1. Introduction
The goal of a novel power system (NPS) is to achieve a sustainable, efficient, and secure energy supply. Accurate short-term load forecasting is one of the key technologies to ensure the safe and stable operation of an NPS. However, the traditional forecasting method faces difficulties, such as large number of users, a high load heterogeneity, a high volatility, and a high randomness, meaning that it is difficult to meet the requirements of load forecasting in an NPS [
1,
2,
3].
With the continuous deepening of distributed power generation technology, photovoltaic, wind, and other types of new energy power generation equipment are widely installed in user terminals, but with the limits of the privacy of user data, it is impossible to concentrate the load data to train forecasting models [
4,
5]. Moreover, the load data are usually processed by multiple masks, and the reverse decoding process also involves the permissions of sensitive information. Therefore, the unprocessed mask load will greatly reduce the final accuracy of the prediction model [
6].
The proposal of federated learning breaks through the regional limitation of data privacy, and allows clients to train global models without sharing data, but frequent cloud-edge communication will generate a large communication load in the process of gradient transmission, and the communication overhead will become larger and larger, as the number of clients increases.
Therefore, the research into load forecasting under the background of an NPS faces the complexity and uncertainty of the distributed power supply, on the one hand. On the other hand, the continuous information and intelligence of the power industry provides a large amount of power load data for the communication system of the smart grid, and also increases the training cost of the forecasting model.
To summarize, this paper studies NPS load forecasting, based on efficient FTL. The innovations are as follows:
An adversarial predictive model training method based on transfer federation learning is proposed. This method extracts the common feature vector between the global model and the local data through adversarial training, so as to compensate the loss of mask load in the prediction accuracy, and improve the prediction accuracy.
In order to improve the efficiency of the gradient compression in federated learning (FL), a compressed sensing method based on the depth dynamic threshold is proposed, which combines compressed sensing with deep learning. This method replaces the sparse signal in compressed sensing with a U-Net model, and achieves an observation dimension reduction through a convolutional neural network (CNN).
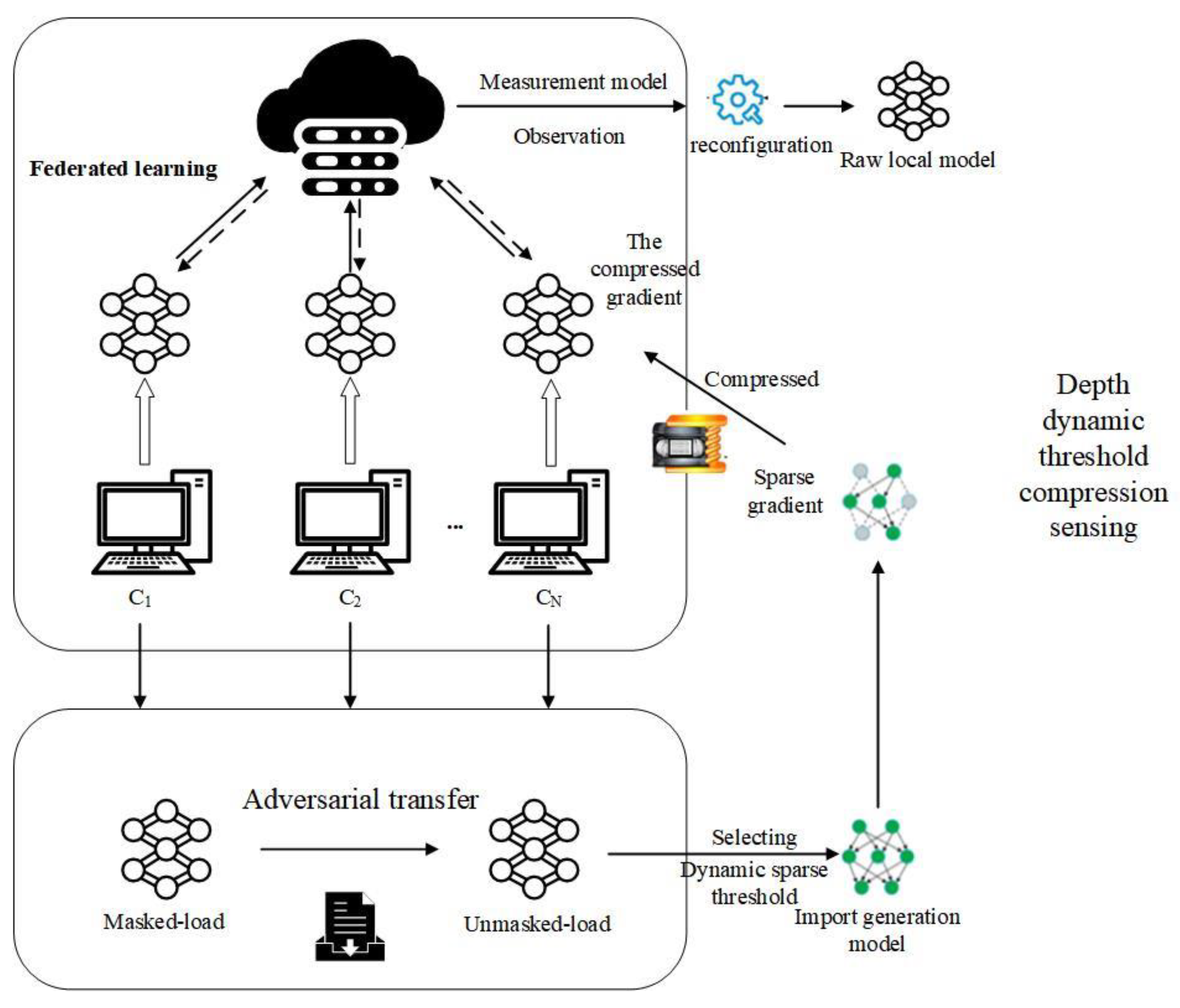
3. Adversarial Transfer Federation Algorithm Framework for Efficient Communication
Based on the difficulties of load forecasting in NPSs, this paper proposes a scheme of load forecasting, based on efficient communication, for federated transfer learning. Firstly, federated transfer learning is used to solve the data privacy problem between different grid regions, and to improve the influence of the mask load on the accuracy of the prediction model. Secondly, according to signal sparsity and the added attention mechanism, a compressed sensing method based on a depth dynamic threshold is proposed, which effectively reduces the huge overhead caused by the frequent cloud-edge communication in federated learning. The specific process framework of the scheme is shown in
Figure 1.
It is assumed that the participants under the federated learning framework belong to different power grid parks, and the user load data are not interoperable. After the federated learning training starts, the cloud service center, firstly, delivers the trained global model parameters, and the client locally migrates the characteristic parameters of the non-mask load to the mask load, and completes the local model update. Secondly, a U-Net structure is used to generate the model, to realize the signal sparse process, and the model gradient features that need to be uploaded to the cloud server are sparse. Finally, the cloud server reconstructs the signal, aggregates all the models, and generates the global model for the next round of federated learning.
3.1. Adversarial Federated Transfer Learning
Aiming at the mask load problem in the load forecasting of NPSs, this paper proposes an adversarial federated transfer learning system, the specific framework of which is shown in
Figure 2. The training framework consists of three modules; namely, feature extraction, result prediction, and adversarial training.
In the federated transfer learning system proposed in this paper, the mask load is taken as the target domain ; the unmasked load in the global model parameter serves as the source domain . Where nT and nS are the amount of sample data in nS and nS, represents the global model unmasked load data input the previous time, during the i round of training. represents the future time. Different from traditional transfer learning, the adversarial federated transfer learning proposed in this paper requires the adversarial transfer of two different load data, so the number of nS is not much larger than nT, but similar. Based on the above related theories, the proposed method trains the prediction model of DT through adversarial training, and transfers knowledge from DS to improve the prediction accuracy. The specific training process is as follows:
First, input global model parameter XS and client local data XT (mask load). The two input data are processed by the feature extractor Gf and the feature vectors are extracted as fS and fT.
The result predictor Go receives the feature vector fS and updates the predicted loss Lo.
The adversarial trainer Gd divides the features into DT and DS, uses gradient reverse layer (GRL) for adversarial training, and updates Ld to minimize the adversarial loss.
Output load data, complete the local FL.
Steps 2 and 3 can be performed simultaneously offline, until the next round of FL local training begins. In the process of forward propagation, the input data are first processed using the feature processor
Gf, with the initialization parameter
θf, and then the result predictor
Gy predicts the load, and calculates the predicted loss
Lo based on the mean square error:
where
nS is the total number of output samples in
DS. Against the trainer
Gd classification feature vector, GRL is used to maintain the calculation results of forward propagation, but the polarity of the gradient calculation is changed during the late update period. The calculation of counterloss
Ld based on the binary cross entropy error is:
and represent the probability of the I-th eigenvector of DS and DT, respectively. If d = 1, the eigenvector comes from DS; otherwise, if d = 0, the eigenvector comes from DT.
Gradient descent is adopted in the training of backward propagation. In the process of backward propagation, the result predictor and adversarial trainer also update the parameters to minimize
Ly and
Lo, as shown in Formulas (3) and (4):
where
θo and
θd represent the parameters in the result predictor and adversarial trainer models, respectively.
After the forward and backward propagation is completed, the output data are finally combined in the feature extractor. The cost function of the feature extractor
Lf can be expressed by Formula (5):
where
Ldiv represents the deviation between
fS and
fT, which can be represented by the following formula:
where σ represents the calculation error of the counter trainer, so
Lf can be further expressed as Formula (7):
Combining the above reasoning process,
λf,o and
λf,d are the learning rates of the outcome predictor and adversarial trainer, respectively. Then, the final data output can be expressed as:
The mask load feature vector, after counter training, can be very compatible with the non-mask load in the output predictor, meaning that load data with a similar feature quantity can be output, and a prediction model with a higher accuracy can be trained.
3.2. Compressed Sensing Based on Dynamic Threshold of Depth
This paper presents a depth dynamic threshold compression sensing algorithm (depth dynamic threshold compression sensing, DDTCS). The sparse process of the federated learning gradient signal based on compressed sensing is replaced by a generative model; that is, the original signal no longer needs to be sparsely processed, and the dynamic threshold of sparsity is set. Finally, the measurement matrix is replaced by a CNN, which is called the measurement model. If we let the sparse gradient be represented as
x and the margin gradient be represented as
n, the original signal
y with sparse gradient can be represented as:
y is pretreated to obtain
, sparse signal
=
Gθ (
) can be generated by input generation model
Gθ, and
x and
then obtain their respective observed signals through the measurement model. When the error between two observation signals is the smallest,
is the reconstructed original signal. The generation model adopts a U-Net structure, as shown in
Figure 3, which consists of four parts: the coding network, skip connection, attention mechanism, and decoding network. The coding network consists of 11 subsampling modules, in which the original gradient signal is obtained via the convolution operation, and the activation function selects PReLU. The decoding network is composed of 11 up-sampling modules, which is the inverse process of the coding network. The gradient signal with the same length of time as the input signal is recovered via deconvolution.
In order to prevent the loss of signal detail features, a jump connection is added between the coding network and the decoding network, and an attention mechanism is added to the last layer of the jump connection [
6,
7], to prune the gradient signal features and remove irrelevant features. The structure of the attention mechanism is shown in
Figure 4.
The input of the attention mechanism is the output of the down-sampled module (V) and the output of the up-sampled module (
Q) in the generation model; W
q, W
v, and W
qv represent the weight of the one-dimensional convolution; b
q, b
v, and b
qv represent the bias; W
att represents the obtained attention coefficient; after multiplication with V, the output feature graph V
att after passing the attention is obtained. The process of the signal passing through the attention mechanism can be expressed as the process of solving Equation (11), where
P[·] and
S{·} represent the activation functions PReLU and sigmoid, respectively:
In the process of compressed sensing, compression is actually very simple, and the focus is on the reconstruction of the signal, and the reconstruction recovery accuracy of the signal is closely related to the sparsity. When the same signal recovery accuracy is achieved, the recovery ability of a low-sparsity signal is stronger, and it is less likely to cause information loss. Therefore, a judgment can be made when the client compresses the model to compare the specific threshold data sizes of different sparse thresholds, as follows. If the threshold data under a high threshold show a small gap with the threshold data of a low threshold, it indicates that there are more contents with a large update range, and then a high threshold is used for compression. Otherwise, only a small number of data have been updated significantly, and a low threshold is used for compression.
We let the user model update amplitude be and the parameter be . User i locally determines the threshold for sparsity during the T-round training according to the given threshold instruction. We let the smallest value of the data with value of 5% in A be , and the smallest value of the data with a value of 10% in be . If , set , otherwise , and finally output . The dynamic threshold is actually determined by the client. As the dynamic threshold is only generated between two values, the number of observations is less when the threshold is low, so the server only needs to judge the actual length of the received data to know which observation model the client uses, and there is no need for the client to transmit the information of the dynamic threshold.
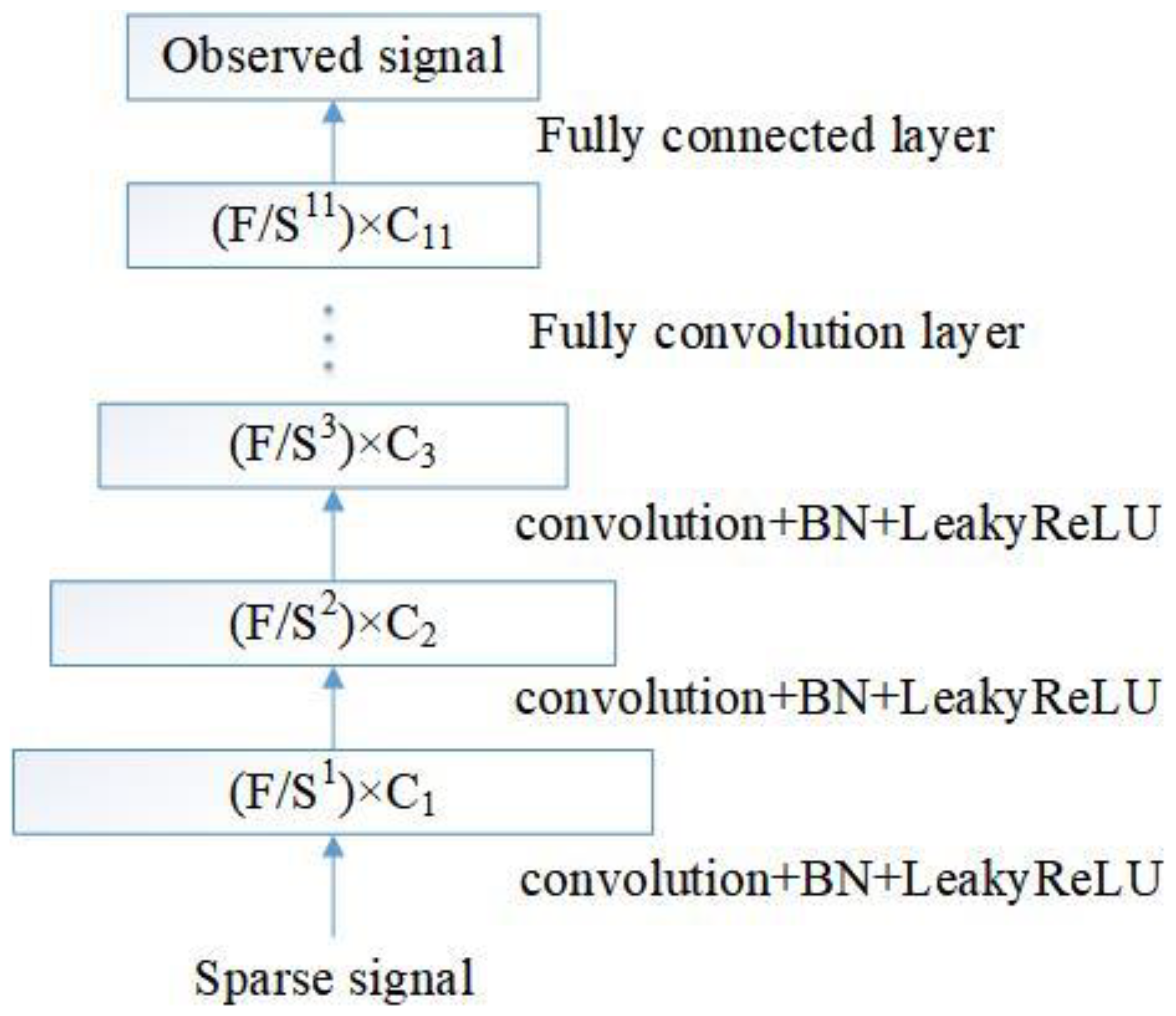
The measurement model is a convolutional neural network (CNN), which is used to observe the gradient signal in X-dimension reduction. The input is the sparse gradient signal, and the feature vector of the specified observation dimension is obtained through eleven convolutional layers and one fully connected layer. The block diagram of the model is shown in
Figure 5, where S represents the convolutional step length, and the S of each convolutional layer is 2. C
i represents the number of channels after the signal passes through each convolutional layer, and the corner mark i represents the index number of the convolutional layer (i.e., 1–11). F represents the input gradient signal length and, after convolution, the eigenvector dimension of each layer is F/S
i. After the convolution of the last layer, the feature graph of 8 × 1024 dimensions is obtained, which is input to the fully connected layer through linear smoothing, and the output dimension of the fully connected layer is determined by the observed dimension. The activation function in the measurement model was selected as LeakyReLU, and the batch normalization module (BN) was added, to prevent gradients and disappearances before the activation function.
4. Experimental Results and Analysis
In order to verify the effectiveness of the adversarial transfer federated learning framework proposed in this paper, we obtain user load data from OpenEI, an open dataset for power analysis. The dataset includes hourly residential load data for 24 locations in New York State in 2012. Each location is made up of data for three types of houses, based on their typical patterns of electricity consumption: low, medium, and high. Half of the data are masked randomly, to mimic the DER load collected from the client in real cases.
In this experiment, the mean absolute percentage error (MAPE) and the root-mean-square error (RMSE) were used to evaluate the model performance, and the
R2 was added to reflect the overall fit degree of the prediction model, where
At represented the actual load, and
Ft represented the predicted load.
In the FL experiment, the deep learning server was configured with an Inteli-9900k CPU and an RTX3080Ti GPU, and the development environment was Ubuntu 16.04, TensorFlow 2.0.0, and Python 3.7. A long short-term memory neural network (LSTM) is used as the target model for load prediction on the local server. The processed load data were used to train the prediction model, and the model was deduced on the test set. The training results were shown as
Figure 6.
It can be seen from the figure that the accuracy of the prediction results of the FL model is not ideal. Due to the influence of the mask load, the global model cannot accurately predict the load change in time when facing the influence of non-human factors (weather, climate). Therefore, the adversarial federated transfer framework proposed in this paper is used to train the load data under the same FL client configuration. The prediction results are shown in
Figure 7.
Through the adversarial transfer processing of the mask load, the accuracy of the improved prediction model is significantly improved, and the data filling process in the data preprocessing stage is reduced. It can effectively cope with the situation wherein the current DER penetration rate is constantly increasing, and the power load data are significantly masked. By changing the proportion of the mask load in the load data, the predictive advantage of the adversarial federated transfer learning system proposed in this paper is verified in the DER environment. The comparison of the MAPE of different prediction models is shown in
Table 1.
The adversarial federated transfer learning training method proposed in this paper can significantly improve the accuracy of mask load prediction. It can be observed that when the mask load accounted for 20% and 30% of the total load data, the MAPE of the prediction model was reduced by 6.7% compared with the traditional FL [
25,
26]. And when the mask load was increased to 50%, the average MAPE was reduced by 9.6%. In order to highlight the significance of the proposed scheme, the accuracy evaluation indexes of the prediction models are compared in
Table 2.
The adversarial FTL proposed in this paper has a higher regression fitting degree. It is proven that the method can be applied in the case of significant-masked-load data.
A DDTCS algorithm is proposed to solve the problem of the high communication cost. The stages of the separate experiments are as follows. Anomaly detection tasks commonly used in the field of machine learning are used as experimental simulation cases. The deep learning framework based on Pytorch version 1.10 is adopted, and the Pysyft library is used to train the federated learning model. The NSL-KDD dataset and UNSW_NB15 dataset, which are widely used in the performance testing of abnormal traffic detection algorithms, are used. Among them, the NSL-KDD dataset is a public dataset provided by the Canadian Cyber Security Institute for network-security-based intrusion detection, and UNSW_NB15 is a public dataset created by the Canberra Network Range Laboratory of the University of New South Wales for network abnormal traffic detection.
For the local computation of model training on each client, the initial learning rate of the stochastic gradient descent (SGD) algorithm with a batch size of 20 is 0.01. Experiments are performed on different sparse thresholds. The accuracy and communication times of different th values are compared. The accuracy (Acc) was used to evaluate the accuracy of the DDTCS algorithm, and the compression ratio (CR) was introduced to measure the effect of the gradient compression. The CR reflects the degree of gradient compression, and is defined as the ratio of the number of gradient exchange communications after compression to the number of communication before compression, under the condition that the target task prediction accuracy is achieved. The lower the compression ratio, the higher the compression degree. In general, reducing the compression ratio can greatly reduce the frequency of gradient communication, and can effectively reduce the communication overhead. But, similarly, a reduction in the compression ratio will also lead to a decrease in the model detection accuracy. Therefore, in order to balance these two indicators, this paper introduces the compressed composite index (CCI) to make the best decision for the model, by adjusting the proportion of the two key indicators. The CCI is defined as:
Among them, β1 and β2 were used to measure the ratio of Acc and CR for two parameters, β1 + β2 = 1, and β1 > 0, β2 > 0. As the final task of the machine learning model in this paper is abnormal traffic detection, the priority of Acc needs to be higher than that of CR; that is, β1 > β2. The evaluation index CCI of model gradient compression comprehensively considers the Acc and CR. The higher the CCI, the better the overall effect of the model gradient compression.
Table 3 is a comparison between the accuracy rate and the communication frequency obtained via experiments with different values for the sparse threshold th. With the increase in th, the average communication frequency of the model continues to decrease, and the interference in the detection accuracy of the model also increases, and the average detection accuracy decreases slightly in general, with little difference. This makes it possible to further compress the data, by setting a dynamic sparse threshold.
Further, it is necessary to calculate the comprehensive compression index (CCI) of the model under th value. Defined by Formula (14), CCIs with different values for the parameter coefficients β1 and β2 are calculated, respectively, and the results are shown in
Figure 8.
Finally, through comparison between the DDTCS algorithm proposed in this paper and the traditional compression sensing CS and the deep compression sensing deep CS, the performance comparison results of each algorithm are shown in
Table 4 from the three indexes of accuracy, compression ratio, and compression composite index. As can be seen from
Table 2, when β1 = 0.5 and β2 = 0.5, the DDTCS algorithm can achieve the maximum CCI value in the same period, and is better than the deep CS algorithm. Although the deep CS can achieve a better compression index, its detection accuracy is significantly different from the DDTCS, which is contrary to our anomaly detection goal. Compared with the traditional federated learning model, the communication cost is further saved by 23.5%; that is, the gradient communication rounds are reduced, but the accuracy is only reduced by 0.26%, which is very small for the federated learning model, which needs to deal with a large number of devices.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}