1. Introduction
Modern power grids must integrate a growing number of decentralized, small-scale renewable energy sources. In addition, climate change, decreasing fossil reserves, and tax regulations are leading to an increase in electrical demand, e.g., through the switch in private mobility from conventional to electric vehicles. As a result, increasing intermittent generation and demand lead to difficulties in balancing supply and demand, which in turn threaten the secure operation of power grids. Many electrical devices such as air conditioners, heat pumps, water heaters and batteries provide operation flexibility and hence there is a prospect for minimizing the operation cost or for providing ancillary services. However, the coordinated control of a large number of flexible devices is challenging due to the computational complexity, communication effort and privacy issues. Therefore, to address these issues, the concept of an aggregator is introduced in the literature.
An aggregator is an entity that can assess and control individual demand-side flexibilities, cf. [
1,
2] for detailed information. The aggregator sells system services to a utility and thereby acts as an intermediary between contracted consumers and the utility. To this end, the aggregator calculates the aggregated flexibility, which is subsequently communicated to the utility to perform optimization tasks. The utility sends back a requested power profile which has to be disaggregated and distributed by the aggregator to the consumers’ devices. This approach reduces the utility’s optimization complexity and communication effort as only aggregated variables and constraints are concerned. In addition, the privacy of consumers is preserved if only the aggregator handles individual consumer data and is allowed to control consumer devices. Therefore, a key challenge is the mathematical modeling and tractable computation of the aggregated flexibility.
We consider a setting in which an aggregator controls household flexibilities provided by batteries serving as electrical energy storages. However, our setting is extendable, for example, to thermostatically controlled loads (TCLs) which can be described by general battery models [
3,
4]. In mathematical terms, the flexibility of a household can be described by the set of all power profiles by which the household’s demand profile can differ from the default demand profile of no flexibility. The aggregated flexibility over all households is then described by the Minkowski sum (M-sum) of individual flexibilities. However, existing algorithms for M-sum calculations are very expensive [
5]. Consequently, different approximations of the aggregated flexibility have been proposed in the literature. These methods range from one step ahead to multi-step ahead and from bottom–up to top–down approaches. Top–down approaches attempt to directly capture the aggregated flexibility, for example, by using probability distributions or Markov transition matrices [
6,
7,
8,
9]. In this paper, we consider bottom–up multi-step ahead approaches which start from individual flexibility sets. Approximations are further divided into inner and outer approximations. Outer approximations typically overestimate the aggregated flexibility, while inner approximations typically do not capture the full aggregated flexibility. Consequently, the main disadvantage of outer approximations is that not all set elements can be disaggregated among the individual flexibilities. For inner approximations, on the other side, some flexibility is generally lost.
We very briefly review some typical approximation approaches. A more detailed description of the approximations evaluated in this paper is given in
Section 3. Outer approximations for linear, second-order cone, and semi-definite constraints were developed in [
4,
10]. The authors determined the accuracy of their approximation by comparing the volume of the approximation to the volume of the exact aggregated flexibility, where the volumes were estimated using a Monte Carlo procedure. In addition, they compared the approximation for linear constraints with the approximation derived in [
11] and reported that their approximation is more accurate by a factor of 1.5–2. He Hao et al. [
11,
12] developed approximations based on a generalized battery model, in which the battery parameters are analytically derived to obtain inner and outer approximations. The authors in [
13,
14] used zonotopes, which are centrally symmetric polytopes, as inner approximations to the individual flexibility polytopes. The benefit of this approach is that the M-sum of zonotopes is computationally efficient. Nazir et al. [
15] introduced an inner approximation whereby each individual polytope is decomposed into a collection of cuboid-homothets. Homothets are scaled and translated sets of a prototype set, e.g., a cuboid, and also have the advantage that their M-sum can be efficiently computed. The authors tested their approximation by relating the estimated volume of the approximation to the estimated volume of the exact aggregated flexibility. They reported that their approximation covered 44% of the exact M-sum for stage 0 and 74% for stage 1. Zhao et al. [
3] developed inner and outer approximations based on homothets where the difference to the latter approach is two-fold: first, the authors used more general prototype sets than cuboids; and second, only one homothet per polytope is fitted. The authors tested their approximation against the approximations developed in references [
12,
16] in a setting with 1000 heterogeneous TCLs, and reported a better coverage of exact flexibility. The authors in [
17,
18] developed inner approximations based on ellipsoidal projection. In this approach, the M-sum is first implicitly described in a higher-dimensional space. An ellipsoid with a maximum volume is fitted into this set. Subsequently, the projection of the ellipsoid on the original space represents an inner approximation. Barot [
17] reported, based on a volumetric consideration, that the approach of Zhen and Den Hertog [
18] provides a superior approximation. Zhao et al. [
19] applied a homothet projection method to obtain an inner approximation. Appino et al. [
20] first added the individual power and energy constraints which lead to an outer approximation. In a second step, the approximations of the aggregated flexibility are constructed, whereby feasible disaggregation is guaranteed.
Despite the large number of approximation strategies documented in the literature, to the best of the authors’ knowledge, no study exists that benchmarks and compares them. The main contributions of this paper are:
We evaluate 10 inner and 3 outer M-sum approximations on real, publicly available data with varying battery settings;
We propose novel practice-oriented criteria to assess the quality of approximations and evaluate them on several algorithms;
We compare the computational complexity and the communication effort associated with the selected algorithms;
We make the code and the detailed results available in a publicly accessible repository giving future authors a tool to evaluate and compare their approximations.
The remainder of this paper is organized as follows: The system model, the general approximation problem and the data sources are described in
Section 2.
Section 3 describes the M-sum approximations considered in this paper.
Section 4 presents the evaluation framework, i.e., the quality criteria to evaluate the accuracy of the approximations and the simulation settings. Finally, we present and discuss the results in
Section 5 and draw conclusions in
Section 6.
3. Overview of Approximation Strategies
In this section, we present the implemented inner and outer approximations in a unified notation and adapted to our system model, such that expressions for computational complexity and communication effort can be derived on a common ground. The approximations are presented in a mathematically coherent order. First, the summation-based approximations are presented, followed by the zonotope- and homothet-based approximations, and finally the projection based approximations. More detailed descriptions of the algorithms can be found in the literature references.
3.1. Outer Approximation by Right-Hand Sides Summation
This outer approximation was developed by Barot and Taylor [
4,
17]. Let
N households with feasible regions
be given, then an outer approximation to the M-sum is described by the set:
For
M time periods,
summations are needed. Note that
is the amount of rows in
A for the setting described in
Section 2.1. The communication effort consists of sending the
matrix
A and the
-vector
of the right-hand sides (RHSs) summation to the utility.
3.2. Outer Approximation by Right-Hand Sides Summation with Preconditioning
This approximation of Barot and Taylor [
4,
17] is an extension of the previous approximation, where each
is maximally shrunk before summation. The flexibility, which is given by the feasible region of the constraints, is not changed by this preconditioning (PC). The hyperplanes describing these constraints are shifted such that each one supports the feasible region
. In detail, let
be the
jth row of
A, then the following linear program is solved to recompute the
jth entry of
:
In total,
linear programs with each
constraints and
M variables have to be solved. The outer approximation to the M-sum is described by the set:
The communication effort again consists of transmitting the matrix A and the -vector to the utility.
3.3. Inner Approximation with Zonotopes
Müller et al. [
13,
14] used zonotopes to obtain an inner approximation to the M-sum. Zonotopes are centrally symmetric polytopes described by
where
G is a matrix with normalized column vectors serving as generating directions;
is a vector of scaling factors; and
is the zonotope center. Following the approach of [
13], we choose the
M unit vectors and additional
vectors of the form
as generating directions.
To compute the matrix
C of the zonotope half-space representation
, Müller et al. [
14] showed that at most
normals, i.e., rows in
C, have to be computed. Subsequently, the offsets
are calculated by shifting the zonotope hyperplanes such that each one supports the given polytope
. This step is analogous to problem (
13) and requires the solution of at most
linear programs per household. The final step is to find inner approximation zonotopes with respect to a given objective. The constraint that enforces a zonotope to be a subset of a given polytope is given in [
14] as
where
is the element-wise absolute value of the matrix
. In [
13], the optimal inner zonotopes are found by minimizing the distance between the offsets in a given norm:
with
. Here,
are the previously calculated offsets and:
are the offsets in terms of the center
and the vector of scaling limits
, cf. [
13,
25]. The matrices
F and
contain the zonotope normals.
Müller et al. [
14] also proposed a slightly different approximation where problem (
19) is solved instead of (
17):
with
, where
is the element-wise reciprocal of
. Finally, the M-sum of these optimal inner zonotopes can be efficiently calculated by summing up the
and
to obtain an aggregate inner approximation:
A maximum of
linear programs with
constraints and
M variables must be solved. In addition,
N linear programs with
constraints and
variables for
norm,
N linear programs with
constraints and
variables for
norm,
N convex programs with
constraints and
variables for
norm and
N linear programs with
constraints and
variables for problem (
19) are solved. The communication effort consists of transmitting the
matrix of generators
G, the sum of
M dimensional centers
and the sum of
-vectors
to the utility.
3.4. Inner Approximation with Cuboid Homothets
Nazir et al. [
15] used unions of homothets to compute an inner approximation to the aggregate flexibility. Given a compact convex set
, a homothet of
is defined as the set:
with
. The key idea is to decompose each polytope
into a collection of homothets. Following [
15], the maximum volume cuboid that fits into, for example, the first polytope
is taken as the prototype set
by solving:
where
and
, cf. [
26]. The objective in (
22) can be equivalently replaced by
, which leads to a convex problem that can be solved by CVXPY [
27]. Subsequently, the edge distances
for
and the distance ratios
for
are calculated. The following optimization problems find the maximum volume homothets of
in all
for
:
Note that the last constraint enforces the solution to be a homothet of .
This procedure can be applied in several stages to cover more flexibility: in stage zero, a maximum volume homothet of
is fitted into each
. In stage one, maximum volume homothets of
are fitted into regions not covered by the stage zero solution. This is performed by extending matrix
A and vector
by a row of the half-space inequalities of the stage zero solution multiplied by −1. The procedure is shown for stages zero and one in
Figure 3.
Each stage s requires the solution of at most optimization problems leading to a total of at most convex problems per household.
Finally, the distributive property of the M-sum is used to obtain an inner approximation to the aggregated flexibility, i.e., instead of first forming the union and then the M-sum, the M-sum is performed first and then the union. Nazir et al. [
15] proposed to only use corresponding combinations for axis-aligned cuboids, e.g., the
kth cuboid of the
sth stage in
is added to the
kth cuboid of the
sth stage in
. The M-sum of homothets is given by
When using cuboids, this can be simplified to the summation of the right-hand vectors in the half-space representation.
The total computational effort consists of solving
convex problems with
constraints and
variables for stage 0,
convex problems with
constraints and
variables for stage 1, up to
convex problems with
constraints and
variables for stage
s. In addition, one convex problem with
constraints and
variables has to be solved. The communication effort consists of sending the
matrix
, the
-vector
as solutions to problem (
22) and a maximum of
scaling factors
and
M dimensional offsets
to the utility.
3.5. Inner Approximation with Battery Homothets
Zhao et al. [
3] used the battery model (
9) as the prototype set
to obtain inner homothet approximations. They used the average individual battery parameters as prototype battery parameters which we denote with
, i.e.,
. To find the maximum volume homothet of
in
one solves:
In [
3], it is shown that the solution to this problem is given by
and
if
is the solution of:
where
means element-wise inequality. Once the inner approximation for all
is obtained, the M-sum of these homothet approximations can be calculated using Equation (
24). The overall computation effort is given by solving
N linear programs with
constraints and
variables. The communication effort consists of transmitting the
matrix
A, the
-vector
, the sum of the scaling factors
, and
M dimensional offsets
to the utility.
3.6. Outer Approximation with Battery Homothets
Zhao et al. [
3] also developed a homothet outer approximation using the same prototype set
. To obtain the outer approximation to
, one has to solve:
which can be reformulated as
The M-sum of the homothet approximations is again calculated by (
24). Similarly to the previous approximation, the overall computation effort is given by
N linear programs with
constraints and
variables. The
matrix
A, the
-vector
, the sum of the scaling factors
, and
M dimensional offsets
must be transmitted to the utility.
3.7. Inner Approximation by Ellipsoid Projection
Barot [
17] assumes that
N households with feasible regions
are given. The M-sum can be implicitly written as
where
. We denote the left
matrix as
Q and the right vector as
p; hence, the feasible region is written as
. The main idea is to fit an ellipsoid with maximum volume in this set. An ellipsoid can be written as the image of the unit ball under an affine transformation as
where the positive definite matrix
G and the center
h are partitioned as
with
. The volume of the ellipsoid is proportional to
, hence the problem of finding an ellipsoid with maximum volume in
can be formulated as follows, cf. [
28]:
where
is the
ith row in
Q and the notation
denotes a positive definite matrix
G. Barot [
17] proposes to maximize the determinant of the submatrix
associated with the M-sum rather than that of
G, leading to the following semi-definite program:
Solving this problem yields an ellipsoid in the
z–
x space which is projected back on the
z space to derive an inner approximation of the aggregate flexibility. Problem (
34) can be solved by CVXPY [
27]. The computation effort is given by one semidefinite program with
constraints and
variables. The communication effort consists of transmitting the
matrix
and the
M dimensional center
to the utility.
3.8. Inner Approximation by Ellipsoid Projection with Linear Decision Rule
Zhen and Den Hertog [
18] developed an inner approximation based on ellipsoidal projection where the inclusion constraint is only defined in
z space:
where
is the unit ball of dimension
M and
the implicitly described M-sum with matrix
Q and right-hand vector
p, cf. (
29). This problem can be interpreted as a robust optimization problem, where
and
are the here and now decision variables and
y the wait and see variable. Assuming a linear decision rule (LDR)
, the above problem can be reformulated as
Solving this problem yields an ellipsoid in z space which is an inner approximation of the aggregate flexibility. The overall computation effort is given by a semidefinite problem with constraints and variables. The M dimensional center and the matrix needs to be transmitted to the utility.
3.9. Inner Approximation by Homothet Projection with Linear Decision Rule
Zhao et al. [
19] developed an inner approximation based on homothet-projection. Similar to the previous approach, the implicit M-sum description in (
29) is used, where the matrix is denoted as
Q and the right vector as
p, which allows to write the feasible region as
. The battery model derived in (
9) is chosen as the prototype set
where again the battery parameters are taken as the average of the individual battery parameters. For a fixed vector
, let
denote the corresponding lift of
in
dimensional space. The problem of finding a maximal homothet of
in
is formulated as
where
is the lift of
t in
dimensional space by setting the additional dimensions to zero. This problem is transformed by the authors to the following linear program:
where
,
and
mean element-wise inequality. The above formulation is conservative, since only solutions contained in the homothet of
are allowed. However, for the approximation, only the following condition is required:
This can be cast into a robust optimization problem. The function
is used as decision rule which is assumed to be linear, i.e.,
. Using these ideas, the problem is restated by the authors as
where
I is the
identity matrix. The computation effort is given by solving a linear program with
constraints and
variables. The
matrix
A, the
-vector
, the scaling factor
, and the
M dimensional offset
t must be transmitted to the utility.
3.10. Comparison of Communication and Computation Effort
In this section, we compare the overall communication and computation effort of the presented algorithms.
Table 1 shows that for all algorithms, the communication effort is quadratic in
M with a factor varying between 1 and 4 and independent of
N. The ellipsoid-based algorithms have the lowest communication effort. On the other hand, the highest communication effort is reached when the Battery Homothet algorithms or the IA with Cuboid Homothets Stage 1 algorithm is used. For comparison, the communication effort without aggregation consists of sending the
matrix
A and
N -vectors
, i.e.,
, which increases with
M and
N.
The computational effort is presented in
Table 1 in terms of linear programs (LPs), convex programs (CPs) and semidefinite programs (SDPs) as a function of
N and
M. We specified the problem dimensions in the columns Constraints and Variables. Where possible, we provided the problem-defining equation numbers. The computation effort for the algorithm OA by RHS Summation is left out, as this only requires the summation of right-hand vectors in the half-space representation. It can be seen that the problem dimension increases with
M and
N for the projection-based algorithms, while for the non-projection-based algorithms, the problem dimension is a function of
M only. On the other hand, the number of problems to be solved increases with
N for the non-projection-based algorithms, which is not the case for the projection-based algorithms.
5. Results and Discussion
Due to space limitations, only the most important results are presented in this paper. However, the interested reader can download all numbers, figures and tables for each algorithm from the supplement website [
29]. For readability, the values of the quality criteria UPR and IER are stated in percent.
5.1. Outer Approximations
In this section, we compare the computation times and quality criteria UPR and IER for the cost and peak power minimization. Since there is more than one way to compare the approximations and visualize the results, we first show the quality criteria and computation time for fixed numbers of households and time periods. Then, we present the results for all numbers of households and time periods for one selected algorithm in a table. Finally, we compare the rows or columns of this table for multiple algorithms to illustrate the dependence on the number of households and the number of time periods. Except for the boxplots, we reduce the distributions with respect to the sampling over the 10 villages and the 12 days by computing median values.
Table 2 shows the evaluation results for 50 households and 24 time periods. The best overall results were obtained by the algorithm OA by RHS summation with PC.
The median cost IER values for all periods and households are shown for this algorithm in
Table 3.
As can be seen in
Table 3, the values increase with households and time periods. The peak power IER is not presented as it is constantly approximately zero.
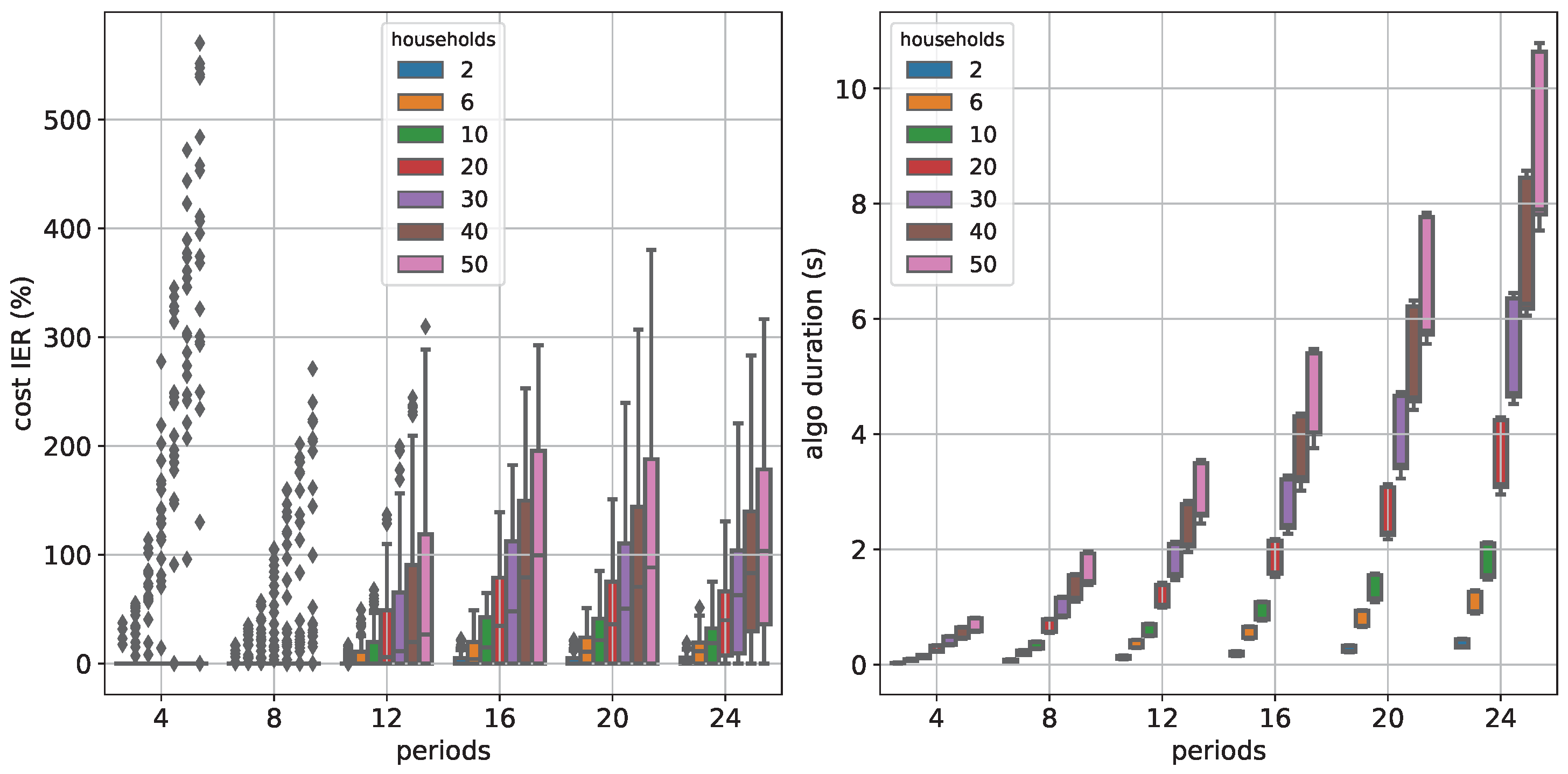
Figure 4 shows the spread of the quality measures cost IER and algo duration as boxplots.
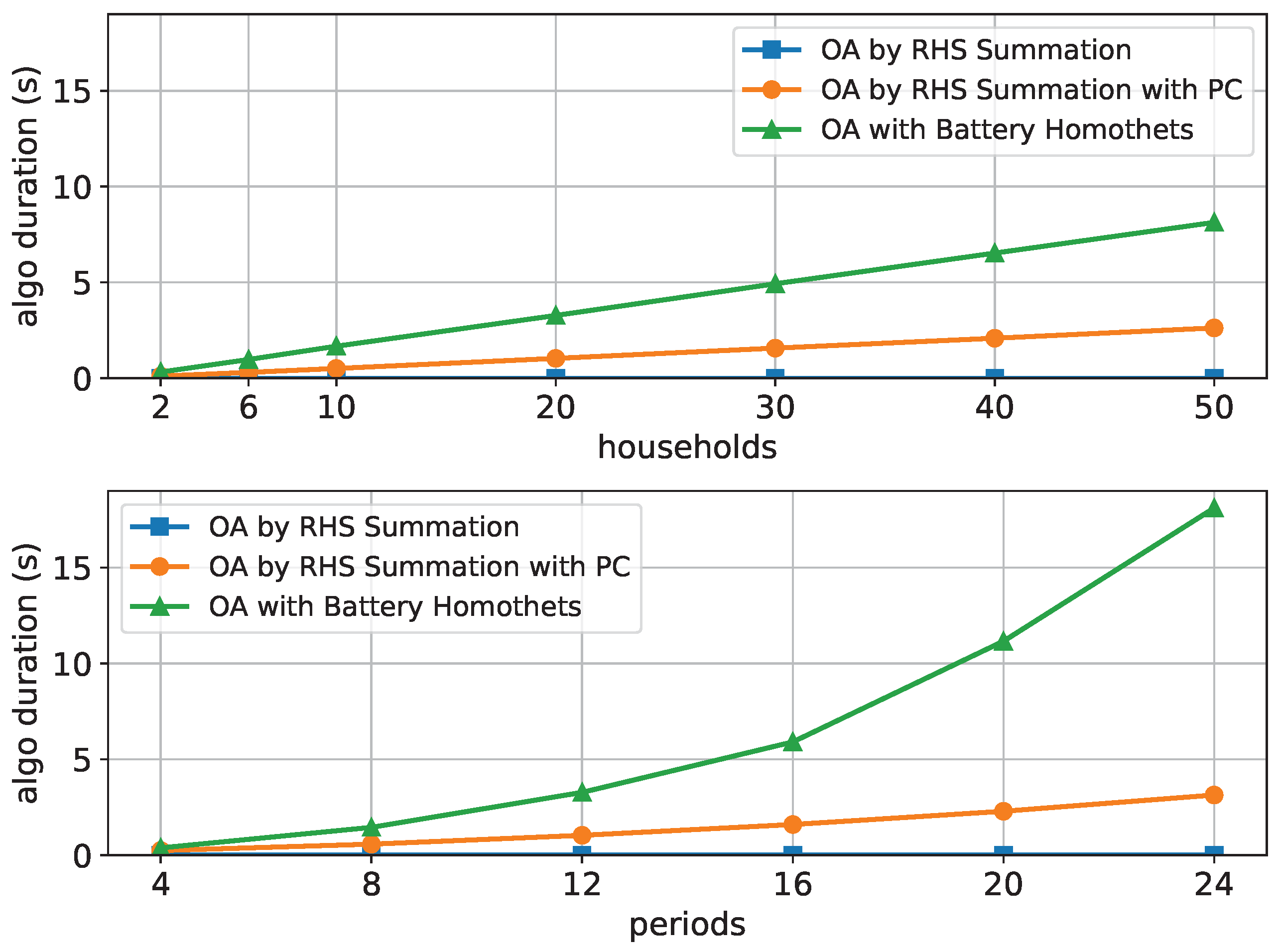
The computation time dependence is shown in
Figure 5 for 12 time periods and increasing numbers of households at the top and 20 households and increasing numbers of time periods at the bottom. It can be seen that the algorithm OA by RHS Summation is the fastest and the algorithm OA with Battery Homothets is the slowest in both cases.
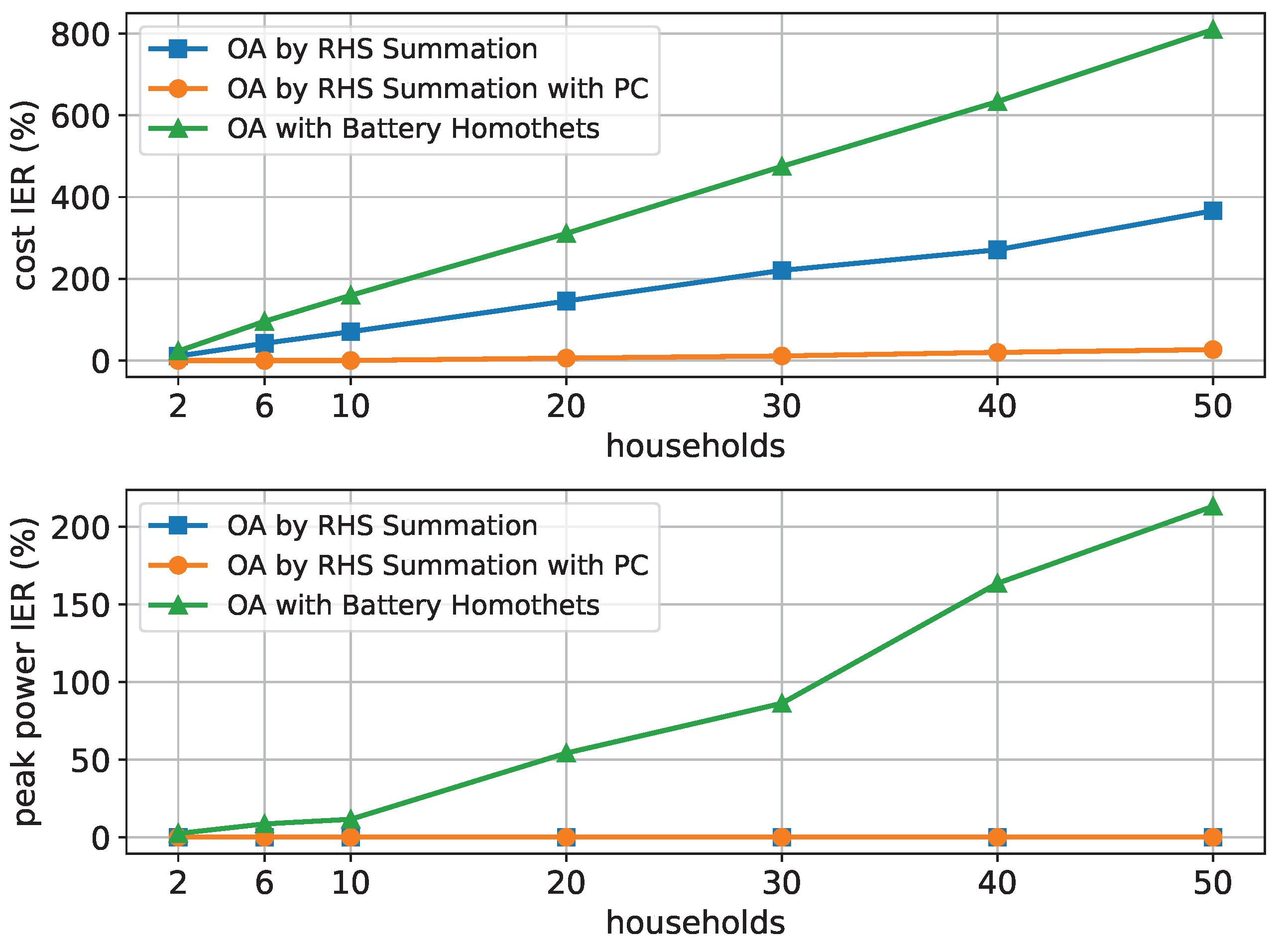
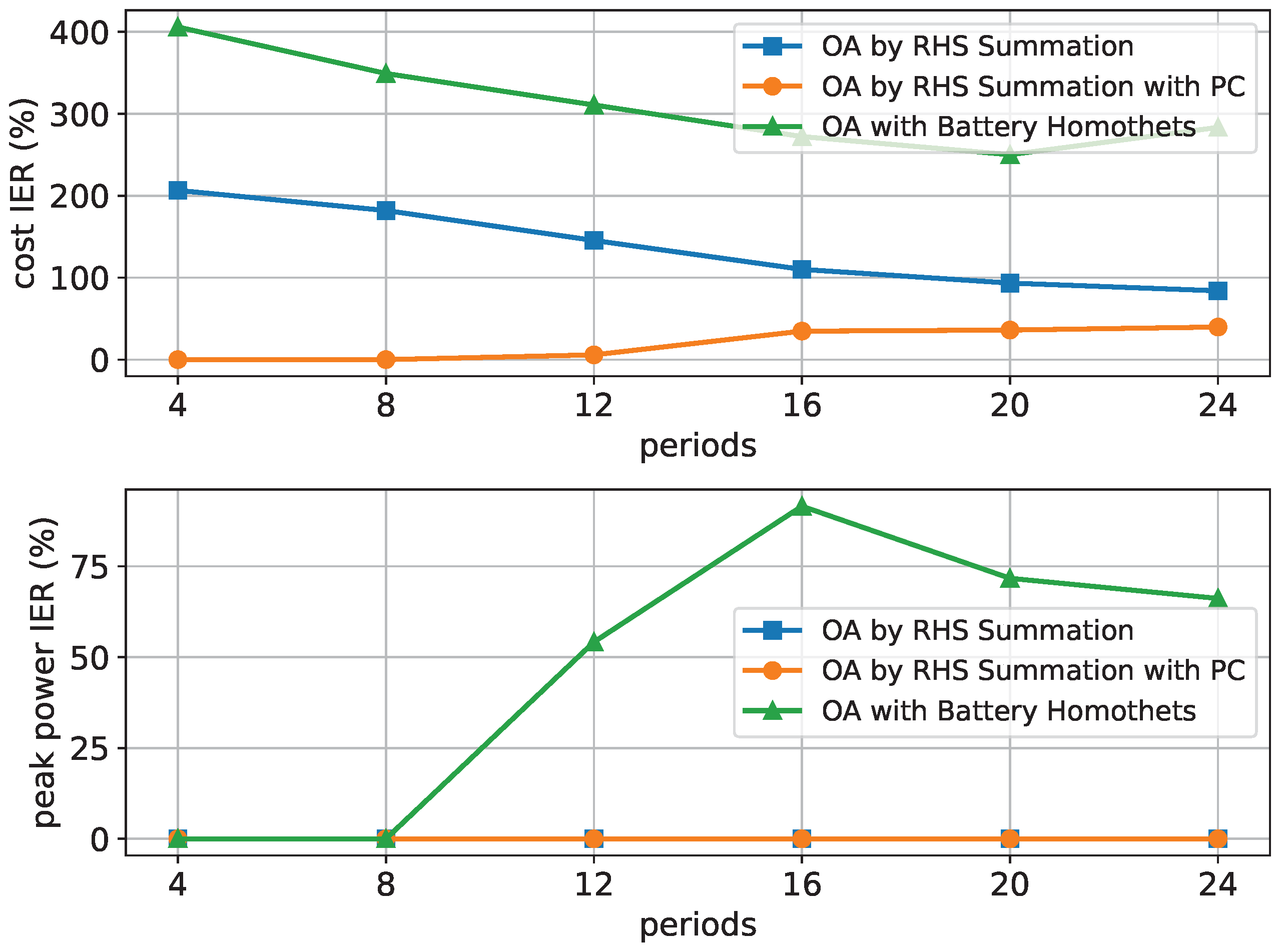
The quality criteria cost IER and peak power IER are shown with an increasing number of households and 12 time periods in
Figure 6.
It can be seen that the OA with the Battery Homothets algorithm generally leads to the highest values while OA by RHS Summation with PC leads to the lowest values. The same is true when the number of households is fixed and the number of periods increases, as shown in
Figure 7.
Although only selected columns and rows of the tables have been presented here, our results have shown that these observations are also valid for other fixed values of up to 50 households and 24 time periods.
5.2. Inner Approximations
This section presents the results for the inner approximations following the same format as the previous section.
The results for
households and
time periods are shown in
Table 4. For higher
values some approximations were skipped because of the chosen computation time limit.
Table 4 shows that the algorithms IA with Cuboid Homothets Stage 0 and IA with Cuboid Homothets Stage 1 perform moderately well for the quality criteria cost UPR and peak power UPR. It is also evident that the ellipsoid-based algorithms perform poorly at cost UPR, but well for peak power UPR. Moreover, the ranking of the algorithms is different for different objectives which indicates that the approximations should be chosen according to the purpose.
For the algorithm IA with Cuboid Homothets Stage 1, the median cost UPR values for all households and time periods are given in
Table 5 which shows increasing values with the number of time periods and the number of households.
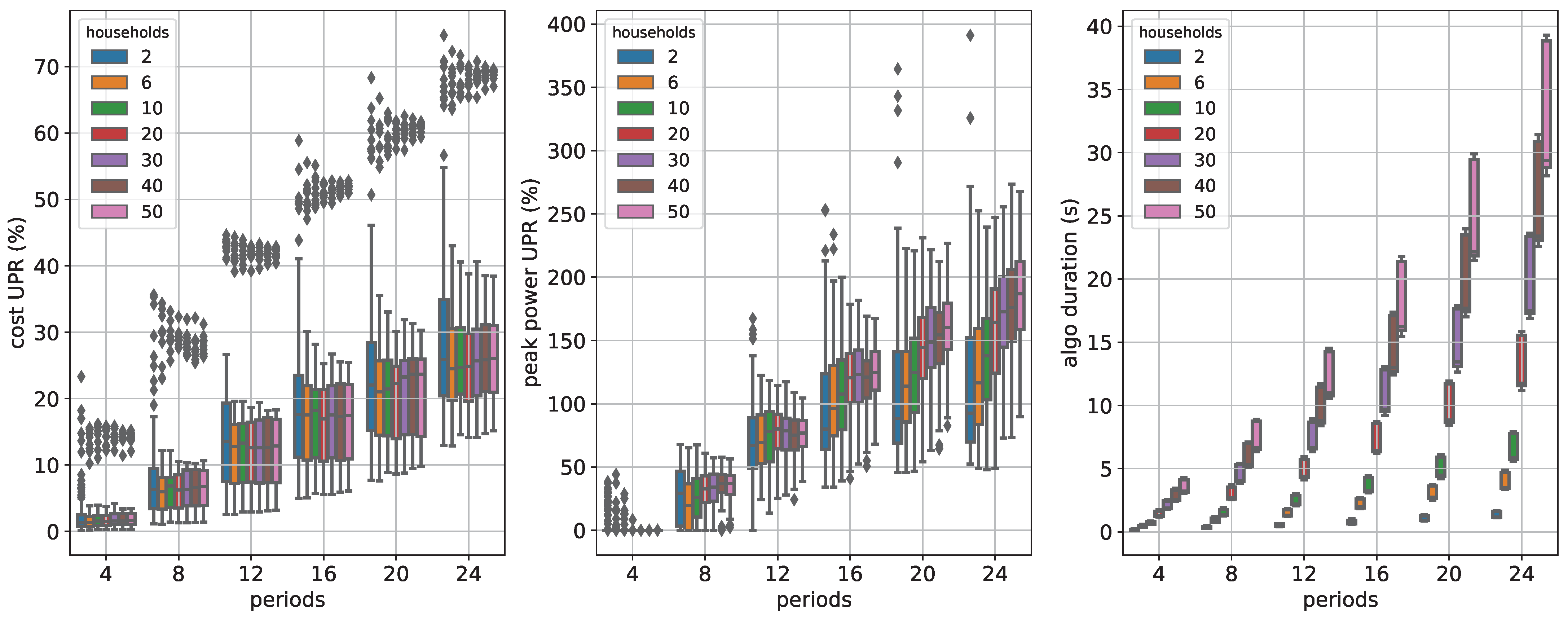
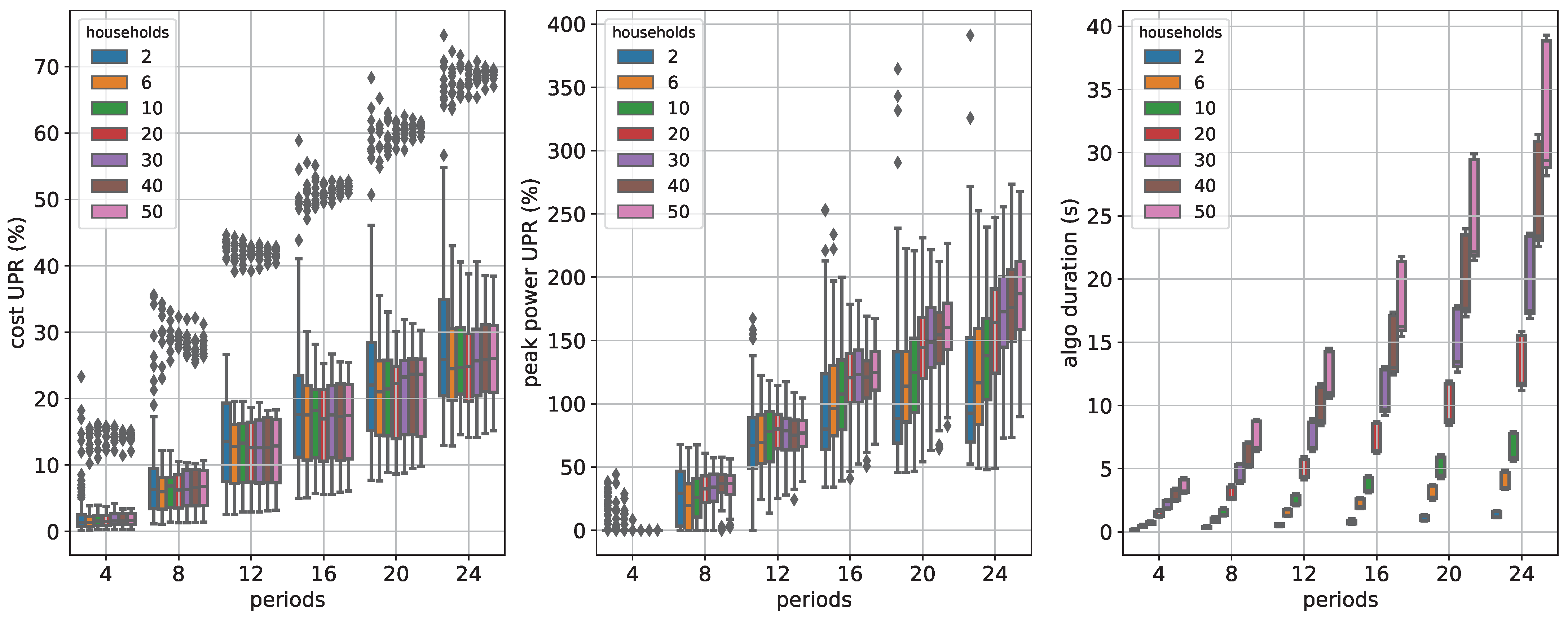
Figure 8 shows the spread of the quality measures cost UPR, peak power UPR and algo time as boxplots.
Note that there are UPR values beyond
, which indicates that the inner approximation gives larger values than without flexibility cf. Equation (
45). Our results indicate that this is especially true when the peak power objective is used. The reason is that the inner approximation does not always contain the element corresponding to not using the flexibility, i.e., in our setting, the
M-vector of zeros.
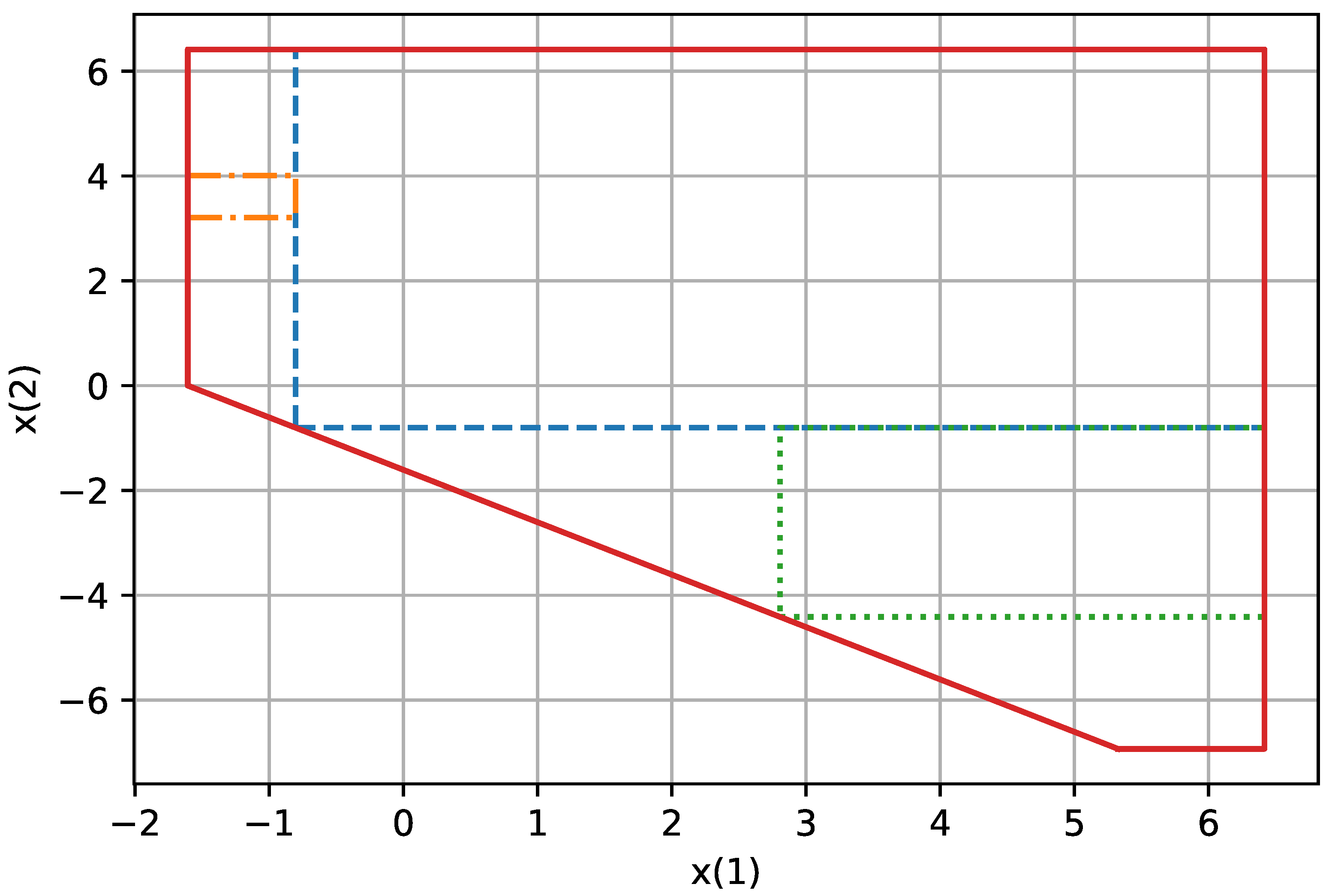
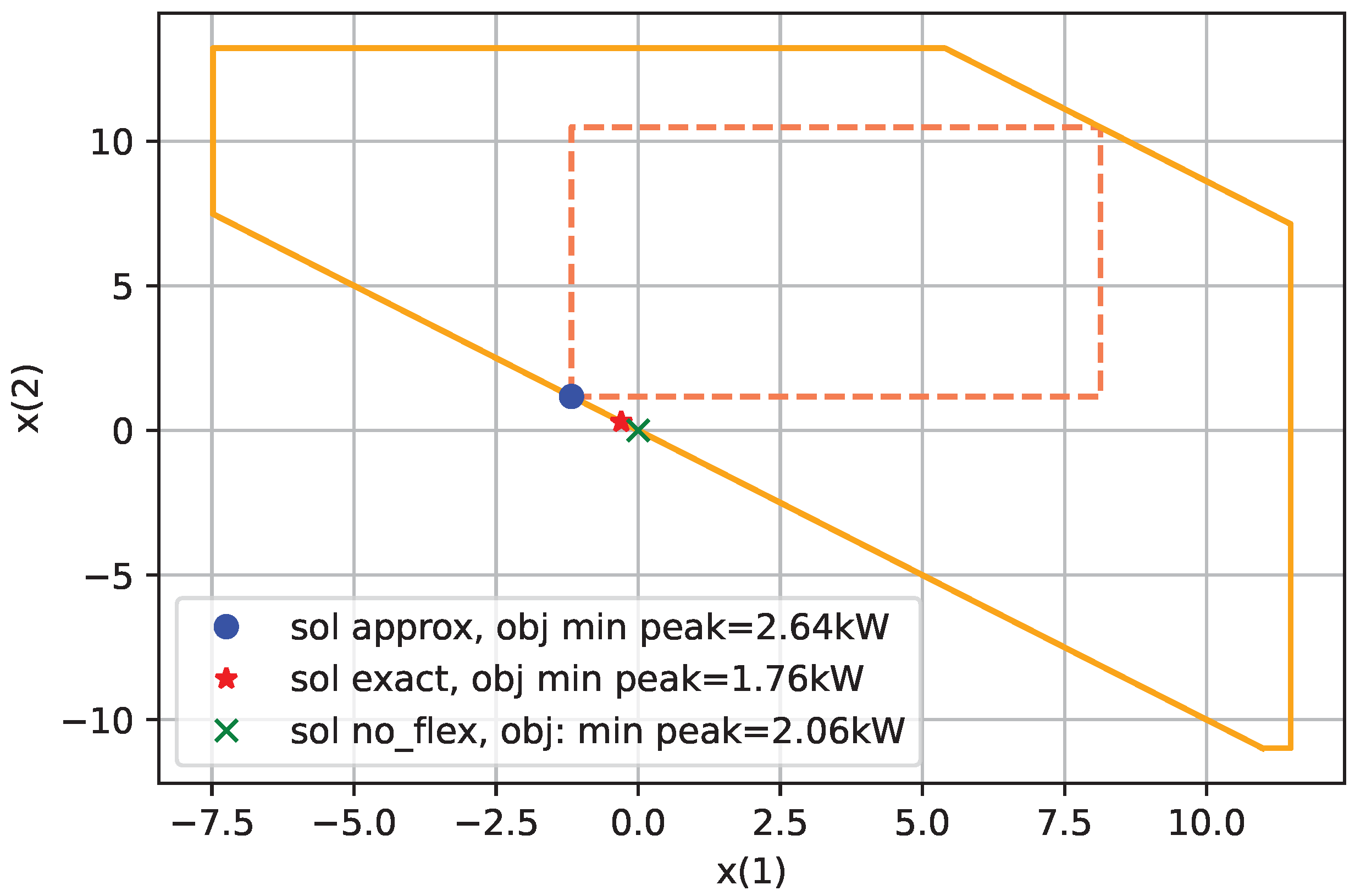
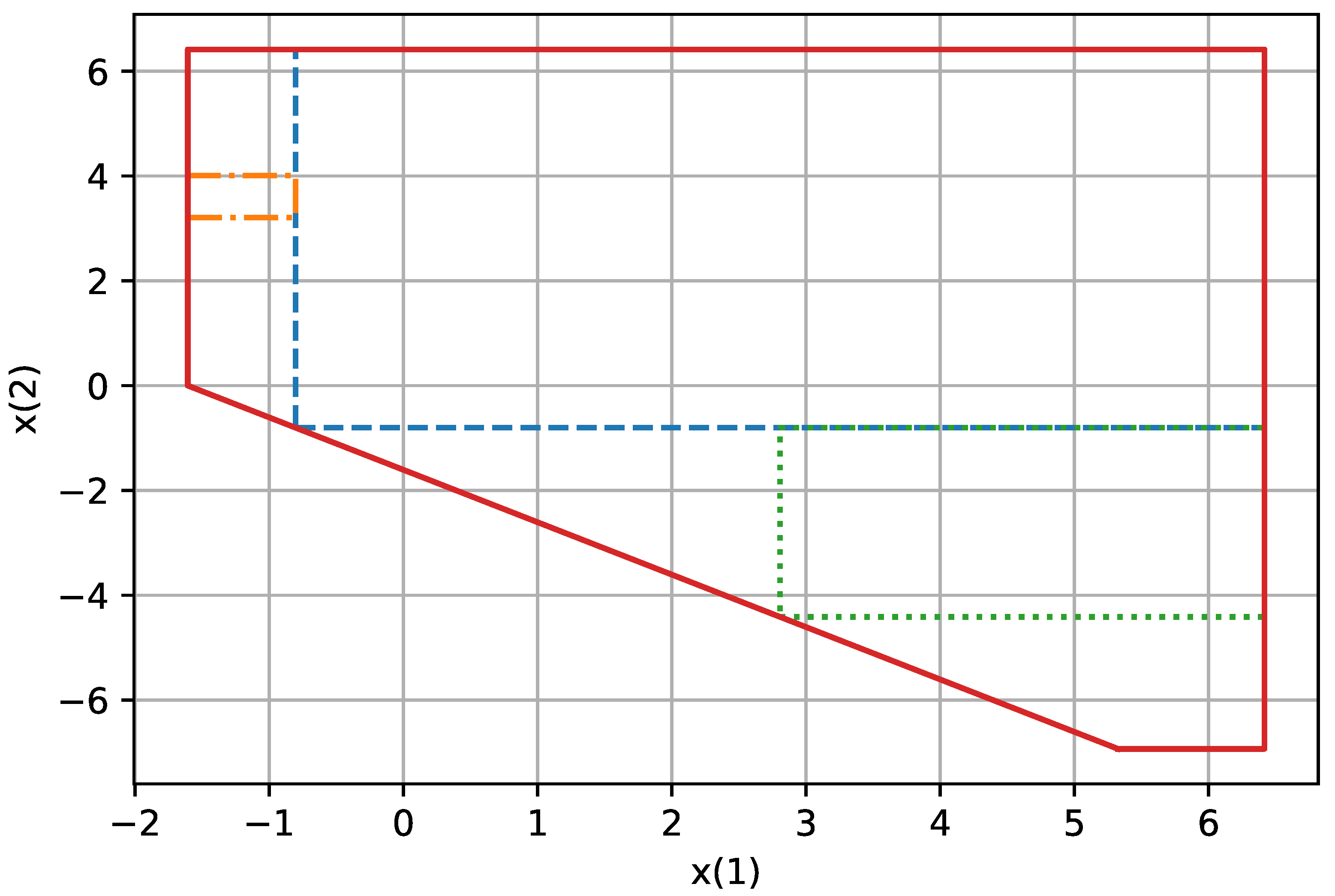
Figure 9 shows this for two time periods and the algorithm IA with Cuboid Homothets Stage 0. We used
=
for this experiment as for
=
, the problem described occurs in dimensions higher than two.
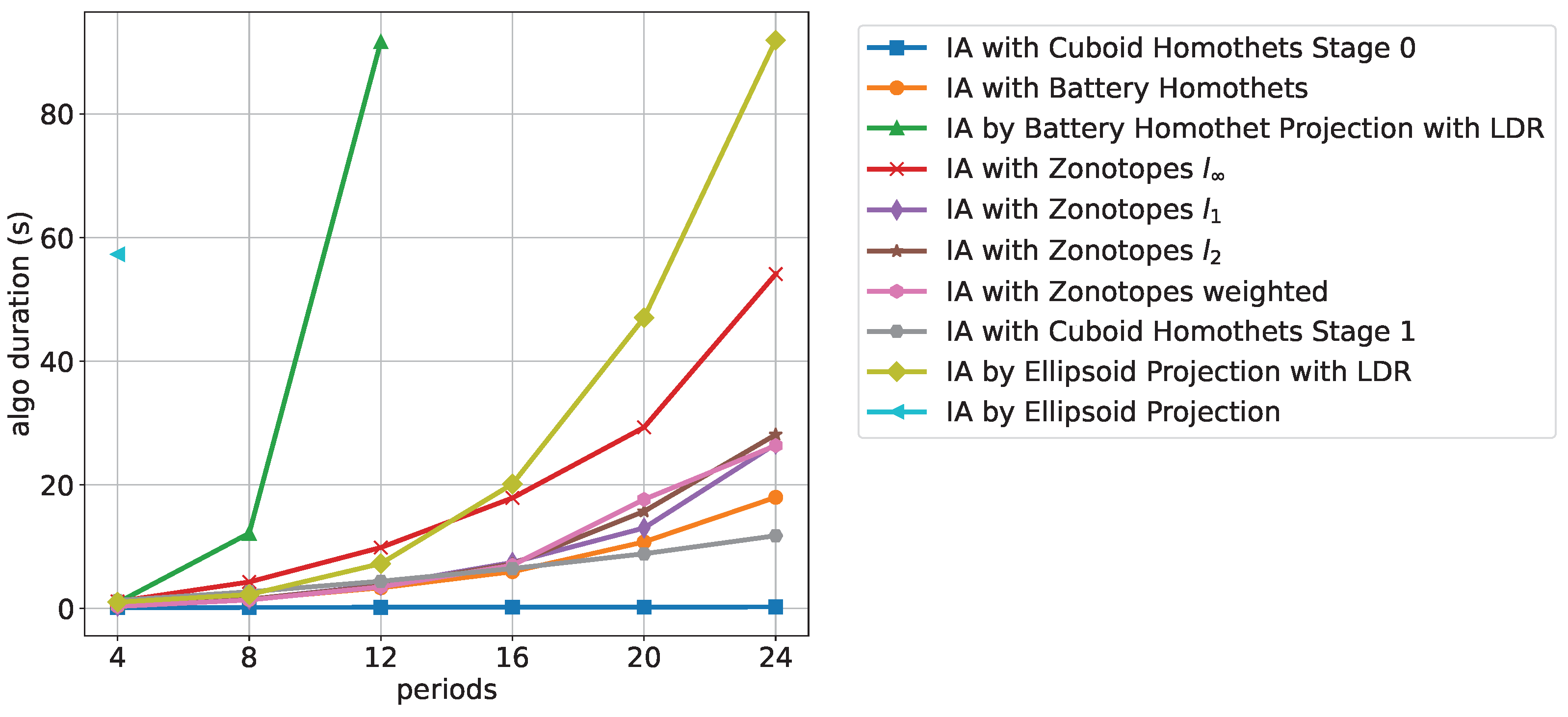
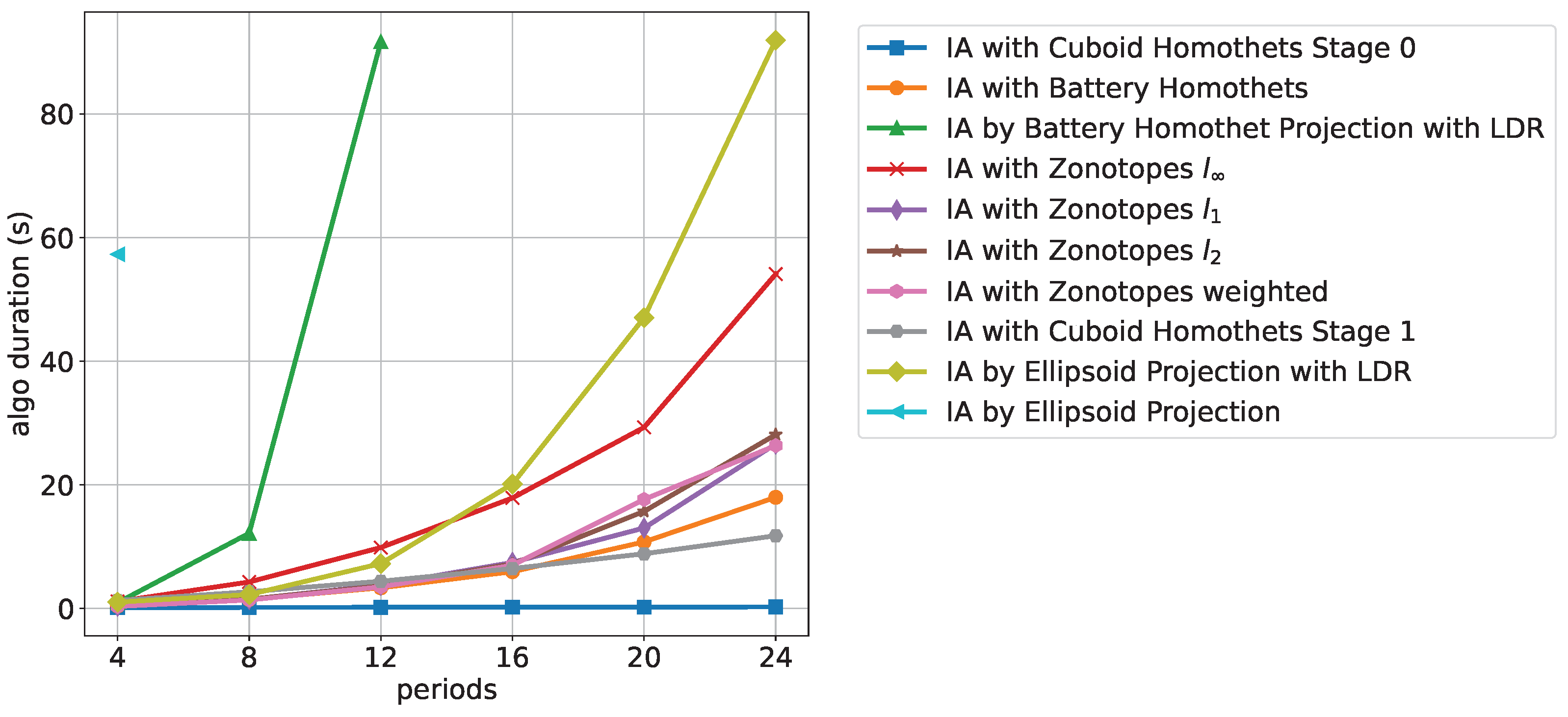
Figure 10 shows the computation time with increasing time periods for 20 households.
It can be seen that the approximations based on projection methods, i.e., IA by Ellipsoid Projection, IA by Ellipsoid Projection with LDR, and IA by Battery Homothet Projection with LDR exhibit the slowest computation times. The best computation times are achieved by the Cuboid Homothets algorithms of stage 0 followed by stage 1.
We observed the same order for an increasing number of households and fixed time periods. The only difference in this case is that all algorithms except for the projection-based ones exhibit linear increasing behavior.
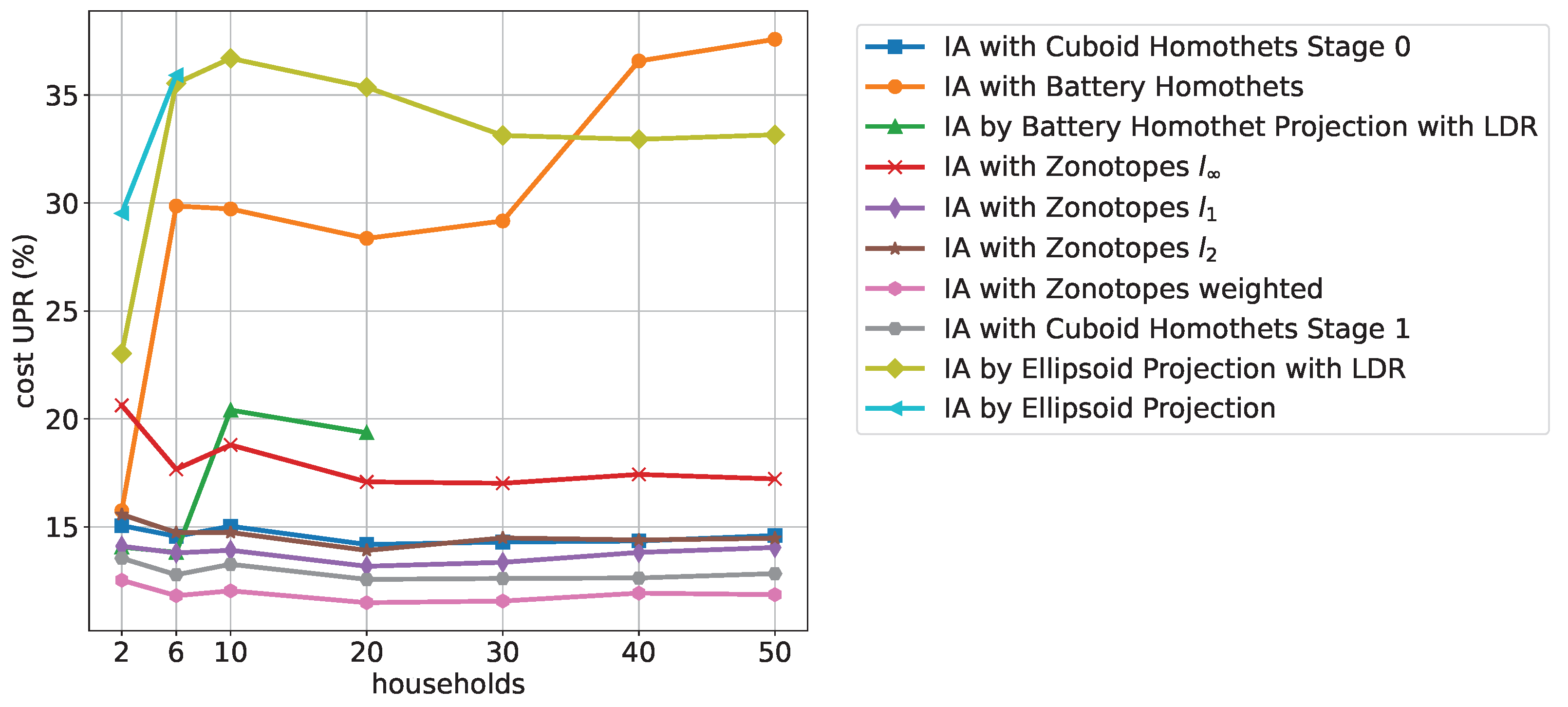
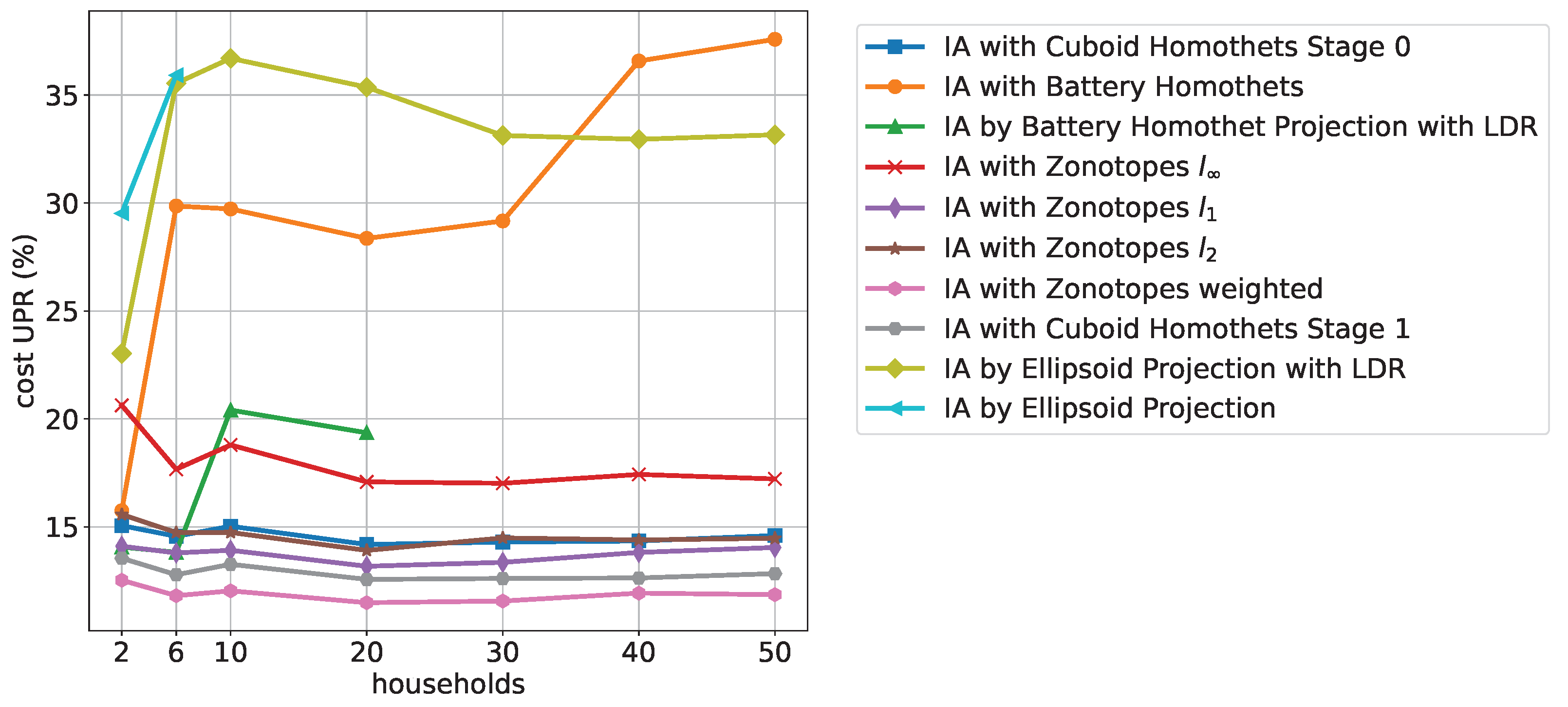
Figure 11 shows the cost UPR with increasing numbers of households for 12 time periods. It can be seen that the ellipsoid-based approximations generally do not perform well, while the zonotopes and the cuboid homothet-based approximations generally give good results. We found that for other fixed time periods, the order is maintained, except that the algorithms IA with Zonotopes
and IA by Battery Homothet Projection with LDR improve:
For increasing time periods and a fixed number of households, the overall same order can be observed; however, with a linearly increasing dependence of cost UPR.
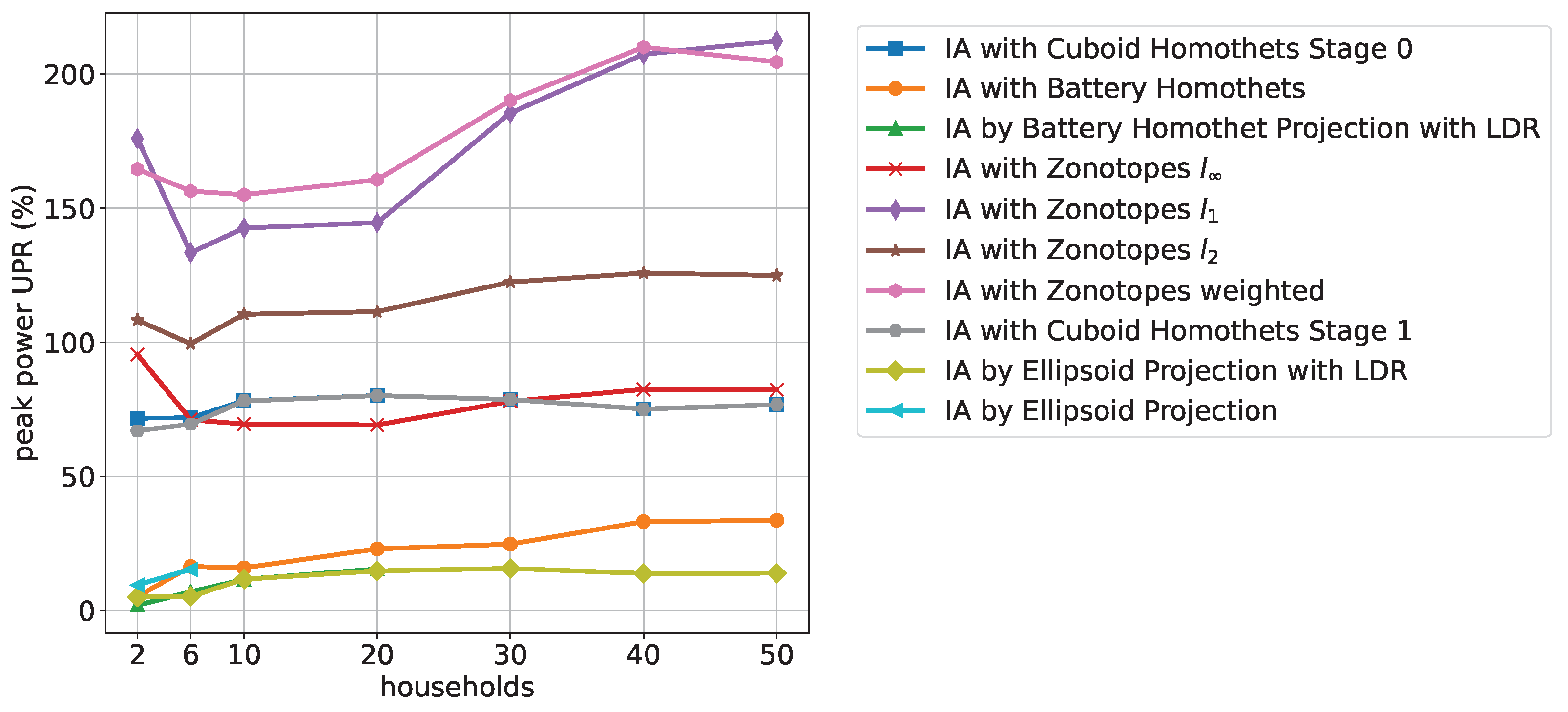
Figure 12 shows an improvement of the ellipsoid-based methods for peak power UPR compared to cost UPR.
The battery and ellipsoid-based algorithms perform best for peak power while the zonotope-based approximations do not perform well compared to the other algorithms. We found that this is also true for other values of fixed time periods, except that the Zonotope algorithm slightly improves. The overall order of best and worst performing algorithms is maintained for the fixed number of households with increasing time periods.
5.3. Overall Ranking
In practice, high N and M values are typically of greater interest. For this reason, we applied the following procedure to obtain an overall ranking of the inner and outer approximations:
We only include approximations that returned results for all N and M values within the chosen computation time limit.
For these approximations, the median values of the cost and peak power quality criteria were computed over all days, samples and and settings.
Table 6 shows the remaining approximations, their median quality criteria values, and in brackets, the rankings depending on the approximation type (inner and outer) and objective function.
Table 6 shows the application-dependent performance of the inner approximations. Well-performing approximations for cost UPR do not perform well in peak power UPR and vice versa. For example, the algorithm IA with Zonotopes weighted ranks first in cost UPR but fifth in peak power UPR. Only mid-ranking algorithms, such as the cuboid-based algorithms, do not show such an extreme deviant behavior. Values above 100% for peak power UPR show that not using the flexibility is more efficient than using the approximation which makes the approximation useless for that purpose. This is the case for all inner approximations expect IA with Battery Homothets. For outer approximations, the algorithm OA by RHS Summation with PC ranks first for both cost and peak power IER. However, for cost IER, approximately 75% of the flexibility energy needs to be purchased as imbalance energy, which is generally expensive.
6. Conclusions
In this paper, we investigated several published approximation methods for aggregating demand-side flexibilities given by energy storage devices. The different approximations were described and compared with respect to communication and computation efforts. Furthermore, we defined and evaluated novel quality criteria to assess the quality of the approximations for their use in practice. Finally, the evaluation framework was made publicly available such that researchers can compare future approximations with the current state of the art.
The evaluation results show that the projection-based algorithms exhibit the highest computation times. The ellipsoid-based algorithms showed the lowest communication effort. For inner approximations, we suggest application-dependent-choices, cf.
Table 6. The best results were obtained for outer approximations when the OA by RHS Summation with PC was used. We conclude that not one of the presented approximations fits all purposes.
Only the cuboid homothets algorithm can configure its accuracy, namely by increasing the number of stages. This, however, is accompanied by an exponential increase in computational effort.
We found a crucial weakness of many inner approximations, especially when minimum peak power is considered, namely that they do not always contain the element corresponding to not using the flexibility and may therefore lead to solutions that perform worse compared to the case where no flexibility is available. Thus, future work should yield inner approximations that overcome this deficiency in all cases.
Our evaluation model is extendable in several ways. First, renewable energy generation can be subsumed into the demand profiles. The inclusion of self-discharge rates
changes the submatrix
in Equation (
9) and results in possibly different
A matrices for different households. This can be transformed in our model with equal
A-matrices by introducing redundant constraints through PC, cf. [
17]. Finally, as TCLs can be described by battery models with a self-discharge rate
, they can also be modeled with different
A-matrices, cf. [
3]. Future work should investigate how an increased diversity of individual flexibilities influences the accuracy of aggregation approximations. Furthermore, the control of reactive power, e.g., by inverters, is becoming more important with the increasing number of PV systems in smart grids. Therefore, future studies should consider the flexibility of active and reactive power simultaneously.
We did not include charging and discharging efficiencies because if simultaneous charging and discharging is not allowed, their inclusion leads to non-convex sets. This aspect of real storage devices as well as uncertainties in data and parameters and model predictive control approaches should also be considered in future work.


 ,
, 
 . All linear programs in this framework were solved with Gurobi 9.5.0 [30], and all nonlinear programs with CVXPY 1.1.18 [27]. An AMD Ryzen 7 5700G processor was used for all computations. Finally, to keep the overall computation time within limits, the framework was configured to skip those calculations of an algorithm with more households and more time periods if the approximation and the optimizations for an -setting took more than 60 s.
. All linear programs in this framework were solved with Gurobi 9.5.0 [30], and all nonlinear programs with CVXPY 1.1.18 [27]. An AMD Ryzen 7 5700G processor was used for all computations. Finally, to keep the overall computation time within limits, the framework was configured to skip those calculations of an algorithm with more households and more time periods if the approximation and the optimizations for an -setting took more than 60 s.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}