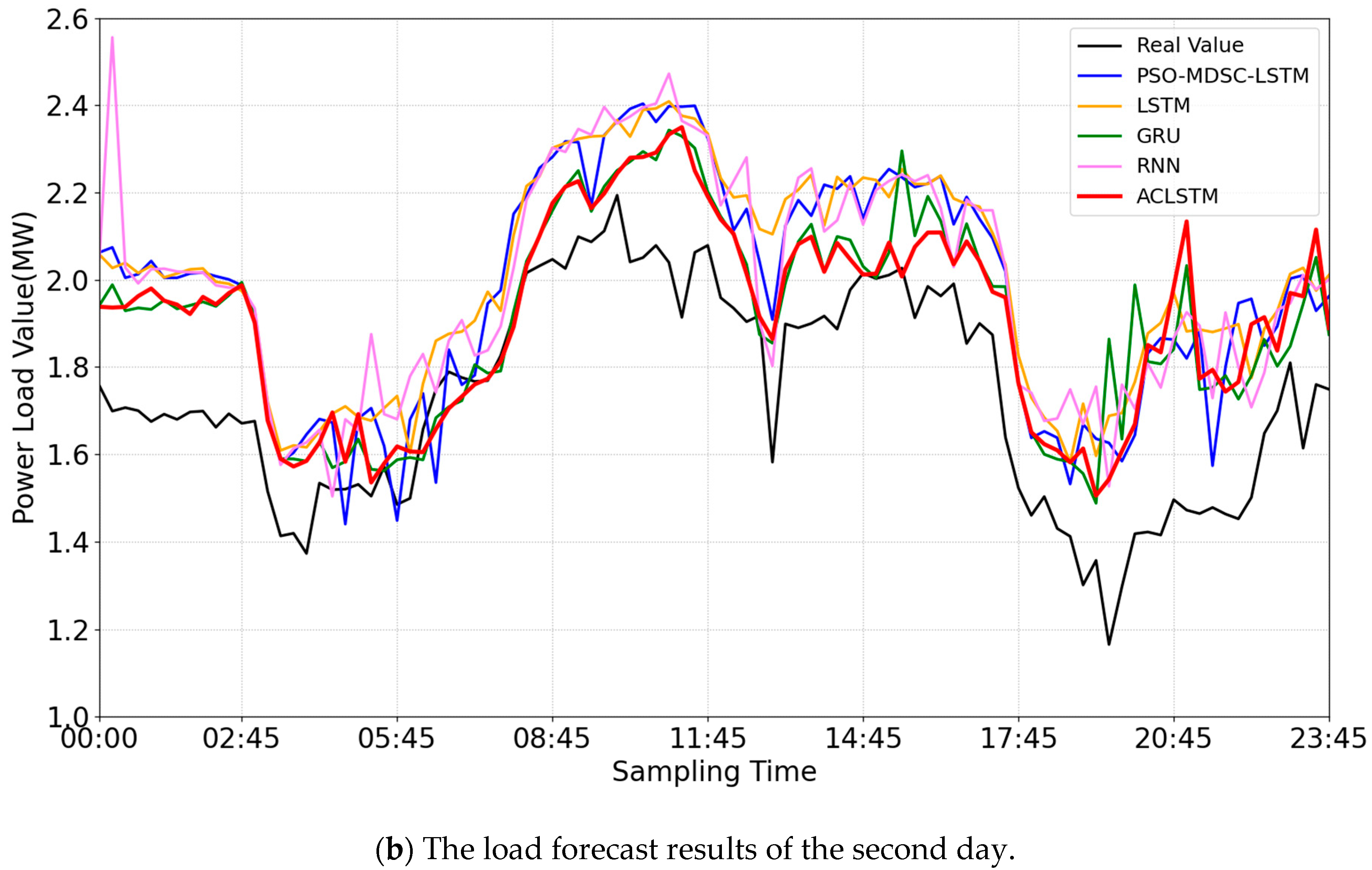
4.3.2. Experiment 2: Prediction Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Papalexopoulos, A.D.; Hao, S.; Peng, T.M. An implementation of a neural network based load forecasting model for the EMS. IEEE Trans. Power Syst. 1994, 9, 1956–1962. [Google Scholar] [CrossRef]
- Ma, H.; Xu, L.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Reducing the consumption of household systems using hybrid deep learning techniques. Sustain. Comput. Inform. Syst. 2023, 38, 100874. [Google Scholar] [CrossRef]
- Wang, B.; Wang, X.; Wang, N.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Machine learning optimization model for reducing the electricity loads in residential energy forecasting. Sustain. Comput. Inform. Syst. 2023, 38, 100876. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Hill, D.J.; Luo, F.; Xu, Y. Short-term residential load forecasting based on resident behaviour learning. IEEE Trans. Power Syst. 2018, 33, 1087–1088. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Coelho, V.N.; Coelho, I.M.; Coelho, B.N.; Reis, A.J.; Enayatifar, R.; Souza, M.J.; Guimarães, F.G. A self-adaptive evolutionary fuzzy model for load forecasting problems on smart grid environment. Appl. Energy 2016, 169, 567–584. [Google Scholar] [CrossRef]
- Pulido, M.; Melin, P.; Castillo, O. Particle swarm optimization of ensemble neural networks with fuzzy aggregation for time series prediction of the Mexican Stock Exchange. Inf. Sci. 2014, 280, 188–204. [Google Scholar] [CrossRef]
- Erdogdu, E. Electricity demand analysis using cointegration and ARIMA modelling. A case study of Turkey. Energy Policy 2007, 35, 1129–1146. [Google Scholar] [CrossRef]
- Hong, W.C. Electric load forecasting by support vector model. Appl. Math. Model. 2009, 33, 2444–2454. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.; Feng, Z.K.; Liu, G.; Yang, Y. A hybrid short-term load forecasting model based on variational mode decomposition and long short-term memory networks considering relevant factors with Bayesian optimization algorithm. Appl. Energy 2019, 237, 103–116. [Google Scholar] [CrossRef]
- Li, J.; Deng, D.; Zhao, J.; Cai, D.; Hu, W.; Zhang, M.; Huang, Q. A novel hybrid short-term load forecasting method of smart grid using MLR and LSTM neural network. IEEE Trans. Ind. Inform. 2020, 17, 2443–2452. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, X.; Feng, P.; Cai, X. Clustering-based short-term load forecasting for residential electricity under the increasing-block pricing tariffs in China. Energy 2018, 165, 76–89. [Google Scholar] [CrossRef]
- Sfetsos, A. Short-term load forecasting with a hybrid clustering algorithm. IEE Proc.-Gener. Transm. Distrib. 2003, 150, 257–262. [Google Scholar] [CrossRef]
- Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. Density-based clustering in spatial databases: The algorithm gdbscan and its applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Bian, H.; Zhong, Y.; Sun, J.; Shi, F. Study on power consumption load forecast based on K-means clustering and FCM–BP model. Energy Rep. 2020, 6, 693–700. [Google Scholar] [CrossRef]
- Han, F.; Pu, T.; Li, M.; Taylor, G. Short-term forecasting of individual residential load based on deep learning and K-means clustering. CSEE J. Power Energy Syst. 2020, 7, 261–269. [Google Scholar]
- Dong, X.; Deng, S.; Wang, D. A short-term power load forecasting method based on k-means and SVM. J. Ambient Intell. Humaniz. Comput. 2022, 13, 5253–5267. [Google Scholar] [CrossRef]
- Gu, J.; Zhang, W.; Zhang, Y.; Wang, B.; Lou, W.; Ye, M.; Liu, T. Research on short-term load forecasting of distribution stations based on the clustering improvement fuzzy time series algorithm. CMES-Comput. Model. Eng. Sci. 2023, 136, 2221–2236. [Google Scholar] [CrossRef]
- Zeng, W.; Li, J.; Sun, C.; Cao, L.; Tang, X.; Shu, S.; Zheng, J. Ultra short-term power load forecasting based on similar day clustering and ensemble empirical mode decomposition. Energies 2023, 16, 1989. [Google Scholar] [CrossRef]
- Yang, W.; Shi, J.; Li, S.; Song, Z.; Zhang, Z.; Chen, Z. A combined deep learning load forecasting model of single household resident user considering multi-time scale electricity consumption behavior. Appl. Energy 2022, 307, 118197. [Google Scholar] [CrossRef]
- Luo, Y.; Cai, Y.; Qi, Y. Short-term power load forecasting algorithm based on maximum deviation similarity criterion BP neural network. Appl. Res. Comput. 2019, 36, 3269–3273. [Google Scholar]
- Niknam, T.; Amiri, B. An efficient hybrid approach based on PSO, ACO and k-means for cluster analysis. Appl. Soft Comput. 2010, 10, 183–197. [Google Scholar] [CrossRef]
- Huang, J.; Xing, Y.; You, H.; Qin, L.; Tian, J.; Ma, J. Particle swarm optimization-based noise filtering algorithm for photon cloud data in forest area. Remote Sens. 2019, 11, 980. [Google Scholar] [CrossRef]
- Perafan-Lopez, J.C.; Ferrer-Gregory, V.L.; Nieto-Londoño, C.; Sierra-Pérez, J. Performance analysis and architecture of a clustering hybrid algorithm called FA+ GA-DBSCAN using artificial datasets. Entropy 2022, 24, 875. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Tianfield, H.; Du, W. Bee-foraging learning particle swarm optimization. Appl. Soft Comput. 2021, 102, 107134. [Google Scholar] [CrossRef]
- Van den Bergh, F.; Engelbrecht, A.P. A cooperative approach to particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 225–239. [Google Scholar] [CrossRef]
- Hassan, R.; Cohanim, B.; De Weck, O.; Venter, G. A comparison of particle swarm optimization and the genetic algorithm. In Proceedings of the 46th AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference, Austin, TX, USA, 18–21 April 2005. [Google Scholar]
- Luo, Y.; Cai, Y.; Qi, Y.; Chen, H.; Wang, S. Long short-term power load forecasting algorithm using long short-term memory neural network with density-based spatial clustering. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019. [Google Scholar]
- Jia, T.; Yao, L.; Yang, G.; He, Q. A short-term power load forecasting method of based on the CEEMDAN-MVO-GRU. Sustainability 2022, 14, 16460. [Google Scholar] [CrossRef]
- Medina-Santana, A.A.; Cárdenas-Barrón, L.E. Optimal design of hybrid renewable energy systems considering weather forecasting using recurrent neural networks. Energies 2022, 15, 9045. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | The Number of Clusters | SSE | DBI |
|---|---|---|---|
| BFLPSO-MDSC | 3 | 1357.22 | 0.14 |
| PSO-MDSC | 3 | 1365.77 | 0.16 |
| DBSCAN | 3 | 1540.66 | 1.48 |
| K-Means | 3 | 1528.11 | 0.76 |
| Prediction | Statistical Project | ACLSTM | PSO-MDSC-LSTM | LSTM | RNN | GRU |
|---|---|---|---|---|---|---|
| the first day | MAPE(%) | 8.05 | 8.21 | 8.27 | 8.18 | 8.55 |
| EMAX(%) | 39.46 | 38.66 | 23.69 | 43.27 | 28.77 | |
| EMIN(%) | 0.30 | 0.07 | 0.09 | 0.02 | 0.55 | |
| MAE | 0.13 | 0.14 | 0.14 | 0.14 | 0.15 | |
| MSE | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | |
| R2 | 0.65 | 0.63 | 0.65 | 0.60 | 0.63 | |
| the second day | MAPE(%) | 11.45 | 11.61 | 14.67 | 15.60 | 16.32 |
| EMAX(%) | 44.97 | 60.02 | 35.82 | 50.44 | 44.90 | |
| EMIN(%) | 0.12 | 0.06 | 0.09 | 0.40 | 4.88 | |
| MAE | 0.19 | 0.25 | 0.27 | 0.26 | 0.19 | |
| MSE | 0.05 | 0.07 | 0.08 | 0.08 | 0.05 | |
| R2 | 0.12 | −0.29 | −0.49 | −0.47 | 0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Y.; Luo, H.; Luo, Y.; Liao, R.; Ye, L. Adaptive Clustering Long Short-Term Memory Network for Short-Term Power Load Forecasting. Energies 2023, 16, 6230. https://doi.org/10.3390/en16176230
Qi Y, Luo H, Luo Y, Liao R, Ye L. Adaptive Clustering Long Short-Term Memory Network for Short-Term Power Load Forecasting. Energies. 2023; 16(17):6230. https://doi.org/10.3390/en16176230
Chicago/Turabian StyleQi, Yuanhang, Haoyu Luo, Yuhui Luo, Rixu Liao, and Liwei Ye. 2023. "Adaptive Clustering Long Short-Term Memory Network for Short-Term Power Load Forecasting" Energies 16, no. 17: 6230. https://doi.org/10.3390/en16176230
APA StyleQi, Y., Luo, H., Luo, Y., Liao, R., & Ye, L. (2023). Adaptive Clustering Long Short-Term Memory Network for Short-Term Power Load Forecasting. Energies, 16(17), 6230. https://doi.org/10.3390/en16176230