
Completed Review of Various Solar Power Forecasting Techniques Considering Different Viewpoints




Abstract
:1. Introduction
2. Learning Techniques for PV Power Forecasting Models
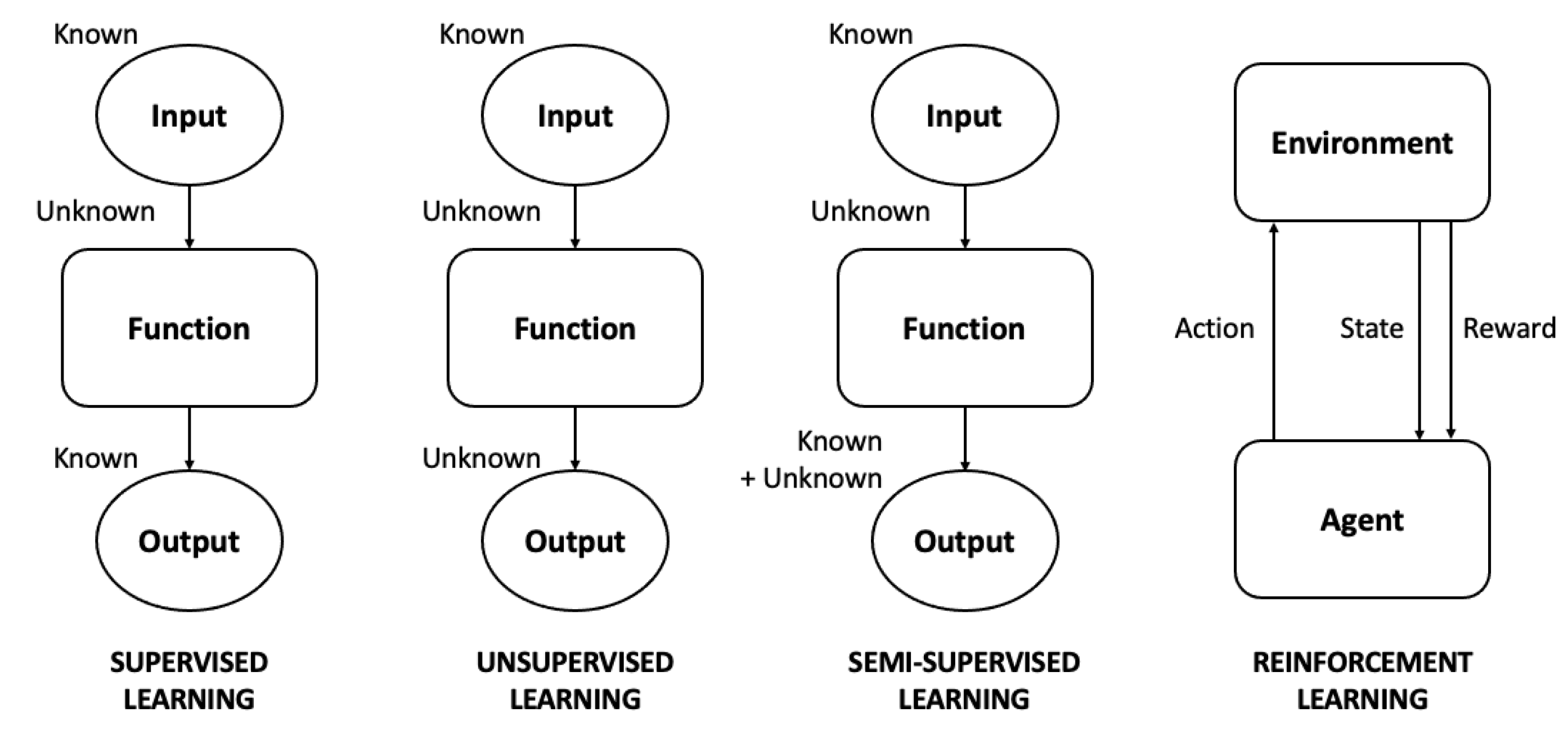
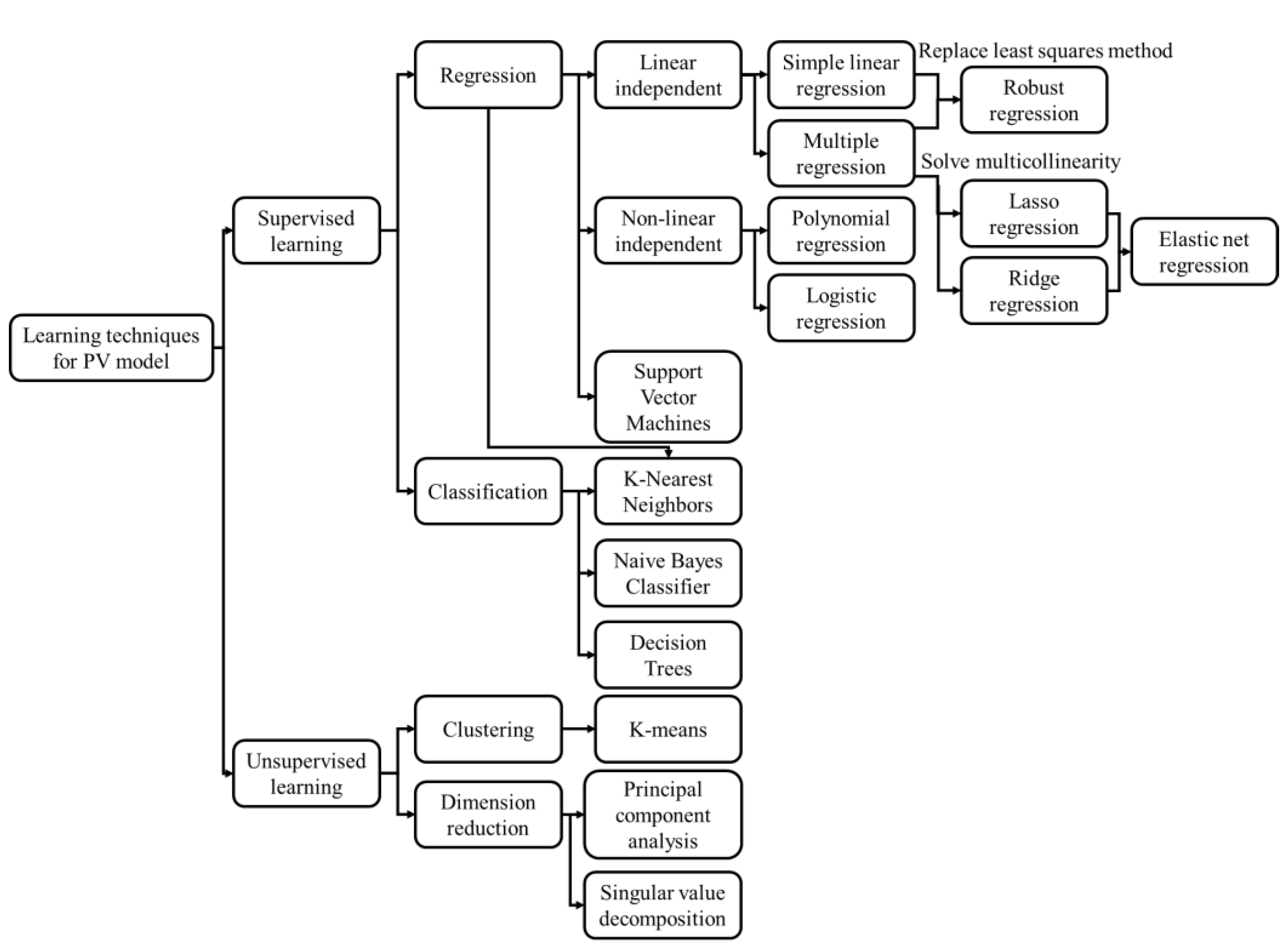
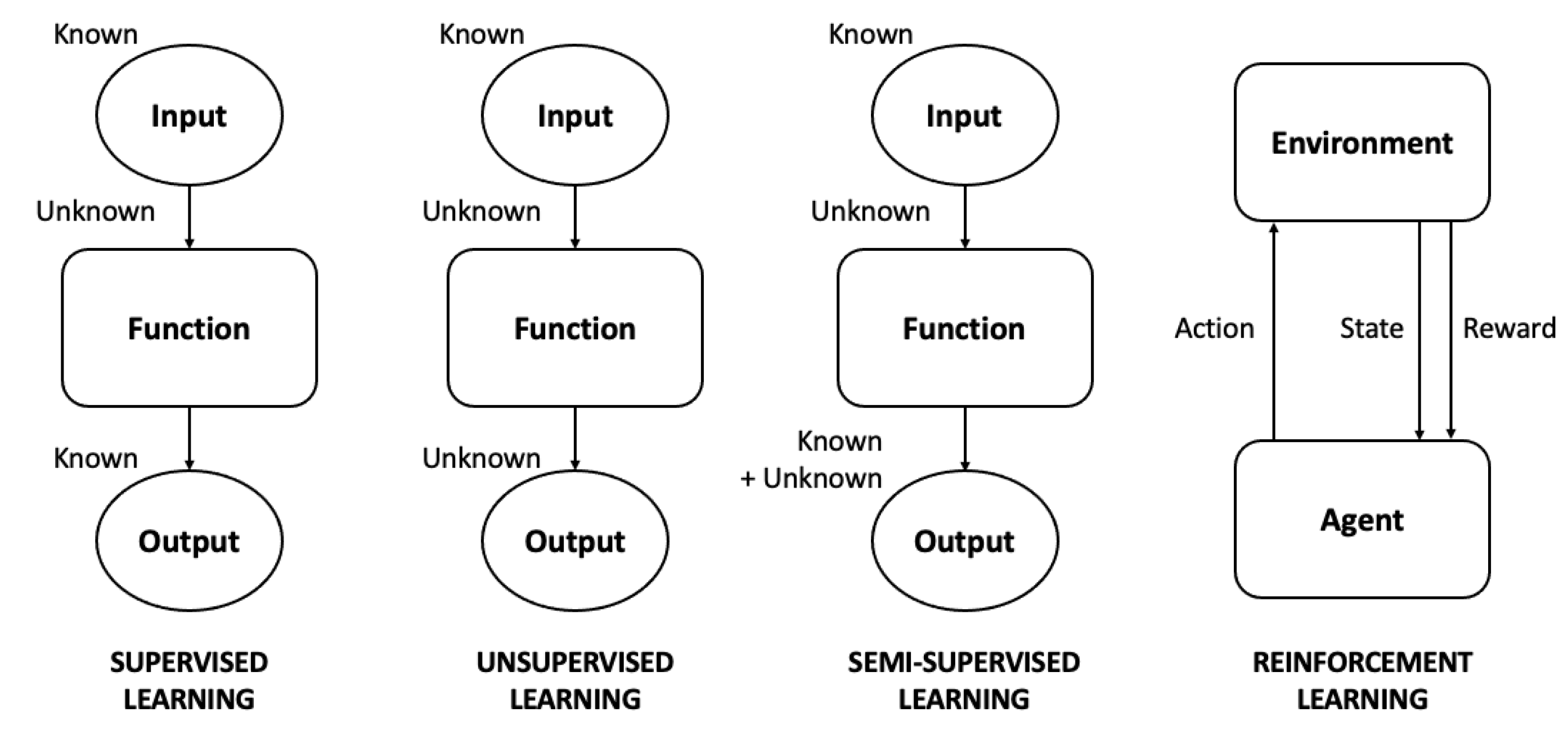
2.1. Supervised Learning
2.2. Unsupervised Learning
3. Pre-Processing Methods
3.1. Data Cleaning
3.2. Normalization
3.3. Z-Score Standardization
3.4. Wavelet Transform (WT)
3.5. Empirical Mode Decomposition (EMD)
3.6. Singular Spectrum Analysis (SSA)
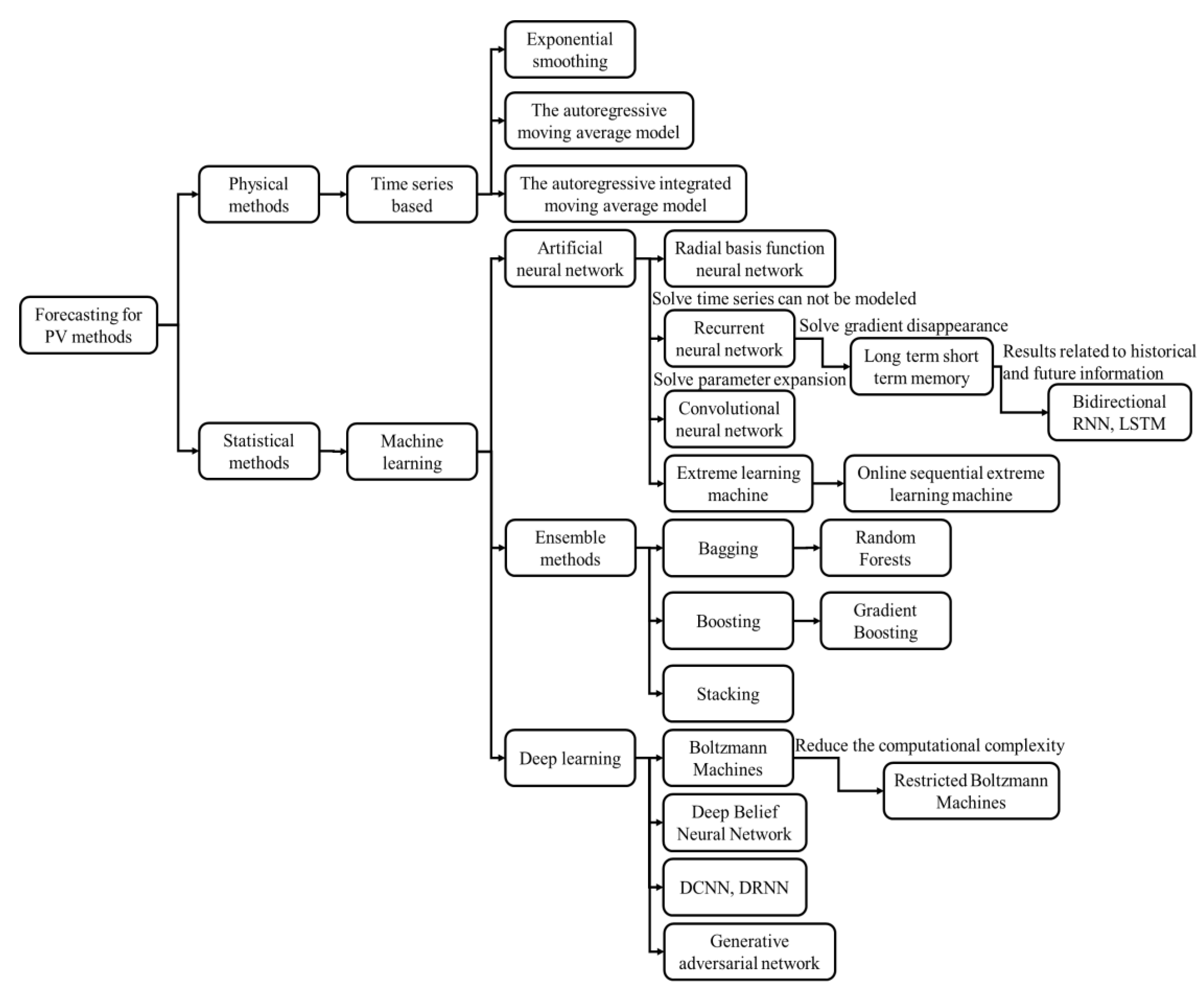
4. Classification of PV Power Forecasting Methods
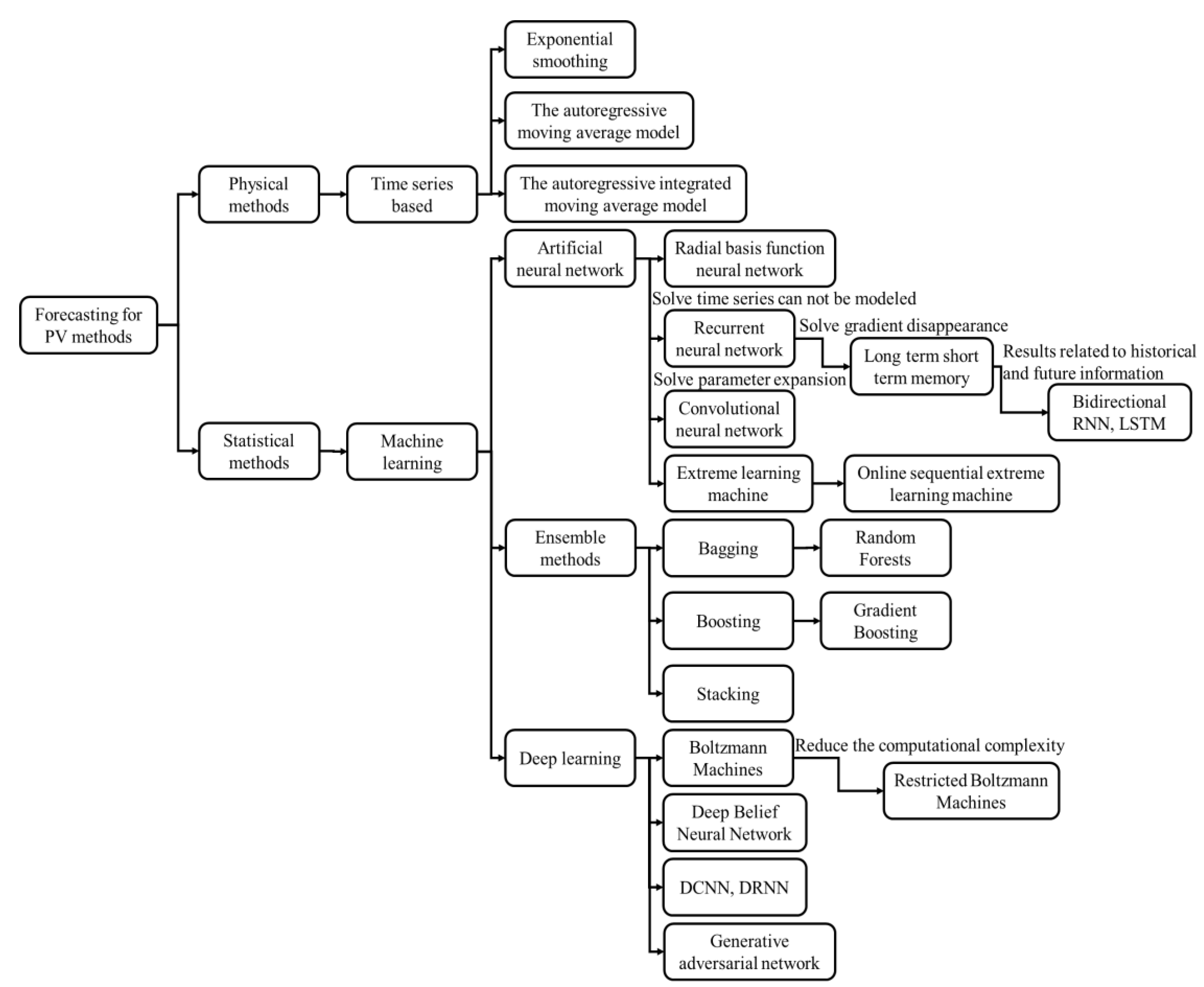
4.1. Physical Methods
4.2. Statistical Methods
4.2.1. Time Series-Based Methods
4.2.2. Machine Learning
4.2.3. Deep Learning
5. Major Factors Affecting Solar Power Forecasting
5.1. Forecasting Horizons
5.2. Weather Classification
5.3. Optimization of Model Parameters
5.4. Performance of Forecast Models
6. Hybrid Models
7. Probabilistic Forecast Techniques
8. Discussions
8.1. Important Findings from Literature Reviews
- The forecasting horizon has a strong influence on forecasting accuracy. When the lead time is shorter, the average forecasting error is smaller.
- The majority of PV forecasts use the inputs of solar irradiation, atmospheric temperature, and wind speed, but some use advanced input variables such as global horizontal irradiance, diffused horizontal irradiance, diffused normal irradiance, and total cloud cover.
- Site-related parameters such as the solar zenith angle are also considered in some papers.
- Different statistical methods can be used to evaluate the performance of the forecasting models, among which the MAE, the MSE, and the RMSE are the most popular indexes.
- Machine learning-based methods that employ optimization parameter searching have been the most popular methods in recent years. Optimizing the model parameters and selecting appropriate input data effectively improves the accuracy of the forecasting model.
8.2. Knowledge Gaps
8.2.1. The Integration of Atmospheric Science with Renewable Power Forecasting
8.2.2. The Restricted Application of Novel AI Models
8.2.3. The Selection of the Optimal Combination of Data Collection Tools
8.2.4. The Implementation of a Cross-Disciplinary Approach
8.2.5. The Stability of Data Collection
8.3. Future Scopes
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Liu, L.; Zhao, Y.; Chang, D.; Xie, J.; Ma, Z.; Sun, Q.; Yin, H.; Wennersten, R. Prediction of short-term PV power output and uncertainty analysis. Appl. Energy 2018, 228, 700–711. [Google Scholar] [CrossRef]
- Shivashankar, S.; Mekhilef, S.; Mokhlis, H.; Karimi, M. Mitigating methods of power fluctuation of photovoltaic (PV) sources–A review. Renew. Sustain. Energy Rev. 2016, 59, 1170–1184. [Google Scholar] [CrossRef]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Almeida, M.P.; Muñoz, M.; de la Parra, I.; Perpiñán, O. Comparative study of PV power forecast using parametric and nonparametric PV models. Sol. Energy 2017, 155, 854–866. [Google Scholar] [CrossRef] [Green Version]
- Lorenz, E.; Heinemann, D. Prediction of solar irradiance and photovoltaic power. Compr. Renew. Energy 2012, 1, 239–292. [Google Scholar]
- Ulbricht, R.; Fischer, U.; Lehner, W.; Donker, H. First steps towards a systematical optimized strategy for solar energy supply forecasting. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECMLPKDD 2013), Prague, Czech Republic, 23–27 September 2013. [Google Scholar]
- Phan, Q.T.; Wu, Y.K.; Phan, Q.D. A Hybrid Wind Power Forecasting Model with XGBoost, Data Preprocessing Considering Different NWPs. Appl. Sci. 2021, 11, 1100. [Google Scholar] [CrossRef]
- Antonanzas, J.; Pozo-Vázquez, D.; Fernandez-Jimenez, L.; Martinez-de-Pison, F. The value of day-ahead forecasting for photovoltaics in the Spanish electricity market. Sol. Energy 2017, 158, 140–146. [Google Scholar] [CrossRef]
- Theocharides, S.; Makrides, G.; Livera, A.; Theristis, M.; Kaimakis, P.; Georghiou, G.E. Day-ahead photovoltaic power production forecasting methodology based on machine learning and statistical post-processing. Appl. Energy 2020, 268, 115023. [Google Scholar] [CrossRef]
- Wang, R.; Li, J.; Wang, J.; Gao, C. Research and application of a hybrid wind energy forecasting system based on data processing and an optimized extreme learning machine. Energies 2018, 11, 1712. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.-K.; Su, P.-E.; Wu, T.-Y.; Hong, J.-S.; Hassan, M.Y. Probabilistic wind-power forecasting using weather ensemble models. IEEE Trans. Ind. Appl. 2018, 54, 5609–5620. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Das, U.K.; Tey, K.S.; Seyedmahmoudian, M.; Mekhilef, S.; Idris, M.Y.I.; Van Deventer, W.; Horan, B.; Stojcevski, A. Forecasting of photovoltaic power generation and model optimization: A review. Renew. Sustain. Energy Rev. 2018, 81, 912–928. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Ogliari, E.; Leva, S.; Lughi, V. Advanced methods for photovoltaic output power forecasting: A review. Appl. Sci. 2020, 10, 487. [Google Scholar] [CrossRef] [Green Version]
- Akhter, M.N.; Mekhilef, S.; Mokhlis, H.; Shah, N.M. Review on forecasting of photovoltaic power generation based on machine learning and metaheuristic techniques. IET Renew. Power Gener. 2019, 13, 1009–1023. [Google Scholar] [CrossRef] [Green Version]
- Ellahi, M.; Abbas, G.; Khan, I.; Koola, P.M.; Nasir, M.; Raza, A.; Farooq, U. Recent approaches of forecasting and optimal economic dispatch to overcome intermittency of wind and photovoltaic (PV) systems: A review. Energies 2019, 12, 4392. [Google Scholar] [CrossRef] [Green Version]
- Trigo-González, M.; Batlles, F.; Alonso-Montesinos, J.; Ferrada, P.; Del Sagrado, J.; Martínez-Durbán, M.; Cortés, M.; Portillo, C.; Marzo, A. Hourly PV production estimation by means of an exportable multiple linear regression model. Renew. Energy 2019, 135, 303–312. [Google Scholar] [CrossRef]
- Mahmud, K.; Azam, S.; Karim, A.; Zobaed, S.; Shanmugam, B.; Mathur, D. Machine Learning Based PV Power Generation Forecasting in Alice Springs. IEEE Access 2021, 9, 46117–46128. [Google Scholar] [CrossRef]
- Dairi, A.; Harrou, F.; Sun, Y.; Khadraoui, S. Short-term forecasting of photovoltaic solar power production using variational auto-encoder driven deep learning approach. Appl. Sci. 2020, 10, 8400. [Google Scholar] [CrossRef]
- Yang, D. Ultra-fast preselection in lasso-type spatio-temporal solar forecasting problems. Sol. Energy 2018, 176, 788–796. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Y.; Li, X.; Wu, J.; He, T. Forecasting daily crude oil prices using improved CEEMDAN and ridge regression-based predictors. Energies 2019, 12, 3603. [Google Scholar] [CrossRef] [Green Version]
- Jordan, D.C.; Deline, C.; Kurtz, S.R.; Kimball, G.M.; Anderson, M. Robust PV degradation methodology and application. IEEE J. Photovolt. 2017, 8, 525–531. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, H.; Liu, J.; Li, K.; Yang, D.; Tian, H. Weather prediction with multiclass support vector machines in the fault detection of photovoltaic system. IEEE/CAA J. Autom. Sin. 2017, 4, 520–525. [Google Scholar] [CrossRef]
- da Silva Fonseca, J.G., Jr.; Oozeki, T.; Takashima, T.; Koshimizu, G.; Uchida, Y.; Ogimoto, K. Use of support vector regression and numerically predicted cloudiness to forecast power output of a photovoltaic power plant in Kitakyushu, Japan. Prog. Photovolt. Res. Appl. 2012, 20, 874–882. [Google Scholar] [CrossRef]
- Harrou, F.; Taghezouit, B.; Sun, Y. Improved kNN-based monitoring schemes for detecting faults in PV systems. IEEE J. Photovolt. 2019, 9, 811–821. [Google Scholar] [CrossRef]
- Tan, J.; Deng, C. Ultra-short-term photovoltaic generation forecasting model based on weather clustering and markov chain. In Proceedings of the 2017 IEEE 44th Photovoltaic Specialist Conference (PVSC), Washington, DC, USA, 25–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1158–1162. [Google Scholar]
- Kwon, Y.; Kwasinski, A.; Kwasinski, A. Solar irradiance forecast using naïve Bayes classifier based on publicly available weather forecasting variables. Energies 2019, 12, 1529. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]
- Zhen, Z.; Liu, J.; Zhang, Z.; Wang, F.; Chai, H.; Yu, Y.; Lu, X.; Wang, T.; Lin, Y. Deep learning based surface irradiance mapping model for solar PV power forecasting using sky image. IEEE Trans. Ind. Appl. 2020, 56, 3385–3396. [Google Scholar] [CrossRef]
- Zhang, H.; Li, D.; Tian, Z.; Guo, L. A Short-Term Photovoltaic Power Output Prediction for Virtual Plant Peak Regulation Based on K-means Clustering and Improved BP Neural Network. In Proceedings of the 2021 11th International Conference on Power, Energy and Electrical Engineering (CPEEE), Shiga, Japan, 26–28 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 241–244. [Google Scholar]
- Lan, H.; Zhang, C.; Hong, Y.-Y.; He, Y.; Wen, S. Day-ahead spatiotemporal solar irradiation forecasting using frequency-based hybrid principal component analysis and neural network. Appl. Energy 2019, 247, 389–402. [Google Scholar] [CrossRef]
- Pierro, M.; De Felice, M.; Maggioni, E.; Moser, D.; Perotto, A.; Spada, F.; Cornaro, C. Data-driven upscaling methods for regional photovoltaic power estimation and forecast using satellite and numerical weather prediction data. Sol. Energy 2017, 158, 1026–1038. [Google Scholar] [CrossRef]
- Prasad, R.; Ali, M.; Xiang, Y.; Khan, H., A. double decomposition-based modelling approach to forecast weekly solar radiation. Renew. Energy 2020, 152, 9–22. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, Z.; Zhang, Y.; Xie, M. Optimal Cleaning Scheduling for Photovoltaic Systems in the Field Based on Electricity Generation and Dust Deposition Forecasting. IEEE J. Photovolt. 2020, 10, 1126–1132. [Google Scholar] [CrossRef]
- Massaoudi, M.; Chihi, I.; Sidhom, L.; Trabelsi, M.; Refaat, S.S.; Abu-Rub, H.; Oueslati, F.S. An effective hybrid NARX-LSTM model for point and interval PV power forecasting. IEEE Access 2021, 9, 36571–36588. [Google Scholar] [CrossRef]
- Arora, I.; Gambhir, J.; Kaur, T. Data Normalisation-Based Solar Irradiance Forecasting Using Artificial Neural Networks. Arab. J. Sci. Eng. 2021, 46, 1333–1343. [Google Scholar] [CrossRef]
- Alipour, M.; Aghaei, J.; Norouzi, M.; Niknam, T.; Hashemi, S.; Lehtonen, M. A novel electrical net-load forecasting model based on deep neural networks and wavelet transform integration. Energy 2020, 205, 118106. [Google Scholar] [CrossRef]
- Zolfaghari, M.; Golabi, M.R. Modeling and predicting the electricity production in hydropower using conjunction of wavelet transform, long short-term memory and random forest models. Renew. Energy 2021, 170, 1367–1381. [Google Scholar] [CrossRef]
- Li, F.-F.; Wang, S.-Y.; Wei, J.-H. Long term rolling prediction model for solar radiation combining empirical mode decomposition (EMD) and artificial neural network (ANN) techniques. J. Renew. Sustain. Energy 2018, 10, 013704. [Google Scholar] [CrossRef]
- Wang, S.; Guo, Y.; Wang, Y.; Li, Q.; Wang, N.; Sun, S.; Cheng, Y.; Yu, P. A wind speed prediction method based on improved empirical mode decomposition and support vector machine. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Harbin, China, 22–24 January 2021; IOP Publishing: Tokyo, Japan, 2021; p. 012012. [Google Scholar]
- Moreno, S.R.; dos Santos Coelho, L. Wind speed forecasting approach based on singular spectrum analysis and adaptive neuro fuzzy inference system. Renew. Energy 2018, 126, 736–754. [Google Scholar] [CrossRef]
- Zhang, Y.; Le, J.; Liao, X.; Zheng, F.; Li, Y. A novel combination forecasting model for wind power integrating least square support vector machine, deep belief network, singular spectrum analysis and locality-sensitive hashing. Energy 2019, 168, 558–572. [Google Scholar] [CrossRef]
- Niccolai, A.; Dolara, A.; Ogliari, E. Hybrid PV power forecasting methods: A comparison of different approaches. Energies 2021, 14, 451. [Google Scholar] [CrossRef]
- Guleryuz, D. Forecasting Outbreak of COVID-19 in Turkey; Comparison of Box–Jenkins, Brown’s Exponential Smoothing and Long Short-Term Memory Models. Process Saf. Environ. Prot. 2021, 149, 927–935. [Google Scholar] [CrossRef]
- Feng, J.; Xu, S.X. Integrated technical paradigm based novel approach towards photovoltaic power generation technology. Energy Strategy Rev. 2021, 34, 100613. [Google Scholar] [CrossRef]
- Das, S. Short term forecasting of solar radiation and power output of 89.6 kWp solar PV power plant. Mater. Today Proc. 2021, 39, 1959–1969. [Google Scholar] [CrossRef]
- Nour-eddine, I.O.; Lahcen, B.; Fahd, O.H.; Amin, B. Power forecasting of three silicon-based PV technologies using actual field measurements. Sustain. Energy Technol. Assess. 2021, 43, 100915. [Google Scholar] [CrossRef]
- Jnr, E.O.-N.; Ziggah, Y.Y.; Relvas, S. Hybrid ensemble intelligent model based on wavelet transform, swarm intelligence and artificial neural network for electricity demand forecasting. Sustain. Cities Soc. 2021, 66, 102679. [Google Scholar]
- Li, G.; Xie, S.; Wang, B.; Xin, J.; Li, Y.; Du, S. Photovoltaic power forecasting with a hybrid deep learning approach. IEEE Access 2020, 8, 175871–175880. [Google Scholar] [CrossRef]
- Cheng, L.; Zang, H.; Ding, T.; Wei, Z.; Sun, G. Multi-meteorological-factor-based Graph Modeling for Photovoltaic Power Forecasting. IEEE Trans. Sustain. Energy 2021, 12, 1593–1603. [Google Scholar] [CrossRef]
- Liu, C.-H.; Gu, J.-C.; Yang, M.-T. A simplified LSTM neural networks for one day-ahead solar power forecasting. IEEE Access 2021, 9, 17174–17195. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Recurrent neural networks. In Neural Networks and Deep Learning; Springer: Beilin/Heidelberg, Germany, 2018; pp. 271–313. [Google Scholar]
- Liu, Z.-F.; Luo, S.-F.; Tseng, M.-L.; Liu, H.-M.; Li, L.; Mashud, A.H.M. Short-term photovoltaic power prediction on modal reconstruction: A novel hybrid model approach. Sustain. Energy Technol. Assess. 2021, 45, 101048. [Google Scholar] [CrossRef]
- Bielskus, J.; Motuzienė, V.; Vilutienė, T.; Indriulionis, A. Occupancy prediction using differential evolution online sequential Extreme Learning Machine model. Energies 2020, 13, 4033. [Google Scholar] [CrossRef]
- El-Baz, W.; Tzscheutschler, P.; Wagner, U. Day-ahead probabilistic PV generation forecast for buildings energy management systems. Sol. Energy 2018, 171, 478–490. [Google Scholar] [CrossRef]
- Rafati, A.; Joorabian, M.; Mashhour, E.; Shaker, H.R. High dimensional very short-term solar power forecasting based on a data-driven heuristic method. Energy 2021, 219, 119647. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, T. Solar power prediction in smart grid based on NWP data and an improved boosting method. In Proceedings of the IEEE International Conference on Energy Internet (ICEI), Beijing, China, 17–21 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 89–94. [Google Scholar]
- Kumari, P.; Toshniwal, D. Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance. J. Clean. Prod. 2021, 279, 123285. [Google Scholar] [CrossRef]
- Guo, X.; Gao, Y.; Zheng, D.; Ning, Y.; Zhao, Q. Study on short-term photovoltaic power prediction model based on the Stacking ensemble learning. Energy Rep. 2020, 6, 1424–1431. [Google Scholar] [CrossRef]
- Ogawa, S.; Mori, H. A gaussian-gaussian-restricted-boltzmann-machine-based deep neural network technique for photovoltaic system generation forecasting. IFAC-Pap. 2019, 52, 87–92. [Google Scholar] [CrossRef]
- Zhu, X.; Yin, R.; Shi, H.; Ma, B.; Li, D. Short-term Forecast for Photovoltaic Generation Based on Improved Restricted Boltzmann Machine Algorithm. In Proceedings of the 2020 IEEE Sustainable Power and Energy Conference (iSPEC), Chengdu, China, 23–25 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 245–251. [Google Scholar]
- Hu, W.; Zhang, X.; Zhu, L.; Li, Z. Short-Term Photovoltaic Power Prediction Based on Similar Days and Improved SOA-DBN Model. IEEE Access 2020, 9, 1958–1971. [Google Scholar] [CrossRef]
- Cui, Q.; Sun, H.; Kong, Y.; Zhang, X.; Li, Y. Efficient human motion prediction using temporal convolutional generative adversarial network. Inf. Sci. 2021, 545, 427–447. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Wang, Y.; Liao, W.; Chang, Y. Gated recurrent unit network-based short-term photovoltaic forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; von Luxburg, U., Guyon, I., Bengio, S., Wallach, H., Fergus, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA; p. 30.
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In Advances in Neural Information Processing Systems, Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019; Association for Computing Machinery: New York, NY, USA, 2019; p. 32. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Rae, J.W.; Potapenko, A.; Jayakumar, S.M.; Lillicrap, T.P. Compressive transformers for long-range sequence modelling. arXiv 2019, arXiv:1911.05507. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI, Palo Alto, CA, USA, 2–9 February 2021. [Google Scholar]
- Das, U.K.; Tey, K.S.; Seyedmahmoudian, M.; Idna Idris, M.Y.; Mekhilef, S.; Horan, B.; Stojcevski, A. SVR-based model to forecast PV power generation under different weather conditions. Energies 2017, 10, 876. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhou, N.; Gong, L.; Jiang, M. Prediction of photovoltaic power output based on similar day analysis, genetic algorithm and extreme learning machine. Energy 2020, 204, 117894. [Google Scholar] [CrossRef]
- Aljanad, A.; Tan, N.M.; Agelidis, V.G.; Shareef, H. Neural network approach for global solar irradiance prediction at extremely short-time-intervals using particle swarm optimization algorithm. Energies 2021, 14, 1213. [Google Scholar] [CrossRef]
- Lin, J.; Li, H. A Short-Term PV Power Forecasting Method Using a Hybrid Kmeans-GRA-SVR Model under Ideal Weather Condition. J. Comput. Commun. 2020, 8, 102. [Google Scholar] [CrossRef]
- Liaquat, S.; Fakhar, M.S.; Kashif, S.A.R.; Rasool, A.; Saleem, O.; Padmanaban, S. Performance analysis of APSO and firefly algorithm for short term optimal scheduling of multi-generation hybrid energy system. IEEE Access 2020, 8, 177549–177569. [Google Scholar] [CrossRef]
- Pan, M.; Li, C.; Gao, R.; Huang, Y.; You, H.; Gu, T.; Qin, F. Photovoltaic power forecasting based on a support vector machine with improved ant colony optimization. J. Clean. Prod. 2020, 277, 123948. [Google Scholar] [CrossRef]
- Heydari, A.; Garcia, D.A.; Keynia, F.; Bisegna, F.; De Santoli, L. A novel composite neural network based method for wind and solar power forecasting in microgrids. Appl. Energy 2019, 251, 113353. [Google Scholar] [CrossRef]
- Hao, J.; Sun, X.; Feng, Q. A novel ensemble approach for the forecasting of energy demand based on the artificial bee colony algorithm. Energies 2020, 13, 550. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.-C.; Huang, C.-M.; Chen, S.-J.; Yang, S.-P. Optimization of module parameters for PV power estimation using a hybrid algorithm. IEEE Trans. Sustain. Energy 2019, 11, 2210–2219. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, D.; Zhu, X. Deep learning based forecasting of photovoltaic power generation by incorporating domain knowledge. Energy 2021, 225, 120240. [Google Scholar] [CrossRef]
- Mayer, M.J.; Gróf, G. Extensive comparison of physical models for photovoltaic power forecasting. Appl. Energy 2021, 283, 116239. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M. PV-Net: An innovative deep learning approach for efficient forecasting of short-term photovoltaic energy production. J. Clean. Prod. 2021, 303, 127037. [Google Scholar] [CrossRef]
- Konstantinou, M.; Peratikou, S.; Charalambides, A.G. Solar photovoltaic forecasting of power output using lstm networks. Atmosphere 2021, 12, 124. [Google Scholar] [CrossRef]
- Lyu, C.; Basumallik, S.; Eftekharnejad, S.; Xu, C. A Data-Driven Solar Irradiance Forecasting Model with Minimum Data. In Proceedings of the 2021 IEEE Texas Power and Energy Conference (TPEC), College Station, TX, USA, 4–5 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Qadir, Z.; Khan, S.I.; Khalaji, E.; Munawar, H.S.; Al-Turjman, F.; Mahmud, M.P.; Kouzani, A.Z.; Le, K. Predicting the energy output of hybrid PV–wind renewable energy system using feature selection technique for smart grids. Energy Rep. 2021, 7, 8465–8475. [Google Scholar] [CrossRef]
- Mazorra-Aguiar, L.; Lauret, P.; David, M.; Oliver, A.; Montero, G. Comparison of Two Solar Probabilistic Forecasting Methodologies for Microgrids Energy Efficiency. Energies 2021, 14, 1679. [Google Scholar] [CrossRef]
- Huang, X.; Li, Q.; Tai, Y.; Chen, Z.; Zhang, J.; Shi, J.; Gao, B.; Liu, W. Hybrid deep neural model for hourly solar irradiance forecasting. Renew. Energy 2021, 171, 1041–1060. [Google Scholar] [CrossRef]
- Hassan, M.A.; Bailek, N.; Bouchouicha, K.; Nwokolo, S.C. Ultra-short-term exogenous forecasting of photovoltaic power production using genetically optimized non-linear auto-regressive recurrent neural networks. Renew. Energy 2021, 171, 191–209. [Google Scholar] [CrossRef]
- Dash, D.R.; Dash, P.; Bisoi, R. Short term solar power forecasting using hybrid minimum variance expanded RVFLN and Sine-Cosine Levy Flight PSO algorithm. Renew. Energy 2021, 174, 513–537. [Google Scholar] [CrossRef]
- Guo, K.; Cheng, X.; Shi, J. Accuracy Improvement of Short-Term Photovoltaic Power Forecasting Based on PCA and PSO-BP. In Proceedings of the 2021 3rd Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 26–29 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 893–897. [Google Scholar]
- Ray, B.; Shah, R.; Islam, M.R.; Islam, S. A new data driven long-term solar yield analysis model of photovoltaic power plants. IEEE Access 2020, 8, 136223–136233. [Google Scholar] [CrossRef]
- Zang, H.; Cheng, L.; Ding, T.; Cheung, K.W.; Wei, Z.; Sun, G. Day-ahead photovoltaic power forecasting approach based on deep convolutional neural networks and meta learning. Int. J. Electr. Power Energy Syst. 2020, 118, 105790. [Google Scholar] [CrossRef]
- Nam, K.; Hwangbo, S.; Yoo, C. A deep learning-based forecasting model for renewable energy scenarios to guide sustainable energy policy: A case study of Korea. Renew. Sustain. Energy Rev. 2020, 122, 109725. [Google Scholar] [CrossRef]
- Tan, Q.; Mei, S.; Dai, M.; Zhou, L.; Wei, Y.; Ju, L. A multi-objective optimization dispatching and adaptability analysis model for wind-PV-thermal-coordinated operations considering comprehensive forecasting error distribution. J. Clean. Prod. 2020, 256, 120407. [Google Scholar] [CrossRef]
- Doubleday, K.; Jascourt, S.; Kleiber, W.; Hodge, B.-M. Probabilistic solar power forecasting using bayesian model averaging. IEEE Trans. Sustain. Energy 2020, 12, 325–337. [Google Scholar] [CrossRef]
- An, Y.; Dang, K.; Shi, X.; Jia, R.; Zhang, K.; Huang, Q. A Probabilistic Ensemble Prediction Method for PV Power in the Nonstationary Period. Energies 2021, 14, 859. [Google Scholar] [CrossRef]
- Al-Gabalawy, M.; Hosny, N.S.; Adly, A.R. Probabilistic forecasting for energy time series considering uncertainties based on deep learning algorithms. Electr. Power Syst. Res. 2021, 196, 107216. [Google Scholar] [CrossRef]
- Yagli, G.M.; Yang, D.; Srinivasan, D. Reconciling solar forecasts: Probabilistic forecasting with homoscedastic Gaussian errors on a geographical hierarchy. Sol. Energy 2020, 210, 59–67. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RBFNN | CNN | RNN | LSTM | ELM | OS-ELM | |
|---|---|---|---|---|---|---|
| Types of input data | Image, Time sequence | Image | Time sequence | Time sequence | Image, Time sequence | Image, Time sequence |
| Weight sharing | Yes | Yes | Yes | Yes | Yes | Yes |
| Feedback connections | No | No | Yes | Yes | Random | Random |
| Gradient problem | Yes | Yes | Yes | No | No | No |
| Short term | Yes | Yes | Yes | Yes | Yes | Yes |
| Long term | No | No | No | Yes | Yes | No |
| Bagging | Random Forests | Boosting | Gradient Boosting | Stacking | |
|---|---|---|---|---|---|
| Processing method | Parallel | Parallel | Sequential | Sequential | Parallel |
| Overfitting | No | No | Possible | Possible | Possible |
| Training dataset | Random | Random | Fixed | Fixed | Fixed |
| Optimization | Easy | Easy | Difficult | Difficult | Difficult |
| Depth of trees | - | Deep | - | Shallow | - |
| Authors (Year) | Input Data | Pre-Processing Methods | Input Data Optimization | Forecasting Model | Accuracy | Ref. |
|---|---|---|---|---|---|---|
| M Massaoudi, et al. (2021) | T, Wd, GHI, RH, PV power | Data cleaning Normalization | Non-linear auto-regressive neural network with exogenous input (NARX)-LSTM | nRMSE = 1.33% | [35] | |
| P Kumari, et al. (2021) | GHI, T, Ws, H, P | Normalized | - | XGBF-DNN | RMSE = 51.35 | [58] |
| X Luo, et al. (2021) | LW, RH, IW, SP, CC, 10U, 10V, 2T, SR, TR, TS, T | Normalization | - | physics-constrained LSTM | (Plant #1) MAE = 2.95 MSE = 4.26 R2 = 91% (Plant #2) MAE = 3.51 MSE = 5.30 R2 = 89.9% | [85] |
| M Konstantinou, et al. (2021) | PV power | Normalization | - | stacked LSTM | RMSE = 0.11368 | [88] |
| C Lyu, et al. (2021) | Si | Kernel-PCAK-means | - | Naive Bayes Classifier | nRMSE = 9.5% | [89] |
| Z Qadir, et al. (2021) | Si, Ws, Ta, H, R, Pa, Wd | Data cleaning RFECV Linear regression | - | ANN | MAE = 0.00083 MSE = 0.0000001 R2 = 99.6% | [90] |
| L Mazorra-Aguiar, et al. (2021) | GHI SZA,HA | ARMA | - | Quantile Regression Models | - | [91] |
| X Huang, et al. (2021) | Si, T, RH and Ws | Wavelet packet decomposition (WPD) | - | CNN–LSTM-MLP | RMSE = 32.1 nRMSE = 15.5% | [92] |
| MA Hassan, et al. (2021) | GHI, Ws, AT, and RH | Normalization | GA | NARX | RRMSE = ~10–20% | [93] |
| DR Dash, et al. (2021) | Power | Empirical wavelet transform (EWT) | PSO | Robust minimum variance Random Vector Functional Link Network (RRVFLN) | - | [94] |
| KZ Guo, et al. (2021) | Si, GHI, T, RH, CC, SP | PCA | ABC, PSO | BP | (Sunny) nMPAE = 1.563 nRMSE = 0.192(Cloudy) nMPAE = 2.451 nRMSE = 0.187(Overcast) nMPAE = 1.029 nRMSE = 0.332 | [95] |
| G Li, et al. (2020) | PV power | - | - | CNN- LSTM | (15min) MAE = 4.134 RMSE = 7.104 (45min) MAE = 12.068 RMSE = 20.401 | [49] |
| B Ray, et al. (2020) | PV power, GHI, DNI, DHI, T | Data cleaning Standardization Normalization | - | CNN-LSTM | RMSE = 3.89 nRMSE = 5.29% MAPE = 2.83 | [96] |
| H Zang, et al. (2020) | PV power, Ws, T, H, GHI, DHI | EMD WT | - | CNN | MAE = 0.152 | [97] |
| KJ Nam, et al. (2020) | GHI | EMD | - | LSTMGRU | LSTM TRAIN MAE = 0.38 Test mae = 2.03 GRU Train mae = 0.47 Test gru = 1.8 | [98] |
| YK Wu, et al. (2018) | PV power, NWP | Data cleaning Standardization Normalization | CSS | ANN | - | [11] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.-K.; Huang, C.-L.; Phan, Q.-T.; Li, Y.-Y. Completed Review of Various Solar Power Forecasting Techniques Considering Different Viewpoints. Energies 2022, 15, 3320. https://doi.org/10.3390/en15093320
Wu Y-K, Huang C-L, Phan Q-T, Li Y-Y. Completed Review of Various Solar Power Forecasting Techniques Considering Different Viewpoints. Energies. 2022; 15(9):3320. https://doi.org/10.3390/en15093320
Chicago/Turabian StyleWu, Yuan-Kang, Cheng-Liang Huang, Quoc-Thang Phan, and Yuan-Yao Li. 2022. "Completed Review of Various Solar Power Forecasting Techniques Considering Different Viewpoints" Energies 15, no. 9: 3320. https://doi.org/10.3390/en15093320
APA StyleWu, Y.-K., Huang, C.-L., Phan, Q.-T., & Li, Y.-Y. (2022). Completed Review of Various Solar Power Forecasting Techniques Considering Different Viewpoints. Energies, 15(9), 3320. https://doi.org/10.3390/en15093320