1. Introduction
The capacity of globally installed wind power is constantly growing due to international efforts to limit the global mean temperature rise by replacing fossil fuels [
1]. A major fraction of the levelized cost of wind energy consists of the operation and maintenance costs of wind farms [
2]. The continuous health monitoring of wind turbine components forms an important part of the work of wind farm operators as it helps to limit the extent of unforeseen maintenance costs. To reduce the operation and maintenance costs of their wind farms, many operators and asset managers are applying remote condition monitoring techniques to detect incipient faults before they result in major damage.
Gearboxes are among the most critical and costly components to replace in a wind turbine in terms of the equipment, replacement work and downtime costs per failure [
3,
4,
5,
6]. Therefore, a growing number of wind turbine gearboxes is being equipped with vibration measurement systems to enable the close monitoring and early detection of developing fault conditions in the gearbox components [
7,
8,
9]. The vibration-monitoring signals require analysis and interpretation to prevent failures. Numerous approaches have been proposed to assess the vibration signals from wind turbine gearboxes in the time and frequency domains. Examples include the time-domain monitoring of waveform features such as root mean square deviations, peak-to-peak amplitudes, and kurtosis. In the frequency domain, methods such as spectral line analysis, envelope and sideband analysis have been proposed [
8,
9,
10,
11]. Thus, the state-of-the-art vibration diagnostics methods applied for wind turbine (WT) gearboxes in practice rely on the extraction of hand-crafted features from the gearbox vibration signals. The features need to be defined by a human analyst before they can be extracted. Only after they have been defined and extracted from the vibration measurements can the features be used to infer information about potential faults in gearbox components based on statistical methods or machine learning models [
12,
13]. Typical handcrafted features that are in use for WT gearbox fault diagnostics are the position and amplitude of spectral lines corresponding to characteristic frequencies of gearbox components, such as gear mesh frequencies, and other characteristic metrics such as the root mean square deviation and kurtosis of parts of the vibration time series [
8,
9,
10,
11]. However, these state-of-the-art vibration diagnostics methods have multiple disadvantages. First, they require a labor-intensive upfront conception and handcrafting of feature definitions, which constitutes a significant time and workforce effort. Second, many state-of-the-art approaches and feature definitions require a highly detailed knowledge of the gearbox type, manufacturer, composition and dimensions, its bearing and gear types, gear teeth numbers, and so on. This information needs to be gathered for every single gearbox before the start of the monitoring. As a result, the state-of-the-art fault diagnostics and feature extraction approaches can generally not be transferred straightforwardly to new turbine types added to an operator’s wind power portfolio. For every new turbine entering the portfolio, detailed turbine composition information needs to be collected from the manufacturer and the vibration features need to be reviewed, adapted and extracted. This constitutes a large, resource-intensive initial effort that many wind farm operators and asset managers are hesitant to make. Third, after a feature definition and extraction method has been implemented, thousands of characteristic spectral values per turbine gearbox need to be stored and monitored, which requires costly storage resources and computing time in the remote monitoring centers of the turbine operators and asset managers. Fourth, the state-of-the-art approaches do not analyze the full vibration spectrum but focus on monitoring only isolated aspects thereof, such as a set of characteristic frequencies, or they focus on the global metrics of the vibration time series or spectrum. Unlike the proposed approach, they do not support the automated, simultaneous vibration monitoring of the full spectral range. Lastly, features defined by human analysts can lead to imprecise decision boundaries and less accurate fault diagnostics predictions than features that have been learnt by machine learning algorithms themselves [
14]. The state-of-the-art feature definition and extraction methods may result in lower diagnostics accuracy, more false alarms and false negatives, especially in ambiguous boundary cases that require additional inspection and decision making by remote monitoring staff, than fault diagnostics methods which learn and extract the optimal features themselves. A reliable feature definition and extraction is essential to the fault diagnostics process. For an illustrative example of how the chosen upfront feature definitions can affect fault detection quality, we refer to the study presented by [
11].
The research gap addressed by this study is the development of a fault diagnostics method for vibration-monitored wind turbine gearboxes that:
- (1)
Learns and extracts an optimal set of discriminative features in an automated manner, not requiring any feature engineering;
- (2)
Analyzes the full vibration spectrum, rather than focusing only on isolated predefined aspects thereof;
- (3)
This is even applicable if only a few fault observations are available.
Consequently, the objective of this paper is to introduce and demonstrate a novel fault diagnostics approach for vibration-monitored wind turbine gearboxes that can overcome the discussed disadvantages of the state-of-the-art methods. In particular, the novel approach is expected to learn optimal discriminative features in an automated manner and classify the gearboxes’ health conditions based on these features without requiring any human feature definition and extraction. It is also expected to analyze the full vibration spectrum and be applicable even in situations where sufficient model training data for fault-type classification are unavailable.
This paper is organized as follows.
Section 2 introduces the proposed fault diagnostics approach.
Section 3 describes the method applied and data employed in a gearbox failure case study, whereas
Section 4 discusses the analysis and results. Our conclusions are presented in
Section 5.
2. Fault Diagnosis Method
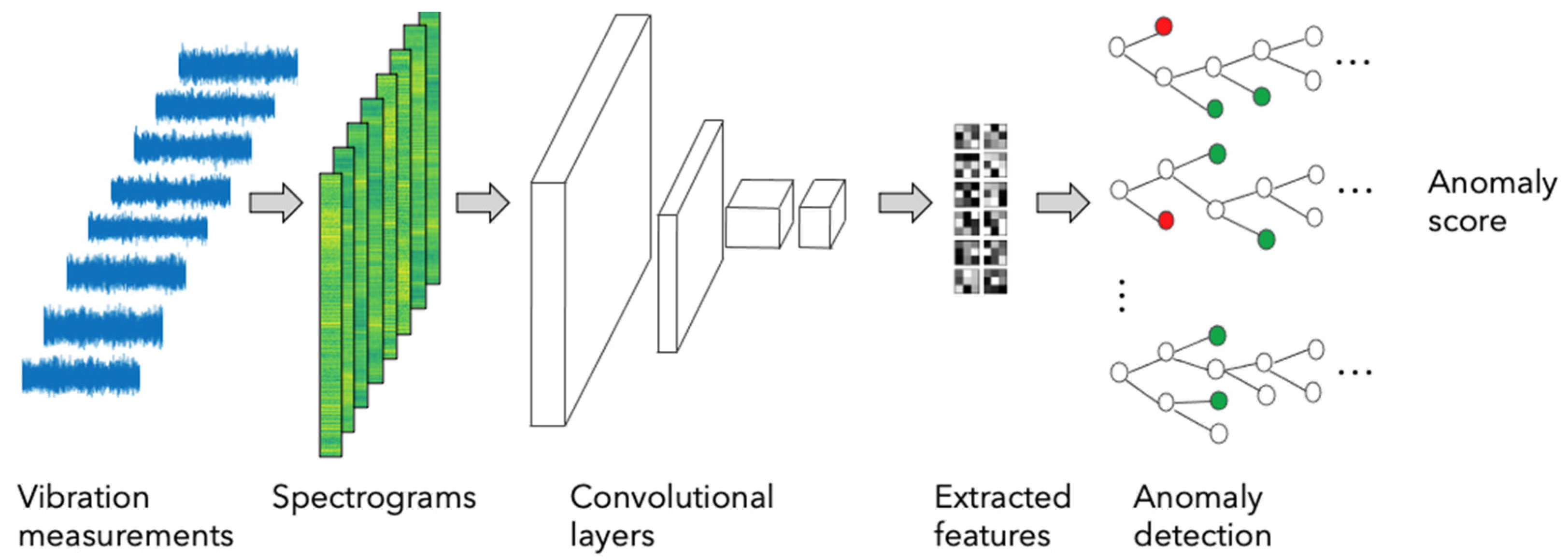
The proposed fault diagnosis method comprises two stages. The first stage performs an unsupervised anomaly detection on the features learnt and extracted from spectrograms of each monitored gearbox component (
Figure 1). This stage one accounts for the fact that many WT operators have access to only a few or even no sensor measurements from actual gearbox fault incidents, as these are relatively rare events and can arise from a range of different causes. While methods that require labeled observations of gearbox faults (as in proposed stage two below) may be less beneficial to such operators, anomaly detection methods based on measurements taken in the normal healthy operation state will still be available and highly useful to them, even in absence of labeled fault observations.
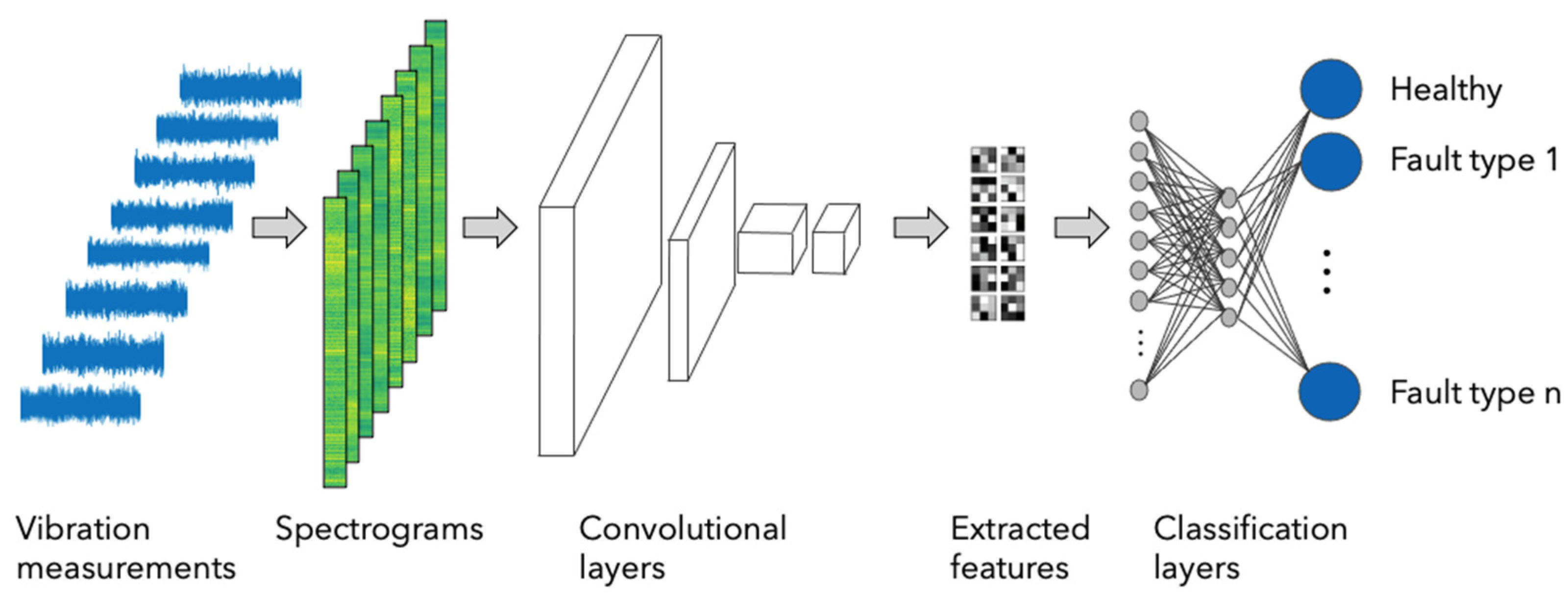
The second stage of the presented approach employs a multi-label classification method to diagnose specific gearbox fault types based on past fault observations (
Figure 2). This stage mainly benefits operators who have access to measurements from observed gearbox faults that enable the training of a corresponding fault type classification model. Therefore, the proposed stage two is performed only if sufficient fault observations are available to the operator’s remote monitoring staff in charge of implementing the proposed approach.
Fault diagnoses are made based on features extracted from vibration spectrograms. To this end, vibration measurements are taken continuously from numerous accelerometer-monitored gearbox components and are accessed through the turbine’s condition monitoring system (CMS). The accelerometer measurement time series are subjected to short-time Fourier transforms (STFT) to monitor the temporal evolution of the vibration spectra in the time-frequency domain. The resulting spectrograms from all accelerometer-monitored gearbox components serve as inputs to feature extraction neural networks composed of convolutional and pooling layers, as described below. Unlike the state-of-the-art fault diagnostics methods, the proposed approach does not require gearbox-type-specific information. Therefore, it can be introduced to even larger WT portfolios without the upfront efforts and investments required for existing methods.
The operators will be informed both in stages one and two in case a significant deviation from healthy component spectrograms is diagnosed. Importantly, both stages of the proposed fault diagnostics approach rely on automated feature learning and extraction that is performed by an algorithm rather than a human analyst. This is achieved by the application of convolutional neural networks (CNNs) [
14,
15], as shown in
Figure 1 and
Figure 2. We refer to [
16] for a technical introduction to CNNs. CNNs were selected for the proposed health state classification approach because, unlike other models, they are capable of learning and extracting features from image data without human assistance.
CNNs are computational models that are capable of extracting the relevant features without any human assistance. They accomplish this by learning optimal convolutional filters based on historical training data, in this case vibration measurements and fault observations. Due to this property, CNNs have enabled major performance improvements in fields such as speech recognition and object detection in recent years [
14,
15]. CNNs are artificial neural networks that consist of convolutional and pooling layers trained to perform feature learning and extraction based on past observations. These layers are subsequently linked to fully connected layers to perform desired classification or regression tasks based on the previously extracted features. During model training, the CNN weights optimization algorithm effectuates automated feature learning and extraction to construct a low dimensional representation of the input spectra, which is subsequently fed to the anomaly detection model (stage one,
Figure 1) or the fault type classification network (stage two,
Figure 2).
In the first stage of the presented fault diagnostics approach, the feature extraction part is succeeded by an isolation forest model (
Figure 1) for detecting anomalous spectrograms in an automated manner. The extracted features serve as input to the isolation forest algorithm [
17] that is adapted to distinguish anomalous from normal spectrograms with regard to the component health state based on historical accelerometer measurements. The isolation forest algorithm identifies potential anomalies by how quickly the input spectrograms can be isolated from the rest of the spectrograms using a decision-tree-based approach. A health-state classifier is trained using examples from only one class, namely observations from healthy gearbox components only. This is a highly relevant scenario in practice because fault observations of WT gearbox components are often lacking: Wind farm operators usually have a large amount of CMS sensor observations from different parts of the drive train from multiple months or years of operation. Typically, the vast majority of these measurements from the CMS system are taken under normal operating conditions from healthy components. Fault conditions and damages occur relatively rarely in commercial turbines that are operated and maintained in accordance with the manufacturer’s recommendations. Therefore, there is a relative lack of such fault observations, which strongly restricts the training and application of machine learning models for fault type classification because those models require a significant amount of training data. Therefore, machine learning models trained only on observations from healthy gearbox components tend to be more widely applicable in practical applications and are highly relevant when comprehensive fault observations are lacking.
To train the health-state classifier using only observations from healthy gearbox components, we compared two anomaly detection approaches: the isolation forest algorithm introduced above and one-class support vector machines [
18]. The isolation forest approach is known for its fast computational training time [
17]. In the case study presented below, it outperformed the one-class SVM by more than a factor of 30 in terms of required training time but provided no advantages in terms of prediction performance. Therefore, our discussion of the case study below focuses on the developed isolation forest model with its more attractive training times and accordingly larger practical relevance.
In stage two of the proposed fault diagnostics method, our goal is to train a health-state classifier to diagnose specific fault conditions in gearbox components using both accelerometer measurements from both healthy and damaged components. The features extracted by the convolutional and pooling layers serve as input to train multi-label fault type classifiers, as illustrated in
Figure 2.
Multi-label classification [
19,
20,
21,
22] is especially beneficial when accelerometer measurements taken during evolving and evolved past gearbox damage are available for the gearbox types of interest. A multi-label classification model is estimated for monitoring multiple gearbox components simultaneously based on high-frequency acceleration measurements from accelerometers attached in close proximity to the monitored components. The multi-label classification enables a joint classification of multiple damage types, wherein each data instance is simultaneously assigned multiple labels. Each label indicates the membership status in one of multiple classes in a binary manner. More formally, a multi-label classification algorithm estimates a map
based on a training set
of size
wherein the coordinates of any
can take binary values only,
.
4. Discussion
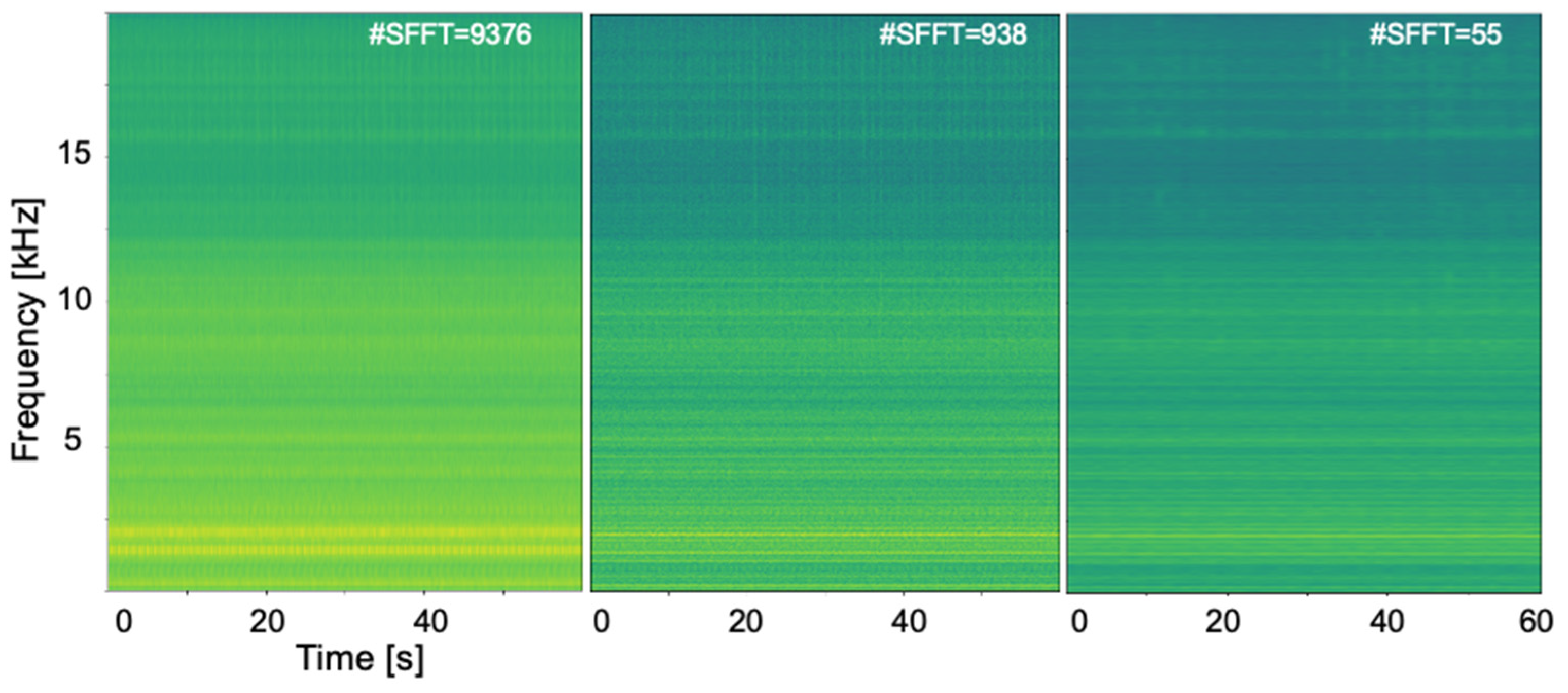
To create the spectrograms that will be input to the CNN for feature extraction, the accelerometer measurements were split into four segments per second and a separate short-time Fourier transform (STFT) was computed for each segment. A short-time Fourier transform enables the frequency analysis of a signal as it changes over time [
25,
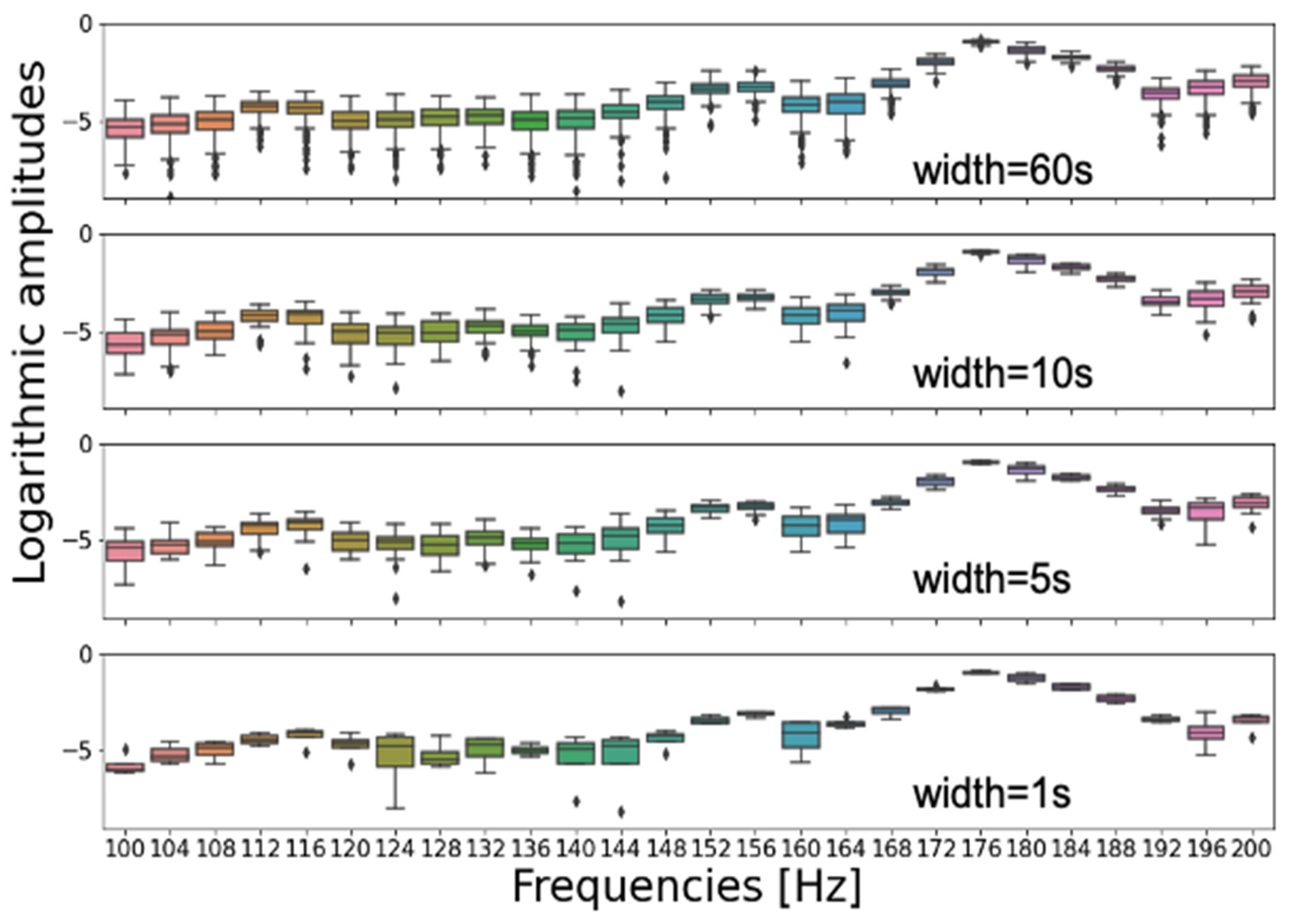
26]. The length of four segments per second was selected by investigating the tradeoff between time and frequency resolution so as to maintain a high-frequency resolution and sufficient temporal resolution, as shown in
Figure 4. The frequency resolution should be sufficient for resolving typical spectral differences arising between healthy and damaged states of the monitored components. The STFTs were computed with an overlap of 0.2 s for adjacent segments. However, the length of the overlap had no significant effect on the performance of the subsequent anomaly detection and classification models. Given the 40 kHz sampling rate, vibration frequencies up to the Nyquist frequency of 20 kHz can be resolved. For the present fault diagnostics case study, we focused the analysis on vibration frequencies up to 1 kHz.
Prior to the model training, we sampled segments from the resulting spectrograms with replacement in order to augment the training dataset. We sampled segments of one second in length to ensure that short vibration measurement periods (of only one second) were sufficient as input to the fault diagnostics model when it was used for inference in a condition monitoring software or CMS system. One-second intervals were found to be sufficiently representative of this amplitude variability when examining the STFT amplitude variability over time for all frequencies up to 20 kHz, as shown in
Figure 5. To test the sensitivity of the presented fault diagnostics approach with regard to the temporal length of the sampled spectrogram segments, we performed our analysis for spectrograms with time lengths of up to 6 s, finding that this choice did not significantly affect the results. After sampling the one-second segments from the vibration spectra of healthy and faulty components, the resulting dataset was randomly shuffled and partitioned into training, validation and test sets. The training set in this case study contained 80,000 instances. The classification method was validated using a validation set of vibration measurements from healthy and damaged components based on 10,000 instances. The test set also contained 10,000 instances.
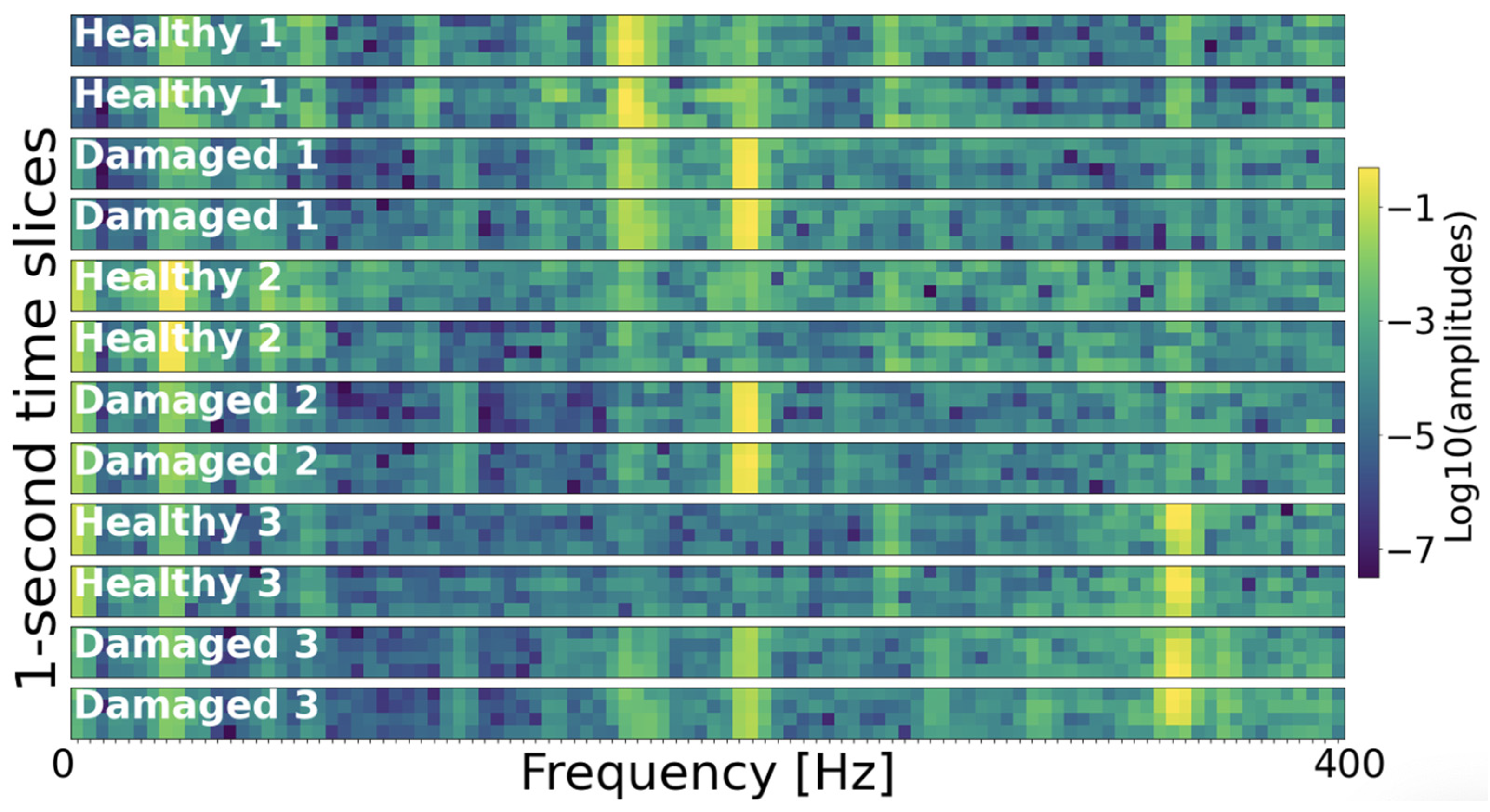
Figure 6 shows subsets of the spectrograms derived from the vibration measurements of the three accelerometers at the healthy and the damaged gearbox components. Two healthy and two damaged instances are shown for each of the three components for illustration. As can be seen in the figure, the spectral differences between vibration measurements from the healthy and the damaged components were sufficiently resolved by Fourier transforms, enabling discriminative feature learning.
Stage 1: Isolation forests for detecting anomalous vibration spectra. The spectrograms prepared as outlined above served as input to the convolutional and pooling layers of a CNN that learned and extracted discriminative features in an automated manner. For feature learning and extraction, we defined a network architecture consisting of one convolutional layer with 16 convolutional filters of 3-by-3 pixels, followed by a max pooling layer with a window size of 2-by-2 pixels and batch normalization [
27]. This architecture is of low complexity and enabled a high classification accuracy in the multi-label classification of stage two of the presented fault diagnostics approach.
The extracted features were input to an isolation forest algorithm for one-class classification [
17], which identified spectral anomalies based on how hard it is to isolate a particular spectrum from the rest of the spectra in the training set. A forest containing 100 isolation trees was trained on the extracted features. The model parameters are summarized in
Table 1. The training dataset contained features from the spectrograms of only healthy components. We specified the fraction of anomalous data instances estimated to be present in the training data to less than one over the training set size. The anomaly score computed by the model for each training, validation and test set instance corresponded to the number of splits averaged across the isolation tree forest that were needed to isolate a data point (
Figure 1). Thus, the anomaly score is the average path length from the root to leaf node in an isolation tree. As shown in
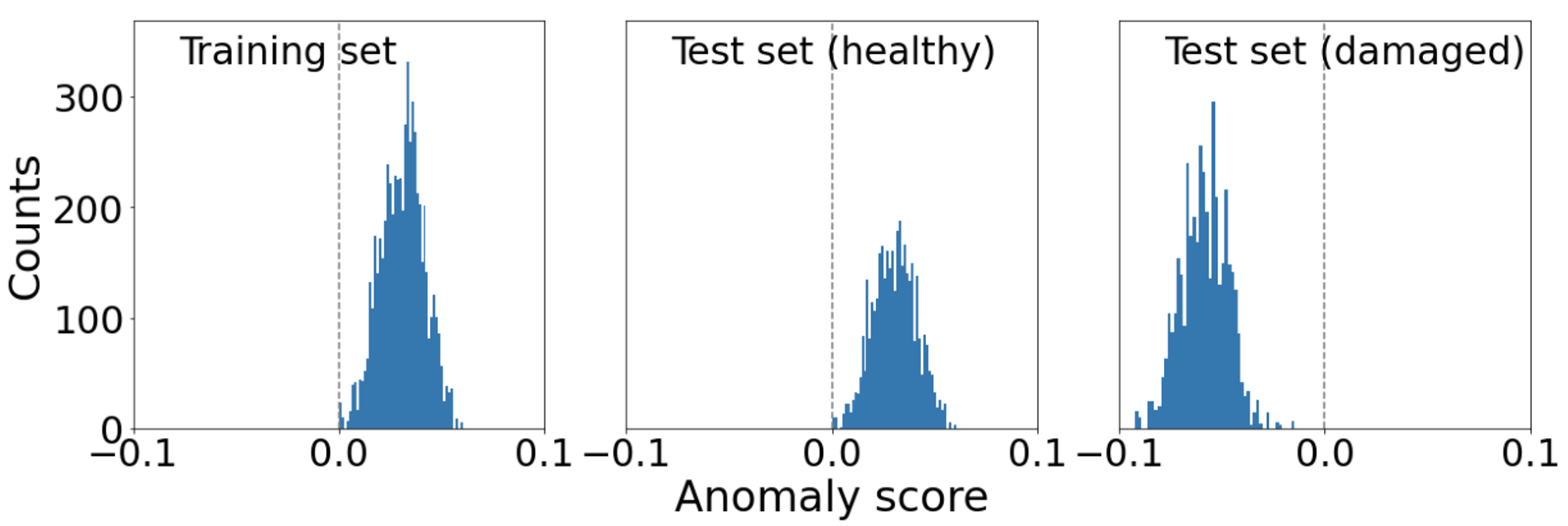
Figure 7, the spectra from the healthy and damaged components are clearly separable using the computed anomaly scores; therefore, the isolation forest model is well-suited for identifying components with anomalous health states, even for high dimensional feature spaces, as in the present case study.
The differentiation of health states is performed in an unsupervised manner to make it applicable to WT operators whose remote condition monitoring team does not have sufficient amounts of fault observations. Since we are actually in possession of such observations in this case study, we employed a test dataset that had not been used in model training (
Figure 7) and estimated performance metrics based on the test dataset. We found both recall and precision to be 100% on the test dataset for the proposed isolation forest approach and model architecture. Recall is a performance metric that designates the fraction of true positives over all actual positives, in this case the fraction of all correctly identified instances of a given fault type over all actual occurrences of that fault type. Precision is an alternative performance metric that denotes the fraction of true positives over all instances that were identified as positive. In other words, the precision states what fraction of the identified observations of a given fault type were correctly identified as observations of that fault type.
We repeated the analysis with the same feature learning and extraction architecture employed in stage two below, which naturally resulted in the same extracted feature set as used in the multi-label classification step. Specifically, this architecture comprised one convolutional layer with only four convolutional 3-by-3 filters, followed by a 2-by-2 max pooling layer and batch normalization. As before, the extracted features were then input into the isolation forest algorithm for detecting anomalous spectra. The change in feature extraction architecture had no significant effect on the spectra’s anomaly scores (
Figure 7) and also resulted in 100% recall and precision.
In addition, one-class support vector machines (SVMs) [
18] were investigated as a further approach for the vibration-based anomaly detection in this study. However, the SVM algorithm required more than 30 times more model training time than the isolation forest on the same training set and processor—an AMD EPYC 7B12 2.25 GHz processing unit—though no improvement in detection performance was observed.
Stage 2: Multi-label classification for fault-type diagnostics. As in stage one, the spectrograms were subjected to convolutional and pooling layers to enable feature learning and extraction based on the training dataset. Subsequently, a fault-type classification was performed with the extracted features using fully connected neural network layers. Jointly, the convolutional, pooling and fully connected layers established the convolutional neural network for the multi-label fault type classification. Once trained, the CNN predicts the probabilities of all three fault types considered in this case study being diagnosed, based on a given spectrogram.
To arrive at the final CNN structure (
Table 1), we started from a more complex CNN architecture and successively reduced the number of convolutional and pooling layers, filters and fully connected layers while maintaining maximal validation set accuracy. We selected the least complex CNN architecture that could achieve the highest possible classification accuracy on the validation set. In this case study, the resulting CNN architecture comprises one convolutional layer with four 3-by-3 filters, followed by a 2-by-2 max pooling layer and batch normalization. This first part ensures the learning and extraction of features, based on which the subsequent classification can be performed. Two fully connected layers were added to the network and a 10% dropout rate applied to avoid overfitting the training data [
28]. The first fully connected layer comprised four nodes and the output layer consisted of three nodes with a sigmoid activation function for the output layer. The model predicts three binary labels, one of which is for each of the monitored gearbox components, and indicates whether or not a fault was detected in the respective component. The output layer with the three neurons and the sigmoid activation functions provides the probabilities for a given spectrum to belong to a particular fault-type class. The model parameters were determined iteratively with the Adaptive Moment Estimation (Adam) optimization algorithm [
29] by optimizing a binary cross-entropy loss function. In doing so, multiple binary classification decisions can be optimized at once. The model training was performed for 20 epochs with a batch size equal to 32. Different batch sizes did not affect the classification accuracy. Logarithmic transformations of the input spectra also had no effect on the classification accuracy. This architecture enabled a 100% classification accuracy for all three component fault type classes on the validation and test sets. We arrived at this architecture through a grid search by starting from a more complex CNN with the number of nodes equal to powers of two, and then reducing the network complexity while maintaining a high accuracy of 100% on the validation set, as described above. The test set classification accuracy of 100% was achieved both with and without the logarithmic transformation of the spectrogram segments inputs to the convolutional and pooling layers (
Figure 6). The models trained as part of the hyperparameter optimization converged to a loss function minimum within 20 epochs without overfitting.
With regard to the limitations and the future research needs arising from the present study, we point out that, first, all acceleration measurements in the present study were taken under constant speed and load conditions on a test stand. The introduced fault detection approach should be field tested under variable speed and load conditions in future work. In practice, the wind speed driving the turbine fluctuates, which results in a variable load and shaft speed and may cause frequency smearing in the spectral representation [
9]. However, this condition can be overcome by synchronizing the measurements with the wind turbine’s rotational speed, for instance by sampling under identical wind and load conditions. Second, for applications in operating wind turbines, the performance of the fault type classification model should also be investigated for a significantly larger number of monitored components and fault types and for damage processes that are evolving over time. This investigation will require more comprehensive field or laboratory measurement datasets. Third, attention also needs to be paid to the avoidance of possible data imbalance issues when training a fault diagnostics model. While this does not affect stage one of the proposed fault diagnosis approach, it may be relevant in the application of the methods introduced for stage two. Data imbalance refers to situations where there is a disproportionate number of observations in the output classes. For instance, there may be a large number of observations for one class, for instance fault type 1, but only few observations for another class. In the presented case study, all fault types were represented with similar numbers of observations. This may not always be the case in practice. Typically, more vibration measurements will be available from healthy components because fault situations are less common than WT gearboxes operating in normal health states. Vibration measurements from damaged components or components in which a damage starts to develop are typically in the underrepresented class. One method to address data imbalance is by over- or undersampling to arrive at an augmented and more balanced training dataset. This may be achieved, for example, by random resampling with replacement (statistical bootstrapping) from the available fault observations, so that all monitored WT components are equally represented, both in healthy and damage states, in the training, validation and test datasets. This approach relies on the assumption that the data used for the bootstrapping are sufficiently representative of the underlying data-generating process. A more comprehensive discussion of methods for addressing data imbalance is not in the scope of this work, and we refer to the work of other authors, e.g., [
30].
5. Conclusions
An increasing number of wind turbines are equipped with vibration-measurement systems to enable a close monitoring and early detection of developing fault conditions in gearboxes. Gearboxes are among the most critical and costly components to replace in wind turbines. The current state-of-the-art gearbox fault diagnostics algorithms rely on upfront definitions of fault signatures by human analysts. The state-of-the-art diagnostics methods have in common that, for each of them, a human analyst has investigated and designed a particular feature (fault signature) to be extracted from the vibration measurements. Each feature has been defined so as to capture a particular aspect that starts to build up in the time- or frequency-domain signals when an incipient fault starts to evolve and intensify in an originally healthy component. For instance, local surface damage on a gear tooth is typically diagnosed based on changes in the residual signal obtained after the gear mesh frequencies and harmonics have been removed. These feature-engineering approaches have multiple disadvantages, as discussed above. They require a time-intensive handcrafting of fault diagnostics features and detailed knowledge of the monitored component. Therefore, they lack scalability with the increasing number of monitored turbines, with different component types and configurations present, each of which has its own characteristic frequencies. Fault signatures defined by human analysts can result in biased and imprecise decision boundaries in the fault diagnostics process.
We presented a novel, accurate fault diagnostics framework for wind turbine gearboxes that overcomes these disadvantages and can be easily incorporated into condition monitoring software or CMS systems for autonomous fault diagnostics decision support. This is based on high-frequency vibration measurements from multiple accelerometers and monitored components. The proposed two-stage framework combines the autonomous data-driven learning of fault signatures and health state classification based on convolutional neural networks and isolation forests. In stage one of the presented approach, an isolation forest algorithm detects anomalous component health states based on the features that have been automatically learnt and extracted from the gearbox component spectrograms. This is particularly suitable for operators and monitoring centers that do not have access to sufficient amounts of accelerometer measurements from gearbox fault events. On the other hand, the availability of such observations is required in stage two, which involves a multi-label classification by fault types based on spectrogram features extracted from past fault observations.
We have demonstrated and tested the proposed fault diagnostics framework by application to gearbox vibration measurements from two wind turbine drivetrains. The case study performed to this end used accelerometer measurements from a test rig measurement campaign for three different fault types and achieved high fault diagnostics accuracy.
Unlike the state-of-the-art approaches [
8,
9,
10,
11], the presented method enables automated feature learning and extraction without a human analyst. As demonstrated, given suitable training data, accurate fault diagnosis is possible without any human feature engineering and without the need for storing thousands of spectral characteristics and threshold values to be predefined by monitoring center staff for every turbine. Moreover, the presented fault diagnostics approach does not require detailed knowledge of the gearbox type, manufacturer, composition, gear dimensions, teeth numbers, characteristic bearing frequencies, and so on. Therefore, it can be applied to arbitrary gearbox types, compositions and manufacturers. In summary, the proposed framework is advantageous over the state-of-the-art approaches, such as the monitoring of spectral lines and other characteristic metrics, in that the fault diagnosis features are learnt by the algorithm, so that no gearbox-type-specific diagnostics expertise and no corresponding human-featured engineering are required. Moreover, it is not restricted to predefined frequencies or spectral ranges but monitors the full vibration frequency spectrum of interest.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}