1. Introduction
There are numerous studies showing that during different time periods, different sets of explanatory variables might play a major role as oil price predictors. For example, during the period before the 1980s, much attention was focused solely on supply and demand factors. However, it was observed that during the 1990s, the role of exchange rates became crucial. Moreover, since the 2000s, much attention has turned towards several other factors, mostly from financial markets, such as stock market indices, stress market indices, global economic activity, etc. [
1,
2,
3]. Some researchers have focused on tight and complicated links between futures and spot prices. Interestingly, several of them have noticed that, for example, fluctuations in open interest (i.e., the total number of not-closed or not-delivered options or futures) can serve as a better proxy for the futures market than just futures prices [
4]. Moreover, several other factors and indices have been considered, such as those connected with policy uncertainty. [
5,
6,
7]. As a result, forecasting methods allowing for the state–space of the model to vary in time have gained much attention [
2,
3,
8,
9,
10]. Detailed analyses and reviews of how these variables can play an important role as crude oil spot price predictors have been presented in numerous other papers or in review articles solely devoted to this problem [
2,
11,
12,
13,
14].
Motivation for the current research arises from the fact that symbolic regression has not yet been extensively applied in economics or finance. Even if certain studies have been conducted in the field of oil markets, they have been mostly focused on forecasting production or emission quotas—not on spot price forecasting in the presence of variable (and model) uncertainty [
15,
16]. On the contrary, genetic algorithms have been used in certain financial and economic models with reasonable success [
17,
18,
19].
Symbolic regression [
20] is a method that automatically searches across different mathematical expressions (functions) to fit a given set of data (consisting of response and explanatory variables). This method does not require a pre-selected model structure, because by searching and evolving different expressions, it aims to find the optimal solution. Usually, genetic programming methods are used in this scope [
21]. In particular, starting from the initial set of potentially interesting expressions (functions), they are modified according to certain evolutionary algorithms [
22] and the next set of expressions (a generation) is created. For this purpose, the expressions present in the current generation can be slightly modified (mutated) or, based on the two already-existing expressions, a third can be built (cross-over). Additionally, during the transition from one generation to the forthcoming generation, some cut-off procedures can be performed. For example, the expressions having the lowest scores according to the given criterion can be deleted and not passed to the forthcoming (next) generation.
The advantage of symbolic regression is that the “true” model structure can be “discovered” by the algorithm itself. Secondly, the numerical coefficients (as in, for instance, a regression model) can also be estimated with the genetic algorithm—contrary to, for example, conventionally used ordinary least squares (OLS). It is important to note that, especially in the case of a financial time series, OLS suffers from serious drawbacks [
23]. First of all, the length of the time series (i.e., the number of observations) must be relatively large compared to the number of explanatory variables. Otherwise, the estimations’ results are not meaningful and, in extreme cases, certain matrices can even be non-invertible, which results in computations being theoretically entirely inappropriate.
Additionally, contrary to the Bayesian approach, frequentist econometrics does not focus on the fact that with every new (financial) period, new market information also becomes available for the market players [
24]. In other words, the forecasting models resembling market reality should rather be updated between the time t and t + 1, instead of setting fixed models to build over some fixed in-sample period. In other words, the in-sample period should rather dynamically expand with time, and, in the case of, for example, 1-period ahead forecasting, the out-of-sample period should consist of one observation (i.e., the forthcoming one) and roll with time [
25]. However, the Bayesian framework is not merely recursive computing but contains deeper insight into prior–posterior inference resembling the changing state of the knowledge of an investor.
The core of genetic programming is, generally speaking, quite similar; the new information is used to narrow the estimated prediction from the previous step. In Bayesian econometrics, this is done by deriving the posterior distribution from a prior distribution, and in genetic programming, the algorithm modifies the set of potentially optimal solutions. Unfortunately, both methods, despite their advantages, suffer from computational issues in many real-life applications [
26,
27,
28,
29]. For example, [
30] and [
31] provided extensive reviews about these issues. However, recently, a new idea, i.e., Bayesian symbolic regression (BSR), was proposed by [
32], which relies on assuming that the output expression (function) is represented by the linear combination of component expressions, which themselves are represented by symbolic trees, i.e., binary expression trees [
33]. The trees’ structures are evolved through the Bayesian inference with the Markov chain Monte Carlo (MCMC) method. According to the authors, this method can improve forecast accuracy, complexity, and computational issues.
Therefore, the aim of this research is to apply this novel method, i.e., BSR, to forecasting crude oil spot prices. First of all, several versions of BSR were estimated: the original version as well as versions containing some model averaging schemes, because such methods can improve forecast accuracy [
34]. Secondly, several other methods that are able to deal with variable uncertainty were taken as benchmark models. As a result, this research collects, in a uniform way, a comparison of other methods such as LASSO, ridge, least-angle regression, and elastic net applied to the same set of variables [
35,
36]. Some of these methods are also quite novel themselves, e.g., dynamic model averaging [
37]. Although these benchmark models have already been used in oil price forecasting, it seems that such a wide comparison within a unified research framework is a novel approach. Nevertheless, the major research aim was to apply a novel BSR method to crude oil spot price forecasting and, as a result, this paper fills a certain important gap in the literature.
Indeed, the recent years resulted in developing various novel methods for oil price forecasting. Just to give a few examples: [
38] focused on the impact of social media information. [
39] combined stochastic time effective functions with feedforward neural networks. [
40] also used Google Trends, online media text mining, and convolutional neural networks to forecast crude oil price. Indeed, the neural network approach has become quite popular. For example, [
41] applied a self-optimizing ensemble learning model which incorporated the improved, complete ensemble empirical mode decomposition with adaptive noise, a sine cosine algorithm, and a random vector functional link neural network to forecast daily crude oil price. Indeed, modelling and forecasting oil prices is an important topic. For example, [
42] discussed how oil price dynamics are associated with domestic inflationary pressures in the developing and oil-depending economy. [
43] discussed the importance of oil prices for the economies of oil- and gas-exporting countries, and how these countries develop in a sense of increasing their income and economic growth. Both positive and negative aspects were discussed, as well as the overall importance of oil price forecasting for policymakers. Further, it was discussed that crude oil plays an important role in energy security issues [
44].
The paper is organised in the following way: In the next section, the data set is described along with the motivation. Thereafter, the following section briefly describes the novel BSR method and briefly reports the benchmark models used, as well as the forecast quality measures used in this research. It also explains how the forecasts that were obtained from different models were compared. The final two sections are devoted to a presentation of the results and summarizing the major outcomes and conclusions derived from the research. The most crucial innovation of this paper is twofold. First, BSR is applied in practice to forecasting spot oil price and its internal features are thoroughly checked and tested. Secondly, a wide array of forecasting methods (dealing with the variable uncertainty issue) is estimated over one data set. As a result, these methods are tested in a consistent way and compared with each other.
4. Results
Initially, pre-simulations were performed. For the sake of clarity and in order not to expand this paper unnecessarily, the details are not reported herein; they will be presented in a separate report, as the thorough examination of the impact of initial BSR parameters on the forecast accuracy in a financial time series can indeed be a fully independent research task requiring the checking of numerous possible specifications [
155].
The specification of the initial set of operators is a non-trivial task [
156]. Indeed, various sets of these operators were tested as some initial simulations. In particular, it seems that inserting operators such as exp, log, sin, cos, etc. into the initial set did not improve the accuracy of the obtained forecasts. This is probably because the time series used in this research were already suitably transformed before inserting into the modelling scheme; therefore, these operators would rather not recover the “true” model. In other words, too “sophisticated” operators did not lead further to important transformations of time series.
Secondly, operators connected with non-linear effects such as second and third powers also did not seem to improve forecast accuracy much. Maybe, the model averaging procedure was a more important feature for the problem addressed in this paper than the direct inclusion of non-linearities, as the variables had been suitably transformed before inserting into the models.
Thirdly, lag or moving average operators also did not improve forecast accuracy in any noticeable way. This can also probably be explained by the proper initial transformations of variables.
Fourthly, BSR, especially in a recursive implementation, had some tendency to generate extreme outlier forecasts. Indeed, during pre-simulations, few forecasts were quite so extreme in the out-of-sample period. One of the solutions to this issue that was effective was to set up some cut-off limits. For instance, if the forecast (of the change of a logarithm of the oil price) for time t was exceeding a fixed limit, then it was substituted by the forecast from time t − 1. However, such issues occurred mostly for big sets of operators—not for those finally chosen for this research.
According to the above considerations, the following set of operators was used in this research: inv, lt, neg, +, and *. In other words, these operators are working in the following way: inv(x) = 1/x, neg(x) = −x. The symbols + and * denote usual addition and multiplication, and lt was explained earlier in the text.
The second problem with BSR is to set up the correct number of linear components k (as described in the Methodology section of this paper). Although, as already mentioned, [
32] suggested moderate values of k; herein, k = {1, …, 12} was tested for the in-sample period. The results are presented in
Table 4. Actually, the smallest RMSE was produced by BSR with k = 7, but the model with k = 9 minimised three forecast accuracy measures, i.e., MAE, MAPE, and MASE. Therefore, for the further analysis, the model with k = 9 was taken.
Table 5 reports out-of-sample forecast accuracy measures of several models estimated in this research; in particular, both a variety of versions of BSR as well as the benchmark models. First of all, it can be noticed that the models which estimated recursively (denoted by “rec”) generated more accurate forecasts than the models with the parameters estimated only on the basis of the in-sample period and kept fixed later (denoted by “fix”). This observation is valid both for BSR models and for symbolic regression models with genetic programming (GP models). The extreme errors for the BSR fix model are consistent with the aforementioned fact that BSR tends to produce noticeable outlier forecasts in certain cases.
It seems that the recursive application, in which the functional form of the model varies in time, is a very important feature in the case of the modelling oil price time series. However, for symbolic regression with genetic programming, this issue does not seem to be so important. Moreover, the genetic programming algorithm seems to lead to smaller forecast errors than the Bayesian algorithm in the case of symbolic regression. This is in contradiction with the outcomes of [
32]. Nevertheless, all BSR models generated errors smaller than those of ARIMA and NAÏVE models (which are the very common benchmark models in numerous other studies).
It can also be seen that a model averaging scheme, instead of model selection, can in numerous cases improve the forecast accuracy. However, this is not a general rule as some models with a model combination scheme generated higher errors than their corresponding basic versions. Finally, it can be seen that RMSE was minimised by the BMA model, whereas MAE and MASE were minimised by the GP av MSE rec model and MAPE by DMA. However, it should be noted that the differences in forecast accuracy measures between these three models are very small and BMA is just a special case of DMA (with all forgetting parameters equal to 1).
For all the estimated models (i.e., those listed in
Table 5) the model confidence set (MCS) procedure selected the superior set of models. This set consisted of BMA and BMS 1V models. The corresponding TR statistic [
151,
152] for this test was 0.4255 and the
p-value was equal to 0.6764. Based on this result, for further analysis, the BMA model was selected as the “best” model out of all those considered in this research.
Table 6 presents the outcomes from the Diebold–Mariano test. The null hypothesis of the test was that forecasts from both models have the same accuracy. In the case of the BMA model, the alternative hypothesis was that the forecasts from the BMA model were more accurate than those from the alternative model. In the case of the BSR rec model, the alternative hypothesis was that the forecasts from the BSR rec model were less accurate than those from the alternative model. It can be seen that in the majority of cases, assuming a 5% significance level, BMA generated significantly more accurate forecasts than those from the other models. Assuming a 5% significance level, the BSR rec model generated significantly less accurate forecasts than most of the GP models. If a 10% significance level was assumed, then it can be said that the forecasts from the BSR rec model were significantly less accurate than those from all the GP models. Nevertheless, forecasts from the BSR rec model cannot be said to be significantly less accurate than those from either ARIMA or NAÏVE models.
Table 7 reports the Diebold–Mariano test outcomes. The null hypothesis in each of these tests was that the corresponding model that was estimated in a recursive manner generated more accurate forecasts than that estimated in a fixed manner. Assuming a 5% significance level, it can be said that in the case of GP av MSE and GP av EW models, the recursive estimations significantly improved forecast accuracies.
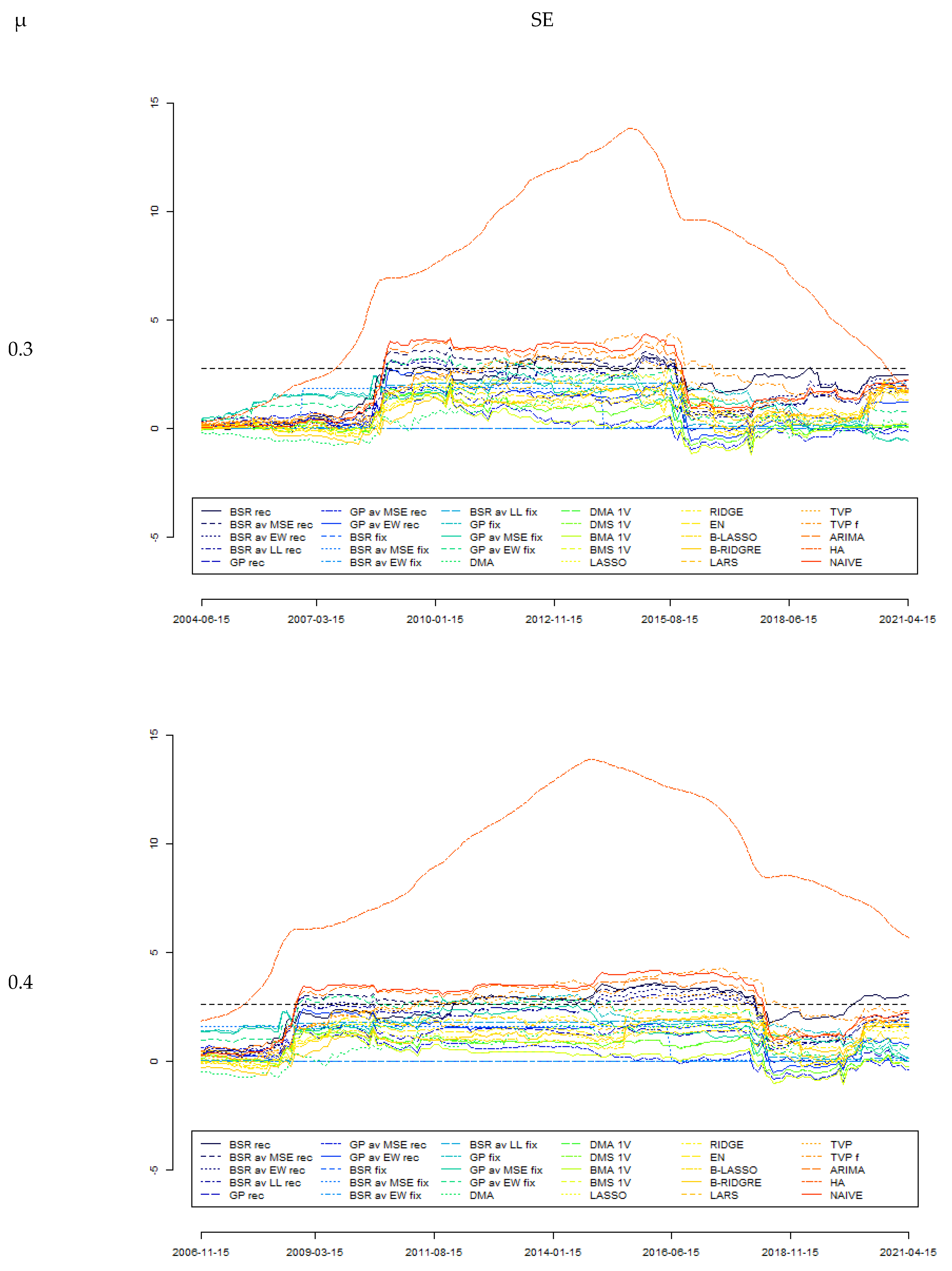
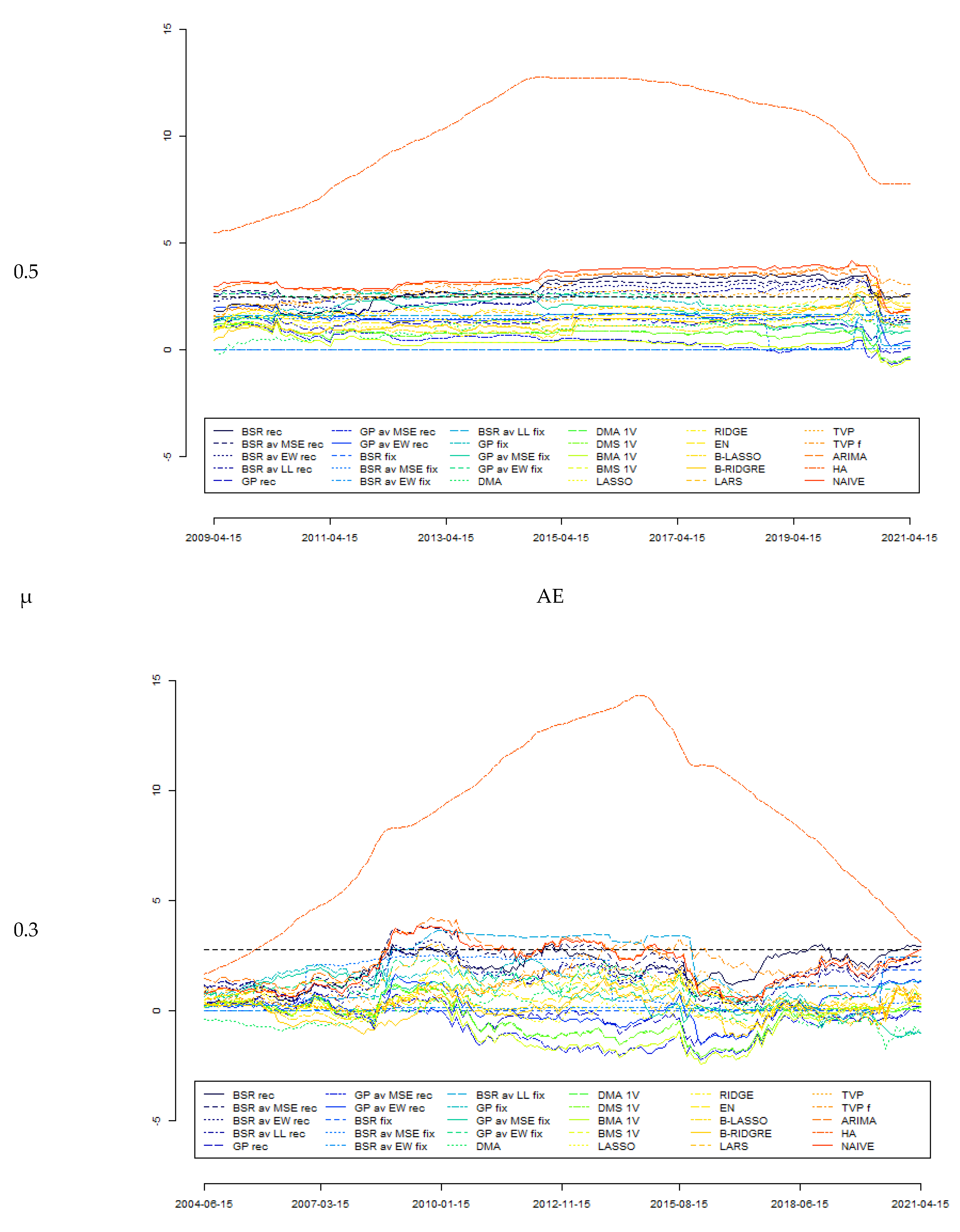
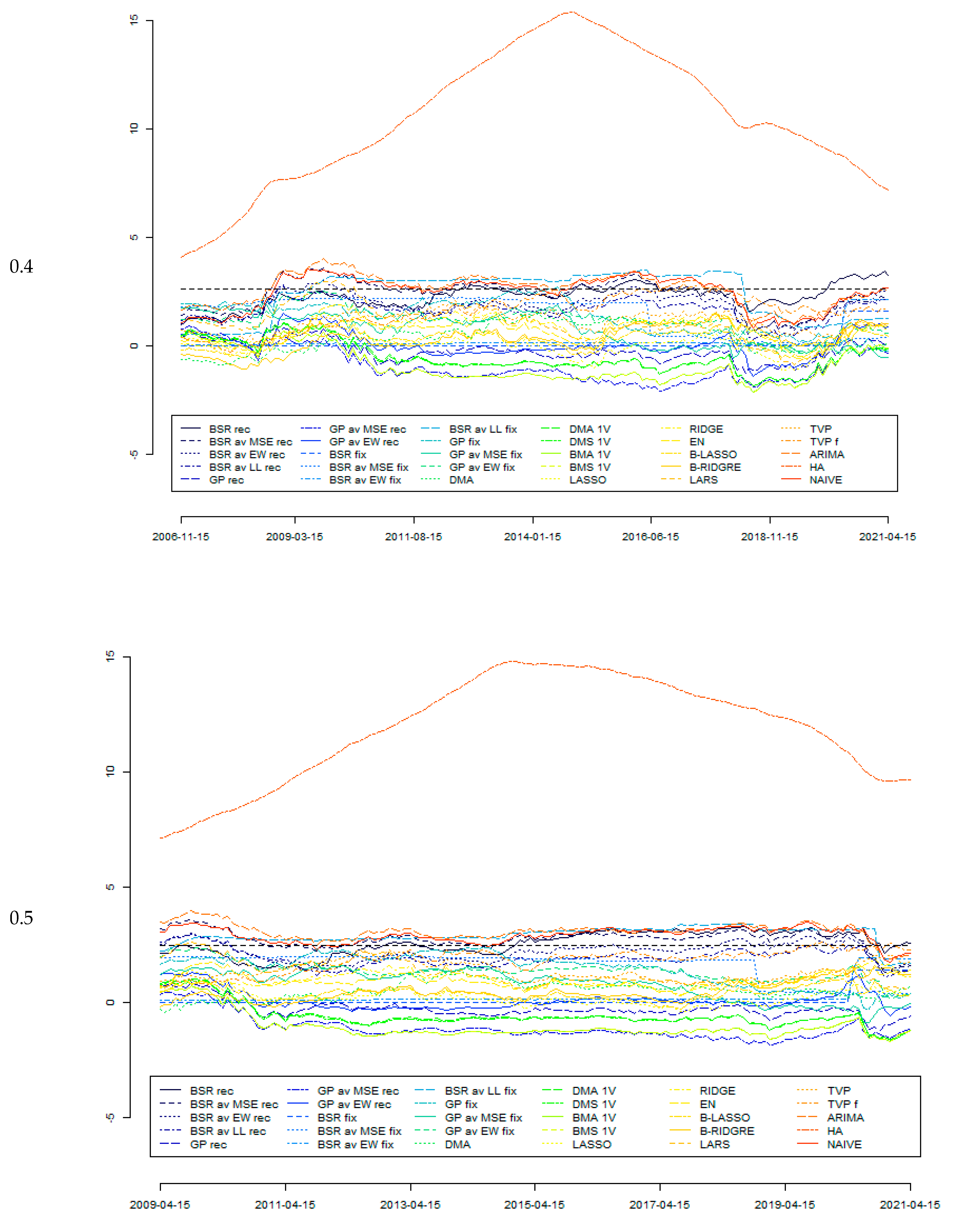
Figure 1 reports the outcomes from the Giacomini–Rossi fluctuation test for various parameter μ and loss functions (as explained previously in this text). It can be seen that the outcomes derived from different specifications are quite consistent with each other. In this test, BMA was assumed to be the “best” model, with forecast accuracy tested against those generated by other models. It can be seen that between 2009 and 2015, forecasts generated by the BMA model can indeed be assumed to be significantly more accurate than those derived from some other models; in particular, those from HA, NAÏVE, ARIMA, TVP, and TVP f models as well as various BSR rec models. On the other hand, there is much less evidence to assume forecasts from BMA as significantly more accurate compared with other models. The conclusions from the Giacomini–Rossi fluctuation test about the “superiority” of certain forecasts are much weaker than those from the Diebold–Mariano test, although there seems to be no contradiction between these two tests.
Finally, it could be interesting to verify which variables were included by the considered models as oil price predictors (explanatory variables).
Figure 2 presents the weighted average coefficients from applicable models (as explained earlier in this text). In other words, these models were composed from linear regression terms, i.e., each explanatory variable was always present in the component model in the same functional form, and this form was linear. It can be seen that only slight discrepancies can be observed so, in general, the predictions from different modelling schemes were the same.
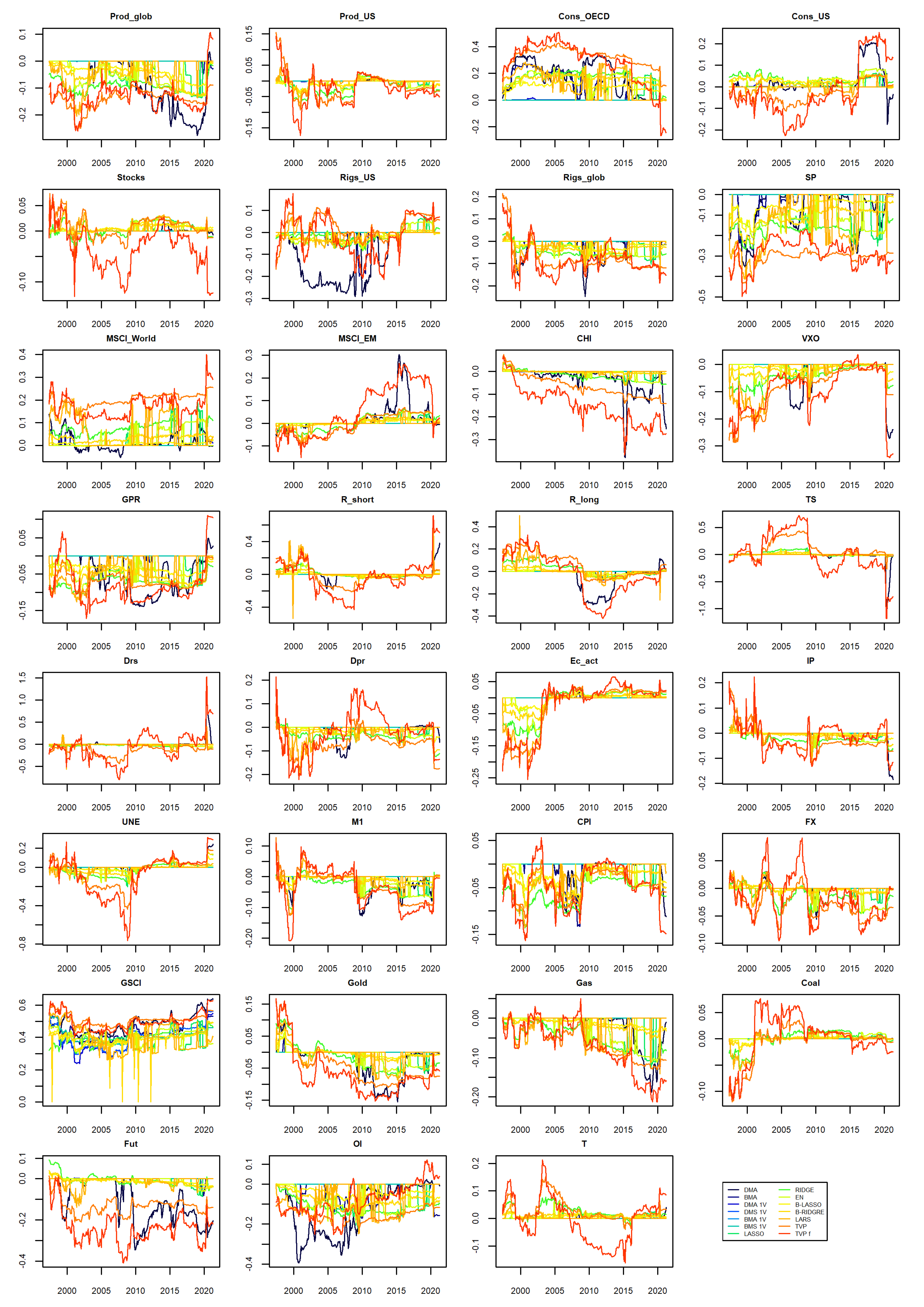
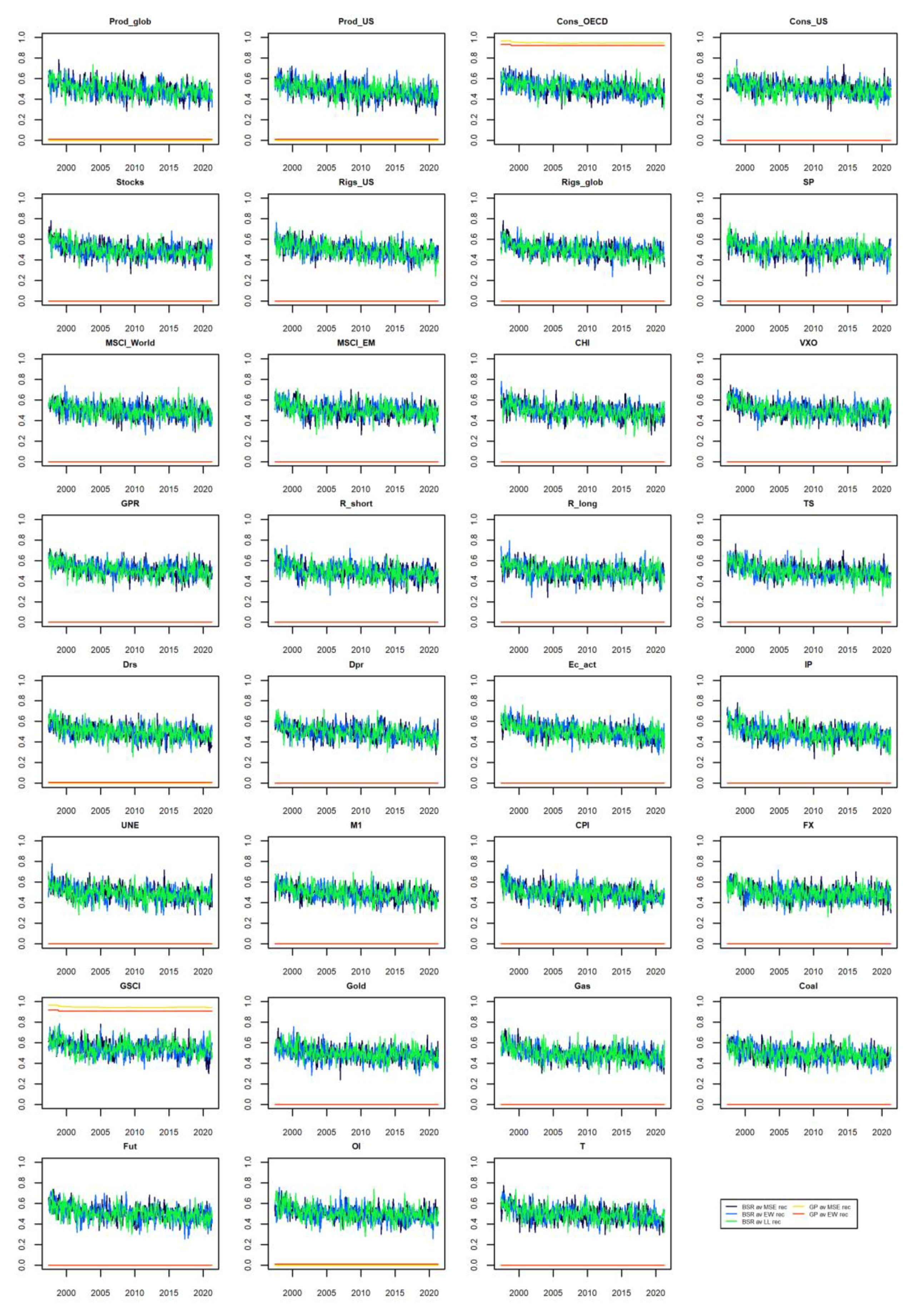
For the model combination schemes in which a given explanatory variable can be present in various functional forms (such as in symbolic regression, where operators during the evolution process can emerge into complicated functional forms), only RVIs are reported in
Figure 3. It can be seen that the GP models were quite uniform and consistent in including explanatory variables. In the case of BSR models, RVIs oscillated around 0.5, meaning that these models do not seem to “prefer” any particular explanatory variables.
For the BSR rec and GP rec models, it happened that they were almost always selecting the same set of explanatory variables. In particular, BSR rec was selecting all the considered explanatory variables. On the other hand, the GP rec model was selecting only Cons_OECD and GSCI explanatory variables.
The entire analysis was also repeated with Brent oil prices and Dubai oil prices as response variables, and the outcomes and conclusions were almost the same as for WTI. Therefore, the outcomes reported herein are robust and can be spread to the oil spot price in general. The particular specification of WTI price was not the issue.
Moreover, the analysis was repeated with a smaller set of explanatory variables (a subset of the set taken for the research reported herein; Prod_glob, Cons_OECD, Stocks, MSCI_World, CHI, VXO, R_short, Ec_act, and FX) and with the very basic set of operators (i.e., neg and +). The outcomes, especially the conclusions from the MCS procedure, were similar and consistent with those presented in the current research. Because the results of these robustness checks actually constituted separate research, and the presentation would be very lengthy, they will be presented in detail elsewhere [
157]. However, it is important to observe that the selection of a particular set of explanatory variables did not influence the outcomes or conclusions; similar but different sets of explanatory variables lead to similar results.
5. Conclusions
In this study, novel Bayesian symbolic regression (BSR) models were estimated in various specifications and the obtained results were reported. In addition, numerous benchmark models were estimated. As a result, the current outcomes fill a certain literature gap. Not only was the novel BSR method tested in real-life, rather than on synthetic data, but also a wide collection of forecasting models were tested for the crude oil spot price.
The analysed models were those commonly used for variable (feature) selection issues (i.e., LASSO, RIDGE, least-angle regressions, dynamic model averaging, Bayesian model averaging, etc.). Although many of these models were already applied to oil spot price forecasting in other studies, they were usually compared with limited benchmarks, as those studies were solely focused on the novel applications of those particular models individually. Contrary to this, the current paper consists of a wide collection of these models estimated over the same data sample and compared with each other in a unified way. Such an approach presents a wider and more general overview of the topic. In any case, the outcomes reported herein are robust; both when the set of explanatory variables is modified as well as when the oil price is measured by different indices.
The chosen forecast evaluation procedures provided much evidence in favour of dynamic model averaging [
37] as a very accurate forecasting tool. In particular, this modelling scheme did tend to be the most accurate amongst several others, for instance LASSO, RIDGE, elastic net, least-angle regressions, time-varying parameters regressions, ARIMA, NAÏVE (no-change) forecast, etc., according to strict statistical test procedures, i.e., model confidence set [
151,
152].
Unfortunately, the novel BSR method did not produce significantly more accurate forecasts than some of those benchmark models. For example, in the case of crude oil price 1-month ahead forecasting, BSR did not seem to increase the forecast accuracy compared with the standard symbolic regression based on genetic programming. On the other hand, BSR could not have been concluded to generate less accurate forecasts than the ARIMA or NAÏVE (no-change) methods. As a result, it seems that BSR still has great potential as an interesting forecasting model for the crude oil spot price; further examination and improvements in the algorithm might result in better outcomes. Moreover, BSR estimations were faster than those for symbolic regression based on genetic programming [
20,
153] and this advantage should also be considered as an important feature of the novel method.
In the case of BSR, it was confirmed that the suitable selection of operators for symbolic regression at the initial stage as well as setting limits on function complexity are not easy tasks. Similarly, as in [
32], in comparison to the number of all possible explanatory variables, relatively moderate values of the number of linear components were preferred in the context of forecast accuracy.
Amongst the limitations of this study, omitting non-linear benchmark models can be stated. Indeed, non-linearities are important characteristics of oil markets [
158,
159]. However, joining model averaging with non-linear regressions is a subtle task [
160]. Indeed, the improving of the studied method with non-linearities can be an interesting topic for further research.
There exist also some general problems with the symbolic regression approach. For example, two expressions, such as
x ∗ x and
x2, are computationally equivalent; however, they are constructed from different operators [
161]. How to store and reduce them and avoid computational cost is a subtle task. Moreover, even different functions can be “approximately” very similar for the given data set problem. Similarly, the estimation of regression coefficients and the numerical accuracy of them pose some issues. There are also still some issues with the computational costs of BSR. Although still faster than genetic programming-based symbolic regression, Markov chain Monte Carlo (MCMC) sampling still generated some significant computational time.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}