

Assessing Machine Learning Techniques for Intrusion Detection in Cyber-Physical Systems

 and
and
Abstract
:1. Introduction
- Assessment of five offline and three online ML algorithms for intrusion detection using traffic from seven datasets related to CPSs;
- Survey of CPSs datasets. The seven most promising datasets are used for the experiments with the ML algorithms, and numerical results are presented for each of them;
- Evidence, based on accuracy, precision, recall, and F1-score results, that offline ML is most suitable when attack signatures are available without time constraints;
- Evidence that online techniques present a greater ability to quickly detect new attacks.
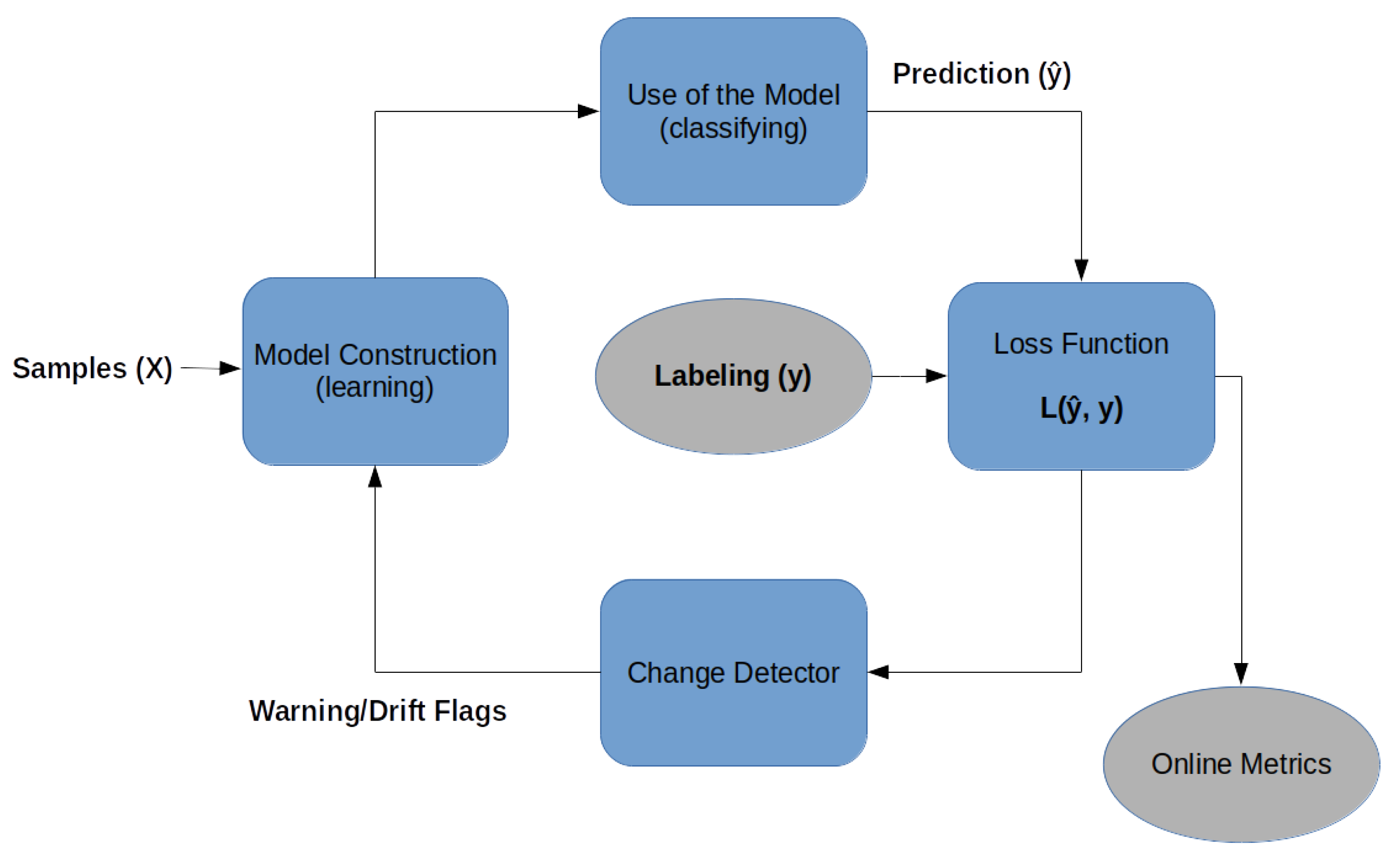
2. Background
- Online model construction (learning): each new sample is used to build the model to determine the class with the attributes and values. This model can be represented by classification rules, decision trees, or mathematical formulas. To control the amount of memory used by the model, a forgetting mechanism is used, like a sliding window or fading factor, that discards samples while keeping an aggregate summary/value of these older samples;
- Use of the model (classifying): it is the classification or estimation of unknown samples using the constructed model. In this step, the model’s performance metrics are also calculated, comparing the known label of the sample y with the classified result of the model (i.e., the predicted label ()), for a supervised classification process.
- Loss function: for each input sample attributes (X), the prediction loss can be estimated as . The performance metrics of this method are obtained from the cumulative sum of sequential loss over time, that is, the loss function between forecasts and observed values.
- Change detector: detects concept drift by monitoring the loss estimation. When change is detected based on a predefined threshold, the warning signal or drift signal is used to retrain the model [17]. Interestingly, as will be shown below, no concept drift was detected in any of the datasets used in this article.
- Holdout: applies tests and training samples to the classification model at regular time intervals (configurable by the user);
- Prequential: all samples are tested (prediction) and then used for training (learning).
- Naive Bayes (NB) is a probabilistic classifier, also called simple Bayes classifier or independent Bayes classifier, capable of predicting and diagnosing problems through noise-robust probability assumptions;
- Hoeffding Tree (HT) combines the data into a tree while the model is built (learning) incrementally. Classification can occur at any time;
- Hoeffding Adaptive Tree (HAT) adds two elements to the HT algorithm: change detector and loss estimator, yielding a new method capable of dealing with concept change. The main advantage of this method is that it does not need to know the speed of change in the data stream.
- Naive Bayes (NB) is available for both online and offline ML versions, making it possible to compare them;
- Random Tree (RaT) builds a tree consisting of K randomly chosen attributes at each node;
- J48 builds a decision tree by recursively partitioning the data based on attribute values, it quantifies the randomness of the class distribution within a node (also known as entropy), to define the nodes of the tree;
- REPTree (ReT) consists of a fast decision tree learning algorithm that, similarly to J48, is also based on entropy;
- Random Forest (RF) combines the prediction of several independent decision trees to perform classification. Each tree is constructed to process diverse training datasets, multiple subsets of the original training data. The trees are built by randomly chosen attributes used to divide the data based on the reduction in entropy. The results of all trees are aggregated to decide on the final class based on majority or average, across all trees.
3. Related Work
4. CPS Related Datasets
5. Material and Methods
6. Results and Discussion
6.1. Summary of Findings
6.2. Detailed Analysis
6.2.1. Online Classifiers’ Metrics over Time
6.2.2. Run Time Performance
6.2.3. Adaptability to New Attack Occurrences
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Quincozes, S.E.; Passos, D.; Albuquerque, C.; Ochi, L.S.; Mossé, D. GRASP-Based Feature Selection for Intrusion Detection in CPS Perception Layer. In Proceedings of the 2020 4th Conference on Cloud and Internet of Things (CIoT), Niteroi, Brazil, 7–9 October 2020; pp. 41–48. [Google Scholar]
- Reis, L.H.A.; Murillo Piedrahita, A.; Rueda, S.; Fernandes, N.C.; Medeiros, D.S.; de Amorim, M.D.; Mattos, D.M. Unsupervised and incremental learning orchestration for cyber-physical security. Trans. Emerg. Telecommun. Technol. 2020, 31, e4011. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A. A Dataset to Support Research in the Design of Secure Water Treatment Systems. In Proceedings of the Critical Information Infrastructures Security, 11th International Conference, CRITIS 2016, Paris, France, 10–12 October 2016; Springer: Cham, Switzerland, 2017; pp. 88–99. [Google Scholar]
- Obert, J.; Cordeiro, P.; Johnson, J.T.; Lum, G.; Tansy, T.; Pala, N.; Ih, R. Recommendations for Trust and Encryption in DER Interoperability Standards; Technical Report; Sandia National Lab (SNL-NM): Albuquerque, NM, USA, 2019. [Google Scholar]
- Almomani, I.; Al-Kasasbeh, B.; Al-Akhras, M. WSN-DS: A dataset for intrusion detection systems in wireless sensor networks. J. Sensors 2016, 2016, 4731953. [Google Scholar] [CrossRef]
- Langner, R. Stuxnet: Dissecting a cyberwarfare weapon. IEEE Secur. Priv. 2011, 9, 49–51. [Google Scholar] [CrossRef]
- Kim, S.; Park, K.J. A Survey on Machine-Learning Based Security Design for Cyber-Physical Systems. Appl. Sci. 2021, 11, 5458. [Google Scholar] [CrossRef]
- Rai, R.; Sahu, C.K. Driven by Data or Derived Through Physics? A Review of Hybrid Physics Guided Machine Learning Techniques with Cyber-Physical System (CPS) Focus. IEEE Access 2020, 8, 71050–71073. [Google Scholar] [CrossRef]
- Mohammadi Rouzbahani, H.; Karimipour, H.; Rahimnejad, A.; Dehghantanha, A.; Srivastava, G. Anomaly Detection in Cyber-Physical Systems Using Machine Learning. In Handbook of Big Data Privacy; Springer International Publishing: Cham, Switzerland, 2020; pp. 219–235. [Google Scholar] [CrossRef]
- Lippmann, R.P.; Fried, D.J.; Graf, I.; Haines, J.W.; Kendall, K.R.; McClung, D.; Weber, D.; Webster, S.E.; Wyschogrod, D.; Cunningham, R.K.; et al. Evaluating Intrusion Detection Systems: The 1998 DARPA Off-Line Intrusion Detection Evaluation. In Proceedings of the DARPA Information Survivability Conference and Exposition, Hilton Head, SC, USA, 25–27 January 2000; Volume 2, pp. 12–26. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Kartakis, S.; McCann, J.A. Real-Time Edge Analytics for Cyber Physical Systems Using Compression Rates. In Proceedings of the 11th International Conference on Autonomic Computing (ICAC 14), Philadelphia, PA, USA, 23–23 July 2014; pp. 153–159. [Google Scholar]
- Hidalgo, J.I.G.; Maciel, B.I.; Barros, R.S. Experimenting with prequential variations for data stream learning evaluation. Comput. Intell. 2019, 35, 670–692. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. ACM Sigmod. Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Nixon, C.; Sedky, M.; Hassan, M. Practical Application of Machine Learning Based Online Intrusion Detection to Internet of Things Networks. In Proceedings of the 2019 IEEE Global Conference on Internet of Things (GCIoT), Dubai, United Arab Emirates, 4–7 December 2019; pp. 1–5. [Google Scholar]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. Issues in Evaluation of Stream Learning Algorithms. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 329–338. [Google Scholar]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kranen, P.; Kremer, H.; Jansen, T.; Seidl, T. Moa: Massive Online Analysis—A Framework for Stream Classification and Clustering. In Proceedings of the First Workshop on Applications of Pattern Analysis, Windsor, UK, 1–3 September 2010; pp. 44–50. [Google Scholar]
- Adhikari, U.; Morris, T.H.; Pan, S. Applying hoeffding adaptive trees for real-time cyber-power event and intrusion classification. IEEE Trans. Smart Grid 2017, 9, 4049–4060. [Google Scholar] [CrossRef]
- Domingos, P.; Hulten, G. Mining High-Speed Data Streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 71–80. [Google Scholar]
- Quincozes, S.E.; Albuquerque, C.; Passos, D.; Mossé, D. ERENO: An Extensible Tool For Generating Realistic IEC-61850 Intrusion Detection Datasets. In Proceedings of the Anais Estendidos do XXII Simpósio Brasileiro em Segurança da Informação e de Sistemas Computacionais, Santa Maria, Brazil, 12–15 September 2022; pp. 1–8. [Google Scholar]
- Radoglou-Grammatikis, P.I.; Sarigiannidis, P.G. Securing the smart grid: A comprehensive compilation of intrusion detection and prevention systems. IEEE Access 2019, 7, 46595–46620. [Google Scholar] [CrossRef]
- Faisal, M.A.; Aung, Z.; Williams, J.R.; Sanchez, A. Data-stream-based intrusion detection system for advanced metering infrastructure in smart grid: A feasibility study. IEEE Syst. J. 2014, 9, 31–44. [Google Scholar] [CrossRef]
- Corrêa, D.G.; Enembreck, F.; Silla, C.N. An Investigation of the Hoeffding Adaptive Tree for the Problem of Network Intrusion Detection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 4065–4072. [Google Scholar]
- Setha, S.; Singha, G.; Chahala, K.K. Drift-Based Approach for Evolving Data Stream Classification in Intrusion Detection System. In Proceedings of the Workshop on Computer Networks & Communications, Goa, India, 30–30 April 2021; pp. 23–30. [Google Scholar]
- Dahal, N.; Abuomar, O.; King, R.; Madani, V. Event stream processing for improved situational awareness in the smart grid. Expert Syst. Appl. 2015, 42, 6853–6863. [Google Scholar] [CrossRef]
- Desale, K.S.; Kumathekar, C.N.; Chavan, A.P. Efficient Intrusion Detection System Using Stream Data Mining Classification Technique. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; pp. 469–473. [Google Scholar]
- Priya, S.; Uthra, R.A. Comprehensive analysis for class imbalance data with concept drift using ensemble based classification. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4943–4956. [Google Scholar] [CrossRef]
- Ida Seraphim, B.; Poovammal, E. Adversarial attack by inducing drift in streaming data. Wirel. Pers. Commun. 2022, 127, 997–1021. [Google Scholar] [CrossRef]
- Aung, Y.L.; Tiang, H.H.; Wijaya, H.; Ochoa, M.; Zhou, J. Scalable VPN-Forwarded Honeypots: Dataset and Threat Intelligence Insights. In Proceedings of the Sixth Annual Industrial Control System Security (ICSS), Austin, TX, USA, 8 December 2020; pp. 21–30. [Google Scholar]
- Taormina, R.; Galelli, S.; Tippenhauer, N.O.; Salomons, E.; Ostfeld, A.; Eliades, D.G.; Aghashahi, M.; Sundararajan, R.; Pourahmadi, M.; Banks, M.K.; et al. Battle of the attack detection algorithms: Disclosing cyber attacks on water distribution networks. J. Water Resour. Plan. Manag. 2018, 144, 04018048. [Google Scholar] [CrossRef]
- Hink, R.C.B.; Beaver, J.M.; Buckner, M.A.; Morris, T.; Adhikari, U.; Pan, S. Machine Learning for Power System Disturbance and Cyber-Attack Discrimination. In Proceedings of the 2014 7th International symposium on resilient control systems (ISRCS), Denver, CO, USA, 19–21 August 2014; pp. 1–8. [Google Scholar]
- Morris, T.; Gao, W. Industrial Control System Traffic Data Sets for Intrusion Detection Research. In Proceedings of the Critical Infrastructure Protection VIII, 8th IFIP WG 11.10 International Conference (ICCIP 2014), Arlington, VA, USA, 17–19 March 2014; Revised Selected Papers 8. Springer: Cham, Switzerland, 2014; pp. 65–78. [Google Scholar]
- Morris, T.H.; Thornton, Z.; Turnipseed, I. Industrial Control System Simulation and Data Logging for Intrusion Detection System Research. In Proceedings of the 7th Annual Southeastern Cyber Security Summit, Huntsville, AL, USA, 3–4 June 2015; pp. 3–4. [Google Scholar]
- IEC-61850; Communication Networks and Systems in Substations. International Electrotechnical Commission: Geneva, Switzerland, 2003.
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Dataset | Experiment |
|---|---|---|---|
| [24] | 2014 | KDD Cup 99 and NSL-KDD | Compare online ML techniques for SG |
| [28] | 2015 | NSL-KDD | Test online ML techniques for SG IDS |
| [27] | 2015 | Real-time digital simulator (RTDS®) | Find best online ML techniques for SG |
| [25] | 2017 | Kyoto2006 | Find the best online ML technique for computer networks |
| [20] | 2017 | SG simulated scenarios | Test resources for online ML technique for SG |
| [17] | 2019 | KDD Cup 99 and UNSW-NB15 | Compare online ML techniques for IoT |
| [29] | 2021 | SEA, KDD and ANSWEM | Compare online ML techniques for computer networks |
| [30] | 2021 | RBF, UNSW-NB15, NSL-KDD and ISCX | Compare online ML techniques for computer networks |
| [26] | 2021 | CICIDS 2018 | Compare online ML techniques for computer networks |
| Dataset | Attack Types | Number of Samples | Attributes | Balance (% Attack Class) |
|---|---|---|---|---|
| SWaT | 1 | 946,719 | 51 | 5.77% |
| BATADAL | 14 | 13,938 | 43 | 1.69% |
| Morris-1 | 40 | 76,035 | 128 | 77.85% |
| Morris-3 gas | 7 | 97,019 | 26 | 36.96% |
| Morris-3 water | 7 | 236,179 | 23 | 27.00% |
| Morris-4 | 35 | 274,628 | 16 | 21.87% |
| Ereno | 7 | 5,750,000 | 69 | 6.60% |
| Dataset | Best | Worst |
|---|---|---|
| SWaT | Random Forest | Naive Bayes |
| BATADAL | REPTree | Random Tree |
| ERENO | REPTree | Naive Bayes |
| Morris-1 | Random Forest | Naive Bayes |
| Morris-3 gas | J48 | Naive Bayes |
| Morris-3 water | REPTree | Naive Bayes |
| Morris-4 | Random Tree | Naive Bayes |
| Leave One Out | Accuracy | Precision | Recall | F1-score | TP | TN | FP | FN |
|---|---|---|---|---|---|---|---|---|
| Random Replay | 99.09% | 100.00% | 90.46% | 94.99% | 70,560 | 742,794 | 0 | 7440 |
| Inverse Replay | 98.66% | 100.00% | 73.46% | 84.70% | 41,397 | 1,057,800 | 0 | 14,955 |
| Masquerade Outage | 95.58% | 100.00% | 0.46% | 0.92% | 160 | 742,794 | 0 | 34,327 |
| Masquerade Equip. Damage | 95.52% | Undef. | 0.00% | Undef. | 0 | 742,794 | 0 | 34,839 |
| Message Injection | 90.50% | 100.00% | 99.94% | 99.97% | 19 | 742,794 | 0 | 77,981 |
| High-Status Number | 99.99% | 100.00% | 99.94% | 99.97% | 77,950 | 742,794 | 0 | 50 |
| High-Rate Flooding | 99.69% | 93.90% | 100.00% | 96.86% | 37,144 | 740,383 | 2411 | 0 |
| Train/Test | Random Replay | Inverse Replay | Masquerade Outage | Masquerade Equip. Damage | Message Injection | High-Status Number | High-Rate Flooding |
|---|---|---|---|---|---|---|---|
| Random Replay | F1-score | 21.82% | Undef. | Undef. | Undef. | 13.42% | 28.99% |
| Inverse Replay | 94.50% | F1-score | 7.54% | Undef. | 0.07% | 99.83% | 96.86% |
| Masquerade Outage | 62.23% | 30.05% | F1-score | Undef. | 33.68% | 60.05% | 100.00% |
| Masquerade Equip. Damage | 95.52% | Undef. | Undef. | F1-score | 0.03% | 66.66% | Undef. |
| Message Injection | Undef. | Undef. | Undef. | Undef. | F1-score | 100.00% | Undef. |
| High-Status Number | Undef. | Undef. | Undef. | Undef. | 40.06% | F1-score | Undef. |
| High-Rate Flooding | 93.38% | 65.28% | 14.82% | Undef. | 2.75% | 13.58% | F1-score |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, V.F.; Albuquerque, C.; Passos, D.; Quincozes, S.E.; Mossé, D. Assessing Machine Learning Techniques for Intrusion Detection in Cyber-Physical Systems. Energies 2023, 16, 6058. https://doi.org/10.3390/en16166058
Santos VF, Albuquerque C, Passos D, Quincozes SE, Mossé D. Assessing Machine Learning Techniques for Intrusion Detection in Cyber-Physical Systems. Energies. 2023; 16(16):6058. https://doi.org/10.3390/en16166058
Chicago/Turabian StyleSantos, Vinícius F., Célio Albuquerque, Diego Passos, Silvio E. Quincozes, and Daniel Mossé. 2023. "Assessing Machine Learning Techniques for Intrusion Detection in Cyber-Physical Systems" Energies 16, no. 16: 6058. https://doi.org/10.3390/en16166058
APA StyleSantos, V. F., Albuquerque, C., Passos, D., Quincozes, S. E., & Mossé, D. (2023). Assessing Machine Learning Techniques for Intrusion Detection in Cyber-Physical Systems. Energies, 16(16), 6058. https://doi.org/10.3390/en16166058