
Short Text Classification for Faults Information of Secondary Equipment Based on Convolutional Neural Networks

Abstract
:1. Introduction
2. Lower-Level Modeling and Optimization
2.1. Data Analysis
- (1)
- Fault and defect data are deeply involved in the professional field of power systems, including many low-frequency words such as electrical professional vocabulary, equipment names, and equipment models. Because the same vocabulary is in different fields, it brings different common names or abbreviations, such as GIS, which represents the geographic location information system at the large level of the power system, and gas insulated combined electrical appliances at the device level.
- (2)
- Due to the classification of the secondary equipment based on the fault category, the same fault location, such as the problem of the display screen, has different defect level definition results according to the display screen, blue screen, and display failure.
- (3)
- Most of the fault data are based on the data manually recorded by the transport inspection personnel. The details of the text records are slightly different. The text length of each piece of defect data varies greatly. The shortest data are less than ten characters, and the longest data can be up to more than 100 morphemes.
- (4)
- The defect data of different fault categories have high similarity and lack sufficient semantic co-occurrence. Traditional text mining methods have limitations for short text data mining and classification with high similarity.
2.2. Text Classification Process for Chinese Characters
3. Short Text Data Model of Secondary Equipment Faults in Power Systems Based on LDA Topic Model and Convolutional Neural Network
3.1. Improved Text Classification Process
3.1.1. Text Preprocessing
- (1)
- Remove useless characters. Defective text generally involves a great deal of spaces. Some useless characters should be filtered, such as punctuation and so on, because they are not related to the text content. In Chinese, the words “I” and “do” are used a lot. By utilizing excessive words, the accuracy of the segmentation is increased and the efficiency is decreased. Meanwhile, the words “no” and “yes” are also used a lot in prepositions, conjunctions, and adverbs. These words are usually meaningless.
- (2)
- English characters are uniformly given in the form of lowercase. In the secondary equipment, the recording format of the defect text is not standardized due to the fact that it includes a lot of English characters, such as “10 KV”, “10 kv”, and “10 Kv” for the description of transformer grades. They all represent the same voltage level, but the recording format is different.
- (3)
- The repeated records and fragmentary text are detected and removed. When the defect records are uploaded, some problems, including data loss and repeated data entry, are produced easily for operation and maintenance personnel due to improper operations. The text classification and information mining are not easy to implement by using such data, where these data should be processed in advance to guarantee the quality of the text.
- (4)
- A professional dictionary should be constructed for secondary equipment. The establishment of a special dictionary corresponding to the professional field is the basic work of text mining in various professional fields. The quality and quantity of words included in its professional dictionary determine the accuracy of word segmentation and the part of speech tagging in text preprocessing. Due to the large number and miscellaneous types of electrical secondary equipment, the number of words related to the construction of this field is very huge, and there are thousands of words describing the equipment itself, such as the transformer station names, equipment protection proper terms, and so on.
3.1.2. Text Classification Model by Using LDA
- (1)
- Initializing model parameters , and , where , and are the denoted prior parameters file-theme distribution parameter, theme-word distribution parameter, and the number of themes , respectively [26].
- (2)
- Traverse and classify short text data, and for each word in terms of the list , build where and , stand for the document-topic distribution and the adjacent word of respectively.
- (3)
- Suppose that Z satisfies the Dirichlet prior distribution, where Z is the potential word set. Moreover, the computational formula is utilized in this step, in which stands for the topic-word distribution.
- (4)
- In view of each word in , choose words and with and being potential and neighboring words, respectively; attain short texts with the help of the documents. Then, the subject matter is inferred from the secondary device short text data on the basis of the following expression:where represents the frequency of the words in the document, and stands for the length of the short text .
3.1.3. Improved LDA Topic Analysis Model Based on Relevance Formula
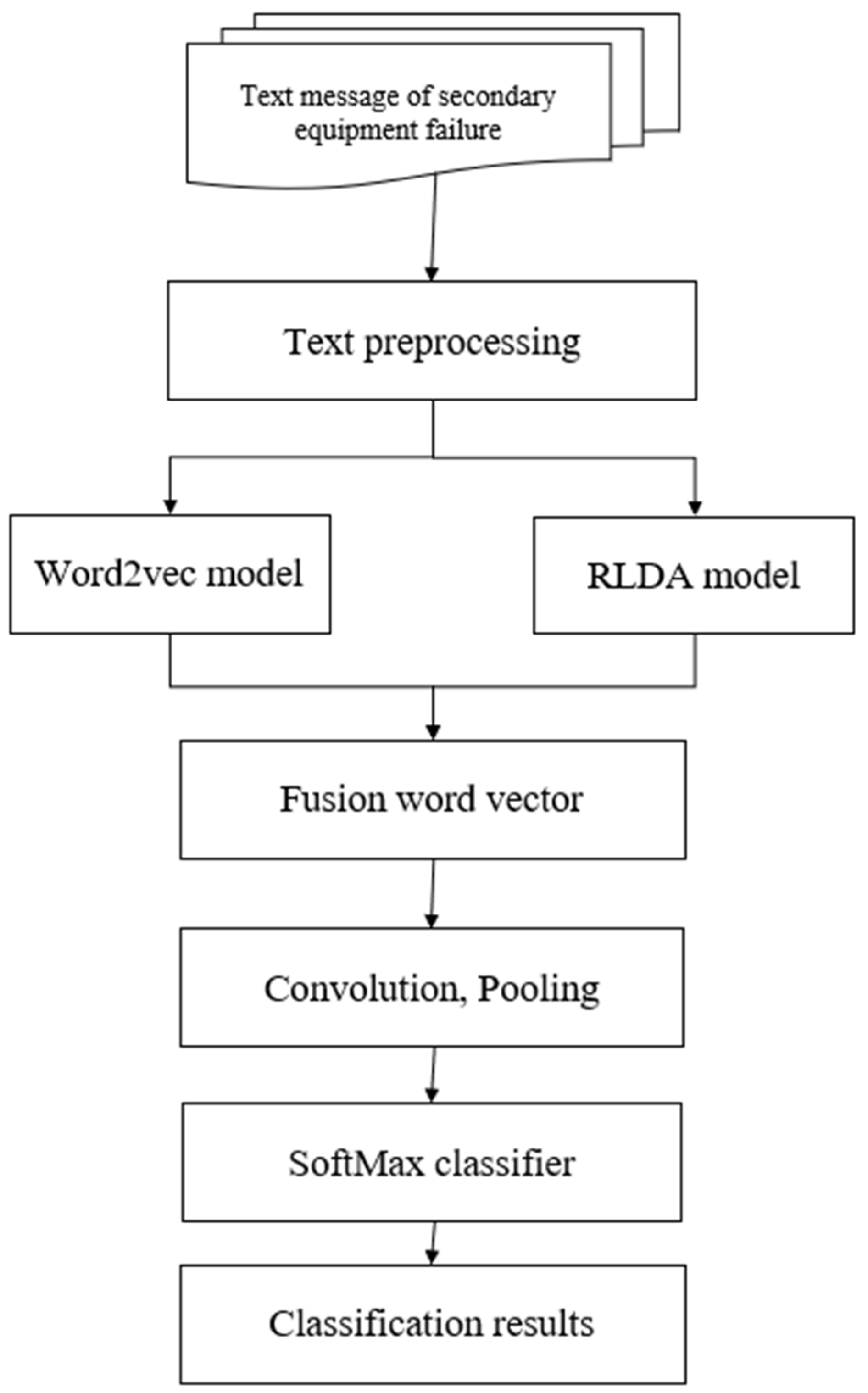
3.2. Fusion of Word2vec Model and RLDA Model
- (1)
- The first layerThe first layer could be defined as the input layer. In this layer, a length of text data was selected, and the vectorization of the text data was implemented with the help of step C. Employing the matrix as the input and defining the number of words as , represents the number of rows in the input layer. Similarly, we defined the dimension of the text vector as , which can represent the columns of the input layer. Then, all word data could be divided into word vectors of equal dimensions, namely, the number of columns is the same in the input layer. Accordingly, matrix was constructed. During the training process, we employed the stochastic gradient descent method to adjust the word vector.
- (2)
- The second layerThe second layer was named as the convolution layer. Each scale includes two convolution kernels that have the scales of , , Then, for the input matrix of the input layer, we needed to implement the convolution operation and acquire the matrix features of the input layer. The corresponding result vector could be attained (), which was input to the pooling layer for data compression. Meanwhile, the activation function ReLU was used to activate the convolution result. After each convolution operation, one convolution result will be obtained:where the size of and are the size of convolution kernel, which represents the number i of h × n matrix block from top to bottom when the matrix I is operated in sequence; “∙” means that the elements at the corresponding positions of two matrix blocks are multiplied first and then added. Meanwhile, the activation function ReLU was used to activate the convolution result. Nonlinear processing was carried out for each convolution result , and the result was obtained after each operation. The formula is as follows:where b is the offset coefficient. Each such operation will produce a nonlinear result . Because , after convolution operations on the input matrix from top to bottom, we should arrange the results in order, and obtain the vector of the convolution layer , which is shown as:
- (3)
- The third layerWe defined the third layer as the poling layer and employed the maximum pooling method for pooling. For the convolution result vector , the largest element was chosen as the feature value, which is defined as . Then, the value was injected in succession into the vector , which was input to the output layer of the next layer. Vector p stands for the global features of the text data, and it can reduce the dimensionality of the features and enhance the efficiency of classification.
- (4)
- The fourth layerHere, the output layer was utilized to name the fourth layer. We plugged the pooling layer completely into the output layer. In the pooling layer, we selected the vector p as an input, which was classified with the help of a SoftMax classifier. Then, the final classification result was output. The probability was computed using SoftMax classification, which is as follows:where the formula (9) refers to the probability that belongs to the secondary device category.
4. Case Study
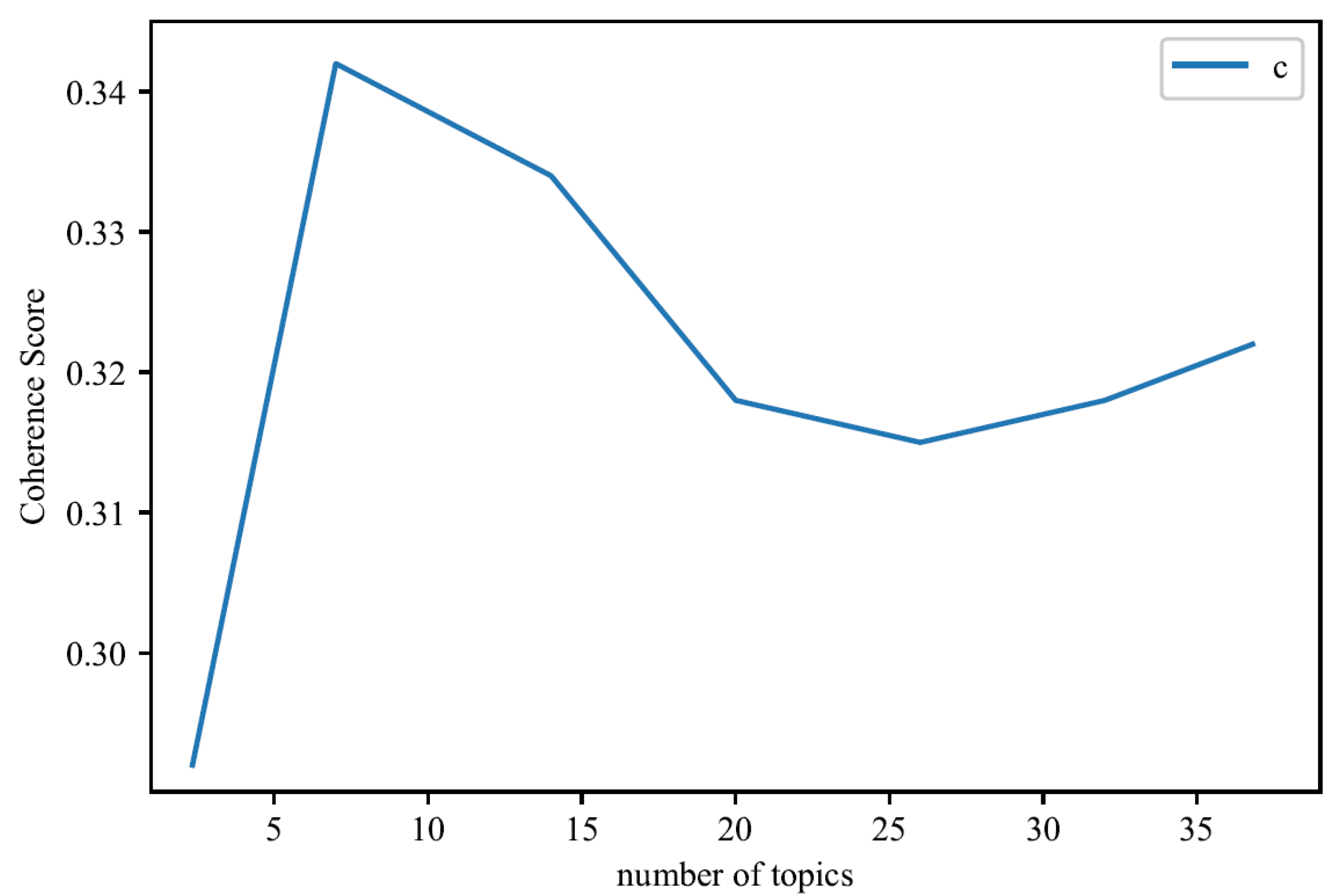
4.1. RLDA Model Experiment
4.2. Results and Analysis of Evaluation Index of Classification Effect
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jin, H.; Liu, X.; Liu, W.; Xu, J.; Li, W.; Zhang, H.; Zhou, J.; Zhou, Y. Analysis on Ubiquitous Power Internet of Things Based on Environmental Protection. IOP Conf. Ser. Earth Environ. Sci. 2019, 300, 42077–42083. [Google Scholar] [CrossRef]
- Chen, K.; Mahfoud, R.J.; Sun, Y.; Nan, D.; Wang, K.; Haes Alhelou, H.; Siano, P. Defect Texts Mining of Secondary Device in Smart Substation with GloVe and Attention-Based Bidirectional LSTM. Energies 2020, 13, 4522. [Google Scholar] [CrossRef]
- Bakr, H.M.; Shaaban, M.F.; Osman, A.H.; Sindi, H.F. Optimal Allocation of Distributed Generation Considering Protection. Energies 2020, 13, 2402. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, P.; Qin, Y.; Zhao, M.; Yang, Z.; Chen, H. Electromagnetic Immunity Performance of Intelligent Electronic Equipment in Smart Substation’s Electromagnetic Environment. Energies 2020, 13, 1130. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q. Research on New Technology of Power System Automation Based on Ubiquitous Internet of Things Technology. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 32101–32110. [Google Scholar] [CrossRef]
- Yu, X.; Xue, Y. Smart Grids: A Cyber-Physical Systems Perspective. Proc. IEEE 2016, 104, 1058–1070. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5 July 2008; pp. 160–167. [Google Scholar]
- El Hindi, K.; Alsalman, H.; Qasem, S. Building an Ensemble of Fine-Tuned Naive Bayesian Classifiers for Text Classification. Entropy 2018, 20, 857. [Google Scholar] [CrossRef] [Green Version]
- Xu, S. Bayesian Naïve Bayes Classifiers to Text Classification. J. Inform. Sci. 2018, 44, 48–59. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Goudjil, M.; Koudil, M.; Bedda, M.; Ghoggali, N. A Novel Active Learning Method Using SVM for Text Classification. Int. J. Automat. Comput. 2018, 15, 290–298. [Google Scholar] [CrossRef]
- Wu, K.; Gao, Z.; Peng, C.; Wen, X. Text Window Denoising Autoencoder: Building Deep Architecture for Chinese Word Segmentation. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Chongqing, China, 15–19 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–12. [Google Scholar]
- Zhang, Y.; Zheng, J.; Jiang, Y.; Huang, G.; Chen, R. A Text Sentiment Classification Modeling Method Based on Coordinated CNN-LSTM-Attention Model. Chin. J. Electron. 2019, 28, 120–126. [Google Scholar] [CrossRef]
- Jing, R. A Self-attention Based LSTM Network for Text Classification. J. Phys. Conf. Ser. 2019, 1207, 12008–12012. [Google Scholar] [CrossRef]
- Zhang, M.; Xiang, Y. A Key Sentences Based Convolution Neural Network for Text Sentiment Classification. J. Phys. Conf. Ser. 2019, 1229, 12062–12068. [Google Scholar]
- Roy, S.S.; Rodrigues, N.; Taguchi, Y. Incremental Dilations using CNN for Brain Tumor Classification. Appl. Sci. 2020, 10, 4915. [Google Scholar] [CrossRef]
- Zahid, M.; Ahmed, F.; Javaid, N.; Abbasi, R.A.; Zainab Kazmi, H.S.; Javaid, A.; Bilal, M.; Akbar, M.; Ilahi, M. Electricity Price and Load Forecasting using Enhanced Convolutional Neural Network and Enhanced Support Vector Regression in Smart Grids. Electronics 2019, 8, 122. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Huang, J.; Ji, S. Bearing Fault Diagnosis with a Feature Fusion Method based on an Ensemble Convolutional Neural Network and Deep Neural Network. Sensors 2019, 19, 2034. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Fan, K.; Lai, Y.; Gao, K.; Wang, Y. Short Texts Classification Through Reference Document Expansion. Chin. J. Electron. 2014, 23, 315–321. [Google Scholar]
- Gao, Y.; Zhu, Z.; Riccaboni, M. Consistency and Trends of Technological Innovations: A Network Approach to the International Patent Classification Data. In Proceedings of the International Conference on Complex Networks and their Applications VI, Lyon, France, 29 November–1 December 2017; Springer: Cham, Switzerland, 2017; pp. 744–756. [Google Scholar]
- Li, J.; Fong, S.; Zhuang, Y.; Khoury, R. Hierarchical Classification in Text Mining for Sentiment Analysis of Online News. Soft Comput. 2016, 20, 3411–3420. [Google Scholar] [CrossRef]
- Wang, L.; Guo, X.; Wang, R. Automated Crowdturfing Attack in Chinese User Reviews. J. Commun. 2019, 40, 1–13. [Google Scholar]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical Text Classification Using Convolutional Neural Networks. Stud. Health Technol. Inform. 2017, 235, 246–250. [Google Scholar]
- Tommasel, A.; Godoy, D. Short-Text Learning in Social Media: A Review. Knowl. Eng. Rev. 2019, 38–49. [Google Scholar] [CrossRef]
- Wang, H.; He, J.; Zhang, X.; Liu, S. A Short Text Classification Method based on N-gram and CNN. Chin. J. Electron. 2020, 29, 248–254. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 993–1022. [Google Scholar]
- Wei, W.; Nan, D.; Zhang, L.; Zhou, J.; Wang, L.; Tang, X. Short Text Data Model of Secondary Equipment Faults in Power Grids based on LDA Topic Model and Convolutional Neural Network. In Proceedings of the 2020 35th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Zhanjiang, China, 16–18 October 2020; pp. 156–160. [Google Scholar]
- Lu, X.; Zhou, M.; Wu, K. A Novel Fuzzy Logic-Based Text Classification Method for Tracking Rare Events on Twitter. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 4324–4333. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Defects and Treatment Methods | Defect Classification |
|---|---|---|
| 1 | The main set B intelligent terminal sends a GOOSE link interruption general alarm, which does not affect the normal operation of the B set protection and needs to be exited for inspection. | Serious defect |
| 2 | General alarm of GOOSE in A set of intelligent terminals of Yanhua Temple Line, data of GOOSE network is interrupted. | Critical defect |
| Parameter | Value |
|---|---|
| Hyperparameter α | 50/K |
| Hyperparameter β | 0.01 |
| Gibbs sampling iterations | 1000 |
| Input word vector | Word2vec |
| Filter size | (3,4,5) |
| Number of filters per size | 100 |
| Activation function | ReLU |
| Pooling strategy | 1-max pooling |
| Dropout rate | 0.5 |
| Classification Category | Manually Marked as Belonging to | Manually Marked as Not Belonging to |
|---|---|---|
| Classifiers marked as belonging to | TP | TN |
| Classifier marked as not belonging to | FP | FN |
| Classifier Name | F1 Value (%) |
|---|---|
| LR | 51.20 |
| SVM | 54.53 |
| KNN | 51.20 |
| CNN | 55.36 |
| WORD2VEC + CNN | 63.63 |
| LDA + CNN | 63.00 |
| WORD2VEC + TEXTCNN | 78.54 |
| WORD2VEC + RLDA + TEXTCNN | 81.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Ma, H.; Xie, X.; Cheng, J. Short Text Classification for Faults Information of Secondary Equipment Based on Convolutional Neural Networks. Energies 2022, 15, 2400. https://doi.org/10.3390/en15072400
Liu J, Ma H, Xie X, Cheng J. Short Text Classification for Faults Information of Secondary Equipment Based on Convolutional Neural Networks. Energies. 2022; 15(7):2400. https://doi.org/10.3390/en15072400
Chicago/Turabian StyleLiu, Jiufu, Hongzhong Ma, Xiaolei Xie, and Jun Cheng. 2022. "Short Text Classification for Faults Information of Secondary Equipment Based on Convolutional Neural Networks" Energies 15, no. 7: 2400. https://doi.org/10.3390/en15072400
APA StyleLiu, J., Ma, H., Xie, X., & Cheng, J. (2022). Short Text Classification for Faults Information of Secondary Equipment Based on Convolutional Neural Networks. Energies, 15(7), 2400. https://doi.org/10.3390/en15072400